Användning av inferensstatistik i
vetenskapliga undersökningar
Horst Löfgren 2015
Det finns tre sorters lögner:
Lögn, förbannad lögn och statistik.
Vilka slutsatser drar ni av följande tre
exempel eller vilka frågor ställer ni till dem
som gjort undersökningarna?
1. I en undersökning av ett slumpmässigt urval av 2000 15-åringar i Sverige (1000 pojkar och 1000 flickor) fann man ett högst signifikant samband
(p<0,001) mellan längd och begåvning (begåvning mätt med ett icke-språkligt intelligenstest).
2. ”Similarly, students with children had also higher ratings on the Content motivational sub-scale (M=6.73, SD=1.12) than students without children (M=6.54, SD=1.30), t=-2.79, df=1,268, p<.05.” (European Journal of Open , Distance and e-Learning – Vol. 16/No.1 (2013).
3. Enligt en avhandling för doktorsexamen visade den framlagda studien att man med data från undersökningsgruppen ”elever på högstadiet” med ca 70 % säkerhet kunde predicera vilka som i vuxen ålder (25 år) skulle vara dömda kriminella handlingar. Analysmetoden var multipel regressionsanalys. Studien uppmärksammades i SDS.
Svar på föregående ruta
1. Vid stora stickprov får man ofta signifikanta
skillnader. Utan att något storleksmått angivet är det
närmast meningslös information. Utvecklingsstörning
kan resultera i svag tillväxt också vad gäller
intellektuell förmåga.
2. Ett storleksmått visar att skillnaden är marginell.
3. Självklart nonsens. I undersökningen hade man
alldeles för få deltagare i förhållande till antalet
prediktorer. Om man har lika många prediktorer som
individer i undersökningen hade man fått 100 %
Varför används signifikansbegreppet alltför
ofta vid rapportering av forskningsresultat och
effektstorlek alltför sällan?
Det enkla svaret är nog, att man inte är tillräckligt
kunnig i grunderna för inferensstatistik.
Man har inte förstått signifikansbegreppet, och man
känner inte till, att det finns olika mått på
effektstorlek.
Begreppet statistisk inferens
Begreppet statistisk inferens refererar till en situation, där man av olika anledningar väljer att (eller inte kan) studera hela populationen. Man bygger på sannolikhetsteori för att kunna dra slutsatser om förhållanden i populationen.
Dock finns alltid en risk (om än liten) för att man, utifrån observation av förhållanden i stickprovet, drar en felaktig slutsats om motsvarande förhållanden i populationen.
Risken för felaktiga slutsatser av s.k. "typ I-fel" reglerar man exempelvis via val av signifikansnivå.
Begreppet statistisk inferens
Ett krav är att man har tillgång till stickprov som baseras på ett slumpmässigt urval från en population. Inom
beteende-vetenskap är detta ett problem, men detta kan attackeras via att man i förväg införskaffar information om status i "relevanta variabler" (kontrollvariabler), dvs. variabler som enligt teori
och tidigare forskning påverkar utfallet i den/de variabler
som man är intresserad av.
Låt oss anta att ålder och social status är sådana variabler. Då gäller att i förväg ta ställning till om denna information finns att tillgå för hela populationen. Vi antar att detta är fallet och då kan man testa, huruvida ett erhållet urval från denna
population är representativt för den studerade populationen. Om denna information inte finns att tillgå, måste man vidta stora ansträngningar för att åstadkomma ett ”representativt” urval och för att undvika bortfall.
När kan således
signifikansprövningar användas?
1. Signifikanstest ska endast användas, när man från ett stickprov vill generalisera till en population. Det krävs således att man har en definierad population från vilket ett representativt urval har gjorts, för att utifrån detta urval generalisera erhållna resultat till den
bakomliggande populationen.
2. Om man endast har en undersökningsgrupp och inget representativt urval ur en population, finns inget behov av signifikanstestningar. De är helt enkelt meningslösa.
3. Om man gör en totalundersökning (populationsstudie) är självfallet signifikansanalyser nonsens. Man har ju redan all information om populationen.
Även om man har en definierad
population och ett representativt
stickprov kan det tyvärr ändå bli fel!
Om man har små stickprov (under ca 30 observationer)
kan signifikanstestningar ändå bli tvivelaktiga, eftersom då ”statistical power”, som är en funktion av stickprovsstorlek, effektstorlek och vald signifikansnivå (p), är för låg för att upptäcka skillnader.
Det s.k. typ II-felet (att felaktigt behålla nollhypotesen, trots att den är fel) riskerar att bli för stort.
Även om styrkan i analysen är hög,
kan signifikansen ändå bli av
tveksamt värde!
Även om man har stora stickprov, och typ II-felet är lågt, kan signifikansanalyser ändå bli missledande. Vid stora stickprov blir nämligen även små och triviala skillnader signifikanta.
Detta är kanske den största faran i många undersökningar. Stickproven är så stora, att även den minsta skillnad blir signifikant!
Stickprovets storlek
Stickprovets storlek avgör hur stort utrymme
slumpfaktorer får att operera. Ju större stickprov desto
mindre risk för att slumpfaktorer påverkar. Dock bör man inte misstro ett ganska litet men korrekt draget stickprov.
Man kan bestämma lämpligt stickprovsstorlek utifrån typ II-fel och styrkan i det statistiska testet. Dock tar man i de allra flesta fall till i överkant, när man väljer stickprovs-storlek.
Bortfall
Det finns olika sätt att hantera bortfall av data, även om det alltid är bäst om man lyckas få kompletta data.
I enkätundersökningar är det ovanligt att utan extra
åtgärder få en högre andel svarande än 70 %, och det är oftast otillräckligt.
Ett sätt att ”få en högre svarsfrekvens” är att ta ut ett
stickprov av icke-svarande och på olika sätt försöka få svar från dessa. Med hjälp av dessa nya data kan man göra
tillförlitliga skattningar som innebär att andelen svarande kan bli betydligt högre och därmed slutsatserna betydligt säkrare.
Vanligt urvalsfel
Om man inte har ett stickprov av individer utan man baserar urvalet på ett antal valda grupper, t.ex. klasser,
skolor eller någon annan gruppering, måste man ta hänsyn till detta.
De signifikanstest som man använder förutsätter att individerna i stickprovet är att betrakta som oberoende observationer och det kan vara mycket tveksamt, om man t.ex. gör ett klassurval.
Vad bör man göra?
Man ska alltid använda mått på effektstorlek. Har man stickprov från någon definierad population, kan man självfallet även använda signifikansanalyser.
Om man alltid tänker på denna regel, kommer effektstorleksmått att bli mer frekvent än
Vad visar det om …?
Storleksmåttet visar en obetydlig eller liten skillnad men signifikansprövningen att skillnaden är signifikant? Då har man haft ett onödigt stort stickprov!
Storleksmåttet visar en påtaglig skillnad men
signifikansprövningen att skillnaden inte är signifikant? Då har man haft ett för litet stickprov!
Storleksmåttet visar en stor skillnad och
signifikansprövningen en högst signifikant skillnad? Då har man haft ett lagom stort stickprov.
Vad bör man således tänka på?
Att mer uppmärksamma effektstorlek än signifikansanalyser, gärna med tillägg av konfidensintervall.
Effektstorlek
Efter att ha påvisat en effekt (skillnad) är den viktigaste frågan:
Krav på storleksmått
I forskningsmetodiska kurser och speciellt de som är inriktade på
statistisk dataanalys betonas alltför mycket inferensmetoder, dvs. signifikansprövningar, och alltför lite ägnas åt effektstorleksmått och konfidensintervallskattning.
I flera decennier har man försökt få forskare att förstå missbruket
av signifikansanalyser, när inte förutsättningarna är uppfyllda och att i stället använda mått på effektstorlek.
Om förutsättningarna är uppfyllda för signifikansprövningar bör
ändå dessa alltid följas av mått på effektstorlek. Det är självfallet viktigt att veta hur mycket, än att bara veta att något med säkerhet finns.
Från och med den femte upplagan av Publication Manual, utgiven
av American Psychological Association, finns ett tydligt krav vid publicering av forskning att förutom ev. signifikans-analyser också ange lämpligt storleksmått.
Mått på effektstorlek
I statistiska programvaror (t.ex. SPSS) finns en del storleksmått tillgängliga.
På senare år finns effektstorleksmått med i handböcker om statistisk dataanalys, t.ex.:
Kline, R. B. (2004). Beyond significance testing. Reforming
data analysis methods in behavioral research. Washington, D.C.: APA.
Löfgren, H. (2014). Grundläggande statistiska metoder för
analys av kvantitativa data – med övningar för
programpaketet SPSS. Barsebäck: PPR-Läromedel för högskolan.
Effektstorlek
Effektstorlek (ES) är en familj av mått som används för att beskriva resultatskillnader mellan behandlingsgrupper. Till skillnad från signifikansanalyser påverkas inte dessa
storleksmått av stickprovsstorlek.
Man använder vanligen endera av följande:
1) Den standardiserade skillnaden mellan två medelvärden.
2) Sambandet mellan den oberoende behandlingsvariabeln och den beroende utfallsvariabeln.
Effektstorlek i metaanalyser
I metaanalyser beräknas effektstorlek (ES) ofta genom den enkla formeln:
Medelvärdesdifferensen mellan experiment- och
kontrollgrupp dividerat med standardavvikelsen för kontrollgruppen. Man kan också vikta ihop de båda standardavvikelserna.
Förslagsvis kan ES ≤ 0,20 betraktas som små skillnader, ES ca 0,40 som måttliga skillnader och ES ≥ 0,60 som stora skillnader.
Cohen’s d och r
Y
Man beräknar effektstorleksmåtten Cohen's d och rY på följande sätt:
Cohen's d = (M1 - M2)/spooled , där sp = √ [(s12+s
22)/2] vid lika stora grupper,
och vid olika stora grupper är spooled = √ [(n1-1) s12 + (n
2-1) s22]/n1 + n2 -2.
rY = d / √(d² + 4)
Anm.: d and rY är positiva om medelvärdesdifferensen är i predicerad riktning.
Beräkning av Cohen’s d och r
Y
utifrån t-värde och antal frihetsgrader
Cohen's d = 2t / √(df)
rY = √ (t2 / (t2 + df))
Anm.: d and rY är positiva om medelvärdesdifferensen är i predicerad riktning.
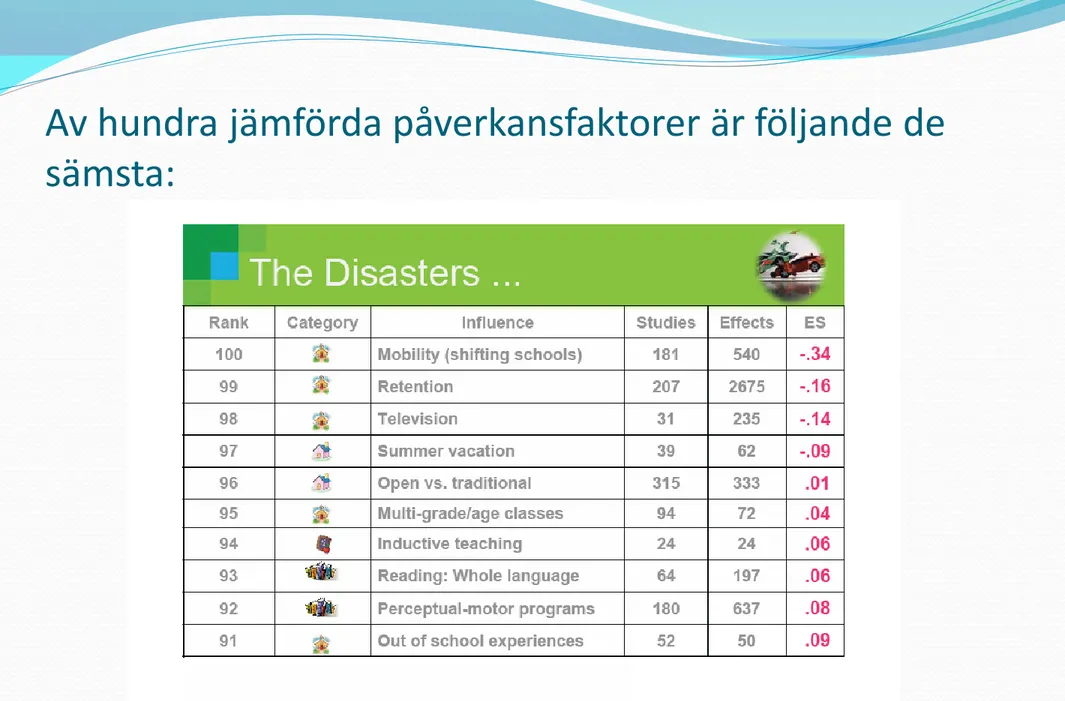
Exempel på effektstorlek (ES) utifrån Hattie’s syntes av
meta-analyser
Tabell från: Hattie, J. A. C. (2009). Visible learning: A synthesis of
Av hundra jämförda påverkansfaktorer är följande de
sämsta:
Tabell från: Hattie, J. A. C. (2009). Visible learning: A synthesis of over 800 meta-analyses relating to achievement. London: Routledge.
Effektstorlek utifrån ett t-värde och
en korrelation
Om man i en artikel får reda på t-värdet för den statistiska skillnaden mellan två stickprov, kan man enkelt beräkna ES för att kontrollera att signifikansen också innebär en betydelsefull skillnad. ES skattas på följande sätt:
ES= 2t/√df
Man kan också erhålla ES via korrelationen mellan den oberoende och den beroende variabeln:
Index på relationen mellan oberoende
och beroende variabel
1) Omegakvadrat
Relationen mellan den oberoende variabeln och
mätvariabeln i en fix variansanalytisk modell kan skattas med hjälp av den s.k. omegakvadrat-koefficienten
(2
est). Kvadratroten ur detta index är jämförbar med en
Index på relationen mellan oberoende
och beroende variabel
2) Eta
Eta är känt under namnet korrelationskvot och är ett lämpligt mått för att beskriva relationen mellan två
variabler med icke-linjära regressionslinjer. För att ange relationen mellan en oberoende variabel
(nominal-skalerad) och en beroende variabel (intervall- eller kvotskalerad) i en undersökning kan detta mått användas.
Eta-kvadrat som index på relationen
mellan oberoende och beroende
variabel
Eta-kvadrat är den delen av den totala variansen som kan
prediceras utifrån den oberoende variabeln (betecknas ofta 2).
I en variansanalys erhålls eta-kvadrat via relationen SStotal/SSmellan grupper
Eta och Eta-kvadrat kan erhållas direkt vid variansanalytisk bearbetning i t.ex. SPSS.
Tolkning av storleken på
2
och eta
2
Bedömningen av vad som är en stor eller liten skillnad är relaterat till vad man har anledning att vänta sig.
I påverkansundersökningar kan förslagsvis följande gränser användas:
0,00 - 0,04 liten skillnad
0,05 - 0,09 medelstor skillnad 0,10 - stor skillnad
Eftersom 2 och eta2 är mått på relationen mellan
oberoende och beroende variabel kan man i stället tala om svag, påtaglig och stark relation.
Tolkning av storleken på samband
Om man beräknar sambandet mellan två variabler måste tolkningen relateras till vad man kan förvänta sig.
Korrelationen är ett storleksmått.
Enklast är att beräkna kvadraten på
korrelations-koefficienten. Då får man andel gemensam varians för de båda variablerna, vilket är lättare att förstå.
Om sambandet mellan två variabler är 0,30 är således endast 9 % gemensam varians, vilket kan anses vara överraskande mycket om det gäller sambandet mellan längd och begåvning, och överraskande lite om det gäller samband mellan betyg i matematik och engelska.
Ett index som bygger på
2
Cramérs index (CV)
Detta index beräknas enkelt genom att ta kvadratroten ur Chi-kvadratvärdet dividerat med antalet observationer (N) multiplicerat med (s-1). s = minsta antalet av rader och/eller kolumner.
För en fyrfältstabell blir s=1 och Cramérs index lika med den s.k. phi-koefficienten (jfr Löfgren, 2014, s. 143)
Vad har vi nu lärt oss?
Att inte längre bli imponerad av en påvisad signifikant skillnad eller signifikant korrelation!
Att storlek är mycket mer intressant än signifikans!
Att om författaren till en forskningsuppsats inte har
definierat population och inte har redovisat hur urvalet av undersökningsdeltagarna är gjort men ändå använder
signifikansprövningar, släng uppsatsen i runda arkivet, dvs. papperskorgen!
Test på måluppfyllelse
Ur European Journal of Open, Distance and e-Learning (Vol. 16/No.1) saxas några slutsatser ur artikeln “Motives for lifelong learners to choose
web-based courses”:
“… However, for the Economic motivational sub-scale males had significantly higher ratings (M=3.84, SD=2.42) than females (M=3.51, SD=2.01), t=-2.21, df=1,268, p<.05.”
…
“However, in this study men had significantly higher rates than women.”
Vad anser du om dessa slutsatser (förutom att det är bra exempel på hur man ljuger med statistik för de okunniga)?
Artikeln bygger på en presentation som nominerades till ”Best Research Paper” vid EDEN-konferensen i Porto, Portugal, 2012. Hade möjligen
bedömarna druckit för mycket portvin eller var de bara okunniga? Om du behöver hjälp, kan du sätta in värdena i formeln som du finner på:
http://www.uccs.edu/~lbecker/
För frågor eller hjälp
kontakta mig på:
horst.lofgren@mah.se
Adress: Golfvägen 24, 24655 Löddeköpinge Tel: 046-772490; 0766-472490