V¨
aster˚
as, Sweden
Thesis for Bachelor of Computer Science
LOAD BALANCING OF PARALLEL TASKS
USING MEMORY BANDWIDTH
RESTRICTIONS
Tommy Ernsund
ted16001@student.mdh.seLinus Sens Ingels
lis16001@student.mdh.seExaminer: Moris Behnam
M¨alardalen University, V¨aster˚as, Sweden
Supervisor: Jakob Danielsson
M¨alardalen University, V¨aster˚as, Sweden
Abstract
Shared resource contention is a significant problem in multi-core systems and can have a negative impact on the system. Memory contention occurs when the different cores in a processor access the same memory resource, resulting in a conflict. It is possible to limit memory contention through resource reservation where a part of the system or an application is reserved a partition of the shared resource.
We investigated how applying memory bandwidth restrictions using MemGuard can aid in synchronizing execution times of parallel tasks. We further investigate when memory bandwidth restrictions are applicable. We conduct three experiments to investigate when bandwidth restrictions are applicable. Firstly, we conducted an experiment to pinpoint when the memory bandwidth saturates a core. Secondly, we investigated our adaptive memory partitioning scheme performance against static and no partitioning. Finally, we tested how our adaptive partitioning scheme and static partitioning can isolate a workload against an interfering memory intensive workload running on a separate core.
As the experiments only were conducted on one system, pinpointing the general point of contention was difficult, seeing that it can differ significantly from system to system. Through our experiments, we see that memory bandwidth partitioning has the ability to decrease the execution time of feature detection algorithms, which means that memory bandwidth partitioning potentially can help threads to reach their synchronization points simultaneously.
Table of Contents
1. Introduction 1 1.1. Research Questions . . . 1 2. Background 2 2.1. Memory . . . 2 2.1.1. DRAM . . . 3 2.1.2. Memory Bandwidth . . . 4 2.1.3. Memory Contention . . . 5 2.2. Parallel Computing . . . 5 2.3. Related Work . . . 6 3. Method 7 4. Implementation 9 4.1. Using MemGuard . . . 94.1.1. Adaptive Memory Bandwidth Partitioning . . . 9
5. Experiments 12 5.1. EX1: Memory Bandwidth Saturation . . . 13
5.2. EX2: No Paritioning and Static Partitioning vs. AMBP . . . 13
5.3. EX3: Isolation . . . 14
6. Results 15 6.1. EX 1: Saturation on The Memory Bus . . . 15
6.1.1. TC1 - Point of Saturation . . . 15
6.2. EX2: No Partitioning and Static Partitioning vs. AMBP . . . 16
6.2.1. Test case 1 - No Partitioning . . . 17
6.2.2. Test case 2 - Static Partitioning . . . 18
6.2.3. Test case 3 - AMBP . . . 19
6.3. Experiment 3: Isolation . . . 20
6.3.1. Test case 1 - No Partitioning . . . 20
6.3.2. Test case 2 - Static Partitioning . . . 21
6.3.3. Test case 3 - AMBP . . . 21
7. Discussion 23 8. Conclusions 25 8.1. Future Work . . . 25
1.
Introduction
Most general purpose computers use a multi-core architecture to run every-day tasks [1]. An integral part of the multi-core processor is the memory subsystem, used for storing run-time data. The internal memory subsystem, such as caches, TLB’s and the system memory bus is however often physically shared between different cores of a multi-core computer. Memory is often physically shared between different computational cores of a multi-core computer. Physically sharing memory between different cores means multiple tasks run concurrently on different cores and compete for the shared memory bandwidth [2]. The processing time for memory access requests in multi-core systems may vary drastically due to several factors including the location of the memory, the state of DRAM (Dynamic Random Access Memory) chips or the DRAM controller [1]. Scheduling algorithms based on First-Ready First-Come-First-Serve (FR-FCFS) [1, 3] conditions can be used by the DRAM controller to boost the DRAM throughput by reordering memory requests because requests from one core can effect requests from other cores. Variables such as DRAM throughput and temporal predictability inflict significant challenges on real-time systems because of potential task invalidation by workload changes in other cores during run time. Resource reservation and reclaiming techniques can be used to assign partitions of a shared resource to different applications [1,2]. Areas such as CPU and disk management has applied resource reclaiming techniques successfully using constant-bandwidth servers [4] and high throughput disk scheduling [5]. Memory bandwidth reservation is less investi-gated, and only a few solutions [4,1] are applicable on Commercial Off-The-Shelf (COTS) computers due to their highly dynamic memory service rate.
Memory bandwidth restrictions are very interesting for multi-core application since they can provide a solution to memory bandwidth being a performance bottleneck for the system [6]. In this study, we investigate how memory bandwidth restrictions can be used to synchronize execution times of parallel tasks. We also aim to find an answer to when bandwidth restrictions are most suitable to apply. This could be beneficial to real-time applications [6] with strict time constraints.
1.1. Research Questions
We present the research questions as follows:
• RQ1: When does the assigned bandwidth reach a point of saturation for a thread?
• RQ2: How can we use memory bandwidth restrictions to force forked threads to reach their synchronization points simultaneously?
2.
Background
Memory management is a complex procedure [7, p. 6] and include units such as the different levels of Cache, Translation Lookaside Buffers (TLB), Memory Bus and DRAM. All user space processes need to have their private section of memory but can share it with other processes. For the CPU to have fast access to frequently used data and instructions, cache memory is commonly integrated directly into the CPU [8]. By doing this, the CPU does not have to read from main memory, which results in an overall speedup of a program. Cache memory is typically composed of multiple levels where each level is slower but larger in terms of memory. The system can also use disk space as additional memory, but this task is made more accessible by the MMU (memory management unit) present in modern CPUs. The MMU (memory management unit) enables a memory management a technique called virtual memory, where a process access memory using a virtual address instead of its physical location. The MMU will translate the virtual address to the address of the physical memory location using a page table [7, p. 182]. The page table is handled by the kernel and consists of pages that are chunks of memory used by processes. Pages are loaded and allocated by the kernel as a process needs them (demand paging ). When a process wants to use a page that is not yet ready, there will be a page fault where the CPU is taken in control by the kernel from the process to get the page ready. If the desired memory page is in the main memory, but the MMU does not know where, a minor page fault will happen. If the desired page is not in memory at all, meaning that the kernel will have to load it from disk, a major page fault will occur. Both minor and major page faults will impact the performance, particularly in memory intensive programs.
The following subsections will describe the memory system in general, DRAM, memory bandwidth, and parallel computing.
2.1. Memory
Memory is one of the primary components in any computer system [9, p. 25]. Memory should be very fast, abundant and at the same time very cheap. However, no current memory technology can satisfy all of the traits mentioned above at the same time. The memory system is therefore built in layers with different speeds and sizes that form a hierarchy (see Figure 1) [10, p. 375], to meet these traits. The structure of this hierarchy is similar to a pyramid consisting of several layers, where the top layers are the closest memory to the CPU and the bottom layers are furthest away from the CPU [9, p. 25–28]. We will itemize the hierarchy below:
• The top layer consists of the internal registers of the CPU. The registers have a minimal storage capacity which is determined by the CPU architecture and are usually 32x32 or 64x64 bit large.
• The second layer consists of the cache memory. Cache memory holds the most fre-quently requested cache lines from the main memory (RAM), and gives the CPU fast access to the data. The cache hardware checks if the cache line is present when a program requests to read a memory word. If it finds the corresponding cache line, it does not send a request to the main memory. Such occurrence is called a cache hit and has a much lower time penalty than if a request is sent to the main memory, which is called a cache miss. Usually, the cache memory consists of three levels, each larger and slower than the previous level.
• Main memory or RAM (Random Access Memory) is the third layer in the memory hierarchy and stores all the data that is currently being used by the computer. Reading from RAM is faster than reading from secondary storage, but is much slower than reading from the cache memory.
• The last layer off the hierarchy is secondary storage (i.e., a hard drive). This storage is non-volatile, which means that the stored content is not lost when the power is switched off. Usually, this memory is the slowest to access.
Secondary storage Main memory CPU cache CPU registers Size of memory Increasing speed
Figure 1: The memory hierarchy Source: Adapted from [10, Fig. 5.3]
2.1.1. DRAM
Dynamic Random Access Memory (DRAM), as seen in Figure 2, stores values in a cell as a charge in a single capacitor [10, p. 379–380], which means DRAMs must be refreshed periodically to maintain data consistency. An entire row is refreshed with a read cycle fol-lowed by a write cycle. DRAMs are organized in multiple banks internally, each consisting of a series of rows of cells. A precharge command is sent to open or close a bank. An activate command containing the row address is sent to have a row transferred to a buffer. DRAMs buffer rows for repeated access, which improves performance by decreasing the access time a considerable amount. Once a row is in a buffer, it can be further transferred by successive column addresses, usually 4-16 bits. By specifying the starting address, it is also possible to do a block transfer. These operations (precharge, activate, accessing a column) can take anywhere from just a few to several dozens of nanoseconds [11, p. 22–23]. With multiple banks within the same channel, multiple different banks can handle any operation at any given time, but only one bank can read or write column data on the bus
at a time. Multiple independent channels can be used to handle simultaneous reads and writes on the memory bus, increasing concurrency.
ACT
PRE
RD/WR Column
Figure 2: Internal organization of DRAM Source: Adapted from [10, Fig. 5.4]
2.1.2. Memory Bandwidth
Memory bandwidth is the number of bytes that can be transferred in a time frame. The bandwidth of memory systems using DRAM is usually not a big problem today as data rates have increased a lot over the generations, and with the use of multiple channels [11, p. 15–16]. Still, there are many different applications (i.e., video processing) where much higher bandwidth is useful. The processor cores of a system share the memory bandwidth, as depicted in Figure 3, meaning that tasks running concurrently on different cores will have to compete for the available bandwidth [2].
There are different ways of assigning memory bandwidth to a shared memory interface (temporal scheduling) [12]. One is static partitioning, where the assignment of memory bandwidth to each core is determined offline and is unchanged over time. However, if the bandwidth is subject to scheduling, it is dynamically assigned. With dynamic bandwidth assignment, an assignment scheme can be made that follows the memory requirements of a scheduled workload over time, which in turn might improve performance significantly.
CPU1
Main memory
CPU2 CPUn
L1 Cache L1 Cache L1 Cache
Memory Bus
L2 Cache L2 Cache L2 Cache
L3 Cache
2.1.3. Memory Contention
Memory bus contention occurs when the cores in a processor compete for the memory bandwidth in a system [13]. One of the factors causing memory bus contention is that the number of cores and computational power in a processor increases at a much faster rate than available memory bandwidth increases for every new generation of technology [13, 14]. This means more cores are demanding memory bandwidth at the same time resulting in bus contention, which can negatively impact the whole system through higher latencies and worse throughput.
Tudor et al. performed various experiments to get a better understanding of how memory bus contention affects programs running in parallel. They discovered that the effect of memory bus contention is proportional to the number of active cores and the problem size and also a 1000% increase in cache misses when executed on a system using 48 cores.
2.2. Parallel Computing
Parallel computing can be achieved through various approaches; one of these is the fork-join model [15], as seen in Figure 4. Fork-join divides a control flow into multiple inde-pendent flows. After a flow has finished the calculations, it is placed in a join state, which waits for the remaining flows. After the join, one flow continues. Fork-join models are often based on divide and conquer algorithms. These algorithms divide the problem into smaller independent sub-problems running in parallel, and as they complete their calcu-lations, they combine into a final solution.
T0 T0 T0 Tn-1 Tn T0 T0 Prepare workload Fork workload Execute algorithm Synchronize threads Write back data . . .
Figure 4: An example of fork-join model where the workload is divided into n threads. Source: Adapted from [16, Fig. 3]
Parallelizing applications using a fork-join model can be an efficient way of increasing application throughput. The fork-join model, however, presents two problems:
speedup gained from parallelism vanishes, or at least decreases, due to memory contention [17]. Unfavorable impacts such as resource contention is a direct consequence because of shared resources and cache memory, which may lead to reduced performance when applications run in parallel [18]. Ekl¨ov et al. refer to recent studies that suggest that applications with higher memory bandwidth demands generate more memory contention and are also more sensitive to memory contention. Results from these studies show that applications can experience slowdowns from 3% - 23% when memory contention occurs.
Synchronization - The fork-join model is commonly used to parallelize workloads for multi-core systems. It has a starting point, the fork stage, from where an application is divided into subthreads. The end stage is called join, from which all threads synchronize and returns to the initial state. This presents problems since the fork-join model will only be as fast as the slowest executing thread. Using bandwidth restrictions, it may be possible to load-balance threads in such a way that the threads will reach the synchronization at the same time [1,2,12,19,20].
2.3. Related Work
Behnam et al. [19] and Inam et al. [21] developed a Multi-Resource Server (MRS) that can be used to reserve CPU- and memory bandwidth on multi-core systems with low over-head. The servers are both useful for hard and soft real-time systems and can partition bandwidth, help with composability and prediction of the system. The authors point out that contemporary scheduling of real-time tasks on multi-core architectures is inherently unpredictable and tasks performed by another core may negatively impact the computer system. One of the causes for this is the contention of physically shared memory, and that general purpose hardware has no techniques to combat the theft of bandwidth from other subsystems. The MRS opens up the possibility for encapsulating a complete sub-system of tasks in a server, which shares an allocation of CPU- and memory-bandwidth resources. Yun et al. [2,1], which developed a bandwidth reservation system called Mem-Guard, says that the MRS approach does not address the problem of wasted bandwidth. In MemGuard, the available memory bandwidth consists of the guaranteed and the best effort memory bandwidth [1]. Regardless of the memory access activities of other cores, a core will always be guaranteed the minimum bandwidth that it has reserved. After each core’s guaranteed bandwidth has been met in a certain period, they can be assigned ad-ditional best-effort bandwidth. They demonstrated that MemGuard can provide isolation of memory performance while having minimal influence on the overall throughput.
In contrast to Behnam et al., since we use MemGuard, which does not restrict resources on a task level, our method restrict bandwidth for the whole core using MemGuard. What also differs their work from ours is that only a portion of the resources can be allocated to a server. We measure the maximum bandwidth for the system and redistribute it across the cores. Since we are using MemGuard, assigning additional best-effort bandwidth dynamically can be done if needed.
Inam et al. wrote an article about the problems of memory contention in multi-core systems [20]. They believe that measuring the consumption of memory bandwidth may play a key role in understanding and resolving performance bottlenecks in multi-core applications. They also envision that tracking the consumed memory bandwidth will help in making more intelligent scheduling decisions and that this will prevent memory contention and also even out the load on the memory bus by spreading the memory access over time. Performance counters can be used to measure the consumed memory bandwidth by collecting low-level information about occurring events in the CPU during execution and are available for most modern processors. The authors continue by saying
that a continuous determination and tracking of the consumed memory bandwidth is challenging without using dedicated external hardware that monitors the memory-bus. However, rough estimates about used memory bandwidth and events may be enough for soft real-time systems to get a fair assessment of consumed memory bandwidth. This becomes much harder with hard real-time systems due to safe estimates, which means that no underestimates are allowed. There are no events that exactly show how much memory bandwidth that is consumed; this needs to be monitored through multiple events to try to determine the number, and size of memory accesses.
Inam’s work is very relevant in aspect to how we measure the memory bandwidth usage of the system. We use performance counters to count the last level cache misses and use the data to get a rough estimate of the used bandwidth for a core. According to Inam et al., this method may not be sufficient for tracking the consumed bandwidth, which can be a limitation in our work.
Agrawal et al. have studied the problems of determining the worst-case response time for sequential tasks, each with different bandwidth-to-core assignments [12]. Their arti-cle provides a general framework to perform response time analysis under dynamically partitioned bandwidth. They later demonstrate how their proposed analysis technique can be used in a time trigger memory scenario, which shows that dynamic allocation of bandwidth outperforms static allocation under varying memory-intensive workloads. A memory bandwidth regulation model, like MemGuard, was used to do this; these models use hardware performance counters to monitor the number of memory transactions per-formed by each core. The idea of memory bandwidth regulation is that a core is given a specified amount of bandwidth based on the number of memory transactions that a core is allowed to perform during a regulation period.
This work shares similarities with our work in terms of static and dynamic memory bandwidth partitioning with the use of MemGuard. What differs our work from the authors is that we dynamically partition bandwidth by predicting future needs, while they already know the characteristics of the used workload to more efficiently distribute the bandwidth.
3.
Method
Memory intensive parallel applications and resource contention can have a significant impact on the performance of the computer system, such a scenario can, however, be solved using memory bandwidth partitioning. If memory bandwidth is partitioned between the cores of a multi-core system, a core is saturated when it can no longer utilize all of the bandwidth it has been assigned. This may cause various problems, such as synchronization and performance issues due to other cores not being able to use memory bandwidth that is reserved for the saturated core.
This study aims to investigate how memory bandwidth partitioning can aid in load balancing of parallel tasks, and to find the point of saturation for a thread that is bound to a core. We also aim to implement a solution that continuously partitions bandwidth between cores based on an algorithm that takes previous execution times and bandwidth into account.
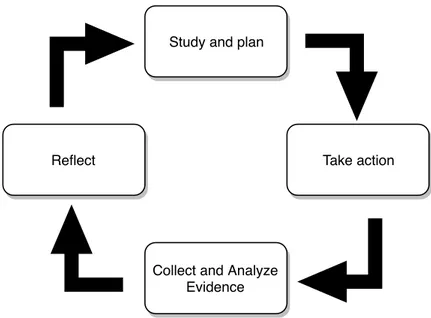
The methodology used to solve the research questions is based on action research [22,23] (see Figure 5). Below follows a summary of each phase of the iterations:
Study and plan
Take action Reflect
Collect and Analyze Evidence
Figure 5: Model of our workphases
Source: Adapted from [22, Fig. 2] and [23, Fig. 1]
1. Study and Plan: In the study and plan phases, we investigated state of the art research on memory contention in multi-core systems and on memory bandwidth re-striction methods. We discovered that new rere-striction methods have been developed in forms of a Multi-Resource Server (MRS) [19,21] and MemGuard [1]. The MRS can encapsulate a subsystem of tasks in order to combat the theft of memory bandwidth from other subsystems, and MemGuard can partition memory bandwidth by first assigning guaranteed bandwidth to a core and then additional best-effort bandwidth once the guaranteed bandwidth has been met in a certain period. This provided a solution to wasted memory bandwidth. Our initial search on memory contention leads us to an article written by R. Inam et al. [20] where they discuss the use of hardware performance counters to measure bandwidth consumption. They believed that this might play a key role in further understanding and resolving performance bottlenecks in multi-core applications.
Based on the information that we gathered from our investigation on state of the art research, we refined the research problem. We started by discussing the problems of forked threads where memory contention and synchronization issues may decrease potential speedup caused by parallelism, and how memory bandwidth restrictions may be able to balance the execution time of forked threads. Based on the research problem, the research questions were then formed.
2. Take Action: To answer our research questions, we implemented a memory band-width partitioning scheme called Adaptive Memory Bandband-width Partitioning, referred to AMBP in the subsequent sections in this thesis. AMBP partitions mem-ory bandwidth between the cores of a system based on the execution time of parallel tasks.
3. Collect and Analyze Evidence: We conducted three experiments using memory-heavy workloads to investigate the performance of different memory bandwidth par-titioning schemes. We monitored the memory bandwidth usage for each core during run time. Calculating the memory bandwidth usage was done with the help of performance counters to get the number of last level cache misses (LLC).
4. Reflect: Finally, the results gained from the experiments was validated and com-pared against each other.
4.
Implementation
OpenCV is an open source library that is used for computer vision and machine learning [24]. Our implementation makes use of OpenCV’s SIFT [25] object detection algorithm to process frames from a video, which is costly in terms of memory bandwidth usage. In OpenCV, a frame is represented as a matrix with the height and width of the frame. Each frame is divided into several sub-frames called regions of interest (ROI) and assigned to different threads that are bound to separate cores.
4.1. Using MemGuard
MemGuard can monitor and regulate the memory bandwidth usage of each CPU core by utilizing hardware performance counters [2]. In MemGuard, the available memory band-width consists of the guaranteed and the best-effort memory bandband-width [1]. Regardless of the memory access activities of other cores, a core will always be guaranteed the minimum bandwidth that it has reserved. After each core’s guaranteed bandwidth has been met in a certain period, they can be assigned additional best-effort bandwidth [2].
MemGuard is loaded as a kernel module into the Linux kernel manually using the insmod command. Several configuration interfaces can be accessed after MemGuard has been loaded into the kernel using three files: Control, Usage, and Limit. Control is used by the module to set or switch between different settings such as maximum bandwidth usage for the cores, and also reservation and reclaim controls that determine how much bandwidth a core can use and how it can distribute surplus bandwidth [1]. Usage displays how much memory bandwidth a core has used in a period and also the total budget for each core. Limit is used to set different memory bandwidth in MB/s for each core. We assign bandwidth using percentages of the system’s maximum bandwidth because we found it easier to determine how the bandwidth was divided between the cores this way. The percentage is later multiplied with the maximum bandwidth to get the value in MB/s. Performance counters are used to collect low-level data about different activities in the CPU, such as the number of cache misses or prefetch misses [20]. We use perf-events, which are Linux based performance counters that have access to multiple software and hardware events [26]. Once the application executes, the performance counters are initiated and started. Performance counters reset as threads are created, and the total number of LLC misses for a core are read by the performance counters before the thread joins. An LLC miss leads to the corresponding block of data being fetched from DRAM. We calculate the memory bandwidth usage for a core by using LLC misses together with the CPU’s cache line size and the corresponding thread’s execution time.
4.1.1. Adaptive Memory Bandwidth Partitioning
Execution times of tasks can fluctuate quite drastically, especially when using heavy mem-ory loads such as feature detection algorithms. For example, consider a feature detection algorithm [17], which is run frame by frame. There is a high chance that the execution times between the current executed frame and the next coming frames differ significantly. It can, therefore, be challenging to create bandwidth partitions based on the execution time of only one frame. It can be even more difficult when the frame is forked to multiple cores, as exemplified earlier in Figure 4, since the thread execution can become dependant
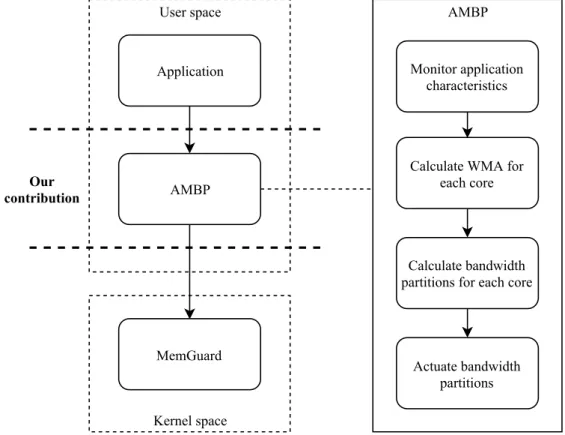
on the frame characteristics. To solve the execution time fluctuation issue, we implement our adaptive memory bandwidth partitioning (AMBP) using a Weighted Moving Average (WMA), described in Equation 1, of the last five execution times for each core. WMA par-tially solves the execution time fluctuation issue since the memory bandwidth partitions assigned by AMBP will have a larger comparison base for execution times, rather than just one execution time, which in turn will make AMBP react at a slower pace. Figure 6 depicts the System architecture of our program.
Application MemGuard AMBP Kernel space User space Our contribution Monitor application characteristics Calculate WMA for each core Calculate bandwidth partitions for each core Actuate bandwidth partitions AMBP
Figure 6: System architecture
The system model shows how AMBP is implemented and how it is connected to mon-itored applications and also MemGuard.
The first step of our model depicts the monitored application. AMBP receives the execution times of the frame from the application. The second step in our model is AMBP, which consists of four different steps:
1. AMBP receives the values from the monitored application, this data is used in the next step to calculate the WMA for each core.
2. AMBP calculates the WMA for each core by using the values received from the application. The formula used for calculating the WMA execution times can be described as:
W M Acore=
Pn
i=1execution timei· i
Pn
i=1i
(1)
where n is the number of values the WMA is based on, with execution time1 being
3. The bandwidth partitions for each core is calculated according to:
BWcore=
wmacore
wmaall cores
· max BW (2)
where max BW is the maximum memory bandwidth of the system and BWcore is
the new guaranteed bandwidth for a certain core.
4. AMBP actuates the new bandwidth partitions by sending them to MemGuard.
AMBP is implemented as an interface to MemGuard, which means that AMBP com-municates with MemGuard. The last step of our model shows that MemGuard receives the calculated partitions from AMBP, which actuates the new partitions.
5.
Experiments
We conducted three experiments in order to answer our research questions. All of the experiments were repeated four times to secure the integrity of the collected data. The experiments are conducted using OpenCV’s SIFT corner detection algorithm to process frames using two different videos (see Figure 7, a lower resolution video of 1280x720 where some ROIs should be faster to process than others, and one with a higher resolution of 1920x1080 and uniform corner distribution among the different ROIs. Each frame is divided into four ROIs which are assigned to different threads, where each thread is bound to a separate CPU core. In each test run, a total of 100 frames are processed.
(a) 1280x720 (b) 1920x1080
Figure 7: A processed frame from each video used in the experiments. Keypoints of different colors belong to different ROIs.
When the SIFT application is set to use memory bus partitioning, MemGuard will partition the guaranteed bandwidth using either AMBP or static partitioning. Static partitioning took place in all of the experiments so that we can control the bandwidth assignment of each core manually in between executions. The maximum bandwidth is measured by the SIFT application using mbw (Memory BandWidth benchmark) [27].
The testing platform is described in Table 1. HyperThreading, ACPI, and CPU idle was disabled during the experiments to limit the number of factors that could affect the results.
CPU Model Intel Core i7 7700HQ Frequency 3,4 GHz Number of Cores 4 Number of threads 8
L1 Cache Size 256 KiB L2 Cache Size 1 MiB L3 Cache Size 6 MiB Main Memory Channels 2
Main Memory Type DDR4 SDRAM Main Memory Size 2 x 4 GB Main Memory Speed 2400 MHz Secondary Storage Type SSD
5.1. EX1: Memory Bandwidth Saturation
Experiment 1 (EX1) consists of one test case with two purposes: To find out when the system should use memory bandwidth restrictions, and when the assigned bandwidth sat-urates a core i.e., the point from which additional memory bus partitions will not be beneficial to the execution time. The 1980x1080 resolution video was used for both of these test cases to load the memory bus as much as possible with SIFT running on cores 0-3.
TC1 - Point of Saturation
TC1 measures the average time it takes for a specific core to process a frame when assigning a statically partitioned size of the memory bandwidth to the core. The test is conducted over an interval of 10% to 50% on the first core, to see how the execution time is affected by memory reservation restraints. Comparing the core’s execution times of a frame, we should see when its assigned memory bandwidth saturates the core. N is the variable of the assigned bandwidth for the specific core.
1. Insert the MemGuard module into the kernel
2. Enable MemGuard
3. N = 10%
4. Assign N of the maximum bandwidth to the first core and the rest of the bandwidth evenly among the other three cores.
5. Execute the application
6. N = N + 5%
7. Return to step 4 until 50% assigned bandwidth has been reached
5.2. EX2: No Paritioning and Static Partitioning vs. AMBP
Experiment 2 consists of three test cases that measure the execution time of the applica-tion when using static, no partiapplica-tioning, and AMBP. The purpose of this experiment is to investigate AMBP’s performance against static and no partitioning in terms of decreasing the execution time of threads. All of the test cases were performed using SIFT on core 0 - 3. We used both the 1280x720 and 1920x1080 video in this experiment.
TC1 - No Partitioning
Test case 1 measures the total execution time of the program when no memory bandwidth partitioning is used.
1. Execute the application TC2 - Static partitioning
Test case 2 measures the total execution time of the application when the memory band-width is statically partitioned to 25% for each core.
1. Insert the MemGuard module into the kernel
2. Enable MemGuard.
4. Execute the application TC3 - AMBP
Test case 3 measures the total execution time of the application when the memory band-width is partitioned between the cores using AMBP.
1. Insert the MemGuard module into the kernel
2. Enable MemGuard and set application to use AMBP.
3. Execute the application
5.3. EX3: Isolation
The third experiment has three test cases that determine if the SIFT application is iso-lated when running interfering workloads on a separate core. This experiment tests how a high bit rate video impacts the execution time of the SIFT algorithm running on cores 0-2. The first two test cases show how no partitioning and static partitioning handles the isolated workload against AMBP.
TC1 - No Partitioning
Test case 1 shows how the program handles the isolated workload when no partitioning is used.
1. Start playing a high bit rate video on core 3
2. Execute the application TC2 - Static Partitioning
Test case 2 shows how the program handles the isolated workload when static partitioning is used.
1. Insert the MemGuard module into the kernel 2. Enable MemGuard
3. Statically assign 30% guaranteed memory bandwidth of the maximum bandwidth to cores 0-2 and 10% to core 3.
4. Start playing a high bit rate video on core 3
5. Execute the application TC3 - AMBP
Test case 3 shows how the program handles the isolated workload when AMBP is used. 1. Insert the MemGuard module into the kernel
2. Enable MemGuard and set application to use AMBP
3. Statically assign 10% guaranteed memory bandwidth of the maximum bandwidth to core 3, let the program dynamically partition the remaining bandwidth among core 0-2.
4. Start playing a high bit rate video on core 3
6.
Results
This section presents collected data from the conducted experiments and is structured as the following: 9.1 presents the results from the saturation experiment, 9.2 presents the No Partitioning and Static Partitioning vs AMBP experiment, and 9.3 presents the isolation experiment.
6.1. EX 1: Saturation on The Memory Bus
The data from TC1 shows that assigning more bandwidth to the core improves the exe-cution time on that core. At around 25% this improvement almost became non-existent which indicates that the core is saturated and does not need more bandwidth. Below follows a more detailed description of TC1.
6.1.1. TC1 - Point of Saturation
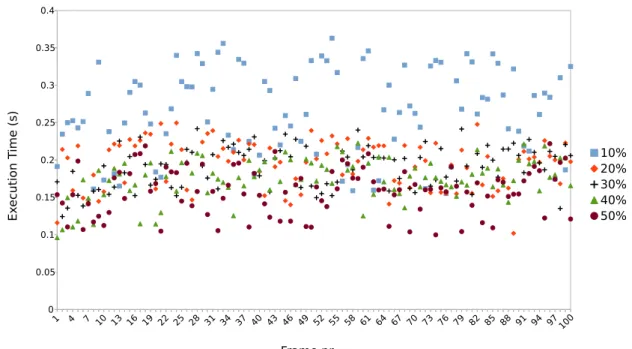
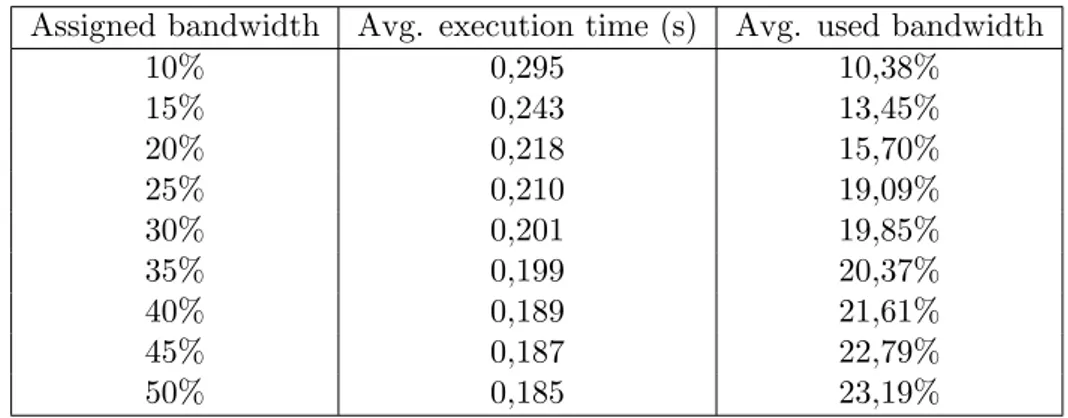
TC1 is repeated over an interval of 10% to 50% of bandwidth that is assigned to one of the cores. Each iteration increases the assigned bandwidth with 5%. The results presented in Figure 8 and Table 2 shows that the average execution time decreases and average bandwidth usage increases as the core is assigned more bandwidth all the way up to 50%. However, at around 25% assigned bandwidth, the core’s used bandwidth ceased to increase as it got assigned additional bandwidth. The same pattern can be observed for the average execution time of the core; between 20%-25% assigned bandwidth the improvement gradually becomes almost non-existent.
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 100 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 10% 20% 30% 40% 50% Frame nr Ex ecution Time (s)
Figure 8: Point of Saturation, test case 1 - Execution times to process a frame for a core with 10% - 50% bandwidth assigned to it. This is a visual example to show that there is a point of saturation for the core. No average values are depicted in this graph.
Assigned bandwidth Avg. execution time (s) Avg. used bandwidth 10% 0,295 10,38% 15% 0,243 13,45% 20% 0,218 15,70% 25% 0,210 19,09% 30% 0,201 19,85% 35% 0,199 20,37% 40% 0,189 21,61% 45% 0,187 22,79% 50% 0,185 23,19%
Table 2: Point of Saturation, test case 1 - Average execution time to process a frame and the used bandwidth for a core with 10% - 50% of guaranteed bandwidth assigned to it.
Figure 8 shows that when a core is assigned 50% of the maximum bandwidth the execution times start to vary more frame-to-frame. These variations are not as prominent in the other cores.
6.2. EX2: No Partitioning and Static Partitioning vs. AMBP
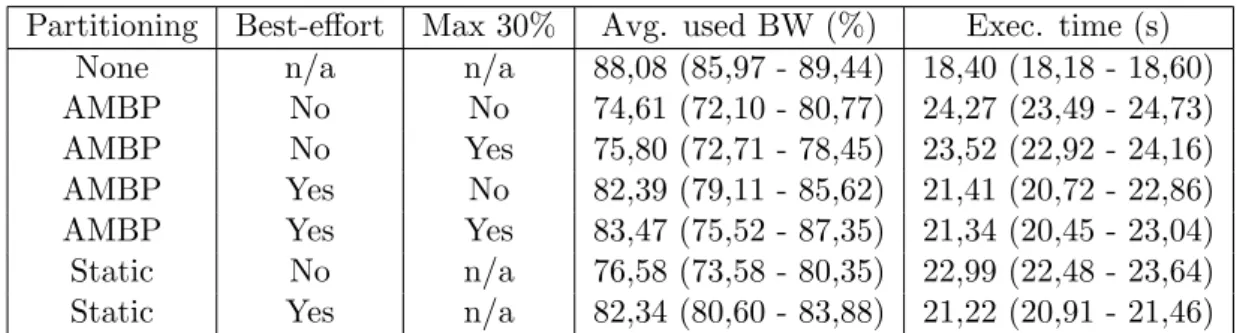
When processing the 1280x720 video (see Table 3), both Static partitioning and AMBP use a higher amount of bandwidth on average and has lower execution times than no parti-tioning. Compared to static, AMBP has a clear edge seen to both of these measurements, particularly when best-effort was used. The results from processing the 1920x1080 video (see Table 4) differ in terms of performance as static and AMBP is similar regardless of whether best-effort is used or not. No partitioning performs best with at least 16% improvement in execution time compared to AMBP and static partitioning when using best-effort, which is a complete turnaround in contrast to when the 1280x720 video was used.
Partitioning Best-effort Max 30% Avg. used BW (%) Exec. time (s) None n/a n/a 71,91 (68,32 - 75,56) 11,03 (10,81 - 11,26) AMBP No No 82,36 (79,15 - 85,73) 10,54 (10,13 - 10,94) AMBP No Yes 81,82 (74,57 - 89,43) 10,46 (9,59 - 11,26) AMBP Yes No 86,15 (79,73 - 94,25) 10,24 (9,68 - 10,91) AMBP Yes Yes 85,02 (79,29 - 93,13) 10,34 (9,42 - 10,92) Static No n/a 73,58 (63,62 - 84,21) 11,46 (10,03 - 12,83) Static Yes n/a 75,53 (71,25 - 78,31) 11,48 (11,01 - 11,84)
Table 3: Average used bandwidth and total execution times for all test cases when running the 1280x720 resolution video. Minimum/maximum values are shown in parentheses.
Partitioning Best-effort Max 30% Avg. used BW (%) Exec. time (s) None n/a n/a 88,08 (85,97 - 89,44) 18,40 (18,18 - 18,60) AMBP No No 74,61 (72,10 - 80,77) 24,27 (23,49 - 24,73) AMBP No Yes 75,80 (72,71 - 78,45) 23,52 (22,92 - 24,16) AMBP Yes No 82,39 (79,11 - 85,62) 21,41 (20,72 - 22,86) AMBP Yes Yes 83,47 (75,52 - 87,35) 21,34 (20,45 - 23,04) Static No n/a 76,58 (73,58 - 80,35) 22,99 (22,48 - 23,64) Static Yes n/a 82,34 (80,60 - 83,88) 21,22 (20,91 - 21,46)
Table 4: Average used bandwidth and total execution times for all test cases when running The 1920x1080 resolution video. Minimum/maximum values are shown in parentheses.
6.2.1. Test case 1 - No Partitioning
In our first test case we test the performance with no partitioning. The results (see Figure 9 and 10) shows that the execution times when running the 1920x1080 resolution video is more stable than when running the 1280x720 resolution video.
Figure 9: Test case 1 - Execution time of a frame using no partitioning for each core. The 1280x720 resolution video was used in this test. No average values are depicted in this graph.
Figure 10: Test case 3 - Execution time of a frame using no partitioning for each core. The 1920x1080 resolution video was used in this test. No average values are depicted in this graph.
6.2.2. Test case 2 - Static Partitioning
In test case 2 we test the performance of static partitioning. Each core has 25% of the maximum bandwidth assigned. Figure 11 and 12 shows that using best-effort decreases the execution time when running both the lower and higher resolution video.
Figure 11: Test case 2 - Execution time of a frame using a 25% static partition for each core.The 1280x720 resolution video was used in this test. No average values are depicted in this graph.
Figure 12: Test case 2 - Execution time of a frame using a 25% static partition for each core. The 1980x1080 resolution video was used in this test. No average values are depicted in this graph.
6.2.3. Test case 3 - AMBP
Test case 3 tests the performance of AMBP. Figure 13 and 14 shows that using best-effort or setting a limit to 30% bandwidth per core has little to no impact on the execution times. However, during the high resolution test some frames show that the usage of best-effort has the ability to greatly improve the execution time, although on very few occasions.
Figure 13: Test case 3 - Execution time of a frame using AMBP for each core. The test shows the execution time when a core can at most use 30% of the maximum bandwidth and when the usage is unrestricted. The 1280x720 resolution video was used in this test. No average values are depicted in this graph.
Figure 14: Test case 3 - Execution time of a frame using AMBP partitioning for each core. The test shows the execution time when a core can at most use 30% of the maximum bandwidth and when the usage is unrestricted. The 1920x1080 resolution video was used in this test. No average values are depicted in this graph.
6.3. Experiment 3: Isolation
Figure 16 and 17 shows that static partitioning and AMBP has very similar performance during the isolation experiment, with consistent minor changes in the execution times of the frames. This behaviour continues when using best-effort, but with a lower execution time overall. With no partitioning used (see Figure 15) the execution times show negligible variance for the majority of the frames, but relatively strongly increased during some periods.
6.3.1. Test case 1 - No Partitioning
With no partitioning (Figure 15), the execution times show that program is very stable during the majority of execution with some periodic discrepancies.
Figure 15: Test case 1 - Execution time of a frame using no partitioning when a interfering workload runs on core 3. The 1920x1080 resolution video was used in this test. No average values are depicted in this graph.
6.3.2. Test case 2 - Static Partitioning
Figure 16 shows that there are no discernible interference from the core playing a high bit rate video when static partitioning is used.
Figure 16: Test case 2 - Execution time of a frame using static partitioning when a interfering workload runs on core 3. The 1920x1080 resolution video was used in this test. No average values are depicted in this graph.
6.3.3. Test case 3 - AMBP
With AMBP (Figure 17), the executions times show more variance than static partitioning but are still consistent.
Figure 17: Test case 3 - Execution time of a frame using AMBP when a interfering workload runs on core 3. The 1920x1080 resolution video was used in this test. No average values are depicted in this graph.
7.
Discussion
Based on the results from experiment 1, the execution times on average lowers as the assigned bandwidth is increased. Table 2 shows that the average used bandwidth is not proportional to the assigned bandwidth for the core. This means that a core on average rarely uses more than 25% of the maximum bandwidth when processing a frame, using our current workload. However, increasing the assigned bandwidth allows a core to use more bandwidth as needed, meaning that the execution times should be lowered. The point of saturation is hard to pinpoint, but according to Figure 8, the system saturates at roughly 30% since this is where the average execution time stabilizes. The results of this test presumably vary greatly depending on the processing speed of the used CPU, and how much of its processing power is needed to process a frame. In figure 8, we can see that when a core is assigned 50% of the maximum bandwidth, it becomes more unstable. We think the limited bandwidth may cause this instability on other cores by forcing the task scheduler in Linux to schedule processes to the core with higher bandwidth, thus potentially increasing the execution time on that core. It could also be theorized that this is a cache related problem. However, we argue that this is not the case, the frames will always fill the cache memory of our test platform since the size of a frame is around 6 MB (1920x1080x3 bytes) and the LLC is 6 MiB.
Experiment 2 compares the performance of AMBP to no bandwidth partitioning and static bandwidth partitioning. The results gathered from all of the test cases show that AMBP better utilizes the bandwidth than when no partitioning is used for processing the 1280x720 resolution video. Furthermore, the results from the 1920x1080 resolution video are different in terms of the performance of AMBP. AMBP has similar performance as static partitioning, with no partitioning having the highest performance with at least 16% improvement in execution time compared to AMBP and static partitioning when best-effort is used. We believe that the 1280x720 resolution video does not saturate the memory bus, which causes the bandwidth partitioning to be less relevant. However, when the 1920x1080 resolution video is processed, the memory bus is saturated. This could mean that the overhead from processing the video becomes more relevant. Another variable that might cause this behavior is how we measure the maximum available bandwidth of the system might not be optimal. With no partitioning, there is no bandwidth usage limit, meaning that the system might be able to use more memory bandwidth. On average, we see that using best effort on top of guaranteed bandwidth is crucial for better performance as less bandwidth stays unused as the cores might be able to use more than the maximum measured bandwidth. As this always requires that each core first satisfy its guaranteed part of the bandwidth, no partitioning should still consistently be able to cross this limit. Setting a maximum of 30% guaranteed bandwidth (where the point of saturation could be) when using AMBP did not result in improved performance. This makes sense since the used bandwidth rarely (or never) reached over 30% per core for a frame. Using previous thread execution times as a basis for AMBP yielded a high variance in the frame execution times. As the results show that it has potential in reducing execution times compared to no partitioning, we think improving the AMBP algorithm can provide more visible results supporting the potential decrease in execution time.
In our third and last experiment, we tested how the application handles interference from other bandwidth-heavy processes executed on a separate core. The results from EX3.TC2 and EX3.TC3 both shows consistent execution times between frames, with a moderately higher variance using AMBP. Comparing these results to test case 1, where no partitioning was used, we see that these have more consistent execution times. We argue
that the inconsistency in test case 1 could be caused by interference from the bandwidth-heavy process. Since we do not see the same inconsistency when using bandwidth parti-tioning, this could imply that the OpenCV workload never was affected by the isolated bandwidth-heavy process. We suspected that the results would look like this, since the bandwidth-heavy process was isolated to a separate core with a statically assigned part of the maximum bandwidth, meaning it could neither take processing power from the cores used by the OpenCV workload or guaranteed bandwidth reserved for them. Static isolation, however, performed best for pure isolation purposes due to the small variances in execution time.
8.
Conclusions
We have investigated when it is suitable to apply memory bandwidth restrictions. Using our framework AMBP, we successfully show how it can be used to synchronize execution times of forked threads.
We investigated a thread’s point of saturation when executing the SIFT algorithm, i.e., the point from which additional memory bus partitions will not be beneficial to the execution time. In our case, the point of saturation occurs at around 30% used bandwidth. We argue that bandwidth restrictions are suitable to apply on parallel tasks when executing an interfering application on an adjacent core. We statically assigned 10% of the maximum bandwidth to the isolated core, which means that the SIFT application is sharing the remaining 90% bandwidth. Restricting the bandwidth usage to 30% per core for the remaining cores achieved the best benefits for the SIFT application. Assigning an additional 5% to each core would not make a significant impact as seen in Table 2. However, making a general cross-platform estimation of the point of saturation is hard. The point of saturation can be dependent on several different factors; memory bus capacity and CPU clock frequency can, for example, differ dramatically. We, therefore, conclude that bandwidth restrictions can help in isolating tasks when an interfering task exceeds the points of saturation, leading to more predictable execution times, which answers RQ1. Based on the results from the experiments, we can see that memory bandwidth par-titioning can decrease the execution time of frames to the point that they are lower than when no bandwidth partitioning is used. However, the results show that the average ex-ecution time of the SIFT application is lower when no bandwidth partitioning is used, meaning that an algorithm based solely on WMA execution times to predict future band-width requirements of a core is not the optimal solution. Decreased average execution times could mean that the threads are more synchronized, which suggests that memory bandwidth partitioning potentially can help the threads to reach their synchronization points simultaneously. These results answer RQ2.
8.1. Future Work
We think that future work could make use of a more extensive variety of workloads when conducting experiments. Using different types of workloads may yield more evident results than using only OpenCV as a workload seeing that the point of saturation was fairly low on our test system. Using other test systems should also make a difference in how much bandwidth can be utilized before reaching the point of saturation.
The results for AMBP show improvements compared to no partitioning in some in-stances, but it is clear that further improvements to the algorithm are needed. I.e., basing the partitioning on retired instructions for a thread instead of its execution time could be worth exploring as it would give a more accurate representation of the processing power needed by the thread. Using an alternative solution to MemGuard could also be a viable alternative seeing that its functionality and documentation is quite limited.
References
[1] H. Yun, G. Yao, R. Pellizzoni, M. Caccamo, and L. Sha, “Memory Bandwidth Man-agement for Efficient Performance Isolation in Multi-Core Platforms,” IEEE Trans-actions on Computers, vol. 65, no. 2, pp. 562–576, feb 2015.
[2] H. Yun, “Improving Real-Time Performance on Multicore Platforms Using Mem-Guard,” Real-Time Linux Workshop (RTLWS), 2013.
[3] K. J. Nesbit, N. Aggarwal, J. Laudon, and J. E. Smith, “Fair Queuing Memory Systems,” in 2006 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06). IEEE, dec 2006, pp. 208–222. [Online]. Available:
http://ieeexplore.ieee.org/document/4041848/
[4] M. Caccamo, G. Buttazzo, and D. Thomas, “Efficient reclaiming in reservation-based real-time systems with variable execution times,” IEEE Transactions on Computers, vol. 54, no. 2, pp. 198–213, feb 2005. [Online]. Available:
http://ieeexplore.ieee.org/document/1377158/
[5] P. Valente and F. Checconi, “High Throughput Disk Scheduling with Fair Bandwidth Distribution,” IEEE Transactions on Computers, vol. 59, no. 9, pp. 1172–1186, sep 2010. [Online]. Available: http://ieeexplore.ieee.org/document/5467047/
[6] N. Dagieu, A. Spyridakis, and D. Raho, “Memguard, Memory Bandwidth Management in Mixed Criticality Virtualized Systems - Memguard KVM Scheduling,” in UBICOMM 2016 : The Tenth International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, 2016, pp. 21–27. [Online]. Available: https://www.semanticscholar.org/paper/Memguard{%} 2C-Memory-Bandwidth-Management-in-Mixed-KVM-Dagieu-Spyridakis/
b556e6146d9ddf9da26f3cc0c92034111c19dbd1
[7] B. Ward, How Linux works: What every superuser should know, 2nd ed. No Starch Press, 2014.
[8] M. Rouse, “What is cache memory? - Definition from WhatIs.com,” 2019. [Online]. Available: https://searchstorage.techtarget.com/definition/cache-memory
[9] A. Tanenbaum and H. T. Boschung, Modern operating systems, 4th ed. New Jersey: Pearson Education, Inc., 2015.
[10] D. Hennessy and J. Patterson, Computer Organization and Design MIPS Edition: The Hardware/Software Interface, 5th ed. Morgan Kaufmann, 2013.
[11] B. Jacob, “The Memory System: You Can’t Avoid It, You Can’t Ignore It, You Can’t Fake It,” Synthesis Lectures on Computer Architecture, vol. 4, no. 1, pp. 1–77, jan 2009.
[12] A. Agrawal, R. Mancuso, R. Pellizzoni, and G. Fohler, “Analysis of Dynamic Memory Bandwidth Regulation in Multi-core Real-Time Systems,” sep 2018. [Online]. Available: http://arxiv.org/abs/1809.05921
[13] B. M. Tudor, Y. M. Teo, and S. See, “Understanding Off-Chip Memory Contention of Parallel Programs in Multicore Systems,” in 2011 International Conference on Parallel Processing. IEEE, sep 2011, pp. 602–611. [Online]. Available:
[14] Rogue Wave Software Inc, “3.11. Memory Bandwidth,” 2011. [Online]. Available: https://docs.roguewave.com/threadspotter/2011.2/manual html linux/ manual html/ch intro bw.html
[15] M. McCool, A. D. Robison, and J. Reinders, Structured Parallel Programming: Pat-terns for Efficient Computation. Waltham: Elsevier, Inc, 2012.
[16] J. Danielsson, M. J¨agemar, M. Behnam, and M. Sj¨odin, “Investigating execution-characteristics of feature-detection algorithms,” in 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA). IEEE, 2017, pp. 1–4.
[17] J. Danielsson, M. Jagemar, M. Behnam, M. Sjodin, and T. Seceleanu, “Measurement-Based Evaluation of Data-Parallelism for OpenCV Feature-Detection Algorithms,” in 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMP-SAC). IEEE, jul 2018, pp. 701–710.
[18] D. Ekl¨ov, N. Nikoleris, D. Black-Schaffer, and E. Hagersten, “Design and Evaluation of the Bandwidth Bandit,” Uppsala, Tech. Rep., 2012. [Online]. Available:
http://www.it.uu.se/research/publications/reports/2012-003/
[19] M. Behnam, R. Inam, T. Nolte, and M. Sj¨odin, “Multi-core composability in the face of memory-bus contention,” ACM SIGBED Review, vol. 10, no. 3, pp. 35–42, oct 2013.
[20] R. Inam, M. Sjodin, and M. Jagemar, “Bandwidth measurement using performance counters for predictable multicore software,” in Proceedings of 2012 IEEE 17th Inter-national Conference on Emerging Technologies & Factory Automation (ETFA 2012). IEEE, sep 2012, pp. 1–4.
[21] R. Inam, N. Mahmud, M. Behnam, T. Nolte, and M. Sjodin, “The Multi-Resource Server for predictable execution on multi-core platforms,” in 2014 IEEE 19th Real-Time and Embedded Technology and Applications Symposium (RTAS). IEEE, apr 2014, pp. 1–12.
[22] University of Bristol, “Action Research — School of Education — Univer-sity of Bristol.” [Online]. Available: http://www.bris.ac.uk/education/study/ continuing-professional-development-cpd/actionresearch/
[23] M. Riel, “Understanding Collaborative Action Research.” [Online]. Available:
http://cadres.pepperdine.edu/ccar/define.html
[24] OpenCV Team, “About - OpenCV library,” 2019. [Online]. Available: https: //opencv.org/about.html
[25] OpenCV: Introduction to SIFT (Scale-Invariant Feature Transform), “About - OpenCV library.” [Online]. Available: https://docs.opencv.org/3.4.6/da/df5/ tutorial py sift intro.html
[26] B. Gregg, “Linux perf Examples.” [Online]. Available: http://www.brendangregg. com/perf.html
[27] Canonical Ltd, “Ubuntu Manpage: mbw - Memory BandWidth benchmark,” 2019. [Online]. Available: https://manpages.ubuntu.com/manpages/cosmic/man1/mbw.1. html
![Figure 1: The memory hierarchy Source: Adapted from [10, Fig. 5.3]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4715167.124270/6.892.214.678.343.714/figure-memory-hierarchy-source-adapted-fig.webp)