Teknik och samhälle Datavetenskap
Examensarbete 15 högskolepoäng, grundnivå
PiEye in the Wild: Exploring Eye Contact Detection for
Small Inexpensive Hardware
PiEye: En Undersökning av Ögonkontakts-igenkänning för Liten och Billig Hårdvara
Karl Casserfelt
Ragnar Einestam
Examen: kandidatexamen 180 hp Huvudområde: Datavetenskap
Program: Datavetenskap och Applikation-sutveckling
Datum för slutseminarium: 2017-05-30
Handledare: Shahram Jalalinya Examinator: Erik Pineiro
Sammanfattning
Ögonkontakt-sensorer skapar möjligheten att tolka användarens uppmärksamhet, vilket kan användas av system på en mängd olika vis. Dessa inkluderar att skapa nya möj-ligheter för människa-dator-interaktion och mäta mönster i uppmärksamhet hos individer. I den här uppsatsen gör vi ett försök till att konstruera en ögonkontakt-sensor med hjälp av en Raspberry Pi, med målet att göra den praktisk i verkliga scenarion. För att fast-ställa att den är praktisk satte vi upp ett antal kriterier baserat på tidigare användning av ögonkontakt-sensorer. För att möta dessa kriterier valde vi att använda en maskininlärn-ingsmetod för att träna en klassificerare med bilder för att lära systemet att upptäcka om en användare har ögonkontakt eller ej. Vårt mål var att undersöka hur god prestanda vi kunde uppnå gällande precision, hastighet och avstånd. Efter att ha testat kombinationer av fyra olika metoder för feature extraction kunde vi fastslå att den bästa övergripande precisionen uppnåddes genom att använda LDA-komprimering på pixeldatan från varje bild, medan PCA-komprimering var bäst när input-bilderna liknande de från träningen. När vi undersökte systemets hastighet fann vi att nedskalning av bilder hade en stor effekt på hastigheten, men detta sänkte också både precision och maximalt avstånd. Vi lyckades minska den negativa effekten som en minskad skala hos en bild hade på precisionen, men det maximala avståndet som sensorn fungerade på var fortfarande relativ till skalan och i förlängningen hastigheten.
Abstract
Eye contact detection sensors have the possibility of inferring user attention, which can be utilized by a system in a multitude of different ways, including supporting human-computer interaction and measuring human attention patterns. In this thesis we attempt to build a versatile eye contact sensor using a Raspberry Pi that is suited for real world practical usage. In order to ensure practicality, we constructed a set of criteria for the system based on previous implementations. To meet these criteria, we opted to use an appearance-based machine learning method where we train a classifier with training images in order to infer if users look at the camera or not. Our aim was to investigate how well we could detect eye contacts on the Raspberry Pi in terms of accuracy, speed and range. After extensive testing on combinations of four different feature extraction methods, we found that Linear Discriminant Analysis compression of pixel data provided the best overall accuracy, but Principal Component Analysis compression performed the best when tested on images from the same dataset as the training data. When investigating the speed of the system, we found that down-scaling input images had a huge effect on the speed, but also lowered the accuracy and range. While we managed to mitigate the effects the scale had on the accuracy, the range of the system is still relative to the scale of input images and by extension speed.
Acknowledgments
We would like to sincerely thank and acknowledge our supervisor Shahram Jalalinya for all the help he gave us during this project. Without his technical expertise, constant feedback and work put into supervising us, we surely would not have been able to produce this essay. We also thank Diako Mardanbegi, who together with Shahram constructed the prototype that we used as a foundation for our research, and which was a large reason for why we could conduct so many different experiments.
We would also like to aknowledge the authors of the article "Gaze locking: passive eye contact detection for human-object interaction" at Columbia University, as their research and findings served as the main inspiration for our project. In addition, they produced and shared the image dataset used for our training which was a huge help.
Contents
1 Introduction 1
1.1 Background . . . 1
1.1.1 The Research Field and History of Gaze Tracking . . . 1
1.1.2 The Context of Use of Gaze Tracking Systems . . . 2
1.1.3 The Purpose of Eye Contact Detection . . . 3
1.2 Problem Formulation . . . 4
1.2.1 Calibration and User Specificity . . . 4
1.2.2 Active, Passive and Intrusive Hardware . . . 5
1.2.3 Privacy Concerns in Gaze Tracking . . . 5
1.2.4 Small and Cheap Hardware . . . 6
1.2.5 Aim and Requirements . . . 6
1.3 Research Question . . . 8 1.4 Research Method . . . 8 1.4.1 Constructive Research . . . 8 1.4.2 Controlled Experiments . . . 9 1.4.3 Systematic Analysis . . . 9 2 Similar Work 10 2.1 Small Hardware Physical Sensor Implementations . . . 10
2.2 Functional and Nonfunctional Requirements . . . 11
2.2.1 Calibration-free Design . . . 11
2.2.2 Active or Passive Design . . . 11
2.2.3 Privacy and Self-Contained Computing . . . 12
2.2.4 Cost and Size of the Hardware . . . 13
2.3 Summary and Overview of Similar Work . . . 14
3 Technical Approaches to Eye Contact Detection 15 3.1 Eye Contact Detection by Tracking Gaze . . . 15
3.2 The Geometric Approaches . . . 15
3.3 Appearance-Based Approaches . . . 16
3.4 Relevant Algorithmic Implementations . . . 16
3.5 The Steps of a Appearance Based Approach . . . 17
3.5.1 Pre-processing . . . 17 3.5.2 Feature Extraction . . . 18 3.5.3 Classification . . . 19 4 Our Solution 20 4.1 Starting point . . . 20 4.2 Technology Used . . . 21 4.2.1 Hardware . . . 21
4.2.2 Software Tools and Libraries . . . 21
4.3 Development . . . 22
4.3.1 Columbia Gaze Dataset . . . 22
4.3.2 In the wild dataset . . . 23
4.3.4 Image Pre-Processing . . . 24 4.3.5 Features . . . 26 4.3.6 Classification . . . 28 5 Experiments 29 5.1 Model Evaluation . . . 29 5.1.1 Metrics . . . 29
5.1.2 Hold out method . . . 30
5.1.3 10-fold Cross validation . . . 30
5.1.4 In the wild . . . 30
5.2 Speed and Range Optimization . . . 31
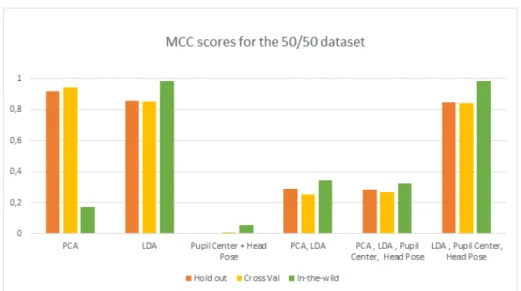
6 Results 33 6.1 Features . . . 33
6.1.1 PCA . . . 33
6.1.2 LDA . . . 33
6.1.3 Head Pose and Pupil Center . . . 33
6.1.4 Feature combinations . . . 34
6.1.5 Summary . . . 34
6.2 Dataset Class Distribution . . . 35
6.3 Optimization results . . . 36
6.3.1 Hardware and Speed . . . 36
6.3.2 Distance and Image Resolution . . . 37
6.3.3 Time Optimization . . . 38
7 Discussion and Analysis 39 7.1 Interpreting the Results . . . 39
7.1.1 Features and Accuracy . . . 39
7.1.2 Dataset Class Distribution . . . 40
7.1.3 Range Testing . . . 40
7.1.4 Speed Testing . . . 41
7.2 Proposed Model . . . 41
7.3 Method Discussion and Self Criticism . . . 42
7.3.1 Important Understudied Aspects . . . 42
7.3.2 Dataset Issues and Live Testing . . . 44
8 Summary, Conclusion and Future Work 45 8.1 Summary . . . 45
8.2 Conclusion . . . 46
8.3 Future Work . . . 46
References 48 A Appendix 53 A.1 The Complete Results from Accuracy Testing . . . 53
B Appendix 55 B.1 Systematic Literature Review . . . 55
1
Introduction
1.1 Background
The field of gaze tracking in computer vision has been an an increasingly popular topic of research, with the aim to develop algorithms with the ability to determine the gaze direction of a person, usually achieved through processing portrait images of the user. The purpose is to enable a system to estimate the direction of a user’s gaze, and by extension determine what the user is looking at. Such systems are capable of improving both ends of human-computer interaction as well as logging human attention for further analysis and insight, which lately have made the general field attractive to both researchers and commercial actors. However, the field is not a new one. Below we outline the history of gaze tracking, fo llowed by the context of gaze tracking today. We also argue for the need for eye contact detection systems, which are only concerned with whether a subject is looking at a camera or not as opposed to attempting to the determine the angle of the gaze. By examining the context of use of eye contact detection systems, we define a set of features that are critical for such systems to be practical in the wild. These features are then used to support our research question.
1.1.1 The Research Field and History of Gaze Tracking
The first research of human gaze tracking began during the 19th century when the french ophthalmologist Louis Émile Javal noticed the difference in gaze direction and visual per-ception of people reading[1]. This discovery later led to the first eye tracking device being built in the early 20th century, which consisted of a contact lens with a hole for the pupil and a connected aluminum pointer. Throughout the 20th century, the focus of eye tracking research was cognition psychology and especially gaze patterns of reading people. In the 1980’s the field expanded to include human-computer interaction for the first time, mainly focusing on how eye movement was affected by user actions, but research soon began to examine how gaze tracking could improve the computer interaction of disabled users[1]. During the 1990’s the first gaze tracking algorithms were created that takes images of users as an input and autonomously estimate the gaze direction of the subject through the use of image processing algorithms, which is the same principle as which is used today when referring to the term[2]. The algorithms typically work by taking a portrait image of a user and then analyzing it to find the pupil center. The gaze can then be estimated by calibrating the system to map the pupil center in the eye image to the points that the user is looking at in the real world or on the computer screen.
The area of gaze tracking has since the 1990’s been divided into several subfields, which can be segmented based on a number of criteria such as application area, required hard-ware, method of gaze estimation or purpose of the software. The latter may include gaze tracking which aims to measure the precise gaze angle of the subject, gaze locking which aims to determine whether a user is looking at a specific area, or eye contact estimation which has the specific aim to determine if the user is looking straight at the camera. This paper aims to explore the area of eye contact detection. While it may come across
as a less versatile area of gaze tracking, it will become evident in later sections of this introduction that eye contact detection has several benefits, not least when implemented in small, cheap and autonomous hardware. However, in the following section we will pro-vide the context of use of fully implemented gaze tracking systems in order to propro-vide the reader with an understanding of the general field.
1.1.2 The Context of Use of Gaze Tracking Systems
From here on forward, note that when the term gaze tracking is used we refer to systems with the aim to measure the vector of the gaze of a subject in relation to the camera, and the term eye contact detection is defined as a subset of gaze tracking which ignores all angles or data except for a twofold value indicating whether a subject is locking their gaze at the camera. Thus, gaze tracking systems capabilities includes, but are not limited to, eye contact detection. In order to argue for the relevance of the more limiting eye contact detection, we first outline the three main benefits of gaze tracking, which include giving the system context of the user, giving the user means of interaction with the system, and giving the owner of the system ways to log attention.
The first and one of the main benefits of gaze tracking systems is the ability to infer the context or tasks of a user, which would enable the system to predict user actions, intentions or needs[3]. This would allow the system to adapt its functionality to suit the needs of the user at the moment. Knowing the user’s context would also facilitate things such as interruptibility[4] which would provide a system with the means to determine so-cially appropriate situations in which the user can be interrupted, which in turn could be used in the scheduling of various types of notifications to the user.
In addition to letting the system infer the user’s context, gaze tracking can be used to provide explicit input to the system. One example of such an implementation lets the user interact with objects on a screen by looking at them[5], and can also be used in non-screen based systems by having the user look at various physical objects. This creates a broader range of modalities for interaction with a system, for example it can provide people suffer-ing from various motor disabilities with alternative means of interaction[6].
The third and final example of application areas for gaze tracking systems is the tracking and measurement of human attention, which can be logged and used for further analysis[7]. For instance, analyzing human attention has been used to investigate the development of young children, by letting a researcher wear a gaze tracking camera that measures the frequency and context of children’s bids for eye contact during social interaction[8]. The purpose of such measurements is to map out the typical development of children inter-action, but it has been proposed as an area suitable for studying autism as well, as eye contact and attention has been shown to be a key feature in both of these areas. Another application area for gaze tracking in medical research is to detect and monitor dementia, as research has shown that certain key features of eye movement has been found in pa-tients suffering from the disease[9]. Medical research is however not the only field that can
stand to benefit from studying human attention. Companies can use similar technology to measure and analyze consumer attention to advertisements or products. Prototypes of gaze tracking systems have also been integrated in museum showcases[10], and also used to track the attention of motorists[10].
1.1.3 The Purpose of Eye Contact Detection
In human-to-human interaction, eye contact functions as a way to convey attention in a nonverbal way and can in group conversations be a reliable way to infer who speaks or listens. It functions as a mean to empower a speaker that is expected to speak next[11]. Previous research has shown that eye contact data can be used to predict who is speaking or being spoken to with 80% accuracy[12]. Eye contact as a communication tool is however not limited to to-human interaction and has been shown to play a role in human-computer interaction as well. For example, research has shown that in human-human-computer interaction contexts where voice commands are not suitable as an input modality, a user normally looks towards the device they wish to communicate with before giving a voice input[13, 14]. Eye contact has also been shown to “provide the most reliable indication of the target of a person’s attention” [12] [15] which by extension is most relevant in any applications where user attention is of relevance.
As mentioned, eye contact detection as a subset area of gaze tracking retains the abil-ity of detecting direct eye contact with the camera, but sacrifices the abilabil-ity to output the vector of the gaze direction. As the need for complex output is limited compared to gaze tracking, eye contact detection systems are likely to perform well with either less complex input images, less extensive operation on the data, or both. This can in turn can lead to faster or less context dependent systems. Our literature review underlines the latter by showing that the methods used to achieve well performing gaze tracking generally have much more specific requirements in terms of camera hardware, illumination, and position of the user, while data on speed performance are scarce.
Even though it holds true that a perfect gaze tracking system with great performance would in theory be preferable to an eye contact sensor, the impractical drawbacks of the method makes it clear that such a system should only be opted for if there is a specific need for it. Although the possible application areas for eye contact detection may be fewer than for gaze tracking, researchers in the field have identified a number of areas where eye contact sensors can be useful.
As with the case of gaze tracking, eye contact detection too can help provide a system with user context. By embedding eye contact sensors into household objects in an smart environment e.g. a smart home, the system can infer the user’s point of interest and improve its performance in line with the user’s needs. In the same fashion, the system may recognize the context of the user based on their current attention pattern, generated by the sensors that they have eye contact with[11]. Mounting a camera on a screen can also enable the system to know if the user is paying attention to the screen or not. This
information can then be used to save energy. In a similar fashion, eye contact sensors have been mounted on robots in order to help them assess human attention, giving the robot a way to assess if the operator is addressing it or not[4].
Having screen mounted eye contact sensors also gives the user a mean of interaction with the screen, by for example letting the user turn on the screen by looking at it[16]. Embed-ding multiple sensors into various items can also be used to specify the object of interest for interaction through other modalities such as giving voice commands in a smart home environment.
Eye contact sensors also have a potential use in the logging of attention data, by plac-ing sensors on objects that could be a potential target for visual attention. This approach has been applied when collecting attention data to help detect neurological disorders such as autism and when studying social interaction development in children[8]. An adult would wear an eye contact sensor during a semi structured play session with a child, recording the child from an egocentric view. The recordings were then used to detect atypical gaze patterns and joint attention. Eye contact detection is also suitable for commercial applica-tions where sensors are placed on advertisements or products to collect consumer attention data[17].
All in all, we believe that there is a potential demand for eye contact sensors for both academic and commercial use in different application areas such as interaction with smart objects, the medical domain, studying customers’ visual attention etc, which does not re-quire full gaze tracking technology. Note that the various contexts of use outlined above generally have a similar set of specific requirements in order to be practically implemented. Most of the applications require multiple sensors, high portability and/or non-calibration to work with new users. The functional requirements and issues with previous eye contact sensor designs will be elaborated upon in the following chapter.
1.2 Problem Formulation
In this section, we will go through and explain the various features that a system requires in order to maximize practicality in real world applications based on the typical context of use for eye contact sensors. We will then present our approach that addresses all these features in a system, and lastly compare our presented approach with previous implementations. 1.2.1 Calibration and User Specificity
Calibration is always cumbersome and time consuming, as it usually means that the user have to perform a series of calibration steps before usage. In order to make eye contact detection sensors as easy as possible for most applications, there is a clear need to make them calibration-free[8, 18, 16]. If a system forces the user to perform a series of calibration steps before being able to accurately detect eye contact it would in many cases eliminate or greatly reduce the benefits of such sensors for that application. It may be acceptable in contexts such as the previously described area of autism and child development research or private usage in smart homes e.g. adjusting the sensor’s target area to match a TV screen. However, when we need to log attentional behaviour of larger groups of people such as
in commercial and advertisement application areas, calibrating the system is not practical as the natural behaviour and attention of the user would be compromised if required to acknowledge the sensor prior to having their eye contact recorded.
While gaze tracking applications generally require some calibration or user specific tuning[19, 5] with some exceptions[3], previous eye contact detection projects have used both calibration-requiring [20] and calibration-free approaches[18, 16]. Our aim in this paper is to make the sensor’s application area as versatile as possible and because of this we’ve opted for a calibration-free design.
1.2.2 Active, Passive and Intrusive Hardware
Active sensors are defined as systems which utilizes their own source of light or any other additional hardware at image capture, prior to processing them. This can include infrared illumination[6], directed illumination for corneal reflection based systems[10, 19], multiple cameras, RGB-D cameras for depth perception[21] or servo cameras for automatically pan-ning toward the subject.
In contrast to active sensors, passive sensors don’t require any additional light source or hardware, but instead rely on measuring existing light, prior to processing the images[16]. Although active systems often show promising performance compared to passive systems thanks to more advanced hardware, they do increase the cost and flexibility, and almost always require some form of calibration or require the subject to stand at a certain distance from the sensor.
Another way to classify hardware used in eye contact detection and gaze tracking is its level of intrusiveness. This aspect is related to the need for a subject to wear any equipment such as special glasses or other wearable equipment that assists the system to detect eye contact, which has been the case in some of the previous implementations[22]. Aside from the inconvenience that this type of hardware creates for the user, it can also be argued that the system becomes user specific if it only acknowledges users wearing the special hardware. Even non-wearable hardware can be viewed as intrusive if the design of it is obtrusive and attracts user attention. In order to reach as high versatility as possible in typical applications of eye contact detection systems, the system would need to be designed to be both passive and non-intrusive.
1.2.3 Privacy Concerns in Gaze Tracking
With the news of Wikileaks revealing that the CIA is conducting surveillance measures using devices such as smartphones and smart TVs[23], privacy concerns of the public are on the rise. Privacy issues related to gaze data collection have so far been a subject that has not been discussed extensively, perhaps due to the fact that the eye tracking field is still relatively young. Only recent advances in software and hardware have resulted in accurate enough gaze tracking to start posing concerns against privacy on par with other types of personal data collection such as GPS location, activity data or images. As gaze tracking systems rely on image capture to operate this may in the future raise privacy concerns if such sensors are placed at home or in public spaces.
Liebling and Preibush raised the issue in their 2014 paper “Privacy Considerations for a Pervasive Eye Tracking World”[7]. The authors argue that eye tracking sensors are sub-ject to privacy issues since the data collected can reveal information about the user which they might not consent to, which is especially true since eye movement and gaze are not always voluntary or conscious acts. The issue is elevated due to the fact that the user of an eye tracking system might not have any control over who is collecting the gaze data, and for what purpose.
In the paper, the authors do offer up some countermeasures that can help retain pri-vacy to some extent. One of the suggestions they present is aimed at developers of such systems, where they suggest adding layers of abstraction to the data. By specifying regions of interest for the output, which could consist of a twofold eye contact indicator and time, fine eye movement or other techniques used to derive at the region, could be filtered out. This would preserve the most sensitive areas unseen and avoid infringing on user privacy. As mentioned, a further issue of privacy is that all gaze tracking systems, including eye contact detection systems, rely on captured images of the user. If the images were to be handled irresponsibly, it could create obvious privacy concerns for users. A strategy for increasing user privacy can be making the eye contact sensor operate in an enclosed and self-contained system. This would allow the sensor to extract the value for eye contact or not and then disregard the image file and any other collected information before even outputting or storing the eye contact data.
1.2.4 Small and Cheap Hardware
By examining the eye contact sensor’s different application areas, outlined in section 1.1.3., it becomes evident that functional requirements such as non-calibration, non-intrusiveness and passive design are essential features in order to create a practical and versatile eye con-tact sensor. Previous research in the field has addressed these types of features and have succeeded in creating systems with promising results for eye contact detection[8, 18, 16]. However, we argue that two non-functional features of eye contact detection systems are generally overlooked by previous implementations, namely the factors of price and size of the system. Given that most eye contact sensors require either wearable sensors (such as autism and child development medical research) or interaction with robotics, small hard-ware would be a requirement. The other application area would be a multitude of cameras such as in smart homes, commercials or advertisements, low hardware costs would be a requirement in making them commercially viable. While some previous implementations have taken these factors into consideration[11, 17, 24], the price of their hardware is still high starting at 500 up to a 1000 US dollars. This will be further elaborated upon in chapter 2.
1.2.5 Aim and Requirements
Based on the typical context of use for eye contact detection sensors, we have outlined a number of functional requirements which are necessary for practicality. In addition, based
on previous implementations of such sensors we have identified the non-functional require-ments of price and size. While other research on eye contact detection has found success in implementing calibration-free, non-user specific and passive systems, in this project we aim to explore the possibility of expanding the focus to comprise the factors of price and size as well. In addition, we explore the possibility of developing a self-contained computer, without need for a remote server to perform image analysis in order to improve simplicity and reduce privacy concerns.
In this paper, we aim to explore the possibility of building a system which conforms to the following requirements;
1. Calibration-free implementation 2. Passive design
3. Minimum sensitivity to head position and angle 4. Small and cheap hardware
5. Self-contained computing
With the emergence of accessible, inexpensive, increasingly powerful and versatile single-board computers and peripherals in recent years such as the Raspberry Pi, an opportunity has arisen to explore the possibility of implementing eye contact detection software on the Raspberry Pi, effectively making it a self-contained system which is both small and inexpensive without the need for any remote computing resource.
Our approach to include the price and size considerations to the established functional requirements is to explore the possibility of implementing an eye contact detection system on a Raspberry Pi 3b. The small size of the Raspberry Pi would make our sensor able to be integrated into other appliances and due to its small size would not be intrusive and attract unwanted user attention. The low price point allows for a multitude of sen-sors being used in a system. An added benefit of having the eye contact sensor being implemented in an autonomous and enclosed system is that the privacy issues discussed in section 1.2.2 could be addressed as all processing occurs locally within the Raspberry Pi. Implementing an eye contact detector on a single board computer is a novel approach to eye contact detection, and by obtaining acceptable speed, range and accuracy performance on small hardware would bring the technology one step closer to widespread adoption. For this reason, this thesis will focus on the implementation, optimization and evaluation of eye contact detection software for the Raspberry Pi. Our aim is to first construct a eye contact detection system that complies with the functional requirements outlined above, and then explore the opportunities to optimize it for the Raspberry Pi.
1.3 Research Question
Given our approach, implementing an eye contact sensor on a Raspberry Pi and adhering to the criteria outlined in the previous section, we define our research question as follows:
What performance in terms of accuracy, speed and range can be reached for practical eye contact detection software implemented on Raspberry Pi 3b?
With this question, we do not imply that we are setting out to evaluate every single approach to eye contact detection there is in order to produce a holistic result answering the question. Rather, we have focused on exploring a limited number of features and algorithms informed by previous studies and our heuristic approach as a starting point with the goal of optimizing it for Raspberry Pi. The approach we choose will be motivated and explained further on and is based on the previously defined criteria and the limitations of the hardware. Thus, this paper can be viewed as an exploration of one possible approach for solving the problem and answering the posed question.
1.4 Research Method 1.4.1 Constructive Research
In order for us to answer the research question, the research method we have opted for is constructive research, which "...implies building of an artifact (practical, theoretical or both) that solves a domain specific problem in order to create knowledge about how the problem can be solved (or understood, explained or modeled) in principle".[25]
The reason for this choice of method stems from the fact that we indeed have a domain specific problem to solve, and due to the novelty of the project there is no previous research on eye contact detection with the same problem formulation. As a result, the approach we take to solve the problem will be based on different parts of a multitude of previous im-plementations and the practicality of the solution can only be measured by implementing the solution and iteratively evaluating and improving the software.
Our starting point for the software implementation is a prototype built by our supervisor Shahram Jalaliniya together with his colleague Diako Mardanbegi at Lancaster University. The implementation is based on a previous eye contact sensor[16] with similar functional requirements as our defined problem statement, but with a few key differences as a result of using different software and hardware resources. We implement the prototype program on a Raspberry Pi and analyze, modify and evaluate the code in iterations in order to optimize its performance in terms of both accuracy, speed and range, effectively aiming to construct the best possible artifact in terms of all performance measures.
1.4.2 Controlled Experiments
Our research, being conducted as experiments, can be seen as a study on how a set of independent variables affect a set of dependent variables. In our case, the dependent variables are the accuracy, speed and range of the eye contact sensor. The independent variables which we test are:
a. features used for training b. input image resolution
c. Constellation of training data (i.e. ratio of classes represented in the data set)
For our experiments we use the Columbia gaze dataset[16] for training and validation. A detailed description of the dataset is found in chapter 4.3.1. In addition we create a dataset of our own for the in-the-wild test. For each implementation we perform controlled experiments where we evaluate the accuracy of the classification algorithm. We do this by running three different tests, 10-fold cross validation, hold out method and our own in-the-wild dataset test. 10-fold cross-validation and hold out method helps us evaluate the classification model accuracy on images from the training dataset, in our case the Columbia gaze dataset[16]. While the in-the-wild dataset test helps us evaluate the accu-racy on images previously unseen by the classifier.
10-fold cross validation and hold out are standard methods when evaluating the perfor-mance of machine learning classification models and provided us with a standardized ap-proach to evaluation. In addition, the in-the-wild test was aimed to emulate a real world scenario and was therefore the closest we had to a live user scenario. As is discussed in the closing chapter of this essay, it turned out to be hard to emulate real world usage accu-rately, but despite this the in-the-wild test was crucial when deciding on what classification model was the optimal choice.
1.4.3 Systematic Analysis
In addition to evaluating the classification accuracy, we need to optimize the software for the Raspberry Pi in terms of frames per second and range. The method we use to achieve this is to systematically measure the average time spent on each step of the algorithm and analyze the results. We do this in order to find out what components consume the most time, and what measures we can take in order to reduce time consumption. While trying different approaches to increase the speed of eye contact detection we keep an eye on the accuracy performance in order to achieve an acceptable level of both accuracy and efficiency.
2
Similar Work
While the specific requirements we have defined for our project in combination creates a unique approach to eye contact detection, there are several studies that are relevant to our approach. In order to ensure that we have accounted for all relevant literature on the subject, we conducted a systematic literature review which can be found in Appendix B. In this section we will first outline the most relevant previous work found in the litera-ture review, and then compare them to the seven requirements we defined in our problem formulation. As we in this paper concern ourselves with both the construction of an algo-rithm, and the implementation of said algorithm on small hardware, we will in this chapter consider similar hardware implementations, and in the following chapter explore technical and algorithmic considerations. We will end this chapter by presenting an overview of the previous work in comparison with our approach in terms of features.
2.1 Small Hardware Physical Sensor Implementations
As we set out to develop our eye contact sensor, we looked at previous work that imple-mented their eye contact sensor on small hardware and shared some similarities to our approach.
EyePliance[11, 26], is an eye contact sensor system developed in 2003, mainly prototyped for attention tracking use in home environments and can be placed on e.g. TV-screens or lamps. It is constructed as a small and portable sensor suitable for placement on various household objects where human attention tracking can be of relevance. In addition to eye contact sensing, the prototype features a simple voice command-interface intended to be used in combination with the attention tracking. Unfortunately, as there is no technical specification available for the device, we can’t really comment on the prototypes accuracy, speed or range performance.
A similar project is the EyeLook[24], which is a platform developed using SonyEricsson’s P900 smartphone, augmented with a sensor the developers calls eyeCONTACT or ECS. This implementation was prototyped for placement on screens where video would only play if the user’s attention was focused on the screen. It was also prototyped in a speed-reading application where words would appeared on a fixed position on a screen and would only updated if the user looked at it.
Lastly, the EyeBox2[17] and its predecessor eyeBox[27] are the only eye contact sensors we have found that were sold commercially. It was developed by the company Xuuk and sold as a complete package with hardware and software included. The sensor[17] itself is small, 9x9x4 cm in dimension and uses a 1.3 megapixel camera with infrared light sources. Worth noting here is that the sensor comes with an additional 9x9x4 cm infrared light source unit that is needed for the sensor to actually operate. The face detection accuracy is >95% under optimal lighting conditions. Important to note here is that this should not be confused with the eye detection accuracy. The operating range of the device is up to 6 meters with a field of view ranging from 30 to 60 degrees and up to 10 meters at 20 degrees field of view, also this under optimal lighting conditions.
Unfortunately, as only the EyeBox2[17] discloses the device’s performance, it makes it difficult for us to compare the different sensors to each other aside from functionality. Also important to mention here is that this section does not provide a complete overview of the field. While we have not found an especially large amount of eye contact sensors im-plemented on small hardware during our literature review there are more implementations than the three outlined above. However, the EyePliance, EyeLook and EyeBox sensors are the works that we deemed the most relevant to include in our paper, partially because they have very similar intended application areas as our project, they explicitly or implicitly are applicable to any area where eye contact detection is relevant, and partially because there are some available information regarding their implementation in terms of hardware and/or software which makes them relevant to both discuss and compare to our project. Other previous work regarding eye contact detection sensors on small hardware that we found[28, 29, 30] are either not relevant for comparison due to wildly differing specifica-tions, or not possible due to the limited information available on their features and/or technical implementation. However, there are still other relevant work such as [16] and [8] that are important to our approach but as their sensor platform differs from ours we choose to discuss them in chapter 3 instead.
2.2 Functional and Nonfunctional Requirements
In this section we go through the five required features that we outlined in section 1.2, and review how the three above mentioned sensors address them. We explain the hard-ware implementation of the sensor to identify how our work differentiates itself from the previous work in order to ensure the novelty of our work. We also review algorithmic implementations in order to identify their relevance to our implementation.
2.2.1 Calibration-free Design
Each of the three sensors previously described have calibration-free and non-user specific design. This might suggest that calibration-free designs are common, but it is important to note that these feature are not the norm in the field of gaze tracking. Designs relying on calibration can generally produce significantly more reliable gaze direction data than their calibration-free counterparts. That is why calibration is still a popular choice in applications where the precise direction of user gaze is integral to the functionality of the application. However, these designs mostly require either specific and sometimes expensive hardware, or require users to be in a specific area for effective gaze tracking. With these disadvantages, in combination with the practical sacrifices calibration creates, it is only natural that [17], [24] and [11] constructed their eye contact sensors calibration-free. 2.2.2 Active or Passive Design
Interestingly, all three sensors use infrared illumination in order to detect eye contact. Both the EyePliance[11] and EyeLook[24] sensors took the same approach, using on-axis and off-axis infrared LEDs with the hertz frequency of the lights synced with the cam-era frequency. The two different light setups produces two different pupil reflections, one
bright and one dark in two different areas in the eye. By subtracting these fields with a simple algorithm, the pupils can be identified in the image. The positions of the pupils is then compared to the position of a third reflection from the surface of the eyes, and the relation between the positions indicate whether eye contact is made. Both EyePliance[11] and EyeLook[24] implement the hardware and software for pupil finding as proposed in the paper "Pupil Detection and Tracking for Using Multiple Light Sources" by Morimoto et. al.[31], which is a method proven effective for pupil estimation in subjects ranged up to 5 meters. However, neither [11] or [24] elaborate on how the authors infer eye contact from the pupil positions apart from that they use an additional eye reflection to do so. The EyeBox2[17] also relies on infrared illumination in order to detect eye contact, al-though it uses a different approach than the two sensors described prior. There is however not much information available on how exactly it operates apart from that it uses a mul-titude of infrared light sources. One non-scientific article[27] claims that it analyzes how many times the images produce red-eye effect, which is the same effect that the previous two implementation call bright pupil reflection.
One aspect of the infrared illumination that is worth noting is that since the natural day-light includes 52-55% day-light in the infrared spectrum[30], infrared-based approaches may prove unreliable in outdoor conditions. This is also noted by Morimoto et. al.[31] who admits that the performance of their infrared pupil detector in daylight conditions remains unclear. It is also unclear whether these implementations can handle arbitrary head poses. Zhang et. al.[18] pointed out that corneal-reflection based implementations require multi-ple light sources or cameras in order to not be limited to fixed head poses and stationary settings.
2.2.3 Privacy and Self-Contained Computing
The EyeLook[24] sensor does not conduct any self-contained computing as the sensor itself captures video and streams it directly to a server using TCP/IP. The server then per-forms all the computing and image processing necessary. The data transmission occurs over either Bluetooth or General Packet Radio Services (GPRS). In terms of the security implications of this practice, researchers have pointed out that both Bluetooth and GPRS suffers from security related issues. Xenakis[32] points out that ".. although GPRS have been designed with security in mind, it presents some essential security weaknesses”. He points out that there are security risks related to both confidentiality and authentication, but more importantly GPRS uses a highly exposed radio interface where encryption is not mandatory. It is even the case in some countries that GPRS operators are not permitted to enforce encryption, resulting in them having to transmit data unencrypted.
Regarding the security situation for Bluetooth, Albazrqaoe et. al.[33] points out that Bluetooth generally has been regarded as relatively resilient to data sniffing due to fea-tures such as “indiscoverable mode, vendor-dependent adaptive hopping behavior, and the interference in the open 2.4 GHz band”[33]. However, the authors present a method that can consistently sniff over 90% of data packages sent over Bluetooth in real world environ-ments, exposing a crucial security risk to using Bluetooth for transmission of private data.
Even with the authors’ suggested security measures employed, around 20% of data packages can still be intercepted. Eventually, by streaming the raw video over GPRS or Bluetooth, the EyeLook could raise concerns for users with high security demands. Another issue with assigning the full computational load to a centralized server is that applications that require multiple sensors would either require multiple instances of the server or increase the server load, which is a limiting factor.
For the EyePliance[11] sensor the authors imply that the computation for eye contact detec-tion occurs in the sensor itself, and sensor data it transmitted to a centralized server which is used to coordinate communication across multiple sensors. However, the EyePliance[11] also supports voice commands and voice data seems to be transmitted to the server which performs a lexical analysis based on which sensor is activated by the user’s gaze[26]. Re-garding privacy issues with this sensor implementation, privacy reRe-garding image data can be sorted by performing the image processing in the sensor itself, however the voice data is still susceptible to the same security issues as the image data for the EyeLook[24] sensor. The EyeBox2[17] also utilizes a server for communication with the sensor. However, the information available on how the sensor works is very limited and we can not properly assess whether the sensor’s computing is self-contained or not. In our implementation on the Raspberry Pi, we aim at processing images on the device itself, granting us full control over what data leaves the sensor which effectively would mitigate several of the security issues as discussed in section 1.2.3.
2.2.4 Cost and Size of the Hardware
Each of the sensors we have chosen to highlight in this chapter have suggested use cases similar to ours, which have caused all of them to aim for small and cheap hardware. While we do not know the exact dimensions of all the sensors, they appear to be about the same size as the Raspberry Pi or smaller which makes them suitable for embedding them into most objects. All three sensors also claim to be low cost. The EyeBox2[17] retails for 1000 US dollars[27], and the EyePliance[11] is said to be under 500 US dollars[26] which does not include retail markup. The EyeLook[24] has no specified retail or production price, however they claim that the sensor is of “low cost”[24]. Given that the EyeLook uses a very similar hardware setup for their sensor in terms of infrared illumination as the EyePliance[11], it might have a similar production cost, however we can not confirm this. Our sensor, being built using only a Raspberry Pi 3b with a power supply, an SD memory card and a case with preferably a heat sink, currently retails at $75 US dollars as a kit, and the native PiCam camera retails at around $22 US dollars, consumer priced. This puts the complete hardware cost, at retail price, for our sensor at less than $100 US dollars, making it the cheapest alternatives by far. Reasons for our sensor being cheaper here might be that our approach does not require infrared illumination or because our sensor is not custom built.
Table 1: Feature overview over similar work, and our solution PiEye Calibration-Free Passive Design Self-Contained Small Hard-ware Cost
EyePliance Yes No No Yes <$500 Production
EyeLook Yes No Partially Yes “Low cost”
EyeBox2 Yes No N/A Yes $1.000 Retail
PiEye Yes Yes Yes Yes <$100 Retail
2.3 Summary and Overview of Similar Work
After studying the previous implementations, we make the following observations. We found that all three of the sensors used a calibration free approach. This is likely due to the application areas of the sensors which more or less requires them to work without calibration. This is why we also have opted for the calibration-free approach. Interestingly, all three sensors used infrared illumination at image capture in order to find pupils and detect eye contact. In our project, we have opted against this in order to keep simplicity up, hardware cost down and making sure it can operate during daylight conditions. We confirmed that our sensor is low cost, the Raspberry Pi together with accessories costs five times less than the production cost of the EyePliance[11] and ten times less than the retail price of the EyeBox2[17]. Worth noting here is that the price we’ve used for the Raspberry Pi and its accessories is the consumer price for a single unit. If the sensor we are prototyping were to be produced in high volumes, the price would likely drop due to bulk orders. Our sensor is also the only one having fully self contained computing, not counting the EyeBox2[17] where we can’t know for certain if it does. Naturally all the sensors use small hardware, which is one reason why we chose to highlight them.
3
Technical Approaches to Eye Contact Detection
3.1 Eye Contact Detection by Tracking Gaze
As pointed out earlier in this paper, eye contact detection is a subarea of gaze tracking. By extension, this means that any approach that can be used to solve gaze tracking can also be applied to eye contact detection, as gaze angles are measured in relation to the camera. If a gaze tracking sensor would find a gaze angle around zero on both the horizon-tal and vertical axis this would imply that the subject is looking at the camera. However, methods developed solely for detecting eye contact can typically not be applied to track-ing gaze angles as the system requires very deliberate effort to measure the gaze angles of a person and usually requires a higher degree of complexity in both software and hardware. Putting aside the complexity of gaze tracking systems, they have one significant advan-tage over sensors that can only detect eye contact, being that in almost all application scenarios, it is not the user’s eye contact with the camera that is of interest, but rather the user’s eye contact with the object that the camera is embedded into (see section 1.1.3). By recognizing the gaze angle of a user, the sensor can determine if the user’s gaze is located in the vicinity of the sensor and if so, by how much.
With this in mind, it’s clear that the possibility of using gaze tracking approaches to detect eye contact is worth exploring. But as our ambition is implementing the eye con-tact detection software on a Raspberry Pi, the hardware and software are limiting factors and don’t give much leeway for intense processor-heavy tasks. This being said, the meth-ods used to detect eye contact are directly derived from the methmeth-ods used in gaze tracking. Below we explain the two main categories of approaches used for gaze estimation from im-ages. Namely, the geometric approaches[34] and the appearance-based approaches which are not limited to either eye contact detection or gaze tracking.
3.2 The Geometric Approaches
Geometric approaches, also referred to as model-based approaches[18], are used to read gaze direction from eye images by calculating and analyzing geometrical relationships be-tween the position of specified points in an eye image. These approaches can be divided into two further categories, which are corneal-reflection based and shape based methods[18]. In corneal-reflection based methods, external light sources are required to produce reflec-tions on the cornea of the eye, which in turn can be used to determine the gaze direction. All three previously mentioned sensors that we discussed in section 2.1.1 use this approach to detect eye contact. A common limitation with these methods is that they often require a fixed head pose in a stationary setting in order to properly function. Only by including multiple cameras or light sources have more recent works been able to handle more varied head poses[18].
Shape-based methods, as opposed to corneal-reflection based methods, do not require any additional illumination in order to function. Shape-based methods[35, 36, 37] can extract features from an eye image and by applying geometrical models on image coordinates,
determine the gaze direction. Possible features can be the pupil center, iris edges, eye-lid edges and eye corners. Extracting these features from an image is usually achieved with a combination of computer vision and machine learning. While shape-based methods do not require additional illumination which is an advantage over corneal-reflection-based methods[18], they still have some drawbacks. Shape-based methods are less accurate and less capable of handling low resolution images and poor lighting conditions. Furthermore, many implementations rely on cameras that in addition to capturing color information also capture depth information, so called RGB-D cameras such as Microsoft’s Kinect[35, 38]. 3.3 Appearance-Based Approaches
Appearance-based approaches, sometimes referred to as view-based approaches[39], takes an eye image as input and through machine learning, the image pixel data is used for classification. Tan et. al.[40] illustrates this by suggesting that you can “...treat an image as a point in a high-dimensional space. For example, a 20 pixel by 20 pixel intensity image can be considered a 400-component vector, or a point in a 400-dimensional space.” To elaborate on this explanation, each image is treated as a data point described by a set of features which in this case is the value represented at each pixel. Another data point (im-age) with similar values in the same pixel positions as the first image would be considered close in range within the high-dimensional space and by extension likely the same class as the first image. The amount of classes varies depending on the application. With gaze tracking implementations a multitude of classes are defined while in eye contact detection the images are classified binary as True of False.
Appearance-based methods have the advantage of being robust, easy to implement[40], and practical even with low resolution images[18] compared to geometric methods. How-ever, appearance-based models require a higher amount of user-specific training data to function, as Zhang et. al. mentions “it remains unclear if the learned estimator can gener-alize to unknown users”[18]. Furthermore, “methods typically assumed accurate 3D head poses as input, which is a strong assumption for unconstrained in-the-wild settings”[18]. 3.4 Relevant Algorithmic Implementations
By conducting a literature review over possible algorithmic approaches to eye contact de-tection, we found two papers that are especially suited for our outlined requirements in that they do not have any requirements on the input except for an image of a user, and no special illumination or camera features required. Both papers use appearance-based approaches and binary classification is used to predict eye contact.
First we have Smith’s et. al.[16] Gaze Locking paper were they propose an eye contact detection algorithm which is very relevant to our project since it does not require any ex-tra hardware and performs the image processing and classification on raw images without needing special illumination. It is an appearance-based machine learning approach that takes images of users as input and performs pre-processing steps to crop the eye images. Then features are extracted from the eye images, and the data of each frame is compressed for classification by a Support Vector Machine. These steps are performed both in training
and in classification. The training data includes images of people with different ethnic makeup, with and without glasses and with different head angles. This should in the-ory make the algorithm able to handle previously unseen faces from different backgrounds located in range of the camera. The authors reports good results[16] for their accuracy tests, 0.83 Matthews Correlation Coefficient score at up to 18 meters in range. They use the Support Vector Machine classifier in order to train and classify the data. The pixel data of each frame is compressed by Principal Components Analysis (PCA) and Multiple Discriminant Analysis (MDA).
Another relevant work to our thesis is Ye et. al.[8] where the authors fitted a wear-able camera on a pair of glasses, giving the camera an egocentric view. They then have a user wear the glasses during a semi structured play session with a child, in order to record eye contact frequency and detect gaze patterns. What makes this work relevant to ours is that the child being detected for eye contact is not wearing any special hardware, and the algorithm they present work without any additional illumination prior to image capturing. In addition, they also use machine learning in order to predict eye contact, but in contrast to the Gaze Locking paper[16] this approach includes a geometrical head pose estimation derived from the position of facial features prior to extracting image features. This is also a feature that we experimented with in our approach. Their algorithm sup-ports calibration-free, non-user-specific and head pose invariant eye contact recognition. The authors experimented with various feature descriptors and learning models, such as Convolutional Neural Networks, Histograms of oriented gradients and Conditional Ran-dom Fields (CRF) during training and classification and found CRF to be the best choice for their implementation. While we did experiment with Ye et al.’s approach of combining geometric data in combination with pixel data for learning, we unfortunately did not have the time to expore the use of CRF as classifier in this project despite the promising results presented by the authors.
3.5 The Steps of a Appearance Based Approach 3.5.1 Pre-processing
Most appearance based algorithms that use images as input in order to estimate gaze need to have the image pre-processed before it can be used. This usually comprises rescaling the image to a preferable size, and then converting the multichannel RGB to a single channel grayscale image for faster processing[8, 16]. As the classifier will use cropped eye images, the eyes need to be located within the image. This is usually achieved by first detecting faces within the image. Two examples of this can be by using Haar feature-based cascade[41] or SURF-cascade[18] to retrieve a bounding box containing the face image. The face-image is then further analyzed in order to extract pixel coordinates for facial features such as eye corners in order to crop out the eye region. A normalizing algorithm can be applied to the cropped out eye images in order to minimize the effect of different lighting conditions. As the bounding box for the eye image is rectangular in shape, and the eye itself is elliptical, an image mask should be applied to filter out the region surrounding the eyes[16] to further remove redundant data. After the pre-processing step is done, the program should have a grayscaled, resized, cropped, normalized and possibly masked image of the eye region left to work with.
3.5.2 Feature Extraction
The feature extraction step retrieves the features from the image that should be fed into the training and classification steps. In purely appearance based systems, the only initial image features is the pixel intensity information, as the image is converted to single channel grayscale in the pre-processing step. As mentioned earlier, the number of dimensions of a data point, in this case an image, is the same as the number of values i.e. pixels needed to describe it fully. By converting the image to grayscale, each pixel position only needs to contain a single intensity value as opposed to the three separate values for red, green and blue intensity values present in an RGB-image. Consequently, by converting the image to grayscale, the dimensionality of the data point is reduced to a third of the original value. In addition, as the amount of pixels is often in the thousands, different techniques have to be applied in order to reduce the dimension space and make it useful for training and classification. The method for reducing dimensions and extracting relevant features from the pixel matrix varies between implementations. For methods that use convolutional neu-ral networks, this is done automatically as dimension reduction is an inherent step of the technique. Worth noting is that the dimension reduction done in neural networks takes control away from the developer, and it is unclear if the resulting features can be used in combination with others. Other kinds of implementations use various techniques for reducing the dimensions of each image manually such as MDA, PCA or LDA[16]. The concept of dimensionality reduction implies that the number of values used to describe a data point is reduced, usually either by filtering out values that has a low variance across the data set (as with PCA), or selecting values that are highly determinant of the classifi-cation (as with MDA and LDA). If the dimensions are reduced enough, the extracted pixel value can be accompanied by additional information such as head pose values[8]. Worth noting is that combining image dimensions with other features relies on the fact that the dimensions have been reduced to a very small amount before being used as features, so that the features derived from pixel data do not severely outnumber the additional head pose features. To exemplify this property, if you would have an image with 20x20 pixels with no dimensionality reduction, and one value that indicates the angle of the head, the resulting feature vector would contain 400 features of pixel information and a single feature for the angle. This would make the impact of the head angle to the classification less significant as the classifier doesn’t distinguish between types of features.
For our solution, we have opted against using neural networks due to time constraints, which means that we need to handle the dimension reduction ourselves. The two most relevant techniques for us to do this is PCA and LDA. PCA, or Principal Component Analysis is a method that reduces the number of dimensions in an image by extracting a specified number of principal components. They in turn are used to extract directions in the data which have the highest variance, i.e. are most spread out, which concentrates the relevant features and removes redundancy. It is an unsupervised method and it can produce any amount of values that are less than or equal to the original number of data points. LDA, or Linear Discriminant Analysis, is also a dimension reduction technique which, as opposed to PCA, is supervised. When reducing the dimensions of the image data, it needs both the features that represent the data, and the classes that the entry belongs to. It can produce a number of new components that are less than the total
num-ber of different classes that belongs to the dataset. Our application only has two classes, TRUE and FALSE which indicates if the user has established eye contact or not, which results in that the only alternative is to let LDA reduce the pixel matrix to one single value as long as we do not include more classes. We experimented with the idea of including more classes for training, but still keep the classification binary, which we elaborate on in the next chapter.
The Gaze Locking project [16] uses a combination of PCA and MDA, with MDA standing for Multiple Discriminant Analysis and is a modified version of LDA. It is unclear to us how LDA and MDA differ, but it is possible that MDA has the ability to produce a larger number of new data points, as it may not be limited to less than the original number of classes as it is specified in the Gaze Locking project [16] that they reduce the dimensions to six features which would be impossible using only two classes and LDA. While this technique would be very relevant for us to explore, we have not found any readily available implementation of the technique for Python and with our limited time-frame we can not produce such an algorithm ourselves.
3.5.3 Classification
After enough image samples have been extracted for features, they are used for training the classifier, this in order to produce a model for classifying unseen data. The most common approach for training a classifier is supervised learning where a training data set needs to be prepared by labeling the data set into the classes of interest. There is a wide range of different classifiers that can be used to achieve this step. Support Vector Machines[16] and Convolutional Neural Networks[8] are among the most common classifiers for gaze estimation that have shown promising results.
4
Our Solution
4.1 Starting point
Our solution to eye contact detection that supports all the requirements listed in the problem formulation is mainly based on the algorithm proposed in the paper by Smith et. al.s Gaze Locking project[16]. A first prototype of the system was built based on the Gaze Locking system by our supervisor Shahram Jalaliniya and his colleague Diako Mardanbegi. We used that prototype as the initial point of departure in our thesis. In the beginning of this thesis project, we experimented with a few other solutions based on a geometrical approach but the initial testing showed that the feature points we would use for calculation were too noisy to produce a meaningful result, and the image processing workload was to heavy for Raspberry Pi. After conducting a literature review it became clear that an appearance-based solution was the most promising approach for reaching our goals, and Shahram’s code served as a suitable starting point for our implementation as it was based on a paper showing promising results. While the original implementation was built in Matlab, Shahram built his prototype in Python with mostly the same general components, but with completely different libraries and tools to achieve them.
Figure 1: Steps of the eye contact detection algorithm of Shahram Jalaliniya’s prototype. Red boxes indicate pre-processing steps, green are feature extraction and blue classification.
Figure 2: Steps of the eye contact algorithm in GazeLocking[16] approach. Red boxes indicate pre-processing steps, green are feature extraction and blue classification
The largest differences of the prototype, apart from the obvious difference in programming language and libraries, are as follows;
1. Where the Gaze Locking project [16] used a commercial face and fiducial point detec-tor, the prototype uses an open source general facial feature detector from Dlib[42]. 2. Where the Gaze Locking project [16] used PCA and MDA feature compression, the prototype only used PCA. This is potentially a very large difference as the features are the deciding factor for accurate classification. Furthermore, MDA and PCA are very different in nature as PCA mostly operates by removing redundancy in data whereas MDA actively performs supervised dimension reduction based on classes.
4.2 Technology Used 4.2.1 Hardware
The main development and tests, not specific to Raspberry Pi, were conducted on an early 2011 MacBook pro with 2,3 GHz Dual-Core Intel Core i5 processor and 8 GB DDR3 1333 MHz RAM. The remaining development and the range tests were conducted in a Ubuntu virtual environment with a Microsoft LifeCam HD-3000.
We developed our sensor for Raspberry Pi 3b connected with the PiCam camera mod-ule, images of which are presented in figure 3 and 4. The Raspberry Pi 3b runs on a 1.2 GHz ARM Cortex-A53 processor and has 1 GB LPDDR2 900 MHz RAM. The PiCam is a 5 megapixel fixed-focus camera capable of video capture at 1080p30. This is however not the only available platform that would fulfill the requirements for this project. There are several single board computer alternatives to Raspberry Pi such as Intel Edison, Pine64, and LattePanda to name a few. However, with the Raspberry Pi 3b being a mid range single board computer both in terms of price and performance, combined with a large open source community and arguably most importantly, a Debian-based operating system. This allows for practical installation of libraries intended for Linux usage, because of this we did not see a reason not to choose Raspberry Pi 3b.
4.2.2 Software Tools and Libraries
The system was programmed in Python 2.7.13 with a number of support libraries. Firstly, we used the open source image processing library OpenCV 2 for all image processing needs such as resize, grayscale and crop images. In order to find faces in images, and find facial feature points on the faces we used the open source library Dlib which is a general purpose library which among other things include image processing and machine learning compo-nents, and face detection and facial landmark extraction functionality. Dlib and OpenCV are used primarily for the pre-processing steps as Dlib finds the facial landmarks, including eye corners, and OpenCV crops the eye images and performs necessary processing before
Figure 3: Raspberry Pi components Figure 4: Raspberry Pi setup
continuing with feature extraction.
For feature compression and dimension reduction we used the SciKit Learn library which contains both PCA and LDA implementations, as well as an SVM implementation. In addition we used a number of standard Python libraries such as the Math library for calculations and the Numpy library for multidimensional data representation.
4.3 Development
Our first goal when developing the prototype was to improve the performance in terms of accuracy as the reported results of the Gaze Locking system[16] outperformed the proto-type provided by our supervisor based on our initial testing. Our two primary goals were as follows: first, achieving a satisfactory accuracy with a classification model, and second is optimization of the system to better suite the Raspberry Pi’s limited hardware capacity. The most obvious difference was that the Gaze Locking project used MDA for feature com-pression in addition to PCA. This is likely a huge difference as the PCA compresses the feature vector to 200 dimensions, and the MDA compresses those 200 dimensions to only 6. Unfortunately, we found that there is currently no available MDA implementation for Python and as time was a limiting factor for us, we did not have the time to create our own. As the large gap in performance between the prototype and the Gaze Locking project strongly suggests that the nature of the feature vector used by the classifier plays an es-sential role in the overall accuracy performance of the system, we decided to focus our research on accuracy improvements on this step of the algorithm. We defined a number of available features to include in the feature vector and designed a number of tests in order to measure the performance gain for each of the features, and different combinations of them.
4.3.1 Columbia Gaze Dataset
The dataset we used during development for classifier training and validation is the Columbia Gaze dataset[16] as this was the only diverse and carefully labeled gaze direction dataset
Figure 5: Columbia Gaze dataset[16] image sample
available to us. The dataset is publicly available and made up of 5,880 images in high resolution 5184 x 3456 pixels. The images were captured using a Canon EOS Rebel T3i camera and a Canon EF-S 18–135 mm IS f/3.5–5.6 zoom lens. The dataset consists of 56 people of which 32 are male and 24 female. The origins of the participants are varied, 21 were Asian, 19 were White, 8 were South Asian, 7 were Black and 4 were Latino. The age of the participants ranged from 18 to 36 and 21 wore prescription glasses. This provides us with a good source of diverse eye images to work with. The Columbia Gaze dataset is a good starting point but it does have some drawbacks, one being that of the 5880 images only 280 of them are eye contact positive, this makes it highly skewed and not yet suitable for training purposes. Another drawback with the dataset is that the head orientation varies only horizontally. This results in the classification model being poorly trained to handle vertical head movements, and affects the models overall robustness.
4.3.2 In the wild dataset
Figure 6: In the Wild dataset image sample
The second dataset that we used, we created ourselves to use with our in the wild test, further explained in chapter 5.1.4. The dataset consists of two people both of which were white males, one of whom wore prescription glasses. The images were captured with Macbook’s FaceTime HD camera at resolution 1280x720. The images were captured during daylight conditions with lots of natural light. The participants were seated with the camera positioned at head height, 1.5 meters away from the camera while seated. As this dataset is supposed to emulate a live scenario we wanted to capture the participants in a natural setting, for this reason we did not try to control the setting aside from distance and position of the participants.

![Figure 2: Steps of the eye contact algorithm in GazeLocking[16] approach. Red boxes indicate pre-processing steps, green are feature extraction and blue classification](https://thumb-eu.123doks.com/thumbv2/5dokorg/4210064.92445/30.892.170.732.951.1079/contact-algorithm-gazelocking-approach-indicate-processing-extraction-classification.webp)

![Figure 5: Columbia Gaze dataset[16] image sample](https://thumb-eu.123doks.com/thumbv2/5dokorg/4210064.92445/33.892.141.772.204.295/figure-columbia-gaze-dataset-image-sample.webp)
![Figure 7: Eye image be- be-fore(top) adding gradient noise and after(bottom)One of the drawbacks of the Columbia Gaze dataset[16] is](https://thumb-eu.123doks.com/thumbv2/5dokorg/4210064.92445/34.892.576.766.259.643/figure-image-adding-gradient-noise-drawbacks-columbia-dataset.webp)