1
Examensarbete
15 högskolepoäng, grundnivåTillämpning av Data
Mining för effektivisering av
planlösningen på
akutmottagningen vid Skånes
universitetssjukhus
Teknik och
samhälle
Datavetenskap
Applying Data Mining for improving the construction plan at Skånes
universitetssjukhus
Erik Erelöf
Henrik Klein
2
Sammanfattning
Socialstyrelsen (2015) visar i en rapport från 2015 att tiden en patient vistas på en akutmottagning ökar för varje år. Detta gäller vid alla akutmottagningar i Sverige. Den här studien syftar till att undersöka hur data mining kan appliceras för att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus med hjälp av positioneringsdata. Genom att effektivisera planlösningen kommer vistelsetiden för patienter att minska.
TagOn är ett forskningsprojekt, vars syfte är att samla in positioneringsdata från Skånes universitetssjukhus. Positioneringsdata från olika objekt, som exempelvis katetervagn, thoraxdrän och akutväska samlas in genom ett Internet of Things-baserat system. I vår studie har sedan data hämtats genom olika anrop till API:et som TagOn:s system tillhandahåller. Detta görs genom Postman, som är ett verktyg för att hämta data från olika API:er. Rådata som hämtades från TagOn gjordes sedan om till CSV-filer. Filerna kunde sedan analyseras med hjälp av data mining. Efter att gått igenom processen informationsupptäckt från data, tillämpades algoritmen simple K- means för att klustra ihop positioneringsdata. När sedan data från TagOn analyserats i Weka visualiserades resultatet för varje objekt i form av koordinater, där objektets omkrets för hur det rört sig visas. Koordinaterna mappas till akutmottagningen vid Skånes universitetssjukhus verkliga position. Därefter har två utgångspunkter för de olika objekten tagits fram. Den ena utgångspunkten är mittpunkten för det område objektet befunnit sig i, inom en viss tidsperiod. Den andra utgångspunkten är det område som objektet befunnit sig mest i under en viss tidsperiod. Resultatet visar på att det med hjälp av data mining går att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus.
3
Abstract
The National Board of Health and Welfare (2015) shows in a report from 2015 that the time a patient stays at an emergency reception increases for every year. This applies to all emergency receptions in Sweden. With this study we want to show how one can apply data mining to streamline the construction plan at the emergency reception in Skånes universitetssjukhus with indoor positioning data. TagOn is a research project, with the purpose of collecting data from the emergency reception at Skånes universitetssjukhus. TagOn collects data from different objects that exist within this emergency reception through an Internet of Things system. Data has then been collected from this system by different calls to the API that TagOns’ system provides. This was done through Postman, which is a tool for collection of data from an API. The raw data we collected was later converted into CSV-files. The CSV-files could later be analyzed with data mining. After doing the Knowledge Discovery from Data process, we applied the algorithm simple K- means with clustering. Later on, when the data from TagOn had been analyzed in Weka, the result was displayed for each of the objects in form of coordinates, for where the object's perimeter is displayed. The coordinates were later mapped to the emergency reception at Skånes universitetssjukhus real position. Based on these coordinates, two starting-points could be found. One starting-point is based on the center for where the area where the object has been. The other starting-point is based on where the object has been the most during a specific time-period. The result shows that with applying data mining, it is possible to make the construction plan more effective.
4 Sammanfattning 2 Abstract 3 1. Inledning 5 1.1. Syfte 6 1.2. Frågeställning 6 1.3. Tidigare arbeten 6 1.4. Avgränsningar 7 2. Teoretisk bakgrund 7 2.1. Data Mining 7
2.2. Knowledge Discovery from Data 8
2.3. Klusteranalys 9 2.4. Simple K- means 9 3. Metod 10 3.1. Klusterproblembeskrivning 12 3.2. Litteratursökning 14 3.3 Metoddiskussion 17 4. Resultat 18 4.1. Akutväska 19 4.2. Thoraxdrän 22 4.3. Katetervagn 25 4.4. Sammanfattning 28
5. Analys och Diskussion 28
5.1. Fortsatta studier 29
6. Slutsats 29
5
1. Inledning
Socialstyrelsens rapport (Socialstyrelsen, 2015) visar att tiden en patient vistas på en akutmottagning ökar för varje år. Från 2 timmar och 28 minuter år 2010 till 2 timmar och 59 minuter år 2015. Vidare, pekar Socialstyrelsens (2015) också på att anledningen till att väntetiderna blir allt längre grundar sig i både personalbrist men också i brist på lokaler, där både patientsäkerhet och vistelsetiden påverkas. I syfte att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus kommer studien att använda sig av positioneringsdata från forskningsprojektet TagOn. Genom att analysera tre olika objekts rörelseområden vill vi hitta utgångspunkter där objekten behöver röra sig så lite som möjligt. Detta sparar tid till personal och på så sätt minskas vistelsetiden för patienter.
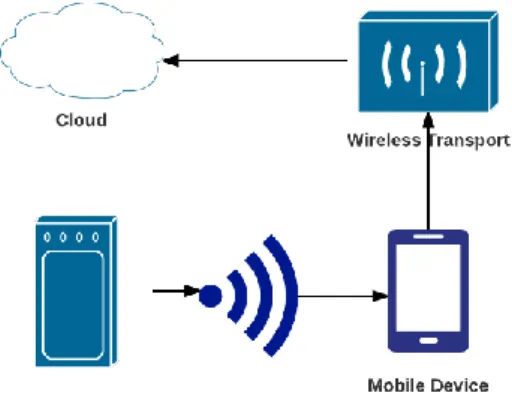
Projektet TagOn samlar in positioneringsdata inom sjukvården på objekt, personal och patienter. Målet är att göra sjukvården säkrare och effektivare. För att samla in data använder sig TagOn av ett system som är baserat på Internet Of Things (IoT). Det IoT-baserade systemet är utvecklat av Sony Mobile i samarbete med Mobile and Pervasive Computing Institute. Datainsamlingen görs med hjälp av Bluetooth Low Energy-enheter. Med hjälp av knutpunkter som utgörs av mobiltelefoner samlas data in och lagras i en molntjänst (TagOn, 2015).
Figur 1: Illustration av hur TagOn samlar in data.
Enligt Liu et al. (2007) är system för inomhuspositionering till för att lokalisera olika objekt. Användningsområdet av inomhuspositionering är stort och är något som kan tillämpas i många olika miljöer. Systemen som används tenderar att använda olika tekniker. Ett exempel på en sådan teknik är Radio Frequency Identification (RFID). Val av teknik grundar sig i vad systemet ska kunna göra och är därför en avgörande roll för hur väl lokaliseringen fungerar.
Tidigare forskning visar att inomhuspositionering har använts i sjukhusmiljöer (Liu et al, 2007; Gu et al, 2009). Vidare, har data mining tillämpats på positioneringsdata. Dock har det inte hittats någon tidigare forskning då syftet varit att effektivisera en viss faktor, så som planlösningen. Därför ser vi ett forskningsgap där data mining tillämpas på positioneringsdata i syfte att effektivisera planlösningen på akutmottagningar.
Med denna studie vill vi hitta rörelseområden i hur objekt på akutmottagningen vid Skånes universitetssjukhus rör sig för att kunna effektivisera planlösningen. De
6 olika rörelsemönstren hittas genom data mining och existerar i positioneringsdata. Data mining är ett av stegen i Knowledge Discovery from Data (KDD). KDD är en iterativ process för att extrahera meningsfull information från given data (Han et al, 2012).
Utdata från KDD-processen visar objektens rörelseområden där vi kan se vart objekten rört sig som mest, samt dess mittpunkt. Dessa punkter används till att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus. Studien tar inte upp andra parametrar som till exempel personalens positioneringsdata på akutmottagningen.
1.1.
Syfte
Syftet med denna studie är att med hjälp av data mining ta fram rörelseområden för objekt på akutmottagningen vid Skånes universitetssjukhus. Data som analyseras ska användas till att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus som i sin tur leder till mer tidseffektiv vård. Resultatets syfte är att visa på hur data mining kan användas som parameter till ombyggnationer, nybyggnationer och planering av akutmottagningar.
1.2.
Frågeställning
Vi har valt att formulera följande huvudfråga:
Hur kan man effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus med hjälp av positioneringsdata från Internet of Things baserade system?
För att besvara vår huvudfråga har vi formulerat två underfrågor:
1. Hur kan man tillämpa data mining på positioneringsdata från TagOn för att få fram rörelsemönster från informationen?
2. Hur kan man använda rörelsemönster från data mining för att effektivisera planlösningen på akutmottagningen vid Skånes universitetssjukhus?
Den första underfrågan kommer att behandla termen data mining samt olika metoder som kan användas vid analysering av data. Vidare, kommer den andra underfrågan att behandla olika utgångspunkter som tas fram från rörelsemönstren som den första frågan behandlade. Sammanslaget dessa två underfrågor kommer studien sedan att besvara huvudfrågan.
1.3.
Tidigare arbeten
Tidigare forskning har studerat hur olika tekniker, som till exempel hur RFID och ZigBee kan användas på olika sjukhusmiljöer (Atkins et al, 2013). Vidare, beskrivs och analyseras de olika teknikerna, både i hur data kan lagras och hur den samlas in. Dessutom, redogör tidigare forskning för vilka processflöden och tekniker som kan användas på en akutmottagning (Miller et al, 2006). Enligt Gu et al. (2009) redogör tidigare forskning för vilka metoder som kan användas för att samla in positioneringsdata, samt om huruvida inomhuspositionering kan tillämpas i olika sjukhusmiljöer. Vidare, tar Gu et al. (2009) också upp de olika tekniker som kan användas vid inomhuspositionering såsom RFID och infraröd teknik, samt vilka system som lämpar sig bäst i olika miljöer. Till exempel, ett RFID-system sträcker sig utan komplikationer genom människor och väggar medans ett system uppbyggt
7 på infraröd teknik inte gör det. Gu et al. (2009) menar att val av teknik grundar sig i vad syftet med systemet är.
Koh et al. (2011; Kudyba, 2016) menar på att data mining de senaste åren har blivit väldigt betydelsefull, inte minst för sjukhus. Vidare, menar Koh et al. (2011) också på att data mining inom sjukhusmiljöer kan användas för att upptäcka typer av missbruk och bedrägerier, till exempel att personal stjäl medicin. Data mining kan också tillämpas för att utvärdera vilken behandling som är bäst och billigast. Detta görs genom att jämföra orsaker, symptom och behandlings-kurer för olika patienter. Vid jämförelse av två grupper patienter som har samma sjukdom, fast tar olika medicin, går det att utvärdera vilken kur som är mest effektiv (Koh et al, 2015).
Socialstyrelsen (2015) redovisar i sin rapport om att väntetider vid sjukhusbundna akutmottagningar ökar för varje år. Socialstyrelsen (2015) tar även upp hur väntetiderna och den totala vistelsetiden har utvecklats sedan år 2010. Tidigare forskning visar att insamling av data i sjukhusmiljöer är vanligt förekommande. Däremot, går inte tidigare forskning in på hur denna data analyseras för att effektivisera planlösningen på akutmottagningar. Därför ser vi ett tydligt gap i forskningen, där vi kan bidra med hur den insamlade data kan analyseras i denna typ av miljöer.
1.4.
Avgränsningar
Då forskningsfrågan tar upp hur planlösningen kan effektiviseras på akutmottagningen vid Skånes universitetssjukhus kommer vi endast att utgå från data vi tagit del av från TagOn. På grund av att fullständig data varken fanns på patienter eller personal, så uteslöts denna data från studien. Studien kommer uteslutande baseras på de rörelseområden för objekt som tas fram baserat på data från TagOn.
2. Teoretisk bakgrund
2.1.
Data Mining
Enligt Rathore et al. (2015) kommer antalet uppkopplade objekt överstiga 50 miljarder vid år 2020. Dessa objekt kommer att samla in stora mängder data. För att analysera denna stora datamängd kan data mining appliceras. Nationalencyklopedins (Nationalencyklopedin, 2017) definition av data mining är:
“Sökning och extraktion av meningsfulla samband i stora mängder data.”
8 Data mining är en process för att hitta meningsfulla mönster i en stor mängd data. Dessa meningsfulla mönster kan sedan användas för att förklara olika koncept och fenomen. Utifrån dessa meningsfulla mönster går det att bygga olika modeller så som klassificeringsmodeller eller klustrings-modeller. Vidare, finns det många olika metoder för data mining. Dessa inkluderar (Pujari, 2013):
• Klassificering
o Denna metod innebär att tidigare data som samlats in blir grunden för vilken klass ny data ska tillhöra. När sedan ny data ska klassificeras är utgångspunkten de fördefinierade klasserna som är kända sedan tidigare.
• Klustring
o Klustring är en metod för att gruppera data i olika grupper så att data i varje grupp har liknande trender och mönster (se 2.3). Då det inte finns några fördefinierade klasser vid användning av denna metod är utgångspunkten istället explorativ, där mönster och samband tas fram.
2.2.
Knowledge Discovery from Data
Enligt Han et al. (2012) är data mining en del av KDD-processen. KDD är en iterativ process som innehåller följande steg:
⚫ Datatvättning
Datatvättning innebär att icke-relevant och icke-konsekvent data tas bort. Exempelvis behöver vi inte veta vad för kön en patient har när vi studerar graviditet.
⚫ Data integration
Data integration innebär att liknande data samlas in från olika källor och dessa kombineras.
⚫ Val av data
Vad är det för mönster som det ska sökas efter? ⚫ Dataomvandling
Dataomvandling innebär att data anpassas för att den ska bli mer lämplig för data mining algoritmerna.
⚫ Data mining
I denna del av processen tillämpas algoritmer för att hitta mönster i data.
⚫ Utvärdera mönster
All data som kommer ifrån data mining processen är inte intressant. Därför gäller det att utvärdera de mönster som hittas. En viktig aspekt i att utvärdera är att se ifall data är läsbar för människor. Vidare, är ett intressant mönster någonting vi får kunskap av.
⚫ Presentation
9 Figur 2: Illustration på hur KDD processen utförs i olika steg.
2.3.
Klusteranalys
Enligt Nationalencyklopedin (2017) är definitionen av klustring:
"Klusteranalys, samlingsnamn på några statistiska metoder med vilka enheter indelas i grupper (kluster) så att enheter som liknar eller ligger nära varandra med
avseende på något mått förs till samma grupp."
Klustring är en process som numera spelar en avgörande roll för att hantera den stora mängd data som existerar i vårt samhälle. För att vi människor ska kunna förstå den stora mängd data, behöver vi komponera ihop de objekt som syftar till att vara av samma kategori (Forsati et al, 2008).
Enligt Cheng et al. (2006) är klustring en process som syftar till att klustra ihop objekt som består av liknande data till en grupp. Klustring innebär också att separera de objekt som inte är lika ifrån varandra för att lättare kunna utläsa data som samlats in.
2.4.
Simple K- means
Forsati et al. (2008) menar att simple K- means algoritmen är den mest använda för klustring av objekt. Algoritmen tillämpar sig väldigt bra då stora mängder data ska hanteras.
Simple K-means algoritmen använder sig av iterativ förfining för att producera ett slutresultat. Algoritmens inparametrar är K antal kluster och uppsättningen av data (datamängd). Datamängd är en samling av egenskaper för varje datapunkt, där
10 en datapunkt kan ses som något som representeras numeriskt eller grafiskt. Vidare, börjar algoritmen med att uppskattningsvis beräkna K antal centroider, som är mittpunkten för klustret. Detta kan göras på två olika sätt, antingen väljs detta helt slumpmässigt, eller slumpmässigt utifrån vår datamängd. Vidare itererar algoritmen mellan två olika steg:
1. I det första steget tilldelas alla datapunkter till dess närmaste centroid. Detta görs med hjälp av Euklidiskt avstånd, vilket innebär att den kortaste vägen väljs ut.
Figur 3: Illustration av det Euklidiska avståndet.
2. I det andra steget görs omberäkningar av centroiderna. Detta görs genom att ta medelvärdet av alla datapunkter som tilldelats en specifik centroid.
3. Metod
Genom att försäkra oss om att våra referenser är fullständiga, och att något liknande arbete inte gjorts tidigare, valde vi att göra en systematisk litteraturstudie. Där visar vi på ett systematiskt sätt hur vi kommit fram till de källor vi använt. För att få ut data från TagOn’s API (Application Programming Interface) användes Postman. Via Postman skickades förfrågningar till TagOns' API och svaret gavs i JSON-format (JavaScript Object Notation). Postman är ett verktyg för att hämta och skicka data från olika API: er genom HTTP-metoder som exempelvis PUT och POST. För att kunna analysera data har JSON-filer konverterats till CSV- filer vilket gör dem lämpliga som indata till vår klusteranalys. Filtypen CSV står för comma separated values, där värden är separerade med kommatecken.
11 Filerna är uppdelade i fem olika attribut. Dessa är:
⚫ Time
Visar när objektet befunnit sig på en given punkt. Tiden är i sekunder med start från 1970-01-01.
⚫ Latitude
Vilken latitud objektet befunnit sig på vid en given tid. ⚫ Longitud
Vilken longitud objektet befunnit sig på vid en given tid. ⚫ Altitude
Vilken altitud (höjd) objektet befunnit sig på vid en given tid. ⚫ Accuracy
Hur stor pricksäkerhet positionen har. Normalvärde är 2–2.5.
De tre objekt som analyserats inkluderar akutväska, thoraxdrän och kateter- vagn. I TagOn’s API var det dessa tre objekt som hade fullständig data. Vid sökning av objekten via TagOn’s API framkom namn, beskrivning och positioneringsdata vilket inte var fallet för andra objekt som var taggade. Objekten har analyserats vid tre olika tidsperioder, en timme, en dag och en vecka. De tre tidsperioderna har samma starttid i sekunder från 1970-01-01 och valdes på grund av att vi ville få en
övergripande bild på hur objekten rör sig. Dessutom försäkrar det om att den positioneringsdata vi fått ut från TagOn är korrekt. Det ser vi genom att områdena där objekten rört sig, från de olika tidsperioderna överlappar varandra.
Vidare, tillämpades KDD-processen för att komma fram till vilken algoritm som skulle användas. Detta gjordes genom att systematiskt följa KDD-processen där vi sorterat samt transformerat data till csv- format. Då målet vi identifierat var att få ut ett rörelseområde från data och att KDD-processen påvisat att mycket data skulle analyseras kunde vi utifrån detta material välja algoritm. KDD-processen användes också för att komma fram till vilket tillvägagångssätt vi skulle använda oss av, klassificering, klustring eller heatmap. Vi tittade på dessa tre alternativ på grund av att klustring samt klassificering är de mest väletablerade metoderna inom data mining. Heatmap var ett alternativ på grund av att mappa rörelseområdena till dess verkliga position samt visualisera resultaten. Efter att ha följt KDD-processen genom att välja data från olika tidsperioder, välja vilka parametrar som behövdes samt göra om data från JSON-format till CSV-format drogs slutsatsen att vi skulle använda oss av klustring. Klustring används till data mining där tidigare klasser inte är identifierade, således är det en utforskande data mining teknik (Hussein, 2012). Denna studie har som syfte att utforska mönster i form av longitud och latitud, var ett specifikt objekt befunnit sig inom en viss tidpunkt. Data från TagOn som analyserades med hjälp av data mining hade inga fördefinierade klasser och är därför mer anpassat för klustring.
För att analysera data från TagOn valdes mjukvaran Weka version 3.8.1 Detta för att användargränssnittet i Weka var mer anpassat för klustring samt att vi sedan tidigare är bekanta med denna mjukvara.
Weka är en mjukvara som hanterar både klassificering och klustring. Mjukvaran innehåller algoritmer för följande ändamål:
⚫ Klassificera data ⚫ Klustring
12 Då Weka använder sig av ett användargränssnitt är denna mjukvara anpassad för såväl erfarna användare inom området som oerfarna användare (Eibe et al, 2010). Simple K-means är en av de väletablerade algoritmerna inom klustring (Forsati et al. 2008). På grund av detta samt resultatet från KDD- processen, valdes denna algoritm.
⚫ Simple K- means.
Denna algoritm delar in data i K olika kluster. Detta görs genom att distansen mellan varje kluster minskar. Samt att distansen av varje inmatning som gjorts minskar (Lee Young et al, 2016).
För att mappa koordinaterna från data mining användes Indoor atlas, som är en hemsida där inomhuspositionering data hanteras. Planlösningen mappades till akutmottagningen vid Skånes universitetssjukhus verkliga position. Klusteranalysen försåg oss med kluster. Ur dessa kluster extraherades gränsvärden utifrån objektens rörelseområde. Då varje tidsperiod hade olika många gränsvärden samt att varje objekt hade olika gränsvärden, försåg Indoor atlas oss med den funktionalitet som behövdes för att mappa varje gränsvärde på den verkliga planlösningen. Gränsvärdena mappades gentemot den verkliga planlösningen för att visa en verklig beskrivning av hur objektet rört sig. Via dessa gränsvärden har mittpunkten kunnat räknas ut för objektens rörelseområden. Områdena hittades genom att ta fram mittpunkten i det största klustret. Det har också hittats ett område där objektet rört sig som mest.
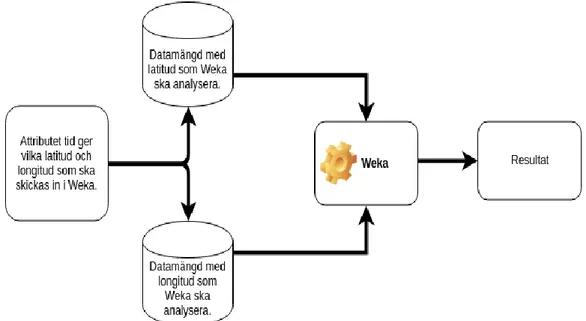
För att förtydliga de olika metodvalen samt de olika stegen, visas nedan en figur på våra aktiviteter för att komma fram till resultatet.
Figur 5: Illustration på aktiviteter i metoddelarna.
3.1.
Klusterproblembeskrivning
De attribut som användes i vår klusteranalys är tid, latitud och longitud. Dessa tre attribut kunde gemensamt förse oss med tillräcklig information för att komma fram till resultatet.
• Tid
o Attributet tid används främst för att kunna skilja på vilken position, exempelvis katetervagnen haft under en viss tid. Vidare, kan vi läsa ut vilka positioner katetervagnen haft från exempelvis 1487110023 sekunder ifrån 01 till 1487110047 sekunder ifrån 1970-01-01.
• Latitud
o Detta attribut används för att få fram den vågräta positionen inom den tidsram som valdes.
13 • Longitud
o Detta attribut används främst för att få fram den lodräta positionen inom den tidsram som valdes.
Attributet tid är en del av klusterproblembeskrivningen då tiden är det som avgör hur stor datamängd som ska analyseras av Weka. Därmed är attributet en viktig del i klusterproblembeskrivningen, utan tid hade all datamängd analyserats samtidigt och klustren hade inte kunnat urskiljas.
Det mått som används för att mäta ut avståndet mellan två punkter är euklidiskt avstånd, vilket innebär den raka linje som kan dras mellan två punkter. I detta fall är det punkterna mellan kluster a och kluster b.
Med hjälp av Weka så genererade vi maximalt 100 kluster, detta då det fanns väldigt mycket data att analysera. De kluster vi valde var de kluster som avgränsar från resterande kluster och inga kluster alls, det vill säga utanför den omkrets som objektet befunnit sig inom.
Altituden hanteras inte när vi modellerar vårt problem. Detta då data vi använt oss av inte gav oss någon altitud. Anledningen till att det inte fanns någon altitud var för att alla objekt vi undersökt har befunnit sig på samma våningsplan på
akutmottagningen vid Skånes universitetssjukhus alltså samma altitud. Då så var fallet kunde alltså altitud som attribut uteslutas.
14
3.2.
Litteratursökning
Databaserna vi använt är de som vi sedan tidigare är bekanta med och som vi vet kan tillämpas på vårt forskningsområde. Vi har framförallt valt att söka i databasen ACM och Google Scholar. Detta på grund av att dessa publicerar datavetenskapliga skrifter och rapporter.
I vår forskning började vi med att söka brett, dels för att få så god kunskap inom området som möjligt. Sökningarna vi har gjort är relaterade till forskningsfrågorna. Nyckelord för våra sökningar:
1. Data mining 2. Internet of Things 3. Indoor positioning 4. Algorithms 5. Simple K- means 6. Clustering 7. Classification 8. Akutmottagningar i Sverige
Vi har tittat närmare på vissa specifika områden och slutligen kommit fram till hur vi ska gå tillväga. Vidare, har vi endast valt källor som är högst 10 år gamla. Detta på grund av att allt inom IT utvecklas så pass snabbt och därför ville vi endast ha med det mest relevanta i vår studie. Det kan också inkluderas som en del i filtreringen. Detta gäller för alla de databaser vi har sökt i. Nedan visar vi hur vi har fått fram relevant information gällande varje huvudområde i vår studie. För att försäkra oss om att vi inte missat någon relevant artikel så tittade vi även på “relaterade artiklar” och artiklar som citerat till artikeln i fråga.
För att hitta material om data mining började vi i Google Scholar söka med sökordet “data mining”. Då data mining är en central del i vårt arbete var det denna sökning vi förstod att vi var tvungna att börja med, samt att vi sedan tidigare är bekanta med just data mining. Efter att ha läst några slumpmässigt valda artiklar fick vi snabbt reda på att det var KDD vi var intresserade av. När vi sedan sökte på “knowledge discovery from data” hade vi sållat bort cirka hälften av träffarna vi fick från sökningen av “data mining”. För att filtrera de kvarstående träffarna använde vi oss av de exakta sökorden “data mining” och med alla orden “knowledge discovery from data techniques” i Google Scholars avancerade sökfält. Vi sökte även mellan åren 2006 - 2017. Efter sökningen hittade vi boken “Data mining: Concepts and techniques”. I sökningen fanns andra böcker som vi valde att inte ha med i vårt arbete, dessa var:
9. Data Mining: Practical Machine Learning Tools and Techniques 10. Principles of data mining.
15 11. Han, Jiawei. Pei, Jian. Kamber, Micheline. 2012. Data mining concepts and techniques. 3. uppl. Waltham: Morgan Kaufmann.
På grund av att boken innehöll all information vi behövde till vårt arbete samt att författarna förklarade utifrån ett tydligt perspektiv där vi på ett tydligt sätt förstod sammanhanget. Dessutom hade boken blivit citerad mest av alla träffar i sökningen. I boken så läste vi om klustring och klassificering. Vi läste också att det används olika algoritmer för både klassificering och klustring. Detta gav oss nya nyckelord att söka på. De nyckelord som vi hittade då var:
12. Klustring 13. Klassificering 14. Algorithms
Eftersom föregående sökning gav oss nyckelordet “Algorithms”, valde vi att slå ihop föregående nyckelord med det nya nyckelordet. Alltså blev vår nya sökning: "top 10 algorithms" + "data mining", där vi filtrerat på år från 2006–2017. Vi valde också att sökorden skulle finnas i rubriken. Detta gav oss två relevanta artiklar, två dubbletter och 6 citat. Efter dessa resultat valde vi att använda:
15. Xindong, Wu. Vipin, Kumar. J. Ross, Quinlan. Joydeep, Ghosh. Qiang, Yang. Hiroshi, Motoda. Geoffrey J. McLachlan. Angus, Ng. Bing, Liu. Philip S, Yu. Zhi-Hua, Zhou. Michael, Steinbach. David J. Hand. Dan Steinberg. 2008. Top 10 algorithms in data mining. Knowledge and information systems 14. s. 1–37. doi: 10.1007/s10115-007-0114-2.
Vi valde just sökorden “top 10 algorithms” och “data mining” för att få så relevanta artiklar till vår studie som möjligt. Då vår forskningsfråga ska besvara hur det via data mining går att effektivisera akutmottagningen vid Skånes universitetssjukhus. Efter att ha läst denna artikel hittade vi en intressant algoritm som ledde till ett nytt sökord:
16. Simple K-means
För att hitta information om algoritmen Simple K-means användes sökfrasen “Simple K-means algorithms” som titel, detta för att artikeln “Top 10 algorithms in data mining” gav oss detta sökord. För ytterligare filtrering sökte vi endast efter artiklar mellan 2006–2017. Då fick vi fram totalt 24 resultat. Eftersom de flesta artiklar var väldigt matematiskt uppbyggda valde vi att använda:
17. Lee Young, Min. Yoon, Taeseon. 2016. Analysis of Methicillin- resistant Staphylococcus Aureus Using Apriori, DBSCAN, and K- means Algorithms. Proceedings of the 3rd International Conference on Biomedical and Bioinformatics Engineering: 23–28. doi: 10.1145/3022702.3022709.
16 För att hitta information om klustring använde vi sökorden “data mining” som generell sökterm och att titeln skulle innehålla “clustering methods”. Nyckelordet klustring fick vi fram ifrån vår första sökning “data mining” och från boken “Data mining: concepts and techniques. Vi filtrerade även på år mellan 2006–2017, vilket gav oss 69 träffar. Efter denna sökning kom vi fram till att vi skulle använda följande artiklar:
18. Forsati, Rana. Meybodi, Mohammad Reza. Mahdavi, Mehrdad. Neiat, Azadeh Ghari. 2008. Hybridization of K-means and Harmony Search Methods for Web Page Clustering. Proceeding WI-IAT '08 Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology 1: 329–335. doi: 10.1109/WIIAT.2008.370.
19. Cheng, David. Kannan, Ravi. Vempala, Santosh. Wang, Grant. 2006. A Divide-and-Merge Methodology for Clustering. Journal ACM Transactions on Database Systems 31 (4): 1499–1525. doi: 10.1145/1189769.1189779.
För att få fram information om väntetider och patientflöden på akutmottagningar i Sverige så började vi med att söka på Google med sökorden “akutmottagning väntetider patientflöden”. Dessa nyckelord var något som vi själva förstod att vi var tvungna att söka på och således inte något vi läst vid tidigare sökningar. Vid sökningen fick vi 8150 träffar varav de flesta var från socialstyrelsen. På grund av att de flesta träffarna var från Socialstyrelsen kunde vi navigera oss vidare till socialstyrelsen.se/publikationer, där vi hittade artikeln vi refererar till i vår studie:
20. Socialstyrelsen. 2015. Väntetider och patientflöden på akutmottagningar.
Rapporten från socialstyrelsen visar på att forskningen vi bedriver är aktuell.
Data som vi analyserade i vårt examensarbete fick vi från forskningsprojektet TagOn. Vi läste på om TagOn via mah.se/Forskning/Sok-pagaende-forskning/TagOn. Där fick vi fram två nya nyckelord till arbetet.
Dessa är:
21. Indoor positioning 22. Internet of things
För att få relevanta artiklar om indoor positioning i sjukhusmiljöer började vi söka på: “indoor positioning” + “hospital”. Dessa nyckelord fick vi fram genom att läsa på om TagOn. Då fick vi 2380 sökträffar. Sedan filtrerade vi på år från 2006–2017 samt att artiklarna skulle ha blivit citerad över 1000 gånger. Då kom vi fram till att vi skulle använda:
17 23. Gu, Yanying. Lo Anthony. Niemegeers, Ignas. 2009. A survey of indoor positioning systems for wireless personal networks. IEEE Communications Surveys & Tutorials 11 (1): 13–32. doi: 10.1109/SURV.2009.090103.
24. Liu, Hui. Darabi, Houshang. Banerjee, Pat. 2007. Survey of Wireless Indoor Positioning Techniques and Systems. IEEE Transactions on Systems,
Man, and Cybernetics, Part C 37 (6): 1067–1080. doi:
10.1109/TSMCC.2007.905750
3.3 Metoddiskussion
Enligt Borges et al. (2013) syftar klassificering till att utifrån en viss uppsättning fördefinierade klasser bestämma vilken klass ett nytt objekt tillhör. Klustring syftar till att analysera huruvida det finns någon relation mellan de olika objekten. På grund av att det tidigare inte fanns några kända klasser, som är ett kriterium för klassificering, föll valet på klustring.
Ett annat sätt att få fram resultatet hade kunnat vara att använda heatmap. Där visas resultat på hur objektet rört sig, och vart det befunnit sig mest. Dock skulle det i detta fall utelämna viktig data så som höjd (vilken våning objektet befunnit sig på), detta på grund av att TagOn inte specifikt talade om vilket våningsplan det gällde, data som fanns visade endast antal meter över havet. En heatmap skulle heller inte visa vilka koordinater ett objekt befunnit sig på vid en exakt tidpunkt. Då studiens syfte var att ta fram specifika positioner för lagringsplats samt mittpunkt var klustring att föredra då klustrings- algoritmen (Simple K-means) visade exakta koordinater för varje punkt i klustren. Användning av en heatmap hade inte gett oss positioner för varje kluster, utan en helhetsbild av koordinater. Positioner för varje kluster behövdes för att kunna mappa de exakta koordinaterna till dess verkliga position. Med hjälp av Simple K-means var det även lättare att visualisera resultatet, detta på grund av att vi fick ut de exakta koordinaterna och enkelt kunde mappa dessa till den verkliga planlösningen. Dessutom medför klustermetoden en beprövad och pålitlig metod för att analysera den typ av data som denna studie gör. På så sätt kan vi garantera att inte något utelämnas samt att resultaten är korrekta.
Inom klustring finns det många algoritmer. Vi valde att fokusera på Simple K-means. Forsati et al. (2008) menar på att Simple K- means algoritmen är den mest använda algoritmen inom området klustring. Dessutom tillämpar sig algoritmen bra på stora mängder data, därför föll valet på den.
Vi valde att inte intervjua någon personal på akutmottagningen vid Skånes universitetssjukhus då detta inte påverkat resultatet. På grund av att resultatet visar på vart det optimala lagringsstället är utifrån data från TagOn, skulle en intervju endast bekräfta att en optimal lagringsplats redan existerar, eller att någon sådan inte finns. Detta kan vi konstatera då data från TagOn inte har analyserats sedan tidigare och därmed har någon utgångpunkt för de objekt studien tar upp inte kunnat inrättas utifrån data utan istället från erfarenhet av personalen.
18 Att använda annan typ av mjukvara för att analysera samt tillämpa klustring av positioneringsdata hade varit möjligt, denna mjukvara kunde till exempel vara Orange. Mjukvaran Orange är ett verktyg som används för att analysera data via följande programmeringsspråk:
⚫ Python ⚫ C++
Mjukvaran är skapad för såväl erfarna användare och programmerare till studenter inom data mining området (Demsar et al, 2013). Till följd av detta valde vi att använda Weka.
Postman är ett plugin till Google chrome, med bra användargränssnitt samt enkelt att göra anrop till önskat API. Det som kunde gjorts annorlunda är att göra ett eget script som hämtar in data från TagOn, dock ansåg vi att det var säkrare och mer effektivt för oss att använda Postman.
För att mappa koordinaterna på den ursprungliga planlösningen använde vi oss av Indoor atlas. Istället för att använda Indoor atlas kunde detta gjorts manuellt. Det vill säga att för varje gränsvärde skulle det vara möjligt att utifrån en bestämd punkt räkna ut vart det nya gränsvärdet ska placeras i förhållande till den bestämda punkten. Dock hade detta varit mycket tidskrävande och då föll valet naturligt för att använda Indoor atlas.
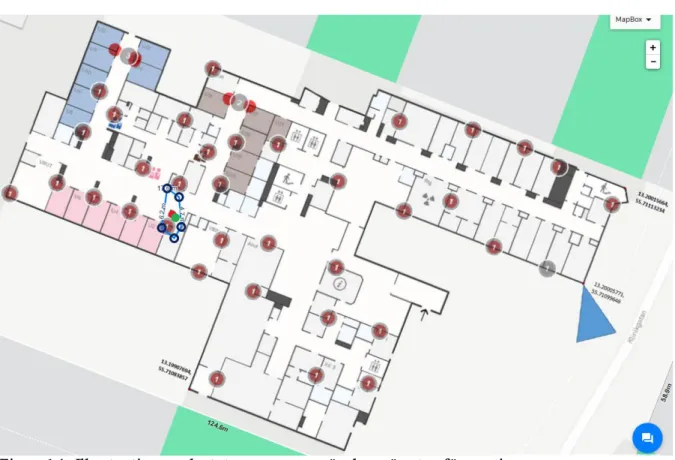
4. Resultat
I Weka klustras CSV-filer med hjälp av algoritmen Simple K-means. Resultatet visualiseras i form av en graf där objektets rörelsemönster visas.
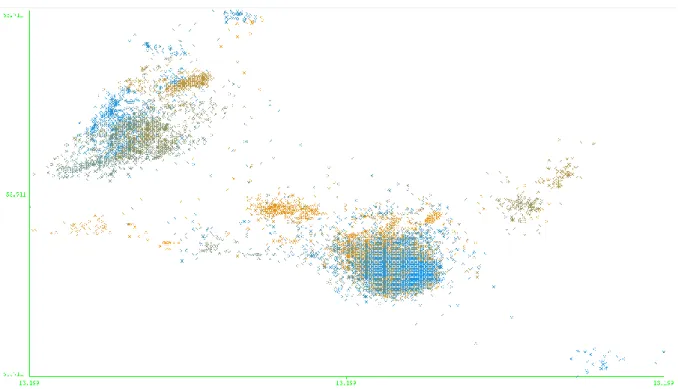
19 Bilden ovan visar ett exempel på utdata från algoritmen Simple K-means från katetervagnens rörelsemönster. Varje punkt i bilden visar en given position vid en given tid. Färgerna blå och orange syftar på tiden. Blått visar vart objektet befunnit sig tidigt och orange visar var objektet befunnit sig sent inom en specifik tidsperiod. Då data från TagOn samlas in var tredje sekund finns mycket data tillgänglig. Eftersom vi valt att fokusera på hur data ser ut under en veckas tid är därför tidsperioden viktig. Vidare, är också tidsperioden viktig då det försäkrar oss om att data är aktuell. Tidsperioden för figur 4 avser 1 vecka. Det blåa avser 2017-01-01 till 2017-01-04 och orange är 2017-01-04 till 2017-01-07. I bilden framgår det tydligt vart objektet rört sig mest.
Bilderna nedan visar områden där de olika objekten har rört sig. Utifrån resultatet av nedanstående bilder kan vi hitta en optimal utgångspunkt som objektet ska ha. Punkterna för området har tagits fram genom att hitta gränsvärden i longitud och latitud för varje objekt. Dessa punkter har tagits fram via vår klusteranalys, som är verifikationen på den faktiska data vi använt. Det finns två punkter markerade inom de olika objekten. Den gröna punkten betyder objektets optimala utgångspunkt utifrån vart den har rört sig mest. Den röda punkten betyder objektets optimala utgångspunkt utifrån mitten av området.
4.1.
Akutväska
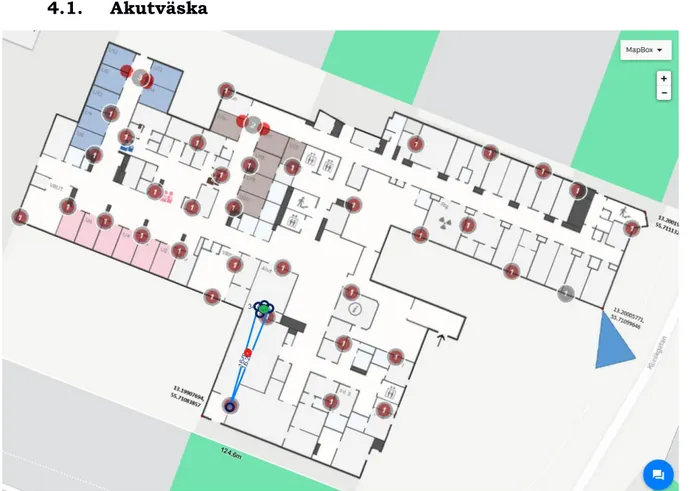
Figur 8: Illustration av akutväskans rörelsemönster för en timme.
Enligt resultatet ovan kan vi se att akutväskan rört sig mellan två punkter. Dessa punkter ligger inom samma rum, som planlösningen visar på. Vidare, kan vi se att objektet rört inom ett område av 16 meter inom tidsperioden en timme.
20 Figur 9: Illustration av akutväskans rörelsemönster för en dag.
Rörelsemönstret för akutväskan under tidsperioden en dag visar på att objektet rört sig i ett diamantformat mönster. Positionering av akutväskan är större för en dag än vad resultatet för en timme visar på. Vidare, kan vi konstatera att akutväskan rört sig inom ett område på 42,5 meter i omkrets under tidsperioden för en dag.
21 Figur 10: Illustration av akutväskans rörelsemönster för en vecka.
Akutväskans rörelsemönster för en vecka kan summeras som en pentagon. Vi kan ytterligare konstatera att objektet befunnit sig i olika rum under denna tidsperiod. Vidare, har akutväskan för en vecka rört sig inom ett område på 68 meter i omkrets.
Sammanfattningsvis kan vi konstatera att ju längre tidsperioden är desto större sträcka rör sig objektet på. Vi kan också konstatera att objektet rör sig inom samma område för tidsperioden en dag. Dock, vad gäller tidsperioden en vecka rör sig objektet mellan fler rum.
22
4.2.
Thoraxdrän
Figur 11: Illustration av thoraxdränens rörelsemönster för en timme.
Resultatet ovan visar på att thoraxdränen rört sig inom ett smalt område. Området som objektet rört sig på uppmätts till 28,3 meter i omkrets. Vidare, kan vi se att thoraxdränen befunnit sig mellan olika rum under en timme.
23 Figur 12: Illustration av thoraxdränens rörelsemönster för en dag.
Som bilden ovan visar kan vi se att dess rörelsemönster liknar på en pentagon. Omkretsen som thoraxdränen befunnit sig inom är en sträcka på totalt 61,8 meter i omkrets under tidsperioden en dag. Vidare kan vi se att thoraxdränen rör sig mellan olika rum, vilket tydligt framgår på bilden.
24 Figur 13: Illustration av thoraxdränens rörelsemönster för en vecka.
Thoraxdränens rörelsemönster för en vecka kan liknas av en parallellogram. Även under denna tidsperiod har objektet rört sig mellan olika rum. Vidare, har objektet rört sig på en större yta, närmare bestämt en omkrets på 79,1 meter i omkrets. Sammanfattningsvis kan vi konstatera att thoraxdränen tydligt rör sig mellan olika rum samt att omkretsen objektet befinner sig på är relativt stor. Dock, kan vi tydligt se att enligt planlösningen är det ett rum som är i centrum för var thoraxdränen befinner sig.
25
4.3.
Katetervagn
Figur 14: Illustration av kateter vagnens rörelsemönster för en timme.
För tidsperioden en timme kan vi se att kateter vagnen rör sig i ett cirkelformat mönster. Objektet rör sig på en distans av 17,6 meter i omkrets under denna tidsperiod samt att den förflyttas mellan olika rum.
26 Figur 15: Illustration av kateter vagnens rörelsemönster för en dag.
Enligt resultatet ovan kan vi se att rörelsemönstret utökas vilket innebär att objektet rör sig inom ett större område i tidsperioden en dag. Kateter vagnen rör sig i ett rektangulärt mönster samt att objektet befunnit sig på olika rum som enligt planlösningen är utspridda och ligger långt ifrån varandra. Objektet har rört sig inom ett område vars omkrets är 95,4 meter i omkrets.
27 Figur 16: Illustration av kateter vagnens rörelsemönster för en vecka.
Kateter vagnens rörelsemönster för tidsperioden en vecka kan liknas vid en oktogon, vilket innebär att objektet rört sig inom området av åtta punkter. Totalt har objektet rört sig på ett område vars omkrets är 106 meter i omkrets och är således ett objekt som förflyttar sig väldigt mycket. Enligt planlösningen kan vi tydligt se att även här har den befunnit sig i olika rum.
Sammanfattningsvis kan vi konstatera att kateter vagnen är ett objekt som rör sig inom ett stort område, som dessutom befinner sig i många olika rum. Ytterligare kan vi konstatera att även om objektet rör sig inom olika rum enligt planlösningen, befinner sig objektet inom samma område för tidsperioden en vecka.
28
4.4.
Sammanfattning
För att summera resultatet kan vi se att data mining är tillämpningsbart på akutmottagningen vid Skånes universitetssjukhus. Med hjälp av data mining har vi kunnat ta fram bilder som visualiserar hur de tre olika objekten har rört sig. Vidare, visar bilderna vad objekten bör ha för utgångspunkt utifrån två olika perspektiv. Det ena perspektivet (grön) visar objektets utgångspunkt utifrån var objektet har befunnit sig som mest. Det andra perspektivet (röd) visar på mittpunkten som avstånd i förhållande till området. Eftersom den gröna punkten inte rör sig nämnvärt finns det en risk för att området är objektets lagringsplats. Genom att konstruera en lagringsplats på den röda punkten ser vi en tydlig effektivisering då objekten behöver röra sig så lite som möjligt.
5. Analys och Diskussion
I resultatet framgår det att två utgångspunkter har bestämts, utifrån var objektet befunnit sig som mest, samt mittpunkten för objektets rörelseområde.
Fördel och nackdel grön punkt:
• Då den gröna punkten är där objektet befunnit sig som mest skulle det vara möjligt att konstruera en lagringsplats här. Fördelen med denna punkt är att arbetet hade effektiviserats i det område där objektet befinner sig som mest. • Genom att använda den gröna punkten som lagringsplats blir effektivisering
endast tydlig vid området för den gröna punkten och således inte för hela rörelseområdet. Dessutom finns det en risk för att denna punkt redan är lagringsplatsen.
Fördel och nackdel röd punkt:
• Den röda punkten är således mittpunkten för objektets rörelseområde. Fördelen med att konstruera en lagringsplats vid denna punkt underlättar arbetet inom hela området och inte bara för där objektet befunnit sig som mest.
• Nackdelen med den röda punkten är denna punkt oftast finns i mitten av ett rum och kan därför påverka dagliga rutiner. Dessutom blir detta en mer generell effektivisering snarare än en specifik, som det hade blivit vid användning av den gröna punkten.
Resultatet visar på att mittpunkten och punkten där objektet rört sig som mest ofta är nära varandra. Genom att konstruera lagringsplatser vid varje objekts mittpunkt kommer därför varje objekt att lättare finnas tillgängligt i hela objektets rörelseområde. På så sätt effektiviseras planlösningen på akutmottagningen vid Skånes universitetssjukhus. Dessutom kan detta tydligt bidra till att patientflöden och väntetider minskar på grund av att personal kan jobba mer effektivt.
Eftersom vi inte vet ifall objekten har en lagringsplats finns det en stor risk att den gröna punkten är lagringsplatsen, istället för det område där den rört sig som mest. Vidare, kan vi dra slutsatsen att vår metod fortfarande går att applicera oavsett om det idag finns en lagringsplats eller inte på grund av att det finns två utgångspunkter, grön och röd.
29 De konsekvenser denna studie för med sig är att det går via data mining att få fram data som visar på att planlösningen kan effektiviseras. Dock, visar resultatet på att det är möjligt ur ett datavetenskapligt perspektiv och inte ur, exempelvis ett medicinskt perspektiv. Verkligheten på en akutmottagning kan se annorlunda ut där det finns fler parametrar att ta hänsyn till, såsom personal på akutmottagningen vid Skånes universitetssjukhus.
5.1.
Fortsatta studier
För att kunna forska vidare i området behövs ett bredare kunskapsområde där personal på akutmottagningen samt byggnadsingenjörer är inblandade. Detta på grund av att utdata från data mining processen kanske inte i verkligheten är applicerbar, utan det kan finnas en del parametrar som data mining inte tar hänsyn till. Den ena parametern är byggnadskonstruktion, om det ur ett ingenjörsmässigt perspektiv är möjligt att konstruera lagringsplatser i rörelseområdets mittpunkt. Den andra parametern är om det ut ett medicinskt perspektiv är lönsamt samt möjligt att konstruera lagringsplatser i rörelseområdets mittpunkt.
Vidare, skulle det vara möjligt att skapa så kallade agenter för varje objekt, där man skulle kunna förutspå objektens rörelser så att dessa objekt själva hittar tillbaka till dess lagringsplats. Detta skulle kunna tillämpas på alla objekt liknande en robotgräsklippare. På så vis skulle personal inte behöva både hämta och lämna objektet efter varje användning.
För fortsatta studier inom detta område bör den nuvarande lagringsplatsen lokaliseras, samt att tiden som sparas på att byta lagringsplats kalkyleras. Detta för att se den verkliga effekten i sjukhusmiljöer.
6. Slutsats
TagOn använder IoT-baserade system för att samla in data på objekt och personal. Data hämtades från TagOns' API i syfte att effektivisera planlösningen på
akutmottagningen vid Skånes universitetssjukhus. Därför behöver data analyseras och det är gjort med hjälp av data mining. Vid användning av Weka och Simple K-means går det att tillämpa data mining på positioneringsdata. Genom att dessutom tillämpa klustring på positioneringsdata, som är en metod i data mining, visas objektens rörelseområden. Vidare, visas också området för var det största klustret befunnit sig mest inom en viss tidsperiod. Via dessa rörelseområden har två utgångspunkter tagits fram. Den ena utgångspunkten är objektets mittpunkt för rörelseområdet. Den andra utgångspunkten är var objektet befunnit sig som mest. Genom att konstruera lagringsplatser för objekten vid rörelseområdets mittpunkt ser vi en tydlig effektivisering av planlösningen. Detta på grund av att objekten förflyttar sig över en kortare sträcka, vart de än befinner sig i området.
Metoden för denna studie kan även vara möjlig att tillämpa på andra områden där det finns positioneringsdata över objekt och människor. Detta kan bidra till att effektivisera andra faktorer inom olika miljöer.
30
Referenser
Alharbe, Nawaf. Atkins, S Anthony. Akbari, Sheikh Akbar. 2013. Application of Zigbee and RFID technologies in Healthcare in Conjunction with the internet of things. MoMM ‘13. Proceedings of International Conference on Advances in Mobile Computing & Multimedia. 191. Wien, Österrike.
Borges, C Luis. Marques, M Viriato. Bernardino, Jorge. 2013. Comparison of Data Mining techniques and tools for data classification. Proceedings of the International C* Conference on Computer Science and Software Engineering: 113- 116. doi: 10.1145/2494444.24944.
Cheng, David. Kannan, Ravi. Vempala, Santosh. Wang, Grant. 2006. A Divide-and-Merge Methodology for Clustering. Journal ACM Transactions on Database Systems 31 (4): 1499- 1525. doi: 10.1145/1189769.1189779.
Data mining. Nationalencyklopedin.
http://www.ne.se.proxy.mah.se/uppslagsverk/encyklopedi/lång/data-mining (hämtad 2017-03-06).
Demsar, Janez. Curk, Tomaz. Erjavec, Ales. Gorup, Crt. Hocevar, Tomaz. Milutinovic, Mitar. Mozina, Martin. Polajnar, Matija. Toplak, Marko. Staric, Anze. Stajdohar, Miha. Umek, Lan. Zagar, Lan. Zbontar, Jure. Zitnik, Marinka. Zupan, Blaz. 2013. Orange: Data Mining Toolbox in Python. 14 (1): 2349- 2353.
Forsati, Rana. Meybodi, Mohammad Reza. Mahdavi, Mehrdad. Neiat, AzadehGhari. 2008. Hybridization of K-means and Harmony Search Methods for Web Page Clustering. Proceeding WI-IAT '08 Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology 1: 329- 335. doi: 10.1109/WIIAT.2008.370.
Gu, Yanying. Lo Anthony. Niemegeers, Ignas. 2009. A survey of indoor positioning systems for wireless personal networks. IEEE Communications Surveys & Tutorials 11 (1): 13- 32. doi: 10.1109/SURV.2009.090103.
Han, Jiawei. Pei, Jian. Kamber, Micheline. 2012. Data mining concepts and techniques. 3. uppl. Waltham: Morgan Kaufmann.
Hossain, Mahmud. (2012). Exploratory Data Analysis using Clusters and Stories. Blacksburg, Virginia.
Jung, Jong- In. Cho, Hyuk-Won. Lee, Sang- Sun. 2012. A Study of Data Mining Method for Indoor Positioning on Smartphones. Lee G., Howard D., Kang J.J., Ślęzak D. (eds) Convergence and Hybrid Information Technology 7425: 683- 697. doi: 10.1007/978-3-642-32645-5_86.
Kluster analys. Nationalencyklopedin.
http://www.ne.se/uppslagsverk/encyklopedi/lång/klusteranalys. (hämtad 2017-03-06).
Koh, Chye Hian. Tan Gerald. 2011. Data Mining Applications in Healthcare. Journal of Healthcare Information Management 19 (2): 64- 72. (Hämtad 2017-02-15).
31 Kudyba, P Stephan. 2016. Healthcare Informatics: Improving Efficiency through Technology, Analytics, and Management. Boca Raton: CRC Press Taylor & Francis Group.
Lee Young, Min. Yoon, Taeseon. 2016. Analysis of Methicillin- resistant Staphylococcus Aureus Using Apriori, DBSCAN, and K- means Algorithms. Proceedings of the 3rd International Conference on Biomedical and Bioinformatics Engineering: 23- 28. doi: 10.1145/3022702.3022709.
Liu, Hui. Darabi, Houshang. Banerjee, Pat. 2007. Survey of Wireless Indoor Positioning Techniques and Systems. IEEE Transactions on Systems, Man, and Cybernetics, Part C 37 (6): 1067- 1080. doi: 10.1109/TSMCC.2007.905750.
Miller, J Martin. Ferrin, M David. Flynn, Tanner. Ashby, Marshall Jr, White, K.Preston. Mauer, G.Michael. 2006. Using RFID technologies to capture simulation data in a hospital emergency department. 1365- 1370. WSC, 2006. Proceedings of the 38th conference on Winter simulation. Monterey, California.
Ne.se. (2017). klusteranalys - Uppslagsverk - NE. [online] Available at: http://www.ne.se/uppslagsverk/encyklopedi/lång/klusteranalys.
Pujari, A. (2013). Data mining techniques. Hyderabad: Universities Press (India) Private Limited.
Rathore, M. Mazhar. Ahmad, Awais. Paul, Anand. 2015. Big data and internet of things: An asset for urban planning. BIGDAS 2015. Proceedings of the 2015 International Conference on Big Data Applications and Services. 58-65. Jeju island, Korea.
Remco R, Bouckaert. Eibe, Frank, Hall, Mark A. Holmes, Geoffrey. Pfahringer, Bernhard. Reutemann, Peter. Witten, Ian H. 2010. WEKA - Experiences with a Java Open-source Project. 11 (3): 2533 - 2541.
Socialstyrelsen. 2015. Väntetider och patientflöden på akutmottagningar. (hämtad 2017-02-14).
TagOn https://www.mah.se/Forskning/Sok-pagaende-forskning/TagOn/ (hämtad 2017-03-06).