Horst Löfgren
Grundläggande statistiska metoder
för analys av kvantitativa data
Med övningar för programpaketet SPSS
©
Kopieringsförbud
Detta verk är skyddat av lagen om upphovsrätt. Kopiering, får endast ske efter tillstånd av författaren.
Förord
Denna bok vänder sig till alla som behöver kunna olika metoder för be-skrivning och analys av data och som helst har tillgång till statistikpro-grammet SPSS. Även om boken kan fungera som en allmän bakgrund till statistiska beskrivningar och analyser av data oberoende av statistisk pro-gramvara är den i vissa delar inriktad mot SPSS.
Även om boken tar upp det mesta från grunden av presenterade statist-iska begrepp, beskrivningar och analyser är framställningen relativt kom-pakt, varför en genomgången nybörjarkurs eller litteratur med långsam-mare progression är lämplig som bakgrund. Innehållet i boken täcker det mesta av de grundläggande statistiska metoder, som behövs vid analys av data för användare av statistik som hjälpvetenskap, dvs. icke-specialister inom ämnet statistik.
Denna bok kan användas av personer med begränsade kunskaper i sta-tistik, men också av dem som vill använda statistisk dataanalys på en mer avancerad nivå. Många studerande inom olika utbildningar har svårigheter att tillgodogöra sig undervisningen i statistik och statistisk dataanalys. Ofta har man en negativ förhandsinställning och denna påverkar givetvis utfal-let av undervisningen och lärandet. Många gånger lär sig studerande kurs-innehållet i kvantitativa analyser på ett mekaniskt sätt och utan att verklig-en förstå vad de gör och varför. Därför är dverklig-enna bok ett försök till verklig-en kon-centrerad framställning med tonvikt på förståelse. Det mekaniska räknan-det klarar datorn av, om man trycker på rätt knappar. Det har emellertid visat sig att en del av lärandetiden borde ägnas åt att för hand räkna ige-nom enkla uppgifter för att verkligen förstå vad datorn gör, när den räknar fram ett resultat. När man väl vet vad man gör och varför, kan huvuddelen av lärandetiden ägnas åt förståelse för statistisk beskrivning och analys.
Även om man själv inte samlar in egna datafiler för att analysera sina frågeställningar, måste man ha grundläggande kunskaper i statistisk dataa-nalys för kritiskt kunna läsa artiklar och resultat av forskning som baserar sig på kvantitativa analyser.
Samtliga metoder som presenteras i boken finns i analysdelen i pro-grampaketet SPSS. Dock finns ännu mer avancerade analysmetoder i SPSS, som inte presenteras i denna bok. Ett par avsnitt i boken är mycket
sällan förekommande i grundböcker, som t.ex. avsnitten om faktoranalys, reliabilitet och index på storleksskillnader. För att resonera om kvalitet i data är det nödvändigt att ha en förståelse för begrepp som validitet och reliabilitet. Därför finns ett kort avsnitt om och förklaring av faktoranalys som en metod att analysera validiteten, dvs. pröva om man verkligen lyck-ats fånga in det som avsikten med de data som insamllyck-ats.
Alldeles för många användare av statistisk hypotesprövning har inte förstått skillnaden mellan statistisk signifikans och storleksskillnader. Där-för finns i boken avsnitt som Där-förklarar skillnaden mellan säkerhet och stor-lek i statistiska slutsatser. Dessutom ges olika mått på effektstorstor-lek. Till boken finns en datafil från en verklig undersökning (IEA-Written Composition; data från det svenska stickprovet ”Elever i årskurs 9”), som tidigare kunde hämtas från min webbsida på Internet. Filen finns nu på en CD-skiva som kan erhållas av mig. På denna dataskiva finns också lös-ningar till bokens övningsuppgifter. CD-skivan innehåller också ett tryck-färdigt manus för hela boken.
Boken innehåller fyra kapitel. Det första kapitlet är en kort introduktion till statistikens huvuddelar, beskrivning och inferens, samt en beskrivning av olika typer av mätskalor. Det andra kapitlet behandlar beskrivande sta-tistik. Här presenteras central- och spridningsmått, grafisk representation, korrelation och prediktion. Kapitlet innehåller också något mer avancerade metoder som multipel regressionsanalys, logistisk regressionsanalys, fak-toranalys och metoder för reliabilitetsskattning. I kapitel tre presenteras olika parametriska hypotesprövningsmetoder, såväl för ett som för flera stickprov. En väsentlig del av texten behandlar enfaktoriella och flerfak-toriella variansanalyser. Förutom signifikansbestämningar presenteras metoder för bedömning av storleksskillnader i undersökningsresultat. Detta avsnitt är synnerligen väsentligt, för att korrekt kunna tolka under-sökningsresultat. Det fjärde kapitlet behandlar icke-parametriska hypotes-prövningsmetoder för ett och flera stickprov.
I Appendix finns statistiska tabeller och en presentation av övningsfilen med tillhörande övningsuppgifter.
Barsebäck våren 2014 Horst Löfgren
Innehåll
Förord ... 3
1 Inledning... 11
2 Beskrivande statistik ... 14
2.1 Central- och spridningsmått ... 14
2.2 Grafisk framställning ... 21
2.3 Sambandsmått - Korrelation ... 22
2.3.1 Pearson's produkt-moment korrelation ... 23
2.3.2 Tolkning av olika värden på korrelationen ... 27
2.3.3 Samband mellan variabler på selekterade grupper ... 29
2.3.4 Linjära och icke-linjära samband ... 30
2.3.5 Spearman's rangkorrelation ... 31
2.4 Den standardiserade normalfördelningen; z-poäng ... 32
2.5 Regression ... 33
2.6 Multipel korrelation och multipel regression ... 38
2.6.1 Stegvis regressionsanalys ... 41
2.6.2 Ett exempel på linjär multipel regression och stegvis multipel regression ... 41
2.6.3 Logistisk regressionsanalys ... 45
2.6.4 Användning av s.k. dummy-variabler ... 47
2.7 Faktoranalys ... 49
2.7.1 Vad är faktoranalys? ... 49
2.7.2 Extrahering av faktorer - ett förklarande exempel ... 51
2.7.3 Gemensam varians, specifik varians och felvarians ... 53
2.7.4 Arbetsgången vid faktoranalys ... 54
2.7.5 Ett praktiskt exempel och förklaring av analysresultatet ... 55
2.8 Reliabilitet ... 59
2.8.1 Beräkning av Cronbach’s alpha ... 61
3 Parametriska hypotesprövningsmetoder ... 66 3.1 Urvalsmetoder ... 66 3.2 Sannolikhetsbegreppet ... 70 3.3 Samplingfördelning ... 71 3.4 Skattningar ... 74 3.5 Hypotesprövning ... 77
3.6 Hypotesprövning av ett stickprov i förhållande till en population ... 84
3.7 Hypotesprövning av en medelvärdes-differens mellan två oberoende stickprov ... 89
3.8 Hypotesprövning av en medelvärdes-differens mellan två beroende stickprov ... 93
3.9 Hypotesprövning av medelvärdes-differenser med hjälp av variansanalys ... 95
3.10Enfaktors ANOVA; oberoende grupper ... 97
3.11Lämpliga index på relationen mellan oberoende och beroende variabel ... 103
3.11.1Omega-kvadrat ... 103
3.11.2 Eta-kvadrat ... 104
3.11.3 Effektstorlek ... 105
3.12Tvåfaktors ANOVA; oberoende grupper ... 107
3.13Enfaktors ANOVA; beroende grupper ... 114
2.14Kovariansanalys, ANCOVA ... 118
4 Icke-parametriska hypotes-prövningsmetoder ... 121
4.1 Analys av stickprovsdata i förhållande till populationsdata .... 122
4.1.1 Chi-kvadrat-testet för ett stickprov ... 123
4.1.2 Run-testet ... 125
4.2 Analys av differensen mellan två oberoende stickprov ... 127
4.2.1 Chi-kvadrat-testet för två oberoende stickprov ... 128
4.2.2 2-analys av en 2x2 kontingenstabell... 130
4.2.3 Mann-Whitney U-test ... 131
4.2.4 Kolmogorov-Smirnov-testet för två oberoende stickprov ... 134
4.3 Analys av differensen mellan två beroende stickprov ... 138
4.3.1 McNemar-testet ... 138
4.3.2 Wilcoxon’s teckenrangtest ... 140
4.4 Några index byggda på 2 ... 143
4.4.1 Kontingenskoefficienten ... 143
4.4.2 Cramérs index ... 145
4.5 Analys av differenser mellan tre eller flera oberoende stickprov ... 145
4.5.1 Chi-kvadrat-testet för tre eller flera oberoende stickprov ... 146
4.5.2 Kruskal-Wallis testet ... 148
4.6 Analys av differensen mellan tre eller flera beroende stickprov ... 150
4.6.1 Cochran Q-test ... 151
4.6.2 Friedman testet ... 152
Appendix ... 155
Ett förenklat exempel på varianskomponenter i variansanalys ... 156
Tabeller ... 157
Enkät och övningsuppgifter ... 173
1
Inledning
Statistik utnyttjas av många vetenskapliga discipliner och ger oss bl.a. metoder för att sammanställa insamlade data och dra generaliserbara slut-satser. Den statistiska kunskapen hjälper oss i forskningsprocessen med frågor rörande urval, beskrivning, analys, tolkning och presentation av data.
I olika typer av undersökningar, både experimentella och icke-experi-mentella, vill vi på lämpligt sätt kunna beskriva de observationer som in-samlats. Med hjälp av de s.k. deskriptiva metoderna kan vi organisera och sammanfatta resultat av observationer. Vi utnyttjar således den deskriptiva statistiken, när vi vill sammanfatta våra observationer genom att t.ex. ange central-, spridnings- och korrelationsmått.
Ofta vill vi uttala oss mera generellt om resultat, som erhållits i en under-sökning från en mindre grupp. För att kunna dra slutsatser från ett stick-prov till en större bakomliggande grupp (population) används den del av statistiken som kallas inferensstatistik. Grunden för de metoder vi utnyttjar för att våga generalisera från observerade data till en population är den s.k. sannolikhetsteorin. Med hjälp av denna sannolikhetsteori kan vi hantera osäkerheten i våra data. Det finns alltid en viss osäkerhet, när man gör prediktioner till andra grupper än den som undersökts.
Om vi har data om hela populationen, kan vi direkt beskriva dess skaper. Medelvärdet och standardavvikelsen i populationen, dvs. egen-skaper i populationen, kallas parametrar och betecknas ofta med grekiska bokstäver. Karakteristika i ett stickprov, t.ex. medelvärde och standardav-vikelse betecknas med vanliga (romerska) bokstäver. Dessa från stickpro-vet beräknade värdena kallas i engelskspråkig litteratur för “statistics“.
Figur 1.1. Beskrivande mått i population och stickprov samt relationen dem emellan
Population
Stickprov M; s
Vid insamling av data utnyttjas olika typer av mätinstrument. En mätning kan definieras som tilldelandet av tal på objekt eller händelser i enlighet med vissa regler. Det faktum att tal kan sättas med utgångspunkt från olika regler leder till olika slags skalor och olika slags mätningar. Vi får då ta hänsyn till följande:
a) olika regler för att sätta siffervärden, b) skalornas matematiska egenskaper,
c) vilka statistiska operationer som kan appliceras på de olika skal-typerna.
Det finns två typer av numeriska data om de fenomen vi studerar. Om vi endast räknar antal av den variabel som studeras erhålls frekvenser. Ex-empelvis räknar vi antalet män och kvinnor i ett observationsmaterial eller antalet elever som väljer olika linjer i gymnasieskolan. Om vi i stället mä-ter den variabel som studeras erhålls metriska värden, dvs. skalvärden. Exempelvis kan vi mäta längden på en grupp män och kvinnor eller kun-skapsprestationer på elever i skolan.
En frekvens anger antalet observationer i en viss kategori. Den enklaste formen av "mätning" är klassifikation av data, vilket ger frekvenser i kvali-tativt olika kategorier. Vid variabler som kan kvantifieras, dvs. anta olika värden, skiljer vi på kontinuerliga och diskreta sådana. En kontinuerlig variabel kan anta vilket värde som helst inom ett givet intervall (längd, kunskaper), medan en diskret variabel endast kan anta vissa bestämda skalvärden (antal barn per familj).
Vi brukar tala om fyra skaltyper: 1. Nominalskala
Detta är egentligen ingen skala utan en klassificering av olika objekt eller individer. Vi gör med andra ord ingen egentlig mätning, när vi arbetar med kvalitativa variabler som exempelvis kön, civilstånd och utfall vid slant-singling.
2. Ordinalskala
Vid denna mätning av kvantitativa variabler utnyttjas endast rangordning-en mellan de tal som tilldelats de olika objektrangordning-en eller individerna. Om ex-empelvis elever har erhållit olika antal poäng på ett prov kan vi utnyttja relationerna bättre än och sämre än. Vi kan däremot inte säga något om
differensernas relativa storlek. De flesta mätningar av förmågor, kognitiva och icke-kognitiva egenskaper, är av ordinalskaletyp. Som exempel kan nämnas kunskaper, betyg och attityder.
3. Intervallskala
Om vi förutom rangordningen mellan mätobjekten kan säga något om in-tervallernas storlek, exempelvis att avståndet mellan 5 och 10 poäng är lika stort som avståndet mellan 10 och 15 poäng, talar vi om ekvidistanta skal-steg. Här kan vi som ett exempel nämna temperaturskalan enligt Celsius. Differensen mellan +10grader och +15 grader är lika stor som mellan +20 grader och +25 grader. Eftersom 0 grader inte är någon absolut nollpunkt kan vi emellertid ej säga att +20grader är dubbelt så varmt som +10 gra-der.
4. Kvotskala
I denna skala kan vi utnyttja alla tre egenskaperna hos talsystemet; ord-ning, differens och nollpunkt. Det innebär att vi kan tala om kvoter. Ett bra exempel på en sådan här skala är längdskalan. Ett objekt som har en längd av 100 cm är dubbelt så långt som ett av längden 50 cm. Viktskalan är ett annat bra exempel.
Detta att vi åsätter våra mätobjekt vissa tal innebär således att vi inte alltid får utnyttja egenskaperna hos dessa tal. Olika statistiska operationer tillåts beroende på skaltyp. Här har man ibland diskuterat, om vi trots sämre ska-lor inom beteendevetenskaperna (oftast ordinalskala) ska få använda stat-istiska beräkningar, som egentligen kräver minst intervallskala. Utan att här närmare gå in på dessa problem kan vi konstatera, att vi kanske ibland efter att ha tilldelat våra mätobjekt ett visst tal fortsätter att resonera som om mätningen har talens egenskaper. Man kan alltid räkna med statistiskt avancerade metoder, men det är de bakomliggande psykologiska relation-erna, som bestämmer huruvida den statistiska metoden leder till vettiga resultat. Man kan nämligen erhålla olika resultat beroende på om man an-ser sig ha en ordinal-, intervall- eller kvotskala, trots att det är samma psy-kologiska egenskaper som ursprungligen mättes.
I många fall kan det räcka med att skilja mellan kategorivariabler (nomi-nal) och kontinuerliga variabler. Om man har data från någon observat-ionsvariabel och kan anta att bakomliggande populationsdata är approxi-mativt normalt fördelade, går det bra att använda metoder som egentligen kräver data på intervall- eller kvotskalenivå.
2 Beskrivande statistik
Man använder sig av beskrivande statistik, när man sammanfattande vill beskriva sina insamlade data. Det kan handla om att beskriva hur data för-delar sig över olika värden, att ange central- och spridningsmått. Man kan också vilja beskriva hur olika mätvariabler förhåller sig till varandra, dvs. hur de samvarierar (korrelerar). Har man flera olika mätvariabler kan man vara intresserad att studera om man utifrån några variabler kan predicera utfallet i en s.k. utfallsvariabel. Man kan också vilja studera, om man kan slå samman olika mätvariabler för att t.ex. bilda summavariabler. För att kunna bilda sådana summavariabler eller index måste vi veta, att det är rimligt att slå samman enskilda mätvariabler. Därför vill vi studera både validitet, dvs. om vi mäter det vi avsåg att mäta och reliabilitet, dvs. hur tillförlitliga våra mätningar är. Det är väsentligt att få mått på kvaliteten i våra data, i synnerhet om vi har konstruerat de begrepp, som vi försöker mäta. Många av de begrepp vi använder oss av och som vi försöker mäta är inte alltid lätta att fånga in. Ofta är de mest intressanta begreppen svår-ast att operationellt definiera och därmed svåra att komma åt. Dessutom innehåller svåruppmätta variabler ofta ganska stora mätfel. Det finns emel-lertid lämpliga metoder för att studera både validitet (relevans) och reliabi-litet (tillförlitlighet).
2.1 Central- och spridningsmått
För att sammanfatta hur insamlade data fördelar sig över olika observat-ionsvärden anger man lämpligen ett mått på centraltendens, dvs. man anger det värde som är mest representativt för det material som insamlats. Dessutom anger man vanligen också hur mätvärdena sprider sig i den vari-abel som observerats.
Det finns tre mått på central tendens, nämligen Typvärde (T), Median (Md) och Medelvärde (M). De engelska termerna är Mode, Median och Mean. Till dessa centralmått hör de tre spridningsmåtten Variationsvidd
(V), Kvartilavstånd och Standardavvikelse (s). Motsvarande engelska ter-mer är Range, Interquartile range (IQR) och Standard deviation.
Typvärdet är det värde som oftast förekommer i det insamlade materialet, dvs. det värde som har den högsta frekvensen. Tillhörande spridningsmått är variationsvidd, vilket är skillnaden mellan det högsta och det lägsta värdet i fördelningen. Dessa beskrivande mått ger ganska lite information. För nominalskalerade observationsvariabler är typvärdet det enda relevanta mått, som kan anges för att ge information om insamlade data.
Medianvärdet används lämpligen vid s.k. sneda fördelningar på ordinal-, intervall- eller kvotskalerade observationsvariabler. Medianvärdet är det värde som den mittersta observationen har. Medianen delar s a s en fördel-ning i två lika stora delar; 50 % av antalet observationer ligger ovanför respektive nedanför medianen. Tillhörande spridningsmått kallas kvartil-avstånd, som är avståndet i x-variabeln mellan den 75 percentilen (P75) och den 25 percentilen (P25). Dessa båda punkter innesluter de mittersta 50 % av observationerna. Divideras kvartilavståndet med två erhålls ett alternativt sätt att uttrycka spridningen på, nämligen kvartilavvikelsen. Observera att avståndet mellan P75 och Md inte är lika stort som avståndet mellan Md och P25 vid sneda fördelningar. Det kan här nämnas att man i forskningsrapporter och artiklar sällan finner att kvartilavstånd eller kvar-tilavvikelsen använts som mått på variationen i ett material.
Om en fördelning är approximativt normalfördelad och därmed någorlunda symmetrisk används det aritmetiska medelvärdet, vanligen endast kallad medelvärde. Det erhålls genom att summera samtliga observationer och dividera med antalet observationer.
xi
M = ___ (formel 2.1) n
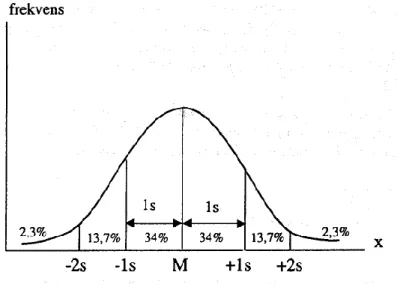
Standardavvikelsen är ett avstånd i mätvariabeln (på x-axeln) så stort att mellan medelvärdet (M) och +1 standardavvikelse (s) ligger ungefär 34 % av alla observationerna i materialet och likaså mellan M och -1s. Mellan minus en standardavvikelse och plus en standardavvikelse ligger således 68 % av samtliga observationer. Mellan M +/- 2s ligger ungefär 95 % av alla observationer.
I normalfördelningen ligger 68,3 % av observationerna i intervallet M +/- s och 95,4 % i intervallet M +/- 2s. Eftersom nästa alla observationer ligger mellan -2s och +2s, dvs. inom fyra standardavvikelser blir standardavvi-kelsen i ett normalfördelat observationsmaterial något mer än en fjärdedel av variationsvidden.
Standardavvikelsen i kvadrat kallas för varians. Variansen i en population är lika med den genomsnittliga kvadrerade avvikelsen från medelvärdet. Roten ur detta värde (variansen) är lika med standardavvikelsen.
xi-M)2
= ________ (formel 2.2) N
Då variansen i ett stickprov tenderar att underestimera variationen i popu-lationen korrigeras formeln vid beräkning av standardavvikelsen i ett stickprov i enlighet med formel 2.3.
(xi - M)2
s = ____________ (formel 2.3)
n – 1
Om vi skriver om formel 2.3 blir det enklare att beräkna standardavvikel-sen.
(x)2 x2 - _____ n
s = ________________ (formel 2.4) n - 1
Vid valet av beskrivande mått, t.ex. central- och spridningsmått är fördel-ningens utseende i observationsmaterialet av stor betydelse. Om mätvär-dena är approximativt normalfördelade, dvs. de flesta observationerna ligger i mitten och färre observationer med extrema värden, används arit-metiskt medelvärde och standardavvikelse. Om mätvärden i stället är på-tagligt snedfördelade är median och kvartilavvikelse lämpligare mått.
Figur 2.2. Medelvärde (M) och standardavvikelse (s)
Observera dock att fördelningens utseende oftast avgör valet av beskri-vande mått. Ovan angivna sambandsmått baserar sig på att båda de stude-rade variablerna är av samma skaltyp. Det finns nämligen ett antal av olika sambandsmått för skilda kombinationer av mätskalor.
Ruta 2.1. Vanliga beskrivande mått vid olika typer av mätskalor Skaltyp Centralmått Spridningsmått Sambandsmått Nominal Typvärde Phi, Cramérs V Ordinal Median Kvartilavvikelse Rangkorrelation Intervall/ Medelvärde Standardavvikelse Produkt-moment-
Kvot korrelation
Vi tänker oss att vi ska genomföra en undersökning om rökvanor i en viss grupp. Vilken är den enklaste frågan som kan ställas för att få information om rökning? Om vi ställer frågan ”Röker du” och svarsalternativen är ”Ja” eller ”Nej” erhålls en viss information om rökvanor i gruppen. Informa-tionen är tillräcklig för att åtminstone klassificera individerna i gruppen som rökare eller icke-rökare och vi kan ange frekvensen av svar i respek-tive grupp. Vi har erhållit data på nominalskalenivå, dvs. en klassificering med kategorierna rökare och icke-rökare. På basis av data kan vi ange typvärdet, dvs. om det finns flest rökare eller flest icke-rökare i gruppen. Som lätt inses är kvalitén i data ganska dålig. I gruppen rökare kan det finns alltifrån feströkare till kedjerökare. Om vi förändrar vår fråga kan vi få mer information.
Nu ställer vi en fråga som lyder så här: Hur mycket röker du? Ange med kryss!
Inte alls Vid enstaka tillfällen Varje dag Flera gånger om dagen
( ) ( ) ( ) ( )
Denna fråga ger mer information än den föregående. Rimligen borde man ganska väl kunna rangordna respondenterna i fyra grupper. Data ligger på ordinalskalenivå. Visserligen skulle man kunna se på resultatet som fyra kategorier, men det går ju faktisk att till viss del rangordna respondenterna. Rökandegruppen har ju differentierats till tre grupper.
Vilken är då den bästa fråga man kan ställa till gruppen för att inte bara rangordna respondenterna utan också säga något avstånden mellan olika
svarsalternativ? Om vi endast håller oss till cigarettkonsumtion kan vi ställa följande fråga:
Hur många cigaretter röker du i genomsnitt per dag? ___________ cigaretter
Nu har vi god information och kan uttala oss om att en viss individ röker dubbelt så mycket som en annan, eller hälften så mycket etc. Eftersom man kan göra detta ligger data på kvotskalenivå, dvs. har en nollpunkt. När man samlar in information bör man sträva efter att få så bra data som möj-ligt. Om man kan erhålla data på intervall- eller kvotskalenivå så är detta naturligtvis bättre än data på endast ordinalskalenivå eller nominalskale-nivå. Effektivare statistiska metoder kan användas om data ligger på en ”högre” nivå.
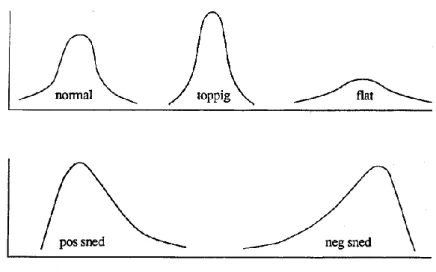
De flesta kvantitativa variabler kan klassificeras som symmetriska eller sneda. I en symmetrisk fördelning kan man dra en vertikal linje genom mittpunkten, så att den ena sidan av fördelningen är en spegelbild av den andra sidan. Fördelningen över data jämförs med normalfördelningen, som är matematiskt bestämd och som har ett visst utseende. Normalfördelning-en är perfekt symmetrisk.
Figur 2.3. Exempel på olika fördelningar i jämförelse med normalfördel-ningen
För att visa tillvägagångssättet vid beräkning av median, medelvärde och standardavvikelse ges följande exempel: I en grupp individer observerades följande resultat på ett test (här presenterade i ordning från sämsta till bästa resultat):
1,2,2,2,3,3,3,3,3,4,4,4,4,4,5,5,5,5,5,5,5,5,6,6,6,6,6,6,7,7,7,7,8,8,9,9 Redovisa resultatet i en frekvenstabell och beräkna medianvärdet, medel-värdet och standardavvikelsen för gruppen!
Eftersom vi i exemplet ovan har 36 observationer blir medianvärdet genom snittet av observation nr 18 och nr 19. Då båda observationerna har värdet 5 blir medianen 5. Kvartilavståndet är 2,5 (P75=6 och P25 ligger mellan 3 och 4, dvs. 3,5) och således kvartilavvikelsen 1,25. För att beräkna medel-värdet och standardavvikelsen används formlerna 2.1 och 2.4.
Frekvenstabell
Variabelvärde Frekvens Kumulativ Relativ
x f frekvens frekvens i % f . x f . x2 1 1 1 2,8 1 1 2 3 4 8,3 6 12 3 5 9 13,9 15 45 4 5 14 13,9 20 80 5 8 22 22,2 40 200 6 6 28 16,7 36 216 7 4 32 11,1 28 196 8 2 34 5,6 16 128 9 2 36 5,6 18 162 Totalt 36 100 180 1040 fxi 180 M = ____ = ____ = 5,0 n 36 fx)2 1802 fx2 - _____ 1040 - ____ n 36 s = ___________________ = ____________________ = 2,00 n – 1 35
2.2 Grafisk framställning
Det kan många gånger vara lämpligt att åskådliggöra de data som samlats in grafiskt. Olika former av diagram kan till läsaren överföra information om observationsmaterialets utseende. Det finns olika typer av diagram, som då kan användas. Bra diagram är de som överför korrekt information till läsaren. I diagram med en horisontell och en vertikal axel (x- och y-axel) anges vanligtvis mätskalan på den horisontella axeln och frekvensen på den vertikala.
Ruta 2.2. Några lämpliga typer av diagram a) Stolpdiagram frekvens x b) Histogram frekvens x c) Frekvenspolygon frekvens x
Vid nominalskala, dvs. när man har frekvenser av olika kategorier, an-vänds stolpdiagram (stapeldiagram). Höjden i varje stapel anger frekven-sen av de olika kategorierna. Stolpdiagram är även lämpligt att använda vid diskreta variabler. Med diskret variabel menas en variabel, som endast kan anta vissa värden.
Vid kontinuerliga variabler, dvs. variabler som kan anta ett obegränsat antal värden, används histogram eller frekvenspolygon. Även vid klass-indelat material, beroende på stort antal variabelvärden, används dessa båda diagram. Om man sammanbinder klassmittpunkterna i ett histogram och därvid börjar och slutar på x-axeln erhålls en frekvenspolygon.
I SPSS kan man ange vilken skalnivå man har på sina mätvärden; nominal, ordinal eller intervall/kvot (de sistnämnda kallas i SPSS för Scale). Man kan dessutom erhålla flera andra typer av diagram. Om man har data på intervall- eller kvotskalenivå (Scale i SPSS) kan man till sitt histogram begära att normalfördelningskurvan läggs in.
2.3 Sambandsmått - Korrelation
Det finns flera olika mått på relationer mellan variabler. Valet av sam-bandsmått beror på typ av skala på respektive variabel. Om vi studerar sambandet mellan två intervall- eller kvotskalerade variabler används Pearson's produkt-moment korrelation. Denna metod används också vid approximativt normala fördelningar, även om de studerade variablerna egentligen endast är på ordinalskalenivå. Om båda variablerna är av ordi-nalskaletyp används i stället Spearman's rangkorrelation. Skulle båda vari-ablerna vara nominalskalerade, dvs. kategorivariabler används Cramérs index (jfr avsnitt 4.4.2). Om båda variablerna är dikotoma är phi-koefficienten det mått man använder för att uttrycka sambandet. För kom-binationer av variabler på olika skalnivå finns speciella korrelationskoeffi-cienter. En sådan, som redan här kan nämnas, är eta. Den används för att uttrycka sambandet mellan en kategorivariabel (nominalskala) och en kon-tinuerlig variabel (jfr avsnitt 3.11.2).
En korrelation mellan två variabler säger ingenting om orsak-verkan relat-ionen. Relationen mellan variabler kan mycket väl vara av kausalt slag, men korrelationskoefficienten säger ingenting om den saken. Inom
sam-hällsvetenskaperna är det ofta så att kausala relationer är sällsynta. Ofta är de ting vi studerar mycket komplexa och relationerna mellan variabler likaså.
Många gånger kan det behövas något beskrivande mått på hur två variabler är relaterade till varandra för en given grupp individer. Vi kan exempelvis vara intresserade att studera sambandet mellan vissa läraregenskaper och elevbeteenden. Många sådana sambandsstudier inom lärarlämplighets-forskningen har genomförts, tyvärr oftast med magert resultat. Finns det, för att nämna ett annat exempel, samband mellan resultat på skolmognads-prov och senare framgång i skolan? Hur är relationen mellan social bak-grund och rekrytering till högre studier? Hur väl kan ett antal prediktorer predicera framgång i högre studier?
2.3.1 Pearson's produkt-moment korrelation
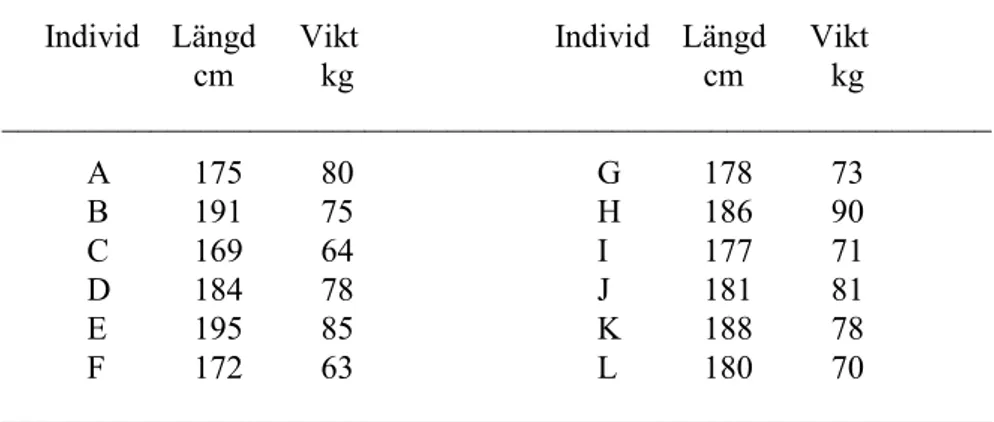
Data har insamlats från 12 elitdomare i fotboll. Bl.a. har man registrerat deras längd och vikt. Vi är intresserade att studera sambandet mellan resul-taten på dessa båda variabler. Eftersom båda variablerna är typiska kvot-skalor, väljer vi Pearson’s produkt-momentkorrelation.
Tabell 2.1. Resultat av längd- och viktmätning av 12 elitdomare
____________________________________________________________ Individ Längd Vikt Individ Längd Vikt
cm kg cm kg ____________________________________________________________ A 175 80 G 178 73 B 191 75 H 186 90 C 169 64 I 177 71 D 184 78 J 181 81 E 195 85 K 188 78 F 172 63 L 180 70 ____________________________________________________________ Utifrån data som presenteras i Tabell 2.1 kan man göra upp ett s.k. prick-diagram (Scattergram i SPSS). Det innebär att varje individs resultat på de två variablerna inprickas i ett koordinatsystem.
60,00 65,00 70,00 75,00 80,00 85,00 90,00 Vikt 165,00 170,00 175,00 180,00 185,00 190,00 195,00 Längd
Figur 2.4. Prickdiagram över resultatet på längd och viktmätning
Av prickdiagrammet framgår att det finns ett påtagligt samband mellan längd och vikt. Långa personer väger mer och kortvuxna mindre. Dock stämmer inte detta perfekt. Den som väger mest är inte den som är längst. Om ett högt resultat på den ena variabeln korresponderar med ett högt resultat på den andra variabeln, och ett lågt resultat på den ena variabeln korresponderar med ett lågt resultat på den andra variabeln leder detta till ett högt positivt samband. Vi kan visa detta genom att uttrycka varje ob-servation som en avvikelse från sitt gruppmedelvärde (xi - Mx) och (yi -
My). Om en individ har ett högt värde på båda variablerna, som exempelvis
domare E, blir produkten (xE - Mx).(yE - My) hög och positiv. På samma
sätt blir produkten hög och positiv om en individ har lågt resultat på båda variablerna (produkten av två negativa tal blir positiv). Om detta gäller för de flesta individerna (högt värde paras med högt och lågt värde paras med
lågt) blir summan av alla produkterna (xi - Mx).(yi - My) hög och
posi-tiv.
Skulle variablerna x och y ha en motsatt relation (högt värde parad med lågt y-värde och vice versa) leder detta till att vi får en negativ och en posi-tiv term, vilket leder till att produkten blir negaposi-tiv. Summan av produkter-na över samtliga individer blir då hög, men negativ.
Finns det slutligen inte någon systematisk relation mellan variablerna x och y erhålls ibland positiva avvikelser och ibland negativa avvikelser. Produkterna för dessa avvikelser (xi - Mx).(yi - My) blir då ibland positiva och ibland negativa. Summerar vi över alla individer erhålls en summa nära noll.
För att summor i olika sambandsundersökningar ska kunna jämföras måste man ta hänsyn till antalet produkter, dvs. till antalet individer. Därför divi-derar vi summan av produkterna med n - 1. Denna genomsnittliga produkt kallas kovariansen av x och y.
(xi - Mx)(yi - My)
Kovxy = _________________ (formel 2.5) n - 1
Eftersom vi nu övergått till observationernas avvikelser från Mx respektive My har vi därmed kommit förbi olägenheten med att variablerna har olika medelvärden.
Kovariansen av x och y är således oberoende av variablernas medelvärden. Fortfarande är dock standardavvikelsen för respektive variabel betydelse-full. För att vi ska erhålla ett standardiserat mått på överensstämmelsen mellan två variabler, dividerar vi kovariansen med standardavvikelserna för de båda variablerna. Detta mått på sambandet mellan x och y kallas för Pearson's produkt-moment korrelation (rxy).
Kovxy (xi - Mx)(yi - My) / (n - 1)
rxy = _______ = __________________________________ (formel 2.6) sx.sy
(xi - Mx)2 / (n - 1) .
(yi - My)2 / (n - 1)
(xi - Mx)(yi - My)
rxy = __________________________ (formel 2.7)
(xi - Mx)2 .
(yi - My)2
Som exempel på uträkning av rxy väljer vi observationerna från tabell 2.1. För att beräkningarna av rxy ska bli enklare att genomföra kan formel 2.7 transformeras till följande:
xy xy - ______ n rxy = ____________________________ (formel 2.8) (x)2 (x)2 (x2 - _____ ) (y2 - _____ ) n n
Tabell 2.2. Resultat av längd- och viktmätning av 12 elitdomare
____________________________________________________________ Individ Längd (x) Vikt (y) x.y x2 y2
____________________________________________________________ A 175 80 14000 30625 6400 B 191 75 14325 36481 5625 C 169 64 10816 28561 4096 D 184 78 14352 33856 6084 E 195 85 16575 38025 7225 F 172 63 10836 29584 3969 G 178 73 12994 31684 5329 H 186 90 16740 34596 8100 I 177 71 12567 31329 5041 J 181 81 14661 32761 6561 K 188 78 14664 35344 6084 L 180 70 12600 32400 4900 ____________________________________________________________ Summa 2176 908 165130 395246 69414 ____________________________________________________________
Enligt formel 2.8 erhålls: 2176 . 908 165130 - __________ 12 rxy = ________________________________ = 0,698 21762 9082 (395246 - _____ ) (69414- _____ ) 12 12
Produkt-moment korrelationen mellan de båda variablerna, längd och vikt är för dessa personer 0,70. Korrelationen i kvadrat kallas determinations-koefficient och ger andel gemensam varians i de båda variablerna. Den anger proportion av varians i den ena variabeln, som bestäms av relationen med den andra variabeln. Sålunda är 49 % (0,702) gemensam varians.
Figur 2.5. Andel gemensam varians mellan två variabler (x och y), vars
korrelation är 0,70
2.3.2 Tolkning av olika värden på korrelationen
Korrelationskoefficienten rxy kan endast anta värden mellan +1,0 och -1,0. Högsta möjliga samband är således +1,0 och även -1,0. Det sistnämnda är ett perfekt negativt, eller omvänt samband (jfr Ruta 2.3).
Vad som avses med ett högt respektive lågt samband bör naturligtvis rela-teras till vilka variabler det gäller och vad som tidigare är kända förhållan-den om relationen mellan dessa variabler. Det kan här också påpekas att lineära transformationer av x och/eller y inte kan påverka korrelationens storlek; rxy är ju ett standardiserat mått.
2.3.3 Samband mellan variabler på selekterade
grupper
Om man studerar samband mellan variabler och där någon av variablerna har begränsad variationsvidd, t.ex. beroende på att det är en selekterad grupp av individer, blir korrelationskoefficienten lägre än om man obser-verat hela gruppen. Efter nedanstående figur följer ett förklarande exem-pel.
Figur 2.6. Samband mellan ett verbalt begåvningstest och ett allmänt språkfärdighetstest i engelska
Exempelvis fann man i några språkfärdighetsstudier, att sambandet mellan ett verbalt begåvningstest och ett antal språkprov på ett främmande språk var måttligt eller till och med ganska lågt i en grupp gymnasieelever. Detta
innebär emellertid inte att sambandet mellan begåvningstest och språkfär-dighetstest är lågt för alla individer. Ovannämnda resultat erhölls för en selekterad grupp av gymnasieelever på humanistisk linje. Eftersom elever med relativt höga resultat på verbala begåvningstest väljer gymnasiesko-lans humanistiska linje blir korrelationskoefficienten mellan provresultat och begåvning ganska låg för dessa elever. Förhållandet kan belysas med hjälp av en tänkt sambandsplott (Figur 2.6).
2.3.4 Linjära och icke-linjära samband
Produkt-moment korrelationen rxy mäter endast linjära relationer mellan x och y. Om man däremot erhåller en korrelationsplott som inte är avvikelser från en rät linje, talar vi om kurvlinjära samband.
Figur 2.7. Exempel på kurvlinjärt samband
Om man beräknar rxy på ovanstående, skulle man få ett värde ungefär rxy= 0. Som framgår av figuren finns det emellertid ett påtagligt samband. Låga värden på x har höga värden på y, medelhöga värden på x har låga värden på y och höga värden på x har höga värden på y. Variationer av kurvlinjära samband kan även erhållas på grund av egenskaper hos testet. Test som ger tak eller botteneffekter kan ge sådana här effekter. I situat-ioner av det här slaget måste man använda sig av andra sambandsmått än rxy, t.ex. korrelationskvoten eta-kvadrat.
Sammanfattningsvis kan sägas att produkt-moment korrelationer används då man har båda variablerna på lägst intervallskalenivå, dvs. har två ap-proximativt normalfördelade variabler.
2.3.5 Spearman's rangkorrelation
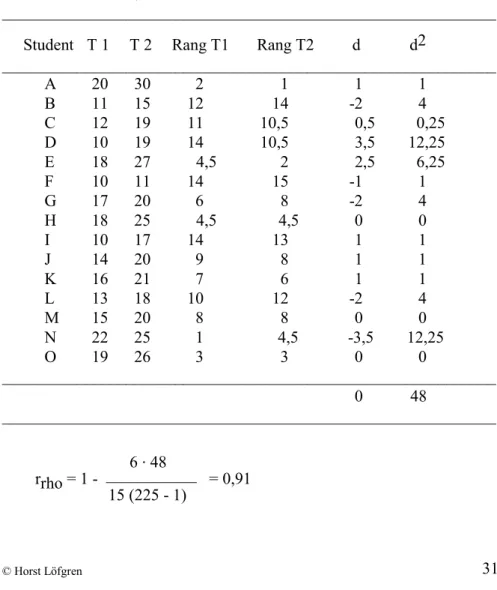
I de fall båda mätvariablerna är ordinalskalerade används Spearman's rang- korrelation (rrho). Data kan vara direkt rangordnade eller rangordnade efter de värden som erhållits vid mätningarna. Vi väljer som exempel på beräkning av rangkorrelation data från två olika tentamina för 15 högsko-lestuderande.
6 d2
rrho = 1 - ________ , där d= differenserna mellan rangtalen (formel 2.9) n ( n2 - 1)
Tabell 2.3. Exempel på beräkning av rangkorrelation mellan två prov- resultat, T1 och T2
____________________________________________________________ Student T 1 T 2 Rang T1 Rang T2 d d2
____________________________________________________________ A 20 30 2 1 1 1 B 11 15 12 14 -2 4 C 12 19 11 10,5 0,5 0,25 D 10 19 14 10,5 3,5 12,25 E 18 27 4,5 2 2,5 6,25 F 10 11 14 15 -1 1 G 17 20 6 8 -2 4 H 18 25 4,5 4,5 0 0 I 10 17 14 13 1 1 J 14 20 9 8 1 1 K 16 21 7 6 1 1 L 13 18 10 12 -2 4 M 15 20 8 8 0 0 N 22 25 1 4,5 -3,5 12,25 O 19 26 3 3 0 0 ____________________________________________________________ 0 48 ____________________________________________________________ 6 . 48 rrho = 1 - ___________ = 0,91 15 (225 - 1)
Vi har sålunda funnit en mycket hög överensstämmelse mellan de två ten-tamensresultaten. Rangkorrelationen kan variera mellan -1,0 och 1,0. Om man har många s.k. ties, dvs. flera observationer med samma rangtal, bör man använda en viss korrektion för detta.
2.4 Den standardiserade
normalfördelningen; z-poäng
Med hjälp av olika central- och spridningsmått kan man beskriva utseendet i ett observationsmaterial. Det kan ibland vara nödvändigt att beskriva var i en fördelning som en enskild observation är belägen. Per har på ett test i statistik erhållit 40 poäng, medan Anders på ett annat statistiktest erhållit 30 poäng. Kan man jämföra dessa båda resultat? Om man känner till kurs-deltagarnas genomsnittsresultat på de båda testen får man viss information. Är standardavvikelserna också kända har man tillräcklig information för att göra en jämförelse mellan de båda testresultaten. Ett enkelt sätt är att överföra testresultaten till en gemensam skala. Vi gör därför en skaltrans-formation till z-skalan, vars egenskaper är kända. En z-poäng anger av-ståndet mellan det erhållna resultatet och gruppens medelvärde uttryckt i standardavvikelseenheter.
xi - µ
z = ______ (formel 2.10)
Om Per erhållit 40 poäng på ett test vars medelvärde är 30,0 och standard-avvikelse 10,00 blir hans resultat uttryckt i z-poäng 1,0. Antag att Anders erhållit 30 poäng på ett test med medelvärdet 24,0 och standardavvikelsen 5,00. Uttryckt i z-poäng blir det senare resultatet 1,2 vilket är något bättre än Pers resultat.
Som framgår av formeln är medelvärdet i z-skalan 0 och standardavvikel-sen 1. Man kan således alltid transformera ursprungliga råpoängsresultat till denna standardiserade skala. Resultat uttryckt i z-poäng kallas stan-dardpoäng. Den standardiserade normalfördelningen finns tabellerad i Appendix (Tabell B). Om testpoängen på det test som Per erhållit 40 po-äng är normalfördelade, finns i populationen endast 15,9 % som är bättre än Per.
2.5 Regression
Om vi känner en individs resultat på variabel x kan vi skatta (eller förut-säga) resultatet på variabel y utifrån kännedom om relationen mellan x och y. Här ges några exempel på frågeställningar för att belysa denna s.k. regressionsskattning.
1 Hur väl kan vi förutsäga studieresultat utifrån resultat på skolmog-nadstest?
2 Hur väl kan vi predicera framgång i yrket utifrån vissa anlags- och lämplighetstest?
3 Hur väl kan vi skatta en individs resultat på ett hörförståelseprov utifrån data från ett läsförståelseprov?
För att kunna skatta (predicera) resultat på y utifrån x måste vi känna till relationen mellan x och y. Den variabel vi skattar kallas beroende variabel, och den variabel vi skattar utifrån kallas oberoende variabel eller prediktor. Relationen mellan x och y erhålls via en sambandsberäkning (rxy). Efter att sambandet är beräknat kan detta senare användas vid regressionsskatt-ningar. Innan vi matematiskt bestämmer skattningen av y utifrån x kan vi belysa innebörden av regression med hjälp av Figur 2.9.
Resultatet i Figur 2.8 erhölls i en undersökning i vilken 67 individer del-tog. Om vi nu vet förtestresultatet (x) på ytterligare en individ, vad blir då den bästa skattningen av denna individs eftertestresultat (y)? Vilken är den bästa skattningen av y, då vi vet att individ NN erhållit 11 poäng på x? I det här exemplet tänker vi oss att det inte skett någon förbättring av resul-taten från förtest till eftertest. Av resultatet ser vi att alla deltagarna inte erhållit samma resultat på för- och eftertestet, trots att ingen förändring skett. Som framgår av resultatet har 4 individer på förtestet erhållit 10 po-äng. Dessa fyra har på eftertestet erhållit 10, 11, 12 resp. 13 popo-äng. Vidare har på förtestet 6 individer erhållit 11 poäng. På eftertestet har dessa erhål-lit 10, 11, 12 (2 individer), 13 resp. 14 poäng. Genomsnittet av de 6 indivi-der som erhållit 11 poäng på förtestet är således 12 poäng på eftertestet.
10 11 12 13 14 15 16 Förtestresultat x y 16 15 14 13 12 11 10 1 1 1 1 1 1 2 1 1 1 2 4 4 2 1 1 1 4 7 4 1 1 1 2 4 4 2 1 1 1 3 1 1 1 1 1 1 Eftertestresultat
regressionslinje x.y; bästa prediktionen från eftertest till förtest
regressionslinje y.x; bästa prediktionen från förtest till eftertest
Figur 2.9. Exempel på regressionslinjer och regressionsskattning
Om man nu har ytterligare en individ, som vi vet har erhållit 11 poäng på förtestet men som inte var med på eftertestet, så blir den bästa gissningen att denna individ skulle ha erhållit 12 poäng på eftertestet. Det är möjligt att denna gissning inte är korrekt, men mot bakgrund av vad vi vet om resultaten så blir det den bästa prognos man kan göra. Den bästa skattning-en måste bli längs linjskattning-en som går gskattning-enom medelvärdet av y på respektive
x-poäng. Denna linje kallas regressionslinjen y.x (utläses y på x) och kan matematiskt bestämmas via den räta linjens ekvation y = a + bx.
Observera att enligt regressionsskattningen erhåller individer som har ett lågt resultat på förtestet oftare ett bättre resultat på eftertestet och individer som har ett högt resultat på förtestet erhåller ett sämre resultat på efter-testet. Vad kan detta bero på, dvs. att sådana här s.k. regressionseffekter uppstår? Jo, det beror på att vi inte har helt mätsäkra test. Om man på basis av extremvärden tar ut individer kommer sådana här effekter att uppstå, om det finns reliabilitetsbrister i mätinstrumenten. Detta bör man ha i åtanke om man jämför grupper som uttagits på basis av extremvärden (t.ex. vid experiment som utnyttjar matchningsförfarande).
Tabell 2.4. Data för bestämning av regressionslinjen y.x (oberoende vari-abel är IQ-poäng i åk 8; beroende varivari-abel är matematikpoäng i åk 9) ____________________________________________________________ Individ x y ____________________________________________________________ A 95 33 B 100 31 C 100 35 D 102 38 x = 2165 E 103 41 y = 824 F 105 37 x2 = 235091 G 106 37 y2 = 34442 H 106 39 xy = 89715 I 106 43 sx = 6,198 J 109 40 sy = 5,095 K 110 41 n = 20 L 110 44 rxy = 0,862 M 111 40 rxy2= 0,743 N 112 45 O 112 48 P 114 45 Q 114 49 R 115 47 S 117 43 T 118 48 ____________________________________________________________
I Tabell 2.4 ovan ges ett exempel där regressionslinjen y.x kan beräknas. Den räta linjens ekvation y = a + bx kan nu användas. Linjens lutning be-stäms av ”b” och kallas regressionskoefficient, medan ”a” är en additiv konstant, som säger var regressionslinjen korsar y-axeln. Regressionskoef-ficienten by.x kan beräknas via formel 2.11 eller direkt (utan att ha bestämt rxy) via formel 2.12.
Beräkning av regressionslinje och skattningens medelfel:
sy 5,095
by.x = ___ . rxy (här by.x = _____ . 0,861 ) (formel 2.11) sx 6,198 x y xy - ______ n by.x = _______________ (formel 2.12) (x)2 x2 - _____ n I exemplet kan by.x beräknas till 0,708.
2165 . 824 89715 - _________ 20 by.x = __________________ = 0,708 21652 235091 - ______ 20
Konstanten ”a” beräknas via a = My - bMx, vilket ger 824 2165
a = ____ - 0,708 (_____ ) = - 35,491 20 20
Skattningen av y kan således bestämmas via regressionslinjen y.x enligt yest = 0,708x - 35,491
Med kännedom om x kan nu y bestämmas. Om x=100 blir y=35,309 och om x=110 blir y=42,389. Självfallet kan vi inte säga att denna skattning av
y är det sanna värdet av y för denna individ. Vi får alltid räkna med ett visst fel ”e”.
yi = a + bxi + ei , varvid ei är skillnaden mellan det sanna y-värdet och det skattade y-värdet.
ei = yi – yiest
Med ovanstående formler för beräkning av regressionslinjen har vi med hjälp av den s.k. minsta kvadratmetoden minimerat e. Standardavvikelsen i skattningsfelet se kallas skattningens medelfel och kan beräknas med hjälp av formeln:
(1 - r2) ssy (y)2
se = __________ , där ssy = (y2 - _____ ) (formel 2.13) n - 2 n
För stora stickprov (n > 50) kan formeln förenklas till se = sy
1-r2 I detta exempel blir skattningens medelfel:
8242
(1-0,743) (34442 - ____ ) 20
se = _______________________ = 2,655
18
För att använda ovanstående beräkningar krävs dock att vissa förutsätt-ningar är uppfyllda (se Figur 2.10):
1. Populationsmedelvärdena för y för varje x-värde ska ligga längs en rät linje.
2. För varje x-värde ska y-värdena normalt fördelade.
3. För varje värde på x har dess y-värden variansen 2y.x och denna
varians ska vara lika för samtliga x-värden (s.k. homoscedastici-tet).
Figur 2.10. Förutsättningar för regressionsskattning
2.6 Multipel korrelation och multipel
regression
Syftet med multipel regression är att kunna skatta en beroende variabel Y utifrån en kombination av de oberoende variablerna X1, X 2, ... Xm. Lika-väl som man vid två variabler kan beräkna den univariata estimationen med hjälp av ekvationen Yest= a + bx, kan man vid flera variabler göra en multivariat prediktion av Y. Härvid använder man sig också av minsta kvadratmetoden enligt nedanstående formel:
Yest = b0 + b1x1+ b2x2+ ... + bmxm (formel 2.14)
Detta är den multipla linjära regressionsekvationen. En produkt-moment korrelation mellan Y och Yest säger hur väl den bästa linjära viktningen av de oberoende X1, X 2, ... Xm predicerar eller korrelerar med den beroende variabeln Y. Detta kallas för den multipla korrelationskoefficienten och skrivs Ry.1,2,..,m.
Observera att viktkoefficienterna maximerar korrelationen med Y, vilket också innebär att slumpfel utnyttjas. Om man i en undersökning erhållit en
multipel korrelation av en viss storleksordning efter viktning av X-variablerna, bör man före generalisering av sambandsresultatet göra en s.k. korsvalidering. Detta är speciellt väsentligt om man har relativt få indivi-der i förhållande till antalet X-variabler. Vid korsvaliindivi-dering kan man ut-nyttja de vid första undersökningstillfället erhållna viktkoefficienterna på ett nytt stickprov för att kontrollera att den multipla korrelationen inte minskat alltför kraftigt. Självfallet bör den minska något, eftersom slum-pen är osystematisk.
I en undersökning av elever i årskurs 9 hade man studerat deras föräldrars utbildningsbakgrund, antalet syskon och hur många års utbildning de räk-nade med efter grundskolan. Nu önskade man ta reda på det multipla sam-bandet mellan mammans utbildningsbakgrund (X1) samt antalet syskon (X2) och antal förväntade studieår (Y). Ett annat sätt att ställa frågan på är om man utifrån mammans utbildningsbakgrund (X1) samt antalet syskon (X2) kan predicera antal förväntade studieår (Y). Avsnittet rubriceras mul-tipel regression, men kunde också ha rubricerats mulmul-tipel prediktion. Re-lationerna mellan variablerna redovisas i nedanstående tabell.
Tabell 2.5. Interkorrelationer, medelvärden och standardavvikelser ____________________________________________________________ 1 2 Y M s ____________________________________________________________ X1 Mammans utbildning 1,000 2,923 1,078 X2 Antal syskon -0,509 1,000 2,359 1,227 Y Antal studieår 0,674 -0,489 1,000 4,064 2,116 ____________________________________________________________ Korrelationskoefficienten mellan antalet studieår (Y) och de från mam-mans utbildningsbakgrund och antalet syskon (X1; X2) predicerade antalet studieår (Yest) är den multipla korrelationen Ry.1,2. Om korrelationerna ry1, ry2 och r12 är kända erhålls den multipla korrelationen enligt följande formel:
Ry.1,2 =
b1.ry1 + b2.ry2 (formel 2.15) där b1 och b2 erhålls ur
ry1 - ry2.r12 ry2 - ry1.r12 b1 = ____________ ; b2 = ____________
I ovanstående exempel blir värdena på b1 och b2 för prediktion av stan-dardpoängen Y från stanstan-dardpoängen X1 och X2:
0,674 - (-0,489.-0,509) -0,489 - (0,674.-0,509)
b1 = ___________________ = 0,573; b2= __________________ = -0,197 1 - (-0,509)2 1 - (-0,509)2
Att vi här talar om standardpoäng beror på att vi använder korrelationer som ju är standardiserade (jfr formel 2.6). Sålunda blir den bästa skatt-ningen av standardpoängen av Y (zy) utifrån standardpoängen av X1 och X2 (z1 och z2):
zyest = 0,573z1 - 0,197z2
Den multipla korrelationen Ry.1,2 erhålls enligt:
Ry.1,2 = b1ry1 + b2ry2 = 0,573.0,674 + (-0,197.-0,489) = 0,695 För att erhålla den multipla prediktionsekvationen för råpoäng (ostandardi-serade värden) utförs följande operation:
sy sy sy sy Yest = (b1___ )X1 + (b2___ ) X2 + (My - b1___ Mx1 - b2___ Mx2) s1 s2 s1 s2 Detta ger följande regressionsekvation:
Yest = 1,125X1 - 0,340X2 + 1,578
Som framgår av den multipla korrelationens värde är denna endast aningen högre än det enkla sambandet mellan mammans utbildning och antalet förväntade studieår. Den högsta ökningen av prediktionsförmågan av Y med två oberoende variabler X1 och X2 får man exempelvis om dessa båda oberoende variabler korrelerar positivt med den beroende variabeln, men sinsemellan korrelerar negativt.
För att man ska kunna tolka viktkoefficienterna b1 och b2 bör man se på de standardiserade värdena. Viktkoefficienterna i regressionsekvationen för råpoäng blir ju beroende av respektive variabels medelvärde och stan-dardavvikelse. I vårt exempel ovan är det inte så stor skillnad i relationen
mellan b1 och b2 för standardiserade respektive ostandardiserade värden, eftersom mätskalorna har ganska lika M och s. I en av resultattabellerna (Coefficients) får man både viktkoefficienterna på råpoäng och standardi-serade poäng. I tabellen ges även t-värden och probabilitetsvärden som ger information för tolkningen av resultatet (jfr kap 3).
2.6.1 Stegvis regressionsanalys
När det gäller regressionsanalys finns olika möjligheter. Förutom att i regressionsekvationen ta med samtliga prediktorer (X-variabler) kan man ”stega in” variablerna i en viss ordning för att endast ta med de som signi-fikant bidrar till prediktionen. Om vi utnyttjar det föregående exemplet kommer en stegvis regressionsanalys innebära att den variabel som högst korrelerar med kriterievariabeln stegas in först. Därefter korrigeras övriga prediktorer genom att de rensas från den del av variationen som redan ta-gits med, när den första variabeln stegats in. Man partialiserar ut den del från övriga variabler, som redan är predicerad i kriterievariabeln. Utifrån de partialkorrelationer som nu är beräknade, stegas den variabel in som nu är högst korrelerad med kriterievariabeln. Nya partialkorrelationer beräk-nas, dvs. den del som de två första prediktorerna bidragit med partialiseras ut, och den variabel som nu korrelerar högst med Y-variabeln stegas in. När alla variabler som signifikant bidrar till prediktionen finns med, är analysen klar och regressionsekvationen redovisas och likaså den multipla korrelationen.
2.6.2 Ett exempel på linjär multipel regression och
stegvis multipel regression
Nedan redovisas resultatet av en regressionsanalys i SPSS med data från en av övningsfilerna (IEA9) till boken. I detta exempel är vi intresserade att se om man utifrån föräldrarnas utbildningsbakgrund och elevens betyg i uppsatsskrivning kan predicera antal år av fortsatt utbildning, som eleven tänker sig. Det är mycket tveksamt om man kan använda utbildningsbak-grund som en prediktor med tanke på hur denna är skapad. Hade man i stället haft tillgång till data som säger hur många års utbildning föräldrarna har, skulle det vara mycket bättre, men som ett belysande exempel tillåter vi oss att använda de data som finns insamlade.
I den sammanfattade översikten (Model Summary) finns den multipla kor-relationen beräknad 0,436. Här finns också den kvadrerade multipla korre-lationen, vilken anger proportionen förklarad varians i den beroende varia-beln. Utifrån de tre prediktorerna kan vi således predicera 19 % av varian-sen i variabeln antal förväntade studieår. Eftersom den kvadrerade multipla korrelationen ökar ju fler prediktorer man har i förhållande till antalet ob-servationer, kan man ibland ha anledning att utnyttja den justerade mul-tipla korrelationen (i det här fallet 0,179). Om man t.ex. vill jämföra resul-tat från olika undersökningar med olika antal prediktorer kan det justerade värdet vara att föredra. Det är s.a.s. ett mer återhållsamt värde som inte överskattar den multipla korrelationen. Observera dock att man alltid måste ha betydligt fler observationer än antalet prediktorvariabler i en mul-tipel regressionsanalys. Ett bra riktvärde är att ha 10 gånger så många ob-servationer som antalet variabler i analysen. Om man har alltför få obser-vationer får mätfelen, som också viktas in, alltför stor betydelse och man får en överskattning av den multipla korrelationen.
ANOVA-tabellen visar att de tre prediktorerna tillsammans högst signifi-kant bidrar till prediktionen av kriterievariabeln. Om F-testet inte skulle vara signifikant, innebär det att den multipla korrelationen inte säkert är skild ifrån 0.
I den nedersta tablån (Coefficients) ges den multipla regressionsekvationen för råpoäng och de standardiserade betavikterna (Beta). De två högra ko-lumnerna säger hur signifikant bidraget är från de tre oberoende variabler-na. Betyget i uppsatsskrivning bidrar mest till prediktionen. Även pappans utbildning bidrar signifikant till prediktionen. Däremot bidrar ej mammas utbildning signifikant till prediktionen av kriterievariabeln ”Antal år av fortsatt utbildning”. Observera dock att inte endast skaleringen av föräld-rarnas utbildning är tveksam utan även att vi har ett mycket stort bortfall som gör att stickprovet knappast längre är representativt för populationen. Ungdomarna i denna studie kanske inte vill svara på frågor om föräldraut-bildning, men framför allt är det nog så, att det faktiskt många som inte vet vilken utbildning föräldrarna har.
Innebörden av t-värden, ANOVA, F-kvot och probabilitetsvärden present-eras i kapitel 3.
Model Summary ,436a ,190 ,179 1,895 Model 1 R R Square Adjusted R Square St d. Error of the Estimate Predictors: (Constant), BETY G PÅ UPPSATSEN, MODERNS UTBILDNING, FADERNS UTBILDNING a. ANOVAb 179,489 3 59,830 16,665 ,000a 764,704 213 3,590 944,194 216 Regression Residual Total Model 1 Sum of Squares df Mean Square F Sig.
Predictors: (Const ant ), BETYG PÅ UPPSATSEN, MODERNS UTBILDNING, FADERNS UTBILDNING
a.
Dependent Variable: ANTAL ÅR FORTSATT UTBILDNING b. Coeffici entsa 1,443 ,473 3,051 ,003 ,075 ,083 ,066 ,902 ,368 ,222 ,075 ,216 2,948 ,004 ,648 ,133 ,305 4,856 ,000 (Constant) MODERNS UTBILDNING FADERNS UTBILDNING BETYG PÅ UPPSATSEN Model 1 B Std. Error Unstandardized Coef f icients Beta Standardized Coef f icients t Sig.
Dependent Variable: ANTAL ÅR FORTSATT UTBILDNING a.
I de följande resultattablåerna visas resultatet av en stegvis multipel regression på samma data (Method: Stepwise i stället för Enter i SPSS). Eftersom betyget i uppsatsskrivning korrelerar högst med den beroende variabeln stegas denna in först. Därefter kontrolleras om det bland de
öv-riga variablerna (i detta fall pappans och mammans utbildning) finns något som ytterligare kan bidra till prediktionen av den beroende variabeln, dvs. utöver vad den första variabeln redan har bidragit med. För detta använder programmet partialkorrelationsberäkningar. Som framgår av resultatet finns något mer att ta in utöver betyget i uppsatsskrivning. Således stegas pappans utbildning in i steg 2 och därmed är analysen klar, eftersom den tredje variabeln inte signifikant bidrar till prediktionen. I den sista resultat-tablån ges vikterna för regressionsekvationen, både viktkoefficienterna för råvärden och de standardiserade betavärdena.
Model Summary ,356a ,126 ,122 1,959 ,432b ,187 ,179 1,894 Model 1 2 R R Square Adjusted R Square St d. Error of the Estimate
Predictors: (Constant), BETY G PÅ UPPSATSEN a.
Predictors: (Constant), BETY G PÅ UPPSATSEN, FADERNS UTBILDNING b. ANOVAc 119,435 1 119,435 31,135 ,000a 824,758 215 3,836 944,194 216 176,568 2 88,284 24,612 ,000b 767,626 214 3,587 944,194 216 Regression Residual Total Regression Residual Total Model 1 2 Sum of Squares df Mean Square F Sig.
Predictors: (Const ant ), BETYG PÅ UPPSATSEN a.
Predictors: (Const ant ), BETYG PÅ UPPSATSEN, FADERNS UTBILDNING
b.
Dependent Variable: ANTAL ÅR FORTSATT UTBILDNING c.
Excluded Vari ablesc ,177a 2,785 ,006 ,187 ,974 ,250a 3,991 ,000 ,263 ,966 ,066b ,902 ,368 ,062 ,714 MODERNS UTBILDNING FADERNS UTBILDNING MODERNS UTBILDNING Model 1 2 Beta In t Sig. Part ial Correlation Tolerance Collinearity St at ist ics
Predictors in t he Model: (Constant), BETY G PÅ UPPSATSEN a.
Predictors in t he Model: (Constant), BETY G PÅ UPPSATSEN, FADERNS UTBILDNING
b.
Dependent Variable: ANTAL ÅR FORTSATT UTBILDNING c.
2.6.3 Logistisk regressionsanalys
Logistisk regression är en parallellteknik till linjär regression. Med båda dessa metoder undersöker man relationen mellan en eller flera oberoende variabler (prediktorvariabler) och en beroende variabel (utfallsvariabel). Om den beroende variabeln är nominalskalerad används logistisk regress-ion. I flesta fall är den beroende variabeln dikotom, dvs. har två möjliga värden (0 och 1), men metoden kan också användas om kategorivariabeln har fler än två värden. De oberoende variablerna kan vara av olika typ, både nominalskalerade och kontinuerliga.
För att man ska anpassa en logistisk regressionsmodell till data krävs att vissa förutsättningar ska vara uppfyllda. Bland annat ska det finnas en linjär relation mellan oberoende och beroende variabler, dvs. ju högre skalvärde på en oberoende variabel desto högre ska sannolikheten vara för att den beroende variabeln har skalvärdet 1 (eller lägre, dvs. skalvärdet 0, om relationen är negativ). Vidare ska alla observationerna vara oberoende.
I en studie av ungdomar i årskurs 9 fick eleverna svar på om man ibland skrev ner något bara för att man tyckte det var roligt att skriva. Svarsalter-nativen var ”Ja” eller ”Nej”. Bland data som samlades in fanns också ele-vernas betyg i uppsatsskrivning, deras attityder till skrivning, självskatt-ning av skrivförmågan och hur många timmar man vanligen tittade på TV på skoldagar. Den modell som prövas i nedanstående exempel är om man utifrån de fyra oberoende variablerna kan predicera elevernas svar på frå-gan om nöjesskrivning. Resultatet av en logistisk analys med SPSS visas nedan.
Som framgår av resultatet erhålls ett inte särskilt högt multipelt samband. Även om man utifrån de valda oberoende variablerna inte särskilt väl kan predicera om elever skriver för sitt nöjes skull, finns ändå signifikanta relationer. Attityder till skrivning är den variabel som bäst predicerar nö-jesskrivning. Självskattning av skrivförmågan är också signifikant relate-rad till nöjesskrivning, likaså TV-tittande om än negativt. Hur bra betyg man har i uppsatsskrivning bidrar inte signifikant till prediktionen.
Model Summary 524,681a ,096 ,139 St ep 1 -2 Log likelihood
Cox & Snell R Square
Nagelkerke R Square
Estimation terminat ed at iteration number 4 because parameter est imat es changed by less than ,001. a.
Variables in the Equation
,083 ,122 ,465 1 ,495 1,087 ,560 ,137 16,731 1 ,000 1,751 ,351 ,156 5,059 1 ,024 1,420 -,192 ,096 3,952 1 ,047 ,826 -1,717 ,560 9,401 1 ,002 ,180 v 22 v 16 v 18 v 14 Constant St ep 1a
B S. E. Wald df Sig. Exp(B)
Variable(s) entered on step 1: v 22, v 16, v 18, v 14. a.
2.6.4 Användning av s.k. dummy-variabler
För att få fördjupad förståelse av hur olika nivåer i en oberoende variabel bidrar till prediktionen av en beroende variabel kan det vara av värde att omkonstruera den oberoende variabeln till en eller flera s.k. dummy-variabler. Även om det i övningsfilen kanske inte finns något riktigt bra exempel på en regressionsanalys med dummy-variabler, kan vi ändå ge-nom ett exempel belysa hur man går tillväga.
I vårt exempel vill se om vi utifrån föräldrars utbildning och det erhållna betyget på uppsatsskrivning kan predicera hur många års utbildning på heltid eleven framöver beräknar att de ska genomgå. Möjligen skulle man kunna kalla denna beroende variabel för utbildningsaspiration. Det är ett rimligt antagande att denna kan prediceras utifrån föräldrars utbildnings-bakgrund och resultat på ett språkligt prov. Vi börjar med att omkoda vari-ablerna moderns och faderns utbildningsbakgrund. Det kan vara lämpligt att låta kategorierna 1-4 erhålla värde 1 (låg utbildning), kategori 5 erhålla värdet 2 och kategori 6 erhålla värdet 3 (hög utbildning). Efter denna om-kodning kan man slå samman moderns och faderns utbildning och därvid erhålla en ny variabel med variationsvidden 2-6. Denna omkodas i sin tur så, att värdet 2 blir 1 (lågutbildade), 3-4 blir 2 och 4-5 blir 3 (högutbil-dade). Som tidigare nämnts finns det tyvärr ett mycket stort bortfall i vari-ablerna moderns och faderns utbildning, varför det ursprungliga stickpro-vet nu knappast längre är ett representativt urval av svenska grundskolee-lever.
Efter dessa omkodningar finns nu ungefär 50 % i grupp 1, 27 % i grupp 2 och 22 % i grupp 3. För att bilda dummy-variabler av denna nya ordinal-skalerade variabel med tre grupper krävs ytterligare en omkodning. Varia-beln ska nu omkodas så, att vi får två grupper men med behållen informat-ionen från de tre grupperna. Man kan välja vilken som helst av de tre grupperna som referensvariabel, men förslagsvis använder vi den lågutbil-dade gruppen som referensgrupp. Dummy-variablerna, som då blir en färre än den ursprungliga med tre grupper, ska endast ha värdet 0 eller 1. Om vi skapar en variabel i vilken vi ger medelutbildade värdet 1 och de båda övriga (låg- och högutbildade) värdet 0 samt en variabel i vilken vi ger högutbildade värdet 1 och de båda andra värdet 0, har vi skapat två variab-ler, som innehåller all den information, som vi hade i variabeln med de tre grupperna. Nu är det dags att utföra en multipel regressionsanalys inklude-rande de båda dummy-variablerna. Resultatet av analysen med SPSS visas nedan.