Teknik och samhälle
Datavetenskap och medieteknik
Examensarbete 15 högskolepoäng, grundnivå
Användande av maskininlärning vid skapande och
utvärdering av kursplaner
Using machine learning in the creation and evaluation of syllabuses
Isabella Andrén
Tim Normark
Examen: Kandidatexamen 180 hp
Huvudområde: Datavetenskap Handledare: Gion Koch Svedberg
Program: Systemutvecklare Examinator: Agnes Tegen Datum för slutseminarium: 2020-06-03
Sammanfattning
Studien undersöker om maskininlärning kan användas för att klassificera kursplaner tillräckligt bra för att eventuellt kunna användas som ett hjälpmedel i processen för att bedöma nya kursplaner. Studien undersöker även om man med unsupervised learning kan se tydliga skillnader gällande semantiken i de olika delarna av lärandemålen i kursplaner. En experimentell forskningsansats har använts och tillvägagångssättet är inspirerat av de olika stegen i CRISP data mining process. I praktiken innebar detta att det byggdes ett antal applikationer för att hämta och bearbeta data i form av kursplaner och därefter skapades maskininlärning-modeller som användes experimentellt för att kunna besvara de forskningsfrågor som formulerats.
Resultatet av studien har visat att klassificerings-modellerna inte är tillräckliga för att kunna användas som ett hjälpmedel i processen att bedöma nya kursplaner. Modellernas bedömning om en kursplan är godkänd eller icke godkänd presterade med hög träffsäkerhet på den data som samlades in och användes för att träna och testa modellerna. För att testa hur väl en modell kunde användas i verkligheten jämfördes sedan klassificeringen av ett set andra kursplaner med en lärares bedömning av samma kursplaner. I detta sammanhang stämde modellens och lärarens bedömningar mycket dåligt överens. Resultaten gällande användning av unsupervised learning i relation till lärandemålen i kursplaner visade att denna maskininlärningsstrategi ser ut att vara effektiv för detta ändamål. Resultatet här visade att det inte finns några klara skillnader mellan indelningen av lärandemålen i de kursplaner som användes som data för modellerna.
Abstract
The study investigates whether machine learning can be used to classify syllabuses well enough to possibly be used as an aid in the process of assessing new syllabuses. The study also examines whether with unsupervised learning one can see clear differences regarding the semantics of the different parts of the learning objectives in syllabuses.
An experimental research approach has been used and the approach is inspired by the various steps in the CRISP data mining process. In practice, this meant that a number of applications were built to retrieve and process data in the form of syllabuses and then machine learning models were created that were used experimentally to answer the research questions formulated.
The results of the study have shown that the classification models are not sufficient enough to be used as an aid in the process of assessing new syllabuses. The model’s assessment of whether a syllabus is approved or not approved had a high accuracy on the collected data that was used to train and test the models. To test how well a model could be used in a real context, the classification of another set of syllabuses was compared to the evaluation of the same syllabuses by a teacher of Malmö University. In this context the result of the model’s and the teacher’s evaluation matched very poorly. The results regarding the use of unsupervised learning in relation to the learning objectives in syllabuses showed that this machine learning strategy appears to be effective for this purpose. The results here showed that there are no clear differences between the classification of the learning objectives in the syllabuses used as data for the models
Innehållsförteckning
1 Inledning 4 1.1 Syfte 4 1.2 Frågeställningar 4 1.3 Bakgrund 4 1.4 Relevanta begrepp 9 2 Metod 10 2.1 Metodbeskrivning 102.1.1 Beslut om vilken data som skulle användas 10
2.1.2 Insamling och klassificering av data 11
2.1.3 Bearbetning av data 13 2.1.4 Supervised modelling 14 2.1.5 Deployment 17 2.1.6 Unsupervised Modeling 18 2.2 Metoddiskussion 19 3 Resultat 21
3.1 Experiment med “supervised learning” 21
3.1.1 Dataset “Transformed Data” 21
3.1.2 Dataset “Real Data” 24
3.2 Experiment med optimerad, tränad maskininlärning-modell 30
3.3 Experiment med tränad klassificerare i ett mer verkligt scenario 32
3.4 Experiment med “unsupervised learning” 32
4 Analys 34
4.1 Experimenten med Supervised learning 34
4.2 Experimenten med Unsupervised learning 35
5 Diskussion och slutsatser 37
5.1 Klassificering av kursplaner 37
5.2 Analys av lärandemål med unsupervised learning 38
5.3 Övriga slutsatser 38
5.4 Vidare forskning 39
Referenser 40
Appendix A 42
1 Inledning
1.1 Syfte
Kursplaner följer ett gemensamt mönster och struktur och av denna anledning passar de väldigt bra för just maskininlärning. Studien syftar till att undersöka om maskininlärning kan användas för att klassificera kursplaner tillräckligt bra för att eventuellt kunna användas som ett hjälpmedel i processen för att bedöma nya kursplaner. Studien ämnar även att undersöka om man med unsupervised learning kan se tydliga skillnader gällande semantiken i de olika delarna av lärandemålen då denna del av kursplanen har som krav att vara väldigt strukturerad och tydlig.
Detta skulle i så fall kunna användas för att underlätta själva bedömningen av framtida kursplaner så att de lever upp till den standard som förväntas. Allt i syfte att reducera tid och simplifiera arbetet som krävs för bedömning av nya framtida kursplaner.
1.2 Frågeställningar
● Kan maskininlärning användas för att klassificera nya kursplaner som godkända eller icke godkända tillräckligt bra för att kunna användas som ett hjälpmedel i processen att bedöma nya kursplaner?
● Kan “unsupervised learning” användas för att bedöma om texten i kursplanens del “Lärandemål” tydligt kan delas in i underrubrikerna: “Kunskap och förståelse”, “Färdighet och förmåga” och “Värderingsförmåga och förhållningssätt
”?
1.3 Bakgrund
Bedömning såväl som skrivandet av kursplaner är en tidskrävande process. Utöver det så behöver kursplaner även upprätthålla en viss standard. För att säkerställa att denna standard uppfylls så måste man som lärare följa specifika riktlinjer och regler i skrivandet av kursplaner. Varje universitet har sina egna specifika riktlinjer som måste efterlevas, och det finns även allmänna regler i högskoleförordningen som även de måste efterföljas för att garantera god kvalitet (högskoleförordningen, 1993:100). Trots de rekommendationer och riktlinjer som finns så är det inte alltid så enkelt att bedöma om en kursplan är godkänd eller inte. Det finns rekommendationer gällande val av verb i skrivandet av lärandemålen beskrivna av Bloom, David & Krathwohl (1956) såväl som Biggs (1996). Det
är dock inte alltid dessa riktlinjer följs och även om de följs så garanterar inte detta heller att kursplanen blir godkänd av kursnämnden. Det är flera olika faktorer som spelar in beroende på om en kursplan blir godkänd eller inte. Denna studie ämnar att undersöka om man med hjälp av maskininlärning kan underlätta denna process av att bedöma nya kursplaner.
Vad är maskininlärning? På denna fråga finns det ett antal olika svar och tolkningar. En definition av maskininlärning ges av Mitchell (1997). Här definieras maskininlärning som den process för hur man skapar program som förbättras automatiskt vid erfarenhet. För att detta ska ske behövs en samling av system och algoritmer som kan lära/träna en modell att se mönster och utifrån dessa mönster lösa och/eller förenkla en given frågeställning. För detta talar man om två olika slags processer; Supervised och unsupervised learning. Provost & Fawcett (2013) beskriver skillnaden mellan dessa två processer på så sätt att vid supervised learning ska data i förväg grupperas i olika kategorier, detta är inte något som görs vid unsupervised learning. Vid supervised learning ges vägledande information om vad man vill åstadkomma med givna exempel medan i unsupervised learning handlar det om att leta efter okända mönster i data och dra slutsatser utifrån det. Båda dessa processer har använts för att lösa frågeställningarna i denna studie. Ett exempel för supervised learning ges i denna studie i samband med klassificeringen av kursplaner. Här kommer samlingen av kursplaner i förväg kategoriseras som antingen godkända eller icke godkända och därefter kommer en maskininlärnings-modell tränas utifrån detta. De kursplaner som ämnas att användas i denna studie kommer samtliga att vara från Malmö Universitet, och de alla följer därmed sina specifika riktlinjer som Malmö Universitet har för skrivandet av kursplaner (Malmö Universitet, 2017).
Studien riktar sig även in på en specifik del av kursplanen; Lärandemålen. Som ett resultat av Bolognaprocessen bestämdes det att alla utbildningar och kurser ska innehålla lärandemål i kursplanen (UHR, 2019) . Dessa ska tydligt beskriva vad en student förväntas inneha för kunskap för att kunna bli godkänd på vald kurs eller utbildning. Lärandemålen är dessutom en central del av 'Constructive alignment' (Biggs,1996). Här hävdar Biggs bl.a att lärandemålen, praktiska aktiviteter i kursen samt examinationen ska ha ett nära samband med vartannat.
För att kunna besvara frågeställningen gällande denna del av kursplanen kommer unsupervised learning att användas. Anledningen till att ett så stort fokus läggs på denna del av kursplanen beror på att det fortfarande idag ägnas mest tid vid bedömningen av en ny kursplan åt diskussionen av just formuleringar för lärandemålen. Enligt universitetets riktlinjer (Malmö Universitet, 2017), ska lärandemålen delas upp i underkategorierna:
● ’Kunskap och förståelse’ ● ’Färdighet och förmåga’
● ’Värderingsförmåga och förhållningssätt’
Betydelsen av dessa underkategorier är att de delar upp lärandemålen i en kunskapstaxonomi, från faktakunskaper och begreppsförståelse till praktiska färdigheter och tillämpningar och slutligen till djupare förståelse som tillåter analys, syntes och
värdering. Ofta nämns i detta sammanhang Blooms taxonomi för lärandemål (Forehand, 2002). Utifrån taxonomin finns anvisningar till lärare för skrivandet av överlagda lärandemål med listor av passande aktiva verb för lärandets resultat (Bloom, David & Krathwohl, 1956).
Studien utgår delvis från bag-of-words ansatsen1 där en jämförelse mellan textvektoriseringsmetoderna TFIDFVectorizer och CountVectorizer kommer att göras.2 3 Med hjälp av CountVectorizer kan man på ett enkelt sätt omvandla textdokument till vektorer av siffror. Metoden ger även möjlighet till att bygga ett bibliotek av vanligt förekommande ord. TFIDFVectorizer är en mer komplex variant där det finns möjlighet att även räkna ut frekvenser av ord. För att besvara studiens andra problemformulering gällande unsupervised learning kommer textvektoriseringsmetoden Word2vec att användas. Metoden finns tillgänglig i python-biblioteket ”gensim” (Rehruvrek & Sojka, 2010). Metoden tar en stor mängd text som input och därefter transformeras texten till ord-vektorer som tillsammans spänner upp ett vektorrum där varje ord är en punkt i rummet. Liknande ord samt ord som följer varandra i texten befinner sig även i vektorrummet i närheten till varandra. Metoden brukar ge bättre resultat jämfört med den traditionella ’Bag-of-word’ ansatsen. Word2Vec behåller den semantiska betydelsen av olika ord i ett dokument. Kontexten av information går inte förlorad. En annan stor fördel med Word2Vec-metoden är att storleken på inbäddningsvektorn är mycket liten. Varje dimension i inbäddningsvektorn innehåller information om en aspekt av ordet. Det behövs inte enorma glesa vektorer, till skillnad från bag-of-words ansatsen.
När det talas om val för klassificerare förklarar Divakar Sing (2013) att klassificeringsmetoder presterar olika beroende på samlingen av data - det finns ingen generell metod som fungerar för alla applikationer, detta efter att han jämfört ett antal olika metoder för klassificering. Även i denna studie utförs en jämförelse mellan ett flertal olika klassificeringsalgoritmer;
Naive Bayes
Naive Bayes är en samling klassificerare som används inom maskininlärning, specifikt inom supervised learning. De räknas som ”naiva” då det utgås från att funktionerna i en mätning är oberoende av varandra. Naive bayes klassificerare har en tendens att prestera bra och kräver inte en stor mängd träningsdata för att hitta optimala parametrar. Multinomial Naive bayes som används i denna studie är speciellt passande för4 klassificering av diskreta värden.
1 https://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html 2 https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html?highlight=tfid#sklearn.feature_extraction.text.TfidfVectorizer 3 https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.Co 4 https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html?highlight=multinomialnb
Support Vector machine (SVM)
SVM är en algoritm som används inom maskininlärning. Den kan användas för klassificiering samt för regression. Algoritmen transformerar datan och sedan utifrån den transformerade datan grupperas den utifrån de fördefinierade regler som bestämts. SVM:s har en tendens att vara enkla att använda såväl som snabba. Det finns ett flertal olika varianter av SVM. I denna studie kommer fokuset att ligga på SVC och NUSVC . De är 5 6 väldigt lika varandra, bortsett från att NUSVC använder sig av en parameter för att ha koll på antalet supportvektorer.
I studien används även SDG-klassificering som är en linjär SVM där SGD används för att7 optimera träningen av datamodellen. SGD använder slumpvalda delar av datan för att träna modellen och på så vis kan man uppnå snabbare skapande av datamodellen med mindre upprepningar vid inlärningen men nackdelen är en förlust av konvergens.
Neural networks
Neurala nätverk är en samling av algoritmer som används inom maskininlärning. Grundidén är att försöka efterlikna hjärnceller på så sätt att den ska kunna självlära sig och kunna ta beslut på ett någorlunda mänskligt sätt. I denna studie används nätverksmodellen Multi-layer Perceptron (MLP) . Modellen består av minst tre lager; Input,8 output samt dolda lager. Varje nod i ett lager är sammankopplat med varje nod i dess närliggande lager. MLP har fördelar såsom att den kan lära sig icke-linjära modeller och har även möjlighet att lära sig modeller i realtid.
Varför valet föll på just dessa metoder beror på att de är några av de vanligaste klassificeringsmetoder och samtliga finns tillgängliga i scikit-learn (Pedregosa et al., 2011). I en tidigare studie där maskininlärning användes för skapa ett samlat bibliotek av kursplaner används klassificeringsmetoden SVM, här motiverar de valet med att SVM är en välanvänd metod av många samt att den har en tendens att prestera bra (Tungare et al.).
Ökat intresse för hur maskininlärning kan användas i relation till kursplaner har gett upphov till forskning av olika slag inom området. I en tidigare studie av Rathod, N & Cassel L.N (2013) har man byggt en sökmotor för att på ett lättare sätt kunna hitta kursplaner inom datavetenskap på webben då de ansåg att den generiska sökmotorn är bristfällig till
5 https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html?highlight=svc#sklearn.svm.SVC 6 https://scikit-learn.org/stable/modules/generated/sklearn.svm.NuSVC.html 7 https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html?highlight=sgdclassifier#sklearn.linear_model.SGDClassifier 8 https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html?highlight=mlpclassifier#sklearn.neural_network.M LPClassifier
att fånga upp kursplaner. Det finns även ett par tidigare studier av Ota & Mima (2011) och även Matsuda, Sekiya & Yamaguchi (2018) som använder analysmetoder inom maskininlärning av läroplaner i syfte att göra dem mer organiserade och lättförståeliga. Vad man kan se utifrån tidigare forskning inom maskininlärning i relation till kursplaner så ligger ett stort fokus på att göra kursplaner mer tillgängliga och sökbara. Det saknas ännu studier som behandlar det specifika problemområde denna studie ämnar att lösa.
1.4 Relevanta begrepp
Bag-of-words ansats:En modell för hur man representerar text. Modellen beskriver och
mäter förekomsten av specifika ord i ett dokument.
Scrapy: Ett verktyg som används för att extrahera data från webbsidor.
Pipeline: En kedja av element som är sammankopplade på så sätt att ett elements output är en annan elements input. I sammanhanget att bygga maskininlärning-modeller innebär en “pipeline” de komponenterna, såsom klassificerare och vektoriserare, som är sammankopplade för att bygga och träna modellen.
Scikit-learn: Gratis maskininlärningsbibliotek för programmeringsspråket Python.
2 Metod
2.1 Metodbeskrivning
I studien valdes forskningsmetodiken experiment att användas i syfte att besvara de valda frågeställningarna. Ett experiment inom akademisk forskning är en strategi som undersöker sambandet mellan orsak och verkan (Oates, 2006). Denna metod används för att utreda ifall det finns ett orsakssamband mellan en viss faktor och ett utfall. Experiment utförs genom att forskarna först utformar en hypotes, som sedan testas empirisk i syfte att bevisa eller motbevisa den utformade hypotesen.
Studiens genomförande inspirerades av CRISP data mining process (Provost & Fawcett, 2013). CRISP är en väletablerad metod för processen att samla och jobba med data, och passade våra behov väl. CRISP data mining processen består av sex steg: Business understanding, Data understanding, Data preparation, Modeling, Evaluation och Deployment.
Tillvägagångssättet som valdes för studien innebar att bygga en serie applikationer för att hämta och bearbeta data i form av kursplaner och sedan bygga maskininlärning-modeller som skulle kunna användas i experiment för att besvara frågeställningarna. Merparten av
applikationerna byggdes med programmeringsspråket Python 3 9. Även
programmeringsspråket C# har använts. För tränandet och användningen av maskininlärning-modellerna användes Python-biblioteket Sckikit-learn (Pedregosa et al., 2011) och Gensim(Rehruvrek & Sojka, 2010) . Tillvägagångssättet för studien är indelad i sex steg som kommer att beskrivas nedan.
2.1.1 Beslut om vilken data som skulle användas
En kursplan består av flera olika delar och i metoden som användes analyserades kursplanerna både som enskilda och hela dokument samt även dess individuella delar. De delar som det beslutades om att en fullständig kursplan ska innehålla och som ansågs relevanta att samla och använda som data studien var:
- Huvudområde - Kursspråk - Införandedatum - Beslutande instans - Förkunskapskrav - Fördjupningsnivå - Syfte - Kursbeskrivning - Kursinnehåll 9 https://docs.python.org/
- Lärandemål
- Arbetsformer
- Bedömningsformer
- Betygsskala
2.1.2 Insamling och klassificering av data
Detta steg innebar att samla den data som skulle komma att användas för att träna och testa de maskininlärning-modeller som skulle byggas. Klassificeringen av data baserades på källan som den kommer från, varpå inget separat steg krävdes för att gå igenom och klassificera den data som samlades. De två kategorier för klassificering av data som valdes var godkända och icke godkända kursplaner. Källan som de godkända kursplanerna hämtades var Malmö Universitets hemsida (MAU,u.å.). Dessa kunde anses vara exempel på godkända kursplaner eftersom de har genomgått en granskningsprocess och blivit godkända samt publicerade av kursnämnden. Vad gäller de icke godkända kursplanerna användes och testades i denna studie två olika dataset. Det första datesetet bestod av en samling nya kursplaner som var inskickade till kursnämnden på fakulteten för Teknik och samhälle på Malmö universitetet och om kursnämnden hade anmärkningar på. Det andra datasetet som representerar icke godkända kursplaner var text som hade transformerats med hjälp av maskininlärning-modellen GPT-2 . För att generera detta10 dataset användes de godkända kursplanerna som input och transformeras sedan med hjälp av denna modell genom att skicka data till OpenAi.com:s API och sedan använda 11 det returnerade resultatet. Det genererade datasetet användes därefter i studien som exempel på icke godkända kursplaner.
En applikation byggdes för att ladda ner alla kursplaner som fanns publicerade på MAU:s hemsida, för att sedan gå igenom dem och samla all nödvändig data från dem. Applikationen byggdes i Python, och biblioteket “Scrapy” användes för att implementera 12 lösningen. På MAU:s hemsida fanns drygt 5000 kursplaner publicerade totalt. Alla dessa13 kunde laddas ner, men på grund av olika faktorer kunde inte all nödvändig data samlas från alla dessa kursplaner. Många kursplaner saknade information om kursens syfte. Detta var en rubrik som skulle undersökas då de ansågs utgöra en viktig del av en kursplan. Kursplaner som saknade detta användes därmed inte i urvalet av kursplaner. En del kursplaner var även skrivna på ett sätt som inte var kompatibelt med majoriteten av kursplaner, genom att en kursplan beskrev en eller flera terminer i en utbildning och olika rubriker beskrev enskilda kurser under de terminerna. Dessa kursplaner var skrivna på olika sätt, och många av de kursplanerna hade vissa rubriker som var gemensamma för alla kurser i kursplanen och vissa rubriker som beskrev element ur de enskilda kurserna. Dessa kursplaner var en minoritet av de totala kursplanerna och eftersom det inte på ett enkelt sätt kunde beslutas om hur data från dessa kursplaner skulle samlas och tolkas 10 https://openai.com/blog/better-language-models/#sample2 11 https://openai.com/blog/better-language-models/ 12https://scrapy.org/ 13 https://edu.mau.se/en/lists/SyllabusList
utan att påverka slutresultaten negativt valdes dessa kursplaner också bort från urvalet. Många kursplaner var publicerade enligt HTML-liknande mallar varpå den nödvändiga informationen kunde samlas ihop på ett pålitligt sätt från dem. Det fanns dock ett antal olika variationer av dessa HTML-mallar, vilket var tvunget att tas hänsyn till i applikationen som användes för insamling av data. Totalt kunde 1969 kursplaner innehållande all nödvändig data samlas från MAU:s hemsida, varav 1587 var kursplaner skrivna på svenska och 382 var skrivna på engelska. Dessa sparades i en Excel-fil där varje rad representerade en kursplan och varje kolumn representerade en av de tidigare definierade delarna av kursplaner, vilka är listade i 2.1.1. Även kursplanens namn, kurskod och språk sparades som kolumner för att kunna hålla reda på och sortera dem vid ett senare tillfälle. Figur 1 nedan visar hur början till denna fil ser ut. Filen innehåller fler rader och kolumner än vad som kan ses på Figur 1.
Figur 1: Utdrag från excel-filen med insamlade kursplaner.
Exempel på ofärdiga kursplaner tillhandahölls av kursnämnden på fakulteten för teknik och samhälle på Malmö universitet i form av filer av olika typ och format som innehöll kursplaner som de beslutat vara ofärdiga och behöva utvecklas mer. Dessa uppgick till totalt 187 kursplaner, varav 176 stycken var skrivna på svenska och 11 stycken var skrivna på engelska. Informationen från dessa kursplaner sammanställdes till en Excel-fil enligt samma format som de godkända kursplanerna (se figur 1). Detta skedde genom skapandet av en applikation i C# för att automatisera en del av kopieringen av kursplanernas innehåll. Detta lyckades dock inte på majoriteten av kursplanerna på grund av att strukturen av rubrikerna i kursplanerna inte var enhetliga. Av denna anledning kopierades majoriteten av kursplanerna manuellt.
Ett alternativt set med icke godkända kursplaner valdes att samlas för att kunna experimenteras med och jämföra resultaten med. Detta innebar att en Python-applikation skrevs för att gå igenom de samlade, godkända, kursplanerna och genom HTTP-anrop till OpenAI:s API “transformera” innehållet och skapa en Excel-fil med samma struktur som
den ursprungliga filen. Efter att ha kört denna process i ca 2 dygn hade totalt 322 “transformerade” kursplaner genererats varav 154 var på engelska och 168 var på svenska. Vid inspektion av den data som genererades kunde slutsatsen dras att den inte var i närheten av att uppfylla kraven för godkända kursplaner. Den engelska text som hade genererats höll betydligt högre kvalitet än den svenska genom att den ofta utgjordes av någorlunda korrekta meningar, medan den svenska texten mycket sällan gick att förstå och ofta blandade in ord på norska, danska och andra språk. Ett exempel på hur den svenska texten såg ut efter att ha transformerats på detta sätt är:
“...Nu sta kunderna i Sättingen är kommunalvägnarna som inte sjäkar vad i så mycket kristdemokraterna måste ändå. I en artikel som är avsäkerande av vädrekigt ett avsättande avsaka. Där måste någon känna för att vämna. Men gärde för att åkna och de måste nästa dyr för att sjäkta förstöäriserna och jag får värt upp svensk...”
Även den genererade engelska texten höll sig sällan till ämnet, utan verkade ofta handla om amerikanska nyheter och nämnde ofta Presidenten Trump och uttalanden från amerikanska politiker. Ett exempel på hur den engelska texten såg ut efter att ha transformerats på detta sätt är:
“...Mr. Graham said that he strongly oppose the proposed $110 billion in arms sales and said the US would feel unable to return to an arms deal without "an incriminating piece of paper" from Saudi Arabia. But a source close to President Donald Trump before the midterm elections said on Friday he would seek a ban on military sales to Saudi Arabia. The source cited several people familiar with a party's decision to elect...”
Med detta i åtanke kan det antas att modellerna som kom att tränas med detta dataset inte kan anses vara tränade i att skilja på godkända eller icke godkända kursplaner, utan snarare på att skilja på om en text är en kursplan eller inte.
Målet med att samla kursplaner från MAU:s hemsida var att kunna använda dem som exempel på godkända kursplaner vid tränandet av maskininlärning-modeller. Med tanke på att antalet exempel på godkända kursplaner lämpligen bör vara proportionellt med antalet exempel på icke godkända kursplaner vid denna inlärning var det i slutändan det antal icke godkända kursplaner som kunde samlas som var den begränsande faktorn. Därpå ansågs det tillräckligt för denna studie med de 1969 godkända kursplaner som lyckades insamlas från MAU:s hemsida.
2.1.3 Bearbetning av data
Den data som samlades in bearbetades och förbereddes för att ligga till grund för uppbyggnad av maskininlärning-modeller. Detta inkluderade bland annat borttagning av stoppord, punkter, specialtecken och radbyten samt uppdelning av data i individuella filer, vilka representerar hela kursplaner på svenska och engelska samt filer som representerar delar av kursplaner på svenska och engelska. Föregående steg resulterade i en strukturerad Excel-fil innehållande alla godkända kursplaner, en likadan fil som innehöll
alla icke godkända kursplaner, samt en likadan fil som innehöll alla “transformerade” kursplaner. En applikation skrevs för att använda Excel-filer med detta format (se figur 2) som input, för att sedan gå igenom innehållet och generera en mappstruktur med textfiler. Textfilerna var uppdelade på olika sätt för att kunna användas i olika scenarion. Det skapades mappar där varje textfil innehöll all data från en enskild kursplan, mappar där varje textfil innehöll data från en viss del av en kursplan och mappar där alla kursplaner på ett visst språk och med en viss klassificering utgjorde en textfil. Mappstrukturen gjorde att de genererade textfilerna kunde hållas sorterade efter sitt innehåll, språket som innehållet var skrivet på och klassificeringen som innehållet hade fått. Denna applikationen såg även till att all text som skrevs i textfilerna hade rensats på symboler som punkter, radbyten, specialtecken, versaler, med mera. Detta gjordes för att textfilerna skulle kunna användas som input vid byggandet och experiment med olika maskininlärningmodeller.
2.1.4 Supervised modelling
För att hitta den typ av klassificerare som bäst skulle kunna förutspå en korrekt klassificering av nya kursplaner utfördes experiment med flera typer av klassificerare, och med flera kombinationer av parametrar till dessa klassificerare. Dessa experiment utfördes genom att skriva en applikation i Python som använde textfilerna från föregående steg (Stycke 3.2) som input, skapade modeller med flera typer av vanliga klassificerare och försökte sedan korrekt klassificera en del av kursplanerna. Automatiserade sökningar gjordes även med de olika klassificerarna för att hitta de optimala parametrarna för varje klassificerare. Denna applikation genererade statistik på hur väl de olika typerna av klassificerarna korrekt kunde klassificera den data som fanns i textfilerna. Diagram för att visa antalet korrekta och inkorrekta klassificeringar kunde även skapas, och de optimala parametrarna kunde testas fram. Resultaten från experimenten i denna applikation är uppdelade enligt de två dataset som samlades och användes i studien. I båda dataseten var kursplanerna uppdelade i kategorierna godkänd och icke godkänd. I båda dataseten representerades godkända kursplaner av data från de kursplaner som var hämtade från MAU:s hemsida. I det ena datasetet representerades de icke godkända kursplanerna av manipulerade versioner av de godkända kursplanerna, som ‘transformerats’ med hjälp av den tränade maskininlärning-modellen GPT-2 . Detta dataset kallas “Transformed Data”.14 I det andra datasetet representerades de icke godkända kursplanerna av en samling ej godkända kursplaner som tillhandahållits av MAU:s kursnämnd. Detta dataset kallas för “Real Data”. De klassificerare från biblioteket Scikit-learn som experimenterades med i denna applikation var:
- MultinomialNB - MLPClassifier
- svm.NuSVC
- svm.SVC
- SGDClassifier
Vektoriserarna från biblioteket Scikit-learn som experimenterades med var: - TfidfVectorizer
- CountVectorizer
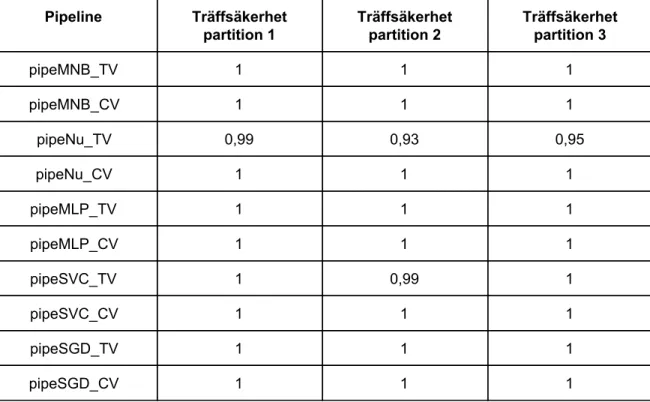
Vid byggandet av alla modeller filtrerades stoppord bort för att ge bättre resultat. I applikationen skapades en “pipeline” för varje klassificerare i kombination med varje vektoriserare. 8 “pipelines” skapades alltså och utgjorde grunden för experimenten i applikationen. Kombinationerna av klassificerare och vektoriserare som utgjorde de 8 “pipelines” visas i tabellen nedan, tillsammans med vars ett alias som användes för experimenten i applikationen.
Tabell 1: Kombinationer av klassificerare och vektoriserare.
Alias Klassificerare Vektorisering
pipeMNB_TV MultinomialNB TfidfVectorizer
pipeNu_TV svm.NuSVC TfidfVectorizer
pipeMLP_TV MLPClassifier TfidfVectorizer
pipeSVC_TV svm.SVC TfidfVectorizer
pipeSGD_TV SGDClassifier TfidfVectorizer
pipeMNB_CV MultinomialNB CountVectorizer
pipeNu_CV svm.NuSVC CountVectorizer
pipeMLP_CV MLPClassifier CountVectorizer
pipeSVC_CV svm.SVC CountVectorizer
pipeSGD_CV SGDClassifier CountVectorizer
För experimenten valdes det att slå ihop de mest kritiska delarna av en kursplan och experimentera med att träna modeller på data från dem. Delarna som valdes ut för experimenten var: - Syfte - Kursinnehåll - Lärandemål - Arbetsformer - Bedömningsformer
Resterande delar av kursplanerna valdes att uteslutas ur dessa experiment, eftersom de ansågs innehålla mindre relevant data, innehåll som ofta var gemensam för många kursplaner eller data som inte nödvändigtvis bör bedömas som godkänd eller icke godkänd, utan bara behöver finnas. Eftersom enbart 11 exempel på icke godkända kursplaner som var skrivna på engelska fanns att tillgå från MAU:s kursnämnd, men 176 exempel på icke godkända svenska kursplaner fanns valdes att enbart utföra experiment på den svenska data som fanns. I experimenten användes 176 av de svenska kursplaner som tidigare samlats från MAU:s hemsida som exempel på godkända kursplaner. Därmed användes en “baseline” på 50% där modellerna tränades med lika många exempel på icke godkända som godkända kursplaner.
Stegen som utfördes i applikationen var:
1. “k-fold cross validation”
För varje “pipeline” delades data upp i tre “folds” eller partitioner. Varje partition användes för att träna en modell med denna “pipeline”. Varje “pipeline” resulterade alltså i tre tränade modeller som testades genom att försöka klassificera en del av den testdata som fanns. Uppdelningen i flera partitioner gjordes för att få flera resultat för varje “pipeline” och kunna ta fram en genomsnittspoäng för varje “pipeline”. Besultet att dela upp data i tre partitioner togs som en avvägning mellan att vilja testa ett flertal tränade modeller per “pipeline”, men inte vilja ha för lite data per partition att träna modellerna med. Genomsnittsresultaten för varje “pipeline” kunde jämföras med varandra efter detta steg. Målet med steget var att identifiera någon tydlig skillnad mellan de olika vektoriserarna TfidfVectorizer och CountVectorizer. Ingen optimering av klassificerarnas parametrar gjordes därför innan detta steg, eftersom målet med steget inte var att hitta den bästa klassificeraren ännu.
2. “Confusion matrix”
För varje “pipeline” tränades en modell med en del av den träningsdata som fanns och testades sedan med resterande testdata. En “confusion-matrix” ritades sedan upp för varje “pipeline” för att visualisera resultaten av testen. De resulterande diagrammen visade antalet korrekta klassificeringar per kategori, samt antalet inkorrekta klassificeringar per kategori. Målet med detta steg var samma som föregående: att hitta en tydlig skillnad mellan de olika vektoriserarna för den data som användes. Den tydliga visualiseringen i detta steg gav dock en mer tydlig bild på hur modellerna hade försökt klassificera data och vilka eventuella fel de vanligen gjort.
3. “Grid Search”
För varje “pipeline” byggdes en tabell av utvalda parametrar och en serie värden per parameter. Parameter-tabellen användes sen för att göra en “Grid Search” på varje “pipeline” för att hitta den optimala kombinationen av värden för parametrarna, vilket
producerade de bästa modellerna för varje “pipeline”. Detta steg gjordes för att kunna undersöka vilken “pipeline” som presterade bäst, med vilka värden på parametrarna. Detta kunde senare användas som underlag i beslut om vilken kombination av klassificerare, vektoriserare och parametervärden som var de optimala för det insamlade datasetet. Intervallet för en del av parameter-värdena experimenterades även med för att säkerställa att de optimala värden som hittades inte låg i övre eller lägre skiktet av intervallet, eftersom det hade kunnat tyda på att det fanns ännu bättre värden utanför det testade intervallet.
4. Test av optimerade “pipelines”
När de optimala parametervärdena hade hittats för varje “pipeline” byggdes slutligen en modell för varje “pipeline” med de parametervärdena. Modellerna tränades med 80% av all befintlig testdata och testade sedan resterande 20% för ett slutgiltligt resultat på hur väl de kunde klassificera denna testdata.
2.1.5 Deployment
Den typ av klassificerare som presterade bäst i ovan beskrivna experiment testades sedan genom att en terminalapplikation som använder sig av de tränade maskininlärningmodellerna byggdes, för att kunna ta emot kursplaner eller delar av
kursplaner som input från användaren och presentera resultatet av hur
maskininlärningmodellen klassificerar inputen. Denna applikation användes som verktyg i manuella, utforskande experiment för att avgöra om maskininlärningmodellerna korrekt kunde klassificera olika nya inputs samt för att kunna hitta svagheter i klassificerarnas kapacitet.
För att testa om de uppnådda resultaten kunden generaliseras till verkliga användningsområden och om de stämmer in på verkliga bedömningar av kursplaner undersöktes hur maskininlärningsmodellen som tränats med datasetet “Real data” skulle klassificera 8 godkända och publicerade kursplaner som hade studerats närmare under studien tillsammans med en lärare på Malmö Universitet och betygsatt på en skala mellan 0 och 15 poäng. Betygsättningen av dessa kursplaner gjordes baserat på en lista med 15 kriterier på hur kursplaner ska skrivas som sammanställdes tillsammans med läraren baserat på befintlig litteratur om ämnet. Läraren betygsatte därefter kursplanerna genom att bedöma varje kriterium för varje kursplan, huruvida detta hade uppfyllts. Varje uppfyllt kriterium gav 1 poäng vilket innebar att varje bedömd kursplan kunde få mellan 0 och 15 poäng, vilket enligt lärarens bedömning representerar kvalitén på kursplanen. Dessa kriterier och bedömningar sammanställdes till ett internt arbetsdokument, och finns bifogat i appendix A. Om resultaten av våra experiment verkligen skulle kunna appliceras i praktiken och stämma överens med riktiga bedömningar av kursplaner var det att förvänta att den tränade maskininlärningsmodellen som har tränats med datasetet “Real data” betygsätter kursplanerna på ett sätt som korrelerar med lärarens bedömning. För att
analysera detta testades det att använda en av applikationerna som hade byggts under studien, vilken låter en användare interagera med de tränade maskininlärningsmodellerna genom att ge en kursplan som input till applikationen och som svar få en bedömd klassificering av kursplanen samt en siffra på hur säker modellen är på denna bedömning. För att modellens bedömningsförmåga skulle korrelera med den verkliga bedömningen av läraren var det att förvänta att alla kursplaner klassificeras enligt kategorin “Godkänd” samt att siffran för modellens säkerhet i denna bedömning korrelerar med lärarens poäng för varje kursplan.
2.1.6 Unsupervised Modeling
Även experiment med “unsupervised learning” utfördes på den data som insamlats och klassificerats som godkända. Detta för att undersöka om det gick att dra slutsatser och få djupare insikter om delar av denna data. Dessa experiment skulle även kunna påvisa om det fanns mönster i hur kursplanerna är skrivna och hur relationerna mellan kursplanens olika delar såg ut i den data som var insamlad. Genom en rad olika algoritmer kunde till exempel avståndet mellan datapunkter beräknas och punkterna grupperas. Texterna transformerades till ordvektorer som tillsammans spänner upp ett vektorrum där varje ord är en punkt i rummet. Liknande ord samt ord som följer varandra i texten befinner sig i vektorrummet i närheten till varandra. Olika algoritmer användes på dessa punkter för att hitta ord som befinner sig i närheten av ett fastställt ord. Resultaten av de algoritmer som användes i detta steg illustrerades med hjälp av funktioner från Python biblioteket “gensim” (Rehruvrek & Sojka, 2010). “Gensim” är specialiserat på att behandla naturligt språk. I “gensim” kan man använda sig av metoden ’Word2Vec’ för att omvandla ord till ordvektorer. Denna metod brukar ge bättre resultat jämfört med den traditionella ’Bag-of-word’ ansatsen som använder sig av CountVector eller TfidfVectorizer.
I varje steg byggdes en eller fleraapplikationer för att hjälpa till att lösa uppgiften. För att på ett strukturerat sätt dokumentera de olika stegen i koden i applikationerna byggdes de med hjälp av verktyget Jupyter . I denna studie användes ett iterativt arbetssätt, där15 ovanstående steg testades och förbättrades flera gånger under studiens gång.
15
Figur 2: Artefakter från studien och deras relation.
2.2 Metoddiskussion
Ett av målen med studien var att undersöka om det går att skapa
maskininlärning-modeller som kunde klassificera kursplaner eller delar av kursplaner som godkända eller icke godkända, med en tillräckligt hög träffsäkerhet för att kunna användas i verkliga sammanhang. Om träffsäkerheten var under 50% är modellen statistiskt sämre än slumpen och kan därmed under inga omständigheter anses vara tillräckligt bra för att kunna tjäna något syfte i processen att bedöma nya kursplaner. För att undersöka detta var det viktigt att ha så mycket data som möjligt av god kvalitet. Automatisering av insamlingen av kursplaner var därför nödvändig. Programmeringsspråket Python 3 användes för detta eftersom där finns ett stort utbud av bibliotek som gör att man enkelt och effektivt kan skapa verktyg för att “skrapa” information från webbsidor samt bygga och testa maskininlärningmodeller. Python 3 är ett programmeringsspråk som prioriterar tidseffektivitet i skrivandeprocessen framför tidseffektivitet i exekverandet av koden. Denna teknologi lämpar sig därför bra i denna studie eftersom syftet inte var att bygga ett effektivt och hållbart system, utan istället att ge sig ut i ett ej tidigare prövat användningsområde för att undersöka om ett användbart verktyg av detta slaget var möjligt att bygga.
En del av experimenten i studien innebar att bygga och testa maskininlärningmodeller med data som redan klassificerats och undersöka om modellerna klassificerar denna data
korrekt. Dessa experiment gav relativt snabba resultat och kunde användas löpande under utvecklingen av modellerna för att försöka skapa så bra modeller som möjligt. De ger även tydlig, mätbar statistik som kan dokumenteras. Ytterligare ett experiment i studien innebar att använda sig av terminalapplikationen som byggdes för att interagera med modellerna. Dessa experiment möjliggjorde att på ett enkelt sätt löpande kunna testa helt ny data, och se om modellerna klassificerar denna data på det sätt som förväntas. Dessa experiment kan motiveras med att de kan göra det möjligt att resonera kring slutsatser om vilken typ av data som modellerna mest korrekt kan klassificera, och även hitta svagheter och brister i modellerna, då användaren får resultat per inmatad input istället för en generell statistik för alla inputs.
3 Resultat
I detta avsnitt kommer resultaten från experimenten att presenteras. Först kommer resultaten från experimenten av supervised learning att presenteras, sedan resultaten från experimenten med en optimerad och tränad klassificeringsmodell och slutligen resultaten av experimenten med unsupervised learning.
3.1 Experiment med “supervised learning
”
Experimenten med supervised learning syftade i att undersöka vilken kombination av
klassificerare och vektoriserare som kunde användas för att skapa
maskininlärningsmodeller som med högst träffsäkerhet kunde klassificera data i de dataset som sammanställts. Experimenten utfördes i fyra steg, och dessa steg utfördes på vardera av de två dataseten “Transformed data” och “Real data”.
3.1.1 Dataset “Transformed Data”
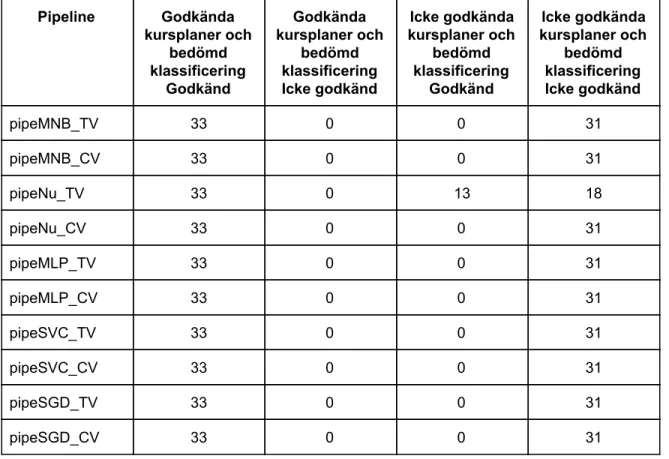
Steg 1: “k-fold cross validation”
Ingen uppenbar skillnad kunde urskiljas mellan TfidfVectorizer och CountVectorizer, se tabell 2. Alla “pipelienes” uppnådde mycket höga resultat, vilket var att förvänta med detta dataset.
Tabell 2: Resultat av “k-fold cross validation” per “pipeline” med tre partitioner, dataset “Transformed Data”.
Pipeline Träffsäkerhet partition 1 Träffsäkerhet partition 2 Träffsäkerhet partition 3 pipeMNB_TV 1 1 1 pipeMNB_CV 1 1 1 pipeNu_TV 0,99 0,93 0,95 pipeNu_CV 1 1 1 pipeMLP_TV 1 1 1 pipeMLP_CV 1 1 1 pipeSVC_TV 1 0,99 1 pipeSVC_CV 1 1 1 pipeSGD_TV 1 1 1 pipeSGD_CV 1 1 1
Steg 2: “Confusion matrix”
Ingen uppenbar skillnad kunde urskiljas mellan TfidfVectorizer och CountVectorizer. Alla “pipelines” uppnådde bra resultat i detta experiment, förutom pipeNu_TV som visade en klar tendens att favorisera kategorin godkänd. Detta illustreras nedan i tabell 3. Kolumnerna i tabellen representerar de olika kombinationerna av verkliga klassificeringar, och modellernas bedömda klassificeringar.
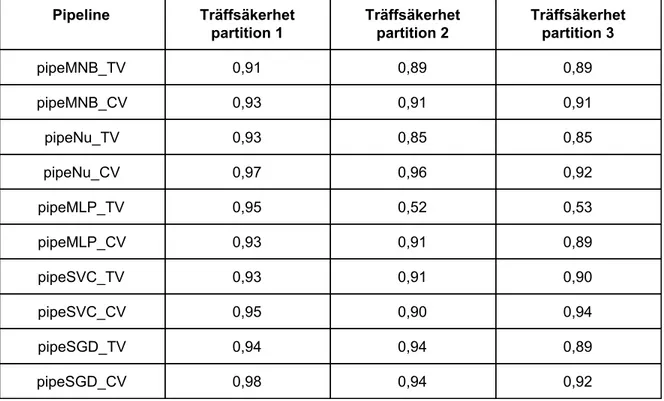
Tabell 3: Resultat av “confusion matrix” per “pipeline”, dataset “Transformed Data”.
Pipeline Godkända kursplaner och bedömd klassificering Godkänd Godkända kursplaner och bedömd klassificering Icke godkänd Icke godkända kursplaner och bedömd klassificering Godkänd Icke godkända kursplaner och bedömd klassificering Icke godkänd pipeMNB_TV 33 0 0 31 pipeMNB_CV 33 0 0 31 pipeNu_TV 33 0 13 18 pipeNu_CV 33 0 0 31 pipeMLP_TV 33 0 0 31 pipeMLP_CV 33 0 0 31 pipeSVC_TV 33 0 0 31 pipeSVC_CV 33 0 0 31 pipeSGD_TV 33 0 0 31 pipeSGD_CV 33 0 0 31
Steg 3: “Grid Search”
Grid Search gjordes för alla “pipelines” för att hitta de bästa parametervärdena för varje “pipeline”. En “score” på 1.0 i träffsäkerhet kunde dock uppnås för alla “pipelines” i detta steg. Detta var att förvänta i detta dataset där det är stor skillnad mellan den data som var godkänd jämfört med den som var icke godkänd. Det ansågs därför irrelevant att här redovisa de optimala parametrarna för varje varje “pipeline”, eftersom det är möjligt att flera olika parametervärden gav samma perfekta “score”.
Steg 4: Test av optimerade “pipelines”
parametervärden visade att alla “pipelines” kunde tränas till att nästan utan undantag kunna kategorisera all data rätt i detta dataset. Se tabell 4 nedan.
Tabell 4: Resultat av experiment med optimerade “pipelines”, dataset “Transformed Data”.
Pipeline Bästa uppnådda träffsäkerhet
pipeMNB_TV 1.0 pipeNu_TV 0.984 pipeMLP_TV 1.0 pipeSVC_TV 1.0 pipeSGD_TV 1.0 pipeMNB_CV 1.0 pipeNu_CV 1.0 pipeMLP_CV 1.0 pipeSVC_CV 1.0 pipeSGD_CV 1.0
3.1.2 Dataset “Real Data”
Steg 1: “k-fold cross validation”
Ingen tydlig skillnad i resultaten mellan de olika klassificerarna kunde urskiljas. Inte heller kunde någon klar skillnad utrönas mellan hur väl TfidfVectorizer klassificerade data mot hur CountVectorizer presterade. I tabell 5 presenteras resultatet avrundat till två decimaler.
Tabell 5: Resultat av “k-fold cross validation” per “pipeline” med tre partitioner, dataset “Real Data”.
Pipeline Träffsäkerhet partition 1 Träffsäkerhet partition 2 Träffsäkerhet partition 3 pipeMNB_TV 0,91 0,89 0,89 pipeMNB_CV 0,93 0,91 0,91 pipeNu_TV 0,93 0,85 0,85 pipeNu_CV 0,97 0,96 0,92 pipeMLP_TV 0,95 0,52 0,53 pipeMLP_CV 0,93 0,91 0,89 pipeSVC_TV 0,93 0,91 0,90 pipeSVC_CV 0,95 0,90 0,94 pipeSGD_TV 0,94 0,94 0,89 pipeSGD_CV 0,98 0,94 0,92
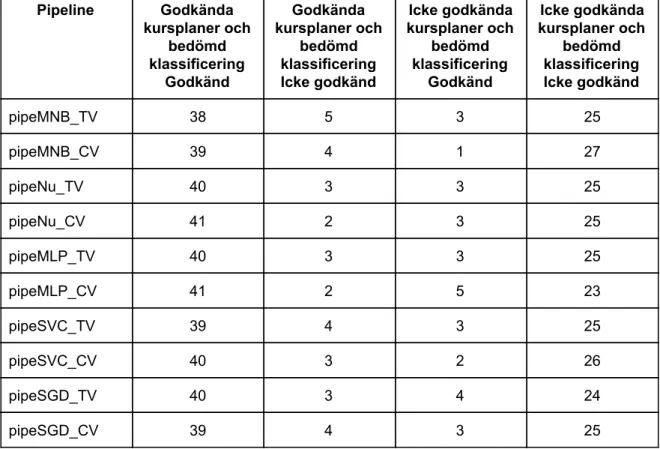
Steg 2: “Confusion matrix”
Spridningen av felgissningar för varje “pipeline” var generellt jämnt fördelad mellan kategorierna i detta experiment. De “pipelines” som noterades ha en tydligt skev fördelning av felgissningar var pipeMNB_TV, pipeMNB_CV och pipeMLP_CV.
Tabell 6: Resultat av “confusion matrix” per “pipeline”, dataset “Real Data”.
Pipeline Godkända kursplaner och bedömd klassificering Godkänd Godkända kursplaner och bedömd klassificering Icke godkänd Icke godkända kursplaner och bedömd klassificering Godkänd Icke godkända kursplaner och bedömd klassificering Icke godkänd pipeMNB_TV 38 5 3 25 pipeMNB_CV 39 4 1 27 pipeNu_TV 40 3 3 25 pipeNu_CV 41 2 3 25 pipeMLP_TV 40 3 3 25 pipeMLP_CV 41 2 5 23 pipeSVC_TV 39 4 3 25 pipeSVC_CV 40 3 2 26 pipeSGD_TV 40 3 4 24 pipeSGD_CV 39 4 3 25
Steg 3: “Grid Search”
I följande tabeller presenteras resultaten från experiment med “Grid Search” för varje “pipeline”. Det som visas för varje “pipeline” är de testade parametervärdena, bästa uppnådda träffsäkerhet och det funna optimala parametervärdena.
Tabell 7: Optimala parametervärden för pipeMNB_CV och pipeMNB_TV för dataset “Real Data”, funna med hjälp av “Grid Search”. Pipeline pipeMNB_CV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfMNB__alpha: [0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] Bästa träffsäkerhet 0.936 Optimala parametervärden clfMNB__alpha: 0.1 vect__ngram_range: (1, 2) Pipeline pipeMNB_TV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfMNB__alpha: [0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] Bästa träffsäkerhet 0.928 Optimala parametervärden clfMNB__alpha: 0.1 vect__ngram_range: (1, 2)
Tabell 8: Optimala parametervärden för pipeNu_TV och pipeNu_CV för dataset “Real Data”, funna med hjälp av “Grid Search”. Pipeline pipeNu_TV Testade parametervärden vect__ngram_range: [(1, 1), (1, 2), (1, 3)] clfNu_nu: [0, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] clfNu__gamma: [0.00000001, 0.0000001, 0.000001, 0.00001, 0.0001, 0.001, 0.01] Bästa träffsäkerhet 0.946 Optimala parametervärden clfNu__gamma: 0.001 clfNu__nu: 0.1 'vect__ngram_range: (1, 3) Pipeline pipeNu_CV Testade parametervärden vect__ngram_range: [(1, 1), (1, 2), (1, 3)] clfNu_nu: [0, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] clfNu__gamma: [0.00000001, 0.0000001, 0.000001, 0.00001, 0.0001, 0.001, 0.01] Bästa träffsäkerhet 0.957 Optimala parametervärden clfNu__gamma: 1e -06 clfNu__nu: 0.3 'vect__ngram_range: (1, 3)
Tabell 9: Optimala parametervärden för pipeMLP_TV och pipeMLP_CV för dataset “Real Data”, funna med hjälp av “Grid Search”. Pipeline pipeMLP_TV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfMLP__hidden_layer_sizes : [(5, 100), (10, 200), (30, 1000)] clfMLP__solver: [‘lbfgs’, ‘adam’, ‘sgd’] clfMLP__learning_rate: [‘invscaling’, ‘adaptive’] clfMLP__learning_rate_init: [0.01, 0.1, 1.0] clfMLP__momentum: [1.0, 0.9, 0.8, 0.7] Bästa träffsäkerhet 0.928 Optimala parametervärden vect__ngram_range: (1, 2) clfMLP__hidden_layer_sizes : (5, 100) clfMLP__solver: ‘adam’ clfMLP__learning_rate: ‘invscaling’ clfMLP__learning_rate_init: 0.01 clfMLP__momentum: 1.0 Pipeline pipeMLP_CV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfMLP__hidden_layer_sizes : [(5, 100), (10, 200), (30, 1000)] clfMLP__solver: [‘lbfgs’, ‘adam’, ‘sgd’] clfMLP__learning_rate: [‘invscaling’, ‘adaptive’] clfMLP__learning_rate_init: [0.01, 0.1, 1.0] clfMLP__momentum: [1.0, 0.9, 0.8, 0.7] Bästa träffsäkerhet 0.957 Optimala parametervärden vect__ngram_range: (1, 1) clfMLP__hidden_layer_sizes : (5, 100) clfMLP__solver: ‘sgd’ clfMLP__learning_rate: ‘adaptive’ clfMLP__learning_rate_init: 0.1 clfMLP__momentum: 1.0
Tabell 10: Optimala parametervärden för pipeSVC_CV och pipeSVC_TV för dataset “Real Data”, funna med hjälp av “Grid Search”. Pipeline pipeSVC_CV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfSVC__C: [1.0, 5.0, 10.0, 50.0, 100.0, 500.0, 1000.0] clfSVC__kernel: [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’] clfSVC__gamma: [0.000001, 0.00001, 0.0001, 0.001, 0.01, 0.1]
clfSVC__tol: [1e-3, 1e-4, 1e-5, 5e-6] Bästa träffsäkerhet 0.957 Optimala parametervärden vect__ngram_range: (1, 3) clfSVC__C: 5.0 clfSVC__kernel: ‘sigmoidr’ clfSVC__gamma: 0.001 clfSVC__tol: 0.001 Pipeline pipeSVC_TV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfSVC__C: [1.0, 5.0, 10.0, 50.0, 100.0, 500.0, 1000.0] clfSVC__kernel: [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’] clfSVC__gamma: [0.000001, 0.00001, 0.0001, 0.001, 0.01, 0.1]
clfSVC__tol: [1e-3, 1e-4, 1e-5, 5e-6] Bästa träffsäkerhet 0.943 Optimala parametervärden vect__ngram_range: (1, 3) clfSVC__C: 5.0 clfSVC__kernel: ‘linear’ clfSVC__gamma: 1e-06 clfSVC__tol: 0.001
Tabell 11: Optimala parametervärden för pipeSGD_TV och pipeSGD_CV för dataset “Real Data”, funna med hjälp av “Grid Search”.
Pipeline pipeSGD_TV
Testade
parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfSGD__loss: [‘hinge’, ‘log’, ‘modified_huber’,
‘squared_hinge’, ‘perceptron’]
clfSGD__penalty: [‘l2’, ‘l1’, ‘elasticnet’]
clfSGD__tol: [1e-3, 1e-4, 1e-5, 5e-6]
clfSGD__alpha: [1e-3, 1e-4, 1e-5] Bästa träffsäkerhet 0.961 Optimala parametervärden vect__ngram_range: (1, 3) clfSGD__loss: ‘hinge’ clfSGD__penalty: ‘l1’ clfSGD__tol: 0.001 clfSGD__alpha: 0.001 Pipeline pipeSGD_CV Testade parametervärden vect__ngram_range: [(1, 1),(1, 2), (1, 3)] clfSGD__loss: [‘hinge’, ‘log’, ‘modified_huber’,
‘squared_hinge’, ‘perceptron’]
clfSGD__penalty: [‘l2’, ‘l1’, ‘elasticnet’]
clfSGD__tol: [1e-3, 1e-4, 1e-5, 5e-6]
clfSGD__alpha: [1e-3, 1e-4, 1e-5] Bästa träffsäkerhet 0.964 Optimala parametervärden vect__ngram_range: (1, 3) clfSGD__loss: ‘perceptron’ clfSGD__penalty: ‘elastivnet’ clfSGD__tol: 0.001 clfSGD__alpha: 1e-05
Steg 4: Test av optimerade “pipelines”
I tabell 12 visas resultat från experiment med de olika “pipelinesen” med de från tidigare steg bästa funna parametervärden.
Tabell 12: Resultat från experiment med optimerade “pipelines”, dataset “Real Data”.
Pipeline Bästa uppnådda träffsäkerhet
pipeMNB_TV 0.915 pipeNu_TV 0.93 pipeMLP_TV 0.901 pipeSVC_TV 0.915 pipeSGD_TV 0.958 pipeMNB_CV 0.915 pipeNu_CV 0.958 pipeMLP_CV 0.887 pipeSVC_CV 0.944 pipeSGD_CV 0.901
3.2 Experiment med optimerad, tränad maskininlärning-modell
Baserat på resultatet från föregående experiment som visas i tabell 8 valdes att fortsätta experimentera med “pipelinen” “pipeNu_CV”, som bestod av klassificeraren svm.NuSVC och vektoriseraren CountVectorizer. Detta eftersom denna “pipeline”, tillsammans med “pipelinen” “pipeSGD_TV” gav bäst resultat i testerna av de optimerade “pipelines”. “pipeNu_CV” använder sig av en CountVectorizer, jämfört med “pipeSGD_TV” som använder en TfidfVectorizer. “pipeNu_CV” är därmed den enklare av de två, och valdes därför framför “pipeSGD_TV”. De optimala parametrar för datasetet “Real Data” som funnits genom “Grid Search” i föregående experiment användes för att i detta skede träna en modell i att klassificera svenska kursplaner, bestående av delana:- Syfte
- Kursinnehåll - Lärandemål
- Arbetsformer - Bedömningsformer
Detta var samma delar som experimenterades på i föregående steg, samt det som resultaten från föregående steg baseras på. Därför valde vi att fortsätta med de delar även i detta experiment. Modellerna tränades med klassificerad data från datasetet “Real Data”. Innan denna träning av modellerna togs dock 5 icke godkända och 5 godkända kursplaner bort från detta dataset, för att sedan kunna användas i följande experiment.
En terminalapplikation byggdes, vilken kan läsa in en till flera tränade maskininlärningmodeller och sedan låta en användare interagera med dem genom kommandon i terminalen. Applikationen möjliggjorde att skicka data till en tränad modell och få tillbaka ett svar på i vilken kategori denna data hade klassificerats av modellen, och med vilken säkerhet modellen gjort denna bedömning, uttryckt i procent. Denna terminalapplikation användes sedan för att testa att klassificera data från de 5 godkända och 5 icke godkända kursplaner som tagits bort ur datasetet innan modellerna tränades. Nedan följer en tabell som visar resultaten av detta experiment:
Tabell 13: Resultat av försök till klassificering av 10 kursplaner från datasetet “Real Data”, som modellen inte har tränats på sedan tidigare.
Test nr
Verklig klassificering Klassificering av tränad ML-modell
Sannolikhet för klassificering av ML-modell
1 Icke godkänd Icke godkänd 96%
2 Icke godkänd Icke godkänd 100%
3 Icke godkänd Icke godkänd 95%
4 Icke godkänd Icke godkänd 83%
5 Icke godkänd Icke godkänd 100%
6 Godkänd Godkänd 100%
7 Godkänd Godkänd 97%
8 Godkänd Godkänd 100%
9 Godkänd Godkänd 99%
3.3 Experiment med tränad klassificerare i ett mer verkligt
scenario
Ett slutgiltligt experiment utfördes med den tränade modellen för att försöka utröna hur väl modellen skulle prestera i ett mer verkligt scenario. Resultatet visas nedan i tabell 14. Alla kursplaner i tabellen var godkända och publicerade. I tabellen framgår en lärares bedömning av varje kursplan, och den tränade modellens bedömning av varje kursplan.
Tabell 14: Resultat av experiment med tränad modell, med kursplaner utanför datasetet som den tränats på, för att se hur bedömningen skiljer sig från en lärares bedömning.
Kursplan (Kurskod) Lärares bedömning (poäng) Modell klassificering Modell säkerhet
BG327A 10-12 Icke godkänd 84%
DA351A 11-12 Icke godkänd 82%
DA380A 9-10 Icke godkänd 89%
DA456A 11-12 Icke godkänd 80%
EK169A 11-12 Godkänd 86%
ME142A 12-13 Icke godkänd 88%
PD132A 11-12 Godkänd 90%
DA383A 6 Icke godkänd 85%
3.4 Experiment med “unsupervised learning
”
För experimenten med “unsupervised learning” användes data från de 1587 svenska kursplaner som hämtats från MAU:s hemsida och strukturerats i tidigare steg. En maskininlärningsmodell tränades med denna data, enligt strategin “unsupervised learning”, med hjälp av Python-biblioteket “gensim”. Delen av kursplaner som heter “Lärandemål” valdes att experimenteras på med hjälp av den tränade modellen i denna del av studien.
Enligt universitetets riktlinjer (Malmö Universitet, 2017) ska lärandemålen delas upp i underkategorierna:
- Kunskap och förståelse - Färdighet och förmåga
- Värderingsförmåga och förhållningssätt
I de insamlade kursplanernas del “Lärandemål” valde vi att med hjälp av den tränade modellen undersöka vilka ord-associationer som finns till orden i ‘Lärandemåls’ underrubriker, dvs till ’kunskap’, ’förståelse’, ’färdighet’, ’förmåga’, ’värderingsförmåga’ och ’förhållningssätt’. ’Värderingsförmåga’ och ’förhållningssätt’ fanns inte med i modellen, istället valdes ’värdera’ och ’förhålla’. Anledningen att orden inte finns med är att det genomfördes ett slags stemning. Om ett visst specifikt vokabulär används för vardera av dessa underrubriker så förväntas associationerna för dessa underrubriker skilja sig åt.
Tabell 15: Resultat av analys med “gensim”.
Testade ord Ordassociation 1 Ordassociation 2 Ordassociation 3 Ordassociation 4 Ordassociation 5
Kunskap Fördjupad: 0,976 Kännedom: 0,967 Visa: 0,967 Uppvisa: 0,966 Godkänd: 0,965
Förståelse Godkänd: 0,996 Kännedom: 0,980 Grundläggande:
0,974
Genomgången: 0,957
Kunskap: 0,955
Färdighet Fördjupad: 0,985 Metoder: 0,977 Visa: 0,974 Uppvisa: 0,963 Kännedom: 0,955
Förmåga Området: 0,969 Visa: 0,959 Lösa: 0,953 Relevanta: 0,944 Information 0,942
Värdera Enlighet: 0,975 Överväganden:
0,972
Vald: 0,972 Relevans: 0,970 Dra: 0,970
Förhålla Vetenskapligt:
0,993
Sammanställa: 0,990
4 Analys
4.1 Experimenten med Supervised learning
Resultaten av experimenten med supervised learning visade att maskininlärningmodeller kunde byggas vilka med en träffsäkerhet på 95,8% korrekt kunde klassificera kursplanerna i vårt dataset “Real data” enligt kategorierna “Godkänd” och “Icke godkänd”. De kombinationer av klassificerare och vektoriserare som gav bäst resultat för detta dataset var:
- SGDClassifier tillsammans med TfidfVectorizer Parametrar: - vect__ngram_range: (1, 3) - clfSGD__loss: ‘hinge’ - clfSGD__penalty: ‘l1’ - clfSGD__tol: 0.001 - clfSGD__alpha: 0.001
- svm.NuSVC tillsammans med CountVectorizer Parametrar:
- clfNu__gamma: 1e -06 - clfNu__nu: 0.3
- 'vect__ngram_range: (1, 3)
För datasetet “Transformed data” var siffran för träffsäkerhet på 100%. Att träffsäkerheten i att klassificera kursplanerna i datasetet “Transformed Data” låg på 100% var att förvänta om maskininlärningsmodellerna har tränats på rätt sätt, eftersom kvalitén på kursplanerna i de två kategorierna markant skilde sig åt. Denna siffra kan användas som en referenspunkt vid studerandet av resultaten för datasetet “Real data”. Om maskininlärningsmodellerna har tränats på rätt sätt borde klassificeringen av kursplanerna i detta dataset vara svårare och en lägre träffsäkerhet borde kunna observeras. Så blev även fallet i resultaten som uppnåddes. Detta är en indikator på att resultaten i dessa experiment har en koppling till verkligheten och inte bara är resultatet av slumpvisa gissningar av de tränade modellerna.
Ett slutgiltligt experiment utfördes för att utröna hur väl den tränade
klassificeringsmodellen skulle prestera i ett mer verkligt scenario. Resultaten presenterades i stycke 3.5. Ingen av kursplanerna som användes i experimentet fanns med i datasetet som klassificeringsmodellen hade tränats upp på. Kursplanerna fungerade alltså som helt ny input för modellen. I tabell 15 syns att den tränade modellen inte bedömde kursplaner på ett sätt som korrelerar med en lärares bedömning av kursplaner. De flesta av kursplanerna bedömdes som “Ej godkänd”, trots att alla dessa kursplaner är godkända och publicerade. Det finns heller inget tydligt mönster mellan hur lärarens poäng varierar och hur modellens klassificering och säkerhet varierar. Detta är en stark indikator på att modellen inte fungerar generellt, utan troligen enbart blivit bra på att
bedöma just de kursplanerna i datasetet som den har övat på.
4.2 Experimenten med Unsupervised learning
En “unsupervised” modell byggdes med data från de insamlade, godkända kursplanerna, och på denna modell undersöktes:
- Vilka ord-associationer finns till orden i ‘Lärandemåls’ underrubriker, dvs till ’kunskap’, ’förståelse’, ’färdighet’, ’förmåga’, ’värderingsförmåga’ och ’förhållningssätt’ ?
Malmö universitets riktlinjer säger att ‘Lärandemål’ ska vara indelat enligt de tre underrubrikerna:
- Kunskap och förståelse - Färdighet och förmåga
- Värderingsförmåga och förhållningssätt
Vidare bör olika terminologi användas för vardera underrubrik, enligt Blooms taxanomi. Med tanke på detta var förväntningen att ord-associationerna till ‘kunskap’ och ‘förståelse’ skulle till stor del överlappa, och skilja sig från de andra rubrikernas ord-associationer. På samma sätt borde ‘färdighet’ och ‘förmåga’ ha överlappande ord-associationer men skilja sig från de andra rubrikernas associationer, och ‘värderingsförmåga’ och ‘förhållningssätt’ borde fungera på samma sätt. Det visade sig dock inte vara fallet i resultatet. Kunskap’ och ‘Förståelse’, som är samma underrubrik, hade bara 2 gemensamma ord i sina ord-associationer (‘Kännedom’ och ‘Godkänd’). ‘Kunskap’ och ‘Färdighet’, vilka tillhör olika underrubriker, hade däremot 4 av 5 gemensamma ord-associationer (‘Fördjupad’, ‘Kännedom’, ‘Visa’ och ‘Uppvisa’). Nedan följer en tabell som visar antalet gemensamma ord-associationer för varje kombination av ordpar för de 6 orden i underrubrikerna:
Tabell 15: Antal gemensamma ordassociationer för orden som ska utgöra underrubriker i kursplanens del
“Lärandemål".
Kunskap Förståelse Färdighet Förmåga Värdera Förhålla Kunskap Förståelse 2 Färdighet 4 1 Förmåga 1 0 1 Värdera 0 0 0 1 Förhålla 0 0 0 0 1
I tabellen ovan (tabell 11) har de 3 cellerna där kombinationen av ord utgör en av ‘lärandemåls’ underrubriker markerats med grön färg. Dessa gröna celler borde haft tydligt högre siffror än resterande celler om man skulle kunna påstå att denna data visar att det finns en tydlig indelning av terminologi som används mellan de olika underrubrikerna. Så är dock inte fallet i resultaten som hittades. Tvärtom verkar inget tydligt stöd finnas i denna data för att ‘lärandemål’ faktiskt är indelad i dessa 3 underkategorierna, med specifik terminologi, i de kursplaner som modellen tränats på. Vid vidare analys kan man se att inget av orden i underrubrikerna har någon nära association till det andra ordet i samma underrubrik, förutom ‘Förståelse’ som faktiskt har en association till ‘Kunskap’. Troligen har denna rekommendation i många fall inte följts vid skrivandet och godkännandet av kursplaner. Detta stämmer överens med den uppfattningen som vi har fått av de många kursplaner som vi manuellt har granskat och läst igenom under studiens gång. En annan förklaring till att den data som genererades inte påvisar någon tydlig indelning i terminologi för dessa underrubriker skulle kunna vara att maskininlärningsalgoritmerna som har använts för dessa experiment inte har använts eller fungerat på rätt sätt.