Västerås, Sweden
Thesis for the Degree of Bachelor in Computer Science 15,0 hp
-DVA331
USING DOMAIN KNOWLEDGE FUNCTIONS
TO ACCOUNT FOR HETEROGENEOUS
CONTEXT FOR TASKS IN DECISION SUPPORT
SYSTEMS FOR PLANNING
Anton Roslund
ard15003@student.mdh.se
Examiner: Ning Xiong
Mälardalen University, Västerås, Sweden
Supervisor: Peter Funk
Mälardalen University, Västerås, Sweden
Supervisor: Ella Olsson,
Saab Group, Arboga, Sweden
Olov Candell,
Saab Group, Arboga, Sweden
Abstract
This thesis describes a way to represent domain knowledge as functions. Those functions can be composed and used for better predicting time needed for a task. These functions can aggregate data from different systems to provide a more complete view of the contextual environment without the need to consolidate data into one system. These functions can be crafted to make more precise time prediction for a specific task that needs to be carried out in a specific context. We describe a possible way to structure and model data that could be used with the functions.
As a proof of concept a prototype was developed to test a envisioned scenario with simu-lated data. The prototype is compared to predictions using min, max and average values from previous experience. The result shows that domain knowledge, represented as functions can be used for improved prediction.
This way of defining functions for domain knowledge can be used as a part of a CBR sys-tem to provide decision support in a problem domain where information about context is available. It is scalable in the sense that more context can be added to new tasks over time and more functions can be added and composed. The functions can be validated on old cases to assure consistency.
Contents
1 Introduction 4
2 Background 6
2.1 Machine Learning . . . 6
2.2 Big Data . . . 6
2.3 Artificial Neural Networks . . . 6
2.4 Case-Based Reasoning . . . 7
2.4.1 Case Representation and Organization . . . 8
2.4.2 Similarity and Retrieval . . . 8
2.4.3 CBR Knowledge Model . . . 9
2.5 Genetic Algorithms . . . 9
2.6 Digital Twins . . . 9
3 Related Work 11 3.1 Fault Diagnosis Based on Interactive Troubleshooting . . . 11
3.2 Prediction of Maintenance costs . . . 12
3.3 Condition Based Maintenance . . . 12
4 Problem Formulation 15 5 Method 16 5.1 Ethical and Societal Considerations . . . 16
6 Context Predictor 17 6.1 Context Rule Functions . . . 17
7 Prototype 20 7.1 Scenario . . . 20
7.2 Model Structure . . . 20
7.2.1 Task Model . . . 20
7.2.2 Atomic Task Model . . . 20
7.2.3 Case Model . . . 21
7.3 Synthesizing Data . . . 21
7.3.1 Data storage . . . 21
7.4 Comparison Predictor . . . 21
7.5 Context Rule Predictor . . . 22
7.5.1 High Level Implementation Details . . . 23
8 Results 25 8.1 Comparison . . . 25
8.2 Context Rule Function Predictor . . . 26
9 Discussion 27
10 Conclusions 27
11 Future Work 28
Refrences 30
List of Figures
1 An example of the structure of an artificial neural network . . . 7
2 The CBR cycle . . . 8
3 The Distribution of Knowledge in a CBR-System . . . 9
4 The user interface of Cassiopee . . . 11
5 Fault diagnosis model diagram . . . 12
6 Overview of the expert system for turbomachinery failure prognostics . . . 13
7 The proposed Fault diagnostic framework . . . 14
8 A Context Predictor . . . 17
9 A Simple Rule Function . . . 17
10 A Chainable Rule Function . . . 18
11 An Adapt Function . . . 18
12 A Sum Function . . . 19
13 Overview of a Context predictor . . . 19
14 Time predictions based on the team’s previous experience . . . 25
15 Time predictions based on all teams previous experience . . . 25
16 Time predictions based on an improvement function . . . 25
17 Time predictions based on knowledge of all context and its impact on the outcome 25
List of Tables
1 Task model properties and their description . . . 202 Case model properties and their description . . . 21
3 Parameters used to synthesize data for testing the prototype . . . 21
4 Time predictions based on the team’s previous experience . . . I 5 Time predictions based on the all teams’ previous experience . . . I 6 Time predictions based on an improvement function . . . I 7 Time predictions based on knowledge of all context and its impact on the outcome I
List of Source Code
1 The types used to represent a Context rule, the Context and Influence . . . 232 Example of a context rule function . . . 23
3 Example of a domain knowledge function . . . 23
4 How context rule functions can be composed together . . . 24
1
Introduction
SAAB Group is interested in how operational aircraft maintenance information systems of today could make more accurate predictions and be more agile in response to changes in the surround-ing environment. One approach is to utilize the information provided by the aircraft’s on-board Integrated Vehicle Health Management systems (IVHM) combined with past maintenance cases, big-data analytics and case based reasoning to provide maintenance diagnostics, prognostics and planning. For planning purposes prognostics in the from of time estimations, need to be provided for different maintenance tasks (corrective maintenance, preventive maintenance etc.) to create a decision support system (DSS) for scheduling. The duration of maintenance tasks is highly de-pendent on the available resources and other context information (e.g. weather, team experience, number of hours the team has worked before carrying out the maintenance). For planning purposes SAAB Group is interested in improving time prediction for maintenance tasks. The approach taken is to reuse experience from previously performed maintenance tasks to improve time prediction. Case Based Reasoning (CBR) has been used for maintenance tasks, e.g for fault diagnosis of air-craft and industrial robots [1][2]. The focus in previous maintenance systems is to guide and help the technicians perform maintenance, often in the form of a flowchart based on previous experi-ence and standardized procedures. Following the flowchart allows the user to perform maintenance tasks according to the guidelines. For corrective maintenance the flowchart allows the technicians to gradually eliminate components as possible fault sources and carry out necessary actions [1][3]. A case study [2] examines a Condition Based Maintenance (CBM) system for industrial robot fault diagnosis using CBR and sound analysis. The system implemented the first 4 levels of the OSA-CBM standard[4], thus prognostics and decision support was not implemented. In an expert system for turbomachinery[5] failure prognostics based on CBR prognostics where implemented. However, the prognostics where only tested with synthesized data since the real data provided at this stage did not contain enough information.
The context is the set of circumstances or facts that surround any given task. Some of these circumstances affect the outcome more than others. By accounting for some of the most vital circumstances more accurate predictions should be possible. It is often known how the most vital circumstances affect the outcome. This thesis explores how this knowledge can be used together with experience reuse to provide more accurate predictions.
To account for the context using domain knowledge we have explored a way to represent domain knowledge as functions and provide an accompanying data model. Our proposed representation is tested through a prototype implementation and the results compared to an implementation pro-viding statistics of historic data. The prototype was tested with synthesized data since we were unable to obtain real data; while not ideal it still demonstrates the potential of the representation. The function representing domain knowledge can be improved and made arbitrarily complex in order to match reality better. The focus in this work is not to come up with the perfect function using domain knowledge and experience to predict the time, but to show that the concept holds. Case Based Reasoning (CBR) is inspired by how humans solve problems by reasoning about simi-larities with previous experience. The solution from previous experience need to be adapted when the circumstances, context, are different. The proposed model for decomposing a task into smaller tasks and combining simple rules to make more complex rules could be used for accounting for the difference in context in higher detail. As an example a team has previous experience with a maintenance task outdoors during summer, however this time is is winter and they are missing a required spare part. These circumstances can be accounted for in different ways, e.g. looking up the order status/delivery time of the part, or recalling how much longer it took to perform the
task under similar conditions.
This thesis is structured as follows: In Section 2 information on machine learning, CBR and digital twins is given. Section 3 summaries some related work in the area of using CBR for maintenance. The problem formulation and research questions are presented in Section 4, research method and ethical considerations in Section 5. The context function structure is presented in Section 6. The developed prototype is described in Section 7 and the results of testing in Section 8. The thesis is concluded with discussion in Section 9 and some ideas of future work in section 11.
2
Background
2.1
Machine Learning
Machine learning is the study of computer systems that learn from experience. It aims to replace manual time-consuming tasks with automation. Machine learning is a big field with many different approaches which all share the same goal. Langley et al. [6] describes five paradigms for machine learning. • Neural Networks • Case-based Learning • Genetic Algorithms • Rule Induction • Analytic Learning
Neural Networks and Case-based Learning, also known as Case-based Reasoning (CBR), are de-scribed in detail in section 2.3 and 2.4 respectively.
Langley et al. [6] also state that the different paradigms historically come from different com-munities that use different metaphors. Neural networks use a metaphor that the nodes in a neural network represent neurons in the human brain. Genetic algorithms use metaphors based on evolu-tion. Words such as generation, population, parents and mutations are used. Case-based reasoning use analogies to human memory, in rule induction analogies to heuristic search and analytic learn-ing to formal logic. Langley et al. question whether this deviation benefits the field or if the different terminologies causes confusion.
2.2
Big Data
It is not uncommon for the term big data to be used interchangeably witch statistics, machine learning and data science [7]. In a technical report from 2001, D. Laney [8] explains the challenges data management, Volume, Velocity and variety, which have become known as the 3Vs that define big data [9]. There are also definitions that add a fourth V [10]. Volume refers to the amounts of data, Velocity to the speed at which data is gathered and/or must be acted upon and variety is the range of data types and sources [10]. Big data includes data sets of sizes beyond what commonly used tools are able to handle. [7].
Big data has many use cases for governments, companies and scientific research. Some exam-ples fields where big data is used are health care, national security, economics and particle physics. In the field of commerce big data is used to improve pricing strategies and advertisements. Wal-Mart have collaborated with Hewlett Packard to build infrastructure to handle and analyze the around 267 million transactions per day in Wal-Mart stores. Big data is also used in scientific research since scientific instruments generate huge amounts of data. The Large Synoptic Survey Telescope generate 30 trillion bytes of image data per day. The Large Hadron Collider, a particle accelerator at CERN can generate 60 terabytes of data per day. [10]
2.3
Artificial Neural Networks
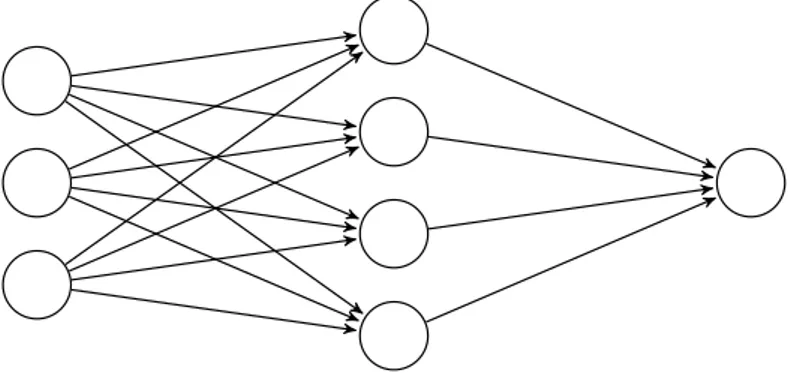
Artificial neural networks take data from an input layer and parse it through internal layers to an output layer. The internal layers are referred to as hidden layers. A neural network with multiple hidden layers is referred to as a deep neural network. A visual representation of an artificial neural network can be seen in Fig. 1. Each connection has weights which are combined with the input and run through an activation function to then be passed on to the outputs. If a neural network
has connections from layers to previous layers it is know as a recurrent neural networks. Training of the network can be done by updating the weights so desired results are achieved on the training data. Some challenges of neural networks include determining a stopping criteria for when to stop the training process and how to choose initial weights. [6][11, pp. 727-729][12]
Figure 1: An example of the structure of an artificial neural network
2.4
Case-Based Reasoning
Case-based reasoning (CBR) is a problem solving method inspired by how humans solve problems. Case-based reasoning is a branch of machine learning that takes into account information from previous experience. It is based on finding a previous case that resembles the current case as closely as possible. If the cases are similar, hopefully the solutions will be as well. The solutions can also be adapted to better fit the current case. [13][14]
A case is an experience of a solved problem. A case has two parts: a problem and a solution. In order to model an experience as a case there is no need to consider all aspects of the experi-ence. Only the important circumstances which impact the outcome and the aspects relevant to the solution need to be modeled, however they can be difficult to identify. A case base is a col-lection of cases is are stored in a case library. Cases can be represented in different ways. [15, Ch. 2] The advantage of case-based reasoning is that the algorithm imposes no demand on the size of the case base and continues to learn from new experience [16]. An experience only needs to be similar to a new problem to be able to be reused. For each new case, the solution will be saved. If the solution was not successful the reason for the failure is saved so it can be avoided in the future. In this way, all future cases can learn from the previous. The more experience stored in the case base, the better the solutions the algorithm suggest. [13]
What case-based reasoning refers to depend on the use case. For example; solving a problem by combining and adapting old solutions, explaining new situations based on previous situations or evaluating new solutions based on experience from previous cases [14]. These aspects can gener-ally be divided into five major types of case-based reasoning: classification, diagnosis, prediction, planning an configuration [15, Ch. 2]. However, in practice the line between the different classifi-cations is blurred and most implementations use a combination [14].
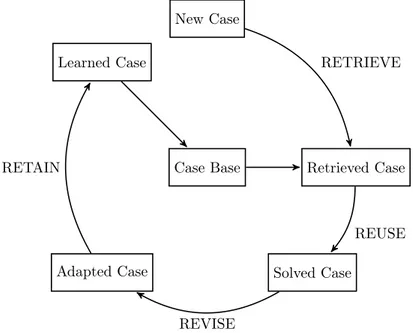
Aamodt et al. [13] describes the steps of problem solving using CBR, known as the CBR cy-cle, as follows:
1. RETRIEVE the most similar case or cases
3. REVISE the proposed solution
4. RETAIN the parts of this experience likely to be useful for future problem solving The CBR cycle starts with a problem, sometimes referred to as a query problem. The problem formulation is important, because it needs to capture the context in which it is stated, since the solution is dependant on context of the problem. A visual representation of the CBR cycle is provided in Fig. 2 [15, Ch. 2] Case Base New Case Retrieved Case Solved Case Adapted Case
Learned Case RETRIEVE
REUSE
REVISE RETAIN
Figure 2: The CBR cycle
The choice of how to represent a case is important, since problems are solved by recalling similar cases. Therefore searching previous cases and match them with the current problem need to be easy. The problem of representation boils down to deciding what to store and finding an appropriate way of storing the contents of a case. Storage, also known as case memory, is important since it need to be easy to retrieve a case and reuse the solution. [13]
2.4.1 Case Representation and Organization
A simple way to represent a case is by key-value pairs, also know as attribute-value or feature-value pairs. The solution can be represented in different ways: solution could contain just a value, or have a complex object oriented structure or include information about the strategy used to obtain the solution. [15, Ch. 2]
There are three main ways to organize cases: flat, structured and unstructured. A flat organization is simple to design and implement. Cases have no relationship between them. A flat organization is suitable for a small number of cases, since the complexity of determining similarity and retrieval is directly related to the number of cases. For a large number of cases it can be beneficial to use a structured organization where cases have relationships between them. It is common to structure cases in hierarchies and networks. [15, Ch. 2]
2.4.2 Similarity and Retrieval
The purpose of retrieval is to retrieve one or more cases from the case library which are similar to the new problem so the solutions can be reused. Determining similarity is referred to as similarity
assessment and is dependent on the use-case. The similarity assessment can be based on the similarity between attributes and relative relevance of each attribute. Each attribute requires a different similarity function depending on what type of value is stored. In some cases the value can either be equal or different, in other cases the value can have a degree of similarity. Not all attributes are equally, important so weights could be applied to the attributes. However, attributes may have relations to each other, adding complexity. [15, Ch 2]
Available Knowledge
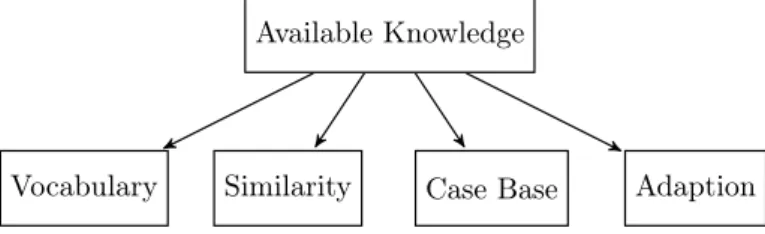
Vocabulary Similarity Case Base Adaption Figure 3: The Distribution of Knowledge in a CBR-System 2.4.3 CBR Knowledge Model
MM. Richter introduced the concept of knowledge containers in 1995 [17][18]. The concept uses four major kinds of knowledge: Vocabulary, Similarity, Case Library and Adaption knowledge and are shown in Fig. 3. These are stored in knowledge containers that contain certain knowledge units which in combination can help solve a problem. The vocabulary container contains knowledge about how to express knowledge. The similarity container contains knowledge about how two cases are similar, what and how to compare. The case base container contains experience in the from of cases. These cases can be from past experience or synthesized representative examples. The adaption container contains knowledge on how to adapt the existing solution to fit a new problem. [15, Ch 2][19]
2.5
Genetic Algorithms
Genetic Algorithms [11, pp. 126-129][20][21] are loosely based on evolution and ”Survival of the fittest”. There is a population of solutions, elements from the population, parents, are selected and combined to create a child. The child contains parts of the solutions of both parents, there is also a chance that the child is mutated. The algorithm then chooses if the child should be added to the population. Normally this is done based on the child’s fitness. Each cycle represents a generation. There are two types of genetic algorithms: stationary and generational. A stationary model works by letting the child compete with the population, while a generational model works by replacing the entire population each generation. The generational model can also use elitism which replaces the entire population except for the best individual.
There are many different models, strategies and parameters and which ones to choose is highly problem specific.
2.6
Digital Twins
The concept of using twins originates from NASA’s Apollo program. During this program at least two identical space vehicles were built, enabling the engineers to mirror the conditions of the ve-hicle in space on the twin on Earth [22]. The digital twin paradigm is a concept were one or more aspects of a physical object is represented as a digital model, a twin to the physical object. NASA has used the concept to create digital twins for their different vehicles, especially spacecrafts. The foundation of digital twins is created by integrating different physics based models with sensor
data and from the vehicle and also historic data from the vehicle and similar vehicles. [23] The digital twin can be used to display different health aspects of the vehicle in real time. By using physical models and machine learning the digital twin can simulate its health status for different courses of actions. This allows operating the vehicle to optimize for different aspects such as short time effectiveness or service life. [23]
3
Related Work
The following section provides some insight into some related work using CBR in the maintenance domain.
3.1
Fault Diagnosis Based on Interactive Troubleshooting
The Cassiopee project [1], launched in 1993, aimed at developing a decision support system (DSS) for maintenance of the engines used by the Boeing 737 aircraft. It uses inductive and case based reasoning (CBR) to derive solutions to maintenance problems. During the project induction was used, requiring structured data, to automatically build decision trees from previous cases. Induc-tion extracts knowledge from domain specialist by their behaviour as stored in previous cases. For engine maintenance a list of the parts used in order to solve the problem is stored.
The initial creation of the case library started with a maintenance database with 30, 000 mainte-nance instances. From the database 1500 failure cases where extracted. The extraction required manual labour by a team if maintenance specialists. The system was designed to be used by air-line maintenance crew, therefore much effort was spent on providing a user-friendly experience, including links to and illustrated parts catalogue and integration into Excel for statistics. Some parts of the user interface can be seen in figure 4.
Figure 4: The user interface of Cassiopee [1]
The research paper concluded that the system had achieved a state of maturity and was ready for validation by engineering staff or airlines.
The article[3] proposes using a combination of fault tree analysis (FTA) and Case based rea-soning (CBR) to diagnose failure in aircraft and quickly find the source. CBR is the most suitable choice for diagnostic of problems in the complex system that an aircraft is. In an aircraft the different systems and parts are dependant on each other making symptoms hard to diagnose. The aviation industry has accumulated massive amounts of knowledge on maintenance, but the case description is not standardized and unstructured. The structure and standardization of case data directly affects performance and correctness of the CBR system.
By using CBR in combination with FTA it is possible to provide the technicians with an in-teractive troubleshooting guide. An example of the troubleshooting steps can be seen in figure 5. Starting with a symptom, the system uses CBR to retrieve similar cases and from them build a
fault diagnosis model diagram, used to diagnose the problem. With each step cases that are not relevant get eliminated.
Figure 5: Fault diagnosis model diagram [3]
3.2
Prediction of Maintenance costs
J. S. Chou[24] compared four CBR approaches for estimating the cost of pavement maintenance projects. The approaches was compared according to their mean absolute prediction error rates. Chou implemented two methods for weighing the attributes, eigenvector weighting method (EM) and equal weighting method (EW). The total project cost can be estimated using four approaches. The first is by retrieving the nearest neighbour from the case library. The second and third is by retrieving the major work items reasoned-out with either equal weights or eigenvector weighting method. The fourth is estimated by, in addition to the eigenvector method using the best training folds for distinct work items, which obtained the most accurate estimation result with 6% mean absolute estimation error rate.
3.3
Condition Based Maintenance
There are two major types of maintenance: preventive and corrective maintenance. Preventive maintenance is performed in time intervals or dynamically, based on the condition of components. Performing maintenance on set time intervals in not optimal for the majority of components since they don’t have well-defined wear out regions. Condition Based Maintenance (CBM) is one so-lution to this issue. CBM is defined as maintenance actions based on real-time assessment of components, in order to perform maintenance when there is an obvious need. [2]
data acquisition, data processing, fault diagnosis, fault prognostics and decision support. Calcu-lating remaining useful life (RUL) is one of the key aspects of fault prognostics. Fault prognostics is a relative new domain and in the literature there are three major groupings of prognostics meth-ods, model-based methmeth-ods, data-driven, and case-based. The model-based methods are based on a mathematical model. ANN and fuzzy logic systems are examples of data-driven models. [25] The paper[2] describes the technical design of a CBM system according to The Open System Ar-chitecture for Condition Based Maintenance organization (OSA-CBM) proposed open standard. A case study was performed on a fault diagnosis system using CBR and sound analysis for industrial robot fault detection. The system in the case study implemented 4 of 7 layers in the OSA-CBM proposed standard. Prognostics and decision support are part of the layers not implemented. The system was able to correctly classify sounds in 90% of all tests. Fault diagnosis using CBR sound analysis was found to be feasible. It was concluded that the OSA-CBM approach is appropriate for developing a CBM system.
I. N. Ferraz et al.[5] presents their experience implementing an expert system for turbomachinery failure prognostics based on CBR. Turbomachinery systems are vital for the petroleum produc-tion on oil platforms. Therefor preventive maintenance is performed to reduce the risk of failure. Scheduled maintenance, while effective, is not optimal since when shutting down a turbomachine production ceases. To perform maintenance more effectively failure prognostics has been used. Failure prognostics has been implemented using different AI techniques such as neural networks, fuzzy systems and expert systems.
Figure 6: Overview of the expert system for turbomachinery failure prognostics [5] An overview of the system can be seen in figure 6. It is a modular system that uses vibration and petroleum flow data from sensors. The data from the sensors are pre-processed and trend values are extracted. The current case is compared to the case base and the three most similar cases are retrieved. A diagnostics module reaches a possible diagnosis and based on the trends a prognostics module presents the most probable date fot the machine to fail. The system store the context of what equipment the sensor readings where from, and uses weights to account for
similarity. However the good results obtained using context seems to have been because similar machinery have a similar frequency spectra, causing cases from those machines to be chosen. The authors conclude that the system provided very good prognostics when using synthetic data. They where unable to provide prognostics when using real data since the available data did not contain any failure dates.
Figure 7: The proposed Fault diagnostic framework [25]
A framework[25] for machine fault prognosis aims to integrate case-based and data-driven models and also use big data, to improve accuracy of predictions. The framework combines case-based reasoning (CBR) with adaptive neurofuzzy inference system (ANFIS), which is an integration of ANNs and fuzzy logic. In the learning phase an ANFIS model is created and trained for each case. During prognosis the ANFIS model of the most similar case(s) is selected. The framework was tested by predicting bearing faults. The tests demonstrated that the proposed framework performed better than the traditional ANFIS.
4
Problem Formulation
The context surrounding a task is always different. A learning system could potentially benefit from taking the context into account in both the retrieval and revise phases of the CBR cycle. In the retrieval phase, similarity of cases could be based on domain knowledge about similarity in context. In the revise phase, the solution could be adapted based on domain knowledge about the difference in context and how it influences the outcome. This leads to two research questions:
1. How can cases and domain knowledge be represented to improve problem solving in decision support for planning?
How context influences the outcome of a task might not be known initially. Thus it is important to be able capture context not previously considered without necessarily having to update old cases.
2. How can domain knowledge about similarity and adaptation be structured as functions to allow cases to have a heterogeneous set of context?
If cases are allowed to have a dynamic amount of context, the domain knowledge functions need to be able to handle cases with different context and missing context.
Different cases may have a different amount of context information available and new context information may arrive for cases at a later stage. By having, or creating domain knowledge functions, this can improve prediction for the time needed to perform a task. The domain knowledge can also fill in missing context information, e.g. if it is february the temperature is between -20 and 0, which may influence the time needed to complete a task.
5
Method
The foundation of this thesis is a literature review. The literature review focuses on machine learning, especially CBR, and on previous work within the area of using CBR in the context of maintenance. The purpose of the literature review is to get an understanding of CBR and to draw lessons from previous work.
Representations of cases and functions were created in an iterative process and explored by creat-ing a prototype. Due to the classified nature of data regardcreat-ing military equipment and operations, data was synthesized. The prototype was tested with a simplified maintenance scenario focusing on duration of tasks. The testing can be seen as a simulations. The generation of the data for the prototype uses a mathematical function to determine the duration. Comparison was made to a simple statistical prediction using historic data.
5.1
Ethical and Societal Considerations
Since this work is a literature review and an implementation of a prototype using synthesized data, we state there are no research ethical considerations.
6
Context Predictor
The context is the set of circumstances or facts that surround a particular task or case. Each time a task is performed it has a context. The context usually has the potential to influence the task. The context can be time, a location, the weather or which team is performs the task. The context is captured as a set of attributes.
A task has a context and an outcome. Since we are interested in time predictions the outcome is the time required to complete the task. What we call a Context Predictor is a set of functions that together produces a prediction given a context. Figure 8 gives a graphical representation of a Context Predictor.
Figure 8: The concept of a Context Predictor. It takes a context and outputs a prediction
6.1
Context Rule Functions
To account for the influence the context has on the outcome we propose a structure for functions to apply domain knowledge to account for the context. Domain knowledge is knowledge related to a specific field. The domain knowledge we focus on is knowledge of cause and effect, how context influences outcomes. This will be different in different problem domains. The domain knowledge is captured as Context Rule Functions that given a context outputs an influence.
The concept of a simple Context Rule Function can be seen in figure 9. The Rule receives the entire context as a set of attributes. The Rule should account for as few attributes as possible. In some cases multiple attributes need to be coincided in the same function e.g harsh weather might greatly affect the duration of a task, but only if the task if performed outdoors. The output of a Rule is the influence the attributes of the context the rule treated.
Figure 9: A simple rule function, which accounts for part of the context and outputs the influence the part has
Since each individual rule should account for as few attributes as possible rules needs the ability to be composed, chained together. To allow the Context Rule functions to be composed they must have the same input as output. This results in the functions taking the context and influ-ence as input and output as seen in figure 10. This allows the creation of more complex rules by composing multiple Context Rule Functions while keeping the base rules easy to survey and curate. When we have multiple chained Context Rule Functions as single rule can account for none, one,
or multiple attributes of the context. If the context the rule treats is not available the function could just, act as an identity function, passing its input along to the next rules.
The output of a Context Rule function is what we call Influence. It is a set of times estimates that together form a prediction. It is a set because the context can affect different parts of the task. As an example: the time required for collecting the necessary tools might be affected by the storage location of the tools, while the time required to preform the task is unaffected.
Figure 10: A Chainable Rule Function. Allowing multiple Rule Functions to be chained together Since the rules output both the context and influence a rules has the ability to could alter the context in addition to the influence. This allows rules to add context, such as part inventory, or remove context if something is not relevant. However, changing the context could be both powerful and dangerous since the order of functions matter because composition is not commutative. One use of rules that add context is making predictions form previous experience. If previous experiences are stored a rule could recall the context and duration of the most similar previous ex-perience. Then subsequent rules could make a prediction of the difference in context to the current task. Another use is adding context information from other systems, such as a part inventory.
Figure 11: An Adapt Function which propose is to serve as the first link in the chain Since the chainable rules have multiple input and outputs two special functions are required. The first is what we call an Adapt Function, a visual representation can be seen in figure 11. The Adapt Functions purpose is to serve as the first link in the chain. It takes a context and returns it together with an empty influence. The other special function is the last function in the chain. We call it an Influence Sum Function, a visual representation can be seen in figure 12. The Influence Sum Function has two purposes. When all rules have been applied, the context is no longer necessary, so the function completely ignores the context. The second purpose is to turn the set of influence into a prediction. Since we are working with time predictions each entry of the influences is a time, therefore the function just sum all time entries and returns it as a prediction.
Figure 12: The Sum Function ignores the context and sum the influence to output a prediction As an example, in figure 13 an overview of a Context Predictor with four Context Rule Functions can be seen. It receives the context as a set of attributes, the Adapt function appends an empty set of Influence. The first rules in the chain could be adding context while the rest of the rules could gradually append information to the Influence. Finally the Sum Function sums all the influences and output a prediction.
7
Prototype
To test our model and domain knowledge representation we have developed a prototype. The prototype is written in the programming language Swift. The prototype works with the problem of teams performing maintenance tasks. It estimates the time required for a specific team to com-plete a specific maintenance task based on previous cases from that and other teams. This is a highly simplified problem using synthesized data that contains a learning trend for all teams and difference in team performance.
The prototype will make predictions using domain knowledge. It uses the context of which task is being performed, by what team and how many times the team has previously performed that task.
7.1
Scenario
The prototype will test a specific scenario. There is a number of teams that all perform tasks. All teams perform all tasks an equal amount of times. Each task has a time specified. All teams differ in effectiveness resulting in tasks taking a different amount of time (time required to execute the task). In this scenario we also simulate that the teams improve for each time they perform a task. The scenario is simplified and contains no layered tasks. The scenario is just used to test the prototype and not representative of a real world scenario. In a real world application much of the context would be unknown and incorrect data needed to be accounted for. Using the number of times a team has performed a task would be problematic in a real world application, individuals could change teams and teams could have experience from before the collection of data started.
7.2
Model Structure
The problem the prototype works with requires three clear models: Task, Team and Case. The prototype has an additional model, Case Library that is used as a container to store and transport data.
7.2.1 Task Model
In our model a task has an ID, name, context, and a set of requirements. The structure of the task is shown in table 1. The requirements need to be fulfilled in order to complete the task. Requirements could be tools, resources, consumables, LRUs, staff. Requirements could also be other tasks needed to be performed in order to complete the task. The structure would allow to recursively compose tasks which will allow reasoning about tasks previously not performed together.
ID A unique identifier Name Describing name
Context Additional information about the task Requirements What is required to complete the task Table 1: Task model properties and their description 7.2.2 Atomic Task Model
An atomic task is a task that is not composed of other tasks. This is the smallest task the system works with. Normally, duration of the atomic task is not being recorded, this is because the task is normally performed as a part of a bigger task.
7.2.3 Case Model
Experience from previous cases will be stored in the case library. When a task is executed infor-mation about the execution will be stored as a case.
Task What Task was "solved" Context Any context documented Status Completed /Aborted / Failed Duration The Duration of the case Notes Potential notes about the case Table 2: Case model properties and their description
7.3
Synthesizing Data
The data used for testing was synthesized since access to real data was not possible. Tasks, teams and cases were all synthesized and stored in a case library. All parameters used when synthesizing data were stored in a separate file: constants.swift. The parameters used during testing are specified in table 3.
Task duration 10 ... 240 minutes
Teams 3 times
Tasks 3
Team skill 50% ... 150% Task repetition 20 times
Table 3: Parameters used to synthesize data for testing the prototype
Each task is generated with a nominal time. The time is chosen at random from a given interval. Each team is given a skill multiplier to simulate that the effectiveness of teams are different. To simulate that a task is performed faster the more previous experience a team has with a task, the following formula was used when generating cases:
( 1 2x−2 + 1 2) · t e (1)
Where x is the x’th time the task is performed, t is the nominal time specified for the task and e is the effectiveness of the team.
7.3.1 Data storage
To test both predictors using the same data, serializing and deserializing JSON was implemented for all models. This allows for transferring the data and saving and loading from file. The serial-ization is implemented as an extension to the Encodable protocol, deserialserial-ization as an extention to the Decodable protocol. This gives any model conforming to the Codable protocol the methods save(to:)and load(from:).
7.4
Comparison Predictor
As as comparison a simple predictor was created, it predicts the time required to perform a task by ether using previous instances of the same task performed by the same team, or the same task performed by all other teams. The prediction contains three parts, the minimum, maximum and average time.
7.5
Context Rule Predictor
The context rule predictor we crated for this scenario uses two context attrebutes, the task and the team. It also has access to the case library for experience reuse. The predictor consists of three context rule functions. The first rule looks up the nominal time of the task and adds the nominal time as context, similar to listing 2. The next function uses the context of the team and checks the case library for how many times the task has been performed by the team. The third context rule function uses the extra context provided by the previous functions in the formula in equation 2.
( 1 2x−2 +
1
7.5.1 High Level Implementation Details
For context rule functions the context and influence is structured as a dictionary containing key-value pairs, using Strings as key to identify the specific context and an Any type for the key-value. The Any type as value allows any type or object to be represented, everything from simple value types as Ints or Strings to Sets or Object-oriented objects. In our specific problem domain, when working with time, the influence is type cast to a Time type that is a dictionary with Minutes as the value. To be able to compose functions together, they take and return a tupel of Context and Influence. The structure as defined in the programming language Swift can be seen in listing 1.
1 typealias Context = [String: Any] 2 typealias Influence = [String: Any]
3 typealias ContextRule = ((Context, Influence)) -> (Context, Influence) Listing 1: The types used to represent a Context rule, the Context and Influence
As seen in the type definition in listing 1 a context rule is a function which takes and return a tupel of Context and Influence. An example of how such a function could look is shown in listing 2. It is a function which checks if a taskID is provided as context, looks up the task in a database and adds the tasks nominal time as context to be used by other functions.
1 func nominalTime(input: (context: Context, influence: Influence))
2 -> (Context, Influence) {
3 guard let taskID = input.context["taskID"] as? Int else { 4 return input
5 }
6
7 let task = Database.Task(WhereIdEquals: taskID) 8
9 var output = input
10 output.context["nominalTime"] = task.nomanellTime 11 return (output)
12 }
Listing 2: Example of a context rule function
Context rule functions can be grouped together in an array, either to make a predictor or create more complex rules. An example of an array of functions can be seen in listing 3. The composition, chaining, of functions is achieved by performing a reduce on an array och context rule functions using the identity function. The code for the chaining is shown in listing 4.
1 let contextRules: [ContextRule] = [
2 adaptFunction // Special function to adapt input 3 nominalTime, // Example context rule function
4 nominalTimePlus20percent // Example context rule function
5 sumFunction // Special function to fum influence and provide prediction 6 ]
1 // Identity function 2 func id<A> (a: A) -> A { 3 return a
4 } 5
6 let contextPredictor = contextRules.reduce(id) { (f1, f2) in 7 return { a in f1(f2(a)) }
8 }
Listing 4: How context rule functions can be composed together
The last function in the chain, the sum function, is responsible for tunging the dictionary into a prediction. How to turn the influences into a prediction is problem specific. When working in a problem domain requiring time estimations, a function summing all values could be used, as seen in listing 5. The entire dictionary with a sum of the values could also be provided to give some insight into the prediction.
1 typealias Time = [String: Double] 2
3 func sumFunction(input: (context: Context, influence: Influence)) -> Double { 4 let timeInfluence = input.influence as! Time
5 let times = Array(timeInfluence.values) 6 return times.reduce(0, +)
7 }
8
Results
In this section the prediction results from the prototype and the comparison predictor is presented. The data the diagrams are based on are presented in table form in Appendix A. The predictions are made based on the synthesized data for the scenario described in section 7.1.
0 5 10 15 20 100 200 300 400 Case Number Duration Actual Min Max Avg
Figure 14: Time predictions based on the team’s previous experience
0 5 10 15 20 0 200 400 600 Case Number Duration Actual Min Max Avg
Figure 15: Time predictions based on all teams previous experience 0 5 10 15 20 0 200 400 Case Number Duration Actual prediction
Figure 16: Time predictions based on an im-provement function 0 5 10 15 20 100 200 300 400 Case Number Duration Actual prediction
Figure 17: Time predictions based on knowl-edge of all context and its impact on the out-come
8.1
Comparison
Fig. 14 depicts the time prediction for one team performing a task, based on previous experience. For the first prediction no previous data is available. Therefore the first prediction is based on the nominal time of the task multiplied by 2.5. Making a prediction with one previous data point causes the minimum, maximum and average value to equal. Since the team continues improving the max value will stay and the min value will be the closest.
In Fig. 15 the prediction is based on all previous teams experience with the task. What is interesting here is that the task being predicted is the task with the shortest duration causing the minimum and average values to decline.
8.2
Context Rule Function Predictor
In Fig. 16, the prediction is based on domain knowledge about how teams improve as they gain experience. Since the data is synthesized we have exact knowledge of the rate of improvement. The prediction is good but not perfect since it does not account for the variance in performance of teams. In Fig. 17 the variance is also taken into account resulting in a perfect prediction. This is because it is a simplified simulation of a scenario where all circumstances and their impact is known.
9
Discussion
The representation is possible to use and provides the ability to layer tasks. It is also possible for the case base to have a heterogeneous set of attributes. However, storage and performance of the representation were not considered.
Context Rule Functions work with dictionary’s, allowing for an arbitrary amount of data to be used. This allow cases to contain an arbitrary amount of context. The context stored for each case in the case library does not need to be the same. This allows for future cases to be stored with more context while still allowing and making use of old cases which do not have as much context. It also allows for different types of cases to be stored in the same case library. Since the functions take and return the same type they can be chained together using function composition. Domain knowledge can be decomposed into multiple functions, this allows a function to only account for a single circumstance. This could help structure and curate domain knowledge.
The prototype demonstrates that representing domain knowledge as functions is possible. The exact scenario tested is an oversimplified simulation, in reality all the circumstances or facts, con-text, surrounding a task would not be known. The representation of domain knowledge is to be used to account for the most influential context. This will allow more accurate predictions by providing context attributes to be used for determining similarity and adapt the retrieved case for the set of circumstances surrounding the new problem.
10
Conclusions
We conclude that is is possible to represent domain knowledge as context functions. Decomposition of domain knowledge into multiple functions could allow for easier structuring and curating of the knowledge. Function composition could allow for creating arbitrary complex functions.
Chaining rules and working with sets of data allows rules to account for the when context in-formation is missing. Additionally, new rules can be added to the chain to account for when new context information is captured.
The context rule functions can be used to add more context before making a prediction. A rule could be used to retrieve context information from other systems, such as part inventory. A context rule can also be used to retrieve similar previous experiences, while subsequent rules can account for difference in context to provide and experience based prediction.
11
Future Work
While the testing we have done so far looks promising there is still much more to explore. For example accounting for parallelism, e.g. some tasks can be performed in parallel, in other cases, two technicians can work on the same work.
The prototype works well with synthesized data. However, the synthesized data contains the context and correlations we choose. Having knowledge of how the data was synthesized makes it a trivial problem predicting how it behaves. Extensive testing needs to be carried out using real data. To create domain knowledge functions, collaboration with domain experts in problem domain is needed.
Another area to explore is integration with different IoT devices directly and exploiting their sensor data. Whats is even more interesting is to work with a digital twin to the IoT device, this allows asking the digital twin for predictions in different context.
The outcome, answer, to a prediction of a problem becomes available when the problem is stored in the case library. While having the answer in the case library could improve future predic-tion, it also gives the opportunity to use the answer to improve the functions used for adaption. Since there could be many functions contributing to the adaption this becomes a complex problem. When the functions become too many and too complex, the basis of a prediction is a black box. Neural networks have the same problem, when they become too complex it is hard to tell what caused them to give a specific output. Some insight into the process could be given if each adaption function also provides a motivation.
References
[1] R. Heider, “Troubleshooting cfm 56-3 engines for the boeing 737 using cbr and data-mining,” in Advances in Case-Based Reasoning, I. Smith and B. Faltings, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1996, pp. 512–518.
[2] M. Bengtsson, E. Olsson, P. Funk, and M. Jackson, “Design of condition based maintenance system—a case study using sound analysis and case-based reasoning,” Condition Based Main-tenance Systems—An Investigation of Technical Constituents and Organizational Aspects; Malardalen University: Eskilstuna, Sweden, p. 57, 2004.
[3] X. P. Yu, Q. L. BeiHang, and X. Hu, “Aircraft fault diagnosis system research based on the combination of cbr and fta,” in 2015 First International Conference on Reliability Systems Engineering (ICRSE), Oct 2015, pp. 1–6.
[4] MIMOSA. Open system architecture for condition-based maintenance. Accessed: 2018-05-21. [Online]. Available: http://www.mimosa.org/mimosa-osa-cbm
[5] I. N. Ferraz and A. C. B. Garcia, “Turbo machinery failure prognostics,” in Modern Advances in Applied Intelligence, M. Ali, J.-S. Pan, S.-M. Chen, and M.-F. Horng, Eds. Cham: Springer International Publishing, 2014, pp. 349–358.
[6] P. Langley and H. A. Simon, “Applications of machine learning and rule induction,” Commun. ACM, vol. 38, no. 11, pp. 54–64, Nov. 1995. [Online]. Available: http: //doi.acm.org/10.1145/219717.219768
[7] A. Mockus, “Engineering big data solutions,” in Proceedings of the on Future of Software Engineering, ser. FOSE 2014. New York, NY, USA: ACM, 2014, pp. 85–99. [Online]. Available: http://doi.acm.org/10.1145/2593882.2593889
[8] D. Laney, “3D data management: Controlling data
vol-ume, velocity, and variety,” META Group, Tech. Rep., Febru-ary 2001. [Online]. Available: http://blogs.gartner.com/doug-laney/files/2012/01/ ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf
[9] A. Abelló, “Big data design,” in Proceedings of the ACM Eighteenth International Workshop on Data Warehousing and OLAP, ser. DOLAP ’15. New York, NY, USA: ACM, 2015, pp. 35–38. [Online]. Available: http://doi.acm.org/10.1145/2811222.2811235
[10] C. L. P. Chen and C.-Y. Zhang, “Data-intensive applications, challenges, techniques and tech-nologies: A survey on big data,” Inf. Sci., vol. 275, pp. 314–347, 2014.
[11] S. J. Russell and P. Norvig, Artificial intelligence: a modern approach, 3rd ed. Malaysia: Pearson Education Limited, Apr 2016.
[12] M. Flasiński, Introduction to artificial intelligence. Springer, 2016.
[13] A. Aamodt and E. Plaza, “Case-based reasoning: Foundational issues, methodological variations, and system approaches,” AI Commun., vol. 7, no. 1, pp. 39–59, Mar. 1994. [Online]. Available: http://dl.acm.org/citation.cfm?id=196108.196115
[14] R. L. de Mantaras, Case-Based Reasoning. Berlin, Heidelberg: Springer Berlin Heidelberg, 2001, pp. 127–145. [Online]. Available: https://doi.org/10.1007/3-540-44673-7_6
[15] M. M. Richter and R. O. Weber, Case-Based Reasoning A Textbook. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013.
[16] E. Olsson, P. Funk, and N. Xiong, “Fault diagnosis in industry using sensor readings and case-based reasoning,” Journal of Intelligent & Fuzzy Systems, vol. 15, no. 1, pp. 41–46, 2004. [17] M. M. Richter, The knowledge contained in similarity measures, 1995.
[18] M. M. Richter and R. O. Weber, Case-based reasoning. Springer, 2016.
[19] M. M. Richter and A. Aamodt, “Case-based reasoning foundations,” The Knowledge Engi-neering Review, vol. 20, no. 3, p. 203–207, 2005.
[20] T. Bäck and H.-P. Schwefel, “An overview of evolutionary algorithms for parameter optimiza-tion,” Evol. Comput., vol. 1, no. 1, pp. 1–23, Mar. 1993.
[21] K. S. Tang, K. F. Man, S. Kwong, and Q. He, “Genetic algorithms and their applications,” IEEE Signal Processing Magazine, vol. 13, no. 6, pp. 22–37, Nov 1996.
[22] S. Boschert and R. Rosen, Digital Twin—The Simulation Aspect. Cham: Springer International Publishing, 2016, pp. 59–74. [Online]. Available: https://doi.org/10.1007/ 978-3-319-32156-1_5
[23] E. Glaessgen and D. Stargel, The Digital Twin Paradigm for Future NASA and U.S. Air Force Vehicles, ser. Structures, Structural Dynamics, and Materials and Co-located Conferences. American Institute of Aeronautics and Astronautics, Apr 2012, 0. [Online]. Available: https://doi.org/10.2514/6.2012-1818
[24] J. S. Chou, “Applying ahp-based cbr to estimate pavement maintenance cost,” Tsinghua Sci-ence and Technology, vol. 13, no. S1, pp. 114–120, Oct 2008.
[25] F. Cheng, L. Qu, and W. Qiao, “A case-based data-driven prediction framework for machine fault prognostics,” in 2015 IEEE Energy Conversion Congress and Exposition (ECCE), Sept 2015, pp. 3957–3963.
Appendix A
Results of the testing of the prototype are presented in the following tables. The testing consisted of predicting task duration based on previous experience. Time represents the X’th time the task was performed. Actual is the actual time the task took to perform.
time actual min max avg 1 404 305 305 305 2 224 404 404 404 3 134 224 404 314 4 89 134 404 254 5 67 89 404 212 6 56 67 404 183 7 50 56 404 162 8 47 50 404 146 9 46 47 404 133 10 45 46 404 124 11 45 45 404 116 12 45 45 404 109 13 45 45 404 104 14 45 45 404 99 15 45 45 404 95 16 45 45 404 92 17 45 45 404 89 18 44 45 404 86 19 44 44 404 84 20 44 44 404 82
Table 4: Time predictions based on the team’s previous experience
time actual min max avg 1 404 70 652 128 2 224 70 652 134 3 134 70 652 137 4 89 70 652 136 5 67 70 652 135 6 56 67 652 134 7 50 56 652 132 8 47 50 652 130 9 46 47 652 129 10 45 46 652 127 11 45 45 652 125 12 45 45 652 124 13 45 45 652 122 14 45 45 652 121 15 45 45 652 119 16 45 45 652 118 17 45 45 652 117 18 44 45 652 115 19 44 44 652 114 20 44 44 652 113
Table 5: Time predictions based on the all teams’ previous experience
time actual prediction 1 404 549 2 224 305 3 134 183 4 89 122 5 67 91 6 56 76 7 50 68 8 47 64 9 46 62 10 45 61 11 45 61 12 45 61 13 45 61 14 45 61 15 45 61 16 45 61 17 45 61 18 44 61 19 44 61 20 44 61
Table 6: Time predictions based on an improvement function
time actual prediction 1 404 404 2 224 224 3 134 134 4 89 89 5 67 67 6 56 56 7 50 50 8 47 47 9 46 45 10 45 44 11 45 44 12 45 44 13 45 44 14 45 44 15 45 44 16 45 44 17 45 44 18 44 44 19 44 44 20 44 44
Table 7: Time predictions based on knowl-edge of all context and its impact on the out-come
![Figure 4: The user interface of Cassiopee [1]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4864831.132489/12.892.301.581.527.778/figure-the-user-interface-of-cassiopee.webp)
![Figure 5: Fault diagnosis model diagram [3]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4864831.132489/13.892.205.690.194.644/figure-fault-diagnosis-model-diagram.webp)
![Figure 6: Overview of the expert system for turbomachinery failure prognostics [5]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4864831.132489/14.892.215.677.622.940/figure-overview-expert-turbomachinery-failure-prognostics.webp)
![Figure 7: The proposed Fault diagnostic framework [25]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4864831.132489/15.892.152.737.304.508/figure-the-proposed-fault-diagnostic-framework.webp)



