GRAMMAR USING STATISTICAL PARSING AND THESAURI
by
Björn Dagerman
A thesis submitted in partial fulfillment of the requirements for the degree
of BACHELOR OF SCIENCE in Computer Science Examiner: Baran Çürüklü Supervisor: Batu Akan MÄLARDALEN UNIVERSITY School of Innovation, Design and Engineering
ABSTRACT
Services that rely on the semantic computations of users’ natural linguistic inputs are
becoming more frequent. Computing semantic relatedness between texts is problematic due
to the inherit ambiguity of natural language. The purpose of this thesis was to show how
a sentence could be compared to a predefined semantic Definite Clause Grammar (DCG).
Furthermore, it should show how a DCG-based system could benefit from such capabilities.
Our approach combines openly available specialized NLP frameworks for statistical
parsing, part-of-speech tagging and word-sense disambiguation. We compute the
seman-tic relatedness using a large lexical and conceptual-semanseman-tic thesaurus. Also, we extend
an existing programming language for multimodal interfaces, which uses static predefined
DCGs: COactive Language Definition (COLD). That is, every word that should be
accept-able by COLD needs to be explicitly defined. By applying our solution, we show how our
approach can remove dependencies on word definitions and improve grammar definitions in
DCG-based systems.
SAMMANFATTNING
Tjänster som beror på semantiska beräkningar av användares naturliga tal blir allt
van-ligare. Beräkning av semantisk likhet mellan texter är problematiskt på grund av naturligt
tals medförda tvetydighet. Syftet med det här examensarbetet är att visa hur en mening
can jämföras med en fördefinierad semantisk Definite Clause Grammar (DCG). Dessutom
bör arbetet visa hur ett DCG-baserat system kan dra nytta av den möjligheten.
Vårt tillvägagångssätt kombinerar öppet tillgängliga specialiserade NLP frameworks för
statistical parsing, part-of-speech tagging och worse-sense disambiguation. Vi beräknar den
semantiska likheten med hjälp av en stor lexikografisk och konceptuellt semantisk
synony-mordbok. Vidare utökar vi ett befintligt programmeringsspråk för multimodala gränssnitt
som använder statiskt fördefinierade DCGs: COactive Language Definition (COLD). Dvs.
alla ord som ska kunna accepteras av COLD måste explicit definieras. Genom att tillämpa
vår lösning visar vi hur vår metod kan minska beroenden på ord-definitioner och förbättra
grammatik-definitioner i DCG-baserade system.
CONTENTS
Page ABSTRACT . . . . i SAMMANFATTNING . . . . ii LIST OF FIGURES . . . . iv CHAPTER 1 INTRODUCTION . . . . 11.1 Thesis Statement and Contributions . . . 2
2 BACKGROUND . . . . 4
2.1 Statistical Parsing . . . 4
2.2 Semantic Knowledge Base . . . 5
2.3 Word Sense Disambiguation . . . 6
2.4 COactive Language Definition (COLD) . . . 6
3 COMPUTING SEMANTIC RELATEDNESS . . . . 8
3.1 Semantic Comparison of Words . . . 8
3.2 Dynamic Rule Declarations . . . 9
3.3 Comparing Natural Language and Definite Clause Grammar . . . 13
4 RESULTS . . . 15
4.1 Semantic Analysis of Natural Language and DCGs . . . 15
4.2 A Framework for Computing Semantic Relatedness . . . 18
5 CONCLUSIONS . . . . 20
LIST OF FIGURES
Figure Page
2.1 COLD source code sample . . . 7
3.1 Graph walk in WordNet . . . 9
3.2 POS dictionary sample . . . 10
3.3 Defining almost identical COLD rules . . . 11
3.4 Nested rule declarations . . . 12
3.5 Simple dictionary sample . . . 12
3.6 Using dictionary-defined parameters . . . 12
3.7 Using multiple dictionary-defined parameters in one rule . . . 13
4.1 COLD semantic DCG sample . . . 15
4.2 A dictionary sample . . . 16
4.3 A natural sentence to be used as an input . . . 16
INTRODUCTION
Applications for computing semantic similarity are becoming more prevalent [1, 5]. A
semantic similarity is a comparison of how similar in meaning two concepts are. These
concepts are associated with some ambiguity, normally related to natural language.
Com-parisons could be between: two words, two natural sentences, or between a sentence and a
predefined statement (a rule). Such a rule would have some grammatical structure, e.g., its
grammar could be described as a set of definite clauses in first-order logic. Such a
repre-sentation is denoted Definite Clause Grammar (DCG). A problem with DCGs is that they
are static as to what they can express. Every combination of possible words needs to be
explicitly defined in order to be acceptable rules. This is a complex problem for systems
comparing a user’s natural language with DCGs, because a user cannot be expected to
con-struct sentences exactly matching rules. As such, rules are defined with close consideration
of natural language, as can be seen in [3].
Conventional approaches for comparing texts fail to deliver human-level (common
sense) results [24]. This is understandable due to the many different ways semantically
identical sentences can be expressed using natural language. Computed semantic similarity
measurements are used in a wide range of services which rely on natural language.
There-fore, increasing the confidence of which texts can be compared is desirable in many natural
language processing applications, including: machine translation [20], conversational agents
[23], web-page retrieval (e.g., by search engines) and image retrieval [21, 19].
This thesis is part of larger project within the field of human robot interaction, aiming
to decrease the drawback of robot deployment for small and medium enterprises (SMEs).
The investment cost of deploying robots for SMEs is partly related to hardware purchases,
language framework is purposed through [4] which aims to remove the dependencies on
the robot programmers, allowing for such tasks, and (re)purposing, to be performed by
manufacturing engineers.
COLD, or COactive Language Definition, is a high level programming language for the
rapid development of multimodal interfaces [3]. In its current version, possible multimodal
sentences are described as context free definite clause grammar. That is, every word that
is desired to be acceptable by COLD needs to be explicitly written as a rule in a COLD
grammar file. This limits the capabilities of the language and make programming it
cum-bersome. For instance, the sentences: ”go to your house” and ”go home” are similar both
semantically and lexically. However, two different rules must be defined to be able to handle
both cases.
1.1 Thesis Statement and Contributions
This thesis contributes to the field of natural language processing. Specifically, it
discusses the benefits of extending static definite clause grammar (DCG) systems–that
match users’ inputs with predefined rules–with tools for semantic analysis. Also, it supplies
a modular framework for DCG–text and text–text comparisons. Although said framework is
not the purpose of this thesis, it can serve as a basis for further development and verification.
The purpose of this thesis is to:
1. present an approach for computing semantic confidence measurements between
natu-ral lingual phrases and DCGs, and
2. show how an existing static DCG-based system can be extended with said
function-ality.
Our algorithm (Section 4.1) combines common natural language processing tasks such as:
statistical parsing, tokenization, parts-of-speech tagging and word-sense disambiguation.
We apply these techniques through the context of the combined word-sense of the input
thesauri. Doing so, our algorithm successfully match linguistic phrases with (somewhat)
ambiguous predefined grammar. We show how our approach can benefit DCG-bases system.
This includes:
• Greater freedom in the definitions of the grammar rules. • Not requiring all usable words to be predefined.
• Parts of parsing can be shifted to the statistical parser, allowing for early termination of parses where further traversing of the parse tree would not otherwise be beneficial.
Furthermore, this could enable rule definitions to be performed without the explicit
con-sideration of users’ natural language, but rather in a way that better conveys the semantic
goal of the rule. Although our approach focuses on DCG-based systems, it is still applicable
in any system where the semantic relatedness of two texts is desired, because in essence, a
CHAPTER 2
BACKGROUND
Before a meaningful semantic comparison can be performed on two sentences of natural
text, they first need to be parsed. This process involves chunking the sentences and tagging
the individual words of a given phrase with its corresponding part-of-speech (POS). In
addition, some semantic relation (known through a knowledge base) must exist between
the words. This chapter presents a broad overview of related work. Furthermore, common
specialized frameworks for natural language processing tasks are presented.
Agent/dialogue systems use Semantic-based Conversational Agents (SCAF) to interact
with users through dialogue, often with scripted responses [23]. Without understanding the
semantics of a user’s input; no intelligible response is possible. Untranslated words are a
major problem in machine translation where a common cause is due to statistical training
of systems where only a small percentage of the corpus is understood [20]. Web-page
retrieval often involves comparing header titles of pages. This is discussed in [21] among
algorithms for web and text classification. The related subject of image retrieval often relies
on semantic hierarchies to classify related images [19]. Social bookmarking enables users to
annotate and share bookmarks of web-pages. Comparing tags to find related sites requires
semantic knowledge of the tag concepts [22]. Tagging of images on social network is a recent
application, which combines these techniques.
2.1 Statistical Parsing
A statistical parser is a type of natural language parser which, given a text, determines
its structure; which words are related, which subjects and objects are related to which
verb, which words are verbs/nouns/adjectives. The parser tries to produce the most likely
There are two actions of specific interest provided by the statistical parser for use in
semantic similarity comparison: tokenization and part-of-speech tagging:
Tokenization: splitting the given text into a set of tokens where a token represents the
smallest part of speech, i.e., the sentence "its color is red" would yield the tokens: " its ", " color ", " is ", " red ".
Part-of-speech (POS) tagging: every token is tagged with its corresponding POS, i.e.,
red which is an adjective is tagged with adjective. Every noun is tagged with noun, etc.
OpenNLP is a machine learning library for processing natural language that can perform
the above desired tasks [6]. Other features include: sentence segmentation, named entity
extraction, chunking, parsing, and coreference resolution. These tasks are usually required
to build more advanced text processing services.
2.2 Semantic Knowledge Base
WordNet is the outcome of a research project at Pennsylvania University regarding the
creation of a large database of English words [2]. It is available both as an online and offline
resource. Any given word in WordNet is tagged as being part of one, or more,
parts-of-speech (POS); verbs, adjectives, nouns or adverbs. Words of the same POS with similar
(conceptual) meaning are grouped together in synonym sets, denoted as synsets.
A synset contains a short text description of its conceptual meaning in addition to
its list of words (synonyms). More interestingly, the sysnets also contain semantic and
lexical references to other synsets. That is, the various synsets reference each other forming
complex networks. The references are of a super-subordinate relation. Meaning, general
sets link to more specific ones (and vice versa), more specific ones link to very specific, e.g.,
the set containing the word { red } would link to the set with { crimson }, as crimson is a
special kind of red. Furthermore, it would also link to { color }, as red is a color.
Relations are inherited from their superordinates, meaning that from the previous
directly connected. The same conclusions cannot be drawn from the subordinates point of
view, e.g., a color could be crimson, but it certainly doesn’t have to be. The same is true
for verbs where hypernym and troponym are related, e.g., { walk } is linked with the synset
{ travel, go, move }, since walking is a more precise way of moving.
For the most part there are no connections between different POS. Some adjectives
have a special relation denoted attribute. An attribute describes the given adjectives
con-nection to a noun, linking two POS together (e.g., linking the adjective happy with the
noun happiness).
2.3 Word Sense Disambiguation
Word sense disambiguation is the process of determining which sense of a word is used
in a text. For instance, consider the sentence ”I’m having an old friend for dinner”. Does
the word having refer to what is being served, or does it refer to the company?
Techniques involve supervised, semi-supervised, unsupervised and cross-lingual
evi-dence methods. They are explained through [13]. Other methods involve the use of
dictio-naries and knowledge-bases. One such method is the Lesk algorithm. Lesk assumes that
the words in a given phrase are likely related to each other and that the relations can be
observed through the words definitions [8]. Words can thus be compared—through their
definitions—finding the pairs that are most closely related.
2.4 COactive Language Definition (COLD)
The main motivation behind this thesis is the inclusion of statistical parsing and
se-mantic analysis—to an existing high level framework for natural language—in human robot
interaction. The framework uses the programming language COactive Language Definition
(COLD), for semantic Definite Clause Grammar (DCG) rule definitions. COLD allows for
incremental multimodal grammar rules. Texts, and speech (which can also be represented
as text) are of most significant interest for our approach. The other modalities are explained
100 command ( R e t v a l ) −−> s e t t h e c o l o r t o r e d { R e t v a l = s e t C o l o r ( r e d ) ; } . 101 command ( R e t v a l ) −−> s e t t h e c o l o r t o b l u e { R e t v a l = s e t C o l o r ( b l u e ) ; } . 102 103 command −−> p i c k u p <O b j e c t ( o b j )> { p i c k u p ( o b j ) ; } 104 105 O b j e c t ( R e t v a l ) −−> t h e box { R e t v a l = p r o p e r t y ( theBox ) ; } . 106 O b j e c t ( R e t v a l ) −−> t h e s p h e r e { R e t v a l = p r o p e r t y ( t h e S p h e r e ) ; } .
Figure 2.1: COLD source code sample
There are two categories of syntax: grammar definitions and semantic representation.
Both are illustrated in Figure 2.1. The semantic representation is any valid C# code and
can be declared in between two ”{ }” clauses.
Note the Prolog-like syntax in Figure 2.1 with the → arrow. The text to the right hand
side of the arrow represents the speakable grammar rule. That is, to call the command on
line 100 the words: ”set the color to red”, should be the input. Calls can be nested, as
shown on line 103. It declares a command with the property ”<Object(obj)>”, which is
defined on lines 105-106. Implying that the valid inputs for rule 103 would be: ”pickup the
box” and ”pickup the sphere”.
The COLD syntax is declared in a script file and an integrated development
environ-ment (COLD IDE) parses these files. It also provides XML files to be used together with
Microsoft’s Speech API (for the speech recognition). The IDE compiles a multimodal
gram-mar graph, which is used in COLD programs to reference the gramgram-mar. See [3] and [14] for
CHAPTER 3
COMPUTING SEMANTIC RELATEDNESS
In its most general form the input and definite clause grammar system depends on (a)
a set of predefined rules e.g., ”Set the color to red”, ”Pick up the biggest box”, etc. and
(b) some input (i.e., a text). Through analyzing the supplied input together with the rules,
a semantic similarity value sim ∈ [0, 1], can be computed. A value of sim = 1 indicates a
perfect, unambiguous relation, whereas sim = 0 implies no connection what so ever. For
every rule the general approach consists of:
1. tokenization and part-of-speech tagging,
2. identifying the words from the input with the closest semantic meaning to those of
the given rule (word-sense disambiguation),
3. comparing pairs of words to find the overall highest scoring combination.
3.1 Semantic Comparison of Words
Popular techniques for evaluating word similarity are compared in [7]. Wu-Palmer
similarity is one such technique originally developed to allow for inexact matches to achieve
correct lexical selection in machine translation [10]. Wu-Palmer exploits the fact that within
a conceptual domain, the relation between two concepts will be directly related to how
closely they are defined in the word hierarchy. This is the same hypothesis of which the
knowledge base WordNet, described in section 2.2, is defined. Within a graph; consider the
two concepts c1 and c2, which are connected at the least common super-concept c3. Denote
the distance between the nodes as: d1 = dist(c1,c3), d2 = dist(c2,c3) and d3 = dist(c3, root).
The similarity sim between c1 and c2 can then be evaluated through:
sim(c1, c2) =
2 · d3
d1+ d2+ 2 · d3
The possibility of multiple paths between c1and c2should be noted. Naturally, the distances
should be the shortest path. Figure 3.1 shows an illustration of a graph search and the
synonym sets along the shortest path.
Figure 3.1: Graph walk in WordNet from the hypernyms tangerine and red to their common hyponym chromatic- and specular color. The numbers represents the length of the walk.
3.2 Dynamic Rule Declarations
Declaring completely static rules is partly a tedious task for the system engineers, but
more importantly, it constrains the users as to how they can interact with the system.
Relying on a user’s ability to construct lexical identical phrases to exactly match predefined
grammar rules is not reasonable [17]. It might be admissible for a classical simple telephone
redirecting service, which states a few rules, e.g., ”Press 1 to ...”, ”Press 2 to ...”, where
the user is presented with the rules and given instructions on how to supply an exact and
unambiguous input (a key press). However, even such systems suffer and often structures
the instructions as to have the last rule provide information on how to repeat the previous
rules.
In recent days dialogue bases systems are becoming more popular [1]. Such systems
100 JJ : red , g r e e n , b l u e , o r a n g e , b l a c k , s m a l l , l a r g e , huge , 101 a c t i v e , i n a c t i v e
102 VB: add , t a k e , change , a t t a c h , s e t , t a k e 103 NN: house , home , b u i l d i n g , box , mountain , sun 104 RB: q u i c k l y , s l o w l y
105
106 ACTION : pick_up , put_down 107 OBJECT: box , s p h e r e
Figure 3.2: Outtake from a dictionary file showing the predefined POS-categories JJ
(adjec-tives), VB (verbs), NN (nouns), and RB (adverbs) on lines 100-104. The POS abbreviations
are the same as those obtained through the statistical parsing, see section 2.1. Lines 106-107 contain user-defined categories.
a problem when declaring the rules—they should be formulated in such a manner as to
best match the user’s expected natural language. To help abbreviate this problem a local
dictionary for the rule-system is proposed. A simple text file containing categories with
comma separated entries (words), as shown in Figure 3.2. The annotations follow the penn
treebank [18] word level tags, as they are commonly used and also present in the statistical
parser.
Using the dictionary from Figure 3.2, a rule such as ”Perform <ACTION> on <NN>”
would be able to match ”Perform pick_up on box” (as ”box” is a defined noun). However,
it would equally match ”Perform pick_up on sun”. In cases where it is desirable to only
have specific words matchable to a given rule/rules, optional user categories can be added.
For instance, defining the category OBJECT on line 107, allows the rule to be changed to:
”Perform <ACTION> on <OBJECT>”.
Some words belong to several categories, for instance, the word ”word” can be a noun
or a verb, depending on which context it’s used in. If such a word is desired to be usable
in more than one POS it should either be defined multiple times (once per POS-category),
or declared in a user-defined category.
The rule definitions are further improved through allowing the statistical parser and
consider the rule: ”Set the color to <JJ>”, using the above dictionary. If given an input
such as: ”Set the color to crimson”; a match would not be possible in a static environment
(as crimson is unknown). However, the semantic analyzer could perform a word-sense
disambiguation, realizing that crimson is a color; a special type of red, allowing for the rule
”Set the color to red” to be matched. Furthermore, this allows for the ability to define rules
without the consideration of an agent’s natural language, but rather in a way that best
explains the semantic goal of the rule.
3.2.1 Extending COLD Grammar
The COLD language syntax is explained in section 2.4. The main limitation of the
grammar defined rules is that they are completely static. For instance, say we want to
define a rule to change the color property of an object. In COLD this is possible through
two solutions, as shown in Figures 3.3 and 3.4.
100 command ( R e t v a l ) −−> s e t t h e c o l o r t o r e d 101 { R e t v a l = s e t C o l o r ( " r e d " ) ; } . 102 103 command ( R e t v a l ) −−> s e t t h e c o l o r t o b l u e 104 { R e t v a l = s e t C o l o r ( " b l u e " ) ; } . 105 106 command ( R e t v a l ) −−> s e t t h e c o l o r t o g r e e n 107 { R e t v a l = s e t C o l o r ( " g r e e n " ) ; } .
Figure 3.3: Defining almost identical new rules
Arguably, the second alternative is more dynamic, but both require predefinition of
every single color to be used (i.e., in this example only the colors red, green and blue
would be valid inputs). If we want to add another color then we need to write more rules.
To improve upon this solution we apply the concepts presented above regarding the local
dictionary. As shown in Figure 3.2. Firstly, rules are added to the COLD compiler to allow
100 command ( R e t v a l ) −−> s e t t h e c o l o r t o <C o l o r ( c l r )> 101 { R e t v a l = s e t C o l o r ( c l r ) ; } . 102 103 C o l o r ( R e t v a l ) −−> r e d { R e t v a l = " r e d " ; } . 104 C o l o r ( R e t v a l ) −−> b l u e { R e t v a l = " b l u e " ; } . 105 C o l o r ( R e t v a l ) −−> g r e e n { R e t v a l = " g r e e n " ; } .
Figure 3.4: Nested calls through defining another rule ”Color”
it (a) checks if it’s defined in the script, or (b) checks if it’s defined in the dictionary. If
either is correct then it’s valid. In the case of (a) it also appends the dictionary with these
definitions. Failure to match both (a) and (b) results in a compile error. This allows for a
dictionary such as the one shown in Figure 3.5 to be used together with the code snippet
in Figure 3.6 to define all the rules from Figure 3.4.
100 JJ : red , g r e e n , b l u e
Figure 3.5: A simple dictionary containing only three color adjectives
100 command ( R e t v a l ) −−> s e t t h e c o l o r t o <JJ> { R e t v a l = s e t C o l o r ( JJ ) ; }
Figure 3.6: A rule using a dictionary-defined parameter, JJ
A common bracket syntax is proposed to allow for different words within the same
dictionary category to be distinguishable within the semantic representation. See Figure
3.7 for a rule that would be able to match an input such as ”change the color from red to
blue”.
Through these additions, COLD rules can be defined in a more natural way. The
100 command ( R e t v a l ) −−> chan ge t h e c o l o r from <JJ> t o <JJ> { 101 i f ( g e t C o l o r == JJ [ 0 ] )
102 s e t C o l o r ( JJ [ 1 ] ) ; 103 } .
Figure 3.7: A rule using two of same dictionary-defined parameters. They do not have to be represented by the same word. The two parameters are distinguished in the semantic representation (within the ”{ }”) through indexing in ”[ ]” brackets.
synonyms could be defined allowing for even more general inputs. However, this still requires
the structure of the input sentence to be the same as that of the rule. Instead of relying on
defined synonyms in the dictionary this information could be obtained through a semantic
knowledge base. The statistical parser, semantic analyzer and the semantic knowledge base
are all contained within the same .Net library, making the integration into COLD simple.
The extra overhead associated with the added NLP methods should be considered.
COLD relies on multimodal inputs, where speech is the most interesting for our purpose.
We suggest that because these computations can be performed while an agent is speaking;
the calculations will have sufficient time to conclude before the speech is complete (as
it is incrementally parsed). As such, no additional overhead would be present for this
environment. An asymptotic time complexity analysis of this algorithm was outside the
scope of this thesis. Obviously, such an analysis should be carried out in order to support
the above claim. See Chapter 5 Conclusions.
3.3 Comparing Natural Language and Definite Clause Grammar
Comparing any two natural language texts is a similar problem to that of comparing
one text with definite clause grammar (DCG). The different DCG rules together provide a
context in which the natural language text can be compared. Such a context is not present
in the former problem.
Firstly, the inputs (a natural language text) word-sense is disambiguated using an
operates on the hypothesis that neighboring words in a text have similar meaning. This
idea is further extended through using the context of the different rules, together with a
dictionary, as suggested in Section 3.2 Dynamic Rule Declarations. Through this process
the input is modified by replacing words with synonyms or hypernyms from the knowledge
base, as to better match the context of the DCG.
Secondly, all individual pairs of words obtainable through selecting one word from the
input and one word form the rule are compared to find the semantic similarity between
each of them, as explained in section 3.1 Semantic Comparison of Words. Pairs of words
are selected as to find the overall highest scoring combination. However, in the case where
multiple dictionary tags are defined in the DCG, i.e., the two JJ ’s in ”Change the color from
<JJ> to <JJ>”, different matches are required for each tag. Consider the input ”Turn the
red to blue”; the word red can only be matched with one of the JJ tags, not both. This is
exclusive to matching dictionary tags and has no impact on how red is matched with other
words, i.e., color.
Through this process the input is scored versus all rules yielding a comparison
confi-dence value together with the suggested dictionary matches, for each rule. Provided with
this data, selecting which rule/rules to fire is a simple design decision (e.g., all rules with
CHAPTER 4
RESULTS
In this chapter, detailed annotated results of a semantic analysis, using the discussed
methods, is presented in Section 4.1. In addition, a general framework for semantic
relat-edness is presented in Section 4.2.
4.1 Semantic Analysis of Natural Language and DCGs
This sections details the semantic analysis algorithm, using the methods discussed in
Chapter 3 Computing Semantic Relatedness. First consider a set of DCGs as shown in
Figure 4.1 together with a lexical dictionary as shown in Figure 4.2. Secondly, the input
from Figure 4.3.
100 command ( R e t v a l ) −−> S e t t h e c o l o r t o <JJ> 101 { R e t v a l = s e t C o l o r ( JJ ) ; } .
102
103 command ( R e t v a l ) −−> Change t h e c o l o r from <JJ> t o <JJ> 104 { 105 v a r c o l o r = g e t C o l o r ( ) ; 106 i f ( c o l o r == JJ [ 0 ] ) R e t v a l = s e t C o l o r ( JJ [ 1 ] ) ; 107 e l s e R e t v a l = c o l o r ; 108 } 109 110 command ( R e t v a l ) −−> Change t h e s i z e t o <JJ> 111 { R e t v a l = s e t S i z e ( JJ ) ; } .
Figure 4.1: Snippet from a COLD script showing some semantic DCGs. The speakable components are to the right of the → arrows
100 JJ : y e l l o w , c r i m s o n , g r e e n , . . . , b i g , s m a l l , l a r g e 101 NN : . . .
102 VB : . . . 103 RB : . . . 104 . . .
Figure 4.2: A dictionary file detailing some of its color- and size-adjectives
from <JJ> to <JJ>” and ”Change the size to <JJ>”, where <JJ> is any word defined in
the dictionary entry represented by line 100 in Figure 4.2.
100 " Turn i t r e d "
Figure 4.3: A natural sentence to be used as an input
The semantic analysis through these criteria is performed as follows:
1. The input is tokenized (split into the smallest word-unit)
ex. ”Turn it red” → ”[Turn] [it] [red]”
2. The tokenized input is tagged with its part-of-speech (POS)
”[Turn] [it] [red]” → ”[VP Turn/VB ] [NP it/PRP ] red/JJ”
3. For every token, get the synonym set (synset) for that word using its corresponding
POS from the thesaurus
4. For every rule:
(a) Get the synset for every dictionary entry of each containing category (<JJ>,
<NN>, ...)
(b) Find the best matching tags (using Wu-Palmer similarity) with confidence value
c ∈ [0, 1], which is not already matched (i.e., two <JJ> in a rule cannot match
i.e., rule 100: sim(red, crimson) = 1.0 ⇒ <JJ>[0] = crimson,
and rule 110: sim(red, crimson) = 1.0 ⇒ <JJ>[0] = crimson
(c) Discard any rule that failed to match all tags
i.e., rule 103: sim(red, crimson) = 1.0, sim( N/A , X) = NaN
⇒ <JJ>[0] = crimson, <JJ>[1] = N/A, therefore discard rule 103
5. For the remaining rule(s) create the sentence s using the best matches from (4b) and
remove all determiners:
s100: ”Set color to crimson”
s110: ”Change size to crimson”
6. For every word in input and every sentence from (5), find the best matched sentence,
through comparing the similarity between pairs of words:
input: ”Turn it red”, [VP Turn/VB ] [NP it/PRP ] red/JJ
s100: ”Set color to crimson”, [VP set/VBN ] [NP color/NN ] [PP to/TO ] crimson/JJ
s110: ”Change size to crimson”, [VP change/VB ] [NP size/NN ] [ PP to/TO ] crim-son/JJ
s100: sim(turn, set) = 0.666, sim(red, crimson) = 1.0, sim(red, color) = 0.428 ⇒ s100 = 0,698
s110: sim(turn, change) = 0.571, sim(red, crimson) = 1.0, sim(red, size) = 0.0 ⇒ s110 = 0,523
7. Select rule r corresponding to the best matched sentence from (6) with the POS
matches from (4b):
r : "Set the color to crimson"
Note how the selected rule is the closest matching, even though the input contained none
of the actual words. The input: ”Turn it red”, contains the color red, which is not defined
in the lexical dictionary of accepted words (Figure 4.2). However, crimson is. Due to the
the color to <JJ>” and ”Change the size to <JJ>” are almost identical, except for the
words color and size. Both use <JJ> tags, which does not exclude as to which words
from that category can be matched. I.e., ”Change the size to crimson” and ”Set the color
to crimson” are both equally good matches as far as the DCGs and lexical dictionary are
concerned. Because of the word-sense of the input and rules, the algorithm could determine
that in this context, the word crimson is more closely related to color than it is to size. As
such, the desired rule was matched.
The example shows how the approach handles ambiguities. It could be noted that
the ambiguity instead could have been avoided altogether by defining the DCGs better.
For instance, this specific problem could have been circumvented by using user-defined
categories instead of general <JJ> tags, i.e., defining the categories colors and sizes.
4.2 A Framework for Computing Semantic Relatedness
Computing semantic relatedness of texts combines many different NLP techniques.
Though these methods complement each other for our purpose, researchers mostly focus
on improving the relations of just one or a few of these. For instance, recent research has
discussed the use of WordNet and how Wikipedia could replace it as a knowledge-base [15,
16].
We have created a general modular framework for the computation of semantic
relat-edness. Each modularity being a NLP technique. All modalities share a common interface
as to how they interact to perform the semantic analysis. As such, different methods can
be replaced as more prominent solutions become available, or to better fit the needs of a
specific system. For example, adding support for Wikipedia in conjunction with WordNet,
would not affect how statistical parsing or part-of-speech tagging is performed.
4.2.1 Test Application
A simple test application is provided to test the functionality of different NLP
tech-niques. It’s included in the delivered modular framework for semantic analysis in COLD.
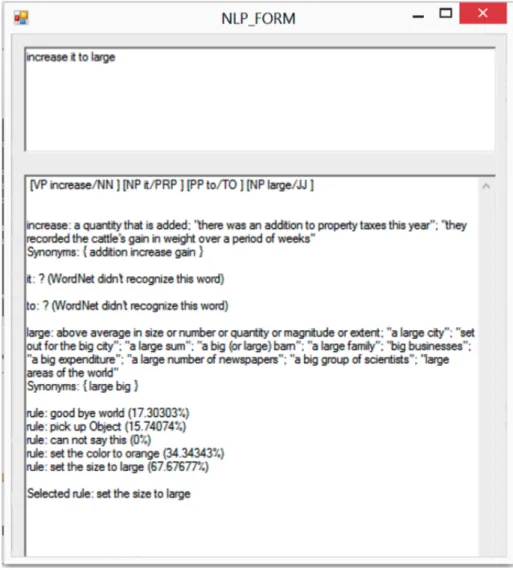
Figure 4.4: Screenshot of the test application. The input ”increase it to large” from the above input box is interpreted and the results printed in the box belove
Any sentence can be written as input. The sentence is parsed, tokenized and
POS-tagged. Gloss and synonyms for each individual word from the thesaurus is shown. The
input is matched against some DCGs. The confidence values for these matches are presented,
together with the most closely matched rule. The application reads DCGs from a script file
and passes them as text strings to a data structure. As an alternative, sentences could be
passed directly to the data structure. As such, the input would instead be compared to any
CHAPTER 5
CONCLUSIONS
In this thesis we have proposed a general natural language processing framework for
computing semantic relatedness of texts. Also, we have shown how our approach can be
used to solve the more specific problem of comparing a text with a definite clause grammar
(DCG) rule. We did this through introducing a lexical dictionary to the DCG and computing
the word-sense using the context of the DCGs and a thesaurus. Although the approach
is explained through a DCG-based system, it is still applicable in any system where the
semantic relatedness of two texts is desired. This is because a semantic DCG includes a set
of words. Expanding a grammar to include the possible acceptable words forms sentences.
Although these sentences are likely fragmented; conceptually they are no different than a
natural language text.
We have shown how an existing incremental multimodal framework (COLD) can benefit
from our approach, rather than its current static grammar definitions. These benefits
include: not requiring a list of all possible words, early termination of rule parsing, and
the ability to make use of word types. The DCG rules can therefore be made much more
dynamic. Furthermore, when defining the rules, no consideration of the natural language
of the users’ is required. As such, rules can be defined as to best express their semantic
meaning, minimizing ambiguities of natural language. Before applying our solution to
COLD; to match a rule defined as ”set the color to crimson”, a user would have to input
exactly that. As can be seen in 4.1, using our method, the input ”turn it red” could
convincingly be matched to the rule ”set the color to crimson”, even though neither of
the words: ”turn”, ”it” or ”red” were explicitly defined. In this case it was sufficient for
the words to be known from the thesaurus, in conjunction with a rule that conveyed its
It should be noted that the goal of this thesis was not to find "the best" method for
comparing DCGs and texts, but rather any method that would be applicable to COLD
(see 2.4). Therefore, extensive testing of the suggested method was outside the scope of
this thesis. Also, the effectiveness of the proposed algorithm for the comparison of natural
language and DCGs (3.3 & 4.1) has not been thoroughly analyzed. Naturally, further testing
is required to determine its effectiveness.
Our approach uses the thesaurus WordNet. Although a respected source, newer
re-search suggests Wikipedia can provide better results [15]. More details on this can further
be seen in [16] which also discusses the benefits of combining WordNet, Wikipedia and
Google. Although an increase in the confidence values of the semantic relatedness could be
achieved, the complete implications of the (presumed) increased asymptotic time and space
complexity is unknown and needs to be further analyzed.
Our approach has made the rule definitions of COLD more dynamic. Part of this is due
to the introduction of the lexical dictionary and the dictionary tags. In the current solution
it is possible to define grammar using <JJ> (adjective), <VB> (verb), <NN> (noun) and
<RB> (adverb) tags, in addition to user-defined categories. We would like to extend this
to also use phrases, i.e., verb-phrases and noun-phrases. This would further improve upon
REFERENCES
[1] Y. et. al, “Sentence similarity based on semantic nets and corpus statistics,”
Trans-actions on Knowledge and Data Engineering, vol. 18, no. 8, pp. 1138–1150, August
2006.
[2] G. A. Miller, “Wordnet: A lexical database for english,” Communications of the ACM,
vol. 38, no. 11, pp. 39–41, 1995.
[3] A. Ameri, “A general framework for incremental processing of multimodal inputs,” in
In Proceedings of the 13th International Conference on Multimodal Interaction, 2001,
pp. 225–228.
[4] B. Akan, “Human robot interaction solutions for intuitive industrial robot
program-ming,” Licentiate Thesis No. 149, Mälardalen University, 2012.
[5] D. Michie, “Return of the imitation game,” 2001.
[6] (2010) Apache opennlp. [Online]. Available: http://opennlp.apache.org
[7] E. Blanchard, M. Harzallah, H. Briand, and P. Kuntz, “A typology of ontology-based
semantic measures.” in EMOI-INTEROP, 2005.
[8] C. Fellbaum, WordNet: An electronic lexical database. Wiley Online Library, 1998.
[9] M. Lesk, “Automatic sense disambiguation using machine readable dictionaries: how to
tell a pine cone from an ice cream cone,” in Proceedings of the 5th annual international
[10] Z. Wu and M. Palmer, “Verbs semantics and lexical selection,” in Proceedings of the
32nd annual meeting on Association for Computational Linguistics. Association for
Computational Linguistics, 1994, pp. 133–138.
[11] S. Banerjee and T. Pedersen, “An adapted lesk algorithm for word sense disambiguation
using wordnet,” in Computational linguistics and intelligent text processing. Springer,
2002, pp. 136–145.
[12] D. Klein and C. D. Manning, “Accurate unlexicalized parsing,” in Proceedings of the
41st Annual Meeting on Association for Computational Linguistics-Volume 1.
Asso-ciation for Computational Linguistics, 2003, pp. 423–430.
[13] C. D. Manning and H. Schütze, Foundations of statistical natural language processing.
MIT press, 1999.
[14] M. Johnston, “Unification-based multimodal parsing,” in Proceedings of the 36th
An-nual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics-Volume 1. Association for Computational
Linguistics, 1998, pp. 624–630.
[15] E. Gabrilovich and S. Markovitch, “Computing semantic relatedness of words and texts
in wikipedia-derived semantic space.” IJCAI’07 Proceedings of the 20th international
join conference on Artificial Intelligence, 2007, pp. 1606–1611.
[16] M. Strube and S. P. Ponzetto, “Wikirelate! computing semantic relatedness using
wikipedia,” in AAAI, vol. 6, 2006, pp. 1419–1424.
[17] B. Galitsky, “Building a repository of background knowledge using semantic skeletons,”
in AAAI Spring symposium 2006 - Formalizing and Compiling Background Knowledge
and Its Applications to Known Represention and Question Ansering, 2006, pp. 22–27.
[18] M. P. Marcus, M. A. Marcinkiewicz, and B. Santorini, “Building a large annotated
corpus of english: The penn treebank,” Computational linguistics, vol. 19, no. 2, pp.
[19] J. Deng, A. C. Berg, and L. Fei-Fei, “Hierarchical semantic indexing for large scale
image retrieval,” in Computer Vision and Pattern Recognition (CVPR), 2011 IEEE
Conference on. IEEE, 2011, pp. 785–792.
[20] Y. Marton, C. Callison-Burch, and P. Resnik, “Improved statistical machine translation
using monolingually-derived paraphrases,” in Proceedings of the 2009 Conference on
Empirical Methods in Natural Language Processing: Volume 1-Volume 1. Association
for Computational Linguistics, 2009, pp. 381–390.
[21] X. Qi and B. D. Davison, “Web page classification: Features and algorithms,” ACM
Computing Surveys (CSUR), vol. 41, no. 2, p. 12, 2009.
[22] B. Markines, C. Cattuto, F. Menczer, D. Benz, A. Hotho, and G. Stumme, “Evaluating
similarity measures for emergent semantics of social tagging,” in Proceedings of the 18th
international conference on World wide web. ACM, 2009, pp. 641–650.
[23] K. O’Shea, “An approach to conversational agent design using semantic sentence
sim-ilarity,” Applied Intelligence, vol. 37, no. 4, pp. 558–568, 2012.
[24] Y. Li, Z. A. Bandar, and D. McLean, “An approach for measuring semantic similarity
between words using multiple information sources,” Knowledge and Data Engineering,