V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Computer Science with
Specialization in Embedded Systems - 15.0 credits
MINIMIZING THE UNPREDICTABILITY
THAT REAL-TIME TASKS SUFFER DUE TO
INTER-CORE CACHE INTERFERENCE
Hena Hodˇzi´c
hhc19001@student.mdh.se
Zenepe Satka
zsa19001@student.mdh.se
Examiner: Saad Mubeen
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisor: Mohammad Ashjaei
M¨
alardalen University, V¨
aster˚
as, Sweden
Company supervisor: Samarth Deo,
ABB, Ludvika, Sweden
Abstract
Since different companies are introducing new capabilities and features on their products, the de-mand for computing power and performance in real-time systems is increasing. To achieve higher performance, processor’s manufactures have introduced multi-core platforms. These platforms pro-vide the possibility of executing different tasks in parallel on multiple cores. Since tasks share the same cache level, they face some interference that affects their timing predictability. This thesis is divided into two parts. The first part presents a survey on the existing solutions that others have introduced to solve the problem of cache interference that tasks face on multi-core platforms. The second part’s focus is on one of the hardware-based techniques introduced by Intel Cooperation to achieve timing predictability of real-time tasks. This technique is called Cache Allocation Technol-ogy (CAT) and the main idea of it is to divide last level cache on some partitions called classes of services that will be reserved to specific cores. Since tasks of one core can only access the assigned partition of it, cache interference will be decreased and a better real-time tasks’ performance will be achieved. In the end to evaluate CAT efficiency an experiment is conducted with different test cases and the obtained results show a significant difference on real-time tasks’ performance when CAT is applied.
Acknowledgements
We would like to express our deep and sincere gratitude to our thesis supervisor, Mohammad Ashjaei, for the continuous guidance and feedback throughout the entire thesis, especially his motivation and support. We would also like to acknowledge our examiner, Saad Mubeen, for his time and valuable feedback during examination phase.
We also want to extend our appreciation to the company supervisor, Samarth Deo, for giving us the opportunity to perform this thesis at ABB. Besides, we would like to thank Alfred Krappman for being a constant source of help with practical things at ABB.
Finally, we would like to thank our families for their love, prayers, caring and support through-out the years of our studies. They all kept us going and this accomplishment would not have been possible without them. Thank you!
Table of Contents
Abbreviations iv 1. Introduction 1 1.1 Motivation . . . 2 1.2 Problem Formulation . . . 3 1.3 Thesis Outline . . . 3 2. Background 4 2.1 Real-time systems . . . 4 2.2 Multi-core processors . . . 4 2.2.1 Caches . . . 52.2.2 Intra and Inter-core interference on multicore . . . 6
2.2.3 Multi-core scheduling . . . 6
2.2.4 Intel’s Xeon Processors . . . 7
2.3 Intel Cache Allocation Technology . . . 7
2.3.1 COMe-bBD7 . . . 8
3. Related Work 10 4. Research Method 12 4.1 System Development Research Method . . . 12
4.2 Application of the research method . . . 12
5. A survey on cache management schemes 14 5.1 Index-based cache partitioning . . . 14
5.1.1 Software-based . . . 14
5.1.2 Hardware-based . . . 17
5.1.3 Summary . . . 18
5.2 Way-based cache partitioning . . . 18
5.2.1 Average-case approaches . . . 19
5.2.2 Real-time approaches . . . 20
5.2.3 Summary . . . 20
5.3 Cache locking mechanisms . . . 21
5.3.1 Static schemes . . . 22
5.3.2 Dynamic schemes . . . 22
5.3.3 Comparison of static and dynamic schemes . . . 23
6. Evaluation of CAT 25 6.1 Prototype . . . 25
6.1.1 INtime operating system . . . 25
6.1.2 Spider Debugger . . . 26
6.2 Experiment . . . 26
6.2.1 Implementation . . . 26
6.2.2 CAT configuration . . . 27
6.2.3 Multiple real-time tasks . . . 31
7. Analysis 33 8. Conclusions 39 8.1 Limitations . . . 39
8.2 Future Work . . . 40
Abbreviations
BAMI Block Address and Miss Information CAM Content addressable memory CAT Cache Allocation Technology CBM Capacity Bitmask
CDP Code and Data Prioritization CMT Cache Monitoring Technology CLOS Class of Service
COTS Commercial-off-the-shelf HRT Hard real-time
HP High priority
IPC Intructions per cycles ISR Interrupt Service Routine LLC Last Level Cache
LRU Least recently used
MBA Memory Bandwidth Allocation MBM Memory Bandwidth Monitoring MSR Model Specific Register
PID Processors identifiers
PMC Performance Monitoring Counter RDT Resource Director Technology RTOS Real-time Operating System SRT Soft real-time
TCAM Ternary content addressable memory VM Virtual Machine
List of Figures
1 Multicore chips perform better – based on Intel tests using the SPECint2000 and
SPECfp2000 benchmarks – than single-core processors [1] . . . 1
2 Basic components of a multi-core processor . . . 2
3 Dual socket system with different L2 cache organization . . . 5
4 A set-associative cache address in a 32-bit system . . . 6
5 Cache hierarchy on Intel’s Xeon Processors . . . 7
6 Intel CAT example with PIDs and two CLOes [2] . . . 8
7 Computer-on-Module COMe-bBD7 [3] . . . 9
8 A multi-methodological research approach [4] . . . 12
9 Stages of the System Development Method [4] . . . 13
10 Overview of the index-based partitioning method [5] . . . 14
11 Memory to cache mapping and page coloring [6] . . . 15
12 COLORIS architecture overview [7] . . . 16
13 Overview of the way-based partitioning method [5] . . . 19
14 Cache-locking variations: a) Locking of the entire way and b) Cache line locking . 21 15 Workflow diagram of the dynamic cache locking scheme [8] . . . 23
16 INtime for Windows [9] . . . 25
17 Cache references of INtime core without CAT configuration . . . 27
18 Configuration of CAT illustrated in INtime Console Window . . . 28
19 Last 4 cache ways reserved only for real-time tasks . . . 28
20 Configuration of CAT illustrated in INtime Console Window - 8 ways reserved . . 29
21 Last 8 cache ways reserved only for real-time tasks . . . 29
22 Cache references in case of 4 ways CAT configuration . . . 30
23 Cache references in case of 8 ways CAT configuration . . . 30
24 Cache references - multiple real-time tasks, both cores running, no CAT . . . 31
25 Cache references - multiple real-time tasks, 4 ways CAT configuration . . . 32
26 Cache references - multiple real-time tasks, 8 ways CAT configuration . . . 32
27 Comparison of the cache references for the first test . . . 33
28 Comparison of the cache references for the second test . . . 34
29 Comparison of the cache hits for the second test . . . 35
30 Execution trace in INScope - Only core 11 running, No CAT . . . 36
31 Execution trace in INScope - Both cores running, No CAT . . . 37
List of Tables
1 Pin Assignment of COMe-bBD7 . . . 9 2 Comparison between the index-based cache partitioning techniques . . . 18 3 Comparison between the way-based cache partitioning techniques . . . 21
1.
Introduction
In recent years, multi-core processors are becoming a mainstream on computer platforms in many market segments starting with personal computers (PCs), embedded and server domains. Multi-core processors consist of two or more Multi-cores working together on a single chip. They allow faster execution of tasks because of parallelism or the ability to work on multiple problems simultaneously. In April 1965 Gordon E. Moore wrote an article titled “Cramming more components onto integrated circuits” [10] where he predicts that the number of transistors on a chip would double every year into the near future. This later has become known as Moore’s law because it remains the driving force behind the integrated circuits industry including memory, microprocessors and graphics processors. According to this law computer performance has been driven by decreasing the size of chips, while increasing the number of transistors that they contain. However, transistors can’t shrink forever and two critical problems that chip manufactures struggles now are power usage and heat generation that are largely discussed in [11][1]. The challenge is to achieve higher performance without driving up power consumption and heat [12]. Performance refers to the amount of time it takes to execute a given task and it can be computed as:
Performance = Instructions executed Per Clock (IPC) * Frequency
One might think that the performance can be improved if we increase the frequency, but unfor-tunately high clock ratio has some implications in power consumption. Gepner and Kowalik [13] provide some solutions that have been developed to face challenges on multi-core processors, while being focused on achieving better performance by increasing the instructions executed per clock. The improvement in performance depends also on the software algorithms used and their imple-mentation. Amdahl’s law describes the expected speedup of an algorithm through parallelization in relationship to the portion of the algorithm [14]. Multi-core systems seek to achieve a better performance while increasing the number of cores in a single chip. In case of multiple tasks running at the same time on the system, each of them can be assigned to a separated core thus achieving better performance as shown in Figure 1 [1].
Figure 1: Multicore chips perform better – based on Intel tests using the SPECint2000 and SPECfp2000 benchmarks – than single-core processors [1]
A lot of research is focused on analyzing and measuring the multi-core processor’s performance and this thesis is focused on measuring performance on Intel Xeon multi-core processors [15]. We are focused on embedded systems that are distinguished from general-purpose systems by the need to satisfy timing constrains of all tasks in the task set. The goal is to design systems with sharp upper and lower bounds on execution times of tasks. The work in [16] presents some of the techniques for achieving timing predictability on multi-cores and survey the advances in research on building predictable systems.
The architecture and memory hierarchy of a multi-core processor depends very much on the manufacturer. How multiple cores are implemented and integrated, affects the overall performance of a multi-core processor that’s why different manufacturers like Intel, IBM, Sun, etc, explore dif-ferent types of microprocessor architectures [1]. However, Figure 2 illustrates the basic components of a generic multi-core processor.
Figure 2: Basic components of a multi-core processor
Except the individual memory, also called private cache, cores on a multi-core processor share the lowest cache level which is called Last Level Cache (LLC) and is utilized by multiple cores simultaneously. Sharing the LLC reduces the design complexity and power consumption since only this unit is connected to the main memory. Increasing the number of cores on a multi-core architecture increases also the contention among shared resources especially the LLC. The cache misses also affect the timing predictability on multi-core systems and many researchers study cache organization and partitioning to achieve scalability [17][6]. A system is time predictable when it can be proven that all timing constraints or requirements are satisfied when the system is executed [18]. Since in this thesis we work on a hard real-time system, all tasks in the task set must meet their timing constraints otherwise the system failure can occur which could result in catastrophic consequences in the case of safety-critical systems. This thesis proposes the usage of a new technology developed by Intel Cooperation, Cache Allocation Technology [19] to decrease the contention and to achieve the timing predictability on multi-core systems.
1.1
Motivation
Multi-core processors usually implement last-level cache, known as LLC, in order to hide the large main memory access latency. Large storage capabilities, as well as high associativity are some of the main characteristics of these systems and because of that these caches are shared among all the cores in the processor. For that reason all the running applications try to get a LLC space, but most of the problems occur in inter-application interactions. The fact is that in the case of sharing caches on multi-core processors it is really hard to predict the outcome of some interactions between the applications. It is almost impossible to know characteristics of each application and also their behaviour in different situations [20].
Cache partitioning has shown to be a good solution for handling this inter-application problem, limiting the influence that applications have on each other but also achieving fairness in the system.
This is the reason that many manufacturers have implemented capabilities of the cache partitioning in their products [21] [22]. An example is Intel company which implemented the Cache Allocation Technology, known as CAT [19]. This technology provides the possibility of limiting the amount of the cache space a hardware task can take in the LLC.
1.2
Problem Formulation
Since the multi-core processors can run many tasks in parallel, the contents of the shared Last Level Cache (LLC) can become overwritten with new data as it is requested from memory by the cores. This situation will depend on the number of simultaneous tasks and by their memory workloads and patterns. The LLC can be overwritten, causing eviction of significant portions of L1 and L2 caches and reducing the performance of cores. Note that the Intel’s Xeon processor architecture [15] is considered in this thesis. This processor’s server is programmed with an interrupt service routine (ISR) to handle high-priority interrupt which is very sensitive to latency. Since the other workloads on the server are low priority, they generate a large amount of memory traffic.
Low priority tasks generate memory traffic during the time between the interrupts and this may overwrite the entire LLC and invalidate everything in all other cores’ caches. In this situation the next higher priority interrupt will see a higher latency, because the code and data necessary to service the instruction is no longer in the cache and must be fetched from memory.
The situation has to be alleviated in order to minimize the unpredictability caused by inter-core cache interference. In this context this thesis will seek to answer the following research questions:
• RQ1: What are the existing solutions and limitations to handle the general inter-core cache interference?
• RQ2: How to use the Cache Allocation Technology (CAT) features to minimize the amount of inter-core data propagation delays and achieve predictability of real-time tasks?
1.3
Thesis Outline
In Section 2. relevant background is provided as well as overview of the main concepts and their explanation. This section represents the base of this thesis because all important terms are explained in details. In Section 3. related work is presented, while Section 4. is dedicated to the research method which is used. Section 4. also includes general explanation of the used research method, motivation for using exactly this method but also demonstration of the applied research method in this thesis work. In Section 5. we present a survey on the existing cache management schemes and a comparison of different cache schemes is provided. In Section 6. some tests are conducted to evaluate the performance of CAT and then results are analysed in Section 7. In the end, Section 8. finalizes the thesis with conclusions, directions for future work and the limitations of this thesis work.
2.
Background
In this section the main concepts which are related to multi-core systems as well as for inter-core cache interference are shown.
2.1
Real-time systems
A good definition of real-time systems is given in [23] where a real-time system is defined as a system that reacts upon outside events, performs a function based on these and gives a response within a certain time. Unlike non-real time embedded systems, in real-time systems the correctness of its function does not only depend on the results but also the timelines of it. Time is a key factor in these systems where each task has a period and a deadline that must be meet in order to make the system functions in the correct way. There exists a wrong way of thinking that the purpose of real-time systems is to make applications execute faster. While this can be true in some cases, they actually make applications more predictable and precise. Real-time does not mean fast, neither slow. It means predictable, so each task in the task set finishes its execution in the exact point of time as predicted. The time scale on those systems depends on the controlled process - some processes request response on seconds, while others at milliseconds or microseconds level.
Real-time systems can be classified as soft real-time or hard real-time systems. In hard real-time systems all tasks in the task set must meet their deadlines, and if any of them miss the deadline that would lead to catastrophic consequences on the controlled environment. An example can be the airbag or the control system of an airplane. If any of the tasks in these systems miss the deadline that will cause loss of life or/and environment destruction. In soft real-time systems a deadline miss does not cause serious damage but it reduces the system’s performance. For example a home temperature monitoring system or any electronic equipment can miss producing some outputs and that wont cause any catastrophe but will reduce usefulness and reliability of the equipment. This thesis is dedicated to hard real-time systems where the time scale of tasks response varies from micro to nano-seconds.
2.2
Multi-core processors
In today’s IT organizations achieving higher performance is becoming more and more important. Historically, processor manufacturers have been delivering faster processor speeds, but the chal-lenge of managing power and cooling requirements for today’s powerful processors has encouraged a reevaluation of this approach to processor design. Different ways of increasing the system per-formance are introduced in [24] but the goal is to achieve higher performance without increasing power consumption and heat. It is evaluated that a multi-core architecture could enable greater performance than a single-core processor architecture, even if the processor cores in the multi-core architecture are running at a lower clock speed than the processor cores in the single-core architec-ture. Multi-core architecture consists of two or more processor cores in a single processor socket that can have independent or shared cache modules, bus implementation or threading capabili-ties such as Intel Hyper-Threading (HT) Technology, which enables processors to execute multiple tasks of an application simultaneously [25] . So by combining multiple logical processing units into a single processor, IT organizations gain superior performance and scalability without increasing power consumption and heat.
Multi-core processors represent a big change in conventional computing history as well as set-ting the new trend for high performance compuset-ting, but there are also some challenges that come with multi-core processors. Intel Cooperation has a long history of exploring instruction-level par-allelism and currently Intel is setting a new standard of high performance multi-core processors. Intel’s multi-core architecture will possibly include dozens or even hundreds of processors on a sin-gle socket. Multi-core CPUs differ from implementation to implementation, where some of them use monolithic design while others represent Multi-Chip Processors. These two implementations have different time to market efficiencies. The monolithic design use has shared L2 cache which increases the efficiency of cache to processor core data transfers as well as processor to processor
communication [13]. An example of different multi-core processors design implementation is shown in Figure 3. Processor 0 Core 0 Core 1 CPU CPU L1 Cache L1 Cache L2 Cache L2 Cache Processor 1 Core 0 Core 1 CPU CPU L1 Cache L1 Cache L2 Cache L2 Cache
System Bus System Memory
Processor 0 Core 0 Core 1 CPU CPU L1 Cache L1 Cache L2 Cache Processor 1 Core 0 Core 1 CPU CPU L1 Cache L1 Cache L2 Cache
System Bus System Memory
Figure 3: Dual socket system with different L2 cache organization
2.2.1 Caches
A cache is a fast memory unit that is used to speed-up the process execution. The cache stores chunks of data in units called cache blocks or cache lines. There are three types of cache organi-zations: direct-mapped, fully associative and set associative. Direct-mapped have sets with only one block at each set. Fully associative caches have only one set that encompasses all blocks. A set-associate cache has more than one set and each set in the cache incorporates more than one block in its equivalence class [26]. A set-associative cache can be imagined as a matrix of cache lines, where the rows represent sets and the columns represent ways. A W-way set associative cache is divided into W ways and according to [26] its number of sets can be calculated as:
numsets =
sizecache
Each data block is mapped to one set that is determined by a subset of bits in the data address -called index. The cache address is divided in three parts: tag, index and offset, as shown in Figure 4.
Figure 4: A set-associative cache address in a 32-bit system
Tag is used for lookup and must be saved in each cache line to distinguish different addresses that could be placed in the set. Tag is the first thing that the system checks when it needs to access data at a given address. In case that the lookup is successful then we have a cache hit -system does not need to access the main memory. Otherwise, when the lookup fails and the data is not found in cache, a cache miss happens - system need to access the main memory. Index is the set part that contains the requested data. Offset identifies a particular location within a cache line.
2.2.2 Intra and Inter-core interference on multicore
Multi-core platforms allow processors to execute multiple tasks simultaneously to increase the system’s performance, but this introduces a problem regarding to system predictability since the various task can interfere with the execution time of others. Task scheduled on a multi-core processor not only suffers from intra-core interference (contention between tasks scheduled on the same core) but also from the inter-core interference (contention between tasks scheduled on different cores). Intra-core interference can also be divided into two types according to [6]:
• Cache warm-up delay that occurs at the beginning of each period of a task and happens due to the execution of other tasks while the pointed task is inactive.
• Cache-related preemption delay which occurs when a task is preempted by another task which priority is higher than the pointed task priority.
Inter-core interference can happen if there are shared caches in the processor. Conflicts among processor cores which want to use the shared cache may result expensive in terms of latency and power. This topic is very important and interesting in the field of real-time embedded systems. Conte and Wolfe [27] have introduced an example technique for creating a compiler determined map for allocation of memory space within a cache.
Intel has also proposed the Intel Advanced Smart Cache where L2 cache is shared between cores and the data has to be stored in one place that each core can access. When one core has minimal cache requirements, other cores can increase their percentage of L2 cache, reducing cache misses and increasing performance.
2.2.3 Multi-core scheduling
The problem of scheduling on multi-core processors can be divided into two parts. Firstly, how would the task be assigned to different cores and then how will tasks scheduling be performed on each core. In past decade, research results have been proposed for real-time task scheduling on multiprocessor systems. The scheduling algorithms can be classified as global, partitioned and semi-partitioned scheduling algorithms. In global scheduling algorithm all task instances are placed in a global queue and sequentially they will be assigned to available processors according to their deadlines. Partitioned scheduling has a fixed allocation of tasks to processors and any time a task instance arrives it will be executed only on the pre-assigned processor. Semi-partitioned scheduling divides a task into sub-tasks and assigns the sub-tasks to processors under the condition that the sub-tasks of a task must execute at different times. A real-time partitioned scheduling on multi-core systems with local and global memories is proposed in [28]. The main contribution of it is the development of algorithm for the joint management of memory allocation and task scheduling to
meet the real-time requirements of real-time systems. Earliest Deadline First policy is used for task scheduling and sporadic tasks, with inter-arrival time known, are taken in consideration. Another thing that comes with this research is the homogeneous and heterogeneous multi-core processors. In the homogeneous multi-core processors the same type of processing units are included into the socket, while heterogeneous systems use different type of processing units such as CPU, GPU, DSP, FPGA etc to achieve higher performance on various type of implementations.
2.2.4 Intel’s Xeon Processors
Since Cache allocation technology is only available on Intel’s Xeon processors the cache hierarchy of those processors is described in this section. There are three levels of cache in Intel Xeon processors: the L1, L2 and L3 caches [19]. L1 is located nearest to the core and it is the fastest cache. L2 or the mid-level cache (MLC) is larger than L1 cache but it does not provide the same low latency and bandwidth as L1. The last level cache or L3 cache that is shared among cores as shown in Figure 5, is the largest and slowest cache on Intel’s Xeon processors.
Figure 5: Cache hierarchy on Intel’s Xeon Processors
2.3
Intel Cache Allocation Technology
LLCs is shared among all tasks running in different cores of a multicore processor, but cache shar-ing yields problems to the system due to the inter-core interference at the shared cache, causshar-ing the system to become unpredictable. Intel has developed Cache Allocation Technology (CAT) [19] to have more control over the Last Level Cache (LLC) and how cores will allocate it. CAT is available in limited models of processors of the Xeon E5 2600 v3 family and in all processors of the Xeon E5 v4 family [2]. This technology provides hardware-software interface allowing the software to distribute the cache among cores. The system administrator can reserve portions of cache for each individual core and in this way only these cores can have access into them. This will prevent other lower-priority tasks to evict cache lines from these reserved portions of the cache via general use of caches. Intel processors provide the CAT feature that limits the amount of cache space that a task can occupy in the LLC. In this way CAT enables privileged software to control data placement in the last level cache and makes it possible to isolate or prioritize the most important tasks of the system.
In fact CAT is a feature of Intel Resource Director Technology (RDT) [29] that provides a framework with several features for cache, memory monitoring and allocation capabilities. It includes Cache Monitoring Technology (CMT), Cache Allocation Technology (CAT), Code and Data Prioritization (CDP) - which is an extension of CAT, Memory Bandwidth Monitoring (MBM) and Memory Bandwidth Allocation (MBA). CAT allows a number of ways to be assigned to a specific set of tasks, a Class of Service or CLOS which acts as a resource control tag. It allocates logical cores or PID (also called CPUID) to CLOes. The Xeon E5 v4 family provides more CLOS than prior generation processors [21], enabling more flexible usage of CAT. In the most recent processors the maximum number of CLOes is 16. The necessary of mapping the tasks to classes according to a given priority comes because of the unlimited number of tasks in a system and the predefined number of classes of services in Intel’s CAT. Each CLOS has a capacity bitmask (CBM) that controls the accessibility of cache resources, where each bit in the mask guarantees the write access to one way in cache. A list of task IDs is stored on each CLOS which are the ones that have write access to the ways set in the bitmask. Cache ways are not necessarily private to a CLOS, but they can be shared to other CLOS by overlapping the CBMs. An example of a possible CAT configuration using 2 CLOes and a cache of 20 ways is shown in Figure 6 provided by [2].
Figure 6: Intel CAT example with PIDs and two CLOes [2]
Here can be mentioned one fact that came due to hardware limitations: all bits of the CBMs must be consecutive. Cache ways can be allocated to a single CLOS hosting a set of applications or allocated to multiple classes of services and different clustering schemes for mapping tasks to CLOS can be applied as shown in [20]. In the end CAT shows high potential to improve system fairness even with a simple policy based on clustering.
Based on the fact that the field of research on this topic is still open for investigation, the main purpose of this thesis work is to find a way to minimize or remove the unpredictability that the real-time tasks suffer from due to inter-core cache interference.
2.3.1 COMe-bBD7
The specific platform which will be used for the evaluation of the CAT technology is COMe-bBD7. COM Express module COMe-bBD7 is part of Kontron’s product family of server class COMR
platforms. Kontron is a global leader in IoT/Embedded Computing Technology (ECT) and it offers a combined portfolio of secure hardware, middle-ware and services for Internet of Things (IoT) and Industry 4.0 applications [30]. COM Express defines a Computer-On-Module which obtainsR
all the components that are necessary for a bootable host computer. COM evaluation boards are frequently used for testing because they minimize installation requirements and reduce design time. Computer-on-Module COMe-bBD7 designed by Kontron S&T group is a COM Express R
basic Type 7 with Intel XeonR and PentiumR D-1500 SOC processors and is shown in FigureR
7. This module features data-centre-grade CPU performance with up to 16 cores and this robust performance is combined with support for two 10GbE-KR ports(10 Gigabit Ethernet) making it ideal for network intensive implementations [3].
Figure 7: Computer-on-Module COMe-bBD7 [3] The Pin Assignemt of COMe-bBD7 is shown in Table 1.
Table 1: Pin Assignment of COMe-bBD7
Feature COMe-bBD7
Gbit Ethernet 1x
10GBaseKR Ethernet 2x
NC-SI 1x
PCI Express 7x or 8x PCIe Gen2
24x PCIe Gen3 Serial ATA 2x USB 3x or 4x USB 3.0 3x or 4x USB 2.0 Serial Ports 2x LPC 1x External SPI 1x External SMB 1x External I2C 1x GPIO 8x
3.
Related Work
Over time, multi-core systems become more and more popular and that is why many proposals have been developed in order to manage shared fast local memory as for example cache. The main aim of them is to minimize the unpredictability and improve schedulability of real-time ap-plications as much it is possible. Unlike other research papers, our thesis work not only gives a simple survey on existing cache partitioning solution, but it also represents an evaluation of one of the hardware-based cache partitioning techniques, Intel’s cache allocation technology. Most of the works in the literature focuses only on cache management and we describe some of the most relevant ones in this section.
Among all solutions that exist, cache partitioning method has shown the best results [31]. Us-age of this method provide not only effective managing of the shared fast local memory, but also optimizing the other design objectives as maximization of the performance, quality-of-service (QoS) enhancement and fairness. Due to the large inter-task interference that comes from large shared resources as LLC, on multi-core platform predictability of real-time systems is being violated. Two Harmonic-Based Cache Allocation algorithms have been proposed in [31]. The first one allocates cache memory based on the relation of WCET (Worst Case Execution Time) and number of cache units for each task. The second one groups tasks according to their harmonic relationship and then it allocates cache units to tasks with the condition to decrease the task set CPU utilization the most. A task set is named harmonic if for every two tasks of this task set τi and τj, either the
period of τi - Ti is multiple of the period of τj, or Tj is multiple of Ti. From the simulation results
it is shown that the second algorithm increases the schedulability of real-time tasks up to 4 times when it is compared to conventional Partitioned Rate Monotonic Scheduling. This paper does not include any research for existing cache management techniques, it only proposes algorithm to increase the schedulability of real-time tasks. The proposed approach is also different from what we suggest, because it is an index-based software approach evaluated on simulation platform. Our thesis evaluates the performance of a hardware-based technology using an evaluation board that will be described on the following sections.
Overall cache partitioning method can be divided into two main groups [17] which are cache allocation policies and cache management schemes. The first group is more dedicated to poli-cies which have different ways of allocating available cache resources to different tasks in order to achieve some of the objectives. Depends on which objectives should be satisfied, there are many different policies. Some of them are devoted to achieving fairness, priorities but also maximization of the performance. The second group that contains cache management schemes is more focused to enforcing the distribution of the outcomes of the cache allocations. That can be accomplished either by using software or hardware and in that way each program can access its allocated cache memory. Multi-core systems have proven to achieve higher performance on computing, but sharing resources as Last Level Cache may result in lower performance and limited quality of service. Even if the new control mechanism, CAT technology, has been supported in many commercial processor families, it allows allocating different amount of cache sizes for executing tasks and prior research have been explored how to use CAT technology to achieve different optimization goals. An appli-cation performance prediction and optimization under CAT is introduced in [32]. In this research a dynamic cache management is proposed. Intel Top-down Micro-architecture Analysis Method selected events are being monitored for the tasks running on the system and IPCs are predicted for different cache way sizes. The proposed technique identifies the optimal combination of cache ways for High Priority tasks in order to minimize a cost function - IPC loss. Cost functions decide the detailed optimization goals based on the IPC prediction table. In the end is observed that when there are more HP tasks, the predictive policy achieves better improvement, since HP tasks are more likely to compete with each other in the limited cache size.
Giovani Gracioli et al. [5] represent a detailed survey of cache management techniques for real-time embedded systems. Similarly with the first part of our thesis, it classifies the cache partitioning on software or hardware-based mechanisms and gives a classification of software techniques as index-based or way-based partitioning. The research study includes techniques proposed from
1990 till 2014, while this thesis focuses on the techniques proposed in the last two decades. The proposed survey also gives a comparison in terms of similarities and differences of different cache management techniques, but it doesn’t evaluate the performance of any specific technique.
Lucia Pons et al. [2] focus on reducing the turnaround time of a set of applications running concurrently. They divide the applications in two main categories according to the impact that the cache space has on their performance: cache critical applications and non-cache critical ap-plications. Cache allocation technology is applied and also an algorithm is created that can also readjust the initial configuration dynamically. The static and dynamic cache behavior is charac-terized when multiple application compete for cache space, finding that some applications need a higher number of cache ways than others to achieve their maximum performance. Selfa et al. [20] proved that if a design have CLOes that share a fraction of the cache ways between them, it will result in better cache utilization. In [6] is presented a cache-aware algorithm that schedules a task set with less number of cache partitions to have some of the cache partitions for non-real time tasks or to save CPU utilization.
4.
Research Method
The main aim of this thesis is to find a better way to minimize the inter-core cache interference that real-time tasks suffer on multi-core platforms. In combination with already existing approaches, new approach should be introduced. Advantages and disadvantages of already implemented algo-rithms should be observed such that new approach do not have same problems.
4.1
System Development Research Method
In order to achieve better minimization as a final result it is important to analyze multi-core systems in detail and all properties and constrains that characterize them. During the analyzing phase, situations that can affect minimization of the unpredictability should be also considered. All this evaluation can be helpful in designing final system and variables that will be used to describe it. Our research procedure will be referred to the model that is presented in [4] - System Develop-ment Method because it is expected to deliver a fully functional approach. The System DevelopDevelop-ment Research Method is usually used in processes that seek to create new systems, approaches and any other product that requires systematic development. This is the reason why we chose to follow this method. It is composed on 4 main phases: theory building, experimentation, systems development and observation. The interconnection of all phases is shown in Figure 8.
Figure 8: A multi-methodological research approach [4]
Transition between each of the processes is allowed. This means that in every phase of the system development, it is possible to proceed or return back and restore the obtained information in the previous phase. The flexibility of this method can significantly improve the process of development.
4.2
Application of the research method
The main idea of this method is to divide project into the phases in order to achieve better final product but also to simplify the overall process. The stages which are part of this method are:
• Qualitative analysis of whole system and its components. • Designing of the system on high as well on the low level.
• Investigation of the already existing approaches that were used to minimize the unpredictabil-ity that real-time tasks suffer from due to inter-core cache interference.
• Selection of the most suitable algorithms, but also tools that can be used during implemen-tation and testing procedure.
• Implementation and testing stage.
• Result analysis and fixing problems that can occur during testing stage. • Documenting whole procedure in detail.
Investigating phase in this process implies systematic search of the relevant documentation which will be the first part of this thesis. It was conducted by searching useful papers and books while using keywords in the research. It was important to summarize the information that can be of great importance and the whole investigation is presented as a survey on the existing cache management schemes in Section 5.
The system development process consists of 5 stages presented in the following figure.
Construct a Conceptual Framework
Develop a System Architecture
Analyze and Design the System
Build the (prototype) System
Observe and Evaluate the System
Final product
Figure 9: Stages of the System Development Method [4]
According to stages presented above, it is necessary to analyze the scheduling on multi-core systems in the context of inter-core cache interference, as well as to model the system with an appropriate set of variables upon which system’s predictability can be achieved. Clearly, the principal reason why we use Cache Allocation Technology is to minimize the inter-core cache interference. The prototype that we use to achieve our goal is better explained in Section 6.2.1.
5.
A survey on cache management schemes
Cache management mechanisms for real-time systems can be categorized in cache partitioning and cache locking mechanisms [5]. The main idea of cache partitioning mechanisms is to assign a portion or partition of cache to a given task or core in the system, to reduce inter-core or intra-core interference that can happen due to shared cache among them. Cache partitioning can be classified as:
• Index-based or way-based: in index-based partitioning mechanisms partitions are formed based on sets, while in way-based partitioning the cache is partitioned by cache ways. • Software-based or Hardware-based: software-based schemes are available on the majority of
COTS systems. Hardware-based mechanisms require specialized implementations, as Cache Allocation Technology which is limited only in systems equipped with Intel’s Xeon Processor V4.
• Compiler-based or OS-based: a sub-classification of software-based approaches. This classifi-cation is made based on the place where support for cache partitioning is added, whether at the compiler level, or at the operating system memory allocator level.
On the other hand, cache locking is a hardware specific feature and the central idea of it is to lock a portion of cache, so that its content cannot be evicted by the cache replacement policy and by intra-core or inter-core interference.
Based on the classification provided above, we present a survey of cache management techniques for multicore real-time embedded systems. Furthermore, we try to classify each approach in either hard real-time or soft real-time approach.
5.1
Index-based cache partitioning
Index-based cache partitioning can be divided in two categories: software and hardware-based. The software-based is fully transparent to applications and does not require any hardware support, while the hardware-based is not available in the majority of the current processors, because it requires special hardware support. An overview of the index-based partitioning method is shown in Figure 10. Each different shade represents an isolated partition of cache.
Figure 10: Overview of the index-based partitioning method [5]
5.1.1 Software-based
During our research we realized that the most famous software index-based partitioning technique is page coloring, also called cache coloring, and it is used in a lot of cache management schemes. According to [33], there are three advantages of cache coloring:
1. Cache coloring can be efficiently implemented, because it does not require specific hardware support, and is transparent to the application programmer.
2. Hypervisors typically already manage the allocation of memory areas for the domains to virtualize their address spaces, and hence come with a software design that is prone to integrate coloring techniques at that stage.
3. Cache Coloring allows exposing a simple configuration interface to the system designer, which is also transparent with respect to the software executing within a domain.
The main idea of page coloring technique is the mapping between cache entries and physical ad-dresses. A detailed description of page coloring is made by [6]. Figure 11 shows how a task’s memory address is mapped to a cache entry. The last l bits of the physical address are used as a
Figure 11: Memory to cache mapping and page coloring [6]
cache-line offset, and the preceding s bits are used as a set index into the cache. The overlapping intersection bits between the physical page number and the set index determine the color index. Page coloring uses these intersection bits to partition the cache into 2s+l−g, where g least signif-icant bits are used as an offset into a page. Physical memory pages with the same color index correspond to a memory partition, and each memory partition corresponds to a cache partition with the same color index. Since the OS has direct control over the mapping between physical pages and the virtual pages of an application task, it can allocate specific cache colors to a task by providing the task with physical pages corresponding to the cache colors [34]. There are several applications that use page coloring techniques on virtualization or non-virtualization settings.
OS-based
Paper [34] proposes a real-time cache management framework for multi-core virtualization. This framework supports two hypervisor-level techniques, called vLLC and vColoring. vLLC is designed for a VM that runs an OS which supports page coloring technique, while vColoring is designed for a VM running on an OS that do not support page coloring. Experimental results on three different OS have shown that both vLLC and vColoring can effectively control the cache allocation of tasks in a VM. This paper also proposes a new cache management scheme that reduces taskset utilization while satisfying all timing constraints. To avoid both types of interference: inter- and intra- VCPU cache interference, this new cache management approach follows the steps as follows:
• allocates cache colors to tasks within a VM while satisfying timing constraints
• designs a VM in a cache- aware manner so that the VM’s resource requirement is specified w.r.t. the number of cache colors allocated
• determines the allocation of cache colors to a set of VMs to be consolidated
The experimentation has been performed on randomly-generated tasksets and the results show that this new scheme yields a significant utilization benefit compared to other approaches. Paper [7] presents a memory management framework named COLORIS which supports both static and dynamic cache allocation on multi-core platforms using page coloring. An issue that page col-oring faces is the significant overhead with re-partitioning also called recolcol-oring. COLORIS is an
efficient page recoloring framework which attempts to isolate cache accesses of different applica-tions. It has two major components: a Page Coloring Manager and a Color-Aware Page Allocator as shown in Figure 12. The Page Coloring Manager assigns initial page colors to tasks, monitors their cache usage metrics and performs colors assignment adjustment according to objectives like fairness, QoS or performance. The Color-Aware Page Allocator is used to allocate page frames of specific colors. The Cache Utilization Monitor measures application cache usage online and
Figure 12: COLORIS architecture overview [7]
triggers re-partitioning to satisfy QoS demands of individual tasks, in the dynamic scheme. The series of experiments to evaluate the effectiveness and performance of COLORIS are conducted for a set of SPEC CPU2006 workloads and the design and evaluation of COLORIS are applied on Linux. The experimental results show that COLORIS reduces the performance variation due to cache interference by up to 39%, and also provides QoS for memory-bound applications.
An efficient OS-based software approach is presented in [35]. This cache partitioning mechanism supports both static and dynamic partitioning policies. The proposed experimental methodology provides the examination of existing and future cache partitioning policies on real systems by using a software partitioning mechanism. The implementation is done in Linux kernel and color-based partitioning mechanism is extended to support page recoloring. In comparison with other approaches, this recoloring scheme is purely based on software and it is able to conduct a compre-hensive cache partitioning study with different policies optimizing performance, fairness and QoS objectives.
A practical OS-level Cache Management for multi-core real-time systems is proposed in [6]. This software-based cache management scheme provides predictable cache performance and addresses two main challenging problems of page coloring technique. The first one is memory co-partitioning problem [35]. Page coloring partitions the entire physical memory into the number of cache par-titions and it assigns them to tasks. The same number of memory parpar-titions is assigned to tasks. Some of the assigned memory would be wasted if a task requires more number of cache partitions, because a task’s memory usage is not necessarily related to its cache usage. The second problem of page coloring is the limited number of cache partitions. The proposed OS-level cache manage-ment scheme uses fixed-priority preemptive scheduling and consists of three components: cache reservation, cache sharing and cache-aware task allocation. Cache-aware task allocation uses cache reservation and cache sharing to determine efficient task and cache allocation to schedule the given taskset. This scheme provides static task allocation and does not require any hardware support or modifications to application software.
Compiler-Based
A new technique that eliminates conflict misses in multi-processor applications is proposed in [36]. This technique is called compiler-directed page coloring (CDPC) and it uses the information available within the compiler to customize the application’s page mapping strategy. CDPC extends the default mapping policy and is compatible with both page coloring and bin hopping [37]. This
technique relies on the interaction of the parallelizing compiler and the operating system and is easy to implement. For the experimental part, researchers use the Stanford SUIF compiler to automatically transform the applications into parallel tasks. The simulation platform is the same with [38]. They both use SimOS simulator to study the performance of the workloads in detail and to analyze the impact of various architectural parameters. The difference is that [36] proposes a new technique that performs better than page coloring and bin hopping and is effective on both direct-mapped and two-way set-associative caches of multi-core systems.
5.1.2 Hardware-based
Page coloring mechanism is restricted to static cache partitioning, where a fixed set of partitions is statically assigned to each task since initialization. Since this approach can under-utilize the cache and CPU resources, [39] proposes a hardware-based mechanism vCAT, which takes advantage of Cache Allocation Technology [21] and can be configured for both static and dynamic allocations. vCAT can be used to achieve hypervisor- and VM- level cache allocations. vCAT is similar to classical virtual memory but with the following differences:
• Although cache partitions can be preempted, the hypervisor cannot save the contents of the preempted partition. Instead of that, the hypervisor can rely on tasks to repopulate the partitions which are assigned to them.
• The allocations on CAT are contiguous. This requires a procedure for handling partition fragmentation.
Through experimentation, researchers’ goal is to evaluate how vCAT’s task-level cache isolation can effectively avoid the WCET slowdown caused by other concurrently running tasks and how CAT virtualization can improve the system’s performance, for both static and dynamic allocations. Another application of cache coloring comes in [33], but in this case it needs special hardware support, that is the reason of classifying it as hardware-based cache partitioning approach. This paper presents a hypervisor support for achieving isolation when accessing the LLC and the DRAM in ARM multicore platforms. The support has been implemented within the XVISOR, which is an open-source hypervisor [40]. It addresses the problem of providing spatial and temporal isolation between execution domains in a hypervisor and the approach consists in: 1) Assigning static colors to domains and 2) Redefining the memory allocation strategy of the hypervisor. So the strict partitioning of the LLC can be achieved by assigning non-overlapping sets of colors to domains running on different cores of the system. Experimental part is performed on the popular Raspberry Pi 2 board, equipped with a quad-core ARM Cortex-A7 processor and has shown that the running time of a state-of-the-art benchmark is significantly reduced in the presence of isolation mechanisms. Nevertheless, such designs are argued as less attractive for safety-critical domains, for which the provision of dedicated cores is a more robust solution [33].
A fully associative cache partitioning for real-time applications is presented in [41]. Multiple memory entries are combined together to be associated with a single tag entry. This is done using a few don’t care cells in the least significant bits of the tag. The tag table entry is built using the content addressable memory (CAM) in conjunction with a few bits of ternary content addressable (TCAM) cells. This architecture consumes less energy and needs less search time to perform tag table search, compared with other fully associative approaches.
Several hardware-based cache partitioning have been proposed for general-purpose applications to improve their performance and power perspectives. [42] uses L2 as the last level of cache hierarchy and the shared processor-based splits the L2 based on CPU ids, rather then on memory addresses. They propose a table-based mechanism that will keep the processor-L2 split associations. Each CPU looks first at its set of units, but can also look up for other units before going off-chip. When a miss happens, the request can allocate the block only into one of its units.
Cache management framework (CQoS) classifies memory accesses streams into priority levels and then assigns more set partitions to higher priority tasks [43]. This paper proposes three different mechanisms: 1) static and dynamic cache partitioning, 2) selective cache allocation and 3) heterogeneous cache regions. Selective cache allocation maintains information about the number of lines which are already occupied in the cache and then the cache requests can be allocated or rejected based on some probabilities.
5.1.3 Summary
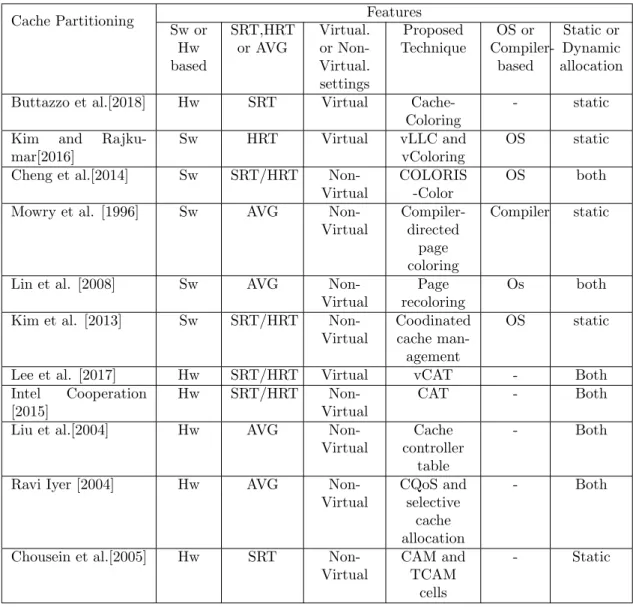
In this section we present a summary of the discussed partitioning mechanisms and present a comparison between them. Those partitioning techniques differ from each other because of different objectives that they want to optimize. We categorize them as hard or soft real-time (HRT/SRT) whether they seek to achieve all timing constraints of tasks. Average-case is also another type of classification used for approaches that focus on achieving a better performance on multi-core platform and are not proposed for real-time systems. The partitioning mechanisms from the papers that we reviewed are implemented on virtual or non-virtual settings. Software-based cache partitioning mechanism can also be categorized as OS-based or Compiler-based mechanisms. This classification is not available on hardware-based mechanisms. The reviewed index-based cache partitioning are summarized in Table 2.
Table 2: Comparison between the index-based cache partitioning techniques
Cache Partitioning Features
Sw or Hw based SRT,HRT or AVG Virtual. or Non-Virtual. settings Proposed Technique OS or Compiler-based Static or Dynamic allocation
Buttazzo et al.[2018] Hw SRT Virtual
Cache-Coloring
- static
Kim and
Rajku-mar[2016]
Sw HRT Virtual vLLC and
vColoring
OS static
Cheng et al.[2014] Sw SRT/HRT
Non-Virtual
COLORIS -Color
OS both
Mowry et al. [1996] Sw AVG
Non-Virtual Compiler-directed page coloring Compiler static
Lin et al. [2008] Sw AVG
Non-Virtual
Page recoloring
Os both
Kim et al. [2013] Sw SRT/HRT
Non-Virtual
Coodinated cache man-agement
OS static
Lee et al. [2017] Hw SRT/HRT Virtual vCAT - Both
Intel Cooperation [2015]
Hw SRT/HRT
Non-Virtual
CAT - Both
Liu et al.[2004] Hw AVG
Non-Virtual
Cache controller
table
- Both
Ravi Iyer [2004] Hw AVG
Non-Virtual CQoS and selective cache allocation - Both
Chousein et al.[2005] Hw SRT
Non-Virtual
CAM and TCAM
cells
- Static
5.2
Way-based cache partitioning
Way-based cache partitioning schemes partition the shared cache by ways and permit each ap-plication to replace cache blocks only within its assigned subset of ways. But due to [44] since the associativity of each cache partition is proportional to the partition size, it can decrease the associativity of each partition. So its limitations are the limited number of partitions and the granularity of allocations due to the associativity of the cache. Researchers in [5] state the two
main advantages of way-based partitioning: (1) Set-associativity organization does not need to be changed and (2) The isolation of the requests from the different compartments from each other. An overview of way-based cache partitioning method is shown in Figure 13. Each way represents an isolated partition and they can be assigned to tasks or cores.
Figure 13: Overview of the way-based partitioning method [5]
5.2.1 Average-case approaches
A hardware way-based partitioning mechanism is presented in [45]. This paper evaluates the potential of hardware cache partitioning mechanisms and policies to reduce the negative effect of co-scheduling and designs a practical algorithm that will divide the LLC among tasks. A prototype version of Intel’s Sandy Bridge x86 processor is used, but with additional hardware support for the way-based LLC partitioning. They have used multiple tasks taken from several modern benchmark suites as PARSEC, SPEC CPU2006, DaCapo and both power and efficiency is measured, to explore the potential benefits of LLC partitioning. After experimental part, the evaluation shows that LLC partitioning presents significant performance improvements (20% in average) in 16% of workloads. Compared with shared caching, cache partitioning was more effective on average: it provides increased performance and energy improvements without the potential performance degradation.
Paper [46] presents a dynamic way-based cache partitioning scheme that allocates cache space among simultaneously executing tasks and minimize the overall cache misses. The proposed par-titioning scheme consists of three parts: marginal gain counters, a parpar-titioning mechanism and an OS controller. The marginal gain at a given allocation represents the number of cache misses that will be reduced if one more cache block is added. They have used a set of counters to collect the marginal gains of each task for the past time period. This mechanism assumes that the cache uses the standard LRU replacement policy [22]. Although our partitioning scheme significantly improves the performance when the LRU is wrong, the experimental results show that the parti-tioning algorithm degrades the performance by a few percent, when the partition period is either too short or too long. If the partition is too short the marginal gains lose the past history, while when the partition is too long it cannot track dynamic changes in the program behavior quickly enough, which results in poor performance.
Marginal gains are also used in scheduling and partitioning algorithms proposed by [47]. The proposed partitioning scheme explicitly allocates cache space to tasks. The LRU policy manages the cache space within a task, but not among tasks. The overall flow of the partitioning scheme can be divided in 4 modules: on-line cache monitor, OS processor scheduler, partition module and cache replacement unit. The replacement unit decides which block within a set will be evicted. On-line cache monitor maintains the scheduling and marginal gain information, which is used by the partitioning module to decide a cache partition. The scheduler provides the set of executing tasks that shares the cache at the same time. The goal of researchers is to provide a methodology that will solve certain scheduling and partitioning problems and will optimize memory usage and overall performance. The main idea is that by knowing the marginal gains of all the jobs, it is then possible to predict the performance of a subset of the jobs executing in parallel.
the problem of allocation of resources such as cache space and memory bandwidth to individual workloads. Researchers describe the hardware/software support required, as well as the operating environment. One of the contributions of this paper is the design and evaluation of several priority-based resource management policies for an effective QoS-aware cache/memory architecture. The evaluation of the framework is based on trace-driven and a prototype QoS-aware version of Linux. This paper work ensures that a high priority task is provided more platform resources than the low priority tasks. Two primary proposed QoS policies are static and dynamic QoS policies. Static policies are defined such that the specified target and constraint do not require continuous adjustment of resources, so the hardware does not need to perform dynamic resource assignment. Since the dynamic QoS policy is based on the resultant performance and the targets/constraints, the amount of resource as well as the resultant performance provided to high priority or low priority tasks need to be monitored at regular intervals in the platform. Through a detailed simulation-based evaluation, researchers have shown that the QoS policies can be effective in optimizing the performance of high priority tasks when they are executing simultaneously with other low priority tasks.
A utility-based approach that performs dynamic partitioning is presented in [49]. This ap-proach partitions the cache between multiple applications depending on the reduction in cache misses that each of them is likely to obtain. To decide the amount of cache resources allocated to each task/application, researchers use the information gathered by a novel hardware circuit that monitors each application at runtime. The evaluation shows that the Utility-Based Cache Parti-tioning (UCP) outperforms LRU on dual-core system by up to 23% and 11% on average, while requiring less overhead.
5.2.2 Real-time approaches
A novel energy optimization technique with both dynamic cache reconfiguration and shared cache partitioning is proposed in [50]. This approach can minimize the cache hierarchy energy con-sumption while guaranteeing all timing constraints. Dynamic cache reconfiguration technique is effective for cache energy optimization [51]. The novel of this approach is the integration between both dynamic cache reconfiguration and cache partitioning mechanism. The reason of choosing way-based cache partitioning stays on the fact that real-time embedded systems usually have small number of cores and way-based partitioning is beneficial enough for exploiting energy efficiency.
A schedule-aware cache management scheme for real-time multi-processors is presented in [52]. Researchers propose an integrated framework that can exploit cache management by building task-level time-triggered re-configurable cache. This means that cache resource is strictly isolated among real-time tasks and cache ways can be efficiently and dynamically allocated to tasks. The proposed framework conducts cache partitioning at hardware level and is implemented on FPGA. In order to offer a fully-deterministic real-time behavior for safety-critical systems, this approach consider a periodic time-triggered non-preemptive scheduling policy.
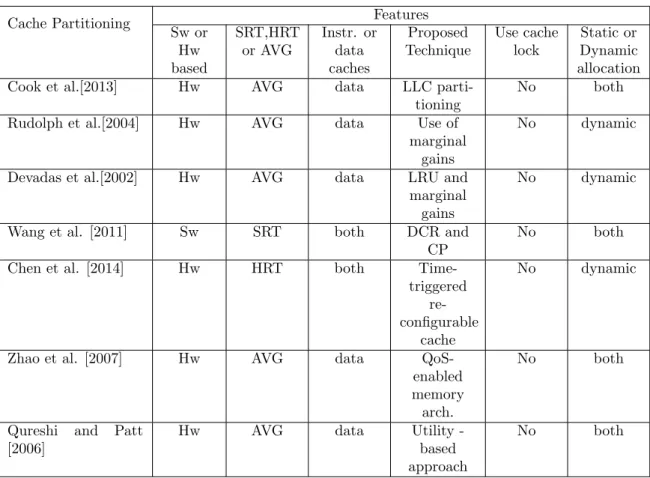
5.2.3 Summary
Most of the reviewed way-based cache partitioning use a hardware-specific implementation. Only two of them [50] [52] were proposed to improve the predictability of real-time systems. The cache partitioning can be also combined with cache locking mechanisms, but the reviewed mechanisms does not include cache locking in their proposed solutions. They are summarized in Table 3. In the classification form we also show if the partitioning is applied in instruction or data caches.
Table 3: Comparison between the way-based cache partitioning techniques
Cache Partitioning Features
Sw or Hw based SRT,HRT or AVG Instr. or data caches Proposed Technique Use cache lock Static or Dynamic allocation
Cook et al.[2013] Hw AVG data LLC
parti-tioning
No both
Rudolph et al.[2004] Hw AVG data Use of
marginal gains
No dynamic
Devadas et al.[2002] Hw AVG data LRU and
marginal gains
No dynamic
Wang et al. [2011] Sw SRT both DCR and
CP
No both
Chen et al. [2014] Hw HRT both
Time-triggered re-configurable
cache
No dynamic
Zhao et al. [2007] Hw AVG data
QoS-enabled memory arch.
No both
Qureshi and Patt [2006]
Hw AVG data Utility
-based approach
No both
5.3
Cache locking mechanisms
Cache locking is another cache management mechanism for real-time embedded systems. The main idea of it is locking a portion of the cache in order to protect it from being evicted by the cache replacement policy or by any type of cache interference. There are two cache-locking variations: 1)locking of the entire way and 2)locking of an individual cache line, as presented in Figure 14. Locking the entire way means that the contents within that way across all sets can not be evicted [5]. Locking the whole way has not been explored deeply, while the cache line locking strategies have been provided by most of the current embedded platforms.
(a) (b)
Figure 14: Cache-locking variations: a) Locking of the entire way and b) Cache line locking Cache locking mechanism can be combined along with the partitioning mechanism for achieving better predictability and higher performance. While cache partitioning supports assigning the
por-tion of the cache to each task or processor, cache locking mechanism provides possibility of loading selected contents into cache and prevents them from being replaced at run-time. A combination of index-based cache partitioning and cache locking mechanisms in the context of preemptive hard real-time embedded systems is explored in [53]. In cache locking techniques time required for accessing the memory is predictable and it already exists in some commercial processors such as PowerPC 440 core, ARM 920T, ARM 940, ARM 946E-S, Motorola ColdFire MCF5249, Motorola PowerPC 440, Motorola MPC7451, MIPS32 and Freescale Semiconductor’s e300 core. [53] [54]
Two schemes of cache locking called static and dynamic can be considered so in the following subsection they will be explained in more detail.
5.3.1 Static schemes
Static type of locking has a couple of benefits. Beside the fact that time required for accessing the memory for this mechanism is predictable, static technique also addresses both intra-task as well as inter-task. It requires only brief loading the contents of the cache during the system start-up and then locking the cache.
From the large number of proposed methods we will single out two low-complexity whose main focus is on multitasking hard real-time systems. The first method in [54] is focused more on minimization of the CPU utilization of the task set and it is called Lock-MU, while the aim of the second one is reducing the interference which occur between tasks due to preemptions and it is called Lock-MI.
In its procedure, Lock-MU uses two important information which are number of accesses to the memory and periods of the tasks. It is based on locking a number of lines with the highest ratio of these important variables in the cache.
Lock-MI has a number of steps that should be performed. They are: initialization of the cache with nothing locked in, then estimation of the worst case execution time for every task with cache contents from the beginning and then the rest of the procedure is focused on the computations for every cache block the program lines to be locked. It actually represents calculation for every program line the interference decrease in regard the other lower priority tasks affected while locking in the cache.
5.3.2 Dynamic schemes
Even though there are a lot of different schemes which can be classified as dynamic [55], in [8] one simple but powerful cache locking method was presented. It gave optimistic results for both sigle-core as well as multi-core. The workflow diagram of this scheme is presented below.
The method proposed in [8] is based on the cache misses which are helpful in selection of the memory blocks that should be locked. Information about the memory blocks which are causing cache misses are gathered together and arranged in descending order by number of cache misses. Term block address and miss information abbreviated as BAMI in Figure 15 represents the infor-mation about cache misses caused by some particular memory blocks. According to this method, memory blocks which have more cache misses should be locked.
Job in this case can imply whole or just one part of application and it contains the number of tasks or some certain segments of code. They are assigned to free cores and after they finish their executions, cores to which they were assigned become free. Only difference is in the case of using way cache locking, where the decision of how much cache a core have to lock is made dynamically. In the end, after execution of all jobs delay for each task and total power are calculated.
START
Select (N or less) jobs;
pre-load CL2 with selected blocks using BAMI; assign jobs among cores
Core 2 Core 3
Core 1 Core N
Yes
Locking?
Yes
Locking? Locking? Locking?
Load BAMI; Lock I1/job Load BAMI; Lock I1/job Load BAMI; Lock I1/job Load BAMI; Lock I1/job Yes Yes
Assign task Assign task Assign task Assign task
Processes Processes Processes Processes
Core 1' Core 2' Core 3' Core N'
Delay = SUM (MAX(delay for each N tasks)) Power = SUM (power for all N tasks)
No
All tasks done? All jobs
done?
Mean Delay per Task = Total delay / Number of tasks Total Power = Total power for all tasks
END
No
Figure 15: Workflow diagram of the dynamic cache locking scheme [8]
Since the aim of this method was improving predictability as well as performance or power ration of the application, this method provides the possibility of changing the locked cache size during the execution time. This is also the reason why this method is singled out among all other cache locking methods.
5.3.3 Comparison of static and dynamic schemes
While static locking implies that cache content is loaded before an execution of the tasks and it is not going to be changed during the execution, in dynamic locking cache content can be changed during the run-time. This means that in case of static scheme tasks are getting just part of the cache, while in case of dynamic scheme each of the tasks can occupy entire cache.
that dynamic scheme is better in combination with tasks which have a large number of regions but also for systems with smaller size of shared cache. Main focus of the [57] was comparison of these two schemes in order to evaluate which one is better in determinism and performance points of view. The same experiments were conducted on both schemes and results showed that static scheme is more predictable but dynamic provided better performance in most cases. The reason that static scheme is more predictable lies in the fact that there is no cache overfill overestimation because cache contents does not change once they are loaded in the cache. On the other side, dynamic scheme is preferable for achieving performance for systems with cache size which is lower than code size. But, the performance is decreasing as cache size is closer to code size so for systems with cache size bigger than code size there is no noticeable performance for dynamic schemes.
![Figure 1: Multicore chips perform better – based on Intel tests using the SPECint2000 and SPECfp2000 benchmarks – than single-core processors [1]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/8.892.224.671.650.937/figure-multicore-perform-better-specint-specfp-benchmarks-processors.webp)

![Figure 6: Intel CAT example with PIDs and two CLOes [2]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/15.892.164.719.434.567/figure-intel-cat-example-pids-cloes.webp)
![Figure 8: A multi-methodological research approach [4]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/19.892.223.674.496.778/figure-a-multi-methodological-research-approach.webp)
![Figure 9: Stages of the System Development Method [4]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/20.892.290.604.348.818/figure-stages-development-method.webp)
![Figure 12: COLORIS architecture overview [7]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/23.892.261.631.248.487/figure-coloris-architecture-overview.webp)
![Figure 13: Overview of the way-based partitioning method [5]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/26.892.264.644.222.417/figure-overview-way-based-partitioning-method.webp)
![Figure 15: Workflow diagram of the dynamic cache locking scheme [8]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4873177.133035/30.892.264.629.121.867/figure-workflow-diagram-dynamic-cache-locking-scheme.webp)
