Stefan Karlsson D S A U G M ENTE D E XP LO R A TO RY TE STI N G 2 02 1 ISBN 978-91-7485-508-1 ISSN 1651-9256
Address: P.O. Box 883, SE-721 23 Västerås. Sweden Address: P.O. Box 325, SE-631 05 Eskilstuna. Sweden E-mail: info@mdh.se Web: www.mdh.se
Mälardalen University Press Licentiate Theses No. 307
TOWARDS AUGMENTED EXPLORATORY TESTING
Stefan Karlsson 2021
School of Innovation, Design and Engineering
Mälardalen University Press Licentiate Theses No. 307
TOWARDS AUGMENTED EXPLORATORY TESTING
Stefan Karlsson 2021
School of Innovation, Design and Engineering
Copyright © Stefan Karlsson, 2021 ISBN 978-91-7485-508-1
ISSN 1651-9256
Printed by E-Print AB, Stockholm, Sweden
Copyright © Stefan Karlsson, 2021 ISBN 978-91-7485-508-1
ISSN 1651-9256
Know thyself. - Delphic Maxim
Know thyself. - Delphic Maxim
Abstract
Software systems have an increasing presence in our society. With our in-frastructure, such as food and water supply, controlled by complex software systems, it is essential to keep failures to a minimum. Exploratory testing has shown to be a good method of finding bugs that require more complex inter-actions, as well as to gain insights into how the system under test behaves. However, tool support in this area is lacking. Supporting exploratory testing with automation tools has the potential of freeing humans to spend their time where it is of the highest yield and also aid in covering the vast state space of testing a complex software system in a meaningful way. To be able to engi-neer such tools, targeting interaction models of contemporary systems, deeper knowledge is needed of the possibilities and limitations of applying available software testing methods.
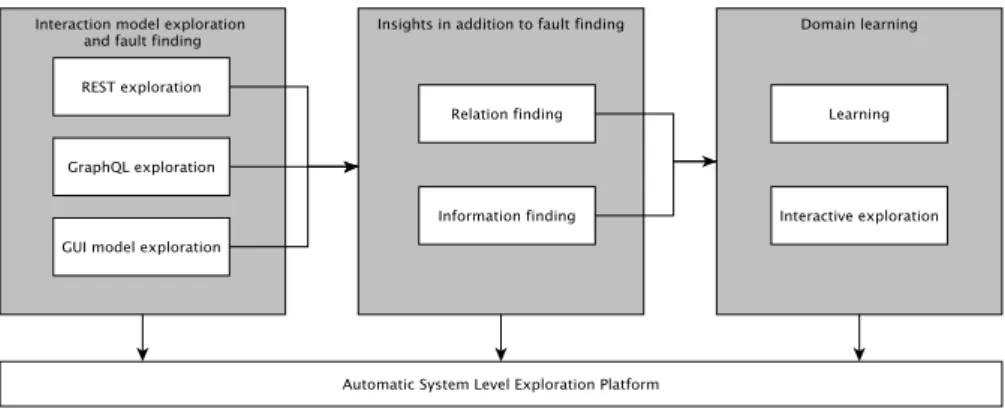
In this thesis we propose and evaluate several approaches that can be used to automatically perform black-box system-level testing, potentially augment-ing humans in exploratory testaugment-ing. We base these approaches on random-based methods, such as property-based testing, and present the results of evaluations on several industry-grade systems.
Our results show that the proposed and evaluated methods automatically can find faults in real-world software systems. In addition to fault finding, our methods can also find insights such as deviations between the specification of the system under test and the actual behavior.
The work in this thesis is a first step towards augmenting developers and testers in exploratory testing.
Abstract
Software systems have an increasing presence in our society. With our in-frastructure, such as food and water supply, controlled by complex software systems, it is essential to keep failures to a minimum. Exploratory testing has shown to be a good method of finding bugs that require more complex inter-actions, as well as to gain insights into how the system under test behaves. However, tool support in this area is lacking. Supporting exploratory testing with automation tools has the potential of freeing humans to spend their time where it is of the highest yield and also aid in covering the vast state space of testing a complex software system in a meaningful way. To be able to engi-neer such tools, targeting interaction models of contemporary systems, deeper knowledge is needed of the possibilities and limitations of applying available software testing methods.
In this thesis we propose and evaluate several approaches that can be used to automatically perform black-box system-level testing, potentially augment-ing humans in exploratory testaugment-ing. We base these approaches on random-based methods, such as property-based testing, and present the results of evaluations on several industry-grade systems.
Our results show that the proposed and evaluated methods automatically can find faults in real-world software systems. In addition to fault finding, our methods can also find insights such as deviations between the specification of the system under test and the actual behavior.
The work in this thesis is a first step towards augmenting developers and testers in exploratory testing.
Sammanfattning
Vårt samhälle har ett ökat beroende av mjukvarusystem. Då vår infrastruktur, så som mat och vattenproduktion, styrs av komplexa mjukvarusystem, är det essentiellt att minimera att dessa system fallerar på grund av mjukvarubug-gar. Utforskande testning kan vara en bra metod för att hitta mjuvkvarufel som kräver mer komplexa interaktioner för att uppstå och för att få insikter om hur systemet som testas beter sig. Dock är tillgången av verktyg i detta om-råde bristande. Verktyg för att stödja utforskande testning har potentialen att frigöra människor att spendera sin tid där den är mest givande och också vara ett stöd i att täcka den enorma sökrymd som finns vid testning av komplexa mjukvarusystem. För att konstruera sådana verktyg, som riktar sig mot mod-erna systems interaktionsmodeller, behövs mer kunskap om möjlighetmod-erna och begränsningarna av att använda tillgängliga metoder för mjukvarutest.
I denna licentiatavhandling föreslår och utvärderar vi flera tillvä-gagångssätt som kan användas för att automatiskt utföra "black-box"-testning på systemnivå, med potential att bistå människor vid utforskande testning. Vi har baserat dessa tillvägagångssätt på slumpbaserade metoder, så som "property-based testing" och presenterar resultatet av att utvärdera dessa på flera system av industriklass.
Våra resultat visar att de föreslagna och utvärderade metoderna automa-tiskt kan hitta fel i mjukvarusystem med verklig användning. Utöver att hitta fel kan våra metoder också hitta insikter såsom avvikelser mellan specifikatio-nen av ett system som testas och det faktiska beteendet.
Arbetet i denna avhandling är ett första steg mot att bistå utvecklare och testare i utforskande tester.
Sammanfattning
Vårt samhälle har ett ökat beroende av mjukvarusystem. Då vår infrastruktur, så som mat och vattenproduktion, styrs av komplexa mjukvarusystem, är det essentiellt att minimera att dessa system fallerar på grund av mjukvarubug-gar. Utforskande testning kan vara en bra metod för att hitta mjuvkvarufel som kräver mer komplexa interaktioner för att uppstå och för att få insikter om hur systemet som testas beter sig. Dock är tillgången av verktyg i detta om-råde bristande. Verktyg för att stödja utforskande testning har potentialen att frigöra människor att spendera sin tid där den är mest givande och också vara ett stöd i att täcka den enorma sökrymd som finns vid testning av komplexa mjukvarusystem. För att konstruera sådana verktyg, som riktar sig mot mod-erna systems interaktionsmodeller, behövs mer kunskap om möjlighetmod-erna och begränsningarna av att använda tillgängliga metoder för mjukvarutest.
I denna licentiatavhandling föreslår och utvärderar vi flera tillvä-gagångssätt som kan användas för att automatiskt utföra "black-box"-testning på systemnivå, med potential att bistå människor vid utforskande testning. Vi har baserat dessa tillvägagångssätt på slumpbaserade metoder, så som "property-based testing" och presenterar resultatet av att utvärdera dessa på flera system av industriklass.
Våra resultat visar att de föreslagna och utvärderade metoderna automa-tiskt kan hitta fel i mjukvarusystem med verklig användning. Utöver att hitta fel kan våra metoder också hitta insikter såsom avvikelser mellan specifikatio-nen av ett system som testas och det faktiska beteendet.
Arbetet i denna avhandling är ett första steg mot att bistå utvecklare och testare i utforskande tester.
Acknowledgments
Thank you to everyone who have supported and inspired me, both emotionally and intellectually.
Thanks to the, many times forgotten, open source contributors who put their time and effort into making software serving as a foundation for much research.
Thanks to Daniel and Adnan, my supervisors, for giving me a lot of free-dom while teaching me the ways of science.
Stefan Karlsson Västerås, 2021
Acknowledgments
Thank you to everyone who have supported and inspired me, both emotionally and intellectually.
Thanks to the, many times forgotten, open source contributors who put their time and effort into making software serving as a foundation for much research.
Thanks to Daniel and Adnan, my supervisors, for giving me a lot of free-dom while teaching me the ways of science.
Stefan Karlsson Västerås, 2021
List of Publications
Papers included in thesis
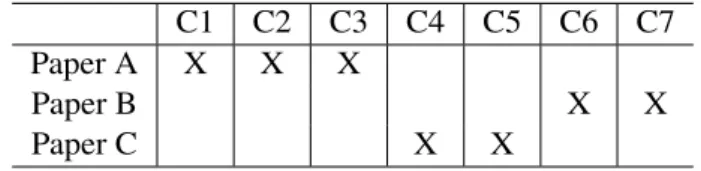
12Paper A: S. Karlsson, A. ˇCauševi´c, and D. Sundmark. QuickREST: Property-based Test Generation of OpenAPI-Described RESTful APIs. In In-ternational Conference on Software Testing, Validation and Verification (ICST). IEEE, 2020. [29].
Paper B: S. Karlsson, A. ˇCauševi´c, D. Sundmark, and M. Larsson. Model-based Automated Testing of Mobile Applications: An Industrial Case Study. In International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 2021. [31].
Paper C: S. Karlsson, A. ˇCauševi´c, and D. Sundmark. Automatic Property-based Testing of GraphQL APIs. In International Conference on Au-tomation of Software Test (AST). IEEE/ACM, 2021. [30].
1
A licentiate degree is a Swedish graduate degree halfway between M.Sc and Ph.D.
2The included papers have been reformatted to comply with the thesis layout.
List of Publications
Papers included in thesis
12Paper A: S. Karlsson, A. ˇCauševi´c, and D. Sundmark. QuickREST: Property-based Test Generation of OpenAPI-Described RESTful APIs. In In-ternational Conference on Software Testing, Validation and Verification (ICST). IEEE, 2020. [29].
Paper B: S. Karlsson, A. ˇCauševi´c, D. Sundmark, and M. Larsson. Model-based Automated Testing of Mobile Applications: An Industrial Case Study. In International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 2021. [31].
Paper C: S. Karlsson, A. ˇCauševi´c, and D. Sundmark. Automatic Property-based Testing of GraphQL APIs. In International Conference on Au-tomation of Software Test (AST). IEEE/ACM, 2021. [30].
1
A licentiate degree is a Swedish graduate degree halfway between M.Sc and Ph.D.
2The included papers have been reformatted to comply with the thesis layout.
Papers not included in thesis
Paper X: S. Karlsson. Exploratory Test Agents for Stateful Software Sys-tems. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 2019. [28].
12
Papers not included in thesis
Paper X: S. Karlsson. Exploratory Test Agents for Stateful Software Sys-tems. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 2019. [28].
Contents
I Thesis 15 1 Introduction 17 1.1 Problem Formulation . . . 19 1.2 Thesis Context . . . 20 1.3 Thesis Overview . . . 222 Background and Related Work 23 2.1 Exploratory Testing . . . 23
2.2 Interactive Search-based Software Testing . . . 25
2.3 Property-based Testing . . . 26
2.4 Chaos Engineering . . . 27
2.5 Web API testing . . . 28
2.6 GUI Testing . . . 30 3 Research Overview 31 3.1 Research Goals . . . 31 3.2 Research Process . . . 32 4 Thesis Contributions 35 4.1 Included Papers . . . 36
4.2 Resulting Software Artifacts . . . 39
4.3 Thesis Contribution Summary . . . 40
5 Summary 43 5.1 Discussion . . . 43 5.2 Conclusion . . . 44 5.3 Future Work . . . 44
Contents
I Thesis 15 1 Introduction 17 1.1 Problem Formulation . . . 19 1.2 Thesis Context . . . 20 1.3 Thesis Overview . . . 222 Background and Related Work 23 2.1 Exploratory Testing . . . 23
2.2 Interactive Search-based Software Testing . . . 25
2.3 Property-based Testing . . . 26
2.4 Chaos Engineering . . . 27
2.5 Web API testing . . . 28
2.6 GUI Testing . . . 30 3 Research Overview 31 3.1 Research Goals . . . 31 3.2 Research Process . . . 32 4 Thesis Contributions 35 4.1 Included Papers . . . 36
4.2 Resulting Software Artifacts . . . 39
4.3 Thesis Contribution Summary . . . 40
5 Summary 43 5.1 Discussion . . . 43
5.2 Conclusion . . . 44
5.3 Future Work . . . 44
II Included Papers 51
6 Paper A: QuickREST: PBT Generation of OpenAPI. . . 53
6.1 Introduction . . . 55 6.2 Background . . . 57 6.3 Proposed method . . . 60 6.4 Implementation . . . 61 6.5 Evaluation . . . 68 6.6 Related work . . . 75
6.7 Discussion and Future Work . . . 76
6.8 Conclusion . . . 79
7 Paper B: Model-based Automated Testing of Mobile Apps. . . 85
7.1 Introduction . . . 87 7.2 Background . . . 88 7.3 Used approach . . . 89 7.4 Implementation . . . 93 7.5 Evaluation . . . 95 7.6 Lessons Learned . . . 99 7.7 Related Work . . . 101 7.8 Conclusion . . . 102
8 Paper C: Automatic Property-based Testing of GraphQL APIs 107 8.1 Introduction . . . 109
8.2 Background . . . 111
8.3 Proposed Method . . . 113
8.4 Evaluation . . . 121
8.5 Related Work . . . 129
8.6 Discussion and Future Work . . . 130
8.7 Conclusion . . . 131
14 II Included Papers 51 6 Paper A: QuickREST: PBT Generation of OpenAPI. . . 53
6.1 Introduction . . . 55 6.2 Background . . . 57 6.3 Proposed method . . . 60 6.4 Implementation . . . 61 6.5 Evaluation . . . 68 6.6 Related work . . . 75
6.7 Discussion and Future Work . . . 76
6.8 Conclusion . . . 79
7 Paper B: Model-based Automated Testing of Mobile Apps. . . 85
7.1 Introduction . . . 87 7.2 Background . . . 88 7.3 Used approach . . . 89 7.4 Implementation . . . 93 7.5 Evaluation . . . 95 7.6 Lessons Learned . . . 99 7.7 Related Work . . . 101 7.8 Conclusion . . . 102
8 Paper C: Automatic Property-based Testing of GraphQL APIs 107 8.1 Introduction . . . 109
8.2 Background . . . 111
8.3 Proposed Method . . . 113
8.4 Evaluation . . . 121
8.5 Related Work . . . 129
8.6 Discussion and Future Work . . . 130
8.7 Conclusion . . . 131
Part I
Thesis
Part I
Thesis
Chapter 1
Introduction
Software is an increasing part of modern infrastructure. Software systems con-trolling critical infrastructures such as food production, water supply, and gen-eration of electricity are essential to modern civilization. Outside of the do-main of critical infrastructure systems, while consequences might not be as severe for society, software systems handle the critical business infrastructure that businesses depend on for daily operation. Any downtime in such systems is costly and disruptive. This makes it essential to find any interactions in these complex systems that result in unwanted behavior such as failures. This is a traditional goal of practices and research in software testing. However, the scale and interaction models of modern systems have changed, hence practices and methods must follow.
The combination of composing services into systems, internally and exter-nally, and systems into systems-of-systems have increased the complexity of software intensive systems. With this increase in complexity the effort of en-suring the quality and the behavior of the systems has also increased. Testing of highly complex software systems is thus a hard problem and any increase in automation in this domain would have the potential of cost savings and in-creased external quality, in addition to sparing practitioners of potentially dull and repetitive work.
In our experience, a trend in current approaches to building large systems and systems-of-systems is to compose and rely on 3rd-party frameworks, li-braries, cloud services, and services developed by other teams in a distributed organization. In addition, the current architectural trend of Microservices1can result in several different technologies used to compose the end-user system. The result from the perspective of a development team, is thus that only a small
1https://en.wikipedia.org/wiki/Microservices
Chapter 1
Introduction
Software is an increasing part of modern infrastructure. Software systems con-trolling critical infrastructures such as food production, water supply, and gen-eration of electricity are essential to modern civilization. Outside of the do-main of critical infrastructure systems, while consequences might not be as severe for society, software systems handle the critical business infrastructure that businesses depend on for daily operation. Any downtime in such systems is costly and disruptive. This makes it essential to find any interactions in these complex systems that result in unwanted behavior such as failures. This is a traditional goal of practices and research in software testing. However, the scale and interaction models of modern systems have changed, hence practices and methods must follow.
The combination of composing services into systems, internally and exter-nally, and systems into systems-of-systems have increased the complexity of software intensive systems. With this increase in complexity the effort of en-suring the quality and the behavior of the systems has also increased. Testing of highly complex software systems is thus a hard problem and any increase in automation in this domain would have the potential of cost savings and in-creased external quality, in addition to sparing practitioners of potentially dull and repetitive work.
In our experience, a trend in current approaches to building large systems and systems-of-systems is to compose and rely on 3rd-party frameworks, li-braries, cloud services, and services developed by other teams in a distributed organization. In addition, the current architectural trend of Microservices1can result in several different technologies used to compose the end-user system. The result from the perspective of a development team, is thus that only a small
1https://en.wikipedia.org/wiki/Microservices
part of the system, the responsibility of the team, has its internals available. The rest of the systems is a composition of black-boxes. Instead of turtles, as the saying goes2, it is Black-boxes all the way down, some of which reside in the cloud. Considering this, white-box testing methods, that leverage the availability of source-code, are of limited use on these kinds of systems when performing system-level tests.
Currently, black-box system-level exploration of software systems, i.e, Ex-ploratory Testing, is a predominantly manual practice. Some aspects of ex-ploratory testing are very reasonable to perform manually, such as evaluation of ease-of-use of a Graphical User Interface (GUI), but other aspects would benefit from more automation. An example of where automation is beneficial is to generate a large number of inputs to several APIs3in a system-of-systems
and find relations between those APIs, e.g, if we create an entity with one op-eration, we expect it to be available when invoking some other operation. Au-tomation should then strive to automate repetitive human tasks, freeing more time for the human testers to spend on other more creative tasks. In addition, such automation could also automatically explore behavior scenarios with a potentially higher state-space coverage in a shorter time, compared to humans, and in that way reveal properties of the system not previously known. An exploratory testing toolbox could thus augment humans, providing tools on different abstraction levels of testing, ranging from, for example, generating random input, allow the user to tweak generators, provide means of stating invariants of the system under test (SUT), record testing sessions, analyze the diversity of test cases, aid in boundary value analysis, provide performance characteristics, etc. This vision is based on software providing the tools and human fine-tuning of parameters to fit the context of the domain of the SUT and in doing so, performing tool augmented exploratory testing experiments.
In recent years there has been a shift in the types of APIs used by automation- and control-system vendors, one of our main contexts. With the introduction of mobile-applications, machine learning4, cloud-computing, and sophisticated dashboards, the need to consume data from a process control system from devices outside of the control system has increased. To leverage infrastructure already in place, such as cloud-based services, available tools, and experiences, Representational state transfer (REST) [16] APIs are increasingly used, as have been the case for Internet-based services such as Twitter, Facebook, and Google. Thus, REST APIs have in many
2
https://en.wikipedia.org/wiki/Turtles_all_the_way_down
3Application programming interface, https://en.wikipedia.org/wiki/
Application_programming_interface
4https://en.wikipedia.org/wiki/Machine_learning
18
part of the system, the responsibility of the team, has its internals available. The rest of the systems is a composition of black-boxes. Instead of turtles, as the saying goes2, it is Black-boxes all the way down, some of which reside in the cloud. Considering this, white-box testing methods, that leverage the availability of source-code, are of limited use on these kinds of systems when performing system-level tests.
Currently, black-box system-level exploration of software systems, i.e, Ex-ploratory Testing, is a predominantly manual practice. Some aspects of ex-ploratory testing are very reasonable to perform manually, such as evaluation of ease-of-use of a Graphical User Interface (GUI), but other aspects would benefit from more automation. An example of where automation is beneficial is to generate a large number of inputs to several APIs3in a system-of-systems
and find relations between those APIs, e.g, if we create an entity with one op-eration, we expect it to be available when invoking some other operation. Au-tomation should then strive to automate repetitive human tasks, freeing more time for the human testers to spend on other more creative tasks. In addition, such automation could also automatically explore behavior scenarios with a potentially higher state-space coverage in a shorter time, compared to humans, and in that way reveal properties of the system not previously known. An exploratory testing toolbox could thus augment humans, providing tools on different abstraction levels of testing, ranging from, for example, generating random input, allow the user to tweak generators, provide means of stating invariants of the system under test (SUT), record testing sessions, analyze the diversity of test cases, aid in boundary value analysis, provide performance characteristics, etc. This vision is based on software providing the tools and human fine-tuning of parameters to fit the context of the domain of the SUT and in doing so, performing tool augmented exploratory testing experiments.
In recent years there has been a shift in the types of APIs used by automation- and control-system vendors, one of our main contexts. With the introduction of mobile-applications, machine learning4, cloud-computing, and sophisticated dashboards, the need to consume data from a process control system from devices outside of the control system has increased. To leverage infrastructure already in place, such as cloud-based services, available tools, and experiences, Representational state transfer (REST) [16] APIs are increasingly used, as have been the case for Internet-based services such as Twitter, Facebook, and Google. Thus, REST APIs have in many
2
https://en.wikipedia.org/wiki/Turtles_all_the_way_down
3Application programming interface, https://en.wikipedia.org/wiki/
Application_programming_interface
4https://en.wikipedia.org/wiki/Machine_learning
cases become the integration method of choice for both external services and internal services. The modern set of interaction models to explore in a testing scenario are thus Web APIs (APIs based on the Hypertext Transfer Protocol5 (HTTP)) such as REST and also the HTTP based query language GraphQL6
and GUIs consisting of Web-applications and Mobile-applications.
In summary, the complexity of software systems is increasing and test generation methods for system-level Web-APIs based on REST and GraphQL are lacking. Web-applications and mobile-applications, leveraging Web-APIs, have been an area of interest for researchers, so methods might exist, but results have not sufficiently been transferred to industry. To alleviate these problems, the goal of the work in this thesis is to put the foundation in place to aug-ment humans in performing exploratory testing of said interaction models and making such methods practical to enable transfer to industry. The complete automation of the exploratory testing process is not a goal of this thesis, as we believe that humans in-the-loop are an important component of successful exploratory testing. Thus, our proposed methods must take human interaction into account.
The automation of human creative activity, like exploratory testing, might steer our thoughts toward applying methods from artificial intelligence, ma-chine learning, or other evolutionary computation methods. But any such methods should be able to outperform a random-based method, given the extra effort needed. In this thesis we will evaluate such a random-based base-line, i.e., how far can we explore the given interaction models, what are the limita-tions, and potential improvements of a random-based method. This will be an important contribution to any further work in this area of research, bringing us closer to augmented exploratory testing.
1.1
Problem Formulation
Consider the development of system-of-systems in general and a development team working on such systems. Such a development team is responsible for developing new functionalities, such as new services running on the back-end platform (platform denoting the common infrastructure parts of the system-of-systems), or some of the clients using those services. As an example, a customer could buy and install, hosted locally or in the cloud, a set of ser-vices and clients solving a specific use-case. An example could be a new set of services aggregating data from the existing system-of-systems and a mobile
5https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
6https://graphql.org/
cases become the integration method of choice for both external services and internal services. The modern set of interaction models to explore in a testing scenario are thus Web APIs (APIs based on the Hypertext Transfer Protocol5 (HTTP)) such as REST and also the HTTP based query language GraphQL6
and GUIs consisting of Web-applications and Mobile-applications.
In summary, the complexity of software systems is increasing and test generation methods for system-level Web-APIs based on REST and GraphQL are lacking. Web-applications and mobile-applications, leveraging Web-APIs, have been an area of interest for researchers, so methods might exist, but results have not sufficiently been transferred to industry. To alleviate these problems, the goal of the work in this thesis is to put the foundation in place to aug-ment humans in performing exploratory testing of said interaction models and making such methods practical to enable transfer to industry. The complete automation of the exploratory testing process is not a goal of this thesis, as we believe that humans in-the-loop are an important component of successful exploratory testing. Thus, our proposed methods must take human interaction into account.
The automation of human creative activity, like exploratory testing, might steer our thoughts toward applying methods from artificial intelligence, ma-chine learning, or other evolutionary computation methods. But any such methods should be able to outperform a random-based method, given the extra effort needed. In this thesis we will evaluate such a random-based base-line, i.e., how far can we explore the given interaction models, what are the limita-tions, and potential improvements of a random-based method. This will be an important contribution to any further work in this area of research, bringing us closer to augmented exploratory testing.
1.1
Problem Formulation
Consider the development of system-of-systems in general and a development team working on such systems. Such a development team is responsible for developing new functionalities, such as new services running on the back-end platform (platform denoting the common infrastructure parts of the system-of-systems), or some of the clients using those services. As an example, a customer could buy and install, hosted locally or in the cloud, a set of ser-vices and clients solving a specific use-case. An example could be a new set of services aggregating data from the existing system-of-systems and a mobile
5https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
6https://graphql.org/
application to view the collected data. From the perspective of the customer this is one application, one new capability that will enable her to view the oper-ation of her systems, such as a factory plant, in a mobile applicoper-ation. However, from the perspective of the development team and architecturally, this new ca-pability consists of a set of services running on the platform and the mobile application itself. The services need to integrate with other existing services and infrastructure in the platform and be tested in that context. While the services will run on the platform, the mobile application will run on the cus-tomers’ hardware and thus have variability in the set of the operating system, operating system versions, and different hardware. The typical development team then, in this general context of system-of-systems development, has the responsibility to test that their services work as a part of the platform and that their clients interact with the system as expected. Thus, the testing effort of the new functionality that the development team has produced, running as part of an existing system-of-systems, is considerable and include several, from the point of view of the team, black-boxes.
In addition to challenges surfacing from the technical parts of a system-of-systems, it is important to consider the human perspective of testing. Even though development teams are responsible to deliver new system capabilities, they do not always have a dedicated test engineer. In this case, all testing prior to formal system testing has to be performed by the developers. This challenge can be alleviated somewhat with a dedicated test professional, but the scope of a large system of mostly black-boxes still poses a testing challenge. As the sys-tem grows in size and the number of clients increases it is no longer practical, within a realistic testing budget, to cover every permutation of inputs and con-figurations. Therefore a more exploratory-based approach is required, where "interesting" (where human intuition typically defines "interesting") tests are executed. Finally, given the time constraints, as is common in most contexts, a method to generate test cases is strongly preferred over having developers, or testers, manually create test cases.
In summary, the problem is thus, how can we enable system-level test case generation targeting a system-of-systems with elements of exploration targeting contemporary system interaction models?
1.2
Thesis Context
In all things we do we bring our personal context. Even while being objective in research, the direction and the questions asked are influenced by our expe-riences and context. Describing my personal and industry context hopefully brings into light the problems, methods, and goals researched in this thesis.
20
application to view the collected data. From the perspective of the customer this is one application, one new capability that will enable her to view the oper-ation of her systems, such as a factory plant, in a mobile applicoper-ation. However, from the perspective of the development team and architecturally, this new ca-pability consists of a set of services running on the platform and the mobile application itself. The services need to integrate with other existing services and infrastructure in the platform and be tested in that context. While the services will run on the platform, the mobile application will run on the cus-tomers’ hardware and thus have variability in the set of the operating system, operating system versions, and different hardware. The typical development team then, in this general context of system-of-systems development, has the responsibility to test that their services work as a part of the platform and that their clients interact with the system as expected. Thus, the testing effort of the new functionality that the development team has produced, running as part of an existing system-of-systems, is considerable and include several, from the point of view of the team, black-boxes.
In addition to challenges surfacing from the technical parts of a system-of-systems, it is important to consider the human perspective of testing. Even though development teams are responsible to deliver new system capabilities, they do not always have a dedicated test engineer. In this case, all testing prior to formal system testing has to be performed by the developers. This challenge can be alleviated somewhat with a dedicated test professional, but the scope of a large system of mostly black-boxes still poses a testing challenge. As the sys-tem grows in size and the number of clients increases it is no longer practical, within a realistic testing budget, to cover every permutation of inputs and con-figurations. Therefore a more exploratory-based approach is required, where "interesting" (where human intuition typically defines "interesting") tests are executed. Finally, given the time constraints, as is common in most contexts, a method to generate test cases is strongly preferred over having developers, or testers, manually create test cases.
In summary, the problem is thus, how can we enable system-level test case generation targeting a system-of-systems with elements of exploration targeting contemporary system interaction models?
1.2
Thesis Context
In all things we do we bring our personal context. Even while being objective in research, the direction and the questions asked are influenced by our expe-riences and context. Describing my personal and industry context hopefully brings into light the problems, methods, and goals researched in this thesis.
1.2.1 Personal Context
At the time of this writing, I have spent 15 years as a software engineer in industry. All of this time I have had a strong interest in automatically testing my software artifacts. I wrote my first automatic unit-test in 2006 and have been exposed to, and tried, Test Driven Development, Behaviour Driven De-velopment, unit-testing, integration-testing, acceptance-testing, mutation test-ing, property-based testtest-ing, and so on. All this before coming to academia.
The realization I have come to, given my personal experience, is that, while traditional example-based tests, automatically executed, can be useful to catch regressions and help in creating a testable code-base, it does not find the hard problems. The problems with high impact that I have seen found have either been found by an experienced tester, exploring the system, or by customers in the field. But applying exploratory testing by domain experts does not scale.
I have felt the pains firsthand of testing and maintaining complex software systems and with this work I want to take the first steps to help my fellow developers. My hope is that in the future there is a tool available where a developer can explore a software system, staying in creative control. The grand vision is to enable, with this research, a professional extendable toolbox for this purpose. Much like other creative professional tools such as a Digital Audio Workbench (audio production) or Photoshop (graphical production). These tools do not perform and generate the complete creative work for you. They provide the tools, and the human provides the composition of the tools.
In addition, my background in industry has given me a strong conviction that proposed methods from academia should be, at least in part, evaluated on industry grade software to give practitioners a notion of how useful the method is in the real world and how it might fit in their context. This is why all work in this thesis has been applied to industry grady systems, at ABB and the open-source industry grade product GitLab, in addition to controlled examples.
1.2.2 Industry Context
The industrial context of the work in this thesis has been at ABB Industrial Automation, Process Control Platform. The main product for this part of ABB has been a distributed control system (DCS), System 800xA. However, in re-cent years much focus has been on building a common digital platform that multiple ABB products can leverage. In the case of System 800xA, this plat-form enables models of objects in the system as well as telemetry data to be published to the cloud. The published data can then be used for analytical purposes, such as predictive maintenance or other machine learning insights, building dashboards, and mobile applications that display data from the
sys-1.2.1 Personal Context
At the time of this writing, I have spent 15 years as a software engineer in industry. All of this time I have had a strong interest in automatically testing my software artifacts. I wrote my first automatic unit-test in 2006 and have been exposed to, and tried, Test Driven Development, Behaviour Driven De-velopment, unit-testing, integration-testing, acceptance-testing, mutation test-ing, property-based testtest-ing, and so on. All this before coming to academia.
The realization I have come to, given my personal experience, is that, while traditional example-based tests, automatically executed, can be useful to catch regressions and help in creating a testable code-base, it does not find the hard problems. The problems with high impact that I have seen found have either been found by an experienced tester, exploring the system, or by customers in the field. But applying exploratory testing by domain experts does not scale.
I have felt the pains firsthand of testing and maintaining complex software systems and with this work I want to take the first steps to help my fellow developers. My hope is that in the future there is a tool available where a developer can explore a software system, staying in creative control. The grand vision is to enable, with this research, a professional extendable toolbox for this purpose. Much like other creative professional tools such as a Digital Audio Workbench (audio production) or Photoshop (graphical production). These tools do not perform and generate the complete creative work for you. They provide the tools, and the human provides the composition of the tools.
In addition, my background in industry has given me a strong conviction that proposed methods from academia should be, at least in part, evaluated on industry grade software to give practitioners a notion of how useful the method is in the real world and how it might fit in their context. This is why all work in this thesis has been applied to industry grady systems, at ABB and the open-source industry grade product GitLab, in addition to controlled examples.
1.2.2 Industry Context
The industrial context of the work in this thesis has been at ABB Industrial Automation, Process Control Platform. The main product for this part of ABB has been a distributed control system (DCS), System 800xA. However, in re-cent years much focus has been on building a common digital platform that multiple ABB products can leverage. In the case of System 800xA, this plat-form enables models of objects in the system as well as telemetry data to be published to the cloud. The published data can then be used for analytical purposes, such as predictive maintenance or other machine learning insights, building dashboards, and mobile applications that display data from the
tem. This new platform has introduced web and mobile technologies to the development teams, which have been the systems of focus in this work.
With the introduction of a digital platform exposing the distributed control system in new ways, we need methods to ensure the quality of these new modes of interaction. The currently new interaction models, to the organization, are Web APIs and mobile applications. In addition, these new interaction models will be hosted on a platform running partly on cloud infrastructure, leveraging services from a cloud provider. The platform is developed by multiple teams in different geographic locations and some parts are delivered by 3rd party hosted services, such as from Microsoft Azure. The resulting platform, the distributed control system, the cloud service, the Web APIs, and the clients result in a system-of-systems with many black-boxes.
1.3
Thesis Overview
This thesis is based on a collection of papers. The thesis consists of two parts. Part I consist of an overview of the research performed and the contributions of the thesis, as well as the background. Part II includes the research papers that contributed to the thesis.
Chapter 1 and 2 introduces the context and the problem that this thesis aims to address, and the related work. The next Chapters, 3 and 4, contains a overview of the research performed, the methods used and the goals. In Chapter 5 the findings of the thesis are discussed and the first part of the thesis is concluded.
22
tem. This new platform has introduced web and mobile technologies to the development teams, which have been the systems of focus in this work.
With the introduction of a digital platform exposing the distributed control system in new ways, we need methods to ensure the quality of these new modes of interaction. The currently new interaction models, to the organization, are Web APIs and mobile applications. In addition, these new interaction models will be hosted on a platform running partly on cloud infrastructure, leveraging services from a cloud provider. The platform is developed by multiple teams in different geographic locations and some parts are delivered by 3rd party hosted services, such as from Microsoft Azure. The resulting platform, the distributed control system, the cloud service, the Web APIs, and the clients result in a system-of-systems with many black-boxes.
1.3
Thesis Overview
This thesis is based on a collection of papers. The thesis consists of two parts. Part I consist of an overview of the research performed and the contributions of the thesis, as well as the background. Part II includes the research papers that contributed to the thesis.
Chapter 1 and 2 introduces the context and the problem that this thesis aims to address, and the related work. The next Chapters, 3 and 4, contains a overview of the research performed, the methods used and the goals. In Chapter 5 the findings of the thesis are discussed and the first part of the thesis is concluded.
Chapter 2
Background and Related Work
With a thesis goal of proposing and evaluating methods to enable system-level test case generation of contemporary system interaction models, we relate to methods applicable to the level of testing. When targeting the system-level, the state space can quickly explode. To mitigate this, we focus on meth-ods with an exploratory component, accepting that we will not cover every possible input value to the system under test. While looking into related work we are also mindful of our goal of proposing practical methods that can be transferred to industry with low effort.
2.1
Exploratory Testing
Exploratory Testing (ET) was introduced as a term in testing in 1983 by Cem Kaner [27]. There is no formal definition of ET but by looking at some of the proposed definitions we can get a notion of the approach. According to Kaner, ET is "a style of software testing that emphasizes the personal freedom and responsibility of the individual tester to continually optimize the value of her work by treating test-related learning, test design, test execution, and test result interpretation as mutually supportive activities that run in parallel throughout the project."[26]. According to Bach, "Exploratory testing is si-multaneous learning, test design, and test execution." [10]. While Hendrickson expands on Bachs’ definition by stating that ET is "Simultaneously designing and executing tests to learn about the system, using your insights from the last experiment to inform the next" [19]. Finally, in the Guide to the Software Engineering Body of Knowledge(SWEBOK), ET is defined as "simultaneous learning, test design, and test execution; that is, the tests are not defined in advance in an established test plan, but are dynamically designed, executed,
Chapter 2
Background and Related Work
With a thesis goal of proposing and evaluating methods to enable system-level test case generation of contemporary system interaction models, we relate to methods applicable to the level of testing. When targeting the system-level, the state space can quickly explode. To mitigate this, we focus on meth-ods with an exploratory component, accepting that we will not cover every possible input value to the system under test. While looking into related work we are also mindful of our goal of proposing practical methods that can be transferred to industry with low effort.
2.1
Exploratory Testing
Exploratory Testing (ET) was introduced as a term in testing in 1983 by Cem Kaner [27]. There is no formal definition of ET but by looking at some of the proposed definitions we can get a notion of the approach. According to Kaner, ET is "a style of software testing that emphasizes the personal freedom and responsibility of the individual tester to continually optimize the value of her work by treating test-related learning, test design, test execution, and test result interpretation as mutually supportive activities that run in parallel throughout the project."[26]. According to Bach, "Exploratory testing is si-multaneous learning, test design, and test execution." [10]. While Hendrickson expands on Bachs’ definition by stating that ET is "Simultaneously designing and executing tests to learn about the system, using your insights from the last experiment to inform the next" [19]. Finally, in the Guide to the Software Engineering Body of Knowledge(SWEBOK), ET is defined as "simultaneous learning, test design, and test execution; that is, the tests are not defined in advance in an established test plan, but are dynamically designed, executed,
and modified. The effectiveness of exploratory testing relies on the software engineer’s knowledge,..." [14]. In summary, ET is thus perceived as a manual approach that incorporates learning, personal creativity, and insights to test a software system.
Given these informal definitions, we in this thesis when talking about ET in the context of test generation, mean a test generation process that can include both a human and a tool, to generate new test cases with a learning component. The learning component can be for the tool, i.e., generating tests based on previously executed tests, or for the human, in the form of data to learn from and make changes to the tooling before the next execution.
Practitioner claimed benefits of ET, summarized in [24], was the basis for several initial studies on the benefits and drawbacks of ET by Itkonen et al. [24, 23]. In their experiment, Itkonen et al. showed that ET could find more defects than a test case based approach, however, the difference was not significant, but show potential benefits of ET. In addition, ET was more efficient, in time consumed and found significantly fewer false-positive defects [23]. The results were later replicated in [22].
Afzal et al. have, in a controlled experiment, shown that ET can be more efficient, considering the time taken, and significantly more effective, in find-ing defects, compared to an approach based on predefined test cases, with no significant difference between the two approaches with regards to the reporting of false-positive bug reports. Users of ET were also found to report a larger number of difficult to find, i.e, requiring a larger number of interactions to re-veal, and more severe defects [2]. These results have some differences to those reported by Itkonen et al. in [23] and this is attributed to the difference in setup, where the design of test cases was included in the testing session in [2].
The experimental results in [2, 23, 22] indicate that ET finds more or the same number of defects as test case based tests, is more efficient, and find the same or fewer number of false positives. This indicates that ET has the potential of being an effective and efficient approach.
Scripted Testing (ST) can be seen to be in direct opposition to ET, but Shah et al., based on their systematic literature review and interview study, proposes a hybrid testing approach that aims to combine the strengths of ST and ET into one process while avoiding the weaknesses of the respective approaches [42]. While Shah et al. focus on the testing process, we in this thesis focus on tooling. From our experience in industry, there is no lack of tools for ST but room for improvements regarding tools augmenting users in ET, enabling tool support for a hybrid process. The lack of tool support in ET is also a finding from an online survey of practitioners performed by Pfahl et al. [39]. Some of the weaknesses of ET identified by Shah et al. are; the difficulty of keeping
24
and modified. The effectiveness of exploratory testing relies on the software engineer’s knowledge,..." [14]. In summary, ET is thus perceived as a manual approach that incorporates learning, personal creativity, and insights to test a software system.
Given these informal definitions, we in this thesis when talking about ET in the context of test generation, mean a test generation process that can include both a human and a tool, to generate new test cases with a learning component. The learning component can be for the tool, i.e., generating tests based on previously executed tests, or for the human, in the form of data to learn from and make changes to the tooling before the next execution.
Practitioner claimed benefits of ET, summarized in [24], was the basis for several initial studies on the benefits and drawbacks of ET by Itkonen et al. [24, 23]. In their experiment, Itkonen et al. showed that ET could find more defects than a test case based approach, however, the difference was not significant, but show potential benefits of ET. In addition, ET was more efficient, in time consumed and found significantly fewer false-positive defects [23]. The results were later replicated in [22].
Afzal et al. have, in a controlled experiment, shown that ET can be more efficient, considering the time taken, and significantly more effective, in find-ing defects, compared to an approach based on predefined test cases, with no significant difference between the two approaches with regards to the reporting of false-positive bug reports. Users of ET were also found to report a larger number of difficult to find, i.e, requiring a larger number of interactions to re-veal, and more severe defects [2]. These results have some differences to those reported by Itkonen et al. in [23] and this is attributed to the difference in setup, where the design of test cases was included in the testing session in [2].
The experimental results in [2, 23, 22] indicate that ET finds more or the same number of defects as test case based tests, is more efficient, and find the same or fewer number of false positives. This indicates that ET has the potential of being an effective and efficient approach.
Scripted Testing (ST) can be seen to be in direct opposition to ET, but Shah et al., based on their systematic literature review and interview study, proposes a hybrid testing approach that aims to combine the strengths of ST and ET into one process while avoiding the weaknesses of the respective approaches [42]. While Shah et al. focus on the testing process, we in this thesis focus on tooling. From our experience in industry, there is no lack of tools for ST but room for improvements regarding tools augmenting users in ET, enabling tool support for a hybrid process. The lack of tool support in ET is also a finding from an online survey of practitioners performed by Pfahl et al. [39]. Some of the weaknesses of ET identified by Shah et al. are; the difficulty of keeping
track of progress, lack of repeatability, longer time to isolate problem causes, and less audit ability [42]. We see no reason why this gap could not be closed with the help of tool augmentation of the exploratory tester.
Ghazi et al. suggest 5 different levels of exploratory testing, ranging from "Freestyle" to "Scripted Manual", making the choice of ET versus ST less of an either/or decision. In addition, using practitioner focus groups, they evaluate the perceived strength and weaknesses of the different levels. According to the focus groups, ET results in the detection of defects that are more difficult to reproduce, hard to trace coverage, difficulties in relating to requirements and their changes, and difficulties to verify legal conformance [17]. This paints a picture with similar weaknesses as some mentioned by Shah et al. In addition, the different suggested levels of ET proposed could be used by any proposed ET tooling, were tooling could start out as fully automatic but then improve to incorporate higher levels of ET, while mitigating the weaknesses.
A recent example of tool-supported ET is proposed by Leveau et al., where a user performing ET of a web application is assisted to perform actions less covered, resulting in more diverse testing [34]. This example shows the poten-tial value of research in tool augmented ET testing.
In summary, ET is used in industry and shows promise of being an effec-tive and efficient testing method but has weaknesses, which we believe can be addressed with better tool support for ET.
2.2
Interactive Search-based Software Testing
As a concept, applying search-based methods to software engineering had been used prior, but the term, Search-based Software Engineering (SBSE) was intro-duced by Harman et al. in 2001 [18]. The application of SBSE in the domain of Software Testing is known as Search-based Software Testing (SBST), where the meta-heuristic optimization search is applied to different testing goals and has been applied in several domains with different techniques [38, 3]. The method relies on finding a fitness function to automatically evaluate different candidate solutions. Finding such fitness functions for different domains can be a hard problem.
Takagi described the concept of user interaction in the general area of evolutionary computation, where a user can use their subjective evaluation to guide the system optimization, serving as the fitness function [43], but in the more specific area of SBST, Marculescu et al. introduce Interactive Search-based Software Testing (ISBST) [35]. ISBST is a method of applying SBST while allowing a user, such as a domain expert, to interactively guide the search while requiring limited experience and knowledge of SBST. Thus, the human
track of progress, lack of repeatability, longer time to isolate problem causes, and less audit ability [42]. We see no reason why this gap could not be closed with the help of tool augmentation of the exploratory tester.
Ghazi et al. suggest 5 different levels of exploratory testing, ranging from "Freestyle" to "Scripted Manual", making the choice of ET versus ST less of an either/or decision. In addition, using practitioner focus groups, they evaluate the perceived strength and weaknesses of the different levels. According to the focus groups, ET results in the detection of defects that are more difficult to reproduce, hard to trace coverage, difficulties in relating to requirements and their changes, and difficulties to verify legal conformance [17]. This paints a picture with similar weaknesses as some mentioned by Shah et al. In addition, the different suggested levels of ET proposed could be used by any proposed ET tooling, were tooling could start out as fully automatic but then improve to incorporate higher levels of ET, while mitigating the weaknesses.
A recent example of tool-supported ET is proposed by Leveau et al., where a user performing ET of a web application is assisted to perform actions less covered, resulting in more diverse testing [34]. This example shows the poten-tial value of research in tool augmented ET testing.
In summary, ET is used in industry and shows promise of being an effec-tive and efficient testing method but has weaknesses, which we believe can be addressed with better tool support for ET.
2.2
Interactive Search-based Software Testing
As a concept, applying search-based methods to software engineering had been used prior, but the term, Search-based Software Engineering (SBSE) was intro-duced by Harman et al. in 2001 [18]. The application of SBSE in the domain of Software Testing is known as Search-based Software Testing (SBST), where the meta-heuristic optimization search is applied to different testing goals and has been applied in several domains with different techniques [38, 3]. The method relies on finding a fitness function to automatically evaluate different candidate solutions. Finding such fitness functions for different domains can be a hard problem.
Takagi described the concept of user interaction in the general area of evolutionary computation, where a user can use their subjective evaluation to guide the system optimization, serving as the fitness function [43], but in the more specific area of SBST, Marculescu et al. introduce Interactive Search-based Software Testing (ISBST) [35]. ISBST is a method of applying SBST while allowing a user, such as a domain expert, to interactively guide the search while requiring limited experience and knowledge of SBST. Thus, the human
expert can use her experience and intuition to guide the search for test cases relevant to the specific domain, serving as a fitness function [35].
This is a method that has proven initial usefulness in industry to allow for domain specialists, without requiring extensive training, to produce interesting test cases covering areas of the SUT that a human might not consider without guidance [36]. Test cases not found by manual techniques can thus be found by interactions between a human and the ISBST system, providing a complement to exploratory black-box testing [37]. However, when interacting with the user care must be taken to not induce fatigue in the user, which is identified as a problem [43, 25], and ISBST can be more mentally demanding than a manual technique [37].
The concept of ISBST can serve as an inspiration for the work in this thesis. Currently, to interact with our proposed toolbox a user need to have software developer skills in order to change, for example, the distribution of random value generation. Thus, as part of this thesis, we evaluate how our testing goals can be achieved by random value generation, given our context of Web-APIs. If they are not fully achieved, human interaction might be a way of increasing their effectiveness, which currently can be achieved if the user has developer experience.
2.3
Property-based Testing
Property-based testing (PBT) is a technique where invariant properties are de-fined for a system and then checked for correctness by generating input to the system and assert that the result conforms to the stated properties. If gener-ated input is found where a property can be disproved, the failing example is presented as a failing test case, after it has been shrunken to the smallest re-producible case. Property-based testing was introduced by Claesson et al. [15] with the random testing tool QuickCheck.
PBT is of interest to us since it provides a proven technique in how to generate random input to a system and evaluate the consistency of defined invariants. PBT tools are also, in general, very open to extension. PBT li-braries provide basic generators as the building blocks needed to build more complex, domain-specific, generators. In practice, this means that if we can automatically create generators for our interactions models, developers using such generators can extend them to fit their specific context.
Random testing in general is an effective technique in software testing [5, 6] and PBT in particular is a technique that has been used in multiple do-mains. In the literature, there are several examples of the usage of PBT to successfully find bugs in software used in industry. Some notable examples
26
expert can use her experience and intuition to guide the search for test cases relevant to the specific domain, serving as a fitness function [35].
This is a method that has proven initial usefulness in industry to allow for domain specialists, without requiring extensive training, to produce interesting test cases covering areas of the SUT that a human might not consider without guidance [36]. Test cases not found by manual techniques can thus be found by interactions between a human and the ISBST system, providing a complement to exploratory black-box testing [37]. However, when interacting with the user care must be taken to not induce fatigue in the user, which is identified as a problem [43, 25], and ISBST can be more mentally demanding than a manual technique [37].
The concept of ISBST can serve as an inspiration for the work in this thesis. Currently, to interact with our proposed toolbox a user need to have software developer skills in order to change, for example, the distribution of random value generation. Thus, as part of this thesis, we evaluate how our testing goals can be achieved by random value generation, given our context of Web-APIs. If they are not fully achieved, human interaction might be a way of increasing their effectiveness, which currently can be achieved if the user has developer experience.
2.3
Property-based Testing
Property-based testing (PBT) is a technique where invariant properties are de-fined for a system and then checked for correctness by generating input to the system and assert that the result conforms to the stated properties. If gener-ated input is found where a property can be disproved, the failing example is presented as a failing test case, after it has been shrunken to the smallest re-producible case. Property-based testing was introduced by Claesson et al. [15] with the random testing tool QuickCheck.
PBT is of interest to us since it provides a proven technique in how to generate random input to a system and evaluate the consistency of defined invariants. PBT tools are also, in general, very open to extension. PBT li-braries provide basic generators as the building blocks needed to build more complex, domain-specific, generators. In practice, this means that if we can automatically create generators for our interactions models, developers using such generators can extend them to fit their specific context.
Random testing in general is an effective technique in software testing [5, 6] and PBT in particular is a technique that has been used in multiple do-mains. In the literature, there are several examples of the usage of PBT to successfully find bugs in software used in industry. Some notable examples
have been in telecom systems [7], Dropbox [21] (a file synchronization ser-vice), the automotive industry [8], and on databases [20].
2.4
Chaos Engineering
Chaos Engineeringis a term coined by Netflix that aims at defining the dis-cipline of "experimenting on a distributed system to build confidence in its capability to withstand turbulent conditions in production" [11]. Although au-tomated robustness testing is not new, it was done in 1998 by Kropp et al. [33], Netflix brings the concept to the distributed system-level and includes experi-mentation on systems running in production.
The area of Chaos Engineering, i.e., testing for robustness and resilience to failures of distributed systems in production, is related to ours since it is a method to test on system-level by performing experiments. Netflix has been the pioneers in this area by popularizing the term and introducing the tool Chaos Monkey1. Chaos Monkey is a tool that will randomly inject failures in a running system infrastructure, such as shutting down running server instances. While this is an interesting aspect of testing a system, we also want to explore behavior, not only the resilience to failure.
In addition to Netflix’s OSS libraries, some products in the domain of Chaos Engineering have emerged. Gremlin2 is a product offering that aims at delivering a "Comprehensive Chaos Engineering Platform". This is a fairly recent tool so its impact remains to be seen. In addition, an important aspect of this kind of system-level testing is observability. Again, we find Netflix at the forefront with their Mantis tooling3. While Netflix provides its tooling as OSS, Honeycomb4provides an observability product for system engineers.
In addition to being at the cutting edge of the Chaos Engineering prac-tice, Netflix is also at the forefront of the state-of-the-art in this area, which is reflected in the literature [13, 12]. However, this is still a new and emerg-ing field. Blohowiak et al. at Netflix proposes a platform to automate chaos experiments [13]. While this is a good start, since resilience to failures is an important aspect of a complex software system, we think that more benefits could be gained if more aspects than resilience are included in such a plat-form. An example of such an aspect would be to evaluate the consistency of an entity through all the interaction models exposed by the system, i.e., an
en-1https://github.com/Netflix/chaosmonkey
2https://www.gremlin.com/
3https://netflix.github.io/mantis/
4https://www.honeycomb.io/
have been in telecom systems [7], Dropbox [21] (a file synchronization ser-vice), the automotive industry [8], and on databases [20].
2.4
Chaos Engineering
Chaos Engineeringis a term coined by Netflix that aims at defining the dis-cipline of "experimenting on a distributed system to build confidence in its capability to withstand turbulent conditions in production" [11]. Although au-tomated robustness testing is not new, it was done in 1998 by Kropp et al. [33], Netflix brings the concept to the distributed system-level and includes experi-mentation on systems running in production.
The area of Chaos Engineering, i.e., testing for robustness and resilience to failures of distributed systems in production, is related to ours since it is a method to test on system-level by performing experiments. Netflix has been the pioneers in this area by popularizing the term and introducing the tool Chaos Monkey1. Chaos Monkey is a tool that will randomly inject failures in a running system infrastructure, such as shutting down running server instances. While this is an interesting aspect of testing a system, we also want to explore behavior, not only the resilience to failure.
In addition to Netflix’s OSS libraries, some products in the domain of Chaos Engineering have emerged. Gremlin2 is a product offering that aims at delivering a "Comprehensive Chaos Engineering Platform". This is a fairly recent tool so its impact remains to be seen. In addition, an important aspect of this kind of system-level testing is observability. Again, we find Netflix at the forefront with their Mantis tooling3. While Netflix provides its tooling as OSS, Honeycomb4provides an observability product for system engineers.
In addition to being at the cutting edge of the Chaos Engineering prac-tice, Netflix is also at the forefront of the state-of-the-art in this area, which is reflected in the literature [13, 12]. However, this is still a new and emerg-ing field. Blohowiak et al. at Netflix proposes a platform to automate chaos experiments [13]. While this is a good start, since resilience to failures is an important aspect of a complex software system, we think that more benefits could be gained if more aspects than resilience are included in such a plat-form. An example of such an aspect would be to evaluate the consistency of an entity through all the interaction models exposed by the system, i.e., an
en-1https://github.com/Netflix/chaosmonkey
2https://www.gremlin.com/
3https://netflix.github.io/mantis/
4https://www.honeycomb.io/
tity should have the same properties regardless of if it is queried through an API or viewed in the user interface.
2.5
Web API testing
As mentioned, in this work we target the two most commonly used methods of exposing Web APIs, REST and GraphQL. In this section we briefly introduce these methods and review the contemporary the-practice and state-of-the-art in automatic testing of such APIs.
2.5.1 REST
REST has become the industry standard way of interacting with internet-based services. This trend has also spread into industries that are not internet-based as, for example, automation systems. REST is a set of architectural guidelines outlined by Fielding[16] and not a protocol, i.e., it is up to each implementation how RESTful (conforming to the recommendations of REST) it is.
To be able to specify a REST API the OpenAPI5 specification have been proposed (formerly known as Swagger). It is currently the industry standard to describe modern REST APIs. Thus, leveraging an OpenAPI specification to generate tests has been of increasing interest in research, which we will expand upon later in this section.
The JavaScript Object Notation6 (JSON) format is the conventional way of formating entities both for the input and the output of REST APIs.
The challenges of automatic test generation for a REST API, compared to other APIs, are; (i) to reach the SUT valid HTTP messages must be pro-duced, invalid messages will not test the SUT but the web-server hosting the SUT, modern frameworks will filter none conformant messages before reach-ing the SUT. (ii) To maximize industry reach, test generation should leverage the industry-standard specification format of OpenAPI. (iii) Input generation must not only conform to the JSON format but also the valid formats of the SUT.
For REST API testing there exist some tools used in industry. Some no-table examples are Postman7, Dreadd8, and Insomnia9. These tools mostly rely on example-based tests, i.e., the user defines test cases that are then executed,
5https://www.openapis.org/ 6 https://www.json.org/json-en.html 7https://www.getpostman.com/ 8https://dredd.org/en/latest/ 9https://insomnia.rest/ 28
tity should have the same properties regardless of if it is queried through an API or viewed in the user interface.
2.5
Web API testing
As mentioned, in this work we target the two most commonly used methods of exposing Web APIs, REST and GraphQL. In this section we briefly introduce these methods and review the contemporary the-practice and state-of-the-art in automatic testing of such APIs.
2.5.1 REST
REST has become the industry standard way of interacting with internet-based services. This trend has also spread into industries that are not internet-based as, for example, automation systems. REST is a set of architectural guidelines outlined by Fielding[16] and not a protocol, i.e., it is up to each implementation how RESTful (conforming to the recommendations of REST) it is.
To be able to specify a REST API the OpenAPI5 specification have been proposed (formerly known as Swagger). It is currently the industry standard to describe modern REST APIs. Thus, leveraging an OpenAPI specification to generate tests has been of increasing interest in research, which we will expand upon later in this section.
The JavaScript Object Notation6 (JSON) format is the conventional way of formating entities both for the input and the output of REST APIs.
The challenges of automatic test generation for a REST API, compared to other APIs, are; (i) to reach the SUT valid HTTP messages must be pro-duced, invalid messages will not test the SUT but the web-server hosting the SUT, modern frameworks will filter none conformant messages before reach-ing the SUT. (ii) To maximize industry reach, test generation should leverage the industry-standard specification format of OpenAPI. (iii) Input generation must not only conform to the JSON format but also the valid formats of the SUT.
For REST API testing there exist some tools used in industry. Some no-table examples are Postman7, Dreadd8, and Insomnia9. These tools mostly rely on example-based tests, i.e., the user defines test cases that are then executed,
5https://www.openapis.org/ 6 https://www.json.org/json-en.html 7https://www.getpostman.com/ 8https://dredd.org/en/latest/ 9https://insomnia.rest/ 28