Examensarbete
15 högskolepoäng, grundnivå
Maskin eller läkare?
En studie om individens attityd till användning av
vårdapplikationer med maskininlärning
Machine or doctor?
A study about attitudes regarding the use of healthcare
applications with machine learning
Frida Berglund & Vendela Talenti
Examen: Kandidatexamen 180 hp Examinator: Fredrik Rutz
Sammanfattning
I denna studie undersöks individers generella attityder till vårdapplikationer som använder maskininlärning. Datainsamlingen har skett genom både kvalitativa och kvantitativa metoder som kompletterar varandra. Metoderna innefattar en enkätundersökning och två fokusgrupper baserade på scenario-based design. Teorin är baserad på forskning inom digitaliseringen av vården, bland annat maskininlärning och mHealth, som ligger till grund och stödjer undersökningen. Även teori om attityder och förtroende till digitaliseringen av vården har underbyggt undersökningen.
I slutsatsen framkommer det att det finns en korrelation mellan hög medvetenhet och positiv inställning när det kommer det användandet av vårdapplikationer med maskininlärning. Den generella attityden till att få en diagnos av maskininlärning är negativ då de flesta föredrar att få en diagnos förmedlad av en läkare. Studien indikerar på att detta kan bero på att patienterna söker empati från vården, vilket artificiell intelligens saknar. Förtroendet för en vårdapplikation grundar sig främst i ryktet om den men även i vilket företag eller organisation som ligger bakom. Studien indikerar på att individer är positivt inställda till att bidra med privat hälsodata till en vårdapplikation om det leder till förebyggande av sjukdom. Studien ger även en antydan på att det finns en rädsla kring var privata hälsodata hamnar när den har lämnats ut.
Nyckelord
Abstract
This study aims to research on individuals’ general attitudes towards healthcare applications that use machine learning. The data collection has taken place through both qualitative and quantitative methods as a complement to each other. The methods include a questionnaire survey, two focus groups based on scenario-based design. The theory is based on research in the digitalisation of healthcare, including machine learning and mHealth, which is based and supports the investigation. The theory of attitudes and confidence in the digitalisation of care also forms the basis for the study.
The conclusion shows that there is a correlation between high awareness and positive attitude when it comes to the use of healthcare applications with machine learning. The general attitude towards a diagnosis from machine learning is negative since most people prefer to get a diagnosis mediated by a doctor. The study indicates that this may be because the patients seek empathy from the healthcare system, which artificial intelligence lacks of. Trust towards a healthcare application is based primarily on the reputation of it, but also in which company or organization that is behind it. The respondents in the survey are positive about contributing with their personal data to a healthcare application if it leads to a prevention of a disease. The study also gives an indication that there is a fear of what happens with private health data.
Keywords
Förord
Tack till vår handledare Johan Salo för ett enormt stöd under arbetets gång. Du har bidragit till intressanta diskussioner inom ämnet vilket har fått oss att ständigt behålla intresse för uppsatsen. Vi vill också tacka medverkande respondenter i fokusgrupperna som delade med sig av sina tankar i en intressant diskussion.
Studien delades upp i metoddelen där Frida undersökte fokusgrupp 1 och Vendela undersökte fokusgrupp 2. Vendela skapade enkäten medan Frida skapade frågorna för fokusgrupperna. Resterande delar utfördes tillsammans.
Benämningar och begrepp
Artificiell intelligens - John McCarthy som är grundaren till begreppet artificiell intelligens
definierar det som vetenskapen av att producera intelligenta maskiner, särskilt intelligenta datorprogram (AISB, 2019). Artificiell intelligens utför ett arbete som i normala fall utgörs av mänskligt intelligens. (Sveriges Kommuner och Landsting, 2017)
Maskininlärning - Maskininlärning är en teknik som styrs av algoritmer och data. Tekniken
kan “tänka själv” och innebär att lära en dator att känna igen mönster. (LeCun, 2018) Programmet lär sig ett beteende och vilka utfall som är bäst, därmed förbättras beteendet ju mer data som kommer in. (Sveriges Kommuner och Landsting, 2017)
mHealth - Dickson (2017) beskriver att Mobile Health (mHealth) är en teknologi som
möjliggör vård genom smarta telefoner. Tekniken är baserad på artificiell intelligens, data, algoritmer och sensorer. (Dickson, 2017)
tracking - Vesnic-Alujevic, Breitegger och Guimaraes Pereira (2018) beskriver
Self-tracking som en teknik där en sensor placeras på kroppen för att systematiskt registrera hälsodata. På så sätt är detta ett verktyg som individer kan använda för att själva hålla koll på sin hälsa. (Vesnic-Alujevic et al., 2018)
Selfcare - Ruckenstein & Schüll(2017) förklarar att selfcare innebär att välfärden går från
Innehållsförteckning
Inledning ... 1
1.1Bakgrund och problematisering ... 1
1.2
Tidigare forskning ... 3
1.3
Syfte ... 4
1.4
Frågeställning ... 4
1.5
Avgränsningar ... 4
1.6
Målgrupp ... 4
1.7
Disposition ... 5
2 Metod ... 6
2.1Forskningsdesign ... 6
2.2
Metodval ... 6
2.2.1
Kvantitativ webbenkät ... 7
2.2.2
Kvalitativa fokusgrupper ... 8
2.2.3
Scenario-based design ... 9
2.2.4
Innehållsanalys ... 9
2.2.5
Signifikansprövning och korrelation ... 10
2.2.6
Urval ... 11
2.2.7
Bortfall ... 12
2.3
Tillvägagångssätt ... 13
2.3.1
Enkätundersökning ... 13
2.3.2
Fokusgrupper ... 13
2.3.3
Bearbetning ... 15
2.3.4
Forskningsetiska överväganden ... 15
2.4
Metoddiskussion ... 16
2.4.1
Enkätundersökningen ... 16
2.4.2
Kvalitativa fokusgrupper ... 17
2.4.3
Scenario-based design ... 18
2.4.4
Urval och bortfall ... 18
3 Teori ... 20
3.1Maskininlärning ... 20
3.1.1
Diagnostisering med maskininlärning ... 21
3.1.2
Datautvinning – mönster i data ... 22
3.1.3
Kritik till maskininlärning ... 22
3.2
Digitalisering av vården ... 23
3.2.1
Mobile Health ... 24
3.2.2
Self tracking ... 24
3.3
Vård genom applikationer ... 25
3.4
Attityder till digitaliserad vård ... 27
3.4.1
Attityder till vård genom digitala tjänster ... 28
3.4.2
Attityder till datautlämning ... 29
4 Resultat ... 31
4.1Enkätundersökning ... 31
4.1.1
Digitalisering av vården ... 31
4.1.2
Attityd till datautlämning ... 34
4.1.3
Samband mellan medvetenhet och attityd ... 37
4.2
Fokusgrupp 1 & 2 ... 38
4.2.1
Erfarenhet ... 38
4.2.2
Attityd ... 40
4.2.3
Scenario 1 – BEATA (med fokusgrupp 1) ... 43
4.2.4
Scenario 2 – SAM (med fokusgrupp 2) ... 44
5 Diskussion ... 46
5.1Diagnostisering med maskininlärning ... 46
5.2
Användning av vårdapplikation ... 48
5.3
Utlämning av hälsodata ... 49
5.4
Framtidsutsikter ... 51
6 Slutsats ... 53
6.1Förslag till vidare forskning ... 53
Referensförteckning ... 55
Bilaga 1 – diskussionsunderlag fokusgrupp ... 62
Bilaga 2 – Scenario 1 BEATA ... 63
Bilaga 3 – Scenario 2 SAM ... 64
Bilaga 4 – Frågor webbenkät ... 65
Inledning
Detta kapitel inleds bakgrund och problematisering till uppsatsens ämne. En problematisering inom ämnet framhålls och följs av syfte, frågeställning, avgränsningar, målgrupp och disposition.
1.1
Bakgrund och problematisering
Enligt en rapport från Socialstyrelsen gällande efterfrågan på personal inom vården framgår det att 20 av 21 regioner i Sverige har rapporterat om brist på vårdpersonal. Katarina Sandberg, utredare på Socialstyrelsen, antyder att människor lever längre idag vilket har lett till ett ökat antal kroniskt sjuka patienter. Detta menar författaren kan vara en faktor som påverkat bristen på vården negativt. (Socialstyrelsen, 2019) Artificiell intelligens sägs vara en av lösningarna på bristen i vården då AI-assistenter kan ge vård till flera miljoner patienter samtidigt som en mänsklig läkare endast kan behandla en person under samma tid (Sveriges Kommuner & landsting, 2017).
Det vanligaste begreppet som används när man talar om Artificiell Intelligens är
Maskininlärning. (Sveriges Kommuner & landsting, 2017) Maskininlärning innebär att lära en
dator att känna igen mönster, till exempel genom att analysera bilder (LeCun, 2018). Inom vården används maskininlärning för att upptäcka mönster i data för att därefter kunna ta beslut (Stewart, Sprivulis & Dwivedi, 2018). Dickson (2017) menar att informationssökning som görs med Artificiell intelligens kan ge säkrare och mer tillförlitliga svar än om individen själv skulle söka på sina symptom. Cabitza, Rasoini och Gensini (2017) anser däremot att det är en brist på studier gällande diagnostisering med maskininlärning. Författarna menar att en implementering av maskininlärning kan ge positiva effekter i sjukvården på kort sikt genom att fungera som ett automatiskt hjälpmedel. På lång sikt kan tekniken dessvärre leda till en minskning av nivån på den färdighet som krävs för att utföra en uppgift, vilket kan skapa allvarliga konsekvenser ifall tekniken går sönder. (Cabitza et al., 2017)
Sveriges Kommuner och Landsting (2017) är optimistiska till maskininlärning och ser möjligheter att förbättra välfärden med tekniken. De menar att välfärden och sjukvården kan gynnas av implementering av artificiell intelligens då risken för fel minskar i och med att de genererar större precision och noggrannhet (Sveriges Kommuner & Landsting, 2017). Bland Sveriges kommuner är Trelleborgs kommun framåt i utvecklingen av välfärdsteknologi och har implementerat en “handläggar-robot”. Syftet med handläggarroboten är att effektivisera
välfärden. (Trelleborgs kommun, 2014) Svensk sjuksköterskeförening (2016) menar däremot att ett grundläggande antagande av omvårdnad utgår från ett humanistiskt perspektiv och innebär att omvårdnad ska ske på personnivå. Med detta menas att mötet mellan patient och vårdare behöver ske där ömsesidighet finns vilket medför att vårdaren behöver reflektera över de ömsesidiga beroenden som finns mellan människor. (Svensk sjuksköterskeförening, 2016) I Sverige har digitaliseringen inom vården utvecklats i en rasande takt under de senaste åren. Denna digitalisering har skett i både inom landstingen och i privata företag. (Socialtjänsten, 2018) Socialtjänsten (2018) ser digitaliseringen inom sjukvården som en möjlighet för patienter att uppnå självständighet och delaktighet.
Dickson (2017) tror att den smarta telefonen som redan är en del av vår vardag kan komma att spela en viktig roll även inom vård och hälsa. Mobile Health (mHealth) som är en teknologi byggd på artificiell intelligens, avancerad data, algoritmer och sensorer kan möjliggöra vård genom smarta telefoner. Forskare är optimistiska till den nya tekniken och tror att mHealth kan komma att revolutionera vård-industrin. Författaren menar att mHealth kan öka effektiviteten i behandlingsprocessen genom att göra vården mer tillgänglig vilket i sin tur kan leda till minskade kostnader inom vården. (Dickson, 2017) Klack (2017) har en mer kritisk syn på ämnet och menar att tekniken kan komma att ta över många yrken då maskininlärning har en förmåga att automatisera och utöva arbete som en människa tidigare gjort.
En viktig del av relationen mellan patient och läkare över digitala hälsosystem är tillit (Adjekum, Blasimme & Vayena, 2018). Tillit till teknologi spelar en stor roll när det gäller att acceptera ny teknik (Fan, Liu, Zhu & Pardalos, 2018). När det kommer till system baserat på digital hälsa är även dessa i stort beroende av tillit från individer för att lyckas (Adjekum et al., 2018) I takt med en digitaliserad sjukvård har individen fått en annan roll än tidigare då det krävs engagemang av både patienter, forskare och AI-system för att kunna generera rätt hälsodata till de nya systemen. Detta genererat i ett nytt behov av förtroende av patienter vilket i sin tur kan påverka patienters trygghet och tillit till vården (Sutton, et al., 2018) Genom att samla in realtidsdata med maskininlärning kan patientens hälsa övervakas genom förutsägelse, förväntningar och intelligent beslutsfattande (Zaouiat & Latif, 2017). Problematiken kring datasäkerheten av algoritmerna innebär en kritisk aspekt till att implementera maskininlärning i sjukvården (Stewart et al., 2018).
Denna studie ska undersöka hur individer hade ställt sig till att använda en vårdapplikation med maskininlärning. Som tidigare presenterat är målet med att implementera maskininlärning i en applikation att vården ska effektiviseras. Samtidigt är baksidan med det att moraliska aspekter
som är unikt för människan inte går att efterlikna, att personlig data kan hamna i fel händer och feldiagnostisering kan uppstå i fall som är unika. Med tanke på att det framställs en rad mängd prototyper för vårdapplikationer med maskininlärning är det intressant att undersöka vad det finns för behov hos individer idag och vad deras attityd är till ett potentiellt användande av en sådan applikation.
1.2
Tidigare forskning
Forskning inom ämnet som undersökningen syftar till är begränsat då vårdapplikationer för patienter som använder maskininlärning inte är implementerat på marknaden i stor utsträckning. De områden som berörs i studien är digitalisering av vården, artificiell intelligens, vård genom applikationer och individers attityder till den digitaliserade vården. Forskare har länge undersökt fenomenet att implementera artificiell intelligens som assistans till läkare och fått positiva reaktioner av försökspersoner (Agah, 2014). Agah (2014) menar att studier har visat en positiv attityd till att AI-system används som assistans till läkare gällande bland annat diagnostisering och terapi.
Brinkel, Dako-Gyeke, Krämer, May och Fobil (2017) har undersökt användares attityder till att använda ett symptom-baserat interaktivt röst-system i mobiltelefonen för att söka vård i Ghana. Resultatet visade att användarna var positiva att använda systemet då deras mobiltelefoner uppfattas som en viktig del av deras vardag. Den generella uppfattningen hos undersökningsgruppen var att de visade ett stort intresse för att använda ett interaktivt system i mobiltelefonen för att uppsöka vård. Något som visade sig vara en bidragande faktor till inställningen var graden av användarvänlighet till tekniken. Studien visar att ett interaktivt röst-system har bevisats vara en billig, tillförlitlig och bekväm metod för att söka vård. (Brinkel et al., 2017)
Andras, Esterle, Guckert, Han, Lewis, Milanovic, Payne, Perret, Pitt, Powers, Urquhart & Wells (2018) menar att intelligenta algoritmer alltmer blir en del av vår vardag då de bland annat rekommenderar produkter för oss och möjliggör självkörande bilar. Andras et al. (2018) förklarar vidare att detta ställer nya krav på förtroendet mellan människan och intelligenta maskiner. Nyholm & Smids (2016) lyfter att självkörande bilar väcker etiska frågor vilket diskuteras av både media och filosofer. Dessa frågor handlar till stor del om hur maskinen ska agera vid en olycka. Det diskuteras om maskinen bör prioritera föraren eller personen som är framför bilen. (Nyholm & Smids, 2016) Artificiell intelligens är även etablerad och börjar bli alltmer framgångsrikt i finanssektorn (Lui & Lamb, 2018). Lui & Lamb (2018) menar att
anledningen till att Artificiell Intelligens har blivit populärt inom finanssektorn är för att tekniken erbjuder billiga, effektiva och skräddarsydda tjänster till kunderna. Även här finns problematik kring bristande förtroende för tekniken av konsumenterna. Detta beror på händelser där algoritmerna har diskriminerat människor. (Lui & Lamb, 2018)
1.3
Syfte
Det huvudsakliga syftet med uppsatsen är att få en djupare inblick i individers attityd till utvecklingen av vårdapplikationer som använder sig av maskininlärning för att samla och analysera hälsodata. Det finns många studier kring hur detta hade kunnat implementeras i samhället och vår uppsats syftar till att undersöka fenomenet från individens perspektiv. Eftersom vårdapplikationer med maskininlärning ännu inte är etablerade på marknaden har vi undersökt hur individers attityd ser ut i till vårdapplikationer med maskininlärning genom fiktiva scenarion.
1.4
Frågeställning
Vad är individens attityd till applikationer som använder maskininlärning för att samla och analysera hälsodata?
1.5
Avgränsningar
Studien kommer att undersöka maskininlärning inom sjukvården och kommer inte att behandla andra områden som använder artificiell intelligens. Studien är avgränsad till att undersöka applikationer som använder maskininlärning för att kunna ge en diagnos till en patient. Studien riktar sig till vårdapplikationer avsedda till patienter. Vidare avgränsar sig undersökningen till vårdsektorn.
1.6
Målgrupp
Uppsatsen syftar till att bidra till det vetenskapliga ämnesområdet om utveckling av ny teknik inom sjukvården. Studien riktar sig till de som vill få en förståelse kring individers syn på den digitala utvecklingen och användandet av maskininlärning i vårdapplikationer. Studien kan även användas som grund för vidare forskning inom området.
1.7
Disposition
Uppsatsen är upplagd efter ME uppsatsmall på Malmö Universitet. Således är den uppdelad i delarna metod, teori, resultat, diskussion och slutsats. I metod presenteras våra utvalda metoder samt en motivering kring varför de valts ut. I teori har relevanta ämnen för studien valts ut för att ge läsaren en bred kunskap kring nya tekniker inom bland annat artificiell intelligens, maskininlärning och vård genom applikationer. Teorin innefattar även fakta om problematik kring dagens sjukvård, såsom bristen på vårdpersonal. I resultatkapitlet redovisas utfall från fokusgrupp 1 och 2 samt från utfallen av enkäten i form av text och tabeller. Diskussionskapitlet innefattar därefter slutgiltiga resonemang och insikter där resultat ställer sig mot teori. Slutsatsen svarar på frågeställningen och ger förslag på vidare forskning.
2
Metod
Denna uppsats är en empirisk studie som har utgått från både en kvalitativ och kvantitativ ansats. I denna uppsats kontrolleras en inställning hos en mindre population till en digital utveckling inom vårdsektorn. Studien har utförts genom tre metoder varav den första var en kvantitativ webbenkät där syftet var att kontrollera om det finns ett samband mellan kunskap om inställning genom att jämföra hård data. Den andra metoden var utförandet av två fokusgrupper med kvalitativa gruppdiskussioner. Syftet med fokusgrupperna var att få en generell bild av deltagarnas inställning till att få vård av en dator istället för en människa. Den tredje metoden är grundad på scenario-based design.
2.1
Forskningsdesign
Forskningsdesign innebär enligt Hjerm et al., (2018) att skapa en mall och struktur för studien. I designfasen av studien behöver författarna eller forskarna fråga sig vilken typ av data som bäst kan svara på undersökningens frågeställning. Att skapa en god forskningsdesign är svårt då planen skapas i ett tidigt skede vilket medför komplikationer med att korrigera misstag i efterhand. (Hjerm et al., 2018) Det var därför viktigt för denna att syftet och frågeställningen inte ändrades under processens gång.
Studien har baserats på både kvalitativa och kvantitativa ansatser för att få ett mer fullständigt resultat (Bryman, 2008). Bryman (2008) menar att de två metoderna kan komplettera varandra genom att en lucka som en kvalitativ undersökning lämnar efter sig kan fyllas med en kvantitativ undersökning. Barajas, Forsberg och Wengström (2013) beskriver att resultatet av en kvalitativ undersökning kan ge nya idéer till frågor som sedan studeras med en kvantitativ utgångspunkt. Fördelen med att använda mixade metoder är att ett fenomen kan belysas ur olika synvinklar (Barajas et al., 2013).
2.2
Metodval
Frågeställningen och syftet styr val av metoder i undersökningen. Forskaren bör även välja metoder efter vilka möjligheter som finns att samla in data. (Byström & Byström, 2011) Kvalitativ forskning till skillnad från kvantitativ forskning fokuserar på beteenden, uppfattningar och upplevelser än på kvantifiering när det kommer till att föra samman och utreda data (Bryman, 2008). Kvalitativ forskning innebär även att studera ett ämne mer
viktig, därför är få mer omfattande svar mer betydelsefulla för studien än många svar. När forskaren vill få en översikt av ett ämne kan den kvantitativa metoden vara ett bättre val. Den kvantitativa forskaren undersöker ofta ett bredare omfång av data. (Byström & Byström, 2011)
Den kvantitativa metoden innebär enligt Barajas et al. (2011) att forskaren ställer en frågeställning med en uppfattning om vilket svar som kommer ges för att sedan testa detta. Forskarens roll i en kvantitativ undersökning är att vara objektiv och göra mätningar med ett standardiserat instrument. Kvantitativa studier handlar även om att se ett samband och kunna förklara ett fenomen. (Barajas et al., 2011) Då kvantitativa metoder använder mätningar bör forskaren däremot vara kritisk till om svaren ger en verklig bild av ämnet (Bryman, 2008). Bryman (2008) menar att respondenter som till exempel svarar på en kvantitativ enkät har olika bakgrund och uppfattningar vilket måste undersökas mer djupgående.
Vid användning av flermetodsforskning är det viktigt att samtliga metoder ska vara lika givande för studien (Bryman, 2008). Bryman (2008) lyfter även en del kritiska aspekter gällande att kombinera olika metoder i en studie. Många författare anser att flermetodsforskning inte är möjlig då olika forskningsansatser leder till olika kunskapsteoretiska konsekvenser. Detta eftersom olika metoder grundar sig i olika syn på hur den sociala verkligheten ska studeras. (Bryman, 2008) Barajas et al. (2013) menar däremot att det är fördelaktigt att kombinera metoder då forskaren får resultat som visar olika perspektiv. Detta ger forskaren en större variation av data och företeelser (Barajas et al., 2013). Hjerm et al. (2018) är likaså positivt inställd till en kombination av både kvalitativa och kvantitativa metoder. De menar att många forskare idag använder sig av en kombination av dessa metoder och att det är ett onödigt och gammalt synsätt att se på de olika metoderna som fiender. Hjerm et al. (2018) menar vidare att det viktiga vid en undersökning är att skapa och dela kunskap om en företeelse. Vid kombination av kvantitativa och kvalitativa metoder bör forskaren utforma studien så att analysstrategierna inte flyter samman. Hur metoderna kombineras måste därför förklaras. Om studiens mål är att få en ökad kunskap om ämnet i studien och metoderna integreras med varandra kallas detta att komplettera analysstrategierna. (Hjerm et al., 2018)
2.2.1
Kvantitativ webbenkät
Kvantitativa strukturerade webbenkäter är en metod som används för att erhålla fasta svarsalternativ (Trost, 2010). Enligt Byström & Byström (2011) finns det många fördelar med att använda enkäter i en studie. En fördel de nämner är att enkäter sparar in på tid då det inte är lika tidskrävande som intervjuer. En annan fördel är att enkäten har möjlighet att samla in svar
från fler individer då det är enklare att nå ut till fler. Enkäter är även en fördelaktig metod då de ofta är enkla att revidera och sammanställa. (Byström & Byström, 2011) Kvantitativa enkätundersökningar som datainsamlingsverktyg är således ett bra verktyg om det eftersträvas en generaliserbar kunskap som uttalar sig om en större population (Hjerm et al., 2018). Enkäter är fördelaktiga när det kommer till att undvika intervjuareffekten (Bryman, 2008). Intervjuareffekten innebär enligt Byström & Byström (2011) att respondenterna påverkas av de frågor och följdfrågor som ställs av intervjuaren. Eftersom enkäten är anonym kan forskaren inte heller utöka svaren med fler frågor om det skulle behövas mer information. (Byström & Byström, 2011)
En nackdel med enkäter är att forskaren inte kan hjälpa respondenterna när de fastnar i en fråga (Byström & Byström, 2011). Bryman (2008) påpekar också detta och menar att det därför är viktigt att enkäten är tydlig och enkel. När forskaren ska formatera enkäten är det värdefullt att vara noggrann. För att undvika att frågor tolkas på olika sätt bör de vara tydligt formulerade. Frågorna bör även vara anpassade efter individerna som ska undersökas. (Byström & Byström, 2011) Djurfeldt et al. (2010) anser att en pilotundersökning kan genomföras för att testa enkäten på ett mindre urval. På så sätt kan validitetsbrister upptäckas i god tid (Djurfeldt et al., 2010).
2.2.2
Kvalitativa fokusgrupper
En fokusgrupp är enligt Bryman (2008) vanligen en grupp på minst fyra personer som deltar i en gruppintervju. Anledningen till att fokusgrupper väljs istället för en individuell intervju är för att skapa ett samspel mellan individerna. I fokusgruppen är forskaren intresserad av att höra hur deltagarna har för tankegångar och uppfattningar av en fråga. En gruppintervju möjliggör utforskning av varandras skäl till sina ståndpunkter. Forskaren får tillgång till en större bredd i åsikter än vid en individuell intervju. (Bryman, 2008) Enligt Byström & Byström (2011) kan intervjuaren uppnå en god kvalitet på en intervju genom att förbereda sig på olika sätt. Att ha i åtanke är att försöka se samband mellan erfarenheter och upplevelser hos människor. Intervjuaren bör använda en rak kommunikation och tydliggör studiens syfte. Eftersom det är en större risk att påverka respondenter med intervjuareffekten i en kvalitativ intervju bör intervjuaren vara uppmärksam på detta. (Byström & Byström, 2011) Därför är det viktigt att intervjuaren låter fokusgruppen själva lyfta och diskutera de viktigaste frågorna, vilket är en viktig del i en kvalitativ undersökning (Bryman, 2008).
vara betydelsefulla för undersökningen. (Bryman, 2008) Bryman (2008) anser att en intervjuare bör undvika att gripa in i diskussionen förutom om intervjuaren ska ställa en ny fråga. Om gruppen fastnar i en diskussion eller talar om något som inte är relevant för undersökningen borde intervjuaren gripa in (Bryman, 2008). Fördelarna med gruppintervjuer är att gruppmedlemmarna kan hjälpa varandra att få en större förståelse för ämnet och den specifika frågan samt till att komma fram till idéer (Trost, 2010). Intervjuaren bör ställa en eller två generella och öppna frågor som kan stimulera samtalet mellan gruppmedlemmarna (Bryman, 2008).
2.2.3
Scenario-based design
Scenario-based design kan användas för att få en djupare förståelse för användarbehov inom ett specifikt område. Metoden används när förståelse behöver uppnås för komplexa problem. (Ruijer, Grimmelikhuijsen, Hogan, Enzerink, Ojo & Meijer, 2017) Ett scenario kan användas för att förstå användarens beteende och att den medverkande ska kunna sätta sig in i ett framtidsscenario (Nilsson, Ericson & Törlind, 2015). Författarna (Nilsson et al., 2015) menar även att metoden kan användas för att utvärdera en idé eller koncept. En strategi är att skriva ett utopiskt scenario vilket beskriver en ideal framtid där inga begränsningar finns (Nilsson et al., 2015).
Ett scenario är enligt Yu & Liu (2006) ofta en detaljerad beskrivning av ett användningsområde med en användares potentiella beteende. Metoden kan bidra med att få insikt om användarens reaktion och beteende, vilket i sin tur leder till kunskap om begränsningar i ett visst användningsområde. (Yu & Liu, 2006) Carroll (2000) menar i sin artikel Five Reasons for
Scenario-Based Design att scenario-based design är en effektiv och viktig metod när det
kommer till utveckling av design av mjukvara. Carroll (2000) beskriver scenarion som människors berättelser om sina aktiviteter.
2.2.4
Innehållsanalys
Innehållsanalys används när målet är att identifiera specifika mönster i data och används bland annat för textanalys. Metoden går till så att forskaren på ett systematiskt sätt kategoriserar data för att sedan kunna beskriva olika fenomen utifrån olika teman. Latent innehållsanalys innebär att datan delas upp i meningsbärande enheter, kodning eller att centrala teman identifieras. Idén är att forskaren först ska förstå djupet av texten för att sedan dela upp datan i en förklaringsmodell. (Denzin & Lincoln, 2011, refererad i Barajas et al., 2013) Bryman (2008)
menar att innehållsanalys används när forskaren vill erhålla en beskrivning eller kvantifiering av ett fenomen. En enkel form av innehållsanalys är att gå igenom fem steg:
1. Gå igenom materialet djupgående för att göra det bekant.
2.
Gå igenom vad texten egentligen handlar om och dela upp den i koder, exempelvis:
inte gilla att läsa, läsa snabbt, läsa långsamt.
3.
Sammanpressa koderna till kategorier som exempelvis “snabbläsare” gällande det
ovan nämnda exemplet.
4.
Kategorisera kategorierna till teman som exempelvis “läsaridentitet”.
5.Sista steget är att läsa och tolka resultatet. (Barajas et al., 2013)
Enligt Bryman (2008) finns det en rad risker som kan uppkomma i och med att göra ett kodningsschema i en innehållsanalys. En av dessa aspekter är att dimensionerna behöver vara tydligt åtskilliga från varandra för att inte få någon teoretisk överlappning. Det är även viktigt att de olika kategorierna i de olika dimensionerna inte överlappar varandra för att undvika missförstånd vid kodning av informationen. (Bryman, 2008) Bryman (2008) belyser även att innehållsanalys generellt sett har fått kritik för att vara ateoretisk. En av anledningarna till detta kan vara att det mesta av resultatet som uppkommer från en innehållsanalys endast är spekulationer. Däremot är det till forskarens fördel att det är en öppen forskningsmetod då det är enkelt att beskriva hur kodningsschemat är utformat vilket medför att det är lätt att utföra uppföljningsstudier. (Bryman, 2008)
2.2.5
Signifikansprövning och korrelation
En signifikansprövning av olika statistiska test görs för att beräkna om ett samband beror på en verklig sann skillnad, ett systematiskt mätfel eller och skillnaden endast beror på slumpmässiga variationer. Genom att göra en signifikansanalys kan forskaren mäta om skillnaden är statistiskt säkerställd eller beror på slumpen. (Barajas et al., 2011) Bryman (2008) beskriver att ett signifikanstest behöver utgå från en nollhypotes som säger att två variabler inte är beroende av varandra. Om resultatet visar en signifikansnivå runt fem procent innebär det att risken för att få ett samband som egentligen inte existerar i populationen är fem på hundra, vilket medför att nollhypotesen kan förkastas. Det betyder i sin tur att resultatet inte beror på en slump. (Bryman, 2008)
En signifikansprövning kan göras med olika test varav ett är chi-två-test (Barajas et al., 2011). Hjerm et al. (2018) beskriver att Chi-två används för att underlätta bedömning av hur stor skillnad det är mellan två kategorier. Detta görs genom att kvantifiera förhållandet mellan två variabler med hjälp av siffror. Chi-två testar om två variabler är beroende av varandra eller inte.
Om det visar sig att de två variablerna inte har något samband så avses det som slumpmässig fördelning. Det som är negativt med ett chi-två-test är att det inte visar om de två variablerna har ett samband utan endast om variablerna har något med varandra att göra. (Hjerm et al., 2018)
För att testa hur starkt samband är mellan två variabler kan ett korrelationstest utföras. Värdet kan variera mellan -1 och +1 och visar om sambandet är negativt eller positivt. (Barajas et al., 2011) Byström och Byström (2011) förklarar att korrelationstester syftar till att uppnå en fördjupad kunskap men används även för att kunna göra förutsägelser i vissa situationer. Författarna menar även att resultatet av ett korrelationstest inte endast ska tolkas genom siffrorna utan att författaren även behöver förstå sambandet (Byström & Byström, 2011). Genom att kontrollera korrelationskoefficienten mellan två variabler går det att kontrollera om sambandet gäller för populationen (Djurfeldt, Larsson & Stjärnhagen, 2010).
2.2.6
Urval
Vid kvantitativa undersökningar är det en förutsättning att använda sig av urval. En population innefattar samtliga enheter som urvalet utgår ifrån och kan till exempel stå för universitet, företag, städer och bostadsområden. (Bryman, 2008) Om det är för dyrt eller tidskrävande att studera en hel population så är det praktiskt att göra ett urval (Hjerm et al., 2018).
Ett sätt att nå ut till en bredare population är genom att göra ett Snöbollsurval. Snöbollsurval även kallad kedjeurval, innebär att forskaren använder sig av respondenternas kontakter för att få tag i ytterligare respondenter. Snöbollsurval kan vara problematiskt då populationen förändras under ett flertal gånger. Det innebär att samplet sällan står för populationen. Däremot kan snöbollsurval vara effektivt för den kvantitativa forskningen då det kan vara intressant att undersöka samband mellan respondenter. (Bryman, 2008) För att nå ut till flera individer kan det vara effektivt att använda sociala nätverk som ett verktyg vilket möjliggör spridning av information (Ejlertsson & Axelsson, 2014). När forskaren använder respondenter som av en händelse finns tillgängliga i närheten kallas detta för bekvämlighetsurval. Då urvalet kan vara en mycket liten del av populationen som undersöks kan detta vara problematiskt för att få fram en generell bild av det undersökta ämnet. (Bryman, 2008) Enligt Bryman (2008) är bekvämlighetsurval ofta en vanlig metod vid undersökningar av organisationer. Bekvämlighetsurval kan vara en mer effektiv metod än stickprov som grundas på
Det finns både positiva och negativa åsikter om att använda sig av en gruppintervju med personer som redan har en relation. En del forskare tror att detta kan påverka diskussionen då det finns samspelsmönster och statusskillnader i relationerna. Andra forskare anser att dessa typer av gruppintervjuer kan bli mer naturliga vilket skapar en bättre dynamik. (Bryman, 2008)
Teoretiska urval styrs av en önskan att hitta intervjupersoner som har olika mycket erfarenheter
av fenomenet så att de kan framhäva olika synvinklar (Barajas et al., 2013).
2.2.7
Bortfall
I en studie är det viktigt att forskaren tar hänsyn till problem med bortfall. (Byström & Byström, 2011) Enligt Byström och Byström (2011) är det trots detta ofta svårundvikligt att undkomma bortfall. För att undvika korrigeringar och komplement av den insamlade datan menar Byström och Byström (2011) att det är fördelaktigt att forskaren har kunskaper om bortfall. Om en särskild grupp hamnat vid sidan av studien kan det leda till att resultatet blir förvrängt. Detta minskar i sin tur på resultatets validitet.
Bortfall beror oftast på brist på kommunikation och tillgänglighet, avhopp, om respondenter vägrar delta eller glömmer att svara. Det räknas även som bortfall när respondenten inte förstår frågorna. (Byström & Byström, 2011) Vid enkätundersökningar är det än större risk för att det blir ett stort bortfall än vid intervjuer. Detta gäller speciellt vid enkäter som skickas ut på via posten. (Bryman, 2008) Byström & Byström (2011) menar att detta beror på att personer börjar tröttna på att besvara en enkät via telefon och på post. Trots ett byte från fysisk post till digital e-post finns det fortfarande risker med höga bortfall. För att minska på bortfallet i studiens enkät kan forskaren skicka ut påminnelser till populationen som undersöks. (Byström & Byström, 2011)
Även struktur och design på enkäten är viktig för att minska bortfall. Enkätens struktur bör vara kort med tydliga instruktioner och en inbjudande layout. (Bryman, 2008) Frågorna bör undvika att vara vinklade då det kan leda till missvisande svar (Byström & Byström, 2011). En viktig aspekt som forskaren inte borde glömma är att vara tydlig med syftet att förklara syftet med studien. Forskaren kan även använda sig av belöningar till de som undersöks genom att till exempel bjuda på lotter. (Bryman, 2008) Vid slumpmässiga urval kan det vara ett problem att forskaren inte har kontroll över datainsamlingen. I webbenkäter vet forskaren inte med säkerhet vem det är som svarar på enkäten. (Byström & Byström, 2011)
2.3
Tillvägagångssätt
Uppsatsen innefattar kritiskt granskad teori och tidigare forskning. För att säkerställa att materialet har en vetenskaplig grund är majoriteten av teorin peer-reviewed och grundad på forskning. Detta har kompletterats med blogginlägg och artiklar utan vetenskaplig grund. Eftersom uppsatsen undersöker en ny digital teknik som är på väg in i samhället har författarna fokuserat på samtida källor.
2.3.1
Enkätundersökning
För att kartlägga individers attityder till vårdapplikationer används kvantitativa strukturerade webbenkäter i studien. Enkätundersökningen skickades ut vecka tio. Den anonyma kvantitativa webbenkäten utformades i Sunet survey vilket är ett molnverktyg som är utformat för enkäter. Enkäten inleddes med en introduktion till där syftet till studien förklarades samt en kortare förklaring av begreppet maskininlärning. Därefter fick respondenterna fem kvantitativa frågor totalt att svara på. De inledande frågorna i enkäten var stängda med ett fåtal svarsalternativ. Dessa följdes av ett fåtal öppna frågor.
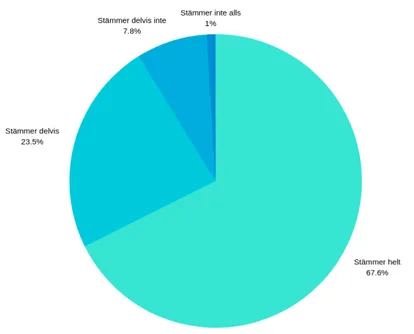
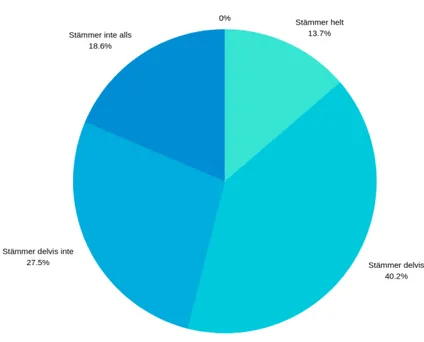
Enkäten undersökte individers attityd till vårdapplikationer som använder sig av maskininlärning. Enkäten undersökte även individers kunskap och erfarenhet kring ämnet (se bilaga 4). Det genomfördes ett bekvämlighetsurval genom Facebook då kontakter som fanns tillgängliga i det sociala mediet utnyttjades. Familjemedlemmar blev även tillfrågade att dela enkäten via sina Facebook-profiler vilket utgjorde ett snöbollsurval. Enkäten låg ute på Facebook under en vecka och nådde upp till 101 svar. Enkäten stängdes med anledning att erhålla tid till att analysera resultatet innan deadline. Fråga två och tre i webbenkäten låg som grund till en statistisk analys som har behandlats med chi-två-test och korrelationstest. Den avslutande frågan bestod av fem påståenden med en skala från stämmer helt till stämmer inte alls (Se bilaga 4).
2.3.2
Fokusgrupper
Nedan presenteras tillvägagångssätten för gruppintervjuer i fokusgrupp 1 och 2 samt scenario 1 och 2. Ett bekvämlighetsurval gjordes även inför fokusgrupperna då respondenterna som deltog var personer som var bekanta till forskarna sedan innan. Fokusgrupp 1 leds av forskare 1 (Frida). Eftersom deltagarna i fokusgruppen skulle bli intervjuad i grupp samlades respondenterna hemma hos en av respondenterna (1:1) under kvällstid 18.00. Samtliga respondenter kände varandra väl sedan innan. Forskaren inledde mötet med att bjuda på fika och
presenterade sedan syftet med studien samt upplägget av intervjun. Vidare spelades intervjun in med mobiltelefoner där respondenterna fick information om att studien är under sekretess och att deras identiteter är anonyma. Därefter inleddes en fråga om varje deltagares sysselsättning. Vidare ställdes de öppna frågorna (se bilaga 1). Fokusgrupp 2 leds av forskare 2 (Vendela). Fokusgruppen samlades hemma hos forskare 2 under kvällstid 18.00. Även här kände samtliga respondenter varandra väl sedan innan. Forskare 2 inledde också mötet med att bjuda på fika. Vidare gick gruppledare 2 igenom samma upplägg som i fokusgrupp 1: förklaring av syftet med studien, sekretess och en runda med deltagarna sysselsättning följt av de öppna frågorna (se bilaga 1).
Intervjuerna i fokusgrupperna innefattade inledande öppna frågor och ett fåtal stängda (se bilaga 1). En av de öppna frågorna var bland annat “Vad tänker ni när ni hör artificiell intelligens” och en av de stängda var “Kan ni tänka er att använda appar med AI? ja/nej”. Efter att de öppna frågorna ställts framfördes en beskrivning av ett scenario i vardera fokusgrupp. Fokusgrupp 1 blev tillägnat scenario BEATA medan fokusgrupp 2 blev tillägnade scenario SAM.
Scenario 1 och 2 (BEATA och SAM) bygger på fiktiva vårdapplikationer som använder maskininlärning. Detta för att undersöka två olika potentiella användningsområden med maskininlärning i en vårdapplikation. Respondenterna fick diskutera på egen hand och avbröts i undantagsfall då diskussionen var något var otydligt eller hade banat iväg åt ett felaktigt håll. Vardera scenario-diskussion pågick i en halvtimme. Fokusgrupp 1 fick reflektera över scenario 1 (se bilaga 2). Scenario 1 inleddes med att förklara ett första scenario med den fiktiva applikationen BEATA. Därefter ställdes frågor om upplevelser samt om de kände tillit till applikationen eller inte. Fokusgruppen fick några minuter att diskutera frågorna på egen hand. Vidare förklarades ännu ett scenario med BEATA som fokuserade på self-tracking, datautlämning, förtroende och användandet av vårdapplikationer. Därefter ställdes liknande frågor om attityder till applikationen. Vidare fick fokusgruppen några minuter på sig att diskutera. Scenario-diskussion med fokusgrupp 1 avslutades därefter och tog totalt 30 minuter. Scenario-diskussion med fokusgrupp 2 utfördes med samma upplägg med scenario 2 SAM (se bilaga 3) som fokuserade på diagnostisering med maskininlärning, förtroende för människa vs maskin, vård på distans och användande av en vårdapplikation.
Intervjuerna spelades in med hjälp av mobiltelefoner för att sedan transkriberas. Eftersom studien ville undersöka ett teoretiskt urval valdes deltagarna i båda fokusgrupper ut efter hur olika mycket kontakt med sjukvården och olika mycket teknisk kunskap de hade sedan innan.
2.3.3
Bearbetning
Bearbetning av den kvantitativa webbenkäten gjordes till en början genom att lägga in datan i cirkeldiagram. Kvalitativa variabler som cirkeldiagram visar informationen på ett tydligt sätt vilket för att en analys av datan kan göras (Djurfeldt et al., 2010). Därefter analyserades två variabler från enkäten genom ett chi-två-test och ett korrelationstest. Korrelationstestet utfördes i Excel och Chi-två-testet utfördes med ett automatiskt beräkningsverktyg på Social Science Statistics (2019). Bearbetning av de kvalitativa fokusgrupperna gjordes enligt Barajas et al. (2013) fem steg för en innehållsanalys. En transkribering gjordes till en början för att bli bekant med materialet. Texten från transkriberingen delades upp i koder, kategorier och teman. Därefter lästes och tolkades resultatet genom att ställa det mot teori.
2.3.4
Forskningsetiska överväganden
Enligt Vetenskapsrådet (2017) bör forskarna göra etiska överväganden för att öka forskningens kvalitet och bidra till utveckling av samhället. Några av de krav som behöver uppnås för en etisk forskning är att forskaren ska tala sanning om sin forskning, forskaren ska redovisa både metoder och resultat öppet, forskningsresultat får inte stjälas från andra, forskaren ska vara rättvis i sin bedömning utifrån andras forskning och forskaren ska medvetet granska samt redovisa de utgångspunkter som funnits för studierna. (Vetenskapsrådet, 2017)
Forskningsetiska överväganden bör göras i en undersökning vilket behandlar frågor kring hur individerna i undersökningen ska behandlas (Barajas et al., 2013). Några principer som studien följde gällande etiska grundläggande frågor som anonymitet, integritet, frivillighet och konfidentialitet var följande:
• Informationskravet. De individer som ska undersökas bör bli meddelade om undersökningens huvudsakliga syfte, vilket även innefattar att de bör få reda på vilka
moment som undersökningen omfattar. (Byström & Byström, 2011)
Enkätundersökningen inleddes således med en informationstext gällande bakgrund till uppsatsen och vad den skulle användas till. Även fokusgruppen inleddes med syfte av studien.
• Samtyckeskravet. Individerna bör vara medvetna om att de själva har rätt till sin medverkan och att de kan bestämma om de vill delta eller ej. (Byström & Byström, 2011) En öppen förfrågan skickades därför ut gällande enkäten för att visa att det var
frivilligt att besvara den. Gällande fokusgrupperna fick deltagarna en inbjudan som de kunde tacka ja eller nej till.
• Konfidentialitetskravet. De personliga uppgifterna som samlas in ska bevaras med konfidentialitet så att obehöriga inte kan tillgå dem. (Byström & Byström, 2011) Enkätundersökningen utfördes via en mjukvaru-tjänst där en “anonymitets”-inställning gjordes så att forskarna inte tillhandahöll några personliga uppgifter. Transkriberingen och behandlingen av texten av fokusgrupperna utfördes som “person a” istället för namn.
• Nyttjandekravet. Den info som samlas in får endast användas i undersökningen. (Byström & Byström, 2011) Detta meddelades både i enkätundersökningen samt i fokusgrupperna.
2.4
Metoddiskussion
För att kunna dra slutsatser av en undersökning behöver den ha hög validitet vilket innebär att det som avses att mätas verkligen mäts. Reliabilitet omfattar mätnoggrannheten och innebär att det ska vara hög kvalitet på undersökningen och att metoden inte ska ändras från tillfälle till tillfälle. Konvergent validitet innebär att validiteten i en undersökning bör värderas genom en jämförelse med ett resultat från ett annat tillvägagångssätt. För att undvika en bristande konvergent validitet utfördes två olika undersökningsmetoder på samma mått. (Byström & Byström, 2011) En faktor som skulle mätas var om det fanns någon korrelation mellan medvetenhet om maskininlärning i sjukvården och attityder till det i vårdapplikationer. Som Barajas et al. (2013) nämner är flermetodsforskning fördelaktigt om forskaren vill ha en större variation av data. Bryman (2008) menar att en kombination av metoder leder till olika kunskapsteoretiska konsekvenser. Om metoderna däremot är relevanta för studien kan en kombination däremot fungera (Bryman, 2008). Hjerm et al. (2018) menar också att flermetodsforskning är lönsamt då det skapar en större bredd i kunskap. Eftersom både enkäten och fokusgrupperna med scenario-based design är relevanta anses en flermetodsforskning vara givande för studien.
2.4.1
Enkätundersökningen
I denna studies enkätundersökning gjordes all datainsamling genom samma metod i ett digitalt verktyg. Byström & Byström (2011) menar att enkätens höga reliabilitet inte förutsätter att den
också får hög validitet. Som Byström & Byström (2011) nämner är en negativ aspekt med enkäter att forskaren inte kan hjälpa till om respondenten fastnar i en fråga. Detta hade kunnat undvikas genom en pilotundersökning då svårformulerade frågor hade kunnat upptäckas i god tid. Eftersom detta inte utfördes i denna studie kan validiteten på enkäten ha sänkts enligt Djurfeldt et al. (2010). Då studiens ämne är relativt outforskat kan det ha inneburit att många respondenter behövde vägledning kring frågorna. Däremot syftar enkäten just till att bland annat undersöka individers kunskap. Om respondenterna hade fått hjälp med forskarens kunskap hade enkäten tappat sitt syfte.
En mätning av relationen mellan två fenomen gjordes till enkätundersökningen genom ett korrelationstest. Som Hjerm et al. (2018) nämner utförs ett chi-två-test med syfte att underlätta bedömning av skillnaden mellan två frågor. Genom att få svar på att det är skillnad mellan hög medvetenhet och positiv inställning kan studien underbygga att det går att öka den positiva inställningen hos en population genom utbildning inom ämnet.
För att öka validiteten jämfördes samma fenomen genom frågor i fokusgrupperna. En negativ aspekt med denna studie är att vårdapplikationer som använder maskininlärning ännu inte är implementerat på marknaden och därför inte testat av de individer vi undersöker. Detta medför ett resultat som inte kan räknas helt reliabelt. Webbenkäten innehåller ett fåtal öppna frågor vilket även sänker validiteten på den kvantitativa mätningen av enkäten. Som Byström & Byström (2011) nämner är enkäter en god metod för att undvika intervjuareffekten. Detta ökar därmed reliabiliteten och validiteten i enkätundersökningarna.
2.4.2
Kvalitativa fokusgrupper
Syftet med en kvalitativ ansats är att undersöka en deltagares upplevelse av ett fenomen (Byström & Byström, 2011). Då ämnet som undersöks innefattar nya tekniker som ännu inte implementerats i individens vardag var det viktigt att använda kvalitativa fokusgrupper. Bryman (2008) menar att gruppintervjuer med fokusgrupper möjliggör samspel och hjälper respondenter att få nya kunskaper och insikter om ett ämne. Då det är större risk att påverka respondenter med intervjuareffekten i kvalitativa intervjuer som Byström och Byström (2011) påpekar, såg respektive gruppledare till att hålla sig i bakgrunden av diskussionerna. Däremot kan respondenterna ha påverkats av scenarionas positiva eller negativa vinkling vilket kan ha sänkt validiteten. För att undvika påverkan av forskarna ställdes få frågor där respondenterna fick lång tid på sig att fundera och diskutera. Detta var även viktigt då innehållet i svaren bör vara
innehållsrika då kvalitativa undersökningar syftar till att vara subjektiv (Byström & Byström, 2011).
2.4.3
Scenario-based design
För att skapa större reliabilitet för undersökningen kompletterades enkätundersökningen med Scenario based design. Trots att scenario-based design är inriktat på design-fasen enligt Carroll (2000) är metoden relevant då Nilsson et al. (2015) syftar till kan scenario-based design användas så att respondenterna ska kunna sätta sig in i ett framtidsscenario. Eftersom vårdapplikationer som använder maskininlärning ännu inte är integrerat i samhället behövde vi skapa scenarion med fiktiva applikationer för att respondenterna skulle få en uppfattning om hur en sådan applikation skulle kunna fungera. För att öka validiteten för respektive scenario baseras applikationerna på andra verkliga applikationer.
2.4.4
Urval och bortfall
Då personer delade enkäten vidare och skapade en större spridning av enkäten mynnade det ut i ett snöbollsurval. Bryman (2008) menar att snöbollsurval kan göra det problematiskt för studien då populationen förändras. Eftersom denna studie undersöker en generell attityd till vårdapplikationer som använder maskininlärning är inte populationen fastställd. Enkäten och fokusgrupperna utgjordes även genom ett bekvämlighetsurval vilket Bryman (2008) menar kan minska validiteten då syftet är att få en generell bild av ämnet som undersöks. Däremot stärks validiteten då respondenterna som undersöks i fokusgrupperna är utvalda genom ett teoretiskt
urval. Genom det teoretiska urvalet framhävs fler synvinklar vilket ger studien ett bredare
resultat (Barajas et al., 2013).
Som både Bryman (2008) och Byström och Byström (2011) nämner är det hög risk för bortfall när enkäter skickas ut via post och e-post. Att publicera enkäterna digitalt genom Facebook var därför ett alternativ som kan ha orsakat stort bortfall. Däremot kan forskaren som Bryman (2008) nämner påminna de som blir undersökta att svara på enkäten. Detta var möjligt på Facebook då inlägg inte “faller bort” i en hög av post eller mail utan kan komma upp i flödet på nytt. Eftersom enkäten endast låg ute under en vecka kan det ha påverkat att bortfallet blivit större då inlägget inte visats upp eller om forskarnas Facebook-vänner inte gått in på Facebook under denna tidsperiod. Enkäterna kunde som tidigare nämnt delas i andras flöden vilket kan ha skapat nya påminnelser hos respondenter.
Eftersom strukturen enligt Bryman (2008) är viktig för att undvika bortfall var det viktigt att studiens enkät var kortfattad och att frågorna var väl formulerade så att så många som möjligt skulle kunna svara utan att fastna. Inför intervjun med fokusgrupperna lockades respondenterna genom att bli bjudna på fika vilket Bryman (2008) menar är en god metod för att hålla kvar respondenter och minimera bortfall. Något som kan sänka validiteten med enkäter är att forskaren inte med säkerhet vet vem som svarar på den (Byström & Byström, 2011). Eftersom undersökningen utgår ifrån att se på en generell attityd bland individer är inte detta något som påverkar resultatet för undersökningen.
3
Teori
Detta kapitel presenterar teori kring hur sjukvården har digitaliserats och nya behov som har uppkommit med detta. Ny teknik har möjliggjort att individer i större utsträckning kan få vård genom en applikation oavsett var personen befinner sig. Digitaliseringen har även medfört att maktbalansen mellan patient och läkare har förändrats. Maskininlärning är en av de funktioner som har möjliggjort en mer automatiserad diagnostisering där läkare inte har samma roll som förr. Slutligen presenteras även attityder som har studerats tidigare gällande att få sjukvård på ett mer digitalt sätt.
3.1
Maskininlärning
Som det nämns i bakgrunden är maskininlärning en teknik som styrs av algoritmer och stora mängder data (LeCun, 2018). LeCun (2018) förklarar i sin artikel The Power and Limits of
Deep Learning hur maskininlärning och dess inlärningsprocess fungerar. Mer ingående är maskininlärning en teknik som är baserad på biologiska neurala nätverk (Jurtz, Johansen, Nielsen, Armenteros, Nielsen, Sönderby, Winther & Sönderby, 2017). Enligt Jurtz et al. (2017) är tekniken under de senaste åren specifikt utvecklad och framgångsrik när det kommer till igenkänning av bilder och röster. Den traditionella konstruktionen av neurala nätverk är uppbyggd genom dolda lager där enskilda neuroner i det dolda lagret är kopplad till varje ingående neuron. I utgångslagret är varje enskild neuron även här kopplad till varje neuron i det dolda lagret. I nätverket riktas samtliga anslutningar från ingång till utgång. Genom att addera fler dolda lager där varje enskild neuron blir ansluten till varje neuron i följande skikt är det möjligt att skapa djupare nätverk. (Jurtz et al., 2017) Förenklat fungerar processen av igenkänning av bilder genom att visa upp bilder för maskinen och låta den räkna ut med hjälp av algoritmer vad det är för objekt. Maskinen får sedan rätt svar och lär sig sedan korrekt information efter miljontals upprepade inmatningar. (LeCun, 2018)
Maskininlärning är ett av de främsta områdena inom Artificiell intelligens som samlar information och statistik för att upptäcka ny kunskap, vilket gör att den är starkt relaterad till sjukvården (Huh, 2018). Ett exempel på ett forskningsprojekt inom maskininlärning som drivs av Sutton, Samavi, Doyle och Koff (2018) förutspår individers cancerrisk från att exponeras för medicinsk strålningsbehandling. De har utvecklat en modell med maskininlärning som konstant genererar ny data då individer bidrar med deras data av strålningsbehandlingen samt biverkningar av detta. Nästa patient kommer därefter att ta fördel av detta då det kommer vara
en uppdaterad riskbedömning. Patienter hamnar i det här fallet i en loop av research då AI-systemet kontinuerligt behöver bli uppdaterat. (Sutton et al., 2018)
Exempel på användningsområden där maskininlärning används inom svensk och internationell sjukvård är läkemedelsforskning, assistent under operation, personlig rådgivning till cancerpatienter. Inom cancersjukvården hjälper maskininlärning till med att fatta beslut och ställa diagnoser. Maskininlärning kan även användas för att förklara hur bilder ser ut för synskadade, ställa prognos för utbredning av smittsamma sjukdomar samt fungera som hjälpmedel till barn med autism. (Sveriges kommuner & Landsting, 2017)
3.1.1
Diagnostisering med maskininlärning
Forskare applicerar i allt större utsträckning maskininlärning på att analysera hälsodata, såsom blodtryck och magnetröntgenbilder, för att hitta mönster som kan vara underlag för en diagnostisering. Kenji Suzuki, en assisterande professor på Chicagos universitet, menar att maskininlärning dessvärre kan förbise cancer som läkare kan identifiera med ögat. I hans test för att identifiera lungcancer identifierade algoritmerna i snitt fem felaktiga sjukdomsförändringar per patient. Suzuki expanderar tekniken till att identifiera cancer genom att kombinera olika metoder av bildscanning. Han menar att det gäller att träna upp maskininlärning med nya bilder. (Savage, 2012)
Maskininlärning kan appliceras på en rad mängd data för att kartlägga en patients medicinska historia över flera år. Genom att jämföra data från tusentals tidigare patienter med en ny liknande patient, kan maskininlärning tillämpa en analys som föreslår en diagnos och behandling för den nya patienten. Den här metoden kan hjälpa läkare att basera diagnoser med hjälp av kvantitativ information, vilken i sin tur ska leda till färre feldiagnostiseringar. (Savage, 2012) I en studie av Semigran, Linder, Gidengi & Mehrotra (2015) där de jämförde diagnostisk noggrannhet framkom det att läkare överträffade algoritmer med stor marginal. 84,3 procent av läkarna gav rätt diagnostisering medan 51,2 procent av algoritmerna gjorde detsamma (Semigran et al., 2015).
En finsk forskargrupp har studerat hur artificiell intelligens kan implementeras i olika plattformar och applikationer för att kunna utföra automatisk diagnostisering. Tillsammans har forskarna utvecklat ett litet och lätt-transporterat mobilt mikroskop som kan användas som ett verktyg för att identifiera parasitinfektioner och cancer. Algoritmerna som ska kunna utföra en automatisk diagnostisering med hjälp av att jämföra bilder som är baserade på maskininlärning. (Holmström, Linder, Ngasala, Mårtensson, Linder, Lundin, Moilanen, Suutala, Diwan, &
Lundin, 2017) Likt tidigare nämnt har författarna Lan, Samy, Alshurafa, Suh, Ghasemzadeh, Macabasco-O'Connell och Sarrafzadeh (2012) utvecklat ett system kallat “WANDA” som med hjälp av algoritmer ska förutse hjärtsjukdomar hos patienter. Det huvudsakliga syftet med metoden är att kunna förutse framtida händelser genom att analysera patientens egna rapporter om hälsan. Den data som samlas in omfattar bland annat vikt, kroppsfett, hjärtfrekvens, blodglukos och kroppsrörelser. Genom att använda relevant information kan systemet med hjälp av maskininlärning och datautvinnings-algoritmer analysera och upptäcka mönster i datan för att sedan förutse det framtida hälsotillståndet. (Lan et al., 2012)
3.1.2
Datautvinning – mönster i data
Datautvinning är en teknik som används för att hitta mönster eller trender i data. Medicinsk datautvinning har haft en stor betydelse i vården då tekniken kan bidra med att förbättra både kvalitet och service. Artikeln belyser att vården kan använda mjukvaror med datautvinnings-tekniker som kan bearbeta bilder för att identifiera tumörer. (Kiranmayee, Rajinikanth & Nagini, 2016) Mia, Hossain, Chhoton & Chakraborty (2018) beskriver att datautvinning har utvecklats som ett nytt informationsverktyg. Det används för att sålla ut gömd information från en större och mer komplex data. Datautvinning har börjat användas i sjukvården genom databaser som samlar medicinsk data från patientens journal. Inom sjukvården har den här metoden funktioner som att upptäcka mönster och bidrar till att få fram orsak till sjukdom. Information kan konverteras till datautvinning genom att gå igenom ett datalager. Forskare diskuterar hur datautvinning kan användas inom sjukvården och menar att hälsoproblem framgångsrikt kan förutspås genom att använda datautvinnings-verktyg. (Mia et al., 2018)
3.1.3
Kritik till maskininlärning
Målet med att implementera AI/maskininlärning i sjukvården idag är att på ett intelligent sätt kunna överstiga människans förmåga att ta in och processa information. En fråga som Sveriges Kommuner och landsting (2017) har lyft är om det går att efterlikna en mänsklig moral som kan få maskinerna att agera etiskt och med sunt förnuft. Detta är viktigt för att kunna uppleva rättvisa och jämlikhet. Om ett fel uppstår som skapar orättvisor kan en stor mängd människor bli drabbade under en längre tid. Det diskuteras även om ett automatiskt system kan göra unika värderingar hos individer med unika behov, vilken annars kan innebära ett hinder när diagnostisering ska fattas. (Sveriges Kommuner & Landsting, 2017) Sendak, Gao, Nichols, Lin och Balu (2019) skriver i sin artikel Machine Learning in Health Care: A Critical Appraisal of
också kritiska till att sjukvården inte är fullt redo för denna typ av digitalisering. Då ny personal och teknik måste implementeras på vårdcentraler och på sjukhus som kan hantera maskininlärning kan detta bli dyrt för samhället.
Ett annat problem är att maskininlärning som köps in inte har samma kliniska resonemang som vårdcentralen eller sjukhuset har. (Sendak et al., 2019) Sveriges kommuner och Landsting (2017) lyfter även problematiken om att artificiell intelligens samlar in personlig data som patienten inte känner till som sedan utnyttjas. Detta kan således leda till att patienter misstror organisationer (Sveriges kommuner & Landsting, 2017). Fler kritiker menar att algoritmer kan diskriminera och utgöra ett hot mot den registrerade datan. Val och beslut som tidigare låg i människans händer har nu blivit delegerat till algoritmer, som kan besluta hur datan ska tolkas och ta ett beslut därefter. Forskare menar att det behöver medvetandegöras att algoritmer är socialt producerade. Algoritmer som är programmerade med ett antagande om sociala skillnader utgör en slags digital sortering. (Ruckenstein et al., 2017)
Sveriges kommuner och Landsting (2017) är trots de negativa aspekterna positivt inställda till implementering av Artificiell Intelligens och maskininlärning i samhället. Som nämnt i bakgrunden tror Sveriges kommuner och Landsting (2017) att Artificiell Intelligens gynnar samhället då tekniken kan minska antalet fel, är mer detaljerad, effektiviserar och är rationell. Tekniken kan även till skillnad från en människa arbeta dygnet runt och obegränsat (Sveriges kommuner och Landsting, 2017).
3.2
Digitalisering av vården
Artificiell intelligens har integrerats i sjukvården för att bland annat kunna generera data från olika delar av individers liv och transformera det till en mer skräddarsydd service (Skiba, 2018). Denna typ av service kan genom smarta telefoner i samband med AI-algoritmer, sensorteknik och avancerad data användas som fullskaliga hälso-plattformar (Dickson, 2017). Mobile Health (mHealth) som innebär hälsa genom mobiltelefonen har möjliggjort egenvård och diagnostisering för patienter. Teknologin artificiell intelligens kan även räkna ut sannolikheter för hur stor chans det är att få vissa sjukdomar. (Khan, Muaz, Kabir & Islam, 2017) Ringquist (2013) anser att den personliga vård-datan som patienten lämnar ut genom AI-applikationer innebär viktig information som i sin tur genererar i en mer effektiv vård. Digitala hälsoapplikationer har i sin tur förändrat hur individer hanterar och kommunicerar hälsorelaterad information (Rahman, Janmohamed, Pirbaglou, Clarke, Ritvo, Herrenan & Katz, 2018).
3.2.1
Mobile Health
I samband med ett ökat användande av smarta telefoner har det även skett en drastisk ökning av användandet av vårdapplikationer (Alessa, Abdi, Hawley & Witte, 2018). Brinkel et al. (2017) anser att mobiltelefoner och trådlös teknologi kan förändra framtidens sjukvård. Applikationer som är fokuserade på hälsa beskrivs idag som datadriven service som kan skräddarsy tjänster efter kundens specifika behov (Van Dijck & Poell, 2016). Brinkel et al. (2017) menar att mHealth har bidragit till att sjukvård även kan erhållas i de länder som annars är resursfattiga.
Bland forskare har mHealth väckt mycket uppmärksamhet gällande validitet och trovärdighet (Van Dijck & Poell, 2016). MHealth erbjuder en rad mängd applikationer som samlar all typ av hälsodata såsom klinisk data, prestandabaserad data och erfarenhetsbaserad data. Det fungerar som ett verktyg som samlar personlig information till både patienter, läkare och forskare. Det finns en rad mängd applikationer som är skapade för självdiagnostisering utifrån symptom. Exempel på dessa är 23andMe, Doctor Diagnose och Virtual Doctor. Datan som samlas in i dessa applikationer analyseras automatiskt för att sedan ge ytterligare service till patienten. (Van Dijck & Poell, 2016)
Forskare som studerar data kritiskt menar att det finns en risk med samhällen som är starkt digitala då insamling av personlig data kan innebära makt över patientens privatliv. (Ruckenstein et al., 2017) Ruckenstein et al. (2017) betonar att myndigheterna och media är “data rich” medan individerna är “data poor” vilket skapar en asymmetrisk relation mellan de som samlar och sparar data och de som är målpunkter för datainsamling. Författarna belyser hur företag använder data som användare frivilligt har lämnat ut för att sedan kombinera det med annan data för att skapa värde på marknaden. Dessa företag ger kunden en föreställning om att deras utlämnande av personlig data bidrar till “folkhälsan” istället för företagets vinst. Det är desto mer sällan som personlig data faktiskt används till forskning och sjukvårdsindustrin. (Ruckenstein et al., 2017)
3.2.2
Self tracking
På grund av höga kostnader inom vården har self-tracking under det senaste årtiondet blivit ett populärt alternativ då individer själva kan undersöka sin hälsa. Self-tracking innebär att individers hälsodata registreras systematiskt vanligtvis genom sensorer som placeras på kroppen. Self-tracking används ofta inom hälsa och fitness och hjälper individer att lära känna sin kropp och förändra sina vanor. Ett exempel på en teknik med sensor som använder