J¨amf¨orelse av olika prognostiseringsmodeller
- en fallstudie av Yaskawa Nordic AB
Av: Daniel Ramljak & David Ramljak
Sammanfattning—F¨oretag str¨avar alltid efter att uppn˚a s˚a effektiv lagerstyrning som m¨ojligt. Samtidigt eftertraktas en tillr¨ackligt h¨og leveransprecision f¨or att kunna tillfredsst¨alla kun-den. En f¨oruts¨attning f¨or att framg˚angsrikt kunna ˚astadkomma detta ¨ar att f¨orutse efterfr˚agan fr˚an kunden i f¨orv¨ag. En approx-imering av efterfr˚agan i f¨ortid kallas f¨or prognostisering. Pro-gnostisering inneb¨ar att olika tekniker anv¨ands f¨or att f¨orutsp˚a framtida efterfr˚agan. De tekniker som anv¨ands kan vara baserat p˚a kvantitativ- eller p˚a kvalitativ data, ¨aven kombinationer av respektive f¨orekommer. En kvantitativ prognos ¨ar baserad p˚a ren historisk data, medans en kvalitativ utg¨ors fr¨amst i form av erfarenhet. Det f¨orekommer skilda anv¨andningsomr˚aden f¨or de olika teknikerna. Arbetet ¨ar baserat p˚a 4 prognosmodeller, best˚aende huvudsakligen av kvantitativ data. Modellerna ¨ar f¨oljande: den naiva metoden, glidande medelv¨arde, exponentiell utj¨amning och ARIMA.
Fallf¨oretaget som har analyserats ¨ar Yaskawa Nordic AB. Det ¨ar ett f¨oretag som specialiserar sig inom robotindustrin. Yaska-wa ¨ar ett dotterbolag till en st¨orre huvudkoncern ursprungligen fr˚an Japan. De s¨aljer ¨over 100 artiklar till konsumenter glo-balt. Konsumenten best˚ar fr¨amsta av st¨orre etablerade f¨oretag. Arbetet behandlar endast de 26 mest frekvent s˚alda robotar. Syftet med detta arbete ¨ar att ta fram beslutsunderlag f¨or best¨allningar av robotartiklar baserat p˚a historisk f¨orbrukning. Underlagen kommer att st¨odja l¨ampliga prognosmodeller som v¨aljs ut. De l¨ampliga modeller motsvarar de prognoser som utg¨or minst avvikelser. Besultsunderlagen ska ¨aven bidra med optimering av lagerniv˚aer, utan risker f¨or s¨amre leveranspre-cision. Prognosmodellerna beskrivs nedan.
I. NAIVA METODEN
Den naiva modellen ¨ar den mest simpla prognosmodell. Den kr¨aver ingen djupare analys och baseras inte, som m˚anga andra modeller, p˚a avancerad matematik. Modellen utg˚ar fr˚an att n¨astkommande periods efterfr˚agan ¨ar lika med f¨oreg˚aende periods efterfr˚agan, f¨orutsatt att den historiska efterfr˚agan ¨ar k¨and. De navia modellen kan beskrivas med f¨oljande ekvation [1]:
ˆ
xt+1= xt (1)
ˆ
xt+1 = Approximerade prognosv¨arde i period t
II. GLIDANDE MEDELVARDE¨
Glidande medelv¨arde ¨ar en av det mer grundl¨aggande icke-betingade ber¨aknings-metoder. Denna metod grundar sig i antagandet att n¨astkommande periods efterfr˚agan motsvarar
ett visst antal tidigare perioder. Efterfr˚agan antas beskrivas i en konstant modell. Syftet med metoden ¨ar att bilda ett medelv¨arde av de senaste antal perioder fr˚an den historiska efterfr˚agan, f¨or att framst¨alla en approximering f¨or kommande period. Prognosmodellen beskrivs med f¨oljande ekvation [2]:
ˆ xt= xt+ xt−1+ · · · + xt−N +1 N = 1 N k X j=−k xt+j (2)
N = Antalet perioder som inkluderas vid ber¨akning k = 2N − 1
III. EXPONENTIELLUTJAMNING¨
Exponentiell utj¨amningkan studeras som en utvecklad form av glidande medelv¨arde. Ist¨allet f¨or att samtliga efterfr˚agev¨arden har samma vikt vid ber¨akning, justeras de, vilket leder till att de senaste v¨ardena har en st¨orre p˚averkan p˚a approxime-ringen j¨amf¨ort med de tidigare. Generellt brukar de senaste v¨ardena besitta ett st¨orre relevant informationsv¨arde relaterat till ¨aldre v¨arden. Grunden utg˚ar fr˚an en linj¨ar kombination av f¨oreg˚aende prognos samt de senaste verkliga efterfr˚agan. F¨oljande ekvation representerar den exponentiella modellen [3]:
ˆ
xt= (1 − α)ˆxt−1+ α · xt (3)
α = Utj¨amningskonstant
0 ≤ α ≤ 1 IV. ARIMA
AR(p) samt MA(q) funktionen skapar tillsammans en AR-MA(p,q) modell. Modellen ¨ar anpassad f¨or station¨ara serier, vilket g¨or att den inte kan utf¨oras f¨or icke- station¨ara serier. De flesta serier som ˚aterfinns i verkligheten ¨ar icke- station¨ara, vilket medf¨or att ARMA(p,q) blir begr¨ansad. F¨oljande ekvation beskriver en ARMA modell [4]:
ˆ xt= a + φ1xt−1+ ... + φpxt−p | {z } pAR termer + θ1εt−1+ ... + θpεt−p | {z } qMA termer +εt (4) F¨or att omvandla ett icke- station¨art tillst˚and till station¨art, utf¨ors differentiering,. Generellt kr¨avs det endast en eller tv˚a differentieringar f¨or att uppn˚at station¨art tillst˚and. F¨or att kunna till¨ampa en mer anv¨andbar modell i verkligenheten, utvecklades ARIMA(p,d,q). Det ¨ar en process framtagen fr˚an 1
2
ARMA(p,q), som kan hantera icke- station¨ara l¨osningar. . Para-meter d motsvarar den integrerade delen. d st˚ar f¨or ordningen av differentiering som kr¨avs f¨or att uppn˚a station¨aritet. Vid skapandet av en ARIMA modell f¨oljs alltid de fyra stegen [4]:
Figur 1: Stegvis process ¨over ARIMA modellen, egen illustra-tion.
V. PROGNOSFEL
Prognosfel ¨ar en v¨asentlig del inom prognostisering. Avvikel-sen utg¨or prognosmodellens precision. Prognosfelet definieras som [3][5]:
et= xt− ˆxt (5)
et= Prognosfel i period t
Tv˚a av de vanligaste prognosfelen ¨ar MAE samt RMSE. Det definieras f¨oljande: M AE = 1 N · N X t=1 et= 1 N · N X t=1 |xt− ˆxt| (6) RM SE = v u u t 1 N · N X t=1 |xt− ˆxt| 2 (7)
VI. PROBABILITETSDISTRIBUTION
Prognoser ¨ar n¨astan alltid felaktiga. F¨or att t¨acka felet, s˚a m˚aste ett s¨akerhetslager s¨attas upp. S¨akerhetslagret ¨ar beroende av f¨ordelningen av efterfr˚agan. Analysen f¨or detta arbetet inklu-derar ocks˚a s¨akerhetslagret f¨or fallf¨oretaget. De f¨ordelningar som behandlas ¨ar normalf¨ordelning, gammaf¨ordelning, negativ binomialf¨ordelning och exponentiellf¨ordelning.
(a) Normalf¨ordelning [6] (b) Poissonf¨ordelning [7]
(c) Gammaf¨ordelning [8] (d) Exponentiellf¨ordelning [9]
VII. S ¨AKERHETSLAGER
Ett s¨akerhetslager konstrueras f¨or att t¨acka brister i hela f¨ors¨orjningskedjan. Syftet med ett s¨akerhetslager ¨ar att uppn˚a eller bibeh˚alla en viss serviceniv˚a, samt att gradera sig mot os¨akerhet i efterfr˚agan, inleveranser och produktion.
Om efterfr˚agan antas vara normalf¨ordelad och efterfr˚agan station¨ar kan s¨akerhets-lagret kan skrivas som [3]:
SS = k · σL= k · σ · Lγ (8)
SS = S¨akerhetslager (eng. safety stock)
σ = Standardavvikelsen f¨or efterfr˚agans prognosfel per period σL= Standardavvikelsen f¨or efterfr˚agans prognosfel under ledtiden
k = S¨akerthetsfaktor
L = Ledtid i antalet prognosperioder γ = Konstant
Vid en diskret icke- station¨ar efterfr˚agan utg˚ar dimensionering-en av ett s¨akerhetslager vanligtvis fr˚an dimensionering-en servicdimensionering-eniv˚a. Varje serviceniv˚a kan uttryckas fr˚an en l¨amplig best¨allningspunkt. Detta samband beskrivs av f¨oljande ekvation [3]:
SS = R − µL (9)
R = Best¨allningspunkt (eng. Reorder) µL = Snittf¨orbrukning under ledtiden
3
Under arbetets g˚ang har serviceniv˚a 1 till¨ampats, vilket kan beskrivas som; Sannolikheten att inte f˚a brist under en lager-cykel. Serviceniv˚a 1 beskrivs av f¨oljande uttryck [3]:
S1= P (D(L) ≤ SS) (10)
P = Sannolikheten att vilkoret uppfylls D(L) = Efterfr˚agan under ledtiden L
VIII. RESULTAT
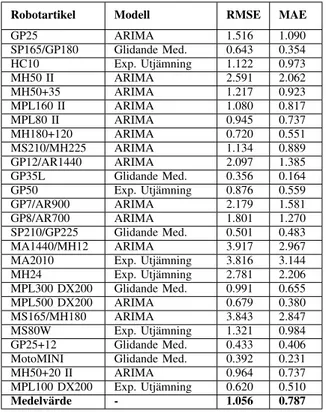
Efter att ha analyserat de fyra prognosmetoderna, ¨ar slut-satsen att ARIMA ¨ar den modell som passar b¨ast f¨or flest produkter. Den t¨acker 54% av produktutbudet. De resterande 46% f¨ordelas j¨amnt av glidande medelv¨arde och exponenti-ell utj¨amning. Den naiva metoden ¨ar inte mest l¨amplig f¨or n˚agon produkt. F¨ordelningen i efterfr˚agan uppskattas efter en exponentialf¨ordelning f¨or samtliga produkter, s¨akerhetslagret dimensioneras d¨arefter. Nedan visas den mest l¨ampliga mo-dellen f¨or respektive artikel.
Robotartikel Modell RMSE MAE GP25 ARIMA 1.516 1.090 SP165/GP180 Glidande Med. 0.643 0.354 HC10 Exp. Utj¨amning 1.122 0.973 MH50 II ARIMA 2.591 2.062 MH50+35 ARIMA 1.217 0.923 MPL160 II ARIMA 1.080 0.817 MPL80 II ARIMA 0.945 0.737 MH180+120 ARIMA 0.720 0.551 MS210/MH225 ARIMA 1.134 0.889 GP12/AR1440 ARIMA 2.097 1.385 GP35L Glidande Med. 0.356 0.164 GP50 Exp. Utj¨amning 0.876 0.559 GP7/AR900 ARIMA 2.179 1.581 GP8/AR700 ARIMA 1.801 1.270 SP210/GP225 Glidande Med. 0.501 0.483 MA1440/MH12 ARIMA 3.917 2.967 MA2010 Exp. Utj¨amning 3.816 3.144 MH24 Exp. Utj¨amning 2.781 2.206 MPL300 DX200 Glidande Med. 0.991 0.655 MPL500 DX200 ARIMA 0.679 0.380 MS165/MH180 ARIMA 3.843 2.847 MS80W Exp. Utj¨amning 1.321 0.984 GP25+12 Glidande Med. 0.433 0.406 MotoMINI Glidande Med. 0.392 0.231 MH50+20 II ARIMA 0.964 0.737 MPL100 DX200 Exp. Utj¨amning 0.620 0.510 Medelv¨arde - 1.056 0.787
Tabell I: Tabellen utg¨or den mest l¨ampade prognosmodell f¨or respektive artikel.
IX. REFERENSER
[1] Chatfield, C., and D. L. Prothero. Box-Jenkins seaso-nal forecasting: problems in a case-study. Journal of the Royal Statistical Society: Series A (General) 136.3 (1973): 295-336. (2019-05-26)
https://www.jstor.org/stable/2344994
[2] Brown, Robert Goodell. Smoothing, forecasting and pre-diction of discrete time series. Courier Corporation, 2004. [3] Axs¨ater, Sven. Inventory Control.
Vol. 225. Springer, 2015
[4] Box, George E. P. & Gwilym M. Jenkins. Time Series Analysis: Forecasting & Control.
[5] Olhager, Jan. Produktionsekonomi: principer och meto-der f¨or utformning, styrning och utveckling av industriell produktion. Studentlitteratur, 2013.
[6] (2019-05-26)
https://upload.wikimedia.org/wikipedia/commons/7/74/ Normal Distribution PDF.svg
[7] E Bruce Brooks, University of Massachusetts at Amherst, The Poisson Distribution, (2019-05-26)
https://www.umass.edu/wsp/resources/poisson/ [8] (2019-05-26) https://upload.wikimedia.org/wikipedia/commons/e/e6/ Gamma distribution pdf.svg [9] (2019-05-26) https://upload.wikimedia.org/wikipedia/commons/e/ec/ Exponential pdf.svg