Teknik och samhälle Datateknik
Bachelor thesis
Virtual office assistant on Magic Mirror
Virtuell kontorsassistent i en "Magic Mirror"
Jonathan Böcker
David Tran
Exam: Bachelor of Science in Engineering Subject Area: Computer Engineering Date of final seminar: 31-05-2017
Examiner: Radu-Casian Mihailescu Supervisor: Dimitris Paraschakis
Abstract
Every second, major companies such as Google, Apple, Amazon and Microsoft are col-lecting a great amount of data from users. Photos, voice and texts etc. are stored in the companies massive server parks. With this amount of data, along with technical benefits such as computing power and exceeding algorithms, the companies can train their ma-chine learning models to levels which is hard for a local computing landscape to reach up to.
Nowadays, the companies allow developers to use their services and this paper proclaims the benefits of using these. The aim for this thesis is to show how cloud based face recognition and speech recognition can be utilized to create a virtual assistant in Magic Mirror. This new concept opens new possibilities for human-computer interaction.
The use case for the assistant was to aid visitors who comes into an office for an appointment with an employee. The prototype of the assistant showed 94% accuracy when identifying faces and fulfilled the task well when the employee name was internationally known, while having difficulties with others, e.g. Swedish names.
Acknowledgments
We would like to express our gratitude to Dimitris Paraschakis for invaluable inputs and feedback during our work of this thesis. We would also like to thank Andreas Kristiansson, Per Sigurdsson and Tomas Nilsson for giving us the opportunity to perform our bachelor thesis at Jayway, and for providing us with the facilities and hardware needed in order to complete this thesis.
Contents
1 Introduction 1 1.1 Background . . . 1 1.2 Magic mirror . . . 1 1.3 Jayway . . . 1 1.4 Research aim . . . 2 1.5 Research Questions . . . 2 1.6 Thesis Scope . . . 2 2 Theoretical Background 3 2.1 Cloud computing . . . 32.2 Face detection and face recognition . . . 4
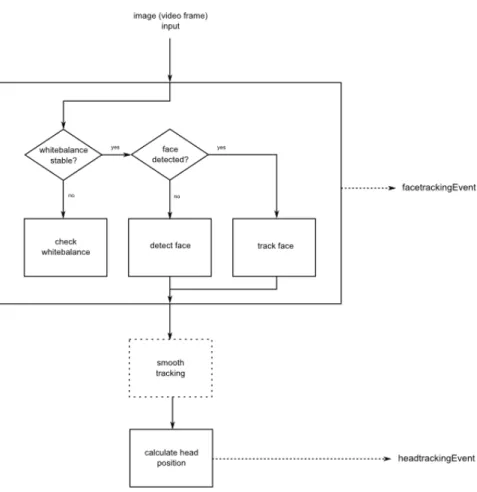
2.3 Face tracking . . . 4
2.4 Speech recognition and natural language processing . . . 4
3 Related Work 5 3.1 Smart mirror: A novel framework for interactive display . . . 5
3.2 Context-aware office assistant . . . 6
3.3 FitMirror: A smart mirror for positive affect in everyday user morning routines 7 4 Method 8 4.1 Construct a conceptual framework . . . 8
4.1.1 Use case . . . 9
4.2 Develop a system architecture . . . 10
4.2.1 System requirements . . . 10
4.2.2 Problem breakdown . . . 11
4.3 Analyze and design the system . . . 12
4.4 Build the system . . . 16
4.4.1 User experience . . . 16
4.4.2 Hardware . . . 17
4.4.3 Speech input . . . 17
4.4.4 System overview . . . 17
4.5 Observe and evaluate the system . . . 18
4.5.1 Face recognition test environment . . . 18
4.5.2 Confusion matrix . . . 19
4.5.3 System testing . . . 20
5 Results and Analysis 21 5.1 User identification . . . 21
5.1.1 Face recognition test result . . . 21
5.1.2 Analysis . . . 21
5.1.3 Analysis of the result . . . 22
5.2 Full system testing . . . 22
5.3 Face detection . . . 23
6 Discussion 24 6.1 Ethics . . . 24
6.2 Limitations . . . 24
7 Conclusions and further work 26 7.1 Answering the research questions . . . 26 7.2 Future Work . . . 27
A Sequence diagram 30
1
Introduction
This chapter introduces the background of the thesis, followed by a brief presentation of Jayway, who is the product stakeholder. Furthermore the research aim, research questions, and limitations are introduced.
1.1 Background
Although machine learning algorithms have been around since late 1950’s, machine learning today is not like machine learning of the past[1]. Big companies like Google, Apple, Amazon and Microsoft have created the possibilities for users to store their data in cloud servers. In 2016, the global internet population was 3.2 billion people, compared to 2.1 billion in 2012[2]. During every minute of 2016, Google translated almost 70 million words, Facebook messenger users shared over 200.000 photos, Youtube users uploaded 400 hours of new videos and Apple’s Siri made almost 100.000 requests. With this much data, along with development of new learning algorithms, cheaper and better computation, the machine learning area has grown rapidly[3][4].
Machine learning and cognitive services are being used today to build really smart solutions which can aid the people and society. Using applied machine learning and allowing the cloud to do the computing improves the speed of processing, which allows developers to create cognitive user friendly systems.
In [5], Brynjolfson et al. announces "end of work", which refers to advances in technology may liberate people from labours and tasks. Artificial systems are now competent enough to manage some human tasks, and an area of occupations which might be at risk are those involving assistance [6]. Companies have developed robots as AI-receptionists[7][8], which are able to interact with human users. A company called Memomi1 offers a smart digital mirror as a shopping assistant and Rahman et al.[9] created a smart mirror to function as a make-up assistant.
1.2 Magic mirror
Smart mirrors, or Magic mirrors, are usually a regular screen displaying personalized infor-mation behind a translucent mirror. Magic mirrors have been a trend among open source communities since the beginning of 2014 [10][11][12]. Michael Teeuw, the founder of the Magic Mirror framework, has created a forum2 for enthusiast, where they can show their developed framework modules. With relatively small budget and fair skills in program-ming, users can create custom made information systems.
1.3 Jayway
The product stakeholder of this thesis is Jayway, an international IT company with offices in Sweden, Denmark and USA. Jayway is an innovative and creative company, and their ambition with this thesis is to explore the area of AI and machine learning. For this thesis,
1http://memorymirror.com 2
Jayway has helped to formulate the research question. Also they contributed by providing hardware for development, and possibility to run experiments in industrial settings.
1.4 Research aim
So far, no systems involving Magic Mirror have utilized cloud computing services to build a virtual assistant for an office environment. In the Magic Mirror framework, there are modules for face recognition and voice control, but these modules are trained and run locally. Therefore, they are not taking advantage of the fast and acknowledged cloud computing services.
The research aim of this thesis is to investigate how cognitive services in the cloud can be applied to create a virtual assistant using the concept of the Magic Mirror.
1.5 Research Questions
The research questions are formed to reflect the requests from Jayway.
RQ 1 How to build a virtual office assistant based on Magic Mirror? RQ 1.1 What is a potential use case for such a virtual assistant?
RQ 1.2 How can cloud-based face recognition and speech recognition services fa-cilitate the development of such a system?
The intent is to develop a prototype based on the concept of "Magic Mirror", and this prototype will be used to evaluate the system.
1.6 Thesis Scope
There is a plethora of applied machine learning algorithms for biometric data. Spatial data, fingerprint data, retinal scan data etc can be used for machine learning. This thesis will focus on utilizing image analysis for face data and sound analysis for voice data. Computationally expensive operations, such as voice and face recognition, will be handled by cloud services for aiding application responsiveness. The cloud service provider for face recognition have been chosen in collaboration with Jayway to be Amazon Web Services (AWS) Rekognition3.
No analysis or tests will be made to compare operations computed in the cloud versus computed locally, although advantages and disadvantages of cloud computing are brought up in section 2.
The application software is written in Electron4, which the Magic Mirror framework is based on. The actual mirror hardware is not built, since all testing can be done on any computer screen and Jayway has provided us with a magic mirror for deployment.
3https://aws.amazon.com/rekognition/ 4
2
Theoretical Background
This section provides theoretical background in some related areas to ease the understand-ing of this paper. The two key features for the system is the ability to recognize people and interact with users, and a briefing of these techniques are presented in this section, along with background theory of cloud computing.
2.1 Cloud computing
The traditional computing landscape is to have the whole infrastructure locally, which includes servers, storage, databases and other pieces of compute requirements [13]. For a corporation, small or big, this means a lot of planning ahead. An example could be a busi-ness website which have few active users during day and very many users during evening. The traditional model would lead to two different outcomes: either the infrastructure is too limited, i.e. it can not handle all active users, or excess capacity, i.e. wasted capital of the infrastructure cost.
Another constraint of local computing is when using machine learning services, such as image recognition. For a computer to learn, it has to train, and for an image recognition model to be good or get better, it has to be trained regularly. And to train, the model has to be fed with new data, and to store new data, the storage size has to increase. This either ends with higher costs or stagnation in functionality.
These are just a few examples of problems with local infrastructure, but allowed rethinking of how to eliminate these problems.
The term cloud computing was already visioned during the 1960s, but it was when former CEO of Google, Eric Schmidt, in 2006 used the term to describe the business model of providing services across the internet where it gained popularity [14]. Cloud computing can be defined as: the ability to use computing resources – applications, storage and processing power over the internet. These computing resources are hosted and managed by “someone else” (the cloud provider) - Qaisar [13].
A few of the biggest providers of cloud computing are Amazon, Alphabet (Google), IBM and Microsoft [15]. Some of the substantial advantages of cloud computing are:
• No upfront cost: The providers offers pay-as-you-go pricing models, which means companies only pay for what they use, i.e. no wasted resources compared to local infrastructures
• Storage: The providers have big server parks, which provides "unlimited" storage capacities for businesses and users.
• Maintenance: Business do not bear the cost of maintenance of servers, since the providers handle this along with upgrading of the server parks.
• Computing advantage: Since providers have the possibility to use the stored data, they have great advantages for example when it comes to training machine learning models. More data and storage allows models to be continuously trained, which benefits in for example image recognition and speech recognition tools.
2.2 Face detection and face recognition
An image based face identification process can be divided into two subproblems[16]: 1. Detecting a face standing in front of the camera.
2. Identifying the face standing in front of the camera.
Simply detecting a face in an image does not give any information about the identity of the face. Detecting a face in an image can be a computationally cheap operation[17] compared to recognizing the identity of the face. State-of-the-art face recognition algorithms rely on complex machine learning algorithms which require powerful GPUs (Graphics Processing Unit) to be able to run in realtime[18]. Using a cloud computing provider to handle the face recognition instead of running it local are desired in a several ways:
• Cloud provider companies has the economic muscles to acquire powerful and fast algorithms and make them proprietary, i.e. no one else is allowed to see or reuse the algorithm.
• Cloud providers possess fast and powerful computation for quicker analyzing, which lets users run application on machines which would not be able to accomplish the task.
2.3 Face tracking
Tracking a face in a series of images e.g. a video stream can be used for controlling applica-tions through a perceptual user interface[19]. A widely adopted algorithm for face tracking in images is CAMshift (Continuously Adaptive Meanshift)[19], and it is computationally cheap enough to run in real time (30 frames per second).
2.4 Speech recognition and natural language processing
Understanding what a person says through audio data can be divided into two subprob-lems:
1. Translating audio to text i.e speech recognition.
2. Understanding the contents of the text i.e. Natural Language Processing (NLP). State-of-the-art algorithms for speech recognition uses varieties of recurrent neural net-works[20][21] which require powerful GPUs to be able to run in realtime. Also a lot of data must be gathered and models be trained, since the human speech varies in tone, dialect, and pronunciation. Cloud providers gathers speech data by offering services involving speech. Digital assistants such as Google Home, Amazon Alexa and Apple Siri are good examples for how users speech data are collected. Along with the computational power the cloud providers possess, a user benefits from using cloud computing compared to running the speech recognition and NLP locally.
3
Related Work
This section describes previous work related to this thesis.
3.1 Smart mirror: A novel framework for interactive display
Athira et al.[22] constructed a smart mirror, with the ambition to ease an everyday user’s desire to retrieve useful information in a comfortable way. They state that people feel the need to be constantly connected and are willing to access information easily. Although peo-ple are busy, they always have a glance at the mirror before they walk out the door.
Figure 1: A mirror with addi-tional information attached The main functionality of their proposed system was to
make a common mirror more functional, i.e. rather than just reflecting the user, it could display something more, see Figure 1. This additional information consisted of weather, time, reminders news headlines and social me-dia notifications. Information was only to be shown when a user was present in front of the mirror, due to the elec-tricity cost of having the screen applied behind the mir-ror. This was made possible by connecting a PIR-sensor (passive infrared sensor) to the system, which is is an electronic sensor that measures infrared light radiating from objects in its field of view
The system was deployed to a Raspberry Pi, a small low powered single-board minicom-puter5 with the capability to run an operating system. In addition to the screen and the PIR-sensor, a USB-microphone was connected to the board. This allowed the user to use voice to control other smart objects, in this case a lamp and a shelf door, which were connected to an Arduino6 microcontroller. Specific voice commands was programmed into the system. When a user says a word or phrase, the phrase is converted into a text using internet and Google speech-to-text service. If the received text matches any keyword, the system will execute the corresponding function, e.g. turning on and off the light or opening and closing the shelf door.
The paper is relevant for this thesis by providing proper discussion as to why and where a smart mirror can be useful, where the authors announce offices as possible environment. Also, it describes a system architecture which gives us useful understanding when planning the system architecture of the prototype developed in this thesis.
5https://www.raspberrypi.org 6
3.2 Context-aware office assistant
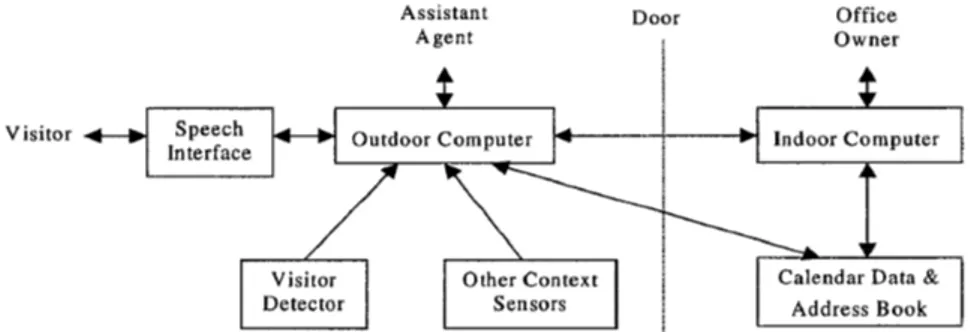
In this paper, Yan and Selker described the design and implementation on an office assistant [23]. The main task of the assistant was to be able to interact with visitors at the office door. Visitors could be given information about appointments, and instructions to set up appointments with the office owner.
Figure 2: Office Assistant System Architecture
Figure 2 shows an overview of the created system. The office agent runs on the outdoor computer, which was installed outside the office, since the purpose of the office assistant was to not interrupt the office owner more than necessary, e.g. if the office owner was not present or in the middle of a meeting.
The agent interacted with visitors primarily with speech, but mouse and keyboard was connected as backup if the speech recognition failed.
To recognize if a user was present, the authors of the paper placed two pressure-sensitive mats on both sides of the office door. The size of the mats where big enough so that it was hard not to step on them, and also the mats looked similar to normal carpets, so people would not notice the sensors. By detecting the state changes of the pressure on the mats the system was able to recognize if a person was entering, exiting or standing by the threshold. A monitor showing a user interface and speakers was connected to the computer, along with a microphone to capture the visitors’ voice. To understand the visitors, the system used local speech recognition, contained of a Speech-To-Text engine from Microsoft and IBM ViaVoice for context understanding.
The program on the outdoor computer was interacting with the indoor computer, and could also access the calender of the office owner. The indoor computer consisted of a computer program controlled with mouse and keyboard.
When a visitor came to the office, the agent recognized a person standing by the outdoor computer. The agent greeted the visitor and asked for its name. The name was used for the agent to check if an appointment had been made between the office owner and the visitor, and to notify the office owner that a visitor was waiting outside. The office owner replied to the agent by choosing from alternatives on the indoor computer, e.g. "Let in", "Wait a minute" or "Come later". A respond to the visitor was then parsed, and if the office owner was not able to meet, the agent could rearrange appointments with the visitor.
The paper is relevant for this thesis, since it helped us with the discussion of use case and research question. Although Yan and Selker’s prototype wished for improvements, this paper was produced in year 2000, and could not benefit from today’s computer and cloud computing powers.
3.3 FitMirror: A smart mirror for positive affect in everyday user morn-ing routines
With a computer, 42" monitor, Microsoft Kinect camera and a Wii balance board, Besserer et al. [24] created a smart mirror to contribute to healthier living. The paper states that many people have serious problems getting up after awakening, to get motivated for the day, or are tired and in a bad mood when going up in the morning. With this project, the authors of the paper wanted to investigate if morning training in front of a mirror could help people with these problems.
They stated five hypotheses:
• Users are feeling motivated to do sports by using Fit-Mirror. • An increase in the level of difficulty motivates the user.
• People who have problems to wake up experience Fit- Mirror as useful. • Fun exercises are more popular than normal exercises.
• After fun exercises the user feels happier than before.
These hypothesis were evaluated from a controlled experiment, and the results showed positive effect in every aspect.
The paper contributes to this thesis by giving good examples to what smart mirrors are being used for. In line with our thesis, the authors of the papers stated that though there exist similar products separately, e.g. smart mirror and a fitness wrist band, no combined product has been developed so far. Also, this paper uses a controlled experiment and a questionnaire for the participants to fill in. Since this thesis also involves human-mirror interaction, same method for gathering user feedback can be used.
4
Method
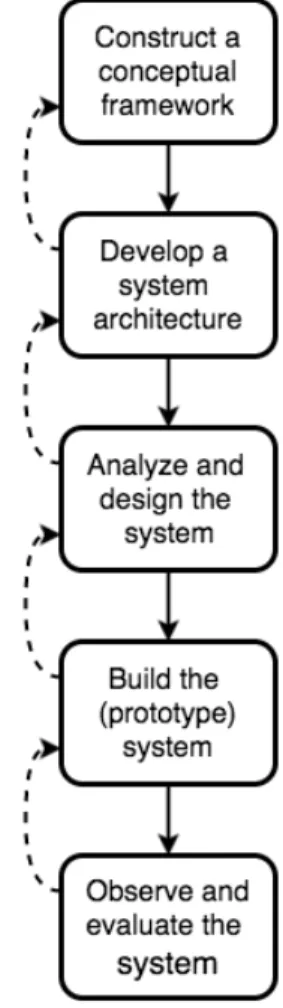
The prototype for this thesis was developed using system development as a research methodology, proposed by Nunamaker et al.[25]. The methodology consists of five stages shown in Figure 3, which describes a systematical approach to construct and evaluate a system. The proposed methodology has a clear process structure, with the possibility to revise earlier stages if needed.
This methodology is primarily used when developing a product, and this thesis aim is a prototype. Nevertheless, we use this methodology, due to its systematical approach in research and development which we believe also qualifies for prototype development.
Figure 3: Nunamaker’s suggestion on system development research process
4.1 Construct a conceptual framework
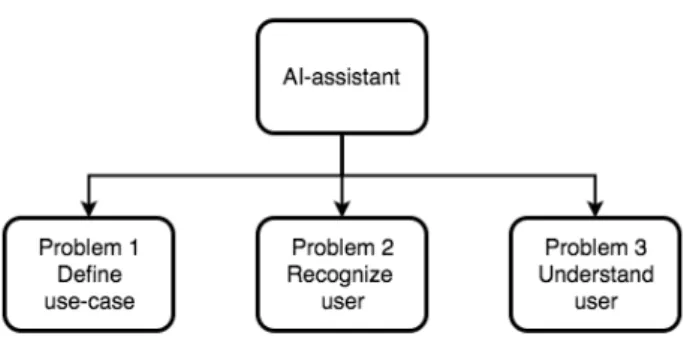
In the first stage of the development it was important to get a clear focus of the problem. To obtain a good overview of the different problem domains of the virtual assistant, a problem tree was created. The two key functionalities of the assistant is the ability to recognize and have a voice interaction with the user.
With these two requirements, along with a use case, the creation of the AI-assistant was broken down into three subproblems, shown in Figure 4.
Figure 4: Overview of problems
we had to start with understanding the concept of a Magic Mirror, along with investigating the system requirements, including literature studies in relevant disciplines and research of previous work. From this, new approaches and ideas could be captured. Then, the research questions and aim for the thesis was formed after meetings with representatives from Jayway, and a suitable use case was designed related to the questions. With a clear definition of the research question, along with its scope and limitations, it was easier to maintain focus on the research throughout the development process.
4.1.1 Use case
Before focusing on one specific use case for the assistant, two alternative use cases were discussed, which are presented later in this section.
The main reason for the choice of use case was that it targeted an actual problem at Jayway, where the assistant could be a possible solution. Below follows a presentation of the chosen use case.
Use case 1: Appointment manager
A visitor steps into the office lounge and is looking for person X, with whom s/he has made an appointment. When the visitor is standing in front of the assistant, the assistant does not recognize the visitor as an employee. Figure 5 shows a possible interaction between the visitor and the assistant.
The employee will then receive a notification on his phone that a visitor is waiting in the lounge.
Alternative use cases
• Use case 2: Virtual time clock
The assistant can be used as a virtual time clock, which help the employees to check in and out of the office. Since the assistant knows the employee name by face recognition, a simple sentence such as ’I want to check in’, would let the assistant fill in the time in a database for the employee’s time card.
• Use case 3: My day at work
The assistant could work as an information screen for the employees. For example, when an employee comes into the office and look at the mirror, information about the employees day would be visual on the screen, e.g. appointments, group meetings etc. And when the employee is on his or her way out, a quick glance at the mirror could give latest traffic information or public transport departure times.
Figure 5: Example of conversation of chosen use case
4.2 Develop a system architecture
At this stage of the research process, a design of the system architecture for the prototype was created. The architecture defines functionalities and relationships among the system’s components. In this section, the system requirements are declared, and a breakdown of the problem tree is demonstrated.
From this point, since the prototype will act as an office assistant, the word assistant in this thesis will refer to the system.
4.2.1 System requirements
The assistant must be able to accomplish specific tasks to fulfill research question 1: How to build a virtual office assistant based on Magic Mirror?
The requirements below are designed for the chosen use case, appointment manager. By fulfilling these requirements, RQ1 can be answered.
1. The assistant must be able to detect if a person is present in front of the camera’s field of view.
2. The assistant should be able to distinguish an employee from a visitor. Images of the employees are stored in the database with picture and name, so if the assistant does not recognize the user, the user is a visitor.
3. When the visitor has declared who s/he intends to meet, the assistant should be able to recognize an employee’s name from the spoken speech.
4. The assistant must be able to notify the employee via a text message on his or her mobile phone, when the name has been extracted from the dialogue and the visitor intends to meet the employee.
4.2.2 Problem breakdown
Problem 2 in Figure 4 concerns the ability to identify the user. Being able to identify people gives the system improved possibilities for more effective tasks, e.g. differentiate employees from visitors. The problem was divided into four subproblems, shown in Figure 6.
Figure 6: Overview of subproblems in Problem 2
• Database: To be able to distinguish people by faces, a database containing user information must be created.
• Image capturing: The assistant is frequently capturing images for further processing. Since the pictures will only be used for identification at precise moment, no biometric data from the camera feed needs to be stored.
• Face detection: The assistant has a face detection mechanism, which determines if a user is present in every picture frame, i.e. standing in front of the screen in a reasonable range and facing the screen.
• Face recognition: The resolved face from the face detection is then analyzed and matched against the stored images in the database. If the user is not recognized by the assistant, the user is referred as a visitor.
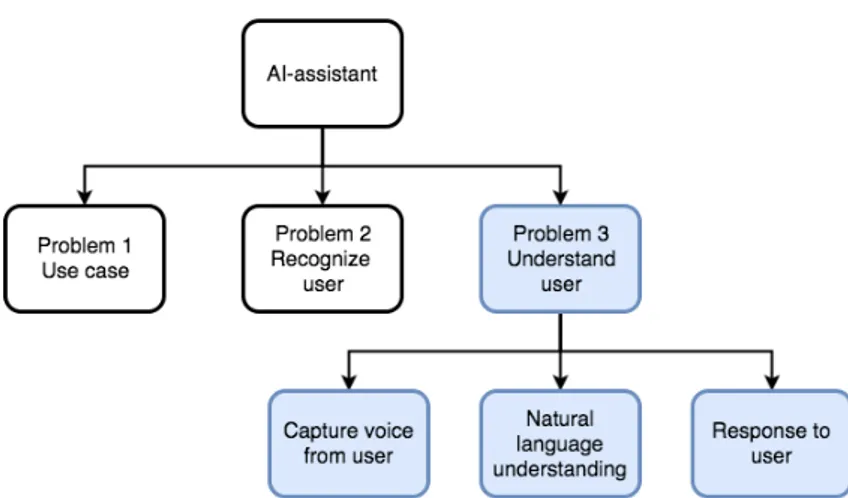
Further on, Problem 3 from Figure 4 is understanding the user through voice interaction. A good and user friendly mechanism facilitates the communication between the user and the virtual assistant. This problem can be divided into three subproblems, shown in Figure 7.
• Capture voice from user; The assistant has to be able to capture the user’s voice and convert it to text, using a Speech-To-Text (STT) tool, which makes the phrase comprehensible for a computer.
• Natural language understanding; To understand the user’s intent in the dialog, the text string must be analyzed by a Natural Language Processor (NLP). The NLP will analyze the text and extract the intention from keywords, and generate a proper response to the user.
• Response to user; The received text-based response from the NLP must be converted to speech, using a Text-To-Speech (TTS) tool. This converted phrase is then to be
Figure 7: Overview of subproblems in Problem 3
streamed to the system’s speaker, for the user to hear.
Figure 8: System overview showing which parts are handled locally or by cloud services With the problem domains acknowledged, a system overview was designed. Figure 8 shows which parts are to be handled locally and which by cloud services.
Due to the complexity of certain tasks and computationally expensive operations, the as-sistant uses the cloud for performing Natural Language Processing, Speech-To-Text, Text-To-Speech, Face Recognition and mobile phone notifications. The database will also run in the cloud, since it makes the assistant mobile and can run on multiple machines. On the local side, the assistant uses microphone and speaker to interact with the user. Also the Face detection is run locally, as sending every frame to the cloud would be an expensive task.
4.3 Analyze and design the system
In this step a detailed system was designed. Each part of the system may have different alternatives. This section describes which service is used for each task, and explains why
it was chosen.
Architecture and hardware
Amazon Echo and Google Home are products that specialize in speech recognition and natural language processing. Both products give developers the opportunity to create their own assistants and connect them to external services through HTTP webhooks. Utilizing such hardware in our project puts constraints on our use case. The user would have to initiate the conversation, saying the products keyword to enable it to listen. Also, the API that is exposed to developers need an internet exposed server to call for extended functionality. In our case that extended functionality would be the camera identifying the user. It poses more architectural challenges to achieve a similar result and could worsen the user experience, if the user is not familiar with the magic mirror concept.
A single computing device with appropriate peripheral devices, such as camera and micro-phone, suits the use case better and gives the developers more control and flexibility.
JavaScript
JavaScript does not offer maximal performance since the source code is parsed in real time. The benefit of using a parsed language is development speed, where no compilation times decreases time between a change in the source code to execution of said code.
Electron
The Electron framework7 lets developers write cross-platform desktop applications using JavaScript, HTML and CSS. It is based on Node.js and Chromium and is used by the Atom text editor and many other apps. The Electron framework allows for application self containment, which means there is no need for additional installs in order to run the application when distributed. The Chromium environment exposed to the application has support for media streaming, such as playing sounds, recording sounds and recording video with a web camera. It is possible to debug the application with Chromiums built in development tools, which requires no extra installations or external programs. Since Electron is based on Node.js it has the advantage of storing dependencies locally, unlike web pages, which downloads dependencies every execution. These features are the reason the Electron framework was used in the application development.
Face detection algorithm
Headtrackr8 is a Javascript library for detecting and tracking a face in a web camera
video stream. Headtrackr uses the Yet Even Faster (YEF) real-time object detection algo-rithm[17] and High-performance rotation invariant multiview face detection[26] algorithm for face detection. Headtrackr offers reasonable performance and accuracy out of the box and works well with the Electron framework. As seen in figure 9, the library can track the
7https://electron.atom.io/docs/tutorial/quick-start/ 8
Figure 9: Overview of Headtrackr algorithm
face after the face is detected and detect when the face exits the frame. This is helpful for providing a fast user experience, when users switch in a rapid succession.
Face recognition
AWS Rekognition was chosen in collaboration with Jayway. The Rekognition API offers direct image transfer through the HTTP protocol without intermediate storage on an internet exposed web server. The HTTP response contains data about found faces in the transferred image, such as location and correlation with faces stored in the Rekognition database. The Rekognition database consists of faces uploaded beforehand and is only accessible by the user who uploaded the images (of the faces). The correlation is measured in a relative confidence between 0.0 and 1.0, where 1.0 is absolutely confident that the supplied image correlates with the face in the database.
Database
MongoDB is a document-oriented database which offers a simple API suitable for database beginners. It is flexible and allows the stored data to change scheme dynamically, which suits rapid prototyping. Every face stored in the AWS Rekognition database has a unique ID. This is stored together with an associated name and phone number in a MongoDB
database hosted at Mlab9. Mlab offers 500MB free database hosting up to that is exposed
to the internet. This makes it possible for several devices spread out in the world to share the same database and reduces database management for the developers.
The face image, name and phone number data is collected from Jayways internal employee management system and transferred to Mlab and Rekognition respectively.
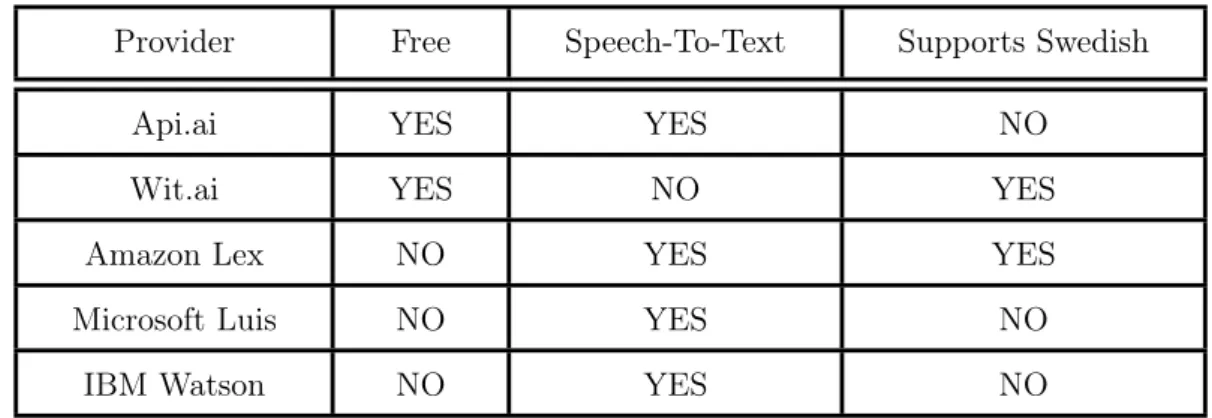
Natural Language Processing and Speech-To-Text
When choosing providers for the NLP, five different alternatives were compared, see Table 1. Three requirements were investigated: cost of the service, ability to stream audio to the service, i.e. Speech-To-Text and if the service had Swedish language support.
Provider Free Speech-To-Text Supports Swedish
Api.ai YES YES NO
Wit.ai YES NO YES
Amazon Lex NO YES YES
Microsoft Luis NO YES NO
IBM Watson NO YES NO
Table 1: Table of NLP providers
Since the difficulty to predict how many requests the assistant would perform to the NLP service, a service which was free from costs was chosen. The only providers who met this requirement were Api.ai and Wit.ai, and from the convenience of streaming the audio to the service, Api.ai was chosen. Also, since the use case involves visitors, which may be of different nationalities, English is the most appropriate language to use, so the lack of Swedish is not crucial.
Extracting keywords from speech
To understand the spoken words from a user, Api.ai converts the audio to text through its built in speech-to-text mechanism. From the text, it looks for specific keywords, called entities, which have been determined programmatically. For example, if the programmer wants to extract a name from the speech, Api.ai uses a predefined database of names, consisting of the 2500 most popular names from Social Security Administration10. If any word in the text correlates with one of these names, that name will be extracted. Instead of using predefined databases of entities, it is possible to build own collections of entities to be used.
When customized criteria has been fulfilled, e.g. a name was found, Api.ai uses intents and actions, which can be parsed back to the assistant along with parameters such as name or other keywords. What the assistant will do with the information is up to the programmer to handle.
9
https://mlab.com/
10
Text-To-Speech
As stated in section 4.2.2, the response from the NLP service returns to the assistant as a text. So a Text-To-Speech tool is used to be able to play it out in the speakers. The chosen provider was Amazon Polly11, after recommendations from employees at Jayway. The text is sent to Polly, and in return the assistant receives a voice stream, which is parsed to the speakers.
Messaging service
Twilio was chosen as the text message provider because it was free of charge when devel-oping, although only one specific number could receive the messages. Other providers were investigated, but the conclusion was that the price plan and implementation process was all essentially the same. The Twilio account includes a phone number, which acts as the sender. The assistant can create SMS with a JSON request to Twilio.
4.4 Build the system
When implementing the system according to the structure generated from earlier steps, in-sights might be gained about possible problems and complexity of the system. This knowl-edge of advantages or disadvantages will be helpful to re-design the system if needed.
4.4.1 User experience
During this part, the User Experience (UX) was acknowledged, since it is difficult to envision how other users will behave in front of the assistant. 8 people from Jayway were gathered, who all work with UX, to have a workshop, where ideas and concepts from experienced people were brainstormed. Without showing the participants the system, a staging of the use case was demonstrated. The participants were then to write or draw on paper how they imagined the system’s GUI would look like.
During this workshop, a lot of information were gained on how important the UX is when developing a system, especially in case like this where most people at this point have not seen something similar. Some key features which were brought up was implemented to the assistant’s GUI.
• Subtitle to the assistant’s spoken words, which reduce misinterpretation.
• A live feed showing the camera’s point of view, to let users know that the assistant uses a camera and is looking for something (a face).
• A dynamic voice amplitude bar, which let the user know that a microphone captures spoken words. A classical interface, where red color means low sound, and goes green when a decibel threshold is exceeded.
11
4.4.2 Hardware
The required peripherals for recording video and audio is a camera and a microphone. A typical low-cost USB webcam with a built-in microphone was used for portability between platforms. A speaker and a screen for playing sound and showing the user interface was also required.
4.4.3 Speech input
Figure 10: Speech state machine
The Api.ai speech recognition library requires manual starting and stopping of audio recordings. In order to decide when to stop the recording, we implemented a simple state machine utilizing Chromiums Web Audio API, which is included in the Electron frame-work. The Web Audio API has functions to extract frequency data from an audio stream. We were interested in the volume amplitude in frequencies between 300Hz and 3000Hz, which is where the majority of voice energy is concentrated [27]. We polled the frequency data in the relevant frequency range periodically to extract the maximum amplitude. If the maximum amplitude exceeds an arbitrary threshold e.g. -45dB enough times in an ar-bitrarily long period of time, we consider the state to be someone speaking at the moment, see Figure 10. If the threshold then is not exceeded for some time, the state goes back to silence and the recording can be stopped.
4.4.4 System overview
Figure 11 presents an overview of the system, showing the relationships between the tasks and services, and if they are local or cloud based. A more detailed sequential diagram is shown in Appendix A, where the flow is shown from the presented use case in section 4.1.1.
Figure 11: System overview showing relationships between different tasks and services
4.5 Observe and evaluate the system
This section describes the process of testing and evaluation of the assistant’s performance in recognizing faces. Furthermore, a description of how the full system was tested is presented.
4.5.1 Face recognition test environment
Before testing, the databases on MongoDB and AWS Rekognition were updated. If a person was registered into Jayways intranet with a profile picture, the assistant should recognize this person as an employee.
A test environment was created to perform the testing, see Figure 12. A simple user interface where the assistant’s point of view is displayed on the screen (upper image). When the assistant detects a face, a still image is shown on the screen (lower image). It is this image which will be sent to AWS for face recognition. If the face is recognized, the assistant will display the name of the person on the screen. Otherwise, if not recognized, the assistant will display "Hello stranger". To store the collected data, a form to submit was added, which parsed the results to a database in MongoDB. Two statements were to be verified: If the name was correct and if the user has a profile picture in the employee intranet.
Figure 12: Face recognition test interface
4.5.2 Confusion matrix
There are five possible outcomes when a person stands in front of the assistant: 1. An employee is correctly recognized
2. An employee is recognized as another employee 3. An employee is recognized as a stranger
4. A stranger is recognized as a stranger 5. A stranger is recognized as an employee
We then used a confusion matrix12to evaluate the accuracy of the recognition. A confusion matrix is a square table, with the predicted outcome on the columns, and the actual outcome on the rows, shown in Figure 13.
Figure 13: Confusion matrix
12
Below we give an explanation of the confusion matrix in relation to the aforementioned outcomes of an experiment
True Positive (TP), a correct prediction that an instance is positive, outcome 1; False Positive(FP), incorrect prediction that an instance is positive, outcome 2 or 5; True Negative (TN), correct prediction that an instance is negative, outcome 4; False Negative (FN), incorrect prediction that an instance is negative, outcome 3.
There are four possibilities in the confusion matrix, and we could have five different out-comes in the test. This is regulated, so outcome 2 and 5 are handled as False Positives (FP), since the common error is that the assistant interpreted the user as to be someone else.
4.5.3 System testing
To test the whole system, a group of 20 people were gathered. The majority of the people had not seen the magic mirror before, or been in contact with anything similar. The participants were asked to try it one by one, and not looking while someone else was testing. A participant was given two instructions:
• No need to trigger the assistant, since the assistant will start the conversation when face is present in the camera’s point of view.
• The participant has a meeting with en employee at the office. The name was set to David Tran, since the SMS notification could be verified at once if succeeded. The testing was measured as succeeded or not succeeded. If the correct employee received an SMS notification from the assistant, the test was classified as succeeded. Otherwise, the test would be classified as failed, and an explanation of the error are presented in the test results, and these errors were then analyzed and discussed.
If a test was failed, the participant was explained the reason of failure, and was prompted to try again.
If a participant was an employee, that person was allowed to declare it’s own name to be notified, since it would be possible to see if the participant received an SMS, i.e. the outcome would be the same as using David Tran as test name.
5
Results and Analysis
This section presents the test results from two completed tests. The first test concerns the user identification using face recognition, and the second one was a full system test, where most of the participants never had seen or heard of a virtual assistant in a Magic Mirror.
5.1 User identification
This section presents the test results of identifying users.
5.1.1 Face recognition test result
The face recognition test was made on 47 different people at Jayway, both employees and non-employees. Table 2 shows the results from the test.
N = 47 Predicted Positive Predicted Negative
Actual positive TP = 24 FN = 2
Actual Negative FP = 1 TN = 20
Table 2: Test results for face recognition
5.1.2 Analysis
With help from the confusion matrix, we can analyze the result. The focus will be on four different rates:
Accuracy: How often did the assistant classify correct? T P + T N
T P + T N + F P + F N =
24 + 20
24 + 20 + 1 + 2 = 0.936 = 93.6% True Positive Rate: When it is person X, how often did the assistant recognize X?
T P
T P + F N = 24
24 + 2 = 0.923 = 92.3%
False Positive Rate: How often did the assistant recognize the user as another user? F P
F P + T N = 1
5.1.3 Analysis of the result
The results shows a couple of incorrect predictions from the assistant. Two False Negatives, i.e. two employees was recognized as strangers and one False Positive, i.e. an employee was recognized as another employee.
The two FN user pictures were investigated, and it turned out that the pictures they had on the intranet was more than 10 years old, and since faces change over time, the assistant had troubles recognizing them.
The FP was caused from a blurry captured picture image of the user, which lead to false recognition from the assistant. A small timeout was implemented so a user could not swipe across the assistant’s point of view and be captured. This lead to more focused images, which should give better results from the recognition.
5.2 Full system testing
As presented in section 4.5.3. the test of the full system was done on 20 participants. Below in Table 3 a summary of the results are presented. Full test result can be seen in Appendix B.
Description Count Percentage
Number of participants 20 100%
Seen or tried the magic mirror before 4 20%
Succeeded the first try 13 65%
Succeeded on second try 5 25%
Failed 2 10%
Table 3: Results of the full system test
Out of 20 participants, 7 people had trouble the first time they tried the assistant. The re-sults showed three different reasons to why they failed, and they are presented below.
Voice too low
As explained in section 4.4.3, an amplitude threshold is used to determine if a user is speaking or has stopped speaking. If the user’s speech volume is below or just around the threshold, the assistant will have issues understanding the words, or even difficulties recognizing if the user is speaking or not.
Understanding
One participant used a synonym for meeting and the assistant was not programmed to understand the word, hence the misunderstanding. We took that as a good user experience
feedback and made changes on Api.ai to acknowledge the synonym.
Name difficulties
During this test, we used the name David. People were able to try the assistant and say other employee names with various result. During the whole development, employees have had the chance to try the system and try to get the assistant to send them an SMS. What we have seen is that names which are "internationally recognized" works fine, while typical Swedish name, e.g. Per, Håkan, Gunnar is by this point impossible to extract from the speech. A further discussion will take part in section 6.2. Jayway has been informed and are aware of the problem, and they do not see any problem with it for this prototype. In the future when the name database preferably expands and the Natural Language Processing improves, the name extraction problem should be solved.
5.3 Face detection
No special test was made to evaluate if the assistant could accomplish system rquirement 1 from section 4.2.1, which says: The assistant must be able to detect if a person is present in front of the camera’s field of view. This has been indirectly tested in the two test environments above, and no signs of not detecting a face has been shown.
6
Discussion
6.1 Ethics
Parts of the virtual assistant might be target for discussion regarding personal integrity. The assistant collects real time data from a camera and a microphone for processing in cloud services, but none of the collected data is deliberately stored. There is of course, however, no guarantee that the cloud services discards all data after usage. If any temporary data is saved in the cloud, it is not accessible to the developers.
6.2 Limitations Image quality
Amazon recommends an image resolution of 640x480 pixels for face recognition, and warns that a resolution below 320x240 pixels increases the risk of missing faces. We used 320x240 in our application for increased performance in face detection, since the processing is done locally. Dark and blurry images decreases the chances of an accurate recognition of the face, which limits the usage to well lit areas and cameras with a reasonably sharp image quality.
Sound quality
Speech recognition is sensitive to background noise and multiple voices, which limits us-age to silent areas and single person use at a time. This is a common problem even in commercial products such as Google Home.
Language
Since the use case involves visitors, which can be of different nationalities, the assistants language is English.
Names
If an employee name is not among the SSA database which Api.ai uses to extract first names, the assistant is not able to fulfill the use case. This database of names (2500 names according to Api.ai) is not retrievable, which means we can not determine which names are possible for the assistant to understand or not.
A few other NLP services, such as Amazon Lex and IBM Watson, has the possibility to train own stored collection names to get correct pronunciation. While this is very convenient, the problem with people speaking different languages and dialects occurs.
Services uptime/existence
The assistant is dependent on cloud services, which all have to be active when running. Any downtime in any service will affect the assistant’s capability to function. This also implies that the internet connection must be stable.
6.3 Error consequence in face recognition
When trying to identify a user there are three possible outcomes which mark a failed recognition stated in section 4.5.2.
1. An employee is recognized as another employee 2. An employee is recognized as a stranger
3. A stranger/visitor is recognized as an employee
Could any of these have negative consequences on the outcome? We have to look at the risk regarding to the selected use case. The first outcome could be troublesome, since employees can use the assistant to contact other employees. But considering that the assistant’s main task is to aid visitors, this outcome is not common and the consequence is not that bad. The second outcome would have the same explanation as outcome 1. The last faulty outcome could be worse. During test, this outcome never occurred though, but suppose a visitor comes into the office and is faulty recognized as an employee. The visitor could believe that the assistant was designed to be used only by employees and feel uncomfortable with the situation.
The consequences are different if thinking of the other possible use cases, stated in section 4.1.1. The Virtual time clock would not aid the employees who the assistant can not recognize and could possibly check in or out other employees, although that may never happen. A visitor to be recognized as an employee and check in and out is also not likely to happen, since the visitor must know the keywords and phrases to the assistant.
Use case 3: My day at work is more personal than the other discussed use cases, since it shows personal information about meetings and other appointments. This information could be confidential and any false positive outcomes (1 and 3 above) can result in leaking confidential information. Either have a 100% accuracy in recognition, which seems hard to reach, or information on screen which do not show confidential information can be a workaround for this problem.
7
Conclusions and further work
The prototype presented in this thesis shows that it is possible to utilize cloud computing services onto the Magic Mirror, to create a virtual assistant. The face recognition test showed nearly 94% accuracy, which we consider passed with distinction, since the faults could be blamed on old and blurry pictures.
When letting 20 people try the Magic Mirror, with focus on the use case where the partici-pant acted as a visitor who has a meeting with an employee, 65% of these succeeded. The hardest part for the assistant is to understand names, especially non-international names, such as Swedish names containing the letters å,ä,ö. Also if the background noise is too loud, the assistant is having troubles understanding when the user is speaking or not.
7.1 Answering the research questions
In section 4.2.1 we presented four system requirements, which needed to be fulfilled in order to answer research question 1: How to build a virtual office assistant based on Magic Mirror? If the system can distinguish an employee from a visitor using face recognition, and having a dialogue with the user, and then accomplish specific tasks, we can acknowledge the system as a virtual assistant. Below we map the results of our tests to the system requirements defined in section 4.2.1.
1. The assistant must be able to detect if a person is present in front of the camera’s field of view.
Verdict: Works in all tested cases
2. The assistant should be able to distinguish an employee from a visitor. Images of the employees are stored in the database with picture and name, so if the assistant does not recognize the user, the user is a visitor.
Verdict: Passed with 94% accuracy
3. When the visitor has declared who s/he intends to meet, the assistant should be able to recognize an employee’s name from the spoken speech.
Verdict: Problems with non-international names, otherwise succeeded 4. The assistant must be able to notify the employee via a text message on his or her
mobile phone, when the name has been extracted from the dialogue and the visitor intends to meet the employee.
Verdict: Works in all tested cases
As mention in section 5.2, Jayway are aware of the naming difficulties, and do not see it as an issue for the prototype, we can consider requirement 2 to be passed.
With these requirements met, we consider research question 1 to be answered.
In section 4.1.1 we presented the use case for the virtual assistant, along with two alter-native use cases. This answers the sub research question 1.1: What is a potential use case for a such an virtual assistant?
For the prototype, we have used cloud computing services for face recognition and speech recognition. The providers offers good documentation on how to utilize their services in projects. Amazon Rekognition was shown very powerful and precise when identifying people, and Api.ai was convenient since the assistant could pass a voice stream to the service, for it to both convert it into text and give a response or recommended action for the assistant to execute. To handle these functionalities locally, in real-time without computational delays, would require a very powerful computer and also a deployment into a mini computer such as Raspberry Pi would not be possible.
This answers the last research question 1.2 How can cloud-based face recognition and speech recognition services facilitate the development of such a system?.
Through our work we have showed that it is possible to create digital assistants without having machine learning expertise. With readily available hardware such as standard USB cameras and microphones it is possible to create desktop applications that does not need manual input such as keyboard or touch interfaces.
7.2 Future Work
The application areas for which cognitive services can be used are many. If the machine learning trend are to continue, the online cognitive services will improve. Through percep-tual interfaces, realized by such services, a greater understanding of the user can lead to more useful tools in peoples everyday life. Future work might find better applications and use cases with the upcoming technologies.
References
[1] Yves Kodratoff. Introduction to machine learning. Morgan Kaufmann, 2014.
[2] Domo. Data Never Sleeps 4.0. June 2016. url: https://www.domo.com/blog/data-never-sleeps-4-0/.
[3] SAS. Machine Learning - What it is & why it matters. Feb. 2017. url: https : //www.sas.com/it_it/insights/analytics/machine-learning.html.
[4] Michael Copeland. What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning? July 2016. url: https://blogs.nvidia.com/blog/ 2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/.
[5] Erik Brynjolfsson and Andrew McAfee. Race against the machine: How the digital revolution is accelerating innovation, driving productivity, and irreversibly transform-ing employment and the economy. Brynjolfsson and McAfee, 2012.
[6] Carl Benedikt Frey and Michael A. Osborne. “The future of employment: How suscep-tible are jobs to computerisation?” In: Technological Forecasting and Social Change 114 (2017), pp. 254–280. issn: 0040-1625. url: http://www.sciencedirect.com/ science/article/pii/S0040162516302244.
[7] JLL. Introducing JiLL – A humanoid robot receptionist at JLL’s newest office. Oct. 2016. url: http://www.jll.com.au/australia/en-au/news/1096/introducing-jill-a-humanoid-robot-receptionist-at-jlls-newest-office.
[8] Softbank Robotics. Who is Pepper? url: https://www.ald.softbankrobotics. com/en/cool-robots/pepper.
[9] ASM Mahfujur Rahman et al. “Augmented rendering of makeup features in a smart interactive mirror system for decision support in cosmetic products selection”. In: Distributed Simulation and Real Time Applications (DS-RT), 2010 IEEE/ACM 14th International Symposium on. IEEE. 2010, pp. 203–206.
[10] Moritz Stückler. Magic Mirror: Spiegel zeigt Wetter und Nachrichten beim Zäh-neputzen – dank Raspberry Pi. Aug. 2014. url: https://www.ald.softbankrobotics. com/en/cool-robots/pepper.
[11] Michael Teeuw. Magic mirror. url: http://michaelteeuw.nl/tagged/magicmirror. [12] Michael Teeuw. Magic mirror. url: https://magicmirror.builders.
[13] E. J. Qaisar. “Introduction to cloud computing for developers: Key concepts, the players and their offerings”. In: 2012 IEEE TCF Information Technology Professional Conference. Mar. 2012, pp. 1–6.
[14] Qi Zhang, Lu Cheng, and Raouf Boutaba. “Cloud computing: state-of-the-art and research challenges”. In: Journal of Internet Services and Applications 1.1 (2010), pp. 7–18.
[15] Fahad Saleem. 10 biggest cloud computing companies in the world. Jan. 2017. url: http://www.insidermonkey.com/blog/10-biggest-cloud-computing-companies-in-the-world-518585/?yptr=yahoo.
[16] Proyecto Fin De Carrera and Ion Marques. “Face recognition algorithms”. In: Mas-ter’s thesis in Computer Science, Universidad Euskal Herriko (2010).
[17] Yotam Abramson, Bruno Steux, and Hicham Ghorayeb. “Yet even faster (YEF) real-time object detection”. In: International Journal of Intelligent Systems Technologies and Applications 2.2-3 (2007), pp. 102–112.
[18] F. Schroff, D. Kalenichenko, and J. Philbin. “FaceNet: A unified embedding for face recognition and clustering”. In: 2015 IEEE Conference on Computer Vision and Pat-tern Recognition (CVPR). June 2015, pp. 815–823.
[19] G. R. Bradski. “Real time face and object tracking as a component of a perceptual user interface”. In: Applications of Computer Vision, 1998. WACV ’98. Proceedings., Fourth IEEE Workshop on. Oct. 1998, pp. 214–219.
[20] A. Graves, A. r. Mohamed, and G. Hinton. “Speech recognition with deep recurrent neural networks”. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. May 2013, pp. 6645–6649.
[21] Bo Li and Heiga Zen. “Multi-Language Multi-Speaker Acoustic Modeling for LSTM-RNN based Statistical Parametric Speech Synthesis”. In: 2016.
[22] S Athira et al. “Smart mirror: A novel framework for interactive display”. In: Circuit, Power and Computing Technologies (ICCPCT), 2016 International Conference on. IEEE. 2016, pp. 1–6.
[23] Hao Yan and Ted Selker. “Context-aware Office Assistant”. In: Proceedings of the 5th International Conference on Intelligent User Interfaces. IUI ’00. New Orleans, Louisiana, USA: ACM, 2000, pp. 276–279.
[24] Daniel Besserer et al. “Fitmirror: a smart mirror for positive affect in everyday user morning routines”. In: Proceedings of the Workshop on Multimodal Analyses enabling Artificial Agents in Human-Machine Interaction. ACM. 2016, pp. 48–55.
[25] Jay F Nunamaker Jr, Minder Chen, and Titus DM Purdin. “Systems development in information systems research”. In: Journal of management information systems 7.3 (1990), pp. 89–106.
[26] Chang Huang et al. “High-performance rotation invariant multiview face detection”. In: IEEE Transactions on Pattern Analysis and Machine Intelligence 29.4 (2007). [27] Behzad Munir. Voice fundamentals - Human speech frequency. Mar. 2012. url: http:
A
Sequence diagram
Figure A.14: Sequence diagram showing the relationships between actors in the system. Conversation flow is from use case 1: Appointment manager
B
Full system test result
ID Passed Comment
1 YES One repetition needed when listening for name
2 YES
-3 YES Wrong name extracted at first, but was corrected by user. Voice too low
4 NO Assistant kept misunderstanding the user. Voice too low
4.1 NO
Same user asked to try again. Same result as before, misunderstanding due to low voice from user
5 YES
-6 NO
User tried his own name, though the name is uncommon and could not be extracted by the assistant
7 NO Assistant kept misunderstanding the user. Voice too low
7.1 YES Same user asked to try again. This time he in-creased his voice level
8 NO
Misunderstanding from assistance. User used appointment which the assistant had not yet been learned to be a synonym to meeting. A programming fault, which was directly fixed. 8.1 YES Same user. Now the word appointment was
ex-tracted from speech
9 NO Assistant kept misunderstanding the user. Voice too low
9.1 YES Same user. This time he increased his voice level
10 YES -11 YES -12 YES -13 YES -14 YES -15 YES
-16 NO Wrong name extracted. Voice too low 16.1 YES Same user. This time higher voice
17 YES
-18 YES
-19 NO Assistant kept misunderstanding the user. Voice too low
19.1 YES Same user. This time higher voice
20 YES An employee tested on own name. International name