Faculty of Technology and Society Computer Engineering
Bachelor Thesis
Investigating techniques for improving accuracy and
limiting overfitting for YOLO and real-time object
detection on iOS
Jakup Güven
Exam: Bachelor of Computer Science in Engineering in Computer Science 180 hp Area: Computer Science
Date for examination: 2019-05-31
Superviser: Blerim Emruli
Abstract
This paper features the creation of a real time object detection system for mobile iOS using YOLO, a state-of-the-art one stage object detector and convoluted neural network far surpassing other real time object detectors in speed and accuracy. In this process an object detecting model is trained to detect doors. The machine learning process is outlined and practices to combat overfitting and increasing accuracy and speed are discussed. A series of experiments are conducted, the results of which suggests that data augmentation, including negative data in a dataset, hyperparameter optimisation and transfer learning are viable techniques in improving the performance of an object detection model. The author is able to increase mAP, a measurement of accuracy for object detectors, from 63.76% to 86.73% based on the results of experiments. The tendency for overfitting is also explored and results suggest that training beyond 300 epochs is likely to produce an overfitted model.
Sammanfattning
I detta arbete genomförs utvecklingen av ett realtids objektdetekteringssystem för iOS. För detta ändamål används YOLO, en ett-stegs objektdetekterare och ett s.k. ihoplänkat neuralt nätverk vilket åstadkommer betydligt bättre prestanda än övriga realtidsdetek-terare i termer av hastighet och precision. En dörrdetekrealtidsdetek-terare baserad på YOLO tränas och implementeras i en systemutvecklingsprocess. Maskininlärningsprocessen sammanfat-tas och praxis för att undvika överträning eller “overfitting” samt för att öka precision och hastighet diskuteras och appliceras. Vidare genomförs en rad experiment vilka pekar på att dataaugmentation och inkludering av negativ data i ett dataset medför ökad precision. Hyperparameteroptimisering och kunskapsöverföring pekas även ut som medel för att öka en objektdetekringsmodells prestanda. Författaren lyckas öka modellens mAP, ett sätt att mäta precision för objektdetekterare, från 63.76% till 86.73% utifrån de erfarenheter som dras av experimenten. En modells tendens för överträning utforskas även med resultat som pekar på att träning med över 300 epoker rimligen orsakar en övertränad modell.
Acknowledgements
The author would like to thank the superviser Blerim Emruli whose academic passion inspired this work. The author would furthermore like to thank Cybercom for requesting this paper and providing all tools neccessary to achieve its goals.
Contents
1 Introduction 1
1.1 Background . . . 1
1.2 Cybercom . . . 1
1.3 Goal of the project . . . 1
1.4 Research questions . . . 2
1.5 Mock-up of the planned product . . . 2
1.6 Related work . . . 4
2 Theoretical background 6 2.1 Machine Learning and Deep Learning . . . 6
2.2 Machine learning process . . . 7
2.3 Computer Vision and Object Detection . . . 8
2.4 YOLO . . . 10
3 Methodology 12 3.1 Methods . . . 12
3.2 Process . . . 13
3.2.1 Systems development research process . . . 13
3.2.2 Machine learning process . . . 14
3.2.3 Experiments . . . 15 3.3 Tools . . . 16 4 Results 17 5 Discussion 20 5.1 Dataset composition . . . 20 5.2 Hyperparameter optimisation . . . 21 5.3 Transfer learning . . . 21
5.4 Limitations and future work . . . 21
6 Conclusion 22
1
Introduction
This chapter introduces the paper and seeks to give an understanding of why the project was done by displaying interests in the technology involved, as well as a background of the field. In section 1.1 a brief introduction of deep learning and convolutional neural networks are made. Section 1.2 we acquaintance ourselves with the company that ordered this project and its interests. Section 1.3 explains what is to be achieved with this project and how. Section 1.4 states the research questions formulated out of this goal. In section 1.5 a brief mock-up of the planned product is submitted. In section 1.6 we explore related work in order to establish areas of interest, high lighting where much is already known and where further investigation is valid.
1.1 Background
Deep learning emulates the way the brain processes information, being able to capture intricate structures and patterns in large-scale data. There has been an increasing interest in this machine learning method, as it has proved able to outperform previous state-of-the-art methods in a variety of tasks. This has meant advances in Computer Vision, where today deep learning is used to solve a variety of problems such as object detection. Object detection is the process of detecting instances of some object of some arbitrary class (door, human, rottweiler) in digital images and video. These neural networks are being brought onto mobile devices with increasingly positive results, enabling an increasing range of applications that can take advantage of the array of sensors modern mobile devices possess. The fact that most people use these devices in their every day life makes it easy for a developer to solve every day problems with the help of this tool. Furthermore Apple has created a processing unit, called the Neural Engine, for the specific purpose of computing neural network operations. This unit is shipped with the newest models of iPhone, suggesting that deep learning on mobile devices is here to stay.
1.2 Cybercom
This paper is written on the request of Cybercom’s Innovation Zone. Cybercom is an information technology consulting company with offices in Sweden, Finland, Denmark, Poland, India, Dubai and Singapore. The Innovation Zone evaluates and assesses new ideas, develops working prototypes in emerging technologies and runs pilot projects in an agile innovative environment. Innovation Zone has great interest in the fields of artificial intelligence, augmented reality and virtual reality. The interests of Cybercom in this paper are two-fold, primarily it wishes to explore object detection, secondly there is an interest in taking this implementation to a customer project wherein it will be used in an augmented reality application for world wrapping, where located doors will be used as biome boundraries.
1.3 Goal of the project
The goal of this project is to create a real time object detection system for the detection of doors, open or closed, for mobile iOS devices. In order to construct this system we must also implement an object detection model suitable in terms of size and speed to run on a
mobile device and detect objects in real time. Additionally a dataset of doors is created for this model to train on. The goal is furthermore to confirm, discover and discuss practices that yield improved performance in terms of accuracy and speed in the domain of object detecting convolutional neural networks. The application of door detection for Cybercom will be biome boundraries in an augmented reality application, but possible applications are wide. For example, a door detector can be used as a navigation aid for the visually impaired for whom locating doors is a challenge.
1.4 Research questions
To achieve these goals two research questions are established, in extension to related works.
• What is a practical solution to real time detection of doors and their location on mobile devices?
• How can hyper parameter optimisation, transfer learning and dataset composition be used to improve the performance in terms of speed and accuracy of a YOLO convolutional neural network?
1.5 Mock-up of the planned product
The system takes the form of an iOS application. Upon starting the application the user is greeted with a live camera feed view showing whatever is in view of the camera at a given moment as demonstrated in Figure 1. When one or more doors are in the view of the mobile device, rectangles will be drawn on the screen noting their position along with a label describing the seen object as can be seen in Figure 2.
Figure 1: The live camera feed view with no doors in sight.
Figure 2: Two examples of the live camera feed view with two doors detected, one open and one closed.
1.6 Related work
Howard et al. (2017) introduce MobileNets, an efficient model for mobile and embedded computer vision applications [1]. They describe previous computer vision models as un-suitable for deployment on mobile and embedded devices. Generally deep convolutional neural networks have been made deeper and more complicated in order to achieve higher accuracy, sacrificing size and speed on the way. By reducing the size of depthwise separa-ble convolutions to 3x3 MobileNets needs 8 to 9 times less computation time with a small reduction of accuracy. The authors point towards an interesting hyperparameter they call the resolution multiplier. By reducing the size of the input layer, every subsequent hidden layer is reduced by the same multiplier and accuracy is traded for speed [1]. Networks designed to be run on mobile devices like MobileNets are interesting in our context be-cause they are more likely to meet the requirements of real-time door detection on a mobile device. Ultimately we choose Fast YOLO over MobileNets due to its better performance both in terms of accuracy and speed. However we test the generalizability of the resolution mulitiplier on our YOLO network.
Alom et al. (2018) present an exhaustive survey of deep learning approaches. They high-light the state-of-the-art performance of deep learning techniques when compared to tra-ditional machine learning approaches in a variety of fields such as computer vision, image processing, speech recognition and many more. They describe convolutional neural net-works as a particularly advantageous form of deep learning in computer vision, since con-volutional neural networks are optimized in structure for processing 2D images and very effective at learning and extracting 2D features [2]. Furthermore they describe some ad-vanced training techniques such as pre-processing of datasets by random cropping, flipping data and color jittering etc. They also discuss transfer learning as a means of improving performance but also of saving time and computation. Instead of generating and annotat-ing large quantities of data which is a very time consumannotat-ing process we can use transfer learning. Such pre-processing of datasets alongside transfer learning is tested in this paper. Atles and Svensson (2018) create a system that successfully combines object detection and augmented reality on a mobile iOS device. They explore various means of classification and object detection, including traditional machine learning approaches, before swiftly moving onto using convolutional neural networks. They find that by using YOLO they achieve the best results. They briefly discuss problems such as overfitting, but beyond splitting their data into a training and test set make no efforts to combat overfitting or improve accuracy and were limited by the hardware available to them in training their model, a MacBook Pro with a 2.8 GHz Intel Core i7 processor, they produce a model that achieves a mAP of 57.61% on their test data [3]. It can be argued that Atles and Svensson were primarily concerned with proving that it was technically possible to solve this problem and were not exploring how to improve results. Our ambition is to do extend upon this and explore means of improving results and hopefully fill this knowledge gap.
Duc (2018) set out to train a neural network object detector to use it in a real time iOS application that he implements. Duc produced a classification application which takes 5 to 20 seconds to classify an object. Duc does not reason about model training and and composition of his dataset, Duc argues that the models he implement are not well trained because they were created for demonstration purposes [4]. What can be said for Atles and Svensson is even more true for Duc. We note that these works prove that it is possible
to create computer vision solutions for mobile devices where all processing is done on the mobile device. Thus in this study we explore what steps can be taken to optimize such a computer vision model, what performance can be gained in this process and attempt to generalize it into guidelines for future work.
He (2016) designs and implements a simplified object detection network based on YOLO [5]. He briefly outlines the machine learning process he uses. In his training process he makes use of transfer learning, suggesting that it is a common practice in the research community to use models trained on the ImageNet dataset [6] as a base for new models [5]. Unlike the previous two mentioned papers He does not create his own dataset to train on. Rather he makes use of the PASCAL VOC 2007 [7] dataset for training and evaluation, which is a benchmark dataset in object category recognition and detection. He achieves a mAP of 43% and concludes that hyperparameters like threshold need to be tuned carefully to achieve greater precision.
2
Theoretical background
There is much interest in machine learning. It is not uncommon to read the terms artificial intelligence, machine learning, deep Learning, and neural networks together in documents with much ambiguity as to how these categories differ from one another and what the essence of their meaning is. This chapter seeks to clear any confusion by providing a theo-retical overview of this domain. In section 2.1 artificial intelligence, machine learning, deep learning and neural networks are explored and put in relation with one another. In section 2.2 the machine learning process is explained by mentioning important steps, problems and common errors that arise during this process such as hyperparameter optimisation and transfer learning. In section 2.3 computer vision is briefly described as well as the problem of object detection and other similar computer vision problems. Finally YOLO is explored in section 2.4.
2.1 Machine Learning and Deep Learning
Machine learning is a subset of artificial intelligence, which is a field of computer science. While scholars have been discussing intelligent machinery and whether computers can be made to think as long as digital computers have existed [8][9], the field was born in 1956 at the Dartmouth college where John McCarthy coined the term "artificial intelligence" [10]. Arthur Samuel, a pioneer in the field of artificial intelligence coined the term "machine learning" [11] in his work Some Studies in Machine Learning Using the Game of Checkers 1, which can be seen as the most significant early mile stone in computerizing learning [12]. Samuel defines machine learning as a "field of study that gives computers the ability to learn without being explicitly programmed" [13]. Tom Mitchell more specifically describes machine learning: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with the experience E" [14]. Deep learning is a machine learning technique that discovers structures in datasets by using multiple layers of neurons between input and output layers. This technique has brought about a breakthrough in machine learning by returning to the idea of general intelligence, with traditional machine learning methods one solves a task by specifically designing several feature extractions algorithms, mapping them to features in data, with deep learning all that work is unnecessary as al-gorithms learn using a general-purpose learning procedure which is not task specific and can be used to solve almost all kinds of problems [15][2]. New generations of graphics card are capable of fast matrix and vector multiplications which is ideal for training neural net-works, they increase learning by a factor of 50 and more, causing a breakthrough in deep learning [16]. Standard neural networks are composed of a large number of computing units called neurons, these neurons are connected to each other in a network organized into layers. Input neurons are activated by sensorial stimulation perceiving the environ-ment, in computer vision networks each input neuron is often most mapped to a pixel in an image, other neurons get activated through connections from previously active neurons eventually producing an output [16]. Deep learning neural network have more layers in be-tween output and input layers, compared to standard neural networks, that are exploited for feature learning and pattern classification [15][16][2]. They make use of feedforward neural network architectures which map a fixed-size input to a fixed-size output, for an
object detection model each pixel value in a frame is the input mapped to a bounding box, class of the object detected and confidence. A specific type of deep neural networks is the convolutional neural network which is able to generalize much better than other networks that have full connectivity between adjacent layers [15]. Convolutional neural networks are inspired by cells in the visual cortex ventral path way. When convolutional neural networks and monkeys are shown an image, the activation of units in the network resembles the activation of neurons in the monkey’s inferotemporal cortex. This type of neural network has been widely adopted by the computer vision community because such networks are designed to process data that comes in the form of multiple arrays, much like the representation of images. An image is composed of three dimensional arrays: height, width and colour channel. It has been applied with great success to the detection, seg-mentation and recognition of objects and regions in images [15][6]. Many more forms of deep learning networks exist such Recurrent Neural Networks (RNN), Long Short Term Memory (LSTM), Gated Recurrent Units (GRU), Auto Encoder (AE), Deep Belief Net-works (DBN), Generative Adversial NetNet-works (GAN) and more [2], but these are outside the scope of this thesis. An example of a convolutional neural network is AlexNet, it is an image classifier which consists of 650,000 neurons and has managed to classify 1.2 mil-lion high-resolution images into 1000 different classes with state-of-the-art results [6][17]. With the success of AlexNet the development of deep neural networks took off [17]. Today deep learning neural networks show state-of-the-art performance in comparison with tradi-tional machine learning approaches in several fields beyond computer vision such as speech recognition, machine translation, natural language processing and more [2]. Convolutional neural networks are relatively expensive and power consuming. In order to bring these networks to mobile and embedded devices Google created MobileNets and solved the issue by factorizing convolutions to decrease model size [1]. Where most convolutional neural networks use 7x7 or 9x9 convolutions [2] MobileNets uses 3x3 convolutions which requires 8 to 9 times less computation with a small reduction in accuracy [1]. Fast YOLO is another convolutional network designed for mobile usage which is particularly interesting as it is able to process 155 frames per second with twice the accuracy of other real-time detectors [18]. Finally, we can understand artificial intelligence as a field of computer science that has existed since the dawn of digital computing. Machine learning is a subset of it which specifically explores the emulation of learning. Furthermore neural networks is a method of machine learning, and in turn deep learning is a subfield of neural networks.
2.2 Machine learning process
Choosing the machine learning algorithm that solves a given problem is important in the machine learning process, rarely should one attempt to implement one from scratch with many algorithms readily available. However, there are many other aspects to take into consideration when solving a problem using machine learning [19]. A solution is dependant on the data at hand which one must carefully gather and label. Overrepresenting a class might cause the model to have difficulty recognizing scarce data instances. Negative data should also be included, especially if there are objects that are commonly falsely identified. Data should also be pruned for inconsistent and outlier values. Overfitting can occur which means that an algorithm will adapt to the data it trains on but perform poorly on any other data. This means it has memorized rather than learned to properly generalize from
it. Adding more data always helps combat this [20]. Data augmentation is used to combat overfitting and is an important step in preparing a dataset for training [21][6][2], which is the process of generating more data from the current data by changing it. A dataset should be split into three parts: training set, validation set and a test set. Not splitting the dataset and testing or evaluating the algorithm on the same data as trained on is a very common error that leads to gross misunderstanding of a models accuracy [19][22]. The training set is used to train the model, the test set is used to evaluate its performance and the validation set should be used to test hyperparameter optimisations. Hyperparameters are properties of the algorithm that strongly influence its complexity, speed in learning and results. They are often described as knobs and success is said to come from twiddling with them [19][20]. A hyperparameter that is of particular interest is the resolution multiplier, by reducing the size of an input layer every subsequent hidden layer is reduced by the same multiplier, trading accuracy for speed and computation. The input layers can also be increased giving the opposite effect, this hyperparameter is effectively changed in accordance with priorities of a given task [1][18]. Two other important hyperparameters are learning rate and decay. Choosing a large learning rate may cause a network to diverge in its generalisations instead of converging, choosing a smaller value will make a model require more time to converge. Decay prevents the overfitting of the network. Ideally these hyperparameter are changed as training goes on [2]. Transfer learning can also be used to to further improve the performance of a model. An object detection solution in another domain can be used to speed up learning and improve accuracy [23][2]. For instance a model trained to detect traffic signs could be used to help another model learn to detect doors.
2.3 Computer Vision and Object Detection
Object detection is a core problem in computer vision [18]. Computer vision aims to create digital systems that can perform vision tasks which the human visual system can perform, sometimes surpassing human ability [24]. We do so by emulating the human visual system [25]. Typically image processing transformations using kernels are applied on an image to detect features, these features are then compared to a catalogue of pre-defined features of objects we wish to detect [26][25]. For example doors generally appear as square shapes with a certain width and height ratio, by using a Sobel operator [27] we can detect all edges in an image [26] and subsequently use high-level analysis algorithms to determine whether any edges have relations to one another matching the relationship of the contours of a door [25]. However as of now convolutional neural networks outperform all other methods in computer vision tasks [2], with some surpassing human ability on the ImageNet im-age classification challenge [24]. Imim-age classification is a problem within computer vision closely related to object detection, it refers to the labelling or clasification of images into pre-determined categories [28]. AlexNet [6] which we have discussed in the previous is a convolutional neural network that performs image classification. If an image might contains multiple pre-determined objects the network processing it will be confused as the output will only have one primary classification. In contrast to object detection image classifi-cation gives us no information about the amount of objects in an image or their loclassifi-cation within the image. As previously mentioned object detection is the process of detecting instances of an object of arbitrary class (door, human, rottweiler) in digital images and video [22], it involves the combination of classification and localization of multiple objects
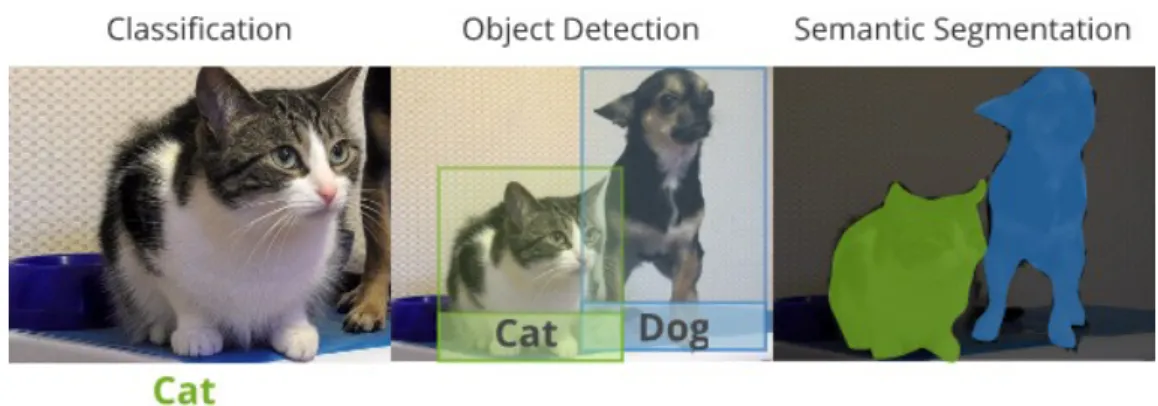
in an image. Given an image input an object detector will produce an output listing each detected object, with a label corresponding to their class, coordinates of a bounding box in which the object exists and a confidence score. Many object detecting convolutional neural networks use a sliding window approach [29] by which they inspect different regions of an image sequentially, making them slow but accurate. One stage detectors like YOLO [18] take a different approach in that it examines the entirety of an image and its context simultaneously, significantly speeding up processing. Image segmentation is another prob-lem in computer vision quite similar to object detection, however rather than producing a bounding box segmentation networks produce segments of pixels in an image that belong to a class or category [30], in Figure 3 we can see the difference in output of the three previously mentioned problems.
Figure 3: The difference between the output of an image classifier, an object detector and an image segmenter.
Mean Average Precision or mAP is the means of evaluating the accuracy of an object detection model [1][18][31][21] and thus the metric which will be used in this paper. In order to explain this metric some terms need to be introduced, namely precision and recall. Precision is a measurement of the accuracy of predictions. Recall is a measurement of how well the model finds all relevant data [32]. The mathematical definitions of precision and recall can be seen in equation 1 and 2 where TP is true positive, TN is true negative, FP is false positive and FN is false negative.
P recision = T P
T P + F P (1)
Recall = T P
T P + F N (2)
The next term we need to define is IoU (intersection over union). It is the measure-ment of the overlap between the boundaries of the ground truth of an annotation and the predicted boundary. The mathematical definition of IoU can be seen in equation 3.
IoU = area of overlap
area of union (3)
In Figure 4 we can see an example of area of overlap, area of union in an object detection prediction.
Figure 4: An example of an object detection prediction with area of overlap and area of union [32].
An IoU threshold is set which determines the correctness of a prediction. For instance a prediction can be deemed correct if IoU is ≥ 0.5 [32]. Thus it is with the help of IoU that we determine precision and recall. Different standards of setting the IoU threshold exist [21]. PASCAL VOC Challenge sets a threshold of 50%. COCO uses a threshold from 50% to 95% with increments 5% increments every iteration [33]. By taking the average value of the precision across all recall values we get the mAP of a model [32]. We find the mathematical definition of mAP in equation 4 where D is the number of detections in the set and AveP(d) is the average precision for a given detection, d.
mAP =
PD
d=1
AveP (d)
D
(4)
2.4 YOLO
You Only Look Once, or more commonly YOLO for short, is an object detection solution composed of a single neural network [18]. YOLO accepts images or video frames as input and produces bounding boxes and the probability of a class being within these boxes in real-time. A single convolutional network simultaneously predicts multiple bounding boxes and thus only looks once at an image to predict what objects are present and where they are. This approach makes YOLO very fast. It is the fastest detector on record for the PASCAL VOC challenge while being twice as accurate as any other real-time detector [18][31][21]. Table 1 presents a comprehensive comparison of performance of a number of object detectors on the PASCAL VOC dataset. PASCAL VOC is a dataset commonly used as a benchmark in visual object category recognition and detection, in fact it has become the main benchmark for object detection with annual challenges being organised since 2005 [7]. An alternate implementation of YOLO called Fast YOLO [18] or Tiny
YOLO exists which is faster but less accurate which is used in this paper to train a door detection model.
Real-Time Detectors Train mAP FPS 100Hz DPM 2007 16.0 100
30Hz DPM 2007 26.1 30 Fast YOLO 2007+2012 52.7 155
YOLO 2007+2012 63.4 45 Less Than Real-Time
Fastest DPM 2007 30.4 15 R-CNN Minus R 2007 53.5 6 Fast R-CNN 2007+2012 70.0 0.5 Fast R-CNN VGG-16 2007+2012 73.2 7 Fast R-CNN ZF 2007+2012 62.1 18 YOLO VGG-16 2007+2012 66.4 21
Table 1: Comparison in the performance and speed of fast detectors on the PASCAL VOC 2007 [18].
3
Methodology
This chapter seeks to account for the research methodology used in this project, explaining it through the categories of methods (3.1), processes (3.2) and tools (3.3), the components of a research methodology as outlined by Nunamaker and Chen [34].
3.1 Methods
This research is based on an multimethodological approach consisting of the system devel-opment method, as reviewed by Nunamaker and Chen [34], and a series of experiments. The system development method is further described in 3.2.1 and can be seen illustrated in Figure 5. Systems development and other research methodologies are reciprocal. This means that a combination of two or more of these methods are often adept in proving or disproving a given hypothesis [34]. The iterative ability, being able to easily move between steps of the method makes it suitable for investigating many different configurations. The creation of at least two artefacts is necessary to answer the research questions mentioned in 1.4: a) an object detection system, and b) one or more object detection models trained to detect doors. It is our aspiration to create multiple such models based on different neural networks in order to compare the performance. Here time is an important resource that limits the extent to which the generalizability may be investigated. Different archi-tectures have different frameworks, tools, ways of interpreting features in data. A lot of time is needed to exhaustively create and test models. Thus the object detection system is designed in such a way that it is general to the extent that any object detection model may easily be plugged in and out. A series of experiments are conducted with the pur-pose of establishing good practices in the machine learning process for the YOLO model which improves performance. These experiments test the object detection system on a mo-bile device, but also without the momo-bile object detection application, directly on the test dataset in a desktop environment. The object detection models will in these experiments be tested on one shared test dataset in order to measure how accuracy improves or dimin-ishes in relation to different configurations of training dataset composition, the usage of transfer learning and hyper parameter optimization. The experiments featuring the object detection system with a mobile device take place in a variety of in-door settings, noting the speed (detection per second) of the system but otherwise with the same intentions as previously mentioned. To evaluate the accuracy of models we use the mAP metric using the PASCAL VOC 50% threshold standard. To evaluate speed we measure detections per second.
3.2 Process
3.2.1 Systems development research process
Figure 5: A process for Systems Development Research [34].
Construct a conceptual framework.
In the initial stage the requirements of Cybercom are taken and processed in order to establish the problem domain and initial research questions. Following this a literature review is conducted to find related work and identify areas that are interesting to investigate and can be further developed in this paper, establish a fundamental understanding of the field of artificial intelligence and the machine learning training process. Research questions are re-iterated during this step of the purpose in order to study important areas in the domain and bridge knowledge gaps where they arise.
Develop a System Architecture.
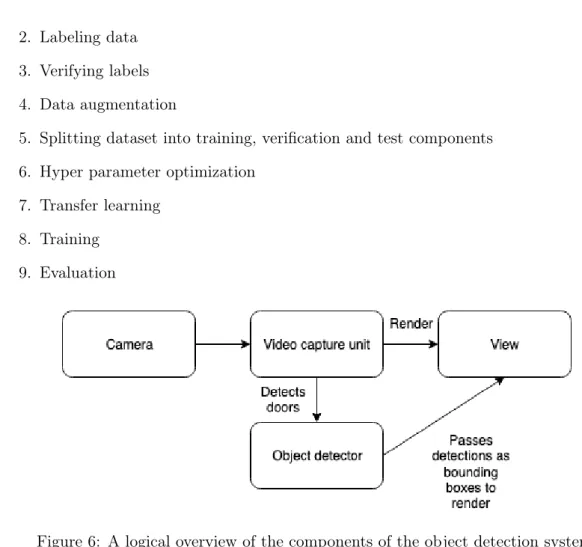
A system architecture is established for the object detection system. Logical components and their interactions with one another are found, which can be observed in Figure 6. Necessary software libraries and tools are obtained. The machine learning training process is also settled with key steps identified:
2. Labeling data
3. Verifying labels 4. Data augmentation
5. Splitting dataset into training, verification and test components
6. Hyper parameter optimization
7. Transfer learning 8. Training
9. Evaluation
Figure 6: A logical overview of the components of the object detection system.
Analyze and design the system.
The object detection system is designed. A video capture unit draws a camera-feed on the screen and passes frames to the object detection model which will output bounding boxes denoting the location of a door. These bounding boxes will then be rendered on screen. Build a prototype system.
A door detecting model is trained. The system is implemented based on the design and the artefacts are integrated.
Observe and evaluate the system.
The system is evaluated as to whether it can detect doors at all. If problems arise relevant previous steps are re-iterated until a functioning prototype is created.
3.2.2 Machine learning process
In this section the machine learning process previously mentioned is expanded upon.
1. Gathering data
In this step we look for existing annotated object detection datasets. The Open Image Dataset V4 was initially chosen because it has doors represented and because of the large amount of data it contains, 15,440,132 images divided in 600 categories. However most images of doors portray closed exterior doors, the few images of open
doors that exist are annotated in a way that is not compatible with the requirements of Cybercom. Therefore the Open Image Dataset cannot directly be trained upon. Rather we train a separate model on the Open Image doors exclusively to later use this model as a foundation to start training on better suited data through transfer learning. Photos are taken of all doors in the offices of Cybercom and in the home of the author, both open and closed. Additional images are downloaded from the internet with an equal distribution of open and closed doors.
2. Labeling data
The images photographed and downloaded are labelled. Text files are created de-scribing every corner of a rectangle marking the location of a door in the image. 3. Verifying labels and data cleaning
The labeled data is verified to make sure that no errors have been made so that no incorrect data slips into the training process. Data that is inaccurate, inconsistent or has outlier values are discarded.
4. Data augmentation
Additional images are created by applying transformations on images in a way that does not invalidate data labels. Brightness, contrast, saturation and hue is altered, blur and grain filters are applied.
5. Splitting dataset into training, verification and test components
The data is split into three sets: training set, verification and a test set with a distribution of 50, 30 and 20 percent of the images respectively.
6. Hyper parameter optimisation
Various hyper parameters are tried and their effect on performance is evaluated. The input layer of the model is altered as well as the learning rate, batch sizes, momentum and decay parameters.
7. Transfer learning
Weights from model architectures ResNet50, Resnet152, DenseNet and YOLO trained on ImageNet and Open Image datasets are used and evaluated.
8. Training
The model is trained on the training set. 9. Evaluation
The model is evaluated on the test set.
3.2.3 Experiments
After the system was constructed, a set of hypotheses have been tested by experiments: a) including negative data improves the accuracy of a model, b) data augmentation improves the accuracy of a model, c) transfer learning improves the accuracy of a model, and d) hyperparameter optimisation increases accuracy and or the speed of a model. Further experiments are carried out on the basis of the knowledge and experiences gathered by previous experiments to the extent that time allows. Common false positives are detected and added to the dataset as negatives. The results will be discussed later in this paper.
3.3 Tools
A Nvidia Geforce GTX 1080 GPU is used to train the models in a short amount of time. What could be done with the GPU of a laptop in one night is achieved here in thirty minutes. YOLOv2 is the architecture model chosen because it is better at detecting larger objects compared to YOLOv3 which trades detection of large objects for small ones. Seeing as doors are relatively large objects in this context, the choice of YOLOv2 is an easy decision. Furthermore the "tiny" version of YOLO was chosen as it is more suited for mobile devices [21].
To train and test the object detection models we make use of Darknet, which is an open source neural network framework written in C and CUDA [35], created by Joseph Redmon, the author of YOLO.
4
Results
A door detector iOS application was successfully produced, as can be seen in Figure 7, able to detect doors in real-time performing 6, 14 or 28 detections per seconds on an iPhone 6s. The speed depends on different hyperparameter configuration where speed is traded for accuracy. A variety of doors can be detected in an array of different sceneries and settings, the model is as likely to correctly identify open doors and closed doors. The usage of data augmentation techniques which among other things reduces the brightness of images proved to improve the ability of the system to detect doors in dark settings compared to models trained on data sets without such augmented data. Early iterations of the system had a tendency to mistake a given fridge for a door, subsequent inclusion of fridges as negative data in a data set reduced the prevalence of false positives, however the inclusion of negative data produced a negligible improvement in mAP on test data sets.
Figure 7: Demonstration of implemented system detecting a door.
Using a training data set of 136 images of doors a model was produced which achieved 63.76% mAP before overfitting. Experiments were conducted altering the composition of this data set which proved that the practice of augmenting the data set yielded nearly a 10% increase in mAP. The inclusion of negative data provided a negligible increase in mAP, in Table 2 we see the difference in mAP across dataset compositions. However when the model was tested on a mobile device, objects that were previously misdetected and not present in the test dataset stopped producing false positives. Further experimentation
used a dataset with images of doors and negatives all augmented.
Dataset composition mAP Plain composition 63.76%
With negatives 64.19% With augmentation 72.25% With augmentation and negatives 73.19%
Table 2: Table illustrating the mAP of dataset compositions once a model has been trained on them.
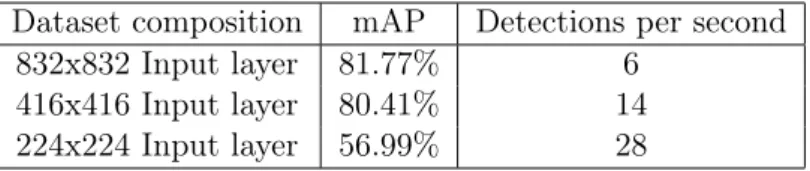
Experiments in hyperparameter optimisation suggest that there exists in YOLO a direct relationship between the size of the input layer of the models, speed and mAP respectively. Increasing the height and width of the input layer produced a slower and slightly more accurate model. Decreasing it produces increased speed but significantly reduced accuracy, as can be seen in Table 3.
Dataset composition mAP Detections per second 832x832 Input layer 81.77% 6
416x416 Input layer 80.41% 14 224x224 Input layer 56.99% 28
Table 3: Table illustrating the relationship between speed, mAP and different configura-tions of model input layers.
Using transfer learning did not necessarily yield higher mAP for models. Using ResNet50 and ResNet152 trained on ImageNet resulted in lower mAP than when the model was trained without any transfer learning at all before overfitting. Using DenseNet did provide a slight increase in mAP. However when a separate model was trained exclusively on im-ages of doors from Open Imim-ages and subsequently used for the transfer learning we note a dramatic increase of accuracy to a mAP of 86.73% which can be seen in Table 4.
Model Dataset mAP
ResNet50 ImageNet 69.26% ResNet152 ImageNet 69.03% DenseNet ImageNet 74.38% Yolov2-Tiny ImageNet 80.41% Yolov2-Tiny Open Images (Doors only) 86.73%
Table 4: Table illustrating the mAP of models using transfer learning from different neural network architectures trained on ImageNet or Open Images.
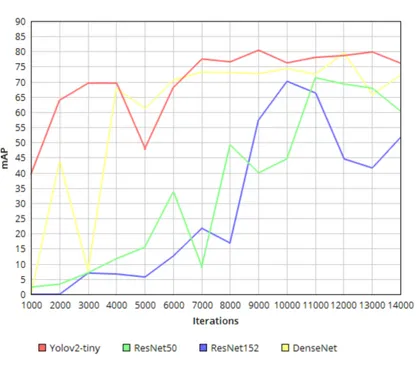
As can be seen in Figure 8, a general trend in training regardless of transfer learning foundation we note that mAP starts to stall or fall when approaching 300 epochs or 14000 iterations. At this point the models become worse at detecting doors in the test dataset as
the models ability to detect doors in general decreases in favour of detecting specific doors of the training dataset.
Figure 8: Graph illustrating mAP during the training process. One iteration processes 64 images. Roughly 516 iterations are one epoch.
5
Discussion
The findings of this study identifies three practices that affect the performance of the YOLO object detector: A) dataset composition; using data augmentation techniques improves the accuracy of an object detection model and also increases training time before overfitting occurs, including negative data in a dataset decreases the likelihood of false detections when tested in the wild but yields a negligible increase in accuracy on test datasets. B) hyperparameter optimization, increasing the size of the input layers of the YOLO object detectors is correlated with improved accuracy but lower detection speed. C) transfer learning, increase in accuracy is not guaranteed. Results vary across network architectures and datasets used. When models that are trained on very general data are used there is some improved accuracy. However when a model is trained on a specific data that is suitable for the problem there is a dramatic increase of accuracy. In this study a very large dataset of closed exterior doors is used for the problem of detecting interior open and closed doors. Furthermore this study suggests that overfitting occurs when training approaches 300 epochs. Practices defined by Chicco [20] such as data pruning, dataset splitting, balancing data instances proved to be generalizable across radically different problem domains and machine learning methods. Chicco focuses on computational biology regardless of machine learning method, yet we apply these practices with success on a computer vision problem using deep neural networks.
5.1 Dataset composition
As previously stated, by making changes to dataset composition we find that the accuracy of the YOLO object detector can be increased significantly. This is of value when one finds the accuracy of an object detector inadequate for a given problem, because collecting and annotating additional data is expensive. By augmenting the existing dataset one generates additional data that is suitable for training. The augmented data is not semantically different from the original data for a human observer and one could suspect that it would rather make the model more likely to overfit, however the differences in pixel values of an image after augmentation is sufficient for the YOLO object detector to generalize and learn more from. In fact as the model trains on the augmented dataset it takes more iterations before overfitting occurs because of the sheer increase in training data. When implementing a object detector for mobile devices it is likely that detections will be performed in a wide variety of settings. By using augmentations that decrease the brightness the study finds that the model becomes better at detections in low light settings such as night time. Thus it is not necessary to gather and annotate data in these settings, further saving time. Including negatives is a cheap way of dealing with false positives as this data doesn’t need to be annotated. In this study it does decrease the likeliness of false detections occuring, but it does not improve accuracy on the test dataset. A possible explanation for this is that the test dataset contains no negatives, including negatives in the future work could determine whether including negatives in a dataset does not increase the overall accuracy of a model.
5.2 Hyperparameter optimisation
This study suggests that increasing the size of the input layer of the YOLO object detector has a significant impact on accuracy and speed of a model, and in extension also power consumption on a mobile device. One can observe a proportional decrease or increase in speed in relation to the adjustment of the input layer size. For instance halving the input layer yields a twice as fast model and vice versa. An explanation for this is that the input layer is mapped to the resolution of an image to be processed, larger images have more data and details for the model to process but requires larger hidden layers which need more computing power. This layer could thus be edited in accordance with the priorities of a use case. In a scenario where speed is not important, the input layer could be dramatically increased with greater accuracy. However in such use cases it is better not to use YOLO at all but an object detector which is designed for slow but accurate detection such as Fast R-CNN [29]. There are additional interesting hyperparameters in YOLO such as learning rate and decay which are ample candidates for further investigation.
5.3 Transfer learning
The results suggest that using transfer learning can indeed improve the accuracy of the YOLO object detector. The datasets that these foundational models are trained upon and its relation with the problem at hand is relevant. Models trained on broad datasets such like ImageNet produce weights for detecting many different objects in the hidden layers, of which not all will be helpful to in detecting one specific object. Indeed this study suggests that specialized models trained on objects of similar shape give the best results, a 13.54% increase in accuracy. We see here that transfer learning yielded the highest increase in mAP out of all investigated practices. The time required in the machine learning process to produce an accurate can be reduced by careful use of transfer learning. Using models of different architectures proved to give mixed results. The dense convoluted neural network gave a minor increase in accuracy, while using the residual neural networks produced even worse accuracy. Explanations to this likely lie in the ability of different networks to gener-alize on large datasets or an inability to transfer these generalizations across architectures. These findings are expected as it has been widely established that convolutional neural networks like YOLO far surpass other architectures. Further investigations into why this difference exists and if it can be attributed to the architectures themselves or problems in transfering experience and knowledge between different architectures are warranted.
5.4 Limitations and future work
This study has outlined practices to improve performance for the YOLO object detector, the consequences of these findings are thus relatively narrow. Indeed there exists many object detectors and a relevant question to pose is whether these practices can be general-ized and applied in the machine learning process when other models are used. Could these practices be used to harvest greater results for other models even if they are not object detectors?
6
Conclusion
The object detection system for iOS devices implemented in this paper is a further confir-mation of the technical viability and overall feasibility of integrating convolutional neural networks with mobile applications. The application is capable of real-time detection with up to 28 detections per seconds with accurate detections. More interestingly this paper also explores means of improving the performance of such applications and the YOLO object detector in terms of accuracy and speed. Indeed this is the primary focus of this study. A series of experiments finds that by altering the composition of a dataset by augmenting data and including negative data, using hyperparameter optimisation and transfer learning, accuracy can be dramatically improved from 63.76% to 86.73% before overfitting, which seems to repeatedly occur when approaching 300 training epochs. This study proves that the machine learning process can be made significantly cheaper by applying the practices outlined. However, this paper is limited to the YOLO object detector, it is uncertain to what extent these practices apply to other machine learning methods. Further studies into the generalizability of these practices are necessary, further investigation into hyperparam-eter optimisation of the YOLO object detector are also of value as this paper touches on this subject in a limited way.
References
[1] Andrew G Howard et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications”. In: arXiv preprint arXiv:1704.04861 (2017).
[2] Md Zahangir Alom et al. “The history began from AlexNet: a comprehensive survey on deep learning approaches”. In: arXiv preprint arXiv:1803.01164 (2018).
[3] Jan Svensson and Jonatan Atles. Object Detection in Augmented Reality. eng. Student Paper. 2018.
[4] Do Dinh Duc. Building real time object detection iOS application using machine learning. eng. Student Paper. 2018.
[5] Yihui He. “Object Detection with YOLO on Artwork Dataset”. In: 2016.
[6] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. “Imagenet classification with deep convolutional neural networks”. In: Advances in neural information processing systems. 2012, pp. 1097–1105.
[7] Mark Everingham et al. “The pascal visual object classes (voc) challenge”. In: Inter-national journal of computer vision 88.2 (2010), pp. 303–338.
[8] Pamela McCorduck et al. “History of Artificial Intelligence.” In: IJCAI. 1977, pp. 951– 954.
[9] Alan Mathison Turing. “Intelligent machinery (1948)”. In: B. Jack Copeland (2004), p. 395.
[10] James Moor. “The Dartmouth College artificial intelligence conference: The next fifty years”. In: Ai Magazine 27.4 (2006), pp. 87–87.
[11] Arthur L Samuel. “Some Studies in Machine Learning Using the Game of Checkers. II—Recent Progress”. In: Computer Games I. Springer, 1988, pp. 366–400.
[12] Donald Michie. ““Memo” functions and machine learning”. In: Nature 218.5136 (1968), p. 19.
[13] Issam El Naqa and Martin J Murphy. “What is machine learning?” In: Machine Learning in Radiation Oncology. Springer, 2015, pp. 3–11.
[14] Tom M. Mitchell. Machine learning. McGraw Hill series in computer science. McGraw-Hill, 1997. isbn: 978-0-07-042807-2. url: http : / / www . worldcat . org / oclc / 61321007.
[15] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. “Deep learning”. In: nature 521.7553 (2015), p. 436.
[16] Jürgen Schmidhuber. “Deep learning in neural networks: An overview”. In: Neural networks 61 (2015), pp. 85–117.
[17] Gary Marcus. “Deep learning: A critical appraisal”. In: arXiv preprint arXiv:1801.00631 (2018).
[18] Joseph Redmon et al. “You only look once: Unified, real-time object detection”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 779–788.
[19] Pedro M Domingos. “A few useful things to know about machine learning.” In: Com-mun. acm 55.10 (2012), pp. 78–87.
[20] Davide Chicco. “Ten quick tips for machine learning in computational biology”. In: BioData mining 10.1 (2017), p. 35.
[21] Joseph Redmon and Ali Farhadi. “Yolov3: An incremental improvement”. In: arXiv preprint arXiv:1804.02767 (2018).
[22] Athanasios Voulodimos et al. “Deep learning for computer vision: A brief review”. In: Computational intelligence and neuroscience 2018 (2018).
[23] Sinno Jialin Pan and Qiang Yang. “A survey on transfer learning”. In: IEEE Trans-actions on knowledge and data engineering 22.10 (2010), pp. 1345–1359.
[24] Kaiming He et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification”. In: Proceedings of the IEEE international conference on computer vision. 2015, pp. 1026–1034.
[25] T Huang. “Computer vision: Evolution and promise”. In: (1996).
[26] Wilhelm Burger et al. Principles of digital image processing. Vol. 54. Springer, 2009. [27] Irwin Sobel. “An Isotropic 3x3 Image Gradient Operator”. In: Presentation at
Stan-ford A.I. Project 1968 (Feb. 2014).
[28] Pooja Kamavisdar, Sonam Saluja, and Sonu Agrawal. “A survey on image classifica-tion approaches and techniques”. In: Internaclassifica-tional Journal of Advanced Research in Computer and Communication Engineering 2.1 (2013), pp. 1005–1009.
[29] Ross Girshick. “Fast r-cnn”. In: Proceedings of the IEEE international conference on computer vision. 2015, pp. 1440–1448.
[30] Song Yuheng and Yan Hao. “Image segmentation algorithms overview”. In: arXiv preprint arXiv:1707.02051 (2017).
[31] Joseph Redmon and Ali Farhadi. “YOLO9000: better, faster, stronger”. In: Pro-ceedings of the IEEE conference on computer vision and pattern recognition. 2017, pp. 7263–7271.
[32] Jonathan Hui. mAP (mean Average Precision) for Object Detection. https : / / medium . com / @jonathan _ hui / map mean average precision for object -detection-45c121a31173. 2018.
[33] Detection Evaluation, Common Objects in Context. http : / / cocodataset . org / #detection-eval. 2019.
[34] Jay F Nunamaker Jr, Minder Chen, and Titus DM Purdin. “Systems development in information systems research”. In: Journal of management information systems 7.3 (1990), pp. 89–106.
[35] Joseph Redmon. Darknet: Open Source Neural Networks in C. http://pjreddie. com/darknet/. 2013–2016.

![Figure 4: An example of an object detection prediction with area of overlap and area of union [32].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4066137.84496/16.892.227.669.206.510/figure-example-object-detection-prediction-area-overlap-union.webp)
![Table 1: Comparison in the performance and speed of fast detectors on the PASCAL VOC 2007 [18].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4066137.84496/17.892.262.630.259.509/table-comparison-performance-speed-fast-detectors-pascal-voc.webp)
![Figure 5: A process for Systems Development Research [34].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4066137.84496/19.892.368.529.296.778/figure-process-systems-development-research.webp)