Examen: Kandidatexamen
Handledare: Helena Holmström Olsson Huvudområde: Datavetenskap
Andrabedömare: Göran Hagert Program: Affärssystem
Slutseminarie: 2014-06-02
Examensarbete
15 högskolepoäng, grundnivåBig Data - Stort intresse, nya möjligheter
Problematik kring appliceringen av Big Data-analyser för
undersökningsföretag
Författare
Hampus Hellström Oscar Ohm
Abstract
Today’s information society is consisting of people, businesses and machines that together generate large amounts of data every day. This exponatial growth of datageneration has led to the creation of what we call Big Data. Among other things the data produced, gathered and stored can be used by companies to practise knowledge based business development. Traditionally the methods used for generating knowledge about a business environment and market has been timeconsuming and expensive and often conducted by a specialized research company that carry out market research and surveys. Today the analysis of existing data sets is becoming increasingly valuable, and the research companies have a great opportunity to mine value from societys huge amounts of data.
The study is designed as an exploratory case study that investigates how the research companies in Sweden work with these data sets, and identifies some of the challenges they face in the application of Big Data analysis in their business. The results shows that the participating research companies are using Big Data tools to steamline existing business processes and to some extent use it as a complementary value to traditional research and surveys. Although they see possibilities with the technology, the participating companies are unwilling to drive the development of new business processes that are supported by Big Data analysis. There is a challenge identified in the lack of competence prevailing in the Swedish market. The result also covers some of the ethical aspects research companies need to take into consideration. The ethical issues are especially problematic when data, that can be linked to an individual, is processed and analysed in real time.
Sammanfattning
Dagens informationssamhälle har bidragit till att människor, maskiner och företag genererar och lagrar stora mängder data. Hanteringen och bearbetningen av de stora datamängderna har fått samlingsnamnet Big Data. De stora datamängderna ökar bland annat möjligheterna att bedriva kunskapsbaserad verksamhetsutveckling. Med traditionella metoder för insamling och analys av data har kunskapsbaserad verksamhetsutveckling tillämpats genom att skicka ut resurskrävande marknadsundersökningar och kartläggningar, ofta genomförda av specialiserade undersökningsföretag. Efter hand som analyser av samhällets befintliga datamängder blir allt värdefullare, har undersökningsföretagen därmed en stor utvecklingsmöjlighet att vaska guld ifrån samhällets enorma datamängder.
Studien är genomförd som en explorativ fallstudie som undersöker hur svenska undersökningsföretag arbetar med Big Data och identifierar några av de utmaningar de står inför tillämpningen av Big Data analyser i verksamheten. Resultatet visar att de deltagande undersökningsföretagen använder Big Data som verktyg för att effektivisera befintliga processer och i viss mån komplettera traditionella undersökningar. Trots att man ser möjligheter med tekniken arbetar man passivt med utvecklingen av nya processer som ämnas stödjas av Big data analyser. Och det finns en utmaning i en bristande kompetens som råder på marknaden. Resultatet behandlar även en etisk aspekt undersökningsföretagen måste ta hänsyn till, speciellt problematiskt är den när data behandlas och analyseras i realtid och kan kopplas till en individ.
3
Innehållsförteckning
1
INTRODUKTION ... 5
1.1
BIG DATA-‐FENOMENETS INTÅG ... 5
1.2
PROBLEMDISKUSSION ... 6
1.3
PROBLEMSTÄLLNING & SYFTE ... 7
2
BAKGRUND ... 8
2.1
BIG DATA:S TEORETISKA DEFINITION ... 8
2.2
MÖJLIGHETER & UTMANINGAR ... 9
2.2.1
De övergripande möjligheterna med Big Data ... 9
2.2.2
Problematik vid tillämpning av Big Data ... 10
3
METOD ... 12
3.1
EPISTEMOLOGI & ONTOLOGI ... 12
3.2
UNDERSÖKNINGSDESIGN ... 12
3.2.1
Forskningsdesign ... 13
3.2.2
Metodansats ... 13
3.2.3
Forskningsstrategi ... 13
3.3
FORSKNINGSPROCESSEN ... 14
3.3.1
Urval ... 14
3.3.2
Semistrukturerad intervju ... 15
3.3.3
Val inför intervju ... 15
3.3.4
Genomförande av intervjuer ... 16
3.3.5
Analysansats ... 17
3.4
LITTERATURSTUDIE ... 17
3.5
VALIDITET OCH RELIABILITET ... 18
4
RESULTAT ... 20
4.1
KATEGORIER ... 20
4.2
FF1: UNDERSÖKNINGSFÖRETAGENS SITUATION ... 21
4.2.1
Definitionen ur undersökningsföretagens perspektiv ... 21
4.2.2
Intresse ... 22
4.3
FF2: UTMANINGAR ... 23
4.3.1
Problematik ... 23
4.3.2
Bristande kompetens ... 24
5
ANALYS ... 26
5.1
PASSIV MARKNAD – PASSIV UTVECKLING ... 26
5.2
PRAKTISK PROBLEMATIK ... 27
5.2.1
Balansen mellan statistisk och etisk problematik ... 27
5.2.2
Teknisk problematik ... 27
6
SLUTSATS ... 29
6.1
SLUTSATSER ... 29
6.2
METODOLOGISK REFLEKTION ... 29
6.3
VIDARE FORSKNING ... 30
6.4
PRAKTISKT BIDRAG ... 30
4
Figurbeskrivning:
Figur 1 - Big Datas 3V, s.8
Figur 2 - Studiens forskningsprocess, s.14 Figur 3 – Huvudbegrepp från empiri, s.20 Figur 4 – Kategorier, s.21
Tabeller:
Tabell 1 – Val inför intervjuer, s.16 Tabell 2 – Detaljer kring intervjuer, s.17
Tabell 3 – Beskrivning av litteratursökningen, s.18 Tabell 4 – Analys av intern validitet, s.18
5
1 I
NTRODUKTION
I introduktionen presenteras och diskuteras studiens bakgrund, ämne och kontext i en teoretisk problematisering för att komma fram till den problemställning som ligger till grund för studien.
1.1 Big data-fenomenets intåg
Idag lever stora delar av mänskligheten i ett informationssamhälle i snabb utveckling. Enligt Singh & Singh [21] skapas 2.5 exabytes data varje dag, och 90% av all data som finns är skapad de senaste två åren. Den exponentiella ökningen av datamängden i samhället förväntas att fortsätta. Inom ett decennium kommer data i samhället öka med 50 gånger vad den är idag [1], vilket erbjuder stora möjligheter för olika intressenter om det finns tekniska förutsättningar och kompetens för att behandla all data. Som resultat av dessa enorma datamängder har begreppet Big Data myntats, och idag kan Big Data anses ligga i centrum för modern forskning och företagande [18].
Enligt Seebode et al [22] är Big Data är ett begrepp för stora datamängder från varierande datakällor. Det är inte bara datakällorna som varierar utan även hur data fördelas, datas format samt hur data bearbetas. Mayer-Schönberger & Cukier [12] redovisar ett exempel på när Big Data-analyser applicerades i en situation där traditionella verktyg och metoder för dataanalys inte var tillräckligt. År 2009 spred sig ett nytt influensavirus kallat H1N1 i snabb takt. För att stoppa spridningen av viruset behövdes information om var smittan fanns och det var problematiskt att spridningsbilden hade en fördröjning på en till två veckor med traditionella metoder för att kartlägga en smittohärd. Bara några veckor innan H1N1 skapade huvudrubriker publicerade Google en artikel i den vetenskapliga tidskriften Nature. Artikeln visade hur Google
kunde förutse vinterinfluensans spridning i USA. Google kunde förutspå
spridningen av vinterinfluensan genom att använda sig av de tre miljarder sökningar som de får varje dag. Google tog 50 miljoner av de vanligaste sökorden amerikanarna använde och jämförde dessa med data från center of disease control and prevention (CDC) som beskrev hur influensan spridit sig
mellan 2008 och 2009. Med sin stora mängd data och analysmöjligheter kom
Google fram till att 45 sökord hade stark korrelation med spridningen av
influensan. När H1N1 bröt ut visade sig Googles metod bidra med mer
användbar och tidsprecis information än CDC:s information som var baserad på mer traditionella metoder.[12]
I exemplet ovan användes varierande datakällor från Google och CDC med varierande format, vilket kan kopplas till Seebodes et al. [22] definition av Big Data. Spridningen av H1N1 viruset är bara ett exempel av de tillämpningsområden Big Data kommer att ha. Enligt Mayer-Schönberger & Cukier [12] kommer fenomenet Big Data utifrån samhällets förmåga att utnyttja data på nya sätt för att hitta nya mönster i datamängder för att skapa förståelse och helt nya varor och tjänster.
6
Sökmotorer som Google är inte den enda källan som på senare år bidragit till
samhällets ökade datamängd. Tack vare Web 2.01, med sociala-medier i
huvudsak, skapas varje dag stora mängder data om samhället och individers beteende. Bara Facebook har över 955 miljoner aktiva användarkonton varje månad som bidrar till 140 miljarder bilduppladdningar, 125 miljarder vänförfrågningar och varje dag registreras 2.7 miljarder “likes” och kommentarer [19]. Även ny teknik bidrar till ökad datamängd, till exempel mobil och sensor-baserad data från diverse produkter som Smartphones, Tablets, Active Bracelets och andra uppkopplade sensorer från moderna bilar, truckar och andra uppkopplade objekt [23,11]. Dagens datamassa består därmed av mängder av data producerat av människor, såväl som maskiner och objekt. Men var finns värdet i datamängderna? Och hur tillgodogör vi oss värdet?
Tillgången till stora datamängder från olika källor innebär nya förutsättningar för mycket. Enligt Karlsson [9] förändrars bland annat förutsättningarna för
att arbeta med kunskapsbaserad verksamhetsutveckling2. Med traditionella
metoder för insamling och analys av data har kunskapsbaserad verksamhetsutveckling tillämpats med exempelvis kunskap om ett företags marknad utifrån marknadsundersökningar eller kartläggningar, ofta genomförda av specialiserade undersökningsföretag. Traditionellt har undersökningsföretagen använt sig av insamlingsmetoder som webbpaneler, enkäter, fokusgrupper mm. Men med dagens redan producerade datamängder finns en möjlighet att flytta fokus från den traditionella datainsamlingen, vilken anses resurskrävande, till analys av befintlig data och rådgivning [9].
1.2 Problemdiskussion
Big Data analyser- är ett begrepp inom Big Data som syftar till att göra rådata till information som är av värde för någon [12]. Men det ligger en problematik i den begränsade och därmed dyra kompetensen för utveckling av Big Data analyser. Med dagens prognoser så kommer datamängden inom det närmaste årtiondet att öka med 5000%, medan specialister som arbetar med data endast kommer att öka med 50% [18]. Sagiroglu och Sinanc [18] samt Chen et all [5] styrker varandras resonemang om att det måste vidtas någon form av förändring för att det ska vara möjligt att analysera framtiden och nutidens stora datamängder. Även Katal et al. [10] belyser att komplexiteten med att analysera de stora datamängderna innebär ett stort behov av specialiserad kompetens. Vidare menar Sagiroglu och Sinanc [18] att Big Data är i ett stadie där företag måste attrahera ny kompetens med diversifierade färdigheter. Och inte bara med tekniska färdigheter utan även inom statistik, ekonomi och organisation.
1 Web 2.0 – För att en hemsida ska kallas Web 2.0 ska användaren kunna bidra till sajtens innehåll & ha kontroll över sin information.
2 Kunskapsbaserad verksamhetsutveckling – Möjligheten för företag att ta mer rationella taktiska, strategiska och operationella beslut grundade i riklig kunskap om verksamheten och omvärlden.
7
Googles chefsekonom Hal Varian [4] uttalade sig om att data är billigt och enkelt att tillgå, men analys och tolkning av data kommer vara värdefull. Och de undersökningsföretag som i många år arbetat med framtagandet av statistiskt material, marknadsundersökningar och analyser har därmed en stor utvecklingsmöjlighet i den Big Data revolution som förutspås av forskare [13], [12].
“So what’s getting ubiquitous and cheap? Data. And what is complementary to data? Analysis. So my recommendation is to take lots of courses about how to manipulate and analyze data: databases, machine learning, econometrics, statistics, visualization, and so on.” [4]
1.3 Problemställning & Syfte
Det potentiella värdet i Big Data analyser gör det nödvändigt för undersökningsföretag att lyfta fram de utmaningar som finns vid tillämpningen av Big Data i deras verksamhet.
För att få en tydligare struktur på studien delas den in i två forskningsfrågor. FF1: Hur arbetar undersökningsföretag med Big Data idag?
FF2: Vilka utmaningar finns för undersökningsföretag vid tillämpningen av Big Data analyser?
Den första forskningsfrågan anses relevant då dagens förutsättningar är oklara och dessa förutsättningar är nödvändiga att förstå för att enklare ge svar åt den andra forskningsfrågan, vilken ämnar uppfylla studiens syfte. Syftet med studien är att utforska vilka utmaningar det kan finnas för tillämpningen av Big Data analyser i verksamheten hos undersökningsföretag. Där resultatet kan bidra till att underlätta en effektivisering och utveckling av
undersökningsföretagens verksamhet och på så vis skapa nya
8
Figur 1 Big Datas 3V [18B]
2 B
AKGRUND
Kapitlet redogör för en teoretisk fördjupning i ämnet, vilken senare används för att analysera studiens empiriska material. Vald teori är ämnad att förklara och analysera empirin och att skapa en teoretisk förståelse relaterat till studiens syfte.
2.1 Big Data:s teoretiska definition
Big Data är ett begrepp för stora datamängder från varierande datakällor. Det är inte bara datakällorna som varierar utan även hur data bearbetas, fördelas samt olika format på data [22]. Ur ett teoretiskt perspektiv går det att fördjupa sig och dela upp ovanstående definition för att skapa en tydligare förståelse. Figur 1 illustrerar begreppet Big Data där de delas upp i tre kategorier. Första kategorin är Volume, vilket syftar på stora mängder data som inte kan hanteras med ”normala” IT-strukturer som idag används av de flesta organisationer. Andra kategorin är Variety, variation i datakällor gör att datamängderna blir stora och komplexa. Det beror på att Big Data innehåller olika typer av data i form av, ostrukturerad, semistrukturerad och strukturerad data. När exempelvis ljud, bild och text ska användas inom till exempel verksamhetsutveckling krävs en bearbetning av data för att den ska vara användbar. Den tredje kategorin är Velocity vilket syftar till att data produceras, bearbetas och analyseras i realtid3, nära realtid eller batch4. [18]
Sagiroglu och Sinanc [18] menar att det är realtidsdata i Velocity som är den mest kraftfulla data då organisationer kan ta reaktiva beslut i ett tidigt stadie, och att data har mest relevans när den produceras då den ständigt förändras.
3 Realtid - det faktum att ett fenomen existerar eller förändrar sig i nuet, utan att tidsmässigt förvrängas, försenas genom buffert e.dyl, eller kronologiskt förenklas.
9
2.2 Möjligheter & Utmaningar
2.2.1 DE ÖVERGRIPANDE MÖJLIGHETERNA MED BIG DATA
Med hjälp av Big Data kan en organisation skapa sig en helhetsbild om hur organisationen fungerar och då ta bättre beslut [24]. Med modellen The blind
men and the giant elephant beskriver de hur otillräcklig information kan leda
till felaktiga slutsatser. Modellen beskriver att det kan vara svårt att dra slutsatser om ett fenomen när man inte får med helhetsbilden. Om tre blinda män känner på olika delar av en elefant så kan männen få olika uppfattningar om vad det är de tar på. När en man känner på snabeln kan han få uppfattningen att det är en slang, när en annan känner på benet tror han att det är ett träd och när den sista drar i svansen tror han att det är ett rep. Genom att förklara för männen att de tar på delar av samma djur så kan de dra slutsatsen att de känner på en elefant. Sensmoralen är att en addition av uppfattad kunskap kan leda till förståelse av ett större fenomen. På samma sätt kan Big Data hjälpa organisationer att få en helhetsbild vid beslutsfattande och ta rationella beslut. Sagiroglu och Sinanc [18] ger förslag på användningsområden där Big Data kan leverera en helhetsbild för ett effektivare arbete. De tar bland annat upp stadsplanering där data från trafikanter sparas och används för att effektivisera trafikflöden i städerna. Samma princip kan användas i sjukvården för individuella bedömningar vid diagnostisering. Det kan göras genom att använda personlig data om arvsanlag och tidigare hälsa i jämförelse med likande fall med samma diagnos med samma profil. Seebode [22] exemplifierar hur Big Data kan utveckla och effektivisera onkologisk forskning och på så vis förbättra behandlingar av cancersjukdomar. Forskningar beskriver att varje patient som behandlas för cancersjukdom genererar stora mängder data. Data som genereras kommer från olika tester som patienten går igenom, hur patienten svarar på behandling samt övrig hälsoinformation. Genom att samla in all och behandla data från cancerpatienter ges möjligheten att skapa personliga behandlingar då det finns dokumenterat hur personer svarar på behandling beroende på medicinsk profil.
Ett annat praktiskt exempel på ett användningsområde för Big Data beskriver Irudeen och Samaraweera [6] hur företag inom resebranschen kan spåra trender och analysera turisters beteenden för att rikta sina erbjudanden till potentiella kunder. Det finns ett praktiskt exempel på hur en sådan lösning kan se ut framtagen av Irudeen och Samaraweera [6]. Genom att använda verktyg för att samla in data från sociala medier och sedan analysera insamlad data har de lyckats presentera vilka kunder som är potentiella kunder till ett visst resmål. Genom att analysera turisters besöksmål, hur mycket de spenderar, välmående i samråd med resan och vilken livsstil de uttrycker har de lyckats identifiera potentiella turister. På så vis kan resebyråer rikta sina erbjudanden till de kunder som har störst sannolikhet att besöka ett visst turistmål.
Sagiroglu och Sinac [18] menar att gränsen för möjligheterna är kompetensen och fantasin för hur Big Data kan användas. Organisationer behöver identifiera hur de kan använda data för att öka värdeskapande i produkten för kunderna.
10
2.2.2 PROBLEMATIK VID TILLÄMPNING AV BIG DATA
Det finns begränsningar för hur data kan användas beroende på dataägaren och datans känslighetsgrad. Det finns därför en del områden som företag måste reflektera över när de ska implementera Big Data lösningar. Olika forskare presenterar olika sorters problematik och nedan förklaras områden som bör tas i beaktning vid användning av Big Data.
Förtroende att använda data – Realtidsdata, som föregående nämnts som
väldigt kraftfullt, är inte helt problemfritt då de ställer krav på att också ha tillgång till data i realtid. För att få det bästa resultatet av en analys kan de finnas krav på datadelning mellan organisationer, vilket kan vara känsligt i vissa fall då vissa organisationer ser deras data som ett konkurrensmedel. Exempelvis kan det vara känsligt för ett företag att lämna ifrån sig data till sina kunder och leverantörer som rör den egna verksamheten [10]. Liknande situationer har uppstått för organisationer tidigare, där företaget måste ha förtroende för att en annan aktör inte ska utnyttja sårbarheten i att du delat med dig av känslig data [16]. Enligt Ribiere [16] finns det många definitioner på förtroende, men en definiton som passar i sammanhanget av att dela med sig av känslig data är:
”Trust consists of a willingness to increase your vulnerability to another person whose behavior you cannot control, in a situation in which your potential benefit is much less than your potential loss if the other person abuses your vulnerability” [16B]
Finns tekniken för att behandla Big Data? Det finns ett problem i tekniken
som används för att genomföra Big Data analyser. Datainsamling, tillgänglighet, lagring och organisering i Big Data sätter krav på prestanda strukturer [18]. Katal et al [10] hävdar att Big Data sätter nya krav på tekniska lösningar, då de väldigt stora datamängderna som samlas in ska lagras, sorteras och analyseras. Han menar därmed att det krävs kraftfull hårdvara i kombination med smarta mjukvarulösningar för att göra arbetet med Big Data hanterbart.
Finns rätt kompetens? - Enligt Sagiroglu och Sinac [18] är det inte enbart
insamlingen och lagringen av de datamängderna som är problematiskt, en huvudfråga är hur organisationer kan skapa värde från de stora datamängderna som samlas in. De menar att det krävs kompetens i organisationerna om vilka mönster som går att hitta och vilka beslut som kan stödjas med hjälp av Big Data analyser. Rajpurohit [15] menar att det första steget för att genomföra en analys är att veta vad som ska och kan analyseras och hur materialet ska bearbetas och sedan sätta upp mål för analysen. Katal et al [10] föreslår i sin rapport att organisationer bör binda kompetens inom Big data för att kunna tillmötesgå krav från kunder. Forskningen belyser att det inte enbart är den tekniska kompetensen som är relevant utan även analytisk, tolkande och kreativa kompetensen. Förslag på problematik där kompetensen blir användbar kan enligt Katal et al [10] vara följande: • Vad händer om datavolymen blir så stor och varierad att man inte vet
hur man ska hantera den? • Måste all data lagras? • Måste all data analyseras?
11
• Hur kan vi ta reda på vilka data som är relevanta? • Hur kan data användas på bästa sätt?
Etisk problematik - Vidare tar forskning på ämnet upp etisk problematik
gällande integritet och säkerhet. Big Data kan leda till att känsliga personliga uppgifter hamnar i oönskade händer. Till exempel används personliga uppgifter för att kartlägga personlighet och beteende för att skapa omedvetna insikter. En annan aspekt är social skiktning där en bildad person blir en vinnare i prediktiva analyser5 medan en obildad lättare identifieras i analyser
som kartlägger personlighet och kvalifikationer, och kanske därför behandlas annorlunda. Enligt Katal et al [10] ökar risken att individer drabbas av negativa konsekvenser där de saknar medel att slå tillbaka eller till och med inte har kunskap och insikt att de blir diskriminerade när Big Data används av myndigheter.
Två andra etiska aspekter inom integritet och säkerhet, är vid generering och lagring av data. Smith et al [20] menar att en situation där data produceras av en individ och sedan används av en annan individ eller organisation kan vara problematisk då det inte är definierat vem ägaren till data är, den personen som gav ifrån sig data eller den som lagrade eller tog del av informationen. Kaisler et al [8] visar ett exempel på data från Twitter och Facebook där de menar att data de lagrar juridiskt sätt inte ägs av organisationerna, trots att den lagras på deras servrar.
Big Data sätter nya krav på hur vi ser på data och hur den används. Problematiken som nämns ovan behöver inte vara ett hinder utan är snarare något som behöver tas med i beräkningarna för att skapa ett effektiv datahantering.
5Prediktiv analys - omfattar en rad olika statistiska metoder från modellering, maskininlärning och data mining som analyserar aktuella och
12
3 M
ETOD
I följande kapitel presenteras studiens metodologiska upplägg vilket är grunden till de val och motiveringar som senare görs i forskningsprocessen. Vidare redogörs det för studiens tillvägagångssätt samt en reflektion över studiens kvalité.
3.1 Epistemologi & ontologi
Våra metodologiska val motiveras i grunden från våra ontologiska och epistemologiska ställningstaganden, alltså vår syn på verklighet och hur kunskap kan genereras från den. Positivism och socialkonstruktivism är två extremer som beskriver verklighet och kunskap på helt olika sätt. Positivismen grundas i naturvetenskapliga metoder och erkänner säker fakta som kan bekräftas via våra sinnen vilket innebär att det är de observerbara fenomenen som är av intresse [14]. Enligt Oates [14] ska och kan observationen vara objektiv, det vill säga värderingsfri. Mätningar sker traditionellt sett statistiskt med siffror som det viktigaste verktyget.
Socialkonstruktivismen ser de sociala aktörerna som byggstenar i den kultur som skapas i det sociala systemet. Oates [14] menar att konstruktivism innebär att sociala företeelser och kategorier inte enbart skapas vid socialt samspel utan att de också ständigt förändras. Som socialkonstruktivist är det ord och betydelser som står i centrum.
Vårt perspektiv ligger närmare det socialkontruktivistiska än det positivistiska. För att förklara vårt ställningstagande mellan dessa extremer så kan vi med vår syn se möjligheter ur positivismen att mäta olika utfall. Tillexempel kan vi förklara att en 25-årig kriminell man är kriminell för att han kommer från ett område med mycket kriminalitet. Då har vi förklarat att han är kriminell. Men för att förstå varför han är kriminell behöver vi analysera mannens egna tankar uppfattningar och erfarenheter. Positivismen och socialkonstruktivismen syftar således i grunden till att uppnå två olika resultat, där det förstnämnda vill förklara fenomenet medan det sistnämnda vill förstå det mänskliga beteendet i fenomenet. För att koppla an till forskningsfrågorna hade vi ur ett positivistiskt perspektiv kunnat identifiera om undersökningsföretagen arbetar med Big Data, samt utreda om det finns någon problematik med arbetet. Men för att förstå hur de arbetar med det och identifiera vad som är problematiskt krävs ett tolkande förhållningssätt likt det socialkontruktivistiska perspektivet.
3.2 Undersökningsdesign
Valet av undersökningens design får stora konsekvenser för undersökningens giltighet [7]. En fråga forskaren bör ställa sig här är: ”Är den uppläggning vi valt för undersökningen lämpad för att belysa den problemställning vi vill undersöka?” Varför denna fråga har tagits i beaktning vid motiveringen av studiens olika val i detta avsnitt.
13
3.2.1 FORSKNINGSDESIGN
Studien är designad som en explorativ fallstudie med fokus att utforska vilka utmaningar det kan finnas vid tillämpningen av Big Data analyser i verksamheten hos undersökningsföretag. Enligt Oates [14] kan en explorativ studie användas för att definiera frågor eller hypoteser som kan användas i fortsatta studier. Den används för att hjälpa undersökaren förstå ett forskningsproblem.
Studien ämnar utforska en bild av ett oklart fenomen vilken gör att ett fallstudieupplägg är lämpligt. Med en fallstudie går undersökningen på djupet för att undersöka ett eller flera specifika fall. Ett fall kan vara ett företag, flera företag i en bransch ett problem eller en situation [2]. Fallet som studien baseras på är: utmaningar inför tillämpning av Big Data analyser i kontexten undersökningsföretag. Valet av fallstudie motiveras utifrån forskningsfrågor och syfte.
Motivet till att göra en explorativ forskning är att forskningsfrågorna i sin natur är explorativt beskrivande. En explorativ studie används för att utforska en situation eller ett problem. En vanlig anledning till att använda en explorativ studie är när frågan är: ”vad det är som händer här, det finns något
som är intressant men det går inte riktigt att klassificera” [2]. Att undersöka hur
företag kommer driva utveckling är en oklar problemställning där utfallet inte går att förutspå eller mäta på grund av att utmaningarna inte är definierade på förhand.
3.2.2 METODANSATS
Oates [14] förklarar två olika ansatser, induktion och deduktion. Induktiva ansatser innebär att forskaren utgår från upptäckter i verkligheten för att sedan analysera och komma fram till teorier, medan deduktion innebär att forskaren utgår från teori, där en kvantitativ metod ofta används för att förkasta eller bekräfta teorin [14].
Jacobsen [7] menar på att de två strategierna skiljer sig mest åt i frågan om hur öppna de är för ny information. Detta betyder att motiveringen för val av ansats i hög grad borde bero på behovet av öppenhet i undersökningen. I de fall då forskaren vill få en syn på klart definierade förhållanden (hypoteser) är en deduktiv metod mer lämplig, men om forskaren är osäker på vad som är relevanta förhållanden är induktiv mer passande, då forskaren är i behov av att vara öppen för ny information.
Då det inte finns några klart definierade förutsättningar eller utmaningar för studiens kontext är problemställningen i behov av att vara öppen för ny information. Med ett induktivt förhållningssätt kartlägger studien hur det ser ut i verkligheten. Första steget i forskningen har därmed varit en kvalitativ empirisk undersökning.
3.2.3 FORSKNINGSSTRATEGI
Den kvalitativa forskningsstrategin baseras på det vetenskapliga
förhållningssättet och relationen till teori och utgör forskningens genomförande. Det finns två olika typer av forskningsstrategier: kvantitativ och kvalitativ [14]. Med en kvantitativ forskningsstrategi ämnar forskaren kvantitativt mäta ett fenomen, strategin har huvudsakligen ett deduktivt förhållningssätt där objektivitet är centralt [14]. Medan kvalitativ
14
forskningsstrategi vanligen har ett induktivt förhållningssätt och fokuserar på att skapa förståelse för ord och termer istället för att kvantifiera dessa.
Den kvalitativa forskningsstrategin utgår inte från objektivismen utan förutsätter att företeelser är konstruerade [14]. Enligt Jacobsen [7] är kvalitativ data mest lämplig när forskaren är intresserad av att skapa klarhet i vad som ligger i ett begrepp eller fenomen, och det syns en tydlig anknytning till en vetenskapsansats som syftar till att tolka och förstå, varför denna strategi och data är lämplig för studien med tanke på vår kunskapsteoretiska ståndpunkt och studiens syfte.
3.3 Forskningsprocessen
Figur 2 beskriver faserna i studiens forskningsprocess och det övergripande innehållet i varje fas. Med hjälp av figuren blir det enklare att förstå studiens process.
Figur 2, Studiens forskningsprocess
3.3.1 URVAL
Urvalet för undersökningen är för FF1 och FF2 personer med insyn i svenska undersökningsföretags arbete med Big Data, eller för FF2 någon med fördjupad kunskap inom Big Data med viss vetskap om studiens kontext det vill säga. undersökningsföretagens situation. För att kontakta urvalet och få till intervjuer skickades en förfrågan om valfritt deltagande ut till samtliga
medlemmar i branschorganisationen SMIF (Svenska
Marknadsundersökningsföretag), i utskicket efterfrågades en vidarebefordring till personer med insyn i företagets arbete med Big Data. Utöver de 20 privata organisationerna i SMIF kontaktades även SCB som är av högt intresse för studien då det är en stor offentlig aktör inom kontexten. De tillfrågade undersökningsföretagen redovisas i listan nedan.
• CMA-Reasearch • Inizio
• Beyond Research • Solvero AB
Bakgrund
• Det finns mycket data
• De stora datamängderna kallas idag Big Data
• Undersökningsföretag har en möjlighet i de stora datamängder • Analys av datamängderna kommer vara värdefullt • Det finns utmaningar för att utnyttja data och skapa värde • Vilka är utmaningarna för undersökningsföretag?
Empiri
• Semistrukturerad intervju med undersökningsföretag • Undersökningsföretagens perspektiv på Big Data analyser • Framtiden enligt undersökningsföretagen
Teori
• Utgår från empirin för att identifiera utmaningar/problemområden.
15
• United Minds • Demoskop • Novus
• SSI – Survey Sampling • PFM-Research • CFI Group • Ipsos Sweden • TNS Sifo • GfK • M3 Research • Concilia Information • Cint • Norstat • Yougov • Zondera • ICquality • SCB
Tre respondenter gav gensvar varav SCB och CMA-Research var villiga att ställa upp på undersökningen. Det tredje gensvaret var från Novus vilka tackade nej till att ställa upp pga. bristande kunskap om ämnet men hänvisade till en av företagets underkonsulter med kunskap inom Big Data. Novus underkonsult är grundare för Queue AB och arbetar med att analysera datamaterial samt bygga matematiska och statistiska modeller. Efter en bristfällig svarsfrekvens på första utskicket skickades ett påminnelseutskick där även SMIF kontaktades. Efter andra utskicket kom vi även i kontakt med Norstat.
3.3.2 SEMISTRUKTURERAD INTERVJU
Som undersökningsmetod för studien genomfördes enskilda intervjuer. Denna utformning är enligt Jacobsen [7] lämplig när relativt få enheter undersöks, när man är intresserad av vad den enskilda individen säger, när man är intresserad av hur individen tolkar och lägger mening i ett speciellt fenomen. Vårt val motiverar sig främst i att det är en lämplig metod för kvalitativ forskning, det finns ett intresse i vad den enskilda individen säger och hur individen tolkar och lägger mening i fenomenet Big Data.
3.3.3 VAL INFÖR INTERVJU
Vid planeringen av enskilda intervjuer beskriver Jacobsen [7] några val som bör göras vilka har en påverkan på studiens resultat, följande val har beaktats i studien:
• Intervjusituation, besök eller telefon. • Grad av struktur på intervjun. • Dolt eller öppet syfte inför intervjun. • Anteckningsstöd, exempelvis bandspelare. • Upprepning av intervju.
För att redogöra för hur intervjuerna har planerats och ge en bild av hur det har gått till redovisas varje val i Tabell 1. I Tabellen framgår det vad vi har gjort för val, hur vi har genomfört valet och varför vi gjort det för att ge läsaren möjlighet att kritiskt reflektera över vårt tillvägagångssätt.
16
Tabell 1, Val inför intervjuer
Vad? Hur? Varför?
Telefonintervju Undersökningens respondenter kontaktades via telefon för utförandet av intervjun.
Enligt Jacobsen [7] finns det nackdelar och fördelar med både besöks och telefon-intervju. Det finns många praktiska fördelar med telefonintervju vilket var anledningen till att denna metod var bäst lämpad för studien. Det blev en resursfråga då Undersökningsföretagen är utspridda över hela Sverige. Den största nackdelen är att det inte är lika lätt att få ett givande och öppet samtal [7]. Semistrukturerad Undersökaren följde en intervjuguide
med teman och stickfrågor för varje tema, ingen fast ordningsföljd ansågs nödvändig men resultatet blev att intervjuerna följde den utsatta ordningsföljden i guiden.
Genom att ha en intervjuguide enbart med teman och stickfrågor behölls ett öppet intervjuklimat där stickorden bara användes om respondenten inte själv berörde ämnet. Enligt Jacobsen [7] bör den kvalitativa intervjun varken vara helt ostrukturerad eller öppen, vilken var anledningen att vi valt denna design på intervjun. Syftet med studien klargjordes för
respondenten. Syftet med undersökningen gjordes klart i det mailutskick som gick ut till samtliga respondenter.
Genom att presentera syftet fick respondenten en bild av vad informationen i intervjun kommer att användas till. Syftet med detta är för att respondenten ska ge så kallat informerat samtycke att delta i studien, vilket är en viktig etisk aspekt att ta i beaktning vid undersökningar [7]. Ljudet fångas upp så att
transkribering av intervjuerna kan ske.
En mjukvara för inspelning
installerades på den mobiltelefon som användes för intervjuerna. I början av varje intervju ställdes frågan om respondenten gav sitt samtycke om att bli inspelad.
Utan att spela in intervjuerna hade det gett stora konsekvenser för validiteten i studien då det enda som funnits till grund i så fall va
undersökarens egna anteckningar och direkta tolkning av situationen, vilka är begränsade och mer styrda av intuition och därmed utsatt för feltolkning eller selektiv anteckning utifrån förväntningar och tidigare kunskap. Att respondenten först tillfrågats är viktigt ur etiska aspekter [7]
Upprepning av intervjuer Upprepning uteblev. För att reda ut oklarheter och öppna upp för eventuell vidare kontakt tillfrågades däremot varje respondent om det var ok att ta kontakt igen, i fall av nya omständigheter
Av resursskäl gavs inte möjlighet att upprepa intervjuerna.
3.3.4 GENOMFÖRANDE AV INTERVJUER
Som framgår under urvalet var endast 4 personer med kunskap om kontexten för undersökningsföretag villiga att ställa upp på en intervju. Med anledning av den bristande svarsfrekvensen kontaktades en expert inom området från företaget Atea för en femte intervju, en så kallad informationsintervju. Enligt Hjerm et al [3] ses respondenten i informationsintervjun som en informant som besitter information eller kunskap om ett fenomen som forskaren är intresserad av och vill veta mer om [3]. Respondenten väljs med grund att den har en förväntad kunskap i ämnet och kan på så vis bidra med informationen till den andra forskningsfrågan FF2 [7].
17
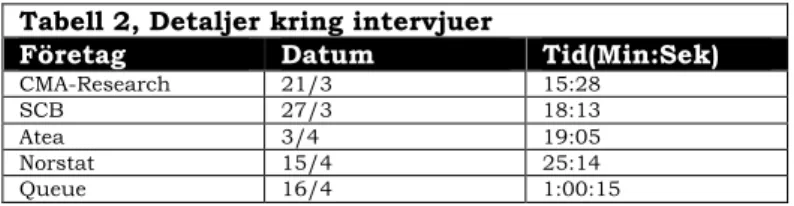
Tabell 2 redovisar datum och längd för de genomförda intervjuerna. Ordningsföljden av intervjuerna är central för att kritiskt kunna reflektera över utspridningen av intervjuerna i kalendertid och tidsstämpeln är central för att ge en uppfattning om hur mycket empiri som har kommit från respektive intervju.
Tabell 2, Detaljer kring intervjuer
Företag Datum Tid(Min:Sek)
CMA-Research 21/3 15:28 SCB 27/3 18:13 Atea 3/4 19:05 Norstat 15/4 25:14 Queue 16/4 1:00:15 3.3.5 ANALYSANSATS
De genomförda intervjuerna transkriberades som underlag för analys av undersökningens kvalitativa data. Som process för dataanalysen följdes rekommendationer från Oates [14]. Första steget i analysen var att sortera ut de data som ansågs relevant för studien, i andra steget behandlades data genom en induktiv kategorisering. Med induktiv kategorisering menas att kategorierna har sitt ursprung ur data från intervjuerna [7]. De kategorier den första analysnivån mynnat ut i för FF1 är ”Definition” och ”Intresse”. Kategorierna för FF2 är ”Problematik” och ”Bristande kompetens”. Kategorierna har kontrollerats att vara begreppsmässigt vettiga genom att testa betydelsen i kategorierna med tidigare förklaringar från forskning samt vilken betydelse kategorierna har för studiekollegor. All data från varje kategori samlades sedan under samma dokument för att ge bättre överskådlighet inför nästa analysnivå, vilken syftar att hitta kopplingar i empirin.
3.4 Litteraturstudie
Efter den empiriska undersökningen genomförts och bearbetats startades en litteraturstudie för att förklara den insamlade empirin ur ett teoretiskt perspektiv. Litteraturstudien bygger vidare på de teoretiska material som använts för att formulera studiens forskningsproblematik. Med utgångspunkt i kategorierna definition, intresse problematik samt bristande kompetens så utformades en sökstrategi för att hitta relevant teoretiskt material. Som bas för litteratursökningen användes IEEE (Institute of Electrical and Electronics
Engineers). Efterkommande redovisas i Tabell 3, de sökord och artiklar som var resultatet av litteraturstudien:
18
Tabell 3, Beskrivning av litteratursökningen
Författare Sökord Artikel
Sagiroglu, S. Sinanc, D. Big data review Big Data: A review
Wu, X. Zhu, X. Wu, G.Q &
Ding, W. Big data mining Data mining with big data," Knowledge and Data Engineering
Katal, A. Wazid, M. &
Goudar, R.H. Big data issues Big data: Issues, challenges, tools and Good practices, Kaisler, S. Armour, F. &
Espinosa, J.A Big data issues Big Data: Issues and Challenges Moving Forward Smith, M. Szongott, C.
Henne, B. & Voigt, G. Big data issues Big data privacy issues in public social media Ribiere, V.M. Organisational trust A Model for Understanding the Relationships
Between Organizational Trust, KM Initiatives and Successes
Rajpurohit, A. Value in big data Big data for business managers - bridging the gap between potential and value
3.5 Validitet och Reliabilitet
Kvalité i forskning bedöms efter extern och intern validitet. Den externa validiteten syftar till huruvida forskningresultatet kan överföras i andra situationer och den interna validiteten behandlar hur hög validiteten är i undersökt kontext. Forskningens interna validitet stärks av den process som bedrivits. I kvalitativa forskningar är det vanligast att fokusera på den interna validiteten då det sällan går att använda resultatet i generaliserande syfte. [17] För att kritiskt granska den interna validiteten i forskningen, analyseras den i Tabell 4 med utgångspunkt i frågor från Jacobsen [7].
Tabell 4, Analys av intern validitet
Har forskaren funnit de rätta
källorna? Ger källorna riktig information Hur kommer informationen fram?
För att få tag i de rätta källorna för studien letade vi efter förstahandskällor med god kunskap om ämnet, i den kontext vi ämnar undersöka. Vid kontakt med undersökningsföretagen hänvisade företaget till den person med mest insyn i arbetet med Big Data. Ett av
undersökningsföretagen hänvisade till en extern konsult då de inte kompetensen om ämnet fanns inom företaget. Tack vare detta är respondenterna de mest relevanta källorna för studien för varje etablerad kontakt.
Det kan vara svårt att avgöra om respondenten berättar sanningen eller inte, men av tradition har forskare satt större tilltro till källor som står nära de fenomen som ska undersökas eller beskrivas [7]. Beroende på fråga så kan sanningshalten i informationen bedömas som mer eller mindre hög. När respondenterna beskriver hur deras arbete med Big Data ser ut bedöms sanningshalten vara hög då de presenterar vad de faktiskt arbetar med i nuläget, och i en sådan fråga inte har
incitament att ljuga. Vad gäller frågor som hanterar vilka utmaningar de står inför så kan sanningshalten ifrågasättas, då trovärdigheten i svaren på spekulativa frågor beror mycket på respondentens kompetens inom ämnet, vilken är svår att avgöra.
Jacobsen [7] skiljer på två olika typer av sätt som information kommer fram vilket påverkar tillförlitligheten. Informationen kan komma spontant, eller efter stimuli från forskaren. Det finns en tydlig indikation på vilka intervjuer svaren har getts spontant respektive på stimuli. Den enda intervju där informationen till stor del kom spontant är den med Queue (Wilhelm) vilken varade mer än dubbelt så långt tid som alla andra. Att informationen kom spontant i denna intervju kan ha en grund i respondentens erfarenhet och kompetens om ämnet, den spontana informationen ses av denna anledning, samt av anledning att
intervjuareffekter inte har lika stor påverkan. Därmed måste det kritiskt reflekteras över det faktum att empiri från resterande intervjuer till stor grad kommit som resultat av en fråga från intervjuaren, följt av ett direkt svar på frågan.
19
Extern validitet innebär resultatets överförbarhet till andra kontexter [17]. Den externa validiteten är mycket bristfällig pga. den låga svarsfrekvensen, då respondenterna endast utgör en liten grupp av Sveriges totala mängd undersökningsföretag. Den låga svarsfrekvensen har alltså haft en stor påverkan på studiens kvalité. Anledningen till den låga svarsfrekvensen kan, med indikationer från studiens respondenter, ligga i att personer med bristande kunskap inom ett ämne sällan är villiga att ge deras perspektiv på ämnet. Logiken i indikationen är givetvis för lite belägg för att dra slutsatser om detta är sanningen bakom den låga svarsfrekvensen eller inte.
Den empiriska undersökningen har trots den låga svarsfrekvensen resulterat i en insikt i några utmaningar branschen står inför. Men med bristen på perspektiv bedöms risken stor att det finns ytterligare utmaningar vilka inte har identifierats samt att identifierade utmaningar utifrån andras perspektiv kanske inte alls ses som en utmaning eller problematik, vilket till stor del hade ändrat studiens resultat.
20
4 R
ESULTAT
Resultatet beskriver en sammanställning av den empiriska undersökningen. Fyra kategorier har identifierats i empirin för att sortera insamlad data och presentera olika infallsvinklar på ämnet.
4.1 Kategorier
Utifrån data från de enskilda intervjuerna med respondenterna har tolv huvudbegrepp identifierats, vilka representerar olika delar av innehållet. Begreppen har förutom en grund i datan identifierats utifrån forskningsfrågorna, där fokus på FF1 ligger på att beskriva var undersökningsföretagen befinner sig i sitt arbete, och FF2 vilka möjligheter och utmaningar som identifierats.
Begreppen listas osorterade i Figur 3, Huvudbegrepp från empiri:
För att skapa en klarare bild av empirin har huvudbegreppen sorterats och placerats inom kategorier. Kategorierna som illustreras i 4 är framtagna för att kategorisera empirin, och används för att svara på forskningsfrågorna. Definition och intresse är framtagna för att svara på FF1 då kategorierna representerar en beskrivning av undersökningsföretagens situation i sitt arbete med Big Data. Begreppen som placerats inom kategorin definition symboliserar undersökningsföretagens befintliga definition och arbete med Big Data. Kategorin ”Definition” har tagit form som hjälp att beskriva hur undersökningsföretagen arbetar med Big Data i nuläget. Kategorin ”Intresse” belyser de intresse som undersökningsföretagen visar för arbete med Big Data där framtida planer och möjligheter beskrivs. Undersökningsföretagens förutsättningar, utifrån det som framgår i kategorierna ”Intresse” och ”Definition” ligger till grund för en analys av framtida problematik utifrån teorin beskriven i kapitel 2.
Problematik och bristande kompetens är två kategorier som skapats utifrån
FF2 som direkt identifierar några av de utmaningar som
undersökningsföretagen står inför. Kategorin problematik grundas i att undersökningsföretagen till stor del lyfter problematiken med att använda Big Data i deras operativa verksamhet. Bristande kompetens baseras på
Mycket data, Medvetande, Bevakning,
Ostrukturerad data, Statistiska metoder, Inga konkreta uppdrag,
Tekniska lösningar, Big Data verktyg, Möjligheter,
Följer utvecklingen, Datarelevans, Begränsningar,
21
undersökningsföretagens beskrivningar att företagen inte har den kompetensen som de behöver för att arbeta med Big Data mer än vad de gör.
4.2 FF1: Undersökningsföretagens situation
4.2.1 DEFINITIONEN UR UNDERSÖKNINGSFÖRETAGENS PERSPEKTIV
Big Data har genom vår undersökning beskrivits genom två olika definitioner: • Big Data är stora mängder ny ostrukturerad data.
• Big Data är ny teknik för att hantera stora datamängder.
Respondenten från SCB belyste även att de finns ett förslag på EU:s bord om att skapa en gemensam definition för Big Data i undersöknings sammanhang:
”Data that is difficult to collect store or process within the conventional systems of statistcal organizations, either the volume velocity, structure or veriety and the adoption of new statistical software or IT-infrastructure to enable cost effective insights to be made.” (Statistiska centralbyrån, Personlig kontakt, 2014)
Ett konkret exempel på hur Big Data används med ny teknik är KPI
(konsumentprisindex) som mäter prisutveckling. Ett av
undersökningsföretagen beskriver att förut gick personalen ut och samlade in
koder för att identifiera priset på olika produkter. Nu kan
undersökningsföretaget importera dessa koder direkt och hantera dem automatiskt. Big Data i sammanhanget förklaras som en effektivisering av hur stora mängder data hanteras.
Informationsintervjun med experten pekade på att hans definition liknar den definition som ligger som förslag till EU. Han tolkar definitionen som att de inte får ut något användbart material av den tekniska prestanda de har idag. Hans egen definition av en Big Data lösning är konsolidering6, det vill säga att
samma arbete kan utföras av färre maskiner än tidigare. En Big Data lösning är en maskin som sköter allt i form lagring, nät servrar och mjukvara. Exempelvis har apoteket köpt en exadata från Oracle som hanterar alla recept till apoteken i Sverige. En färdigkonfigurerad lösning som bara är att plugga in
6 Konsolidera – förstärka eller förbättra strukturen hos något, särskilt abstrakta ting.
Definition Mycket data, Ostrukturerad data, Tekniska lösningar BRISTANDE KOMPETENS Inga konkreta uppdrag, Begränsningar INTRESSE Möjligheter, Följer utvecklingen, Bevakning PROBLEMATIK Big Data verktyg, Statistiska metoder, Datarelevans Figur 4, Kategorier
22
och koppla på lagring så fungerar allt ganska omgående. Organisationer har krav som deras befintliga infrastruktur inte klarar av och då behövs mer kraft för att hantera dessa krav. Big Data används för att lösa samma funktion som tidigare men med större datamängder och med färre maskiner.
4.2.2 INTRESSE
Idag använder undersökningsföretagen Big Data i en väldigt liten utsträckning. Norstat använder vissa externa Big Data tjänster, som exempelvis hur många som sökt på ett varumärke. Men informationen används endast som en kompletterande kontroll på det man fått ut från andra undersökningar. Även CMA använder Big Data som ett komplement till traditionella undersökningar. Respondenterna beskriver det som att det är i ett bevakande stadie, det diskuteras på luncher och sinns emellan via undersökningsföretagens branschorganisation. En respondent tror att analyser för att hantera Big Data med ny teknik först och främst kommer outsourcas av undersökningsföretagen men att det på sikt kommer att integreras i organisationerna. Båda respondenter från de privata undersökningsföretagen uttrycker tydligt att de är följare i ett bevakningsstadie och har ingen ambition att driva utvecklingen av Big Data-analyser.
Men samtliga deltagare presenterar att det finns ett intresse för Big Data-analyser, av olika anledningar. Respondenten från SCB ser tre intressen; för det första i att göra datainsamlingen billigare, då det är väldigt dyrt att samla in data direkt från personer och företag; för det andra att snabba upp datainsamlingsprocessen som idag tar långt tid för att säkerställa kvalitén och för det tredje att man försöker hitta nya saker som man inte kan göra idag. Intresset tolkas som spekulativt då det inte finns många konkreta exempel för användningsområden, utan endast spekulativa potentiella användning av både ostrukturerad men även strukturerad data. Några exempel på intresseområden för de olika strukturerna tas upp:
• Strukturerad data – En av respondenterna beskriver att de i dagsläget använder satellitdata för att kartlägga parkytor och grönområden i städer. Men ser en möjlighet att med ny teknik och ytterligare datakällor, kan olika träd, buskar och växter kartläggas och med hjälp av satellitdata och ge en exaktare bild av området.
• Ostrukturerad data – Det framkommer spekulationer om hur odefinierad osorterad data kommer att kunna användas med olika syften. Den vanligaste ostrukturerade datamängden som tas upp är den som kommer från sociala medier. Användningsområden för denna data är exempelvis i en kundundersökning där en normal undersökning kan kompletteras genom att analysera en verklig kund på individnivå. Genom att analysera kunden går det att skapa sig en uppfattning om vad kundens attityd till varumärke och produkter. Ett annat exempel på användning som tas upp är förmågan att förutspå sociala händelser i form av till exempel ekonomisk kris.
23
Respondenten från Norstat uttrycker liknande intressen i form av kostnadseffektivisering och snabbare undersökningsprocesser.
”Vi gör väldigt mycket enkätundersökningar och då kan man ju tänka sig att man frågar en grupp personer om dem har handlat på en viss butik kanske, men idag så finns det ju det här med transaktionsdata. Så kreditkortsbolagen kan kolla väldigt noga på vad då människor handlar och det här är ju gigantiska datamängder så det är egentligen bara fantasin som sätter gränsen där. Och den typen av beteendedata är ju otroligt värdefull” (Norstat, Personlig kommunikation, 2014-04-15)
Som exempel på det tredje intresset, nya saker som inte kan göras idag beskriver Norstats respondent nya möjligheter i att använda datas realtidsaspekt. Rent spontant beskriver respondenten möjligheten att i framtiden använda Big Data för trafikoptimering och trafiksäkerhet. Men mer kopplat till kontexten förklarar han möjligheter med realtids bevakning på deras kunder kopplat till övriga undersökningar.
”Ponera att vi har IKEA som kund och så sitter vi och tittar på dem i sådana här system som bevakar på sociala medier till exempel. Sådana system finns ju och det handlar mer om att det är vi som ska erbjuda det i dem sammanhangen så att det kan kopplas ihop med andra undersökningar och så.” (Norstat, Personlig kommunikation, 2014-04-15)
Som ett exempel på var intresset i Big Data kan finnas tar Wilhelm från Queue upp ett exempel kopplat till Läkemedelsindustrin.
”Hela ditt förhållande till läkemedelsföretagen kommer vara mycket mer personlifierad, om du tar en treo tub så står det alla kvinnor tar två och alla män tar 3. Så kommer det inte se ut i framtiden” (Wilhelm, Personlig kommunikation, 2014-04-16)
Wilhelm menar att det kommer finnas en så stor databank i hur olika personer reagerar på olika läkemedel. På så vis kommer varje person beroende på sin hälsomässiga status finnas en mer specifik rekommendation på läkemedel, vilket leder till mer specialanpassade läkemedel.
4.3 FF2: Utmaningar
4.3.1 PROBLEMATIK
Empirin belyser några olika sorters problematik. Den ena problematiken handlar om att det är svårt att genomföra statistiska undersökningar enligt
statistiska principer7 och det kan vara svårt att skapa relevans i
undersökningarna. SCB lyfter problematiken att de är lagstyrda och har vissa krav på att redovisa hur undersökningen har gått till eftersom de arbetar med officiell statistik. Undersökningen ska exempelvis vara reproducerbar, precis och konfidentiell, det vill säga det ska inte gå att se vem som gett ifrån sig
24
data. Data ska mäta rätt sak och undersökningen ska vara mätbar över tid. Norstat beskriver även problematiken med att analysera trafikanter som reser med SL-kort. Mängderna av de som pendlar måste kopplas ihop på något sätt och det är viktigt att veta vem det är som drar kortet, vad det är för människa för att göra en bra analys. Ovanpå detta kommer problematiken med integritet och konfidentialitet.
”Alltså kopplingen till vad är det för människor är det turister/pendlare. man behöver ändå koppla ihop mängderna på ett bra sätt det… ...Det är ju ett hinder, sen ett annat hinder integritetsfrågan. Och sådana hinder alltså övervakningsrädsla.” (Norstat, Personlig kontakt, 2014-04-15)
Undersökningsföretaget CMA-research beskriver en annan praktisk problematik i att dem inte har tillgång till de tekniska lösningar som behövs
för att analysera stora ostrukturerade datamängder. Undersökta
undersökningsföretag ser inte heller att de inom de närmsta åren kommer att ha tillgång till egna tekniska lösningar utan att kompetensen kommer at köpas in om kunderna ställer krav på Big Data analyser. Norstat tror att de kommer använda Big Data analyser när det finns en tilläggsmodul i ett system som behandlar detta.
”Ponera att vi har IKEA som kund och så sitter vi och tittar på dem i sådana här system som bevakar på sociala medier till exempel” (Norstat, Personlig kontakt, 2014-05-15)
4.3.2 BRISTANDE KOMPETENS
Den empiriska undersökningen har identifierat en bristande kompetens. Deltagarna i undersökningen beskriver att de ser sig har bristande kompetens inom området för att bruka Big Data lösningar. Som ovan nämnt anser CMA och Norstat sig följa utvecklingen för att kunna leverera en lösning till kund när ett sådant uppdrag blir aktuellt. Dessa mindre företag, i förhållande till SCB:s storlek, menar då att de kommer outsourca dessa lösningar då de inte tror att deras företag kommer att ha kompetens eller verktyg för att hantera uppdragen på egen hand. SCB som är ett större företag menar att de nu börjat engagera sig för att driva utvecklingen och har det senaste året börjat komma ifatt och anser sig vara med i utvecklingen av Big Data analyser.
Matematikern och Data Scientisten Wilhelm Landerholm från Queue uttrycker att Sverige ligger lite efter i intresset av att visualisera information och utnyttja Big Data, och att det grundar sig i en bristande beställarkompetens, och att det till exempel. på en amerikansk marknad, där beställarkompetensen är högre, finns ett större utrymme för Big Data bolag. En faktor som skiljer beställarna från till exempel. USA och Sverige är en annorlunda företagsmentalitet. Som ett exempel berättar Wilhelm om responsen från ett blogginlägg han författat nyligen.
”... Jag skrev på min blogg varför vi har så dålig säkerhet kring pengar, vad är det som är problemet? Det är ju kanske enkelt att skapa prediktionsfunktioner... … När jag skrev det så svara alla banker; vi har redan ett sådant system, samtidigt så ringer en New York kille till mig… ... Här kommer företagskultur in, när han ringer och säger: Det är klart att vi ska utveckla en tjänst ihop som då
25
bygger på en sådan funktion.” (Wilhelm Landerholm, Personlig kontakt, 2014-04-16)
Vidare beskriver Wilhelm fördelarna med Sverige ur ett Big Data perspektiv. Vi i Sverige är duktiga på att kategorisera och samla in data, vi har ett samhälle som bygger på att vi kategoriserar och gärna binder information till personnummer, vi har ett organisationssystem som samlar in data. Det gör ju också att det blir möjligt att få en urvalsram8 även för Big Data analyser.
Vilket gör att vi sitter på datamaterial som skulle kunna vara till stor nytta vid Big Data analyser, men det görs inte mycket för att utnyttja dem.
26
5 A
NALYS
För att skapa en djupare förståelse för undersökningsföretagens utmaningar analyseras resultatet från undersökningen med det teoretiska perspektiv på Big Data och dess utmaningar som presenterats i Kapitel 2.
5.1 Passiv marknad – Passiv utveckling
Undersökningsföretagens beskrivning av Big Data matchar i många avseenden den teoretiska definitionen Big Datas 3 V [18], men respondenterna har en tendens att fokusera på stora ostrukturerade datamängder där data kan produceras på olika sätt i form av text, ljud och bild. Ur ett teoretiskt perspektiv förbiser alltså undersökningsföretagen en stor del av begreppets infattning. Även om undersökningsföretagen talar om strukturerade datamängder som Big Data så tar de främst upp möjligheter och problem med ostrukturerad data. Som Wilhelm säger så har Sverige stora förutsättningar för att även utnyttja strukturerad data som redan är kategoriserad, tack vare att vi i Sverige är duktiga på att kategorisera och samla in data har undersökningsföretagen en möjlighet att börja i denna ände. Att utgå från strukturerad data gör det även enklare att kringgå de statistiska problem som finns kring oklara urvalsramar och resultatets representativitet för undersökningens population.
I ett exempel ur empirin på hur undersökningsföretagen använder sig av stora mängder strukturerad data, till exempel SCB som arbetar med KPI, är det insamlingsprocessen som ser annorlunda idag jämfört med tidigare, inte användningsområdet. Men deras största intresse i Big Data är möjligheterna för hur data kan analyseras för att komma till nya insikter.
Undersökningsföretagen verkar förbise att de redan har stora insamlade datamängder som är strukturerad och kan användas i olika undersökningar. Varje undersökning samlar in data vilket skapar en stor databank som undersökningsföretagen har till förfogande. Genom att kombinera data från olika undersökningar skulle undersökningsföretagen kunna hitta nya möjligheter för de data som redan produceras. Ett exempel från empirin där data måste vara strukturerad och kategoriserad för att kopplas till en person, är hur läkemedelsföretagen kommer kunna använda varierande datamängder
för att personifiera doseringsrekommendationer på läkemedel.
Undersökningsföretagen kan på liknande manér använda sig av data som de redan samlar in och genom nya idéer hitta fler användningsområden för data. Paralleller kan dras till Wu et al [24] The blind men at the giant elephant som beskrivs i teorin. Elefanten kan representera undersökningsföretagens totala databank och människorna är olika personer som granskar delar av den totala datamängden. Bildens huvudbudskap är att det finns möjligheter med att kombinera olika delar data för att skapa nya möjligheter.
Det finns alltså ett övergripande intresse för Big data men de undersökta undersökningsföretagen har svårt att i dagsläget presentera konkreta och innovativa exempel på hur de kan använda data. Bristen på idéer kan grundas i den bristande kompetensen inom ämnet och från beställarna, alltså undersökningsföretagens kunder. Som belyses i exemplen från Atea:s
27
respondent är en drivande kraft för utveckling ofta att det finns ett krav på utveckling från marknaden.
”Det är inget företag som vaknar på morgonen och tänker att nu spenderar vi ett antal miljoner på detta, utan det kommer ju utifrån att det är ett krav från allmänheten.” (Atea, Personlig kontakt, 2014)
Ett sådant krav och efterfrågan i att hitta nya mönster verkar inte i dagsläget finnas, men kommer troligtvis infinna sig så fort beställarkompetensen inom ämnet utvecklats. Bristen i beställarkompetens kan vara anledningen till att kompetensen även är bristande hos de undersökningsföretag som kan förväntas vara producenter och erbjuda denna tjänst. Respondenten från Norstat uttrycker den bristande kompetensen som ett branschproblem. Och som teorin föreslår så är det inte bara den tekniska kompetensen som krävs utan även en analytisk, tolkande och kreativ kompetens för att utnyttja datamängderna på ett effektivt sätt.
De undersökta undersökningsföretagen har således ett intresse och en kunskap om övergripande teori inom Big Data men det finns en problematik att omsätta den i praktiken. Summan av detta är att det idag inte finns en utvecklad marknad för Big Data då det saknas kompetens av både beställare och producenter.
5.2 Praktisk problematik
5.2.1 BALANSEN MELLAN STATISTISK OCH ETISK PROBLEMATIK
För att en undersöknings resultat ska vara representativt för en viss population och data ska vara relevant ur statistiska perspektiv så måste datamängderna som en människa genererar kopplas till en person, här finns ett etiskt dilemma pga. den oklarhet som finns i att definiera vem som äger data. Som respondenten från Norstat lyfter upp finns ytterligare en problematisk aspekt till detta, folkets övervakningsrädsla. Företagen är alltså i ett behov av att kunderna ska känna förtroende för dem, för att de personer som utgör urvalet för diverse undersökningar ska vara villiga att dela med sig av det data dem genererar. Wilhelm menar på att det är folket, alltså skattebetalarna ur ett statligt perspektiv och kunderna ur ett företagsperspektiv, som är de stora vinnarna. Det finns då ett värde för undersökningsföretagen och deras kundföretag att förmedla detta budskap till dem som genererar värdefull data. Det finns alltså en problematik i att uppfylla grundläggande statistiska krav för en Big Data analys utan att kränka människors integritet, och problematiken kan lösas genom att människorna ger sitt samförstånd och inte känner sig kränkta.
5.2.2 TEKNISK PROBLEMATIK
I bakgrunden belyser Katal et al [10] ett behov av avancerade tekniska lösningar för insamling, sortering och analysering av Big Data och undersökningsföretagen pekar på just en brist på sådana verktyg. Och en ovilja att driva utvecklingen själva. Denna ovilja kan kopplas till det som belyses i föregående kapitel Passiv marknad – Passiv utveckling. Wilhelm
![Figur 1 Big Datas 3V [18B]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4094285.86095/8.892.233.640.676.1058/figur-big-datas-v-b.webp)