Utvärderingsmetod av
kurvanpassningar för identifiering av
trender i cykelbarometerdata
Evaluation method of curve fitting for
identifying trends in bicycle
barometer data.
Gabriel Moltubakk
Jody O’Neill
Datavetenskap Kandidatnivå 15 hp VT18Sammanfattning
Inledning: Maskininlärning kan användas för att göra förutsägelser på mängder av data. Vi presenterar en studie där vi analyserat data från en cykelbarometer som registrerar förbipasserande cyklar vid en cykelväg i Malmö. Genom att komplettera cykeldatan med andra uppmätta värden som exempelvis väder och veckodagar förbättras förutsättningarna för maskininlärningsalgoritmer att lära sig prediktera antalet registrerade cyklar baserat på olika faktorer. För att mäta hur framgångsrik olika kurvanpassningar var togs en utvärderingsmetod fram. Denna metod effektiviserade arbetet i att använda kurvanpassningar i regressionsalgoritmer för prediktion av cykelbarometerdata.
Mål: Målet med vår studie var att ta fram en metod för att utvärdera kurvanpassningar på insamlad data.
Syfte: Vårt arbete syftar på att möjliggöra förbättrade prediktioner av cykelflöden genom maskininlärning. Gällande specifikt förbättrad prediktion på cykelflöden kan detta leda till mer välinformerade beslut vid stadsplanering.
Metoder: Vår metod togs fram genom en tudelad process enligt Design Science, vilket består i konstruktion följt av utvärdering. Konstruktionen var att ta fram stegen, utvärderingen var analysen av våra resultat producerade av metoden. Vi bearbetade datamängden från cykelbarometern och SMHI, fyllde igen uppenbara hål i datamängden med data under samma tidsperiod från åren innan och efter. På datan från cykelbarometern utförde vi kurvanpassningar med olika grader av polynom. Med de ny datamängderna skrev vi ihop tester med olika maskininlärningsalgoritmer. Vi använde Ten Fold Cross Validation i våra tester för att skapa ett större statistiskt underlag och underlätta analysen av resultaten.
Resultat: Utvärderingsmetoden togs fram och kan användas för att utvärdera kurvanpassningar på data.
Slutsatser: Kurvanpassningar som representerar långtidstrender kan
utvärderas med vår metod. Genom resultaten från metoden kunde vi se hur maskininlärningsalgoritmerna klarar prediktion och hur bra kurvanpassningar kan bidra till bättre prediktion av cykelflöden.
Abstract
Introduction: Machine Learning algorithms can be used in prediction on large quantities of data. We present a study where we have used data values that we have extracted through the use of curve fittings on bicycle data. This data was retrieved from a bicycle barometer that registers passing bicycles by a bicycle road in Malmö. By supplementing the bicycle data with other measured values like for example weather and weekdays the conditions are improved for machine learning algorithms in the effort of prediction. To measure how successful each algorithm was a evaluation method was created. This method streamlined the work in testing different machine learning algorithms on the collected data.
Objectives: Our objective have been to create a method for evaluation of curve fittings on collected data.
Purpose: The purpose of our work is to enable improved predictions of bicycle flows through machine learning. In regards to improved prediction specifically on bicycle data this leads to more well informed decisions within urban planning.
Methods: Our method was created through a two part process devised from the Design Science principles, which is construction followed by evaluation. The construction was to create our method parts, the evaluation was the analysis of our results produced by the method. We processed the data from the bicycle barometer and SMHI, filled obvious anomalies in the statistics with data from the year before and after during the same period of time. Upon this data we performed curve fitting with the use of polynomial of different degrees. With the data we created tests using scikit-learn with several different Machine Learning Algorithms. We used Ten Fold Cross Validation to create a larger statistical basis upon which our analysis of the results is based upon.
Results: The evaluation method was created and can be used to evaluate curve fittings on data.
Conclusions: Curve fitted data representing long-term trends can be evaluated using our method. Through the evaluation of the method, we could see how machine learning algorithms are capable of prediction and how well curve fitted data can contribute to better prediction of cycling.
Innehållsförteckning
Inledning 5 1.1 Mål 7 1.2 Syfte 7 1.3 Forskningsfråga 71.4 Tidigare och relaterad forskning 7
1.5 Avgränsningar 9
2. Metodik 10
2.1.1 Litteratursökning 10
2.1.2 Datainsamling och databearbetning 11
2.1.3 Design av utvärderingsmetod 12
2.1.4 Experiment och Utvärdering 12
2.2 Implementering 13 2.3 Metoddiskussion 13 3. Teoretisk bakgrund 14 3.1 Övervakad inlärning 15 3.2 Oövervakad inlärning 15 3.3 Korsvalidering 16 3.4 Kurvanpassning 16 4. Utvärderingsmetoden 16 4.1.1 Databearbetning 17
4.1.2 Formulera regressionsmodell, kalibrera basfall 17
4.1.3 Skapa kurvanpassningar 18
4.1.4 Bestäm avvikelser 18
4.1.5 Välj algoritmer, testa kurvanpassningar 19
5. Experiment 19 5.1 Databearbetning 19 5.1.2 Datainsamling 19 5.1.3 Kontroll av data 20 5.1.4 Interpolering 20 5.1.5 Sammansättning 20
5.2 Formulera regressionsmodell, kalibrera basfall 20
5.4 Bestäm avvikelser 21 5.5 Välj algoritmer, testa kurvanpassningar 21
6. Resultat, analys och diskussion 22
6.1 Resultat från experiment 22
6.1.1 Test på medianen i den normaliserade cykeldatan 22 6.1.2 Test mot medelvärdet på den normaliserade cykeldatan 22
6.1.3 2:a gradens polynom 23
6.1.4 3:e gradens polynom 23
6.1.5 4:e gradens polynom 24
6.1.6 5:e gradens polynom 24
6.1.7 6:e gradens polynom 24
6.1.8 7:e gradens polynom 25
6.1.9 8:e gradens polynom 25
6.1.10 9:e gradens polynom 26
6.1.11 10:e gradens polynom 26
6.1.12 11:e gradens polynom 26
6.1.13 12:e gradens polynom 27
6.1.14 13:e gradens polynom 27
6.1.15 14:e gradens polynom 28
6.2 Analys 28
6.3 Diskussion 31
6.4 Validitetshot 32
7. Slutsatser och framtida arbete 32
7.1 Slutsats 32 7.2 Framtida arbete 33 8. Referenser 34 Bilaga A - Litteratursökning 37 Bilaga B - Grafer 40
1. Inledning
Cykeln är ett populärt transportmedel i urbana miljöer och dess användande har många fördelar jämfört med andra transportslag, som till exempel den privatägda bilen. Som transportmedel bidrar cykeln bland annat till en hälsosam livsstil och en mer hållbar stadstrafik. Med hållbar trafik menas framför allt att en cykel inte producerar utsläpp av växthusgaser och den anses således vara ett mycket mer miljövänligt alternativ än motorburna fordon. Att öka andelen cykeltrafik är viktigt, särskilt som städerna ökar i befolkning och bebyggelse, och utrymmet för stora mängder motortrafik således minskar. Utöver detta har cykeln starka fördelar när det kommer till parkering och förvaring då den kräver relativt lite utrymme. Även ekonomiska aspekter spelar in både vid inköp och underhåll eftersom cykeln är betydligt billigare än en bil.
Som nämns ovan är det viktigt att öka andelen cykeltrafik, vilket man kan uppnå genom att till exempel implementera åtgärder som underlättar för cyklister, eller att införa olika typer av restriktioner för att göra bilen mindre attraktiv. Men för att kunna implementera rätt åtgärder krävs kunskap om cyklister och hur de använder trafiknätet.
Det finns idag stora mängder statistik kring cykeltrafik, både på lokal och regional nivå. Bland annat finns ett stort internationellt projekt vid namn “Bike Data Project” (Bike Data Project, 2017), som syftar till att aggregera data kring människors cykelvanor. Detta projekt genomför sin datainsamling genom att koppla till privatpersoners applikationer på sina telefoner, till exempelvis applikationerna Moves och Runkeeper . Med syftet 1 2 att samla information till trafiksamordnare och stadsplanerare kan den insamlade datan användas vid planering av cykelbanor, vägar och stadsbilden i stort.
På lokal nivå används idag olika typer av cykelräknare, även kallat cykelbarometrar, för insamling av cykelflödesdata. En cykelbarometer är en cykelräkningsstation som räknar antalet cyklister som passerar. Cykelbarometrar förses med en skärm som visar antal cyklister som har passerat per dag, månad och år. Enligt Claes, Slegers och Vande Moere (2016) kan denna visualisering motivera trafikanter att välja cykeln som färdmedel, då cyklisterna på så sätt kan se sin kollektiva insats på skärmen. 1 Moves-app.com. (2017). Moves - Activity Diary for iPhone and Android. [online] Tillgänglig
på: https://moves-app.com/ [Åtkomst 21 Aug. 2017].
2 Runkeeper.com. (2017). Runkeeper - Track your runs, walks and more with your iPhone or Android phone. [online] Tillgänglig på: https://runkeeper.com/ [Åtkomst 21 Aug. 2017].
Utöver detta bidrar cykelbarometrarna med detaljerad data avseende hur många cyklister som faktiskt passerar en viss punkt i nätverket (Swarco.se, 2017).
Denna studie fokuserar på att analysera data från en cykelbarometer belägen längs med det viktiga cykelstråket vid Kaptensgatan i centrala Malmö. Denna cykelbarometer är en punktmätstation, vilket innebär att den vid den givna punkten räknar antalet passerande cyklar i vardera riktning. För att kunna uppskatta hur många cyklar som förväntas passera en cykelbarometer för ett visst tidsintervall, givet tidpunkt (klockslag och tid på året), veckodag och givna väderförhållanden har tidigare forskning (Aspegren och Dahlström, 2016; Holmgren, Aspegren, Dahlström, 2017) visat att man kan använda sig av regression. Denna typ av uppskattningar kan användas för att uppnå förbättrade trafikprognoser när man arbetar med trafikmodeller som exempelvis Sampers (Trafikverket, 2015) och ASIMUT (Hajinasab m.fl., 2016). Sampers (Trafikverket, 2015) används bland annat av trafikverket för att utföra trafikprognoser i Sverige på nationell såväl som på regional nivå. Detta genom att modellera resor som genomförs av privatpersoner. ASIMUT (Hajinasab m.fl., 2016) är en agentbaserad simuleringsmodell som uppskattar hur resenärer väljer att resa utifrån olika förutsättningar (till exempel, väder och avstånd mellan start och målpunkt). Med mer detaljerad kunskap om hur cyklister påverkas av olika attribut, finns det mer information tillgänglig för att modellera resenärers val av trafikslag i ovanstående och andra modeller.
Tidigare resultat (Aspegren och Dahlström, 2016; Holmgren m.fl., 2017) visar på att variationen i antalet cyklister till stor del kan förklaras av variation i attributen veckodag, nederbörd och temperatur. Dock påverkas även cykeltrafik av förändringar inom staden, som till exempel infrastrukturens utveckling. Ett exempel på detta är byggnationen av Citytunneln och dess nya tågstation vid Triangeln i Malmö. Triangelstationen blev ett nytt mål i vägnätet för cyklister och vissa cyklister som tidigare skulle passerat cykelbarometern valde i stället en annan resväg eftersom de hade en annan målpunkt. Efter Triangelstationens öppnande minskade antalet registrerade cyklar vid cykelbarometern successivt, men detta berodde med största säkerhet inte på att Malmöborna blev mindre benägna att cykla, utan istället på att cykeltrafiken ökade med motsvarande mängd någon annanstans i nätverket. Typiskt finns det en långtidstrend som är specifik för en viss mätstation (cykelbarometer) som beskriver hur många cyklar som förväntas passera givet att man antar att dagsegenskaper och väder är neutrala. Holmgren m.fl. (2017) indikerar att man kan uppnå förbättrade prediktioner genom att använda förväntat antal registrerade cyklar (utifrån en uppskattad långtidstrend) istället för det absoluta antalet registrerade cyklar som målvärde i en regressionsmodell. Dock kan det vara
svårt att identifiera långtidstrendkurvor som väl beskriver hur antalet cyklar förväntas förändras över tiden.
Gällande utvärderingar kring kurvanpassningar har exempelvis Holmgren m.fl. (2017) sett mycket till visuell representation av kurvanpassningarna tillsammans med den ursprungliga datan och på detta vis kunnat utföra en okulär besiktning. Med detta menas att man jämför kurvan med den ursprungliga datans linjer och ser om den avviker kraftigt eller inte.
1.1 Mål
Målet med vår studie var att ta fram en metod för att utvärdera kurvanpassningar som beskriver långtidstrender avseende mängden cyklar som registreras av en cykelbarometer.
1.2 Syfte
Med hjälp av en metod som på ett tillförlitligt och snabbt sätt möjliggör att analysera kvaliteten hos olika kurvanpassningar, syftar vårt arbete till att möjliggöra förbättrade prediktioner av cykelflöden med hjälp av maskininlärning, närmare bestämt regression. Med långtidstrender menas de flödesförändringar som sker över längre perioder av tid, och som inte kan kopplas till egenskaper som väder, veckodag, och andra faktorer som kan ändras från dag till dag. Bidraget här blir alltså möjligheten för förbättrade prediktioner av cykelflöden; gällande trafik kan detta exempelvis bidra till ett verktyg i stadsplaneringen.
1.3 Forskningsfråga
Baserat på vårt mål har vi formulerat följande forskningsfråga:
● Hur kan man utvärdera kvaliteten hos kurvanpassningar motsvarande långtidstrender i en serie cykelvolymmätningar?
I ovanstående forskningsfråga är det underförstått att den serie mätningar som avses är generade vid samma plats, till exempel av en cykelbarometer.
1.4 Tidigare och relaterad forskning
Sett till studier som är direkt relevanta för vår egen finns ett arbete från föregående 2016 skrivet av studenterna Sebastian Aspegren och Jonas Dahlström på Malmö Högskola (Aspegren och Dahlström, 2016). Med verktyget “Weka” jämför de olika regressionsmetoder avseende hur väl de lyckas prediktera antal cyklar registrerade vid en cykelbarometer. I deras resultat framkom det att av de testade algoritmerna var Random Subspace och Bagging bäst för att uppskatta antal cyklar. Holmgren m.fl. (2017) presenterar en utökad regressionsmodell baserat på Aspegren och Dahlströms resultat. Skillnaden är att Holmgren m.fl. även inkluderar
skollov, helgdagar och mellandagar som attribut i sin regressionsmodell, och på så sätt lyckas de uppnå resultatförbättringar. Deras modell liknar vår modell, fast vi exluderar lov och skoldagar samt inkluderar olika väderattribut.
Inom transportområdet identifierar Sigakova m.fl. (2015) faktorer som påverkar effektiviteten av transporttrafik, dvs väder, veckodag, vindstyrka och temperatur. Deras studie handlar om godstransport på vägar, men vi anser att det finns relevans för cykeltrafik eftersom studien anser att väderdata är slumpmässig, rik i variation och volym och på så sätt svår att bearbeta.
Även Wu m.fl. (2004) pekar på att variabler som veckodagar, månader och säsonger påverkar och hänvisar till tydliga mönster gällande hur människor väljer att färdas.
Tsapakis m.fl. (2013) visar att väder och temperatur är viktiga eftersom de påverkar människors val av transport eller om man ställer in resan helt. Därför har vi valt att se vad vi kan få för resultat genom vår metod med hjälp av sådana attribut.
Altshuler m.fl. (2012) och Guyon och Elisseeff (2013) pekar på att det är viktigt att välja bra datavariabler för att hjälpa en maskininlärningsalgoritm att träna på en datamängd. Detta hjälper maskininlärningsalgoritmerna att få bättre prediktioner och spara tid i processering av stora mängder data. Attribut kan vara bra att dela upp i kategorier om de är många.
Tsapakis m.fl. (2013) lyfter även fram att snö är det attribut som påverkar trafiken mest, men tyvärr var detta en typ av data vi inte kunde få tillgång till i vår studie. Snödata är dessutom data som kan bidra med brus i algoritmerna. Dock så skall det nämnas att vi hade en väldigt kall vinter 2011, vilket syns tydligt i vår cykelbarometerdata. Tsapakis kom även fram till att snö och regn påverkar trafiken olika mycket beroende på dess intensitet.
Etzioni m.fl. (2003) lyfter betydelsen av att välja rätt attribut och att klassificiera dem rätt. Att välja fel attribut eller klassificera dem felaktigt kan kosta precision i prediktion och tid i processering.
Vehtari och Lampinen (2002) visar att om det finns en osäkerhet om vilka attribut man skall använda så kan man börja med få attribut och sen lägga till fler för att se om prediktionen blir bättre, detta kallas simplicity postulate. Studien nämner dock att denna ansats har varit under kritik eftersom det inte alltid är lätt att veta vad som är enkla attribut.
Kohavi och John (1997) drar slutsatsen att attribut bör väljas utifrån algoritm då det som är optimalt för en algoritm inte behöver vara det för en annan.
Lavesson (2006) diskuterar betydelsen av urvalet av invariabler när maskininlärningsalgoritmer testas där bland annat Stödvektormaskin används i testerna. Vidare så resoneras det kring att kvalitetsattribut skapar en möjlighet att förstå sig på hur inlärningalgoritmerna fungerar och hur de kan förbättras. Däremot skapas svårigheter med attribut/variabler som är beroende av varandra då det kan försämra resultatet för algoritmen avsevärt.
Philip George Guest (2013) redogör de matematiska uträkningarna bakom kurvanpassningar. Speciellt intresse för oss och vårt arbete ligger i hans kapitel som diskuterar kurvanpassning med polynom och vad som krävs för att möjliggöra dessa.
Så som forskningsläget ser ut idag är området kring urvalet av data som skall användas som attributdata till maskininlärningsalgoritmer väl genomarbetat. Däremot är forskning och resonemang kring vilken data som skall användas vid en specifik situation desto mindre. I detta mindre utforskade område befinner sig vårt arbete till stor del. Detta då vi resonerar kring urval av attributsdata kring ett givet tema (cykelflöden), vilket i dagsläget inte alls är lika utforskat som exempelvis urval av attributsdata baserat på vilken algoritm som används.
1.5 Avgränsningar
Vi har valt att avgränsa oss på flera sätt. Som beskrivs ovan är målet med vårt arbete att skapa en metod för utvärdering av hur väl kurvanpassingar motsvarar den verkliga långtidstrend som existerar i den serie av mätvärden (till exempel antal registrerade cyklar per timme) som genereras över tid av en cykelbarometer. Vi har valt att utvärdera vår metod genom att analysera ett antal kurvanpassningar för en datamängd som samlats in från en cykelbarometer i Malmö.
Eftersom vårt mål inte var att finna bästa möjliga kurvanpassning för en viss datamängd valde vi att begränsa oss till att studera anpassade polynom upp till 14:e graden. Dock är det viktigt att nämna att vår utvärderingsmetod kan användas för att utvärdera vilka kurvanpassningar som helst, inte bara polynom. Som ett av stegen i vår metod (se avsnitt 5) ingår det att formulera regressionsproblem där man applicerar och utvärderar resultaten för ett antal olika typer av regressionsalgoritmer. Vi har valt att inkludera följande regressionsalgoritmer:
● Stödvektormaskin ● Linjär regression ● Ridge regression
● Bayesian Ridge Regression ● Lasso
Då många regressionsalgoritmer är väldigt snarlika har vi valt algoritmer på ett sådant sätt att vårt urval representerar de vanligaste typerna av regressionsalgoritmer.
2. Metodik
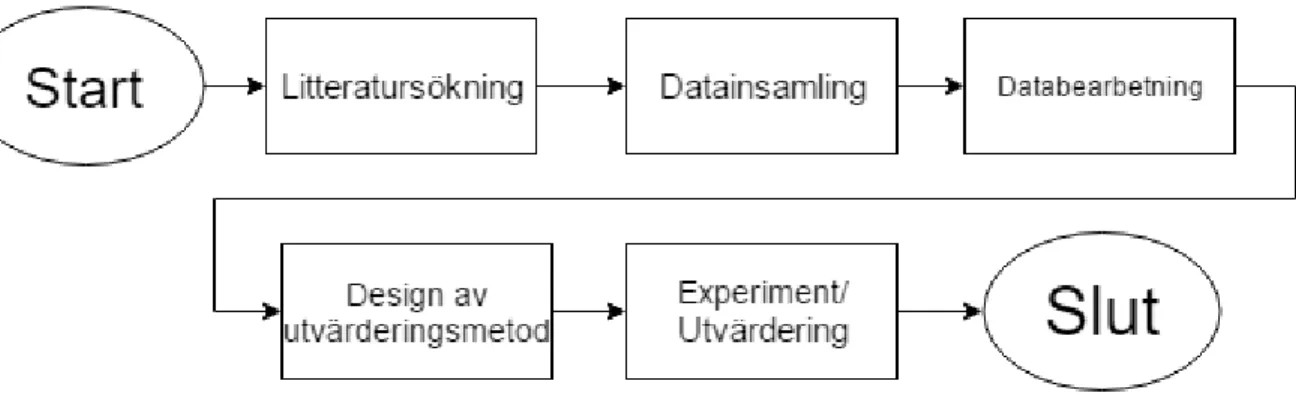
Vår studie utfördes i fem steg enligt illustrationen i Figur 1.
Figur 1: Flödesschema på metodiken.
Första steget var insamling av relevant litteratur. Syftet med vår litteraturstudie var att identifiera forskning som relaterar till vårt problem samt att lära oss om de metoder och teorier som är nödvändiga för att kunna konstruera och utvärdera vår utvärderingsmetod (för kurvanpassningar). Därefter samlade vi in den nödvändiga data som behövdes för vår studie, det vill säga flödesdata från cykelbarometern på Kaptensgatan i Malmö som vi erhöll från Malmö stad. Den väderdata som vi ansåg relevant att inkludera i vårt regressionsproblem (som användes som en del av utvärderingsmetoden) samlade vi in från SMHI via deras öppna API. Den insamlade datan bearbetade vi inför våra experiment.
Därefter utförde vi våra experiment med syftet att utvärdera vår utvärderingsmetod. Avslutningsvis är det viktigt att poängtera att databearbetningen och experimenten är essentiella för utvärderingen av vår metod.
2.1.1 Litteratursökning
Vi började vår sökning i databaserna ACM och Google Scholar. Vi satte tidiga krav på att vi skulle fokusera våra sökningar på vetenskapliga artiklar samt att vi skulle begränsa våra sökningar till artiklar som var tillgängliga i fulltext. Därefter sökte vi i ovan nämnda databaser med utvalda sökord och på så vis fick vi fram ett antal artiklar. I Bilaga A anger vi vilka sökord och filter som användes samt antalet träffar för varje sökning. Utifrån våra första resultat (se bilaga A) samt snow-ball metodik med utgångspunkt i Aspegren och Dahlström (2016) erhöll vi ett första urval. Med snow-ball menas att ur de artiklar som har valts ut som referenser, så tittar man på källorna som
angivits där och på så vis fortsätter tills man finner all relevant forskning. Dessa funna artiklar filtrerades efter ha vi granskat deras abstrakt för att skapa ett än mindre urval. När vi efter denna filtrering kommit fram till ett antal artiklar och uppsatser lästes dessa och de som var relevanta avseende vår studie blev det urval vi slutade på. Exempelvis fokuserade vi på arbeten som främst behandlat attribut och dess urval.
2.1.2 Datainsamling och databearbetning
Den mest grundläggande datan för vår studie är den erhållna cykelflödesdatan från en cykelbarometer vid Kaptensgatan i Malmö. Denna data är insamlad mellan åren 2006 och 2014. Barometern mäter antalet passerande cyklister samt åt vilket håll dessa färdas. I den data vi hade tillgång till anges antalet cyklar per hel timme, alltså finns det 24 datapunkter per dygn. Varje datapunkt (alltså varje timme) innehöll i denna datamängd datum, tidpunkt, antalet cyklister på väg norrut, antalet cyklister på väg söderut och totalt antal cyklister.
Genom vår litteraturstudie så har vi sett att det är viktigt att välja rätt variabler enligt Altshuler m.fl. (2012) och Guyon och Elisseeff (2013). För algoritmerna så har vi valt att avgränsa oss från variabler som vi har misstänkt skulle kunna ge oss brus i vår data. Utifrån Lavessons (2006) arbete så resonerade vi att de olika loven och helgdagarna spenderades på olika sätt av olika människor, vilket kunde ge oss brus i vår data. Vi resonerade att skoldagar var ett attribut som var knutet till veckodagar och kunde försämra våra resultat.
Eftersom väder enligt tidigare forskning (Aspegren och Dahlström,2016), Tsapakis m.fl. (2013), Sigakova m.fl. (2015), Wu m.fl. (2004) och Holmgren m.fl., (2017) visat sig vara en starkt påverkande faktor för cyklisters benägenhet att cykla, valde vi att inkludera väderdata i vår regressionsmodell. Vi inhämtade väderdata via SMHIs öppna API som 3 erbjuder nedladdning av historisk väderdata. Från SMHI inhämtade vi temperatur, vindhastighet och nederbörd för den valda tidsperioden via en väderstation i Malmö.
I vår bearbetning av datan läste, omformaterade och filtrerade vi vår data (cykelbarometerdata och insamlad väderdata) för att datan skulle passa vårt syfte. Vi kontrollerade datamängderna så att där inte fanns avsaknad av data eller avvikelser. Där data saknades interpolerade vi data från föregående och nästkommande år och på så vis gjorde datan komplett. Sedan skapade vi dagliga medelvärden genom att aggregera vår väderdata så att de visade ett värde per dag.
För varje datapunkt (dag), så räknade vi ut det årliga medelvärdet av cyklar per dag genom att summera antalet cyklar från alla dagar under ett år, centrerat i det aktuella året för att sedan dividera med antalet dagar. På så sätt erhöll vi en serie datapunkter där vi använde årsmedelvärden huvudsakligen för att avlägsna årsvariationer. För att estimera långtidstrender för vår tidsserie med cykelbarometerdata anpassade vi sedan polynomiska funktioner från andra till fjortonde graden till vår dataserie med årsmedelvärden. Se bilaga B för grafer med denna data tillsammans med den kurvanpassade datan. I fallen då data saknades utförde vi interpolering mellan kända historiska värden för att kompensera och minska mängden anomalier.
2.1.3 Design av utvärderingsmetod
Den utvärderingsmetod vi har för avsikt att utveckla är essentiellt en sekvens av steg som man kan genomföra för att undersöka hur väl olika anpassade kurvor stämmer överens med den långtidstrend som finns i en tidsserie insamlad från en cykelbarometer.
I vår metod valde vi att använda regression som huvudbeståndsdel för att avgöra hur väl en kurva anpassad till vår cykelbarometer fungerar i praktiken. Mer specifikt använde vi en formulering av målvariabel som användes av Holmgren m.fl. (2017), det vill säga, det värde som man försöker uppskatta med hjälp av regression är avvikelsen mellan antalet registrerade cyklar (vid cykelbarometern) och det värde som den uppskattade långtidstrenden föreslår.
Design Science ligger som en grund för vårt arbete då det är en process enligt March och Smith (1995) som i regel består av två basmoment:
● Konstruktion, som innebär att man skapar en artefakt som syftar till att uppfylla ett verkligt behov. I vårt fall är artefakten en utvärderingsmetod.
● Utvärdering, som innebär att man utvärderar den artefakt som skapats, vilket vi gjort genom att använda vår utvärderingsmetod i experiment.
Enligt Hevner m.fl. (2004) är just utvärderingen en iterativ process, vilket lämpar sig mycket väl till vår metod då vi genom upprepade experiment kunde testa för att sedan utvärdera.
2.1.4 Experiment och Utvärdering
I detta skede utvärderade vi vår utvärderingsmetod genom att konstruera ett antal kurvanpassningar för vår cykelbarometerdata. Var och en av dessa kurvanpassningar undersökte vi med hjälp av den föreslagna
utvärderingsmetoden. Mer specifikt bestod kurvanpassningarna av polynom av olika grad (2-14:e gradens polynom).
För att möjliggöra okulär besiktning av våra kurvanpassningar samt grafiskt illustrera dessa generade vi för varje anpassning en graf innehållande vår ursprungliga data samt aktuell kurvanpassning (se Bilaga B). Med hjälp av vår okulära besiktning valde vi att inte undersöka polynom med högre grad än 14:e graden. Anledningen var att vi kunde se överanpassning mot datan ju högre upp i grad vi gick därefter. Dessutom kunde vi se ändpunktsproblematik, det vill säga att de anpassade polynomen passade grunddatan väldigt dåligt i början och slutet av tidsserien.
2.2 Implementering
I detta steg använde vi programmeringsspråket Python i utvecklarverktyget Notepad Jupyter som är ett webbbaserat utvecklarverktyg som tillhandahåller paket såsom Scikit Learn, statistisk modellering och datavisualisering.
2.3 Metoddiskussion
I fallet av generell forskningsmetodik har vi huvudsakligen använt oss av Design Science, detta för att vår forskning går ut på att konstruera och utvärdera en ny artefakt (i vårt fall en metod). Detta är stammen av Design Science och av den anledningen är Design Science den lämpligaste metoden för vårt arbete (Hevner m.fl. 2004).
Lämpligheten för valet av metod gällande dataanalys (som utvärderingsmetoden bygger på) grundas i att det är en kvantitativ metod. Detta för att exempelvis datan presenteras i form av historisk data i en kvantitativ form, vilket lämpar sig väl för en statistisk analys som maskininlärning. En kvalitativ undersökning kan inte, med till exempel intervjuer och enkätundersökningar, ge den data som behövs för att kunna driva igenom tester med maskininlärningsalgoritmer eller besvara forskningsfrågan (Olsson och Sörensen, 2007).
3. Teoretisk bakgrund
Figur 2. Diagram på grenar inom maskininlärning.
Inledningsvis, för att ge läsaren en övergripande förståelse kring maskininlärning, ger vi en överblick över de huvudsakliga grenarna i maskininlärning. Därefter diskuteras regression som vårt arbete använder sig utav.
Maskininlärning beskrivs ofta som den del av datavetenskapen som handlar om att bygga system som lär sig utifrån erfarenhet. Ofta delar man in området i grenarna övervakad inlärning, oövervakad inlärning, och semiövervakad inlärning. Övervakad inlärning syftar på bygga system som lära sig att generalisera från exempel, där varje exempel består av en vektor med input-värden och ett output-värde. Målet är att lära ett system att förutsäga värdet av en beroende variabel. Inom övervakad inlärning ingår klassificering där den beroende variabeln är ett kategoriskt värde (till exempel, blå, grön eller röd) och regression, där den beroende variabeln är en kontinuerlig variabel. Oövervakad inlärning syftar till att hitta mönster i datamängder där det inte finns kända exempel att lära sig från. Inom oövervakad inlärning ingår till exempel klusteranalys som syftar till att hitta kluster av datapunkter, där punkterna inom samma kluster anses höra ihop på något sätt. Inom semiövervakad inlärning ingår till exempel förstärkt inlärning (eng. Reinforcement learning) där inlärning sker genom att återkoppling sker ibland.
Maskininlärningsalgoritmer syftar till att bearbeta stora mängder data och för att finna olika mönster som i vissa typer av inlärning därefter kan användas för att göra prediktioner.
Inlärning sker i de flesta fall av att man söker efter mönster bland de attribut som beskriver den datamängd man försöker analysera. Exempel på attribut kan vara saker som tidpunkter, veckodagar och säsong. Användningsområdena för maskininlärning är de områden som är dataintensiva, det vill säga där det finns data där man vill kunna beräkna för framtiden. Ett exempel är att analysera priser från flera olika leverantörer på en och samma vara från flera perioder för att kunna utföra en prediktion på kommande priser, eller att finna gemensamma nämnare för varför en viss typ av händelse sker (Groves och Gini, 2015).
3.1 Övervakad inlärning
Som nämns ovan används övervakad inlärning för att träna en algorithm att generalisera från märkta exempel, och inom denna gren ingår huvudsakligen klassificering och regression. Klassificeringen utförs för att träna en algoritm att identifiera vilken klass ett objekt i datan tillhör. Att klassificera datan skapar möjligheter för exempelvis en maskininlärningsalgoritm att fatta beslut och gå vidare med den givna informationen. Inom regression är målet att träna en algorithm att prediktera en kontinuerlig variabel, vilket genomförs genom att studera förhållanden mellan variabler. Att använda sig av regression är vanligt när det kommer till prediktion och prognoser (Hall, 1999).
I algoritmer för klassificering och regression matas inlärningsdata som består av en mängd märkta exempel, där varje exempel består av en vektor med input-värden och ett “korrekt” värde för en beroende variabel. Ofta använder man en mängd exempel (träningsmängden) för att träna algoritmen och en annan mängd exempel (testmängden) för att utvärdera hur väl algoritmen fungerar. Som nämnts ovan är klassificering och regression de två vanligaste inriktningarna inom övervakad inlärning. Klassificering syftar till att prediktera en klass eller kategori på den nya observationen, tex blå, gul eller röd, medans regression handlar om att prediktera ett kontinuerligt värde (Guyon och Elisseeff, 2013). Till exempel,
linjär regression är en metod för att finna en linje som avviker så lite som möjligt från mätvärdena. Den bäst passande linjen är den linje som minimerar summan av avvikelsen mellan punkterna och linjen. ( Hackeling, 2014).
3.2 Oövervakad inlärning
De oövervakade inlärningsalgoritmerna delar upp datan de får efter olika statistiska sammanhang och grupperar den (Hackeling, 2014).
En vanlig typ av inlärningsuppgift inom oövervakad inlärning är klusteranalys som syftar till gruppera datamängder i mindre delmängder som kallas för kluster. Detta genomförs genom att man definierar ett avståndsmått, utifrån de attribut som beskriver ett element. Efter detta beräknas avstånden, vilket möjliggör en visualisering. På detta sätt visar elementen i ett givet kluster likheter baserat på de ingående attributens värden (Lindblad, 2015).
3.3 Korsvalidering
Korsvalidering (eng: Cross-Validation) är en statistisk metod för utvärdering av prediktionsfel (till exempel inom regressionsanalys). Korsvalidering används när man vill vara säker på att algoritmerna har lärt sig att generalisera från datan och inte enbart memorerat den. Metoden bygger på principen att man slumpmässigt delar upp sin träningsmängd i k delar som man sedan tränar och testar maskininlärningsalgoritmer på. I k iterationer tränar man algoritmen på k-1 olika delar och i varje iteration sparar man en del för utvärdering. Man roterar sedan de olika k-delarna så att varje del får agera utvärderingsdata exakt en gång (Hackeling, 2014). En vanlig variant av korsvalidering är 10-delad korsvalidering där datamängden delas upp i 10 olika delar. I detalj tas data upp av metoden så att nio delar (av tio) används för träning en del används för att kontrollera hur väl inlärningen för den givna algoritmen har gått.
3.4 Kurvanpassning
Kurvanpassning är ett tillvägagångssätt som i regel används inom prediktiva analyser för att skapa en kurva som representerar en matematisk funktion som bäst passar datapunkter i en serie av data. Kurvan kan avvika från den faktiska datan vid flera datapunkter eller följa majoriteten av datan. Då kurvan avviker och ignorerar en del datapunkter är det med förhoppningen att finna trender inom datan. I den typ av kurvanpassning som användes i denna studie används en enskild matematisk funktion, med målet att anpassa alla datapunkter till en kurva som har egenskapen att avslöja trender och underlätta prediktion (Lancaster och Salkauskas, 1990).
4. Utvärderingsmetoden
Utvärderingmetoden utgår från idén att jämföra de procentuella avvikelserna mellan det faktiska antalet cyklar som uppmätts av en cykelbarometer och det antal cyklar som föreslås av en kurvanpassning som genomförts på en tidsserie registrerad av cykelbarometern. För att skapa ett basfall för att kunna jämföra kvaliteten för olika kurvanpassningar utgår metoden från de
procentuella avvikelserna från medianen respektive medelvärdet över värdena i tidsserien. Eftersom ett regressionsproblem formuleras som en del av metoden tränas olika regressionsalgoritmer på datan för att sedan med hjälp av 10-delad korsvalidering presentera vilken nivå av precision som uppnåddes för olika regressionsalgoritmer och kurvanpassningar.
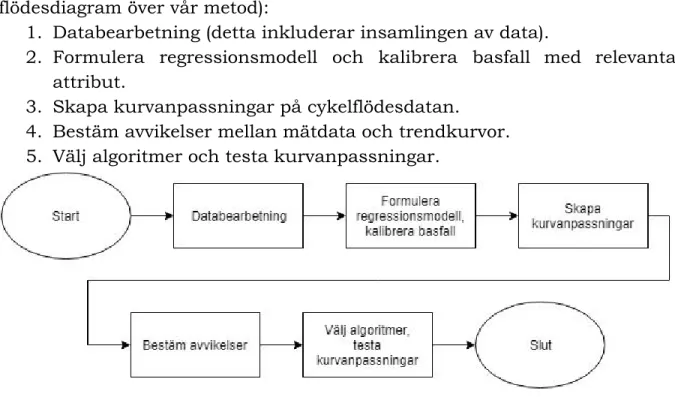
Vår utvärderingsmetod består av följande fem steg (se även Figur 4 för ett flödesdiagram över vår metod):
1. Databearbetning (detta inkluderar insamlingen av data).
2. Formulera regressionsmodell och kalibrera basfall med relevanta attribut.
3. Skapa kurvanpassningar på cykelflödesdatan. 4. Bestäm avvikelser mellan mätdata och trendkurvor. 5. Välj algoritmer och testa kurvanpassningar.
Figur 4. Flödesdiagram över vår utvärderingsmetod.
4.1.1 Databearbetning
I detta steg skall all data som behövs för vidare arbete samlas in. Detta innebär dels den data som man önskar finna en trendkurva på, dels kringliggande data som efter efterforskning anses relevant för att konstruera en lämplig regressionsmodell prediktion av datavärden i den analyserade tidsserien.
När all data är insamlad skall den kontrolleras om det finns tomma dataposter och interpoleras vid behov för att ha ett så komplett set data som möjligt.
4.1.2 Formulera regressionsmodell, kalibrera basfall
I det här steget formuleras det regressionsproblem som senare (i steg 5) används för att utvärdera de trendkurvor, dvs identifiera de attribut som skall ingå i regressionsmodellenförslagsvis kvantitativ data som anses vara relevant. Här rekommenderar vi att undvika data som skapar onödigt brus. I vårt arbete är snö definitivt ett exempel på sådant attribut, då det i Skåne
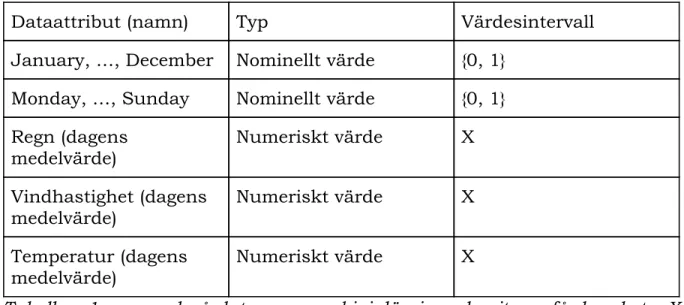
knappt är märkbart och tillför inte mer än det skadar statistiken. Värt att nämna är att detta steg hade kunnat utföras efter steg 4.1.3 då denna data är självständig från den data som det skall utföras prediktion på. Först när datan är sammanställd inför experimenten hör de ihop i en större helhet. Ett exempel på vår data finns i Tabell nr 1.
Dataattribut (namn) Typ Värdesintervall January, …, December Nominellt värde {0, 1}
Monday, …, Sunday Nominellt värde {0, 1} Regn (dagens
medelvärde) Numeriskt värde X
Vindhastighet (dagens
medelvärde) Numeriskt värde X
Temperatur (dagens
medelvärde) Numeriskt värde X
Tabell nr 1, exempel på data som maskininlärningsalgoritmen får bearbeta. X är mängden av reella tal.
4.1.3 Skapa kurvanpassningar
I detta steg genereras de kurvanpassningar på datan som valdes och samlades in samt bearbetades i steg ett. Exempelvis kan polynom användas som kurvanpassning i detta steg.
4.1.4 Bestäm avvikelser
Steg fyra består av att för varje trendkurva (som genererats i Steg 3) räkna ut avvikelserna från datan. Detta innebär att för varje tidpunkt räkna ut hur många procent som skiljer mellan det observerade värdet och det värde som ges av den kurvanpassade trendkurvan. Detta utfördes med formeln nedan:
, där Observation(d) är det registrerade antalet cyklar under dag d och
Kurvvärde(d) är det antal cyklar under dag d som föreslås av kurvanpassningen. Som nämns ovan ger ger formeln ovan den procentuella avvikelsen mellan det observerade antal cyklar och antalet cyklar som ges av
kurvanspassningen för en viss dag. För att ha en bas att utgå ifrån och jämföra med rekommenderar vi dessutom att använda sig av medianen och medelvärdet på den observerade datan.
4.1.5 Välj algoritmer, testa kurvanpassningar
I detta steg görs ett val av vilka algoritmer som skall testas. Detta är ett exempel på regressionalgoritmer:
● Linjär regression ● Ridge regression
● Lasso
När man utvärderar ovanstående algoritmer på en mängd data får man ut ett värde mellan 0 och 1 (mer i detalj om detta i avsnitt 5) utifrån en värdering med korsvalidering . Detta värde visar hur väl algoritmen har tagits sig an datan i sin inlärning.
5. Experiment
Vi utvärderade vår utvärderingsmetod experimentellt på en serie cykelbarometerdata. I avsnittet beskriver vi genomförandet av varje steg. I efterföljande avsnitt presenteras och diskuteras resultatet av utvärderingsprocessen.
5.1 Databearbetning
Inom ramen för vår studie samlade vi in data som vi sedan bearbetade på olika sätt. Gällande behandlingen av datan i något mer detalj så skedde det enligt sekvensen som figuren nedan visar:
Figur 3. Flödesschema av vår databehandlingsprocess.
5.1.2 Datainsamling
Från Malmö stad erhöll vi cykelflödesdata som registrerats av en cykelbarometer placerad längs med cykelstråket vid Kaptensgatan för tidsintervallet 2006-09-13 till 2014-08-31. För detta tidsintervall laddade vi ner nederbörd-, vind- och temperaturdata från SMHI via deras öppna API . 4 4 Opendata-catalog.smhi.se, 2017
Viktigt att nämna här är att den erhållna och insamlade datan innehöll en mätpunkt för varje timme under vårt tidsintervall.
5.1.3 Kontroll av data
I detta skede utförde vi en kontroll på all data så att det inte saknades datapunkter. Gällande cykeldatan kontrollerade vi att antal dagar var rätt, där vi även hade skottår i åtanke. Utöver det så sökte vi av och såg till så att ingen post var helt tom på grund utav till exempel strömavbrott eller vägarbete. Väderdatan kontrollerades på samma sätt så att alla dagar fanns listade inom det givna tidsintervallet. Gällande tomma datapunkter kontrollerades även väderdatan men inte enligt exakt samma kriterier. Då både temperatur, vind och regn kan bestå av värdet noll kontrollerade vi att inga perioder hade tomma dataposter. Vi gjorde även ett medel per dag av nederbörden då denna var uppdelad timvis, och ett medel per dag av vindhastigheten och temperatur då dessa också skiftade och var uppmätta flera gånger per dygn. Därefter la vi till dataattribut som veckodag och månad. Utöver detta tog vi ut medianen och medelvärdet på cykeldatan.
Där data saknades utfördes interpolering som beskrivs nedan. Utöver detta sökte vi även av datan avseende anomalier, det vill säga extrema temperaturer som inte hade varit rimliga. Denna typ av anomalier återfanns ej i datan.
5.1.4 Interpolering
När vi kontrollerade vår data visade det sig att i datamängden innehållande data från cykelbarometern vid Kaptensgatan saknades data under vissa tidpunkter. För att ersätta saknade datavärden använde vi oss av interpolering. Vi återskapade värden för saknade datapunkter i cykelbarometerdatan genom att ta medelvärdet av värdet från motsvarande dag ett år tidigare och ett år senare. Detta kunde vi utföra då vi inte saknade datavärden under det första och sista året. Här vill vi också nämna att vår väderdata från början var komplett, det vill säga inga datavärden saknades.
5.1.5 Sammansättning
I den här fasen av vår databearbetning tog vi datan som tidigare var uppdelad i olika datamängder och sammanförde dem till en enda datamängd. Med denna sammansättning kunde vi nu enklare hantera och modifiera datan vid behov.
5.2 Formulera regressionsmodell, kalibrera basfall
Här modifierades datan, vilket innebär att vi utelämnade attribut innan experimenten, exempelvis om vi önskade att testa vår data utan regn är det
något vi utförde här. Cykelflöden togs även ut som en egen fil innan experimentens påbörjan då maskininlärningsalgoritmerna tar emot dessa separat.
5.3 Skapa kurvanpassningar
Med hjälp av funktioner för kurvanpassning med hjälp av NumPy, som är ett klassbibliotek i Python, skapade vi ett antal kurvanpassningar som vi sedan utvärderade med hjälp av vår utvärderingsmetod som beskrivs nedan. Mer specifikt skapade vi polynom från andra till fjortonde graden. Vi valde att inte anpassa polynom av högre grad än fjorton eftersom vi genomförde en okulär besiktning som visade att dessa inte gav så bra anpassningar. Som vi nämnde i avsnitt 2.1.5 skedde en överanpassning på datan för polynom av högre grad än fjorton.
5.4 Bestäm avvikelser
Som tidigare nämnts, använde vi oss av korsvalidering för att utvärdera hur väl olika regressionsalgoritmer presterar för våra kurvanspassningar. Korsvalidering ger ett värde (CRE - Cross Evaluation Score) som i regel ligger mellan 0 och 1, vilket är en indikation på hur träffsäkert algoritmen lyckas prediktera absoluta antalet cyklar. Dock kan det vara ett negativt värde om algoritmen inte klarade datan väl alls, dvs vi får en negativ korrelationskoefficient. Om vi får ett negativt tal så betyder det att vi uppnått negativ korrelation mellan det observerade värdet och det estimerade värdet. Målet var att uppnå ett värde så nära 1 som möjligt. Det var här den kurvanpassade datan kommer med i bilden då en förhoppning var att få ett resultat närmare 1 med den, jämför med när prediktion utförs mot absoluta antalet cyklar (se Holmgren mfl., 2017). Utöver detta hade vi även med median och medelvärde för jämförelse.
5.5 Välj algoritmer, testa kurvanpassningar
Vårt val var en kombination av linjära samt icke-linjära regressionsalgoritmer. Se nedan:
● Stödvektormaskin: Polynomisk kärna (3:e graden), RBF kärna, Sigmoid kärna och linjär kärna
● Linjär regression ● Ridge regression
● Bayesian Ridge Regression
● Lasso
Dessa algoritmer testades enligt modellen som sattes, resultaten återges i avsnitt 6.
6. Resultat, analys och diskussion
6.1 Resultat från experiment
Tabellerna nedan visar våra resultat från experimenten då vi analyserat den interpolerade datan utan kurvanpassning (median och medelvärde för avvikelsevärdet) samt med kurvanpassning (polynom av 2-14:e graden) med hjälp av olika maskininlärningsalgoritmer.
6.1.1 Test på medianen i den normaliserade cykeldatan Tabell 1
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.44 SVM - RBF kernel 0.43 SVM - Sigmoid kernel -28.59 SVM - Linear kernel 0.40 Linear Regression 0.37 Ridge Regression 0.37 Lasso 0.36
Bayesian Ridge Regression 0.38
6.1.2 Test mot medelvärdet på den normaliserade cykeldatan Tabell 2
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.44
SVM - RBF kernel 0.43
SVM - Sigmoid kernel -31.25
Linear Regression 0.37
Ridge Regression 0.37
Lasso 0.35
Bayesian Ridge Regression 0.38
6.1.3 2:a gradens polynom Tabell 3
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.64 SVM - RBF kernel 0.66 SVM - Sigmoid kernel -146.25 SVM - Linear kernel 0.66 Linear Regression 0.67 Ridge Regression 0.67 Lasso 0.35
Bayesian Ridge Regression 0.67
6.1.4 3:e gradens polynom Tabell 4
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.64 SVM - RBF kernel 0.65 SVM - Sigmoid kernel -143.22 SVM - Linear kernel 0.66 Linear Regression 0.67 Ridge Regression 0.67 Lasso 0.35
6.1.5 4:e gradens polynom Tabell 5
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63 SVM - RBF kernel 0.65 SVM - Sigmoid kernel -142.93 SVM - Linear kernel 0.66 Linear Regression 0.67 Ridge Regression 0.67 Lasso 0.35
Bayesian Ridge Regression 0.67
6.1.6 5:e gradens polynom Tabell 6
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63 SVM - RBF kernel 0.65 SVM - Sigmoid kernel -142.90 SVM - Linear kernel 0.66 Linear Regression 0.67 Ridge Regression 0.67 Lasso 0.34
Bayesian Ridge Regression 0.67
6.1.7 6:e gradens polynom Tabell 7
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63
SVM - Sigmoid kernel 0.16
SVM - Linear kernel 0.28
Linear Regression 0.31
Ridge Regression 0.31
Lasso 0.32
Bayesian Ridge Regression 0.32
6.1.8 7:e gradens polynom Tabell 8
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.40 SVM - RBF kernel 0.38 SVM - Sigmoid kernel 0.16 SVM - Linear kernel 0.28 Linear Regression 0.31 Ridge Regression 0.31 Lasso 0.32
Bayesian Ridge Regression 0.32
6.1.9 8:e gradens polynom Tabell 9
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.39 SVM - RBF kernel 0.38 SVM - Sigmoid kernel 0.16 SVM - Linear kernel 0.28 Linear Regression 0.31 Ridge Regression 0.31 Lasso 0.31
Bayesian Ridge Regression 0.31
6.1.10 9:e gradens polynom Tabell 10
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.39 SVM - RBF kernel 0.38 SVM - Sigmoid kernel 0.16 SVM - Linear kernel 0.27 Linear Regression 0.30 Ridge Regression 0.30 Lasso 0.31
Bayesian Ridge Regression 0.31
6.1.11 10:e gradens polynom Tabell 11
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.39 SVM - RBF kernel 0.38 SVM - Sigmoid kernel 0.16 SVM - Linear kernel 0.28 Linear Regression 0.31 Ridge Regression 0.31 Lasso 0.31
Bayesian Ridge Regression 0.31
6.1.12 11:e gradens polynom Tabell 12
Algoritm Cross Evaluation Score
SVM - RBF kernel 0.65 SVM - Sigmoid kernel -146.14 SVM - Linear kernel 0.65 Linear Regression 0.66 Ridge Regression 0.66 Lasso 0.34
Bayesian Ridge Regression 0.66
6.1.13 12:e gradens polynom Tabell 13
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63 SVM - RBF kernel 0.65 SVM - Sigmoid kernel -147.44 SVM - Linear kernel 0.65 Linear Regression 0.66 Ridge Regression 0.66 Lasso 0.34
Bayesian Ridge Regression 0.66
6.1.14 13:e gradens polynom Tabell 14
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63
SVM - RBF kernel 0.65
SVM - Sigmoid kernel -140.54
Linear Regression 0.66
Ridge Regression 0.66r
Lasso 0.34
Bayesian Ridge Regression 0.66
6.1.15 14:e gradens polynom Tabell 15
Algoritm Cross Evaluation Score
SVM - Polynomial kernel 0.63 SVM - RBF kernel 0.65 SVM - Sigmoid kernel -149.60 SVM - Linear kernel 0.65 Linear Regression 0.66 Ridge Regression 0.66 Lasso 0.34
Bayesian Ridge Regression 0.66
6.2 Analys
I resultaten från vårt experiment kan man se att de olika regressionsalgoritmerna genererar CRE-värden mellan 0.36 och 0.44 när vi tränade vår regressionsmodell avseende avvikelser från medianen. När vi istället använde avvikelsen från medelvärdet såg vi en liten skillnad till det sämre med CRE-värden mellan 0.35 och 0.44. I båda fallen presterade SVM med Polynomial kernel bäst och Lasso sämst om vi bortser från SVM med Sigmoid kernel, som gav oss ett negativt värde. Just mot medianen och medelvärdet var SVM i framkant med de olika kärnorna, där den sämsta var SVM. I båda fallen var SVM med Linear kernel sämst (om vi bortser från Sigmoid kernel) och den bästa regressionsalgoritmen var Bayesian Ridge Regression.
I testet med andra gradens polynom ser vi att alla algoritmer presterar bättre än föregående test och att de SVM-algoritmer som presterat bättre på de två första testerna presterar sämre. Lasso hänger dock inte med och presterar likvärdigt som i de första två testerna. Sigmoid ger fortfarande
poäng utanför intervallen mellan 0 och 1. Den bästa SVM algoritmen var den med Linear Kernel som gav oss ett resultat på 0.66 och Bayesian Ridge Regression presterade bäst med 0.67.
Från den andra gradens till den 5:e gradens polynom ser vi små skillnader till det sämre i varje test tills vi kommer till den 6:e gradens polynom. Här mer än halveras poängen för algoritmerna förutom SVM med Polynomial- eller RBF-kärna. Den starkaste algoritmen för 5:e graden polynom är Linear Regression som tappar med 52.44% från 0.67 till 0.31. Ett liknande fall sker för de andra regressionsalgoritmerna. Lasso presterar fortfarande dåligt men har inte lika stor skillnad jämfört med de andra. SVM med Sigmoid kernel börjar att ge resultat inom den accepterade intervallen men presterar sämst och ger aldrig resultat över 0.16. I 7:e gradens polynom så är det försämringar där även SVM med Polynomial och RBF kernel presterar markant sämre och tappar mer än en tredjedel i sina poäng. Från att SVM med RBF-kärna presterat 0.65 och SVM med Polynomial kernel 0.63 så hamnar RBF på 0.38 vilket är en nedgång med 40.60% och Polynomial på 0.40 vilket är en nedgång med 36.79%.
I testerna med 8:e till 9:e gradens polynom så ser vi att algoritmerna presterar sämre för varje test. I 10:e gradens polynom så presterar de lite bättre, medans de för 11:e gradens polynom får skarpa förbättringar. Bayesian Ridge Regression presterar 113.61% bättre än 10:e gradens polynom och i 12:e gradens test så ökar den minimalt men ytterligare med 0.02%, vilket är 1.44% sämre än 2:e gradens polynomtest.
Genom testerna så ser vi att Bayesian Ridge Regression presterar bäst genom de olika graderna av kurvanpassning. Förutom nedgången i mitten där SVM med Polynomial kernel presterade bättre.
Median
SVM med polynom och RBF presterade bäst i detta test. SVM - Polynomial kernel 0.44 SVM - RBF kernel 0.43 Medelvärde
SVM med polynom och rbf gav bäst resultat
SVM - Polynomial kernel 0.44
2:e gradens polynom
Bayesian Ridge Regression 0.67
3:e gradens polynom
Bayesian Ridge Regression 0.67 -0.44%*
* Procentuella förändringen jämfört med föregående test.
4:e gradens polynom
Bayesian Ridge Regression 0.67 -0.07%*
* Procentuella förändringen jämfört med föregående test.
5:e gradens polynom
Linear Regression 0.67
-0.27%*
* Procentuella förändringen jämfört med föregående test.
6:e gradens polynom
SVM - Polynomial kernel 0.63 -0.29%*
* Procentuella förändringen jämfört med föregående test.
SVM - RBF kernel 0.65
-0.13%*
* Procentuella förändringen jämfört med föregående test.
7:e gradens polynom
SVM - Polynomial kernel 0.40 -36.79%*
* Procentuella förändringen jämfört med föregående test.
8:e gradens polynom
SVM - Polynomial kernel 0.39 -0.42%*
* Procentuella förändringen jämfört med föregående test.
9:e gradens polynom
SVM - Polynomial kernel 0.39 -0.47%*
* Procentuella förändringen jämfört med föregående test.
10:e gradens polynom
SVM - Polynomial kernel 0.39 0.20%*
* Procentuella förändringen jämfört med föregående test.
11:e gradens polynom
Bayesian Ridge Regression 0.66 113.61%*
* Procentuella förändringen jämfört med föregående test.
12:e gradens polynom
Bayesian Ridge Regression 0.66 0.02%*
* Procentuella förändringen jämfört med föregående test. 13:e gradens polynom
Bayesian Ridge Regression 0.66
14:e gradens polynom
Bayesian Ridge Regression 0.666181033646 -0.13%*
* Procentuella förändringen jämfört med föregående test.
6.3 Diskussion
Vi kan se att där algoritmerna presterar bäst så är kurvanpassningarna inte överanpassade till den faktiska datan, då den visar en bredare trend som i tabellerna som visar 2:e gradens till 5:e gradens polynom. Där kan man se en trend som sträcker sig över år. De fungerar även bra vid 11:e gradens polynom då kurvan ligger närmare datan och kan ge en bild över trender under kortare tidsperioder.
Så hur kan hur kan långtidstrender i form av kurvanpassningar i cykelbarometerdata utvärderas? Baserat på våra experiment föreslår vi att de kan utvärderas med hjälp av vår metod. Gällande metoden i sig och vårt urval av attribut anser vi att noggrannhet i urvalsprocessen är synnerligen
viktigt. Vi har tidigare benämnt vintern år 2011 som går att utläsa i vår insamlade data och även kurvanpassningarna. Trots detta är inte snö ett attribut vi har med i våra tester. Detta beror på att nederbörden även då i Skåne inte var konsekvent utan temperaturen var det som vi anser vara den stora påverkan. Som tidigare skrivet har bristfällig data mer skadlig påverkan på en maskininlärningsalgoritm. Möjligen hade detta kunnat undersökas närmare men det fanns ingen data på snödjup då det inte uppmättes. På grund utav detta ser vi temperaturen som den starkare faktorn jämfört med snö i detta fallet.
Altshuler m.fl. (2012), Guyon och Elisseeff (2013), Etzioni m.fl. (2003) betonar i sina artiklar vikten av att välja bra attribut och med uppbackning av vad Lavesson (2006) påpekar angående att vissa attribut kan vara direkt skadliga för resultaten, så har vi kanske varit för restriktiva i vad vi har vågat ha med i vår testdata och därför inte fått lika bra resultat som Holmgren m.fl. (2017). Då våra tester har liknande data men inte exakt samma urval av attribut och vi har även använt olika algoritmer. Vi hänvisar här till Kohavi och John (1997) som visar att attributdata som fungerar väl med en algoritm inte nödvändigtvis behöver fungera väl med en annan och därigenom så drar de slutsatsen att man borde välja attributdata utifrån vald algoritm.
6.4 Validitetshot
Utvärderingsmetoden testades endast på kurvanpassning med polynom. Splines,exempelvis, är en annan form av kurvanpassning som hade kunnat ge andra resultat. Dock ser vi inte valet av metod för kurvanpassning som avgörande för hur väl vår utvärderingsmetod fungerar, utan den förväntas fungera oavsett om man använder polynom, splines, eller någon annan metod för generering av kurvanpassningar.
Urvalet av attribut kan vara ett hot mot validitet i vår studie då den är avgränsad till inte bara vad vi fått fram i litteraturstudien utan även vad för data vi faktiskt kunna komma åt, dessutom är en del attribut mindre lämpade för maskininlärning och de kan därför skapa mer brus än klarhet vid inlärning.
7. Slutsatser och framtida arbete
7.1 Slutsats
Baserat på resultaten från vår studie drar vi slutsatsen att långtidstrender i form av kurvanpassningar kan utvärderas med vår metod.
Mer specifikt visar våra experiment att de maskininlärningsalgoritmer som tränas som en del av vår utvärderingsmetod klarar prediktion olika väl för olika kurvanpassningar, och på sätt ger vår metod en bra indikation på kvaliteten på olika kurvanpassningar. Våra resultat visar också att kurvanpassningar av tidsserien från en cykelbarometer bidrar till bättre prediktioner av cykelflöden.
För att underlätta identifieringen av långtidstrender och underlätta lösningen av problemen vi formulerade fungerade som bäst vid 2:a gradens polynom, 11:e och 12:e graderna av polynom i spektrumet vi valt. Vid de högre graderna fanns det en större risk för överanpassning på datan. Det finns även en möjlighet att tidsserien vi hanterat inte är lämplig för just polynom av en högre grad.
När det kommer till regressionsalgoritmerna kom vi fram till att Bayesian Ridge Regression var den som verkar fungera bäst av som har testats under experimenten.
Gällande specifikt kurvanpassningar fungerade olika regressionsmetoder olika bra beroende på vilken polynom som användes vid kurvanpassningen. Därför har vi kommit fram till att det är viktigt att ta med olika regressionsalgoritmer i en utvärderingsmetod. Annars kommer inte resultatet vara meningsfullt.
7.2 Framtida arbete
Som framtida arbete föreslår vi att studera andra typer av kurvanpassningar såsom splines, just eftersom våra resultat antytt att vår data i sig inte nödvändigtvis är linjär och till skillnad från splines så kan kurvanpassning med polynom skapa kurvavvikelser i start och slutpunkter när man kommer till högre graden av polynom. En sådan studie skulle kunna bidra till att ytterligare utvärdera vår utvärderingsmetod, till att uppnå förbättrade prediktioner av cykelflöden med hjälp av maskininlärning.
För att ytterligare utvärdera vår utvärderingsmetod föreslår vi att genomföra experiment vid andra mätstationer. Malmö har fler cykelbarometrar och det finns cykelbarometrar även i andra städer. Alltså hade framtida arbete kunnat vara att utöka testningen av metoden, utröna om den fortfarande fungerar med nya datamängder och attribut av samma typ som vi använt fast på nya platser och kanske över andra tidsperioder.
Ett spännande användingsområde för metoden som utvecklats skulle vara att utföra en kvalitativ studie kring vilka attribut som borde användas som indata utöver det som redan använts. Detta skulle kunna vara allt från enkätundersökningar till litteraturanalyser. I syftet att utröna vilka andra faktorer som påverkar en cyklist.
8. Referenser
A. Vehtari och J. Lampinen. Bayesian input variable selection using posterior probabilities and expected utilities. Report B31, 2002.
Altshuler, Y., Aharony, N., Fire, M., Elovici, Y. and Pentland, A. 2012. Incremental Learning with Accuracy Prediction of Social and Individual Properties from Mobile-Phone Data. 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Conference on Social Computing.
Aspegren, Sebastian, och Jonas Dahlström. En Jämförelse Av Maskininlärningsalgoritmer För Uppskattning Av Cykelflöden Baserat På Cykelbarometer- Och Väderdata. Malmö: Malmö Högskola, 2016.
Bi, J., Sun, J., Wu, Y., Tennen, H. och Armeli, S. 2013. A machine learning approach to college drinking prediction and risk factor identification. ACM Transactions on Intelligent Systems and Technology, 4(4), pp.1-24.
Claes, S., Slegers, K. and Vande Moere, A. 2016. The Bicycle Barometer.
Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems - CHI '16.
Etzioni, O., Tuchinda, R., Knoblock, C. och Yates, A. 2003. To buy or not to buy. Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining - KDD '03.
Groves, W. och Gini, M. 2015. On Optimizing Airline Ticket Purchase Timing. ACM Transactions on Intelligent Systems and Technology, 7(1), pp.1-28.
Guest, Philip George. Numerical Methods Of Curve Fitting. 1st ed. Cambridge: Cambridge University Press, 2013. Print.
Guyon och A. Elisseeff. An introduction to variable and feature selection. Journal of Machine Learning Research, 3:1157–1182, 2003
Hackeling, G. 2014. Mastering Machine Learning with scikit-learn. Birmingham, UK: Packt Publishing Ltd, pp. 8 - 13.