Teknik och samhälle
Datavetenskap och medieteknik
Examensarbete
15 högskolepoäng, grundnivåEffektivisering av automatiserad igenkänning
av registreringsskyltar med hjälp av
artificiella neurala nätverk för användning
inom smarta hem
Streamlining automated license plate recognition with help of
artificial neural networks for usage in smart homes
Jens Andreassen
Alexander Drottsgård
Examen: Kandidatexamen 180 hp Huvudområde: Datavetenskap Program: Systemutvecklare Datum för slutseminarium: 31/5-2019Handledare: Reza Malekian Examinator: Johan Holmgren
Sammanfattning
Konceptet automatiserad igenkänning och avläsning av registreringsskyltar har utvecklats mycket de senaste åren och användningen av Artificiella
neurala nätverk har introducerats i liten skala med lovande resultat. Vi
undersökte möjligheten att använda detta i ett automatiserat system för garageportar och implementerade en prototyp för testning. Den traditionella processen för att läsa av en skylt kräver flera steg, i vissa fall upp till fem. Dessa steg ger alla en felmarginal som aggregerat kan leda till över 30% risk för ett misslyckat resultat. I denna uppsats adresseras detta problem och med hjälp av att använda oss utav Artificiella neurala nätverk utvecklades en kortare process med endast två steg för att läsa en skylt, (1) lokalisera registreringsskylten (2) läsa karaktärerna på registreringsskylten. Detta minskar antalet steg till hälften av den traditionella processen samt minskar risken för fel med 13%. Vi gjorde en litteraturstudie för att identifiera det lämpligaste neurala nätverket för uppgiften att lokalisera registreringsskyltar med vår miljös begränsningar samt möjligheter i åtanke. Detta ledde till
användandet av Faster R-CNN, en algoritm som använder ett antal artificiella
neurala nätverk. Vi har använt metoden Design och Creation för att skapa en Proof of Concept prototyp som använder vårt föreslagna tillvägagångssätt för
att bevisa att det är möjligt att implementera detta i en verklig miljö. NYCKELORD: AI, Artificiell intelligens, Neuralt nätverk, Maskininlärning,
Faster R-CNN, Registreringsskylt, Registreringsskyltsigenkänning,
Abstract
The concept of automated recognition and reading of license plates have evolved a lot the last years and the use of Artificial neural networks have been introduced in a small scale with promising results. We looked into the
possibility of using this in an automated garage port system and we
implemented a prototype for testing. The traditional process for reading a license plate requires multiple steps, sometimes up to five. These steps all give a margin of error which aggregated sometimes leads to over 30% risk for failure. In this paper we addressed this issue with the help of an Artificial
neural network. We developed a process with only two steps for the entire
process of reading a license plate, (1) localize license plate (2) read the characters on the plate. This reduced the number of steps to half of the
previous number and also reduced the risk for errors with 13%. We performed a literature Review to find the best suited algorithm for the task of
localization of the license plate in our specific environment. We found Faster R-CNN, an algorithm which uses multiple artificial neural networks. We used the method Design and Creation to implement a Proof of Concept prototype using our approach which proved that this is possible to do in a real
environment.
KEYWORDS: AI, Artificial Intelligence, Neural Network, Machine Learning, Faster R-CNN, License Plate, License Plate Recognition, Number Plate, Number Plate Recognition, ALPR, ANPR.
Ordlista
AI
AI (Artificiell Intelligens) är intelligens som uppvisas av maskiner och inte av naturliga entiteter.
Annotering
En markering av intressant data för användande inom maskininlärning. Markeringen beskriver vad datan representerar och var den befinner sig i exempelvis en bild. API
Application Programming Interface är en specifikation på hur ett program ska användas.
Artificiellt neuralt nätverk
Algoritmer som används för självinlärning inom maskininlärning. Designat för att efterlikna ett biologiskt neuronnät, t.ex. hjärnan.
CNN
En typ av artificiellt neuralt nätverk, se ingående beskrivning under rubrik: 3.2 CNN. Endpoint
En åtkomstpunkt till ett API. Enkortsdator
En dator som är byggd på ett enda kretskort. False positive
Data som en modell har klassificerat som den förväntade outputen men i det själva verket inte är rätt.
Faster R-CNN
En typ av artificiellt neuralt nätverk som används för objektigenkänning, se ingående beskrivning under rubrik: 3.3 Faster R-CNN.
Histogram
Ett stapeldiagram som visar hur en bilds olika egenskaper är representerade. IoT-enhet
IoT står för “Internet of Things”, där en IoT-enhet är en enhet som är uppkopplad till internet.
Maskininlärning
Förmågan av ett datorprogram att kunna lära sig och tolka data. Modell
Produkt av det tränade neurala nätverket. Proof of Concept
Python
Ett högnivåprogrammeringsspråk. SSD
En typ av artificiellt neuralt nätverk som används för objektigenkänning, se ingående beskrivning under rubrik: 3.5 SSD.
Träningsdata
En samling data som innehåller önskat svar, detta ges som input för maskininlärning, ofta kallat dataset.
YOLO
En typ av artificiellt neuralt nätverk som används för objektigenkänning, se ingående beskrivning under rubrik: 3.4 YOLO (You only look once).
Skrivkonventioner
Samtliga ord som förekommer i ordlistan påträffas i texten i kursiv stil. Vissa begrepp som inte är grundläggande och inte förekommer i ordlistan beskrivs mer ingående i uppsatsen där de tas upp, se innehållsförteckning för dessa begrepp.
Innehållsförteckning
1 Inledning 1
1.1 Introduktion 1
1.2 Bakgrund och tidigare forskning 1
1.3 Syfte 2
1.4 Frågeställning 3
1.5 Avgränsning 3
2 Metod 4
2.1 Motivering av Litteraturstudie 4
2.2 Motivering av Design and Creation 4
2.3 Tillvägagångssätt för testning av modellen 5
2.4 Tillvägagångssätt för testandet av prototypen 5
3 Teoretisk bakgrund 7
3.1 Grundläggande information om området 7
3.2 CNN 8
3.3 Faster R-CNN 8
3.4 YOLO (You only look once) 8
3.5 SSD 9
4 Litteraturstudie 10
4.1 Tillvägagångssätt för utförandet av litteraturstudie 10
4.2 Vad vi sökte i ett neuralt nätverk 10
5 Design and Creation 11
5.1 Tränandet av det neurala nätverket 11
5.2 Systemets konstruktion 11
5.2.1 IoT-enheten 12
5.2.2 Servern 13
5.2.3 Mobilapplikationen 14
6 Resultat och Analys 15
6.1 Resultat av litteraturstudien 15
6.1.1 Det neurala nätverket vi valde 16
6.2 Resultat av tränandet av modellen 16
6.2.1 Första iterationen 18
6.2.2 Andra iterationen 18
6.2.3 Tredje iterationen 18
6.3 Resultat av testningen av modellen 19
6.4 Resultat av testandet av systemet som helhet 20
7 Diskussion 22
7.1 Litteraturstudien 22
7.2.1 Variabler i tränandet 22
7.2.2 Träningsdata 22
7.3 Testandet 23
7.3.1 Testdatan 23
7.3.2 False positives i resultatet 23
7.3.3 Val av testmetod 23
7.4 Tankar kring mobilapplikationen 23
7.5 Reflektion kring en kortare process 24
8 Slutsats och framtida forskning 25
8.1 Slutsats 25
8.2 Framtida forskning 25
8.2.1 Träningsdata 25
8.2.2 Djupare förståelse och tid 26
1
1 Inledning
1.1 Introduktion
De senaste åren har tekniken som används för igenkänning av objekt samt karaktärer i bilder utvecklats en hel del. Det vanligaste sättet för detta är att använda sig av
bildprocess-algoritmer. Dessa identifierar mönster och samband och jämför
mönstren/sambanden med data som representerar önskvärda identifierbara objekt eller karaktärer [1][2]. Med hjälp av dagens datorkraft och artificiella neurala nätverk så går det att effektivisera dessa operationer markant [3][4][5]. Artificiella neurala nätverk har använts och utvecklats inom delar av området. Exempelvis för att känna igen samt läsa av registreringsskyltar i bilder, antingen från lågupplösta övervakningsbilder eller från bilder tagna med syftet att lokalisera registreringsskyltar [4][6]. Det sistnämnda
exemplet är vad denna uppsatsen fokuserar på, att använda bilder tagna i en hemmamiljö med syftet att lokalisera och läsa av registreringsskyltar. Detta för att senare avgöra huruvida en garageport ska öppnas eller ej. Öppnandet av porten avgörs genom avläsning av en skylt, om denna matchar en av de betrodda skyltarna i systemet så öppnas garageporten. Närmare bestämt att se om processen som helhet går att effektivisera med hjälp av att använda artificiella neurala nätverk. Specifikt när detta görs för att användas i en redan känd miljö i form av förväntade vinklar och
ljusförhållanden. Att öppna garageportar eller andra typer av dörrar, grindar eller liknande beroende på vem som vill komma in är ett problem som traditionellt har lösts via manuell input från en användare. Tekniker som RFID, fingeravtryck, kodlås och liknande har introducerats för att ge tillträde för betrodda människor [2]. Dessa tekniker kräver dock att en användare utför någon form av aktivitet och förlitar sig på att dessa tekniker är fungerande för tillfället. För att automatisera systemet ytterligare kan vår föreslagna teknik användas.
1.2 Bakgrund och tidigare forskning
Den traditionella metoden som ofta används i system för att avläsa registreringsskyltar består i de flesta fall av fyra steg. Första steget är lokalisering av ett fordon i bilden, detta exempelvis genom att använda ett histogram för att upptäcka skillnader på
fordonets färg mot färgen på bakgrunden. Efter lokalisering av ett fordon samt isolering av fordonet i bilden, så påbörjas steget för lokalisering av registreringsskylten. För att identifiera registreringsskylten så är en kombination av flera bild-operationer det vanligaste tillvägagångssättet. Genom exempelvis omvandling av bildens färgskala till svartvit så går det sedan att använda en kantdetekteringsalgoritm på bilden.
Kantdetekteringsalgoritmen gör det möjligt att jämföra kanterna i bilden mot en
rektangel med samma skala som en förväntad registreringsskylt och således identifiera skylten. Efter detta beskärs bilden så att enbart registreringsskylten återstår. På den beskärda bilden utförs sedan segmentering av karaktärerna genom att exempelvis använda histogram för att jämföra karaktärernas färger mot den förväntade
bakgrunden på registreringsskylten. De segmenterade karaktärerna går att identifiera med ytterligare bildbehandlings-algoritmer, mönstermatchning eller genom att använda sig av ett artificiellt neuralt nätverk [1][2][20][21].
2
Att utföra den beskrivna processen slutar i det här exemplet i fyra steg. Varje steg innefattar en risk för fel. Även när de olika stegen isolerat har hög precision så leder flera steg till att risken för fel i processen som helhet ökar. Något som också bör tas i åtanke är att om ett steg går fel så blir samtliga efterkommande steg drabbade av detta [3]. I artikeln Real-Time Automatic License Plate Recognition through Deep Multi-Task
Networks från 2018 har forskarna räknat ut att även när varje steg i processen har en
precision på 98% träffsäkerhet så leder detta till ett sammanlagt värde på 72%
träffsäkerhet vid fyra steg [3] och sju karaktärer i skylten. Detta leder till 28% risk för fel. Tillvägagångssättet de föreslår innebär då istället att eliminera vissa steg och korta ner processen. Exempelvis endast lokalisering av registreringsskylten och sedan
avläsning av karaktärerna, detta innebär färre steg och en lägre risk för fel. Fler
artiklar har de senaste åren tagit upp alternativ till de olika stegen i processen i form av att använda sig av maskininlärning istället för traditionella metoder [4][5][7].
Användandet av maskininlärning för ändamålet att lokalisera samt läsa av
registreringsskyltar är redan ett använt och bevisat fungerande koncept. Författarna av
License Plate Detection and Recognition Using Deeply Learned Convolutional Neural Networks skriven 2017 ser ett positivt resultat av att kombinera flera modeller som var
för sig utför ett steg i den traditionella processen. Detta är dock riktat mot användning i trafiksituationer [4]. Författarna av Real-Time Brazilian License Plate Detection and
Recognition Using Deep Convolutional Neural Networks skriven 2017 föreslår att
utveckla detta ytterligare genom modifiering av träningsdatan för tränandet utefter förväntade förhållanden som passar just deras ändamål. Även de visar ett lyckat resultat, dock riktat mot användande i video [5]. Författarna av Robust license plate
detection in the wild skriven 2017 förespråkar maskininlärning för just steget som
innebär att lokalisera registreringsskylten och uppnår ett bra resultat när detta används i trafikvideos [7].
Författarna av Automatic License Plate Recognition Using Computer Vision for Door
Opening utvecklar ett system med samma ändamål och miljöbegränsningar som det
denna uppsatsen studerar [6]. De fokuserar främst på problemet som innebär att
skyltar har olika färger, vilket blir ett problem för traditionella metoder [6]. De tar dock inte upp förslag på lösning av detta med artificiella neurala nätverk vilket denna
uppsatsen gör. Författarna av Identity verification using computer vision for automatic
garage door opening använder sig av objektigenkänning för samma syfte som vi, men
dock med ett steg mer än vad vi föreslår [33]. De utför steget för lokalisering av bilen innan skylten [33], detta steg vill vi eliminera för att ytterligare effektivisera processen genom att använda ett minimalt antal steg.
1.3 Syfte
Vårt arbete är en fortsättning på artikeln Home automation - an IoT based system to
open security gates using number plate recognition and artificial neural networks. I
artikeln bygger författarna en prototyp för ett automatiserat system för öppning av garageportar. Forskarna använder den traditionella flerstegs-metoden [2]. Studien lokaliserar skylten genom att ta en bild, använda kantdetektering för att identifiera former och jämför sedan dessa former mot förväntat utseende på en registreringsskylt. Då resultatet i den forskningen ger en relativt låg precision på 87% för identifiering av registreringsskylten vill vi undersöka möjligheten för huruvida ett artificiellt neuralt
3
automatiserade systemet bryter även det traditionella tillvägagångssättet av att använda sig av fler steg än nödvändigt. Vi bryter ner det till två steg, (1) lokalisera registreringsskylten med hjälp av ett artificiellt neuralt nätverk, (2) läsa av
karaktärerna på skylten. På grund av att vi har ett förutbestämt användningsområde för systemet som denna uppsatsen har valt att fokusera på, så kan vi förutspå hur bilderna kommer att se ut till viss del. Exempelvis så kommer kameran att ha ett förutbestämt avstånd till bilen som ska analyseras, ljusförhållanden i bilden kan styras med lampor samt förväntade vinklar kan kontrolleras via hur systemet monteras i riktning mot det förväntade fordonet. Dessa aspekter anser vi tyder på att ett mer specialiserat neuralt nätverk kan tränas. Ett lyckat resultat på detta kan visa att denna processen är den rätta vägen att gå för detta område men även för områden liknande vårt. Vidare forskning kan då utveckla detta ytterligare och på så sätt skapa mer träffsäkra eller effektivare system för deras användningsområden.
1.4 Frågeställning
De frågorna vi vill besvära är:1. Kan vi uppnå ett bättre resultat än traditionella metoder genom att använda ett
artificiellt neuralt nätverk för det steg som lokaliserar registreringsskylten?
2. Vilket neuralt nätverk passar bäst för lokalisering av registreringsskyltar i bilder tagna för ett automatiserat garageportssystem?
3. Går det att implementera vårt nätverk i ett system och testa det i en verklig miljö som representerar det tänkta användningsområdet?
1.5 Avgränsning
Vårt fokus ligger på steget som innebär lokalisering av registreringsskyltar i bilder. Vi lägger stor vikt på vilken typ av neuralt nätverk vi använder. Vi lägger större vikt på resultatet från träningen av det neurala nätverket än att den prototyp vi tar fram presterar felfritt. Detta då steget vi fokuserar på enkelt kan testas i en kontrollerad virtuell miljö. Vi tar även fram en IoT-enhet för att vi anser att det är viktigt att vi har belägg för att vår metod fungerar även i en verklighetstrogen miljö. Prototypen vi implementerar representerar ett helt system för testning, men vissa delar eller komponenter av systemet är utvecklat av andra.
4
2 Metod
Vår frågeställning bestod av flera olika moment: träna ett artificiellt neuralt nätverk för lokalisering av registreringsskyltar, ta reda på vilket befintligt neuralt nätverk som är lämpligast för detta samt att testa det neurala nätverket i en verklighetstrogen miljö. På grund av att frågeställningen innefattar olika delar så ansåg vi oss behöva olika
metoder för dessa. En Litteraturstudie för att ta reda på vilket neuralt nätverk som passar vårt användningsområde bäst. Design and Creation för tränandet av det neurala
nätverket samt tillverkandet av prototypen som det testades i.
Nedan presenteras en diskussion för val av metoderna samt motivering till dessa. Sedan följer en beskrivning av metoden för testandet av det neurala nätverket samt testandet av hela systemet. En beskrivning av genomförandet av litteraturstudien beskrivs under rubriken: 4. Litteraturstudie. En beskrivning av systemet som använts för testning av det neurala nätverket beskrivs under rubriken: 5. Design and Creation.
2.1 Motivering av Litteraturstudie
Då uppsatsen syftar till att använda ett artificiellt neuralt nätverk samt att det finns flera sådana för olika ändamål så valde vi att utföra en Litteraturstudie. Detta för att identifiera vilket som passade det tänkta användningsområdet bäst. Vi såg att det fanns
neurala nätverk som presterar med högre hastighet än andra; dessa används exempelvis
i videoanalys. Det framkom även neurala nätverk som presterar högre precision och dessa kan användas vid rättsväsende eller bevisanskaffning; dessa har en lägre hastighet. På grund av att det fanns olika typer av neurala nätverk för olika
användningsområden så behövde vi information och belägg om vilket neuralt nätverk som passade oss bäst. En annan motivering till litteraturstudien var att under
förstudien som gjordes under uppsatsens introduktion så stötte vi på nya, välciterade artiklar som gjorde jämförelser mellan olika nätverk. Med hjälp av litteraturstudien kunde vi visa att vi fått kunskap inom ämnet [24]. Litteraturstudien gav oss även grunder för de olika för- och nackdelar de olika nätverken har [24]. För att komma fram till ett lämpligt neuralt nätverk var även metoden experiment ett tillvägagångssätt som övervägdes. Det hade varit möjligt att i en kontrollerad miljö utföra en reproducerbar och metodisk process för att ta fram resultat kring hur olika neurala nätverk presterar för det tänkta användningsområdet. Då vi under förstudien såg att information om de olika neurala nätverk fanns väl dokumenterade och även jämförda så bestämde vi oss för att inte utföra experiment. Även den korta tidsramen som arbetet håller sig inom samt vår begränsade förkunskap om olika sorters neurala nätverk gav motivering till att utföra en litteraturstudie istället för experiment.
2.2 Motivering av Design and Creation
Uppsatsen använde metoden Design and Creation för att ta fram en prototyp och en
modell. Genom detta så skapades belägg för att besvara fråga 1 från frågeställningen
“kan vi uppnå ett bättre resultat än traditionella metoder genom att använda ett
artificiellt neuralt nätverk för det steg som lokaliserar registreringsskylten?”.
Framtagandet av prototypen var viktig för att kunna visa att vår metod, innehållande färre steg, är effektivare än tidigare metoder och kan anses som rätt metod att använda i liknande system i framtiden. Tränandet av det neurala nätverket använde sig av delar
5
från Design and Creation metoden [24], detta då tränandet skedde iterativt för att bäst kunna påverka och förbättra det neurala nätverket så mycket som möjligt. Även för att åtgärda problem som uppstod och för att komma fram till slutsatser med hjälp av iterationerna. En alternativ metod för att försöka bevisa att det är möjligt hade kunnat vara ytterligare en litteraturstudie [24]. Detta för att hitta tidigare implementationer som stämmer överens med vår teori. Då en förstudie redan gjorts i en liten utsträckning och ingen information om system som hade en liknande avgränsning som oss hittades, ansåg vi att det var bäst att försöka träna ett nätverk själva.
Prototypen vi implementerade användes för att demonstrera ett komplett fungerande system. Denna prototyp innehöll olika konstrukter, modeller och metoder [24]. Vi anser även att framtagandet av en IoT-enhet som en del av prototypen ses som viktigt. Detta för att visa möjligheten av att skapa ett fungerande system med rimligt billig hårdvara. Prototypen fungerade även som ett verktyg för den maskin-inlärningsmodellen som vi tränade för lokalisering av registreringsskyltar [24]. Detta gav oss grunder för att svara på fråga 3 gällande huruvida vi kan implementera modellen i en verklig miljö.
2.3 Tillvägagångssätt för testning av modellen
Modellen som vi tränade testades i en kontrollerad miljö genom att den i ett
testprogram fick prova att lokalisera registreringsskyltar i 300 bilder. Testprogrammet använde sig av Tensorflow som är ett ramverk utvecklat av Google. Tensorflow används för att enklare träna samt använda sig av maskininlärningsmodeller [11]. Utöver
Tensorflow biblioteket så användes Keras API för att underlätta träningen ytterligare. Keras gjorde så att användandet av Tensorflows mer matematiska
användningsområden abstraherades till viss del [12]. Modellens gissningar på skyltar i test-bilderna från Open Images dataset [34] jämfördes med bildernas tillhörande
annoteringar för att avgöra om gissningen var korrekt eller ej. Modellen gav utöver sin
gissning även ett värde från 1–100% för hur säker den var på att detta är en korrekt gissning, där 100% är helt säker och 1% inte alls säker. Detta värde kunde i sin tur användas för att eliminera gissningar som gjorts med för låg säkerhet då modellen kan leverera flera gissningar på samma bild. Med hjälp av att anpassa värdet för hur säker
modellen behöver vara samt genom att testa modellen mot test-bilderna fick vi fram en
siffra visande hur bra den levererar korrekta resultat.
2.4 Tillvägagångssätt för testandet av prototypen
Testandet av prototypen gjordes utomhus, detta för att det vanligasteanvändningsområdet är en utomhusmiljö. I testerna närmade vi oss bilen med
IoT-enheten tills den kände av bilen. IoT-IoT-enheten tog då ett en bild och skickade denna till
servern. Sedan observerades via en dator hur servern hanterade lokalisering av
registreringsskylten i bilden. I servern gick det att se om skylten lokaliserades samt om det externa API:et lyckades läsa av karaktärerna. Detta test upprepade vi både dagtid och kvällstid. Vid båda tillfällena så testades bilen en gång framifrån och en gång bakifrån. Detta för att testa de olika förhållanden som det verkliga systemet skulle tänkas stöta på.
Det fanns flera anledningar till att vi utförde ett begränsat antal testfall. En av dessa anledningarna var att prototypens syfte enbart var att visa modellens möjliga
6
testa på samt en begränsad tid för att utföra testerna. Anledningen till att vi inte utförde testerna i en mer kontrollerad lab-miljö var för att det tänkta
användningsområdet var utomhus och att modellen var tränad på skyltar sittandes på bilar. En inomhusmiljö hade betytt att bilderna hade behövt tas på en skylt utan bil och detta riskerade att ge missvisande resultat.
7
3 Teoretisk bakgrund
Här presenteras grundläggande information och ett antal termer som tas upp frekvent i uppsatsen, detta för att ge en ökad förståelse för våra resonemang samt slutgiltigen vårt val. Termerna som presenteras är: CNN vilket är en typ av neuralt nätverk, YOLO,
Faster R-CNN och SSD, vilka är algoritmer för objektigenkänning som jämförs i
resultatet av litteraturstudien. Anledningen till att just dessa algoritmer nämns presenteras vidare under rubriken: 6.1. Resultat av litteraturstudien.
3.1 Grundläggande information om området
Maskininlärning kan förklaras som förmågan av ett datorprogram att kunna lära sig
och tolka data [32]. Programmet innehåller en algoritm som automatiskt lär sig efter varje input som den får. Det finns olika sätt för en algoritm att träna på data, bland annat “Unsupervised Learning” och “Supervised Learning”.
Unsupervised learning översatt till svenska är: “oövervakat lärande”, vilket innebär att
träningsdatan inte är förarbetad med önskade svar. Eftersom träningsdatan inte
innehåller några svar så går det inte att beräkna precision på modellen. Istället så lär
modellen sig att förstå samband och liknelser i data. Denna sortens inlärningsteknik
kan användas för algoritmer som ska göra grupperingar eller hitta associeringsregler. Eftersom vi inte var intresserade av grupperingar eller associationer mellan data så är unsupervised learning inte en metod som passade för vårt användningsområde.
Supervised learning eller på svenska “övervakat lärande” innebär att inputdatan, den så kallade träningsdatan, är förarbetad och innehåller önskade svar som algoritmen eventuellt ska lära sig generalisera från [25]. Vid tränandet av en algoritm med övervakad inlärning så tar algoritmen emot bilderna och ger sitt svar. Är algoritmens svar fel så korrigeras svaret och modellen blir bättre med tiden. Övervakad inlärning är den vanligaste metoden för klassificering och lokalisering av objekt [25] och är just därför den metod som vi valde att använda för tränandet av vår modell.
Ett artificiellt neuralt nätverk är en algoritm som inspireras av hur ett biologiskt
neuralt nätverk fungerar. Det används för att exempelvis lösa komplexa klassificerings- och detekteringsproblem [25]. Det är konstruerat som ett nätverk av noder
sammankopplade av viktade bågar. Vikterna i dessa bågar är ofta slumpmässiga värden till en början men kan också vara värden anpassade för träning av olika typer av
nätverk. I sammanhanget som är objektigenkänning i bilder så byggs nätverket upp som så att noderna finns i ett flertal lager. Ett första lager i nätverket kan
representeras som ett inputlager, exempelvis representerande olika delar eller pixlar i en bild. Varje nod i ett lager tar input från samtliga noder i lagret innan. Beroende på vilket syfte nätverket har så används en viss typ av beräkning i varje nod som med hänsyn till inputvärdet de tidigare noderna tillsammans med värdet för vikten på bågen mellan dem avgör huruvida värdena uppfyller ett beskrivet tröskelvärde. Om
tröskelvärdet uppfylls ges ett visst värde till nästa nod och om inte ett annat. Efter detta upprepas processen tills det sista lagret är nått, där ett värde då beräknas som ska representera exempelvis ett ja eller ett nej, eller en bil eller en buss. Genom att använda värdet i det sista lagret och jämföra detta med det korrekta resultatet så kan sedan vikterna i bågarna ändras i de tidigare lagren för att sedan upprepa processen,
8
detta tills ändringen av värdet i bågarna blir minimal på grund av att ett mer korrekt resultat ges [29].
3.2 CNN
Convolutional Neural Networks (CNN) är en typ av neurala nätverk som är effektiva för objektigenkänning i bilder. Till skillnad från ett vanligt neuralt nätverk så utförs
manipulering av bilden innan den vidare används i det neurala nätverket [27]. Detta sker i en process som kallas faltning, flera filter representerade av olika matrix-värden används. Dessa passerar över bilden för att med hjälp av filtrets värde i kombination med bildens olika pixelvärden skapa nya versioner av bilden med vissa utseenden förstärkta. Dessa nya versioner av bilden manipuleras ytterligare i form av att en försäkran görs om att dessa enbart innehåller positiva pixelvärden. Efter detta utförs Pooling som innebär att genom exempelvis max- eller min-pooling, skapa en ny version av den förstärkta bilden i form av en summering av antingen de högsta eller lägsta pixel-värdena i ett närliggande område. Resultatet blir en mindre bild men som dock har kvar de mest framstående värdena från den tidigare förstärkta bildens delar. Det dessa olika steg kortfattat gör är att skapa en ny komprimerad bild bestående av de mest relevanta och framstående dragen från originalbilden. Detta upprepas flera gånger med olika värden tills resultatet används som input till det neurala nätverket [27].
3.3 Faster R-CNN
R-CNN är ett neuralt nätverk som adresserar problemet som fanns i traditionella CNN:s gällande svårigheter med att identifiera samt lokalisera flera föremål av samma typ i en bild och detta inom en rimlig tid [18]. Detta utförs genom att dela in bilden i ett bestämt antal områden för att sedan hantera dessa dels individuellt men även i kombination med varandra. Dessa delar av bilden passerar sedan genom ett neuralt nätverk för att sedan klassificeras av en SVM (Support Vector Machine) [18]. Tiden för att utföra en objektigenkänning med detta angreppssätt kan ta väldigt lång tid. För att effektivisera denna process presenterades Fast R-CNN av Ross Girshick. Skillnaden från tidigare metod är användande av ytterligare ett nätverk med syftet att hantera hela bilden utan den ovan nämnda uppdelningen. Detta för att extrahera bildens mest intressanta drag. Sedan identifieras bildens intressanta regioner med en metod som heter region of interest pooling [16]. Resultatet blir ett snabbare nätverk men med en prestandamässig flaskhals vid steget som innebär att föreslå intressanta regioner [17]. Faster R-CNN är en vidareutveckling av Fast R-CNN som eliminerar processen som innebär identifiering av de intressanta regionerna och använder istället ett separat neuralt nätverk för att identifiera intressanta regioner från de framstående dragen som ges som resultat från det första nätverket. Detta snabbar upp processen till en grad då en fullständig
klassificering kan ske på en bråkdel av tiden det tar för ett vanligt CNN [17].
3.4 YOLO (You only look once)
YOLO är till skillnad från Faster R-CNN inte regionsbaserad, utan här delas bilden upp
i ett rutnät i en storlek definierad av användaren. Bilden passerar endast en gång genom det neurala nätverket och i denna passering sker igenkänningen. För varje ruta i bilden ges definieras ett antal områden och ett värde för hur troligt det är att just dessa områden innehåller ett visst objekt. Med denna informationen går det sedan att avgöra
9
om ett objekt finns i bilden samt vart. Denna bedömning görs genom att sortera ut de områden med ett lägre värde för trolighet enligt en användaren bestämt gränsvärde. De områden som finns kvar kan sedan kombineras för att genom att se till intilliggande områden med bra värde för säkerhet avgöra att objektet troligtvis är på en viss plats [15]. Denna metod gör nätverket väldigt snabb jämfört med de som gör flera passeringar genom ett neuralt nätverk, detta då YOLO enbart gör en. Detta gör tyvärr också
nätverket sämre på att känna igen mindre objekt [15].
3.5 SSD
Även SSD (Single Shot multibox Detection) bygger på användande av ett CNN, och precis som YOLO så använder den sig enbart av ett nätverk och gör enbart en passering genom detta. SSD tar efter passeringen genom nätverket fram ett fixerat antal möjliga positioner för objekt samt deras klasstillhörighet för att sedan med hjälp av non-max suppression (metod för att eliminera alternativt kombinera överlappande gissningar vid objektigenkänning i bilder) eliminera objekt som har identifierats flera gånger på
samma position. Nätverket är snabbt jämfört med nätverk som använder flera neurala
nätverk i processen men är dessvärre även då mindre träffsäker i sina klassificeringar
10
4 Litteraturstudie
I denna del beskriver vi hur Litteraturstudien utfördes, vi presenterar några grundläggande begrepp och en mindre beskrivning av området maskininlärning i relation till artificiella neurala nätverk. Vi presenterar också målet med det neurala
nätverket och vilken typ av nätverk som är lämpligast för vårt användningsområde.
4.1 Tillvägagångssätt för utförandet av litteraturstudie
Under den förberedande litteraturstudien som gjordes under uppsatsens början hittade vi många benämningar om vilka neurala nätverk som var troliga kandidater för vårt arbete [22][23][3][4][7]. Vi byggde även upp en bra samling söktermer som vi sedan använde vidare i sökningen av information till denna studie. Vi ville hitta en trovärdig källa som beskrev vilka de mest framstående neurala nätverken för objektigenkänning i bilder, samt jämförelser mellan dessa. Vi använde oss av databaserna IEEE och ACM för sökandet efter relevanta studier eller artiklar och hittade flertalet artiklar som innehöll detta. Genom att fortsätta utveckla våra söktermer utefter att vi hittaderelevant information samt att bakåt och framåt-referera från de relevantaste artiklarna så ansåg vi ha tagit fram en bra grund och förståelse för området. Den mest relevanta och övergripande artikeln som vi upptäckte var enligt oss från forskarna vid Facebooks
AI Research avdelning [13] och även en artikel som jämförde hastighet och precision hos
olika neurala nätverk för objektigenkänning [14]. Ett neuralt nätverk som presenterades som framstående i artikeln från Facebook var YOLO. Skaparna av det neurala nätverket
YOLO hade själva publicerat en artikel där olika neurala nätverk jämfördes [15]
däribland Faster R-CNN som även den nämndes i artikeln från Facebook. Skaparna av
Fast R-CNN och Faster R-CNN hade även de publicerat artiklar [16][17] och med hjälp
av dessa samt ovan nämnda artiklar kunde vi bakåt och framåt-referera till ytterligare jämförelser. Exempelvis till en studie som jämförde snabbhet och precision mellan olika
neurala nätverk [14]. Med dessa artiklarna ansåg vi oss ha bra grund att stå på för att
skapa oss en uppfattning om vad för neuralt nätverk vi är ute efter.
4.2 Vad vi sökte i ett neuralt nätverk
Det vi främst sökte av ett neuralt nätverk och i slutändan den modell vi tog fram med hjälp av nätverket var precision. Flera av de mest framstående neurala nätverken har testats med fokus på både precision samt prestanda i form av hur många bildrutor i sekunden de hanterar [13][14]. Men då vår implementation enbart skulle hantera stillbilder, behövde den inte vara snabbare än att den kunde hantera en bild på några sekunder, detta eftersom att det inte kommer flera efterföljande förfrågningar direkt, som vid exempelvis analys av video.
11
5 Design and Creation
5.1 Tränandet av det neurala nätverket
Efter att litteraturstudien genomförts och visat vilken typ av neuralt nätverk som var optimalt för vårt användningsområde så skapades ett program för att träna det neurala
nätverket. Koden för detta skrevs i Python och programmet använde sig av biblioteket
Keras [11] samt ramverket Tensorflow [12]. Valet av Python gjordes för att mycket av den information som hittades om att utveckla denna typ av system använde sig av just detta språk. Vid sökandet efter träningsdata hittades flera olika samlingar av Open Source träningsdata som innehöll annoterade bilder indelade i olika klasser. Kandidater värda att nämna var COCO [8], PASCAL [9] och Open Images Dataset av Google [10]. Valet blev Open Images Dataset med anledningen att det var lättillgängligt samt att det innehöll ett stort antal annoterade bilder med just klassificeringen registreringsskyltar. Totalt innehöll samlingen cirka 6500 bilder indelade i träningsbilder samt testbilder. Även testbilderna var annoterade för att enkelt kunna avgöra huruvida modellen förutspår ett korrekt resultat eller inte. Ytterligare detaljer gällande träningen kan läsas under rubriken: 6.2. Resultat av tränandet av modellen.
5.2 Systemets konstruktion
Med målet att svara på fråga 3 “går det att implementera vårt nätverk i ett system och testa det i en verklig miljö som representerar det tänkta användningsområdet?” gjordes valet att bygga ett system bestående av tre olika komponenter. En IoT-enhet för
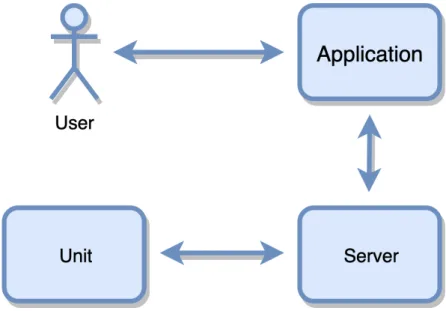
montering på garageport, en server för hantering av förfrågningar från IoT-enheten samt en mobilapplikation för kommunikation med användaren av systemet. Dessa tre presenteras mer ingående i styckena nedan, se också Figur 1 för en översikt av
systemet, IoT-enheten representeras i Figuren som “Unit”.
12
5.2.1 IoT-enheten
Enheten för montering på garageport hade flera uppgifter: att känna av om en bil närmar sig, att ta en bild av bilen, skicka en förfrågan till servern innehållandes denna bild, ta emot svar från servern och visa huruvida bilden var godkänd eller inte. För att bygga en enhet som kunde utföra detta så användes följande delar:
● En enkortsdator av modell “Raspberry Pi 3 model B” vilket är en kompakt dator med storleken av en kortlek. Den har inbyggd funktionalitet som WIFI samt möjligheten att köra ett linux-operativsystem och den kan på detta köra Python-script. Se Figur 2 för bild.
● En ultraljudssensor av modell “HY-SRF0” för att kunna mäta avstånd till närmande objekt. Se Figur 4
● En kamera av modell “Raspberry Pi camera version 2” som har möjlighet att filma i 1080p alternativt fotografera med en upplösning på: 3280 x 2464 pixlar. Se Figur 3
● En grön och en röd lampa för att visa antingen ett godkänt eller inte godkänt svar från servern.
IoT-enhetens funktion var att med ett fast tidsintervall kontrollera med
ultraljudssensorn huruvida ett fordon befann sig inom ett förutbestämt avstånd. När ultraljudssensorn kände av ett fordon togs en bild och denna skickades till servern för behandling. Om svaret från servern indikerade att fordonet var godkänt för passering så tände enheten den gröna lampan, och om svaret indikerade att så inte var fallet så tändes istället den röda lampan. En bild av den färdiga enheten presenteras i Figur 5.
Figur 2: Enkortsdator “Raspberry Pi 3 model B”. Figur 3: Kameramodul.
13
Figur 5: Bild på den färdiga IoT-enheten bestående av enkortsdator med tillhörande kamera, sensor och lampor.
5.2.2 Servern
Servern hade främst två uppgifter: att hantera förfrågningar från IoT-enheten samt att kommunicera med mobilapplikationen. En förfrågan från IoT-enheten besvarades med hjälp av den framtagna modellen, där kommunikationen med denna gjordes med biblioteket Keras [11] och ramverket Tensorflow [12]. Förfrågan behandlades
slutgiltigen även med hjälp av ett externt API som heter Platerecognizer [31] som läser karaktärer i bilder. Flödet för en förfrågan från IoT-enheten såg ut som nedan:
1. Servern tog emot en bild via en http-post endpoint.
2. Bilden konverterades till det format som förväntades av modellen.
3. Genom att använda Tensorflow och Keras analyserades bilden sedan med hjälp av vår maskininlärningsmodell. Om det enligt modellen fanns en eller flera registreringsskyltar i bilden så levererade den koordinater för dessa regioner. 4. Regionen eller regionerna extraherades från originalbilden och dessa skickades
sedan till det externa API:et för läsning av eventuella karaktärer.
5. Svaret från API:et jämfördes sedan mot de värdena som representerade betrodda registreringsskyltar.
6. Svar skickades till IoT-enheten med information om huruvida den skulle signalera för godkänt eller inte.
Kommunikationen mellan mobilapplikationen och servern gjordes via tre endpoints: en för att leverera information till mobilapplikationen vid en godkänd eller icke godkänd förfrågan, en för att lägga till registreringsskyltar samt en för att ta bort
registreringsskyltar från listan över godkända bilar. Servern skrevs i
14
applikationer online) [26] och distribuerades med hjälp av Docker (verktyg för enklare distribuering av applikationer) [28].
5.2.3 Mobilapplikationen
Mobilapplikationens syfte var att användas som kommunikationsmedel mellan användaren och det övriga systemet. Den innehöll ett enklare användargränssnitt för att visa information samt för att ta emot input från användaren. I Figur 6 visas två bilder. Den vänstra visar vyn där en användare kan se, lägga till, samt ta bort registreringsskyltar, den högra bilden visar vyn som visar en lista på notifikationer gällande lyckade eller misslyckade förfrågningar som gjorts av IoT-enheten. Som nämnt i stycket ovan så kommunicerar applikationen med servern genom ett API.
15
6 Resultat och Analys
Nedan presenteras resultatet av litteraturstudien som genomfördes och därmed vilken typ av neuralt nätverk vi valde att använda. Sedan följer ett stycke om vad vi kom fram till efter framtagandet av träningsdatan samt tränandet av det neurala nätverket. Efter detta följer resultatet av de tester som gjordes av modellen och sedan resultatet av testerna på prototypen. I detta avsnitt presenteras resultat samt viss analys av detta; diskussion om vad detta betyder presenteras under rubriken: 7. Diskussion.
6.1 Resultat av litteraturstudien
Facebook AI Research kom 2017 med artikeln Focal Loss for Dense Object Detection där författarna presenterar en metod som alternativ till de redan etablerade metoderna för objektigenkänning. Denna levererar hög precision samtidigt som den enbart använder ett neuralt nätverk [13]. Utöver att presentera sin egen metod så genomför de även flertalet tester av vad de presenterar som de mest relevanta neurala nätverken.
Testerna utförs på open source träningsdata från COCO [8]. Nätverken de nämner som de mest framstående är Faster R-CNN, YOLO samt SSD. YOLO presenteras som
snabbast mätt i millisekunder, medans Faster R-CNN levererar näst bäst träffsäkerhet, bäst träffsäkerhet ges av en av deras egna metoder. Författarna nämner dock i
slutsatsen av artikeln att en ny version av Faster R-CNN har presenterats efter deras tester som presterar bättre än deras egen metod [13]. Resultat finns i tabell 1.
Tabell 1: Precision kontra tid för utförande av objektigenkänning (Faster R-CNN benämns som FPN FRCN)
Källa: Lin T-Y, Goyal P, Girshick R, He K, Dollár P. [13]
I artikeln Speed/accuracy trade-offs for modern convolutional object detectors så jämför författarna olika neurala nätverk jämföra hur de presterar jämte varandra gällande snabbhet och precision [14]. Här jämförs bland annat nätverk som SSD, Faster R-CNN och R-FCN. Samtliga nätverk tränas på samma träningsdata och testas även på samma testdata. Resultatet visar att SSD-modellen presterar snabbast medans Faster
16
I artikeln från skaparna av YOLO som kom 2018, presenteras en ny version av deras nätverk kallat YOLOv3 [15]. Artikeln presenterar flera jämförelser med deras nya version gentemot de stora befintliga nätverken däribland Faster R-CNN, SSD med flera. Resultatet visar att YOLOv3 presterar snabbast medans Faster R-CNN långsammast men däremot med högst träffsäkerhet. Se tabell 2.
Tabell 2: Precision kontra tid för utförande av objektigenkänning (Faster R-CNN benämns som FPN FRCN)
Källa: Redmon J, Farhadi A [15]
6.1.1 Det neurala nätverket vi valde
Eftersom att artikeln Focal loss for dense object detection tar upp Faster R-CNN,
YOLOv3 samt SSD som de främsta kandidaterna till effektiv objektigenkänning i bilder
[13]. Samt att studien i artikeln visar att Faster R-CNN jämfört med YOLO och SSD leverer en högre träffsäkerhet med en kostnad av en för oss irrelevant hastighet. Artikeln nämner även att deras eget nätverk är bristfälligt gentemot den nyare Faster
R-CNN versionen [13]. Även YOLOv3s artikel visar ett resultat där Faster R-CNN har
en högre träffsäkerhet än YOLOv3, dock även att hastigheten inte är lika hög vilket för oss återigen är irrelevant [15]. Även att artikeln Speed/accuracy trade-offs for modern
convolutional object detectors kommer fram till att Faster R-CNN var den träffsäkraste
metoden med en kostnad på snabbhet [14]. Detta gjorde att vi ansåg att Faster R-CNN var den typ av neuralt nätverk vi sökte.
6.2 Resultat av tränandet av modellen
Tränandet som gjordes resulterade i tre olika modeller; dessa tre modellers träning benämns nedan som tre iterationer. Modellerna tränades i något som kallas epoker vilka i det här fallet bestod av 1000 iterationer. Mellan dessa iterationer så delades
träningsdatan upp lika, dvs. träningsdata innehållandes 6000 bilder, ger ~3 bilder per
iteration. I varje epok så tränas modellen på all träningsdata. För att se hur modellen utvecklades så tittade vi på ett värde kallat den totala förlusten. Den totala förlusten är
17
resultatet av en funktion som beräknar hur väl ett nätverk identifierar den annoterade datan som den fått som input [30]. När modellen gör en gissning som är långt ifrån det faktiskt korrekta resultat så blir värdet för den totala förlusten högre. I Faster
R-CNN-modellen som vi tränade så finns det två neurala nätverk som tidigare nämnts, ett som
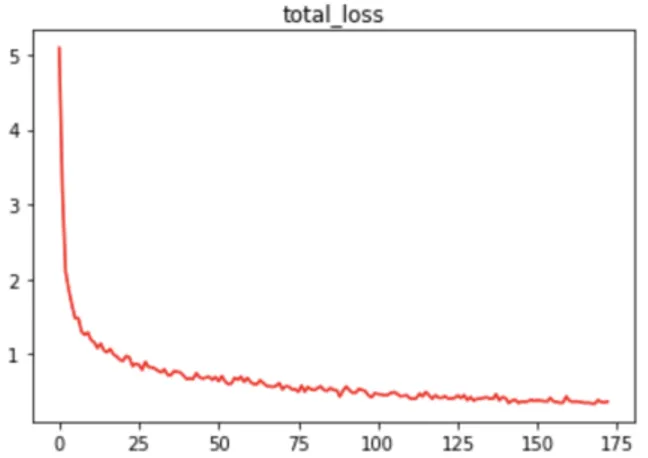
hittar intressanta regioner i bilden och ett som hittar objekt i dessa regioner. För att få ut den totala förlusten ur vår modell så behövs alltså en förlustfunktion köras på båda dessa neurala nätverken. I Figur 7, 8 och 9 visas träningsresultat för den tredje och sista
modellen, Figurerna 7 och 8 visar förlusterna för de två nätverken som används i Faster R-CNN och Figur 9 visar det totala förlustvärdet för nätverken tillsammans.
Figur 7: Diagram för förlust-värdet för nätverket som hittar RoI (Region of Interest). X-axel: Antal epoker.
Y-axel: Värdet för förlust.
Figur 8: Diagram för förlust-värdet för nätverket som hittar objekt. X-axel: Antal epoker.
18
Figur 9: Diagram för totala förlusten av modellen, värde aggregerat från Figur 7 och 8. X-axel: Antal epoker.
Y-axel: Den totala förlusten.
6.2.1 Första iterationen
Under den första iterationen tränades en modell strax över 200 epoker, modellens totala förlust slutade efter detta att minska i samma utsträckning som tidigare och därför avslutades träningen. Efter tester med modellen kunde vi se att den inte alls presterade enligt förväntningarna vi hade. Modellen gav på majoriteten av bilderna ett stort antal felaktiga förslag på regioner innehållandes registreringsskyltar, detta även om
testbilden enbart innehöll en skylt. Träningsdatan undersöktes för att se huruvida det fanns bristfälliga bilder i denna. Det visade sig att så var fallet då träningsdatan till viss del innehöll bilder som inte var av intresse för oss. Anledningen var att de visade fordon på ett längre avstånd, med en annan vinkel, i dålig kvalitet, osv. Därför
begränsades träningsdatan och vi rensade ur de bilder som inte passade in. Detta lämnade oss med träningsdata på cirka 2300 bilder.
6.2.2 Andra iterationen
För iteration två så valde vi att öka storleken på bilderna som modellen tränades på. I de två övriga iterationerna som nämns så används en pixelstorlek på 300 x 300 för bilderna, nu ökades storleken på bilderna till 600 x 600 pixlar. Med högre storlek på bilderna så sparas mer detaljer som annars försvinner vid en komprimering och med mer detaljer så kan modellen nå en högre precision. Det som märktes väldigt snabbt var dock att med en storlek på 600 x 600 pixlar så ökade träningstiden avsevärt. En epok med bilder av storlek 600 x 600 tog över en timme, för att komma upp i samma antal epoker som i första iterationen så skulle det tagit över 200 timmar att träna modellen. Med en högre GPU kraft än vi hade så skulle detta möjligtvis fungerat bättre, men för oss så märkte vi snabbt att vi inte skulle hinna med större bilder och avbröt därför denna iterationen.
6.2.3 Tredje iterationen
Den tredje iterationen avslutades efter 173 epoker, eftersom den totala förlusten inte längre påverkas i samma grad som i epokerna innan. Det finns även en risk att
överträna (att modellen endast lär sig känna igen objekt i träningsdatan) modellen som vi var tvungna att ta hänsyn till. Hade träningsdatan som användes varit större så
19
skulle träningen kunna fortsätta då modellen inte tränar om på bilder den redan tränat på tidigare.
6.3 Resultat av testningen av modellen
Under testningen av modellen så ansåg vi att ett lyckat resultat var när
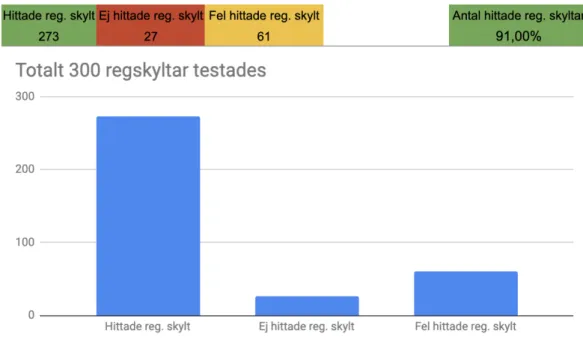
test-programmet tillsammans med modellen lokaliserade en skylt om en sådan fanns. Vi bortsåg alltså från huruvida skylten sedan kunde läsas av det externa API:et. Detta för att isolera just modellens prestanda då detta är den huvudsakliga inriktningen i denna uppsats. Modellen testades med annoterade bilder från Open Images Dataset [10]. Bilderna var av samma art som modellen hade tränats på, alltså bilder tagna i vinklar och ljusförhållanden som liknade det tänkta användningsområdet. Ett tröskelvärde för hur säker modellen skulle vara på en igenkänning användes för att sålla bort felaktiga gissningar; ett för högt värde ger färre gissningar och då även fler bilder utan gissning, medans ett lägre värde ger ett större antal gissningar innehållande både korrekta och inkorrekta sådana. Efter att olika värden testats kom vi fram till att ett bra värde för tröskelvärdet låg på runt 75% då denna på några enstaka testfall gav oss bra resultat. Totalt användes 300 bilder för testningen och i 273 av fallen lyckades programmet att utläsa skylten samt ange var i bilden den befann sig. I de övriga 27 fallen så
antecknades hur bilden såg ut, om den hade speciella drag som ansågs kunna vara relevanta till varför modellen inte kunde lokalisera skylten i just denna bild. Några av dessa förekommande anledningar var:
● Bilden var svartvitt alternativt manipulerad med filter.
● Skylten var fotograferad med en vinkel som gjorde den svår att se. ● Skylten var fotograferad på ett stort avstånd.
● Skyltens text var censurerad.
● Bilden innehöll mycket text bortsett från skylten.
Detta var drag som återfinns i flera av bilderna och det är därför de är nämnda, det fanns dock även fall då inget speciellt drag kunde identifieras. Bildernas karaktär och dess påverkan på resultatet nämns mer under rubriken: 7. Diskussion.
I 61 av de 273 korrekta fallen hittades även områden som felaktigt påstods innehålla en skylt. Detta då modellen kan ge fler gissningar på en och samma bild. Dessa kallas false
positives. Bortsett från dessa 61 fall så nådde vi en träffsäkerhet på 91%, anledningen
till varför vi här bortser från dessa tar vi upp under rubrik: 7.3.2. False positives i resultatet, se Figur 10 som visar resultatet av testandet. Ovan nämnda false positives nämns i tabellen som “Fel hittade reg. skylt”.
20
.
Figur 10: Resultat av tester utförda på modellen
Bortsett från de 61 gånger ett false positive värde gavs från modellen så har vi alltså ett resultat på korrekt värde vid 91% av fallen. Om vi då kopplar tillbaka till artikeln Home
automation - an IoT based system to open security gates using number plate recognition and artificial neural networks som byggde på ett system tänkt att användas i en
liknande miljö som vårt så kan vi där avläsa att deras resultat för samma uppgift var på 87%. Vi har då en förbättring på 4 procentenheter med denna nya metod. Värt att nämna är att även denna studie innefattar false positives vilka den bortser från i sitt resultat.
6.4 Resultat av testandet av systemet som helhet
Vid testandet av systemet som helhet så nåddes ett bra resultat. I alla de testerna som utfördes på en bil, med foton tagna framifrån och bakifrån, under dagtid och kvällstid så gav alla ett positivt resultat. Detta innebär att IoT-enheten lyckades känna av fordonet, ta ett foto, skicka detta till servern och inom en rimlig tid få svar att modellen lyckats lokalisera skylten. Vinkeln som testades var rakt framifrån och avståndet till bilen var cirka 2 meter. Bilen som användes hade en svensk registreringsskylt i gott skick. Detta innebär då att vi har lyckats bryta ner processen till endast två steg (1) att lokalisera registreringsskylten samt (2) att läsa av karaktärerna på registreringsskylten. I Real-Time Automatic License Plate Recognition through Deep Multi-Task Networks nämner författarna den ökande felmarginalen vid fler steg i processen som även nämndes i inledningen [3]. Jämförelsevis ser vi att om vi använder vår modells
träffsäkerhet: 91% och samma siffra för träffsäkerhet för igenkänning av karaktärerna i skylten som studien använder: 98%, når vi siffran 73%. Det vill säga vi når 73% chans att hela processen ska lyckas (0.91^2 * 0.98^6). Anledningen till att vi använder samma siffra som studien använder för träffsäkerhet vid läsning av karaktärerna är för att vi inte har statistik för det API vi använder. I studien så nämns att chansen för ett lyckat resultat med det traditionella antalet steg blir 72% (0.98^2 * 0.98^2 * 0.98^6 * 0.98^6). I denna uträkningen så används fyra steg: (1) lokalisera ett fordon (2) lokalisera en registreringsskylt (3) segmentera karaktärer från registreringsskylt (4) identifiera de segmenterade karaktärerna. I denna jämförelse har vi endast en förbättring på ~ 1%,
21
men vi diskuterar ytterligare varför vårt resultat kan ses som lyckat under rubriken: 7. Diskussion.
22
7 Diskussion
I detta avsnittet diskuterar vi resultatet och analysen från tidigare rubrik. Denna del innehåller våra tankar kring och tolkningar av resultatet.
7.1 Litteraturstudien
Litteraturstudien gav en bra grund att stå på då det kommer till kunskap inom området samt val av metod men tog en väldigt stor del av vår tid som fanns till den här
uppsatsen. Hade förkunskaperna redan funnits så hade det gått fortare eller alternativt kunnat inkluderats helt i förstudien vilket hade gett mer tid till det övriga arbetet. Exempelvis tränandet av flera olika neurala nätverk, att jämföra dessa och ytterligare utvärdera optimala träningsmetoder.
7.2 Tränandet av modellen
7.2.1 Variabler i tränandet
När det kommer till tränandet av modellen så kunde antagligen ett bättre resultat kunnat uppnås med hjälp av ett antal olika variabler som tid, datorkraft, kunskap och
träningsdata. Med mer datorkraft hade vi kunnat tränat fler modeller snabbare eller
tränat enstaka modeller längre för att se vad detta skulle ge för resultat. Hade vi haft mer tid hade vi kunnat lägga denna på att skaffa oss ytterligare kunskaper om de olika momenten som ingår i tränandet samt dess samverkans betydelse för slutresultatet. Mer tid hade även inneburit att vi kunnat tränat fler olika modeller med olika inriktningar i form av bildstorlek eller träningsdata för att se om detta hade lett till förbättringar i precision. Vi hade även kunnat lägga mer fokus på att ta fram bättre
träningsdata som hade varit mer anpassat för oss, exempelvis en större mängd bilder
innehållandes just de aspekter som vi förväntar oss att se i vårt tänkta användningsområde.
7.2.2 Träningsdata
Under tränandet av modellen så upptäckte vi vikten av en korrekt konstruerad
träningsdata. Redan efter första iterationen så togs cirka hälften av den träningsdata vi
använde bort, detta på grund av dess bristande kvalitet i form av att den inte passade för hur modellen skulle användas i slutändan. Även om vi nådde ett förhållandevis bra resultat med den slutgiltliga modellen så anser vi att ett bättre träningsdata hade gett ett ännu bättre resultat om det var väl konstruerat. Även om vår kunskap inte är komplett när det gäller hur vi mest optimalt konstruerar träningsdata så kan vi efter vad artikeln Real-Time Brazilian License Plate Detection and Recognition Using Deep
Convolutional Neural Networks säger dra slutsatsen att mer fokuserad träningsdata
kan ge ett bättre resultat [5]. Detta kan även styrkas av vad vår rensning av dåliga bilder ur vår träningsdata gav för resultat och det går att argumentera för att ytterligare arbete med detta hade gett ett ännu bättre resultat. Andra metoder som hade kunnat ge ett ännu bättre resultat är att enbart träna en modell på en nations eller en regions design av skyltar, detta istället för en stor blandning av olika former och format. Nämnas bör också att vi hade kunnat lägga tid på att ta fram egen träningsdata
23
men på grund av vad vår träningsdata skulle bestå av så hade det varit ohållbart med vår tid och med våra resurser. En annan aspekt är också begränsningen av vad som är juridiskt och moraliskt korrekt när det kommer till insamlande av denna data, ett område vi ej är insatta i.
7.3 Testandet
7.3.1 Testdatan
För testandet av modellen så använde vi oss av den testdata som vi fick från Open Images Dataset av Google. Eftersom vi rensat vår träningsdata så fick vi även rensa testdatan. Vissa av bilderna som var kvar i testdatan var dock av dålig kvalitet, och om vi även här lagt mer tid på att samla korrekt testdata så hade resultatet möjligtvis varit högre än de 91% som modellen nu gav.
7.3.2 False positives i resultatet
Som presenterat i Figur 10 under rubrik: 6.3 Resultat av testandet av modellen, så syns i 61 av de totalt 273 positiva testfallen en felaktig gissning tillsammans med den
korrekta. Dessa nämns tidigare som false positives. Vi har inte med dessa som ett
misslyckat resultat vilket kan anses som fel, anledningen för detta är att vi anser oss ha belägg för att dessa kan hanteras i vår server. Vi kan exempelvis skicka den felaktiga gissningen vidare till det externa OCR-API:et och se huruvida ett korrekt värde skickas tillbaka. Får vi inte tillbaks ett korrekt värde skickar vi nästa gissning och om denna returnerar ett korrekt värde så har systemet fortfarande lyckats lösa uppgiften. Detta borde dock enbart ses som ett lyckat resultat om det nämns inom gränsen för hela systemet, skulle modellen vi tagit fram användas i något annat fall så skulle detta kunna vara ett resultat som ger andra följder än de vi får här. Värt att nämna är också att den studie vi jämför resultatet mot Home automation - an IoT based system to open
security gates using number plate recognition and artificial neural networks, också får
false positives men bortser från detta i sitt resultat, samt att deras träning och testdatas mängd och utformning skiljer sig från vår [2].
7.3.3 Val av testmetod
Anledningen till att vi testade hela systemet på endast en bil var dels för att vi ej hade tillgång till fler bilar men framförallt för att prototypen endast var implementerad som
proof of concept. För att visa att det går att implementera vår modell i en verklig miljö.
Därför räckte det med test på endast ett fordon för att se ett lyckat resultat.
7.4 Tankar kring mobilapplikationen
Vi märkte under arbetets gång att framtagandet av den mobila applikationen kan anses som överflödig med begränsningen på vår undersökning i åtanke. Detta på grund av att den inte kan påverka någon av svaren på våra forskningsfrågor. Vi hade kunnat skapa systemet och bevisat funktion utan denna. Detta genom att programmera in värdena som var tänkta att levereras som input från en användare. Detta hade även kunnat
24
anses vara tillräckligt för att visa att modellen hade fungerat i en verklighetstrogen miljö.
7.5 Reflektion kring en kortare process
Under rubriken: 6.4 Resultat av testandet av systemet som helhet, så jämförs resultatet med en annan studie som fokuserar användande av minimalt antal steg. I denna
jämförelsen ser vi att för hela processen innehållandes lokalisering och avläsning av en registreringsskylt så har vi endast en ökning till 73% för ett lyckat resultat från
studiens 72% [3]. Detta ger en ökning på 1%. Den beräkningen som gjordes i tidigare forskning utgick från att varje steg har en precision på 98% [3], vilket är en hög siffra. Hade vi haft mer tid, bättre kunskaper inom maskininlärning, bättre träningsdata så är en ökning av träffsäkerhet för vår modell något vi tror starkt på. Skulle vi lyckas nå upp till en precision på 98% för den slutgiltliga modellen så hade detta lett till att vi fått 85% chans för att processen ska lyckas, alltså en förbättring på cirka 13% (0.98^2 * 0.98^6 *).
25
8 Slutsats och framtida forskning
8.1 Slutsats
Vi lyckades besvara den första frågan i frågeställningen, att det är möjligt att använda
Artificiella neurala nätverk för att utföra lokalisering av registreringsskyltar i en bild.
Samt att vi kan göra detta med ett resultat som kan mätas med tidigare nämnda processer. Vår litteraturstudie gav oss belägg för att Faster R-CNN var det optimala
neurala nätverket för att användas i det användningsområde vi fokuserat på. Med detta
så svarade vi på vår andra fråga. Vi visade att denna metod kunde mäta sig och i vissa fall vara bättre än traditionella metoder med ett resultat på 91% träffsäkerhet i vårt fall och 87% träffsäkerhet med en traditionell metod. Observeras skall att det inte var samma testdata som användes under de båda testen.
Vi visar också med vår implementation att det är möjligt att eliminera steg från den traditionella processen på ofta fyra steg, ned till endast två steg. Detta ger en minskning på 13% för att fel ska uppstå i processen, en helt klart tydlig förbättring.
Med hjälp av den proof of concept prototyp som vi tagit fram går det att se att en implementation är möjlig när det kommer till användande av artificiella neurala
nätverk i denna typ av system. Detta besvarar vår sista fråga, att bevisa om det går att
implementera i ett verkligt system som är tänkt att användas i den miljö som studien riktar sig emot. Vi visar även att det är möjligt att göra detta till en relativt låg kostnad med tanke på priset av de olika komponenterna som används för prototypen.
Bortsett från att svara på våra frågeställningar så visar vi också vikten av en korrekt konstruerad träningsdata när en modell tränas för ett specifikt användande. Samt vikten av bra förståelse av det som ingår i träningsprocessen.
8.2 Framtida forskning
Ett bra resultat nåddes och vårt testresultat bevisade att flera av våra teorier stämde. Vi nämnde dock även en hel del brister med vårt tillvägagångssätt och våra
förkunskaper. Med detta nämnt så förutspår vi att ännu bättre resultat skulle kunna nås med mer fokus på följande områden och utvecklade detta vidare:
8.2.1 Träningsdata
I framtida studier inom ämnet så ser vi ett stort behov av att fokusera på den
träningsdata som tas fram för tränandet av det neurala nätverket. Vi upptäckte vikten
av en bra uppsättning träningsdata och kunde med små justeringar se goda resultat. Under ett framtagande av träningsdata så går det att styra exakt hur bilderna ska se ut och få dessa att vara lämpliga för den situationen som modellen sedan ska användas i. Mer kunskap och fokus på andra detaljer som innefattar framtagandet av en bra mängd
26
8.2.2 Djupare förståelse och tid
Även med hjälp av mer tid och djupare kunskap inom maskininlärning och neurala
nätverk kunde experiment använts för att hitta optimala träningsmetoder för detta
ändamålet. En hel del olika variabler finns inom processen och en djupare förståelse för dessa och deras påverkan på slutresultatet var något vi saknade och tror påverkade vårt resultat negativt.
27
9 Referenser
1. Beibut A, Magzhan K, Chingiz K. Effective algorithms and methods for automatic number plate recognition. I: 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT). 2014. s. 1–4. 2. Cowdrey KWG, Malekian R. Home automation - an IoT based system to open security gates using number plate recognition and artificial neural networks.
Multimedia Tools and Applications. 2018 Aug;77(16):20325–54.
3. Gonçalves GR, Diniz MA, Laroca R, Menotti D, Schwartz WR. Real-Time Automatic License Plate Recognition through Deep Multi-Task Networks. I: 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). 2018. s. 110–7. 4. Masood SZ, Shu G, Dehghan A, Ortiz EG. License Plate Detection and
Recognition Using Deeply Learned Convolutional Neural Networks. arXiv:170307330 [cs] [Internet]. 2017 Mar 21 [hämtad: 2019 Feb 14]; Tillgänglig från:
http://arxiv.org/abs/1703.07330
5. Silva SM, Jung CR. Real-Time Brazilian License Plate Detection and Recognition Using Deep Convolutional Neural Networks. I: 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). 2017. s. 55–62.
6. Jayalakshmi P, Kumar R. Automatic License Plate Recognition Using Computer Vision for Door Opening. från 2013.
7. Hsu G, Ambikapathi A, Chung S, Su C. Robust license plate detection in the wild. I: 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). 2017. s. 1–6.
8. Lin T-Y, Maire M, Belongie S, Bourdev L, Girshick R, Hays J, et al. Microsoft COCO: Common Objects in Context. arXiv:14050312 [cs] [Internet]. 2014 May 1 [Hämtad: 2019 Mar 12]; Tillgänglig från: http://arxiv.org/abs/1405.0312
9. Premachandran V, Bonev B, Lian X, Yuille A. PASCAL Boundaries: A Semantic Boundary Dataset with a Deep Semantic Boundary Detector. I: 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). 2017. s. 73–81.
10. Projects [Internet]. opensource.google.com. [Hämtad: 2019 Apr 23]. Tillgänglig från: https://opensource.google.com/projects/
11. Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, et al. TensorFlow: A System for Large-Scale Machine Learning. från: 2016 [Hämtad: 2019 Apr 2]. s. 265–83. Tillgänglig från:
https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi
12. Home - Keras Documentation [Internet]. [Hämtad: 2019 Apr 23]. Tillgänglig från: https://keras.io/