Artificial intelligence
in banking
A case study of the introduction of a virtual assistant into customer service
MASTER THESIS WITHIN: IT, Management and Innovation
NUMBER OF CREDITS: 30 ECT
PROGRAMME OF STUDY: JIBS
AUTHOR: Mehmet Ate¸s
Master Thesis in Informatics
Title: Artificial intelligence in banking — A case study about
the introduction of a virtual assistant into customer service
Authors: Mehmet Ateş
Tutor: Prof. Dr. Christina Keller
Date: 2017-08-31
Key terms: Artificial Intelligence, Banking, Customer service, virtual assistant
Abstract
The usage of artificial intelligence in banking is an important theme within entrepreneurial research. The purpose of the study was to analyse the motivations, challenges and oppor-tunities for Swedish banking institutes to implement artificial intelligence based solutions into their customer service process. The research is based on a case study of the Swedish banking institute Swedbank AB, who introduced an AI based virtual assistant (Nina) to deal with customer requests. For the qualitative study, interviews with Swedish banking customer and experts were conducted. Further, to understand the managerial moti-vations of Swedbank, a theory of Moore (2008) regarding innovation management was applied. The findings display that Nina improved the service spectrum of Swedbank with the potential of decreasing costs, while maintaining customer satisfaction. Further, the results displayed a high acceptance of new technologies from the customer perspective. This provides the foundation for Swedbank to introduce further artificial intelligence based services. Banking institutes and other service oriented organisations with high customer interaction can use the implications of the thesis when considering to more effectively handle customer requests.
Table of contents
1. Introduction 1 1.1. Problem definition . . . 1 1.2. Purpose . . . 2 1.3. Research questions . . . 3 1.4. Delimitations . . . 3 1.5. Definitions . . . 4 2. Theoretical framework 6 2.1. Development of artificial intelligence . . . 62.2. Current popularity of artificial intelligence . . . 10
2.2.1. Moores Law . . . 10
2.2.2. Big Data . . . 10
2.3. Development of chatbots . . . 11
2.4. Artificial neural networks . . . 13
2.5. Prerequisites within Sweden for utilising innovative digital technologies . 17 2.6. The Core/Context model . . . 22
3. Methods 25 3.1. Research approach . . . 25
3.2. Methods of data collection . . . 26
3.3. Data analysis . . . 29
4. Results 31 4.1. Case description . . . 31
4.1.1. Swedbank . . . 31
4.1.2. The problem at Swedbank . . . 33
4.1.3. Nina the virtual assistant . . . 34
4.2. Customer interviews summary (Appendix A) . . . 38
4.3. Expert interview summary (Appendix B) . . . 39
5. Analysis 42 5.1. Customer interviews: Report . . . 42
5.2. Customer interviews: Analysis . . . 52
5.2.1. Basic banking related information . . . 52
5.3. Application of the Core/Context model on Swedbank . . . 54 6. Conclusion 56 7. Discussion 59 7.1. Results discussion . . . 59 7.2. Methods discussion . . . 61 7.3. Further research . . . 62 References 63 Appendices 72 A. Swedish banking customer interviews . . . 72
B. Expert interview . . . 86
B.1. German version (original) . . . 86
B.2. English version (translation) . . . 95
List of Figures
1. Awarded patents in artificial intelligence . . . 8
2. GO Board with GO stones . . . 9
3. Visualisation of the Turing Test . . . 11
4. Screenshot: FaScan . . . 16
5. Billion dollar software companies originating from Sweden . . . 18
6. Internet users per 100 population . . . 19
7. Availability of latest technologies; Firm- level technology absorption . . . 20
8. Use of virtual social networks . . . 21
9. Core/Context model . . . 23
10. Swedbank: Visits per day and channel . . . 33
11. Screenshot: Exemplary conversation with Nina web. . . 35
12. Schematic hot-line service centre . . . 60
List of Tables
1. Overview of customer interviews . . . 281. Introduction
The first section of this thesis starts with a brief introduction into the topic of artificial intelligence and banking. Further, the problem definition, the purpose of the thesis and the research questions are stated. The section ends with delimitations of the research and key definitions.
The ongoing era of digitalisation, decentralisation and disruption is shaping industries and consumption on a broad scale (Desai, 2014).
Digital technologies are connecting billions of consumers and allow the deployment of low cost connected devices in every business sector. The current generation is adjusted to the digital environment and naturally expects services and products to meet the current digital technology standards. Further, investments into digital technologies and businesses have risen and are rewarded by the public markets (PWC Editorial, 2016). Artificial intelligence (AI) technologies are part of this development and the banking sector is hereby deemed to see a major impact. According to a report by Accenture, a global management consulting and professional services company, four out of five bankers assume that AI is going to revolutionise the way banking is executed. The report suggests that artificial intelligence will affect banking by enhancing the customer experience. Banking products and service may become increasingly personalised giving customers the impression that their banking institutes know their specific habits and needs (Accenture, 2016).
But the introduction of AI technologies comes with potential challenges and risks. Banks are processing highly sensitive data. Thus, privacy and data security concerns are es-sential elements of the process. Additionally, customers might prefer the contact with persons regarding certain issues, leading to a rejection of AI based interfaces (Kelly, 2017). Hence, the introduction of such technologies into the active process should be executed with consideration of the possible risks.
1.1. Problem definition
The way private customers are interacting with banks is changing. Ashoka and Vinay (2017) are differentiating between millennial generation banking, which is also referred to as digital banking and traditional brick and mortar banking. They described that the banking industry as a whole is making a consistent effort to shift progressively towards
digital channels. This shift is embracing a change from an account based view of a banking customer to a perspective, which sees customers as unique individuals with different needs. The challenge is to provide digital services that improve the customers experience by considering their personalised and specific needs. This is a key factor for the creation of banking services and products of the future.
Consumers have already in multiple areas of their lives adapted a digital lifestyle sub-stituting daily habits with various digital channels. Skinner (2014) states that digital social networks have large effects on the digitalisation process of various industries. As a result digital solutions are increasingly becoming an extension of traditional social interactions. During this conversion consumers are increasingly expecting that financial services are continuously digitally available in a customer friendly manner (Cuesta et al., 2015). Thus, one field which is supposed to leverage AI technologies are customer services. The development of solutions involving artificial intelligence approaches are seeing an increase in popularity within research and business (IBM - Watson, 2016). According to a report created by Oracle (2016) already eight of the ten investigated businesses implemented or are planning to implement artificial intelligence technologies into their customer service processes until the year 2020.
The author has identified a knowledge gap regarding the usage of artificial intelligence technologies in banking and customer service. The problem is that specific research is absent in respect to the motivations and reasons for Swedish banking institutes to implement artificial intelligence solutions including the customer perspective. For this purpose, the Swedish banking sector with Swedbank as a case is studied.
1.2. Purpose
The purpose of this thesis is to analyse the motivations, challenges and opportunities for Swedish banking institutes to implement artificial intelligence based solutions into their customer service process.
1.3. Research questions
The intention of the following research questions are to frame the present knowledge gap within the banking sector regarding the usage of artificial intelligence technologies. The first research question addresses specifically the research problem by investigating the case study of Swedbank in detail. The second research question is formulated in a broader scale and intends to address general concerns, challenges and chances regarding the usage of artificial intelligence technologies in banking.
Research Question 1
What are the main motivations for banking institutes in Sweden to implement artificial intelligence technology solutions into their customer service?
Research Question 2
What are the challenges and opportunities for banking institutes to implement artificial intelligence technology solutions into their customer service?
1.4. Delimitations
The following list includes topics which are out of the scope of this thesis.
Engineering
The thesis is not going to provide a description on how named artificial intelligence so-lutions work in detail. Instead, the thesis will focus on their impacts and functionalities.
Institutes/Organisations
Elements from multiple financial sectors are relevant for the thesis but the focus is on banking institutes whose main customer base are private customers.
Outcome
The outcome of the study focuses on the Swedish banking sector and the implications are limited to the European market.
1.5. Definitions
The following list of definitions includes key terms used in the thesis, which are described shortly for a better understanding. New terms were added to the list during the period of the creating of this thesis.
Artificial intelligence
Artificial intelligence (AI) refers to simulated intelligence in machines. The computer programs of those machines are intended to make decisions in a way comparable to a human being. The goal for AI computer programs is to mimic human behaviour (Barr and Feigenbaum, 1982).
Artificial neural networks
The term artificial neural network (ANN) refers to computational modelling tools, which are inspired by the biological neural network of the human brain. ANN’s can be used to address problems with high complexity (Basheer, 2000).
Brute force search
Brute force search or exhaustive search describes a method in informatics for solving general decision based problems. The main concept is about calculating all possible so-lution candidates and then select the soso-lution, which best addresses the problem (Robin, 2009).
Chatbot
Chatbots are software programs which can interact with human users via written or spoken communication channels using natural language (Shawar and Atwell, 2007).
Direct contact/Communication
During the thesis the term "direct contact" or "direct communication" is used multiple times. These terms both refer to communication which addresses a specific human person using channels such as telephone or face-to-face contact.
Intelligent automation
Intelligent automation describes software, which is able to make decisions within a spe-cific business unit comparable to a human being. To give an example, an intelligent production robot would not simply redo its manual activities, but it would execute them depending on dynamic information and handle errors and exceptions autonomously (Javed, 2015).
Keyword spotting
The term keyword spotting describes a sub field of the speech recognition research field. Its aim is to detect predefined keywords within natural language. This task is important in numerous applications such as voice mail retrieval, voice command detection or when communicating with a chatbot system (Gragier et al, 2009).
Soft computing
"Soft computing differs from conventional (hard) computing in that, unlike hard com-puting, it is tolerant of imprecision, uncertainty, partial truth, and approximation. In effect, the role model for soft computing is the human mind. The guiding principle of soft computing is: Exploit the tolerance for imprecision, uncertainty, partial truth, and approximation to achieve tractability, robustness and low solution cost." (Jin, 2014)
2. Theoretical framework
The following chapter will present the theoretical framework and important topics rel-evant for the present thesis. The topics are the development of artificial intelligence, an assessment of the popularity of AI, the history of chatbots, an overview on artifi-cial neuronal networks and the two key research fields associated with AI in banking, advanced analysis and customer support. The section ends with an assessment of the prerequisite of Sweden for utilising innovative digital technologies and the introduction of the Core/Context model created by Moore (2008).
2.1. Development of artificial intelligence
Artificial Intelligence also called artificial human intelligence describes an effort to create intelligent machines and computer programs. The unique purpose of AI technologies is to mimic the human brain, mainly within the following categories:
• visual perception, • speech recognition, • decision making
• and translation (John, 2007).
AI technologies can be classified into two types: 1. Artificial machine intelligence
a) Refers to a top down, human engineered approach in which, the computer ex-ecutes tasks and makes decisions based on predefined rules and requirements. 2. Natural machine intelligence
a) Implies a bottom-up approach in which the computer uses self-improvement algorithms to increase its performance and abilities for each task handled (Dubinsky and Hawkins, 2016).
Research about artificial intelligence started in the 1950s with scientific articles written by the mathematician Claude E. Shannon about the development and programming of a chess playing machine (Shannon, 1950). His publication lead to a collaboration between Princeton mathematicians Marvin Minsky and John McCarthy. In 1952 they organised a conference together with the subject of automation in order to promote their studies around the topic of artificial intelligence. After the conference Shannon, McCarthy and other scientist approached the Rockefeller Foundation to formally propose a funding, which they were able to receive. They used this fund to form a research team including a well-known industrial researcher from IBM, namely Nathan Rochester (Kline, 2011). Together they created a proposal for a new conference with the main statement:
"Every aspect of learning or any other feature of intelligence can be so pre-cisely described that a machine can be made to simulate it" (McCarthy et al. (1955), Proposal for Rockefeller Foundation. Page 1 of the original proposal) The conference took place at the Dartmouth College and was the first conference devoted to artificial intelligence. The Conference was very popular and created an atmosphere of discovering and exploring among the research community during the following years. Among the most successful developments at that time were programs based on artificial machine intelligence, which were able to make intelligent decision and programs which were able to understand natural language. Creating machines with these kinds of abilities were not seen as being possible before. From the early 1980s until the 2000s AI saw multiple research boom and winter phases. But the overall interest in AI has constantly risen (McCarthy, 2007).
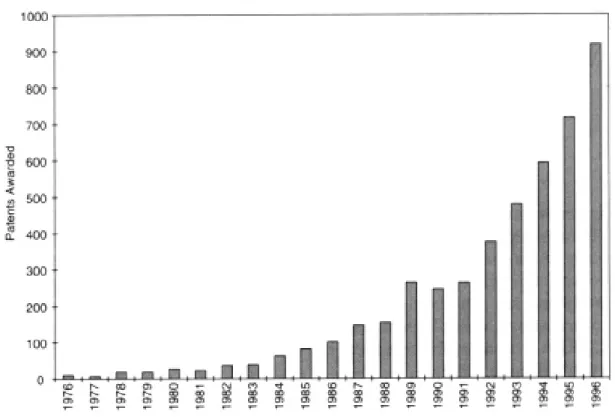
Figure 1: Awarded patents in artificial intelligence - Graph created using compiled from data in the U.S. Patent and Trademark Office’s (National Research Council, 1999)
Figure 1 visualises the patents awarded for technologies regarding AI, displaying a con-stant rise in patents being placed and approved (National Research Council, 1999). The Dartmouth Conference coined the term artificial intelligence and is often described as the birthplace of AI. The core nature of AI including the named statement has not changed since and is still about designing systems that mimic properties of human intelligence (McCarthy, 2007).
Nowadays AI technologies are again seeing an increase in popularity in research and media. A prominent example is Google’s AI based GO player. GO is a strategy board game which is played since at least 2000 years. The main characteristics of the game is its simple yet deep strategic nature. The most popular version of the game is being played on a 19 x 19 GO board (see figure 2). Each player is assigned either black or white stones. These stones are placed on the board one by one in alternating order. The goal of the game is to cover a larger part of the field then the opponent. GO has been played by a wide range of players from simple farmers to kings and is still the most played game in and around China (Guru, 2008).
Figure 2: GO Board with GO stones (Novet, 2016)
What makes GO so interesting for AI research is that in opposite to other board games like chess it is not possible to apply the brute force search method. Chess computers are often superior to humans because they simply calculate all possible moves and combi-nations and then pick the solution path with the highest winning chance. But using the brute force search for GO is simply impossible. This is because there are more possible combinations of moves in GO then there are atoms in the universe, thus exceeding the capacity of every computer. In order to play the game in a successful way it is important to be creative and pick a good strategy. Remi Coulumn, a computer scientist developed a highly capable GO computer named Crazy Stone. He estimated in 2014 that it would take at least ten more years until a computer would have a reasonable chance against a professional GO player (Wang et al. (2016), Levinovitz (2014)).
In January 2016 Google released a statement in which they described how their own developed system named AlphaGO managed to beat some of the best human GO players (Silver and Hassabis, 2016).
The success of AlphaGO is based on its deep learning technology, which mimics the neurones in a human brain. AlphaGO initially analysed over 30 million moves of top GO players worldwide. Afterwards the system played the game against itself for several weeks utilising server farms. Every game played helped AlphaGO to learn if a certain move leads to a good or worse outcome.
"In comparison to a human player, AlphaGo never forgets a single move" (Sven Magg, 2017)
This behaviour lead to minimising the total number of possible moves by adjusting the play style depending on earlier failures and successes (Wang et al., 2016). While playing, AlphaGO came up with new moves, which were unjustifiable by top GO players but eventually contributed to a positive outcome. This kind of behaviour started a discussion about machine creativity (McFarland, 2016).
2.2. Current popularity of artificial intelligence
Research and solutions including artificial intelligence are becoming increasingly popular. In the following, two main reasons on why AI is currently popular are described in more detail.
2.2.1. Moores Law
The core statement of Moores Law is that the number of transistors on integrated circuits doubles every 18 months since their invention (Moore, 1998). This is ultimately leading to decreasing computing costs. Moores Law affects the development of artificial intelligence technologies in two ways.
First, as a result of the effect of Moores Law the cost of computing decreased over the past years. This progress benefited the development of artificial machine intelligence because it made it possible to deal with the naturally high computing consumption of AI technologies at an affordable cost level.
Second, a report created by the European Semiconductor Industry Association (2015) called "International Technology Roadmap for Semiconductors (ITRS)" predicts that Moores Law will stop being valid from the year 2021 onwards due to physical limitations. The consequence would be a stagnation in computing power. Scientists and futurists predict that this stagnation of computing power could lead to an increase in research resources towards natural machine intelligence like the deep learning approach used by Googles AlphaGO. Artificial intelligence technologies based on natural machine learning are overall using less computing resources compared to technologies utilising on artificial machine intelligence (Arbesman (2016); Smart (2016)).
2.2.2. Big Data
The foundation for an effective application of AI based technologies is a significant level of data. AI based systems are using input and output data to calculate and determine the underlying function relevant for solving the initial problem.
"What an artificial intelligence system does is observing input and output data in order to determine a function connecting both." (Sven Magg, 2017)
AI approaches like artificial neural networks provide an alternative to logistic regression methods, which are driven by larger amounts of data (Tu, 1996). Due to the development of data generating technologies such as smartphones, wearables, digital social networks and other information creating elements within the past decade a large amount of data has been accumulated (Lohr, 2012). To fully utilise on this development new methods and technologies are required. A Report by Manyika et al. (2011) concluded that in the United States up to 190.000 data experts with "deep analytical thinking" are going to be needed to cope with the large amounts of data to be analysed. The report also suggests that over a million data science educated managers need to be hired or retrained in order to take full advantage of the opportunities coming with big data analysis. AI assisted machines could take over a key role in analysing large data sets in a meaningful way (Daugherty and Purdy, 2016).
2.3. Development of chatbots
Chatbots refers to a group of computer programs, that are able to interact with humans using natural language such as spoken or written communication. Another term often associated with chatbots is conversational agent (Atwell, 2003).
The term "chatbot" was first introduced by Mauldin (1994) within a research paper based on the Turing test in 1994. Alen Turing wrote a paper in 1950, in which he introduce the Turing Test to asses the artificial intelligence capabilities of computers.
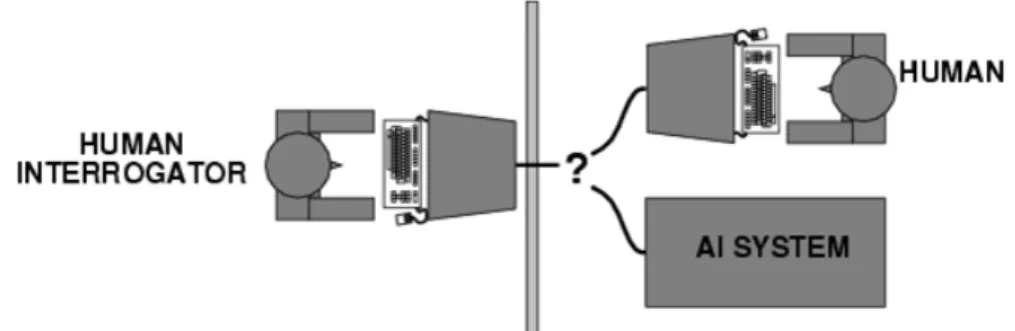
Figure 3: Visualisation of the Turing Test (DTC, 2007)
The Touring test is an experiment to find out whether a computer can imitate human behaviour. The modified research question of the paper was:
"Are there imaginable digital computers which would do well in the imitation game?" (Turing, 1950).
The test describes a game called the imitation game which is played with three entities — a human interrogator (player C), a human test person (player B) and an AI assisted computer (player A). Player C has to be in a separate room and is exposed to two digital conversations partners named X and Y (See Figure 3). One of the two conversations is controlled by the human player B and the other is controlled by the AI system player A. Player C is able to ask both conversation partners questions. Based on the responses player C has to identify the real person respectively the computer system. By performing this game Turing (1950) attempted to determine whether a machine is able to win this imitation game. Based on its success rate Turing made assumptions about his initial research questions (Turing, 1950).
"I propose to consider the question can machines think?"(Turing (1950), p. 1)
In the year 1991 a competition was started by Hugh Loebner offering a price of 100.000$ to the person who could create the first program to pass the Touring test. Based on this competition Mauldin (1994) wrote a research paper about the development of a partici-pating Turing system involving the technical performance and the technical design. He thereby used the term ChatterBot, which later became chatbot.
Chatbots are human-dialogue systems that are able to receive natural language mes-sages and process them using auditory or textual analysis techniques. Chatbots respond typically with natural language (Shawar and Atwell, 2007). Possible use case scenarios are language education, linguistic research, digital assistance and customer service. The development of a chatbot generally involves that responses are predefined by a human and coded into the system of the chatbot. Consequently, a chatbot is only able to answer predefined questions (Atwell, 2003).
To create chatbots with higher capabilities the Artificial Intelligence Markup Language (AIML) was developed in 2001. It is a XML based programming language to create natural language software agents. AIML enables a system to process human conversa-tions and detect patterns and templates within the dialogues (Atwell, 2003). Since its development a chatbot system named A.L.I.C.E. utilising on the AIML won the Loeb-ner Prize Competion in Artificial Intelligence consecutively three times (LoebLoeb-ner Prize, 2015).
2.4. Artificial neural networks
A complex financial institute like a bank has to have a large variety of skills in order to be successful. Core fields are to make financial products available, make proper predictions regarding financial trends, the simulation of investment behaviour, portfolio management, the prediction of bankruptcies and various other topics (Holsapple et al., 1988).
To cope with the tasks a variety of methods are used. These methods can be divided into three categories:
• Parametric statistical methods refer to a sub area of inductive statistics. Its underlying purpose is to evaluate drawn samples and make assumptions over a pop-ulation. A possible parametric tool is the logistic regression analysis.
• Nonparametric statistical methods refers to methods in which the acquired data does not have to fit a normal distribution. The data used usually includes ordinal values like rankings or sorting orders. A possible nonparametric method is a decision tree.
• Soft-Computing approaches refer to computer programs, which are tolerant of im-precision and calculate with partial truths and approximation. Soft-computing is key for algorithms based on artificial intelligent algorithms (Jin, 2014).
Artificial neural networks (ANN) are algorithms which are able to learn and mimic some of the functionalities of the human brain. The solution used to develop the previously mentioned AI system AlphaGO is based on an artificial neural network. By using artifi-cial neural networks it is possible to assess complex problems involving decision making processes, information search and analysis. Especially during the past decades, research on neural networks increased heavily amplifying the progress for ANN’s (Lam, 2004). In respect to the future development of artificial intelligence in banking Sven Magg (2017) refereed to neural networks as a key element. The interviewee predicted that progress over the next years is to be expected in data based decision making and customer sup-port. In the following the current and possible usage of ANN’s within the fields of credit evaluation is described.
Credit evaluations is a banking technique first used in the 1950s and deals with the analysis and evaluation of a persons credit worthiness. The problem financial advisors are trying to solve is to classify clients into categories according to their credit risk. The
credit risk describes the risk of a person in debt to fail to make payments. The tradi-tional methods to calculate the credit risks involve algorithms, regression analysis and other mainly parametric statistical methods. Well calculated credit scores are essential for a bank to handle their loans profitably. With the development of new digital tech-nologies, the finance industry is able to evaluate the data increasingly better, leading to more accurate credit scores. Artificial intelligence approaches based on ANN’s are promising in creating credit ratings with higher quality. An analysis tool backed up by an ANN would receive input and output information about clients such as financial information (income, loans, debts, spending behaviour), demographic information (age, gender, marital status) and past decisions made by financial credit advisors. The ANN would then evaluate the information and try to act like an advisor with the objective of providing accurate credit scores. ANN’s are able to make sense out of a large diversity of information. An increase of input and output data would benefit the reliability and accuracy of a system.
The Lloyds banking group provides an example on how to use ANN’s for credit evalu-ation. The banking group acquired the car financing company Bowmaker whose main business was to provide credits for customers wanting to purchase a new or used car. Lloyds implemented a system for the creation of credit score rankings, which was based on a neural network. The systems main purpose was to improve the decision making process on whether to provide a customer with a credit or not. In comparison to the previous system, the neural network based system improved the success rate by 10% (Treleavan, 1995)
Advanced analysis in banking
The usage of computer assisted systems to analyse financial data is not an invention of the present. The past century has opened up a wide variety of tools to be used in order to analyse and predict financial data (Bhargava et al., 1999). Leigh et al. (2002) conducted a study in which he investigated a technical analysis method for making predictions for stock market price changes by utilising a decision support system. In order to create a forecast, the authors combined various techniques such as machine learning, neural networks, genetic algorithms and soft computing, which represent key artificial intelligence approaches. The results displayed a large potential for new technologies in analysing and recognising patterns in financial stock markets (Leigh et al., 2002). Especially machine learning is described as promising because banks can in most cases use them with their current systems without the need of heavy hardware purchase. The
core job of these systems would be to analyse new information in order to compare it with existing financial data to make better financial decisions. Further, a study about simulated financial trades displayed that non-random price movements and historical data of stock markets can be utilised through machine learning by creating computer algorithms to predict financial developments like price changes (Lebraron et al., 1992). A benefit of AI in finance is that it can redo decision based labour work at a faster rate and scale and often perform better compared to a human. The possible productivity benefits are immense. An artificial intelligence assistant could review 1.000 legal docu-ments within the course of a few days. On the other hand, a group of human workers would need up to six months for such a task (Sobowale, 2016). To give a use case exam-ple, a German real estate company ran a project in which they developed a solution to automatically handle credit proposals. The problem the company was trying to address was that credit proposals were often handed in, in low quality with a decreased read-ability. This was leading to an increase in time and manpower resources spent trying to correctly identify and classify the documents. In order to solve this problem, the soft-ware tool "FaScan" was developed. FaScan combines artificial intelligence technologies with machine learning algorithms to identify and classify financial documents according to their layout and content. The software assistant is able to identify key elements on each page, understand which documents belong together and recognises the specific type of a document (purchase contract, salary statement, loan balance, etc.). When FaScan is done gathering all documents belonging to one case it creates an index. Finally, the sorted and categorised documents are stored into the internal document management system. Overall, FaScan works faster compared to humans and increased the productiv-ity up to 90% with the workload of 30 minutes being done by the software assistant in only 3 minutes. The tool improves its text and graphics recognition abilities with each document read (IT-Magazine, 2016).
Figure 4: FaScan Screenshot: Screenshot visualised the document master of FaScan, which allows a subsequent processing and classification of the document. (IT-Magazine, 2016)
Customer support
Personal digital assistants like Siri on Apples Iphone or Google Now on Android smart-phones are already part of the daily lives of private consumers. A financial digital assis-tant seems to be the logical continuation of this process. Hereby, artificial intelligence based services could have a major benefit compared to non AI tools. This is relevant within the context of future customers who seem to put more value on personalised products. According to Goldsmith (1999) the preference trend of customers is moving towards an increase in individualisation and mass-customisation which is summed up by the author as personalisation. Due to this he proposes that the traditional 4Ps of the marketing mix1 are going to expand beyond price, product, place and promotion to
also include personalisation.
AI assisted technology can use algorithms in order to make the whole banking experience more simple and aid in discovering new financial products, which suit the customers needs more then its current service catalogue. A modern use case for AI in banking is provided by the virtual cognitive agent Amelia. Amelia is a digital assistant, which is
1Marketing mix: A planned mix of the controllable elements of a product’s marketing plan commonly termed as 4Ps:
able to provide simple financial advice based on the evaluation of data using AI tools. A global bank made an experiment, in which they integrated Amelia into their mortgage advisory system. The intention was to demonstrate the capabilities of Amelia. Mortgage brokers from all over the world are permanently requesting financial information about banking services and policies. The information needs to be correct in order to ensure a successful approval process (IPsoft - case study, 2016). Furthermore, the answer should be quick because the response time has a significant impact whether the broker is going to sell the financial product of the bank or another product from a competitor. In the beginning of the integration process Amelia received all necessary information about the most common inquires. During a testing period Amelia received questions to challenge its ability to understand the underlying issue of a request:
"My customer is self employed and has land and property income, do you take this into account [when giving advice for a mortgage product]" Amelia: "Is your mortgage type residential or buy to let?" (IPsoft - case study, 2016) Within this conversation Amelia understood the intent of the inquiry, which is to provide confirmation if a mortgage application should be approved or not. The only unclear variable in this question for Amelia is the phrase "land and property income". Thus, Amelia’s response includes a question about the rental income of the mortgage. Af-terwards, Amelia could provide a reliably answer based on the information given. The final experiment displayed that Amelia was able to understand and answer 120 of 160 question with a high success rate of 89% (IPsoft - case study, 2016).
2.5. Prerequisites within Sweden for utilising innovative digital
technologies
Various highly technology oriented innovations which shaped the digital market originate from Sweden. Businesses like the music streaming service Spotify, the voice and video communication tool Skype or the torrent service utorrent were all created in Sweden (Davidson, 2015). According to the world intellectual property organisation, Sweden takes the second place, in a global comparison of the most innovative economies. Hereby it is ranked higher than other countries like the US, the United Kingdom or Germany (World Intellectual Property Organization, 2016).
Figure 5: Billion dollar software companies originating from Sweden, Skype was the first Swedish company reaching the billion dollar barrier (Atomico, 2015)
Further, data collected by entrepreneurial experts of a venture capital firm, displayed that 269 software companies founded since 2003 that had reached at least a value of one billion dollars. Hereby, according to the report Sweden is the largest hub for innovative technologies within Europe (figure 5). Outside of Europe it is only surpassed by the Silicon Valley, which solely placed higher then Sweden. The research compared the ratio of highly profitable technology enterprises with the population of the country (Atomico, 2015).
In the following it is clarified why in respect to the adoption of new technologies Sweden has beneficial conditions supporting the development of innovative digital technologies. The World Economic Forum collected data regarding several technological indicators measuring the digital development of a country. The results were made public and can be accessed freely, displaying a comparison of the countries.
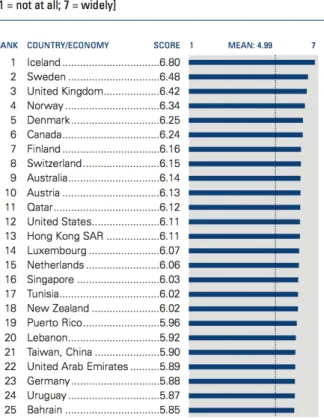
Figure 6: Internet users per 100 population. Sweden ranks third. Excerpt, only the top 25 are shown (World Economic Forum, 2011)
Figure 6 shows that Sweden ranks within the top three countries regarding the number of internet users. This increases the possible customer targets for online banking services, whose services can be accessed more easily by new technology. Further, from the high number of internet users the assumption can be drawn, that the general population within Sweden is open towards the usage of digital tools through the internet.
(a) Sweden ranks first. (b) Sweden ranks second.
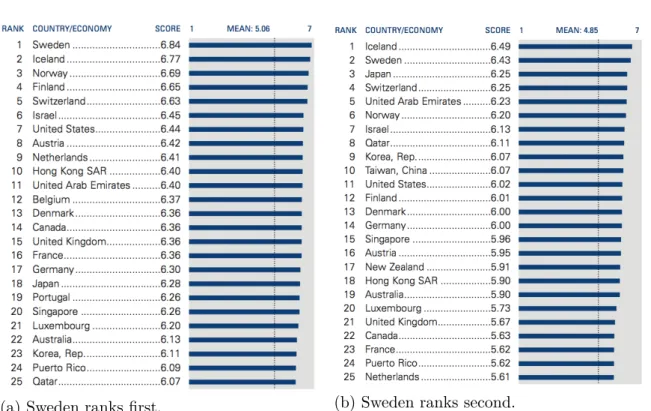
Figure 7: (a) Availability of latest technologies; (b) Firm- level technology absorption. Excerpt, only the top 25 are shown
Regarding the usage of the technology, Sweden tops the availability of latest technologies and ranks second for the absorption of new technologies on firm level (Figure 7). These are indicators for a broad present interest within Sweden regarding new technologies and innovations of businesses. The coupled high ranking in both lists points towards a culture of making new technologies available as fast as possible and implementing them into current business models. This adoption culture within firms may be the reason for Swedish organisations to bring out new successful innovations on a high frequency.
Figure 8: Use of virtual social networks. Sweden ranks second. Excerpt, only the top 25 are shown (World Economic Forum, 2011)
The openness towards digital communication technologies is a major element regarding human-robot interactions. An indicator displaying that Swedes are likely to engage through digital technologies is the usage of digital social media tools like Facebook, Twitter, etc. From figure 8 it can be seen, that Swedes are highly involved in social media, ranking second in the category use of virtual social networks.
2.6. The Core/Context model
Geoffrey Moore analysed the effect of innovations on management decisions and their success on enterprises. Hereby he elaborated various types of innovations such as break-through innovations and market changing innovations. His findings were aimed at man-agers to make better strategy decision (Moore, 2008).
Moore (2008) developed a theoretical model, in which he classified the current state of a business process and its enabling IT applications. He stated that a business constantly needs to innovate in order to stay competitive and relevant on the market. Within his model he differentiates between "Core" and "Context" business activities.
CORE "[A core business activity represents] any aspect of a company’s
op-eration that creates differentiation leading to customer preference" (Moore (2008), p. 6)
CONTEXT "[A context business activity] represents everything else, all other
work performed by the enterprise" (Moore (2008), p. 7)
The main distinctive factor between Core and Context activities are their level of devel-opment and their identity adding value.
Core business activities are those which differentiate a company from its competitors. From the viewpoint of a customer, core activities make up the identity of a company and are representative (Moore, 2008).
Context refers simply to all other business activities. An activity is classified as a context activity if it falls within one of the following categories:
• The activity has reached a maturity degree, where it can be standardised and sold to other businesses.
• The activity has become a commodity within the business field.
Thus, Context activities do not add extra value to the products and services, compared to competitors. But Context activities are not less important for an enterprise. According to Moore 90% of a companies activities can be classified as Context. Yet, he advises to keep focussing on the Core activities (Moore, 2008).
Figure 9: Visualisation of the Core (left side)/Context (right side) model (Moore, 2008)
Within the two categories business processes and their enabling IT applications go through four stages:
1. The innovation process starts with an invention, which does not have to be a new technological invention. It can also refer to the utilisation of a technology in an innovative way. The invention is usually kept on a small scale in order to limit the possible risk and provide a trial time.
2. When the invention has successfully managed the trial time and is ready to move up, the second stage begins and it becomes an innovation. The innovation activity is utilised to gain differentiation, which in turn enables customer preferability. The organisation should focus on keeping the innovation for as long as possible by utilising on marketing measures and releases of updated versions of the innovation.
3. When the level of differentiation cannot be maintained anymore, it moves into the third stage. The target in this stage is to manage the business activity in the most profitable way. This can be done by transferring it to sub companies or selling it to other businesses.
4. The fourth and last stage describes that the business activity has become a com-modity. Thus, the resources should be redirected into other projects and the business activity should be outsourced to increase productivity (Moore, 2008).
3. Methods
The following section is intended to inform the reader about the research methods used to investigate the research problem.
3.1. Research approach
A differentiating factor regarding the design of a research is the consideration of the rela-tionship between theory and research. The awareness about the theory in the beginning of a research shapes the research approach. This stage defines what research process should be followed. Generally it can be differentiated between inductive and deductive reasoning. The main distinctive factor between the named research approaches is the relevance of hypothesises to the study, making both approaches unique. The deductive process involves the creation of a theory with one or multiple hypotheses and the de-velopment of a research strategy to validate the hypotheses. The inductive process on the other side involves the creation of a theory as a result of a data collection process (Saunders et al., 2009).
Deductive research is used to identify causal relationships between variables (Saunders et al., 2009). It is informally also referred to as "top down" approach because it follows a path of conducting the research from a general to a more specific angle. The funnelling of the theory happens in different phases. According to Tochim (2016) the common phases start with the development of a theory. This theory is more precisely framed by the formulation of hypotheses. These hypotheses are investigating through a predefined research strategy. The theory is finally narrowed down further by the collection of data, which address the hypotheses (Tochim, 2016). Within natural science deductive research is the predominant approach used due to the research fields nature of testing physical laws, allowing the prediction and anticipation of phenomena ultimately making them controllable and testable (Collis and Hussey, 2003). Deductive research is executed using a highly structured methodology in order to provide replicable results (Gill and Johnson, 2002).
Inductive research works in comparison to deductive research in a different way. It is informally also refereed to as "bottom up" approach because it moves from specific observations to generalisation and theory. The inductive approach involves analysing the present data and looking for patterns throughout the research. The results of the observation can be summarised in the formulation of a theory (Bernard, 2011).
Induc-tive research was developed within social science to cope with the problem of having to state cause-effect links between variables without a clear understanding of how humans interpret their social world (Saunders et al., 2009). The development of that kind of an understanding is the strength of inductive research. In contrast to deductive research inductive research does not involve a highly structured research design and thus is more flexible to alternative explanations (Saunders et al., 2009).
The author has chosen to work with an inductive approach to address the research problem. The reasoning for this choice is going to be explained in the following.
The present thesis focusses on the usage of artificial intelligence in customer service. Existing data and literature for artificial intelligence technologies in use (Kerly et al. (2007), Jia (2009)) and innovative technologies in banking (Sadiq and Shanmugham (2003), Lyons et al. (2007), Devlin (1995)) provide the basis for a possible deductive research. But the combination of the usage of AI and the banking sector provides a knowledge gap, which would not be fully addressed by a deductive research design. Elo and Kyngas (2008) state that deductive approaches are most useful when the aim is to test previous theories within different environments and situations whereas inductive approaches are superior when there is less previous knowledge about a topic. The information gained throughout the data collection are going to be used in order to form an understanding about the main motivations of banking institutes to apply artificial intelligence technologies into their services from both a customer and an expert point of view.
3.2. Methods of data collection
Interviews
According to Kahn and Cannell (1957) "an interview is a purposeful discussion between two or more people". Interviews may be used in order to gain understanding about a research topic by collecting information. More specifically through the usage of inter-views one can gather reliable and valid data that is relevant to specific research questions and objectives. There are three main types of interviews: structured interviews, semi structured interviews and unstructured interviews.
Structured interviews involve predefined questions and follow a predefined sequence while asking the questions. Due to this structured interviews are also refereed to as interviewer administrated questionnaires. The main advantage of structured interviews are their
replicable nature as well as an increased comparability of the results (Saunders et al., 2009).
Semi structured interviews involve a set of predefined questions and themes but the sequence and questions might be changed from interview to interview. Further new questions might be added during the process of the interview (Saunders et al., 2009). Unstructured interviews involve no predefined set of questions and promote a more open and free discussion but within a frame of a predetermined research field (Saunders et al., 2009). In-depth interviews are a form of unstructured interviews which offer the opportunity to capture rich, descriptive data about people’s behaviours, attitudes and perceptions, and unfolding complex processes.
Private banking customers
For conducting the interviews with the private banking customers, the author has chosen to apply a semi structured approach. Before each interview, the interviewee was asked whether it is allowed to record the interview, for the purpose of creating interview transcripts as a source for the thesis. One interviewee did not want to be recorded thus, in order to capture the answers the author took handwritten notes.
At the beginning of the interview, a set of initial questions was asked in order to under-stand the kind of relationship the interviewee has with the bank. The following part of the interview was based on the initial answers. An interview guide was used in order to navigate through the conversation. The interviews did not involve preconceived theories or ideas in order to receive unbiased answers from the participators.
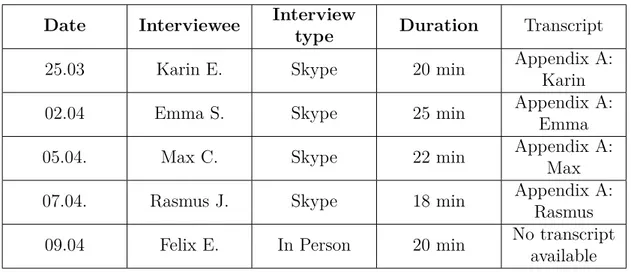
The Swedish banking customers were interviewed with the aim to explore their ex-periences, views, beliefs and motivation about topics relevant for the research. The interviewees were selected randomly with the only criteria of being a Swedish banking customer and belonging to the millennial demographic cohort identified as being born after 1990 and before 2005. The reason for choosing only millennials is that millennials are overall more motivated towards the adoption of new technologies and therefore act as early adopters within the digital financial market (Ashoka and Vinay (2017), Hussain and Wong (2015)). Five interviews were performed (see table 1).
Date Interviewee Interview
type Duration Transcript
25.03 Karin E. Skype 20 min Appendix A:
Karin
02.04 Emma S. Skype 25 min Appendix A:
Emma
05.04. Max C. Skype 22 min Appendix A:
Max
07.04. Rasmus J. Skype 18 min Appendix A:
Rasmus
09.04 Felix E. In Person 20 min No transcript
available
Table 1: Overview of customer interviews
Expert interview
An unstructured interview with a post-doctoral teaching associate from the "Knowl-edge Technology Group" of the University of Hamburg was conducted. The interviewee is specialised in human- robot interaction and artificial neural networks. The inter-view was conducted using themes to navigate through the conversation. Afterwards, an unstructured conversational interview followed, in order explore different topics raised during the interview. The expert interview defines a method of qualitative empirical research, which is meant to explore the knowledge of an expert within a certain focus area (Meuser, 2009).
The purpose of the interview was to gain expert knowledge about: • the overall development of artificial intelligence technologies, • the usage of artificial intelligence within banking,
• the usage of artificial intelligence within customer service and • the future development of artificial intelligence technologies.
Secondary data
The secondary data source used for the thesis is a conference transcript with the mar-keting channel manager of Swedbank, which can be found in appendix C and usage data of Nina, virtual assistant.
3.3. Data analysis
Content analysis describes different techniques used to systematically analyse qualitative data such as spoken or written communication (Cole, 1988). It can be used to evaluate various types of media such as print media (e.g.: magazines, articles, newspapers), visual media (e.g.: movies, videos or television) or content on the internet. Within research, content analysis is used as a technique to analyse qualitative data in a systematic and objective manner to quantify phenomena (Elo and Kyngas, 2008). It allows researchers to concentrate qualitative data into content related categories with the goal to cluster related statements, phrases or words which share the same meaning (Cavanagh, 1997). The outcome of a content analysis is a summarised and general description of the inves-tigated phenomena. Hereby Elo and Kyngas (2008) differentiate between two types of terms used when describing the outcome – "concept" and "category". The term concept is used in a more specific context when the aim is to built a new theory whereas category describes a broader approach.
For the analysis of the interviews, the author has followed the scheme identified by Elo and Kyngas (2008) for creating a content analysis. Elo and Kyngas (2008) state that conducting a content analysis involves the three phases: preparation, organising and reporting.
Preparation phase
During the preparation phase the author read through the material and derived the core elements from the interviews. These elements or "unit of meanings" can be single words or whole statements and may contain more then one meaning relevant for the topic (Elo and Kyngas, 2008). The choice of the unit of meaning has an impact on the analysis process. Identifying units of meanings with too many meanings may result in making the analysis process too complex (Catanzaro, 1988). However the choice of elements which are defined too narrowly could also negatively impact the analysis process leading to fragmentation (Graneheim and Lundman, 2004). Further Graneheim and Lundman (2004) specified that while conducting a content analysis it is important to state whether latent content such as the notice of non verbal communications, laughter, silence or other types of subtext is to be included into the analysis. The rules regarding the inclusion of latent content for the analysis are specified within the Rules for transcription section below.
Organisation phase
During the organisation phase, the author has read through the written material again‚ and created headings when necessary to describe the content. The identified units of meaning were analysed in greater detail. Afterwards categories were created and ab-stractions were made (Elo and Kyngas, 2008). According to Dey (1993) the purpose of categorisation should not be to simply group similar elements together. Instead each element should after its assessment belong logically to a category. Each category sum-marises units of meanings belonging to the same
Reporting phase
The results of the analysis are summarised within a report. The report includes a compact overview of the results, the descriptions of the categories in a sufficient level of detail and the core units of meanings classified for each category. The meaning and the relevance of each predefined headline is elaborated. A connection of the data to the results is made to increase the reliability of the analysis (Polit and Beck, 2004).
Rules for transcription
In the following the rules used for transcribing the interviews are summarised. The rules contain the choices the author has made regarding the inclusion of latent and manifest content as identified by Elo and Kyngas (2008).
• The only latent content included in the transcription is laughter, which is written as (laughs).
• Further latent content such as silence, pauses, sighs or posture is not included in the transcription.
• Half and broken sentences are left out, if they do not add any value to the conversation. • Inaudible short pieces below 2 seconds, where it is not clearly understandable what a
person said, is written as [inaudible].
• Incorrect grammatical errors such as wrong word choices or faulty sequences of words are not corrected.
4. Results
The following section is intended to inform the reader about the results from the re-search investigation. The case of Swedbank and their introduction of the AI system Nina is described. Hereby key information about Swedbank are summarised, the problem of Swedbank is stated and Nina is introduced. Further the customer interviews and the expert interview are summarised
4.1. Case description
4.1.1. Swedbank
Swedbank is the Swedish banking institute that implemented the AI based customer service assistant Nina. It is one of the largest banking institutes with a Nordic-Baltic origin. Its main target market is Sweden but it also takes leading positions in other countries such as Lithuania, Finland and Latvia. Further, Swedbank is also present within the Chinese and US market. Swedbank was founded in 1820 in Gothenburg and served as a traditional and classic savings bank only.
Key Figures
• Private customers: 4m in Sweden (10m world wide) • Corporate customers: 263.000
• Branches: 300 • Employees: 6.700
Key Services
• Loans and mortgages • Savings and investing
• Payment services and private banking • Insurance (Swedbank, 2016).
Until today, the banking institute has widened its scope offering retail banking, financial advisory and financial asset management, which can be accessed through their branches, by phone or through the internet. Even though Swedbank has grown massively over time, its customer base still mainly consists of private customers. The main objective of Swedbank, as described by themselves as to be close to the customer by valuing long-term customer relationships. For example, one of the products the bank offers is a "Barn och ungdomar" accounts (children and teenager accounts) with extended functionalities, like special saving features, free credit cards which can be individually designed and discounts for theatres, cinemas and other activities (Swedbank, 2016).
Further, Swedbank gradually implemented new technologies into its banking services. Swedbank states, that its motivation is to actively make the banking process easier on an end-to-end basis for their clients. For this purpose Swedbank has already implemented successfully various technologies into their service prospect. The following is a non exhaustive list with examples.
• Internet banking: Overall account handling through an online interface (checking balance, money transfer orders,...)
– 80% of Swedbank customers login at least once a month.
– Login possibility through Smart-ID smartphone app: A tool, which can be used for
authentication and for approval of payments and agreements.
• Mobile banking: Mobile banking refers to a smartphone and tablet application, created by Swedbank, which covers all necessary banking functionalities, as well as provide their customers with extra services like "shake for balance", which displays the real- time account balance of a customer’s bank account, when the smartphone is shook.
– 39% of Swedbank customers use mobile banking only, with an average of 21 logins
per month excluding balance checking.
• E-invoice: e-invoices are like regular bills but they do exist digitally. They are accepted as original documents in accounting and can be handled and moved within business software.
• Swish: Swish is a mobile payment service that was established in Sweden in 2012. The main usage is to send money between private persons or make payments. For the transaction the mobile phone number, which is linked to the banking account, is used (Swedbank, 2016).
Customer contact happens mainly through three channels – online channels, branches and via telephone. Figure 10 visualises the increase of interactions happening between Swedbank and its customers from the year 2011 to 2015. Telephone banking and branch offices remain stable in their interaction numbers and have not grown significantly. On the other hand the online channel has grown from 350 million digital visits to over 1.000 million (Kedbäck, 2016).
Figure 10: Swedbank: Visits per day and channel (Kedbäck, 2016)
4.1.2. The problem at Swedbank
In the year 2016 overall 4.5 million physical customer interactions (phone or branch contact) happened at Swedbank. Two million of these interaction were transactional, meaning that customers could have executed the request by themselves but chose to engage with Swedbank (Kedbäck, 2016). This indicates that the customers are either not aware of the information being present or that it is more comfortable for the customer to contact the bank.
The problem identified by Swedbank is that customer service staff is spending too much time looking up information. This is done by asking each other or searching the in-tranet and internet trying to find the information the customer could not find. These interactions are not adding value to Swedbank and are a misuse of available resources. Representatives from Swedbank stated that the company is concerned about new fin-tech competitors like Trustly or Tink. These pose a threat to Swedbank by providing additional financial services for customers (Hernaes, 2015).
prob-lem statement. The first intention of Swedbank was to create a Wiki for their own services, in order to help their customers and customer service staff to more comfortably look up information. Various companies including IBM and other high profile organisa-tion, responded stating that they were able to solve their problem (Nuance, 2016). Swedbank chose to go with the software technology cooperation Nuance Communication. Together with Nuance, Swedbank decided that the main objective should be to minimise the number of non value adding customer interaction in order to be able to focus on the value adding interactions (Kedbäck, 2016)
4.1.3. Nina the virtual assistant
Nina is a chatbot which serves as a virtual assistant and is based on artificial machine intelligence. The Nina project started in the year 2015. Nina is accessible through the home page of Swedbank. The main differentiation between Nina and a simple QandA search engine is that in response to a question of a customer Nina prompts the user to ask more questions. The goal behind this approach is to let Nina understand the purpose of a user’s inquiry to a degree in which it can provide an adequate advice. Nina provides an automated conversation around the problem using the answers to make sure that the root cause of the problem has been identified correctly and the solution fits the customer. The appeal of the chat function purposely resembles popular search engines like Google (figure 11). The intent hereby is to present Nina as open and inviting as possible. A typical inquiry from a customer could be: "What are the steps for opening a savings account?". Afterwards Nina would response either with an answer, or with a counter question to prompt the customer to ask more questions.
Figure 11: Screenshot: Exemplary conversation with Nina web (Swedbank, 2016). Google translate was used to translate the website from Swedish to English.
Nina is created with two layers, an external and an internal layer. The external layer is visible for customers, visiting the Swedbank website. The internal layer is only accessible for Swedbank service staff. The purpose for having two layers is that if the customer is not happy with the answer provided by Nina, they can opt to escalate the inquire to a Swedbank support centre. Afterwards the service staff can choose to access the internal layer, which contains more specific information which might be more useful for the customer (Kedbäck, 2016).
Metric Value
Nr. of Conversations 30.000/ month
First Contact Resolution 80%
Deflected 62%
Channelled 18%
Attempted 20%
Abandoned 18%
Escalated 2%
Table 2: Usage data for Nina web (Kedbäck, 2016)
Table 2 displays the usage data of the first months after the introduction of Nina. The results display an immense first contact resolution rate of 80%. 62% of these are deflected, meaning that customers did not have to get in contact with Swedbank at all in order to solve their problem using Nina web. The other 18% are channelled, meaning that Swedbank chose to redirect the users to another channel, e.g. their call centre, a branch or to the internet banking platform. 20% of all interaction are categorised as attempted or unsolved inquires. 18% of those are abandoned, meaning that the user did stop to interact with Swedbank for an unknown reason (Kedbäck, 2016).
The main success of Nina can be attributed to four factors.
1. Nina is customer driven meaning that it only includes information about topics which the customers ask about. For instance, an insurance company, which works together with Swedbank, complained on why its products where not mentioned in Nina’s conversations. The issue hereby was, that the customers did not ask question about the insurance products.
2. Nina is easily accessible through the web browser of Swedbank and according to the results, especially the first contact resolution, performs well and solves the customer’s problems quickly.
3. The facts that Nina is a joint project between Swedbank and Nuance and a cloud based solution, leads to a less complicated and faster implementation process. According to Kedbäck (2016) these factors were key aspects in gaining top level management support.
4. A dedicated staff responsible for the stakeholder management and content man-agement assure that Nina is supported with the right information pipelines. The content management teams main tasks are to monitor conversations, checking if the information used by Nina is up to date and the management of the various stakeholders in order to assure that product owners, legal parties and overall com-munication about Nina are handled in an appropriate manner (Kedbäck, 2016). The introduction of Nina web on the website of Swedbank was the first step.
The next step for Swedbank is to integrate Nina into the 58 banks which belong to Swedbank but have their own representation and service catalogue. Hereby Nina is supposed to cover the same tasks, but adjusted for each bank (Kedbäck, 2016).
The next target is to expand Nina to the mobile channel in the form of a dedicated virtual assistant. This would be a major step since about 40% of the customers use Swedbank’s digital services only through the mobile channel. The ultimate goal hereby is to create an intelligent virtual assistant, which can assist the customer throughout their whole customer experience. A possible banking service named by Kedbäck (2016) which could be addressed via Nina are consumer loans. A user could indicate the intent to make a purchase such as a new computer, through the virtual assistant. Nina would initiate the loan process and guide the user through the necessary steps. The user could have the possibility to continue the loan process when at home.
4.2. Customer interviews summary (Appendix A)
Short profiles of the interviewees
Karin(23): Bachelor student from Jönköping.
Emma(24): Apprentice from Malmö.
Max (27): Final year master student who was on an exchange semester in the
Nether-lands. Originally from Stockholm.
Rasmus (22): Bachelor student at Lund University.
Felix(24): Inhabit from the area around Vaxjö.
To gain understanding about the experiences, views, beliefs and motivations of Swedes regarding banking and virtual assistance multiple interviews were conducted with private Swedish banking customers. The interviews were conducted through Skype in English. All interviewees were informed that their full names would not be stated within the thesis. The complete transcripts of the interview can be found in Appendix A.
The interviewed Swedish banking customers have banking accounts at Swedbank AB, Svenska Handelsbanken AB, SEB AB and Länsförsäkringar AB. They represent three out of the big four banking institutes in Sweden, with only Nordea Bank AB missing. The interviewees can be divided into two groups, one group being members of Swedbank and the other being members of other banks. This is important due to the studies focus on Swedbank and its virtual assistant Nina. The interviewees all use the digital banking services of their respective banks and would appreciate further digital services. The in-terviewees also indicated possible changing user habits with changing life circumstances.
4.3. Expert interview summary (Appendix B)
To gain expert knowledge for writing the present master thesis, the author interviewed Sven Magg, who is a postdoctoral teaching Associate of the Knowledge Technology Group at the University of Hamburg. His main research field involves human robot interaction including artificial intelligence based communication. The interview took place within the office of Sven Magg at the department of informatics of the university of Hamburg. The interview was conducted in German language. All quotes in English referencing Sven Magg are translated by the author with an effort to provide the most fitting translation without losing the content of the quotation. The following write up covers the interview subject wise and not chronologically. The complete interview can be found in Appendix B.
The initial subject of the interview was the overall development of artificial intelligence technologies, but the interviewee stated that the field of research is too large to be addressed as a whole within the frame of the interview. That is why, we more specifically discussed the current state of technologies within the human robot interaction field. The interviewee stated that on one side AI technologies are well-advanced regarding the recognition of natural input such as visual, textual and audio communication and succeed in distinguishing grammatical elements within sentences.
Understanding on the the other side is mainly obtained through keyword spotting. Hereby requests from human users are best understood if the sentences are short and grammatically correct. If conversations and dialogues are longer and become more com-plex the system is not able to identify the underlying meaning of the message.
"If the words ‘didn’t got money’ and ‘broken’ appears within a sentence then [the chatbot] assumes that an ATM is broken, but in the end this is just guessing" (Sven Magg, 2017)
The interviewee addressed the issues of what understanding is, what the criteria for understanding are and whether a machine is capable to understand at all. As an example the interviewee stated that at the current level of development it is not possible for a computer to identify sarcasm.
"What is understanding? Does the human brain also follow a keyword spot-ting principle?" (Sven Magg, 2017)
The interviewee made a statement regarding the future development of the research field of human-robot interaction. He stated that progress over the next years is most likely to be expected in understanding of textual, audio and especially visual content.