Digital Object Identifier 10.1109/ACCESS.2019.2944765
Computationally Efficient Light Field Image
Compression Using a Multiview
HEVC Framework
WAQAS AHMAD 1, MUBEEN GHAFOOR2, SYED ALI TARIQ2, ALI HASSAN2,
MÅRTEN SJÖSTRÖM1, AND ROGER OLSSON1
1Department of Information Systems and Technology, Mid Sweden University, 851 70 Sundsvall, Sweden 2Department of Computer Science, COMSATS University Islamabad, Islamabad 45550, Pakistan
Corresponding author: Waqas Ahmad (waqas.ahmad@miun.se)
The work was supported in part by the Swedish Foundation for International Cooperation in Research, and in part by the European Union Horizon 2020 Research and Innovation Program, European Training Network on Full Parallax Imaging, through the Marie
Sklodowska-Curie Grant under Agreement 676401.
ABSTRACT The acquisition of the spatial and angular information of a scene using light field (LF) tech-nologies supplement a wide range of post-processing applications, such as scene reconstruction, refocusing, virtual view synthesis, and so forth. The additional angular information possessed by LF data increases the size of the overall data captured while offering the same spatial resolution. The main contributor to the size of captured data (i.e., angular information) contains a high correlation that is exploited by state-of-the-art video encoders by treating the LF as a pseudo video sequence (PVS). The interpretation of LF as a single PVS restricts the encoding scheme to only utilize a single-dimensional angular correlation present in the LF data. In this paper, we present an LF compression framework that efficiently exploits the spatial and angular correlation using a multiview extension of high-efficiency video coding (MV-HEVC). The input LF views are converted into multiple PVSs and are organized hierarchically. The rate-allocation scheme takes into account the assigned organization of frames and distributes quality/bits among them accordingly. Subsequently, the reference picture selection scheme prioritizes the reference frames based on the assigned quality. The proposed compression scheme is evaluated by following the common test conditions set by JPEG Pleno. The proposed scheme performs 0.75 dB better compared to state-of-the-art compression schemes and 2.5 dB better compared to the x265-based JPEG Pleno anchor scheme. Moreover, an optimized motion-search scheme is proposed in the framework that reduces the computational complexity (in terms of the sum of absolute difference [SAD] computations) of motion estimation by up to 87% with a negligible loss in visual quality (approximately 0.05 dB).
INDEX TERMS Compression, light field, MV-HEVC, plenoptic.
I. INTRODUCTION
In the recent past, capturing the spatial and angular infor-mation of a scene [1], [2] has influenced numerous research problems, namely reconstructing 3D scenes [3], [4], process-ing [5]–[8], renderprocess-ing novel views [9], [10], and refocus-ing [11], [12]. G. Lippmann [13] introduced the concept of recording spatial and angular information in 1908. In 1991, E.H. Adelson [14] characterized the light information of a scene in observable space by using a seven-dimensional plenoptic function that represents each ray by considering its The associate editor coordinating the review of this manuscript and approving it for publication was Gangyi Jiang.
direction, spatial position, time, and wavelength information. In 1996, M. Levoy [15] proposed to parameterize each light ray in a scene by recording its intersection with two parallel planes using four parameters and referred to it as a light field (LF).
With the availability of computing resources, initially, multiple camera systems (MCSs) were used to capture the LF information of the scene [15]. Each camera records the single perspective of the scene, and hence the number of cameras defines the angular resolution of the captured LF. The physical limitations of the capturing setup result in sparse LF sampling. The advances in optical instruments have led to the development of plenoptic cameras [16] that capture
the spatial and angular information of a scene onto a single image referred to as a plenoptic image. The multiplexing of spatial and angular information is achieved by placing a lenslet array between the main lens and the image sensor that enables the dense LF sampling. The optical configuration of lenslet array relative to the main lens and image sensor results in two different types of plenoptic cameras (i.e., a con-ventional plenoptic camera and a focused plenoptic camera). The conventional plenoptic camera was initially introduced for the consumer market [16], and later on, a focused plenoptic camera targeting commercial applications was also proposed [17].
The scene information whether captured by an MCS or by a plenoptic camera requires high storage, processing and transmission resources. The increase in the size of the data captured is a direct consequence of the increase in sensor resolution for plenoptic cameras and the number of cameras in MCSs. The Lytro Illum [16] and Raytrix R29 plenoptic cameras capture scene information by consuming 50 MB and 30 MB of storage space for a single plenoptic image, respectively. On the contrary, the MCS-based LF acquisition systems, namely the Franhoufer High-Density Camera Array (HDCA) [1] and the Stanford HDCA [18] require 20 GB and 400 MB of storage, respectively, for a single capture. The recent initiative to develop a standard framework for representing and signaling LF modalities, also referred to as JPEG Pleno [19], underscores the requirement of efficient compression solutions that address the correlation present in LF data.
Standard image and video encoders can be used to com-press the LF data with limited comcom-pression efficiency since these encoders are built on the assumptions of image and video signals. The image and video signals contain spa-tial and temporal correlations that are efficiently exploited by intra-prediction and inter-prediction tools available in high-efficiency video coding (HEVC). As LF data pos-sess spatial and angular correlations, they require additional improvements in image- or video-compression schemes. Ini-tially, the HEVC intra-prediction scheme was modified for plenoptic image compression [20]–[24] by enabling each micro-lens image to make predictions from already encoded micro-lens images. The encoding scheme exploits the limited correlations in the plenoptic image that is mainly defined by the search window around the current micro-lens image. An alternative scheme uses a sub-aperture image (SAI) representation [25] of the plenoptic image. The SAIs are transferred as a pseudo video sequence (PVS) to an HEVC video-coding scheme that only exploits a 1D inter-view cor-relation. The same methodology was also applied to LF data captured using an MCS by interpreting each view as one frame of multiple PVSs. To exploit the 2D inter-view correla-tion present in the LF data, the multiview extension of HEVC (MV-HEVC) was proposed [26].
The MV-HEVC scheme was proposed with the assump-tion of a multiple video camera system [27] as an input, which exploits the temporal and inter-view correlation.
Due to the nature of MV-HEVC input, various modules of HEVC were directly incorporated into MV-HEVC. The single-layer HEVC prediction structures are used to define the group of pictures (GOPs) of each video layer of the MCS. The rate allocation of HEVC is directly applied to individual video layers of the MCS. In MV-HEVC the inter-prediction is performed by using temporal motion vectors (TMV) and disparity motion vectors (DMVs). Due to the high temporal correlations in multiple video camera systems, MV-HEVC uses an HEVC based motion estimation (ME) strategy to compute TMVs and DMVs.
A. MOTIVATION AND CONTRIBUTIONS
In this paper, we present a framework for the compression of LF data by proposing modifications to MV-HEVC. The proposed compression framework introduces a hierarchical organization of the input LF views that assign a specific level to each frame based on its location in the 2D grid. The rate-allocation scheme uses a hierarchical view organization and distributes better quality to a sparse set of views relative to the remaining views. A 2D prediction structure is devised that utilizes better quality frames as references to improve the overall compression efficiency. An optimized ME method is proposed that relies on a rectified LF assumption and reduces the computational complexity. The contributions of this paper are as follows.
• The paper presents a detailed description of our initial LF compression proposal [26].
• The experimentation is performed by following the JPEG Pleno common test conditions [28].
• The variation of quality among views is defined as a free parameter in the proposed coding scheme that can be adapted according to the intended application.
• A ranking based on the quality and distance of each predictor frame relative to the current frame is used to select the best references. The maximum number of references is defined as a free parameter in the proposed coding scheme to address different memory constraints. • The proposed compression scheme exploits the rectified LF assumption and restricts the 2D motion-search space into a single dimension. Moreover, a dynamic motion-search range estimation scheme is also proposed to fur-ther reduce the computational complexity.
• The proposed compression scheme presents a general-ized solution for plenoptic images and MCSs.
The proposed compression scheme performs, on aver-age, 0.75 dB better than the state-of-the-art plenoptic image scheme [29] and 2.5 dB better than the JPEG Pleno refer-ence anchor. Similarly, in the case of MCSs, the proposed scheme performs 2.3 dB better than the JPEG Pleno ref-erence anchor. On average, the proposed motion optimiza-tion reduces the computaoptimiza-tional complexity in terms of the number of times sum of absolute differences (SADs) are performed by 87% with respect to the reference MV-HEVC. The presented scheme is based on a previously developed MV-HEVC, and it will benefit from further improvements to
the reference MV-HEVC. Numerous methods [30]–[32] use a sparse set of views to reconstruct the input LF views, and such methods rely on video-coding tools to compress the sparse set of views. In addition, MV-HEVC enables each view to take 2D inter-view correlations, and hence it can serve as a test bench to develop novel prediction tools for LF data.
The remainder of this paper is organized as follows: Section II presents a detailed account of state-of-the-art LF compression schemes; Section III describes the proposed compression framework (i.e., the hierarchical organization of views, reference picture selection, rate allocation, and motion-search optimization); Section IV presents the test conditions and experimental results, and Section V presents the conclusion of the paper.
II. LITERATURE REVIEW
In this section, we present the literature review on compres-sion schemes for LF data captured by conventional plenoptic cameras and MCSs. The presented schemes can be classi-fied with different labels, including disparity-based methods, PVS-based methods, deep-learning based methods, view-synthesis based methods, and so forth. To better explain the state-of-the-art schemes in the context of this paper we categorized the prior schemes into two groups: plenoptic image compression and MCS. The plenoptic image compres-sion schemes are further divided into two subgroups: lenslet coding (schemes directly coding plenoptic images) and SAI coding (schemes converting plenoptic images into SAIs prior to coding).
A. PLENOPTIC IMAGE COMPRESSION
The plenoptic contents from conventional plenoptic cameras have received significant attention from the research commu-nity mainly due to the availability of benchmark datasets [18], [33] and its usage in various competitions [34], [35]. The initial solution proposed to directly compress the plenop-tic image and later on its conversion into SAI [12] is also used to exploit the state-of-the-art video-coding tools for LF data.
1) LENSLET COMPRESSION
Li et al. [20] have extended their previously proposed method [36] to compress conventional plenoptic images. A block-based bi-prediction capability is used in the HEVC intra-coding scheme to better exploit the correlation present in neighboring micro-lens images. Related to similar block matching strategies, Conti et al. [21] added a self-similarity (SS) operator, and Monteiro et al. [22] proposed integrating SS and local linear embedding (LLE) operators in the HEVC intra-coding scheme. Monteiro et al. [23] further proposed a high-order prediction mode in the HEVC intra-coding struc-ture. The prediction scheme exploits the non-local spatial redundancy present in plenoptic images using block matching with up to eight degrees of freedom. Zhong et al. [24] have proposed two prediction tools in the HEVC intra-coding scheme. The first prediction tool modifies the directional
modes of HEVC intra-coding by updating the prediction samples with the pixel values of already encoded neighbor-ing micro-lens images. The second prediction tool enables a block-matching scheme to predict the current micro-lens image by estimating a linear combination of already encoded neighboring micro-lens images. Chao et al. [37] proposed a graph lifting transform for the coding of plenoptic images prior to pre-processing and demosaicing. Conti et al. [38] proposed a scalable coding framework that provided field of view scalability with regions of interest (ROI) support. The input plenoptic image with a limited angular resolution is compressed in the base layer of scalable HEVC (SHVC) and additional angular information of selected ROI is progres-sively encoded in the enhancement layers. Perra et al. [39] partitioned the plenoptic image into equally sized tiles and compressed the tiles as a PVS using HEVC video-coding tools.
2) SUB-APERTURE IMAGE COMPRESSION
Instead of providing the video-coding scheme a non-natural image, following the initial idea to provide integral images as PVSs to a video encoder [40], Liu et al. [25] converted plenoptic images into SAIs and compressed them as a single PVS using HEVC video-coding tools. Jia et al. [41] intro-duced an optimized ordering of SAIs that take into account the correlation present in the SAIs in order to improve the compression efficiency of the coding scheme. Zhao et al. [42] divided the input SAIs into two groups. The first group of SAIs is compressed as a PVS using HEVC and the second group of SAIs is estimated by taking the weighted average from the neighboring SAIs of the first group. Li et al. [43] presented a 2D hierarchical coding structure that partitions SAIs into four quadrants and restricts the prediction structure within each quadrant to address the reference picture buffer management in HEVC. Ahmad et al. [26] demonstrated the application of MV-HEVC for LF data by interpreting the SAIs as multiple PVSs prior to compression. In this way, SAIs are allowed to utilize the 2D inter-view corre-lation using the temporal and inter-view prediction tools of MV-HEVC. Tabus et al. [44] segmented the central SAI into regions and estimated the displacement of each region in the side SAIs relative to the central SAI. The researchers proposed a prediction scheme that uses the segmentation information of the central SAI, the region displacement of side SAIs, a JPEG2000 decoded version of selected SAIs, and a JPEG2000 decoded version of lenslet image to reconstruct the SAIs. Tran et al. [45] proposed motion-compensated wavelet decomposition and estimated the disparity map using a variational optimization scheme. An invertible motion-compensated wavelet decomposition scheme is applied to effectively remove redundant information across multiple SAIs. The JPEG2000 is used to encode a sub-band of SAIs and the estimated disparity map. Chen et al. [46] introduced a disparity-guided sparse coding scheme for plenoptic image compression. A set of sparse SAIs is used to train the sparse dictionary that is later used to reconstruct
the non-selected SAIs. Bakir et al. [32] have compressed a sparse set of SAIs as PVS using HEVC and reconstructed the remaining SAIs using a convolutional neural network (CNN) based view synthesis scheme.
B. MULTIPLE CAMERA SYSTEM COMPRESSION
Hawary et al. [31] exploited the sparsity present in the angular domain of LF using a sparse Fourier-transform based method. A set of views at pre-defined positions is compressed in the base layer of SHVC, and the corresponding decoded set is used to reconstruct the remaining views. The remain-ing views are compressed in SHVC enhancement layers by taking the prediction from previously reconstructed views. Ahmad et al. [47] extended their previous method [26] and interpreted views of MCSs as frames of multiple PVSs and compressed them using MV-HEVC to demonstrate the applicability of the scheme for a sparsely sampled LF. Ahmad et al. [30] presented a shearlet transform based pre-diction tool for compression of MCS. A sparse set of views are encoded as a PVS using HEVC and at the decoder side, missing views are reconstructed using the shearlet-transform based prediction (STBP) scheme. Xian et al. [48] proposed a homography based LF compression solution. The homographies between the side views/SAIs and the central view/SAI are estimated by minimizing the error in the low-rank approximation model. The scheme is further refined by using the specific homography corresponding to each depth layer in the scene. Senoh et al. [49] proposed a depth-based compression solution for MCSs and plenoptic images. A subset of views/SAIs are encoded using MV-HEVC along with depth maps, and on the decoder side, view synthe-sis is performed to estimate the non-selected views/SAIs. Carvalho et al. [50] have created a 4D discrete cosine transform (DCT)-based compression scheme for MCSs and plenoptic images. Views/SAIs are divided into 4D blocks, and DCT is applied on each block. The generated coefficients are grouped using a hexadeca-tree structure on a bit-plane by bit-plane basis, and the generated stream is encoded using an adaptive arithmetic coder.
C. SUMMARY
The following key findings can be concluded regarding state-of-the-art LF compression schemes:
• Plenoptic image compression has received signifi-cant attention from the research community compared to MCS, mainly due to availability of benchmark datasets and plenoptic image compression grand challenges [34], [35].
• Plenoptic images captured with Lytro cameras are mainly used in plenoptic image compression grand chal-lenges. The plenoptic image compression is performed either directly on raw lenslet images or on sub-aperture images.
• Researchers have introduced LF reconstruction schemes for LF compression that use video-coding tools for the encoding of sparse LF views [30], [44], [46].
• Special compression requirements have also been proposed in numerous schemes, including ROI-based coding [38], reference picture management [43], and scalable coding [31], [38], [51].
At present, it is inevitable to avoid video-compression tools for LF data compression since the compression effi-ciency of video data has significantly improved with the last two decades of research efforts. The interpretation of LF views as a PVS enables video-coding schemes to exploit the correlation present in LF data [25], [26], [41]. More-over, LF reconstruction methods are drawing attention in the LF compression field [30]–[32]. These methods reconstruct the input LF views using a sparse set of views that are initially compressed using video-coding tools. The enhancement and customization of video-coding schemes to improve the com-pression efficiency of LF data can significantly influence the LF compression process.
III. PROPOSED COMPRESSION SCHEME
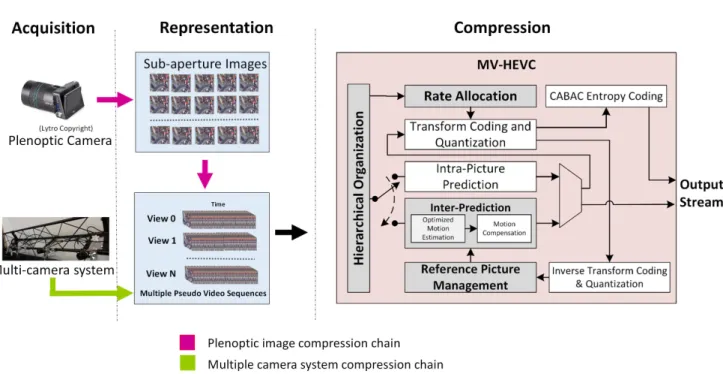
The block diagram of the proposed framework is displayed in Fig. 1 and consists of LF acquisition, representation, and compression. The proposed compression framework is applicable for both dense as well as sparse LF data cap-tured using plenoptic cameras and MCSs, respectively. The LF data acquired using plenoptic cameras is converted into SAIs and then into multiple PVS (MPVS), whereas the LF views acquired from MCSs are directly converted into MPVS. In the rest of this paper, SAIs from plenoptic cameras and views from MCSs are referred to as ‘‘LF views’’. Fig. 1 illustrates that, after LF acquisition and its representa-tion as MPVS, it is compressed using MV-HEVC. The com-pression blocks highlighted in gray represent the modules that have been either added or modified from the reference MV-HEVC modules, whereas the non-highlighted (white) blocks represent reference MV-HEVC modules that are not modified in the proposed framework. The compression scheme initially organizes the LF views in hierarchical order, followed by the rate-allocation scheme that assigns the qual-ity to individual LF views in terms of quantization levels. The reference frame management scheme arranges the indexes of frames according to the hierarchical organization used for the prediction of other frames in the LF views. Finally, an optimized motion search is performed by taking advantage of the temporal and inter-view dependencies of LF views to reduce the computational complexity. The following subsec-tions discuss the compression modules in detail.
A. HIERARCHICAL ORGANIZATION OF LIGHT FIELD VIEWS
The proposed scheme divides the input LF views into hier-archical levels, and later the assigned levels are used by reference picture management and rate-allocation schemes to improve the compression efficiency. The central LF view (referred to as central-LF) is considered as the most essential view, and it is placed in the first hierarchical level. A uni-formly sub-sampled sparse representation of input LF views
FIGURE 1. Block diagram of the overall proposed framework. The input from plenoptic cameras or MCSs is converted into MPVS and transferred as input to the MV-HEVC based LF coding framework. A hierarchical organization of frames is introduced in MV-HEVC, and modifications are proposed in reference picture management, rate-allocation, and ME schemes.
FIGURE 2. Hierarchical organization for horizontal parallax only LF data (17 views). The central view at index 8 is of high importance, and it is placed in the first level. Views with indexes {0,4,12,16} are placed in the second level, views with indexes {2,6,10,14} are placed in the third level, and the remaining views are placed in the last level. The same hierarchical organization is applied to 2D LF views.
is interpreted as the next important piece of information of the scene and is placed in the second hierarchical level. With-out relying on any prior information, it is assumed that the uniformly distributed sparse views contain most of the scene information. Similarly, the remaining LF views are placed in subsequent hierarchical levels. Fig.2contains an example of the hierarchical organization for Stanford LF data in a single dimension. The central view at index eight {8} is placed in the highest hierarchical level. Views with indexes {0,4,12,16} are placed in the second level, views with indexes {2,6,10,14} are placed in the third level, and finally, the remaining views
are placed in the last level. The views placed in higher levels are assigned with the best available quality and are used for the prediction of same and lower level views. The lowest level views are not used for prediction of any other view. The presented hierarchical organization scheme is extended for 2D LF views.
The hierarchical organization of a single layer with Mviews is presented in Algorithm1. The central-LF view is assigned to the highest level. The algorithm then successively partitions the input LF views into two parts and assigns sub-sequent levels until further division is not possible. Finally,
the remaining LF views are assigned to the lowest level. The left and right side of the hierarchical structure are stored in two separate lists (i.e., HL and HR) and are provided as an
output by Algorithm1. The same methodology is extended for 2D input LF views with the size M xN .
Algorithm 1 Hierarchical Organization of input LF Views
Input:Total Number of views M 1: HL(1, 1) = bM −21c 2: HR(1, 1) = bM −21c 3: C = {0, L0, M − 1} 4: i =1 5: while bM −1 2i+1 ≥2c do 6: for k = 1 : numel(C) − 1 do 7: F = C(k) + bM −1 2i+1 c; 8: if F ≤ bM −21cthen 9: HL(i, 1) = F; 10: else 11: HR(i, 1) = F; 12: C =updatelist(C, Li) 13: i = i +1 14: for m = 1 : M do 15: Lm= m, ∀ m /∈ C ; 16: HL(1, numel(HL(2, :)) + 1) = 0 ; 17: HR(1, numel(HR(2, :)) + 1) = M − 1 ; 18: Output: HL, HR
B. REFERENCE PICTURE SELECTION/MANAGEMENT The reference picture list maintains the indexes of frames used for the prediction of other frames in the video data. In video coding, various prediction structures [52]–[55] are proposed by taking into account the properties of image and video signals. The reference MV-HEVC uses the same video signal assumptions for the management of reference picture lists. However, in our proposed compression scheme, we have considered the following important factors for LF data.
1) Block Level Analysis: In the presence of occlusion, it will be beneficial to select a reference view that is further away from the current view since nearby views will most likely contain the same occlusion.
2) Frame Level Analysis: In video data, the residual between consecutive frames is mainly incurred by the motion of objects. However, the residual between consecutive views in LF data is mainly incurred by perspective changes and occlusion due to objects in the scene. Generally, the correlation of the current frame/view decreases as predictions are taken from further away frames/views. However, this behavior is more likely in the case of LF data compared to video data. Therefore, encoding efficiency increases if views are encoded from references selected in close vicinity of the current view.
Algorithm 2 Reference Picture Selection
Input HL,HR, PMAX
1: RL(1, 1) = NULL; Base frame is Intra coded 2: DL(1, 1) = HL(1, 1); Base frame is encoded first 3: Calculating Reference pictures for Left side 4: k =2 5: for s = 2 : size(HL, 1) do 6: for t = 1 : size(HL, 2) do 7: if HL(u, t) 6= NULL then 8: DL(1, k) = HL(s, t) 9: for u = 1 : k − 1 do 10: if u ≤ PMAXthen 11: RL(k, u) = DL(1, u) 12: end 13: end 14: k = k +1 15: end 16: end 17: end
18: Calculating Reference pictures for Right side 19: k =2 20: for s = 2 : size(HR, 1) do 21: for t = 1 : size(HR, 2) do 22: if HR(u, t) 6= NULL then 23: DR(1, k) = HR(s, t) 24: for u = 1 : k − 1 do 25: if u ≤ PMAXthen 26: RR(k, u) = DR(1, u) 27: end 28: end 29: k = k +1 30: end 31: end 32: end 33: R =[RL; RR] 34: DO =[DLDR] 35: end 36: Output: DO, R
3) GOP Level Analysis: In LF compression, it has been demonstrated that [25], [26] providing better quality to predictor frames improves the compression efficiency. The variable quality of the predictor frame will require joint analysis of the impact of the distance and quality of the predictor frame on the encoding of the current frame.
Therefore, it is proposed to select a combination of ref-erence views such as to keep the views near the current view (to exploit the high correlation), and also the views that are relatively farther away from the current view (to handle the occluded regions). However, increasing the ref-erence frames improves the compression efficiency at the cost of additional memory and computational complexity of the encoding scheme. Experimentation is performed to
quantify the impact of the number of reference frames on overall compression efficiency, and the results are reported in SectionIV-D.
Algorithm2explains the proposed reference picture selec-tion scheme for a 1D case. The proposed scheme takes the maximum number of predictor (PMAX) frames as an input parameter along with the left (HL) and right (HR) lists from
Algorithm 1. References for each list are maintained inde-pendently, and both lists only share the central view. The reference list index for the first frame is assigned with null value since it will be encoded in intra mode. From lines 5-17, the algorithm iterates over all the remaining views and esti-mates the reference list for each view. Similarly, the reference list for views placed on the right-side list (HR) is estimated
from lines 18-32. The algorithm also sets the decoding order (DO) of the input LF views.
C. RATE-ALLOCATION SCHEME
The rate-allocation scheme [47] makes use of the hierarchical structure of the input LF views to assign a specific quan-tization parameter (QP) to each view. The views placed in higher levels are assigned with better quality compared to remaining views placed in the subsequent levels. The rate-allocation scheme tends to keep better quality in terms of QP for views that are used for the prediction of other views; the greater the dependency on a view, the lower will be its QP. The views that are not used in the prediction of any other views are assigned with relatively higher QP values. The scheme uses MV-HEVC parameters including picture order count (POC), view ID (VID), decoding order (DO), and view order index (VOI) to estimate the QP for each view. The parameters POC and VID represent the location of each view in the input LF grid. While the parameters DO and VOI represent the decoding order of each view in the horizontal and vertical axes.
Algorithm 3 presents the rate-allocation scheme used in the proposed compression scheme. The algorithm takes the following parameters as input: the number of views in both dimensions (M × N ), POC and VID of the central frame (cPOC, cVID), POC array (APOC), DO array (ADO), VID array (AVID), VOI array (AVOI), and prediction level arrays (PPOC and PVID). Views belonging to the central column or row are assigned QP offset equal to the maximum of their prediction levels. For each remaining view, the QP offset is estimated by calculating the frame distance and decoding distance between the current frame and the base frame. The proposed rate-allocation scheme limits the extent of the QP offset by nor-malizing the calculated QP offset with the parameter Qmax.
The normalized QP offset of each frame is added to the QP of the central frame (Qc) to determine QP of each frame,
as explained in equation (1). QP(m, n) = M X m=1 N X n=1 Qc+ Q0(m, n) max(Q0) × QMAX (1)
Algorithm 3 Rate-Allocation Scheme
Input: M, N , cPOC, cVID, APOC, ADO, AVID, AVOI, PPOC, PVID
1: for x = 1:M do
2: for y = 1:N do
3: if x == cPOCk y == cVIDthen 4: Qo(x,y)= max(PPOC(x), PVID(y))
5: else
6: W = Weightage(sPOC(x), tVID(y)) 7: dPOC= b|APOC(x)−cW POC|c
8: dVID= b|AVID(y)−cW VID|c
9: dDO=remainder(ADO(x), cPOC) 10: dVOI=remainder(AVOI(y), cVID) 11: Qo(x,y)= dPOC+ dVID+ dDO+ dVOI
12: end
13: end
14: end
15: Output: Qo
D. MOTION-SEARCH OPTIMIZATION
The reference MV-HEVC was initially proposed for MCSs that contain temporal and inter-view correlations. Since the MCS data are mainly dominated by temporal correlations, it forced MV-HEVC to adopt a conventional 2D ME scheme for finding the best possible match of the current block namely a motion vector (MV). The MV-HEVC mainly relies on test zone search (TZS) [56] ME scheme that consists of three stages: 1) initial position selection, 2) coarse search, and 3) refined search. In the first step, the initial center position of the search window is selected by choosing the MV informa-tion of the neighboring coding units (CUs). In the second step, a coarse diamond-pattern search is performed using the initial center position to find the MV that yields the minimum SAD. In cases where the difference between the obtained MV and the initial position is higher than the specified threshold, an additional raster search is performed to obtain a closer estimate of the MV. In the final step, refinement is performed by changing the initial center position to the estimated MV of the second step, and a diamond-pattern search is performed again to obtain the refined MV. This diamond-pattern based 2D motion search in MV-HEVC is computationally expen-sive, which significantly contributes to the overall encoding time [56].
In LF data, the motion can be modeled by the disparity between the views. Disparity depends on the position of objects in the scene, and since each camera/view is essentially looking at the same scene, the views contain similar infor-mation, which can be exploited to optimize the ME process. In the proposed framework, we have exploited the rectified LF assumption to optimize the ME process in two ways: (i) We restricted the motion search in either horizontal or ver-tical directions depending on the orientation of the ref-erence and current frame, and (ii) the range of motion search is dynamically adapted based on the disparity between
cameras/views and the maximum motion encountered in the central LF column.
In the proposed LF compression framework, the central column of the 2D input LF is encoded first. The maximum MV between the current and reference frames is estimated and normalized by using the distance between the current and reference frames. For the remaining columns of the LF, whenever inter-view prediction is performed, the motion search is limited to the vertical direction only, with search range equal to the maximum motion found in the central column. Similarly, for temporal prediction, the motion search is restricted only to the horizontal direction. The maximum horizontal search range is defined based on the maximum vertical search range, and the horizontal and vertical distances between adjacent cameras. The motion-search complexity is significantly reduced from 2D to 1D with a negligible loss in rate-distortion (RD) performance.
The pseudo algorithm of the proposed optimization in the ME module is presented in Algorithm4. The algorithm takes POCi, POCref, CPOC, nPOC, Viewj, Viewref, stepX , and stepY parameters as input. POCi and POCref represent the POC number of the current frame being encoded and the ref-erence frame respectively. Moreover, CPOCrepresents POC number of the central LF column, nPOCrepresents the number of frames in each view, and nViewrepresents the number of views; Viewjand Viewrefrepresent the VID of the current and the reference frames, respectively. The parameters stepX and stepY indicate the horizontal and vertical distance between adjacent cameras.
In the proposed scheme, the first frame belongs to the central LF column (CPOC). The maximum motion between
the current (Viewj) and the reference views (Viewref) is
found using the ‘‘FindMaxVerticalMV’’ function that uti-lizes the reference ME process. The maximum motion vec-tor, V , is normalized by the distance between the refer-ence and the current view. If the normalized MV is larger than the previous maximum vertical motion, Vmax, then
Vmaxis updated. Subsequently, the maximum horizontal MV,
Hmax is scaled by multiplying Vmax with the ratio of the
horizontal and vertical distance between the adjacent views
stepX and stepY , respectively. The process is repeated for all the frames in the central LF column, and after encod-ing the central LF column, the estimated motion-search ranges Vmax and Hmax are fixed for the rest of the LF.
In non-central LF frames, optimized motion estimation is performed. If the VID of the current and reference frames (Viewj, Viewref) is same, then a horizontal motion search is
performed with a range limited to the maximum horizontal motion given by Hmax. Similarly, if VIDs of reference and
current frames do not match, then vertical motion estimation is performed with a search range limited to the maximum vertical motion, Vmax.
IV. EXPERIMENTAL RESULTS AND DISCUSSION
The experiments were performed to analyze the following aspects of the proposed compression framework:
Algorithm 4 Optimized Motion Estimation
Input: POCi, POCref, CPOC, nPOC, nView, Viewi, Viewref, stepX, stepY
1: Vmax=0 FInitialized once
2: for i = 1 : nPOCdo 3: for j = 1 : nViewdo
4: if POCi== CPOCthen FPerform Reference Motion Estimation with default search range, i.e., (x, y) = (±64, ±64)
5: V =FindMaxVerticalMV(Viewj, Viewref) 6: Vnorm= V/abs(Viewj− Viewref)
7: if Vnorm> Vmaxthen
8: Vmax= Vnorm
9: Hmax=(stepX/stepY ) ∗ Vmax
10: end
11: else FPerform optimized motion search
12: if Viewj== Viewrefthen Fi.e. same Layer (temporal prediction)
13: Hscaled =abs(POCi− POCref) ∗ Hmax
14: SetMvSrchRng(±Hscaled, 0)
15: else F i.e. same POC (inter-view prediction) 16: Vscaled(y) = abs(Viewj− Viewref) ∗ Vmax
17: SetMvSrchRng(0, ±Vscaled) 18: end if 19: end if 20: end for 21: end for 22: Output: MvSrchRng
• to select the appropriate input format for the proposed coding scheme,
• to analyze the impact of variable quality allocation on rate-distortion improvement,
• to quantify the number of reference pictures for LF data, • to estimate the reduction in computational complexity
using the proposed motion-search optimization, and • to demonstrate the performance of the proposed
com-pression scheme in comparison with state-of-the-art methods.
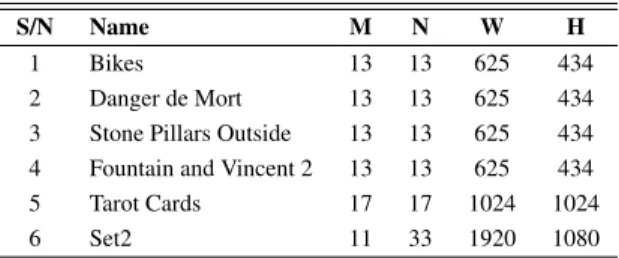
A. TEST ARRANGEMENT AND EVALUATION CRITERIA The proposed LF compression scheme was tested on six LF images selected from three different datasets [1], [18], [57]. Table1displays the selected LF images that contain M × N views in RGB format, and their equivalent YUV444 format was used as a reference input signal.
Following the JPEG Pleno common test conditions [28], weighted peak signal-to-noise ratio (PSNR) as presented in (2) was used to estimate the degradation in reconstruction quality relative to the reference input. The mean PSNR for the Y, U, and V components was evaluated by following equations (3) to (5). The proposed scheme is compared with the JPEG Pleno reference scheme (x265) and a state-of-the-art graph-learning based plenoptic image compression
TABLE 1. Selected LF images from JPEG Pleno datasets. scheme [29]. PSNRYUV = 6PSNRY + PSNRU+ PSNRV 8 (2) PSNRmean= 1 MN M X m=1 N X n=1 PSNR(m, n) (3) The PSNR of each view is calculated by
PSNR(i, j) = 10log10
(1023)2
MSE(i, j), (4) and the mean square error is calculated using
MSE(i, j) = 1 WH W X x=1 H X y=1 [I (x, y) − I0(x, y)]2 (5)
where I and I0 represent the reference and decoded view, respectively, and W and H represent the width and height of the view, respectively.
B. INPUT FORMAT SELECTION
The Lytro and HDCA LF images are provided in 10 bpp RGB format, and the Stanford LF image is given in 8 bpp RGB format. To find the optimum input format for the proposed encoding scheme, the ‘‘Bike’’ LF image from Lytro dataset was tested with three different input formats (10-bit YUV444, 8-bit YUV444, and 8-bit YUV420 format). Fig.3 displays the rate-distortion curves for three different variations of the input LF data. In all the test cases, the comparison was performed with the original input format. The results clearly indicate that the quantization of the input LF image from 10 bpp to 8 bpp and chroma sub-sampling from YUV444 to YUV420 yields better compression efficiency with an aver-age Bjøntegaard delta PSNR (BD-PSNR) gain of 0.45 dB. Hence, in the proposed compression scheme, the reference input is converted into an 8-bit YUV420 format prior to encoding.
C. FIXED VERSUS VARIABLE QUALITY
To analyze the impact of variable quality allocation among different views of input LF, an experiment was performed with two different quantization schemes: i) a variable QP scheme, as explained in SectionIII-C, and ii) a fixed QP scheme for all the frames. The experiment was performed on
FIGURE 3. Rate-Distortion comparison for three different input formats (10-bit YUV444, 8-bit YUV444, and 8-bit YUV420 format).
FIGURE 4. The rate-distortion analysis between the fixed quality compression scheme and the variable quality compression scheme on the ‘‘Bikes’’ LF image.
the ‘‘Bikes’’ LF image, and the RD curves presented in Fig.4
show that, overall, better compression efficiency is achieved by assigning variable QPs compared to fixed QPs among the input LF frames. The variable QP scheme shows a BD-PSNR improvement of 0.58 dB.
The mean PSNR measure, as suggested by JPEG Pleno, does not represent the variation among the views; hence, in Fig.4, the variance of PSNR among compressed views is also presented. In the ‘‘Bikes’’ LF image, the fixed QP scheme has an average variance of 0.53 dB for four selected bitrates, whereas the variable QP scheme has an average variance of 1.13 dB. The variable coding of LF views organized in hierarchical groups can be beneficial for appli-cations such as disparity estimation, view synthesis, and so forth. Moreover, the presented scheme can also benefit novel prediction tools [30] that use a sparse set of views to pre-dict the remaining views. However, some applications might require consistent quality among views (i.e., refocusing). Hence, in the proposed framework, the maximum variation in QP values is defined as a free parameter to better address the desired requirements.
FIGURE 5. The impact of the number of reference pictures on rate-distortion curves for Lytro, Stanford, and HDCA LF images.
FIGURE 6. The rate-distortion analysis between reference motion-search (RMS) and the proposed LF motion-search (LMS) for the ‘‘Bikes’’ LF image.
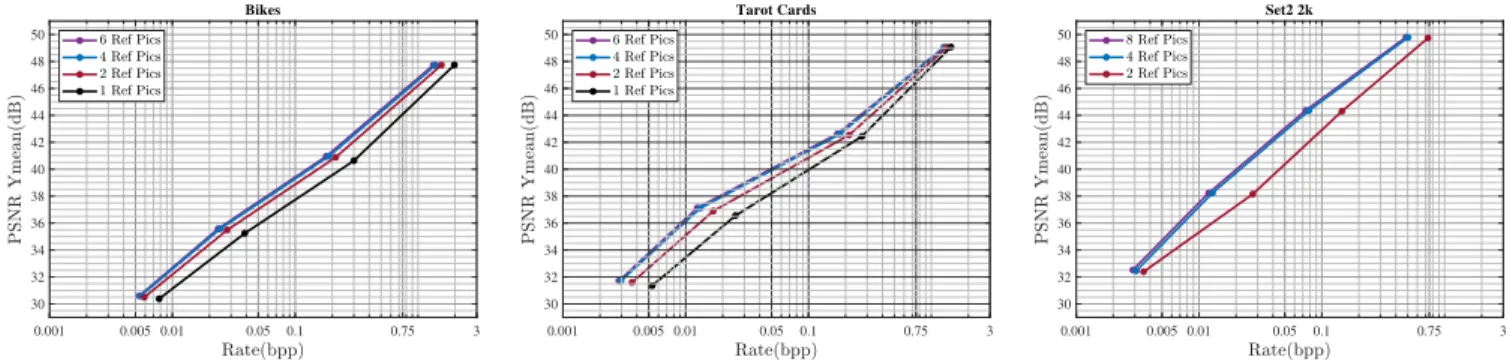
D. REFERENCE PICTURES SELECTION
An analysis was performed to quantify the effect of the num-ber of reference pictures on the RD improvements relative to computational complexity. The experiment was performed on ‘‘Bikes’’, ‘‘Set2’’, and ‘‘Tarot Cards’’ LF images taken from three different datasets as mentioned in Table 1. The improvements in the RD curves as a consequence of the increase in the number of reference pictures is illustrated in Fig.5. A significant improvement in the RD curves can be seen when more than two references in each dimension (hori-zontal and vertical) are selected. However, at a certain number of reference pictures, the improvement in RD performance becomes saturated, and the execution complexity increases unnecessarily. Based on the analysis, a parameter was defined that quantifies the number of reference pictures for each LF dataset. We chose a maximum of five horizontal and five vertical references for the Stanford and HDCA datasets; however, for the Lytro dataset, we decided on a maximum of three reference pictures in each dimension.
E. MOTION-SEARCH OPTIMIZATION
An analysis was performed to estimate the reduction in computational complexity using the proposed motion-search
TABLE 2.The reduction in number of times SAD is computed using the proposed motion-search optimization.
optimization. The LF image ‘‘Bikes’’ from Lytro dataset was encoded using the reference (MV-HEVC TZS scheme) and the optimized motion-search scheme and the computa-tional complexity was compared in terms of the reduction in the number of SAD computations during the motion-search process. Table 2 presents the motion optimization analysis, which demonstrates that the proposed motion opti-mization scheme results in more than an 80% reduction in the SAD computations for each LF image. Fig.6consists of an RD comparison between the reference motion-search and the proposed motion-search optimization, which demonstrates that the proposed optimization in motion-search results in a negligible loss in the RD curves, mainly due to the rectifica-tion process. The experiment revealed that, when providing the rectified LF as input to MV-HEVC, the search for the best candidate block can be reduced to a single dimension with minimum loss in perceived quality.
F. PROPOSED COMPRESSION SCHEME
The proposed compression scheme was evaluated on all the selected LF images, and the RD curves are presented in Fig. 7. In plenoptic image compression, the proposed compression scheme performs better than [29] and the x265-based schemes with an average BD-PSNR gain of 0.7 dB and 2.5 dB, respectively, as presented in Table3. Similarly, in the case of MCSs, the proposed scheme is compared with the x265-based scheme, and it reveals a PSNR improvement
FIGURE 7.The rate-distortion comparison of the proposed scheme with graph learning scheme [29] and JPEG Pleno anchor scheme for selected LF images.
TABLE 3. BD-PSNR gain of the proposed scheme relative to graph learning scheme [29] and JPEG Pleno anchor schemes.
of 2.4 dB for the ‘‘Tarot cards’’ LF image and 2.2 dB for the ‘‘Set2’’ LF image. In all the RD comparisons, the proposed scheme performs equally better in all the tested bitrates. The RD information indicates that gains in compression effi-ciency for plenoptic images are higher compared for MCS. The SAIs of plenoptic images contain high angular correla-tion, which is a consequence of the narrow baseline; also in addition, the small disparity among SAIs contributes to less overhead of MVs. In an alternative perspective, the proposed coding scheme relates the disparity information to the frame-per-second (FPS) analogy of video acquisition systems. The lower disparity in the captured SAIs represents high FPS, which in turn, reflects high correlation in neighboring SAIs. On the other hand, high disparity relates to low FPS and lower correlation among neighboring views.
V. CONCLUSION
In this paper, we have presented an optimized LF com-pression framework built on the multiview extension of high-efficiency video coding (MV-HEVC). In this process,
the views/SAIs are converted into multiple pseudo video sequences (MPVSs) and are hierarchically organized into groups. Variable quality is distributed among frames based on their assigned hierarchical level. A sparse set of views belonging to higher hierarchical level is assigned with bet-ter quality and used as reference pictures for the remaining views to improve the compression efficiency. An analysis was performed to quantify the number of reference pictures for LF data. Moreover, a motion-search optimization suitable for LF data is proposed to reduce the computational complex-ity (in terms of the number of SADs computed) by up to 87% with negligible loss in perceived quality. The pro-posed scheme is compared with the x265-based JPEG Pleno scheme and the graph-learning scheme by following the common test conditions set by JPEG Pleno. The proposed scheme leads to a 2.5 dB PSNR improvement compared to the x265-based JPEG Pleno anchor scheme and is 0.75 dB better then the graph-learning scheme.In the future, we intend to investigate various aspect of compression schemes, such as rate-control, random access, scalability, and so forth.
ACKNOWLEDGMENT
The software code of proposed scheme is made available at https://urn.kb.se/resolve?urn=urn:nbn:se:miun:diva-37186.
REFERENCES
[1] M. Ziegler, R. O. H. Veld, J. Keinert, and F. Zilly, ‘‘Acquisition system for dense lightfield of large scenes,’’ in Proc. 3DTV Conf., True Vis.-Capture,
Transmiss. Display 3D Video (3DTV-CON), Jun. 2017, pp. 1–4. [2] M. Martínez-Corral, J. C. Barreiro, A. Llavador, E. Sánchez-Ortiga,
J. Sola-Pikabea, G. Scrofani, and G. Saavedra, ‘‘Integral imaging with Fourier-plane recording,’’ Proc. SPIE, vol. 10219, May 2017, Art. no. 102190B.
[3] D. Cho, M. Lee, S. Kim, and Y.-W. Tai, ‘‘Modeling the calibration pipeline of the Lytro camera for high quality light-field image reconstruction,’’ in
Proc. IEEE Int. Conf. Comput. Vis., Dec. 2013, pp. 3280–3287. [4] C. Kim, H. Zimmer, Y. Pritch, A. Sorkine-Hornung, and M. Gross, ‘‘Scene
reconstruction from high spatio-angular resolution light fields,’’ ACM
Trans. Graph., vol. 32, no. 4, pp. 1–73, Jul. 2013.
[5] H. Mihara, T. Funatomi, K. Tanaka, H. Kubo, Y. Mukaigawa, and H. Nagahara, ‘‘4D light field segmentation with spatial and angular con-sistencies,’’ in Proc. IEEE Int. Conf. Comput. Photography (ICCP), May 2016, pp. 1–8.
[6] Z. Yu, J. Yu, A. Lumsdaine, and T. Georgiev, ‘‘An analysis of color demosaicing in plenoptic cameras,’’ in Proc. IEEE Conf. Comput. Vis.
Pattern Recognit., Jun. 2012, pp. 901–908.
[7] T. E. Bishop, S. Zanetti, and P. Favaro, ‘‘Light field superresolution,’’ in
Proc. IEEE Int. Conf. Comput. Photography (ICCP), Apr. 2009, pp. 1–9. [8] A. Ansari, A. Dorado, G. Saavedra, and M. M. Corral, ‘‘Plenoptic image
watermarking to preserve copyright,’’ Proc. SPIE, vol. 10219, May 2017, Art. no. 102190A.
[9] S. Hong, A. Ansari, G. Saavedra, and M. Martinez-Corral, ‘‘Full-parallax 3D display from stereo-hybrid 3D camera system,’’ Opt. Lasers Eng., vol. 103, pp. 46–54, Apr. 2018.
[10] P. A. Kara, A. Cserkaszky, A. Barsi, M. G. Martini, and T. Balogh, ‘‘Towards adaptive light field video streaming,’’ COMSOC MMTC
Commun.-Frontiers, vol. 12, no. 4, p. 61, 2017.
[11] D. G. Dansereau, O. Pizarro, and S. B. Williams, ‘‘Linear volumetric focus for light field cameras,’’ ACM Trans. Graph., vol. 34, no. 2, pp. 1–15, 2015. [12] D. G. Dansereau, O. Pizarro, and S. B. Williams, ‘‘Decoding, calibration and rectification for lenselet-based plenoptic cameras,’’ in Proc. IEEE
Conf. Comput. Vis. Pattern Recognit., Jun. 2013, pp. 1027–1034. [13] G. Lippmann, ‘‘Épreuves réversibles donnant la sensation du relief,’’
J. Phys. Theor. Appl., vol. 7, no. 1, pp. 821–825, 1908.
[14] E. H. Adelson and J. R. Bergen, ‘‘The plenoptic function and the ele-ments of early vision,’’ in Computational Models of Visual Processing, M. Landy and J. A. Movshon, Eds. Cambridge, MA, USA: MIT Press, 1991, pp. 3–20.
[15] M. Levoy and P. Hanrahan, ‘‘Light field rendering,’’ in Proc. 23rd Annu.
Conf. Comput. Graph. Interact. Techn., 1996, pp. 31–42.
[16] R. Ng, M. Levoy, M. Brédif, G. Duval, M. Horowitz, and P. Hanrahan, ‘‘Light field photography with a hand-held plenoptic camera,’’ Comput. Sci. Tech. Rep., vol. 2, no. 11, pp. 1–11, 2005. [17] C. Perwass and L. Wietzke, ‘‘Single lens 3D-camera with extended
depth-of-field,’’ Proc. SPIE, vol. 8291, Feb. 2012, Art. no. 829108.
[18] V. Vaish and A. Adams. The New Stanford Light Field Archive. Accessed: Sep. 27, 2019. [Online]. Available: http://lightfield.stanford. edu/lfs.html
[19] P. Schelkens, Z. Y. Alpaslan, T. Ebrahimi, K.-J. Oh, F. M. B. Pereira, A. M. G. Pinheiro, I. Tabus, and Z. Chen, ‘‘Jpeg pleno: A standard frame-work for representing and signaling plenoptic modalities,’’ Proc. SPIE, vol. 10752, Sep. 2018, Art. no. 107521P.
[20] Y. Li, M. Sjöström, R. Olsson, and U. Jennehag, ‘‘Coding of focused plenoptic contents by displacement intra prediction,’’ IEEE Trans. Circuits
Syst. Video Technol., vol. 26, no. 7, pp. 1308–1319, Jul. 2016.
[21] C. Conti, P. Nunes, and L. D. Soares, ‘‘HEVC-based light field image coding with bi-predicted self-similarity compensation,’’ in Proc.
IEEE Int. Conf. Multimedia Expo Workshops (ICMEW), Jul. 2016, pp. 1–4.
[22] R. Monteiro, L. Lucas, C. Conti, P. Nunes, N. Rodrigues, S. Faria, C. Pagliari, E. da Silva, and L. Soares, ‘‘Light field HEVC-based image coding using locally linear embedding and self-similarity compensated prediction,’’ in Proc. IEEE Int. Conf. Multimedia Expo Workshops
(ICMEW), Jul. 2016, pp. 1–4.
[23] R. J. S. Monteiro, P. J. L. Nunes, N. M. M. Rodrigues, and S. M. M. Faria, ‘‘Light field image coding using high-order intrablock prediction,’’ IEEE
J. Sel. Topics Signal Process., vol. 11, no. 7, pp. 1120–1131, Oct. 2017. [24] R. Zhong, S. Wang, B. Cornelis, Y. Zheng, J. Yuan, and A. Munteanu,
‘‘Efficient directional and L1-optimized intra-prediction for light field image compression,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 1172–1176.
[25] D. Liu, L. Wang, L. Li, Z. Xiong, F. Wu, and W. Zeng, ‘‘Pseudo-sequence-based light field image compression,’’ in Proc. IEEE Int. Conf. Multimedia
Expo Workshops (ICMEW), Jul. 2016, pp. 1–4.
[26] W. Ahmad, R. Olsson, and M. Sjöström, ‘‘Interpreting plenoptic images as multi-view sequences for improved compression,’’ in Proc. IEEE Int.
Conf. Image Process. (ICIP), Sep. 2017, pp. 4557–4561.
[27] G. Tech, Y. Chen, K. Müller, J.-R. Ohm, A. Vetro, and Y.-K. Wang, ‘‘Overview of the multiview and 3D extensions of high efficiency video coding,’’ IEEE Trans. Circuits Syst. Video Technol., vol. 26, no. 1, pp. 35–49, Jan. 2016.
[28] F. Pereira, C. Pagliari, E. da Silva, I. Tabus, H. Amirpour, M. Bernardo, and A. Pinheiro, JPEG Pleno Light Field Coding Common Test Conditions, Standard ISO/IEC JTC 1/SC29/WG1N81022, 81st Meeting, Vancouver, BC, Canada, 2018.
[29] I. Viola, H. P. Maretic, P. Frossard, and T. Ebrahimi, ‘‘A graph learning approach for light field image compression,’’ Proc. SPIE, vol. 10752, Sep. 2018, Art. no. 107520E.
[30] W. Ahmad, S. Vagharshakyan, M. Sjöström, A. Gotchev, R. Bregovic, and R. Olsson, ‘‘Shearlet transform based prediction scheme for light field compression,’’ in Proc. Data Compress. Conf. (DCC), Snowbird, UT, USA, Mar. 2018, p. 396.
[31] F. Hawary, C. Guillemot, D. Thoreau, and G. Boisson, ‘‘Scalable light field compression scheme using sparse reconstruction and restoration,’’ in Proc.
ICIP, Sep. 2017, pp. 3250–3254.
[32] N. Bakir, W. Hamidouche, O. Déforges, K. Samrouth, and M. Khalil, ‘‘Light field image compression based on convolutional neural networks and linear approximation,’’ in Proc. 25th IEEE Int. Conf. Image Process.
(ICIP), Oct. 2018, pp. 1128–1132.
[33] P. Paudyal, R. Olsson, M. Sjöström, F. Battisti, and M. Carli, ‘‘SMART: A light field image quality dataset,’’ in Proc. 7th Int. Conf. Multimedia
Syst., 2016, p. 49.
[34] M. Rerabek, T. Bruylants, T. Ebrahimi, F. Pereira, and P. Schelkens, ‘‘ICME 2016 grand challenge: Light-field image compression,’’ Call
Pro-posals Eval. Procedure, to be published.
[35] Call for Proposals on Light Field Coding, JPEG Pleno, Standard ISO/IEC JTC 1/SC29/WG1N74014, 74th Meeting, Geneva, Switzerland, Jan. 2017. [36] Y. Li, R. Olsson, and M. Sjöström, ‘‘Compression of unfocused plenoptic images using a displacement intra prediction,’’ in Proc. IEEE Int. Conf.
Multimedia Expo Workshops (ICMEW), Jul. 2016, pp. 1–4.
[37] Y.-H. Chao, G. Cheung, and A. Ortega, ‘‘Pre-demosaic light field image compression using graph lifting transform,’’ in Proc. IEEE Int. Conf. Image
Process. (ICIP), Sep. 2017, pp. 3240–3244.
[38] C. Conti, L. D. Soares, and P. Nunes, ‘‘Scalable light field coding with support for region of interest enhancement,’’ in Proc. 26th Eur. Signal
Process. Conf. (EUSIPCO), Sep. 2018, pp. 1855–1859.
[39] C. Perra and P. Assuncao, ‘‘High efficiency coding of light field images based on tiling and pseudo-temporal data arrangement,’’ in Proc.
IEEE Int. Conf. Multimedia Expo Workshops (ICMEW), Feb. 2016, pp. 1–4.
[40] R. Olsson, M. Sjöström, and Y. Xu, ‘‘A combined pre-processing and H.264-compression scheme for 3D integral images,’’ in Proc. Int. Conf.
Image Process., Oct. 2006, pp. 513–516.
[41] C. Jia, Y. Yang, X. Zhang, X. Zhang, S. Wang, S. Wang, and S. Ma, ‘‘Optimized inter-view prediction based light field image compression with adaptive reconstruction,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 4572–4576.
[42] S. Zhao and Z. Chen, ‘‘Light field image coding via linear approxima-tion prior,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 4562–4566.
[43] L. Li, Z. Li, B. Li, D. Liu, and H. Li, ‘‘Pseudo-sequence-based 2-D hierarchical coding structure for light-field image compression,’’ IEEE
J. Sel. Topics Signal Process., vol. 11, no. 7, pp. 1107–1119, Oct. 2017. [44] I. Tabus, P. Helin, and P. Astola, ‘‘Lossy compression of lenslet images
from plenoptic cameras combining sparse predictive coding and jpeg 2000,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 4567–4571.
[45] T.-H. Tran, Y. Baroud, Z. Wang, S. Simon, and D. Taubman, ‘‘Light-field image compression based on variational disparity estimation and motion-compensated wavelet decomposition,’’ in Proc. IEEE Int. Conf. Image
Process. (ICIP), Sep. 2017, pp. 3260–3264.
[46] J. Chen, J. Hou, and L.-P. Chau, ‘‘Light field compression with disparity-guided sparse coding based on structural key views,’’ IEEE Trans. Image
Process., vol. 27, no. 1, pp. 314–324, Jan. 2018.
[47] W. Ahmad, M. Sjöström, and R. Olsson, ‘‘Compression scheme for sparsely sampled light field data based on pseudo multi-view sequences,’’
Proc. SPIE, vol. 10679, May 2018, Art. no. 106790M.
[48] X. Jiang, M. Le Pendu, R. A. Farrugia, and C. Guillemot, ‘‘Light field com-pression with homography-based low-rank approximation,’’ IEEE J. Sel.
[49] T. Senoh, K. Yamamoto, N. Tetsutani, and H. Yasuda, ‘‘Efficient light field image coding with depth estimation and view synthesis,’’ in Proc. 26th Eur.
Signal Process. Conf. (EUSIPCO), Sep. 2018, pp. 1840–1844.
[50] M. B. de Carvalho, M. P. Pereira, G. Alves, E. A. B. da Silva, C. L. Pagliari, F. Pereira, and V. Testoni, ‘‘A 4D DCT-based lenslet light field codec,’’ in
Proc. 25th IEEE Int. Conf. Image Process. (ICIP), Oct. 2018, pp. 435–439. [51] K. Komatsu, K. Takahashi, and T. Fujii, ‘‘Scalable light field coding using weighted binary images,’’ in Proc. 25th IEEE Int. Conf. Image Process.
(ICIP), Oct. 2018, pp. 903–907.
[52] H. Schwarz, D. Marpe, and T. Wiegand, ‘‘Analysis of hierarchical B pictures and MCTF,’’ in Proc. ICME, 2006, pp. 1929–1932.
[53] S. Matsuoka, Y. Morigami, T. Song, and T. Shimamoto, ‘‘Coding efficiency improvement with adaptive GOP size selection for H.264/SVC,’’ in Proc.
3rd Int. Conf. Innov. Comput. Inf. Control, Jun. 2008, p. 356.
[54] H.-W. Chen, C.-H. Yeh, M.-C. Chi, C.-T. Hsu, M.-J. Chen, and M.-J. Chen, ‘‘Adaptive GOP structure determination in hierarchical B picture coding for the extension of H.264/AVC,’’ in Proc. Int. Conf. Commun., Circuits
Syst., May 2008, pp. 697–701.
[55] B. Zatt, M. Porto, J. Scharcanski, and S. Bampi, ‘‘Gop structure adaptive to the video content for efficient H.264/AVC encoding,’’ in Proc. IEEE Int.
Conf. Image Process., Sep. 2010, pp. 3053–3056.
[56] N. Purnachand, L. N. Alves, and A. Navarro, ‘‘Fast motion estimation algorithm for HEVC,’’ in Proc. IEEE 2nd Int. Conf. Consum.
Electron.-Berlin (ICCE-Electron.-Berlin), Sep. 2012, pp. 34–37.
[57] M. Rerabek and T. Ebrahimi, ‘‘New light field image dataset,’’ in Proc. 8th
Int. Conf. Qual. Multimedia Exper. (QoMEX), 2016, pp. 1–2.
WAQAS AHMAD received the M.Sc. degree in electronics engineering from Mohammad Ali Jin-nah University, in 2012. He is currently pursuing the Ph.D. degree with the Department of Infor-mation Systems and Technology (IST), Mid Swe-den University. His research interest includes light field compression.
MUBEEN GHAFOOR received the Ph.D. degree in image processing from Mohammad Ali Jinnah University, Pakistan. He is currently an Assis-tant Professor with the Computer Science Depart-ment, COMSATS University Islamabad. He has vast research and industrial experience in the fields of data sciences, image processing, machine vision systems, biometrics systems, signal anal-ysis, GPU-based hardware design, and software system designing.
SYED ALI TARIQ received the B.S. degree in computer and information sciences from the Pakistan Institute of Engineering and Applied Sci-ences (PIEAS), Pakistan, and the M.S. degree in computer science from Abasyn University, Islamabad. He is currently pursuing the Ph.D. degree with COMSATS University Islamabad, where he is also with the Medical Imaging and Diagnostics Lab. His research interests include image processing, deep learning, biometric sys-tems, and GPU-based parallel computing.
ALI HASSAN received the M.S. degree in computer science from COMSATS University Islamabad, where he is currently a Researcher with the Medical Imaging and Diagnostics Lab. His research interests include image processing and deep learning.
MÅRTEN SJÖSTRÖM received the M.Sc. degree in electrical engineering and applied physics from Linköping University, Sweden, in 1992, the Licen-tiate of Technology degree in signal processing from the KTH Royal Institute of Technology, Stockholm, Sweden, in 1998, and the Ph.D. degree in modeling of nonlinear systems from the École Polytechnique Fédérale de Lausanne (EPFL), Lau-sanne, Switzerland, in 2001. He was an Electrical Engineer with ABB, Sweden, from 1993 to 1994, and a Fellow with CERN, from 1994 to 1996. In 2001, he joined Mid Sweden University, and he was appointed as an Associate Professor and a Full Professor of signal processing, in 2008 and 2013, respectively. He has been the Head of the computer and system science at Mid Sweden University, since 2013. He founded the Realistic 3D Research Group, in 2007. His current research interests include multidimensional signal processing and imaging, and system modeling and identification.
ROGER OLSSON received the M.Sc. degree in electrical engineering and the Ph.D. degree in telecommunication from Mid Sweden University, Sweden, in 1998 and 2010, respectively. He was with the video compression and distribution indus-try, from 1997 to 2000. He was a Junior Lecturer with Mid Sweden University, from 2000 to 2004, where he taught courses in telecommunication, signals and systems, and signal and image pro-cessing. Since 2010, he has been a Researcher with Mid Sweden University. His research interests include plenoptic image capture, processing, and compression, plenoptic system modeling, and depth map capture and processing.

![FIGURE 7. The rate-distortion comparison of the proposed scheme with graph learning scheme [29] and JPEG Pleno anchor scheme for selected LF images.](https://thumb-eu.123doks.com/thumbv2/5dokorg/5428926.139979/11.864.56.817.96.469/figure-distortion-comparison-proposed-scheme-learning-scheme-selected.webp)
