”Är XML redo att tillämpas?” (HS-IDA-EA-00-324)
Lars Olofsson (a96larol@student.his.se)
Institutionen för datavetenskap Högskolan i Skövde, Box 408
S-54128 Skövde, SWEDEN
Examensarbete på det systemvetenskapliga programmet under vårterminen 2000.
Är XML redo att tillämpas?
Examensrapport inlämnad av Lars Olofsson till Högskolan i Skövde, för Kandidatexamen (B.Sc.) vid Institutionen för Datavetenskap.
2000-06-08
Härmed intygas att allt material i denna rapport, vilket inte är mitt eget, har blivit tydligt identifierat och att inget material är inkluderat som tidigare använts för erhållande av annan examen.
”Är XML redo att tillämpas?”
Lars Olofsson (a96larol@student.his.se)
Nyckelord: XML, RDBHS, webbgränssnitt
Sammanfattning
XML är ett märkordsspråk som utvecklats för att dels komplettera och ersätta HTML-baserade system och dels för att möjliggöra tillgänglighet för Webben på nya plattformar och miljöer. XML är en arvtagare till SGML och på motsvarande sätt ett metaspråk. XML erbjuder möjligheter att utveckla egna element, attribut och entiteter samt möjligheter att definiera egna dokumentstrukturer.
XML tar sikte på att implementeras i webbtillgängliga gränssnitt och kommer i sådana system även att få en datalagrande funktion, åtminstone enligt hur XML-standarden för närvarande är definierad. I detta sammanhang är det därför intressant att jämföra XML med de befintliga RDBHS som sedan ett flertal år bygger upp datalagrande funktioner i webbtillgängliga gränssnitt. Denna rapport redogör för ett projekt där XML prövats som datalagringsteknik och då ur perspektiv av ett RDBHS-baserat och webbtillgängligt prototypsystem.
Resultatet visar att XML inte kan implementeras på motsvarande sätt som RDBHS och att XML som datalagringsteknik bör ifrågasättas. Orsaken står att finna i att XML:s datamodell identifieras som hierarkisk och att XML därvidlag lider av denna datamodells brister i jämförelse med RDBHS relationsdatamodell. Vidare föreligger ett antal praktiska problem vilka har sin orsak i att det ännu inte har implementerats något kommersiellt tillgängligt DBHS för XML. Denna rapport redogör dock för förslag till lösning på XML:s brister som datalagrare. Det principiella lösningsförslaget går ut på att transformera XML:s hierarkiska datamodell till en objektorienterad datamodell. På så sätt kan DBHS-funktionalitet möjliggöras via ODBHS, eller så kan objektorienterad åtkomst av XML-data möjliggöras via objektorienterade programspråk.
Innehållsförteckning
1
Inledning ...1
2
Bakgrund ...3
2.1 Märkordsspråk... 3
2.2 SGML... 3
2.2.1 Tre gemensamma faktorer ... 4
2.2.2 DTD och ”taggar” ... 4
2.2.3 Attribut... 7
2.2.4 Entiteter och markerade sektioner ... 8
2.2.5 Att köra SGML-märkt information... 9
2.2.6 Sammanfattning om SGML... 9
2.3 HTML... 11
2.3.1 HTML i relation till SGML ... 11
2.3.2 HTML byggs ut och kompletteras ... 13
2.3.3 Kritik mot lappverket ... 15
2.4 XML ... 16
2.4.1 XML tar ett steg vidare med XSL... 16
2.4.2 Länkar, XPath, XPointer och XLink... 18
2.4.3 XHTML – en ny definition av HTML... 20 2.4.4 Sammanfattning av XML ... 21 2.5 Relationsdatabaser... 22 2.5.1 SQL ... 22 2.5.2 RDBHS och märkordsspråken ... 23
3
Problembeskrivning ...24
3.1 XML - inte bara möjligheter ... 24
3.2 Problemspecificering... 26 3.3 Avgränsning ... 26 3.4 Förväntat resultat ... 26
4
Metod ...27
4.1 Om vetenskapligt utredningsarbete ... 27 4.1.1 Perspektiv... 27 4.1.2 Angreppssätt ... 28 4.1.3 Struktur ... 284.2 Förutsättningar hos problemet... 29 4.3 Möjliga metoder ... 30 4.3.1 Litteraturstudie... 30 4.3.2 Simulering... 30 4.4 Val av metod ... 30
5
Genomförande...33
5.1 Litteraturstudie ... 33 5.1.1 Tillgången på material ... 335.1.2 Klarar XML av sina tänkta uppgifter? ... 33
5.1.3 Vilka lösningar och utvecklingsstrategier föreslås? ... 35
5.1.4 XQL ... 36
5.1.5 Andra föreslagna frågespråk ... 39
5.1.6 ”LORE” – Ett DBHS för XML... 42
5.1.7 SAX och Java... 43
5.1.8 Microsoft och XML ... 44
5.1.9 Summering... 44
5.2 Simulering ... 46
5.2.1 Praktiska förutsättningar ... 46
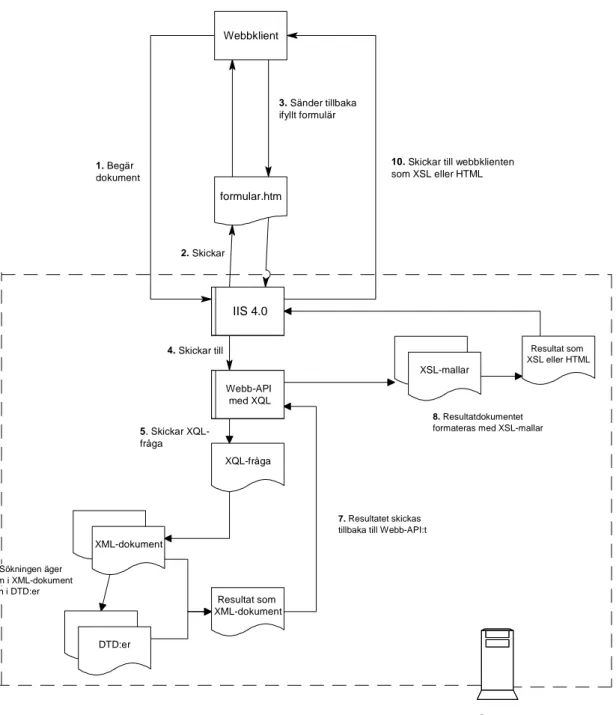
5.2.2 Beskrivning av prototypsystemet... 47
5.2.3 XML-versionen - avgörande problem tillstöter ... 49
5.2.4 Fortsatta problem – XQL och API-kopplingar ... 52
6
Analys av genomförandet ...55
6.1 Litteraturstudie ... 55
6.1.1 XML som datalagrare ... 55
6.1.2 Utvecklingsförslag ... 56
6.2 Simulering ... 58
7
Slutsats och diskussion ...60
7.1 Slutsats... 60
7.2 Diskussion ... 62
7.2.1 Generella synpunkter ... 62
7.2.2 Om litteraturens och källornas kvalitet ... 62
7.2.3 Effektivare utveckling av XML ... 63
7.2.4 Förslag till fortsatt utredningsarbete ... 65
Bilagor ...69
Bilaga 1 - Tabeller över RDBHS-versionen av prototypsystemet... 70
Bilaga 2 – Relationer för RDBHS-versionen av prototypsystemet ... 74
Bilaga 3 – Exempel på HTML-dokument för webbgränssnittet... 75
Bilaga 4 – Exempel på ASP-applikation för Bilaga 3 ... 76
Bilaga 5 – Dynamiskt HTML-dokument från Bilaga 4 ... 78
Bilaga 6 – XML-versionen av prototypsystemet – DTD:er ... 79
Bilaga 7 – XML-versionen av prototypsystemet – XML-dokument... 85
Bilaga 8 – XML-versionen av prototypsystemet – XSL:er ... 95
1 Inledning
Sedan mitten av 1990-talet har användningen av Webben ökat explosionsartat. Befintliga informationsprocesser har omarbetats och kompletterats till att kunna göras tillgängliga över Webben. Vidare har även nya informationstillämpningar gjorts möjliga tack vare Webbens egenskaper. I takt med att användningen nått fler användargrupper och kompletterats med nya tekniska möjligheter, har kraven och lösningarna på webbtillgängliga gränssnitt blivit allt mer omfattande och sofistikerade. Ytterligare pådrivande faktorer bakom denna utveckling är att webbplattformen börjat användas till organisations- och företagsinterna system, så kallade ”intranät”, samt att andra kategorier av system, däribland databaser, har kommit att integreras med de webbaserade systemen. Den huvudsakliga programutvecklingsplattform som använts inom webbutveckling har bestått av märkordspråket HTML. Med den ökade nivån av komplexitet och krav på funktionalitet i de webbtillgängliga systemlösningarna, har HTML kommit att bli allt mer otillräckligt för att lösa utvecklingsuppgifterna, då systemkraven har passerat den samlade funktionalitet som HTML ursprungligen utrustats med. Parallellt med utvecklingen av de webbtillgängliga gränssnitten har nya behov och krav uppstått, bestående i att kunna publicera Webben på nya plattformar såsom till exempel mobiltelefoner, hushållsapparater och handdatorer. Nya tekniker som till exempel mobilt Internet, WAP och e-handel, har kommit att ställa än mer långtgående krav inom bland annat behovet av struktur, centraliserad hantering av data och en hög nivå av flexibilitet och anpassningsbarhet vad gäller hur webbinformation skall definieras och kategoriseras. I syfte att tillföra en ny webbfokuserad teknik som skall avhjälpa de brister som observerats i HTML, samt möjliggöra webbtillgänglighet över de nya plattformar som utvecklats, har standardiseringsorganisationen för HTML, ”World Wide Web
Consortium” (W3C) sedan 1996 arbetat med ett nytt märkordspråk kallat XML. En
version 1.0 av XML presenterades av W3C i slutet av oktober 1998. Med detta nya språk skall utvecklaren själv, med utgångspunkt i samma märkordsmiljö som finns i HTML, kunna utveckla egna element- och attributdefinitioner, deklarera egna strukturer för informationen samt kunna definiera layout- och formateringsinnehåll av informationen separerat från de informationsbärande dokumenten. Genom att skapa element- och attributdefinitioner tillsammans med strukturella regler i särskilda dokument, kan till exempel två affärspartners använda varandras definitioner för att upprätta automatiska transaktionsdokument. Denna möjlighet öppnar för en helt automatiserad hantering av till exempel ordrar, följesedlar och fakturor. Vidare kan utvecklare i XML skapa mallar för att formatera XML-informationen mot olika publiceringsmiljöer. Mallarna ifråga utvecklas med ett eget språk (XSL) och med layout- och formateringsdefinitionerna åtskilda från själva informationen, kan samma XML-dokument via olika XSL-mallar, publiceras på vitt skilda webbplattformar, till exempel mobiltelefoner, handdatorer och standarddatorer.
I diskussionen och framställningarna om möjligheterna med XML, är det ofrånkomligt att observera att XML kommer att behöva interagera med olika former av befintliga databaser eller webbtillgängliga system där databaser utgör en central komponent. Det är därför viktigt att försöka utreda på vilket eller vilka sätt XML är planerat att fungera i detta avseende samt vilken roll XML kan bedömas få vad gäller datalagrande uppgifter.
Frågeställningen motiveras av att databaser, och då i synnerhet de så kallade relationsdatabaserna, ofta förekommer som centrala komponenter i webbtillgängliga system. Vidare har stora ekonomiska resurser investerats i dessa databaser och dess omgärdande system. Det här projektet inriktar sig därför på att utreda huruvida XML enligt sin standard, är förberett att hantera integration och interaktion med, i synnerhet, relationsdatabaser och om så är fallet, hur denna integration och interaktion kan förväntas fungera.
2 Bakgrund
I det här kapitlet presenteras och förklaras grundläggande begrepp och kompetensområden som är nödvändiga att känna till för att kunna tillgodogöra sig det fortsatta materialet i arbetet.
Inledningsvis presenteras en grupp av programspråk som benämns ”märkordsspråk” (eng. ”markup languages”) till vilken bl.a. ”eXtensible Markup Language” (XML) hör. Därefter presenteras databasteknologi inom ramen för relationsdatabaser och användning av sådana i samband med tillämpningar på ”World Wide Web” (WWW).
2.1 Märkordsspråk
Begreppet ”märkord” (eng. ”markups”) kommer ursprungligen från det typografiska området där märkord användes för att instruera en sättare eller typograf hur en text skulle se ut i färdig form [Uvl00]. Märkordstekniken bestod bl.a. i vågig understrykning för att markera fetstil och särskilda symboler för att markera användning av vissa typsnitt. När denna hantering datoriserades kom begreppet märkord att omfatta alla former av noteringar och tillägg i dokument som avsåg information kring sättning, layout och eventuella processer som skulle företas i samband med skapandet av dokumentet. Den ursprungliga domänen av märkordstekniker och märkordsspråk betecknas som procedurella, då de redogör dels för informationens kontext och struktur, men också för vilka processer och vilken hantering informationen skall genomgå för att nå fram till det önskade resultatet. Återstoden av det här delkapitlet kommer att ägnas åt att introducera en familj av datorbaserade märkordsspråk, i vilken bl.a. XML hör hemma. Inledningsvis presenteras ett ursprungsspråk, kallat SGML, vars koncept och arkitektur utgör grund åt de i tiden senare, men med SGML besläktade, märkordspråken HTML och XML. Presentationerna av SGML och HTML tar inte sikte på att vara detaljerade utan avser endast ge en översiktlig grund till hur utvecklingen har löpt från SGML till HTML och nu senast från SGML och HTML i kombination till XML.
2.2 SGML
Publicering av datorbaserad information bjuder förutsättningar som i vissa fall kan betraktas som problem. Publicering är till exempel beroende på datorplattform, operativsystem, applikationer för publicering och filformat för informationslagring. Således kan publicering försvåras eller i värsta fall omöjliggöras, då information som är skapad i en typ av datormiljö inte på ett korrekt sätt kan åskådliggöras i en annan typ av datormiljö [Vik96].
Redan 1969 iscensattes ett arbete av Goldfarb, Mosher och Lorie vid IBM vilket gick ut på att finna ett programspråk eller en kodningsmiljö som skulle kunna användas till att märka upp information efter struktur och kontext [Vik96, Gol90]. Arbetet resulterade i ett språk som med hjälp av så kallade ”taggar” kan förse datorbaserade dokument med metainformation. Metainformationen beskriver innehåll och struktur men inte utseendet eller layouten hos informationen.
Språket, som initialt benämndes ”Generalized Markup Language” (GML) kom senare att utvecklas till ”Standard Generalized Markup Language” (SGML) vilket är en ISO-standard1 (ISO 8879:1986) som senast reviderades 1991.
SGML kan användas i sammanhang där utvecklare vill strukturera och publicera tidigare pappersbaserad information som upprättats i datorbaserad upplaga. SGML kan vidare förse utvecklare med möjligheter att skapa en informationskälla som är fri från metainformation kring utseende och layout. Avsaknaden av layout-information möjliggör att samma SGML-källa, via separata, från SGML åtskilda, layoutdefinitioner, kan användas som bas för publicering mot olika medier [Uvl00]. SGML kan således möjliggöra en effektiv publicering mot olika datormiljöer men också en centraliserad hantering av till exempel uppdateringar och revideringar av informationen.
2.2.1 Tre gemensamma faktorer
Ur pappersbaserad information kan tre gemensamma faktorer identifieras [Vik96]. Faktorerna utgörs av:
• Innehåll • Struktur • Utseende
SGML tar sikte på att beskriva ett dokuments innehåll och struktur och utelämnar således utseendet eller layouten. Innehållet beskriver dokumentets faktiska innehåll i termer av text, bilder, tabeller och andra typer av information. Strukturen beskriver dokumentets uppbyggnad i termer av till exempel rubriker, brödtext, listor, kommentarer samt strukturens relationer. En strukturell relation kan till exempel utgöras av att en rubrik på nivå tre aldrig kan föregå en rubrik på nivå ett i samma stycke eftersom detta skulle bryta mot dokumentets struktur. Således har dokument en struktur av mer eller mindre komplexitet.
SGML fäster inget hänseende vid dokumentets utseende och på så sätt lämnar dokument kodade i SGML öppet för flera från SGML åtskilda layoutlösningar. Layoutdelen av ett system som implementerat SGML, får hanteras av de komponenter i systemet som använder sig av SGML-källorna, då SGML självt inte uttrycker någon information i termer av layout eller utseende.
2.2.2 DTD och ”taggar”
Metainformation som beskriver ett dokuments struktur samlas i särskilda filer som beskriver regler för dokumentets element, relationer och olika dokumentdelar. Filerna benämns ”Document Type Definitions” (DTD’s) [Vik96, Uvl00]. DTD:n innehåller definitioner om vilka element som informationen består av. Vidare kan DTD:n ange elementens datatyp i termer av ett eller flera element, ”parsed” data från dokumentet självt (vilket kan vara vilken valid datatyp som helst, till exempel text, heltal, booleska värden och strängar) eller av en ”non-parsed” datatyp, till exempel en kommentar.
1 Den fullständiga ISO-beteckningen lyder enligt: ”ISO 8879:1986 – Information Processing – Text and Office Systems – Standard Generalized Markup Language (SGML)”.
Uppmärkningen av informationen i dokumentet som skall SGML-kodas, äger rum med hjälp av s.k. ”taggar” av vilka det finns en ”start-tagg” och en ”slut-tagg”. Taggar skrivs inom jämförelsetecknen ”större än” respektive ”mindre än” enligt:
<starttagg> information </sluttagg>
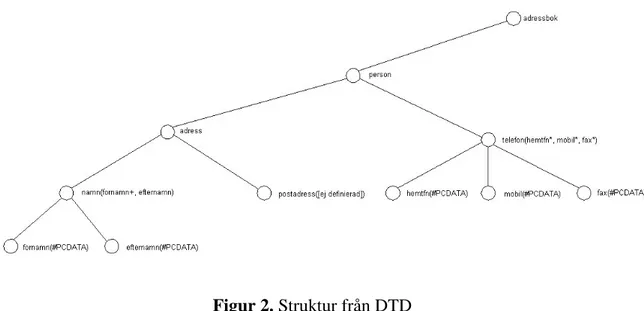
En tagg beskriver att ett stycke information tillhör ett visst element. DTD:n kan som tidigare nämnts ange ett elements datatyp som en typ sammansatt av andra i DTD:n förekommande element. DTD:n använder sig av en enkel deklarativ syntax som beskriver elementets namn och typ. Figur 1, som är ett icke fullständigt utdrag ur en DTD för en adressbok, beskriver ett exempel på hur syntaxen för DTD:er ser ut.
<!DOCTYPE adressbok [
<!ELEMENT adressbok - - ((person+), +(not | ant))>
<!ELEMENT person - - (adress+, telefon*)>
<!ELEMENT adress - - (namn, postadress)>
<!ELEMENT namn - - (fornamn+, efternamn)>
<!ELEMENT fornamn - 0 (#PCDATA)>
<!ELEMENT efternamn - 0 (#PCDATA)>
<!ELEMENT telefon - - (hemtfn*, mobil*, fax*)>
<!ELEMENT hemtfn - 0 (#PCDATA)>
<!ELEMENT mobil - 0 (#PCDATA)>
<!ELEMENT fax - 0 (#PCDATA)>
<!ELEMENT (not | ant) - - ((#PCDATA), -(not | ant))> ]>
Figur 1. DTD-syntax
En genomgång av DTD-exemplet ger att en elementdefinition inleds med det i SGML-standarden reserverade ordet !ELEMENT, som därefter följs av ett beskrivande
elementnamn (adressbok), därefter av en förekomstindikator (- -) och
avslutningsvis av en datatypsdefinition med tillhörande så kallade gruppkopplingsindikatorer (((person+), +(not | ant))).
• !DOCTYPE är ett reserverat ord enligt SGML-standarden och det anger med ett
nyckelord dokumentets typ. Dokumenttypen i Figur 1 utgörs följaktligen av en
”adressbok”. Notera att dokumenttypsnamnet måste vara av samma slag som
elementet på den högsta nivån i strukturen, det vill säga rotelementet. Varje ny DTD inleds med en <!DOCTYPE[]>-definition och den kan bara
förekomma en gång per DTD.
• !ELEMENT är ett reserverat ord enligt SGML-standarden. Det inleder
definitionen av en elementtyp i en DTD.
• adressbok är ett exempel på ett elementnamn.
• - - är ett exempel på en förekomstindikator. Denna kombination innebär att
elementet måste ha både en start-tagg och en slut-tagg. En 0:a innebär ett utelämnande (men att det fortfarande är tillåtet att ha med taggen).
• (person+) är ett exempel på en datatypsdefinition som i det här fallet utgörs
av ett annat element. +-tecknet är en så kallad gruppkopplingsindikator vilken anger att elementet får förekomma en (tvingande) eller flera gånger. Övriga gruppkopplingsindikatorer är ?-tecknet som anger att elementet kan förekomma en och högst en gång men att det inte är tvunget att elementet förekommer. Vidare anger *-tecknet att elementet kan förekomma en eller
flera gånger men att det även helt kan utelämnas. Saknas gruppkopplingsindikator anger detta att elementet skall förekomma en och endast en gång. #PCDATA (”parsed character data”) är en reserverad datatyp
som anger att vilken i dokumentet valid datatyp som helst kan användas. Denna datatyp är den mest förekommande och det är denna datatyp som hanterar den specifika informationen i dokumentet.
• Vi kan i SGML styra nästlade element genom att använda + och – före
respektive efter datatypsdefinitionerna. Figur 1 anger för elementet adressbok att elementet (not | ant) (avser i det här fallet en ”notering” och/eller en
”anteckning”) kan förekomma var som helst i adressboken, det vill säga inom
<adressbok> </adressbok>. Det sammansatta elementet (not | ant) i sin
tur måste ha både en starttagg och en sluttagg till följd av att det kan förekomma fritt i adressboken. Elementets datatyp är #PCDATA men innehåller
också tillägget att elementet inte får innehålla några nästlade element av sin egen typ, vilket ges av -(not | ant).
• Utöver vad som visas i Figur 1, finns också möjligheter att med hjälp av |
-tecknet ange selektioner i datatypsdefinitionerna enligt exemplet i Figur 1:
Elementet telefon kan bestå av exakt en (ej tvingande) element av typen
hemtfn eller mobil eller fax. Med ”eller” avses i detta fall inklusivt eller.
Ur DTD:n kan vi också ana hur dokumentets struktur har definierats. Ur Figur 1 kan vi se att strukturen bildar ett träd, vilket illustreras i Figur 2.
Figur 2. Struktur från DTD
2.2.3 Attribut
Elementen som definieras i en DTD kan utöver specifikationerna av deras datatyper, förekomstindikatorer och gruppkopplingar också förses med attribut. Ett attribut ger information som är relevant för ett element men inte för den information som elementet märkt upp.
<person id=1 kategori=kamrat> (…) </person>
Figur 3. Attribut hos ett element – utrdag ur SGML-dokumentet
Figur 3 återger ett exempel i vilket elementet person har försetts med två stycken attribut, ett som anger ett ID-nummer (en räknare) för elementet ifråga och ett som anger vilken kategori elementet tillhör.
<!ATTLIST person
id ID #IMPLIED
kategori (kamrat | arbete | slakting) kamrat>
Figur 4. Deklaration av attribut för ett element – utdrag ur DTD-dokumentet
Attribut definieras i DTD:n med hjälp av det reserverade ordet !ATTLIST enligt Figur
4. Syntaxen är mycket lik den för definitionen av element och deklarerar en lista av giltiga attribut för ett eller flera element. Vidare deklareras för varje attribut dess namn, vilka värden attributet kan anta samt vilket värde som attributet antar som standard (eng. ”default value”).
De värden som ett attribut kan anta kan uttryckas med hjälp av kombinationer av andra element (med villkor, såsom selektioner, tvingande eller icke tvingande o.s.v.) samt med hjälp av något av de i SGML reserverade orden:
• ID – vilket anger ett för elementet unikt numeriskt värde.
• CDATA – ”character data”, vilket är ett värde som SGML utelämnar vid
”parsing”. Detta värde kan användas för att till exempel skapa en kommentar
eller använda taggar som vi vill att SGML skall ignorera.
• IDREF – vilket anger att attributet pekar (refererar) till något annat element.
• NMTOKEN – vilket anger att attributet kan anta en godtycklig giltig sträng av
numeriska värden
• NUMBER – vilket anger att attributet endast består av tal.
Som avslutning i attributdeklarationen anges vilket standardvärde ett attribut kan eller måste anta. I de fall där ett attribut deklarerats i termer av ett annat eller av andra element kan antingen elementet eller något av de förekommande elementen väljas som standardvärde. Figur 4 illustrerar detta för attributet ”kategori”, vilket har
”kamrat” som standardvärde. Utöver ett element kan också ett attribut anta något av
följande i SGML fördefinierade standardvärden:
• #REQUIRED – anger att ett standardvärde måste deklareras.
• #IMPLIED – anger att ett standardvärde kan utelämnas.
• #CURRENT – anger att det senast angivna värdet för attributet antas.
En slutlig genomgång av Figur 4 ger oss att det för elementet ”person” deklareras två
stycken attribut, id och kategori, för vilket id antar värden av den reserverade typen ID och för vilket attribut antar värden av något av elementen kamrat, arbete eller
slakting. Standardvärde för id kan utelämnas och för kategori är det elementet
kamrat.
2.2.4 Entiteter och markerade sektioner
Dokumenttyper, element och attribut har samtliga att göra med SGML:s taggar och den uppmärkning av ett dokument som dessa kan utföra. SGML innehåller dock en funktion som kan användas för att namnge och urskilja godtyckliga delar av ett dokument. I SGML betecknar en entitet en namngiven del av ett uppmärkt dokument, eller ett helt dokument, som är oberoende av i DTD:erna förekommande strukturella regler. Entiteter deklareras i det uppmärkta dokumentet med hjälp av det i SGML reserverade ordet <!ENTITY> och den kan vara av intern typ eller av systemtyp.
En intern entitet kan till exempel deklareras enligt:
<!ENTITY forfattare ”Lars Olofsson”>
Genom att låta entitetens namn föregås av SGML:s interna kod för ”&”-tecknet kan vi varhelst i dokumentet vi önskar referera till entitetens värde. Textstycket enligt ”Med det här arbetet har &forfattare precis kommit till kapitel 2”
skulle när det blivit inläst enligt SGML resultera i: ”Med det här arbetet har
En entitet kan också utgöras av en referens till en, relativt vårt SGML-dokument, extern resurs. Vill vi till exempel att ett SGML-dokument skall innehålla ett sidhuvud, kan vi definiera en så kallad extern systementitet för ett i förväg upprättat sidhuvud. Referensen kan se ut enligt följande:
<!ENTITY SidHuvud SYSTEM ”sidHuvud.txt”>
Inkluderar vi referensen &SidHuvud på avsedd plats i dokumentet, kommer
innehåller i sidHuvud.txt att åskådliggöras på motsvarande plats.
Systementiteter kan utgöras av filer, resultat av databasfrågor, systemkommandon och andra operationer och objekt som kan utföras inom ramen för operativsystemet i den aktuella datormiljön.
Entiteter ger en SGML-utvecklare möjligheter att på ett centraliserat och effektivt sätt kunna referera till helheter eller delar av dokumentbaserad information.
2.2.5 Att köra SGML-märkt information
Till skillnad från de äldre procedurella märkordsspråksteknikerna är SGML att betrakta som deklarativt [Uvl00]. Detta till följd av att SGML endast tillhandahåller namn som vi kan använda till att kategorisera informationens kontext. Således finns i språket ingen metainformation som anger eventuella processer vid inläsningen av informationen.
SGML kan i sig självt inte generera körbara program utan för detta ändamål krävs en applikation som utrustats med en SGML-tolk [Aho86] så att applikationen kan läsa in SGML-uppmärkta textfiler, som utöver SGML-märkningen också innehåller själva informationen. Vidare måste applikationen på rätt sätt kunna läsa in DTD:erna så att reglerna för informationens struktur kan användas när textfilerna skall formateras till sitt slutliga utseende. Att kunna läsa in DTD:er på ett korrekt sätt medför att applikationens tolk måste ha utrustats med en så kallad ”parser” vilken läser in DTD:n med början vid rotnivån och sedan ut genom respektive nod till dess att den når löven [Aho86]. Att utföra ”parsing” innebär att det inlästa dokumentet valideras mot SGML:s syntax och DTD:ernas struktur. SGML:s plattformsoberoende egenskaper uppnås genom att vi kan utveckla en tolk för respektive datorplattform. En SGML-applikation skapar således körbar SGML i samband med att textfilerna läses in av SGML-tolken tillsammans med att dokumentet valideras mot SGML:s syntax och mot förekommande DTD:er. Funktionssättet ligger till grund för märkordsspråken HTML (som dock är begränsat i jämförelse med SGML, se avsnitt 2.3) och XML, vilka båda har sitt ursprung i SGML.
2.2.6 Sammanfattning om SGML
SGML är ett märkordsspråk med vilket vi kan strukturera och märka upp, dokumentbaserad information. Vi kan skapa egna deklarationer av dokumenttyper, element av information och attribut för elementen. Vidare kan vi referera och hantera skillnader i standardiserad information med hjälp av entiteter och markerade sektioner. SGML ger oss en möjlighet att särskilja informationens innehåll från dess struktur. SGML hanterar inte informationens utseende eller layout utan lämnar öppet för andra tekniker och applikationer att definiera det området.
SGML är ett språk som sparar sin kod i textfiler och som behöver tolkas och valideras för att åskådliggöras i ett datorsystem. Tolkningen och valideringen måste utföras av
till exempel en applikation i vilken det har byggts in stöd för dessa uppgifter. SGML:s arkitektur för körning ger att det kan utvecklas en tolk för varje datormiljö som vi vill kunna köra SGML-koden på. Detta ger indirekt att SGML kan göras plattformsoberoende.
SGML är ett språk som existerat som ISO-standard sedan mitten av 1980-talet och det ligger till grund för de senare utvecklade märkordspråken HTML och XML.
2.3 HTML
År 1989 lade forskaren Tim Berners-Lee vid ”European Laboratory for Particle Physics” (CERN) fram ett förslag till en arkitektur och ett utkast till ett märkordspråk som skulle möjliggöra publicering av dokument över kommunikationsinfrastrukturen Internet [W3C90, W3C99a]. Arkitekturen innehöll två grundläggande idéer, dels att all information skulle göras åtkomlig via så kallade ”URI:s” (eng. ”Universal Resource Indicators”) och dels att det skulle vara möjligt att i dokument kunna referera till andra dokument oavsett URI, så kallade ”hyperlänkar”. Arkitekturen kom senare att ges namnet ”World Wide Web” eller ”WWW”. Märkordspråket som Berners-Lee förordade kom senare att utvecklas till ”HyperText Markup Language” (HTML), vilket idag har nått standard 4.01 och med vilket vi kan skapa dokument avsedda för publicering över WWW [W3C99a].
Det ligger utanför det här arbetets avgränsning att grundligt gå igenom HTML, utan den intresserade hänvisas till W3C:s webbplats på Internet. W3C är en organisation som ansvarar för och definierar HTML-standarden. Målet med presentationen av HTML i det här arbetet är att ge en förståelse kring hur HTML spelar in i utvecklingen av XML samt HTML:s kopplingar till sitt ursprung i SGML.
2.3.1 HTML i relation till SGML
HTML är konstruerat med SGML som grund, vilket bl.a. kan betraktas i HTML:s användning av SGML:s tagg-syntax. Precis som i SGML beskriver taggarna element vilka ger informationen i ett HTML-dokument en viss bestämd innebörd. Taggarna kan vidare förses med attribut vilket också följer SGML:s modell [W3C99a]. Vidare delar HTML med SGML förfarandet med behovet av en tolk för språket Det åligger således en HTML-användande applikation att tolka HTML-koden och dokumenttypsdeklarationerna när HTML-dokument skall åskådliggöras. En mycket spridd typ av applikationer för att läsa in HTML-dokument i allmänhet, samlas under beteckningen ”webbläsare”.
På en viktig punkt skiljer sig dock HTML från SGML, och den punkten avser tekniken med DTD:er. I HTML är det till skillnad från SGML inte möjligt att definiera egna DTD:er och därmed egna element, attribut eller entiteter. Istället är HTML utrustat med i förväg upprättade och i språket inbyggda DTD:er (beroende på HTML-version) som definierar vilka element som kan användas, vilka regler som gäller för förekomstindikatorer, vilka attribut de olika elementen kan använda sig av, samt vilka datatyper elementen kan lagra [W3C99a]. Gruppkopplingsindikatorerna är även de deklarerade som standard.
Ett exempel på en DTD för HTML är DTD:n som deklarerar HTML version 4.01, det vill säga hela språkets dokumenttypsdeklaration i en enda DTD. För att markera att ett dokument är ett HTML-dokument av standard 4.01 inkluderas som första rad i dokumentet ifråga, koden enligt Figur 5.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
Figur 5. DTD-deklaration av ett HTML 4.01-dokument
HTML:s förfarande med en enda DTD innebär en mycket viktig observation som vi tar med oss vidare in i diskussionen om XML i avsnitt 2.3. Förfarandet ger oss att vi är bundna att använda oss av den element- och attributsamling som konstruktörerna
(W3C) förser oss med i standardens DTD. Ett exempel av ett stycke HTML-kodad information kan därför se ut enligt exemplet i Figur 6.
<HTML> <HEAD>
<TITLE>Ett exempel på ett HTML-dokument</TITLE> </HEAD>
<BODY>
<H1 COLOR=”#0000FF” ALIGN=”left”>Detta är en rubrik på
nivå 1. </H1>
<P ALIGN=”center”>Detta är ett stycke brödtext</P> <A HREF=”http://www.w3c.org”>Detta är en
hyperlänk till W3C.</A> </BODY>
</HTML>
Figur 6. Ett enkelt HTML-dokument
Ur Figur 6 kan vi se att HTML:s rotelement utgörs av <HTML>-elementet. Vidare är
HTML specificerat enligt att <HEAD>-elementet, som innehåller metainformation om
dokumentet, alltid följer direkt på rotelementet och att <HEAD>-elementet alltid följs
av <BODY>-elementet, vilket innehåller den information som kan göras synlig i en
applikation, till exempel en webbläsare. Figur 6 ger också exempel på både metainformationselement och på element för att hantera dokumentets innehåll.
<TITLE> anger dokumentets titel, <H1> anger att texten är en rubrik på nivå ett, <P>
anger att texten är brödtext och <A HREF> anger en hyperlänksreferens till ett annat
HTML-dokument som finns vid URI:n ”http://www.w3c.org”. Vi kan också se
exempel på användandet av attribut hos <H1>-elementet (”COLOR” för textens färg och
”ALIGN” för textens relativa placering) och hos <P>-elementet (”ALIGN”, som för
<H1>).
Attributens funktion enligt Figur 6 ger oss en ytterligare indikation på en skillnad i funktionalitet mellan HTML och SGML, nämligen att HTML ger anvisningar om dokumentets utseende och layout, något som SGML inte gör.
Vad beträffar HTML:s förmåga att skapa referenser till andra HTML-dokument vid samma eller en från det aktuella dokumentet åtskild URI, benämns denna förmåga ”HyperText References” (”hyperlänkar”) och de är specialfall av entiteter i HTML. En hyperlänk refererar absolut eller relativt till ett annat HTML-dokument eller en kombination av URI och dokumentnamn (filnamn). Det är främst upp till webbläsaren att i dokumentet särskilt åskådliggöra hyperlänken, men senare HTML-standarder har även utrustat hyperlänksentiteten med vissa attribut för att ytterligare kunna styra layouten av densamma.
Vi finner alltså att HTML:s koncept till sin helhet ärvt SGML:s syntax, arkitektur (element, attribut, entiteter och så vidare), exekveringssätt och indirekta plattformsoberoende. Till skillnad från SGML har dock HTML inskränkts till en i förväg upprättad DTD med tillhörande uppsättning av element, attribut och entiteter samt att språket har utrustats med möjligheter att uttrycka utseende och layout hos dokumenten.
2.3.2 HTML byggs ut och kompletteras
Från de första enkla textdokumenten som publicerades vid CERN har webben idag utvecklats till ett gränssnitt för miljoner användare och med sammanhang och syften som spänner över mycket stora och vitt skilda områden. Idag utvecklas hela informationssystem som använder webben som primärt gränssnitt, så kallade ”webbapplikationer” [Eng98].
Den miljö och de krav under vilka HTML idag används för att utveckla allt mer avancerade och komplexa webbaserade informationssystem ställer långt fler och högre krav på språket än vad det ursprungligen skapades för att hantera. Bland annat ställs idag krav på att i detalj kunna styra layouten genom att till exempel exakt placera text- och bildelement på gränssnittet och detta oavsett datorplattform. Vidare skall webbläsaren kunna läsa in och skicka iväg data till en server i syfte att till exempel kunna utföra sökningar eller manipulera data i databaser. Ytterligare krav är att HTML-dokumenten skall kunna agera interaktivt på till exempel olika val i en flerstegsprocess, som gås igenom av en användare.
De utökade och kontinuerligt tillkommande kraven orsakar svårigheter och problem för HTML av bland annat följande anledningar:
• HTML:s attribut som styr layoutfunktioner skapades till att endast uttrycka
format i relativa termer. Detta medför att det till exempel är svårt att i ett HTML-dokument exakt styra placeringen på bildskärmen av ett stycke text eller en bild, vilket vi kan göra i andra applikationer som till exempel ordbehandlare. Beroende på datorplattform och webbläsare kan textstyckets storlek och placering i ett HTML-dokument variera [Mor99].
• Webbens tekniska grund består i att en webbserver på begäran av en viss URI
från en klient (webbläsare) skickar dokument till klienten som därefter tolkar och slutligen åskådliggör informationen för användaren. Det finns således inga möjligheter för en klient att modifiera HTML-dokument på en server, en begränsning som har sin grund i kravet på säkerhet för system och information hos en server. Envägskommunikationen ger att HTML inte kan uppfylla krav på att användaren till exempel skall kunna skicka tillbaka data till servern eller att materialet på servern skall kunna förändras beroende på hur användaren reagerar på och därefter manipulerar den information vederbörande har förevisats av servern [Mor99].
• HTML innehåller till sin grund inget stöd för interaktivitet eller föränderligt
beteende hos det material som märkts upp. HTML-dokument är i grunden statiska, vilket rimmar illa med typiska krav på applikationer vilka till exempel kan utgöras av menyer, knappar, bläddringsbara fomulär, bildväxlingar med flera
I syfte att möta de ökade kraven har dels HTML utvecklats till nya standarder och dels har kompletterande tekniker tagits fram för bland annat servrar och webbläsare. En översikt ger följande [Eng98]:
• HTML har utökats med nya elementdefinitioner. Bland annat har språket fått
element för att kunna hantera formulär, olika typer av fält, så kallade ”lager” samt element som kan läsa in data från tilläggsprogram som till exempel ”java-appletar”.
fram en hierarkisk objektmodell (eng. ”Document Object Model” DOM) för HTML-dokumenten [Goo98]. Rotobjektet utgörs av webbläsaren självt och därefter följer noder i form av överordnade element ned till löven som utgörs av all #PCDATA i dokumentet. DOM:en medger till exempel att servern och
dess interagerande tillägg i form av program, skript, databaser och andra komponenter, tillsammans med klienternas skriptspråk kan referera till hela eller olika delar av det formaterade HTML-dokumentet.
• Kommunikationsprotokollet för HTML-dokument mellan URI:erna och
klienterna, ”HyperText Transfer Protocol”, ”HTTP”, har tillförts ett särskilt gränssnitt för att kunna skicka och ta emot data. Detta gränssnitt benämns ”Common Gateway Interface” eller ”CGI” [Dee96]. Med CGI är det till exempel möjligt för en server att ta emot en textsträng från en klient där användaren har matat in strängen i ett textfält och sedan klickat på en knapp i gränssnittet för att skicka strängen till servern. Textsträngen kan härefter behandlas av servern och generera ett resultat som skickas tillbaka som ett nytt HTML-dokument till klienten.
• Servrarna har utrustats med programspråk som kan exekveras före,
tillsammans med, eller åtskilt från HTML-dokumenten. Tekniken möjliggör till exempel att HTML-koden skapas i det ögonblick som dokumentet efterfrågas av klienten eller en annan process på servern. Teknikerna kallas också för ”inbakade skript” (eng. ”embedded scripts”) eller dokumentbaserade applikationer.
• Servrarna har också utrustats med dels kopplingar mellan servern och
datormiljön i övrigt och dels med särskilt utvecklade skriptspråk. Den första kategorin innebär till exempel att servern kan skicka och hämta data från befintliga applikationer, från särskilt skrivna program och från databashanterare [Mic98]. Den andra kategorin möjliggör för servern att kunna samköras med särskilt utvecklade program som skrivits i språk som fokuserar på att ge utbyggnadsmöjligheter hos servern och skapa en länk mellan servern och datormiljön i övrigt. Bland de för ändamålet särskilt utvecklade skriptspråken finns bland andra ”ASP” från Microsoft Corporation och ”PHP3” som är ett oberoende utvecklingsprojekt. Skriptspråken kan utnyttja kopplingar mot andra program, databashanterare och andra datorer, vilket ger möjligheter för en utvecklare att göra en server med HTML-dokument betydligt mer interaktiv och dynamisk, än vad HTML ensamt förmår att prestera. Skriptspråken och kopplingarna benämns serverbaserade applikationskomponenter.
• Även klienterna har utrustats med kompletterande skriptspråk. Språken kan ge
dokumenten interaktiva beteenden genom att de till exempel kan kontrollera inmatningar i fält samt hämta data och funktioner från den datormiljö som klienten befinner sig i, och inkludera denna data och dessa funktioner i det formaterade HTML-dokumentet [Goo98]. Teknikerna benämns klientbaserade applikationskomponenter
Vi finner att HTML har behövt utrustas med utökad inneboende funktionalitet i form av nya element, attribut och entiteter. Utöver detta har det mot olika strategier (serverbaserat eller klientbaserat) tagits fram nya komponenter och skriptspråk vilka har gjort det möjligt att koppla ihop ett datorsystems befintliga resurser i form av till exempel applikationer och databaser med den aktuella URI:ns server, samt att det har
blivit möjligt att särskilt utveckla program som bygger ut URI-serverns respektive klientens funktionalitet. Den samlade kombinationen av olika strategier, tekniker och komponenter används idag till att utveckla komplexa och omfattande webbapplikationer.
2.3.3 Kritik mot lappverket
Arbetet tar sikte på att presentera märkordspråket XML vars utveckling har sina incitament bland annat i HTML:s inneboende tillkortakommanden vad gäller att bereda möjlighet till dynamik, föränderlighet och anpassning i webbapplikationer. I fallet med HTML har vi nu sett hur det har varit nödvändigt att utveckla kompletterande tekniker och komponenter vilket har skapat ett ”lappverk” av standarder, språk, förutsättningar och begränsningar. Att vissa skriptspråk endast kan exekveras på vissa datorplattformar, att vissa element i HTML är beroende av en viss klientutvecklare och att klientbaserade komponenter kan öppna säkerhetsluckor i systemet, är exempel på aspekter och problem som dagens utvecklare av webbapplikationer har att arbeta med.
Kärnan till problemen består i att dagens krav på webbapplikationer går bortom den funktionalitet som HTML till sitt ursprung utvecklades att prestera. HTML:s tillkortakommanden i dagens kravmiljö, samt nya gränssnitt och plattformar för webben har tillkommit och medfört att behovet av ett nytt märkordsspråk, en arvtagare till HTML, har vuxit fram under de senare åren av 1990-talet.
2.4 XML
Vi har presenterat HTML som ett specifikt märkordsspråk med en ursprunglig tämligen begränsad uppgift och ett specificerat tänkt tillämpningsområde, det vill säga webben. Vi har betraktat hur webbens ökade användning kommit att ställa nya, mer omfattande och mer komplexa krav på dels HTML, men även på hela informationssystemslösningar som har webben och HTML som huvudsaklig plattform. Vi har avslutningsvis noterat hur tillägg och sidotekniker kring HTML har utvecklats tillsammans med HTML självt, för att kunna svara mot de ökande kraven. När HTML och dess tillhörande ”lappverk” av tilläggstekniker kom att bli allt mer svåröverskådliga, initerades 1996 av bland andra W3C och företaget Sun Microsystems ett utvecklingsarbete kring ett nytt språk som skulle kunna komma tillrätta med HTML:s brister. Arbetet skulle även syfta till att utöka webbens tillgänglighet på nya plattformar, till exempel mobiltelefoner, handdatorer och specialdatorer [W3C98, Mor99]. Utvecklingsarbetet benämndes inledningsvis ”The SGML Review Board” vilket avslöjar att strategin för att utveckla ett nytt märkordsspråk hade sin grund i att utgå från SGML. Till en början bestod utvecklingen i att återgå till SGML genom att använda SGML:s arkitektur och konstruktionsidé som grund för det nya språket. Vidare ställdes krav i form av till exempel enkel hantering av språket, att det skulle gå snabbt att skriva dokument, att språket skulle vara helt kompatibelt med SGML samt att språket skulle kunna tillämpas inom hela webben, både på de idag kända och på kommande plattformar. Med ”eXtensible Markup Language” (XML) skall det bli möjligt för utvecklare att definiera egna element, attribut, entiteter och strukturella regler och lägga upp dem i DTD:er [W3C98]. Därefter skall dokument kunna märkas upp med dessa egendefinierade DTD:er som grund. Vi finner med detta funktionssätt en exakt likhet med SGML, vilket på samma sätt som SGML, gör XML till ett metaspråk för uppmärkning av dokument. Tolkningen av dokument åligger en XML-processor att utföra, det vill säga en applikation som utrustats med en XML-tolk. Exekveringssättet är utformat på samma sätt som hos SGML. XML delar med HTML en dokumentobjektsmodell (”XML Document Object Model” (XDOM)) som tar sin början i XML-dokumentet självt istället för i webbläsaren som är fallet med HTML, vilket naturligtvis beror på att klienten (XML-processorn) i fallet med XML inte är lika självklart definierad som i fallet med HTML. HTML har till sin största del kommit att användas med hjälp av webbläsare. XML förväntas däremot få en mer allmän tillämpning i form av operativsystem, standard applikationer samt, för respektive XML-system, särskilt utvecklade applikationer [Mor99]. På motsvarande sätt som i fallet med DOM kan XDOM användas till att med utgångspunkt i DTD:erna för XML-dokumentet ifråga, referera till element, attribut, entiteter, XSL:er (se 2.4.1.) och olika former av länkar (se 2.4.2.).
2.4.1 XML tar ett steg vidare med XSL
XML är i enlighet med de krav som sattes upp inför utvecklingen av språket, helt kompatibelt med SGML, men det går även vidare och definierar tekniker för att beskriva layout. För layout och formateringsinstruktioner av XML-dokument används ytterligare en fristående dokumenttyp som benämns stilmall (eng. ”style sheet”) vilken utvecklas i märkordsspråket ”eXtensible Style Language”, (XSL) [W3C00a]. Genom att särskilja XML som hanterar själva dokumentet och dess information, från stilmallar, behåller XML fullständig kompatiblitet med SGML. XML tar dock ett steg
vidare genom en teknik som åtskilt från XML-dokumenten, definierar separata stilmallar, av vilka det kan utvecklas en för varje publiceringsändamål. Detta ger att samma XML-dokument kan ges olika layout och format via stilmallar beroende på klient, plattform eller behörighet hos användaren [Mor99, Sta99]. Det är också i fråga om stilmallar och XSL som XML börjar skilja sig från SGML. Vi kan alltså så här långt i diskussionen om XML utan modifieringar eller andra åtgärder använda oss av det adressboksexempel med tillhörande DTD som vi tog upp under presentationen av SGML2 (Figur 1.).
XSL är även det ett märkordsspråk vilket använder sig av procedurella satser som till exempel iteration och selektion [W3C00a]. Vidare kan XSL matcha element- och attributnamn för att deklarera en viss stil för ett visst element eller attribut, samt uttrycka i vilken omfattning stilen skall tillämpas.
XSL-processen består av två huvudsteg. Inledningsvis inventeras XSL-dokumentet efter formateringsinstruktioner och jämförs därefter mot den XML-fil som XSL-dokumentet skall formatera. Denna process benämns ”XSLT” eller ”XSL-Transformation”. När XSLT är avslutad och formateringen har passerat XSL-tolken utan fel, formateras slutligen själva dokumentet till det utseende som den mottagande applikationen kan ta emot [Mor99, W3C00a]. Figur 7 åskådliggör ett exempel på en XSL som formaterar ett SGML- eller XML-dokument, innehållandes adressboken enligt Figur 1, att på HTML-format lista alla personer och de anteckningar som finns om dem.
De operatorer som förekommer i Figur 7 är de operatorer som enligt [Mor99] vunnit störst gehör i utvecklingen av XSL som helhet. Operatorerna är:
• <xsl:stylesheet> - Definierar ett XSL-dokument.
• <xsl:template [select=”[URI | element]” |
match=”[elementNamn]”]> - Definierar en mall för ett element eller en
grupp av element.
• <xsl:for-each select=”[URI | element]”> - itererar en mall för ett eller
flera element.
• <xsl:apply:template select=”[elementNamn]”> - Tillämpar en mall för
ett elementnamn, vilket inte behöver vara exakt det element som förekommer i SGML- eller XML-dokumentet.
Argumenten <(…) xmlns:xsl:”http://www (…)> till <xsl:stylesheet> i Figur 7 utgör sökvägar till av W3C upprättade valideringsdokument för XSL och HTML 4.0. Argumenten anges för att de webbläsare som endast har ett begränsat stöd för XSL, skall kunna validera att XSL-dokumentet ifråga är valid mot det XML-dokument som XSL-dokumentet ifråga är skapat för att formatera.
2 Vi måste dock deklarera dokumentets !DOCTYPE som ett XML-dokument istället för ett SGML-dokument.
<?xml version='1.0'?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl" xmlns="http://www.w3.org/TR/REC-html40" result-ns=""> <xsl:template match="/"> <html> <head> <title>Vår SGML-adressbok</title> </head> <body bgcolor="#FFFFFF"> <xsl:for-each select=”adressbok”> <xsl:apply-templates select=”person” /> <xsl:apply-templates select=”not” /> </xsl:for-each> </body> </html> </xsl:template> <xsl:template match=”person”> <h1><xsl:value-of /></h1> </xsl:template>
<xsl:template match=”(not | ant)”>
<p><xsl:value-of /></p>
</xsl:template> </xsl:stylesheet>
Figur 7. Exempel på XSL-kod för adressboken
Vi kan i Figur 7 se hur till exempel elementet ”<person>” matchas mot
HTML-elementet ”<H1>” och hur varje upprepning av elementet ”<not | ant>” matchas
mot dito elementet ”<P>”. På detta sätt kan vi bygga upp en HTML-layout för ett
XML-dokument, men om vi avser att publicera mot till exempel en applikation som kan tillgodogöra sig XML och XSL, kan vi även bygga en XSL för detta publiceringsmål.
Att samla XSL-formateringen i en eller flera separata filer medger att vi kan administrera layout för samma XML-dokument på ett centralt sätt för alla de publiceringsändamål som vi vill ge XML-dokumenten.
XSL är i sig själv en omfattande märkordsteknik och detta projekt avser endast ta upp de grundläggande steg som krävs för att skapa valida XML- och XSL-dokument. Intresserade läsare hänvisas till W3C:s XSL-dokumentation eller till den facklitteratur som börjat publiceras inom området.
2.4.2 Länkar, XPath, XPointer och XLink
I jämförelse med HTML:s hyperlänkar erbjuder XML betydligt mer komplexa tekniker för referenser och länkning. Det utvecklas för närvarande tre separata standarder för att hantera olika typer av referenser och länkningar. Ingen av dem är
vid det här projektets genomförande ännu någon standard hos W3C utan utgörs endast av arbetsdokument eller utkast. Det är därför fortfarande oklart hur länknings- och referensfunktionerna i XML är tänkta att slutgiltigt fungera. En jämförelse med HTML:s hyperlänkar ger dock att XML vid en och samma referens till exempel kommer att kunna visualisera multipla referenser till andra XML-dokument, delar av dokument eller till och med enskilda element i ett dokument. Vidare kommer XML att vid tolkning av dokumentet direkt kunna inkludera3 information från andra XML-dokument, eller ge användaren en fråga om huruvida inga, delar av, eller alla de referenser som finns vid en referenspunkt skall inkluderas i dokumentet. Ett ”klick” på en länk i ett XML-dokument kommer att kunna presenteras på vanligt HTML-manér, det vill säga att klienten ersätter det länkande dokumentet med det länkade, men också som att det länkade dokumentets innehåll inkluderas i det länkande dokumentets.
Till följd av att referens- och länkningsteknikerna i XML fortfarande befinner sig i ett utvecklingsskede går denna rapport därför endast översiktligt igenom koncepten för de tre länkningsteknikerna [Mor99, W3C99b, W3C99c, W3C00b].
• XPath – är inget XML-kompatibelt eget språk på samma sätt som XSL, då det
inte använder sig av XML-konstruktorer såsom element, attribut och entiteter. Istället använder sig XPath av en URI-liknande syntax med vilken vi kan uttrycka sökvägar i XML-, XSL-dokumentet med hjälp av dess hierarkiska struktur (jämför Figur 2). Vi kan bygga upp referenser till delar av dokumentet genom att på URI-form deklarera en sökväg, till exempel:
#xpath=/adressbok/person/adress/namn/fornamn
Resultatet av länkningen är helt beroende av sammanhanget i vilken länkningen efterfrågades, vilket gör XPath till en abstrakt teknik. Det är upp till XML-processorns kontext att avgöra vad XPath-uttrycket skall få för innebörd.
• XPointer – är inte heller det ett XML-kompatibelt språk utan det använder
sig, i likhet med XPath, av en deklarativ syntax för att referera till delar av ett XML-dokument. XPointer skall användas när vi vill referera till element, attribut, värden på attribut och värden på noder. Ett exempel kan se ut enligt:
#xpoint(namn(fornamn(”lasse”))
Skall vi referera till ett helt XML- eller XSL-dokument är XPointer-tekniken onödig. Då kan vi istället använda oss av XLink.
• XLink – är ett XML-baserat referensspråk vilket innebär att språket använder
sig av XML-syntax för att bygga upp länkar och referenser. XLink är den teknik som mest påminner om HTML:s hyperlänkar, men en XLink kan vara av fler typer än en hyperlänk som endast kan vara en referens till ett annan URI. En XLink kan utgöra flera samtidiga referenser till olika URI:er, en direkt eller delvis utförd inkludering av referenser, eller en valmöjlighet för användaren att välja hur referenser skall hanteras av klienten. XLink-referenser kan också kombineras med XPath och XPointer enligt till exempel:
3 Vi tror oss kunna likna denna funktionalitet vid den tilläggsteknik som idag erbjuds av de flesta webbservrar och benämns ”Server Side Includes”.
<lank_element> <xlink:href=”/data/adressbok.xml”> <#xpoint(namn(”fornamn”))> <#xpoint(namn(”efternamn”))> </xlink> </lank_element>
Exemplet definierar ett element (i ett XML-dokument eller i en DTD) som kommer att ges värdet av elementen ”fornamn” och ”efternamn” i
XML-dokumentet ”adressbok.xml”. Observera att det är upp till XSL-mallen för
det aktuella XML-dokumentet att deklarera vilken layout alla förnamn och efternamn (referensen genererar troligtvis en lista av förnamn och efternamn) skall ges i den klient som används för att betrakta XML-dokumentet ifråga. Vi ser med detta exempel hur vi kan kombinera XLink och XPointer till ett avancerat referenssystem som går betydligt längre i funktionalitet än hyperlänkar gör i HTML.
XML håller under projektets genomförande på att utrustas med tre huvudsakliga tekniker för att kunna hantera referenser och länkar. XML kommer att kunna referera till helheter eller delar av andra XML-dokument, ned till elementnivå. XML kommer vidare att kunna samla flera länkar vid samma referenspunkt i dokumentet samt direkt eller på användarens uppmaning inkludera valda referenser i det aktuella XML-dokumentet. Funktionaliteten, syntaxen och formen för teknikerna XPath, XPointer och XLink befinner sig fortfarande under utveckling.
2.4.3 XHTML – en ny definition av HTML
Till följd av att HTML baseras på en i förväg deklarerad DTD som följer SGML:s arkitektur menar [Mor99] att HTML är att betrakta som en SGML-applikation snarare än ett eget metaspråk. Detta påstående har effekt på de egenskaper som utvecklats i XML i syfte att avhjälpa motsvarande brister i HTML. [Mor99] menar att det är nödvändigt att definiera om HTML som en XML-applikation för att få XML att ersätta HTML på smidigast möjliga sätt.
Med ”eXtensible HyperText Markup Language” (XHTML) har HTML definierats som en XML-applikation med DTD och XSL innehållandes HTML:s uppsättning av element, attribut, entiteter och layoutregler. XHTML är dock till skillnad från HTML valid enligt XML. Ett HTML-dokument kan på enklaste sätt omformas till ett XHTML-dokument genom att [Mor99]:
• det inleds med den obligatoriska XML-definitionen
• det ges en relativ referens till en XHTML DTD och till en XHTML XSL
(finns utvecklade av W3C)
• alla taggar, attribut och värden inom taggarna skrivs med gemener
• alla taggar görs valida, det vill säga alla taggar skrivs med starttagg respektive
sluttagg
På detta sätt kan ett dokument skrivas om utan synlig skillnad för HTML-applikationer men nu med en helt ny innebörd för XML-HTML-applikationer.
2.4.4 Sammanfattning av XML
XML är ett nytt märkordsspråk som fungerar som ett metaspråk för uppmärkning av dokument. XML har utvecklats med SGML som grund och är helt kompatibelt med SGML. Till skillnad från SGML har XML i XSL en teknik för att uttrycka layout och då med den informationsbärande delen i XML-dokumenten åtskild från layoutdeklarationerna. Vi kan med XSL utveckla olika layouter beroende på publiceringsmedia.
Referenser och länkningar kombineras i XML med både entiteter från SGML och med hyperlänkar från HTML. Utöver arven från de tidigare språken har XML försetts med utökade tekniker som bland annat kan samla flera referenser vid en plats i dokumentet, automatiskt inkludera andra XML-dokuments information och inkludera de av användaren valda referenserna i ett aktuellt dokument, om användaren ber om detta. Referens och länkningsteknikerna är vid detta projekts genomförande fortfarande arbetsdokument hos standardiseringsorganisationen W3C. Referens- och länkningsteknikerna samlas under begreppen XPath, XPointer och XLink.
XML förväntas kunna ersätta HTML inom de områden där HTML idag är otillräckligt till sin funktionalitet eller måste kompletteras med tilläggstekniker för att uppnå de allt mer komplexa och omfattande krav som bland annat utvecklingen av webbapplikationer ställer på märkordsspråket ifråga [Mor99]. XML förväntas också kunna möjliggöra publicering av webbmaterial på helt nya plattformar såsom mobiltelefoner, handdatorer och specialdatorer. Vidare kan XML användas som ett verktyg i de sammanhang där vi till exempel kan dra nytta av XML:s plattformsoberoende egenskaper. En XML-applikation kan enligt [Mor99] bland annat användas till att flytta data från en typ av databas på en viss datorplattform till en annan typ av databas på en annan plattform. XML iklär sig i en sådan roll egenskapen av ett slags ”filter”. Vidare kan XML användas till att bygga upp en applikation för automatiserad ekonomisk transaktionshantering och till att utgöra en konverterare mellan olika idag förekommande standarder för informationsutbyte. Utvecklare inom till exempel elektronisk handel och datalager bör enligt [Mor99] intressera sig för XML som en ny och inom deras respektive områden, problemlösande teknik.
Trots att XML i stort tar sikte på webbtillämpningar så kan språket användas, i likhet med SGML, till generell informationssystemsutveckling där vi önskar märka upp information och presentera den på olika sätt mot en eller flera olika plattformar. I egenskap av märkordsspråk med de exekveringsförutsättningar som gäller för dessa, är XML indirekt plattformsobereonde och kan dessutom administeras centralt tack vare åtskillnaden av de informationsbärande dokumenten, DTD:erna och i fallet med XML, även XSL:erna.
I syfte att på ett enkelt sätt kunna överföra HTML-dokument till att bli valida XML-dokument har W3C tagit fram DTD:er och XSL:er vilka definierar HTML i termer av XML. Den XML-applikation som bildas av dessa specialutvecklade DTD:er och XSL:er benämns XHTML. Alla HTML-dokument kan överföras till XHTML-dokument.
2.5 Relationsdatabaser
Ett mycket centralt tillämpningsområde för datorteknik i allmänhet utgörs av att lagra stora mängder med data, vilket oftast äger rum i någon form av databas [Elm94]. När vi lagrar stora mängder med data i datorsystem uppkommer snart problem och aspekter som vi måste hantera. Det kan till exempel röra sig om sökbarhet, sortering, effektivitet i användadet av diskutrymme, behörighetskontroll, säkerhetskopiering, felhantering och goda prestanda i hanteringen av datan. I syfte att komma åt dessa problem och att kunna lösa uppgifter specifikt relaterade till datalagring har det utvecklats databashanteringssystem eller DBHS [Elm94].
Data existerar sällan som en isolerad företeelse utan ingår ofta relationer med annan data, i synnerhet om datan hör hemma i ett informationssystem av något slag. För att hantera relationer och strukturer hos data har det utvecklats datamodeller vilka har sin grund i matematik, logik och mängdlära. Med modellerna kan vi efter den aktuella modellens algoritm eller princip modellera naturliga problem och uttrycka dem i termer av en datamodell. Ett DBHS kan sedan utvecklas till att stödja en viss eller flera typer av datamodeller. Detta medger att lagring och hantering av data i databaserna kan äga rum med vetskap om att transaktionerna i ett DBHS verkställs i enlighet med de regler som modellerna ifråga har satt upp.
En mycket vanligt förekommande (och på webben helt dominerande) typ av DBHS är den så kallade relationsdatabashanteraren (RDBHS), vilken har sin grund i relationsdatamodellen, och som presenterades av Codd 1970 [Cod70]. Relationsdatamodellen representerar data i en databas som en uppsättning av relationer [Elm94]. Varje relation bildar en egen tabell vilken kan uppfattas som ett objekt i den verklighet som vi vill uttrycka något om i vår databas. En tabell innehåller värden som kan anses vara relaterade till varandra. Tabellens kolumner uttrycker attribut till relationen och varje attribut består av värden inom en och samma domän. Tabellens rader utgör instanser av relationen och benämns ”tuppler”. Relationsdatamodellen kan användas till att modellera en databas som i sin tur kan hanteras i ett RDBHS. Genom att använda ett RDBHS kan vi utnyttja dess verktyg och funktioner, vilka bland annat utgörs av datahantering, felhantering, replikering och intergritetskontroll hos datan.
Relationsdatamodellens tydliga koncept tillsammans med det stora utbudet av RDBHS och utvecklingsverktyg på marknaden, har medfört att RDBHS blivit den mest spridda och använda databastekniken. RDBHS popularitet förde dem ut på webben, där de ofta förekommer som en central komponent i webbapplikationer eller som egna resurser med ett webbaserat gränssnitt i syfte att möjliggöra access till ett RDBHS via webben.
2.5.1 SQL
”Structured Query Language” (SQL) är ett frågespråk som utvecklats med grund i relationsdatabaser tillsammans med ett behov av att med en egen teknik kunna manipulera och administrera data [Elm94]. SQL använder sig av en deklarativ syntax för att uttrycka vad som skall vara resultatet av den transaktion som SQL-satsen utgör när den exekveras av ett RDBHS. Ett resultat av en SQL-sats kan till exempel vara svaret på en fråga som ställts mot databasen. Frågan har besvarats genom att SQL valt ut och
därefter presenterat den data ur databasens tabeller, kolumner och tuppler som matchats mot de villkor som formulerats i SQL-satsen. Resultat av SQL-satser presenteras alltid i form av en ny tabell.
Egenskapen att kunna uttrycka vad som skall uppnås utan att behöva ange hur, innebär att SQL betraktas som ett frågespråk på hög nivå [Elm94]. Frågespråkets höga nivå tillsammans med dess goda koppling till mänskligt logiskt problemlösande har givit språket omfattande spridning, vilket också är nära kopplat till RDBHS:ens popularitet. 2.5.2 RDBHS och märkordsspråken
Som komponenter i informationssystem måste både märkordsspråken och RDBHS kunna samspela och interagera i syfte att lösa informationssystemets uppgifter. SGML har inga inbyggda metoder eller funktioner för att hämta eller lämna ifrån sig data från sin egen domän utan den funktionaliteten överlåter SGML till andra applikationer och tekniker att hantera.
HTML kom tidigt att användas till att skapa webbtillgängliga gränssnitt för databaser i allmänhet och då för RDBHS i synnerhet. HTML utvecklades inte med målet inställt på att kunna interagera med RDBHS varför en del av de tilläggskomponenter och –tekniker som nämns i 2.3.2 kom att utgöras av funktioner och metoder för att exportera, importera och manipulera data i RDBHS. Tilläggsteknikerna har under senare år förfinats och allt mer integrerats i bland annat webbservrarnas driftsmiljö emedan HTML självt förblir ett omständigt märkordsspråk att använda i interaktion med RDBHS.
XML å sin sida har utvecklat ett eget koncept för datalagring, vilket består i de XML-filer som utgör en av komponenterna i ett XML-system. Stora mängder med information förväntas kunna lagras i XML-filerna, vilka kommer att utgöra grunden i informationssystem som implementerat XML [Mor99, Sta99]. Vid detta projekts genomförande pågår dessutom forskning inom utvecklandet av frågespråk, som likt SQL i förhållande till relationsdatabaser, skall kunna söka och administrera data i XML-filer [Bon99]. Forskningen har bland annat föreslagit den i XML inkluderade layouttekniken XSL som ett sätt att utveckla ett XML-anpassat frågespråk. Utöver detta föreslås även ett nytt hierarkiskt och XML-elementbaserat frågespråk vilket går under arbetsnamnet ”XML Query Language”, (XQL) [W3C00c]. Med grund i den stora utbredningen och det stora antalet användare föreslås även SQL, om än i XML-anpassad version, som ett frågespråk för XML-dokument.
3 Problembeskrivning
I det här kapitlet presenteras det problem som projektet har valt att försöka angripa. Preciseringen av problemet kompletteras med motivation och argumentation kring varför det är att betrakta som ett problem, samt varför vi funnit det angeläget att försöka lösa det. Ytterligare en viktig komponent i detta kapitel är de avgränsningar vi har gjort och mot vilka problemlösningen skall beaktas.
I kapitel 2 har vi presenterat och identifierat hur XML har vuxit fram som en nödvändig utveckling av HTML:s brister i samband med mer komplexa WWW-baserade system, men också till följd av krav på dynamik hos märkordsspråken. Vidare har vi funnit att XML, och för den delen även HTML, vilar på en stabil och väl beprövad grund med sitt ursprung i SGML. Stora aktörer inom informationssystem- och mjukvaruutveckling (till exempel [Mic00, WMD00, Syb00]) förespråkar XML som en avgörande lösning på dagens svårigheter och problem med att hantera ökande komplexitetskrav hos informationssystem som skall interagera med webben, eller till och med helt baseras på webben [Sta99, Sun99]. Vidare framgår det av såväl facklitteratur, t.ex. [Mor99], såväl som av W3C:s mer eller mindre färdigutvecklade standarder för XML [W3C98, W3C00a], att XML har planerats och utrustats med tekniker och metoder för att kunna hantera information ur alla de aspekter som XML:s decentraliserade och dekomponerade arkitektur innebär. XML-dokumenten skall utgöra grunden med uppmärkt data, DTD:erna skall hantera de egendefinierade element- och attributabstraktionerna, XSL skall svara för att formatera aktuell data till information mot olika plattformar och XQL skall medge fråge- och urvalsprocesser i de data som märkts upp. XML förefaller ”på papperet” vara en komplett och nära nog perfekt lösning och därmed strategi för dagens problematiska ”lappverk” av olika tekniker, vilka ha byggts upp eller modifierats för att komplettera bristerna hos HTML.
3.1 XML - inte bara möjligheter
XML omgärdas av nästan uteslutande positiva bedömningar och åsikter, men det finns också källor som varnar för negativa konsekvenser av ett alltför okritiskt användande av XML. En källa som talar om XML som ett problem är [Ber98] som pekar ut XML som en kommande skapare av kaos för DBHS. [Ber98] varnar för att XML kan komma att ge upphov till enorma mängder med data vars form kommer att vara hierarkisk snarare än baserad på relationer eller objektorientering. [Ber98]:s varningar för XML:s bakomliggande datamodell, skulle kunna innebära problem för utvecklare i samband med till exempel modelleringen av datalagringen i ett informationssystem.
Utöver nämnda farhågor observerar vi själva ett konstruktionsrelaterat problem i XML:s arkitektur bestående i de datavolymmässigt mycket omfattande och talrika textfiler, som kommer att uppstå i informationssystem som implementerats med hjälp av XML. Hur skall dessa textfiler hanteras vad beträffar till exempel indexering, sökbarhet, prestanda och lagringseffektivitet? Samtidigt som [Ber98] och vi själva observerar nu nämnda svårigheter, lyfter [Mor99] fram XML som en utmärkt datalagringsstragegi. [Mor99] föreslår XML framför RDBHS som datalagrare i vissa sammanhang, till exempel när antalet attribut för en entitet är oregelbundna till antalet eller när vi behöver kunna beskriva relationer mellan elementen i termer av den hierarki som de befinner sig i.
Vi identifierar i frågan om XML som datalagrare ett område där vi finner det intressant att se RDBHS:ens stabila tillämpningsgrund bli utmanad av en ny teknik i form av ett märkordsspråk. Projektet riktas därför in på att försöka utreda XML:s nivå av fullständighet att hantera de olika deluppgifter som ställs på en komplett webbapplikation. Finns det områden och punkter där XML saknar eller lider av ofullständighet för att kunna klara av att lösa de uppgifter som vi kan förvänta oss skall utföras av dagens webbapplikationer?
Vi finner det angeläget att en standard som redan i förväg tillskrivs så positiva omdömen och som väntas få så utbredd tillämpning också kan förväntas fungera på ett effektivt sätt inom ett för XML så förväntat centralt tillämpningsområde som webbapplikationer.
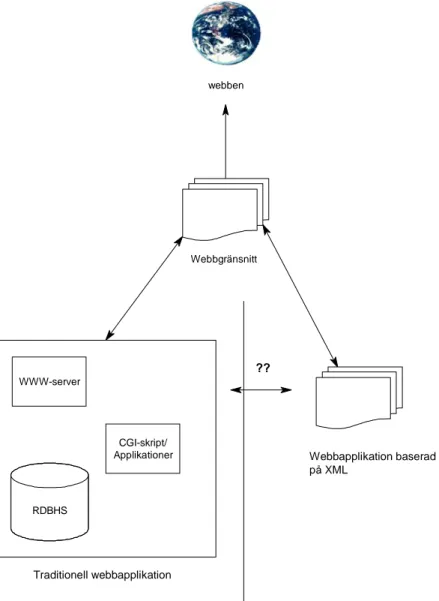
RDBHS webben Webbgränsnitt Webbapplikation baserad på XML WWW-server CGI-skript/ Applikationer Traditionell webbapplikation ??
Figur 8. Illustration över problemområdet. Pilen med tillhörande frågetecken markerar kunskapsluckan kring effekter av att ersätta ett traditionellt RDBHS-baserat system