Teknik och samhälle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Visualisering av träd och multi-agent traversering
Tree visualization and multi-agent traversation
Björn Svensson
Omar Aldulaimi
Examen: Kandidatnivå 180 hp Huvudområde: Datavetenskap Program: Applikationsutveckling
Datum för slutseminarium: 30 maj 2018
Handledare: Bengt J Nilsson Examinator: Mia Persson
Sammanfattning
Examensarbetet består av att skapa ett visualiseringsverktyg med syfte att bidra till en ökad förståelse hos en forskare att följa interaktion och beteende mellan multi-agenter när de traveserar ett träd. Av detta kommer forskaren enkelt kunna jämföra två studier och ta reda på om det är möjligt att minska overheadgapet mellan övre och undre gräns. Det främsta syftet med verktyget är det ska kunna visualisera specifika regler som forskaren har skrivit till en form av ett datavetenskapligt träd och låta en grupp agenter traversera igenom. Verktyget har skapats med hjälp av Java som programmeringsspråk samt JUNG visualisering-biblotek. Resultatet av detta arbete blev ett fungerande visualiseringsverktyg som följer forskarens regler samt har enkla traverseringsfunktioner.
Abstract
The thesis consists of the creation of a visualization tool which purpose is to contribute to an increased understanding of following interactions and behaviors between Multi-agents when traversing a tree. With this a scientist would be able to easily compare two studies to find out if it’s possible to shorten the overhead gap between the upper and lower limit. The prime purpose of the tool is to visualize specific rules written by the scientist, as a tree and letting a group of agents traverse in. The tool has been created in the programming language Java along with the visualization library JUNG. The result of this thesis was a functional visualization tool which follows the scientist’s rules as well as simple traversal functions.
Innehållsförteckning
1. Inledning ... 1 1.1 Bakgrund ... 1 1.1.1 Träd inom datavetenskap... 1 1.1.2 Trädtraversering ... 2 1.2 Problemformulering ... 3 1.3 Krav ... 31.4 Syftet och frågeställning ... 4
1.5 Avgränsningar... 4 1.6 Etiska aspekter ... 4 1.7 Disposition ... 4 2. Teori ... 5 2.1 Algoritmvisualisering ... 5 2.2 Grafvisualisering ... 5 2.3 Visualiseringsbibliotek ... 6 2.3.1 JGraph ... 6
2.3.2 JUNG: Java Universal Network/Graph Framework ... 8
3. Metod ... 10 3.1 Metodval ... 10 3.2 Metoddiskussion ... 10 3.3 Genomförandet ... 11 3.4 Utvecklingsspråk ... 12 4. Litteraturstudie ... 12 5. Implementering av visualiseringsverktyget ... 14 5.1 Primärprototyp ... 14 5.2 Agenttraversering... 14 5.3 Slutlig prototyp ... 16 6. Resultat ... 16
6.1 Verktygets slutliga form ... 16
6.2 Slutlig klasstruktur ... 19
7. Analys och diskussion ... 20
7.2 Multi-agenttraversering ... 21
7.3 Jämförelse med andra visualiseringsverktyg ... 22
7.4 Inlärning ... 23
8. Slutsatser ... 23
1
1. Inledning
1.1 Bakgrund
Visualisering är en förlängning av ett medfött mänskligt drag, det är något synligt eller en form av en mental modell eller mental bild [1]. Vi människor är visuella varelser och vi använder ofta grafik för att ge mening om stora uppsättningar av information [2]. Visualiseringen är ett sätt för oss människor att förstå olika typer av data och information samt för skapelse av bilder, diagram eller animationer för att kommunicera mellan olika datatyper. Ett verktyg kan skapas utav visualiseringen för att visualisera olika ting, där ett exempel är visualiseringen av algoritmer med syfte på att visa något komplext eller ge lösning till problem med hjälp av ett visualiseringsverktyg [2]. Visualiseringsverktygen är mer än ett verktyg för att hitta mönster i data, den utnyttjar mänskliga visuella systemet för att förstärka mänskligt intellekt. Det kan användas för att bättre förstå dessa viktiga abstrakta processer, samt möjligtvis andra komplexa saker därtill [2]. Att visualisera representationer av data samt algoritmer är en ökande viktig del av kognitiva system [1]. En användare som arbetar med ett datorbaserat visuellt verktyg utgör ett kognitivt system baserat på två viktiga komponenter, människans visuella system som kombinerar upptäckande av mönster med beslutsfattning samt datorns förmåga att visa stora mängder information [1]. En interaktiv visualisering utgör gränssnittet mellan dessa komponenter och när detta gränssnitt förbättras ökar det kognitiva systemets prestanda [1]. Algoritmer är ett fascinerande användningsfall för visualisering. För att visualisera en algoritm anpassar vi inte bara data till ett diagram, utan istället finns det logiska regler som beskriver beteendet. Det kan vara av den anledningen som algoritmvisualiseringar är ovanliga, eftersom designers experimenterar med nya grafiska former för att förbättra kommunikationen mellan slutanvändare och rådata [1].
Tack vare förmågan att visualisera och förmedla en algoritm kan visualiseringssystem hjälpa observatörer för att få insikt om algoritmernas svagheter i test-implementeringen och förstå dessa beteenden. Med hjälp av till exempel ett träd i en kompakt form, som lätt kan uppfattas av en människa, kan en lämplig heuristik ställas in genom att förbättra de praktiska resultaten av algoritmiska termer [2].
1.1.1 Träd inom datavetenskap
Inom datavetenskap är träd en vanlig datastruktur som ordnar en mängd element hierarkiskt i ett riktat träd, där varje nod kan ha en eller flera bågar som leder från noden [3]. Rotnoden, den första noden i trädet, är den som inte har några bågar som leder in. Från rotnoden finns det exakt en väg till varje annan nod i trädet [3]. De noder som man direkt kan ta sig till från en nod högre upp i hierarkin kallas för barn. Ovanstående nod kallas för förälder. De noder som har samma förälder kallas för syskon. En nod som saknar barn kallas löv och de övriga noderna, som har åtminstone ett barn, kallas för inre noder (Figur 1). En nod kan maximalt ha en förälder, men antalet barn är inte begränsat [3]. Ett undantag är
2
en variation kallat “binärt sökträd”, som delar samma egenskaper fast varje nod kan ha maximalt två barn.
Figur 1 - Träd inom datavetenskap
1.1.2 Trädtraversering
När man utforskar träd med n noder används ofta en samling av robotar som genom ett kollektivt samarbete traverserar och noterar samtliga noder. Dessa robotar, även kända under namnet “agent”, som är ett element i det kollektiva arbetet, följer en viss algoritm för sin egen förflyttning i trädets noder samt markerar alla besökta noder som traverserade. En samling av noder kan bilda ett känt eller okänt träd som modellerar nätverket där noderna motsvarar de intressanta platserna som en agent kan traversera igenom samt bågarna modellerar tillgängligheten mellan dessa platser [4].
En samling av agenter (multi-agenter), som ursprungligen är belägna vid en nod av ett kopplat träd, måste utforska trädets samtliga noder och sedan återgå till startpunkten [5]. Samtliga agenter som traverserar trädet kan kommunicera mellan varandra och informera om vilka noder som har blivit traverserade och vilka vägar som ännu är obesökta [5]. Trädet undersöks om varje nod är traverserad av minst en agent. Varje agent traverserar varje nod i enhetstid, och tiden för kollektiv utforskning är den maximala tiden som används av någon agent i gruppen [5].
3
1.2 Problemformulering
Vår beställare och handledare Bengt J. Nilsson, professor i datavetenskap med forskningsintressen inom algoritmer som specifikt rör geometriska och kombinatoriska beräkningsproblem på Malmö universitet, har ett forsknings-problem om trädtraversering (avsnitt 1.1.2) baserat på en studie [5]. Studien ger en beskrivning om hur flera agenter samarbetar för att gemensamt besöka alla noder i ett okänt träd med okänt antal noder så fort som möjligt. Agenterna placeras initialt i roten av det okända träd som modellerar nätverket. Dessutom är alla bågar och noder på trädet märkta och sålunda kan lokalt avskiljas av en agent [4,5]. Agenterna tillåter fullständigt utbyte av information om nya fynd och kommer överens om undersökningsstrategier. Ett preliminärt resultat från en studie [5] om trädtraversering visades att problemet med att hitta den optimala kollektiva utforskningen av trädet när trädet är känt i förväg, är NP-svårt. Studien visade också en algoritm som garanterar en overhead på O (k/ log k) om k agenter utforskar ett träd. De visar också att varje algoritm kräver minst overhead 2-1/k [5]. En annan studie [4] visade att nedre gränsen kräver minst Ω (log k / log log k) overhead. Gapet mellan övre och undre gräns för overhead är därmed exponentiellt. Nilsson vill ta reda på, med hjälp av experimentmjukvara, om det är möjligt att minska overheadgapet mellan övre och undre gräns, dels genom att försöka hitta bättre algoritmer, dels genom att hitta träd med mer komplexa egenskaper. En form av ett visualiseringsverktyg skulle kunna hjälpa honom att besvara hans två forskningsfrågor:
1. Kan vi hitta träd som är ännu svårare?
2. Kan vi hitta en bättre algoritm för agenternas förflyttning?
För att besvara Nilssons forskningsfrågor ber han oss om hjälp att utveckla ett program i form av ett visualiseringsverktyg, för att få honom att kunna visualisera sina regler som bygger ett träd och presentera dem för honom. Den generella målsättningen med detta examensarbete är att ta fram en lämplig prototyp för att visualisera trädet med hjälp av specifika regler och sedan, om möjligt, låta agenterna traverseras i trädet. Att förstå beteendet hos multi-agent-system är mer utmanande med tanke på de ytterligare tids- och informationsdelningsproblemen.
1.3 Krav
Detta arbete ska skapa en prototyp av ett program i form av ett grafiskt verktyg med vilket regler ska kunna läsas in och presenteras visuellt. För att kunna tillhandahålla olika regler och visa dem på ett tydligt sätt har beställaren upprättat en kravspecifikation på visualiseringsverktyget:
Programmet skall kunna visa ett träd på ett tydligt sätt då det kan handla om tusentals noder.
Zoomning skall kunna genomföras på visualiseringen.
Användaren skall kunna följa en specifik agents tagna väg.
Programmet skall kunna visa den snabbaste samt den långsammaste agenten.
4
1.4 Syftet och frågeställning
Syftet med examensarbetet är att skapa ett program i form av ett visualiseringsverktyg för att bygga ett träd med hjälp av beställarens regler samt veta hur multi-agent traversering visualiseras i träd. Vi fokuserar på att bygga ett visualiseringsverktyg till ett träd med hjälp av beställarens regler och sedan låta multi-agenterna traverseras i trädet för att hjälpa en forskare att förstå beteende och interaktioner mellan multi-agenterna i ett träd. Följande frågor ställer vi:
1. Hur visualiseras ett träd?
2. Vilken layout lämpar sig bäst för denna typ av visualisering? 3. Hur visualiseras multi-agentsökning i träd?
1.5 Avgränsningar
För att besvara vår första forskningsfråga kommer vi fokusera på att utveckla en programprototyp i form av ett visualiseringsverktyg. Vårt fokus är enbart inom visualiseringsdelen och inte att besvara beställaren frågor.
För att besvara vår andra forskningsfråga kommer en jämförelse mellan olika layouter att genomföras för att välja den mest lämpliga layouten. Tredje forskningsfrågan kommer att besvaras genom att låta agenterna sprida sig jämnt i det okända trädet.
1.6 Etiska aspekter
Detta arbete handlar om utveckling av ett visualiseringsverktyg, som körs lokalt på forskarens dator utan att lagra eller skicka vidare information, varken under eller mellan programkörningar. Det är inte relevant att utvärdera några etiska aspekter som själva verktyget berör.
1.7 Disposition
Avsnitt 2 beskriver kortfattat delar av det teoretiska bakgrundsmaterialet som detta arbete vilar på. Avsnitt 3 presenterar och motiverar den metod som valts för att ta fram verktyget och utvärdera dess effekter på tolkningen samt valet av utvecklingsverktyg som gjorts under utvecklingsmomenten. Litteraturstudien beskrivs i avsnitt 4. Avsnitt 5 innehåller olika delar i hur vi implementerar vår primärprototyp samt den slutliga prototypen. Avsnitt 6 tar upp de resultat som nåtts under arbetets gång och den efterföljande utvärderingen, medan avsnitt 7 analyserar och diskuterar kring dessa resultat. Avsnitt 8 tar upp slutsatserna.
5
2. Teori
Det teoretiska ramverket syftar till att utgöra en grund för studien och lyfta fram olika teorier inom algoritmvisualisering, grafvisualisering samt visualiserings-bibliotek.
2.1 Algoritmvisualisering
Visualisering omvandlar data från olika former till en visuell form samt utnyttjar fördelarna med människors naturliga förmåga att snabbt kunna identifiera visuella mönster som hjälper till med observation, uppfattning och förståelse av information [6].
När man använder algoritmer för visualisering är det viktigt att kunna modifiera och ändra algoritmen/algoritmerna och se hur det ändras i visualiseringen. I en prototypprocess kan en algoritm ofta vara så komplex eller opraktisk att människor enkelt avstår från att använda visualiseringsverktyget [7][8].
Detta problem belyses vanligtvis som en kombination av tre typiska fall [8]:
1. För att generera visualiseringar krävs en algoritm för att bygga om eller röra det med visualiseringsspecifika konstruktioner.
2. Hela visualiseringen måste byggas från början till en visualisering som passar algoritmen vilket programmet är riktad åt.
3. För att visualisera ett program måste delar av programkoden migreras och byggas i andra miljöer. Denna process kan introducera nya fel och avbrutna beroenden.
En av de viktigaste aspekterna av visualiseringen är att utvecklarna väljer ett visualiseringsbibliotek som bör vara standard för visualiseringar av någon typ av algoritmer och regler som kan anpassas till utveckling specifika ändamål [1]. Visualiseringsverktyg ska kunna visualisera inte bara en typ av algoritm utan betydligt mer komplexa algoritmiska koder och att testa deras beteende på stora datamängder [1].
2.2 Grafvisualisering
Grafvisualisering är en visualisering av noder och bågar i ett träd [9]. Samma graf kan ha olika former beroende på vilka regler som väljs för att generera den. Med de valda reglerna påverkas också grafens betydelse och användbarhet. Storleken på grafen som ska visas är ett nyckelproblem i visualiseringen, stora grafer medför flera svåra problem. Om antalet element är stora kan det kompromissa prestanda eller till och med nå gränserna för betraktningsplattformen [9]. Även om det är möjligt för layouterna att visa alla element är frågan om synbarhet eller användbarhet uppstår, eftersom det kommer blir omöjligt att skilja mellan noder och bågar [9].
6
2.3 Visualiseringsbibliotek
Visualiseringsbibliotek är en viktig del av visualiseringen. Nedan är en beskrivning av två Java visualiseringsbibliotek, JGraph och JUNG, som använder grafer för att bygga träd.
2.3.1 JGraph
JGraph är ett Javabaserat system för att rita grafer och för att köra grafer för algoritmer [10]. JGraph är ett modernt, funktionsrikt grafisk visualiseringsbibliotek som är skrivet i Java. JGraph är skrivet för att vara en komplett Swing-kompatibel komponent, både visuellt och i sin design arkitektur [11]. Det finns tre olika träd layouter i JGraph [11]:
• com.jgraph.layout.tree.JGraphTreeLayout
• com.jgraph.layout.tree.JGraphCompactTreeLayout • com.jgraph.tree.JGraphRadialTreeLayout.
Tree layout
Tree layout arrangerar noderna, från en specificerad nod till en trädliknande struktur. Trädet kan orienteras enligt de fyra väderstrecken alternativt inkludera justering av val av samma nivå nod på layouten, val av minsta avstånd mellan noder på intilliggande nivåer av trädet samt ställa in minsta avstånd mellan noder på samma nivåer [11]. Figuren nedan (Figur 2) visar ett exempel på hur ett träd layout kan se ut i JGraph.
Figur 2 - Tree layout [11]
Compact Tree layout
Compact Tree layout är en annan layout i JGraph, som gör några förbättringar över standard träd layouten [11]. Layouten tar cellformer med hänsyn till koncentration att den producerar så kompakt resultat som möjligt. Kompakt träd beskriver också mekanismer för att beräkna delarna av layouten, hela beräkningen behöver inte utföras på varje layout. Kompakt träd hanterar att komprimera mer
7
tätt än standard trädet genom att lagra sub-träd som polygoner [11]. Figuren nedan (Figur 3) visar ett exempel på hur ett kompakt träd layout kan se ut i JGraph.
Figur 3 - Compact Tree layout [11]
Radial Tree layout
Radial Tree layout ritar trädets rotnod i mitten av layouten och lägger ut de andra noderna i koncentriska ringar runt om roten [11]. Varje nod ligger på ringen som motsvarar det kortaste nätverksavståndet från roten. Grannar av rotnoden ligger på den minsta inre ringen, deras grannar ligger på den näst minsta ringen tills de flesta distans noder bildar de yttersta ringarna [11]. Figuren nedan (Figur 4) visar ett exempel på hur en radial träd layout kan se ut i JGraph.
8
2.3.2 JUNG: Java Universal Network/Graph Framework
JUNG är ett open source mjukvarubibliotek som tillhandahåller ett gemensamt och utvidgat språk för modellering, analys och visualisering av data som kan representeras som en graf eller nätverk. Det är skrivet i Java, vilket gör det möjligt för JUNG-baserade applikationer att använda sig av de omfattande inbyggda funktionerna i Java API, liksom för andra befintliga Java-bibliotek från tredje part [12].Arkitekturen i JUNG är utformad för att stödja en rad olika representationer av enheter och deras relationer, såsom riktade och oreglerade grafer, multimodala grafer, grafer med parallella kanter och hypergrafer. Det tillhandahåller en mekanism för annotering av diagram, enheter och relationer med metadata. Detta underlättar skapandet av analytiska verktyg för komplexa datamängder som kan undersöka relationerna mellan enheter såväl som metadata som är kopplade till varje enhet och relation [12].
JUNG ger också en visualiseringsram som gör det enkelt att konstruera verktyg för den interaktiva utforskningen av nätverksdata. Användare kan använda en av de layoutalgoritmer som tillhandahålls, eller använda ramverket för att skapa egna anpassade layouter. Dessutom tillhandahålls filtreringsmekanismer som tillåter användare att fokusera sin uppmärksamhet eller deras algoritmer på specifika delar av grafen. Som ett bibliotek med öppen källkod tillhandahåller JUNG en gemensam ram för graf, nätverksanalys och visualisering [12].
JUNG innehåller implementeringar av ett antal algoritmer från grafteori, datautvinning och social nätverksanalys. I dessa används rutiner för klustrering, sönderdelning, optimering, slumpmässig grafgenerering, statistisk analys och beräkning av nätverksavstånd, flöden och viktåtgärder [13]. Nedan ges några exempel på olika layouter i JUNG:
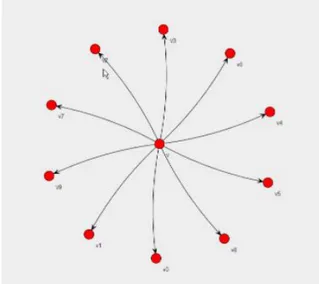
RadialLayout
En Layout-implementering som positionerar vinklar lika fördelade på en vanlig cirkel [12] (Figur 5).
9
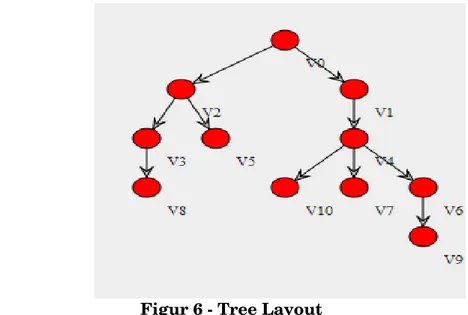
TreeLayout
TreeLayout-klass representerar en visualisering av en uppsättning liknande som ett vanligt träd [12] (Figur 6).
Figur 6 - Tree Layout
SpringLayout
SpringLayout-klass representerar en visualisering av en uppsättning noder [12] (Figur 7).
10
3. Metod
Det följande avsnittet beskriver vald metodik, metoddiskussion, genomförande samt programmeringsmiljön.
3.1 Metodval
I detta arbete kommer en ny IT-artefakt att utvecklas, vilket medför att den huvudsakliga forskningsstrategin för denna avhandling är "Design and Creation Research" [14]. Design and Creation Research är en forskningsmetod som fokuserar på utvecklingen av IT produkter och innebär att forskaren designar en artefakt av något slag baserat på den forskning denne utför, för att sedan skapa artefakten [14]. Utvecklade artefakter kan vara:
Konstrukt: Koncept eller betydelsen av ett ord inom ett specifikt IT område. Exempel på det entities, objekt eller dataflöden [14].
Modell: En kombination av flera konstruktorer som representerar en situation och används för att hjälpa till att lösa ett komplicerat problem [14].
Metod: Informella beskrivningar av praxis baserat på erfarenheter [14].
Instans: Ett fungerande system som demonstrerar att konstrukter, modeller, metoder, idéer eller teorier kan bli implementerade i ett IT system [14].
IT-produkten (artefakten) kan ha en av följande roller för att på olika sätt bidra till kunskap. Antingen är artefakten den stora rollen, all fokus ligger på den, eller är den bara ett verktyg eller hjälpmedel för något annat, alternativ en komplett slutprodukt som är redo att sättas i bruk. Det som skiljer ett Design and Creation Research från ett Design and Creation-arbete är fokuset på artefakten [14].
3.2 Metoddiskussion
Forskningsstrategin “Design and Creation Research” har använts i detta examensarbete. Denna strategi skapar en IT-artefakt som en del av en lösning till problem eller ett bidrag till ny kunskap. Andra strategier som är dominerande är Survey som är till för att samla data från en stor grupp människor eller det kan användas för att tolka och dra slutsatser om ett ämne genom att intervjua, observera eller dokumentera. Hypotes eller teori finns inte därför väljs experiment strategi bort då vi inte kan motbevisa hur visualiseringsverktyget kan kunna se ut. Eftersom en utvecklingsdel finns i programmet, väljs strategi fallstudie bort då utveckling inte är en del i fallstudier. En annan metod som också valdes bort är Action Research som oftast är till för att utveckla och förbättra forskningsmetoder eller rutiner och Etnografi som undersöker människors kulturer vilket inte passar in i vår kontext.
Valet av Design and Creation Research som arbetets forskningsstrategi baseras på resulterar i att någon typ av ny artefakt, vårt visualiseringsverktyg skapas. Samtidigt kan forskaren av den processen dra slutsatser som leder till svar på forskningsfrågan samt ett kunskapsbidrag [14].
11
3.3 Genomförandet
Studien påbörjas genom att ta kontakt med vår handledare och beställare Bengt J. Nilsson via mail och tid för möte fastställs. Under första mötet med Nilsson presenterade han sin algoritms problem och varför han vill ha ett visualiseringsverktyg och vilka krav han har på programmet (avsnitt 1.4). I samband med mötet får vi två vetenskapliga artiklar som hans forskning är byggt på [4][5] samt en regel (avsnitt 5.3) som ska visualiseras i vårt visualiserings-verktyg.
Materialet samlas genom att få en del kod av Nilsson [22] som är tidigare skriven för att översätta sina regler. Koden är skriven i Python och vår utmaning är att översätta den till Java eftersom vårt visualiseringsverktyg ska vara skrivet i Java. Anledning till att Java används för detta examensarbete är på grund av att vi anser att objektorienterat programspråk fungerar bra för denna typ av program samt att vi har mest erfarenhet inom detta språk. För att kunna göra en djup sökning för att besvara forskningsfråga och finna inspiration och kreativa lösningar genomförs en litteraturstudie genom sökningar i databaser. Sökningarna utförs genom Malmö universitets biblioteks tillgängliga databaser. De databaser som används är ACM digital library och IEEE Xplore eftersom dessa två databaser är inriktade mot teknik och datavetenskap (avsnitt 4).
En tidigare studie beskriver att när en visualisering för en algoritm byggs är det första beslutet att ta del av vilket visualiseringsbibliotek som ska användas [7]. En avgörande modul som ger de grundläggande verktygen för visualisering, exempel-vis den grafiska vokabulären, samt hur programmet kan ses i slutändan [7]. Eftersom kravlistan av beställaren styr valet av visualiseringsverktyg, måste nästa steg i vårt examensarbete vara att leta efter ett bibliotek i Java som kan användas för att skapa verktyget och uppfylla beställarens krav. För att hitta ett bra sätt att rita upp grafer och fylla forskarens krav sker en jämförelse mellan olika tillgängliga Java visualiseringsbibliotek för att hitta bästa alternativet. De två bibliotek som diskuteras är JGraph (avsnitt 2.3.1) och JUNG (avsnitt 2.3.1). Efter en jämförelse och en diskussion har vi bestämt oss för att använda biblioteket JUNG (Java Universal Network/Graph Framework) eftersom JUNG tillåter zoomning, vilket är ett krav från vår beställare, samt att den har tydliga layouter som kan hjälpa oss att besvara vår andra forskningsfråga.
När visualiseringsbiblioteket är tillgängligt behöver vi revidera genomförandet av de ursprungliga datatyperna för att stödja visualiseringens förmågor [7]. Vilken typ av data som ska läsas påverkar sättet hur utvecklare bygger programmet [7]. Utmaningen är i detta steg att förstå hur olika regler som ska visualiseras fungerar för att kunna implementera de i koden.
För att kunna göra konstruktionen av programmet tydligt bestämmer vi oss för att dela implementeringen av programmet i två delar. En preliminär prototyp av ett visualiseringsverktyg där ett slumpmässigt träd byggs och agenterna traverserar, utan att följa beställarens regler, för att få en tydlig bild på hur programmet fungerar samt en slutlig prototyp som innehåller översättningen av koden vi fått av beställaren. Innan preliminärprototypen kan kopplas ihop med beställarens regler för att skapa slutlig prototyp är utmaningen att översätta Python koden vi
12
har fått av beställaren, eftersom vi inte har arbetat i programmeringsspråket tidigare. Detta åstadkoms genom att läsa Pythondokumentationen och se på olika videos om programmeringsspråket.
Under arbetet har en dialog med handledare, som även är beställare, varit behövligt för att skapa innehållet i programmet och veta hans synpunkter om arbetet. Test på programmet har gjorts kontinuerligt efter varje avslutad del i examensarbetet, samtliga delar har testats på programmet för att kunna läsa olika regler och visualisera dem.
3.4 Utvecklingsspråk
För utveckling av verktyget kommer programmeringsspråket Java användas. Java är ett generellt programmeringsspråk som är samtidigt, klassbaserat, objekt-orienterat [15] och speciellt utformat för att vara så lite implementeringsberoende som möjligt. Koden i Java innebär att de samlade instruktionerna kan köras på alla plattformar som stödjer Java utan att behöva kompilera. [16] Javaapplika-tioner sammanställs vanligen till bytecode som kan köras på vilken Java virtual machine (JVM) oberoende av datorns arkitektur. Java ett av de mest populära programmeringsspråken och har sedan 2016 nio miljoner utvecklare [16].
Ett alternativ till Java skulle kunna vara Python eftersom delkoden vi har fått av beställaren är i det programspråket, men valet föll till sist på Java beroende på personliga kunskaper och erfarenheter. Som utvecklingsmiljö valde vi IntelliJ IDEA som utvecklingsverktyg till detta examensarbete eftersom IntelliJ IDEA ger en mycket strukturerat kod jämfört med andra utvecklingsmiljöer.
4. Litteraturstudie
Litteraturstudien består av artiklar som behandlat relevanta områden för våra frågeställningar: visualisering av trädet samt multi-agenttraversering. Av våra sökningar har vi funnit ett antal artiklar om trädvisualisering, algoritm-visualisering, grafritning samt multi-agenttraversering [17] [18] [19] [20] [21]. En relevant artikel hittades om ämnet trädvisualisering [17]. Artikeln handlar om utveckling av ett visualiseringsverktyg riktat för utbildningssyfte. Detta verktyg kallas för iSketchmate och används för att skapa samt manipulera splay-träd genom ett animerat gränssnitt. Artikeln innehåller även två experiment där iSketchmate testas mot traditionella utlärningsmetoder, exempelvis whiteboard samt papper och penna, för att få fram vilken metod som är bäst. Båda experimenten genomförs av studenter och all utrustning är densamma för alla experimentdeltagare. Det första experimentet bestod av speciella instruktioner som deltagarna skulle genomföra och bli graderade på tiden arbetet tog samt korrektheten på resultaten. Instruktionerna innehöll delar som skulle skapas i iSketchmate samt på papper [17]. I experiment två skulle deltagarna genomföra en presentation och därefter besvara på ett antal frågor om innehållet i
13
presentationen. Här blev deltagarna uppdelade där vissa fick tillgång till iSketchmate och övriga en whiteboard och pennor.
Resultaten från båda experimenten visade på att samtliga genomföranden med iSketchmate hade både kortare tid för varje svar samt dess korrekthet var nästan 100%. De traditionella sätten tog betydligt längre tid för varje instruktion och fråga samt att korrektheten låg på runt 30 - 35%. Slutsatsen som kan tas från artikeln är att visualiseringsverktyg bidrar starkt till ökad förståelse om visualiseringens innehåll jämfört med andra traditionella metoder [17].
Gällande algoritmvisualisering har J. Ma et al. [18] utvecklat ett visualiserings-verktyg kallat SHAvisual som hjälper studenter att lära sig krypteringsalgoritmen SHA. Detta verktyg kommer hjälpa instruktörer att hantera sina tider under undervisningarna samt väsentligt förbättra oberoende studier för intresserade studenter [18]. Behovet av detta verktyg uppkom då det inte fanns många publicerade visualiseringsverktyg för SHA-algoritmer vid denna tid. SHAvisual är utformat för att matcha de flesta krypterings- och datasäkerhetsböckers layout för att minimera förvirring hos användaren. Verktyget är också till hjälp för de som undervisar i kryptering och datasäkerhetskurser samt för studenter som kan behöva ytterligare hjälp att lära sig kryptografiska metoder [18].
Ett par artiklar hittades kring grafritning [19][20] och dessa artiklar fokuserar på användbarhet hos användare. R. Shannon et al. presenterar Showtime, en visualiseringsteknik som använder grafer för att ge observatörer mer tid att förstå varje förändring i en visualisering baserat på aktivitetens förflyttningar [19]. Detta är ett sätt att utnyttja användarens förmåga att förstå förändring när den stegvis presenteras i visualiseringen samt gör det möjligt att påskynda spelning av hur data utvecklas jämfört med att titta på händelser som förekommer i realtid [20]. En annan studie [20] presenterar PieVis, ett kompletterande visualiseringssystem med syftet att förbättra befintliga metoder samt att presentera data på en tydlig layout. PieVis är en interaktiv grafvisualisering som använder en trädritnings-algoritm och användarinteraktioner för att visa detaljer om intressanta områden i grafer och kunna visa nodetiketter på ett användarvänligt sätt. Studiens resultat var en cirkulär layout med användarvänliga etiketter som inte överlappar varandra samt tydligt visar deras nodtillhörighet [20].
En artikel om multi-agenttraversering hittades [21]. Här presenterar A. Bezek en metod för strategisk modellering av multi-agenter under namnet MASM (Multi-Agent Strategic Modeling) som appliceras i en robotfotbollsdomän [21]. Metoden omvandlar multi-agent sekvenser till ett grafiskt visuellt diagram, kallat ”Action diagram”, vilket är ett riktat diagram där noderna representerar agenterna. Noderna a och b är anslutna, om nod b ligger direkt efter nod a, då är a → b en agents väg. Studien resulterade i en abstrakt grafisk modell av agensbeteende som även kan beskriva en specifik agents väg bland många grafer [21].
Relevanta artiklar om forskning kring multi-agenttraversering i träd har visat sig vara i stort sett obefintlig.
14
5. Implementering av visualiseringsverktyget
Detta avsnitt innehåller beskrivning av steg som följs under implementering av visualiseringsverktyget. Här beskrivs konstruktionen av primärprototypen samt slutliga prototypen.
5.1 Primärprototyp
Efter beslutet att JUNG kommer användas som verktygets visualiseringsbibliotek, börjar en diskussion om hur noderna skall skapas samt hur agenterna ska traverseras i trädet. För att börja med en primär prototyp blir valet att bygga trädet på ett slumpmässigt sätt beroende på vilken input på antal noder som ges från användaren. Nedan beskrivs uppbyggnad av trädet och agenttraversering av primärprototypen.
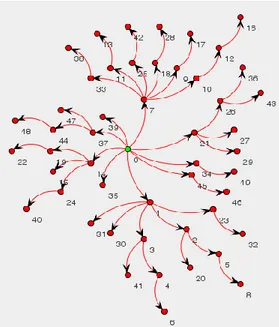
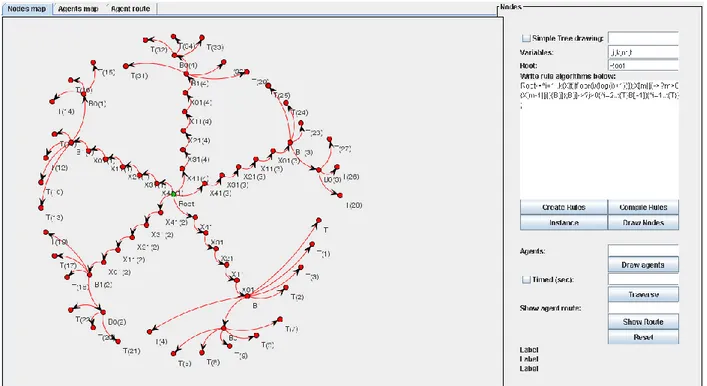
För att uppfylla beställarens krav har trädet byggts på ett sätt där roten är tydligt markerad med grön färg samt röd färg på övriga noder. Figur 8 visar ett träd i en RadialTreeLayout som byggts upp på ett slumpmässigt sätt med 50 noder.
Figur 8 - Träd som är byggt slumpmässigt med 50 noder
5.2 Agenttraversering
När en agent förflyttar sig i trädet, läggs en ny nod till i visualiseringen. Om en nod innehåller en eller flera agenter markeras noden genom att färgas turkos (Figur 9). Detta medför att användaren enkelt kan följa hur agenterna arbetar i nätverket.
15
Figur 9 - Agenttraversering
Ett krav från beställaren är att kunna följa en specifik agents väg samt visa den snabbaste respektive långsammaste agenten. Figur 10 och figur 11 nedan visar en specifik agents väg samt den snabbaste respektive långsammaste agenten. Figurerna visar en agent som traverseras i ett träd med 50 noder.
Figur 10 - Enskild Agents väg
16
5.3 Slutlig prototyp
Efter att vi har visat primärprototypen för beställaren stod det klart att han var nöjd med uppbyggnaden av trädet och agenttraverseringen. För att kunna tolka reglerna vi fått av beställaren har vi översatt Python kod till Java för att kunna visualisera dem senare och skapa slutliga prototypen. Nedan är reglerna som vår beställare vill att vi visualisera för att bygga ett träd är följande:
Root -> ^i=1..k{X[t][floor(i/(log(i)+1))]}; X[m][j] -> ?m>0{X[m-1][j]}{B[j]};
B[j] -> ?j>0{^i=2..t{T}B[j-1]} {^i=1..t{T}};
“Root” är var trädet börjar, termerna Root, X och B är regler, variablerna (i, l, j, t, m) ska ges ett värde för att kunna bygga trädet, “^“ är en for loop, “?” är ett query (fråga som ger en boolean som retur), “..” för att särskilja startvärde och slutvärde i en loop och bokstaven T är ett löv i trädet.
Vårt skrivna program tolkar reglerna och rensar undan alla icke behövda tecken samt strukturerar upp regeln i en operationssekvens. Denna sekvens ser ut på följande vis:
Root: [^, i, 1, 2, S, X, 3, 4] X: [?, 5, S, X, 6, 7, else, S, B, 8]
B:[?, 9, ^, i, 10, 11, S, T, S, B, 12, else, ^, i, 13, 14, S, T]
När en regel körs i programmet, exekveras hela sekvensen från första tecknet fram tills antingen sekvensen är slut, eller om programmet försöker anropa “else”. “Else” används för att ändra vilket steg som skall köras härnäst när ett query (“?”) exekveras och påståendet som testas resulteras som falskt. Samtliga siffror i operationssekvensen refererar till ett påstående eller en uträkning som programmet har lagrat i klassen AlgorithmList. Den resulterande sekvensen ska därefter visualiseras i en grafisk design.
6. Resultat
Detta avsnitt innehåller det slutliga visualiseringsverktyget som skapats genom examensarbetet. För att illustrera finns bilder med förklarande text. Resultatet visar verktyget i sin slutliga form.
6.1 Verktygets slutliga form
I denna sektion beskrivs den slutgiltiga prototypen. Prototypen består av en exekverbar fil. För att framställa prototypen används en version som visar beställarens regler. När applikationen startas visas användargränssnittet (se Figur 12). Gränssnittet består av två delar: en del som visar den grafiska visualiseringen för användaren samt en del som innehåller samtliga inställningar. Den grafiska visualiseringen är uppdelad i tre separata flikar som visar trädets
17
uppritade struktur, agentnätverkets gemensamma uppritade struktur samt en enskild agents valda väg genom trädet.
Figur 12 - Användargränssnitt
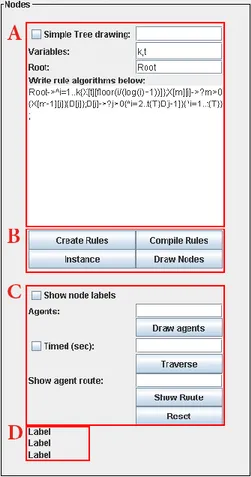
Inställningsdelen (Figur 13) innehåller ett flertal textrutor och knappar som hanterar indata och hanterar inställningar för trädets uppritning, visade namn för noder samt om agenternas traversering skall hanteras stegvis eller på tid. Längst upp i denna del finns en checkbox som bestämmer om trädet skall konstrueras på ett så kallat “enkelt” vis (område A i Figur 13). Tillsammans med denna finns en tillhörande inmatningsruta där användaren skriver in hur många noder trädet skall bestå av. De nästkommande rutorna ovanför knapparna tillhör inställningar för trädkonstruktion genom regler. Inmatningsrutan “variables” efterfrågar vilka variabler som reglerna behöver ha värden på när de behandlas av konstruktionsalgoritmen och “Root” efterfrågar vilken regel som bygger roten samt bestämmer var konstruktionsalgoritmen skall börja. I den stora textrutan skriver användaren in alla reglerna som skall användas när trädet konstrueras. Dessa regler kräver en speciell syntax för att kunna konstruera trädet och separeras med semikolon.
Under inmatningen för regelhanteringen finns 4 stycken knappar (område B i Figur 13). När programmet startar är enbart den första knappen tillgänglig, som används för att skapa input till reglernas exekvering samt skapa en operationslista som programmet använder för att hämta specifika värden eller genomföra en beräkning. Här skriver användaren även in värden på samtliga variabler som skrevs in i rutan “variables”. Om någon regel är felskriven eller ett värde på en variabel inte är korrekt kommer programmet varna och öppnar ej upp nästa knapp.
18
Nästa knapp sköter en körtidskompilering av operationslistan och om kompil-eringen blir godkänd öppnas den tredje knappen upp, vilket är instansierings-knappen. Denna knapp skapar ett objekt och en instans av den kompilerade operationslistan för att kunna fungera i programmet. Om denna instansiering också är godkänd kan trädet konstrueras med hjälp av den sista knappen. När denna knapp klickas på ritar programmet upp trädet i den första fliken på den grafiska visualiseringsdelen (se Figur 13).
Nästa del av inställningarna hanterar agenterna och deras traversering (område C i Figur 13). I denna version av programmet bestämmer användaren hur många agenter som skall skapas i den första inmatningsrutan. Antalet agenter godkänns sedan med knappen “draw agents”. Efter denna knapp kommer en checkbox och en annan inmatningsruta. Checkboxen bestämmer om traverseringen skall skötas på tid istället för genom klickningar. Den tillhörande inmatningsrutan bestämmer antalet millisekunder som väntetiden mellan varje steg skall vara. Traverseringen genomförs med knappen “traverse” och om checkboxen för tid är ifylld, då flyttar sig samtliga agenter ett steg varje gång väntetiden har uppnått sitt inställda värde, annars genomför agenterna en förflyttning för varje gång användaren klickar på knappen.
För att nollställa alla värden samt rensa alla grafiska visualiseringar används knappen “reset”. Längst ner finns tre labels (område D i Figur 13) som under exekveringen visar vilket steg traverseringen är i samt visar den snabbaste och den långsammaste agentens steg (se figur 11).
19
Figur 14 - Ett träd byggts med hjälp av reglerna
6.2 Slutlig klasstruktur
Den slutliga prototypen har 15 klasser fördelade i fem paket, Tree (3 klasser), AgentNetwork (4 klasser), grafiskt gränssnitt GUI (3 klasser), Rule (3 klasser) och Commands (2 klasser). Figur 15 visar ett reducerat klassdiagram över den struktur programmet har, där endast kopplingarna mellan områden visas utan att avslöja något om deras medlemmar.
20
7. Analys och diskussion
I det här avsnittet analyseras och diskuteras projektets resultat med avseende på vad som har gjorts för att kunna besvara våra forskningsfrågor. Här beskrivs även hur agenterna traverseras i trädet. Vidare beskrivs vad vi har lärt oss under detta examensarbetes arbetstid.
7.1 Layoutmotivering
Resultat vi har fått ger svar till vår frågeställning 1 “Hur visualiseras ett träd”, resultatet visar ett träd som byggs med hjälp av beställarens regler (figur 14). För att kunna välja den mest lämplig layouten och besvara frågeställning 2 “Vilken layout lämpar sig bäst för denna typ av visualisering?” behöver olika layouter jämföras och analyseras. Vi har gjort en jämförelse av olika visualiseringslayouter genom att testa uppbyggnaden av trädet på olika layoutstilar. Vi testade tre layouter som finns i JUNG bibliotek, RadialTreeLayout, TreeLayout och SpringLayout, för att sedan välja den lämpligaste layouten som svar till frågeställning 2. Figurerna 16a, 16b, 16c nedan visar uppbyggnader av trädet i en RadialTreeLayout, en SpringLayout respektive en TreeLayout med 50 noder samt ett med 1000 noder (Figur 17a, 17b, 17c).
Figur 16a och 16b – RadialLayout och SpringLayout (50 noder)
21
Figur 17a och 17b - RadialLayout och SpringLayout (1000 noder)
Figur 17c - TreeLayout (1000 noder)
Ett krav av Nilsson [22] var att visualiseringsverktyget skulle kunna visa trädet på ett tydligt sätt då det kan handla om mer än 1000 noder. Figurerna 17a, 17b och 17c visar hur trädet kan se ut om det byggts med 1000 noder. Det lämpligaste svaret till vår frågeställning 2 är att trädet bör visualiseras cirkulärt för att kunna ses på ett tydligt sätt och därför är RadialLayout i JUNG den lämpligaste layouten för denna typ av visualisering, då SpringLayout är för svårt att tyda och att TreeLayout försvinner utanför skärmens bredd.
7.2 Multi-agenttraversering
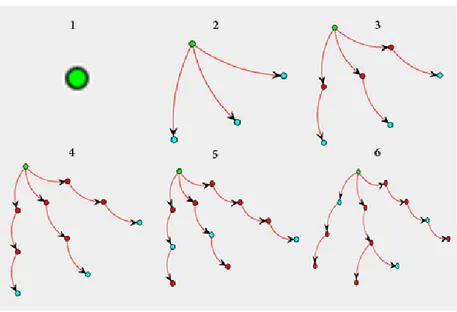
Vår tredje forskningsfråga är “Hur visualiseras multi-agentsökning i träd?” och nedan visas hur ett träd som följer beställarens regler där fem agenter förflyttar sig med en preorder traverseringsalgoritm (Figur 18), samt (Figur 19) visar den snabbaste och långsammaste agenten vilket är ett av beställarens krav vad som skulle genomföras. Agenterna noterar varje besökt nod till nätverket och med resultatets traverseringsalgoritm medför detta att samtliga agenter inte får traversera en redan besökt nod, bortsett från när de går uppåt i nivåerna. I vårt visualiseringsverktyg särskiljer vi noderna som innehåller en eller flera agenter i sig för att kunna ge en tydlig bild för användaren samt att på ett lättare sätt
22
kunna följa agenternas förflyttningar och beteenden. I figur 18 går det att se hur agenterna utforskar trädet som skapat genom beställarens regler från figur 14. I steg 1-4 förflyttar sig varje agent nedåt i nivåerna tills de befinner sig i ett löv. I steg fyra befinner sig alla agenterna i ett löv, vilket medför att i steg fem backade samtliga agenter upp ett steg. Steg sex visar hur agenterna traverserar ner i en ny nod i trädet från deras nuvarande position och skapar ett subträd i visualiseringen, vilket medför att alla vägarna sprids jämnt ut i en hel cirkel med syfte att skapa tomrum för ytterligare noder och subträd.
Figur 18 - Agenttraversering
Figur 19 - Visning av agenternas traverseringstider
7.3 Jämförelse med andra visualiseringsverktyg
Det finns redan många visualiseringsverktyg som används för olika syften. Vårt verktyg är unikt och har inte tidigare existerat bland visualiseringsverktygen. Det som vi ansåg saknades bland dessa verktyg var en koppling mellan abstrakta begrepp av rådata och den praktiska implementeringen. Vårt program kan med hjälp av regler samt grafer skapa en anpassningsbar visualisering för rådata i grafisk design.
Det finns ett antal visualiseringsverktyg som på olika sätt liknar vårt verktyg. iSketchmate [17] som används för att skapa samt manipulera splay-träd genom ett animerat gränssnitt, har en ganska otydlig design. Vårt verktyg är bättre strukturerat än iSketchmate då vi har tagit hänsyn till användargränssnittets utformning för att underlätta navigering i programmet.
23
Vårt verktyg har nästan samma syfte som SHAvisual [18]. Verktyget hjälper studenter att lära sig krypteringsalgoritmen SHA. Detta verktyg hjälper instruktörer att hantera sina tider under lektionerna samt väsentligt förbättra för oberoende studier för intresserade studenter. SHAvisual-verktyget kan förklara olika steg i en känd algoritm, vilket vårt verktyg inte kan då vi får mycket lite information om vad de visualiserade reglerna ska göra på förhand. På grund av detta är det svårt att förutsäga hur man bäst kan visualisera trädet. Detta beslut lämnas till beställaren.
Vår grafiska design är något liknande verktyget Showtime [19]. Showtime är en visualiseringsteknik som använder grafer för att ge observatörer mer tid att förstå varje förändring i en visualisering baserat på aktivitetens förflyttningar. Vårt verktyg följer den här principen genom att utnyttja användarens förmåga att förstå förändringar när de händer stegvis. Trädet kan presenteras i en grafisk miljö och verktyget gör det möjligt att ge förståelse till hur rådata presenteras med hjälp av grafer jämfört med att läsa rådata i dess ursprungliga form. En viktig aspekt i vårt visualiseringsverkyg är att vi presenterar trädet på ett tydligt sätt vilket är ett krav av vår beställare, något liknande programmet PieVis [20]. PieVis är ett komplett visualiseringssystem med syftet att förbättra befintliga metoder samt att presentera data med en tydlig layout. Programmet är en interaktiv grafvisualisering som använder en trädritningsalgoritm och användarinteraktioner [20]. Studien använder en cirkulär layout vilket understödjer vårt val av layout, RadialLayout.
7.4 Inlärning
Detta examensarbete har bidragit med mycket värdefull kunskaper för oss. Ett av de främsta kunskapsbidragen är att förstå nyttan av att visualisera data för att kunna förstå vad dessa data syftar till och dess interaktion med alla delar. I början av arbetets genomförande hade vi svårigheter med att kunna tyda beställarens regler men efter implementationen i verktyget var det betydligt lättare att förstå. En annan bidragande kunskap är att kunna tyda och tillämpa olika programspråks syntax genom kodöversättning, då vi översatte beställarens givna Python-kod till Java. Vi har även lärt oss hur externa Java-bibliotek inom grafiska områden kan importeras för att använda till visualiseringen.
En viktig del i arbetet har även krävt att skapa, kompilera och exekvera kod dynamiskt under programkörning, då beställarens regler innehåller både olika beräkningar och variabelreferenser. Detta har bidragit till att vi kan använda manuell input för beräkningar, som inte är implementerade i programmet, utan att behöva ändra i källkoden.
8. Slutsatser
Den främsta slutsatsen som kan dras utifrån arbetet är att ett program i form av ett visualiseringsverktyg som uppfyller de krav som presenteras i krav-specifikationen har skapats. Med hjälp av beställarens regler kan ett träd
24
konstrueras och möjliggöra att en grupp agenter kan traversera trädet samt föra statistik på deras förflyttningar. Programmet som utvecklats lyckas uppfylla önskemålen och genom vår analys har vi tagit fram våra slutgiltiga riktlinjer som en lösning på våra frågeställningar. Den valda metod “Design and Creation Research” som används i detta examensarbete har visat sig rätt för vårt arbete eftersom denna strategi skapar en IT-artefakt vilket är vårt visualiseringsverktyg som en del av en lösning till problem som kan användas för att jämföra två olika applikationer, i detta fall studier, som ett bidrag till ny kunskap. Visualiseringsbiblioteket JUNG har visat sig rätt för vårt verktyg då den uppfyller de ställda kraven.
Uppsatsens syfte uppfylls eftersom den presenterar hur vi implementerar och redogör för skapandet av vårt verktyg. Kunskap som denna uppsats bidrar till är ett verktyg som omvandlar rådata till grafisk data för att underlätta tydligheten av traverseringars flöde. Verktyget ger möjligheten att kunna följa hur en specifik agent beter sig under traverseringens exekvering.
Då vårt verktyg är ämnat för ett specifikt syfte, medför detta att fortsatta studier kan bli en svårighet. Ett förslag på vidare forskning kan vara att utvidga vilka datastrukturer som kan visualiseras. Detta kan genomföras genom en vidare-utveckling i vårt visualiseringsverktyg.
25
Referenser
[1] Ware, C. (2000). Information visualization. San Francisco: Morgan Kaufman.
[2] Demetrescu C., Finocchi I. and Italiano G.F. (2004) Engineering and Visualizing Algorithms. In: Liotta G. (eds) Graph Drawing. GD 2003. Lecture Notes in Computer Science, vol 2912 pp 509-513. Springer, Berlin, Heidelberg.
[3] FreeCodeCamp. (2017). Everything you need to know about tree data structures. [online] Available at: https://medium.freecodecamp.org/all-you-need-to-know-about-tree-data-structures-bceacb85490c [Accessed 8 Apr. 2018].
[4] Dynia M., Łopuszański J. and Schindelhauer C. (2007) Why Robots Need Maps. In: Prencipe G., Zaks S. (eds) Structural Information and Communication Complexity. SIROCCO 2007. Lecture Notes in Computer Science, vol 4474. Springer, Berlin, Heidelberg
[5] Pierre F., Leszek G., Dariusz K. and Andrzej P. (2006) "Collective tree exploration", Networks, vol. 48, no. 3, pp. 166-177.
[6] Yingjian Q., Xinyan Y., Guoliang S. and Ying L. (2015) Visualization in Media Big Data Analysis, Faculty of Science and Technology Communication University of China Beijing, China, pp. 571-574.
[7] Camil D., Irene F., Giuseppe. F. I. and Stefan N., (2002) “Visualization in algorithm engineering: Tools and techniques1” Lecture Notes in Computer Science,
vol. 2547, pp. 1–3. [Online]. Available:
http://wwwusers.di.uniroma1.it/~finocchi/papers/dfin02.pdf
[8] Matthew L. C., Clifford A. S., Stephen. H. E. and Sean. P. P. (2014) “Open source software and the algorithm visualization community” Science of Computer Programming, vol. 88, pp. 82–91, 2014.
[9] Ivan H., Guy M. and Scott. M. (2000) "Graph visualization and navigation in information visualization: A survey", IEEE Transactions on Visualization and Computer Graphics, vol. 6, no. 1, pp. 24-43.
[10] Jay B. and Adrian H. (2001) “JGraph- A Java Based System for Drawing Graphs and Running Graph Algorithms.” SpringerLink, Springer, Berlin, Heidelberg.
link.springer.com /chapter/10.1007/3-540-45848-4_45.
[11] Gaudenz A. Citeseerx.ist.psu.edu. (2005). JGraph in Action. [online] Available at:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.180.6827&rep=rep1&type =pdf . [Accessed: 04- Apr- 2018].
26
[12] Jung.sourceforge.net. (n.d.). JUNG - Java Universal Network/Graph Framework. [online] Available at: http://jung.sourceforge.net/ [Accessed 24 Feb. 2018].
[13] Joshua M., Danyel F., Padhraic S., Scott W and Yan Biao B. (2005). "Analysis and visualization of network data using JUNG". Journal of Statistical Software: 1– 25.
[14] Oates, B. (2006). Researching information systems and computing. Los Angeles: Sage.
[15] “Java.” Vad Är Java?, 7 May 2015,
www.java.com/sv/about/whatis_java.jsp?bucket_value=desktop-chrome65-osx10126&in_query=no.
[16] Oracle.com. (n.d.). Oracle | Integrated Cloud Applications and Platform Services. [online] Available at: https://www.oracle.com/index.html [Accessed 6 Mar. 2018].
[17] Michael C. O., Bradley T. V. Z. and Christopher H. S. (2012). Experiments with algorithm visualization tool development. In Proceedings of the 43rd ACM technical symposium on Computer Science Education (SIGCSE '12). ACM, New York, NY, USA, 559-564.
[18] Jun M., Jun T., Melissa K., Jean M., Ching-Kuang S. and Chaoli W. (2014). SHAvisual: a secure hash algorithm visualization tool. In Proceedings of the 2014 conference on Innovation & technology in computer science education (ITiCSE '14). ACM, New York, NY, USA, 338-338.
[19] Ross S., Aaron Q. and Paddy N. (2010). Showtime: increasing viewer understanding of dynamic network visualisations. In Proceedings of the International Conference on Advanced Visual Interfaces (AVI '10), Giuseppe Santucci (Ed.). ACM, New York, NY, USA, 377-380.
[20] Adrian R., Andrew C., Bryan B. and Andrew F. (2011). “PieVis: Interactive Graph Visualization Using a Rings-Based Tree Drawing Algorithm for Children and Crust Display for Parents. ” 2011 15th International Conference on Information Visualisation, 2011, doi:10.1109/iv.2011.68.
[21] Andraz B. (2005). Discovering strategic multi-agent behavior in a robotic soccer domain. In Proceedings of the fourth international joint conference on Autonomous agents and multiagent systems (AAMAS '05). ACM, New York, NY, USA, 1177-1178.

![Figur 2 - Tree layout [11]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3952158.75735/13.892.289.599.657.923/figur-tree-layout.webp)
![Figur 3 - Compact Tree layout [11]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3952158.75735/14.892.147.795.206.489/figur-compact-tree-layout.webp)