Malmö Universitet
Fakulteten för lärande och samhälle Institutionen Idrottsvetenskap
Examensarbete
15 hpVariabler bakom sportslig
framgång
Variables behind sport success
Robin Stockman
901024
Idrottsvetenskapligt program Handledare: Tomas Peterson 2018-05-22 Examinator: Lars Lagergren
Abstract
This bachelor thesis intends to highlight factors behind sporting success. As a result of the major economic focus in sports, the aim of this study is instead to find macroeconomic factors that affect sporting success. To this study, the top 20 European football teams were selected based on their ranking points between year 2000 and 2016. Ranking points, measurements of sports success, have been compared to five selected country-specific macroeconomic
factors; inflation, GDP growth, unemployment, political stability and population. These factors have also been collected over the period 2000-2016.
The study has used a multiple linear regression analysis to identify correlations between the selected factors and sporting success. The statistics software SPSS, Microsoft Excel, and Microsoft Azure Machine Learning Studio have helped to process and analyze collected data. The result shows no strong linear relationship between the chosen variables and sporting success. At the same time, the result explains that the coefficient of determination of the factor unemployment is 63%. This study can’t take credits for any revolutionary
discovery. On the other hand, the study can help by saying which country-specific factors most likely do not correlate with sporting success. At the same time, the study can serve as a basis for further research on the subject; factors behind sporting success.
Keywords:
Sammanfattning
Denna kandidatuppsats har för avsikt att belysa faktorer bakom sportslig framgång. Till följd av det stora ekonomiska fokus inom idrotten är studiens syfte att istället hitta
makroekonomiska faktorer som påverkar sportslig framgång. Till studien valdes de 20 främsta europeiska fotbollslagen ut baserat på deras rankingpoäng mellan åren 2000 - 2016. Rankingpoängen, tillika mått på sportslig framgång har sedan jämförts med fem utvalda landspecifika makroekonomiska faktorer; inflation, BNP-tillväxt, arbetslöshet, politisk stabilitet och befolkningsmängd. Dessa faktorer har också samlats in över tidperioden 2000 - 2016.
Studien har använt sig utav en multipel linjär regressionsanalys för att identifiera korrelationer mellan de utvalda faktorerna och sportslig framgång. Statistikprogrammen SPSS, Microsoft Excel och Microsoft Azure Machine Learning Studio har bistått med hjälp för bearbetning och analys av insamlade data. Resultatet påvisar inget starkt linjärt samband mellan de utvalda variablerna och sportslig framgång. Samtidigt redogör resultatet för en
förklaringsgrad på 63 % gällande faktorn arbetslöshet. Studien kan inte stoltsera med någon revolutionerande upptäckt. Däremot kan studien bidra med att landspecifika faktorer högst troligt inte korrelerar med idrottslig framgång. Samtidigt kan studien fungera som ett underlag för vidare forskning på ämnet om faktorer bakom sportslig framgång.
Nyckelord:
INNEHÅLLSFÖRTECKNING 1. INLEDNING ...7 2. SYFTE OCH FRÅGESTÄLLNINGAR ...8 2.1 INFORMATIONSSÖKNING ... 8 2.2 KÄLLKRITIK ... 8 3. TIDIGARE FORSKNING ... 10 4. TEORETISKT RAMVERK ... 14 4.1 ROTTENBERG’S INVARIANCE PRINCIPLE ... 14 4.2 SPLISS ... 14 4.3 BEGREPP ... 15 4.3.1 Sannolikhet ... 15 4.3.2 Korrelation ... 16 4.3.3 Regression ... 16 4.3.4 Standardavvikelse ... 16 5. METOD ... 17 5.1 VETENSKAPLIGT ARBETSSÄTT ... 17 5.1.1 Kvantitativ metod ... 17 5.1.2 Induktion och deduktion ... 18 5.2 URVAL ... 18 5.2.1 Beroende variabel ... 19 5.2.2 Oberoende variabler ... 19 5.3 DATAINSAMLING ... 22 5.3.1 SPSS ... 23 6. BEARBETNING OCH ANALYS ... 24 6.1 STATISTISK ANALYS ... 24 6.1.1 Multipel regressionsanalys ... 25 6.1.2 Standardisering ... 26 6.1.3 Regressionsskattning – minsta kvadratmetoden ... 26 6.1.4 Förklaringsgrad ... 28 6.1.5 Hypotesprövning ... 29 6.2 FÖRVÄNTAT RESULTAT ... 30 6.3 VALIDITET OCH RELIABILITET ... 31 6.4 ETISKA ÖVERVÄGANDEN ... 31 7. EMPIRI OCH ANALYS ... 33 7.1 VARIABLERS MÄTVÄRDEN ... 33 7.2 MACHINE LEARNING ... 34 8. STATISTISK ANALYS ... 35 8.1 HYPOTESPRÖVNING ... 35 8.2 MULTIPEL REGRESSION ... 36 8.2.1 Regressionsskattning ... 37 8.2.2 Förklaringsgrad ... 38 9. DISKUSSION ... 39 10. SLUTSATS ... 41 11. FRAMTIDA FORSKNING ... 41 REFERENSER ... 42 BILAGOR ... 45
... 45 BILAGA 2 – REGRESSIONSKURVA – SIGNIFIKANTA X-VARIABLER ... 46
Förord
Inför detta examensarbete fanns många utmaningar. Viljan att testa nya saker och ödmjukhet inför uppgiften har präglat detta arbete. Ett mer positivt resultat hade varit att önska, men den lärdom och erfarenhet arbetet inneburit väger tyngre. Förhoppningen är att denna studie ska vara en ögonöppnare för andra att forska på samma ämne.
Slutligen ska ett stort tack riktas till Malmö Universitet för tre givande år.
Ciao Tutti!
1.
Inledning
Under de senaste decennierna har idrottsvärlden utvecklats och förfinats. Fotboll är en idrott som oavbrutet legat i framkant och genomgår en ständig förändring och utveckling. Idag ligger stort fokus på lagens ekonomiska förutsättningar, vilket anses vara en självklar kvalifikation för att nå sportslig framgång. Sporten är starkt kommersialiserad och det ekonomiska vinstintresset blir allt mer en central del. Fotbollens professionalism och kommersialism är faktorer som hjälpt till att skapa ett ekonomiskt fokus runt fotbollen – pengar föder framgång (Dubal, 2010). Det återfinns dock exempel där lag inte omtalats för sina ekonomiska muskler, men ändå uppnått sportslig framgång. Ett tydligt exempel på detta är Leicester City som 2016 lyckades vinna engelska Premier League, ett sportsligt utfall som resulterade i förvåning (theguardian, 2016).
Syftet med denna studie är göra ett kvalificerat försök att hitta andra faktorer än ekonomiska som påverkar sportslig framgång. Ett fastställande av att sportslig framgång endast beror på fotbollslags betalningsförmåga gör att idrotten förlorar sin oförutsägbarhet och konkurrens. Det går tydligt att urskilja ett toppskikt, ett kluster av lag som ständigt är med och konkurrerar om de mest ädla placeringarna i fotbollseuropa, men hypotesen är att det ligger mer bakom deras sportsliga framgångar än deras ekonomiska betalningsförmåga. Denna studie ska försöka hitta och urskilja några av dessa andra omständigheter som påverkar sportsligt utfall inom idrotten fotboll.
2.
Syfte och frågeställningar
Syftet med denna studie är att undersöka möjliga samband mellan makroekonomiska landspecifika faktorer och sportslig framgång inom fotbollsvärlden. Arbetets syfte sammanfattas i följande frågeställning:
”I vilken omfattning har makroekonomiska landspecifika faktorer påverkat sportlig framgång för europeiska toppfotbollslag åren 2000–2016?”
Tidigare forskning på faktorer bakom sportslig framgång har ett starkt fokus kring ekonomi och finansiell styrka. Syftet med denna studien är att bidra till ämnet genom att fokusera på andra faktorer än direkt ekonomiska. Baserat på tidigare forskning på sportslig framgång i kombination med modeller ska samband mellan makroekonomiska faktorer och europeiska fotbollslags placeringar utefter UEFA:s klubb-koefficienter försöka belysas med hjälp av multipel regressionsanalys. Studien kommer undersöka en period över 17 år.
2.1 Informationssökning
I detta kapitel redogörs för det tillvägagångsätt som nyttjats för att söka den kunskap som undersökningen använder sig av. Det som klarläggs i detta kapitel är sekundärdata, det vill säga kunskaper och uppgifter som redan finns insamlade och som denna studie lutar sig mot. Informationssökningen sker som en successiv process. Den mest tillgängliga informationen bedöms först för att sedan analysera undersökningens behov av att söka vidare. Internet ger både tillgänglighet och träffsäker information. Internets databaser tillsammans med
kurslitteratur och övrig litteratur på aktuellt ämne kommer ligga som grund för detta arbete. Databaserna som kommer användas i första hand är Google Scholar, Libsearch och
Worldbank som tillsammans erbjuder massvis av vetenskapliga artiklar, studier, böcker och data (Eriksson & Wiedersheim-Paul, 2011).
2.2 Källkritik
För att undvika den så kallade haloeffekten, vilket innebär en påverkan av annat än det man ska bedöma vid insamling av sekundärdata, har ett skattningsschema formulerats. Det görs för
att granska dokumentens validitet och reliabilitet. Avsikten med källkritik är att värdera om källan mäter det den utger sig för att mäta, samt om den är relevant för den egna
undersökningen och om den är tillförlitlig (Eriksson & Wiedersheim-Paul, 2011). Skattningsschemat som upprättats för att bedöma dessa avseenden innehåller följande punkter:
• Tillförlitlighet - kan man lita på vad som står i texten? Originalkällan?
• Auktoritet - vem har skrivit? Kan man lita på författaren?
• Objektivitet - försöker texten påverka läsaren i någon riktning?
• Aktualitet - när skrevs texten? Är den fortfarande aktuell?
• Validitet - täcker texten in det område den utger sig för att göra?
• Målgrupp - vilka riktar sig texten till?
Dessa punkter, tillsammans med källkritiska kriterier som samtidkrav, tendenskritik,
beroendekritik och äkthet utgör bedömningsgrunder som undersökningen tar i beaktning vid insamling av sekundärdata (Eriksson & Wiedersheim-Paul, 2011).
3.
Tidigare forskning
I detta kapitel redogörs tidigare forskning inom ämnen som berörs i denna studie. Denna forskningsöversikt ligger till grund för arbetets syfte samt dess teoretiska ramverk. Den tidigare forskning som inhämtats förhåller sig till de aspekter som nämnts i tidigare kapitel om informationssökning. Nedan följer en litteraturgenomgång med tidigare forskning och artiklar för att sätta den egna studien i ett adekvat sammanhang och används som underlag för denna studie.
Idrottens ekonomi är ett ämne som första gången kom upp till ytan på 1950-talet. Simon Rottenberg skrev 1956 ”the Baseball Players' Labor Market”, en artikel som publicerades i
Journal of Political Economy (Sloane, 2006). Rottenberg tittade på en öppen arbetsmarknad
med lag vars finanser såg olika ut. Rottenberg argumenterade för att en begränsning av systemet för att fritt överföra spelare, idag mer känt som en stängd liga, inte var ett verktyg för att förbättra konkurrenskraftig balans. Han menade att en arbetsmarknad där spelare fick ”röra sig fritt” inte nödvändigtvis skulle leda till en koncentration av de bästa spelarna i de rikaste lagen. Vidare menar Rottenberg att lagidrott och dess klubbar behöver, olikt företag, konkurrens. Det är inte lönsamt att förvärva och knyta till sig alla stjärnspelare då följden sannolikt blir en kraftigt minskad konkurrens. Inget lag kan lyckas om inte konkurrenterna överlever och är på en någorlunda jämn nivå (Rottenberg, 1956). Sammanfattningsvis menar Rottenberg att en begränsning av den fria arbetsmarknaden inte är ett verktyg för att öka tävlingsbalansen. Marknaden sköter spridningen av spelarna själv. Spelare går inte nödvändigtvis till det lag som betalar bäst utan till det lag som värdesätter dem mest. Rottenberg avvisar allt vad idrottslig begränsning innebär till förmån för en fri idrottslig arbetsmarknad.
Hans argumentation har kallats ”Rottenbergs invariance principle” (Sloane, 2006). Denna har sedermera utvärderats av Peter J. Sloane 2006. I ”Rottenberg and the Economics of Sport after 50 Years: An Evaluation” utvärderas Rottenbergs framställning för att bedöma dennes relevans 50 år senare. Sedan Rottenbergs artikel har idrottsmarknaden utvecklats. Begreppen nordamerikansk- och europeisk modell har utvecklats, en tv-marknad har öppnats och en allt mer kommersialiserad idrott uppvisas. Sloane menar att Rottenbergs insats inte borde
forskning. Sloane ställer sig trots detta frågande till argument runt att behandla lagidrotter som konventionella industrier. Sloane menar att det återfinns stora skillnader i målbilder och framför också idrotters instabilitet, särskilt mot att internalisera externa effekter.
“Sports Policy Factors Leading to International Sporting Success An International Comparative Study” (2006) av Veerle De Bosscher, Jerry Bingham. Simon Shibli, Maarten van Bottenburg, Paul De Knop, går tydligare utanför de ekonomiska faktorerna inom idrotten. Genom en undersökning av sex länder och deras nationella elitsports-politik, tittar de på andra faktorer som påverkar sportslig framgång inom individuell idrott. Genom att titta på nationella faktorer, som (på originalspråk för ökad transparens) financial support, integrated approach to policy development, participation in sport, talent identification and development system, athletic and post career support, training facilities, coaching provision and coach
development, samt international competition, har studien resulterat i en rad nya insikter om faktorer som påverkar sportslig framgång och hur nationers idrottspolitiska inställning utvecklar en miljö som ökar konkurrens. Studien använder sig av en input-output-analys och visar sammanfattningsvis på att den absoluta summan av anslag som tilldelats elitsport som den bästa förutsägelsen för hur framgångsrikt landet kommer att bli. Studien visar alltså en tydlig koppling mellan finansiell support och framgång inom elitsport.
Vidare argumenterar Downward and Dawson i “The economics of professional team
sports” att, när det finns strikta regler på arbetsmarknaden, är inte lönekostnaderna en lika bra indikation på hur idrottskvalitén blir jämfört med i en öppen marknad. Detta skulle vara ett argument för att den europeiska fotbollen, tillika europeiska modellen, är mer förutsägbar och utefter lags ekonomiska förutsättningar (Downward and Dawson, 2000). I studien “Can sporting success in Norwegian football be predicted from budgeted revenues?” av
Kringstad och Olsen undersöks sambandet mellan intäkter och sportligt utfall för fotbollslag i Norge. De finner ingen signifikant korrelation mellan dessa faktorer för de lag som placerade sig på övre hälften av ligatabellen. Däremot återfanns en tydligare samband mellan intäkter och sportsligt utfall för de lag som återfanns på de nedre tabellplaceringarna. Resultaten i denna studie är intressanta och belyser, potentiellt bevittnar, en irrelevans av intäkter bland Europas främsta fotbollsklubbar.
Winners and Losers: The Business Strategy of Football av Stefan Szymanski och Tim Kuypers (1999), undersökte om det fanns något samband mellan profit och tabellplacering. De belyser den nödvändiga anspänningen mellan tävling och samverkan i sportliga ligor. Szymanski och Kuypers omprövar de förändrade mönstren för klubbintäkter över en 100-årsperiod. Tidigare stora inkomster från publikintäkter är idag mindre än 50% av de totala intäkterna. Det är ett resultat av kommersialiseringen inom idrotten då intäkter för tv-sändningar, sponsring och reklamvaror ökat markant de senaste åren. Författarna ställer sig frågan; Vad gör fotbollsklubbar framgångsrika? De presenterar två hypoteser. Dels att lagprestationer positivt korrelerar med löneavgifter, men också att klubbintäkter positivt korrelerar med lagprestationer. Szymanski och Kuypers har valde att prova sina hypoteser med hjälp av regressionsanalyser. Deras statistiska resultat visar på godtyckliga
förklaringsgrader som bekräftar deras hypoteser. Denna forskning visar sammanfattningsvis på ett tydligt samband mellan ekonomiska faktorer sportslig framgång.
Den klassiska boken Moneyball, skriven av Michael Lewis, utvärderades av Hakes och Sauer (2005) i studien “An Economic Evaluation of the Moneyball Hypothesis, med syftet att omtesta Moneyball-hypotesen. Författaren Michael Lewis menade att det fanns en
felprissättning på de amerikanska baseball-spelarna, en hypotes som Hakes och Sauer stödjer med en mätning av förhållandet mellan spelarnas produktivitet och lön under perioden 1999 till 2004. Denna hypotes stärker också den egna teorin att sportlig framgång inte enbart är förenat med den som har störst betalningsförmåga.
Artikeln “Is Football an Indicator of Development at the International Level?” (2014) av Gásquez och Royuela publicerades i Social Indicator Research 2014. Artikeln undersöker huruvida framgång inom fotboll, baserat på FIFA:s ranking, kan indikera internationell utveckling baserat på BNP per capita och the Human Development Index. Med hjälp av ekonometriska modeller kommer de fram till att FIFA:s rankings kan fungera som ett komplement till multidimensionell förståelse av internationell utveckling. Detta samband gäller särskilt i länder där fullständiga data inte finns tillgänglig.
Artikeln ”Europe’s Elite Football: Financial Growth, Sporting Success, Transfer
Investment, and Private Majority Investors” (2016) av Marc Rohde och Christoph Breuer, verksamma vid Institute of Sport Economics and Sport Management, belyser ekonomiska faktorer och ägandeförhållande. De tittar på de trettiotalet europeiska fotbollslag som har
gemensamt att de toppar Deloitte's Football Money League ranking baserad på årlig vinst. I artikeln framgår att dessa lag vinner majoriteten av de nationella och internationella tävlingar de ställer upp i, samt att de ingår i en stor del av FIFA:s framträdanden. De visar på
att finansiell framgång driver nationell och internationell sportslig framgång samt brand value. De visar också på att sportslig framgång drivs av laginvesteringar samtidigt som laginvesteringar drivs av utländska privata majoritetsinvesteringar.
”Private Firm, Public Corporation or Member`s Association – Governance Structures in European Football” av Egon Franck, baseras på en jämförande analys av miljöerna som olika fotbollsklubbar tävlar i. De kategoriserar tre olika paradigmstrukturer av fotbollsklubbs-styrning; klassik (privatägd) moderna (aktieägda med spritt ägarskap) och medlemsägda klubbar (som fungerar som egen juridisk person). Franck studerar hur dessa olika
klubbstyrningar påverkar klubbinvesteringar och drar slutsatsen att privatägda klubbar är överlägsna i att attrahera investeringar. Artikeln Interactive: Wealth, Equality, and
Olympic Success, skriven för the New Yorker (2014), tittar på hur ett lands förmögenhet mätt i GINI-koefficienten och BNP per capita korrelerar med framgång i vinter-OS. De visar att olika sporter påverkas olika mycket av landets förmögenhet.
Presenterad tidigare forskning leder fram till denna studies teoretiska ramverk. Från
forskningsöversikten anses det mest centrala vara att ekonomisk framgång inte nödvändigtvis innebär sportslig framgång. Detta klargörande ligger som grund till studiens syfte och
4.
Teoretiskt ramverk
Detta kapitel har för avsikt att åsyfta de tidigare vetenskapliga kunskaper och beprövade erfarenheter som finns dokumenterade och som denna studie nyttjat. I denna studie är ambitionen att utifrån den teoretiska referensramen formulera hypoteser som testas mot verkligheten (Eriksson & Wiedersheim-Paul, 2011).
Sports management är ett relativt nytt akademiskt ämne och forskningen är begränsad. Det finns ingen teori eller ramverk för att bestämma den ultimata strategin för sportslig framgång, inte heller någon modell som jämför effektiviteten i sportsliga investeringar. Denna studie är ett försök att bidra till ett bredare teoretiskt ramverk som förklarar sportslig internationell framgång. Detta kommer utföras med hjälp av tidigare forskning och teorier som är applicerbara på ämnet.
4.1 Rottenberg’s Invariance principle
Rottenberg (1956) argumenterar för att en fri idrottslig arbetsmarknad inte nödvändigtvis leder till att de bästa spelarna koncentreras till de rikaste lagen. Rottenbergs argumentation benämns som Rottenberg’s invariance principle. Han menar att lagidrott är i behov av
konkurrens. Det därför inte är lönsamt att knyta till sig alla de bästa spelarna då konkurrensen med största sannolikhet hade minskat kraftigt. Vidare menar Rottenberg att marknaden sköter spridningen av spelare själv då spelare i slutändan återfinns i de lag som uppskattar dem mest. Rottenbergs’s princip anses förkasta hypotesen att lönsamhet är den enda avgörande faktorn för sportslig framgång. Argumentationen bakom denna princip ligger bakom denna studies angreppspunkt; att hitta andra faktorer som påverkar sportslig framgång.
4.2 SPLISS
Veerle De Bosscher, Jerry Bingham. Simon Shibli, Maarten van Bottenburg, Paul De Knop, 2007 modell, Sport Policy Factors Leading to International Sporting Success visar relationen mellan faktorer som bestämmer sportsliga framgångar. Denna modell används för att försvara
hypotesen att sportlig framgång inte endast beror på ekonomisk förmåga. Samtidigt legitimerar modellen denna studies urval och de variabler som kommer utses.
4.3 Begrepp
I detta avsnitt beskrivs de facktermer och begrepp som är relevanta för studien, mot bakgrund av att de är begrepp med stor vikt för undersökningens förståelse.
4.3.1 Sannolikhet
Sannolikhetsbegreppet är centralt inom statistiken. Med statistik kan man inte bevisa något utan endast visa att något gäller med en viss grad av sannolikhet. Statistiska slutsatser är också förenat med en risk att ta felbeslut och då följaktligen också en viss grad av sannolikhet. En förståelse om begreppet sannolikhet uppfattas som centralt i framställandet av en statistisk studie. För att beräkna sannolikheter bör kännedom finnas om två lagar; additionssatsen och
4.3.2 Korrelation
Det återfinns många olika sätt att mäta relationen mellan olika variabler, så kallade
sambandsmått. En korrelation är ett sambandsmått mellan två variabler, men säger ingenting om orsaken bakom relationen. Variablers relationer kan mycket väl ha ett kausalt samband, men korrelationskoefficienten säger ingenting om orsaken bakom. Inom
samhällsvetenskaperna är kausala relationer sällsynta. Ofta är det som studeras mycket komplexa och relationerna mellan variabler likaså. Vanligen behövs något beskrivande mått på hur två variabler är relaterade till varandra (Löfgren, 2016).
4.3.3 Regression
Regression är en statistisk behandling som används för att försöka bestämma styrkan i
förhållandet mellan en beroende variabel och en oberoende variabel. Regression hjälper bland annat investerare och finansiella ledare att värdera tillgångar och förstå förhållandet mellan variabler. De två grundläggande typerna av regression är enkel linjär regression och multipel linjär regression Det finns även icke-linjära regressionsmetoder för mer komplicerade data och analys. Till denna studie kommer en multipel regression fungera som statistiskt analysverktyg då två eller flera oberoende variabler kommer användas för att predicera resultatet. Ett mer ingående klargörande, samt tillvägagångsätt vid användande av multipel regression redogörs för senare i studien (Investopedia, u.å.).
4.3.4 Standardavvikelse
Standardavvikelse kan skildras som ett mått på spridningen i datamaterialet. Det är således ett mått på hur stor den genomsnittliga spridningen kring de olika medelvärdena är i
datamaterialet. Varians är ett annat mått på spridning och fås genom att kvadrera standardavvikelsen. Spridningsmåttet varians innehåller alltså samma information som standardavvikelsen (Lantz, 2011).
5.
Metod
I detta kapitel skildras den metodologi som denna undersökning kommer att använda sig av. Arbetsprocessen kommer att redogöras, samt de förväntade resultat som följer valet av tillvägagångssätt. Slutligen kommer forskningsetiska principer att belysas. Detta görs då de utgör riktlinjer för studiens planering och tillvägagångsätt (Vetenskapsrådet, 2002).
Vid val av metod handlar det om att skapa ett verktyg som tar fram de uppgifter som undersökningen kräver för att svara på undersökningens frågeformulering (Eliasson, 2013). För att fullfölja undersökningens syfte och svara på den frågeställning som tidigare nämnts är en kvantitativ metod mest lämpad för att utföra studien, och i förlängningen undersöka och analysera det utfall undersökningen visar. En statistisk studie har valts utifrån det kvantitativa forskningsfältet. Den noggranna redovisningen av metodval bidrar till en god transparens av undersökningen (Bryman, 2011).
5.1 Vetenskapligt arbetssätt
I detta avsnitt beskrivs mer ingående tillvägagångssätt vid kvantitativa metoder. Fördelar med att använda sig av kvantitativ metodologi kommer belysas.
5.1.1 Kvantitativ metod
Kvantitativa metoder innefattar en stor mängd insamlad information eller data. I detta arbete ligger intresset i att genom kvantitativa analysmetoder visa på hur olika kvantitativa variabler förhåller sig till varandra. Kvantitativa metoder är bäst lämpade när det är viktigt att kunna sätta siffror på det insamlade materialet (Eliasson, 2013).
Kvantitativ forskning förknippas vanligtvis med ett deduktivt tillvägagångssätt, där fokus ligger på att använda data till en testteori. Så är också fallet i denna studie. Kvantitativ forskning undersöker relationerna mellan variabler som mäts och analyseras med hjälp av ett antal statistiska tekniker. Det innehåller ofta kontroller för att säkerställa datas validitet (Saunders, 2012).
används som oberoende variabler mot den ensamma beroende variabeln, UEFA:s koefficient, som avser belysa de sportsligt mest framträdande europeiska fotbollsklubbarna. Analysen syftar till att undersöka möjliga makroekonomiska korrelationer som förklarar sportslig framgång.
5.1.2 Induktion och deduktion
Begreppen induktiv och deduktiv metod är i hög grad kopplat till forskningsansats och uppfattningen om relationerna mellan teori och empiri. Den induktiva metoden innebär att man utgår från datainsamling och ur den försöker finna generella och teoretiska slutsatser. I induktiva ansatser har teorin en mer tillbakadragen roll. I motsats till de induktiva ansatserna har teorin i deduktiva ansatser en mer central och viktigare ställning (Wallén, 1993).
Induktion innebär således att man drar allmänna slutsatser utefter empiriska data. Utifrån observationer inducerar man slutsatser. Det innebär att man inte göra några exakta antaganden om man inte besitter tillräckligt med kunskap om verkligheten. Den deduktiva metoden kräver istället kunskap om befintliga teorier och utgår från dessa för att testa om arbetshypotesen stämmer överens med verkligheten. Till denna studie återfinns inget starkt teoretiskt ramverk. Istället dras generella slutsatser från insamlade data. Således intar studien en induktiv
forskningsansats (Thuren, 2007).
5.2 Urval
I detta avsnitt redovisas det urval som gjorts och åskådliggörs för vilka val av variabler som gjorts tillsammans bakomliggande motivering. Med variabler avses en egenskap som
studeras. Till denna studie används kvantitativa variabler som mäter någon form av kvantitet. Variabler representerar därmed numeriska mätvärden (Eljertsson, 2014).
Det återfinns en mängd olika urvalsmetoder. Vid val av urvalsmetod är inte den valda
metoden det viktigaste. Istället är det viktigt att urvalet dras slumpvis utan subjektiv påverkan. Till denna studie har ett systematiskt stickprovsurval valts. Det innebär att en liten del av en större population valts ut systematiskt. I detta fall representeras urvalet av de 20 främsta fotbollslagen på UEFA:s ranking (Eljertsson, 2014).
Undersökningen kommer att använda sig av ett antal oberoende variabler och en beroende variabel. De oberoende variablerna kan förklaras som oberoende eller orsak till fördelningen av den beroende variabeln som till motsats förklaras som en effekt av de oberoende
variablerna (Eljertsson, 2014).
De oberoende variablerna representerar makroekonomiska faktorer som i studien prövas mot den beroende variabeln; sportslig framgång. Urvalet av oberoende variabler har till stor del valts utifrån den tidigare litteratur som redovisas i kapitel tre och kopplat till studiens syfte.
5.2.1 Beroende variabel
Sportlig framgång agerar i denna studie som beroende variabel, mer specifikt UEFA:s klubbkoefficient, tillika rankingsystem.
UEFA har en säsongsbaserad ranking-koefficient för de klubbar som deltar i de turneringar som arrangeras av organisationen. Koefficienten är baserad på de resultat de tävlande lagen presenterar i dessa turneringar (Uefa, 2018a).
5.2.2 Oberoende variabler
De oberoende variablerna är utvalda utefter tidigare forskning och är förenade med studiens syfte och frågeställningar. De oberoende variabler representerar makrofaktorer som om möjligt kan påvisa en korrelation till sportslig framgång. Valet har fallit på fem faktorer som potentiellt påverkar den beroende variabeln.
BNP-tillväxt
För att mäta marknadsstorleken på en ekonomi kan BNP argumenteras vara den mest tillförlitliga och mångsidiga mätningen. Mätningen av BNP ger ett övergripande tillstånd av ekonomin som gör det möjligt för banker, politiker och institutioner att analysera och bedöma hälsan i en nationell ekonomi (Nordhaus och Samuelson 2010).
BNP tillväxt är summan av bruttovärdet av alla slutliga varor och tjänster som produceras i ekonomin av alla inhemska producenter under en viss period. BNP står för all inhemsk produktion och tar inte hänsyn till inkomstflödena till inhemska eller utländska institutioner. I denna studie mäts BNP-tillväxt årligen och redovisas procentenheter. Data kommer hämtas från Världsbankens nationalräkenskapsdata och OECD National Accounts datafiler. De siffror som representerar tillväxten på marknaden är baserade på den årliga procentuella tillväxten av landets BNP (Worldbank, 2018).
Inflation
För att mäta makroekonomisk miljö används inflationen i lagens tillhörande land som mätvärde. Inflationen återspeglar den årliga procentuella ökningen eller minskningen av kostnaden för genomsnittskonsumentens inköp av varor och tjänster. Den procentuella förändringen motsvarar konsumentprisindexet. Även här kommer data hämtas från Världsbankens nationalräkenskapsdata (Riksbanken, 2018)
Politisk stabilitet
Siffrorna som mäter Politisk stabilitet hämtas från Världsbankens globala styrindikatorer och representerar politisk stabilitet enligt definitionen av avsaknad från våld och terrorism. Världsbankens data mäts årligen och baseras på en grupp av enskilda variabler från sju olika externa datakällor. De representativa källorna är Economist Intelligence Unit Riskwire & Demokrati Index (EUI), som mäter våldsamma demonstrationer, social oro, väpnade konflikter, ordnade överföringar och internationella spänningar / terroristhot. World
Economic Forum Global Competitiveness Report (GCS), som mäter kostnaden för terrorism. Cingranelli Richards Human Rights Database och Politisk Terror Scale (HUM), som ger en politisk terrorskala; IJET Country Security Risk Ratings (IJT), som ger en
säkerhetsriskbedömning; Den institutionella profildatabasen (IPD), som mäter intensiteten av religiösa, etniska eller regionala interna konflikter, intensiteten av våldsamma aktiviteter hos underjordiska politiska organisationer och intensiteten av sociala konflikter. Den
internationella riskhanteringsguiden för politiska risker (PRS), som mäter statlig stabilitet, interna och externa konflikter och etniska spänningar, och slutligen Global Insight Business Conditions och Risk Indicators (WMO), som mäter protester och upplopp, terrorism och mellanstatlighet och inbördeskrig. Mätvärdet för politisk stabilitet är således baserad på en uppsättning av sju variabler. Statistiken mäts ursprungligen mellan ett intervall på -2,5 och
2,5. För att anpassa mätvärdena till denna studie kommer värdena justerats på 0 till 1. (Worldbank, 2018)
Arbetslöshet
Arbetslöshet avser den andel av en befolkning som är utan arbete men är tillgänglig för arbetsmarknaden och söker arbete. Motsägelsefullt kan låg arbetslöshet dölja stor fattigdom i ett land, men samtidigt kan hög arbetslöshet uppstå i länder med hög ekonomisk utveckling och låg fattigdomsgraden. Hög och långvarig arbetslöshet i ett land indikerar en allvarlig ineffektivitet i resursallokering. Ungdomsarbetslöshet är en viktig politisk fråga för många länders ekonomier. Arbetslösa eller underarbetade ungdomar kan inte bidra effektivt till nationell utveckling och har färre möjligheter att utöva sina rättigheter som medborgare. Arbetslöshet är en nyckelåtgärd för att övervaka om ett land är på rätt väg för att uppnå målet om hållbar utveckling för att främja en hållbar, inkluderande och hållbar ekonomisk tillväxt, full och produktiv sysselsättning och anständigt arbete för alla (Worldbank, 2018).
Befolkning
Den totala befolkningens mätvärde är baserad på det faktiska antalet av invånare. Till befolkning räknas alla invånare oavsett status eller medborgarskap.
Ökningar av den mänskliga befolkningen är antingen en följd av invandring eller ett resultat av fler födda än dödsfall. Befolkning kan påverka naturresurser och social infrastruktur och kan sätta press på ett lands hållbarhet. En betydande befolkningstillväxt kan också påverka tillgången på jord till jordbruksproduktion negativt, vilket kommer att förvärra efterfrågan på mat, energi, vatten, sociala tjänster och infrastruktur. Samtidigt kan en minskad
befolkningsstorlek påverka en regerings engagemang för att upprätthålla tjänster och infrastruktur (Worldbank, 2018). Alla variabler är kvantitativa, inkluderande numeriska mätvärden och mäter således någon form av kvantitet (Eljertsson, 2014).
Bakgrunden till valet av oberoende variabler är att de på ett tydligt och relevant sätt påvisar ett lands välmående. Sammanfattningsvis kommer dessa variabler via en multipel
regressionsanalys ge svaret på frågan om ett lands välmående påverkar nationella fotbollslags sportsliga framgång och därav summera studiens syfte. Med andra ord kommer ett samband mellan ett lands mående och sportslig framgång antingen bekräftas eller avvisas. Då
5.3 Datainsamling
I detta avsnitt redogörs för tillvägagångsätt för insamling av empiri till det kvantitativa metodvalet.
Inom det kvantitativa metodfältet är enkät- och intervjuundersökningar de vanligaste
utförandeformerna för datainsamling. Vid dessa tillvägagångssätt insamlas egna originaldata. I detta arbete används istället sekundärdata, det vill säga information som någon annan samlat in, men då samlats in i annat syfte. (Eliasson, 2013). I detta fall ska sekundärdata utgöra variabler som jämförs för att hitta korrelationer; samband till sportslig framgång. Sekundär data har valts utefter den tidigare forskning tidigare redogjorts för och urval har presenterats i föregående avsnitt.
Data gällande de makroekonomiska faktorerna kommer att hämtas från en av Världsbankens statistiska databaser, ”World development indicators”. Världsbanken har 189 medlemsländer och arbetar som en överstatlig institution inom ramen för FN:s ekonomiska och social råd. Databasen ”World development indicators” innehåller data från åren 1960-2016. Databasens information är indelad i sex olika underkategorier; Poverty and shared prosperity, people, environment, economy, states and markets och global links. Syftet med databasen är att på ett transparent sätt belysa de indikationer som mäter världsekonomin och dess utveckling. Alla de länder som berörs i studien återfinns representerade i databasen(Worldbank, 2018).
Databasen är lättillgänglig vilket underlättar genomförandet av en omfattande statistisk
analys. I studien kommer varje variabel enskilt bedömas utifrån dess relevans för arbetet, samt för tillvägagångssättet vid insamling och utformandet.
Den beroende variabeln kommer inte att införskaffas från samma källa. Istället kommer sekundärdata hämtas från UEFA:s Club Licensing Benchmarking Reports att användas och deras egna rankingregister.
UEFA, Union of European Football Associations, är en organisation som bildades år 1954 för att värna och säkerhetsställa den europeiska fotbollen. Organisationen fungerar som det styrande organet för europeisk fotboll och agerar som en paraplyorganisation till de 55 nationella fotbollsförbund i Europa. UEFA:s mål är att främja fotboll i en anda av solidaritet, fred, förståelse och rättvis lek, utan diskriminering. UEFA arbetar mot att skydda värdena för
europeisk fotboll, främja och skydda etiska normer och goda styrelser i europeisk fotboll. De vill samtidigt upprätthålla relationer med alla intressenter som är involverade i europeisk fotboll och stödja och skydda sina medlemsförbund för det övergripande välbefinnandet inom europeisk idrott (Uefa, 2018b).
5.3.1 SPSS
SPSS ”Statistical Package for the Social Sciences” är ett statistiskt mjukvaruprogram och utvecklades 1968 vid Stanford University. Programmet bygger på att man ur rådata använder statistik för att utvinna nödvändig information. SPSS är underlättar statistisk beskrivning och analys. Programmet används således för att genomföra statistiska metoder och analyser, samt ange vilka oberoende variabler som är signifikanta i studien (Eriksson & Wiedersheim-Paul, 2011). Nedan visas hur insamlade data kommer dokumenteras i SPSS för att sedan kunna genomföra valda statistiska analyser.
Tabell 1 - En enkel datamatris
ID Variabel 1 Variabel 2 Variabel 3 Variabel 4
Lag 1 1 1 4 34 1
Lag 2 2 3 2 21 1
Lag 3 3 4 6 42 2
6.
Bearbetning och analys
Analys av insamlade data är en aktiv process för att skapa en helhetsbild och förståelse av informationen. Analysen av de variabler som används kommer att ske individuellt och gemensamt. Variablerna kommer att sättas i perspektiv till tidigare litteratur på ämnet och sättas i ett perspektiv till respektive land/lag som analysen syftar till. Baserat på utfallet av undersökningen kommer variablerna att analyseras i relation till varandra för att ge en bild av hur en möjlig korrelation kan förklaras och utredas.
För att analysera insamlade data finns olika dataverktyg som fungerar som hjälpmedel med ekvationer, presentationer och dylikt. Till hjälp kommer tre dataverktyg att fungera som stöd och hjälp för att analysera insamlade data.
Förutom SPSS som tidigare nämnts (5.3.1) kommer även programmen Microsoft Excel och Microsoft Azure Machine Learning Studio att användas. Bakgrunden till denna kombination av dataprogram är åsikten att de är bra på olika saker, samt en nyfikenhet att lära och se nya företeelser.Azure Machine Learning Studio är en molntjänst utvecklad av Microsoft för Machine Learning. Azure Machine Learning Studio fungerar som ett ”dra och släpp”-verktyg som kan användas för att bygga, testa och distribuera prediktiva analyslösningar på valda data. Till hjälp återfinns hjälpmedel i form av handböcker och exempel på modeller som visar hur Machine Learning Studios fungerar för att kunna bygga och distribuera machine learning-modeller (Azure Microsoft, u.å.).
6.1 Statistisk analys
Detta avsnitt kommer redogöra för de statistiska metoder och tester som denna studien kommer använda sig utav för att besvara frågeställningarna. Statistik nyttjas av många vetenskapliga discipliner och frambringar metoder för att sammanställa insamlade data och dra generaliserbara slutsatser. Statistisk kunskap hjälper forskningsprocessen med frågor rörande urval, beskrivning, analys, tolkning och presentation av insamlade data (Löfgren, 2006). I många vetenskaper är analys av samband mellan olika variabler i centrum, så även i denna studie. Den kanske vanligaste statistiska metod för behandling av samband mellan variabler är regressionsanalys (Lantz, 2011).
6.1.1 Multipel regressionsanalys
I denna statistiska analys ska en multipel regression genomföras för att undersöka sambandet mellan undersökningsvariablerna och den konstanta variabeln för sportslig framgång. Vid en enkel regressionsanalys beskrivs sambandet mellan en beroende variabel, y, och en
oberoende, förklarande variabel, x. Vid en multipel regression analyseras variationen av en beroende variabel (y) med hjälp av flera oberoende variabler (x1, x2 osv.). För att mäta det linjära sambandets förklaringsgrad används determinationskoeffecienten b (Edling &
Hedström, 2003). Denna statistiska metod är obestridligt den mest använda analystekniken för att påvisa korrelationer (Allison, 1999).
Modellen som används vid enkel linjär regressionsanalys är således:
𝑦 = 𝛼 + bx + ε. (Formel 1)
I denna formel representerar 𝛼 regressionslinjens skärningspunkt på y-axeln och b (regressionsfaktorn) symboliserar regressionslinjens lutning. Symbolen ε betecknar slumpavvikelse (Lantz, 2011).
Med multipel regression kan alltså mer än en oberoende variabel inkluderas i ekvationen. Bakgrunden till detta val är att det möjliggör en mer fullständig förklaring om den beroende variabeln. Tekniken för multipel regression har stor räckvidd och dess duglighet att analysera nästan vilken uppsättning kvantitativa data som helst är en egenskap som ligger bakom valet av denna statistiska analys (Lewis-Beck & Lewis-Beck, 2016).
Regressionsanalys används för att informera om förutsägelser och är en datamodellteknik som fungerar som hjälpmedel för att förstå hur olika variabler förändras med varandra. En
regressionsmodell måste innehålla minst en beroende variabel och oberoende variabel (Quick, 2010). Avsikten bakom användandet av en multipel regression är möjligheten att kunna bedöma den beroende variabeln utifrån en kombination av de fem valda oberoende variablerna. Formeln blir följaktligen: (Löfgren, 2006).
Vid regressionsanalys finns olika möjligheter. Förutom att i regressionsekvationen ta med samtliga oberoende variabler kan man ”stega in” variablerna i en viss ordning för att endast ta med de variabler som signifikant bidrar till den beroende variabeln. Denna metod kommer även denna studie nyttja genom att göra en stegvis multipel regression. Det innebär således att i ett första steg inkludera alla oberoende variabler, för att sedan göra om regressionen och utesluta de variabler som inte är statistiskt signifikanta. Istället inkluderas endast de variabler som högst korrelerar med variabeln för sportslig framgång (Löfgren, 2016).
6.1.2 Standardisering
En standardisering möjliggör tolkning och jämförelser av olika oberoende variabler i regressionsmodellen trots att de har olika mätenheter och skalor. För att transformera alla oberoende variablers mätvärden till en gemensam skala genomförs en skaltransaformation till z-skalan. En z-poäng anger avståndet mellan oberoende variablernas mätvärden och
tillhörande variabels medelvärde uttryckt i standardavvikelseenheter. Nedanstående formel används vid standardisering till z-skalan (Allison, 1999; Löfgren, 2016).
𝑧 =
/0123 (Formel 3)
Medelvärdet (𝜇) i z-skalan är alltid 0. Samtidigt är standardavvikelsen (𝜎) 1. Detta möjliggör att på ett enkelt sätt transformera ursprungliga mätvärden för de oberoende variablerna till den standardiserade skalan (Löfgren, 2016).
6.1.3 Regressionsskattning – minsta kvadratmetoden
Vid en regressionsskattning vill man skatta (förutsäga) utkomsten av värdet på den beroende variabeln y, i denna studie sportslig framgång. Detta förutsätter att vetskap föreligger om mätvärdet för de oberoende variablerna, x, samt relationen till den beroende variabeln y (Löfgren, 2016). På detta sätt kan följande fråga besvaras, för att vidare kunna besvara studiens frågeställning:
Hur väl kan sportlig framgång förutsägas utifrån mätvärdena på de oberoende variablerna?
Är relationen mellan variablerna x och y känd genom en sambandsberäkning kan detta senare användas vid regressionsskattning (Löfgren, 2016).
I regressionsekvationen återfinns symbolen e (se formel 3). Denna symbol uttrycker
skillnaden mellan det observerade värdet av den beroende variabeln (y) och regressionslinjens uppskattade värde av den beroende variabeln (ŷ). Formel 4 nedan tydliggör ovanstående resonemang (Körner & Wahlgren, 2015).
𝜀 = 𝑦 − ŷ (Formel 4)
Denna skillnad benämns som en residual och är alltså den felterm som uppstår vid den bäst anpassade ekvationen. I denna studie kommer benämningen residual fortsättningsvis användas vid belysning av denna beskrivna skillnad (Körner & Wahlgren, 2015).
Vid regressionsskattning erhålls även en förklaringsgrad (R2) som presenteras som ett tal mellan 0 och 1. Denna förklaringsgrad brukar utryckas i procent och är ett mått på hur mycket av variationen i beroende variabeln som förklaras av modellen. Nackdelen med
förklaringsgraden är att den inte utrycker någonting om den statistiska signifikansen eller kausalitetssambanden. Istället utrycker förklaringsgraden endast ett mått på modellens prediktionsförmåga (Stock & Watson, 2011).
För att estimera regressionsekvationen används minsta kvadratmetoden. Denna metod
används för att skapa en optimalt anpassad linje utefter det valda datamaterialet. Denna metod förutsätter dock ett antal antaganden om verkligheten. Medvetenhet om dessa antaganden måste infinnas för att kunna bedöma validiteten i den kommande analysen. Dessa antaganden följer nedan: (Lantz, 2011).
- Sambandet måste beskrivas med en rät linje - Variablerna måste ligga på en kvantitativ skala
- Avståndet mellan punkterna och linjen i spridningsdiagrammet måste var en normalfördelad variabel.
Minsta kvadrat-metoden innebär att anpassa en linjär funktion genom att bestämma värdet på a och de olika värdena för b i formeln för multipel regression (formel 2). Denna metod
∑= (𝑦<
<>? − b?𝑥?<− bA𝑥A<− bB𝑥B<− bC𝑥C<− bD𝑥D<)A (Formel 5)
6.1.4 Förklaringsgrad
Förklaringsgrad är ett tal mellan 0 och 1 och skrivs ut R2. Förklaringsgraden beskriver hur väl en regressionslinje approximerar och förklarar hur väl modellen är lämplig för att beskriva sambandet mellan variablerna. En hög förklaringsgrad, även kallad determinationskoefficient, innebär ett starkt linjärt samband (Lantz, 2011).
Förklaringsgraden visar den andel av den totala variationen i responsvariabeln som förklaras av en bestämd linjär modell och är ett anpassningsmått som ofta används vid
regressionsanalys för att jämföra olika modeller med varandra (Lantz, 2011). Andelen av den totala variationen utvinns av formeln:
(Formel 6)
En nackdel med förklaringsgraden är att dess värde alltid ökar när fler oberoende variabler inkluderas i regressionen.Mot bakgrund av detta kommer den justerade förklaringsgraden användas då detta anses var ett bättre alternativ i studiens regression. R2j justerar för antalet oberoende variabler i modellen. Den justerade förklaringsgraden utvinns genom formeln nedan där k representerar antalet oberoende variabler i modellen. Den justerade
förklaringsgraden är alltid densamma eller mindre än R2(Kahane, 2007).
6.1.5 Hypotesprövning
Till studien kommer en hypotesprövning genomföras. En hypotesprövning kommer fullföljas för att om möjligt påvisa att arbetshypotesen, H1, inte är en tillfällighet och för att förkasta nollhypotesen, H0 (Eljertsson, 2014). En statistisk hypotesprövning innebär att man bedömer trovärdigheten i hypoteser eller antaganden om hela populationen, i det här fallet alla
europeiska fotbollsklubbar. En statistisk hypotesprövning kan utföras på olika sätt. I denna studie har ett lag valts ut för att se om arbetshypotesen kan bekräftas; att de oberoende variablerna påverkar sportslig framgång (Körner & Wahlgren, 2015).
I en hypotesprövning är nollhypotesen utgångspunkt, det vill säga att det inte finns något samband mellan valda oberoende variabler och sportslig framgång inom fotbollsidrotten. I nästa steg anges en mothypotes, en arbetshypotes (H1) som avspeglar frågeställningarna och negerar nollhypotesen. Därefter bestäms signifikansnivå – sannolikheten att eller den risk man tar att felaktigt förkasta en sann nollhypotes. Nedan sammanfattas hypotesprövningens princip som en funktion kopplat till regressionsanalys. Med detta menas om oberoende variabel verkligen påverkar den beroende variabeln y och åskådliggörs i formel 3 nedan. (Eljertsson, 2014).
H0: β = β0 ≡ 0 (Formel 8)
H1: β ≠ 0
Denna studie kommer använda sig av hypotesprövning med p-värde. I detta sammanhang kan p-värdet ses som ett mått på hur troligt det är att nollhypotesen är sann. Om p-värdet är lägre än signifikansnivån förkastas nollhypotesen (Lantz, 2011).
Den valda signifikansnivån som används i denna studie är 5 %. Det är den mest förekommande och står i enighet med studier i litteratursökningen. Signifikansnivån
bestämmer alltså när nollhypotesen ska förkastas. I detta fall innebär det således att risken att förkasta en sann nollhypotes inte får överstiga 5%.
6.2 Förväntat resultat
Förväntan är att besvara studiens frågeställningar och påvisa att det finns ett samband mellan de valda oberoende variablerna och sportslig framgång.
För att kunna påvisa ett tillförlitligt samband är förhoppningen att regressionskoefficient och förklaringsgrad ska vara godtyckliga och därmed beskriva ett så linjärt samband som möjligt. Samtidigt ska de utvalda variablerna vara statistiskt signifikanta för att således redovisa ett resultat för de variabler som högst korrelerar med sportslig framgång. Syftet är att besvara studiens frågeställningar; går det att fastslå andra faktorer än betalningsförmåga som påverkar sportslig framgång?, vilka faktorer påverkar sportslig framgång?, samt i vilken omfattning.
6.3 Validitet och Reliabilitet
Validitet och reliabilitet är två begrepp som närmast beskriver kvaliteten på metodval och bearbetning. Reliabilitet beskriver tillförlitligheten hos det som mäts i studien. En hög
reliabilitet förutsätter stabilitet, att sättet man mäter är stabilt och går att upprepa med samma resultat vid ett senare tillfälle. Den interna reliabiliteten är något som tas i beaktning i denna studie då det är en indikation på hur olika variabler är relaterade till varandra (Bryman, 2011).
Reliabilitet kan sägas beskriva noggrannheten i studiens mätning. Validiteten beskriver således studiens giltighet. En hög intern validitet är ett resultat av säkerheten i att de oberoende variablerna påverkar den beroende variabeln. Extern validitet syftar till urvalet i studien. En hög extern validitet är beroende av generaliserbara studiens slutsatser kan anses vara (Bryman, 2011). I denna studie anses dessa begrepp vara av stor vikt. En stabil mätning, noga begrundande urval och tydliga redogörelser bedöms essentiellt för studiens utfall och mottagande.
6.4 Etiska överväganden
Etiska överväganden eller forskningsetik avser frågor om undersökningens metoder för utförande, datainsamling, analysering, formulering etc. Det innebär att undersökningen måste vara utformad på ett sådant sätt så att den är både metodologiskt korrekt och moraliskt
försvarbar gentemot de individer som undersökningen berör (Saunders et al 2012).
De forskningsetiska principerna är mer av vägvisande karaktär snarare än detaljerade regler. Detta är ett medvetet val då problemen kan variera avsevärt, samt att de inte är avsedda att ersätta och hindra forskares egna bedömningar och ansvar. Individskyddskravet är ett grundläggande krav för forskningen och kan preciseras i fyra huvudkrav. Dessa krav kan sedan specificeras ytterligare i ett antal regler. De fyra huvudkraven inrymmer;
informationskravet, samtyckeskravet, konfidentialitetskravet och nyttjandekravet. Detta är fyra grundkrav som undersökningen värderar och respekterar vid insamling av data. Vid eventuell kontakt med undersökningsdeltagare kommer också information ges om i vilken
att inkluderas. Individskyddskravet kommer således endast visas som en vetskap att ta i beaktning snarare än vara applicerbar på denna studie.
Helsingforsdeklarationen, utarbetad av världsläkarförbundet, är en samling etiska principer. Deklarationen har som primärt syfte att vägleda läkare och medicinsk forskning som
inbegriper mänskligt material eller uppgifter. Deklarationen belyser faktumet att medicinsk forskning är underordnad etiska normer och åsyftar istället att främja människors hälsa och rättigheter. I paritet till detta bör beskrivande protokoll redovisas till etiska rådet. Protokollet innehåller en redovisning av de etiska överväganden som gjorts samt att tydligt tillkännage att denna studie är förenlig med Helsingforsdeklarationens principer (Läkartidningen, 2002). Även i detta fall belyses närmast en kännedom än en direkt koppling till den studien.
7.
Empiri och analys
I detta kapitel redogörs för det resultat som insamlats. Till denna studies resultatdel är förhoppningen att illustrera ett så rättvist resultat som möjligt utefter det som utvunnits. För att skapa en större förståelse beträffande den insamlade data kommer först insamlingen av de valda variablerna att presenteras.
Insamlingen av mätvärden till de fem oberoende variablerna resulterade i en stor mängd data och närmast inget bortfall. Gällande studiens beroende variabel, UEFA-koefficienten, infann sig en del bekymmer. Den insamlade empirin redovisas i nästa avsnitt.
Microsoft Azure har varit central i sammanställning av mätvärden och analys. Hela statistiska händelseförloppet illustreras i Bilaga 1. Microsoft Excel har också använts i syfte att enklare redovisa för studiens statistiska resultat.
7.1 Variablers mätvärden
Nedan redovisas den resulterande empirin vid insamling av data. För att närmare förstå variablernas betydelse hänvisas till avsnitt 5.2 Urval.
Insamling av mätvärden tillhörande de urval av 20 lag som gjorts resulterade i 309 stycken rader. Då studien görs över 17 år borde logiskt sätt detta resultera i 340 stycken rader. Bakgrunden till denna reducering förklaras genom bortfall. Variabeln politisk stabilitet saknade mätvärden för år 2001, detta resulterade i att år 2001 uteslöts i studien. Samtidigt saknades värden för den beroende variabeln totalt elva gånger. Utan oberoende variabel har gjort att även dessa rader uteslutits i studien. Dessa bortfall förklaras som interna.
Alla oberoende variabler har standardiserats. En standardisering har medfört en gemensam skala för de olika variablerna och därmed möjliggjort senare statistiska analyser. En
standardisering har också gjort mot bakgrund av att värdet på variabeln inte är av intresse. Det är istället relation dem emellan som är intressant. Den beroende variabeln, tillika mätvärdet för sportslig framgång har fasthållits i sina originalvärden. Nedan illustreras insamlingen av
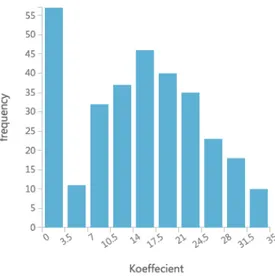
Figur 1 - Histogram beroende variabel
7.2 Machine Learning
För att förstå och illustrera hur de olika oberoende variablerna förhåller sig till den beroende variabeln har Machine Learning används, med hjälp av programspråket Python 3. Med Pythons datakodning har den insamlade data enkelt kunnat programmeras för att illustrera de oberoende variablerna separat gentemot den beroende variabeln. Resultatet från denna körning presenteras i en separat loggbok till arbetet (PM Python 3 notebook) (python, u.å ). Nedan visas ett utdrag ur detta programspråk som presenteras i den separata loggboken.
In [42]: from azureml import Workspace In [43]: frame
In [44]: num_cols = ["Inflation","BNP-growth", "Un-employment","Population","PoliticalStability"] def Lag_box(df, cols):
import matplotlib.pyplot as plt
## Loop over the columns and create the box plots
for col in cols:
fig = plt.figure(figsize=(8, 6))
fig.clf()
ax = fig.gca()
df.boxplot(column = 'Koeffecient', by = col, ax =
ax)
ax.set_xlabel(col)
ax.set_ylabel('Koeffecient')
ax.set_title('Koeffecient vs. ' + col)
8.
Statistisk analys
I detta avsnitt analyseras den insamlade empirin. Avsnittet struktureras upp utefter det tänkta tillvägagångsättet (kapitel 6), för att sedan redovisa en slutsats kopplat till undersökningens syfte. För ytterligare förtydligande av tillvägagångsätt hänvisas till bilaga 1.
8.1 Hypotesprövning
Vid hypotesprövning valdes ett lag ut för att om möjligt förkasta nollhypotesen. Val av hypotesprövnings-modell har tidigare presenterats i studiens metod-del där den bestäms till p-värdet.
Nedan visas den regressionsstatistik som framkommit efter en regressionsanalys av Real Madrids beroende variabel för sportslig framgång och de oberoende variablerna.
Real Madrid Regressionsstatistik Multipel-R 0,93549612 R-kvadrat 0,875153 Justerad R-kvadrat 0,79192166 Standardfel 3,89817747 Observationer 16 Tabell 1- Hypotesprövning t-kvot p-värde Inflation -0,1793128 0,86166402 BNP-tillväxt 0,86579121 0,40909063 Arbetslöshet 1,75401277 0,11332574 Befolkning 0,26691508 0,79554974 Politisk stabilitet 0,58618484 0,57215724
8.2 Multipel regression
Inledningsvis inkluderades alla oberoende variabler i regressionen: - Inflation
- BNP-tillväxt - Arbetslöshet - Befolkning - Politisk stabilitet
Resultat av denna regression illustreras i tabell 2 nedan.
Regressionsstatistik inkluderande alla oberoende variabler
Multipel-R 0,233554038
R-kvadrat 0,054547489
Justerad R-kvadrat 0,038945962
Standardfel 9,168513855
Observationer 309
Tabell 2-Regression, alla oberoende variabler
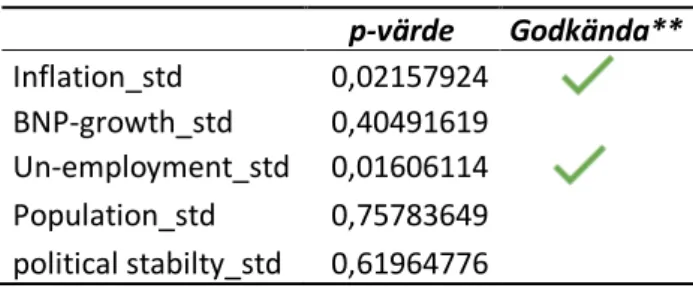
Nedan visas de utvunna p-värdena för de olika variablerna i regressionsanalysen. Med anledning av det höga p-värdet hos de oberoende variablerna görs bedömningen att utesluta de oberoende variablerna; BNP-tillväxt, befolkning och politisk stabilitet, detta då de inte infinner sig inom den valda signifikansnivån. Beslutet grundar sig också i den valda signifikansnivån 5%, samt konfidensintervallet som således är 95%
p-värde Godkända** Inflation_std 0,02157924 BNP-growth_std 0,40491619 Un-employment_std 0,01606114 Population_std 0,75783649 political stabilty_std 0,61964776 Tabell 3 - p-värden
Efter att de statistiskt signifikanta variablerna identifierats har en ny multipel regression gjorts som inkluderar endast de oberoende variablerna; inflation och arbetslöshet. I tabell 4 nedan redovisas resultatet ur denna andra regression.
Regressionsstatistik med godkända signifikanta variabler Multipel-R 0,227545484 R-kvadrat 0,051776947 Justerad R-kvadrat 0,045579411 Standardfel 9,136817312 Observationer 309
Tabell 4 - Regression med signifikanta variabler
8.2.1 Regressionsskattning
En regressionsskattning har utförts för att hitta den bäst lämpade regressionsekvationen där sambandet beskrivs som en rät linje. Nedan följer det resultat som utvunnits efter att den valda metoden (4.1.7) använts.
Tabell 5- Lutningskoefficienter
Ovanstående koefficienter har därefter applicerats i regressionsekvationen (formel 2). Det gör att den estimerade regressionsekvationen utfaller enligt följande:
𝑦 = 14,50600109 − 1,284327842x + 1,588498529x + ε.
I Bilaga 2 redovisas det linjära sambandet för de statistiskt signifikanta variablerna separat från varandra. Regressionsekvationen ha applicerats på alla kombinationer av oberoende variabler med hjälp av Azure Machine Learning Studio. Bakgrunden till detta är att då kunna analysera alla skattade y-värden för alla olika lag och år, samt att jämföra dem med de observerade värdena. Nedan förtydligas denna redogörelse.
Koefficienter
Konstant (Y-variabel) a =14,50600109
Inflation b=-1,284327842
……….
Därefter har de skattade värdena för jämförts med de faktiska värdena för y i form av en ny regressionskurva. Denna illustreras i Bilaga 3.
8.2.2 Förklaringsgrad
Förklaringsgraden tillhörande regressionsanalysen med statistiskt signifikanta variabler framgår av tabell 3. Förklaringsgraden skrivs till 4,6% vilket innebär ett exceptionellt lågt linjärt samband. På grund av antalet oberoende variabler väljs det justerade R2-värdet för att förklara det linjära sambandet. En låg förklaringsgrad indikerar troligtvis att den
slumpmässiga variationen har en stor inverkan och att sambandet mellan oberoende- och beroende variabler är icke-linjärt.
Analys av de signifikanta variablerna, separerade från varandra, visar på följande förklaringsgrader:
- Arbetslöshet R2 = 0,6274 = 63 % - Inflation R2 = 0,3917 = 39 %
9.
Diskussion
Denna studie har försökt hitta variabler som korrelerar med sportslig framgång. Samtidigt har utvalda variabler representerat makroekonomiska variabler som inte direkt inverkar på idrott. Studien har gjorts i syfte att undersöka om andra faktorer än ekonomiska förutsättningar påverkar sportslig framgång. Stegvis multipel regressionsanalys visade att två, arbetslöshet och inflation, av fem oberoende variabler visade ett giltigt p-värde, samt att dessa två resulterade i förklaringsgrader om 63 % respektive 39 %. En multipel regressionsanalys visade vidare på att de två signifikanta oberoende variablerna i kombination resulterade i en förklaringsgrad på 4,6 %.
Redan vid studiens hypotesprövning misstänktes det slutgiltiga utfallet. Hypotesprövningen resulterade inte i några statistiskt signifikanta variabler. Trots det erhölls en förklaringsgrad på 79% (Tabell 1). Det var mot denna bakgrund som studien trots allt valde att fortsätta, trots hypotesprövningens motsägelse. En medvetenhet om att det återfinns andra faktorer som är närmare kopplat till den sportsliga världen bör belysas. Faktorer som är tydligare förknippade med idrotten fotboll och samtidigt inte alls relaterade till det ekonomiska. Faktorer som spelsystem, ägarskap, nationaliteter i spelartrupp är bara några exempel på faktorer som varit intressanta som alternativa faktorer att analysera i samma syfte som den befintliga studien. Möjligen hade en större och tydligare korrelation då kunna påträffats. Den hade samtidigt varit lättare att motivera.
Fotbollslagens spelarlöner har uteslutits i studien då den inte representerar en
makroekonomisk faktor. Denna faktor har således inte varit intressant för att nå studiens syfte. Trots detta har en analys gjorts av de utvalda lagens medellöner gentemot deras
rankingkoefficienter för att försöka bekräfta den tidigare forskningens argumentationer och visa på bakgrunden till studien syfte. Trots en hel del bortfall presenteras resultatet av denna analys i den särskilda bilagan ”PM Python 3 notebook”, s 12. Resultatet visar inte på någon korrelation mellan lagspelarnas löner och lagens rankingkoefficienter. Då studien valt ut de 20 främsta lagen i Europa, ger resultatet anledning till en vidare diskussion av Kringstad & Olsens (2016) argumentation; Att det inte finns någon korrelation mellan finansiell styrka och
där mer pengar gav mer framgång. Att den egna studien, med fokus på topplag, inte heller visar på någon korrelation mellan spelarlöner och sportslig framgång, kan tolkas som ett ytterligare bevis till tesen att sportlig framgång för topplag inte påverkas av finansiell styrka. Denna koppling ger upphov till vidare diskussion av Moneyball-teorin. Moneyball-teorin, som visade på en felprissättning av amerikanska baseball-spelare, leder till slutsatsen att lag kan prestera bättre vad deras finansiella situation borde ge möjlighet till. Dessa lag besitter alltså en konkurrensfördel som inte är relaterad till finansiell styrka, vilket gör att även Moneyball-teorin stödjer tesen att finansiell styrka inte är den enda variabeln som bör tas i beaktning vid en analys av sportslig framgång. Slutligen ger även Rottenberg’s Invariance principle, som utgör stommen till studiens teoretiska ramverk, stöd till studiens syfte, då den förkastar lönsamhet som den enda avgörande faktorn för sportslig framgång.
Sammanfattningsvis visade studiens analys ingen korrelation mellan de undersökta
makroekonomiska faktorerna och sportlig framgång. Studiens syfte har därmed uppnåtts; Att undersöka om makroekonomiska faktorer kunde förklara den icke-finansiella
konkurrensfördelen som enligt tidigare litteratur och studiens analys bevisligen existerar. Resultatet gav däremot ingen förklaring till vilken variabel som kan förklara sportslig framgång, utan ger endast bevis på att de valda makroekonomiska faktorer inte står som giltiga förklaringsvariabler. Vidare forskning på hur sportslig framgång kan förutses krävs för att täcka upp det hål som litteraturen på ämnet lämnar.
Vidare har beslutet att välja landspecifika variabler försvårat studiens tillvägagångssätt och medför därmed ett något missvisande resultat. Då många av lagen återfinns i samma land och därmed nationella liga, är många av variablernas mätvärden desamma för de olika lagen. Samtidigt återfinns alla lagen i Europa vilket gör att spridningen på variablernas mätvärden inte blir så stort. Intressant hade varit att inkludera lag från hela världen, för att på så sätt få en större spridning av mätvärden och ett tydligare svar på om de korrelerar på den beroende variabeln; sportslig framgång. Svårigheten i detta var att det inte finns något rättvist sätt att jämföra lag från olika världsdelar, vilket gör det ohållbart att använda sig av en större global spridning på utvalda lag.
Att genomföra en stegvis multipel regressionsanalys där endast de statistiskt signifikanta variablerna inkluderas i regressionsekvationen anses öka resultatets reliabilitet och validitet. Oavsett positivt eller negativt resultat förenat till studiens frågeställningar anses en hög tillförlitlighet viktigt för studiens mottagande.
10.
Slutsats
Studien har gjort en ansats till att påvisa en korrelation mellan fem makroekonomiska faktorer och sportslig framgång. Studiens resultat framhåller inget tydligt samband mellan de valda variablerna och sportslig framgång. Trots en stegvis multipel regression anses inte
korrelationskoefficienterna och den statistiska signifikansen tillräckligt tillfredställande.
11.
Framtida forskning
Framtida forskning på samma ämne kan innehålla en annan uppsättning oberoende variabler som är mer förankrade i idrottens värld. Framtida forskning bör också utvidga den statistiska analysen och genomföra en logaritmisk analys för att hitta ytterligare relationer mellan variablerna. Samtidigt hade framtida forskning kunnat gå djupare in på utvalda lag och jämföra korrelationen mellan variablerna och olika länder. Möjligtvis återfinns en tydligare korrelation mellan vissa lagnationaliteter och de oberoende variablerna, ett resonemang som helt frångåtts i denna studie.
Referenser
• Allison, P. D. (1999). Multiple regression: a primer. Thousand Oaks, Calif.: Pine Forge Press.
• Bingham, J., De Bosscher, V. & Shibli, S. (2008). The global sporting arms race: an
international comparative study on sports policy factors leading to international sporting success. Oxford: Meyer & Meyer.
• Lewis-Beck, C. & Lewis-Beck, M. (2016). Quantitative Applications in the Social
Sciences: applied regression. Thousand Oaks, CA: SAGE Publications Ltd doi:
10.4135/9781483396774
• Bryman, A. (2011). Samhällsvetenskapliga metoder. (2., [rev.] uppl.) Malmö: Liber. • Downward, P. & Dawson, A. (2000). The economics of professional team sports.
London: Routledge.
• Dubal, S. (2010). The neoliberalization of football: Rethinking neoliberalism through the commercialization of the beautiful game, 45(2), 123-146,
https://doi.org/10.1177/1012690210362426
• Edling, C. & Hedström, P. (2003). Kvantitativa metoder: grundläggande
analysmetoder för samhälls- och beteendevetare. Lund: Studentlitteratur.
• Ejlertsson, G. (2014). Enkäten i praktiken: en handbok i enkätmetodik. (3. [rev.] uppl.) Lund: Studentlitteratur.
• Eliasson, A. (2013). Kvantitativ metod från början. (3., uppdaterade uppl.) Lund: Studentlitteratur.
• Eriksson, L. T. & Wiedersheim-Paul, F. (2011). Att utreda, forska och rapportera. (9. uppl.) Malmö: Liber.
• Gásquez, R. & Royuela, V. (2014). Is Football an Indicator of Development at the International Level?, 117(3), 827–848. https://doi.org/10.1007/s11205-013-0368-x • Hassmén, N. & Hassmén, P. (2008). Idrottsvetenskapliga forskningsmetoder. (1.
uppl.) Stockholm: SISU idrottsböcker.
• Investopedia (u.å.). What is Regression. Hämtad 2018-05-21 Från https://www.investopedia.com/terms/r/regression.asp
• Kahane, L. H. (2007). Regression Basics [Elektronisk resurs]. Sage Publications. • Klein, B (1995). Tillgångar, ansvar och maktcentra. Om reflexivitet och