Teknik och samhälle
Datavetenskap och medieteknik
Examensarbete
15 högskolepoäng, grundnivå
Flödesbaserad visualisering av ett scriptspråk och hur det
kan påverka användbarhet på en dataanalytisk plattform
Flow-based visualization of a scripting language and how it can affect usability ona data-analytical platform
Ludwig Ninn
Jonatan Wahlstedt
Examen: kandidatexamen 180 hp Huvudområde: datavetenskap Program: applikationsutveckling Datum för slutseminarium: 2018-05-24Handledare: Mia Persson Examinator: Olle Lindeberg
Sammanfattning
Programmering kan stundtals vara utmanande även för den erfarna. Det finns mängder med olika programmeringspråk som alla i sin tur har olika syntax. Programmering blir även allt mer vanligt i yrken som inte jobbar primärt inom IT. Det är därför viktigt att sänka inlärningskurvan för oerfarna programmerare.
I denna studie undersöker vi vad visualisering av ett scriptspråk kan göra för att sän-ka inlärningskurvan och vilsän-ka potentiella fördelar eller nackdelar det för med sig. Studien utgår från aktuell forskning vid ett företag med syftet att utforma en prototyp som visu-aliserar ett scriptspråk. Användartester i form av intervjuer används sedan för att testa prototypen på olika målgrupper. Resultatet av intervjuerna visar att visualiseringen är till användning för både erfarna och oerfarna användare. Användingsområdena skiljer sig dock beroende på vilken erfarenhet användaren har. Det krävs därför vidare forskning för att implementera en visualisering som är anpassad för olika typer av användare.
Abstract
Programming can sometimes be challenging even for the experienced. There are lots of different programming languages, each of which has different syntax. Programming is also becoming more common in professions that do not work primarily in IT. It is therefore important to lower the learning curve of inexperienced programmers.
In this study we investigate what visualization of a scripting language can do to lower the learning curve and what potential benefits or disadvantages it entails. The study is based on current research at a company with the purpose of designing a prototype that visualizes a scripting language. User tests in the form of interviews are then used to test the prototype on different target groups. The results of the interviews show that the visu-alization is useful for both experienced and inexperienced users. The uses differ, however, depending on the experience the user has. Further research is therefore required to imple-ment a visualization that is adapted to different types of users.
Innehåll
1 Inledning 1 1.1 Bakgrund . . . 1 1.2 Avgränsning . . . 2 1.3 Syfte . . . 2 1.4 Frågeställning . . . 2 1.5 Tidigare forskning . . . 3 2 Metod 7 2.1 Metodbeskrivning . . . 72.2 Design Science Research Methodology . . . 7
2.3 Litteraturstudie . . . 8
2.4 Intervjuer . . . 9
2.5 Metoddiskussion . . . 9
3 Resultat 11 3.1 Design Science Research Methodology . . . 11
3.2 Iteration 1 . . . 11
3.3 Iteration 2 . . . 13
3.4 Iteration 3 . . . 14
3.5 Intervjuer . . . 15
4 Analys & diskussion 18 4.1 Iteration 1 . . . 18
4.2 Iteration 2 . . . 18
4.3 Iteration 3 . . . 19
5 Slutsatser och vidare forskning 22
Referenser 23
A Intervju Frågor 25
B Intervju Bilder 26
1
Inledning
1.1 Bakgrund
Enligt en undersökning gjord av Statistiska Centralbyrån(SCB) är programmerare och systemvetare den utbildningsgrupp som flest arbetsgivare tror att antalet anställda kom-mer öka mellan åren 2016-20191. Samma trend kan ses i Europa och USA, där det är brist på arbetare inom samma arbetsgrupp2 3. Ökad efterfråga tillsammans med att program-mering genomsyrar allt mer yrken i samhället, gör att det kommer finnas en stor grupp som kommer behöva lära sig att förstå och skriva kod. Inkluderat är även individer som kommer behöva integrera programmering i sina nuvarande jobb [1][2]. Stigande behov av programmerare innebär också ett stigande antal individer som kommer behöva lära sig att programmera. Detta resulterar i att smidig användbarhet värderas högt som egenskap hos ett programmeringsspråk eller utvecklingsmiljö.
Forskningsstudier på användbarhet inom programmering har gjorts under de tre senaste decennierna. Identifieringen av bra respektive dåliga aspekter inom programmeringsspråk samt utvecklingsmiljöer är väl utforskat [3][4]. Generellt uppstår problem i att drivet för utvecklingen ligger i tekniska bedrifter som generering av snabbare kod eller en närhet till maskinnivå. Resultat kan bli en produkt som presterar men som har brister i använ-darvänlighet [5]. Att anpassa programeringsspråk med avsikt att nå en större publik har gjorts sedan 60-talet. Programeringsspråk tenderar att ha rigid syntax och tillsynes arbi-trära eller förvirrande namnscheman för en nybörjare [5]. Flertalet forskningsinsatser har ägnats åt att utveckla nya programmeringsspråk och miljöer som är från början anpassade till användaren [6] för att lösa den branta inlärningskurvan. Visualisering är ett vederta-get koncept för att komma över några av de sämre aspekterna med programmering[5][6] [7][8][9]. Mjukvara är abstrakt i den mån att den inte har en faktiskt fysisk form vilket gör den svår att kunna få ett konkret grepp om [6]. Grafiska representationer anses vara ett kraftfullt verktyg för att snabbt få en förståelse av helheten och att göra den greppbar [7].
Historiskt sett har textbaserad programmering dominerat bland programmeringsspråk, men värdet av att kunna visualisera och simplifiera kod har funnits länge. Ett flertal pro-dukter har släppts exempelvis LabView 4släpptes redan 1986 och hade sin senaste uppda-tering 2018. Företaget Google har utvecklat det visuella programmeringsspråket Blockly5 och håller även på, med hjälp av Scratch 6 som är en av de mer kända visuella program-meringsspråk, att göra Scratch Blocks.
De flesta visuella programmeringsspråk kan delas in i två kategorier, flödesbaserad och blockbaserad visualisering [2]. Flödesbaserad visualisering är en paradigm som represente-rar flödet av processen [10] medan blockbaserad visualisering fungerepresente-rar mer som pusselbitar som ger ledtrådar till hur användaren ska gå tillväga [11]. De är användbara för olika typer
1Yrkesregistret med yrkesstatistik. [Online] http://www.scb.se 2
Skill shortage and surplus occupations in europe. [Online] http://www.cedefop.europa.eu
3
U.S. bureau of labor statistics. [Online] https://www.bls.gov
4
Flowhub. [Online] https://docs.flowhub.io
5
Blockly. [Online] https://developers.google.com/blockly
av problem, men har samma slutmål vilket är att göra programmering mer nåbart för allmänheten.
Företaget
Studien utförs på företaget Qlik och delar av studien utförs på plats vid deras kontor i Lund. Företagtes produkt är en dataanalytisk plattform, vilket även andra företag ut-vecklar, därför är studien relevant för liknande produkter. För att ladda in data som ska analyseras och visualiseras används ett scriptspråk som företaget själv utvecklat. Det kan exempelvis vara data från en Excel-fil eller från en databas. Scriptspråket gör det möjligt för användaren att välja vilken data som ska laddas in från de externa källorna och var den sparas i programmet.
1.2 Avgränsning
Eftersom denna studie utförs på ett företag blir forskningen fokuserad på den produkt som företaget utvecklar. Flödesbaserad visualisering valdes som implementering efter utvärde-ring av mjukvaran i det redan existerade programmet. Det scriptspråk som visualiseras har redan sin syntax beskriven i graf-form när det tolkas, vilket gör flödesbaserad visualisering mer naturlig. I studien kommer enbart visualisering implementeras och inte förmågan att programmera. Anledningen till att visuell programmering inte implementerades i vår studie är att tiden som var given för studien inte var tillräcklig för en fullständig implementation.
Företaget som utvecklar produkten använder sig av Javascript och HTML5/css. Därför använder sig studien av samma programmeringsspråk för att lättare integrera prototypen. Vid utförandet av intervjuer väljer vi olika målgrupper för att representera olika användare av programmet. Eftersom det är en bred variation på användare av programmet finns det ingen tydlig avgränsning av vem som deltar i intervjuerna. Avgränsningen sker istället på vilken målgrupp intervjudeltagaren ska tillhöra.
1.3 Syfte
Användare av den aktuella plattformen upplever en svåröverkomlig barriär runt det script som ska vara ett hjälpmedel för att lättare hantera dataanalysen, men som har fått motsatt effekt i vissa fall. Syftet med föreliggande studie är att implementera en flödesbaserad visualisering på en redan existerande dataanalytisk plattform7. Visualiseringen jämförs sedan med motsvarande textbaserad lösning för att få fram fördelar och nackdelar.
1.4 Frågeställning
Studien ska undersöka om det går att implementera en visualisering av ett script i en befintlig produkt. Studien ska också kunna urskilja vilka nackdelar kontra fördelar som finns i en visuell implementation. Studien ska även undersöka hur användaren ställer sig till flödebaserad programmerings-implementation.
7
I vår studie kommer följande frågeställningar att besvaras:
1. Vilka fördelar och nackdelar finns med visualisering av ett scriptspråk för användare av en dataanalytisk plattform?
2. Hur vill användare av produkten använda en implementation av flödesbaserad pro-grammering?
1.5 Tidigare forskning
I följande avsnitt presenteras tidigare relaterad forskning inom ämnet visuell programme-ring.
Problem i programmering
Det finns ett växande intresse att programmering borde vara en fundamental kunskap som lärs ut i tidig ålder. Tyvärr anses programmering av en del vara komplext och svårt att närma sig. Det finns därför behov att sänka inlärningskurvan inom programmering för att nå den potentiella fördel det kan medföra på en global nivå ifall det lärs ut till fler, som tas upp i [11][12]. Problem uppstår vid inlärningen av programmering då det finns åtskilliga språk och sätt att använda dessa språken. Det finns också en generell tro att programmering enbart är användbart för individer som ska göra karriär inom ett IT relaterat yrke enligt [12].
Perception
Egenskaper som visuell avkodning har varit mycket viktiga för överlevnad för människan. Att urskilja form och färg sker på en låg nivå i den visuella processen, vilket resulterar i en mindre krävande process. Skilja på olika former eller färger i ett ögonblick kunde vara skillnaden mellan liv och död och kan förklara varför processen har blivit reducerad. Att kunna knyta an befintliga kunskaper som den visuella processen för färg och form är ett vedertaget koncept för att öka förståelsen och förkorta inlärning. Bra design ser till att det som är mest relevant för användaren är lättare att avläsas, genom till exempel olika färger och former [13][14].
Visuell programmering
Visuell programmering är ett tillvägagångssätt som drar nytta av den visuella processens styrkor. Genom att visualisera kod och kunna abstrahera bort krånglig syntax kan an-vändaren potentiellt få en bättre förståelse och en kortare inlärningskurva [5][6][7][8][9].De flesta visuella programmeringsspråk hamnar i två kategorier, block-och flödesbaserad.
Flödesbaserad programmering
Flödesbaserad Programmering (FBP) tolkar applikationer som ett nätverk av komponenter som körs asynkront [15]. Varje komponent har en eller flera inportar och utportar som tar emot och skickar data till en annan process. Komponenterna kan även transformera och behandla datan som de tar emot och sedan skicka vidare den. Tanken med detta är att
göra det lättare för användaren att förstå applikationens arkitektur och dataflöde. Varje komponent i applikationen kan visualiseras som en nod i en graf med en eller flera ingång-ar/utgångar till andra komponenter.
NoFlo är ett företag som implementerat FBP i språket Javascript 8. De har skapat ett Javascript-bibliotek som gör det möjligt att använda FBP i Node.js 9 applikationer. In-om webbutveckling behöver man ofta modifiera eller lägga till ny data till sin applikation som kan påverka hela dataflödet. Med NoFlo är syftet att göra det lättare att hantera när dataflödet ständigt ändras. NoFlo använder sig av en tydlig grafisk representation för att visualisera flödet i applikationen. Användaren får en tydlig överblick över alla processer och hur datan rör sig i applikationen. Man kan även använda visualiseringen för att pro-grammera. Genom att skapa nya bågar eller flytta om befintliga i grafen genereras kod som motsvarar flödet.
Ett exempel där FBP används för att göra applikationer enklare att modifiera är i en studie om Participatory sensing (PS) [16]. Inom PS använder man sensorer från flera olika enheter för att samla in data som sedan kombineras och analyseras. Det betyder att det kan vara flera olika komponenter i applikationen som behandlar olika sorters data och sedan skickar till en annan komponent. Data från mobilens sensor skickas t ex till en komponents inport som sedan tolkar den och skickar vidare till en annan komponents inport. Med FBP implementerat i applikationen blir det lättare för användaren att modifiera en komponent så att den kan ta emot och tolka rätt typ av data. Detta ökar återanvändbarheten av ap-plikationen och låter användare lägga till nya funktioner för att anpassa apap-plikationen åt ens eget syfte. Tanken med detta är att genom FBP och visuella element göra det lättare för “end-users” att utnyttja applikationens flexibilitet.
Flödesprogrammering behöver inte vara sin egna entitet utan kan vara integrerat i ett annat program som stöd. Kristensson m.fl. [6] utvecklade ett plug-in verktyg som hjäl-per programmerare som använder en IDE, i detta fallet Eclipse IDE. Den underliggande designtekniken är hierarkisk trädbaserad kodvisualisering, inkremental sökning, filtrering och bildnavigation mellan utvecklingsmiljön och den interaktiva kodvisualiseringen. Verk-tyget ska komplettera utvecklingsmiljön som möjliggör användaren att uppfatta strukturer i deras aktiva kod (se figur 1).
Blockbaserad programmering
Blockbaserade programmeringsmiljöer använder sig av en pusselbitsmetafor som ger visuel-la ledtrådar till användaren om hur och var kommandon kan användas inom det ramverket som är givet. Kodstyckena har formen av ett block och man kan koppla ihop dem med andra block för att bilda meningsfylld kod. Om två block inte kan förenas för att bilda ett giltigt syntaktiskt uttalande hindrar programmeringsmiljön detta,vilket i sin tur förhindrar syntaxfel, enligt [11].
Integrationen av datavetenskap inom grundskolan är något som uppmuntras av flera lärare
8NoFlo. [Online] https://noflojs.org 9
Figur 1: Eclipse plug-in visuliserar kod i form av ett hierarkiskt träd
och studier [17][18]. Scratch10 är ett blockbaserat program som är rekommenderat och väl
använt inom grundskolan. Programmeringsspråket i Scratch är visuellt och man använder blockelement för att skriva kod. Ledande inom blockbaserad programmering tillsammans med Scratch är programmeringsspårket Blockly11. Precis som i Scratch används
blockele-ment för att skriva kod men mindre lekfullt. Det talas även om ett samarbete mellan dem två för att skapa Scratch Blocks som ska leda utveckling inom blockbaserad programmering framåt men också visuell programmering i sin helhet (se figur 2)
Figur 2: Scratch till vänster och blockly till höger
Ball m.fl. [12] visar att det finns tydliga fördelar med att använda ett visuellt programme-ringsspråk, utöver grundläggande programmeringsteori, under utbildningen. Aktivt läran-de, konst och historia, beräkningsmetoder, användbarhet och nöje är faktorer som påverkas positivt. Med ett aktivt pedagogiskt användande av visuella programmeringsspråk förbätt-ras elevens förståelse av programmeringskoncept, logik och beräkningsmetoder. Att arbeta
10
Scratch. [Online] Available: https://scratch.mit.edu
11
med visuella programmeringsprojekt ökar elevens motivation, nöje och engagemang. Ak-tivt lärande och projektbaserade uppgifter fick positiva resultat för elevens förmåga att utveckla projekt och produkter.
Blocklys grundare skriver i en studie [19] att det mest troligt inte kommer sökas program-merare med Scracth eller Blockly erfarenheter i framtiden. Tanken med dessa blockbaserade programmeringsspråk är inte att revolutionera hur vi skriver kod, utan de existerar för att sänka inlärningskurvan för programmering i allmänhet. Viktigt att ta med sig är att ha en strategi för att slutligen gå över till textbaserad programmering. Då det är ingen debatt om att det ska ske, utan när det ska ske.
Visualisering av End-User Program
Digitala kalkylark är populärt och används ofta av så kallade “end-users” [20]. End-users i detta fall är användare som inte jobbar primärt med programmering eller IT, utan måste använda någon form av programmering för att utföra sina arbetssysslor. Att förstå och fel-söka digitala kalkylark kan vara svårt eftersom dataflödet och cellernas formler är gömda i programmets arkitektur. En formel kan påverka flera celler i arket utan att detta är direkt synligt för användaren. Det är därför svårt att få en helhetsbild av flödet och strukturen i arket när databehandlingen är osynlig. Genom att visualisera detta i kalkylarket med hjälp av grafer får användaren en bättre bild av flödet av datan och hur olika celler påverkar varandra[21].
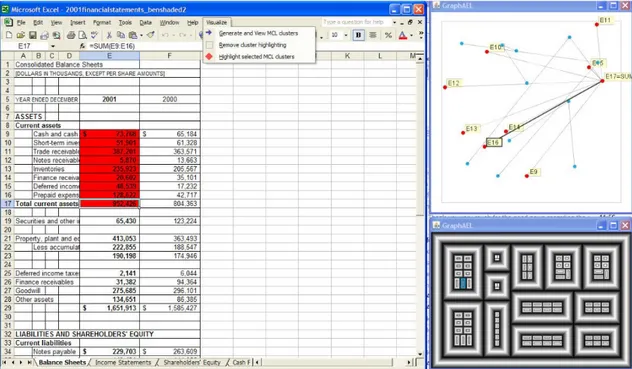
En studie [20] har nyligen utförts för att undersöka ett effektivt sätt att visualisera ett kalkylark för att öka användarvänligheten. För att skapa visualiseringen använder studien sig av Markov Clustering-algoritmen som skapar kluster av celler. Prototypen integreras i Microsoft Excel där man implementerar en graf och treemap för att hjälpa användaren att navigera genom datan (se figur 3). En analys av prototypen visar att det är lättare att förstå och navigera sig genom större kalkylark med hjälp av de visuella verktygen. Visu-aliseringen av dataflödet i form av en graf och treemap gör det lättare att se och förstå helheten av arket. Utveckling av prototyper som visualiserar dataflöden och processer är efterfrågat inom framtida forskning [1]. En väl fungerande prototyp gör det lättare för användare att felsöka och förstå helheten i ett kalkylark.
Figur 3: Visualisering av ett kalkylark i form av en graf och treemap
2
Metod
2.1 Metodbeskrivning
Den här studien är indelad i tre olika delar. En litteraturstudie utförs för att samla infor-mation och data om dagens forskning inom området. Datan som samlas in används som grund för den andra delen av arbetet, utvecklingen av en prototyp. Det tredje steget består av en intervju där användare testar prototypen. Användaren jämför prototypen med mot-svarande textbaserad script-editor som redan finns implementerad i plattformen. Datan som samlas in från intervjun analyseras och jämförs med den data som samlats in från litteraturstudien och utvärderingen av prototypen.
2.2 Design Science Research Methodology
För att göra utvecklingen av prototypen systematisk och iterativ använder vi oss av me-toden Design Science Research Methodology(DSRM)[22]. DSRM är tänkt att bidra med en mall vid utvecklingen av en IT-artefakt vilket förbättrar produktionen, presentationen och utvärderingen [23]. Mallen består av sex steg som itereras ett antal gånger. DSRM fungerar som ett stöd för utvecklingen av prototypen och den behöver inte följas strikt utan kan anpassas efter forskarens miljö. Syftet med DSRM i denna studie är att jobba agilt under utvecklingen av prototypen och genom att följa de sex stegen dokumentera en process som går att återskapa. Prototypen ska testa användarvänlighet och integreras i en redan existerande plattform. Flera iterationer under utvecklingen kommer göra det möjligt att reflektera och utvärdera prototypen i ett tidigt stadie.
DSRM består av följande sex steg [23]:
Steg 1: Identifiera problemet
Identifiera problemet som ska lösas och motivera varför en prototyp behövs. Därför behö-ver man studera bakgrunden inom ämnet och var forskningen står idag för att hitta ett forskningsgap. Litteraturstudien fungerar som en datainsamling för detta ändamål i vår studie.
Steg 2: Definiera kriterier och målsättning
Bestämma hur problemet ska lösas. Definiera olika mål och kriterier som behöver mötas för att komma fram till en lösning. En kunskap behövs om vilka tekniker, metoder och teorier som är relevanta för att lösa problemet. Även här fungerar litteraturstudien som verktyg för att jämföra liknande studier och motivera varför en viss teknik, metod eller teori används.
Steg 3: Design och utveckling
Design och utveckling av en prototyp. Utifrån resultatet av de två tidigare stegen utvecklas en prototyp som löser problemet som identifierats.
Steg 4: Demonstration
Här visar man att problemet kan lösas med hjälp av prototypen som skapats. Beroende på vilken iteration man befinner sig i kan problemet delas upp i olika delar och då visa hur en del av problemet kan lösas.
Steg 5: Utvärdering av prototypen
En datainsamling utförs om hur väl prototypen motsvarar lösningen av problemet. Uti-från den insamlade datan jämför man med de tidigare satta målen och kriterierna för att utvärdera hur prototypen löser problemet och vilka nackdelar samt fördelar som finns.
Steg 6: Redovisning
Redovisa problemet, lösningen samt nackdelar och fördelar med lösningen för andra fors-kare och relevanta målgrupper.
2.3 Litteraturstudie
För att få en bild av var forskningen står idag och bakgrunden inom ämnet utförs en litteraturstudie (se sektion 1.5). Eftersom prototypen utvecklas och utvärderas iterativt är också insamling av referenser till litteraturstudien en iterativ process. Insamling av nya referenser behövs när prototypen utvecklas och nya funktioner läggs till eller modifieras. Vetenskapliga journaler och konferenser samt papper från industrin är det material som
används i litteraturstudien. De databaser som används för sökningarna är ACM och IEEE. För att definiera sökningar används ett flertal sökord som reflekterar ämnet. Exempel på sökord är “Visual Programming”, “Flow-based”, “Script Visualization”, m.fl.
2.4 Intervjuer
För att analysera prototypen och jämföra resultat med tidigare forskning utförs intervjuer på olika typer av användare. Intervjuer används för att samla in kvalitativ data för att sedan utvärdera prototypen som skapats. Strukturen på intervjuerna är semistrukturerad vilket betyder att det är färre antal förbestämda frågor och öppet för följdfrågor enligt [24]. Deltagaren tillåts därför att tala fritt och diskutera om en fråga. Syftet med detta är att få en bättre bild av hur användaren uppfattar och skulle använda prototypen. Med enbart förbestämda frågor går man eventuellt miste om användarens feedback på specifika områden.
För att utföra intervjuerna använder vi ett statiskt exempel av prototypen som kan vi-sas på ett utskrivet papper (se bilaga B). Den statiska prototypen visar visualisering av ett script men det går alltså inte att programmera. För att inkludera programmeringen behandlar några frågor hur användaren skulle göra för att programmera en ändring i da-taflödet. Den statiska prototypen visas tillsammans med det script som har visualiserats för att sedan låta intervjudeltagaren jämföra hur dataflödet och inladdning av data visas.
Deltagarna till intervjun väljs utifrån tre målgrupper som studien ska jämföra. Den förs-ta målgruppen är användare som har ingen eller mindre kunskap av programmering eller program som liknar företagets. Denna målgrupp används för att se om prototypens visua-lisering av kod och flöde kan förstås av oerfarna användare. Ett av målen med prototypen är att göra det lättare för nya användare att använda scriptspråket i produkten och därför är det intressant att intervjua deltagare med minimal erfarenhet. Den andra målgruppen är användare som har god erfarenhet av programmering och mer komplicerade IT-system. De deltagare som tillhör den här målgruppen har aldrig använt företagets produkt men har kunskap om liknande scriptspråk och allmän datavetenskap. Syftet är att jämföra vad som skiljer användare med tidigare erfarenhet av programmering gentemot de som är nybörja-re när de testar prototypen. Tnybörja-redje målgruppen är användanybörja-re som har god erfanybörja-renhet av företagets produkt och av allmän programmering. Den här målgruppen använder produk-ten flera gånger i veckan inom arbetslivet och känner till dataflödet. Eftersom prototypen behandlar ett företags produkt, som används av ett stort antal användare, är det därför viktigt att få en bild av deras uppfattning.
2.5 Metoddiskussion
Den här studien fokuserar på att utveckla en prototyp som ska testa hur visualisering kan implementeras i ett redan existerande program. Prototypen ska sedan jämföras med det scriptspråk som redan är implementerat för att svara på studiens forskningsfrågor. Där-för valdes Design Science Research Methodology(DSRM), som är en form av Design and Creation [25], som metod för studien. Utvecklandet av en IT-artefakt(prototyp) med hjälp av Design and Creation gör det vetenskapliga bidraget tydligare. Det finns alltid en risk
när man utvecklar en IT-artefakt i en studie att det sker åt industrins fördel istället för det vetenskapliga syftet. DSRM ger forskaren en mall för att dokumentera och utvärdera utvecklingen [22]. Syftet är att jobba i iterationer för att nå de bestämda målen och då samtidigt dokumentera processen. Detta gör det lättare att bidra med ny vetenskap då utvecklingsprocessen är väldokumenterad och har ett tydligt vetenskapligt syfte.
Enkät kunde använts som metod för insamling av data till utvärderingen av prototypen. Fördelen med en enkät är att resultatet ger en bred och representativ undersökning. Det är också effektivt för att samla större mängd data, t ex från många olika människor på skiljda platser [25][26]. Resultatet är kvantitativt vilket gör det mätbart och lätt att dra slutsatser ifrån. Nackdelen är att det kan vara svårt att hitta rätt målgrupp och ett rimligt antal deltagare till enkäten. I denna studie skulle det vara svårt att få tillgång till ett stort antal användare av produkten som kan representera den målgrupp som prototypen är utvecklad åt. Med en enkätundersökning går man även miste om chansen att ställa följdfrågor och skapa en diskussion med deltagaren.
För att få en bättre bild av hur en användare skulle använda prototypen passade det därför bättre med intervjuer som metod i denna studie [24]. Med intervjuer kan man ställa frågor som kräver djupare svar och sedan ställa följdfrågor för att få en detaljerad beskriv-ning av användarens upplevelse och åsikter. Användaren är i stort fokus i denna studie då prototypen direkt handlar om användarvänlighet. Om deltagarna i intervjun får tala fritt och diskutera kring frågorna blir det lättare för deltagaren att beskriva sina reaktioner och upplevelser. Olika urvalsgrupper används för att kunna jämföra resultaten från intervju-erna. Visar det sig att svaren skiljer sig väsentligt mellan urvalen finns det anledning att anpassa och utvärdera prototypen fler gånger.
Öppna observationer var tänkt att användas i studien tillsammans med användartester. Tanken var att observera användare när de använde prototypen i företagets program. Da-tan som samlas in skulle vara i form av mätningar av hur lång tid det tog för användaren att lösa specifika problem. Det skulle även loggas hur ofta prototypen användes för att lösa problemen. Datan blir då i kvantitativ form vilket skulle vara intressant att analysera och jämföra med den kvalitativa datan från intervjuerna [27]. Men eftersom prototypen inte blev fullständig och integrerad under denna studie var det svårt att skapa bra användar-tester att observera. Därför valde vi att fokusera på intervjuerna i denna studie.
3
Resultat
I denna sektion redovisas processen och resultatet av iterationerna under utvecklingen av prototypen. Under utvecklingen följs de sex moment som beskrivs av DSRM [22]. Det första momentet, problem identifiering, kvarstod under hela utvecklingen och inkludera-des inte i iterationen. Det sista steget, redovisning, sker enbart under sista iterationen. Redovisningen går ut på att presentera denna studie för intressenter. Intervjuer var in-te tillgängligt att utföra under de första iin-terationerna utan användes enbart på den sista iterationen av prototypen. För att utvärdera de första iterationerna användes istället den data som samlats in från litteraturstudien. Datan jämfördes med prototypen och hur väl den representerade den textbaserade koden. Under varje iteration användes anteckningar och samtal med handledare för att samla och utvärdera processen.
3.1 Design Science Research Methodology
Det första steget enligt DSRM är att identifiera problemet och motivera varför det behövs utvecklas en lösning [22]. Eftersom studien utförs på ett företag och ska implementeras i deras nuvarande produkt presenterade företaget ett flertal problemformuleringar. Littera-turstudien används för undersöka om det redan finns lösningar på problemen och var forsk-ningsfronten befinner sig idag. Efter diskussion med handledare på företaget identifierades ett problem. Steget att identifiera problemet ingår inte i iterationen under utvecklingen utan kvarstår under hela processen.
Identifiering av problem
Företagets produkt är ett business intelligence verktyg12. Det är väl använt runt om i
världen för att analysera och visualisera data. Företaget har fått feedback att många an-vändare har svårt att använda sig av scriptspråket, som vi kallar Qlik-script, som är inbyggt i produkten. En stor del av användarna är “End-users”, vilket betyder att de inte jobbar primärt med programmering eller IT [20]. Det krävs en viss programmeringskunskap för att förstå och arbeta med Qlik-scriptet vilket en del användare saknar. Enligt den feedback företaget fått uppstår det en barriär vilket gör att scriptspråket inte utnyttjas av alla an-vändare. Det finns därför behov av att göra scriptspråket mer användarvänligt och sänka inlärningsnivån.
3.2 Iteration 1
Hur ska det lösas? Mål/kriterier
Det huvudsakliga målet är att göra Qlik-script mer användarvänligt. En visuell represen-tationen av scriptet föreslogs av företaget för att ge användaren en helhetsbild och hur dataflödet ser ut. Under första iterationen ska en grafisk prototyp utvecklas för att utvär-dera hur gränssnittet ska se ut. En jämförelse utförs mellan den grafiska prototypen och ett Qlik-script för att se hur väl dataflödet och processer visualiseras. Utifrån jämförelsen utvärderas hur prototypen kan förändras och vad som fungerar bra.
12
Design
Första designen av prototypen är lokalt integrerad i produkten. Det innebär att prototypen enbart fungerade på de datorer den var implementerad på. Den visuella representationen är flödesbaserad och följer inget designval utan utseendet av prototypen är inte i fokus utan kommer utvecklas mer under andra iterationen. Gränssnittet utvecklas i HTML5/CSS och Javascript. För att skapa en flödesbaserad visualisering används det externa Javascipt-biblioteket NoFlo13. NoFlo genererar noder med anslutningar som går både in och ut från
noden. Attributerna läses in från ett JSON dokument där noderna kallas “processes” och anslutningarna kallas “connections”. Även färger och former kan ändras, detta sker dock på programmeringsnivå.
Demonstration
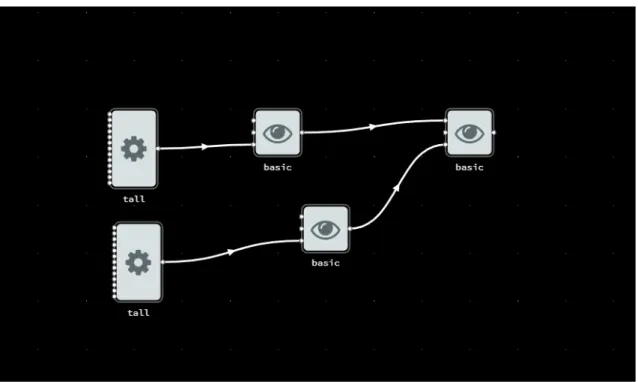
Demonstrationen för denna iteration hölls med den handledare som efterfrågat studien på företaget. Prototypen visades upp på en dator tillsammans med det Qlik-script som visualiserats (se figur 4).
Figur 4: Första design av en grafisk representation av Qlik-script, gjort med NoFlo.
Utvärdering
Utefter data insamlad från produktutvecklare och intressenter av prototypen kunde följan-de fastställas. En helhetsbild kan ges över dataflöföljan-det men visualiseringen generas statiskt och är ännu inte en sann bild av Qlik-scriptet. Integrationen av prototypen kunde delvis
13
uppfyllas genom lokal körning. Prototypen klarade av målsättningarna för denna interation genom att visualisera Qlik-script och dess dataflödet korrekt.
3.3 Iteration 2
Hur ska det lösas? Mål/kriterier
Målet under andra iterationen är att läsa in ett Qlik-script från en lokal källa och dyna-miskt skapa en visualisering av detta som motsvarar prototypen från första iterationen. Prototypen ska klara av att läsa in ett flertal exempel av Qlik-script och göra en visu-alisering av dataflödet. Inläsningen av script sker lokalt under denna iteration eftersom prototypen inte är integrerad i företagets produkt.
Design
Qlik-script följer en BNF-notation (Backus-Naur-form) för att beskriva språkets syntax. För att läsa av ett Qlik-script används ett verktyg som företaget skapat för att färglägga syntax utifrån BNF-notationen i script-editorn. Utifrån detta verktyg skapar vi en egen applikation som tolkar hur ett Qlik-scripts dataflöde hänger ihop och var datan kommer ifrån. Applikationen är skriven i Javascript eftersom det är företagets standardspråk för produkten. Qlik-scriptet delas upp i olika processer för att kunna visualisera det enligt prototypen i iteration ett. I vår applikation representeras varje process som en nod i en graf. Varje nod innehåller metadata från processen och vilka andra noder den känner till. Grafens noder och bågar representerar hur ett Qlik-scripts dataflöde ser ut. För att visualisera grafen använder vi NoFlo-biblioteket som tolkar grafens noder för att rita upp en grafisk representation. Designen av prototypen följer företagets produktdesign. Prototypen kommer följa vedertagna designprinciper med avseende på hur man får relevant information att visas genom färg och form (se t ex [13][14]). I graferna är flödet det viktiga och får därmed huvudfokuset med en klar och stark färg mot en vit bakgrund. Noderna är inte lika viktiga och har en liknande färg som bakgrunden för mer effekt. Vidare är tanken att noderna ska ha olika symboler för en tydligare särskiljning av olika datatyper. Viktigt för visualiseringen är också att informationen inte blir för överväldigande för användaren då detta är ett negativt attribut hos scriptet. Därför är grafen nedskalad och innehåller den väsentligaste informationen för användaren.
Demonstration
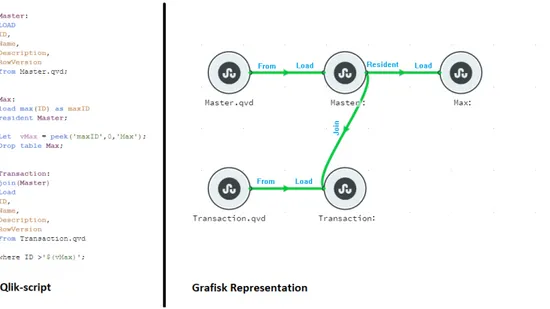
Handledare och intressenter vid företaget närvarade vid demonstrationen. Ett flertal test-script lästes av dynamiskt av prototypen som sedan skapade en grafisk representation(se figur 5).
Utvärdering
Utifrån data insamlad från produktutvecklare på företaget och intressenter av prototypen kunde följande fastställas. En helhetsbild kan ges över dataflödet men visualiseringen gene-ras statiskt och är ännu inte en sann bild av scriptet. Det är viktigt att bestämma vad som kan abstraheras bort samt vad som är väsentligt när scriptet ska representeras grafiskt. Vi
Figur 5: Exempel av ett Qlik-script och hur prototypen skapat en grafisk re-presentation.
blev även rekommenderade att använda ett flertal exempel-script som intressenter ville se visualiserade.
3.4 Iteration 3
Hur ska det lösas? Mål/kriterier
Huvudmålet med iteration tre är att utforma användartester för att kunna utvärdera pro-totypen. Under tidigare iterationer har feedback kommit från personer som är intressenter eller delaktiga i studien. Nu ska användartester i form av intervjuer generera feedback från olika typer av användare. Utvecklingen kommer fokusera på att göra prototypen testbar och jämförbar med ett motsvarande Qlik-script.
Design
Användartestet utförs med hjälp av intervjuer med olika målgrupper som representerar olika användare av produkten (se sektion 2.4). För att utforma användartestet använder vi oss av ett statiskt exempel av prototypen. Detta görs eftersom prototypen inte hunnit bli integrerad och fullt användbar i företagets system ännu. Prototypen har därför inte stöd för att kunna programmera men för att kunna svara på studiens forskningsfrågor räcker det med ett statiskt användartest för att generera ett resultat vi kan analysera. Prototypen visar därför en grafisk representation statiskt på ett papper tillsammans med det Qlik-script som visualiserats. På pappret visas tre olika Qlik-script med respektive visualisering. De tre Qlik-scripten är av olika komplexitet vilket i sin tur påverkar den grafiska representationens innehåll. Tanken är att se hur prototypen klarar av att visualisera större och mer komplexa Qlik-script samt om det blir mer förståeligt för användaren.
Demonstration
De intervjuade får studera ett Qlik-script tillsammans med den grafiska representationen som prototypen genererat. Det ställs sedan frågor som låter deltagaren beskriva dataflödet eller hur de skulle utföra specifika uppgifter (se bilaga A, B och C). Därefter ställs följdfrå-gor om vad prototypen gentemot Qlik-scriptet gav dem för hjälp. Intervjuerna utförs med tre olika målgrupper med olika erfarenheter av script och IT-system. Ingen av de inter-vjuade har varit närvarande vid skapandet av studien och vet därför inte vad syftet med prototypen är ännu. Anledningen är att resultatet från intervjuerna ska vara så objektivt som möjligt.
Utvärdering
Den tredje iterationen är den sista iterationen i studien och utvärderas utifrån de samman-ställda intervjuerna. Prototypen blev inte fullständig under studien och därför utfördes intervjuer på en statisk version av prototypen utan programmeringsmöjlighet. I interju-verna undersöks även hur deltagarna ställer sig till en fullständig implementation med möjligheten att programmera.
3.5 Intervjuer
Intervju-deltagarna delas in i tre olika målgrupper. Grupp ett är de personer som saknar erfarenhet av programmering, grupp två har god erfarenhet av programmering i någon form. Slutligen har vi grupp tre vilka är personer med god erfarenhet av produkten och som använder scriptet. Varje person intervjuas enskilt och samtliga är anonyma i studien.
Målgrupp 1 (Minimal erfarenhet av programmering)
Första frågan vi ställde till deltagarna handlade om vad de kunde urskilja i bilden. Del-tagarna förstod att grafen var en representation av ett script utan någon information om detta sedan innan. Alla deltagare kunde också urskilja att någon form av dataflöde ägde rum. Deltagarna fick sedan svara på om visualiseringen hjälpte dem att förstå vad som pågick i scriptet. Konsensus var att visualiseringen hjälpte men avtog när det fanns mer programkod i scriptet som i bild 2 (se bilaga B), men var som mest användbart i bild 3 (se bilaga B) där mängden script var störst. Dock upplevde några av deltagarna att efter de förstått vad flödet gjorde ökade det inte förståelsen om vad som skedde i skriptet. Bara en av deltagarna kunde följa flödet från grafen och härleda vart i koden detta stycket hade sitt ursprung. Nästa fråga var om det var något som var otydligt i bilden varpå deltagarna sva-rade relativt olika men samtliga nämnde att syntaxen i scriptet var förvirrande men också att ikonen på noderna var oklar. Sista frågan innan de mer generella frågorna var vad gra-fen representerar. Denna fråga ställdes ifall deltagarna inte svarade tillräckligt utförligt när de skulle urskilja vad som hände i bilden. Alla deltagare kunde ge en utförlig förklaring på vad dem tyckte bilden representerade, deras svar stämde relativt bra överens med varandra.
Intervjun gick sedan över till mer generella frågor som inte nödvändigtvis är baserad på specifika bild. Första frågan handlade om deltagarna hade föredragit att skriva i scriptet eller använda sig av grafen för att ändra saker. Alla deltagare sa att de hellre föredragit
grafen men var reserverade för att det skulle kunna vara begränsade och inte enbart räcker till. En följdfråga ställdes sedan om vilka element som de skulle vilja använda sig av i grafen för att kunna programmera. Deltagarna uppvisade en viss förvirring över frågan om vad som menades med programmering. Vid ett förtydligande av frågan kunde deltagarna förmedla att de skulle vilja kunna flytta noder och deras pilar mellan varandra. Men också att man borde kunna trycka på en nod för att kunna se var i scriptet den befann sig. Nästa fråga handlade om huruvida deltagarna kunde förstå vad som pågick om de bara hade ett av element synligt, det vill säga scriptet eller grafen. Varpå samtliga deltagarna svarar att de inte hade förstått scriptet utan bilden. Person D svarade också att scriptet kan ge mer i längden men att det är svårt att veta om förståelsen av scriptet kommer från bilden eller inte. Slutligen frågade vi deltagarna om det var något som de kände var överflödigt eller saknas. Övergripande svaret var att det hade behövts någon form av instruktioner eller dylikt för att kunna förstå vad de olika begreppen betyder.
Målgrupp 2 (God erfarenhet av programmering)
Första frågan vi ställde till deltagarna i målgrupp två var vad de kunde urskilja i bilderna. Deltagarna kunde svara till att börja med i detalj vad som pågick. När bilderna ökade i komplexitet beskrev deltagarna mestadels flödet och inte vad scriptet gjorde. När vi frå-gade om visualiseringen hjälpte var svaret att till en början var det överflödigt, men när komplexiteten ökade användes det mer och slutligen på sista bilden utgjorde det merpar-ten av förståelsen. Även målgrupp två svarade att syntaxen var det mest otydliga i bilden, både i grafen och i skriptet. Deltagarna förstod också vad grafen skulle presentera och kunde gissa vad programmet skulle kunna användas till. Precis som i målgrupp ett ställde vi denna frågan när vi kände att det vara frågetecken i föregående frågor om deltagarna hade förstått bilden.
Samtliga deltagare i målgrupp två trodde att grafen skulle vara lättare att programme-ra i men på lång sikt hade de använt scriptet på grund av att det är mer familjärt för programmerare. Det framkom också att en kombination av de båda hade varit önskvärt. Deltagarna svarade att de vill att grafen skulle kunna föra dem till platsen i koden som grafen representerade när dem blev tillfrågade om det fanns något dem skulle vilja använda grafen till. Samtliga deltagare sa att de skulle kunna förstå scriptet om de hade fått sitta en längre stund. På de två första bilderna räckte scriptet för att förstå vad som hände. På sista frågan, om det saknades något eller något var överflödigt, svarade deltagarna att grafen kunde varit indelad i olika färger och ikoner för att skilja olika typer av syntax i scriptet.
Målgrupp 3 (God erfarenhet av företagets produkt)
Det första vi bad om var att intervjudeltagarna skulle beskriva deras uppfattning om vad som sker i bilden. På alla tre bilder kunde de förklara att det var ett Qlik-script tillsammans med en grafisk representation av samma script. Alla var även överens om att data laddas från olika filer eller databaser för att sedan användas i olika tabeller i programmet. För var-je bild (se bilaga B) påpekade person G och F att den grafiska representationen var väldigt abstrakt och att viktig information från scriptet saknades. De förstod dock att allt inte kun-de visas i grafen utan att göra kun-det för kladdigt. Därför såg kun-de grafens användningsområkun-de
som begränsat för att förstå helheten av scriptet. Alla intervjudeltagare var dock överens om att den grafiska representationen ger en tydlig och snabb överblick över hela dataflödet.
Vid frågan om visualiseringen hjälpte dem att förstå scriptet skiljde sig svaren beroen-de på vilken bild beroen-det var. För bild 1 och 2 (se bilaga B) var visualiseringen inte till någon hjälp när det gällde att förstå scriptet. Den kunde dock fungera som en snabb överblick av strukturen, men det fanns inget behov av detta då scripten var korta och tydliga enligt deltagarna. Det var först vid bild 3 (se bilaga B) som visualiseringen var till hjälp att förstå scriptet enligt alla tre deltagare. När vi frågade om något var otydligt på bilderna var alla deltagare snabba med att påpeka ikonerna i noderna. Alla tre föreslog att ikonerna skulle vara olika beroende på vilken datakälla noden representerade. Detta skulle göra det tydligare att förstå helheten och dataflödet enligt de intervjuade.
När vi frågade de intervjuade om de hade föredragit att programmera med scriptet el-ler med hjälp av grafen skiljde sig svaren. Person H skulle enbart vilja programmera i scriptet då det känns mer naturligt och av vanesak. Visualisering kunde fungera som stöd för att navigera i scriptet men inte för att utföra eller skapa funktioner. Person G och F föredrog också att jobba huvudsakligen i scriptet då de ville ha tillgång till alla detaljer och funktioner. De påpekade dock att om tillräckligt med nödvändiga funktioner imple-menteras i grafen skulle de gärna använda det beroende på vilken applikation de jobbade med. De höll även med om att grafen skulle vara ett bra verktyg för att navigera i scriptet. Om man t.ex hade dubbelklickat på en nod i grafen skulle man hamnat på samma ställe i scriptet. Att använda grafen för att felsöka sin kod var något alla föreslog som funktion. Eftersom grafen visar flödet av data skulle det göra det enklare att se var i flödet felet uppstår.
4
Analys & diskussion
Analysen kommer delas in i de olika iterationerna av prototypen för att kunna analysera varje steg i utvecklingsprocessen. Intervjuerna ägde rum efter sista iterationen, innan dess har feedbacken varit från handledaren som ligger bakom problemförslaget. Vi valde att inte genomföra intervjuer i de två första iterationerna av prototypen med motiveringen att prototypen inte hade nått ett stadium där intervjuer kunde ge ett resultat som var givande. Majoriteten av analysavsnittet kommer bestå av analys och diskussion baserat på intervjuer. Detta grundar sig i att intervjuer är studiens insamlingsmetod och prototypens första iterationer delvis utvärderas under utvecklingsprocessen.
4.1 Iteration 1
Målet med första iterationen var en grafisk prototyp som hade två delar att implementera, visualiseringen och en integration i företagets produkt. Målet uppfylldes genom upptäck-ten av Noflo och en lokal implementation av prototypen i produkupptäck-ten. Implementationen bestod av en simpel kommunikation mellan visualiseringen och företagets produkt. I denna iteration fungerade kommunikationen som ett bevis på en möjlig lösning. Valet av Noflo grundades av att det innefattade ett välutvecklat visualiseringsverktyg som har förmågan att grafiskt representera ett flöde. Noflo var även kapabelt att animera dynamiska änd-ringar som att flytta noder eller byta kopplingar. Kvaliteterna ansågs vara högst relevanta för studien, delvis för att samma implementation skulle ta fokus från studiens faktiska mål. Noflo har också en förankring i forskningen sedan tidigare då andra studier även har argumenterat för användningen av Noflo [10]. Noflo verkade vara perfekt passform för stu-dien men visade sig ha ett fåtal negativa aspekter som påverkade stustu-dien i sin helhet. Den största negativa aspekten var möjligen det faktumet att Noflo inte är vidare brett använt. Detta kombinerat med en sparsam dokumentation gjorde Noflo svårt att lära sig. Det gick att argumentera för implementationen av ett eget konstruerat visualiseringsverktyg för att undvika en del av problemen. Detta skulle dock medföra en stor satsning i tid som hade en osäker utbetalning. Faktumet kvarstår att NoFlo hade alla verktyg som krävdes för studien vilket var grunden för vårt beslut.
Flödesbaserad visualisering var inte det självklara valet, det fanns tidigt ett mer tidsak-tuellt visuellt programmeringsverktyg, blockly, som precis som NoFlo gick att implemen-tera i en annan produkt. Motiveringen för valet av flödesbaserad visualisering gjordes på grund av de egenskaper som det medför. Det efterliknar tillståndet som företagets produkt bakomliggande struktur hade och det var på grund av den slutsatsen det valdes.
4.2 Iteration 2
Målet med iteration två av prototypen var att kunna läsa av ett script och dynamiskt göra en visualisering. För att tolka scriptet krävdes det att vi kunde läsa av och strukturera det efter syntaxen scriptet följer. Resultatet var att bara de mest vanliga och viktigaste delarna av scriptet kunde visualiseras. Delar av scriptet som inte påverkade dataflödet eller som exempelvis variabelnamn abstraherades därför bort. Motiveringen till abstrahering-en förankras i tidigare forskning där konceptet “less is more"var grund till att ha abstrahering-en mer
avskalad visualisering [13][14]. Användandet av flödesbaserad visualisering passade bra för att beskriva de olika processerna i scriptet. Eftersom scriptet används för att ladda data från externa källor och sedan skickas vidare, blir det naturliga processer och flöden av data. Efter att ha tolkat ett script och definierat processerna användes flödesbaserad visualise-ringen för att skapa en dynamisk visualisering. Scriptet har ett väldigt tydligt dataflöde då olika datakällor laddar data från varandra vilket passar flödesbaserad visualisering [16].
Vår implementation av flödesbaserad visualisering används för att lättare tolka och struk-turera scriptet som läses av. Syftet med detta är att göra det lättare att justera och anpassa visualiseringen efter behov. Detta gör programmering eller någon slags av interaktion med visualiseringen lättare att implementera i framtiden. Att låta användaren programmera med visualiseringen, exempelvis genom att flytta eller skapa nya noder för att generera ett nytt script, var först tänkt att implementeras. Detta visade sig dock snabbt vara väldigt tidskrävande att lösa eftersom att generera ett nytt script kräver en komplicerad algo-ritm. Exempelvis om en användare flyttar en nod som är ihopkopplad med flera andra noder kommer scriptet förändras på många olika ställen. Det blir därför snabbt väldigt många parametrar att ta hänsyn till när ett nytt script ska genereras. Om det hade funnits mer tid skulle vi implementerat någon slags av programmering i visualiseringen. Vi ansåg dock med den implementation vi hade kunde vi utföra intervjuer och svara på studiens forskningsfråga.
4.3 Iteration 3
Den sista iterationen av prototypen utvärderades genom intervjuerna med de tre olika mål-grupperna. Företaget som äger produkten har ett stort spektrum av användare där pro-grammeringserfarenhet skiljer sig bland användarna. Resultatet från intervjuerna med de olika målgrupperna gav olika typer av användares perspektiv på hur dessa använder proto-typen. Den första målgruppen, användare som saknar programmeringserfarenhet, använde prototypen för att förstå vad varje script gjorde. De fann stor användning av visualisering-en vid varje script-exempel (se bilaga B) som de fick titta på. Flera av de intervjuade i dvisualisering-en första målgruppen uttryckte sig tydligt att de hade svårt att kolla på scriptet när det blev mer och mer kod. De kände sig avskräckta och att de inte hade en chans att förstå enbart scriptet, men att visualiseringen gjorde det enklare att förstå vad scriptet representerade.
När man jämför detta resultat med målgrupp två och tre skiljer sig perspektiven. Mål-grupp två, användare med god programmeringserfarenhet, valde i de flesta fallen att hu-vudsakligen fokusera på scriptet. De förklarade att de ville förstå scriptet först och använde visualiseringen för att bekräfta deras uppfattning. Målgrupp tre, användare med erfarenhet av scriptet, liknar målgrupp två då de fokuserade på scriptet i första hand. Med deras erfa-renhet var visualiseringen inte till någon hjälp vid de enklare exemplen (se bilaga B, figur 6,7). En jämförelse mellan målgrupp två och tre är att de båda använde visualiseringen för att få en övergripande bild av dataflödet och arkitekturen. Detta är något som tas upp i [21], där visualisering av komplexa kalkylarks dataflöde hjälper användaren att se helheten.
Intervjuerna återgav även en viss förvirring kring symbolerna i graferna som var en ikon för NoFlo biblioteket och fungerade mest som en platshållare för en framtida implementation.
Det medförde att vissa deltagare la ner tid och fokus på att försöka förstå vad symbolerna var. En oönskad reflektion som kan ha tagit fokus från det viktiga i grafen men visar på hur stor vikt design har. Speciellt för målgrupp ett där det redan är många nya koncept som ska tolkas kan små detaljer bidra med förvirring. Abstraktionsnivån på grafen fungerar bra på målgrupp ett som inte har programmerat förut men avtar i effekt för målgrupp tre där det inte ger användaren någon detaljerad information. Ovanstående diskussion och analys gör det möjligt att dra slutsatser kring forskningsfrågan Vilka fördelar och nackdelar finns med visualisering av ett scriptspråk för användare av en dataanalytisk plattform?
Ett designval som har diskuterats men som aldrig implementerats är möjligheten till olika svårighetsgrader på graferna beroende på användaren. Det skulle då möjliggöra att an-vändaren får välja fritt vilken nivå visualiseringen ska ligga på. Även personer i målgrupp tre kan få användning av en nerskalad graf för en lättare navigeringen eller översikt av scriptet. Målgrupp ett skulle också kunna ha användning av olika svårighetsgrader som en inkörningsport som trappar upp svårighetsgraden efter behov. Designvalet hade hjälpt att överkomma svårigheter att hitta rätt design till rätt typ av beteende[4]. Deltagare med lägre förståelse för scriptet, mestadels målgrupp ett, kunde i stora drag återge vad grafen representerade och därmed även scriptet. Detta visar på hur grafiska representationer har förmågan att överkomma språkliga barriärer vilket även har påvisats i diverse tidigare stu-dier [5][7][11]. Även om deltagarna vid förfrågan påtalar att visualiseringen är anledningen till att de förstår scriptet, speciellt i de mer avancerade exemplen, är det värt att notera att det kan ha varit en kombination av både scriptet och grafen som ökade förståelsen.
För att motverka detta kunde intervjubilderna varit strukturerade på så sätt att grafen och scriptet var separerade. Problemet med denna lösning är dock att oberoende på vad som visas först kan intervjupersonen få en ökad förståelse för motsvarigheten i antingen graf-eller scriptform innan de sett den andra bilden vilket gör det svårt att härleda vad som faktiskt hjälpte. Tredje alternativet kunde varit att varje script eller graf inte hade någon motsvarighet utan att varje bild var unik. Detta hade bidragit med att förståelsen inte påverkades av föregående bilder eller som lösningen i studien med samma bild. Problemet med denna metod blir att bedöma svårighetsnivå mellan script och graf. Vilka faktorer är det som egentligen gör en graf eller script svår att förstå? Detta kan vara svårt att ta reda på med tanke på vad olika personer uppfattar som svårt. Att hitta och förklara olika beteenden hos användare är problematiskt [4]. Besultet togs istället att vara så trogna till en verklig implementation som möjligt för att kunna få resultat som var mer relevanta för prototypen och i sin tur mer relevanta för studien.
När det kommer till att programmera och interagera med visualiseringen skiljde sig motiva-tionen hos de olika målgrupperna. Målgrupp två och tre var skeptiska och trivdes bra med att enbart programmera med scriptet. De är vana vid textbaserad programmering och har svårt att se visuell programmering vara lika effektiv och kraftfull som textbaserad. Några av deltagarna påpekade att visualiseringen kunde vara bra att använda för att navigera i scriptet eller för att skapa en mall i början av ett projekt. Målgrupp ett som saknar pro-grammeringserfarenhet var dock positivt inställda till att använda visuell programmering med hjälp av prototypen. Möjligheten att generera script genom att skapa nya noder eller interagera med grafen var alla i första målgruppen positivt inställda till. Om man jämför
med tidigare studier [5][6][7] om användning av visuell programmering stämmer målgrup-pernas perspektiv överens med tidigare forskningen.
Med ovanstående diskussion kan det dras slutsatser från frågeställning som lyder "Hur vill användare av produkten använda en implementation av flödesbaserad programmering?". Interjuverna visar indikationer på att flödesbaserad programmering kan vara positivt för både användare som är oerfarna och erfarna av programmering. Det visar även att förde-larna skiljer sig åt mellan målgrupperna och vad som kan vara positivt för en användare kan vara det negativt för en annan. Det gäller därför att hitta en lösning som kan anpassas efter användaren.
5
Slutsatser och vidare forskning
Målet med denna studie är att utveckla en flödesbaserad visualisering av ett scriptspråk för göra det mer användarvänligt. Studien utförs på ett företag vars produkt använder sig av ett scriptspråk för att ladda och bearbeta data. Företaget har fått feedback från sina användare att scriptspråket är svårt att lära sig och att det finns en inlärningsbarriär som många användare inte kommer över. För att lösa problemet utvecklas en visualisering av scriptet som även har förutsättningar för interaktion och visuell programmering. Med hjälp av intervjuer av användare jämförs visualiseringen med det textbaserade scriptet. Resultatet visar att visualiseringen är till användning för både oerfarna och erfarna an-vändare. För de oerfarna ger visualiseringen en tydlig överblick om vad scriptet gör, men abstraherar bort många detaljer. Även om en användare inte är bekant med scriptspråket kan de förstå dataflödet och scriptets syfte med hjälp av studiens visualisering. De mer erfarna användarna hade mindre användning för visualisering för att förstå själva scriptet. Visualiseringen användes istället för en snabb överblick och som stöd när scriptet blev längre. Användsningsområdena skiljer sig därför mellan olika typer av användare. Att im-plementera olika svårighetsgrader som användarna kan välja mellan är ett intressant öppet problem. Implementationen hade tagit positiva aspekter från både oerfarna och erfarna användare för att skapa en prototyp.
På grund av tidsbrist har denna studie inte testat en fullständing implementation av visu-ell programmering, utan enbart visualisering av scriptspråket. Under intervjuerna ställdes hypotetiska frågor om hur användarna hade velat använda visualiseringen för att program-mera. Intervjuerna gav bra svar på hur användarna vill programmera med visualiseringen. Det är därför intressant att vid framtida forskning utveckla en prototyp som använder intervjusvaren från vår studie som grund vid design och implementation.
Flödesbaserad visualiserings styrka kan tolkas utefter intervjuerna som ett verktyg för att få en snabb överblick men riskerar att bli kontraproduktiv om detaljnivån är fel. Pro-totypen har ett relativt lågt tak för komplexitet, där av fick de mer erfarna grupperna som blev intervjuade mindre ut av graferna. Huvudsyftet med visualiseringen är dock inte att hjälpa erfarna användare med komplex syntax utan existerar för att sänka inlärningskur-van för nya användare. Det skulle även vara intressant att göra en så kallad blockbaserad implementation och se vilka fördelar eller nackdelar det kan bidra med. Blockbaserad pro-grammering kan ge en ny infallsvinkel på problemet och har sedan tidigare visat sig vara effektivt för nya användare [2][11].
Referenser
[1] A. J. Ko, B. Myers, M. B. Rosson, G. Rothermel, M. Shaw, S. Wiedenbeck, R. Ab-raham, L. Beckwith, A. Blackwell, M. Burnett, M. Erwig, C. Scaffidi, J. Lawrance, and H. Lieberman, “The state of the art in end-user software engineering,” in ACM Computing Surveys, vol. 43, no. 3, pp. 1–44, Apr 2011.
[2] D. Mason and K. Dave, “Block-based versus flow-based programming for naive pro-grammers,” in 2017 IEEE Blocks and Beyond Workshop (B B), pp. 25–28.
[3] J. F. Pane and B. A. Myers, “Usability issues in the design of novice programming systems.” in Computer Science Technical Reports 1996, CMU-CS-96-132, p. 86. [4] A. J. Ko, B. A. Myers, and H. H. Aung, “Six learning barriers in end-user programming
systems,” in 2004 IEEE Symposium on Visual Languages - Human Centric Computing, pp. 199–206.
[5] T. Ball and S. G. Eick, “Software visualization in the large,” in IEEE Computer, vol. 29, no. 4, pp. 33–43, Apr 1996.
[6] P. O. Kristensson and C. L. Lam, “Aiding programmers using lightweight integrated code visualization,” in Proceedings of the 6th Workshop on Evaluation and Usability of Programming Languages and Tools, ser. PLATEAU 2015. ACM, pp. 17–24. [7] Z. Sharafi, A. Marchetto, A. Susi, G. Antoniol, and Y. G. Guéhéneuc, “An
empiri-cal study on the efficiency of graphiempiri-cal vs. textual representations in requirements comprehension,” in 2013 21st International Conference on Program Comprehension (ICPC), pp. 33–42.
[8] D. Stein and S. Hanenberg, “Comparison of a visual and a textual notation to express data constraints in aspect-oriented join point selections: A controlled experiment,” in 2011 IEEE 19th International Conference on Program Comprehension, pp. 141–150.
[9] A. Jbara and D. G. Feitelson, “JCSD: Visual support for understanding code control structure,” in Proceedings of the 22Nd International Conference on Program Compre-hension, ser. ICPC 2014. ACM, pp. 300–303.
[10] T. Szydlo, R. Brzoza-Woch, J. Sendorek, M. Windak, and C. Gniady, “Flow-based pro-gramming for IoT leveraging fog computing,” in 2017 IEEE 26th International Con-ference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WE-TICE), pp. 74–79, Jun 2017.
[11] D. Weintrop and U. Wilensky, “Comparing block-based and text-based programming in high school computer science classrooms,” ACM Transactions on Computing Educa-tion, vol. 18, no. 1, pp. 1–25, Oct 2017.
[12] J.-M. Sáez-López, M. Román-González, and E. Vázquez-Cano, “Visual programming languages integrated across the curriculum in elementary school: A two year case study using “scratch” in five schools,” Computers & Education, vol. 97, pp. 129–141, Jun 2016.
[13] C. Ware, Visual Thinking: For Design. Morgan Kaufmann Publishers Inc. 2008.
[14] D. A. Norman, Things That Make Us Smart: Defending Human Attributes in the Age of the Machine. Addison-Wesley Longman Publishing Co., Inc. 1993.
[15] B. Zarrin and H. Baumeister, “Towards separation of concerns in flow-based program-ming,” in Companion Proceedings of the 14th International Conference on Modularity, ser. MODULARITY Companion 2015. ACM, pp. 58–63.
[16] J. Zaman, L. Hoste, and W. De Meuter, “A flow-based programming framework for mobile app development,” in Proceedings of the 3rd International Workshop on Pro-gramming for Mobile and Touch, ser. PROMOTO 2015. ACM, pp. 9–12.
[17] M. Noone and A. Mooney, “First programming language: Visual or textual?” Compu-ting Research Repository - arXiv (CoRR), vol. 1710.11557, Oct 2017.
[18] M. Armoni, O. Meerbaum-Salant, and M. Ben-Ari, “From scratch to “real” program-ming,” Trans. Comput. Educ., vol. 14, no. 4, pp. 25:1–25:15. Feb 2016.
[19] N. Fraser, “Ten things we’ve learned from blockly,” in 2015 IEEE Blocks and Beyond Workshop (Blocks and Beyond), pp. 49–50.
[20] B. Kankuzi and Y. Ayalew, “An end-user oriented graph-based visualization for spre-adsheets,” in Proceedings of the 4th International Workshop on End-user Software Engineering, ser. WEUSE ’08. ACM, pp. 86–90, Feb 2018.
[21] U. Jugel, “Visual, in-place data flow modeling,” in Proceedings of the International Conference on Advanced Visual Interfaces, ser. AVI ’10. ACM, pp. 303–306.
[22] K. Peffers, T. Tuunanen, M. Rothenberger, and S. Chatterjee, “A design science re-search methodology for information systems rere-search,” J. Manage. Inf. Syst., vol. 24, no. 3, pp. 45–77, Dec 2007.
[23] G. L. Geerts, “A design science research methodology and its application to ac-counting information systems research,” International Journal of Acac-counting Infor-mation Systems, vol. 12, no. 2, pp. 142–151 Jun 2011.
[24] M. D. Myers and M. Newman, “The qualitative interview in IS research: Examining the craft,” Inf. Organ., vol. 17, no. 1, pp. 2–26. Jan 2007.
[25] B. J. Oates, Researching Information Systems and Computing. Sage Publications Ltd. 2006.
[26] G. Ejlertsson and J. Axelsson, Enkäten i praktiken : en handbok i enkätmetodik. Stu-dentlitteratur 2005.
A
Intervju Frågor
PERSON X Yrke: X Ålder: X Erfarenhet av programmering: X Bild 1• Vad är din uppfattning om vad som sker i bilden, vad skulle du säga är data flödet?
• Hjälpte visualiseringen dig att lättare förstå?
• Var det något som var otydligt?
• Vad representerars i grafen?
Bild 2
• Vad är din uppfattning om vad som sker i bilden, vad skulle du säga är data flödet?
• Hjälpte visualiseringen dig att lättare förstå?
• Var det något som var otydligt?
• Vad representerars i grafen?
Bild 3
• Vad är din uppfattning om vad som sker i bilden, vad skulle du säga är data flödet?
• Hjälpte visualiseringen dig att lättare förstå?
• Var det något som var otydligt?
• Vad representerars i grafen?
Generella frågor
• Hade du föredragit att skriva liknande text som visas eller att skapa liknande visua-liseringar för att till exempelvis lägga till ett till dataset.
• Vilka element i grafen hade du velat ändra för att kunna modifiera det nuvarande tillståndet?
• Hade du förstått vad som pågick med bara en av elementen synliga, det vill säga texten och visualiseringen?
B
Intervju Bilder
Figur 6: Bild 1 i intervju.
Figur 7: Bild 2 i intervju.
C
Deltagande i intervju
Deltagare
ID Yrke Ålder Programmeringserfarenhet Målgrupp
A Logoped 26 Ingen 1
B Student Applikationsutveckling 22 Kandidat i datorvetenskap 2 C Student Applikationsutveckling 23 Kandidat i datorvetenskap 2
D Student Elektroteknik 24 Ingen 1
E Student Miljövetare/Biomedicin 26 Ingen 1 F Produkt Ansvarig 60 40 år av programmering 3 G Support Tekniker 32 2 år av programmering 3 H Student Astrofysik 26 2 år av studier 3
![Figur 1: Eclipse plug-in visuliserar kod i form av ett hierarkiskt träd och studier [17][18]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3949941.73518/12.892.133.767.201.513/figur-eclipse-plug-visuliserar-form-hierarkiskt-träd-studier.webp)