Teknik och Samhälle Datavetenskap
Examensarbete 15 hp, grundnivå
Empirisk undersökning av ML strategier vid prediktion av cykelflöden baserad på cykeldata och veckodagar.
Empirical examination of ML strategies in prediction of cycle flows based on cycle data and weekdays.
Ramadan, Charif
Kakadost, Naser
Examen: (Högskoleingenjörsexamen 180 hp) Huvudområde: (Datavetenskap)
Program: (Datateknik Mobil-IT) Datum för slutseminarium: 2019-05-30
Handledare: Ivan Kruzela Examined by: Magnus Krampell
Sammanfattning
Detta arbete fokuserar på prediktion av cykeltrafik under en månad på en given gata i Malmö med hjälp av maskininlärning. Algoritmen som används är Python-implementering av Stöd-vektormaskin (Support Vector Machine) från Scikit . Data som används är antalet cyklister/dag under 2006-2013 från en cykel-barometer som är placerad på Kaptensgatan i Malmö. Barome-terns funktion är att räkna antalet cyklar som passerar samt registrera tiden. I vår studie under-söker vi hur precision av prediktionen av antalet cyklister varje dag under fyra veckor i oktober 2013, mätt med metoderna RMSE och MAPE, beror av valet av indata (cykeldata och angivelse av veckodag). Ett antal experiment med olika kombinationer av indata och representanter av veckodagar genomfördes. Resultaten visar att testet med störst indata-mängd och veckodagar, angivet som 1-7, gav bäst prediktion.
Abstract
This work focuses on the prediction of bicycle traffic for a month on a given street in Malmö by means of machine learning. The algorithm used is the Python implementation of Support Vector Machine from Scikit. The data used is the number of cyclists / day during 2006-2013 from a cycle barometer placed on Kaptensgatan in Malmö. The function of the barometer is to count the number of cycles that pass and register the time. In our study we investigate how precision of the prediction of the number of cyclists each day for four weeks in October 2013, measured by the RMSE and MAPE methods, depends on the choice of input data (cycle data and the weekday indication). A number of experiments with different combinations of input data and representatives of weekdays were conducted. The results show that the test with the largest input amount and week days indicated as 1-7 gave the best prediction.
Förord
• Stort tack till handledaren Ivan Kruzela som har spenderat mycket tid på de möten vi har haft med honom. Han har varit engagerad i arbetet från början till slutet och varit till stor hjälp.
Akronymer
MSE: Mean Squared Error MAD: Mean Absolute Deviation
MAPE: Mean Absolute Percentage Error API: Application Programming Interface. RMSE: Root-Mean-Square deviation. SVR: Support-Vector-Regression. SVM: Support-Vector-Machine.
Innehåll
1 Introduktion 1
1.1 Bakgrund . . . 1
1.2 Syfte och problemformulering . . . 2
1.3 Problemformulering . . . 4 1.4 Avgränsning . . . 4 2 Teori 5 2.1 Python . . . 5 2.2 Scikit-learn . . . 5 2.2.1 Stödvektormaskin . . . 6 2.2.2 Normalisering . . . 7 2.2.3 RMSE . . . 7 2.2.4 MAPE . . . 7
2.3 One Hot kodning . . . 8
3 Relaterat arbete 9 3.1 En jämförelse av maskininlärningsalgoritmer för uppskattning av cykelflöden ba-serat på cykelbarometer- och väderdata . . . 9
3.2 Prediction of bicycle counter data using regression . . . 10
3.3 Analys av prediktiv precision av maskininlärningsalgoritmer . . . 11
3.4 Prediction of Bike Sharing Demand by Sachdeva . . . 11
3.5 Predicting bike-share usage patterns with machine learning . . . 13
4 Metod 15 4.1 Nunamakers metod . . . 15
4.1.1 Problemområde . . . 15
4.1.2 Utveckla systemets arkitektur . . . 15
4.1.3 Analysera och designa systemet . . . 16
4.1.4 Experiment . . . 16
4.1.5 Observera och utvärdera systemet . . . 16
5 Experiment och Resultat 17 5.1 Problemområde . . . 17
5.2 Utveckla systemets arkitektur . . . 17
5.3 Analysera och designa systemet . . . 18
5.3.1 Strategier för val av indata till modell . . . 18
5.3.2 Indata . . . 21
5.4 Resultat . . . 27
7 Diskussion 31 7.1 Diskutera relevanta arbeten . . . 31
8 Slutsats och vidare forskning 32
8.1 Slutsats . . . 32 8.2 Vidare forskning . . . 32
Referenser 33
1 Introduktion
1.1 BakgrundMaskininlärning är ett forskningsfält inom området artificiell intelligens. Denna maskininlär-ningen handlar om att extrahera kunskap från data till datorer så de kan lära sig själva utan att vara uttryckligen programmerade [2]. Maskininlärning har blivit allt mer relevant inom områ-den som produktutveckling, rekommendationssystem för fotokodning på sociala medier, till medicinsk bildläsning [1][2]. En av huvudfaktorerna som bidrar till snabb utveckling av ma-skinlärande applikationer är tillgänglighet av moderna öppen källkod-bibliotek som erbjuder algoritmer inom maskininlärning. Bibliotek som Scikit-learn möjliggör mönsterigenkänning och framtida förutsägelser [1][2].
David Cournapeau grundade och startade Scikit-learn som ett Google Summer of Code-projekt 2007. Sen dess har Davids projekt varit aktiv och utvecklats av många bidragsgivare [4]. Scikit-learn erbjuder olika standardalgoritmer för övervakat och oövervakat lärande. Detta biblioteket erbjuder ett kortfattat och ett användarvänligt programmerings API. Detta underlättar för fors-kare inom datavetenskap att effektivt tillämpa algoritmer för de flesta stora dataproblem [4]. Två olika typer av lärande används för olika ändamål. Den mest praktiska maskininlärnings-varianten är övervakat lärande. Detta lärande används när man har bestämda inmatningsva-riabler(X) och en utvariabel (Y). Man tillämpar sedan en algoritm för att lära mappfunktionen från ingången till utgången. Syftet är utveckla en funktion som kan ge en bra approximations-värde till utvariabeln (Y) med ny inmatnings data. I oövervakat lärande har man inget korrekt svar och man förutsäger utvariablen (Y) genom att analysera den underliggande strukturen i träningsdatan. Jämfört med övervakat lärande så ges inga uttryckliga instruktioner i oöverva-kat lärande [2][3][4].
Ett område där det finns ett växande intresse av att tillämpa maskininlärning är förutsägelse av cykeltrafik då databaser blir mer tillgängliga för forskare inom datavetenskap [5][6]. Majorite-ten av cykelstudierna fokuserar på cykeldelningssystem i vilka användningsmönster och krav förutses med hjälp av olika faktorer som väder, arbetsrelaterade faktorer, kalenderhändelser etc. [5]. Cykelanvändning inom cykeldelningsystem har en obalanserat efterfrågan och är tem-porärt mellan olika geografiska områden. Detta orsakar problem för den dagliga verksamheten. Man kan minska de operativa problemen om man med hjälp av algoritmer försöker förutspå användning och efterfrågan på de olika cykelstationerna [9]. Förutom användning och efter-frågan förutspås också cykeltillgänglighet på stationer för att underlätta återlämning av cyklar och för cykeluthyrning [10].
Förutsägelse av cykeltrafikflödet är ett annat utmanande problem på grund av komplexitet, olinearitet och osäkerhet. En lösning som kombinerar kluster och maskinstöds vektor kan vara användbart för förutsägelsen av trafikflödet. Den förutspådda cykeltrafiken kan användas till hjälp i planeringen av nya infrastruktur för att underlätta cykeltrafiken [11].
1.2 Syfte och problemformulering
Detta arbetets syfte fokuserar på att bygga förutsägbara modeller för allmän cykeltrafik på en given gata i Malmö, från år 2006 till 2013. Datavärden är samlad från en cykel-barometer som är placerad på Kaptensgatan i Malmö. Barometerns funktion är att räkna antalet cyklar som passerar samt registrera tiden. Tidigare har andra forskare använt Scikit-learn algoritmer på träningsdata för att bestämma den algoritm som ger den bästa prediktionen.
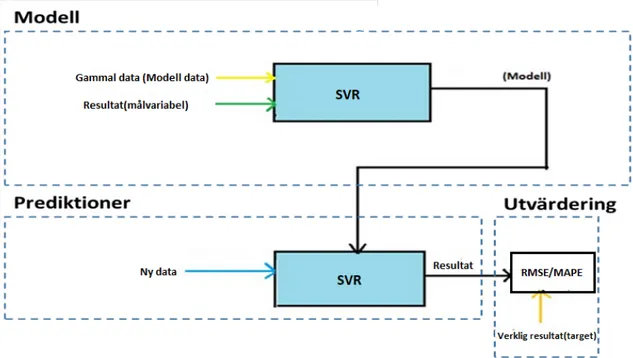
Principen för arbetet illustreras i Fig. 1. Gamla data tillsammans med målvariabel (resultat) används för att skapa en modell (funktion som från indata räknar framtida resultat). För när-varande finns det i litteraturen beskrivna över 10000 inlärningsalgorittmer. Vi valde algoritmen SVM (Stödvektormaskin) eftersom i de relevanta arbeten [5][15][16] har man tillämpat SVM i undersökning av cykeltrafikflödet. Resultatet i detta arbete kan då lättare jämföras resultaten i de angivna relevanta arbeten. Problemet som vi angriper är att bestämma vilka indata ska användas för att skapa den bästa modellen. Den cykeldata vi har tillgång till används för att un-dersöka olika testmodeller för prediktioner av cykeltrafiken i oktober månad år 2013. Resultatet från testerna jämförs med riktiga datavärden för år 2013 i datamängden vi fick från cykelbaro-metern. Kvalitet på resultatet utvärderas med RMSE- och MAPE-metoderna.
Figur 1: Processen för övervakad lärande
Fig. 1 representerar hur processen för SVM-algoritmen fungerar. Processen för hur algoritmer inom övervakat lärande fungerar kan beskrivas med två termer som är “tränings frågor med svar” och “träningsfrågor utan svar”. “Träningsfrågor med svar” innebär att maskininlärnings-algoritmeren skapar en modell baserad på indata och målvariabel som den tar emot. I detta skede lär sig algoritmen hur den ska generalisera den data den har tagit emot för framtida in-matningsdata. Nästa del i processen är att algoritmen tar emot data men utan målvariabel som “frågor utan svar”. Målet här är att med hjälp av modellen förutsäga en målvariabel. Sista steget i processen är att beräkna RMSE och MAPE genom att jämföra den målvariabel som förutsägs med det verkliga värdet. RMSE och MAPE är två olika ofta använda mått som beskriver storle-ken på fel i resultatet, se avsnitt 2.2.3 och 2.2.3.
Fig. 2 visar ett exempel på vilka data som ska användas för att bygga modell och vilka data vi ska använda för att testa modellen. Data från år 2006-2007 (gul färg) tillsammans med målvariabel-data som är år 2008(grön färg) används för att skapa en SVR-modell. SVR-modellen ska sedan användas tillsammans med data från år 2006-2007(blå färg) för att förutsäga år 2009(orange färg) som målvariabeln. Det finns naturligtvis många fler alternativ till valet av indata men i detta arbetet är valet av indata systematiskt valda.
Figur 2: Ett exempel på val av testdata
1.3 Problemformulering
Forskningsfrågorna i denna studie är följande:
RQ1 : Hur påverkas precision av prediktioner av cykeldata för en given månad, mätt med RM-SE och MAPE, av val av indata(cykeldata och tidsangivelse)?
RQ2 : Hur påverkas resultatet av hur man representerar veckodagar i indata?
1.4 Avgränsning
Mängden av data som kan användas är mycket omfattande och antalet möjliga algoritmer som finns i Scikit är stor. Avgränsningarna i detta arbetet är följande:
• Vi har använt SVR algoritmen i Python för att testa den med cykeldata och beräkna RMSE och MAPE.
• Vi fokuserade på fyra veckor under oktober för år 2006-2013 eftersom i de andra måna-derna förekom det stora avvikelser i datan.
• Det år som vi har förutsagt och har använt för att utföra olika tester är år 2013. Vi har valt år 2013 eftersom vi vill maximera mängd data som testdata. År 2013 kan använda 7 år gammal data från 2006 till 2012 som träningsdata.
Prognosmodellen för cykeltrafik i detta arbete kan inte generaliseras för att förutsäga cykeltra-fik utanför den specicykeltra-fika platsen i vilken träningsvärden samlats. Detta beror på att cykeltracykeltra-fik- cykeltrafik-flödet vanligen varierar från plats till plats. Resultaten av denna studie förutser inte framtida förändringar av transportsystem, händelser, naturkatastrofer, vägar, semester, och potentiella klimatförändringar. De nämnda ändringarna kan påverka cykeltrafikflödet och det förutspåd-da resultatet.
2 Teori
Nedanstående fakta är tekniska beskrivningar av Python, Scikit-Learning och Regression som är de viktigaste verktygen i denna studie.
2.1 Python
Python är ett objektorienterad programmeringspråk som har blivit populärt bland dataveten-skapare [8]. En av anledningarna till varför Python har blivit känt och användbar är p.g.a. dess enkelhet att programmera och dess implementeringar av grafer,mönster samt maskininlärning [7]. Programmering i Python är inte bara begränsad till vetenskaplig beräkning utan det kan an-vändas för att bygga ett brett utbud av applikationer som webb- och skrivbordsutveckling [7]. Python innehåller paket som erbjuder grundläggande funktioner. En känd faktor som känne-tecknar Python är dess öppna källkodspaket, som är kända som Scipy, Numpy, Pandas, Mat-plotlib och Scikit-learn som har blivit allt mer kända. Anaconda-paketet är ett av de enkla sät-ten att få Python och dess kärnpaket på alla plattformar [7]. En kort beskrivning för Python och Anaconda paketet visas i Fig. 3
Figur 3: Olika paket i Python [7]
2.2 Scikit-learn
Scikit-Learning är ett öppet bibliotek som erbjuder ett integrerat, användarvänligt maskinin-lärningssystem som erbjuder den senaste tekniken av många välkända algoritmer. Dess funk-tion är att erbjuda datautvinning och maskininlärningsanalys till forskare och datavetenskapa-re över olika områden [8]. Visionen om Scikit-learning-projektet drivs av fem aspekter, som är: kodkvalitet, BSD, licensiering, grund design och API, drivna bidragsgivare och dokumentation [8]. I detta projektet används Scikit-learn för att hämta information om stödvektormaskin, RM-SE, Normalisering och MAPE.
Scikit-learn bygger inte allt själv, den är beroende av 3 olika paket. De olika paketen är Numpy, Scipy, och Cython. Numpy ger effektiv databasstruktur som lätt integreras med andra paket , och den erbjuder också grundläggande operationer [7]. Fig. 4 visar hur numpy D-dimensionell
array ser ut . Scipy erbjuder effektiva algoritmer för linjär algebra ,matriser och andra statis-ka funktioner [7]. Det finns 5 huvudfunktioner i Scikit-learn, nämligen: datatransformation,
Figur 4: Numpy D-dimensional array [14]
övervakad lärande, obevakat lärande, modellutvärdering och urval [7]. Vanliga uppgifter i da-tatransformation är normalisering och kodning. Normalisering är en viktig process för att sä-kerställa att varje inmatningsfunktion ligger inom samma intervall (t.ex. mellan -1 och 1) och det har visat sig bidra till att förbättra träningen.
Övervakat lärande är kartläggningen mellan ingångar eller funktioner och utgångar. En algo-ritm inom övervakat lärande kan vara uppdelat i klassificiering och regression [2][3][4][7]. De flesta maskininlärningsuppifter är antingen regression eller klassificering. I detta arbete an-vänds regressionsalgoritmer eftersom arbetets syfte är att prediktera målvariabel.
En annan delmängd av maskininlärningsalgoritmer är oövervakat lärande där det inte finns något mål eller utgång för att förutsäga. Denna typ av inlärning innebär att identifiera underlig-gande mönster eller grupper till vilka ingångar eller funktioner kan tilldelas på grund av likhet. Denna typ av problem är känt som kluster [2][3][4][7].
2.2.1 Stödvektormaskin
En av de mest kända algoritmerna inom maskininlärning är stödvektormaskin(SVM) [23]. Den-na algoritm kan tillämpas vid både klassificering och regression. Algoritmen bygger ett eller fle-ra hyperplaner som kan användas för både klassificering och regression. Algoritmen tar emot inmatningsdata och placerar alla värden i ett plan och konstruerar därefter hyperplanet som separerar olika datavärden i två olika områden. Ett hyperplan som har långt avstånd till när-maste träningsdatapunkt i en klass(marginal) anses vara en bra separation inom klassificiering. I regression vill man att datapunkterna ska vara så nära hyperplanet som möjligt för att få ett bra prediktionsvärde. Punkter på hyperplanet(linje) är det värde man vill prediktera och om da-tapunkterna är nära hyperplanet så innebär det att man har en bra prediktion. Det unika med SVR är att hyperplanet kan vara icke-linjärt, för att göra det icke-linjärt så ändrar man i kernel-funktionen. Nedan visas Python kod som beskriver standard egenskaper hos en SVR-algoritm har :
2.2.2 Normalisering
Normalisering är en datahanterings process som används för att omvandla datavärden till vär-den mellan 0-1, där 0 motsvarar det lägsta värdet och 1 det högsta värdet i det ursprungliga dataset [19]. I de flesta fall tillämpas normalisering för att underlätta jämförelse mellan värden från olika databaser. Normalisering kan också vara ett krav när man ska integrera data-värden med algoritmer eller programmering. Inom maskininlärning kräver vissa algoritmer att datavärden man har som inmatningsvärde är normaliserade.
Formeln för normalisering är följande:
x0= (x − Mi n)/(M ax − Mi n) (2) Där x‘ är det normaliserade värdet mellan 0 och 1, Min och Max är det minsta respektive det största talet i den ursprungliga datamängden.
2.2.3 RMSE
Root Mean Square Error (RMSE) är ett mått som presenterar det genomsnittliga avståndet mel-lan alla datapunkter och det predikterade värdet som är i form av en linje [16][23]. Denna RMSE mått används mycket inom statistik och regression för att visa hur stora felvärden man får och för att kunna jämföra olika resultat.
Ekv 3 presenteras formeln för RMSE. Ordet “Actual” är värdet man vill prediktera och “Predic-ted” är värdet man har predikterat. N står för antalet datapunkter(predicted) man ska jämfö-ra med Actual-värden. RMSE resultatet blir kvadjämfö-raten ur summan av alla jämförelsen mellan Predicted-värden och Actual-värden. Ur formeln ser vi att ju större N är desto mer nogrann blir RMSE resultatet. R M SE = s PN i =1(P r ed i c t edi− Act uali)2 N (3) 2.2.4 MAPE
Det genomsnittliga absoluta procentsatsfelet (MAPE) är en statistisk mätning i procent och an-vänds för att mäta felet i en prognos [23]. Prognosen inom statistik och regression i maskininlär-ning, där “Actual” är det värdet man vill prediktera och Predicted"värdet man har predikterat. Med hänsyn till formeln så ser vi att formeln blir ogiltig om “Actual” är lika med noll. Även om “Actual”-värdet inte är noll men mycket liten så blir MAPE resultatet extremt högt. Detta mått bör undvikas när man använder en liten mängd data eftersom resultatet blir inte så noggrant. Det bör också undvikas om nollor finns med i datavärdena.
Formeln för MAPE visas i eqv 4
M APE = Ã 1 n XP r ed i c t edi− Act uali |Act uali| ! (4)
2.3 One Hot kodning
One Hot kodning är en standard metod att omvandla variabler med kategoriska värden till en form som är lämplig för vanliga maskininlärningars-algoritmer. Fig. 5 visar variabeln Veckodag med kategoriska värden (Må, Ti, On, To, Fr, Lö eller Sö) omvandlad till sju variabler Må, Ti, On, To, Fr, Lö, Sö med värden (0 eller 1) [24]
3 Relaterat arbete
Under denna sektionen skall relaterade arbeten inom cykelstudier med maskininlärning redo-göras. Arbeten inom cykelstudier med maskininlärning är relevanta för denna studiens under-sökning eftersom denna studien utforskar inom samma problemområde. De relevanta arbete-na tar upp olika problemområden i cykelsystemet, bland lösningen på den ökade efterfrågan på cykeluthyrning i framtiden, genom att prognosera kvantumen cyklister i framtiden. Dem fem bestämda relevanta använder maskininlärning som tillvägagångsätt för att bearbeta pro-blemen.
3.1 En jämförelse av maskininlärningsalgoritmer för uppskattning av cykelflöden baserat på cykelbarometer- och väderdata
Sebastian Aspegren och Jonas Dahlström [19] har använt olika maskininlärningsalgoritmer för att prediktera cykelflödet baserat på data med hjälp av en barometer och väder data. Barome-tern är placerad på en gata och räknar antalet cyklister som passerar gatan varje dag. Väder-data består av både temperatur och nederbörd, det används som inmatningsVäder-data tillsammans med cykeldata. Aspegren och Dahlström har implementerat och testat dem valda algoritmer i programvaran Weka. De utvalda algoritmerna som har testats och jämförts med varandra har bestämts utifrån en litteraturstudie om relevanta arbeten. De algoritmerna som har valts ut och som de undersöker närmare är Random Subspace (slumpmässigt underutrymme), Bag-ging (säckväv algoritm) , och REPTree (en trädbaserad regressionsalgoritm). Vid implemente-ringen av algoritmerna i Weka har dem bearbetat data och filtrerat bort det som dem ansåg vara oviktigt, det är bland annat helgdagar. Syftet med arbetet är att testa de utvalda algoritmerna och framhäva den algoritm som predikterar cykelflödet bäst:
De olika algoritmerna testades med följande experiment: • Icke-normaliserad data i timformat
• Normaliserad data i timformat • Normaliserad data i dygnsformat • Eliminering av variabler
Problemformuleringarna som har besvarats är:
• Hur är det lämpligt att formulera inlärningsproblemet för att uppskatta cykelflöden ba-serat på faktorer såsom antal cyklister, datum, tid, temperatur och nederbörd?
• Vilken maskininlärningsalgoritm är bäst på att uppskatta antalet cyklister baserat på cykelbarometer-och väderdata?
I studiens resultat framkom det att Random Subpace gav bättre prediktions värde än de andra tillämpade algoritmerna. RMSE värdet för Random Subspace gav överlägset bättre resultat än REPTree men bättre än Bagging. Random Subspace fungerar ungefär som Bagging algoritmen, de tar slumpmässiga tal utifrån inlärningsdatan och använder det för att minska korrelationen mellan estimatorer. Det framkom även att Bagging och Random Subspace kan ge bra predik-tionsvärde trots avvikande värden i inlärningsdatan.
3.2 Prediction of bicycle counter data using regression
I arbetet [5] använder författarna regressionsalgoritmer för att förutspå det dagliga antalet cyklar med hjälp av data från Malmö stad. Författarna formulerar två regressionsproblem, det ena är att förutse det antalet dagliga cyklister och den andra är att förutse avvikelsen från en långsiktig trendberäkning. Cykeldatans period är från år 2006 till 2014. Faktorer som användes som in-gångar är väderdata (temperatur och nederbörd) och information om helgdagar. Inmatnings-funktionerna som används är angivna i Fig. 6. Det noteras att författarna använder boolesk kodning istället för One Hot kodning, för att koda vardag, helg och semester.
Figur 6: Inmatningsfunktionerna [5]
För att hantera saknade inmatningsfunktioner tillämpas en enkel linjär interpolering. Saknad faktor mellan tiden i och j ges som:
xk= xi+ xj− xi
tj− ti ∗ (tk− ti
) (5)
Sex algoritmer används för att träna datasatsen:
• regler (beslutslista genererad med en serie modellträd, var och en genererar en M5-regel)
• M5P(modellträd där varje blad är en M5-regel)
• Rep träd (regression träd byggd med hjälp av informationsvinst)
• Linjär regression (linjär regressionsfunktion byggd med Akaike-metriska) • Multi-layer perceptron (nätverksmodell baserad på återförökning) • SMOReg (Stödvektor regression med 1,2 och 3 graders polynom kärnor)
Prestationsjämförelserna av olika algoritmer på de båda regressionsproblemen ges i Fig. 7. Slutsatsen är att stödvektormaskin (SVM) med kärnor och trädregression fungerar bäst för den-na dataset.
Figur 7: Prestationsjämförelser av olika algoritmer [5]
3.3 Analys av prediktiv precision av maskininlärningsalgoritmer
I detta arbete har Jonas Remgård [22] fokuserat på att undersöka hur mängden indata och dess struktur påverkar algoritmers prediktiva precision. Mängden inlärningsdata och dess struk-tur har testats på maskininlärningsalgoritmerna Stödvektoralgoritm, K-Nearest Neighbor (när-maste grannar) och Decision Tree Classifier (bestämd trädklassificering). Remgård har använt olika typer av indata till algoritmerna för att testa exempelvis skillnaden i precisionen för sym-metriska och dubbelsymsym-metriska indata. Den största mängden indata som användes i studien är 2000 instansvariabler, Remgård har påpekat att resultatet inte kan generaliseras med tester som använder större mängd indata.
Resultatet i studien visar att mängden indata har stor påverkan på algoritmernas prestation. Ju större mängd indata som användes desto bättre prediktion gav det. Alla algoritmer preste-rade likartade resultat vid olika mängd indata därav är slutsatsen att det är generaliserbar för andra algoritmer med samma mängd indata. Resultat visar även att strukturen på indata hade en påverkan på resultatet där samtliga algoritmer gav ett mer distinkt resultat med dubbelsym-metriska indata jämfört med symdubbelsym-metriska indata.
3.4 Prediction of Bike Sharing Demand by Sachdeva
Sachdeva [15] utforskar problemet ”cykeldelningsbehov” som innebär att förutspå antalet hyr-da cyklar vid en viss tidpunkt i en bestämd stad. Datafunktioner och värden som forskaren
använder sig av visas i Fig. 8. För att datan ska vara förståelig har forskaren gjort följande steg för att omvandla data till ett systematiskt användbar dataset
• Ändrar datum i tidsstämplar
• organiserar tidsstämplar i dagar, månader, år och veckodag.
• konverterar säsong, semester, arbetsdag och väder i kategoriska variabler eller faktorer. • Konvertera timmar i en faktor.
Sachdeva använder sig av maskininlärningsalgoritmerna SVM(Stödvektormaskin), regression och slumpmässiga skogar(random forest). Algoritmerna jämförs och analyseras för att sedan välja den som ger bäst effekt. Andra tekniker som också används är linjärkombination och dis-kriminerande linjär kombination(Discriminant Linear analysis)
Figur 8: variabler i datasetet [15]
Prestationsjämförelser av olika algoritmer i termen av RMSE ges i Fig. 9. Där framgår det att lin-jär kombinationsmodell och diskriminerande linlin-jär kombinationsmodell överträffar de andra deltagande algoritmerna. För framtida arbeten rekommenderar författaren att dela upp data och sedan träna två separata modeller eller använda timefrekvenser för olika funktioner.
Figur 9: Prestationsjämförelser av olika algoritmer [15]
3.5 Predicting bike-share usage patterns with machine learning
Kumar [16] försöker att förutsäga cykeluthyrnings trafiken genom att använda olika maskinin-lärningsalgoritmer. De olika algoritmerna som används är slumpmässig skog (randomforest), besluts träd(decision tree) och förstärkt beslutsträd(boosted decision tree). Faktorer som han tillämpar i algoritmerna och som påverkar algoritmens förutsägelse är vädret, geografisk plats, tidpunkt på dagen, dagen i veckan m.m. på en given cykelstation. Avsikten med problemlös-ningen är att hjälpa både kunder och operatörer. Kunder sparar tid och pengar eftersom de får veta i förväg om det finns tillgängliga cyklar på en given station. För operatörer är lösningen användbar eftersom de i förväg kan bestämma om de behöver åtgärda problem eller underhål-la en given station.
Dataset som används i den här studien omfattar tre månader från maj till juli 2014. Dataset ob-serveras i Washington, D.C. Författaren använder 80-20-regeln för att dela upp data i tränings-och testningsuppsättning. Indata som används för att träna maskinlärningsmodellerna är :
• Time of day (hours • Day of week • Day of month • Month • Station lattitude • Station longitude • Satation altitude • Temperature in degree • Precipitation in mm
• Cloud cover in Okta
Författaren tittar på hur standard maskininlärningsalgoritmer som beslutsträd, slumpmässigt skog och förstärkt beslut-träd utför i jämförelse. Prestationsjämförelser för de olika modeller visa i Fig. 10. Det visade sig att förstärkt träd hade bästa RMSE på 4.01, medan beslut-träd hade en på RMSE på 5.3, och slumpmässing skog hade RMSE på 4.15.
4 Metod
I detta kapitel presenteras metoden som har tillämpats i detta arbete. Den mest lämpligaste arbetsmetoden för detta arbete är en iterativ process där man hela tiden gör ändringar mel-lan början och slutet av arbetsprocessen. Det kan vara allt från ändringar i problemområde till ändringar i utvärderingen. Det därför vi har valt att använda oss av Nunamaker metoden ef-tersom dess process är iterativ [17] . Iterativ process är väsentlig efef-tersom om vi missar några små ändringar i mitten av arbetet så ska det kunna ändras utan komplikationer.
4.1 Nunamakers metod
Nunamaker är en iterativ arbetsmetod som används av forskare inom datavetenskap för att beskriva en process för bland annat systemutveckling. Vi har valt att göra en ändring i den ursprungliga versionen av Nunamaker. Den består av fem arbetsdelar där “Bygga (prototyp) system” är en av dom, vi har ändrat “Bygga (prototyp) system” till “Experiment” eftersom vår arbete går ut på att experimentera olika tester med maskininlärning och inte bygga en prototyp eller ett system. Metodiken innehåller fem olika delar som ska behandlas och de är följande:
Figur 11: Metod
4.1.1 Problemområde
Det första steget i metoden är att hitta problemfrågor som ska lösas. För att hitta problemfrågor har vi valt att göra en litteraturstudie om vår problemdomän. I litteraturstudien har vi bland an-nat läst om olika maskininlärningsalgoritmer och relevanta arbeten som har gett oss en bättre förståelse för vår problemdomän. Litteraturstudien är också väsentlig för att hitta information om olika aspekter såsom krav på systemet, funktioner och teorier inom vårt problemområde 4.1.2 Utveckla systemets arkitektur
I denna del utvecklas systemets arkitektur. Vi har granskat vilka funktioner och krav det ställs för att lösa vår problemformulering. Några enstaka maskininlärningsalgoritmer har granskats och en har valts ut. Ett bra sätt att summera och presentera de olika delarna i systemet är genom att bryta ner problemet. En noggrann problemnedbrytning om hur maskininlärningsalgorit-men ska fungera har gjorts. Problemnedbrytningen beskriver de olika stegen som exekveras sekventiellt Python.
4.1.3 Analysera och designa systemet
I detta delmoment har vi tagit reda på om alla krav från de två föregående delarna har uppfyllts för att gå vidare till experimentdelen. Vi har gått igenom de olika datavärdena, som vi fick från barometern som är placerad på Kaptensgatan i Malmö för att analysera och identifiera missade värden eller enhet. Vi har även undersökt om de datavärdena vi har fått kan tillämpas i stöd-vektoralgoritmen utan filtrering. Val av tester och strategier granskas också i detta delmoment 4.1.4 Experiment
Testerna och de olika strategierna utfördes med maskininlärningsalgoritmen SVM i Spyder-programmet för att prediktera målvariablerna. Först testades en sekvens av kod i python ge-nom att läsa in en liten mängd indata och skriva ut den för att säkerställa att vi importerar rätt datamängd från Excelfilen. Vi ökade mängden kod successivt och exekverade den efter varje liten ändring för att testa så inget var felprogrammerat. När vi utförde alla tester dokumen-terade, plottades och sparades resultaten i ett Excel-dokument. Vi beräknade även RMSE och MAPE värden för alla tester, eftersom vi i nästa delmoment behövde det för att utvärdera och analysera experimenten
4.1.5 Observera och utvärdera systemet
Här har vi analyserat och utvärderat resultaten vi har fått från tidigare moment. De olika tes-terna vi utförde har utvärderats med hjälp av deras beräknade RMSE- och MAPE-värde. Om RMSE/MAPE-värden för testerna var dåliga så undersöktes nya val av indata och strategier. Ett dåligt RMSE- eller MAPE -värde kan vara exempelvis ett som skiljer sig mycket jämfört med ett annan liknande test
5 Experiment och Resultat
5.1 ProblemområdeVi har kommit fram till våra problemfrågor och syfte med detta arbetet genom att söka infor-mation om relevanta artiklar från sökmotorerna Libsearch, IEEE, Google scholar och ACM. Det finns flera relevanta arbeten [5][15][16][18][19] och det är därför viktigt för oss att läsa igenom dem så vi inte gör en likadan. Vi skiljde på de olika relevanta arbeten genom att jämföra deras metod med varandra. Det gav tillräckligt mycket med information för att inte göra ett likadant arbete.
5.2 Utveckla systemets arkitektur
I detta steget har vi utvecklat systemets arkitektur som vi har använt i våra experiment. turen grundas på en Python-kod implementering av ML-algoritmen SVM från Scikit. Arkitek-turen presenteras i Fig. 12.
Systemet består av följande steg som exekveras sekvensiellt.
1. Import av indata från excel. Data är i form av en matris, där kolumner svarar mot variab-ler med cykeldata elvariab-ler tidangivelse, en kolumn för varje år (2006-2013). Vid vissa experi-ment använde vi data som var tidsangivelse(veckodagar), se t.ex. Fig. 19. Raderna svarar mot dagarna under oktober.
2. Användardialog som bestämmer vilka variabler är indata, vilken är målvariabel och vil-ken variabel (år) ska predikteras vid test av modellen.
3. Kopiering av valda variabler (från moment 2) till interna Pythonvariabler. 4. Skapande av SVM modell med Scikit implementering av SVM.
5. Beräkning av prediktioner från modellen.
6. Beräkning av RMSE och MAPE mått från verkliga och predikterade värden.
5.3 Analysera och designa systemet
5.3.1 Strategier för val av indata till modell
Fig. 2 illustrerar en strategi för val av data för bildandet av modell. Det finns många alternativ för val av indata. Vi valde två strategier som vi kallar Strategi A, se Fig. 13 och Strategi B, se Fig. 14.
I Strategi A skapar vi en serie av modeller från data i år 2006 och efterföljande och testar de-ras precision på förutsägelser om framtida åren. I Strategi B skapar vi en serie av modellerna från år 2012 och tidigare. Anledningen till varför vi valde dessa två strategier är att systemati-sera undersökning av hur valet av indata påverkar precisionen av förutsägelse för år 2013 som målvariabel.
Strategi A
A1) Första två åren (2006-2007) som indata (gul färg) och tredje året (2008) som målvariabel (grönt)
A2) 2006-2008 som indata, 2009 som målvariabel A3) 2006-2009 som indata, 2010 som målvariabel A4) 2006-2010 som indata, 2011 som målvariabel A5) 2006-2011 som indata, 2012 som målvariabel
Modellen användes för prediktion av cykeltrafiken i efterföljande åren:
A11: Modell A1 med indata (2007-2008) (blå) användes för prediktion av cykeltrafik i oktober året 2009 (orange).
A12: Modell A1 med indata (2008-2009) användes för prediktion av cykeltrafik i oktober året 2010.
. . .
A51: Modell A5 med indata (2007-2012) användes för prediktion av cykeltrafik i oktober året 2013.
Strategi B
B11: 2010-2011 som indata, 2012 som målvariabel
Modell B11 med indata (2011-2012) användes för prediktion av cykeltrafik i oktober året 2013. B12: 2009-2011 som indata, 2012 som målvariabel
Modell B12 med indata (2010-2012) användes för prediktion av cykeltrafik i oktober året 2013. . . .
B15: 2006-2011 som indata, 2012 som målvariabel
Modell B15 med indata (2007-2012) användes för prediktion av cykeltrafik i oktober året 2013.
5.3.2 Indata
För att kunna bygga användbara modeller för maskininlärning räcker det inte med mycket data och en bra inlärningsalgoritm. All inlärning bygger på hypotesen att det finns mönster i data som algoritmer som bygger modellen identifierar, avvikande värden som inte följer mönster motverkar detta. [21]
Problem kan vara att data är korrekta men inte typiska och försämrar kvalitet inlärning. Test A13 i Fig. 21 illustrerar detta påståendet, där MAPE med ursprungliga data (Exp1) blev 22% och MAPE i korrigerat data (Exp2) blev det bara 8%. I vårt konkreta fall kan det vara ett ovanligt dåligt väder i en viss dag, gatuarbeten som hindrar cyklisterna, gatufest etc, som resulterar i ett icke typisk värde som förekommer bara en gång under 8 år.
Innan användningen måste data analyseras och avvikande värden korrigeras så dom inte bryter mot mönstret (t.ex. ovanligt stora eller ovanligt små värden). Vid bedömningen fick vi stor hjälp från grafisk representation av data.
Fig. 15 visar uppmätta data under 24 timmar under en typisk dag. Man kan se två toppar, en på morgonen (7-9) när cyklisterna åker till jobbet eller skolan och en på eftermiddagen (16-19) när cyklisterna åker hem.
Den höga upplösningen på timmar behövdes inte, intresset i föreliggande studie är trafiken per dag och därför har vi summerat cyklister under alla dagens timmar till ett värde per dag. Fig. 16 visar cykeltrafiken under fyra veckor i en månad. Första och fjärde veckan ser avvikande ut. Veckorna två och tre kan betraktas som typiska - ungefär konstant trafik måndag-fredag och en kraftig nedgång på lördag och söndag.
Fig. 17 presenterar 4 veckors cykeldata under varje oktober månad i år 2006 till år 2013. Den första dagen i oktober kan infalla på olika veckodagar t.ex. 1/10/2006 är söndag men 1/10/2007 är en måndag. Vi har därför valt att strukturera data enligt veckodagar och inte efter datum. Det innebär att första värdet i tabellen från Fig. 17 är första måndagen i oktober. Datavärden börjar med den första Måndagen och slutar med en Söndag fyra veckor senare.
Vi ser att oktober år 2011 har stor avvikelse i första veckan jämfört med samma period under de andra åren. Avvikelser i datavärden har påverkats av temperaturen och evenemang i om-rådet där barometern placerades. Eftersom faktorerna som påverkar datavärden negativt inte förekommer under det andra åren så har vi bestämt att korrigera datavärdena för år 2011. Kor-rigeringen skede genom att byta ut cykeldata för året 2011 mot medelvärdet av åren 2006-2010 och 2012-2013.
Fig. 18 visar data efter korrigeringen av år 2011 och fem specifika dagar som är markerat med gult.
SVM algoritmen från Scikit som vi använder i vår studie, förutsätter att indata har värden mel-lan 0.0 och 1.0. Vi har använt en standardfunktion som beskrivs i ekv. 2 som ger värdet 1.00 till det högsta och 0.0 till det minsta originalvärdet,se Fig. 19
I några av våra experiment använder vi utöver data om antalet cyklar också information om veckodagar. Vi var tvungna att normalisera veckodagarna (1-7) också, även om det logiskt bor-de vara kategorier.
I ett experiment testade vi att ange data med One Hot kodningstekniken, där vi i istället för en veckodags variabel med 7 möjliga värden har 7 veckodags variabler där alltid en har värde 1 och resterande sex har värde 0, se Fig. 20.
5.4 Resultat
Fig. 21 och Fig. 22 sammanfattar resultatet av våra experiment. Vi har utfört fem olika experi-ment för att undersöka precision vid inlärningen.
1. I det första experimentet har vi använt okorrigerade data för att skapa modeller för pre-diktion med SVM och räknade fram RMSE samt MAPE av resultatet, se Fig.17
2. I det andra experimentet har vi använt korrigerade data, se Fig.18
3. I det tredje experimentet använde vi veckodata (0.0-1.0) som en variabel, se Fig.19 4. I det fjärde experimentet använde vi veckodata One Hot kodade, se Fig.20
5. I det femte experimentet genomförde vi i excel. Vi använder en mycket enkel linjär inlärnings-modell baserat på Baseline inlärnings-modellen som används av Amazon Machine Learning System [20]. Vi behövde den för att kunna göra jämförelsen med andra modeller som skapades av mer avancerat SVM. Principen är att beräkna medelvärdet av målvariabeln och använda det som prediktion för alla efterföljande värden. [20]
6 Analys
I det följande har vi analyserat två strategier, Strategi A och Strategi B, se Fig. 21 och Fig. 22. Utöver numeriska värden på prediktionernas kvalitet (RMSE och MAPE) var vi också intressera-de i hur utvecklingen av succesiva prediktioner “ser ut”. Graferna i Appendix A visar resultaten av inlärningen enligt strategier B11-B15. År 2012 är målvariabel och 2013 är året som SVM algo-ritm predikterade. Med ökat antal år som används för framtagning av modellen ökar precision.
Strategi A
I Strategi A har vi fem olika delstrategier som vi tidigare beskrivit i kapitel 5.3.1. I varje delstra-tegi har vi utfört olika tester.
Modell A1 till A15: Här byggs modellen med två års data, år 2006 och år 2007, målvariabeln är 2008. Resultatet för Baselineexperimentet på alla tester från A1-A15 är relativt bäst, det beror på att Baseline använder medelvärdet av de två tidigare åren för att prediktera målvariabeln. Vid användning av SVM-algoritmen är resultatet bäst med korrigerad data utan tidsangivelse. Test A13-A15 visar ett tydligt försämrad resultat jämfört med test A1-A12, speciellt resultatet för test A13 på okorrigerade data, detta p.g.a. test A13-A15 använder år 2011 som testdata. Under år 2011 var det litet antal cyklister jämfört med de närliggande åren. Detta kan vara en anledning till varför resultatet hade stor avvikelse jämfört med de andra testerna.
Modell A2-A24: Resultaten är likt den föregående modellen men här (A2) används ett år extra indata i skapandet av modellen. En skillnad i resultat här (A21-A24) jämfört med föregående (A11-A15) test är att experiment med korrigerad data (Exp2) gav bättre resultat i MAPE än ex-periment med Baseline (Exp5). Anledningen kan vara att modellen (A2) är ett år närmare 2013 än föregående modell (A1).
Modell A3-A33 : Experiment Baseline test A33 gav bäst resultat jämfört med de andra expe-rimenten men det blev sämre än resultaten för de tidigare modellerna. En anledning till varför experimenten för dessa tester (A3-A33) gav sämre resultat kan för att modellen (A3) använder år 2010 som målvariabel. År 2010 har en liten avvikelse i cykeltrafiken jämfört med de närlig-gande åren.
Modell A4-A42: Resultatet för experiment med korrigerade data och år 2013 som målvaria-bel(A42) gav den bästa RMSE värdet jämfört med de tidigare testerna (A11-A15, A21-A24, A31-A33). Alla experiment (Exp2,Exp3,Exp4) med korrigerade data som använder SVM algoritmen gav bättre resultat än Baseline i test A42 och A51. Detta kan vara p.g.a. att modellen A4 använ-der mer indata än de föregående modellerna. Ju mer indata man använanvän-der desto bättre blir algoritmen prediktera målvariabeln eftersom vid större mängd data påverkas inte resultatet av små avvikelser i datavärden. Detta ser man i resultatet med korrigerade data(Exp2) för test A42 och A15. Där RMSE för A42 blev 548 och RMSE för A15 blev 637.
Modell A5-A51: Experiment med korrigerad data på test A51 gav bästa resultatet i Strategi A. Några möjliga faktorer till varför detta testet gav bäst resultat är bland annat den stora mäng-den indata vid skapandet av modellen och i testet A51. Även resultatet med okorrigerade data i datavärden. Resultaten för experimentet med okorrigerade data i de tidigare testerna hade mindre datamängd som indata jämfört med test A51. Ur ett logiskt perspektiv har små avvikel-ser i datamängden liten påverkan på resultatet.
Strategi B
Strategi B innehåller tester som har året 2013 som målvariabel. Resultaten visar att experiment ger oftast bättre RMSE och MAPE (förutom för Baseline) ju flera år man använder för att ska-pa modellen. Om man t.ex. studerar Exp3 i Fig. 22 (med de bästa värdena) ser man en ständig förbättring av RMSE från 468 i B11 (2 år) till 408 i B15 (6 år). Förbättring av MAPE i samma test är från 7% till 5%. Ständig förbättring behöver dock inte gälla alltid som man kan se i resultatet av Exp2, även om skillnaden inte är stor. Detta pekar på behovet av att experimentera och testa modeller innan deras användninge i skarpa prediktioner.
Om man jämför resultaten av experiment i Fig. 21 och Fig. 22 ser man att Strategi B ger bättre RMSE/MAPE värden. Anledningen till skillnaden i prestation av modellerna i Strategi B (B11, B12, B13, B14) och modellerna i Strategi A (A15, A24, A33, A42, A51) är att i Strategi B skapas modellerna med indata från de närliggande åren. I Strategi A skapas modellerna med indata från åren som kan ligga längre bort från målvariabeln, som är år 2013. Exempelvis används in-data för år 2006 och 2007 i modellen A1, som test A15 använde för att prediktera målvariabeln 2013.
7 Diskussion
Vi har plottat grafer som representerar de ursprungliga data värdena vi fått från barometern och undersökt vilka dagar som har stor avvikelse jämfört med andra dagar. Vi har med hjälp av graferna upptäckt ett mönster i cykeltrafiken som visar att de dagar som behöver korrigeras p.g.a. stor avvikelse är vardagar och inte helger. Mönstret visar att de dagar som behöver inter-poleras p.g.a. stor avvikelse är vardagar och inte helger. Möjliga orsaker till detta kan vara att de byggarbeten på vägarna är mer på vardagar eller att antalet bussar i trafik är fler på vardagar än helger. En annan möjlig orsak är också vädret, stor avvikelse i vädret från dag till dag kan påverka cykeltrafiken. Det är viktigt att ta hänsyn till att de framtida datavärden kan ha stora avvikelser som kan påverka resultat negativ eller positivt. Om det avvikelser i datavärden som är orimliga jämfört med andra datavärden så bör man korrigera det för att få ett bra resultat. Vi har utvärderat resultaten av våra olika testmodeller med både MAPE och RMSE. De två olika utvärderingsmetoderna kan användas vid olika jämförelser. Måtten för RMSE är i antalet cy-klister, d.v.s. om RMSE är lika med 500 så innebär det att felvärden är 500 cyklister mer eller mindre än det förväntade resultatet. Om man ska göra en prognos på exempelvis 100 000 cy-klister i framtiden så är 500 i RMSE mycket bra men om prognosen är 1000 cycy-klister så är 500 i RMSE mycket dåligt. Det är därför vi också har använt MAPE. MAPE ger oss felvärden i procent, vilket innebär att det inte spelar roll i hur stor skala prognosen är. MAPE kan användas för att jämföra två olika tester som förutsäger olika antal cyklister.
7.1 Diskutera relevanta arbeten
Dem relevanta arbeten från avsnitt 3 har gett oss viktiga förkunskaper om cykelsystemet och användning av maskininlärningsalgoritmer i cykelsystmet. Vi kan med hjälp av de relevanta arbetena säkerställa att våra resultat är realistiska och relativt bättre. Aspegren och Dahlström har använt olika experiment i sitt arbete “En jämförelse av maskininlärningsalgoritmer för upp-skattning av cykelflöden baserat på cykelbarometer- och väderdata” där det mest relevanta ex-perimentet är prediktion med normaliserade data, som gav ett RMSE värde på cirka 2000. Det sämsta RMSE värdet vi fick var 1658 för test A13 Exp1. Det är cirka 20% bättre prediktion än Aspegrens och Dahlströms bästa resultat. En anledning till att vi fick bättre resultat än de kan vara för att SVM algoritmen är mer lämplig för prediktioner av cykelflöden än Random Subspa-ce, Bagging och REPTree.
Ett annat resultat som är intressant för vår studie är resultaten från “Prediction of bicycle coun-ter data using regression” där forskarna har använt bland annat stödvektoralgoritmen med 1,2 och 3 graders polynomkärnor för prediktion av cykelflöden. Deras resultat gav RMSE värden mellan cirka 800 till 1000, vilket är mycket sämre än vårt bästa testresultat (B15 Exp2) som gav 402 i RMSE. Majoriteten av våra tester gav ett RMSE värde på mellan 800 till 1000 vilket gör det är svårare att granska vilka faktorer som kan ha påverkat resultatet betydligt.
En stor skillnad mellan vår studie och de relevanta arbeten [19][5][16] är att vi inte har använt oss av väderdata och temperaturdata. Vi tycker att dem relevanta arbeten borde ha gett bättre prediktion än oss eftersom fler indata variabler bör ge bättre kännedom om cyklisterna bete-ende och därmed ge bättre prediktion, men så blev det inte. Det kan var något att undersöka i framtida studier.
8 Slutsats och vidare forskning
8.1 SlutsatsVi valde två teststrategier för att kunna organisera arbetet eftersom det finns stor mängd av möjligheter att välja indata för modellskapande. Våra val av tester och modeller är systematise-rade, indata mellan varje test ökar successivt och är i kronologisk ordning. De två strategierna vi har använt är Strategi A och Strategi B. Resultaten av vår studie är sammanfattade i Fig. 21 och Fig. 22. Strategi B är intressantare och vi diskuterar den när vi besvarar vår forskningsfråga. RQ1: Hur påverkas precision av prediktioner av cykeldata för en given månad, mätt med RMSE och MAPE, av val av indata (cykeldata och tidsangivelse)?
Utifrån våra resultat så har vi kommit fram till att i vissa experiment blir resultatet mer precis ju större mängd indata som används. Exempelvis blir resultatet av alla fyra SVM experimenten mer precis ju större mängd indata som används men inte för experiment med Baseline. Experiment med korrigerade indata gav bättre resultat än experiment med okorrigerade data. Korrigerade indata ger automatiskt inte bättre resultat med större mängd indata, se test B12 och B13 för korrigerad data i Fig. 22 Resultaten vi fick med okorrigerat data var dåliga och vi fann ingen tydlig mönster mellan de olika testfallen.
RQ2: Hur påverkas resultatet av hur man representerar veckodagar i indata?
Experiment med veckodagar tid(0,1) är bättre och blir konsistent bättre med flera år. Denna indata gav bättre resultat än experiment med One Hot kodning och korrigerade indata. Avslutningsvis gav experimentet med veckodagar som 0.0-1.0 bästa resultatet av alla tester i Strategi B.
8.2 Vidare forskning
Det finns många andra regressionsalgoritmer som kan testas för att utföra samma undersök-ning som vi. Det är möjligt att våra resultat, med en SVM algoritm, kan förbättras. Vi studerade prediktion av oktober år 2013 med oktober-data från de tidigare åren. Man skulle kunna under-söka möjlighet att använda data från andra månader än oktober.
Man kan också använda sig av informationen av tiden vid skapande av testmodeller för att på-verka resultatet. Vi använde cyklister/dag enhet för att utföra våra tester. I framtiden kan man testa med år, årstid, månad eller timmar för att undersöka om tidens information kan ha en påverkan på resultatet. I framtiden kommer datamängden för cykelflödet vara större eftersom barometern räknar antalet cyklister framöver. Utöver cykeldata så kan man tillämpa informa-tion om vädret och temperaturen i utforskningen om cykeltrafiken.
Referenser
[1] Merembayev, T., Yunussov, R., Yedilkhan, A. (2018). Machine Learning Algorithms for Classification Geology Data from Well Logging. 2018 14th International Conference on Electronics Computer and Computation (ICECCO). doi:10.1109/icecco.2018.8634775 [2] muler, A. C Guido, S. (2017). Introduction to machine learning with Python: A guide for
data scientists. Sebastopol, CA: OReilly.
[3] Raschka, S. (2015). Python machine learning. Birmingham: Packt.
[4] Garreta, R., Moncecchi, G. (2013). Learning Scikit-learn: Machine learning in Python: Ex-perience the benefits of machine learning techniques by applying them to real-world problems using Python and the open source Scikit-learn library.
[5] Holmgren, J., Aspegren, S.,Dahlströma, J. (2017). Prediction of bicycle counter data using regression. Procedia Computer Science, j.procs.2017.08.312
[6] Romanillos, G., Austwick, M. Z., Ettema, D.,Kruijf, J. D. (2015). Big Data and Cycling. Transport Reviews, 2015
[7] Hao, J., Ho, T. K. (2019). Machine Learning Made Easy: A Review of Scikit-learn Package in Python Programming Language. Journal of Educational and Behavioral Statistics, [8] Pedregosa et al., (2011). Scikit-learn: Machine Learning in Python.
[9] Yang, H., Xie, K., Ozbay, K., Ma, Y.,and Wang, Z. (2018). Use of Deep Learning to Pre-dict Daily Usage of Bike Sharing Systems. Transportation Research Record: Journal of the Transportation Research Board.
[10] Ashqar, H. I., Elhenawy, M., Almannaa, M. H., Ghanem, A., Rakha, H. A.,and House, L. (2017). Modeling bike availability in a bike-sharing system using machine learning. 2017 5th IEEE International Conference on Models and Technologies for Intelligent Transpor-tation Systems (MT-ITS).
[11] Xu, H., Ying, J., Wu, H., Lin, F. (2013). Public Bicycle Traffic Flow Prediction based on a Hybrid Model. Applied Mathematics and Information Sciences, 7(2).
[12] Vanderplas, Jacob T. Python Data Science Handbook: Tools and Techniques for Develo-pers. Beijing: OReilly, 2016.
[13] Bishop, Christopher M. Pattern Recognition and Machine Learning. 2006
[14] Scipy Lecture Notes. Accessed March 13, 2019. http://scipy-lectures.org/index.html. [15] Sachdeva, Purnima, and K N Sarvanan. “Prediction of Bike Sharing Demand.” Oriental
Journal of Computer Science and Technology, vol. 10, no. 1, 2017,
[16] Datta, Arnab Kumar. Predicting bike-share usage patterns with machine learning. Master thesis, University of Oslo, 2014
[17] Jay F. Nunamaker J, Minder C, Titus D. M. P. Systems Development in Information Systems Research. Journal Of Management Information Systems.1990
[18] Regression-based evaluation of bicycle flow trend estimates. Department of Computer Science and Media Technology, Malmö University, 2018
[19] En jämförelse av maskininlärningsalgoritmer för uppskattning av cykelflöden baserat på cykelbarometer- och väderdata. Sebastian Aspegren, Jonas Dahlström 2016-05-27 [20] Amazon Machine Learning Development Guide,
https://aws.amazon.com/machine-learning/ 2019-05-20
[21] Marsland, Stephen. Machine Learning: an algorithmic perspective. CRC press, 2015. [22] Analys av prediktiv precision av maskininlärningsalgoritmer Jonas Remgård Teknik och
samhälle Datavetenskap 2017-05-30
[23] https://scikit-learn.org/stable/modules/svm.html 2019-05-01
[24] https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html 2019-05-03

![Figur 3: Olika paket i Python [7]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/12.892.200.686.625.816/figur-olika-paket-i-python.webp)
![Figur 4: Numpy D-dimensional array [14]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/13.892.236.642.314.501/figur-numpy-d-dimensional-array.webp)

![Figur 6: Inmatningsfunktionerna [5]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/17.892.267.607.444.676/figur-inmatningsfunktionerna.webp)
![Figur 7: Prestationsjämförelser av olika algoritmer [5]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/18.892.185.698.285.424/figur-prestationsjämförelser-av-olika-algoritmer.webp)
![Figur 8: variabler i datasetet [15]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/19.892.306.563.548.865/figur-variabler-i-datasetet.webp)
![Figur 9: Prestationsjämförelser av olika algoritmer [15]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/20.892.295.590.251.466/figur-prestationsjämförelser-av-olika-algoritmer.webp)
![Figur 10: Jämförelse mellan 3 maskininlärningsalgoritmer [16]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4176010.90601/21.892.222.697.395.716/figur-jämförelse-mellan-maskininlärningsalgoritmer.webp)
