V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Engineering - Robotics
and Master of Computer Science - Intelligent Embedded Systems
30.0 credits
A METHOD FOR OPTIMISED ALLOCATION
OF SYSTEM ARCHITECTURES WITH
REAL-TIME CONSTRAINTS
Marcus Ventovaara
mva13001@student.mdh.se
Arman Hasanbegovi´c
ahc16002@student.mdh.se
Examiner: Mikael Sj¨
odin
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisor: Saad Mubeen, Mikael Ekstr¨
om
M¨
alardalen University, V¨
aster˚
as, Sweden
Company supervisor: Jimmie Wiklander
Volvo Construction Equipment, Eskilstuna, Sweden
4th Jun 2018
Abstract
Optimised allocation of system architectures is a well researched area as it can greatly reduce the developmental cost of systems and increase performance and reliability in their respective applica-tions. In conjunction with the recent shift from federated to integrated architectures in automotive, and the increasing complexity of computer systems, both in terms of software and hardware, the applications of design space exploration and optimised allocation of system architectures are of great interest. This thesis proposes a method to derive architectures and their allocations for sys-tems with real-time constraints. The method implements integer linear programming to solve for an optimised allocation of system architectures according to a set of linear constraints while tak-ing resource requirements, communication dependencies, and manual design choices into account. Additionally, this thesis describes and evaluates an industrial use case using the method wherein the timing characteristics of a system were evaluated, and, the method applied to simultaneously derive a system architecture, and, an optimised allocation of the system architecture. This thesis presents evidence and validations that suggest the viability of the method and its use case in an industrial setting. The work in this thesis sets precedence for future research and development, as well as future applications of the method in both industry and academia.
Acknowledgements
The authors would like to extend gratitude to the supervisor of this thesis, Saad Mubeen, co-supervisor Mikael Ekstr¨om, and thesis examiner, Mikael Sj¨odin, for their continuous guidance and feedback that shaped the direction and quality of this thesis for the better. Furthermore, as this work was done in cooperation with Volvo Construction Equipment, it is the wishes of the authors to display gratefulness for the opportunity and support provided to them by the company and acknowledge the active participation in this thesis by appointed company supervisor, and thesis issuer, Jimmie Wiklander. This work surely would not have been possible without the participation and assistance of the aforementioned people, and the authors would like this fact to be recognised as it has been of direct benefit to this thesis.
Contents
List of Figures v List of Tables vi 1 Introduction 1 1.1 Motivation . . . 2 1.2 Problem formulation . . . 2 1.3 Initial assumptions . . . 2 1.4 Thesis outline . . . 3 2 Background 4 2.1 System architecture topology . . . 42.2 Hardware considerations . . . 5
2.3 Software considerations . . . 5
2.4 Design space exploration . . . 6
2.5 Real-time scheduling and schedulability analysis . . . 6
3 Related work 8 3.1 System architectures in vehicular research . . . 8
3.2 Fault tolerance . . . 8
3.3 Functional safety . . . 9
3.4 Architectural design space exploration . . . 10
3.5 Worst-case execution time analysis . . . 11
3.6 Discussion . . . 12
4 Research method 13 4.1 Systems development research method . . . 13
4.2 Platform-based design . . . 14
4.3 Discussion . . . 14
4.4 Application of the research method . . . 15
4.5 Strategy for evaluation . . . 16
5 Industrial use case 17 5.1 System overview . . . 17
5.1.1 Existing system architecture . . . 18
6 Proposed method 19 7 Implementation 21 7.1 Sample-based worst-case execution time estimation . . . 21
7.2 Design space . . . 21
7.3 Design objectives . . . 24
7.4 Schedulability analysis . . . 25
8 Evaluation 26 8.1 Worst-case execution time analysis . . . 26
8.1.1 Validating the worst-case execution time estimates . . . 27
8.2 System architecture allocation . . . 29
8.3 Discussion . . . 30
8.3.1 Application of the research method . . . 30
8.3.2 Worst-case execution time analysis . . . 31
8.3.3 System architecture allocation . . . 32
8.3.4 Functional safety guidelines . . . 33
8.3.5 Final assumptions . . . 35
9 Conclusion 36 9.1 Research questions . . . 36
10 Future work 38
References 39
List of Figures
1 Three different architectural topologies: centralised (left), decentralised (centre), distributed (right) [1]. The size of the circles, or nodes, predicate authority in the system. . . 4 2 Example polytope bounded by the linear constraints c1, c2, c3, c4. The feasible
re-gion represents the set of feasible solutions for a bounded, two-variable optimisation problem. . . 6 3 Outline of a multi-methodological research approach [2]. . . 13 4 Design-flow of the platform-based design methodology [3]. The figure portrays the
methodological relation between application development and architectural devel-opment (upper and lower triangles respectively). . . 14 5 The process for Systems Development Research [2]. . . 15 6 Abstract system level overview of the system in an autonomous construction vehicle. 17 7 The functional architecture of the system in question and the communication
de-pendencies between each task considered. . . 18 8 Flowchart of the proposed method depicting the possibility of reiterating the design
space exploration as a result of the schedulability analysis. . . 19 9 The plots portray the observed number of execution times and the expected amount
once according to the resulting probability distribution for tasks A and B. . . 26 10 The plots portray the observed number of execution times and the expected amount
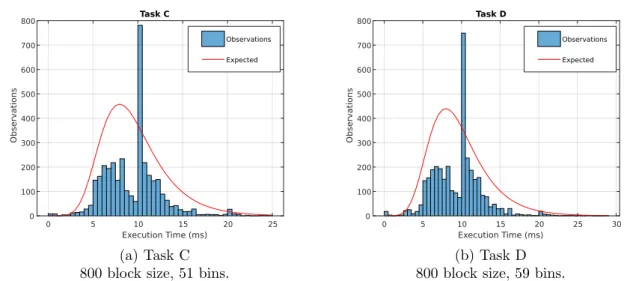
once according to the resulting probability distribution for tasks C and D. . . 27 11 The plots portray the observed number of execution times and the expected amount
once according to the resulting probability distribution for tasks E and F. . . 27 12 Observed and expected occurrences over execution times the task used for validation.
The maximum sampled execution time for the task was 92.061µs. The figure is the resulting plot of 4,000,000 execution time samples reduced into 306 bins using a block size of 250. . . 28 13 Resulting System Architecture Allocation. . . 29 14 Task B observations over execution time for different block sizes. The figure depicts
the accumulation of observations observed around 10ms as a direct consequence of increasing the block size. . . 31 15 Task B observations over execution time with block size 10 and a smaller range on
List of Tables
1 Table listing the periodicity and WCET estimate for each task in the evaluated system. Tasks with the period denoted N/A did not have a defined period, therefore
the metric is not applicable for such tasks. . . 26
2 Possible variable combinations and outcomes for Equation 12. . . 45
3 Possible variable combinations and outcomes for Equation 13. . . 45
1
Introduction
Presently, there is a noticeable strive towards automation within the automotive industry, and many vehicle manufacturers are researching this area in order to build knowledge and develop products. Consequently, automation has become an interesting topic in the construction vehicle industry as well. The push for automation does not only consider highly automated machines capable of manoeuvring in complex urban environments, but also to develop various driver assist-ance functionalities that can assess and alleviate risks and increase driver comfort. In the past, such functionalities would each have been allocated onto their own computer, in what is called a federated architecture [4]. However, with the availability of increasingly powerful processors, and the growing demand on communication induced partly by additional and more precise sensors, such schemes can no longer be justified. Therefore, in recent years, many vehicle developers have started moving to what is commonly denoted integrated architectures [4, 5], where one computer can accommodate multiple functionalities at any given time. Integrated architectures have many advantages over their federated counterparts, such as reduced system complexity and cost, lower demands on communication, and increased dependability [6].
Although in general, the software functionality of an automotive computer system is a major in-fluence on the hardware architecture, the case differs between federated and integrated approaches. In federated architecture design, the amount of processors is directly correlated to the number of independent software functions. Albeit the number of functions is a necessary consideration in integrated architecture design as well, such correlations are invalidated by the possibility of accom-modating multiple functions on one processor. This predicates an entanglement between software and hardware architectures, which is very prevalent in the design process of integrated architec-tures.
The newly acquired focus on automation in the automotive industry introduces many new challenges and requirements on the performance and reliability of the system architecture. While the argument can be made that implementing an integrated architecture on a single, centralised system is efficient, the fact remains that a centralised system is inherently susceptible to a single-point-of-failure. Moving to a more decentralised system to combat that susceptibility comes with additional challenges and constraints that need to be considered. Ensuring that a system operates properly in response to its regular inputs while managing failures and errors is one of the missions of functional safety. Functional safety is a very important aspect of any vehicular system.
Decentralisation of the system architecture considers the cooperation of functionalities between multiple discrete hardware platforms. The means of communication and load distribution are two main focal points in this. Decentralisation within the vehicular domain should, however, not in-fringe on the productivity of the vehicle. There should not be a noticeable decrease in productivity in a decentralised system compared to a centralised one, in order to adequately justify a distrib-uted or decentralised approach. Although performance and operational speed make up for a large portion of such metrics, they may both be sacrificed for increased uptime, which, in turn, accounts for another major portion of the productivity metric. One aspect of the system architecture which may benefit from decentralisation are the real-time characteristics of the system. Parameters such as task response times and processor utilisation can be improved by an increase in the number of processors and a division of responsibility between them. Therefore, real-time characteristics need to be taken into consideration while designing the decentralised architecture. As such, a ro-bust method for architectural design, from which an adequate amount of computational platforms can be decided upon, and an optimal functional distribution across the platform, is needed. The method must also be able to sufficiently address the requirements on fault-tolerance set by machine autonomy.
This research focuses on optimised allocation of system architectures with real-time constraints, exerting special attention to the construction vehicle domain. This thesis incorporates an industrial use case in cooperation with an established Original Equipment Manufacturer (OEM) of construc-tion vehicles. The industrial use case in this thesis serves to compile state-of-practice requirements related to the architectural design method and means of substantial evaluation of the results.
1.1
Motivation
Design space exploration and optimised allocation of system architectures are heavily researched areas as they have many use cases and direct implications on industrial efficiency. This is especially evident in the automotive industry as it is inherently restricted by performance constraints and requirements on reliability. Distributing the functionality of a system across multiple discrete hardware platforms can generally help to reduce the risk of a single-point-of-failure. In the vehicular domain, knowing the implications of decentralisation in an automation system would be beneficial for future vehicular automation development. This is especially interesting for the construction vehicle domain, where there are specific requirements on standardisation [7,8] and productiveness from the manufacturer [9]. Deciding on an optimal system architecture would, by extension, likely result in safer products. Another major benefit of decentralised systems is the induced executional independence and ease of continued development. A new or updated subsystem can be verified and tested independently from the remainder of the system, reducing the complexity and scope.
Certifying safety-critical parts of a system is a costly process, and therefore, the implement-ational independence of safety-critical functionality is also important in this regard, especially considering cost. Making these design decisions and later providing solid evidence needed for certification can easily be solved by using an automated optimisation method. If the design re-quirements can be accurately defined and fed to one such method, it can be guaranteed that the system architecture meets these requirements. Therefore, it is worth investigating such concepts and developing one such tool that can derive the system architecture allocation specifications, whilst explicitly incorporating real-time and safety requirements.
1.2
Problem formulation
There are a lot of challenges when facing decentralisation of system architectures in vehicular computer systems. Trends in the vehicular domain suggest that the architecture should remain integrated in terms of not isolating the hardware platforms from one another [4]. The topic of this work ventures into fairly new territory, especially since it tackles autonomous construction vehicles. There is no industry standard for solutions within this practice, and many solutions for automation are not benefited by pre-autonomous experiences. There are, however, various different, recently developed approaches, that can be considered as guidelines when constructing a new method. Accounting for such, the work in this thesis aims to answer the following questions whilst maintaining the focus on construction vehicles and construction equipment:
Research Question 1: How can real-time characteristics be taken into account while allocating a system architecture?
Research Question 2: How does functional safety affect the allocation of a system architecture? Research Question 3: How does the degree of decentralisation of the system architecture affect
meeting real-time and functional safety requirements?
This thesis approaches the answering of such questions in a systematic way that is backed up by an appropriate research method. In addition to answering the formulated research questions, this thesis further aims to answer how the degree of centralisation is correlated to reliability and productivity in an automation system for construction vehicles — though as a secondary concern after addressing the research questions. Finally, the outcome of this work should be a method and a tool that automatically generates an optimised allocation of system architectures based on system requirements specified by the designer.
1.3
Initial assumptions
For the purpose of limiting the scope of this work, several assumptions have to be made before-hand. Execution times, communication, and timing requirements, to an extent, are among such assumptions. Worst-case execution times, scheduling, and deadline hits and misses are all assumed to be within acceptable margins. This was assumed in order to reduce the complexity of both the hardware and software perspectives.
Regarding communication, which includes inter-process communication and the communication between independent devices, bandwidth, and hardware medium: it is assumed that these support the specified requirements and expectations laid out. Because of such, more focus is directable towards the hardware architecture, e.g., the number of computational platforms and their respect-ive roles in the system. Finally, timing requirements of non safety-critical tasks are not going to be considered in this work. However, regarding safety-critical functions, the timing requirements will be kept in mind. A hypothetical scenario, in which an obstacle is detected and the system needs to halt, could be considered. In such a case, the timing requirements are important, and the system architecture should be designed to sufficiently account for delays in communication in order to assure operational safety.
Further assumptions include the type of computational platforms, i.e., specifications such as memory, processing capabilities, and hardware architecture (single or multi-core, etc.). The as-sumption made is that all the hardware platforms in the system support the requirements on safety and uptime, as well as the requirements set by the software.
1.4
Thesis outline
The remainder of this thesis explores relevant background in Section2, and covers a wide range of related work in Section3. Continuing, an in-depth analysis of the research methodology followed in this thesis is presented in Section4with ample advocacy for the chosen methodology. An industrial use case is proposed in Section5, a use case that forms the basis on which the evaluation is later extrapolated upon.
The subsets of the method proposed in this thesis are described in Section6and their various implementations, and, the additions to them are explained in detail in Section7. Additional details and examples regarding the implementation have been compiled in AppendixA.
Section 8 contains extensive evaluations and validations regarding the implementation, the results, and methods used and Section8.3 further discusses these along with addressing, among others, the limitations of this work. Finally, the thesis is concluded in Section9, followed shortly with proposals of future work in Section10.
2
Background
There is a close link between the construction vehicle industry and the automotive industry since they benefit from the same technological advancements. This can be seen by the similarity between the trends that both of these domains follow. In the present, these industries are striving towards automating vehicle operation. To achieve this, research is focused on challenges such as safety, predictability, and improving the overall operational performance. The end goal is to achieve automated vehicle operation that will outperform human operation in every aspect.
One topic of research within the automotive industry, and therefore, interesting for the con-struction vehicle domain as well, is system architectures. Both hardware and software components need to be specifically designed for usage in vehicles since they have strict requirements on safety and durability, and are subject to various limitations. The hardware platform generally has limited resources, as all the computers in vehicles are embedded systems that must conform to requirements on cost and dependability as well as real-time constraints, such as task deadlines and utilisation limitations. Development of embedded systems also necessitates that attention be given to safety issues and a closer connection to lower levels of hardware. Within this context, the topic of research extends into the software domain also, specifically in regards to the allocation and implementation of the software functionality. There are methods to approach software allocation in a systematic way, such as by modelling all the requirements imposed onto the system and finding an optimal solution. This section, in order to fully explore such methods in this work, gives an overview of common concepts and general theory of a few related topics and research areas.
2.1
System architecture topology
Within the domain of computer system architectures, there are three main focal points, or topolo-gies, to consider. The architectural topologies are: centralised, decentralised, and distributed, and are depicted in Figure1, as first described in terms of network topologies by Baran [1].
Figure 1: Three different architectural topologies: centralised (left), decentralised (centre), distrib-uted (right) [1]. The size of the circles, or nodes, predicate authority in the system.
A centralised system consists of one central node, and if existent, manages its adjacent nodes in a master-slave scheme. Centralised systems are highly efficient as the master node can easily distrib-ute processes and functionality in an optimal way — although, the system is entirely dependent on the master node not failing. Decentralised systems enforce the division or distribution of the master role across multiple nodes. This increases the redundancy of the system at the expense of efficiency and increased latency. One master node failure in a decentralised system does not inherently force the entire system to fail. The third structure is what is commonly denoted a distributed architecture. In such systems, the master role can be considered as distributed across all cooperating devices, rendering them equal in terms of authority. Such systems are highly re-dundant as they are not inherently subject to a single-point-of-failure, though they suffer from inefficient synchronisation between nodes, and due to this, the complexity of a distributed system is generally higher than its centralised and decentralised counterparts.
architectures are of high interest as both induce a level of fault-tolerance. Though attention must then be given to communication, synchronisation, and timing in order to satisfy the required system performance.
2.2
Hardware considerations
After computers and electronics were first introduced to cars, all electronic components in cars were connected with regular wires. Introducing the Controller Area Network (CAN) [10] to the automotive field allowed an expansion in the use of embedded systems. Every subsystem of the car (the braking system, speed control, fuel injection system, etc.) ended up having its own Electronic Control Unit (ECU). An industry-wide practice was developed for each of these ECUs to serve a single purpose and to be connected to the rest of the system through the CAN bus. This is usually called a federated architecture [4]. The philosophy of this architecture for expanding functionality is to add a new ECU for each new function and connect it to the CAN bus.
Since this federated approach was first introduced, electronics in cars have become more com-plex. New breakthroughs in sensor technology has allowed more precise measurements to be collected at a much higher rate. With the advances in computing ECUs have become more power-ful, even overly powerful to justifiably be limited to accommodating only one functionality each. The number of tasks cars are expected to perform has increased significantly as well, introducing more and more functions for driver comfort, safety, and efficiency. The increasing number of func-tionalities has required a large increase in the number of ECUs connected to the internal network of cars, which is still a standard CAN bus in many cases.
Current research is focused on moving the system architecture from a federated to an integrated design, reducing the number of ECUs and allowing one ECU to have more than one role in the overall system [4]. This trend was set by advances in avionics [5] and is now establishing itself as the standard in the automotive domain as well. An integrated architecture places all the functionality onto a distributed computer system. The system can have one or multiple hardware platforms, as long as their connection allows uninterrupted computation while sharing roles and resources. This is different from the federated approach because each hardware resource (ECU) can have more than one task, and one task can be distributed among multiple resources.
Realising a distributed system architecture following the concept of integrated systems raises new challenges in research. One research topic is optimising the distribution of functionality across multiple hardware resources. Since the architecture is not federated, there is no longer a direct correlation between the number of functions and the number of ECUs in charge of those functions.
2.3
Software considerations
In order to proficiently utilise the hardware platforms in any given application, the focus drifts towards software optimisation. The newly arrived need for highly complex and computationally demanding functions that an autonomous vehicle is expected to perform places great stress on the hardware. Such functions, e.g., self-localisation and mapping, and image processing, may be allocated to specific computational platforms within the system. Image processing benefits greatly from the highly parallel pipeline of a Graphics Processing Unit (GPU), and therefore, it is logical to utilise such devices. This approach is generally not true for most of the functionality in an automation system as the complexity of the system increases with each added ECU. This is made especially evident by the opposition towards federated architectures in the industry, and its push for integrated architectures in vehicles and automated vehicle research [4,5]. Other optimisation techniques that can be undertaken include parallelism, wherein a software component is split up into atomic subsets and executed in parallel or in a pipeline. Albeit parallelism may sound appealing, it is not without its flaws. Latency, synchronisation, and timing are all problems that must be resolved or accounted for in such implementations. Requirements on power consumption and hardware limitations must also be considered [11].
In relevancy, the disentanglement of the different levels of architecture involved is a necessary concern as it would, in effect, reduce its overall complexity [12]. As described in [13], enforcing a distinction between logical and technical architectures would allow the concentration of ECU-independent functionality from many ECUs to few — lowering the requirements on communication
and thereby reducing the system and developmental complexity, and allowing for the system to be continuously developed and tested.
2.4
Design space exploration
One way of systematically designing a system architecture is by formulating all the requirements as a mathematical model and then optimising the architecture based on some cost function. This type of systematic approach is known as Design Space Exploration (DSE) [14].
DSE is commonly done by finding an optimal design in reference to a certain cost. When the characteristics of the problem at hand can be described with a system of linear equations and inequations, and when the optimisation criteria can be written in the form of linear constraints, the DSE problem can be solved using linear programming. If an extra limitation, that states that variables of the optimisation problem must be represented in an integer domain, exists, the problem can be solved using Integer Linear Programming (ILP). In ILP, the constraints that define the problem are referred to as linear constraints, and the relation that defines the optimisation criteria is commonly known as the objective function. ILP can be used for both minimising or maximising the objective function. Common usages of ILP in DSE problems include minimising the cost of a system, minimising the number of used resources, and minimising or maximising overall resource utilisation, among others. Since ILP defines a pseudo-Boolean problem, the solution, i.e., the optimum, can be found using a pseudo-Boolean solver. Although minimising, or, maximising a pseudo-Boolean problem is NP-hard [15], a set of feasible, or candidate solutions is known to exist if a polytope can be described within the combined bounds of the linear constraints — the problem for which is trivial.
Figure 2: Example polytope bounded by the linear constraints c1, c2, c3, c4. The feasible region represents the set of feasible solutions for a bounded, two-variable optimisation problem.
Figure2exemplifies a proof-of-existence of a set of candidate solutions in a bounded ILP problem, wherein every integer-point within the feasible region is a candidate solution and conforms to the set of constraints. Although the figure gives a simplified view of a two-variable example, the theorem holds true for n-variable system models, though, the dimensionality of the polytope is directly correlated to the number of variables considered by the linear constraints and objective functions. Solving for the optimum thereon after is performed by sequentially iterating through the candidates until the optimal solution can be determined.
2.5
Real-time scheduling and schedulability analysis
When discussing real-time characteristics of a system, software components of the system are viewed as a set of tasks. These tasks have characteristics such as periods (T ), deadlines (D) and
worst-case execution times (C). The first requirement for each task is that the worst-case execution time (WCET) is less than or equal to the deadline of the task, and for the deadline to be less than or equal to its period, as shown in Equation1.
C ≤ D ≤ T (1)
The next real-time requirement is for the task set to be schedulable. This means that every task needs to have a maximum response time — i.e., the maximum amount of time that can theoretically elapse between the moment the task becomes ready for execution and the moment the task completes its execution [16] must be less than or equal to the its deadline.
When considering priority assignment, scheduling algorithms are divided into two groups: fixed priority and dynamic priority algorithms. An example of a dynamic priority assignment algorithm is the Earliest Deadline First (EDF) algorithm. Like the name suggests, the algorithm assigns the highest priority to the task that has the earliest upcoming deadline. This means a priority of a task can change in run-time, as another task becomes ready. If the priority allocation is done using the EDF algorithm, schedulability is guaranteed for any task set that has a utilisation that is less or equal to 100% [16], though, as stated in the paper, EDF is not very common in real-time applications.
Rate-monotonic scheduling (RMS) is a static-priority assignment algorithm that is much more common in the industry [16]. In RMS, priorities are assigned with inverse proportion to their periods. The shorter the period of a task, the less time that task has available to execute, and therefore, it is given a higher priority. To perform a schedulability test and verify that a system allocation is a viable candidate for implementation, Response Time Analysis (RTA) can be used [16,17]. The main idea behind RTA is to check if the maximum response time of each task is lower than its deadline.RTA is necessary and sufficient to conclude the schedulability of a system. RTA can be used with any arbitrary priority assignment algorithm. Additionally, RMS is optimal among static prioirty assignment algorithms [16]. This means, if a static priority assignment algorithm that can schedule a task set exists, then even RMS will manage to schedule the task set.
Incorporating aperiodic tasks into a set of periodic tasks is generally done in various ways. One way is to use background scheduling. Background scheduling gives aperiodic tasks a low priority and leaves the processor idle time at the disposal of the aperiodic tasks. Another, more fair way to handle aperiodic tasks is to incorporate aperiodic servers. Servers can usually be considered as periodic tasks that are scheduled as normal tasks. Their role is to reserve a certain amount of resources required by aperiodic tasks and can therefore guarantee that such tasks have their share of processing time. One example of a real-time server is the polling server [16]. It has a fixed priority and a pre-calculated execution capacity which is used to service aperiodic tasks. The main advantage of using servers lies in the fact that RTA does not need to be modified when including aperiodic tasks.
3
Related work
Since this thesis is closely related to a number of different research areas, the analysis of related work makes up a significant portion of it. The topics being addressed in this section relate to current research and practice in the automotive industry regarding system architectures and design, fault tolerance and redundancy, functional safety, as well as real-time analysis.
The following subsection presents current vehicular research, focusing on system architectures in vehicles, and relates to the recent trend of moving towards integrated architectures in auto-motive systems [18]. Section3.2 explores methods for achieving fault tolerance in systems. The section gives insight into the current practice and current research regarding fault tolerance, both from a hardware and a software perspective. Section3.3summarises current approaches regarding functional safety and how the concept is being addressed in practice and in research. The sec-tion further addresses the funcsec-tional safety standards ISO 26262 [8] and IEC 61508 [7] and their respective roles in the automotive domain.
Section 3.4 presents research in architectural design, specifically design space exploration, which, in relation to this thesis, is a topic of great interest because the proposed method in this thesis was partially derived from such papers. A selection of real-time analyses, focusing on worst-case execution time analysis, are presented in Section3.5. Finally, Section3.6presents some concluding remarks and discussions regarding the topic of related work and their relevancy to the work in this thesis.
3.1
System architectures in vehicular research
In the automotive industry, system architectures have attracted a consistent amount of researchers throughout the years. The move from federated to integrated architectures has sparked new discussions and an expansion of the research area [4].
A description of a prototype electric car developed with future autonomous capabilities in mind while running on a fully functional integrated computer architecture is given in [19]. Large automotive companies are also researching the field of system architectures in cars. A research paper published by Reinhardt and Morgan [20], the former of whom is affiliated with BMW, shows the tendency of the industry in moving towards utilising virtualisation in the architectural context, which supports the shift to a more integrated architecture.
A standard problem when discussing computer architectures is selecting the physical charac-teristics of the system, i.e., the hardware that the system will be implemented on. This implies discussing computational components and their connections. Research shows a wide range of technologies that are utilised in the automotive industry [21], with the industry moving away from exclusively using ECUs because of the large necessity of computational power enforced by self-driving cars. Platforms like GPUs have been gaining a large following recently due to their dominance in the applications of artificial intelligence and parallel computing. One example is given in [22], which discusses usage of convolutional neural networks running on a GPU for road detection.
3.2
Fault tolerance
Kohn et al. [23] describe currently applicable architectures for transitioning from safe to fail-operational behaviour in automotive embedded systems. The core concepts explained are dual-and triple modular redundancy — dual-and some variations of each — which relies on either two or three simultaneous executions of the same instruction set on independent processors. In the case of triple modular redundancy, a consensus on the output is reached by a voting scheme, while in dual modular redundancy the output is decided by comparison. This further enables the detection of faults by detecting differences in the outputs from each processor.
Similar architectures have been explored by Baleani et al. [24] and evaluated in accordance with their respective level of fault tolerance. The aforementioned evaluation suggests that lock-step architectures outperform loosely-synchronised approaches in critical executions due to the lower executional overhead.
Albeit extensive, the limited scope of the papers by Kohn et al. and Baleani et al., leaves neither to address fault recovery to a desirable degree. However, a method for such has been proposed in [25], where an extension to the dual modular redundancy architecture enables fast recovery on the node level. The method applies pipeline register parity bits that allow instruction-level fault detection to be performed in parallel with system execution. The fault recovery is performed at the event of error detection and either resets both systems or raises a trap/exception in order to re-execute the previous instruction set. By applying low-level fault detection and fault tolerance in such a way, violations of real-time constraints is avoidable and the uptime of the system can be maximised by enabling fail-operational behaviour.
Another method of facilitating fault tolerant behaviour and redundancy is the practice of vir-tualisation. The term virtualisation in this context predicates itself on the temporal and spatial isolation of processes allocated to the same resource. This ensures executional independence and redundancy in the functional domain so long as the hardware remains functional [4]. An example is the work done in [26], wherein the use of virtualisation is advocated for with regards to the benefits of reduced system and communication complexities.
In [27], definitions for all the important fault-tolerance concepts are given. The paper defines faults and metrics for evaluation of reliability, i.e., mean time to failure, mean time to recovery. It shows how error detection can work, defines the lockstep concept, as well as Triple Modular Re-dundancy (TMR). It is a fairly aged paper, though very useful to reference for the basic definitions on which much of the state-of-the-art is built upon.
An overview of concepts used to increase reliability in vehicles is offered in [28]. The paper mentions redundancy, particularly dual modular and triple modular redundancy (DMR and TMR) as the costly way, and parity bits and error-correcting codes as a more cost-efficient approach. It starts from the low level, considering different cores of one CPU, but also addresses challenges in vehicles on a higher level, where communication between ECUs introduces threats to reliability.
The research presented in [29] postulates that TMR is often used and that DMR can be used as an alternative in the case of single event transients. The work serves as a good example of utilising DMR to overcome soft errors in a system.
A work of a rather large group of researchers is presented in [30]. It is closely related to the work done by BMW and shows how overall system redundancy is not only achieved by the computer architecture, but also by redundant sensor systems. Its implementation, in particular, uses two Linux-based computers and one dSpace real-time system.
The research presented in [31] addresses the problems of extensibility, fault-tolerance, and latency as parameters to evaluate while designing a system architecture in the vehicle domain. It mentions a lot of relevant related work regarding TMR and watchdog timers for error detection. The work postulates a formal definition of extensibility and fault tolerance, and shows the common trade-offs between these parameters and suggests an algorithm for solving this problem.
The research covered in [32] tackles flexibility, adaptive graceful degradation, and smart use of sensor/actuator modalities. The paper is fairly recent and covers one aspect of a large research project that won the 2007 DARPA challenge. The proposed solution is an expansion of the already developed system, SAFER, a real-time fault-tolerant computing platform. It utilises hot standbys, cold standbys, and task re-execution and is built on top of Linux and addresses issues such as fault detection.
The studies conducted in the above-cited papers have significant implications on the work covered in this thesis due to the inherent fault-tolerance exerted by modular redundancy archi-tectures. Although to consider implementations for fault recovery lies outside of the scope of this thesis, such methods and concept have relevance for future applications of the method proposed in this thesis.
3.3
Functional safety
An example of how using a design environment, i.e., Metropolis, and the platform-based design methodology helps for selecting the system architecture is shown in [33]. It gives a good example of metrics to take into account when evaluating the architecture. A particularly good proposal in the paper is to construct scenarios of failures of subsystems, testing to see what faults the architecture can overcome. The paper further contains a demonstration of this process with an
example architecture, proving the viability of the method.
A thorough literature overview that lists the outlook and challenges for autonomous driving is given in [34]. A historical overview of approaches, out of which a particularly interesting one is the description of the achievements made by the teams competing in the DARPA challenge, are presented. The paper explores the state of the current research of, among other topics, functional safety in autonomous vehicles. It defines the need to transfer the vehicle to a safe state when faced with a hazard. It shows that in current research, all autonomous vehicles have some kind of human interference mode, where a safety driver takes over or a human remotely monitors the system while it is operating in an urban environment. The paper notes research projects such as BRAiVE [35] and SAFER [32].
In [36], a proposal for a method for certifying an autonomous vehicle running the Robot Operat-ing System1(ROS) is presented. It gives an example of this using two discrete hardware platforms.
The paper describes the ISO 26262 standard and how a ROS implementation can be mapped to the generic system proposed in the standard.
Another widely used standard discussing functional safety is IEC 61508 — Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems [7]. It is a standard well established in the industry. It defines a plethora of techniques and concepts that should be followed to achieve functional safety at a certain level. The standard defines Safety Integrity Levels (SIL), which are metrics for quantifying the risk reduction level of a system. There are four Safety Integrity Levels, with SIL 1 being the lowest and SIL 4 the highest. The Safety Integrity Levels correspond to the probability of failure — the higher the SIL, the lower the probability of a failure occurring during the lifetime of the system.
A good general overview of safety-related research in the vehicle domain can be attained from [37] and [38]. The former of the two papers mention hazard analysis as something most research papers take into consideration, and the latter lists redundancy as something to be considered thoroughly in the future, when designing vehicle platooning systems.
A large interviewing process, including 15 practitioners from six different companies is docu-mented in [39]. Its goal was to show how these companies address the challenges they face regarding functional safety in the design process. It concludes that two big challenges the practitioners agree still exist in the industry are applying safety procedures to reusable assets and communicating complex requirements and strategies among teams and suppliers.
3.4
Architectural design space exploration
Optimising the allocation of tasks on distributed systems has attracted the component-based soft-ware engineering research community to the area of computer architectures in vehicles. This specific area has been heavily researched, although currently, the research has yet to produce a solution that is a viable candidate for an industry standard [40]. The allocation of software com-ponents on a distributed set of ECUs is troublesome. Currently, much of the research is focused on multi-objective evolutionary algorithms (EA) for deriving an optimised system allocation. Such research was performed in [41], where a Pareto Archived Evolutionary Strategy [42] was used for multi-objective optimisation in task allocation on a real-time system.
Another method that relies on EA, to an extent, was developed by Peng, Li, Yao, and Sun [43]. In their method, the software components were divided between ECU dependent and independ-ent tasks, the former being mapped manually, and the latter mapped by an EA. This approach was able to reduce inter-ECU communication and increase system efficiency according to the met-rics described in the paper. Manual constraints on system allocation are useful if specific tasks should ideally be allocated on specific hardware resources, such as the mentioned case with image processing and GPUs, therefore, in this thesis, such concepts are of high interest.
The method described by ˇSvogor and Carlson [44] is based on an analytic heuristics process to perform multi-objective optimisation of the distribution space. The mapping of the software components in the cited work is also performed using EA.
In design space exploration (DSE), the methods generally conform to two types of concepts: evolutionary architecting and revolutionary architecting. Evolutionary architecting revolves around evolving a preexisting architecture to suit new needs and additional functionality. Such methods
1
have a variety of suitable approaches, e.g., designing a reference architecture, on a logical level, from which a new architecture can be extrapolated in an evolutionary fashion. Lind and Heldal [45] proposed and evaluated such a process and concluded it to be a viable strategy of approach. Other methods for evolutionary architecting have been proposed and compared in [46]. The paper further contains a comparison between the proposed method and a selection of other methods for DSE. The general approach presented consists of a mixed integer linear program [47] and a genetic algorithm for multi-objective optimisation. The results suggest great improvements in computational cost for optimising the search space partly because the proposed method of modelling is not limited by legacy constraints.
In the second concept within DSE, i.e., revolutionary architecting, no pre-existing architecture is available, and therefore, an entirely new architecture is expected to be produced. A method for revolutionary architecting that uses mixed integer linear programming to solve for a suitable candidate architecture based on the modelling was proposed in [48]. Although the paper describes revolutionary architecting from a software perspective, the method is sufficiently general to be used for optimising hardware architecture design. The architecture is generated by the aforementioned methods and then refined by a process of heuristic analyses and iterative methods to assign software and communication priorities. The method does not consider uncertainty in the modelling but requires rudimentary knowledge of system and functionality to be specified. Continuing on the topic of uncertainty, it is one of the major challenges in DSE and very rarely accounted for in DSE methods [49].
A method that accounts for uncertainty was presented in [50]. The method can accommodate evolutionary and revolutionary architecting and is executed in an iterative approach with sim-ultaneous analysis of multiple candidate architectures. The literature overview provided in the cited paper addresses concepts such as task scheduling, task partitioning, CPU utilisation, com-plex hardware topologies, and functional safety and how these concepts are considered by different methods. The paper provides information that these concepts can be taken into account or solved with DSE, which gives relevance to the whole approach. The evaluation of the approach shows its effectiveness whilst accounting for uncertain information regarding the requirements.
The research documented in [51] produces a DSE approach that optimises topology, process bindings, and communication routing of a system. It uses multi-objective optimisation to find a solution and provides a use case of the approach for a Motion-JPEG decoder application on a multimedia hardware architecture.
DSE is an important part of the automotive industry as an optimal integrated architecture designs and allocations can significantly help to alleviate complexity and reduce cost [6], and correlates heavily with the work presented in this thesis. The need for an explicit proof that certain techniques are provided by the system architecture makes DSE a viable candidate for the approach chosen in this thesis. Such methods as the ones described are usable to extract necessary considerations and requirements, and, to derive a method for architectural design.
A concept that can be used in conjunction with DSE is Resource Reservation [52]. It is com-monly used in model-based and component-based software engineering. Such methods enable independent development of different parts of a system in parallel by reserving the required re-sources beforehand. One way to combine these approaches is to reserve rere-sources while performing DSE, by enforcing constraints on those resources, such that the end architecture meets the resource requirements of each subsystem.
3.5
Worst-case execution time analysis
Worst-case Execution Time (WCET) analysis [53] is the school of study that aims to determine the maximum execution time a task may experience during uninterrupted execution. The metric is hardware dependent, and thus, the WCET of a task is not transferable from one hardware resource to another. Currently, there exists a wide range of different methods, both static and statistical, out of which some are discussed in this section. Static methods generally aim to derive an absolute WCET that will never be exceeded while statistical, sample-based, methods aim to estimate a probabilistic WCET that is guaranteed to only be exceeded by a given probability.
In [54], a method for statistically estimating a WCET by utilising Extreme Value Theory [55] (EVT) is presented. The method fits a Gumbel distribution to a set of data samples and evaluates
the quality of the fit, and estimates a WCET if the quality of the distribution is deemed sufficient. Because the estimation process is statistical, and therefore, subject to a probability of exceedance, the estimated WCET is guaranteed to only be exceeded by future invocations at the same rate as the exceedance probability. This adds flexibility to the process since the exceedance probability can be chosen to suit necessary requirements set by, e.g., industrial standards. The rate of exceedance is later validated and the method can thus be considered viable to estimate the WCET of a task. In [56], a method for measurement-based WCET estimation is presented. The method applies a per-task tailored application of EVT and further discusses the prevalent issues with solely EVT based estimations and different hardware resources. The attention of the discussion is especially given to the implication of using L2 cache. The paper further addresses these problems by proposing a method revolving around the coefficient of variation, which shows accurate WCET estimations at low exceedance probabilities.
Static timing analysis is a general concept regarding the analysis of the real-time characteristics of software and has seen multiple adoptions and applications in industrial settings, e.g., tools such as Heptane [57] and aiT [58]. The Swedish Execution Time tool (SWEET) [59] is another such tool that performs high-level static flow analyses to compute, among other, the best and worst-case execution times. The tool is further appended to by [60], wherein methods and means for generating timing models from high-level source code are proposed. Additionally, an industrial use case and the proof of the viability of SWEET is provided and evaluated in [61]. Overall evaluations and validations of the tool suggest an underestimation of the actual WCET, noticeable, and, noted in [60].
3.6
Discussion
The main purpose of performing an extensive literature study into the-art and state-of-practice methods relevant to this thesis is to limit its scope.
The study into system architectures in vehicular research was necessary in order to limit the focus of such to only consider integrated architectures. The literature reviewed shows viable efforts of solving problems similar to the problem this thesis aims to address. The given solutions are carefully analysed and used as a basis for the methods constructed in this work. Some of the interest points from these research papers that hold relevance are decisions regarding the number of computational platforms, their type, the way resources are shared amongst them and how they are connected.
Studying literature in the fields of fault tolerance and functional safety is highly relevant for this thesis. The study provides necessary direction in terms of requirements for an autonomous system regarding safety and correct operation, as well as principles of architectural design that support error detection and graceful degradation. Standards such as ISO 26262 and IEC 61508 are widely used and followed by OEMs in the automotive field, which provides sufficient justification for using them to extrapolate guidelines and requirements for developing a tool for system architecture allocation and design.
The topic of Design Space Exploration holds the key to solving the problem at hand, i.e., a systematic method for taking safety and real-time requirements into consideration and providing the best possible architecture with respect to functional and hardware limitations. The literature review gives an insight on how DSE is used in the automotive industry and what approaches of DSE can be adopted and adapted to solve the problem addressed in this thesis.
Knowing the timing characteristics of a system is valuable in order to assure functional safety and continuous operation of the system. In addition, applying optimisation techniques that optim-ise for system utilisation requires a metric of such, a metric which can be derived if the periods, WCETs, and deadlines of a task set are known. Therefore, the analysis of a selection of WCET estimation techniques has relevance for this thesis in the sense of finding and adopting a suitable and general approach.
4
Research method
This section presents and discusses the scientific research method followed in this thesis, along with a comparison with another suitable methodology and advocacy for the choices made. Computer science is considered to be a relatively new discipline within the scientific community, as noted by Dodig-Crnkovic [62]. It has, however, developed into a widely researched area that is closely related to technology. The scientific community of computer science has adapted the hypothetico-deductive methodology, which is iterative in its essence. Based on the iterative nature of all scientific research, and the problem at hand, two scientific methodologies have been evaluated. After a brief overview of two methodologies, a discussion is held regarding their differences as well as motivations for the choices made. Continuing, a section detailing the intended application of the research method is presented, after which the section is concluded by describing the initial strategy of evaluating the work and the results in this thesis.
4.1
Systems development research method
The systems development research method, per the analysis of Nunamaker and Chen [2], is a multi-methodological approach to research. As demonstrated in Figure 3, the approach consists of four parts: theory building, system development, observation, and experimentation. System development lies within the heart of this approach, with all the other parts interconnected.
Figure 3: Outline of a multi-methodological research approach [2].
The idea of this methodology is to conduct the research in an iterative manner and be able to refine and change the direction of the research during every step based on the results of the preceding steps. It is designed to fit the needs of research in engineering and technical sciences, where it is hard to postulate research questions and determine its exact direction in the early stages. Certain usefulness predicated by the methodology is the ability to backtrack on a certain direction taken in the early stages once, or if, a more viable approach to solving a specific problem becomes apparent.
4.2
Platform-based design
The previously described methodology shares similarities with another approach to embedded systems development closely related to vehicular automation known as Platform-based Design (PBD). PBD for embedded systems development, as described by Sangiovanni-Vincentelli and Martin [3], shares the concept of reiterative implementation with the systems development research method.
Figure 4: Design-flow of the platform-based design methodology [3]. The figure portrays the methodological relation between application development and architectural development (upper and lower triangles respectively).
PBD further extrapolates on this with a meet-in-the-middle approach, wherein which the highest level of abstraction is first described, hiding specific implementational details. The concept of meet-in-the-middle can, in essence, be visually explained as in Figure4. Consequently, this leads to a consecutive limitation of the design space exploration during the development process. The meet-in-the-middle approach is then considered as a sequence of refinement steps in order to implement and revise both the abstracted model and the implementation — as seen in the Figure4 with the convergence of the two instances towards each other and to the resulting system platform.
4.3
Discussion
Differentiating between the methodologies, PBD and the system development research method, one can note key differences between the two. One such difference is found in the initiation. PDB defines an abstracted model of the end system, which is then continuously revised concurrent to the implementation, whereas the system development research method does not establish a model initially, but rather, in an iterative approach defines the system via research and implementation. Another difference is the domain of applicability of the two. PDB is aimed towards system design more so than research, whereas the system development research method is generally applicable for either. This claim can be substantiated by the analysis of Shaw [63] regarding software architecture research, where the main aspects of the paradigm and maturation of software architectures are
concerned.
Considering the established direction, and the issues being addressed by this research, the system development research method is the more well-suited of the two. The advocacy for the methodology is derived from the uncertainty of the end system. The question of the degree of centralisation predicates an inquiry into subjects such as the number of computational units in the system. Therefore, because PBD is more suited as a methodology for development in which an arbitrary goal, or objective, is predefined, a research method such as the systems development research method is more applicable. In the case of such, research in system development, and specifically architectural design can establish and utilise a common base and branch off to each their own as the research progresses. This could not be considered viable, or rather, as viable, following the PBD methodology due to the abstract model definition in the initiation. Although one may initiate the model with an uncertain amount of computational units, the iterative development would be offset with an additional level of abstraction, which, elsewise, would not necessarily be the case.
4.4
Application of the research method
The systems development research method in the general case can be described with the flowchart depicted in Figure5.
Figure 5: The process for Systems Development Research [2].
The steps can be applied to this work in the following way:
• Construct a Conceptual Framework — The main research question of the work is defined in this step. The scientific contribution of the work is noted. The related literature is studied and an overview is documented, as to better select a specific approach to the solution of the problem at hand.
• Develop a System Architecture — This step defines what components will be needed for the system to work, as well as the functionalities of the system needed for the defined goals to be met. In this step, a use case will be considered. The components are the hardware platforms available for decentralisation, along with a model of the current system functionality, that needs to be produced.
• Analyse and Design the System — Making the decision on the system architecture of the system and distributing the aforementioned functionalities across the hardware platforms
are the tasks that need to be addressed in this step. It is important to make these decisions based on facts acquired in earlier steps, e.g., literature studies.
• Build the Prototype System — This step will consider actually implementing the architecture and distributing the functionalities across the hardware platforms described in the discussed case study.
• Observe and Evaluate the System — Evaluating the system is important in order to provide feedback on the quality of the design proposed and implemented in previous steps. In this work, metrics such as system uptime, redundancy, and fault tolerance are taken into consideration for such evaluations.
It should be noted once more that this method is iterative in nature which means that all of the steps listed can be reiterated if the need to do so arises. For example, if the evaluation step proves that the design has inherent flaws, the analysis and design step will be reiterated to provide a new candidate architecture for evaluation.
4.5
Strategy for evaluation
The evaluation of the inquiry will be carried out in three steps. The first step will be to study relevant literature and current state-of-the-art and state-of-practice methods and solutions and formulate an overview of the literature studied. Thereafter, for the second step, an approach to the decentralisation problem will be theorised and proposed. The third step will focus on developing and testing the relevant aspects of the proposition made on a prototype system. The hauler prototype provided by the OEM, Volvo Construction Equipment, will serve as an evaluation platform. The evaluation will consider parameters such as system uptime and safety in terms of redundancy and fault tolerance. Evaluation will be done by laboratory and industrial experiments initially, with a currently implemented system available for comparison.
5
Industrial use case
To extract necessary state-of-practice requirements of the formulated problem, this thesis presents a proof of concept use case in an industrial setting at Volvo Construction Equipment (Volvo CE). The company is developing, among others, an autonomous hauler that currently has a set of functionalities implemented on a single, centralised, hardware platform. The automation projects and research at Volvo CE have so far mostly been focusing on implementing software functionalities for different prototypes, and therefore, less attention has been given to the specific design of the system architecture. This use case provides an excellent proof of concept and evaluatory platform for the method developed in this thesis as it both addresses the appropriate degree of centralisation and derives an optimised allocation of the resulting system architecture. Such work is further constrained by the requirement of meeting the needs of both Volvo CE and the needs of future vehicular automation system architectures. The specific needs of Volvo CE in this context are an assessment of the effects of decentralisation, and, to find an appropriately decentralised architecture that can retain a similar level of productivity compared to the existing architecture. This is a complex task since there are a great number of considerations that must be taken into account, many regarding safety and redundancy, but also efficiency and cost as well as extensibility. Volvo CE relies on IEC 61508 for standardising functional safety, therefore, this standard was chosen as the basis on which the goals and requirements for the system architecture allocation tool were formulated.
5.1
System overview
The system of interest in this use case is denoted machine automation system, depicted in Figure
6. The machine automation system is integrated into the machine and it operates the machine via an interface to the machine platform — based on missions that are received from a remote fleet management system. Moreover, any sensor needed for sensing the environment is also considered part of the machine automation system while the position of the machine is part of the machine platform.
Fleet Management (Back office) Machine System
Machine Automation System (System of interest) Machine Platform Commands Status Fleet Management Commands Status
Figure 6: Abstract system level overview of the system in an autonomous construction vehicle.
The functions considered in this use case are generally essential to any vehicular automation system, though in this case, specifically developed for the autonomous construction equipment vehicle domain. These include path execution, object detection, collision avoidance, remote control and operation, teleoperation, and safety-critical functions. The functions are currently implemented
on one single computer, and the aim of this use case is to provide a proof-of-concept by applying the proposed method on the existing system at Volvo CE.
5.1.1 Existing system architecture
The existing system that was available for the demonstration of the use case consisted of a cent-ralised approach where all the functionality was executed on one computer. The functional archi-tecture was an atomic implementation consisting of several functionalities such as object detection and machine control.
Task A
Task B
Task C
Task D
Task E
Task F
Figure 7: The functional architecture of the system in question and the communication depend-encies between each task considered.
In Figure7, an abstracted overview of the functional architecture of the machine system in focus is depicted, where, the communication between tasks are represented by the edges in the graph. Communication between tasks was implemented such that each task was at the distance of one hop from every other task. Task A was further periodic with a period of 10ms while tasks B–F were aperiodic and had additional communication dependencies derived from sensors, though in accordance with the initial assumptions taken in Section1.3, these were neglected.
6
Proposed method
Any method for optimised allocation of system architectures with real-time constraints is subject to several requirements. In order to sufficiently guarantee that no resource in the system ends up over or under-allocated, certain characteristics, such as WCET and periodicity, of the functionality must be assessed. The WCETs, periods, and deadlines of tasks can further be used in a real-time schedulability analysis which, in turn, can be used to provide information on the schedulability of each subsystem, and the system in its entirety.
The proposed method consists of three steps, visualised in Figure8, that all need to be passed in order to guarantee an optimised allocation. The first step is an assessment of the functionality, i.e., the WCET, periodicity, and communication dependencies for each task in the system. These are the necessary preconditions that allow a set of tasks to be optimally allocated across a set of resources. Secondly, the variables defined previously are used to formulate a set of linear constraints and an objective to optimise towards in a step of design space exploration. The third and final step also utilise the initial variables assessed in the real-time analysis by performing an early validation of the system. This is a schedulability analysis in which the schedulability of the individual resources in the system are assessed.
Functional Assessment Design Space Exploration Schedulability Analysis Allocation
Figure 8: Flowchart of the proposed method depicting the possibility of reiterating the design space exploration as a result of the schedulability analysis.
Extrapolating on the first step, this thesis proposes the use of a statistical method for estimating WCET according to [54]. The method is general for a given set of samples — the samples may be collected either by adding additional overhead in the existing functionality or using dedicated hardware timers to measure and sample execution times. It further guarantees that the WCET estimate is only exceeded by future invocations at the same rate as the exceedance probability. Periodicity and communication dependencies should be assessed by manual analysis of the existing codebase. Continuing the extrapolation of each step, the second step is utilising such metrics to optimise the allocation of a system architecture. Accounting for such metrics and systematically mapping processes onto multiple resources is done by applying methods for design space explora-tion. The idea is to formulate the mapping problem as an Integer Linear Program (ILP), which can then easily be solved using an ILP solver. The problem is defined as:
min x f Tx (2) Ax ≤ b Aeqx = beq x ≥ 0 x ≤ 1 x ∈ Z. (3)
Expression2consists of the objective function, f , and the vector, x, containing all the system vari-ables. Equation set3consists of all the linear constraints that define the problem, i.e., equations, inequations, and constraints limiting the system variables to only assume binary values 0 and 1. Matrices A and Aeq are matrices of coefficients, b, beq, and f are vectors of coefficients, while Z is
the set of all integers. These equations can be interpreted as a linear minimisation problem where the variables are binary and are subject to linear constraints. The linear constraints and objective function are then tailored to model the specifics of the architecture being analysed. The linear
constraints are dictated not only by the conventions and logic the implementation set but also by the real-time characteristics of the individual processes.
As the constraints in question cannot ensure, nor enforce, the schedulability of a system, a schedulability analysis is necessary. This forms the third step of the proposed method. This thesis proposes the use of mathematical schedulability tests as said tests can be applied directly after the DSE. This way, unfeasible allocations are discarded at an earlier stage. However, the schedulability test can only be performed after a system allocation has been generated as the results of the schedulability test determine the feasibility of the allocation. If even one task allocated to one resource is proven not to be schedulable, the whole allocation needs to be reconfigured by modifying the linear constraints. This reiteration of the design space exploration step is depicted in Figure8and happens as a result of an unschedulable allocation. It is assumed that all computing platforms are single-core processors, so a uniprocessor schedulability test can be used.
![Figure 1: Three different architectural topologies: centralised (left), decentralised (centre), distrib- distrib-uted (right) [1]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4821967.129908/12.892.190.706.622.829/figure-different-architectural-topologies-centralised-decentralised-distrib-distrib.webp)

![Figure 3: Outline of a multi-methodological research approach [2].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4821967.129908/21.892.190.699.498.974/figure-outline-multi-methodological-research-approach.webp)
![Figure 4: Design-flow of the platform-based design methodology [3]. The figure portrays the methodological relation between application development and architectural development (upper and lower triangles respectively).](https://thumb-eu.123doks.com/thumbv2/5dokorg/4821967.129908/22.892.263.640.265.695/methodology-methodological-application-development-architectural-development-triangles-respectively.webp)
![Figure 5: The process for Systems Development Research [2].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4821967.129908/23.892.369.528.477.843/figure-process-systems-development-research.webp)