Teknik och Samhälle Datavetenskap och Medieteknik
Examensarbete
15 högskolepoäng, grundnivå
Rekommendation av automatiserade verktyg för att
detektera plagiat i källkod på högre utbildningar
Recommendation of automated tools for detecting plagiarism in source
code in higher educations
Henrik Ahlqvist
Ossian Hjort Magnusson
Examen: kandidatexamen 180 hp Handledare: Annabella Loconsole Huvudområde: datavetenskap Examinator: Carl Magnus Olsson Program: Systemutvecklare
Abstract
Manual methods for detecting plagiarism in source code among students have for a long time been a heavy task for teachers in programming classes. As these courses tend to contain a large number of students per teacher, it is usually unrealistic for teachers to manually detect plagiarism in all student submissions. Since detecting instances of plagiarism is problematic for this reason, some students will inevitably pass courses with wrong grades. The goal of this thesis is therefore to supply a satisfactory recommendation regarding which automated tool is best suited for usage within a higher education environment.
In order to reach the goal of this study, a thorough literature review and several interviews with higher education teachers were performed, and a practical study was done in order to find out which automated tools work best, and satisfies all the requirements set by the teachers and the literature review. After the practical study was performed, it was discovered that there were more than one optimal automated tools available for higher education teachers, depending on different factors, biggest of which being if the tool is meant to be integrated into a bigger system, such as an online school platform, or being used directly by the teacher. The result of the thesis has also provided a possible solution to the problem of providing teachers with adequate evidence.
Sammanfattning
Arbetsprocessen med att manuellt upptäcka plagiat i källkod har länge varit ett stort problem för programmeringslärare. Detta beror på att den manuella processen är väldigt tidskrävande, eftersom att kurserna ofta innehåller ett stort antal studenter. Processen medför även en stor risk för att studenter som plagierar ofta passerar obemärkt, vilket resulterar i att dessa studenter tilldelas felaktiga betyg. Den tidskrävande aktiviteten blir för lärarna i slutändan också väldigt oekonomisk jämfört med användning av en automatiserad lösning. Syftet med det här arbetet är att slutligen ge en fullgod rekommendation av vilket automatiserat verktyg som passar bäst för användning på högre utbildningar.
De verktyg som utvärderas i detta arbete har valts ut genom att först utvärdera resultatet från en litteratur- och en intervjustudie. Resultatet från intervjustudien ger även en inblick i vad lärarna på Malmö Högskola har för önskemål angående ett automatiserat verktyg. Valideringen av verktygen har genomförts genom att utföra en praktisk testning på dem. Denna praktiska testning består av tre delar, där två av dem innehåller verkliga inlämningsuppgifter gjorda av studenter på Malmö Högskola. Den tredje testdelen innehåller kod som korrigerats till att innehålla olika varianter av plagiat studenter kan använda, i syfte för att försäkra att verktygens detektering fungerar. Resultatet av studien har också bidragit till en möjlig lösning på problemet med att förse lärare med godtycklig bevisning gällande instanser av plagiat i källkod.
Från resultatet av arbetets olika datainsamlingsmetoder dras slutsatsen om vilket verktyg som passar bäst för att användas på högre utbildningar. Rekommendationen av det lämpligaste verktyget varierar beroende på hur det faktiskt är planerat att användas. Faktorer som spelar in i valet är bland annat vilka programmeringsspråk som används i undervisningen på universitetet i fråga eller om verktyget är tänkt att integreras tillsammans med ett större system.
Innehåll
Abstract ... 2
Sammanfattning ... 3
Innehåll ... 4
1 Inledning ... 6
1.1 Bakgrund och tidigare forskning ... 6
1.1.1 Övergripande bakgrund ... 6
1.1.2 Vikten av att upptäcka plagiat inom programmering ... 6
1.1.3 Definition av plagiat inom text- och programmeringsuppgifter ... 6
1.1.4 Inledning till automatiserade verktyg ... 7
1.1.5 Förankring i verkliga problem ... 8
1.2 Syfte och frågeställning ... 8
2 Metod ... 10 2.1 Metodbeskrivning ... 10 2.1.1 Genomförande av litteraturstudie ... 10 2.1.2 Genomförande av intervjustudie ... 10 2.2 Metoddiskussion ... 11 2.2.1 Diskussion av Litteraturstudie ... 11 2.2.2 Diskussion av intervjustudie ... 12 2.2.3 Intervjufrågor ... 13
3 Datainsamling genom litteratur- och intervjustudie ... 16
3.1 Litteraturstudie ... 16
3.1.1 Förebygga problemet med ökat plagiat bland studenter ... 16
3.1.2 Beskrivning av hur olika verktyg kan analyseras ... 17
3.1.3 Varianter av plagiat och hur de kan upptäckas ... 19
3.1.4 Plagiatdetekteringsverktyget JPlag ... 23
3.1.5 Plagiatdetekteringsverktyget MOSS ... 25
3.2 Intervjuer med lärare och jurist från Malmö Högskolas disciplinnämnd .. 26
3.2.1 Intervjuer med lärare ... 26
3.2.2 Intervju med Hans Jonsson, jurist på disciplinnämnden ... 29
4 Tolkning av insamlad data från intervjustudien ... 31
4.2 Tolkning av juristens svar ... 33
4.3 Sammanfattning av intervjustudien ... 33
4.4 Avgränsningar gällande framtagandet av guidedokument ... 34
5 Lista över kriterier för granskningsverktyg ... 36
5.1 Sortering och val av verktyg ... 36
5.2 Metodik för att validera de utformade kriterierna ... 37
6 Diskussion av metodik för praktisk testning ... 39
7 Resultat från den praktiska testningen ... 41
7.1 Teknisk information angående förkortningar i resultatet och förklaring av hur verktygen används ... 41
7.2 Första samlingen, kriteriet att kunna exkludera baskod. ... 42
7.3 Andra samlingen, kriteriet att kunna hantera en grupp av filer som en inlämning ... 43
7.3.1 JPlag ... 43
MOSS ... 45
7.4 Tredje samlingen, säkerställa verktygens faktiska funktion ... 47
7.5 Guide för plagiat i källkod ... 47
8 Analys av resultat från den praktiska testdelen ... 48
8.1 Sammanfattning av resultatet från den första samlingen ... 48
8.2 Sammanfattning av resultatet från den andra samlingen ... 48
8.3 Sammanfattning av resultatet från den tredje samlingen ... 49
9 Diskussion ... 50
9.1 Kriteriet för att exkludera baskod ... 50
9.2 Kriteriet för att hantera inlämningar med flera filer ... 51
9.3 Garanti för verktygens funktion ... 52
10 Slutsats ... 54
10.1 Delfrågor ... 54
10.1.1 Delfråga 1 ... 54
10.1.2 Delfråga 2 ... 54
10.1.3 Delfråga 3 ... 55
10.2 Sammanfattning och huvudsaklig forskningsfråga ... 56
1 Inledning
1.1 Bakgrund och tidigare forskning
1.1.1 Övergripande bakgrund
Sedan mängden studenter på programmeringskurser börjat öka sedan slutet av 90-talet har även frekvensen för fusk ökat stadigt [5]. Detta då en programmeringskurs kan innehålla mer än hundra studenter [5]. Det stora antalet har resulterat i att det blivit svårare att upptäcka plagiat bland studenter för lärare [5]. Det kan då tolkas som att det för en ensam lärare är nästintill omöjligt att granska alla uppgifter på ett tillräckligt noggrant sätt för att upptäcka alla instanser av plagiat.
Det har identifierats flera anledningar till varför studenter väljer att fuska på sina programmeringsuppgifter. En av dem är att studenterna tror att de kan komma undan med plagiat [8]. En annan är att mer begåvade studenter ofta har lättare för sig att dela med sig av sina lösningar utan att förstå att det bör undvikas [5]. Dessutom finns många lösningar av uppgifterna redan tillgängliga online [12]. Detta, kombinerat med att det ofta existerar en miljö där studenterna uppmuntras att lära av varandra kan skapa fler tveksamheter [8]. Tveksamheterna kan leda till att studenter gemensamt skriver sin kod och uppmuntras att inte återuppfinna hjulet [8]. Det senare kan resultera i att de letar efter lösningar online och kopierar dem i sin helhet [12]. I tidigare forskning framgår det även att mängden fusk också kan bero på en lägre förståelse bland studenterna för vad som räknas som fusk [8]. Den lägre förståelsen kan leda till att studenter samarbetar eller kopierar av varandra på ett sätt som inte tillåts eller bör tillåtas [5].
1.1.2 Vikten av att upptäcka plagiat inom programmering
Ett av de stora problemen med att studenter plagierar källkod är att deras förståelse för programmering inte förbättras. Istället utvecklar de sin förmåga att fuska, vilket gör att de blir svårare att upptäcka om de fortsätter plagiera [5]. När klasserna blir större och lärare inte har tid att granska inlämningar lika noggrant ökar också mängden fusk [5]. Om inga åtgärder tas för att hantera detta kan det antas leda till att fler studenter tar sig igenom utbildningen utan att tillgodoräkna sig de färdigheter de borde få. På så sätt kan studenter, om de inte upptäcks, få examen utan att besitta de förväntade kunskaperna, något som kan komma att sänka universitetets anseende om det upptäcks. Vidare kan det argumenteras för att detta kommer sänka kvaliteten hos programmerare på arbetsmarknaden, vilket i längden kan leda till att det skapas sämre mjukvaruprodukter [2]. En studie fann att det låg ett värde i att föra diskussioner med studenter om hur plagiat i källkod fungerade, då många studenter inte har tillräcklig förståelse för vad som klassificeras som fusk [8]. Sådana diskussioner hade exempelvis kunnat ta upp konsekvenser med plagiat, såsom att inte utvecklas som programmerare, snarare än att fokusera på vad som händer med dem som ertappas med att fuska [8]. Detta kan tolkas som en metod för att avråda plagiat på ett uppmuntrande sätt, snarare än att framstå som hotfull genom att ta upp möjliga akademiska konsekvenser.
1.1.3 Definition av plagiat inom text- och programmeringsuppgifter
Plagiat inom programmering definieras, enligt Cosma, som ett verk vilket framställs som ett original, men i själva verket är grundat på någon annans tidigare existerande utformning [2]. I textuppgifter kan detta innebära användning av en annan personsresonemang utan att hänvisa till källa [2]. Det räknas också som plagiat om ett stycke är kopierat rakt av utan att citera det tagna stycket [18]. Verktyg för att hitta plagiat i vanliga textuppgifter har också skapats [16], vilka för analys av källkod hade kunnat användas för att upptäcka likheter i kommentarer.
Enligt en studie av Frew och Mann kan arbetet med att upptäcka plagiat inom programmering vara komplicerat, då vissa metoder för plagiat är svåra att upptäcka [8]. I sådana fall kan studenter sedan skylla likheter på begränsningar i uppgiften eller ett likartat tankesätt från att ha lärt sig i samma miljö [8]. För att underlätta undersökningen av plagiat i källkod, behöver de existerande tillvägagångssätten för att begå plagiat tydligt definieras. Exempel på detta finns i arbetet av Martins m.fl. [9], där åtta metoder för att begå plagiat omnämns. Cosma [2] definierar följande övergripande tillvägagångssätt för plagiat inom källkod:
1. Kopiera hela stycken från en annan källas kod utan att ändra något.
2. Kopiera stora stycken från en annan källas kod och ändra betydelselösa saker som exempelvis metodnamn och kommentarer, eller ändra ordningen på koden.
3. Kopiera stora stycken från en annan källas kod och ändra loopar och metoddetaljer utan att egentligen påverka vad koden gör.
Enligt Joy och Luck [5] finns det två olika sätt att gruppera de metoder som studenter använder för att begå plagiat inom källkod. Den första av dessa är lexikala förändringar, där exempelvis kommentarer ändras. Den andra är strukturella förändringar där ordningen på statements ändras utan att det påverkar kodens faktiska funktion. Om så är fallet går det att anta att ett verktyg som undersöker plagiat måste granska hur koden faktiskt fungerar, snarare än hur exakt den är skriven.
Studien av Frew och Mann [8] fann också att studenter inte alltid har en tillräckligt god förståelse för hur lik kod faktiskt kan bli. Detta då vissa studenter i deras studie menade att kod med över 30 procents likhet borde misstänkas, när deras egna uppgifter allt som oftast översteg 50 procents-gränsen. En tolkning är att författarna vill att studenter mer noggrant ska diskutera med lärare vilken gräns för likhet som kommer misstänkas [8]. Deras studie behandlar dock inte om detta är något som studenter och lärare redan gör.
1.1.4 Inledning till automatiserade verktyg
För att upptäcka plagiat i källkod i programmeringskurser existerar det redan ett flertal automatiserade verktyg [9]. I tidigare forskningsarbeten har verktyg som till exempel JPlag, MOSS, Marble, SIM, och Plaggie analyserats i olika sammanhang [9], [4].
För att kunna använda ett automatiserat verktyg för detektering av plagiat bör man även se till att verktyget har en godtyckligt låg frekvens av så kallade false positives [7]. Med false positives menas de fall där verktyget felaktigt markerar misstänkt fusk. När det uppstår många false positives innebär det extra arbete för den mänsklige granskaren. False positives kan också leda till ogrundade misstankar mot en student som granskas men är oskyldig [2]. Detta innebär att verktygen inte kan användas som absolut bevisning, utan behöver hjälp av mänskliga granskare för en korrekt bedömning [4].
Även uppgiftens svårighetsgrad kan påverka hur likartade studenters lösningar blir. I uppgifter på grundnivå är det möjligt att det bara finns ett fåtal lösningar, då uppgiften ämnar lära ut specifika kunskaper. I sådana fall är det naturligt att de inlämnade lösningarna har väldigt liten variation [8], vilket gör att det blir i det närmaste omöjligt för en lärare att upptäcka plagiat, såvida inte eventuella kommentarer är oförändrade från originalversionen [2].
1.1.5 Förankring i verkliga problem
Grunden för denna studie ligger i det faktum att Malmö Högskola idag inte använder en automatiserad lösning för att upptäcka plagiat i programmeringsuppgifter. Det innebär att allt arbete med granskning av källkod måste göras manuellt, något som blir väldigt tidskrävande för lärare [4].
Från ett historiskt perspektiv började problematiken med att upptäcka plagiat i källkod växa fram tydligast under 90-talet [5]. Detta eftersom mängden studenter inom sådana kurser ökade, vilket gjorde det svårare att undersöka all inlämnad kod [5]. Då skapades det ett allt större behov av att skapa en automatiserad lösning, vilket resulterat i att det idag existerar ett antal automatiserade verktyg att välja mellan. Flertalet av dem har både genomgått analyser för hur bra de är på att upptäcka plagiat och hur användarvänliga de är i tidigare forskningsarbeten, vilket underlättar utvärderingen av dem [4], [9], [10].
Att bevisa misstankar om plagiat är också en stor svårighet, då det krävs någon med goda kunskaper i varje led av granskningen för att kunna utläsa det misstänkta fusket [12]. Med detta menas att alla involverade, från läraren hela vägen till granskaren på disciplinnämnden, måste besitta programmeringskunskaper. Ofta är det en omöjlighet för någon utan kunskaper inom programmering att göra en fullgod granskning av misstänkt plagiat inom ämnet [12]. På så sätt skapas ett behov av att möjliggöra en metodik för att underlätta både granskningsarbetet och arbetet med eventuell bevisning.
För denna studie ligger fokus på hur arbetet med att på högre utbildningar upptäcka fall av plagiat i källkod kan underlättas. En viss sektion av studien tar även upp hur bevisningen kan förstärkas i misstänkta fall för att försäkra att rätt beslut tas. Med detta menas att visa vad som kan göras för att hjälpa högre instanser i sin granskning av plagiat i källkod.
1.2 Syfte och frågeställning
Målet med det här arbetet är att ge en fullgod rekommendation av det verktyg som passar bäst för lärarna på Malmö Högskola för att automatiskt upptäcka plagiat i källkod bland studenter. Arbetet har också som mål att ta reda på hur bevisningsprocessen i anmälda fall av plagiat kan förbättras för beslutsfattande personer utan programmeringskunskaper. Trots att rekommendationen av verktyg är riktat åt Malmö Högskola kan även andra högskolor eller universitet ta del av resultatet i det här arbetet. Om de anser sig vara i en liknande situation som Malmö Högskola. För att ta uppnå dessa mål angriper arbetet en huvudsaklig forskningsfråga, vilken lyder: “Hur kan arbetet med att upptäcka plagiat i källkod på högre utbildningar underlättas med hjälp av automatiserade verktyg?” Svaret på denna fråga är tänkt att uppnås genom att först besvara tre delfrågor, vilka är:
1. Vilken hjälp behöver lärarna på Malmö Högskola i sitt arbete med att upptäcka plagiat i källkod?
2. Vilket granskningsverktyg passar bäst för de behov som lärarna vid Malmö Högskola har?
3. Hur kan det göras enklare för lärare att bevisa fall av plagiat när dessa tas upp för granskning?
Huvudfrågan syftar till det generella ämnet att försöka hitta en väl fungerande lösning på problemet med att granska källkod. Detta genom att hitta det mest lämpliga verktyget för att analysera inlämningar enligt problematiken som beskrivs i avsnitt 1.1. Syftet är inte att skapa ett nytt verktyg, utan att utvärdera och granska existerande lösningar för problemet. Detta för att kunna ge en fullgod rekommendation för hur lärare mer effektivt kan upptäcka misstänkt plagiat i källkod.
Delfråga 1 är till för att uppskatta vad som i praktiken är problematiskt med granskningen av källkod. Genom att svara på detta kan vi bilda en förståelse för det praktiska arbetet kring granskningen av källkod. Således går det att bilda en bättre uppfattning om vilka kriterier en lösning bör uppfylla. Dessutom möjliggör svaret på denna delfråga att observera vilka av de tidigare definierade metoderna för plagiat [9] som studenter använder.
Delfråga 2 baseras till stor del på vad som kan utläsas av delfråga 1, men kommer även att granska tidigare forskning för att bilda en förståelse om hur de existerande lösningarna fungerar. Den kommer också att besvara om de idag existerande lösningarna är tillräckliga, eller om nyutveckling krävs. Den exakta metodiken för hur verktygen sedan utvärderas finns att läsa i arbetets metodbeskrivning, avsnitt 2.1.3. Denna utvärdering kombineras sedan med resultatet från en intervjustudie för att slutligen rekommendera det mest lämpliga verktyget för användning på Malmö Högskola.
Delfråga 3 ska ge svar på vad som kan göras för att se till att rätt beslut fattas när plagiat misstänks. Detta ska uppnås genom att skapa en förståelse för vad som faktiskt behöver bevisas för att få ett korrekt beslut gällande plagiat av kod. På så vis går det att försäkra för lärare att det arbete de bedriver med att granska kod inte är förgäves.
2 Metod
2.1 Metodbeskrivning
Det här arbetet är indelat i två stora delar. Den första behandlar en litteratur- och en intervjustudie. Den data som samlas in genom denna del står till grund för den andra stora delen av arbetet, vilken består av en praktisk testdel där de valda verktygen undersöks. Den tar även upp en möjlig lösning till delfråga 3: “Hur kan det göras enklare för lärare att bevisa fall av plagiat när dessa tas upp för granskning?”. Målet med testdelen är att forma ett underlag av argument för vilket verktyg ett universitet skulle ha störst användning av.
2.1.1 Genomförande av litteraturstudie
Litteraturstudien behandlar tidigare forskning inom området. I denna bearbetas även relevanta analyser och tidigare infallsvinklar för att ge god insyn för relevanta punkter inom ämnet. Litteraturstudien beaktar Oates [1] tankesätt gällande användning av litteratur i datavetenskapliga arbeten. Med detta menas hur den kan användas som bevis för att studien både är relevant och inte upprepar ett arbete som tidigare gjorts. Från litteraturstudien får vi därmed kriterier att basera vår testning på. Detta innebär att litteraturstudien görs för att besvara delar av delfråga 2: “Vilket granskningsverktyg passar bäst för de behov som lärarna vid Malmö Högskola har?”. För att hitta relevant material det här arbetet kan bygga vidare på används bland annat sökfraser som: “plagiarism detection language”, “Automatic plagiarism detection”, ”Code Plagiarism” och “Source-code plagiarism detection analysis”. För att reducera antalet sökträffar efterfrågas artiklar där sökfrasen finns med i titeln och är publicerade inom lämpliga tidsramar. Majoriteten av sökningarna ger ungefär mellan 5 till 15 träffar. För att ytterligare sålla bort irrelevanta artiklar studeras sammanfattningarna för att avgöra om de är relevanta eller inte. Referenslistorna i de funna artiklarna studeras också för att inte utelämna betydelsefulla forskningsartiklar de tidigare sökfraserna missat. Vid försök att hitta arbeten fokuserade på evaluering och jämförelser av populära verktyg används söktermen ”Sherlock JPlag source code plagiarism detection investigation programming python java”. Sökningen är inte begränsad till att sökfrasen enbart är inkluderad i titeln, utan kan även finnas med i innehållet. Tidsperioden för artiklarna med denna sökfras väljs att vara publicerade mellan 2010 och 2016 för att anses relevanta. De funna artiklarna användes därefter också för att hitta modernare eller andra betydelsefulla forskningsartiklar, med hjälp av snöbollsmetoder.
2.1.2 Genomförande av intervjustudie
Det andra momentet av arbetets första del är en intervjustudie, där fem personer intervjuas på ett semi- strukturerat sätt [1]. Fyra respondenter är lärare på Malmö Högskola medan den femte är en jurist från Malmö Högskolas disciplinnämnd. Anledningen till att använda just fem intervjurespondenter är för att kunna samla data rörande olika utbildningsnivåer, samtidigt som intervjuerna inte ska bli en för stor del av arbetet. Detta då syftet med intervjuerna, likt litteraturstudien, är att samla in data för resten av arbetet. Den data intervjuerna genererar är till för att skapa en förståelse kring intervjurespondenternas behov. Detta ger en bild av vad individer vars arbete inkluderar granskning av programmeringsuppgifter vill få ut av ett eventuellt automatiserat verktyg. Intervjustudien tar även upp hur dessa individer ser på problematiken gällande plagiat i källkod. Dessutom ger intervjuerna
information om hur personer utan programmeringskunskaper ser på problemet. Denna information kan sedan användas för att ta fram potentiella lösningar för enklare granskning av plagiat. Intervjustudien görs för att besvara delfråga ett “Vilken hjälp behöver lärarna på Malmö Högskola i sitt arbete med att upptäcka plagiat i källkod?”. Den har även inverkan på de resterande två delfrågorna. Den inverkan den har på delfråga två “Vilket granskningsverktyg passar bäst för de behov som lärarna vid Malmö Högskola har?” är att ytterligare kriterier utformas för validering i testdelen. Den genererar även data för att svara på delfråga tre “Hur kan det göras enklare för lärare att bevisa fall av plagiat när dessa tas upp för granskning?”.
De specifika detaljerna för hur intervjuerna utförs baseras på Oates [1] metod för semi-strukturerade intervjuer. Den första av dessa riktlinjer är att vara väl förberedd inför intervjun [1]. Med detta menas att de intervjuande sätter sig in i relevant bakgrundsinformation som berör respondenternas relation till ämnet. För att skaffa denna information påbörjas litteraturstudien, med fokus på hur lärares arbete med att upptäcka plagiat ser ut. Litteraturstudien ger även inspiration till de fem huvudfrågor den planerade delen av intervjun består av. Enligt Oates princip för schemaläggning (scheduling) informeras intervjurespondenterna via mail om vad intervjun ska behandla och estimerad tidslängd. Den planerade tiden är utsatt till max en halvtimme, då detta anses täcka in både de fem utformade frågorna och eventuella följdfrågor. En begränsning bestäms även till att ha maximalt två intervjuer per dag, för att ge tillräcklig tid att bearbeta den insamlade datan.
Intervjuerna utförs på intervjurespondenternas respektive arbetsplatser, specifikt på en plats som respondenterna själva väljer. Tanken med detta är att få dem att känna sig bekväma med situationen och därför ge sina svar på ett naturligt sätt [1]. Innan intervjuerna utförs presenterar de intervjuande sig och syftet med intervjun och arbetet för intervjurespondenten. Respondenten tillfrågas slutligen om denne vill ge tillåtelse för att dennes namn och arbetstitel nämns i klartext i arbetet. Intervjun utförs av två intervjuande, där den ena personen tar en mer passiv roll och för anteckningar medan den andre i huvudsak ställer frågor och eventuella följdfrågor. Syftet med att de intervjuande har var sin roll, vilket respondenterna upplystes om i förväg, är för att se till att allt som sägs skrivs ner, utan att samtalet ska avbrytas i onödan. Samtalen spelas inte in, då detta kan anses vara för inkräktande för respondenterna [1].
2.2 Metoddiskussion
2.2.1 Diskussion av Litteraturstudie
Litteraturstudien i detta arbete har som syfte att validera valet av ämne samtidigt som den bidrar med relevant information till ämnet. Detta följer Oates [1] syfte gällande hur och varför en litteraturstudie bör utföras.
De resurser som används i litteraturstudien är, med några få undantag, akademiska och online-baserade. Detta då resurser i exempelvis bokformat snabbt kan bli utdaterade, särskilt när det gäller ett ämne som inte är fullt etablerat [1]. Då vetenskapen kring ämnet plagiat i källkod fortfarande utvecklas måste moderna och relevanta resurser användas. Detta betyder dock inte att gamla resurser måste ignoreras, då dessa kan vara bra att ha med för att skapa en historisk bakgrund. På grund av detta har litteratursökningen skett inom databaserna Google Scholar och ACM Digital Library. Detta då dessa erbjuder innehåll från flera olika IT-relaterade
källor. En komplett tabell över söktermer och motivationer till valda och bortsorterade verk finns i bilaga 3.
I huvudsak behandlar litteraturstudien tidigare forskningsarbeten där flera verktyg har evaluerats och jämförts mot varandra. Den tar även upp information om vilka plagiatmetoder studenter brukar använda. Syftet med litteraturstudien är att skapa en klar bild av vad tidigare forskning byggt upp. En möjlig svaghet med litteraturstudien är dock att den inte behandlar plagiatets påverkan på studenters lärande på ett djupare sätt. Detta därför att det inte finns någon tidigare forskning som uppvisar några konkreta teorier om detta. Plagiatets påverkan på studenters lärande förlitar sig därför till enklare analyser som redan gjorts [8]. Detta gör dock att det skapas mer diskussionsmaterial för intervjuerna, som kan ge möjliga svar på den tveksamheten.
2.2.2 Diskussion av intervjustudie
Tidigare studier har visat att bevisningen gällande plagiat i källkod är svår att hantera [4], [12]. Dock behandlar tidigare arbeten [4], [12] sällan mer än den huvudsakliga författarens åsikt gällande problematiken. Dessa åsikter har sedan använts som underlag för den kvalitativa utvärderingen av verktygen [4], [12] snarare än att använda intervjuer eller någon alternativ metod för att ta reda på vad slutanvändaren faktiskt är ute efter. Artikeln av Frew och Mann [8] kan tolkas använda sig av en sorts intervjuer. Dessa fokuserar dock på studenter och deras uppfattningar, vilket inte blir relevant. Då detta arbete ämnar undersöka användningen av ett automatiserat verktyg i en verklig miljö räcker inte detta som motivation. För att kunna göra en fullgod rekommendation av ett verktyg krävs därför att arbetet undersöker lärares uppfattningar och erfarenheter kring arbetet med att upptäcka plagiat i källkod. Vidare bör också lärares synpunkter på att använda automatiserade lösningar undersökas, för att förstå under vilka omständigheter en sådan lösning skulle vara lämplig.
Målet med intervjuerna i detta arbete är att behandla hur arbetet med att upptäcka plagiat i källkod kan förenklas. Detta uppnås genom intervjuer med respondenter som är inblandade i detta på Malmö Högskola. Intervjuerna är också tänkta att visa problem som inte nödvändigt framkommer i litteraturstudien, samtidigt som potentiella lösningar kan diskuteras. Anledningen att använda en semi-strukturerad intervjuform är då denna enligt Oates anses bäst tillåta den som intervjuas att dyka in på djupet i ett ämne när det behövs [1]. Detta tillåter intervjuerna att vara utforskande snarare än att användas som bekräftelse. Då vi i huvudsak fokuserar på utforskande frågor måste därför enkäter och fullt strukturerade intervjuer tas bort, då dessa inte kan behandla sådana frågor tillräckligt väl. Inte heller ostrukturerade intervjuer används. Detta då flera olika huvudfrågor och följdfrågor måste introduceras, vilket en sådan intervjuform inte kan hantera [1].
En möjlig nackdel med den semi-strukturerade intervjuformen är att respondenten riktar in sig på en specifik fråga och dyker för djupt i detaljerna för den. Detta kan resultera i att andra viktiga frågor inte behandlas tillräckligt genomgående. Det är också svårt att kvantifiera den data som ges av denna intervjuform, eftersom de svar man får alltid påverkas starkt av respondenten [1].
Samtalen spelas inte in, då detta kan anses vara för inkräktande för respondenterna [1]. Inspelning undviks i syfte att få en respondent att tala friare och förklara eventuella oklarheter i de svar denne ger. Frågorna och eventuella följdfrågor
ställs i neutral ton, utan att vara värderande, för att inte leda respondenten i sitt svar. Vid slutet av varje intervju meddelas respondenten om att denne kommer få ta del av en transkriberad version av sina svar. Detta för att respondenten ska få möjlighet att ge sitt godkännande, så att inga missuppfattningar uppstått och att datan stämmer. Alternativet att låta respondenten vara anonym har valts bort, då detta anses sänka trovärdigheten i intervjuerna. Ett antagande kan dock vara att respondenterna hade kunnat tala ärligare kring ämnet om de tillåtits vara anonyma. Vi ansåg dock att respondenterna var tillräckligt professionella för att inte kräva anonymitet och valde således bort det.
2.2.3 Intervjufrågor
I detta arbetets intervjuer används frågor som tas fram i relation till de övergripande forskningsfrågorna. Två olika uppsättningar frågor tas fram, då både lärare och en representant från disciplinnämnden ska intervjuas. Då dessa har olika förutsättningar och inblick i ämnet måste frågorna vara åtskilda. De frågor som ställs till lärarna relaterar i huvudsak till delfråga ett och två. De frågor som ställs till representanten från disciplinnämnden relaterar i huvudsak till delfråga tre. Även om frågorna till viss del liknar varandra ställs de på ett sätt som är anpassat till den respondent som intervjuas. Dessutom tillåts intervjurespondenterna tala fritt kring en fråga om de finner det nödvändigt, och är medvetna om att följdfrågor kan förekomma. Detta då intervjuerna följer en semi-strukturerad form. Alla intervjufrågor har också granskats och diskuterats med projektets handledare innan intervjuerna utfördes, för att få ett perspektiv på dem utifrån.
Motiveringen till den första intervjufrågan: ”Hur många fall av plagiat upptäcker du per kurs?” står i relation till den svårighet med att upptäcka plagiat i källkod som uppkommit [4], [5], [12]. Frågan besvarar dels om denna svårighet existerar i en verklig miljö, men ger också data för jämförelser. Dessa jämförelser kan göras mellan denna data och det som uppkommer i intervjun med juristen från Malmö Högskolas disciplinnämnd, men även i framtida forskning på ämnet.
Fråga två, ”Vilken är den vanligaste typen av plagiat du ser i elevinlämnad kod?” motiveras då det finns ett definitivt värde av att veta vilka plagiatmetoder som lärarna faktiskt upptäcker. Detta kan då jämföras med tidigare forskning som definierat olika plagiatmetoder [9]. Detta görs dels för att se vilka metoder som är vanligast förekommande, men också för att se ifall det är någon plagiatmetod som lärarna ofta inte upptäcker. Om det senare av dessa visar sig vara sant kan detta också bli ett argument för att använda en automatiserad lösning.
Den tredje frågan, ”Hur skulle du vilja att ett automatiserat verktyg fungerade för att underlätta ditt arbete?” är den första frågan i intervjun som följer ett öppet format [1]. Motiveringen bakom frågan är att den ämnar att antingen bekräfta tidigare kriterier för verktyg [4], [9] eller att skapa nya kriterier för liknande bedömning. Fråga fyra, ”Vi har tänkt oss utforma ett form av hjälpande dokument för att underlätta bedömningen av eventuellt plagiat för de som möjligen inte är insatta i kod. Vad tror du om detta?” motiveras med det faktum att det är det första konkreta förslaget på en lösning gällande problemet med att bevisa plagiat i källkod. Tidigare forskning [8], [12] har påpekat svårigheten med att bevisa plagiat för någon utan kodkunskaper. Dock saknas konkreta förslag på att lösa detta, då all tidigare forskning istället fokuserar på hur väl verktygen kan upptäcka plagiat i källkod. Då detta bara är en del av problemet avseende lärares faktiska arbete med detektering av plagiat måste
även en konkret lösning för bevisningen tas fram. Genom att föreslå en möjlig lösning startar en diskussion gällande om den är möjlig i praktiken, eller om någon alternativ lösning finns att föreslå.
I tabell 1 beskrivs de intervjufrågor som ställs till lärare, vilket inkluderar dess klassificering och vilken forskningsfråga de relaterar till.
Intervjufråga Klassificering Relaterad forskningsfråga 1. Hur många fall av plagiat upptäcker du
per kurs? Stängd 1
2. Vilken är den vanligaste typen av
plagiat du ser i elevinlämnad kod? Stängd 1
3. Hur skulle du vilja att ett automatiserat verktyg fungerade för att underlätta ditt arbete?
Öppen 2
4. Vi har tänkt oss utforma ett form av hjälpande dokument för att underlätta bedömningen av eventuellt plagiat för de som möjligen inte är insatta i kod. Vad tror du om detta?
Öppen 1
5. Har du något övrigt du vill ta upp? Öppen -
Tabell 1: Intervjufrågor till lärare
I intervjun med Hans Jonsson från Malmö Högskolas disciplinnämnd gäller motiveringen samtliga frågor. Syftet är att få bättre insyn i hur arbetet med att bedöma anmälda fall av plagiat går till. Detta relaterar till den tidigare forskning [8], [12] som menat att det finns svårigheter med att bevisa plagiat i källkod för någon utan kodkunskaper. Fråga ett är till för den tidigare nämnda jämförelse med hur många fall av plagiat som lärarna upptäcker kontra hur många som anmäls. Fråga två, tre, fyra och fem riktar till att ge en mer noggrann inblick och bättre förståelse för disciplinnämndens arbete. I detta diskuteras också potentiella lösningar och huruvida dessa skulle vara användbara.
Intervjufråga Klassificering Relaterad forskningsfråga 1. Hur många anmälningar om plagiat i
kod får ni in per termin? Stängd 3
2. Hur går ert arbete med att undersöka
plagiat i källkod till? Öppen 3
3. Hade ni behövt ett verktyg för att hjälpa er undersöka eventuellt plagiat i källkod? Varför, varför inte?
4. Vilka är de största svårigheterna ni
upplever när ni granskar just källkod? Öppen 3 5. Vi har tänkt oss utforma en form av
hjälpande guide för att underlätta bedömningen av eventuella plagiat för de som möjligen inte är insatta i kod. Vad tror du om detta?
Öppen 3
6. Har du något övrigt du vill ta upp? Öppen -
3 Datainsamling genom litteratur- och intervjustudie
3.1 Litteraturstudie
I denna sektion presenteras tidigare forskningsarbeten, vilka har ett stort inflytande på hur den praktiska testningen i det här arbetet utformas. Litteraturstudien kommer bland annat ta upp olika anledningar till varför vissa studenter väljer att plagiera samt vilka metoder av plagiat de ofta använder. Förutom att förklara olika varianter av plagiat kommer litteraturstudien även ge förståelse för hur verktygens algoritmer för att detektera plagiat fungerar. Det kommer också att redogöras vilka egenskaper ett verktyg bör uppfylla för effektiv användning. Flera av de tidigare forskningsarbetena ger även god insyn i hur olika verktyg kan analyseras och jämföras på ett metodiskt tillvägagångssätt. Två populära verktyg kommer också att skildras mer detaljerat. Där kommer det att meddelas om information från tidigare forskningsarbeten som behandlar verktygen fortfarande stämmer överens med aktuell information från verktygens respektive webbplatser. Utöver litteraturstudiens inverkan på den praktiska testdelen i arbetet påverkar den även andra delar. Den har stor betydelse för vilka av de existerande verktygen som väljs ut för vidare undersökning i arbetet, vilket presenteras i avsnitt 5. Den kommer också att användas som ett underlag för både diskussionen och de slutsatser som dras från resultatet av den praktiska testningen.
3.1.1 Förebygga problemet med ökat plagiat bland studenter
Forskningsämnet inom det här arbetet handlar till stor del om automatiserade verktyg för att upptäcka plagiat i programmeringsuppgifter. Det existerar flera tidigare forskningsarbeten som berör ämnet. År 1999 publicerades forskningsartikeln “Plagiarism in programming assignments” av S. Joy och M. Luck [5]. Målet med arbetet var att assistera programmeringslärare med en automatiserad lösning för att upptäcka plagiat bland studenter. Bakgrunden till forskningsarbetet berodde på att antalet studenter i programmeringskurserna ökade, vilket i sin tur resulterade i fler fall av plagiat.
Till följd av ett högre deltagande i kurserna blir det betydligt svårare för lärare att upptäcka de studenter som använde sig av plagiat, särskilt när klasserna kan innehålla upp mot 100 studenter. Författarna menar att det inte är tillräckligt att endast påminna studenterna om att plagiat är förbjudet [5]. De skriver också att de måste förstå att fusk kommer att upptäckas och att det inte heller kommer att tolereras. Lärarna är därför i stort behov av ett automatiserat verktyg som kan effektivisera denna del av arbetsprocessen. På grund av detta presenterar författarna i sin artikel ett nytt verktyg konstruerat för att upptäcka plagiat av källkod i programmeringsuppgifter. Verktyget heter Sherlock. Författarna redogör också i artikeln tre skäl till varför studenter väljer att plagiera. De två första står i samband med att studenten besitter en lägre förståelse för programmering eller programmeringsuppgiften och den tredje handlar om att minimera det totala arbetet. När studenten besitter en lägre förståelse kan personen antingen samarbeta nära en kamrat i tron om att det är tillåtet eller kopiera samt redigera den personens program och hoppas på att det inte ska upptäckas. Det sista skälet behöver inte innebära att studenten har låg förståelse för programmerings eller programmet utan endast vill minimera det totala arbetet. I de fallen där studenten kopierar och redigerar en
kamrats program är det vanligt att studenten endast göra lexikala ändringar i källkoden, vilket enkelt kan göras med en sofistikerad textredigerare. I texten skildrar författarna fyra lexikala respektive sex strukturella plagiatmetoder. Om studenten inte har bra förståelse för programmet kan endast begränsade ändringar göras för att programmet ska fungera. Därför är det rimligt att Sherlock implementerar metoder för att upptäcka lexikala ändringar samt ett begränsat antal av de strukturella. Sherlocks designprincip inkluderar fyra stycken viktiga aspekter programmet måste uppfylla. Den första är att algoritmen måste vara pålitlig. Den andra är att algoritmen måste vara flexibel för att kunna lägga till nya programmeringsspråk. Den tredje är att verktyget måste vara användarvänligt. Läraren måste på ett snabbt sätt kunna identifiera vilka program som kan innehålla plagiat. Den fjärde och sista principen är att programmet måste kunna framkalla tydliga bevis på plagiering som kan visas för de som blir inblandade i fallet.
I artikeln [5] använder författarna ett program som använder en Neural Net algoritm för att generera en bild som visar hur stora likheterna är mellan studenternas lösningar. Programmet för att generera den grafiska bilden använder resultatet från Sherlock som input. Sherlock har validerats framgångsrikt genom en mängd olika tester. Verktyget användes i sex olika programmeringskurser med upp mot 100 studenter i varje. Sherlock upptäckte plagiat bland studenter i samtliga kurser. Sherlock lyckades även med att detektera plagiering i de tester där skickliga programmerare medvetet försökte lura programmet med att dölja modifikationer. Statistik på antalet plagieringsförsök varje år på The University of Warwick visar en minskning när de började använda Sherlock. Det beror på att studenterna blev mer medvetna om att ett automatiserat verktyg användes. När fler studenter är medvetna om att fusk kommer att upptäckas väljer de att avstå.
3.1.2 Beskrivning av hur olika verktyg kan analyseras
År 2011 gjordes ett forskningsarbete av Hage m.fl. [4] där författarna analyserar den senaste teknikens automatiserade verktyg för att upptäcka plagiat i källkod skriven i Java. I deras artikel “Plagiarism Detection for Java: A Tool Comparison” analyserar de verktygen JPlag, Marble, MOSS, Plaggie och SIM. Målet med arbetet är att hjälpa lärare och lärarassistenter med att få en övergripande bild av den senaste teknikens automatiserade verktyg. Den övergripande bilden ska upplysa läsaren om vilka fördelaktiga funktioner varje verktyg har och hur bra de presterar på att upptäcka plagiat i källkod skriven i Java. Detta för att läraren ska kunna ta ett korrekt beslut om vilket verktyg som passar bäst för det önskade ändamålet. Författarna hoppas också på att utvärderingen av verktygen ska ge indikationer på förbättringar till de som underhåller verktygen. Bakgrunden till arbetet är att plagiat ofta begås i akademiska miljöer. Författarna skriver att manuella inspektionsmetoder för att upptäcka plagiat är en omöjlighet och oekonomiska. Särskilt när samlingar med inlämningsuppgifter består av flera hundra studentinlämningar. Detta har resulterat i att flera automatiserade verktyg har utvecklats för att underlätta arbetsprocessen med att upptäcka plagiat för lärare. Tidigt i artikeln vill författarna förmedla att inga av verktygen faktiskt kan bevisa instanser av plagiat. Egentligen mäter endast verktygen hur lika studenternas program är varandra. Efter att verktygen analyserat likheten mellan inlämningarna krävs det en mänsklig skådare som kan bedöma om
likheterna är orsakade av plagiat eller inte. Detta då likheter också kan uppstå när inlämningsuppgifter är utformade på att implementeras efter ett standardiserat sätt.
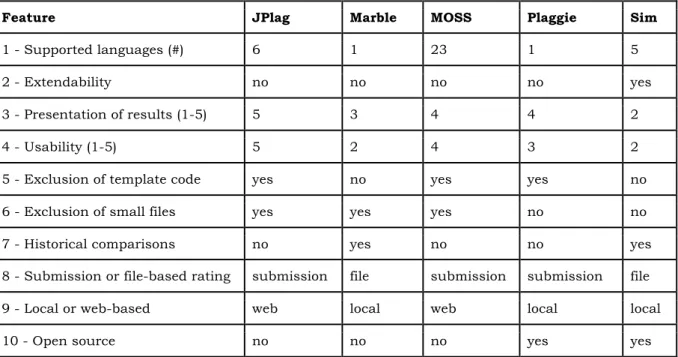
Enligt författarna [4] kan analysen av verktygen delas in i två kategorier. En kvalitativ och en kvantitativ. Den kvalitativa jämförelsen behandlar vilka egenskaper verktyget tillhandahåller användaren. I artikeln presenteras en lista på 10 stycken olika egenskaper. På svenska är de översatta till:
1. Antalet programmeringsspråk verktyget klarar av att analysera. 2. Utbyggbarhet, Om verktyget ger möjlighet till att utöka antalet
programmeringsspråk. 3. Presentation av resultat 4. Användbarhet 5. Exkludera mallkod 6. Exkludera små filer. 7. Historiska jämförelser
8. Katalog- eller filbaserad inlämning 9. Lokalt eller webbaserad
10. Öppen källkod
Presentationen av resultatet ska enligt författarna presenteras på ett effektivt sätt [4]. Med det menas hur lång tid det tar för granskaren att efterbehandla resultatet. För att säkerställa om likheterna beror på plagiat eller inte. Författarna understryker att presentationen minst måste innehålla en sammanfattning av resultatet och att programparen ska sorteras efter hur lika de är varandra. Det ska även vara möjligt för användaren att bestämma ett tröskelvärde för vilka programpar som ska inkluderas i resultatet. Användaren ska också på ett smidigt sätt kunna jämföra programparen sida vid sida där likheterna är markerade.
Den kvantitativa analysen jämför istället hur bra verktygen presterar på att upptäcka plagiat i källkod [4]. Detta görs ofta med att köra olika experiment på verktygen för att sedan jämföra deras resultat. I artikeln [4] utför författarna den kvantitativa analysen med hjälp av två experiment. Det första experimentet författarna utför behandlar en känslighetsanalys på verktygen. Känslighetsanalysen bygger på att författarna strukturerar om två Java-klasser till 17 olika versioner. Detta för att sedan mäta skillnaderna i likhet mellan de modifierade versionerna och originalet enligt verktygen. Med resultatet av känslighetsanalysen hoppas författarna kunna identifiera verktygens svaga respektive starka punkter på att detektera plagiat. Författarna utökar också känslighetsanalysen med att kombinera olika plagiatmetoder utifrån de 17 de tidigare definierat. Anledningen till utökningen berodde på att författarna tidigt i sina experiment upptäckt att kombinationer av olika varianter av plagiat försämrade verktygens resultat ytterligare. I det andra experimentet applicerar författarna verktygen på en samling av programmeringsuppgifter studenter lämnat in. Det är känt att samlingen innehåller gömda fall av plagiat. Denna del känner författarna är nödvändig eftersom att de då manuellt kan inspektera om verktyget upptäckter de rätta plagiatmetoderna.
Hage m.fl. [4] presenterar resultatet från den kvalitativa jämförelsen med hjälp av en matris. I tabell 3 går det att utläsa vilka kvalitativa egenskaper verktygen stödjer:
Feature JPlag Marble MOSS Plaggie Sim
1 - Supported languages (#) 6 1 23 1 5
2 - Extendability no no no no yes
3 - Presentation of results (1-5) 5 3 4 4 2
4 - Usability (1-5) 5 2 4 3 2
5 - Exclusion of template code yes no yes yes no
6 - Exclusion of small files yes yes yes no no
7 - Historical comparisons no yes no no yes
8 - Submission or file-based rating submission file submission submission file
9 - Local or web-based web local web local local
10 - Open source no no no yes yes
Tabell 3: Kvalitativ jämförelse av verktygen av Hage m.fl.
Från resultatet av den kvantitativa analysen av verktygen kom författarna [4] bland annat fram till att flera av verktygen är känsliga mot många små ändringar i källkoden. Detta kan göras med att modifiera koden enligt den tolfte plagiatmetoden författarna definierat.
Det andra experimentet visade bland annat att JPlag, Marble och MOSS presterade snarlikt med varandra [4]. Från det andra experimentet var det en inlämning som inte kunde analyseras av JPlag och Plaggie på grund av parse errors. Dessa parse errors uppstår då studenten skickat in en inlämning som innehåller syntaxfel. Ett förslag författarna ger för att undvika detta problem är att endast tillåta körbara program för bedömning.
3.1.3 Varianter av plagiat och hur de kan upptäckas
Ytterligare ett arbete som också behandlar analyser av automatiserade verktyg är forskningsartikeln “Detection of plagiarism in software in an academic environment” [10]. Artikeln är skriven av Vítor T. V. Martins och publicerades år 2016. Målet med artikeln är att skapa ett nytt automatiserat verktyg för att upptäcka plagiat. Det nya verktyget Spector ska vara bättre på att upptäcka metoder av plagiat i större omfattning än vad de existerande verktygen är [10]. Bakgrunden till arbetet baseras på resultatet från två tidigare forskningsarbeten [10]. De är “Plagiarism detection: A tool survey and comparison” [9] och “The source code plagiarism detection using AST” [6]. Den första publicerades år 2014 och skrevs också av Martins tillsammans med tre andra forskare. Den andra publicerades 2010 och skrevs av författarna X. Li och X. J. Zhong.
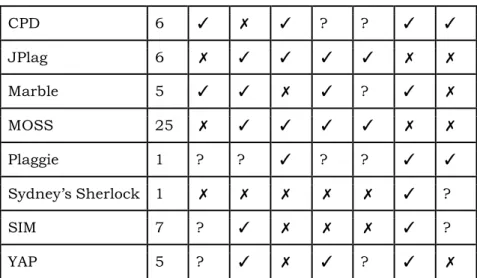
I artikeln “Plagiarism detection: A tool survey and comparison” [9] analyserar författarna den senaste teknikens automatiserade verktyg. Syftet med arbetet är att slutligen komma fram till vilken teknik som är lämpligast att efterlikna i deras planerade verktyg som är tänkt att integreras med universitetets automatiska bedömningssystem [9]. Författarna analyserar verktygen CodeMatch, CPD, JPlag, Marble, MOSS, Plaggie, Sherlock, SIM, and YAP.
Den empiriska analysen består både av en kvalitativ och en kvantitativ jämförelse [9]. Den kvalitativa jämförelsen omfattar åtta egenskaper, istället för tio som i Hage m.fl.:s forskningsarbete [4]. Det enda som skiljer dem åt från varandra är att Martins m.fl. inte valt med kriterierna för om verktygen kan exkludera små filer och om det är möjligt att göra historiska jämförelser [9]. Martins m.fl.:s åtta egenskaperna är, översatt till svenska [9]:
1. Stödjande programmeringsspråk: De språk verktyget stödjer.
2. Expanderbart: Funktionalitet för att enklare utöka verktyget med nya språk. 3. Kvaliteten på resultatet: Om resultatet är tillräckligt beskrivande för att kunna
urskilja plagiat från eventuellt falska plagiatförsök.
4. Gränssnitt: Om verktyget erbjuder ett GUI eller om resultatet presenteras på ett grafiskt sätt.
5. Uteslutning av baskod: Kan baskod väljas att ignoreras i särskilda programmeringsuppgifter.
6. Inlämning som grupp av filer: Kan överväga en grupp av filer som en inlämning.
7. Lokalt: Är verktyget tillgängligt utan att behöva ansluta till en extern webbtjänst.
8. Öppen Källkod: Verktyget släppt under en open-source licens.
Den kvantitativa analysen är systematiskt konstruerad för att ta reda på hur bra verktygen är på att upptäcka olika sorters försök av plagiat [9]. Den är på många sätt väldigt lik Hage m.fl.:s känslighetsanalys [4]. Avvikelserna är endast de program verktygen analyserar och de varianter av plagiat författarna definierat. Till den kvantitativa analysen har Martins m.fl. skrivit två olika program i både Java och C. Det första programmet är en kalkylator och det andra är spelet 21 Matches [9]. De både programmen är sedan modifierade till åtta stycken versioner. Varje version reflekterar en utav de åtta metoderna för att begå plagiat som författarna definierat i artikeln [9]. De åtta varianterna av plagiat är på svenska översatta till:
1. En exakt kopia av originalet.
2. Kommentarer ändras eller tas bort.
3. Namn på identifierare ändras, såsom variabel- och funktionsnamn. 4. Gör om lokala variabler till globala variabler och tvärtom.
5. Operander i likhetsjämförelser och matematiska uträkningar ändras utan att byta innebörd.
6. Variabeltyper och kontrollstrukturer byts ut mot likvärdiga uttryck för att inte förändra kodens funktion.
7. Statements(delar av koden), har förflyttats utan att kodens innebörd förändras.
De två samlingarna av kalkylatorprogrammet och spelet 21 Matches för analysen innehåller då åtta versioner med olika varianter av plagiat och en originalversion. Från ett teoretiskt perspektiv bör då varje version klassificeras med en likhetsprocent på 100% gentemot originalet [9].
Resultatet från den kvalitativa jämförelsen presenteras likt Hage m.fl. också med hjälp av en matris. Denna återfinns i tabell 4, där siffrorna på översta raden refererar till egenskaperna i Martins m.fl.:s egenskapslista [9]:
Name 1 2 3 4 5 6 7 8 CodeMatch 36 ✗ ✓ ✓ ✓ ✗ ✓ ✗ CPD 6 ✓ ✗ ✓ ? ? ✓ ✓ JPlag 6 ✗ ✓ ✓ ✓ ✓ ✗ ✗ Marble 5 ✓ ✓ ✗ ✓ ? ✓ ✗ MOSS 25 ✗ ✓ ✓ ✓ ✓ ✗ ✗ Plaggie 1 ? ? ✓ ? ? ✓ ✓ Sydney’s Sherlock 1 ✗ ✗ ✗ ✗ ✗ ✓ ? SIM 7 ? ✓ ✗ ✗ ✗ ✓ ? YAP 5 ? ✓ ✗ ✓ ? ✓ ✗
Tabell 4: Kvalitativ jämförelse av verktygen av Martins m.fl.
Resultatet från den kvantitativa analysen av verktygen gav författarna [9] motivationen till att skapa ett nytt verktyg. Eftersom att de existerande verktygen inte upptäcker alla sorters plagiatmetoder helt felfritt. Det nya verktyget ska då baseras på en strukturbaserad metod för att upptäcka plagiat. Den strukturbaserade metoden ska då använda AST(Abstract Syntax Tree) som datastruktur för att representera programmen. Annars tycker författarna att de flesta av de existerande verktygen är enkla att använda med förvalda inställningar. Författarna fann att JPlags användargränssnitt var mycket intuitivt och att verktyget erbjöd en mängd betydelsefulla inställningsmöjligheter.
Den andra forskningsartikeln skriven av X. Li och X. J. Zhong [6] behandlar två detekteringsalgoritemer för att upptäcka plagiat i källkod. Den ena är baserad på att representera programmen med hjälp av tokens och den andra med hjälp av AST(Abstract Syntax Tree). Den tokenbaserade detekteringsalgoritmen är den mest förekommande detekteringsalgoritmen. Den förekommer i sofistikerade system såsom JPlag, MOSS och YAP. Författarna ger en generell förklaring på hur denna process fungerar. Processen består av tre steg. Det första är att ta bort kommentarer, identifierare och blanktecken från koden. Det andra är att transformera programmet till en tokensträng. Det tredje och sista steget är att jämföra tokensträngen mot ett annat programs tokensträng, för att slutligen kunna räkna ut likhetsprocenten mellan dem, vilket brukas göra med strängmatchningsalgoritmen RRB-GST (Running Rabin-Karp Greedy String Tiling) [11]. De detekteringsalgoritmer som applicerar dessa tre steg för att räkna ut likheten mellan två program namnger författarna som tokenbaserade detekteringsalgoritmer. Li och Zhong [6] berättar att denna algoritm
kan på ett effektivt sätt upptäcka enklare metoder av plagiat, som till exempel att ändra namn på variabler, funktioner, kommentarer och blanktecken. Däremot är den inte lika effektiv på att upptäcka plagiat där kodblock har strukturerats om i källkoden. För att bevisa detta demonstrerar författarna ett kort experiment. Experimentet består av två C++ program där den enda skillnaden är att fyra av funktionerna har positionerats om. Resultatet av detta när de låter JPlag analysera likheten mellan de två programmen är en likhetsprocent på 87%, vilket författarna tycker är orimligt [6].
För att effektivare upptäcka plagiat där kodblock strukturerats om, presenterar författarna [6] den andra detekteringsalgoritmen baserad på AST(Abstract Syntax Tree). För att identifiera plagieringsförsök skapar den nya detekteringsalgoritmen först ett AST (Abstract Syntax Tree) istället för en tokensträng för att representera programmet. Detta då ett AST kan utmärka strukturen av ett program tydligare än vad tokens kan göra. Efter att algoritmen har skapat ett abstrakt syntaxträd av programmet, behöver den därefter dela upp syntaxträdet i subträd. Slutligen jämför algoritmen subträden mellan två program för att på så sätt räkna ut hur stor skillnaderna är mellan dem. Enligt författarna är uppdelningen av subträd den betydande faktorn för att algoritmen ska vara effektivare på att upptäcka plagiat där kodblock strukturerats om. Resultatet skulle vara detsamma som de tokenbaserade detekteringsalgoritmerna om syntaxträdet delas upp efter tokens. Om syntaxträdet delas upp efter statements blir subträden för små för att överhuvudtaget fungera. Därför väljer författarna att dela upp subträden efter funktioner.
I slutet av artikeln [6] jämför Li och Zhong den nya detekteringsalgoritmen mot JPlag i ett experiment som omfattar 40 små filer. Resultaten av testerna visar tydligt att den nya detekteringsalgoritmen är effektivare än vad JPlag är på att upptäcka plagieringsförsök där kodblock har strukturerats om. Den AST-baserade algoritmen hade en lyckad andelsprocent på 100% och JPlag hade 77%. I slutet av artikeln nämner författarna ett existerande problem med den nya detekteringsalgoritmen jämfört med de tokenbaserade. Problemet är att det är svårare att utöka antalet stödjande programmeringsspråk. Det beror på att det inkluderar flera steg än vad det krävs för en tokenbaserad detekteringsalgoritm, vilket författarna hoppas på att förbättras i framtiden.
De här två tidigare arbetena står som sagt till grund för implementationen av verktyget Spector [10]. Det gemensamma i resultaten från de två tidigare studierna var att den tokenbaserade metodologin för att upptäcka plagiat och verktygen som använder den har svårare för att upptäcka strukturella förändringar i koden [9], [6]. De flesta av de existerande verktygen använder den tokenbaserade metoden för att upptäcka plagiat såsom JPlag och MOSS [10]. På grund av detta fanns det ett behov av ett verktyg vars detekteringsalgoritm är baserad på AST. Detekteringsalgoritmen i Spector valdes därför till att implementera denna detekteringsalgoritm [10].
Artikeln “Detection of plagiarism in software in an academic environment” av Martins behandlar främst implementationen av det nya verktyget Spector. Utav de åtta kvalitativa kriterier från den första artikeln [9], anser Martins att för högre utbildningar är följande fyra kriterier viktigast för ett verktyg att uppfylla [10]:
● Kvaliteten på resultaten ● Uteslutning av baskod ● Inlämning som grupp av filer ● Lokalt
Martins anser att kriterierna för att kunna utesluta baskod och att verktyget kan hantera en grupp av filer är mycket viktiga [10]. Detta då de låter läraren att filtrera bort oönskad källkod från att medverka i resultatet. Med verktyg som JPlag och MOSS kan läraren göra en ordentlig filtrering av den inlämnade källkoden [10]. Martins anser även att den sjunde respektive den åttonde kvalitativa egenskapen också är av stort värde, för de som vill återanvända eller anpassa verktyget. Den sjunde var att verktyget är lokalt och den åttonde var att verktyget är baserad på öppen källkod. Dessa två kriterier främjar enligt Martins utvecklingen av ett större system om verktyget är distribuerat tillsammans vid sidan om applikationen. Spector genomgår också följande tester som de andra verktygen gjorde i den första artikeln [9], men endast för de versioner av programmen som var skrivna i Java, eftersom att det är det enda språket Spector stödjer för tillfället [10]. Resultaten från Spector visar att verktyget är mycket lämpat åt att hitta de fall av plagiat som de flesta andra verktyg hade problem med [10]. I diskussionen nämner författaren att detekteringsalgoritmen Spector använder är lämpad för att hitta likheter, vilket leder till att verktyget kommer att producera falska alarm av plagiat för vissa typer av uppgifter [10]. Författaren förklarar därför att verktyget är mer av en likhetsdetektor av källkod istället för en plagiatdetektor [10]. Av detta slutleder författaren att det bidragande arbetet är i form av en strukturellbaserad likhetsdetektor byggd på öppen källkod. Verktyget kan således byggas ut med mer funktionalitet för att utföra olika tester specificerade till det önskade ändamålet [10].
I denna senare artikel av Martins [10] klargörs det att det finns två verktyg med namnet Sherlock. Det ena verktyget är från Sydneys universitet och det andra från Warwicks universitet. Utav de två var det Sydney’s Sherlock som behandlades i den första artikeln av Martins m.fl. I det senare arbetet inkluderades även Warwick’s Sherlock tillsammans med de tidigare verktygen och uppfyller de kvalitativa egenskaperna som presenteras i tabell 5.
Name 1 2 3 4 5 6 7 8
Warwick’s Sherlock
3 ✓ ✓ ✓ ✓ ? ✓ ✓
Tabell 5: Kvalitativa egenskaper för Warwick’s Sherlock
I forskningsartikeln “Plagiarism in programming assignments” [5] av S. Joy och M. Luck, vilken behandlas i avsnitt 3.1.1, är det Warwick’s Sherlock som berörs.
3.1.4 Plagiatdetekteringsverktyget JPlag
JPlag skapades av Guido Malpohl år 1996 som ett forskningsarbete i University of Karlsruhe [4]. En kort tid därefter utvecklades verktyget till ett onlinesystem och år 2005 skapade Emeric Kwemou och Moritz Kroll en webbtjänst av JPlag [4]. Idag är JPlag publikt och publicerad med en GPLV3 licens och tillgänglig för hämtning från dess GitHub-repository, sedan år 2015 [20]. Tidigare har JPlag endast varit tillgängligt som en webbtjänst [4], [9]. Idag går endast webbtjänsten att användas av gamla användare med ett konto [17]. JPlag kan nu köras som ett lokalt verktyg på datorn i form av ett konsolbaserat program eller köras som en lokal webbtjänst [17]. På verktygets GitHub-sida rekommenderar underhållarna att endast använda den konsolbaserade versionen, eftersom att webbtjänstversionen använder utdaterade
bibliotek och behöver rensas upp [17]. JPlag har nu också stöd för att analysera programmeringsuppgifter skrivna i Python, då en Python3-tolk har implementerats som en front-end till verktyget [17].
På GitHub-sidan ges även instruktioner för hur användare kan utöka antalet programmeringsspråk för verktyget. I den kvalitativa jämförelsen mellan verktygen i Martins m.fl.:s forskningsartikel [9] stämmer inte alla värden överens med vilka egenskaper JPlag stödjer idag. Då artikeln skrevs uppfyllde inte JPlag kriterierna två, sju och åtta, som står listade i avsnitt 3.1.3. Hade den jämförelsen genomförts idag hade JPlag uppfyllt alla åtta egenskaper. Det skulle också stå att JPlag stödjer sju programmeringsspråk istället för sex, då verktyget nyligen fått stöd för att analysera programmeringsuppgifter skrivna i Python [17]. Utöver Python, har JPlag även stöd för programmeringsspråken: C, C++, C#, Java, Scheme och Natural language [9]. Från Martins m.fl.:s artikel “Plagiarism detection: A tool survey and comparison” [9], publicerad år 2014, uppfyller JPlag de kvalitativa egenskaper som presenteras i tabell 6.
Name 1 2 3 4 5 6 7 8
JPlag 6 ✗ ✓ ✓ ✓ ✓ ✗ ✗
Tabell 6: Kvalitativa egenskaper JPlag uppfyller i Martins m.fl.:s artikel
De kriterier JPlag uppfyller idag ser ut enligt det som står i tabell 7.Name 1 2 3 4 5 6 7 8
JPlag 7 ✓ ✓ ✓ ✓ ✓ ✓ ✓
Tabell 7: Kvalitativa egenskaper JPlag uppfyller idag
JPlag använder sig av en tokenbaserad detekteringsalgortim vilken genomgår två fraser för att räkna ut likheten mellan två program [3]. De program som ska jämföras är först parsade, vilket betyder att de omvandlas till ett nytt format. Efter att de blivit parsade konverteras de sedan till tokenstängar [15]. Denna första process i JPlag kallas för “the front-end process” [15]. Detta är den enda process som är programmeringspråksberoende i JPlag [15]. Fördelen med att använda en front-end parser är att det ger möjligheten till att representera mer semantisk information i tokensträngen [15]. JPlag är därför bra på att detektera plagiat när studenten försöker dölja det, eftersom att verktyget tar hänsyn till programmeringsspråkets struktur [9]. Dessa tokensträngar jämförs sedan mot varandra med hjälp av en modifierad version av Wise’s [11] strängmatchingsalgoritm RKR GST [15]. Modifieringarna av algoritmen i JPlag är till för att förbättra dess körtidseffektivitet [15]. Likheten i procentform mellan två tokensträngar räknas ut genom att se hur mycket den ena överlappar den andra [15].
En av JPlag största styrkor är presentationen av dess resultat [15]. Resultatet sparas i form av ett antal html-dokument där huvudsidan låter användaren se en översikt av resultatet [15]. Användaren kan se vilka inställningar JPlag kördes med och ett histogram över likhetsvärdena funna för alla programpar [15]. På huvudsidan kan användaren även se två listor över programmen organiserade efter genomsnittliga och maximala likheter utan repeterade värden, vilket låter användaren se om ett
program tillhör en grupp av liknande program [15]. Användaren kan välja att inspektera två misstänkta program för att kunna se en detaljerad jämförelse av källkoden sida vid sida där likheterna markeras i olika färger [15]. En annan fördelaktig egenskap JPlag erbjuder är alternativen för hur inlämningar kan hanteras [15], [17]. JPlag förväntar sig att indatan är en katalog innehållande underkataloger vilka representerar studenternas enskilda inlämning som ska jämföras mot varandra [15]. Varje underkatalog kan innehålla ett godtyckligt antal källkodsfiler som tillsammans representerar programmet [15], [17]. Avancerade inställningsmöjligheter tillåter även användaren att rekursivt skapa en sammanhängande programrepresentation av de filer som befinner sig i ytterligare underkataloger i studentens huvudkatalog [17].
3.1.5 Plagiatdetekteringsverktyget MOSS
MOSS utvecklades på Standford University år 1994 av Aiken m.fl. [4]. Verktyget är tillgängligt i form av en extern webbtjänst [4]. Åtkomst till webbtjänsten sker via ett script som användaren kan erhålla via MOSS hemsida [4]. Användaren behöver också skapa ett konto via email från moss@moss.stanford.edu, för att få åtkomst [4]. Tidigare var tjänsten endast tillgänglig för lärare och personal för programmeringskurser [19]. Idag kan dock vem som helst skapa ett användarkonto och få tillgång till tjänsten [12]. Utöver det script MOSS tillhandahåller existerar det också ett flertal “community contributions” av scriptet [19]. Resultatet av de uppladdade programmeringsuppgifterna hålls säkert och erhålls av användaren genom att använda en unik URL [12]. Resultaten tas automatiskt bort efter 14 dagar, vilket betyder att de inte lagras permanent på servern [12].
MOSS använder en tokenbaserad detekteringsalgoritm för att hitta likheter mellan två program [4]. Till skillnad från JPlag skapar MOSS ett fingeravtryck av varje program, istället för en tokensträng. Programmens fingeravtryck jämförs sedan mot varandra för att på så sätt upptäcka likheter [4]. För att skapa bra fingeravtryck använder MOSS detekteringsalgoritm sig av algoritmen Winnowing [4]. Algoritmen Winnowing [14] är effektiv när det gäller att välja ut den delmängd av programmets tokens som ska utgöra dess fingeravtryck. Med denna metod utesluter MOSS viss information av programmet medans det behåller de kritiska delarna [10]. På så vis kan därför falska plagieringsalarm undvikas [10]. Verktyget har stöd för många programmeringsspråk som används i programmeringskurser [10]. Det stödjer följande språk: A8086 Assembly, Ada, C, C++, C#, Fortran, Haskell, HCL2, Java, Javascript, Lisp, Matlab, ML, MIPS Assembly, Modula2, Pascal, Perl, Python, Scheme, Spice, TCL, Verilog, VHDL, Visual Basic, vilket totalt är 25 stycken [10]. Resultatet presenteras på ett grafiskt sätt för användaren med hjälp av HTML-sidor [10]. Det grafiska HTML-gränssnittet har tagits fram av Guido Malpohl, grundaren av JPlag [10]. Användaren kan betrakta resultatet både från ett översiktligt perspektiv och i mer detaljerade former [10]. MOSS visar en procentsats för varje inlämnad fil i programmet [12]. Procentsatsen för varje fil representerar mängden kod den ena filen innehåller som anses motsvara liknande kod i andra filer [12]. Fördelen detta ger är möjligt till att kunna urskilja vilken av filerna som är original- eller plagiatversionen. På startsidan presenteras också hur många överensstämmande rader två program delar [12]. Användaren kan på startsidan välja att inspektera två misstänkta program i mer detalj genom att klicka sig vidare via en länk [12]. Den nya sidan användaren kommer in på visar den utvalda filen gentemot den motsvarande filen [12]. De matchande sektionerna i de båda filerna är