Teknik och samhälle
Datavetenskap och medieteknik
Examensarbete 15 högskolepoäng, Grundnivå
Adopting Machine Learning in Small Companies
Att Anpassa Maskininlärning för Små FöretagYun-Fah Chow
Jakob Kennerberg
Examen: Kandidatexamen 180 hp Huvudområde: Datavetenskap Program: Systemutvecklare Datum för slutseminarium: 2020-06-04Handledare: Yuji Dong Examinator: Lars Holmberg
Abstract
Machine Learning (ML) has become a hot topic in recent years because of its potential benefits for many companies. Especially some big companies such as Amazon, Google and Microsoft have shown several successful cases on integrating AI capability in their own businesses. Although the interest in machine learning is rapidly increasing in almost all the business sectors, there is still a lack of knowledge of how to apply ML in small companies. Different from the big companies, smaller companies usually do not have massive resources such as the capital investment, infrastructures and expertise in machine learning. The lack of resources does not only make it difficult to adopt machine learning in small companies, but also makes the existing solutions from big companies difficult to be applied in the more general business environments.
This thesis aims to help small companies to adopt machine learning by integrating the machine learning activities in their existing agile software development processes. Thus the companies can reuse most of their existing resources and let the developers apply machine learning by following the proposed model.
Throughout the work, a literature review, a survey and an interview were conducted to find the challenges for small companies regarding adopting machine learning. The identified major challenges include affording to hire the right talents working with machine learning, the sufficient amount of data at their disposals, the general knowledge regarding the Machine Learning Process (MLP) and what can/cannot be done with machine learning. These challenges were identified as requirements for the proposed model to make machine learning more accessible to small companies.
The proposed model called Machine Learning for All (ML4A), is divided into two major sections for the investigated challenges. The first section is a Machine Learning Usage Model to give a guideline to the non-experts for a better view of what can be accomplished with machine learning techniques. This should be used before starting a project related to machine learning. To implement the project, a process model called Agile Machine Learning (AML) is proposed in the second section. AML is a proposition of how machine learning can be integrated into an agile software engineering process, which also fits the requirements for small companies.
A case study was conducted at a small Swedish company called SportAdmin to validate ML4A. The results showed the effectiveness of the proposed model by letting non-experts in machine learning to apply machine learning techniques in a small company.
Contents
1 Introduction 1 1.1 Background . . . 1 1.2 Research Question . . . 2 1.3 Concept List . . . 2 1.4 Contributions . . . 3 2 Related Work 3 3 Method 5 3.1 Method Description . . . 5 3.2 Method Discussion . . . 64 Study on the Challenges 7 4.1 Literature Review . . . 7
4.2 Survey . . . 10
4.3 Interview . . . 13
4.4 Investigation Results . . . 15
5 Machine Learning for All (ML4A) Model 16 5.1 Machine Learning Usage Model . . . 17
5.2 Adopt Machine Learning in Agile Software Process . . . 19
5.2.1 Classical Agile Software Process . . . 19
5.2.2 Machine Learning Process . . . 20
5.2.3 Agile Machine Learning Model . . . 24
5.3 Case Study: SportAdmin . . . 29
5.3.1 Integrate MLP in Scrum . . . 30
5.3.2 Project . . . 31
5.3.3 Evaluation . . . 32
5.3.4 Important takeaway factors . . . 35
6 Analysis and Discussion 35 6.0.1 Analysis of Case Study and changes made to ML4A . . . 36
6.0.2 Project Reflection . . . 38
6.0.3 Ethical Discussion . . . 39
6.0.4 Methodology Reflection . . . 40
6.0.5 Research Question reflection . . . 41
6.0.6 Summery of Analysis & Discussion . . . 41
7 Conclusion and Future Work 42 7.0.1 Conclusion . . . 42
7.0.2 Limitations . . . 43
7.0.3 Future Work . . . 43
7.0.4 Acknowledgement . . . 43
A Appendix 1 46
B Appendix 2 51
1
Introduction
1.1 Background
Machine learning (ML) has become one of the most hyped technologies in recent years, be-cause it has proven its effectiveness and offered interesting solutions to different problems. However, even though the ML theories already have made big progress, the knowledge of how to develop a ML system is still lacking because of the differences compared to tra-ditional software systems. In contrast to tratra-ditional software, ML system is data-driven, making the development severely different and challenging.
With the use of ML, some business value have been accomplished by improving areas such as the marketing and the customer service, especially in the big companies. Many business values for big companies are also important for small companies, so ML is also possible to benefit the small companies. However, ML is not truly viable for small com-panies in the current ecosystem [8].
Machine learning can improve a company’s efficiency in many ways and across different departments. For instance, the top management can get better information and predictions to where the market is going to make smarter business decisions. The marketing strategies can be optimized by delivering more personalized advertisements for customers. ML can also help with customer engagement using solutions such as chatbots [10]. Different tasks previously done manually in a company can be automated by using ML, thus freeing up time for the employees to do other crucial tasks for the company [10].
The benefits of incorporating machine learning has already been proven by many big companies like Amazon, Netflix and Microsoft who’s already been using the technology with success to further the growth of their companies. For instance, Netflix uses ML to enhance customer engagement and thus keeping their monthly subscription by recom-mending movies they may like, based on their preferences’ similarity [3]. At Amazon, ML is relied upon to improve the customer experience, as well as scaling their operations by automation [21]. At Microsoft, the capabilities of ML have been used to build applica-tions such as Microsoft Translator and the Cortana virtual assistant [4]. These are all examples of how big companies have leveraged ML in a way that is hugely profitable. For the big companies, there are usually fewer roadblocks to utilize technologies such as ML since the required resources are available to them. However, for small companies, these resources simply don’t exist to the same extent, making the adoption of ML extremely hard. Resources such as large amounts of data, a robust data infrastructure, ML and re-lated domain expertise and capital investment are all favourable when developing an ML system. Regarding the required expertise, ML expertise is about the knowledge regarding the development of machine learning systems while domain expertise is about the exper-tise in the area in which ML should be applied to. To develop a successful ML system, ML experts need to cooperate with domain experts to find suitable data and algorithms for the given problem. Because of the lack of such resources, small companies cannot fully benefit from the recent advances in ML, which is a loss for the society. ML could have a bigger impact if it could be widely used in all kind of companies.
During a study on small businesses in the U.S and Mexico [11], several common prob-lems for small businesses were identified. Probprob-lems such as developing financial strategies, expanding the business, assessing the financial needs, marketing and recruiting employees
were all common in small companies. Customer service was also identified as a critical success factor for a company of a smaller degree. The same patterns were found in “Prob-lem och svårigheter för svenska nystartade småföretag“[6], indicating that this work is applicable in a Swedish context.
A major common thing among these problems are that they all have been successfully helped by machine learning solutions previously, further strengthening the fact that the impact of ML on small companies would be significant. This is also beneficial for a country’s economy as a whole. In Sweden, studies have shown that small companies today are responsible for the economical development in the country [6]. Thus, sometimes the wellbeing of a country’s economy largely depends on the development of its small companies.
However, as of today, machine learning is still a very complex and broad field in computer science and is extremely expensive for small companies to invest in [8]. For this to change, the community needs to continue developing machine learning solutions to the point that it becomes something that everybody can use [8]. It is also the motivation of this study.
1.2 Research Question
To reduce the machine learning usage gap, this study aims to investigate how small compa-nies can adjust their current agile Software Engineering Process (SEP) to adopt machine learning in a way that is feasible for them by taking their limitations into consideration.
In the current ecosystem, there are no ML guidelines for small companies which have no previous experience in machine learning and have restricted resources to the best of our knowledge. To investigate this problem, the following research question is created:
• How can small companies change their agile software engineering process to integrate machine learning technology?
The goal of this study is to provide a general ML adoption guideline for the companies with less resources, mainly aimed towards small companies. We assume that at least some small companies use agile software engineering process in their current environment. The guideline proposes a general Agile Software Engineering Machine Learning process for developing ML systems. It also provides a Machine Learning Usage Model to identify business problems where ML has the ability to make a difference.
1.3 Concept List
This section contains a list of concepts and abbreviations used throughout the thesis. • Machine Learning(ML) - regards training computers to discover and to learn how to
solve specific tasks using data, without explicitly being programmed to do so. • Software Engineering Process(SEP) - development workflow in developing software
systems.
• Machine Learning Process(MLP) - the different stages in the ML life-cycle. • Machine Learning for All(ML4A) - a model created by the authors.
• Agile Machine Learning(AML) - a submodel of ML4A, representing a process model. • Data Science - A field using scientific methods to extract knowledge from data. Can
range from analysing data to mining data. • Data Scientist - A practitioner of Data Science. 1.4 Contributions
As mentioned above, the contributions made by this study are all towards enabling machine learning for small companies, especially those with no previous experience with ML. By identifying common problems in small businesses, proven successful ML solutions could be proposed to solve these problems. These proposals, found in the Machine Learning Usage Model, can act as a guide for small businesses when assessing which type of ML system to build in order to solve their identified problem. To enable small businesses to develop such systems, a general Agile Software Engineering Machine Learning process has been created, suited for businesses with limited resources. Our work hopes to inspire more small businesses to adopt machine learning in their own business, since it really has the possibility to make a major difference. The contributions made by this study are:
• Investigation of the current challenges encountered by small companies in adopting machine learning in their own business
• A guideline for ML adoption for small companies, considering common potential business issues
• A model to integrate a Machine Learning process into an agile software engineering process with limited resources while considering ethical aspects as well
2
Related Work
Machine Learning (ML) in Software Engineering is quite a well researched topic. The main portion of the research done this far has been about the general usage, the struggles and the difficulties regarding machine learning. However, very limited research has been done regarding the adoption of machine learning and its development process in small companies. This section presents the most relevant papers for this study, along with how they differ from our work.
In a case study performed by Amershi et al. [4], an observation was made on how a machine learning workflow was integrated into a agile-like software engineering process at Microsoft. The researchers observed different software development teams at Microsoft who developed AI-based applications. The participating employees at Microsoft were asked how software development problems related to AI was solved. A commonly used machine learning workflow at Microsoft was presented, composed of nine different stages, dealing with data and modelling. A ML process maturity metric was also presented in this paper, used by teams to self assess how well they worked. The goal of the case study was to showcase detailed insight on ML-specific best practices at Microsoft. This paper by Amershi et al. [4] is very valuable for our study, because it shows the importance of
finding a standardised process for machine learning. The difference between the work of Amershi et al. and ours are that their work was conducted at a huge company with lots of resources, Microsoft. Their work was not considering how companies with less resources could integrate machine learning into their own Software Engineering Process(SEP).
In the work from L.E.Lwakatare et al. [17], the challenges of incorporating ML in software engineering were studied. They performed six different case studies at six different companies across various domains to identify the challenges. Through these case studies, a taxonomy that showed five maturity stages of ML components in commercial software-intensive systems was created. Some of the challenges that were identified regarded not having the right people for the task and some regarded data collection. All challenges identified in the case studies falls into one of the five maturity stages. The five stages were;
• Experimentation & Prototyping
• Non-critical deployment of Machine Learning components • Critical Deployment of Machine Learning components
• Cascading deployment of Machine Learning components and lastly • Autonomous Machine Learning components
This work provided a very good view of the difficulties of machine learning. However, no process of how to use ML was provided in this study. It focused on finding the actual problems and solutions rather than providing guidelines for applying a machine learning process into agile SEP.
Kim Miryung et al.[15] wrote about the work of a data scientist in the software devel-opment context in their paper “Data scientists in software teams”. The study was based on a survey (793 participants) conducted at Microsoft. The survey covered the education of data scientists, their skills, tool usage, challenges faced and best practices. The content of this study was about the challenges of a data scientist rather than machine learning. This study is relevant for our work since the challenges of a data scientist are connected to the challenges of using ML, with both focus points being about the data. This study is included in our related work section because it is important to understand the data science practice when trying to integrate ML into a software engineering process. Data science has a big part in making a great adoption of machine learning.
The work by Nascimento et al. [7] is very relevant to our study. In their work, the challenges of working with machine learning in small companies were discussed. They also proposed checklists to help overcome the challenges. This study was conducted at three small companies to analyse how ML was used as well as the challenges that came with it. Some of the identified challenges regarded identifying the actual problem which can be solved with machine learning, problems with data handling and difficulties to design the database structure. Another highlighted problem was the general lack of knowledge regarding ML in small companies. This work is very valuable for our study. Even though small companies were addressed, this study was based on companies that had previous experience with machine learning systems. This differs from our work, since ours focuses more on companies that do not have any previous experience with ML. Our study also
focuses on the integration of a Machine Learning Process into agile SEP, which Nascimento et al didn’t.
In the work presented by M.Hesenius et al.[12], an approach towards engineering data driven applications(EDDA) and its underlying software development process was intro-duced. This process integrated the ML stages into a software engineering process. The EDDA process included four different roles which should be utilized during different phases of the development cycle;
• Software Engineer • Data Scientist
• Data Domain Expert • Domain Expert
These roles could be covered by one or multiple persons. This study is highly relevant for our study since their approach of utilizing the available expertise actually should be feasible for small companies, even if it isn’t stated in the work by M.Hesenius et al. The difference between their and our work is that ours is solely aimed towards small companies, considering multiple factors that affect small companies which weren’t considered in their work.
3
Method
The Method section consist of two subsections. The first section is Method Description, describing the used data generating methods in this thesis. The way in which these methods will be used are also discussed in this subsection. The second subsection is Method Discussion, arguing for the selection of the data generating methods and discussing their strengths and weaknesses. The dismissal of other data generating methods is also briefly discussed in this subsection.
3.1 Method Description
There were four data generation methods used in this thesis, a literature review, a survey, an interview and a case study. In order to make sure that this study actually provided helpful results for small companies, an understanding of the current situation in small companies was needed. To gather a correct understanding of the current situation, multiple relevant data sources needed to be gathered.
A literature review [18] was used to get an understanding of the what has been done in the field of ML and how different companies use ML. Several presented ML development processes were also investigated to get an understanding of how ML systems are currently developed. The goal of the literature review was to identify challenges small companies face when trying to use ML. By understanding the challenges, a solution could be developed.
For obtaining the large portion of the data, a survey [18] was used. The survey was dis-tributed among small companies in order to get an understanding of the general knowledge regarding machine learning and its development process within small companies. The view on potential roadblocks in adopting ML was also investigated during this survey. Based on
the findings of the survey, the descriptions of the different stages in the proposed process model gets the required level of detail. The survey was brief and easy to answer. It took no more than five minutes to answer it, ensuring the engagement of the participants.
An interview [18] was conducted to get a better understanding of ML from the per-spective of a small company and potential problems which can be encountered when using it. The interview was a semi-structured interview to ensure follow up questions could be asked. Being able to ask follow up questions to the answers provided by the respondent made it easy to get more in-depth answers. The approach to the interview was to have one person ask the prepared interview questions while the other would be listening and asking relevant follow up questions. By using a qualitative data generation method such as an interview, more detailed data could be obtained, thus making it a good source of information for this study.
The findings from the survey and interview served as an indication to what was im-portant to consider when creating the solution for helping small companies to utilize ML technology. The purpose of this study is based on helping small companies in ML adoption and thus, getting relevant information from them is extremely valuable. By having both quantitative and qualitative data generation methods, the obtained data have the possi-bility to be both broad and representative as well as having depth. These data generation methods does also complement each other, with the survey gathering a broader view of the problem and the interview getting more in-depth information, which is hard to obtain with a survey.
The validation of the proposed model was done conducting a case study [18]. The case study served as both an evaluation and a validation of the model. The case study was conducted at a small company called SportAdmin. SportAdmin develop administrative systems for non-profit sport organizations. They use Scrum as their software engineering methodology, one of the most common agile software methodologies. The case study thus had the optimal prerequisites to get a good evaluation, since the proposed process model integrates a machine learning process in an agile software engineering process.
To evaluate and validate the process model, it was integrated into SportAdmin’s cur-rent software engineering process and a small project involving machine learning was conducted. The project’s primary objective was to validate the proposed model. Since the proposed process model is an abstract agile process model, it was incorporated in Scrum in order to fit SportAdmin’s current way of working.
3.2 Method Discussion
The different data generation methods selected in this thesis serves different purposes. In order to get an understanding of the subject, a literature review was chosen. The reason for the selection of the survey and the interview was to ensure both quantity and quality in the gathered data. The case study methodology was chosen since it was the best way to evaluate and validate the proposed model.
One of the strengths of the literature review is to be able to increase the knowledge of a certain field [18]. Hence to why literature review was chosen. Using this knowledge in the targeted field, it became easier to find challenges small companies face when trying to use ML. To the best of our knowledge, this was the most suited research method to use for both gaining knowledge about this research field and identifying challenges at the
same time.
The quantitative data generation method of choice in this study was a survey. The advantage of using an survey is that it’s great for establishing a broader picture of the general opinion on a subject [18]. In the case of this study, the survey was used to get an idea of what people in small companies knew about ML and their opinion on what may hinder their company in adopting ML. The survey is the most powerful tool when the practitioner want data in masses and that is why it was chosen.
The qualitative data generation method of choice in this study was a semi-structured interview. The semi-structured interview was selected since it was the most suited data generation method for gathering the information needed to make the integration of the proposed model in the correct way. To ask prepared questions with the possibility to follow up the interviewee’s answers with new questions was crucial to get the quality of data that was needed. The semi-structured approach was chosen ahead of its counterparts, the unstructured and the structured approach. Using an unstructured approach, the interviewee can talk more freely, however the needed information was not guaranteed to be provided this way. Using a structured approach, the level of detail in the information would not have been on the desired level, making this approach not suitable.
The case study methodology was considered the most suitable methodology for this thesis in order to validate the proposed model. To get a fair evaluation and validation of the model, it needed to be conducted in a real industry environment, where all necessary factors could be accounted for. This is one of the strengths of a case study [18] and thus the reason for why this method was chosen instead of other data generation methods such as e.g. an experiment. In an experiment the phenomenon is isolated from the real-life context [18], which is the opposite to what is needed when evaluating the proposed model. Because of this the experiment methodology was ruled out.
A drawback with a case study is that it is not guaranteed to be generalizable, in this case, all small companies does not look the same. This case study only integrated ML into one agile methodology, Scrum. Hence, generalizations are hard to make based on this study. To try and make it more generalizable, the authors used the survey as a complement to make this study more useful to a broader audience. Another disadvantage of a case study is that it can be time-consuming and the presence of the researchers can affect how people behave [18].
4
Study on the Challenges
In order to provide a solution which is useful for small companies, the different challenges that small companies encounter regarding ML adoption must be understood. In the fol-lowing sections, a literature review, a survey and a interview is conducted to investigate the challenges in adopting machine learning in small companies.
4.1 Literature Review
As stated in the article [8], machine learning is not truly viable for small businesses in the current ecosystem. The main reason for this are the common occurrence of small compa-nies having less resources. To create a successful ML solution, the following resources are most likely required; Large amounts of data, robust data infrastructure, AI/ML expertise,
deep domain knowledge and venture money according to article [8]. While all these re-sources might be scarce in a small company, the expertise might be the hardest to obtain. The required expertise for a ML project includes both ML knowledge and data science knowledge [15]. For small companies, obtaining data science expertise can be both difficult and expensive. The general selection of data science talent in the current ecosystem is scarce and the big companies are often a more attractive proposition. However, the chal-lenge of obtaining data science talent is a factor that needs to be handled because without capable data science talent, many of the ML solutions are not reasonable investments for small companies [8].
One possible solution for small companies when adopting ML is to hire a vendor company to build the ML solutions for them. This is an expensive solution compared to developing it themselves and it comes with other drawbacks. The problem of maintaining and integrating the built system into their current system still exists even if a vendor company is hired. To solve these problems, the right talent still needs to be acquired, further emphasizing the importance of acquiring the required expertise [8].
Data science in software development emphasizes on understanding customer and user behaviour [15]. It can also be used to assess the organization’s own productivity and software quality [15]. Data scientists faces challenges such as handling poor data quality, missing or delayed data and the reshaping of data in a ML project [15]. Validation of the results produced from the ML model is another big challenge which a data scientist has to deal with [15], [13]. The issue for small companies are that it is not feasible for them to utilize the data science talent in the same way that big companies does. In the big companies, there are specialized teams or roles for each stage in the ML development cycle. However to make ML feasible in a small company, one person will have to take on multiple roles, including the data science role [7].
There is a way to evade the need of explicitly hire data science talent - to obtain it in-house instead. In the study by M.Kim et al. [15], a large number of data scientists at Microsoft were surveyed. During this survey a new special category of data scientists were identified - the Moonlighters. A Moonlighter is a person who was initially hired to a non data scientist role but has incorporated data analysis as a part of their engineering work. To make this transition, the need for formal training was emphasized. The most popular suggestion for this was to take coursework, since it was the most feasible for adult learners in a full-time position with little time for university degree programs. This approach is a truly viable way for small companies to obtain data science talent. Instead of hiring data scientist talent, make them in-house instead!
To further strengthen that this approach is feasible, the study by F.Ishikawa and N.Yoshioka [14] highlighted that out of the significant causes of difficulties when devel-oping ML systems, the lack of expertise was the least significant factor. F.Ishikawa and N.Yoshioka came with the suggestion that this meant that developers did not hesitate to learn new theoretical backgrounds. However they also added that it could point to the opposite situation, that they did not respect the necessity of learning it.
Another mentioned resource which most likely is scarce in a small company is the data. To build a successful ML solution, a certain amount of data is required. A too small data set will most likely not be able to provide enough data for the valuable features to solve the specified problem. Thus, not having enough data is a problem until enough data has been obtained [8]. There are algorithms and methods which work better with smaller
amounts of data. Example of such an algorithm is SVM [16]. However, even SVM will not work optimally with a data set that is too small. Transfer Learning is an example of a method that can work with insufficient amounts of data in a new domain. However, even for Transfer Learning a big pool of data from a similar domain is needed [24]. The required amount of data is of course context dependent, but in most cases a sufficient amount of data will be required, even when using methods that can work better with small data.
It is important to assess the available data before going into an ML project and if the amount isn’t sufficient enough, collect enough until it is. Having a clear business solution along with enough data is key when adopting ML.
This study aims to provide a guideline to how a Machine Learning process(MLP) can fit into an agile software engineering process. Previous research has provided different process models for developing ML systems [4], [19], [25], [13], [12]. However only the work by M.Hesenius et al. [12] has incorporated it into a software engineering process.
The need for a general software engineering methodology for developing ML systems has been highlighted in multiple studies [14], [7], [13], [4]. As stated in “How do engi-neers perceive difficulties in engineering of machine-learning systems“[14], the lack of a general methodology can even become expensive since without it, it’s necessary to discuss approaches to individual cases, which is expensive. The study by E.S.Nascimento et al. [7] interviewed practitioners in small companies focusing on developing ML systems, with the purpose to depict the ML workflow used and the challenges faced. The participants highlighted the lack of a defined process which is usable for a small company. The need for a general methodology was extra obvious with less experienced practitioners, since they failed to perform subtasks during certain steps. The most affected stage was when handling the data(Data Preprocessing) and failure to perform some of the subtasks led to poor performance by the system. In the study by C.Hill et al. [13] the need for a ML development process usable by ordinary practitioners was again highlighted. Even if the practitioners had experience working with ML, they conceded that their workflow was ad hoc and that they struggled to establish a repeatable process, further strengthening the need for a general process.
Another challenge this study aims to solve is the knowledge gap in what can and cannot be done with ML, mainly aimed towards those new to ML. As reported in the article [14], the understanding with customers new to ML was perceived to be the biggest cause of difficulty during the engineering process of ML. The reason for this difficulty was the recently mentioned knowledge gap existing between them as well as that customers didn’t know what data and which metrics were required for actually solving the problem [7].To successfully conduct a ML project, it is important to set a clear goal agreed by all stakeholders. Because of this, it is important to consider this challenge.
To sum up, beyond the research question of this study, a few challenges have been identified in the literature review.
• The difficulty to obtain Data Science talent • Having too little data
• The knowledge gap in what can and cannot be done with ML
To sum up the literature review, challenges have been identified that needs to be handled in order to facilitate ML adoption in small companies. The guidelines provided
must consider these challenges in order to be useful. The need for a defined process was highlighted in this section. Because of this a process model needs to be provided. The purpose of this process model is to facilitate easier ML development and thus deprive the common ad hoc workflow. The process model must also consider limitation in resources such as small amounts of data, expertise and financial power. One major challenge which the guideline have to tackle is the difficulty for small companies to obtain data science talent. However, a potential solution to this challenge was found in the literature, by obtaining them in-house. This concept was used at Microsoft and is actually also suitable for small companies. Another major challenge identified was having a too small data set for initiating a ML project. The challenge of decreasing the knowledge gap in what can and cannot be done with ML for those new to ML is also considered in this study. To solve this, a solution which can ease the understanding of what can actually be done with ML needs to be provided. Addressing these challenges from the literature review, a survey and interview are made to further investigate and validate the findings from the literature review.
4.2 Survey
In order to make machine learning viable for small companies, ensuring their understanding of ML and its development process is crucial. To gather information about the general knowledge regarding machine learning in small companies, a survey was conducted. This information could later be used when designing the proposed model. The purpose of this survey was two-fold. The first purpose was to get a picture of how much knowledge people in small companies have regarding ML. This information was valuable to know how in-depth the description of the different ML stages should be. The second purpose was to get a brief picture of how their current software development process looked like. This information was valuable to validate our assumption that at least some small companies do use agile SEP for software development. The survey was pilot tested before being distributed to identify possible errors. Some errors were identified and corrected. Following this, the survey was distributed on the Web. The complete list of answers of the survey can be found in Appendix 1. The survey covered the following;
• The respondent’s role within the company
• The software development process which their company used • The respondent’s general knowledge about ML
• The respondents general knowledge regarding the different stages in ML development • The respondents knowledge of what can be done with ML
• If the respondent think their company is ready to adapt ML
• If the respondent thinks there are any specific problems hindering integration of ML Some of the more valuable results from the survey are displayed below. The survey retrieved answers from 13 respondents, employed amongst three different companies. As shown in Figure 1, the majority of the respondents had heard of the term machine learning,
however they had never used it, at least not to their knowledge. This result indicates that machine learning has not been widely used in the small companies, which also fit the goal of this study.
Figure 1: Chart displaying how wide the general knowledge of ML is in small companies The answers displayed in Figure 2 gives an indication to which level of detail the descriptions of the different MLP stages need to be in. According to the survey, the stages Model requirement, Data collection, Model training and Model evaluation are at least briefly known. However, the general knowledge regarding MLP stages is extremely limited in small companies.
Figure 2: Chart displaying how wide the knowledge of the different ML process stages are in small companies
Another interesting set of answers are shown in Figure 3. Although ML is not used to near the degree of their operation depending on it, the majority of the respondents indicate that their company actually uses ML to a small degree. However, this question did not dig deeper into the subject. Due to the lack of knowledge regarding ML which was displayed in the first chart, this result indicates that it might not be their own solution that is used, but maybe a ML service or something similar.
Figure 3: Chart displaying the degree of how much small companies use ML Regarding how much the respondents knew about what can be done with ML, the results were more anticipated. As displayed in Figure 4, the majority only have a brief understanding of what can be done with ML, further emphasizing the need for providing a solution which gives insight into what can be done with ML. However more than a third states that they actually know what can be done with ML, which indeed is interesting.
Figure 4: Chart displaying the knowledge in small companies regarding what can be done with ML
In Figure 5, the results of potential problems for the respondents’ companies if adopting ML is shown. Interestingly, the majority sees the lack of ML experts as the biggest problem. Even if this result might have been expected, this result contradicts results found in the literature review. A small section also indicates that the lack of a process might be a problem, which strengthens the previous findings in the literature. The answer “Others“ did not turn out to be useful, since the supplied text space for the respondents
to fill in their own answers were never used. Because of this, this answer indicates that the respondent didn’t know whether their company had problems adopting ML.
Figure 5: Chart displaying potential problems when adopting ML in small companies To sum up, the findings from the survey mostly supported the challenges which were identified in the literature review. However, a new challenge were also identified in the survey.
• The lack in knowledge regarding the different stages in MLP
Machine learning is a known term in small companies and some of the possible usages seems to be known to the majority. Despite this, only a few have actually used the technology. Indications were also given that the knowledge regarding the different stages in MLP is low in small companies. The biggest perceived roadblock in adopting ML in small companies according to the survey is the lack of ML expertise. This finding further emphasises the challenge of needing to obtain the right talent, also identified in the literature review. 4.3 Interview
To further complement the survey and get some more qualitative data, a semi-structured interview was conducted. The selected participant was the head of development at the company where our case study took place. This person also had previous experience with ML. The interview had two focus points. The first focus point was to get a deeper understanding of their company’s way of working. The second focus point was to get a deeper understanding of the problems which the participant had faced during previous encounters with ML. The interview was conducted 19th of March, in Swedish and recorded with permission from the respondent. The interview lasted for 20 minutes. It was later transcribed and can be found in its complete form in Appendix 2. The interview covered the following;
• The company’s usage of a software engineering process and the experienced struggles
• How the company’s software engineering process worked regarding the following stages: – Requirements engineering – Design – Implementation – Test – Deployment – Maintenance
• The respondent’s previous encounters with ML
• What the respondent think needs to be done in order to adopt ML into their company • General problems which the company as a whole has encountered
Out of the two subjects which the interview gathered information about, the first subject, regarding the understanding of their company’s way of working, was more for our own usage. Because of this, the snippets of the interview displayed below, regard the second subject, the encountered ML problems. This subject is more relevant for the study itself. As mentioned above, the interview in full can be found in Appendix 2. When asked about the experienced problems and limitations when working with machine learning, the following was said;
Yes, there was. ML was already a concept and you noticed pretty early that there could be problems, because we took data from 150 projects and in quite a few cases that was too little data to be able to make it a trend so to speak. We got a result but I experienced that it was quite a limitation to not have more data. Another limitation was maybe that I experienced that you had to tinker quite a lot with the tools. It felt like we came, we wanted to use the data, then the ones who did the actual work tinkered a lot, simulated and then two weeks later we returned and got results. We were not too involved in the process to be honest, however that might just have been a bad arrangement from us.
As a follow up on the above, when asked about the potential roadblocks which his company could stumble upon if they where to adopt ML, these were his thoughts;
I think a problem for us, is that we didn’t think of ML from the beginning. So to be able to find interesting data points over time we need to think, what is it we must log, what type of behaviour will we make sure exists, so we can learn. So it’s more that we should be better when we write the requirements that ML is one of them. If we want to learn ML we would have to put it in earlier and actually think of it in the requirements process, then it might have been better.
Further along in the interview, the question of whether the respondent sees lack of data science competence to be a problem when conducting an ML project was asked. His thought were the following;
I think from the perspective of smaller companies it’s pretty rare to have, depending on the product of course, but I can imagine that it’s pretty rare to have a data scientist employed solely for that purpose. In our case we try to combine together the different parts of the skill set of a data scientist in a mix among my colleagues. But I think that as long as
you don’t have an extremely data driven product, to the point that you make money out of it and you have 28 employees, I’m not too sure that one of them should be a data scientist. So it could be a problem with the lack of knowledge of how a data driven company should work and so on. I can definitively imagine this to be a challenge for smaller companies.
And lastly regarding the ML part, as an follow up on the previous question, his thoughts on whether the lack of an employed data scientist actually could be solved by splitting the required competence among multiple persons was expressed like this;
If you can be clear which competences are important for making ML work so can you evaluate if they are to your disposal or not. In this way it might be easier to estimate if you can succeed with a project or not. If the case is that no one is interested in data at all, it would have been pretty difficult to succeed with ML. So I’m thinking that it has to involve, to get it really good, you need to involve it as early as possible in the product development.
To sum up, the findings from the interview provided further support for the findings in the literature review and survey. One of the problems which were highlighted was having an insufficient amount of data. The respondent had encountered this issue in a previous ML project, emphasising it to be a big problem. However, a solution to this problem was also proposed. By considering ML from the beginning, before developing a system and logging interesting data points which provide useful data, this issue can be overcome. Another problem which also were highlighted was the need for having the required expertise in a ML project. The respondent had encountered this problem as well, when in a previous project handing over the project to a different team with the required expertise due to the difficulty in working with the tools. The rarity of having such expertise in a small company was also touched upon as well as it indeed being more feasible for a small company to split the skill set between different current employees rather than explicitly hiring a data scientist.
4.4 Investigation Results
Following the Study on the challenges, challenges that must be considered in order to make this study helpful for small companies were identified. Regarding the main purpose of this study, to provide a guideline for ML adoption in small companies, several challenges which needs to be tackled were found. These challenges were considered when forming the proposed model. The need for obtaining the right talent - the data science expertise, was highlighted via the literature review, the survey and the interview. For small companies without the resources to hire such an asset, the proposed model needed to provide a solution for accessing this talent without having to explicitly hire.
Another challenge identified via both the interview and the literature review was the potential problem of having too little data to get valuable results, a common occurrence in small companies. The proposed model needed to provides guidelines to how to ap-proach this challenge, allowing small companies to gather the right amount of data before initiating their ML project.
The need for broad descriptions of the different stages in MLP was also an identified challenge. Findings via the survey indicated that the general knowledge of MLP is poor in small companies, thus the descriptions need to be broader and easy to understand. The descriptions of the different stages in MLP can be found in the subsection Machine
Challenge Description Identified in The difficulty to obtain
data science talent
In most cases it is necessary to obtain data sci-ence talent in order to conduct a successful ML project, however for small companies, this is dif-ficult. The most apparent reason being the lack of financial power.
Literature review, Survey, Interview
Having too little data
To make the ML model detect patterns in the data, a sufficient amount of data is required. Although there are methods which work better with small amounts of data, a sufficient amount must be obtained.
Literature review, Interview The lack in knowledge
regarding the different stages in MLP
The knowledge regarding the different stages in MLP were found to be low in small companies. The understanding of these stages are crucial in order to succeed with a ML project
Survey
The knowledge gap in what can and cannot be done with ML
The knowledge gap in what can be accomplished with ML and what cannot has been identified as a difficulty in ML projects, especially during the planning phase. Those new to ML often have unrealistic expectations and no good perception of what is needed in order to execute a certain ML application.
Literature review
Table 1: The identified challenges for ML adoption in small companies Learning Process 5.2.2.
Lastly, the challenge of bridging the knowledge gap of what actually can and cannot be done with ML was identified in the literature review. The survey slightly contradicted this challenge by indicating that the majority of the people have a brief understanding of what can be done with ML. However the answers neither have the quantity or validation to make absolute conclusions. This question mainly acted as a brief check on whether people think they know ML. The respondents of the survey work within the industry and had likely heard about ML. However, based on the literature review a solution for those who are new to ML is still needed. To solve this challenge, a usage model is provided in the proposed model. This usage model allow those new to ML to get a quick and accurate insight to what actually can be done with ML given different business problems.
5
Machine Learning for All (ML4A) Model
From the investigation above section 4.4, several challenges that need to be considered when conducting this study were identified, found in Table 1. These challenges needs to be handled in order to make ML truly viable for small companies in the current ecosystem. The difficulty in obtaining ML competence and more importantly, data science talent in a ML project was identified as a major challenge. Since small companies often cannot afford to explicitly hire such talent, a solution to this challenge needed to be provided. Having
too little data to get valuable results is also a common occurrence in small companies, thus being another challenge which needs to be considered. Findings via the survey indicated that the general knowledge regarding MLP is also low in small companies, making the descriptions of the different MLP stages an important challenge. In order to make this study useful to a broader audience, this challenge needed to be taken into consideration. Bridging the knowledge gap regarding what can and cannot be done with ML is also a challenge considered by this study. This is important to consider in order to overcome the identified initial difficulties for those new to ML in understanding what actually is a plausible solution for a given problem.
Based on the investigation, a model called Machine Learning for All (ML4A) is created, aiming to provide guidelines to ease ML adoption in small companies. The ML4A contains two submodels, a Machine Learning Usage Model and a process model called Agile Machine Learning(AML). The Machine Learning Usage Model is used to identify potential machine learning solutions to certain business problems. The usage model is created for those new to the subject and with lesser knowledge in what actually can be done with ML. Although not fully covering all possible solutions, it gives a general insight of what is possible to do with ML given a certain business problem. AML is made for small companies to be able to develop their own ML solution. AML is a process model integrating MLP in agile SEP, created to fit the requirements of small companies. To make AML truly usable for small companies, it takes several of the identified challenges in Table 1 into consideration. The next section further describes the Machine Learning Usage Model.
The section following Machine Learning Usage Model is Adopting Machine Learning in a Agile Software Process. In this section, topics such as Classical Agile Software Process, Machine Learning Process and Integrate Machine Learning Process in Agile are discussed. These topics are relevant for this study since they are the building blocks for combining an agile SEP with MLP. Because of this, this section provides an overview of the subjects. The submodel AML is presented in this section.
The last section regards the case study, where ML4A were used. During the case study the submodel AML were integrated into a specific agile SEP, Scrum. The case study was conducted with SportAdmin, a small company working daily with Scrum. The case study was used to evaluate and validate ML4A. In order to give the best possible evaluation, a small project was conducted using ML4A. The results and findings of the case study is presented in this section.
5.1 Machine Learning Usage Model
This section strives to solve one of the identified challenges from Table1. The findings in the literature review pointed out the knowledge gap in what can and cannot be done with machine learning. In small companies new to ML and wanting to adopt it, guidance may be needed to identify which solutions are feasible for their identified business problem. Thus, the ML4A provides a Machine Learning Usage Model, striving to decrease this gap. The Machine Learning Usage Model serves as a guide for companies to identify their business problems and provide solutions which can make a difference to their business. Before machine learning is adopted in a company, it’s important to identify a problem where machine learning actually can make a difference [8]. The purpose of the Machine Learning Usage Model is to give people who are not familiar with ML an insight into what
Figure 6: Decision tree for identifying problem areas in businesses where machine learning can be applied to improve the situation. Full list in Appendix 3
actually can be done with machine learning given certain business problems. First when the goal is clear, the company should start the machine learning process.
As depicted in Figure 6, the first step regards identifying the problem area. Going further down the decision tree, the problem areas become more specific to further tailor the business need. Suggestions for solutions to the different problem areas are provided in Appendix 3. The decision tree is based upon the work by Hayes et al [11], which identified the most common problems in small businesses in the U.S. Although conducted in the U.S, findings via the interview and in the paper[6] indicates that the patterns are similar in Sweden, where this study is conducted and are thus relevant for this study. The identified problem areas have all been successfully solved by the different solutions in Appendix 3 previously, proving the solutions to actually improve the conditions of these problems, if not solve them all together. It should be noted that the solutions provided in Appendix 3 is not covering all possible solutions, but more giving an insight into what can be accomplished.
Appendix 3 is structured as tables with three columns. The columns contain the names of the solutions, the ML tasks which the solutions belong to and a brief description of the solutions. The ML task column is included to give the developer of the ML system a starting point when selecting the algorithm. The tables are divided by the different problem areas found in the Machine Learning Usage Model decision tree. To get a better understanding of how this constellation works, some examples are provided below;
For instance Recruiting Employees, where a company has identified their recruit-ing of employees as a business problem. With the help of the Machine Learnrecruit-ing Usage Model decision tree, they get to the leaf node ‘Recruiting Employees’. Matching it to the corresponding problem area in Appendix 3, the company finds a potential ML solution to this problem in the form of Application and Resume review. In the table in Appendix 3,
there is a description of this solution, along with the type of the ML task, in this case a
Classification task.
Another example is Customer Service, where a company has identified their cus-tomer service as a business problem. With the help of the Machine Learning Usage Model decision tree, they get to the leaf node ’Customer Service’. Matching it to the corre-sponding problem area in Appendix 3, the company finds a potential ML solution to this problem in the form of Customer Support Prio. In this case, this is a Ranking task. 5.2 Adopt Machine Learning in Agile Software Process
To help the adoption of ML in small companies, a workflow guideline is provided in ML4A. This specific guideline comes in the form of a process model called Agile Machine Learning(AML). AML proposes an abstract guideline of how MLP can be integrated in agile SEP. Because of the nature of the agile approach, this software development methodology was thought to be the best suited for integrating ML. Findings via the survey validated that the agile methodology indeed is used by some small companies. AML differs from other presented works since it is based upon the identified ML challenges encountered by small companies, found in Table 1. AML strives to be feasible for small companies to integrate and use in order to start adopting ML into their existing development process.
5.2.1 Classical Agile Software Process
Since the agile software development methodology was introduced, it has had a signifi-cant impact on how software has been developed worldwide [9]. The core values of agile development was described in the “Manifesto for Agile Software Development” [5] as:
• Individuals and interactions over processes and tools • Working software over comprehensive documentation • Customer collaboration over contract negotiation • Responding to change over following a plan
The agile development methodology emphasizes on the human interactions rather than processes and tools. In agile development methods this is shown through practices that enhance the team spirit, such as a close working environment.
It is also very important in agile development to regularly provide tested and working software in frequent intervals. Agile software development is incremental, providing small software releases in fast cycles. It’s important to deliver code that is simple and straight-forward to the extent that the need for documentation can be reduced to an appropriate level.
As stated by the third core value, emphasis in agile development is more directed towards the collaboration and cooperation between the developers and clients rather than on strict contracts, even though there is of course a need for a well drafted contract. From a business point of view, agile development focuses on delivering business value straight away, thus reducing the risk of not delivering according to the contract and also gaining early feedback from the client.
It is of importance in agile development to be adaptive, to be able to consider possible changes that emerges during the life-cycle of the project. This regards both the software development side and the client side. Thus the contracts must be formed in a way that supports this.
Other characteristics of agile development methods are that they should be easy to learn and to modify [2]. Some of the most well known software development methods that have adopted these values and are considered agile development methods are Scrum, Extreme programming, Lean software development and the Crystal methodologies [9].
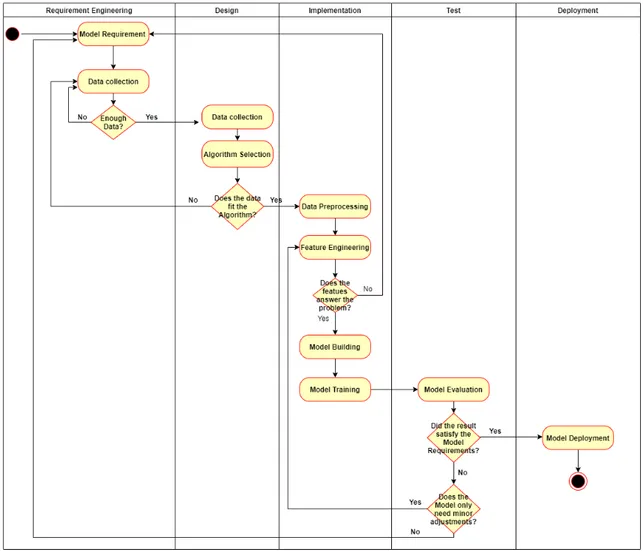
5.2.2 Machine Learning Process
This section strives to solve one of the identified challenges in Table 1. The findings via the survey indicated that the general knowledge regarding MLP is not great in small com-panies. Thus, this section will give a broader insight into the different stages in MLP. By doing this, small companies will be provided with a great foundation to start developing their ML system. Previous works has identified machine learning processes for both big [4], [19], [13] and small companies [7]. The proposed stages in our machine learning process are mainly based on the work presented by Amershi et al.[4] with some modifications. The modifications are based on suggestions found in the other presented works and the results from the case study of this thesis. The modifications are made to make the process better suited for the goals of this study and to provide a solution to the challenges identified in Table 1. Important considerations from the ethical perspective is also mentioned for the different stages. The entire development process must be conducted in a transparent man-ner and the decisions taken should be documented. The documentation should strive for auditability, accessibility, meaningfulness, and readability while data flows, performance, limitations and risks should be well documented. This is important to keep designers and operators responsible and accountable for their work [23]. The following stages in ML development have been identified:
• Data Science Training: The goal of the Data Science Training stage is to gather the Data Science skill set required for conducting a ML project. The most useful skills of a Data Scientist include: Probability and statistics, Machine learning, Data analytics, Data visualization, Data wrangling and Programming[15], [20], [22]. It’s up to the company to decide how these skills are divided, it could be among multiple employees or a single individual, as long as the wanted skills are covered.
Employees involved with ML systems should also be given an education in the ap-plied ethics. Subjects such as understanding the possible impact on society and environment by the system is important, while the knowledge also further improves the development process from an ethical perspective in general. It is crucial to make factors such as human rights a natural part of the design process [23]. The rec-ommended form of training is to take online coursework, allowing the employee to continue their daily works to a certain degree.
• Model Requirements: The goal of the Model Requirements stage is to clearly understand the problem, both from a business perspective and from a machine learn-ing perspective. The latter is important to be able to decide which model is most
suited for the given problem. During this stage, the business metrics which are al-ready used by the company should be assessed to get a better understanding of the goal of the project. It’s important to set a clear and detailed goal for the project during this stage, agreed by all stakeholders. It is also important to identify the form in which the data should be visualized and the data which is necessary to meet the set goal during this stage.
From an ethical perspective it is important to ensure that the requirements does not enforce infringement on factors such as human rights. It is also crucial to consider laws such as the General Data Protection Regulation (GDPR) [1] when forming the requirements involving user data. Furthermore, it is of importance to consider the proposed system to be subject to the applicable regimes of property law and to identify possible risks with the system. By doing this, risks such as systems being misused can be minimized [23].
• Data Collection: The goal of the Data Collection stage is to collect the data, either by integrating available data sets or by collecting new data. The collection should aim for completeness (representative of full range of behaviours), accuracy (correctness of the data), consistency (no contradictory data) and timeliness (rele-vant to the current state of the system) of data to ensure data quality [19]. During this stage it is also important to get familiar with the data, to be able to identify data quality problems and get first insights into the data [25]. Data collection is closely tied with the previous stage(Model Requirements) since it is very important to have an understanding of the available data to be able to correctly formulate the machine learning problem.
Laws such as GDPR must be considered when collecting the data, with consent given from the rightful owners of the data before using the data. The rightful owners should also be provided with access to modify their information [1]. By documenting the decisions taken during this stage, those involved in handling the data can be kept responsible and accountable for it usage which is important from an ethical perspective [23].
• Algorithm Selection: The goal of the Algorithm Selection stage is to select the initial algorithm to use for the model. An algorithm works with features and training data as input and produces a model, which is run to produce the output. Different algorithms can perform differently on the same data. However it is hard to determine which algorithm is the best suited for the given problem right away. Generally it’s about testing the way forward, it might be necessary to change the algorithm later if the required goals aren’t achieved during Model Evaluation. The recommended approach is to start with the simplest algorithms and then progress to the more advanced algorithms if the requirements aren’t met. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken.
• Data Preprocessing: The goal of the Data Preprocessing stage is to construct the data set, which is used in the modeling tools(e.g Tensorflow, RStudio, Sci-kit Learn, Keras, PyTorch). This stage includes an iterative work of both data cleaning
and data labeling. Data cleaning focuses on removing inaccurate or noisy records from the data set. To clarify the term noisy records, a noisy record are a record containing data anomalies or a record which doesn’t follow the required form. Noisy data can have harmful effects on the learning part and therefore also on the final model. Normally this is a time consuming step, often performed by those with greater knowledge in data science. Data labeling focuses on assigning ground truth labels to the records. By assigning ground truth, the right answers are set to the records. Data labeling is required for most of the supervised machine learning techniques since they involve classification, however for unsupervised machine learning techniques such as cluster analysis, data labeling is not required.
The main part of Data Preprocessing, Data Cleaning was found via the survey to be one of the least known MLP stages. Since Data Cleaning is considered to be very important in order build a successful ML model, this section strives to be extra informative and explanatory, providing further support in enabling the practitioner to perform this stage correctly. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken.
• Feature Engineering: The goal of the Feature Engineering stage is to extract and select informative, independent and discriminating features for the machine learning model [13]. The aim during this stage should be to select the features which characterizes the solution to the problem the most. During Feature Engineering, input data is transformed into feature vectors for the algorithms. It can be described as the art of extracting new and more valuable data from existing data. Feature Engineering is closely tied to both Data Preprocessing, Model Building and Model Training since these steps will most likely be worked in a iterative manner. Feature Engineering is an important step since it greatly influences the performance of the model.
Findings via the survey indicated that Feature Engineering was one of the least known MLP stages. However, Feature Engineering is crucial to conduct in order to build a successful model. Therefore this section strives to be extra informative and explanatory, providing further support in enabling the practitioner to perform this stage correctly. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken.
• Model Building: The goal of the Model Building stage is to construct the ML model. Before this stage can be started, the data must have gone through prepro-cessing and the Feature Engineering must have been conducted. This data then serves as the input for the model. There is a big variety of tools that can be chosen from when building the model, such as pyTorch, Scikit-learn or Tensorflow. This stage solely focuses on building the model and the goal is to have a working model after finishing this stage. Model Building is tightly coupled with Feature Engineer-ing, Model Training and Model Evaluation, since these stages often are performed in a iterative manner when improving the model. It’s important to split the input data into two sets of data during the Model Building, one that will be used for the Model Training and the other for the Model Evaluation. A split that can be used when dividing the dataset into the training and evaluation datasets is by splitting
it 80/20. 80 percent of the data is used when training the model and 20 percent of the data is used when evaluating the results of the model.
A common challenge in Model Building is to find the simplest model to build that does the required job. If the model is too simple it often fails to detect the hidden patterns in the data, a problem called ‘underfitting’. However the model can also perform great with the training data, but fail to generalize when exposed to data in a more real environment. This problem is called ‘overfitting’ and is often caused by the model being too complex. So it is about finding the simplest model to build that does the job. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken.
• Model Training: The goal of the Model Training stage is to train the model built in Model Building with the selected features chosen from the Feature Engineering stage. Model Training is often performed in iterative manner along with Feature Engineering, Model Building and Model Evaluation. Performing the actual training often means to run the model. The training data set from the Model Building is used during this stage. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken.
• Model Evaluation: The goal of the Model Evaluation stage is to evaluate the trained model, using the evaluation data set from the Model Building stage. The evaluation data set is used to confirm that the model can make the correct con-clusions on data that it has not been trained on. This is measured using different evaluation metrics. An example of such an metric for a classification model can be the accuracy metric, measuring the number of correct predictions made by the model. It is important to consider that all business objectives have been met during the Model Evaluation stage. If not the case, some of the previous stages needs to be revisited. The evaluation of a model as a whole is done in two parts, with this being the first part, the pre-deployment evaluation. The evaluation of a model should after this stage be continuous, performed continuously during its entire life cycle. This stage often requires data science expertise in order to understand the meaning of the produced results, as pointed out by[13]. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken. • Model Deployment: The goal of the Model Deployment stage is to deploy the
built model on the targeted devices. During this stage, the model is integrated into the intended system and the results can thus be visualized. This stage should only be performed after the decision has been taken that the model has reached the desired results and meets all the requirements set during the Model Requirements stage. Then the model is ready for deployment. As with each stage, it is important to conduct this stage in a transparent manner and to document the decisions taken. • Model Maintenance: The goal of the Model Maintenance stage is to monitor the model during its life cycle. Identified errors should be fixed. In practice, this stage involves multiple others, such as Model Training, Model Deployment and Model Evaluation. The reason being that it might be necessary to revisit these stages during the Model Maintenance. Since the input data characteristics can change over