ALEKSANDER FABIJAN
DEVELOPING THE RIGHT
FEATURES: THE ROLE AND
IMPACT OF CUSTOMER
AND PRODUCT DATA IN
SOFTWARE PRODUCT
DEVELOPMENT
MALMÖ UNIVERSIT Y , S TUDIES IN C OMPUTER SCIEN CE N O 3, LICENTIA TE THESIS ALEKS ANDER F ABIJAN MALMÖ UNIVERSIT DEVEL OPIN G THE RIGHT FEA TURES: THE R OLE AND IMP A CT OF CUS T OMER AND PR ODUCT D A TA IN SOFTW ARE PR ODUCT DEVEL OPMENT L I C E N T I A T E T H E S I SD E V E L O P I N G T H E R I G H T F E A T U R E S : T H E R O L E A N D I M P A C T O F C U S T O M E R A N D P R O D U C T D A T A I N S O F T W A R E P R O D U C T D E V E L O P M E N T
Malmö University
Studies In Computer Science No 3,
Licentiate Thesis
© Aleksander Fabijan
ISBN 978-91-7104-736-6 (print) ISBN 978-91-7104-737-3 (pdf) Holmbergs, Malmö 2016
ALEKSANDER FABIJAN
DEVELOPING THE RIGHT
FEATURES: THE ROLE AND
IMPACT OF CUSTOMER
AND PRODUCT DATA IN
SOFTWARE PRODUCT
DEVELOPMENT
Electronically available at:
ABSTRACT
Software product development companies are increasingly striving to become data-driven. The access to customer feedback and prod-uct data has been, with prodprod-ucts increasingly becoming connected to the Internet, demonetized. Systematically collecting the feedback and efficiently using it in product development, however, are chal-lenges that large-scale software development companies face today when being faced by large amounts of available data.
In this thesis, we explore the collection, use and impact of cus-tomer feedback on software product development. We base our work on a 2-year longitudinal multiple-case study research with case companies in the software-intensive domain, and complement it with a systematic review of the literature. In our work, we iden-tify and confirm that large-software companies today collect vast amounts of feedback data, however, struggle to effectively use it. And due to this situation, there is a risk of prioritizing the devel-opment of features that may not deliver value to customers.
Our contribution to this problem is threefold. First, we present a comprehensive and systematic review of activities and techniques used to collect customer feedback and product data in software product development. Next, we show that the impact of customer feedback evolves over time, but due to the lack of sharing of the collected data, companies do not fully benefit from this feedback. Finally, we provide an improvement framework for practitioners and researchers to use the collected feedback data in order to dif-ferentiate between different feature types and to model feature val-ue during the lifecycle. With our contributions, we aim to bring
soft-ware companies one step closer to data-driven decision making in software product development.
Keywords. Customer feedback, data-driven development, feature val-ue, feature differentiation
ACKNOWLEDGMENT
First, I would like to thank my main supervisor Helena Holmström Olsson. Her insights and tips on conducting interviews, how to an-alyze the data, and her continuous availability significantly con-tributed to my research. She provided all the necessary guidance throughout this research.
Second, I would like to thank Jan Bosch. Although he contribut-ed to my research in a number of different ways, I would like to emphasize two in particular. First, his engineering mind-set. As be-ing one myself, I really enjoyed workbe-ing with him. Second, he pro-vided continuous critics to my research work, however, never without ideas on what to do to improve it.
I would like to thank everyone at Malmö University that has been involved in the process of this research, especially (1) Bengt J. Nilsson and Ulrik Eklund that are all members of my evaluation group, and (2) my examiner Paul Davidsson. In addition to them, I wish to express my gratitude to Annabella Loconsole, who was re-sponsible to plan my teaching activities and made this process smooth, Romina Spalazzese, whom I also learned a lot from during our common lunches and breaks, and finally Enrico Johansson and Antonio Martini, who provided input to parts of my research and made the research work and experience exciting not only in the of-fice.
Last but not least, a great thank to Software Center companies with which I had a chance to work closer with during this research. Without them, this research would not be possible. The practition-ers in the companies were always supportive and helpful. Their
in-LIST OF PUBLICATIONS
Included papers
[A] Fabijan, A., Olsson, H.H., Bosch, J.: Early Value Argumen-tation and Prediction: An Iterative Approach to Quantify-ing Feature Value. Shorter version of this paper appeared in: Proceedings of the 16th International Conference on Product-Focused Software Process Improvement. pp. 16– 23. Springer, Bolzano, Italy. (2015).
[B] Fabijan, A., Olsson, H.H., Bosch, J.: The Lack of Sharing of Customer Data in Large Software Organizations: Chal-lenges and Implications. In: Proceedings of the 17th Inter-national Conference on Agile Software Development XP2016. pp. 39–52. Springer, Edinburgh, Scotland. (2016).
[C] Fabijan, A., Olsson, H.H., Bosch, J.: Time to Say “Good Bye”: Feature Lifecycle. To appear in: Proceedings of the 42nd Euromicro Conference on Software Engineering and Advanced Applications, SEAA 2016. Limassol, Cyprus. (2016).
[D] Fabijan, A., Olsson, H.H., Bosch, J.: Commodity Eats In-novation for Breakfast: A Model for Differentiating Fea-ture Realization. Shorter version of this paper to appear in: Proceedings of the 17th International Conference on Prod-uct-Focused Software Process Improvement. Trondheim, Norway. (2016).
[E] Fabijan, A., Olsson, H.H. and Bosch, J. “Customer Feed-back and Data Collection Techniques: A Systematic Litera-ture Review on the Role and Impact of Feedback in Soft-ware Product Development”. Submitted to a journal. (2016).
Related papers but not included in the thesis
[F] Fabijan, A., Olsson, H.H., Bosch, J.: Customer Feedback and Data Collection Techniques in Software R&D: A Lit-erature Review. In: Proceedings of the Software Business, ICSOB 2015. pp. 139–153., Braga, Portugal (2015).
[G] A Fabijan, A., Olsson, H.H., Bosch, J.: Data-driven deci-sion-making in product R&D. In: Lect. Notes Bus. Inf. Process. vol. 212, pp. 350–351, XP 2015, Helsinki, Fin-land (2015).
Personal contribution
For all publications above, the first author was the main contribu-tor with regard to inception, planning, execution and writing of the research.
TABLE OF CONTENT
ABSTRACT ... 7
ACKNOWLEDGMENT... 9
LIST OF PUBLICATIONS ... 11
Included papers ... 11
Related papers but not included in the thesis ... 12
INTRODUCTION ... 17
BACKGROUND ... 21
The Role of Feedback in Product R&D ... 21
Collection and Use of Customer Feedback ... 23
Feature Differentiation and Lifecycle ... 24
RESEARCH DESIGN AND METHODOLOGY ... 27
Case Study Research ... 27
Software Center Collaboration ... 28
Case Companies ... 29
Software Center Sprints ... 30
Design and Methodology of our Research ... 31
Research Design and Activities ... 31
Data Collection ... 34
Data Analysis ... 38
Threats to Validity ... 39
PAPER OVERVIEW ... 41
Paper [A]: Early Value Argumentation and Prediction: an Iterative Approach to Quantifying Feature Value ... 43 Paper [B]: The Lack of Sharing of Customer Data in Large
Paper [C]: Time to Say 'Good Bye': Feature Lifecycle ... 47
Paper [D]: Commodity Eats Innovation for Breakfast: A Model for Differentiating Feature Realization ... 49
Paper [E]: Customer Feedback and Data Collection Techniques: A Systematic Literature Review on the Role and Impact of Feedback in Software Product Development ... 51
DISCUSSION ... 53
Contributions to the research questions ... 54
RQ1: How can customer feedback and product data be collected and used in software-intensive companies? ... 54
RQ2: How does customer feedback impact R&D activities in software-intensive companies and how does this impact evolve over time? ... 61
RQ3: How can software-intensive companies use customer feedback to steer feature development? ... 64
Future work ... 69
CONCLUSION ... 71
BIBLIOGRAPHY ... 73
APPENDIX ... 79
PAPER [A]... 81
Fabijan, A., Olsson, H.H. and Bosch, J. ‘‘Early Value Argumentation and Prediction: An Iterative Approach to Quantifying Feature Value’’. ... 81
PAPER [B] ... 111
Fabijan, A., Olsson, H.H. and Bosch, J. ‘‘The Lack of Sharing of Customer Data in Large Software Organizations: Challenges and Implications’’. ... 111
PAPER [C] ... 135
Fabijan, A., Olsson, H.H. and Bosch, J. ‘‘Time to Say 'Good Bye': Feature Lifecycle’’. ... 135
PAPER [D] ... 163
Fabijan, A., Olsson, H.H. and Bosch, J. ‘‘Commodity Eats Innovation for Breakfast: A Model for Differentiating Feature Realisation’’. ... 163
PAPER [E] ... 193 Fabijan, A., Olsson, H.H. and Bosch, J. ‘‘Customer Feedback and Data Collection Techniques: A Systematic Literature Review on the Role and Impact of Feedback in Software
Product Development’’. ... 193 APPENDIX A – LITERATURE SELECTION ... 237
INTRODUCTION
“A customer is the most important visitor on our premises, he is not dependent on us. We are dependent on him. He is not an in-terruption in our work. He is the purpose of it. He is not an outsider in our business. He is part of it. We are not doing him a favour by serving him. He is doing us a favour by giving us an opportunity to do so”
~ Mahatma Gandhi Learning from and about customers is the essential unit of progress for companies employing agile development practices [1]. Whether developing a new product or improving an existing feature, only by learning what the customer needs are and validating how their so-lution addresses them in every iteration, it is clear if progress was made and value created. In this context, efficiently collecting and learning from customer feedback is the main challenge for software companies to be on par with their competitors where competing, and to innovate where they aim to excel [2].
Software development companies and their product development teams have been reaching out to customers since the era of tradi-tional waterfall development [3], [4]. The collection of customer feedback has always been important for R&D teams in order to better understand what customers want. Interviews, surveys, ob-servations and focus groups are only a few techniques that have regularly been used to involve with the customers and collect feed-back on software products. Today, in the era of agile software de-velopment and ‘Big Data’, and with products increasingly getting connected to the Internet, the qualitative techniques above are
be-18
ing complemented with quantitative and automated data collection [5], [2], [6], [7].
Not only that the quantitative collection can be cheaper and faster, the actual product usage data has the potential to make the prioritization process in product development more accurate [7][8]. The reason for that is the continuous collection of user activity throughout the product lifecycle, which focuses on what customers do rather than what they say [7], [9], [10].
Today however, more data is available than ever before to learn about customer habits, needs and preferences [11]–[13]. From the user perspective, products such as connected car are now becoming platforms where new types of content (e.g. relevant news, travel tips, status of home appliances) are being consumed. In addition, the communication channels are bi-directional. This means that new forms of expression, opinions and preferences can be captured and communicated as feedback to the product development organ-ization. In-product surveys, feature usage, and marketing of other products suddenly became new communication practices that are available for the users of once isolated products [2]. The users of these products are not only the consumers, but by contributing and providing feedback also co-creators of better products and valuable content [14], [15], [16].
How to benefit from these increasing amounts of data and syn-thesize it to learn from customers, products and other sources of feedback, is one of the main challenges that software industry ex-periences today [11],[17], [18].
The amount of software in products is rapidly increasing. At first, software functionality was required in order to support tangi-ble hardware without delivering any other perceptitangi-ble value for the customers. Organizations accepted developing the software as a necessary cost without exploring the value of software features as such [19]. Today, however, once isolated systems and hardware-only components such as connected cars and radio systems contain logic that enables them to communicate over the Internet,
change information and self-improve over time. Software features suddenly became the main competitive advantage of the product, and at the same time, the detail that delivers value to the customers [20], [21].
Using the feedback to predict and validate which features in the products actually deliver the value to the customers and how to quantify it is, however, challenging [8]. New features cost to de-velop, operate, can be expensive to support, and always increase the overall product complexity [22], [23]. Surprisingly, and despite knowing this, companies celebrate when a new feature is complet-ed and ready to be deploycomplet-ed to customers, even though the opening of the champagne should be kept aside until it is clear what value the new feature delivers. Transition to become value-driven within the organization comes with pain points for both the technology and organization [24].
Companies are adopting techniques to validate the value of the features during development, shortly after and while they are being deployed [10], [25], [26]. The remainder of the feature lifetime is, however, considered to be forgotten. Very little is known on how to track feature value over its lifetime. When is it optimal to actual-ly introduce the feature in the product and, more importantactual-ly, what to do when a feature no longer adds value to the product?
To summarize, there are two main challenges that prevent soft-ware companies from closing the ‘open loop’ between them and their customers: First, companies struggle to efficiently collect cus-tomer feedback and benefit from increasing amounts of data. Se-cond, companies fail to differentiate between features and model how the value of features in changes over time.
Based on the challenges, we aim to answer the following three re-search questions:
20
RQ1: How can customer feedback and product data be collected and used in software-intensive companies? RQ2: How does customer feedback impact R&D activities
in software-intensive companies and how does this im-pact evolve over time?
RQ3: How can software-intensive companies use customer feedback to steer feature development?
This thesis provides a threefold contribution that is applicable to companies employing large-scale software development practices:
• We present a comprehensive and systematic review of ac-tivities and techniques used to collect customer feedback and product data in software product development.
• We show that the impact of customer feedback evolves over time, but due to the lack of sharing of the collected data, companies do not fully benefit from this feedback. • We provide an improvement framework for practitioners
and researchers to use the collected feedback data in order to differentiate between different feature types and to mod-el feature value during the lifecycle. With this framework, we give software companies guidelines on how to prioritize development activities based on the type of the feature be-ing developed and the realized feature value.
The thesis is structured as follows. In the next chapter, we out-line our theoretical background and all the components necessary to discuss our work. Next, we describe our research design and methodology, based on the case study and review of literature. In the Papers Overview chapter, we present the included publications. Next, we discuss our publications in relation to the research ques-tions above. The thesis ends with the conclusions drawn from this set of studies.
BACKGROUND
In this section, we present the role of customer feedback as de-scribed in the research literature. We start by introducing the topic of customer feedback and provide a number reasons why collecting and using feedback in software product development matters. Next, we provide an overview of the different ways that companies collect and use feedback in software product development. We rec-ognize that software development companies strive towards using the feedback data in order to very early and efficiently prioritize product development activities, however, fail to achieve this. As companies develop many features at a time, they need to be able to differentiate them in order to know how and to which extent to develop them, and when to deploy or remove them from the prod-uct.
The Role of Feedback in Product R&D
Rapid delivery of value to customers is one of the core priorities of software companies [26]. With many ideas and opinions on what might be good for the business and customers, however, it is im-portant to prioritize those that inherently deliver value, and discard those that do not. In order to achieve this and develop only the fea-tures and products that customers appreciate, software develop-ment companies and their product developdevelop-ment teams collect
cus-22
tomer feedback. Customer feedback steers software product devel-opment in a number of different ways.
In product management literature [27], [28], [2], customer feed-back is considered as a source of knowledge for many scenarios. First, it is used as input to steer development activities of ongoing and existing products [2]. Next, the collection of customer feed-back provides companies with a competitive advantage during the innovation process [29]. This was recognized already by Von Hippel [27] in 1986. He discovered that certain groups of users, namely ‘lead users’ experiment with the products and services, and that they should be considered as a source of feedback used for in-novating new features or products, a concept that is used today in various product and service companies.
In Requirements Engineering [4] research, the term feedback re-fers to the comments and evaluations that users express upon hav-ing experienced the use of a software application or service. With this information, companies learn how their customers use the products, what features they appreciate, and what functionality they would like to see in new products [30].
In Web 2.0 domain, customer feedback has extensively been col-lected and used to experiment with the customers throughout the development process. By running continuous controlled experi-ments [6], [31], [32], [18], companies use customer feedback in or-der to confirm their hypothesis on the actual value of their devel-opment efforts. This enables them to incrementally improve their products and innovate over time.
In summary, customer feedback has a large impact on steering product development throughout the development pipeline. In the next section, we provide an overview of the different ways to col-lect customer feedback.
Collection and Use of Customer Feedback
In the previous section, we provided a brief overview the different ways that customer feedback impacts product development. In this section, we illustrate the different ways that customer feedback can be collected and used.
On a high level, customer feedback collection techniques span from qualitative techniques capturing customer experiences and behaviors [1], [2], towards quantitative techniques capturing prod-uct performance and operation [5], [2].
Qualitative customer feedback collection techniques typically re-quire active participation from customers and generate a small amount of qualitative feedback. The strength of such techniques is their ability to provide rich textual descriptions, opinions, and in-formation of how individuals experience a given situation [33]. As such, they provide in-depth information about the ‘human’ side of a situation and they reveal peoples’ perceptions of a given phenom-enon [33]. Examples of qualitative techniques are e.g. interviews [1], [2], user studies [34], [35], experience querying [36], [37], usa-bility studying [38], filming and observations [1], [2] etc.
Quantitative customer observations, on the other hand, focus on instrumentation and data from products in the field. Examples of quantitative techniques of customer feedback collection are e.g. operational data collection [39], [7], sentiment analysis [40] and controlled experimentation [31], [32], [18].
Regardless of the type of the technique that the data is being col-lected, however, the main goal of the collection activities is to pro-vide input to product development to (1) know what to develop or improve next [41], [31], [42], [8] and (2) how to prioritize it [7], [10], [25]. And to correctly decide on both, measuring the value of features in product is of significant importance. For this purpose, experimentation with the products used by the customers is a re-search area gaining momentum. The Hypex model [10] was the first attempt to support companies in initiating, conducting and
24
evaluating feature experiments, focusing on shortening the feed-back loops during the development of a feature. Olsson et [10] al. suggest to deploy a minimal viable instance of the functionality under development to customers, collect relevant quantitative feedback in metrics, and compare the measurement to previously defined and expected behavior. The Hypex model builds on the ‘Build-Measure-Learn’ methodology presented by Eric Ries [42] which was recognized and advocated as a scientific approach for creating, managing, and deploying a desired product to customers in the Lean Methodology. To complement the primary quantitative Hypex model, the QCD model [25] was developed as a response to the needs to integrate qualitative customer feedback in the experi-mentation process. It helps companies to move away from early specification of requirements and towards continuous validation of hypotheses by combining different types of feedback data and lev-ering the strength of synthesis and triangulation. Fagerholm et. al [43], [26], similarly, provided a process for continuous experimen-tation with software-intensive products that consists of building blocks, following the lean Start-up methodology [44].
In the next section, we describe the use of customer feedback to differentiate feature types and measure their value over time.
Feature Differentiation and Lifecycle
Conducting experiments as described above typically aims to iden-tify which features deliver value to customers [25], [32]. Using feedback to define the value of a feature or a product from the cus-tomer point of view is an increasingly studied concept in the litera-ture [45], [46], [47]. Porter’s [46] value chain framework, for ex-ample, analyzes value creation at the companies level that identifies the activities of the firm and then studies the economic implications of those activities. Hemilä et al. [47] divide the benefits of a prod-uct or a feature among four types, i.e. functional, economic, emo-tional and symbolic value.
However, and as a consequence of another step in the development pipeline, experimentation has the potential to delay feature ployments and take time and resources away from the feature de-velopment. For this purpose, and to shorten development cycles, companies seek to identify ways of differentiating between features that should be extensively developed and experimented with, and features where being on-par with the competitors will be sufficient [22]. To recognize the importance of distinguishing between differ-ent types of functionality from a complexity point of view, Bosch [22] developed the ‘Three Layer Product Model’. The model pro-vides a high-level understanding of the three different layers of fea-tures, i.e. commodity, differentiating and innovative, however, does not give guidance on how to distinguish between the different types, neither which activities to invest into for each of them. Pre-vious research shows that the number of requests and ideas that originate from customer feedback often outnumbers available en-gineering resources [48]. Having a clear plan of which features to develop to what extent is thus essential for successful product de-velopment.
And as new software features are being developed and intro-duced to the product, existing products and features age and be-come over time less and less amenable to necessary adaptation and change [49], [50], [22]. As companies have been successful in re-moving developing constraints [51] and advancing towards contin-uous integration[52] and contincontin-uous deployment [53], [3], they deploy more features to their products as ever before. And with more features, the products often results in higher maintenance cost and overall product complexity [22], [23]. Due to this reason, introducing new features to customers using the product should be done systematically when they deliver value, not when they are de-veloped. And when operational costs exceed the return on invest-ment, features should be removed from the product before the re-moval costs more than the operation. Very little is known in the
26
literature on how to model feature value, how it changes over time and how to use novel approaches to feature development such as e.g. continuous experimentation to influence it.
To summarize, customer feedback has the potential to steer product management in differentiating and developing features that will deliver value to their customers. However, without a framework that practitioners can use to know which features to develop to what extent, when to introduce them to- and which ones to remove from products and when, companies risk to waste development resources. In the remainder of this thesis, and based on the longitudinal multiple-case study that we present in the next section, we confirm that this situation is indeed an issue and that companies do not fully benefit from the feedback data that they collect.
RESEARCH DESIGN
AND METHODOLOGY
In this section, we describe our research strategy. In principal, we conducted a longitudinal multiple-case study research with case companies. We start by first introducing the case study research methodology and explain how it relates to our research challenges. Next, we introduce the Software Center, an industry-academia col-laboration that enabled us to conduct this research and the case companies we worked with. Finally, we detail how we applied the described methodology in our research.
Case Study Research
Case study research is a strategy used to investigate individual, group, organizational or social phenomena [54]. It is typically used to explain ‘how’ and ‘why’ type of questions that require an exten-sive and in-depth understanding of the phenomenon being studied [54], [55]. As a result, case studies can provide descriptions, test theories, or generate them. The case study strategy focuses on the dynamics within the setting and can involve either single or multi-ple cases, [55], [56]. Selection of cases is an important aspect of building theory from case studies. It is typical for case studies to perform multiple techniques of data collection such as conducting
28
interviews, writing field notes, conducting observations and focus groups, etc. [54], [56]. Both qualitative (e.g. interview statements) and quantitative (e.g. frequency of counts of some variable) types of data can be collected while conducting a case study. To under-stand and detail every case being studied, a case study typically in-volves within-case studies, which are central for insight generation and help researchers to cope with the often large quantities of data [56]. And by capturing the collection and analyses process over a period of time, a case study can be developed into a longitudinal case study [57].
Software Center Collaboration
As briefly mentioned above, selecting the right cases for a case study is of significant importance. Motivated by our research ques-tions that address challenges related to large-scale software devel-opment companies, we conducted our research as part of a collab-oration with Software Center. Software Center is a collabcollab-oration between companies and universities in the Nordic region in Europe that consists of a wide range of projects. At the moment of writing this thesis, there are five universities and ten companies collaborat-ing in Software Center on multiple projects at the same time. The universities are the following; Chalmers University, Gothenburg University, Malmö University, Linköping University and Mälardalen University. The companies, on the other hand, are the following: Axis Communication, Ericsson, Grundfos, Jeppesen, Saab, Siemens, Tetra Pak, Verisure, Volvo Cars and Volvo Trucks. As the name Software Center depicts, companies in this collabora-tion develop products and services consisting solely of, or support-ed with, software. Each of the companies employs several thou-sands of practitioners.
Below, we describe the case companies involved in our research and the sprints methodology of working with them.
Case Companies
Our longitudinal multiple-case study has been conducted as part of an ongoing work with one of the Software Center projects. In this project, we worked with five case companies that are involved in large-scale development of software products. Although we met with other companies that are part of the collaboration as well (and are in-volved in the same project), we studied in detail five of them. This is due to the availability of practitioners and the resources available. Four of the companies are based in Sweden, however, they conduct work in multiple sites around the world. The fifth company is based in Denmark. We briefly describe the case companies next.
• Company A is a provider of telecommunication systems and equipment, communications networks and multimedia solu-tions for mobile and fixed network operators. It is a multina-tional company with headquarters in Sweden. The company employs over hundred thousand employees worldwide and owns several thousands of patents. Throughout the longitu-dinal study, we met with representatives from three different sites. The first two sites are in two cities in Sweden. The third site is in China.
• Company B is a software company specializing in naviga-tional information, operations management and optimiza-tion soluoptimiza-tions. Their focus is in providing software soluoptimiza-tions with accurate and timely navigational information. The company’s headquarters are in the US and they have offices in more than fifty countries. Throughout the longitudinal study, we met with practitioners that primary work in Swe-den.
• Company C is a manufacturer and supplier of transport so-lutions, construction technology and vehicles for commercial use. They specialize in producing transport solutions that op-timize their customers’ needs in many different domains. The
30
company’s headquarters are in Sweden, however, their prod-ucts are sold and used in most of the countries worldwide. • Company D is a world leading company in network video
and offers products such as network cameras, video encod-ers, video management software and camera applications for professional IP video surveillance.
• Company E is a manufacturer and supplier of pump systems. They produce circulator pumps for heating and air condi-tioning, as well as centrifugal pumps for transporting liquids. The company’s headquarters are in Denmark. They employ about twenty thousand employees and for the purpose of this research, we met with representatives of the company from their headquarters office.
Software Center Sprints
Researchers from partner universities collaborate with company practitioners on an ongoing basis. The work is organized in two six-months sprints per a calendar year. During a typical sprint, company practitioners and university researchers with similar in-terests meet on a regular basis to identify current research chal-lenges, advance on-going research, coordinate work, or to present and validate the findings. As research projects normally do not have immediate impact, maintaining organization interest is essen-tial with both presenting on-going work as well as communicating results [58].
A typical sprint starts with a joint “kick-off” workshop session where case company practitioners and researchers meet to agree on a research focus of the sprint. Multiple companies present their challenges related to the project domain and an agreement on a common and most important topic is selected for the focus of the sprint. At the same time, activities for the rest of the sprint are planned. The focus of the sprint is then further discussed on indi-vidual workshops with each of the case companies that wish to participate in the sprint. Researchers in the sprint typically
up the workshop with a number of individual interviews with the participants. Aggregated data is analysed by the researchers and findings are validated with each of the case companies in a validat-ing session. This session is typically near the end of the sprint and is in a form of a reporting workshop with all of the case compa-nies. In addition to the research activities above, Software Center days are organized at least once per year where all of the compa-nies and universities meet and discuss recent research and industry challenges.
Design and Methodology of our Research
As mentioned above, we decided to conduct a longitudinal multiple case study. As this type of research design involves a repeated ob-servation of the phenomena studied over a period of time in multi-ple cases [55], sprints in Software Center were a good fit. We de-scribe the research activities and the data collection and analysis in the remainder of this section.
Research Design and Activities
We conducted our study in four sprints. In the first sprint, we in-vestigated the potential of customer feedback to steer data-driven decisions early in product development. In the next sprint, we in-vestigated how companies collect and use customer feedback in conducting data-driven decisions throughout a product and feature lifecycle. In the third sprint, we investigated how customer feed-back enables companies to differentiate product features and prior-itize product management decisions to maximize feature value over time. Finally, and in the sprint that started in August 2016 and will last until December 2016, we focus on modelling the value of the product and using continuous experimentation as a driver for business innovation.
32
Sprint 1: The first sprint started in January 2015 and lasted until July 2015. In this sprint, we first conducted a literature review that focused on the feedback data collection practices as identified in the software engineering research. For details see reference to Paper [F]. In parallel, we followed the Software Center sprint activities as outlined in the previous section. The initial cross-company work-shop session took place in January 2015 in Göteborg, Sweden. Par-ticipants from five case companies involved in the project of data-driven development were present at this session. The joined work-shop served as a platform to introduce our previous research and other experience with data-driven development practices. The par-ticipants and researchers agreed to focus the sprint on feature ex-perimentation. All of the five companies agreed that they already collect data from their products and their customers in order to better understand and debug their products. What they were strug-gling with is to use the same data in product development to priori-tize feature development (e.g. identify how the value of a feature changes when a change in the system is deployed). We followed the development of the work in three of the case companies by (1) par-ticipating in company-specific workshops at each of the three com-panies and conducting individual interviews with company repre-sentatives (2 with practitioners from company A, 2 with practi-tioners from company B, and 2 interviews with participants from company C). We presented our results and validated our findings with the case companies at the end of the sprint, where all five case companies provided input on the findings. At the same time, each of the case companies presented their learnings and sprint results to other companies and researchers. In addition to the research activi-ties above, we organized two Software Center days (one at Com-pany A and one at Malmö University) with all of the case compa-nies participating.
Sprint 2: The second sprint started in August 2015 and lasted until January 2016. We started with a cross-company workshop meeting
with the researcher and company representatives from the five case companies to decide on the sprint activities. The practitioners and researchers agreed to focus the sprint on identifying the different techniques used to collect customer feedback and product data. We conducted company-specific workshops with three of the case companies. During the individual workshop sessions, we conduct-ed a post-it exercise where the practitioners were askconduct-ed to write down the different techniques that they use to collect feedback on the products that they develop. Each of the workshops was fol-lowed-up by individual interviews with practitioners at each of the three case companies that were chosen for a deeper study. In prin-cipal, this was an embedded multiple-case study with three case companies. We compared and synthesized the ways that our case companies collect and more importantly, use customer feedback to impact product development activities. On average, the interviews lasted 60 minutes. In total, we conducted twenty-two interviews with 13 open-ended questions. In addition to the research activities above, we organized a Software Center day at Company C with all of the case companies participating. We concluded the second sprint by presenting our results in a cross-company workshop at the end of the sprint, which also served as a validation session. Sprint 3: In the third sprint that was taking place between January 2016 and July 2016, we performed another level of analysis on the data that was collected in the first two sprints. As our questions were initially open-ended and covered several aspects of our inter-est, we could analyze how companies use the feedback data to dis-tinguish types of features and how they model their value over time. We triangulated this data with three company-specific work-shops at each of the case companies and by conducting a systemat-ic literature review that is appended to this thesis as Paper [A]. The findings were validated throughout the sprint and in a cross-company workshop at the end of the sprint.
34
Sprint 4: The ongoing sprint four started in August 2016. So far, we have initiated contact with the case companies and agreed on the focus of the sprint. We scheduled company-specific workshops with three of our case companies and informed the practitioners about planned follow-up interviews. The sprint will last until De-cember 2016 and during this sprint, we focus on extending the concept of modelling feature value throughout the development process towards modelling product value and using continuous ex-perimentation to drive product innovation.
Data Collection
During our longitudinal study, we carried a number of activities to collect data. First, we conducted a number of joint and individual workshops with each of the case companies. Second, we conducted open-ended interviews with individual practitioners from these companies. All workshops and interviews were conducted in Eng-lish. We describe the format of each of the data-collection activities next.
• Cross-Company workshops: Joint workshops were conduct-ed with practitioners from all of the case companies. During the joint workshops we asked open-ended questions and took field notes by writing our observations and what re-spondents answered. As mentioned above, in the beginning of the sprint the joint workshop served to establish a com-mon agreement between the companies and researchers on the focus of the sprint. The results were presented and find-ings validated in the joined workshop at the end of the sprint.
• Company-specific workshops: Individual workshops served as an activity where more company specific questions could be asked. We held the individual workshops with three of the case companies involved in this research due to resource limitations. At the individual workshops, we conducted fo-cus groups sessions, where topics of interest were disfo-cussed.
At each of the workshops, we took field notes that captured not only what the participants said, but also the way the said it (e.g. the emotional responses behind their statements). • Interviews: We interviewed in-depth the practitioners that
participated in the joined and individual workshops. The in-teractive nature of the interviews was helpful to capture and develop interesting and unexpected themes brought-up by the interviewee. The interview format started with an intro-duction and a short explanation of the research being con-ducted. Participants were then asked on their experience with the research focus. We also asked for examples on suc-cesses, pitfalls, and pain points that they experience with the focus topic of a sprint.
36
Collected Data: During sprint 1, we collected 32 pages of qualita-tive data that consisted of field notes and interview transcriptions. During the second sprint, we collected 13 pages of workshop notes, 176 post-it notes, 138 pages of interview transcriptions, and 9 graphical illustrations from the interviewees. During the third sprint, we collected 8 pages of qualitative text. In the ongoing sprint, the data collection activities only started and what we col-lected so far are 2 pages of e-mail communications.
We visualize the high-level data collection activities and interac-tions with our practitioners in Timeline 1 below.
Timeline 1. Data collection activities visualized.
Below, we present the detailed roles of practitioners from the three case companies A, B and C, with whom we conducted several in-depth studies throughout this longitudinal research. We summarize their involvement in our research throughout the three completed sprints by marking how and where they contributed with “x” in Timeline 2.
Timeline 2.
Interactions
with practitioners.
Below, we present the detailed roles of practitioners from the three case companies A, B and C, with whom we conducted sev-eral in-depth studies throughout this longitudinal research. We summarize their involvement in our research throughout the three completed sprints by marking how and where they con-tributed with “x” in Timeline 2.
Tim
elin
e 2
. I
nt
era
ct
io
ns
w
ith
p
ra
ct
iti
on
ers
.
38
Data Analysis
During analysis, the workshop notes, interview transcriptions and graphical illustrations were used when coding the data. The data collected were analyzed following the conventional qualitative con-tent analysis approach [59], where we derived the codes directly from the text. We describe the method in detail below.
Analysis method. We read raw data word by word in order to de-rive codes. In this process, we first highlighted individual phrases that captured our attention in the transcriptions. We used color coding to highlight different topics that emerged during the analy-sis process. In this process, we reflected on the highlighted text sev-eral times and took notes. As this process continued for a few itera-tions (e.g. by analyzing the first few interviews), codes emerged from the highlights. In the next step, we sorted these codes into categories (e.g. grouping them by color). This type of design is ap-propriate when striving to describe a phenomenon where existing theory or research literature is limited. After we emerged with a few codes, we created definitions for those codes and continued to code the rest of the data using the definitions. We deducted subcat-egories from a code category in the later iterations. As we show on the example in Table 2, The high-level category “Use of feedback data” was further deducted into subcategories (“use purpose”, “use challenge”, and “use destination”). The advantage of this ap-proach was that we gained information from study participants without imposing preconceived categories. And since the amount of data was manageable, we did not use advanced coding tools during this study. We first independently and then jointly analyzed the collected data by following the approach above and derived the codes that were consolidated with an independent researcher that also participated in joint data-collection activities.
In Table 1, we show a coding example from the empirical data. Raw
Text
And internally use it as powerful information to improve our
prod-ucts and features and align our offer with the actual needs.
Code Tree
USE OF FEEDBACK DATA
• USE PURPOSE
• USE CHALLENGE
• USE DESTINATION
Table 1. Coding example.
Threats to Validity
To improve the study’s construct validity, we used multiple tech-niques of data collection (e.g. workshops, interviews, post-it exer-cises) and multiple sources of data collection (Product managers, software engineers, Sales representatives). Meeting minutes from the workshops and interview transcriptions were independently as-sessed by three researchers to guarantee inter-rater reliability. Since this study builds on an ongoing research with the Software Center companies, the participants were familiar with the research topic and expectations between the researchers and participants were well aligned. Using a ‘venting’ method, i.e. a process whereby in-terpretations are continuously discussed with professional col-leagues, we iteratively verified and updated our theories. As soon as any questions or potential misunderstandings occurred, we veri-fied the information with the participating representatives from the case companies. The external validity of our research results is lim-ited to large-scale software companies that are transitioning from e.g. mechanical or electrical-first to software-first type of compa-nies. The main results of this study cannot be directly translated to other companies. The concepts, however, are discernible and rele-vant to other domains as well as the collection, use and impact of customer feedback and product data is a topic of discussion in eve-ry product or service development company.
40
PAPER OVERVIEW
In this section, we summarize our papers and present the main re-sults from each of them. Figure 1 shows the relations below the five included papers (4 published to international scientific confer-ences, 1 in submitted to a journal) and 2 excluded papers (1 pub-lished at an international conference, 1 pubpub-lished at a doctoral symposium).
42 .
Fi
gure
1.
Re-latio
ns
be-twee
n
pa-pers.
42 44 .Fi
gu
re
1.
R
ela
tio
ns
b
et
ween
p
ap
ers
.
Paper [A]: Early Value Argumentation and Prediction: an
Iterative Approach to Quantifying Feature Value
Problem. In Paper [A], we investigated how to use feedback data that our case companies already collect to identify the value of a feature that is under development early in the development cycle. Specifically, the paper is addressing a situation where a minimal viable version of a feature has been developed and product devel-opment requires advice to either invest further in the develdevel-opment of the feature, or pivot the investments to other features.
Findings. Our findings indicate that predicting value for features under development is possible with the data that is already being collected by our case companies. Furthermore, we demonstrate with four feature experiments in Paper [A] that product manage-ment in large organizations can correctly re-prioritize R&D in-vestments to allocate resources to projects that will capture it. Contribution. We developed an actionable technique that practi-tioners in organizations can use to validate feature value early in the development cycle.
44
Paper [B]: The Lack of Sharing of Customer Data in Large
Software Organizations: Challenges and Implications
Problem. In this paper, we investigated in detail on how large software companies collect and use customer feedback and product data. We were interested which techniques do practitioners in dif-ferent stages of the product development (e.g. in the pre-development, development and post-deployment) use to collect feedback from their customers and products.
Findings. Based on the case study research in three large software-intensive companies, we provide empirical evidence that lack of sharing of customer feedback and product data is the primary rea-son for insufficient use of customer data.
Contribution. Based on the empirical data that we collected, we developed a model in which we identify what feedback data is col-lected by what role, how it is used within the development stage, and how it is shared across the development stages. In particular, we depict the critical hand-over points where the data gets ‘lost’ and collection activities are repeated.
46
Paper [C]: Time to Say 'Good Bye': Feature Lifecycle
Problem. In Paper [C], we propose and study the concept of a software feature lifecycle, i.e., how does feature value change over time.
Findings. We identified that as a consequence of poor sharing of customer feedback across the organization, teams at different stag-es of the development cycle interpret feature value in their own and known way. In practice, this causes collisions on what to optimize a feature for, how much, and whether it delivers value.
Contribution. This paper is addressing the problem by providing a ‘Feature Lifecycle Model’. The main contribution of is a single-metric model (see its visualization on Figure 4) that can be used to identify when to add a feature to a product (A), which activities to prioritize during the growth period (C), and how to act when fea-ture value starts to decline(D) and become negative (E) by remov-ing it from the product before it’s operation costs becomes greater than its removal.
48
Paper [D]: Commodity Eats Innovation for Breakfast: A
Model for Differentiating Feature Realization
Problem. In Paper [C], we developed a model that can be used to measure and validate feature value over time. During that study, however, we got an indication that value for all features cannot be expressed in the same way and that different activities need to be prioritized for different types of features.
Findings. What we identify and confirm in Paper [D] is that com-panies typically do not differentiate between feature types (e.g. which are the innovative features that should be developed exten-sively and which not). Consequently, the development activities are prioritized evenly and every feature that the companies develop is extensively developed and optimized.
Contribution. In response to this issue, we develop a model that helps companies to differentiate between different types of features and correctly prioritize activities for each of the types.
50
Paper [E]: Customer Feedback and Data Collection
Tech-niques: A Systematic Literature Review on the Role and
Im-pact of Feedback in Software Product Development
Problem. In our empirical research, we identified that the collection and use of customer feedback is unsystematic. Although practition-ers collect feedback data or know othpractition-ers that perform these activi-ties, there is a lack of a common model that would illustrate all the data-collection activities in a certain stage of a product develop-ment and data that originates from them.
Findings. In this paper, we provide a comprehensive overview of the sources of feedback data, the different activities and techniques documented in the research literature to collect these data, and the impact of it on product R&D
Contribution. We provide a systematic identification of activities and categorization of feedback collection activities and sources of feedback data. In addition, we categorize them in a 2-2 model (see Figure 6) and recognize their impact on software product develop-ment.
52
DISCUSSION
Today, more data is available than ever before to learn about cus-tomer habits, needs and preferences [11]–[13]. Companies collect data using qualitative techniques capturing customer experiences and behaviors [1], [2], [34], [36], [37] [38] and quantitative tech-niques capturing product performance and operation [5], [2], [39], [7], [40] [31], [32], [18]. Although most of the data typically serves as evidence to develops and debug products [39], we show in Paper [A] that using feedback data early in the development stage enables companies to correctly prioritize development activities and cap-ture value. However, and although the data exists in their data-bases, companies are not able to efficiently learn from these data and close the ‘open loop’ between them and their customers [8]. We identify in our research that lack of sharing of feedback data within the organization is the primary reason for this situation. Due to this, companies do not fully benefit from the learnings that they collect (see Paper [B]). In response to this situation, a number of models for experimenting with products and their features [10], [25], [26] building on top of the ‘Lean Startup’ practices [44], [42] has been developed. And although these models can be used to as-sess the value of a feature ad-hoc in a given point in time, they do not provide mechanisms to follow-up on how it changes through time and what activities to do to have an effect on it. As a conse-quence, companies do not know when to introduce a feature, to
54
what extent it should be developed, or when to remove it from a product. We address this issues separately by providing a ‘Feature Lifecycle Model’ (see Paper [C]) and ‘Feature Differentiation Mod-el’ (see Paper [D), and synthesize them below in what we name “The Feature Differentiation and Value Modelling Framework”.
The framework leverages the systematic collection of customer feedback (for details on the techniques and sources of feedback see our systematic literature review in Paper [E]). ‘Feature Lifecycle Model’ enables companies to identify critical points in a feature lifecycle (e.g. when to introduce a feature to a product, how to pro-ject the value of the feature over time, and when to remove it from the product). ‘Feature Differentiation Model’, on the other hand, enables practitioners to differentiate between feature types to be able to optimally prioritize the development activities (e.g. which features are differentiating or innovative and should be extensively developed, and which not).
Below, we discuss our contributions to each of the research ques-tions in detail.
Contributions to the research questions
RQ1: How can customer feedback and product data be
col-lected and used in software-intensive companies?
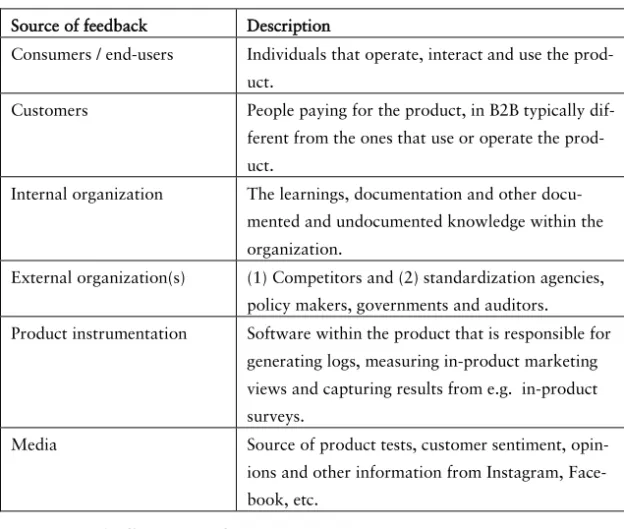
We addressed this research question in two streams in parallel. First, we conducted a systematic literature review of customer feedback and data collection techniques. We analyzed 71 papers on this subject and identified 15 high level feedback collection activi-ties, each with a number of techniques to collected feedback from 5 different sources of data. The sources of feedback that we recog-nized are: customers, users, regulators, product instrumentation and internal organization. We present them in detail in Table 2.
Source of feedback Description
Consumers / end-users Individuals that operate, interact and use the
prod-uct.
Customers People paying for the product, in B2B typically
dif-ferent from the ones that use or operate the prod-uct.
Internal organization The learnings, documentation and other
docu-mented and undocudocu-mented knowledge within the organization.
External organization(s) (1) Competitors and (2) standardization agencies,
policy makers, governments and auditors.
Product instrumentation Software within the product that is responsible for
generating logs, measuring in-product marketing views and capturing results from e.g. in-product surveys.
Media Source of product tests, customer sentiment,
opin-ions and other information from Instagram, Face-book, etc.
Table 2. Sources of Feedback.
Next, we organize the activities in three groups following the stag-es of a product development cycle. First, we list and dstag-escribe the activities and data collection techniques that are used early in the development cycle, i.e. in the pre-development stage. We recog-nized five high-level activities in this stage with a number of feed-back techniques under each of the activities. We briefly describe them in Table 3.
56
Activity name Techniques Description
Requirements elicitation
Interviews, user studies, viewpoints, scenarios, use cases, ethnography
Elicitation, analysis, valida-tion and management of product requirements.
Storyboarding User stories capturing, notes
keeping, card or post-its sort-ing exercises
Graphically organizing illus-trations or images displayed in sequence to simulate a product behavior. Experience
que-rying
Exchanging e-mails, reading content from internal sites, browsing customer relation-ship databases
The different ways that dev. organization communicates and exchanges knowledge about the customers and previous products. Usability
study-ing
Usability Interviews Monitoring how end-users
perform specific tasks, focus-ing on identifyfocus-ing gaps and situations that confuse the end-users.
Voting Hand-held device voting,
theater voting
Quantify customer wishes and ideas.
Table 3. Pre-development stage collection activities.
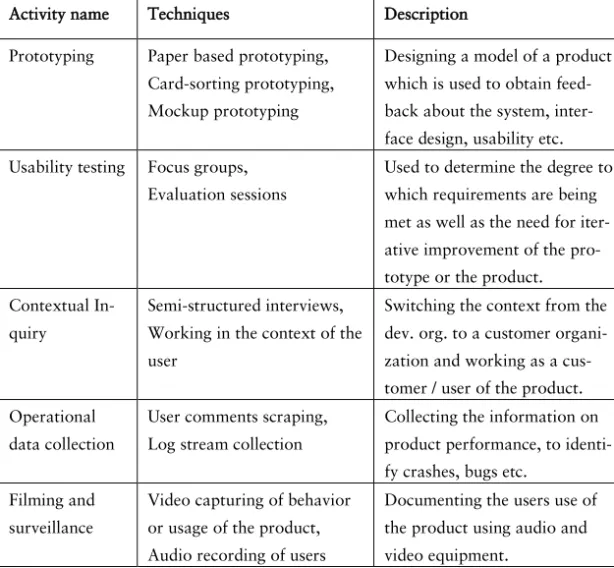
Next, we show the different activities that are typically utilized to collect feedback in the development stage in Table 4 below.
Activity name Techniques Description
Prototyping Paper based prototyping,
Card-sorting prototyping, Mockup prototyping
Designing a model of a product which is used to obtain feed-back about the system, inter-face design, usability etc. Usability testing Focus groups,
Evaluation sessions
Used to determine the degree to which requirements are being met as well as the need for iter-ative improvement of the pro-totype or the product. Contextual
In-quiry
Semi-structured interviews, Working in the context of the user
Switching the context from the dev. org. to a customer organi-zation and working as a cus-tomer / user of the product. Operational
data collection
User comments scraping, Log stream collection
Collecting the information on product performance, to identi-fy crashes, bugs etc.
Filming and surveillance
Video capturing of behavior or usage of the product, Audio recording of users
Documenting the users use of the product using audio and video equipment.
58
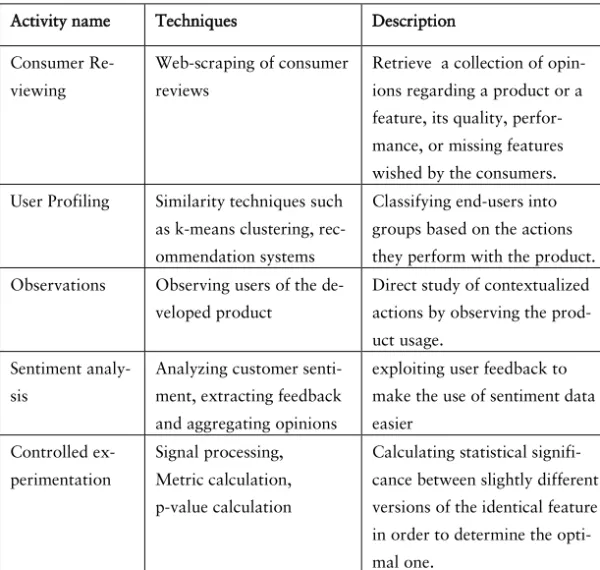
Finally, we list and describe the activities that are used in the post-deployment stage in Table 5.
Activity name Techniques Description
Consumer Re-viewing
Web-scraping of consumer reviews
Retrieve a collection of opin-ions regarding a product or a feature, its quality, perfor-mance, or missing features wished by the consumers.
User Profiling Similarity techniques such
as k-means clustering, rec-ommendation systems
Classifying end-users into groups based on the actions they perform with the product.
Observations Observing users of the
de-veloped product
Direct study of contextualized actions by observing the prod-uct usage.
Sentiment analy-sis
Analyzing customer senti-ment, extracting feedback and aggregating opinions
exploiting user feedback to make the use of sentiment data easier Controlled ex-perimentation Signal processing, Metric calculation, p-value calculation
Calculating statistical signifi-cance between slightly different versions of the identical feature in order to determine the opti-mal one.
Table 5. Post-deployment stage collection activities.
In addition to the literature review, we collected an inventory of data collection techniques used in practice, where we identified three techniques of feedback collection that were previously not recognized in the research literature. The additional techniques are: market analysis (e.g. identifying what other organizations are suc-cessful in selling), personas generation (defining a few groups of people with similar needs) and trend analysis (predicting how the needs and competitors will change over time). We list the activities that we identified empirically in Table 6 below.Roles that collect customer feedback
Common customer feedback collection techniques
Common types of customer feedback collected Pre -D evel opm en t Strategy specialists, Product managers, Product owners
Reading of industry press, Reading of standards, Reading of internal reports, Reading customer visit re-views
Customer wishes, Short/Long market trends, Competitors ability of deliv-ering the product
Strategy specialists, Feature owners
Telephone interviews, Face-to-face interviews, Conducting group interviews
Existing product satisfaction, Future product specification, Personas and User Journeys
D eve lo pm ent UX specialists, Software Engineers
System Usability Scale Form, Asking open ended questions, Demonstrating prototypes, Filming of users' product use
Acceptance of the prototype, Eye behavior and focus time, Points of pain,
Bottlenecks and constrains, Interaction design sketches System managers,
System architects, Software engineers
Consolidate feedback from other projects,
Reading prototype log entries
Small improvement wishes, Configuration data, Product operational data
Pos t-D epl oym en t Release managers, Service managers Software engineers
Reading of customer reports, Analyzing incidents, Aggregating customer re-quests,
Analyzing product log files
Number of incid. and req., Duration of incid. and req., Product operational data, Product performance data
Sales managers Reading articles in the media,
Sentimental analysis Customer events participa-tion,
Reading industry press, Performing trend analysis
Opinions about the appeal of the product,
Performance of the product, Business case descriptions
60
And although customer feedback is being extensively collected, the use of it lacks structure. In Paper [B], we recognize that feedback data that is collected does not succeed in being shared across the company in a way that others could benefit from it. Individuals in-dependently collect increasing amounts of customer feedback, analyze the data they obtained, and store their findings on local repositories. Although these findings are occasionally presented at meetings, the lack of transparency and tools prevents others in the organization to use and benefit from the data. Instead of sharing the already collect-ed information across the organization, practitioners tend to share it within the department and the development stage that they work in. The only data that is successfully shared among people and de-velopment phases is quantitative data representing those things that can be easily measured. We illustrate this situation on Figure 2 below.
Figure 2. Feedback Sharing Model from Paper [B].
RQ2: How does customer feedback impact R&D activities in
software-intensive companies and how does this impact evolve
over time?
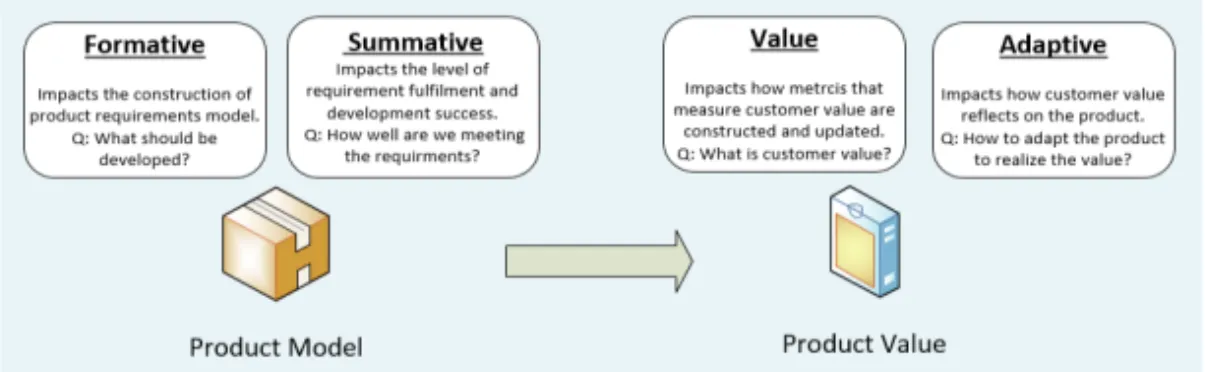
In our research, we identified four distinct ways of customer im-pacts on the development activities in companies. First, we identi-fied Formative Impact (A). This is the customer feedback collected early in the development of a product and focuses on functional requirements, steering of prioritization decisions and shaping of the feature or a product before the actual development. Next, Adaptive impact (B) is the feedback that impacts products capabilities, de-sign decisions and identifying missing features. Summative impact (C) is another type of customer feedback role in product develop-ment. It is used to verify whether and to what extent the developed software meets the defined criteria (as defined by the Formative impact). Finally, we identify value impact (D). It is used to identify the value of a certain feature or product for a customer. These four types of feedback impact and distinguishing between them enable companies to prioritize collection activities based on the needs and maturity of the product. We illustrated the four impacts by plotting the different ways that customer feedback is being collected and used on a 2-2 model. We present them on Figure 3.
62
And although all of the four impacts are important for successful
product development, they do not all have an equal influence throughout the product development. In the early stages of the de-velopment summative and formative impact are the strongest (as indicated by the majority of pre-development techniques in the left quadrants on Figure 3). Companies focus, in the early stages and until a product is mature, their R&D investments in determining what the requirements for a product are and how much they are fulfilling them with their prototypes. In our research we named this milestone “The Product Model” and emphasize the central concern of the development organization to be the focus on the product. The feedback techniques and types of data collected reflect the sit-uation where two questions are being answered: (1) “What should be developed?”, and (2) “How well the requirements are met?”.
However, we recognized in our research (see Paper [E]) that in product development, there is a point where formative and summa-tive impact become less influential. This typically occurs in the




![Figure 2. Feedback Sharing Model from Paper [B].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4017652.81592/62.892.148.709.640.1009/figure-feedback-sharing-model-paper-b.webp)
![Figure 3. Customer Feedback Model (Paper [E]).](https://thumb-eu.123doks.com/thumbv2/5dokorg/4017652.81592/64.892.143.714.143.635/figure-customer-feedback-model-paper-e.webp)