Malm¨
o University
VT2019-DA613A-TS018
Master thesis
Natural Language Understanding for
Multi-Level Distributed Intelligent
Virtual Sensors
Authors:
Angelos Papangelis
Georgios Kyriakou
Supervisor: Radu-Casian Mihailescu Examiner: Johan HolmgrenAbstract
In our thesis we explore the Automatic Question/Answer Generation (AQAG) and the application of Machine Learning (ML) in natural language queries. Initially we create a collection of question/answer tuples conceptually based on processing re-ceived data from (virtual) sensors placed in a smart city. Subsequently we train a Gated Recurrent Unit(GRU) model on the generated dataset and evaluate the accu-racy we can achieve in answering those questions. This will help in turn to address the problem of automatic sensor composition based on natural language queries. To this end, the contribution of this thesis is two-fold: on one hand we are providing an automatic procedure for dataset construction, based on natural language question templates, and on the other hand we apply a ML approach that establishes the correlation between the natural language queries and their virtual sensor represen-tation, via their functional representation. We consider virtual sensors to be entities as described by Mihailescu et al, where they provide an interface constructed with certain properties in mind. We use those sensors for our application domain of a smart city environment, thus constructing our dataset around questions relevant to it.
Keywords: internet of things; virtual sensing; dataset generation; deep learning; natural language understanding
Popularised summary
As human machine interaction is becoming more seamless in people’s every day life, as well as machine learning techniques becoming more complex in order to serve more intricate tasks, the need for improved ways for machines to analyze language becomes apparent. The current work explores a new method of text generation in the context of Question Answering, keeping in mind how best to imitate questions asked in daily life by non tech savvy people. The result of this work is an algorithm which is capable of generating large enough datasets with questions-answers. Furthermore the output of the generator is used to train a neural network, who’s purpose is to learn how to accurately understand natural language questions and provide an appropriate answer.
This work can be helpful to machine learning researchers, when there is a need for a text based dataset, which will then be used to train, validate, and test a neural network.
Acknowledgements
We would like to take this moment to thank our supervisor Radu-Casian Mihailescu for his trust and encouragement to get us forward with this thesis, as well as our families for their love and support.
Contents
1 Introduction 8 1.1 Related Work . . . 8 1.2 Goals . . . 9 1.3 Motivation . . . 10 1.4 Research Questions . . . 10 1.5 Limitations . . . 10 2 Theory 11 2.1 Natural Language Processing . . . 112.2 Dataset Generators . . . 11
2.3 Environment Sensors . . . 11
2.3.1 Smart Cities . . . 11
2.4 Machine Learning . . . 12
2.4.1 Supervised, Unsupervised, Semi-Supervised learning . . . 12
2.4.2 Neural Networks . . . 13
2.4.3 LSTM . . . 14
2.4.4 GRU . . . 14
3 Research Method 16 3.1 Method Description . . . 16
3.1.1 Construct a conceptual framework . . . 16
3.1.2 Develop a system architecture . . . 16
3.1.3 Analyze and design the system . . . 17
3.1.4 Build the system . . . 17
3.1.5 Observe and evaluate the system . . . 18
4 Method 19 4.1 Data construction . . . 19
4.1.1 Templates . . . 19
4.1.2 Analyze the generated dataset . . . 20
4.1.3 Averages of the generated dataset . . . 21
4.2 Generate Dataset . . . 21
4.2.1 Generator . . . 21
4.2.2 Metadata . . . 22
4.2.3 Generating answers . . . 22
4.3 Machine Learning approach . . . 23
4.3.1 Data processing - Tokenisation . . . 23
4.3.2 Setting parameters . . . 24
4.3.3 Encoder and Decoder . . . 24
4.4 Implementing Attention layer in the GRU . . . 25
5 Results 27
5.1 Environment for Development and Testing . . . 27
5.2 Generated Dataset . . . 27
5.3 GRU Model . . . 27
5.4 GRU Attention Model . . . 30
6 Discussion 34
7 Conclusion and Future Work 36
List of figures and templates • Template 1: Structure
• Figure 1: Long Short-Term Memory with i=input, f=forget, and o=output-gate,c=memory cell, c ˜=new memory cell
• Figure 2: Gated Recurrent Unit r=reset, z=update gate, h=activation, ˜h=candidate activation
• Figure 3: Research methodology • Figure 4: System Architecture • Figure 5: Tokenisation
• Figure 6: Encoder and decoder diagram in seq2seq network where relu and softmax are funtions
• Figure 7: Attention decoder diagram where relu, attnsoftmax and softmax are Activation functions, bmm is calculating the weights and dropout reduces over-fitting
• Figure 8: Loss/Epochs graphs without Attention • Figure 9: Loss/Epochs graphs with Attention
• Figure 10: Heatmaps training with 40 Epochs with Attention • Figure 11: Heatmaps training with 150 Epochs with Attention • Figure 12: Heatmaps training with 350 Epochs with Attention
List of tables
• Table 1: WER results without Attention • Table 2: WER results with Attention • Table 3: Comparison of WER results
• Table 4: Model performance for different classes and questions
List of abbreviations
Internet of Things . . . IoT Visual Question Answering . . . VQA
Visual Question Generation . . . VQG Automatic Question Generation . . . AQG Machine Learning . . . ML Dynamic Intelligent Virtual Sensor . . . DIVS Distributed Goal-Oriented Computing Architecture . . . DGOC Automatic Speech Recognition . . . ASR Natural Language Queries . . . NLQ Gated Recurrent Unit . . . GRU Recurrent Neural Network . . . RNN Long Short Term Memory . . . LSTM Sequence to Sequence . . . Seq2Seq Stochastic Gradient Descent . . . SGD Start of Sentence . . . SOS End of Sentence . . . EOS Word Error Rate . . . WER Position-independent Error Rate . . . PER
1
Introduction
Due to the proliferation of Smart City technologies, the need of meaningfully mea-suring the data output from the city sensors has increased [3]. In this project, practices from Visual Question Answering (VQA) technology are used to analyse and generate open-ended natural language queries.
Despite the topic of VQA being relatively new and poorly explored, its potential has attracted the attention of researchers, especially since the creation of the VQA Challenge [8]. VQA is a task to reason over natural language queries and to answer relevant details [4], a novel problem in the field of ML. It is considered to be AI-Complete, which means that at its core the algorithms used to solve such problems try to perform as intelligently and ‘intuitively’ as humans. Frequently the Turing Test is cited as a basic reference to how well they perform [5], in which an interviewer blindly asks questions to a machine or a human and is tasked to define who gave the answer. The complexity of this task becomes even greater when we consider the complementary question to VQA, Visual or Automatic Question Generation (VQG/AQG).
AQG focuses on automatically creating datasets of semantically correct questions, which when answered provide a good understanding of the environment to which they refer to [6]. Our research will focus on this task, and a similar approach will be applied to the one used in generating the CLEVR dataset. CLEVR is a visual reasoning model which comprises a program generator that creates a direct representation of the reasoning process to be executed, as well as an execution engine which is executed in order to produce the answer [1]. Based on this we produce a dataset from a mesh of virtual sensors as inputs, which unlike the visual representation of a small environment of up to eight objects that was the context within which CLEVR functioned, will describe a full-scale smart city.
1.1
Related Work
When it comes to technological developments in the field of IoT, Machine learning, inter-connectivity and human-centered design, one key aspect rises above all else in importance and that is the Human-Machine interaction technologies [28]. In this process, the main complexities of interacting with systems have been abstracted away from the user, going beyond traditional setups where organizing the data gathering and routing protocols are in the helm of what is necessary for the system to be functional [30].
A distributed goal-oriented computing architecture (DGOC) is proposed from Palanca et al [29]. This architecture is implemented for smart-home environments where de-pended on a predetermine model the users should demonstrate their goals. Then by utilizing a case-based reasoning approach, agent actions that need to be taken are
planed which should be unambiguous to the users. Correspondingly, in [31] seman-tic web ontologies are used aiming to solve the problem of goal oriented end-user development for web of things devices. Those ontologies intend to perform logi-cal reasoning in order to derive adequate knowledge about the classification of the procedures that machines offer. Cooperating services in systems are increasing the complexity, for instance in cases of smart city environments or factories, so recon-figuration of environments is increasing in importance. For such tasks to be solved, dynamic orchestration of semantic web services is used [32]. A visual programming tool is suggested in [33] where the user is allowed to define visually the the state of a smart city. Thus, in order to complete the user goal, semantic API descriptions are utilised operating an automatic service composition.
Another booming market that deals with human-machine interaction is identified in the intelligent personal assistants, such as Alexa, Siri, and Google Home. These assistants enable users to interact with them in a much natural way, seamlessly integrating them into their daily life, similar to how humans would interact with each other. The success of this technology is mostly due to the improvements in Automatic Speech Recognition (ASR) [34] and Natural Language Processing [35]. Machine learning has steadily improved and/or replaced techniques in language tech-nology, in areas such as translations, speech recognition, question answering, text summarization, and so on [36][37][38]. This is not the case for most IoT applica-tions such as IFTTT (https://ifttt.com/), which are based on simple conditional statements and are limited to how much control they give to the user (number of available commands), as well as keeping availability to one device per time
In contrast to the above related work, we design a system capable of adapting to the needs of a smart city context, by facilitating natural language queries as a means of interaction and information extraction. By avoiding strict language patterns and predefined commands, we create a system capable of dealing with a wide variation of tasks.
1.2
Goals
The scope of this work is two-fold:
1. Automatically generate a questions dataset, large enough to generalize the as-sociation between natural language queries(NLQs) and their answers as func-tional program representation
2. Identify a suitable ML approach that is able to learn the correspondence be-tween NLQs and functional representations in a generalized manner
1.3
Motivation
Large-scale deployments of Internet of Things (IoT) sensing technologies and Big Data have opened up new avenues regarding the types of data that can now be collected and information that can be inferred [19]. The smart city context was chosen due to the growing prevalence of IoT devices in day to day life [9]. Inherently, this raises the problem of effectively extracting valuable insights, as the volume of data continues to increase at an exponential pace. In our case, we chose to abstract this kind of information with the concept of digital virtual sensors. Hence, we only need to refer to those sensors, which in turn could be translated to a variety of other data. We aim to create a mechanism for generating large datasets of question-answer tuples, which can be used as a training set generator for sequence to sequence (seq2seq) machine learning algorithms. The breakthrough in this case, is that due to the customizable nature of the generator, it is possible to create context-specific questions, based on the requirements of each use-case.
1.4
Research Questions
1. How can we generate an NLQ dataset associated to virtual sensors in a Smart city environment?
2. How accurate will our ML approach be in answering a generic natural language query, by assessing the resulting virtual sensor representation, after it has been trained with the generated dataset from the first research question?
1.5
Limitations
The limitations of this thesis can be narrowed down to the creation of the QA dataset. This is due to the fact that in this stage of our work, we have created a dataset based on our own ideas of what can constitute an adequate number of templates/questions generate. As we state in section 8, this is to be addressed in our future work.
2
Theory
2.1
Natural Language Processing
Machine translation and language understanding has at its core the concept of Nat-ural Language Processing. Zong and Hong [21] suggest a simplified way of looking at machine translation as a ”noisy channel model” in which a source text is in-putted through the model and distorted to the desired output. Therefore the biggest achievement of a machine translation algorithm is evaluating the corresponding in-put text based on the outin-put [21]. The idea behind this is the aim towards automatic translations of languages with the use of AI, hence the use of encoder-decoder mod-els with sequence-to-sequence conversions as their main task. To accommodate this task, a method of transforming words to vector representations is necessary. Word embedding is used for this reason, which is a mapping of a word in the form of a vector of numbers ∈ R [22].
2.2
Dataset Generators
As the name suggests, dataset generators are applications with the purpose of gen-erating synthetic data, that is then used for testing data analytics applications [23], such as machine learning algorithms on topics of natural language understanding and more. The way that these generators work is by manipulating descriptive infor-mation, in our case sensor data and template literals, through programming interface and work iteratively to create a dataset. Generators give the user control over data types and format, outliers, dimensions, and missing values [23],
2.3
Environment Sensors
The concept of the environment sensors was inspired by the work of Mihailescu et al [2], where the Dynamic Intelligent Virtual Sensor (DIVS) is introduced. This enables the abstraction of describing an environment through various sensors, by directly providing the necessary data for each specific context. Based on this, we consider each sensor as a functional representation of the data required to build the answer for any given question over the smart city environment.
2.3.1 Smart Cities
The concept of a smart city refers to the idea conceptualised at the beginning of the 21st century, as the correlation between the technological and societal aspects of a city. It is composed from the following components including smart economy, governance, people (education), mobility (transport), and quality of life [15]. Base on those components, we decide to focus our questions on sensors that would give us
information regarding mobility and people. For example, a question such as ”Where is the loudest place in town” could be answered if a mesh of decibel level meters is laid across various points of interest around the city.
2.4
Machine Learning
The basic concept of ML is that an algorithm will analyse some starting data and based on those try to make predictions/assessments about newly presented data. For example, one application of ML is to predict cancer from medical data of a patient. The algorithm has analysed numerous other cases of patients with cancer and has learnt to determine if a new patient has cancer or not. IBM in their article about the basic theory of ML, puts it simply as the applications of learning from experience and improving predictions over time [39].
The steps that are required in any ML algorithm are the following four. First the dataset is selected and prepared in order to correctly represent the topic in question. Subsequently the appropriate algorithm is chosen amongst the ones available. The most commonly used algorithms using labeled data are Regression algorithms, De-cision trees, and Instance-based algorithms. The most commonly used algorithms using unlabeled data, are Clustering algorithms, Association algorithms, and Neural networks [39]. A deeper analysis of Neural Networks is found bellow, since a type of such algorithm is used in this thesis. After the algorithm is chosen, the model is created with some initial training and capabilities. Finally the model is used and it will continue learning and improving over time [39][40].
2.4.1 Supervised, Unsupervised, Semi-Supervised learning
The created model from the final step of the algorithmic process, can follow one of three methods of learning.
• Supervised: Supervised machine learning uses training labeled data. The ma-chine learning model is created in order to define the information which is included in the labeled data [39]. Thus, It can predict results of values that are invisible by utilising classification [42].
• Unsupervised: As opposed to the above method of learning, unsupervised learning uses unlabeled data. It makes use of a very large, or as large as possible, variety of data in order to understand patterns, classify, and label them [39].
• Semi-Supervised: Due to the vast majority of available data being unlabeled (eg. amount of articles in the web, as opposed to articles that a user has marked as interesting), there is a need of a method which can make use of both in order to build efficient models. This type of learning focuses on the smaller
labeled data which will aid to extract information from a larger unlabeled dataset [39][42]
2.4.2 Neural Networks
Language processing is a task of sequence representation of data (i.e. sentences), and how this data, is interpreted by the neural network. Neural networks can process and manipulate the distributed representations of data concurrently, thus offering a viable solution to the traditional symbol processing. In the case of this thesis, a subcategory of Neural Network is used which is called Deep Learning. The main difference here is that the data is passed through a sequence of hidden layers which filter and refine the information until it reaches the output layer. Thus deep learning is passing information recurrently through the neurons and for this reason they are also called Recurrent Neural Networks (RNNs). Research has shown that RNNs when setup correctly, can represent sequential data of any length, keeping in mind that the longer the sequence becomes, the harder the learning for the network itself is [18]. This means that the words that are in a long distance in a long sequence, will be difficult to be controlled [20]. This is where Long Short-Term Memory (LSTM) and GRU architectures came to solve this problem when using RNN. Those types of networks make use of a ”memory” by passing valuable information down from each node to the next, via the hidden state.
2.4.3 LSTM
LSTM is presented for the first time by Hochreiter and Schmidhuber [24]. It is an RNN architecture which has its own memory thus, it is easier to remember the previous data [20]. This solves the problem mentioned in section 2.5. LSTM incorporate three gates(input, output and forget gate) as well as memory cells as shown in Figure 1. The memory holds all the information from the input but it is restricted by the output gate [20].
(a)
Figure 1: Long Short-Term Memory with i=input, f=forget, and o=output-gate, c=memory cell, c˜=new memory cell [25]
2.4.4 GRU
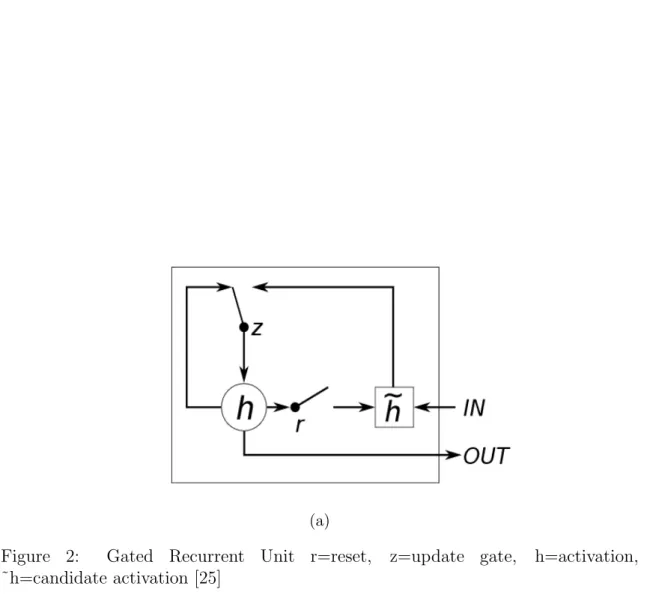
GRU was proposed first time by Kyunghyun Cho et al [16] and it is a variation of LSTM, but it has fewer parameters since GRU doesn’t have an output gate. It has two gates (reset and update), in contrast to a more complex LSTM [20]. Thus the update gate does similar work as the input gate and forget gate from LSTM network while the reset gate controls the candidate activation as can be seen in Figure 2. The main advantage of GRU network is that it is as capable as LSTM but it uses less processing capacity and the architecture is simpler than LSTM [16][20]. Primarily however, GRU networks have already been successfully utilized in applications revolving natural language processing [13][14], and perform on par level as their more complex RNNs [18].
(a)
Figure 2: Gated Recurrent Unit r=reset, z=update gate, h=activation, ˜h=candidate activation [25]
3
Research Method
This chapter describes the research methodology that we have used in order to construct our thesis. Due to our intention of building a working model and evaluate it, Nunamaker methodology [26] is the method that satisfies the demands of this thesis.
3.1
Method Description
Nunamaker research methodology describes a development as an iterative form which is the main reason why this method is chosen. Figure 3 illustrates the method-ology devided in 5 different iterative phases. In the following subsections each step is elaborated independently.
Figure 3: Research methodology [26]
3.1.1 Construct a conceptual framework
The first phase in the process is to build the conceptual framework. The aim of this step is to construct the research questions which define the path for the research process. Research questions are the questions that they lead us to solve our research problem. Thus, the research problem and domain should be well understood. The comprehension of that is gained by conducting a literature review and with the help of our supervisor, the formulation of these questions is completed (see section 1.4). For the first question, this thesis is concentrated on proving that a question-generation dataset can be implemented in a larger environment, in this case a smart city, using virtual sensors. For the second question, a ML technique should be used in order to measure how well the system will perform when it is fed a natural language query in producing the corresponding representation.
3.1.2 Develop a system architecture
In this phase a system architecture is created which is a plan of the system’s building process, thus the elements of the system are added into a context. The functionalities of the system are stated as well as the relationships between those are described. In Figure 4 the system architecture is illustrated showing all the steps of the building process.
Figure 4: System Architecture
3.1.3 Analyze and design the system
In this phase the system architecture is analysed. In other words the generated dataset and the ML approach are designed and analysed in order to be build the system in the next phase. Taking into consideration the research for this thesis (see section 2), the dataset is created as well as a ML model solution is provided. The ML model then is improved by using attention mechanism which is further explained in section 5.4.
3.1.4 Build the system
This phase of the research method is where the complete system is put together. The generated dataset is separated in chunks of training and testing subsets in ration of 80% - 20%. Then the model’s hyper-parameters are fine-tuned via an iterative process, until the desired prediction accuracy is reached. Overall, the system con-sists of the dataset along with the ML model both without and with the attention technique.
3.1.5 Observe and evaluate the system
This is the final phase of the research methodology where the complete system is evaluated. As mentioned in section 1.2 the thesis is two-fold since a dataset is generated and a ML model is implemented, therefore the validity and reliability of the thesis has to cover both of these aspects. By separating the dataset into different categories of questions and with a large enough metadata collection, high complexity and novelty in the types of questions generated is ensured, as they would naturally arise in a smart city environment. These characteristics of the dataset provide a challenging task for the model, which has to achieve high accuracy, but also avoid being over or under fitted. Metrics of quality are used to validate the predictions of the model, which are chosen based on existing literature and common practices [12][16][17]. Namely those metrics are loss/train graphs, Word Error Rate (WER), and heatmaps.
4
Method
In this section we provide information on how the dataset and machine learning model is built.
4.1
Data construction
To generate our dataset we separated various questions in the following categories: • Compare questions: ”Is A larger than B”?
• Count questions: ”How many...” • Existence questions: ”Are there any...” • Query questions: ”What is the length...”
Then, building upon the work of the CLEVR team [7], we created sentence tem-plates accordingly.
Furthermore, we distinguish all generated questions into three categories based on their word length: Short/Average/Long. This we do for each category thus ending up with the following dataset configuration:
• Shortest question overall inside the dataset is of 6 words • Longest question overall inside the dataset is of 24 words • Questions with length between 6 to 12 words: 35245 (83.23%) • Questions with length between 13 to 18 words: 1585 (3.74%) • Questions with length between 19 to 24 words: 5518 (13.03%)
4.1.1 Templates
We devise templates, as shown below, where we replace keywords with variable placeholders. Thus by replacing those variables, we generate multiple complete -grammatically correct - sentences
Each template object is consisting of the question templates, the variable parameters, and the nodes and functions map that will help the generator build the answer. We build functional programs and text templates, which will be shown in detail in sections 2.3 2.4, in order to provide numerous ways of expressing these programs in natural language. All of the templates are following the same structure which can be seen in template 1 below, and is similar to the one used in [1].
{
"params": [
{ "type": "Location", "name": "<L>" }, { "type": "Vehicles", "name": "<V>" }, { "type": "VehicleState", "name": "<VS>" } ],
"questions": [ {
"text":
"How many <V> are illegally <VS> at <L>?" },
{
"text":
"Are there <V> are illegally <VS> at <L>?If yes, how many?" },
{
"text":
"Give me the number of <V> that are <VS> illegally at <L>?" }
],
"nodes": [
{ "inputs": [], "type": "scene" }, {
"side_inputs": ["<L>", "<V>", "<VS>"], "inputs": [0]
},
{ "inputs": [0, 1], "type": "count" } ],
"functions_map": [
{ "function": "filterVehicles", "name": "<V>" }, { "function": "filterLocation", "name": "<L>" }, { "function": "filterVehicleState", "name": "<VS>" } ]
}
Template 1: Structure
4.1.2 Analyze the generated dataset
To validate a complete dataset two requirements should be fulfilled.
therefore no sentence with the variable type of ”< X >” had remained.
B) No duplicate sentences were found in the resulting dataset. This was achieved due to the recursive nature of the dataset generator, which went through all potential combinations of words/synonyms, without ever backtracking to an already visited combination.
4.1.3 Averages of the generated dataset
The average number of placeholders/parameters per question: • 2.85
The average number of text templates per template object: • 21
The number of templates for each of the 4 classes of questions:
count: 12 existence: 17 query: 27 compare: 28
4.2
Generate Dataset
In this section we provide information on how the dataset is built. This algorithm consists of the following:
• Main question generation file
• A json file containing all the metadata
• A folder containing all the templates with the questions to be generated • A folder containing all the helper functions we have created and used for the
question/answer generation
4.2.1 Generator
The function of the generator is directly linked to how we have formatted the sen-tence templates (see above 1.6.2). Each template is imported in the main ‘gener-ate questions.js‘ file, along with the required metadata to build the sentence. Then we map through all the template’s questions, and replace the placeholders with actual words. The number of permutation generated is linked to the number of placeholders in the sentence and the number of words available to replace them. The process is repeated for all questions, for all templates. We keep in mind that
each template creates multiple ways to phrase the same question, meaning that they all have the same answer.
4.2.2 Metadata
We consider a set of metadata to be a group of words which fall under a specific categorical description. If we take the above template (Template 1) as an example, and look at the { type: Location } parameter, the corresponding metadata are as follows:
"Location": [
"central train station", "city center",
],
We use those synonyms in all their possible combinations, and (after removing du-plicates) we replace the ”T”, ”L”, ”PR” variables of the template sentence. The generated questions will therefore look as follows:
"Give me the number of cars that are parked illegally at malm¨o university?"
"Give me the number of motorcycles that are parked illegally at malm¨o stadium?"
"Give me the number of trucks that are parked illegally at folkets park?"
"Give me the number of trucks that are driving illegally at malm¨o stadium?"
...
4.2.3 Generating answers
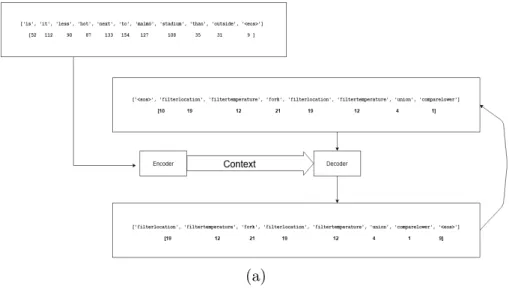
All questions in the same set of ”params”, ”questions”, ”nodes”, and ”functions map” are answered with the same functional representation, meaning that we get a string with the names of the functions required to be called in a sequence to get the correct answer. For example, the following question:
In the suburbs, is the temperature lower compared to the city center?
scene filterLocation filterTemperature fork filterLocation filterTemperature union compareLower
In this way we are only concerned with the theoretical composition of how we can reach the required answer. To get to it, we go through each node, and depending on what kind of input each step has, we build up to the final answer.
In section 2.1 above, we asked the following question:
"Give me the number of <V> that are <VS> illegally at <L>?"
This means that we would require a sensor to give us the type of vehicle we want to specify, a sensor for the location, and a sensor for the state of that vehicle. Instead of having to focus on creating such sensors we make use of DIVS and instead get the desired data assuming the following predefined functions
• filterVehicles • filterLocation • filterVehicleState
4.3
Machine Learning approach
In this section ML approach is provided. As mentioned in section 2.5.2 GRU is computationally more efficient when it comes to smaller and less frequent datasets. As a consequence GRU technique is chosen instead of LSTM. We also use the Seq2seq architecture in which two recurrent neural networks work together to map a sequence of words illustrating the question to a sequence of words illustrating the answer [10]. Subsequently, we describe the process of creating our GRU model in order to achieve good accuracy and right predictions.
4.3.1 Data processing - Tokenisation
Our dataset consists of questions and answers. The answers are in the form of a sequence of functions including virtual sensors as filter functions to represent the questions. Firstly, the maximum length of all sentences, both questions and answers, has been calculated and padding has been implemented to the shorter sentences. In this way, we achieve a predetermined length for all sentences. In addition, tokens have been used as a means to specify the Start-Of-Sentence(SOS) and End-Of-Sentence(EOS) of the output, as the input question does not require to process. Finally, we have removed all the punctuation characters, as well as we have set lower case letters in all sentences(see Figure 5). Tokenisation and padding is fundamental for our system. With tokenisation we are able to convert the sentences
into numbers, so each word corresponds to a number. This step is crucial because machine learning algorithms process the data with numbers.
(a)
Figure 5: Tokenisation
4.3.2 Setting parameters
In this stage, we are randomly setting the hyper-parameters of the model which are: • Hidden size = 128
• Batch size = 32 • Teacher forcing = 0.5
However, these parameters are about to be fine-tuned in the Results section in order to achieve the best results for our dataset. In sections 5.3 and 5.4, the final values of the parameters are provided.
4.3.3 Encoder and Decoder
An encoder network turns an input sequence into a vector, and a decoder network unfolds that vector into a new sequence [11]. In our implementation, there is one input which is the initial question for the encoder which then produces two outputs: a vector and a hidden state. The encoder uses the hidden state for the next input word of the sentence while the decoder uses the vector(s) in order to form a sequence of words which will be the the final answer. Figure 6 illustrates the process of both the encoder and the decoder.
(a) Encoder
(b) Decoder
Figure 6: Encoder and decoder diagram in seq2seq network where relu and softmax are funtions [11].
4.4
Implementing Attention layer in the GRU
Attention is a mechanism that addresses a limitation of the encoder-decoder archi-tecture on long sequences, and that, in general, speeds up the learning and improves performance on seq2seq prediction tasks [11].
4.4.1 Attention Decoder
In our model Attention is implemented on the decoder. Firstly, the attention weights are calculated utilising the hidden state and the input of the decoder. Those weights are multiplied with encoder output vectors in order to create a weighted combination. The result should hold information about that specific part of the input sequence, and thus helps the decoder to optimally generate the next word in the sequence(see Figure 7). Finally, since our dataset consists of different length of sentences, those with the greater length will use more attention weights than those with shorter sentences.
(a)
Figure 7: Attention decoder diagram where relu, attnsoftmax and softmax are Activation functions, bmm is calculating the weights and dropout reduces over-fitting [11].
5
Results
In this section the final generated dataset is provided as well as the machine learning results of our model.
5.1
Environment for Development and Testing
For the first part of our work we use plain JavaScript as our generator engine, and output the result in a json formatted file.
For Machine Learning model the development environment of choice is Python 3.7. Additionally pytorch is used which is an open source python library optimised for natural language processing and it uses CPU and GPU resource [12]. Taking into account those resources, Google colab is used because of the convenience and power that provides in terms of resources since training a model a lot of computing power is needed.
5.2
Generated Dataset
For our first research question, we ask whether or not it is possible to generate a large enough question answering dataset, that would enable a machine learning model to generalize the association between them. Our solution has enabled us to produce 42348 QA pairs between the four predetermined question categories. This was proven to be an adequate number for our model to achieve the desired goal and has provided a method of building generic datasets of text.
5.3
GRU Model
In this section we train the model as well as we depict the training process by plotting the Loss/Epoch graphs. In the beginning, we use random parameters and along the way we are tuning the model by changing them. Teacher forcing is also implemented, which is the concept of using the real target outputs as each next input, instead of using the decoder’s guess as the next input. Hence we set the input to the next state as the actual target, not the predicted target.
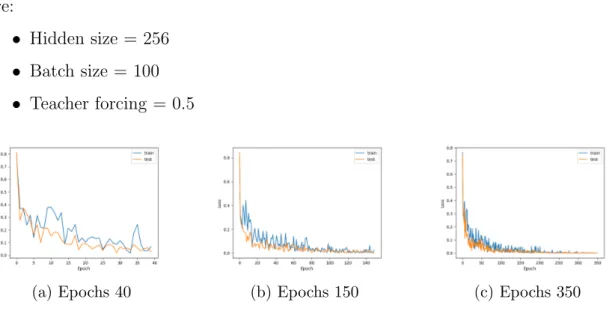
In Figure 8 we present three graphs with different number of epochs which illustrate the training Loss of our model. The optimised parameters for these visualisations are:
• Hidden size = 256 • Batch size = 100 • Teacher forcing = 0.5
(a) Epochs 40 (b) Epochs 150 (c) Epochs 350
Figure 8: Loss/Epochs graphs without Attention
As the Figure 8 shows, the loss is close to zero which means that we have very good accuracy. However, if we see closely in Figure 8(b) the Loss has a plateau from 20th to 80th epoch. We will discuss more about this in section 6.
Several questions are listed below which provided as input to our model, with their respective predicted answers:
Question(input): can you count how many car are driving at shopping mall ? Answer: filterLocation filterVehicles filterVehicleState union count
Prediction:filterLocation filterVehicles filterVehicleState union count Question(input): is it less freezing next to park than outside ?
Answer: filterlocation filtertemperature fork filterlocation filtertemperature union compare
Prediction: filterlocation filtertemperature fork filterlocation filtertemperature union compare
In order to evaluate our model we calculated the WER which is the number of words that differ between the generated answer(hypothesis) and the ground truth [17]. The following figure illustrates the formula where:
• S is the number of substitutions, • D is the number of deletions, • I is the number of insertions, • C is the number of correct words,
• N is the number of words in the reference (N=S+D+C) W ER = S + D + I
N =
S + D + I S + D + C
Thus, the minimum number of word insertions, substitutions and deletions nec-essary to convert the hypothesis into the reference translation is the Levenshtein distance [17]. Then this distance is divided by the number of words of the reference sentence from which it derives the WER. Substitutions, insertions and deletions have the same weights. The closer to zero the number of WER is, the lower the number of changes have been done to the sentence, hence a lower value for WER is preferable [17].
In Table 1 can be seen the average WER of the wrong answers. The dataset was split into train-test sets with 80/20 ratio and the WER is calculated for each wrong answer. Then we computed the sum and we divided with the number of wrong answers. Again the WER is close to zero which is indicating a good result.
No Attention
WER Wrong answers Accuracy(%) 5.25 17 99.66
5.4
GRU Attention Model
In this section we are training and evaluating the model similar to the previous model which was without Attention. The only difference is that Attention Decoder is used. We use the same parameters as we used in the model without Attention. In Figure 9 there are three graphs with different number of epochs which illustrate the training Loss of our model. The optimised parameters of those visualisations are:
• Hidden size = 256 • Batch size = 100 • Teacher forcing = 0.5
(a) Epochs 40 (b) Epochs 150 (c) Epochs 350
Figure 9: Loss/Epochs graphs with Attention
We list below several questions provided as input to our model, with their respective predicted answers: :
Question(input): How far is the furthest police car to the on going hurricane ? Answer: filterEmergency filterLocation fork filterEmergencyVehicles filterLocation union query
Prediction: filterEmergency filterLocation fork filterEmergencyVehicles filterLoca-tion union query
Question(input): is it more cold outside folkets park than inside ?
Answer: filterlocation filtertemperature fork filterlocation filtertemperature union compare
Prediction: filterlocation filtertemperature fork filterlocation filtertemperature union compare
Question(input): Is there any man riding their bicycle at city hall ? Answer: filterHuman filterAction filterLocation union exists
The following graphs(see Figures 10, 11, 12) are heat-maps showing the attention output as a matrix. The figures show the heat-maps for different number of epochs. Each figure illustrates 4 heat-maps for each class of questions. The columns illus-trate the question tokens, while the rows illusillus-trate the answer tokens. In this way we have a better understanding on where the network is focused most at each time step. The scale is from 0(black) to 1(white). Hence this means that when a square is brighter, the model paid more attention to that specific word.
It is worth noting, for those heat-maps that in Figure 12 there are more and brighter squares than in Figures 10 and 11. This implies that as the number of epochs is increased the more attention is used which leads to better accuracy. In addition, in Figure 10d can be clearly seen that the function sequence is missing the comparison operator, while the heat-map representation appears difficult to interpret. On the other hand in Figure 12d the model provides the correct functional representation for the given query, after 350 epochs.
(a) Compare (b) Count
(c) Existence (d) Query
(a) Compare (b) Count
(c) Existence (d) Query
(a) Compare (b) Count
(c) Existence (d) Query
Figure 12: Heatmaps training with 350 Epochs with Attention
As with the previous model without attention, we also calculated the WER in this model which has Attention Decoder. The table bellow (see Table 2) illustrates the results of this model.
With Attention
WER Wrong answers Accuracy(%)
3 10 99.85
6
Discussion
The results indicate that our model can generate a dataset of question and answers as well as by using ML methods, predict the answer with very good accuracy. We also enhanced our model by using Attention on our decoder in order to improve results leading to an increased accuracy and a decreased loss in number very close to zero. This shows that our model can be used in more complicated datasets, for instance creating longer questions and producing more complicated answers. In addition, as it can be seen in the Figures 8(b) and 8(c) there is a plateau between 20th and 80th epoch in the model without attention and this leads to a slower learning rate. On the other hand, the model with attention is learning faster as from the 75th epoch the loss is already close to zero.
In order to achieve better evaluation we also calculated the WER. Since WER re-quires exactly the same order of the words in hypothesis and reference, we do not need to evaluate our model with position-independent error rate(PER) [17] which neglects word order completely.This happens due to the fact that, in our model, the hypothesis and the reference always have the same order since the output is a series of functions representing the desired answer. Table 3 illustrates the results of WER of both models, with and without Attention.
Evaluation Table
Model WER Wrong answers Accuracy(%) No Attention 5.25 16 99.66
Attention 3 10 99.85 Table 3: Comparison of WER results
As it can be seen, even though both WERs are close to zero the one with attention is lower than the one without by a margin of 2.25. This means that the model with attention had fewer words to insert, delete or substitute which leads to more accurate results. In addition, we provide in Table 4 a more in-depth evaluation calculating the WER and the accuracy between long and short questions as we mention in 1.6.1 section. The model performs very well in the case of the comparison and attribute classes of question, for both with and without the attention mechanism. However, the model returns a number of errors for existence and counting classes, when it comes to short questions. It can be easily observed that the attention model has approximate 5(%) more accuracy than the model without attention for these particular instances.
7
Conclusion and Future Work
Our thesis project is based on the topic of natural language query generation, where the Smart City-NLQ dataset is introduced. The dataset includes question answer tuples based on a mesh of sensors inputs, which represents an environment of a Smart City. By providing common language patterns and avoiding predefined commands, we built a system having the ability of dealing with a wide variation of tasks, thus it can be implemented in a Smart City environment. Then by using ML techniques, we created a model which can predict the answers of the generated questions and increased the accuracy of the model by using attention layer to our model. We have shown that our model can translate efficiently novel generated questions to functional representation answers. Notably, the dataset is easily expandable given the template generation procedure presented in this thesis, making it a versatile tool for researchers who would like to expand the concern of the dataset outside of a smart city environment.
One of the key directions for future work includes applying transfer learning tech-niques for natural language processing in order to determine the extent to which our approach can work with limited label data, as well as to increase the language diversity, by enabling the system multiple ways of expressing various sensing tasks through natural language. Specifically for this latter task, one possibility for the fu-ture work is to further evaluate our system based on real human utterances collected through crowd-sourcing.
8
References
[1] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, Ross Girshick by 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Year: 2017 Pages: 1988 - 1997
[2] Radu-Casian Mihailescu, Jan Persson, Paul Davidsson, Ulrik Eklund, ”Collabo-rative Sensing with Interactive Learning using Dynamic Intelligent Virtual Sensors”, Internet of Things and People Research Center Malm¨o University, School of Tech-nology Malm¨o Sweden Conference paper First Online: 08 October 2016
[3] Joe Colistra, School of Architecture and Design, University of Kansas, Lawrence, Kansas, USA by 2018 IEEE International Smart Cities Conference (ISC2) 16-19 Sept. 2018
[4] Iqbal Chowdhury, Kien Nguyen, Clinton Fookes, Sridha Sridharan by 2017 IEEE International Conference on Image Processing (ICIP) Year: 2017 Pages: 1842 - 1846 [5] Mikyas T. Desta, Larry Chen, Tomasz Kornuta by 2018 IEEE Winter Conference on Applications of Computer Vision (WACV) Year: 2018 Pages: 1814 - 1823 [6] P Pabitha, M. Mohana, S. Suganthi, B. Sivanandhini by 2014 International Conference on Recent Trends in Information Technology Year: 2014 Pages: 1 - 5 [7] Yikang Li, Nan Duan, Bolei Zhou, Xiao Chu, Wanli Ouyang, Xiaogang Wang, Ming Zhou by 2018 IEEE/CVF Conference on Computer Vision and Pattern Recog-nition Year: 2018 Pages: 6116 - 6124
[8] Virginia Tech ”Visual Question Answering” https://visualqa.org/challenge.html (last accessed 3/2021)
[9] Preeti Yadav, Sandeep Vishwakarma: ”Application of Internet of Things and Big Data towards a Smart City”, 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU)
[10] Quoc V. Le, Oriol Vinyals, Ilya Sutskever: Sequence to Sequence Learning with Neural Networks by Google Year:2014
[12] Sean Robertson, ”Translation with a Sequence to Sequence Network and Atten-tion”; Retrieved from: https://pytorch.org/tutorials/intermediate/seq2seq_ translation_tutorial.html?highlight=nlp (last accessed 3/3/2021)
[13] Wei Huang, Xiao Dong, Wenqian Shang, Weiguo Lin: ”Research on Man-machine Conversation System Based on GRU seq2seq Model”, 2019 6th Interna-tional Conference on Dependable Systems and Their Applications (DSA)
[14] Rahul Dey and Fathi M. Salem: ”Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks”
[15] Emile Mardacany, ”Smart Cities Characteristics: Importance of Built Environ-ment Components”, IET Conference on Future Intelligent Cities Dec. 2014
[16] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio ”Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation” arXiv:1406.1078 [17] Arne Mauser, Saˇsa Hasan and Hermann Ney ”Automatic Evaluation Mea-sures for Statistical Machine Translation System Optimization” Human Language Technology and Pattern Recognition Lehrstuhl f¨ur Informatik 6, Computer Science Department RWTH Aachen University, D-52056 Aachen, Germany
[18] D. Liu and X. Zou, ”Sequence Labeling of Chinese Text Based on Bidirectional Gru-Cnn-Crf Model,” 2018 15th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 2018, pp. 31-34, doi: 10.1109/ICCWAMTIP.2018.8632570.
[19] Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for internet of things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
[20] Nicole Gruber; Alfred Jockisch; Are GRU Cells More Specific and LSTM Cells More Sensitive in Motive Classification of Text? Department of Culture, Speech and Language, Universit¨at Regensburg, Regensburg, Germany, Department of Informa-tion Technology, UKR Regensburg, Regensburg, Germany
[21] Z. Zong and C. Hong, ”On Application of Natural Language Processing in Machine Translation,” 2018 3rd International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Huhhot, China, 2018, pp. 506-510, doi: 10.1109/ICMCCE.2018.00112.
[22] R. S. Trofin, C. Chiru, C. Vizitiu, A. Dinculescu, R. Vizitiu and A. Nistorescu, ”Detection of Astronauts’ Speech and Language Disorder Signs during Space Mis-sions using Natural Language Processing Techniques,” 2019 E-Health and Bioengi-neering Conference (EHB), Iasi, Romania, 2019, pp. 1-4, doi:
10.1109/EHB47216.2019.8969950.
[23] S. D. P. Mendon¸ca, Y. P. D. S. Brito, C. G. R. D. Santos, R. D. A. D. Lima, T. D. O. D. Ara´ujo and B. S. Meiguins, ”Synthetic Datasets Generator for Testing Information Visualization and Machine Learning Techniques and Tools,” in IEEE Access, vol. 8, pp. 82917-82928, 2020, doi: 10.1109/ACCESS.2020.2991949.
[24] Hochreiter S., and Schmidhuber J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780.
[25] Chung, J., Gulcehre, C., Cho, K., and Bengio, Y. (2014). Empirical evalu-ation of gated recurrent neuronal networks on sequence modeling, Neuronal and
Evolutionary Computing, 1412. arXiv [Preprint]. arXiv:1412.3555.
[26] J. F. Nunamaker and M. Chen, ”Systems development in information systems research,” Twenty-Third Annual Hawaii International Conference on System Sci-ences,vol. 3, pp. 631-640, Jan 1990.
[27] F. Middleton, ”Reliability vs validity: what’s the difference?”; Retrieved from https://www.scribbr.com/methodology/reliability-vs-validity/
(last accessed 28/2/2021)
[28] Reddy, Y.V. Pervasive Computing: Implications, Opportunities and Challenges for the Society. In Proceedings of the 2006 First International Symposium on Per-vasive Computing and Applications, Pisa, Italy, 13–17 March 2006; p. 5.
[29] Palanca, J.; Val, E.d.; Garcia-Fornes, A.; Billhardt, H.; Corchado, J.M.; Juli´an, V. Designing a goal-oriented smart-home environment. Inf. Syst. Front. 2018, 20, 125–142.
[30] Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor net-works: A survey. Comput. Netw. 2002, 38, 393–422Akyildiz, I.; Su, W.; Sankara-subramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422
[31] Lastra, J.L.M.; Delamer, M. Semantic web services in factory automation: Fun-damental insights and research roadmap. IEEE Trans. Ind. Inform. 2006, 2, 1–11. [32] Feldmann, S.; Loskyll, M.; R¨osch, S.; Schlick, J.; Z¨uhlke, D.; Vogel-Heuser, B. Increasing agility in engineering and runtime of automated manufacturing systems. In Proceedings of the 2013 IEEE International Conference on Industrial Technology (ICIT), Cape Town, South Africa, 25–28 February 2013; pp. 1303–1308.
[33] Mayer, S.; Verborgh, R.; Kovatsch, M.; Mattern, F. Smart Configuration of Smart Environments. IEEE Trans. Autom. Sci. Eng. 2016, 13, 1247–1255.
[34] Wang, D.; Wang, X.; Lv, S. An Overview of End-to-End Automatic Speech Recognition. Symmetry 2019, 11, 1018.
[35] Jain, H.; Mathur, K. Natural Language Processing Through Different Classes of Machine Learning. In Proceedings of the Fourth International Conference on Computer Science Information Technology, Sydney, Australia, 21–22 February 2014; Volume 4, pp. 307–315
[36] Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165.
[37] Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining
Approach. arXiv 2019, arXiv:1907.11692
[38] Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv 2019, arXiv:1909.08053.
[39] ”Machine Learning” https://www.ibm.com/cloud/learn/machine-learning (last accessed 3/2021)
[40] S. Ray, ”A Quick Review of Machine Learning Algorithms,” 2019 Interna-tional Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 2019, pp. 35-39, doi: 10.1109/COMITCon.2019.8862451. [41] P. K. Mallapragada, R. Jin, A. K. Jain and Y. Liu, ”SemiBoost: Boosting for Semi-Supervised Learning,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 11, pp. 2000-2014, Nov. 2009, doi: 10.1109/TPAMI.2008.235. [42] M. Aboubakar, M. Kellil, A. Bouabdallah, P. Roux, ”Toward Intelligent Recon-figuration of RPL Networks using Supervised Learning” Publisher: IEEE, Date of Conference: 24-26 April 2019, Date Added to IEEE Xplore: 13 June 2019, Confer-ence Location: Manchester, UK
![Figure 1: Long Short-Term Memory with i=input, f=forget, and o=output-gate, c=memory cell, c˜=new memory cell [25]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4018832.81693/16.893.326.658.358.635/figure-short-memory-input-forget-output-memory-memory.webp)
![Figure 3: Research methodology [26]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4018832.81693/18.893.131.771.468.579/figure-research-methodology.webp)

![Figure 6: Encoder and decoder diagram in seq2seq network where relu and softmax are funtions [11].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4018832.81693/27.893.157.490.169.413/figure-encoder-decoder-diagram-network-relu-softmax-funtions.webp)
![Figure 7: Attention decoder diagram where relu, attnsoftmax and softmax are Activation functions, bmm is calculating the weights and dropout reduces over-fitting [11].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4018832.81693/28.893.144.496.267.917/figure-attention-decoder-diagram-attnsoftmax-activation-functions-calculating.webp)