An exploration of the
test prioritization
process on large
software projects with
no requirement
specification
MAIN AREA: Computer engineering AUTHORS: Adam Clettborn, Edwin Wallin SUPERVISOR:Muhammad Ismail JÖNKÖPING 2020-04
Postadress: Besöksadress: Telefon:
Box 1026 Gjuterigatan 5 036-10 10 00 (vx)
551 11 Jönköping
This final project work is performed at Jönköping’s School of Engineering within [see main area on previous page]. The authors are solely responsible for expressed opinions, conclusions, and results.
Examiner: He Tan
Supervisor: Muhammad Ismail Extent: 15 hp
ii
Abstract
Software projects with a larger code base can be hard to maintain, and testing could therefore be a necessity. But how would one prioritize tests in their existing software project, if their project never had any tests? The purpose of this study is to find concrete steps of how to prioritize tests in a software project, independent of project type and development language. Said steps were found through two iterations of the Action Learning method. The results were found without any requirements specification, which lead to using intuition, together with code complexity, to prioritize test cases, after breaking down the project into its modules. As the study was conducted on only one specific software project, the result is limited to that specific software project until further research is conducted.
iii
Summary
This study conducted an experiment at Qsys Sverige AB, to find concrete steps of how to prioritize tests in a software project, independent of project type and development language, using Action Learning (AL). AL is a method that works in iterations, where each iteration has four steps; Study & Plan, Take Action, Observations and Reflections. Each iteration is working with the reflections of the previous iteration, which will provide help to improve next iteration. The result of the study concludes that it is possible to prioritize tests in an already existing software project, independent of development language and project type. The findings gave concrete steps of how to prioritize tests, which are the following:
1. Break down the project into its modules
2. Set the likelihood of failure and failure severity level for each module, and calculate the intuition priority
3. Generate the number of revisions and cyclomatic complexity, and calculate the revision risk
4. Combine the intuition priority and revision risk into combined priority
5. Repeat the steps for top prioritized module’s child modules, recursively, until no further depth can be reached
The last depth will then provide the test cases, which can also be prioritized using the same steps.
The result of the study implies that it is possible to prioritize tests without having any requirements specification. It is also proven that code complexity is an important factor when selecting test cases.
The study was only conducted on one software project, which limits the result for this particular study, but could be more generalized when performing the same study on different software projects, which is something that could be further researched.
iv
Acknowledgements
To reach the point we have alone would have been impossible, so we would like to take a moment and thank everyone who directly or indirectly contribute to where we are today. A great amount of gratitude is given to He Tan for the constructive criticism and knowledge distributed to us during the writing of this thesis.
We also want to thank Jasper van der Ster a friend who helped us understand and construct some of the mathematics in our study.
We also want to thank each other for the continued support and understanding towards our situations and obstacles we faced together and separately.
Lastly, almost as per tradition, we want to thank our families for continued support for all these years, especially the past three.
v
Content
Abstract ... ii
Summary ... iii
Acknowledgements ... iv
Content ... v
1
Introduction... 7
1.1 BACKGROUND ... 7 1.2 PURPOSE ... 8 1.3 RESEARCH QUESTIONS ... 8 1.4 DELIMITATIONS ... 9 1.5 DISPOSITION ... 92
Method ... 10
2.1 CONNECTION BETWEEN RESEARCH QUESTIONS AND METHOD ... 10
2.2 WORKING PROCEDURE ... 10
2.2.1 Study & plan ... 10
2.2.2 Take Action ... 10
2.2.3 Observe (collect & analyze evidence) ...11
2.2.4 Reflect ...11
2.3 CREDIBILITY ... 11
3
Theoretical- and technical framework ... 12
3.1 CONNECTION BETWEEN RESEARCH QUESTIONS AND THEORY ... 12
3.1.1 Research question 1 ... 12 3.1.2 Research question 2 ... 12 3.2 TECHNICAL FRAMEWORK ... 12 3.2.1 Qpick ... 12 3.2.2 Automated testing ... 12 3.2.3 Unit testing ... 12 3.2.4 Microsoft Excel ... 13 3.2.5 Maintainability index ... 13
vi
3.2.6 Requirements specification ... 13
3.3 THEORETICAL FRAMEWORK ... 13
3.3.1 Automated Test Integration Process (ATIP) ... 13
3.3.2 Integration ... 13
3.3.3 Implementation... 13
3.3.4 Code and project analysis ... 13
4
Empirics ... 17
4.1 PRE-STUDY... 17 4.2 ACTION LEARNING ... 17 4.2.1 Iteration 1 ... 17 4.2.2 Iteration 2 ... 185
Assessment ... 19
5.1 RESEARCH QUESTION 1 ... 19 5.2 RESEARCH QUESTION 2 ... 196
Discussion and conclusion ... 20
6.1 RESULT ... 20
6.2 IMPLICATIONS ... 20
6.3 LIMITATIONS ... 20
6.4 CONCLUSIONS AND RECOMMENDATIONS ... 21
6.5 FURTHER RESEARCH ... 21
7
1
Introduction
The landscape of the software development world is always moving towards more and more large programs which extend the previous functionality, often without writing new replacements to the older components. This introduces a multitude of new complexity issues and adds an ever-increasing need for software tests to ensure quality and service availability. Outages and issues can cost both the developers and customers a great deal [1, 2]. With software testing becoming more and more of the norm, legacy and old systems have a harder time with keeping up ensuring that at least their most critical and used modules are properly tested. The purpose of this study is to explore the prioritization process of automated tests in an existing software project and see if it is possible to further extend the current ideas. This means that an investigation of what problems you can encounter when prioritizing test cases and how it can be achieved with minimal information of the system. The study was done in collaboration with the IT-company Qsys, who has developed a warehouse management system (WMS), named Qpick, which is integrated with customer’s enterprise resource planning (ERP) software. However, the study aims to provide a more generic result, which could be applied to other similar software projects that are structured such a way that it is easily divided into modules, such could be object oriented.
The target projects for this study are projects with a lot of technical debt that lack a well-constructed or simply no requirement specification, minimal previous testing efforts and has been developed for some time; preferably at least one year as complexity has shown to be relatively stable at this point [3]. It is also crucial that the project is large enough to require multiple maintainers, because of size or complexity. The area to which the project is applied, or architecture of underlying systems should be of minimal importance. It is also important to note that this study focuses on existing software, that is a piece of software that is not in its idea stage, planning stage or similar; it should to a large extent already be finished and in use.
1.1 Background
As of now, there are almost no automated tests for Qpick, which is a problem for the developers and system reliability. Currently, most of the software is tested manually which wastes unnecessary time on something that could have been spent on progressing the backlog. Manual testing is also affected by the human factor, which could lead to untested and potentially defect code. In a business system like Qpick this could have massive consequences for their customers. Automated tests, of any kind, can solve big portions of these problems as the developers do not have to spend time doing manual testing. By using automated tests, we can eliminate the human factor and use the developers’ time more efficiently. Good unit tests can lead to less bugs which in turn leads to a decrease in maintenance costs [2]. Automated testing also ensures that partial and complete failures occur less frequently, due to being able to systematically test the code to catch bugs and errors.
Automated test integration process (ATIP) is the idea of having a well-defined method around how automated tests are integrated, which is a local term coined for this particular paper. There are several steps in adding automated tests; typically, it involves extracting test data from the application’s requirements specification, selecting the test architecture, creating test specification and then implementation, which often follows the application development. Most of these steps have an interchangeable order, depending on constraints such as development method, architecture, and application type.
8
Figure 1: A regular test integration process.
However, a system without any previous test integration process is a bit more challenging, especially if the requirements specification is non-existing or limited. This also makes the financial decisions whether to implement tests at all or not, and where in the code base, very difficult since in many cases testing the whole codebase might not be feasible, at least within a reasonable timeframe. A lot of the integration process is to some extent already explored, but often in a very technology specific way, such as in [4] where they focus on .NET and Java programs. There are also papers which try to generalize the issues, like [5], where they examine data collection and generation for exception conditions based on multiple case studies, rather than one specific language or case. These are not as common, which is why this study focuses on contributing to a more generalized ATIP primarily by looking at the prioritization of the test cases since it could be deem that this part is the least explored and most impactful; both for the developers but also at a business level.
1.2 Purpose
Security and stability are important factor in today’s society, which highlights the importance of testing software projects. Today, generalized material that could help developers identify the most critical parts to test, independent of underlying system or development language, is basically non-existent. According to Daka and Fraser [6] there seems to be least academical support for areas such as:
• What should you test? • What are realistic tests?
• How do you make sure the tests are easy to maintain?
These are some of the questions that we plan to study in conjunction with examining the process of prioritization. As of now, there are a lot of focus on what the best framework is, instead of a more abstract understanding of the test integration. If people would have a more generalized view of tests, the decision and the introduction of tests would be simpler and more efficient; regardless of the programming language or technologies that are used.
The study is aimed to provide easier test prioritization and ultimately integration, giving companies a chance to test their software thoroughly. This could also lead to more software being tested, as it might be easier to evaluate the value and therefor convince more companies to integrate tests into their software project. The study should also provide a way to find the balance between what is efficient production-wise and what has a good coverage of the software project when it comes to prioritizing.
1.3 Research questions
With the results from this work it should become easier to analyze an existing software project or architecture and identify potential obstacles when both integrating, but most importantly prioritizing test cases. The main goal is to facilitate the introduction of automated tests for companies without disrupting the development that is already going on at an abstract level. This means that this study does not focus on specific frameworks, but instead try to create an abstract view of what method to use when prioritizing tests, which can then be used both to
Application
requirements
Selecting test architecture and frameworks Create test specification from application requirements Implement tests9 select the order of implementation but also give an indication of what need and does not need to be tested.
As previously mentioned, there is not much material to help developers identify what the most crucial part of a project is, and therefore the developer cannot know with certainty what is crucial and what is worth testing. This is something this study intends to find a solution for, which sets the purpose for this study:
To find concrete steps of how to prioritize tests in a software project, independent of project type and development language.
In order to find a solution to the purpose, the purpose has been divided into two questions: [1] How could test cases be prioritized when a limited or no
requirements specification is present?
[2] With a limited or no requirements specification, what are some important factors in a software project, regarding test case
prioritization?
1.4 Delimitations
This project does not necessarily cover any specific test type, such as UI- or unit testing, when investigating the prioritization of test cases, instead it focuses on testing in general.
Automated tests are the focus however the final report should not only be applicable with such tests.
As the study is performed with Qsys, specifically with Qpick, there are some limitations of what result can be expected and how generic the result can be. However, the result is intended to provide a base to a more generic result, which can be found when conducting the study on different software projects.
As with everyone we were also affected by COVID-19 which introduced troubles with communication and an uncertainty, both for us but particularly Qsys. With this, our experiments became a lot slower mostly because of poor communication from both parties and Qsys’ ability to disposition employee time since they had a lot to do, which is
understandable at these times. This, in conjunction with miscalculations of our estimated time for each cycle and our early poor understanding of our process’ and the subject, led to only being able to do two full iterations. Would the experiments have started earlier the study could possibly have contained more iterations.
1.5 Disposition
The study is, after this introduction, structured as the following:
Chapter 2: Method; a brief description of the study’s working procedure.
Chapter 3: Theoretical- and technical framework; a theoretical- and technical foundation and
explanatory approach for the study, its purpose and the research questions that have been formulated.
Chapter 4: Empirics; provides a general description of the empirical domain as a base for the
study.
Chapter 5: Assessment; answers the study’s research questions through processed collected
10
Chapter 6: Discussion and conclusions; provides a summary of the study’s results, its
limitations and implications, conclusion, recommendations, and further research suggestions.
2 Method
2.1 Connection between research questions and method
To conduct our research, we intend to use an Action Learning (AL) approach, a type of Action Research (AR) focused on an experimental learning. It is important to note that we chose AL over a case study as we want the results of this work to be applicable across projects, domains, and programming languages. The cyclic behavior allows us to have a very structured process and not be limited to one perspective; it lets us reiterate over previous findings and ensure its validity. Testing is also the most important for practitioners and that means that being able to discuss results with Qsys and their employees lets us have the practitioner’s way of working in mind. Since we are exploring the process rather than the resulting tests it is important to have more perspectives since it can easily become a mix of subjective and objective which the participative nature of AL deals with very well by giving opportunities to external parties to discuss the issues or findings. Overall, the method suits our purpose well by giving us well-balanced aggregated results.
The AR constraints we are working by are defined by Santos and Travassos [7, p. 1] as “a real need for change, theory-based iterative problem solving, genuine collaboration with participants and honesty in theorizing research from reflection”. To further distinguish AL from AR Rigg and Coghlan [8] mention that AL usually focus on a single organization or group and often is not concerned with a wider perspective. This is true for us because of our limitation of one software project; however, we still intend to find a more generalized result applicable to many projects.
2.2 Working procedure
During each AL step and iteration, everything is documented during the working procedure, such as what was done to come up with a specific idea, or if something was tested that lead to a conclusion of some sort.
2.2.1 Study & plan
The first step in the AL cycle, study & plan, is to define a real-world problem. As specified before, the focus of the study is to find a process to prioritize unit tests in an already existing, software project with a larger code base. To find said process, a literature study is conducted. Relevant literature should provide insight in:
• What the process can provide to fill some of the gap • Steppingstones of using a prioritization process
The findings are then aggregated with the next coming iteration to continuously build upon the process and any results. The reflections from the previous iteration provides the next iteration with useful information, which can then be used to improve the current process by trying to eliminate the problems that were raised.
2.2.2 Take Action
In this step, practical work is executed, based on the findings from the previous step, study & plan. In other words, test cases will be prioritized and selected. The way the test cases are prioritized could differentiate each iteration, as each iteration have different findings from the
11
study & plan step. However, as each iteration is based on the previous one, the iterations should
show similarities between each other.
2.2.3 Observe (collect & analyze evidence)
During the observation phase the intention is to compile and categorize any data created during the Take Action phase. This is done though reflections on this data based on the process. We also want to include questions which touch on the subjects mentioned by [6] that has less academical support such as the questions mentioned in our introduction chapter. Most, if not all, data will be a reflection based on a series of questions to give the possibility of further discussions to be had around each participants perspective.
2.2.4 Reflect
The reflection phase is the most important phase where we reflect over the observations done in the previous step. Reflecting over the observations are important to improve the process of the next iteration. During the reflections, we want to find answers to questions such as, why did we succeed or fail, why was it so hard or easy to implement and also if and why the time needed to implement the prioritization was faster or slower than the previous iteration. A look at any larger than expected deviation between cycles will also be done and noted.
Finding answers to these questions lets us define the positives and negatives about this iteration’s process. It is important to highlight the negative part of the process to be able improve it during the next iteration. All the positive parts will also be carried over and used in the next iteration.
2.3 Credibility
Using AL, multiple iterations are performed based on the previous iteration’s result, which provides the study with good opportunities to improve each iteration, which in its turn would increase the credibility.
To further keep the credibility as high as possible, only relevant, peer-reviewed, and credible sources are referenced. Credible sources can be defined as well known, often referenced published articles or conference papers.
It should also be noted that in the case of this study, the limitations are very apparent and has a high likelihood of affecting the results. The conclusions of this study are a collection of reflections of one explored case which intends to be a starting point for future improvements. This also means that the way conclusions should be presented in this study is transparent with its intended purpose and related credibility.
12
3 Theoretical- and technical framework
3.1 Connection between research questions and theory
To answer any research question regarding the prioritization process, we used action learning as the method [8].
3.1.1 Research question 1
To answer research question 1, “How could test cases be prioritized when a limited or no requirements specification is present?”, the use of intuition and a risk matrix made up the main components; which is described at 3.3.4.4 and later expanded upon during iteration 2, when the maintainability index was found, which is described at 3.2.5.
This question is important when looking at the purpose of the whole study, as the answer should be generalized to make it applicable to any kind of project type and development language.
3.1.2 Research question 2
Research question 2, “With a limited or no requirements specification, what are some important factors in a software project, regarding test case prioritization?”, point towards investigating if and how software complexity can play a role is prioritizing test cases. This means that a way of including code complexity in the prioritization process has to be identified, which could be done using combined priority, defined in section 3.3.4.4.3. Microsoft Excel was used to structure the module break down and to easily construct formulas, as defined in section 3.3.4, which calculated data, such as the combined priority. The modules were broken down from the source code of Qpick.
3.2 Technical framework
3.2.1 QpickQpick is a WMS developed by Qsys to simplify warehouse management. Qpick integrates with several other software, and also interacts with hardware, such as handheld scanners.
3.2.2 Automated testing
According to [1, pp. 320-321], it is troublesome to manually repeat tests after corrections have been made, such as manually supplying the data needed or modifying code that is tested. Such situations call for regression testing, which is a type of testing which could easily be
implemented through automated processes with a higher certainty than manual testing. Regression testing means that tests are repeated to ensure that the modifications made is working correctly and have not introduced other problems, doing this manually could be very error prone in comparison, lowering the reliability significantly. Regression testing is not the only type of tests that can be automated, most types of tests can to some extent be automated. These are just some examples of why automated testing is important; how and in what kind of situations it can be conducted.
3.2.3 Unit testing
A unit test exercises a specific “unit” of a system. The actual outcome of the test is compared to the expected result, which defines the result of the test [1]. The purpose of testing the code as units is to be able to test the logic without relying on all the other systems. This ensures that the data coming in is viable and that the logic works on consistent data which is then easy to test.
13
3.2.4 Microsoft Excel
Microsoft Excel is a spreadsheet software developed by Microsoft, featuring calculations, graphing tools, and pivot tables. This study used Excel to easily calculate different values based on the formulas provided at 3.3.4.
3.2.5 Maintainability index
Maintainability index is described by Microsoft as “an index value between 0 and 100 that represents the relative ease of maintaining the code. A high value means better maintainability.” [9]. The idea of this index was integral inspiration for these study’s final processes.
3.2.6 Requirements specification
According to [10, p. 1], it is deemed that a software requirements specification determines the quality of the software. In [11, p. 179], it is stated that a requirements specification can define detailed test cases.
This helps prove that defining, selecting, and prioritizing test cases could be hard with a limited or no requirements specification.
3.3 Theoretical framework
3.3.1 Automated Test Integration Process (ATIP)
ATIP is an acronym that was constructed in this study to simplify writing and reading. “Automated test integration process” simply stands for the overall process of integrating automated tests in any kind of project. ATIP can be seen as the “how” in making it possible to implement tests in a project. Before implementing tests, you need to perform some pre-requisites such as selecting test cases and prioritize said test cases; such is covered in the ATIP.
3.3.2 Integration
Integration, for this study, is defined as the whole process around creating tests, i.e. selecting test cases, test case prioritizing, defining a technical specification of the tests etc. This is specifically for this study and not necessarily a widely applicable use of the terminology.
3.3.3 Implementation
The idea of implementation is the execution of a plan, idea, model, or design. More specifically in the case of this study, it is the realization of the technical specification of the test integration or test prioritization. Which is specifically defined for this study and not necessarily a widely applicable use of the terminology.
3.3.4 Code and project analysis
3.3.4.1 Modules
In this study, a module is defined as a sub-part of a project. For example, a project can be divided in to two modules, server, and client. Both modules can have submodules. For example, server can have a “validators” module which handles all kind of validations on the server. The validators module can also have submodules. This creates a recursively defined method to
14 modularize a project which ends when deemed appropriate for the use case; in this study it ends where it is most effective to create unit tests on each lowest depth module.
As an example seen in Figure 2, the server module has been calculated to be the top prioritized module in depth 1. Then, in depth 2, the server has three different modules, where the validators module got the top priority. Depth 3 then has the child modules of the validators module.
Figure 2: A visualized explanation of how modules are defined in a project.
3.3.4.2 Likelihood of failure
Likelihood of failure defines how likely it is that a particular module fails, relatively compared to the other the modules in the same depth. Basically, the one that is the most likely to fail has the maximum value on the scale, and the one that is least likely to fail has the lowest value. This study used 5 as the maximum value and 1 as the lowest value. The scale can be adjusted to fit the project, as likelihood of failure is just a number. As an example, if the project has a larger code base with many types of modules, a scale of 1-10 could be used instead, where 10 is the most likely module to fail and 1 is the least likely module to fail.
3.3.4.3 Severity
Severity is a scale of what consequences could arise if a module would fail. The scale can be adjusted to fit a specific project. The scale used in this study is specific to this the software project in this study, as seen in Table 1. However, it is possible that this scale could be applied to any kind of software projects.
Severity Description
1 Something went wrong, try again (Not severe, just try again)
2
Something went wrong, try again with new data (Not severe, triggered by invalid
data, such as user input)
3 Reboot of the system/web page/program is required (Bad, but not that severe)
4 The client is not able to use the system, at all (Severe, but not fatal)
5 Data could be lost (Severe, could have fatal consequences)
15 3.3.4.4 Risk as a prioritization
Risk is a widely used method for determining extra sensitive parts of software projects or otherwise [12], intuitively making it a great way to prioritize important modules to test. Assessing the risk of a module is simply described as assessing how severe the damage could be if that module failed. A higher value means a higher severity, while a lower value means a lower severity. This study has three types of assessed risks: intuition, revision and combined.
3.3.4.4.1 Intuition priority
Intuition priority is a value that was constructed in this study based on the idea of risk matrixes, which can be used in different kinds of projects, as seen in [12]. A risk matrix is used to determine different parts of a projects risk. Intuition priority is defined as the mean value of a module’s likelihood of failure and severity. The whole point is to set the two values completely based on intuition and project knowledge, hence the name, intuition priority.
The intuition priority has some incredible characteristics which gets strengthened by the amount of people contributing. If the value is given to both project managers and developers, the more of them that fill it in and combine it, the more accurate it should be, as long as they all know the project well to an extent. This method is not only limited to developers, in fact, on the earliest depths, it is quite important to involve project managers, key stakeholders and other relevant employees as well. Knowing which parts of the project is the most involved for the user is something that might be hard for developers to know, whilst coding and system errors is the developers’ and administrators’ expertise. An averaged result from as many employees as possible should therefore result in a more well thought through priority.
3.3.4.4.2 Revision risk
According to Antinyan [13, pp. 40-44], both high code complexity and lots of code revisions can be indicative of potential risks in said code. Where there is high complexity, it is more likely that a coding error [13, 14], logical or otherwise, might occur, which could be a large cost for the company or its customers. Antinyan [13] also proposes a method to assess the possible risk through two non-correlated measurements as:
𝑅𝑖= 𝐶 × 𝑁𝑟 (1)
where 𝑅𝑖 is the revision risk, and 𝐶 is the cyclomatic complexity which is based on a graphical
representation of a programs control flow graph. It is mathematically defined as: 𝐶 = 𝐸𝐶− 𝑁𝑐+ 2𝑃 (2)
where 𝐸𝐶 is the number of edges on the graph [14, p. 1]; 𝑁𝑐 is the number of nodes on the graph
and P is the number of connected components. The result of cyclomatic complexity is the number of linear independent paths within a section of the source code. Since the measurements in eq. (1) are combined with multiplication, they are dependent on each other resulting in [13]:
1. Often changed code with low complexity (𝐶 → 0) still results in low risk 2. Complex code that is rarely changed (𝑁𝑟→ 0) also results in low risk
3.3.4.4.3 Combined priority
To make it easier to comprehend and analyze the results from multiple methods (intuition priority and revision risk), a combination formula was constructed during iteration two. If we let S be a partition of our project P, such that 𝑆 = {𝑠1, … , 𝑠𝑛} with 𝑠𝑖 being a selection of code (e.g.
16 a function, file or folder or a combination of these such as it is consistent among all elements in S). Using this to extract the comparable complexity each part of the code has on the whole projects combined complexity. Let K be the maximum number on the scale of the intuition priority. Finally let 𝑃𝑖 be the intuition priority, then the combined priority 𝐶𝑖 of 𝑠𝑖 follows:
𝐶𝑖= 1 2× 𝐾 𝑅𝑖 ∑ 𝑅𝑆 𝑖 +1 2× 𝑃𝑖 (3)
This effectively creates an averaged result which could possibly be used to compare the individual methods accuracy to an extent. The combined formula is the definite priority that is used as the final priority of the test cases. It is useful as it combines intuition with actual data about the complexity of the source code of the module, which can help identify prioritization issues that could not be seen using only intuition or only complexity.
17
4 Empirics
4.1 Pre-study
During the beginning of this study, a pre-study had to be conducted to find relevant papers to support the research questions, more specifically how to perform test prioritization with a limited or no requirements specification. Relevant papers include papers that focuses on methods of integrating tests, such as While searching for relevant papers, an article by Microsoft was found, which proposed a method to measure code complexity with a code metric called maintainability index [15]. The formula is a combination of well-established code measurements, such as the previously mentioned cyclomatic complexity. The presented formula gave some inspiration for the study to combine intuition-based prioritization with code complexity.
The pre-study also gave inspiration of how to select the test cases, more specifically with risk-based assessment. In [16, pp. 595-620], risk estimation is risk-based on two factors, failure
probability and importance. There is a clear inspiration in this study from [16], where failure probability can be compared to likelihood of failure, and importance can be translated to severity. Failure probability, in [16], is evaluated with mathematics, whereas likelihood of
failure in this study is based on intuition. However, the two values are used in the same way; to measure how likely it is that a module/service/function fails. Importance, in [16], is used to estimate the consequences of when a module/service/function fails, which can directly be linked to this study’s severity value.
4.2 Action Learning
The plan for this study was to have three iterations, however, as explained in the delimitations, a set of unfortunate circumstances resulted in only performing two. Partly because a lack of time and understanding of the subject and partly because the results after two iterations showed great potential.
4.2.1 Iteration 1
During the first iteration, each module was prioritized by intuitively setting the likelihood of failure and the severity level, which in other words simply means guessing values for the two level based on knowledge about the code, the modules and the project as a whole. The priority list was then created by taking the mean value of the combined likelihood of failure and severity level values, for each module. The child modules of top prioritized module were then selected as the next depth to undergo the same prioritization procedure. This was recursively repeated until no further depth could be reached.
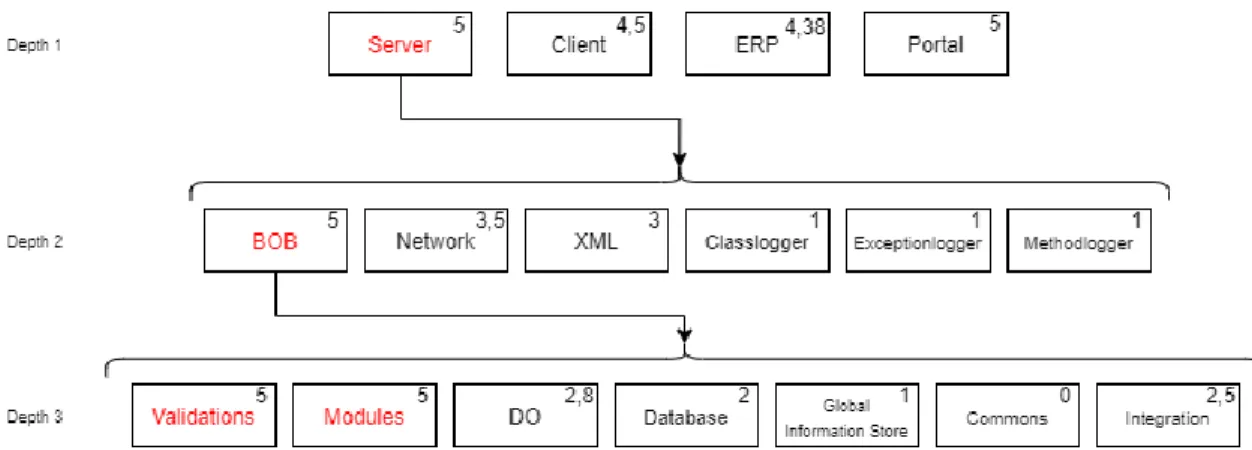
As seen in Figure 3, there are a total of three prioritization depths. The value inside each module box represents the module’s prioritization. In the first depth, there are two modules with the same top priority. Which one to choose is up to the testers to decide. In this case, the “Server” module was selected. This means that in depth 2, the server’s child modules would be selected for prioritization. In this case, the “BOB” module was top prioritized in depth 2. Depth 3 had two top prioritized modules, where both of them had a combined total of over 100 modules. Normally, you would prioritize those as well. However, as this study was conducted by external individuals, that was not a part of the actual Qpick development team, there were too many modules to go through to understand each one of them. In this study, depth 3 is the maximum depth due limited time, which hindered the prioritization of the fourth and actual final depth.
18
Figure 3: Qpick test prioritization trough intuition from the first iteration.
4.2.2 Iteration 2
The second iteration added another value, revision risk. The intuition priority and revision risk were then combined into one, called combined priority.
As seen in Figure 4, the priorities have changed. In this iteration, “ERP”, had the highest priority value. However, to be able to see if, and how, the priority of the “server” modules changed, compared to the first iteration, the “server” module was selected again.
In depth 2, the “BOB” module was once again top prioritized. Expanding from BOB to depth 3, the prioritization values changed. In iteration 1, “Validations” and “Modules” were both top prioritized. However, in the second iteration, only one of the two modules were top prioritized, which was the “Modules” module.
19
5 Assessment
5.1 Research question 1
As this study worked without using any requirement specifications, test prioritization had to be done without it. The relevant literature that was found in each study & plan step mostly focused on one thing, requirement specifications, such as in [12]. As Qsys did not provide any requirements specification, a work-around had to be found to still be able to prioritize the test cases, which could finally answer research question 1, “How could test cases be prioritized when a limited or no requirements specification is present?”.
The software project modules were prioritized through intuition, which was done completely without any requirements specification. This means that each module was prioritized based on what was deemed to be the most important module, based entirely on likelihood of failure and failure severity.
During the second iteration, a new value was added; revision risk, which was given by the product of the number of revisions and the cyclomatic complexity, for that specific module. Combining intuition- and revision risk, a new priority was given. This combined priority should somewhat match the intuition value that was presented in the first iteration, which it did. Looking at Table 2: Excel sheet of the base depth., it shows that the combined priority almost has the same order as the intuition priority. The reason why the “ERP” module has a higher combined priority is due to how high the cyclomatic complexity is. However, as ERP and Server had very close intuition priority to begin with, it just shows that the combined priority could work even better, as it can catch those small differences to provide a more accurate and final priority.
Module Intuition Priority Revision risk Combined Priority
Server 5 10570507 3,12
ERP 4,4 26540962 3,73
Client 4,5 3344561 2,44
Portal 2,8 2427221 1,52
Table 2: Excel sheet of the base depth.
5.2 Research question 2
Studies, such as [13, pp. 41-44] and [17], indicates that code complexity is an important factor to error-prone modules, which is important to consider when selecting and prioritizing test cases. Also, [12] gives an example of how to prioritize test cases based on risk factors, which was one of the papers that inspired to the idea of using a priority value based on intuition, by recursively breaking down each module of the software project, and then assess the risk of each module. Expanding on code complexity, integrated with intuition, the option to select and prioritize test cases without a requirements specification is enabled.
The formulated variables, likelihood of failure and failure severity, are important to consider when working with little to no requirement specifications; both defined by intuition. As each module were listed, the two variables could easily be set based on intuition. This, of course, requires the person grading the modules to be familiar with the source code, or the software project structure at the very least.
20
6 Discussion and conclusion
6.1 Result
The study’s analysis in section 5.1 states that it is possible to prioritize test cases with little to no requirement specifications. Based on intuition, combined with raw data in the form of number of revisions and code complexity, selecting test cases becomes efficient and reliable. Intuition priority sets the steppingstone for the combined priority, which is the final priority to look at when selecting test cases. Without intuition, the priority is completely based on the code complexity, which could prioritize less important and risk-filled modules, just because another module has more complex code. Combining the two prioritizes catches the importance and risks, and also complex parts of the system.
The second part of the combined priority is the revision risk, which is the product of the number of revisions and the cyclomatic complexity, for that specific module. A revision is basically a committed change. I.e. when a module is updated, a revision has been made. The point of the revision risk is to help identify error-prone modules, which could also be hard to maintain [13, pp. 41-44].
As stated in section 5.1, the prioritization order of the modules slightly changed from iteration 1. When comparing depth 2 from iteration 1, to the same depth in iteration 2, it shows that the prioritization values had more fidelity and provided better accuracy to the prioritization order, in iteration 2. This could be useful when having multiple modules with the same likelihood of failure and severity values. By incorporate the revision risk into the first prioritization order, which generated the formula for the combined priority, the prioritization order has more fidelity and will better distinguish the prioritization values.
The analysis in section 5.2 shows that software complexity could play a role in prioritizing test cases, if the person assessing the modules has adequate knowledge of the code base. It also shows that modules with a higher number of revisions has a higher complexity. For this study, software complexity played a pretty big role when used together with intuition when selecting and prioritizing test cases.
6.2 Implications
This study intends to provide help to prioritize test cases, in an already existing software projects, specifically with a limited or no requirements specification, using the presented technical methods in section 3. The study’s implications are
• That it is advantageous to break down a software project into modules by recursively iterating each module.
• That it is possible to prioritize test cases from modules with a limited or no requirements specification, using intuition combined with relative revision risk. • That it is possible to prioritize test cases in an already existing, software project, without any requirements specification, using the specified methods in section 3.
6.3 Limitations
The study had a slow start, which limited the number of AL iterations that were conducted. If the study began earlier, the number of iterations could possibly have been greater, which could have improved the result.
21 The study was only conducted on one software project, which limits the result for this study, but could be more generalized when performing the same study on similar software projects, which is something that could be further researched.
6.4 Conclusions and recommendations
The result that is provided by the study concludes that, it is possible to prioritize test cases in a software project with a limited or no requirements specification. Before doing the prioritization, a breakdown of the project has to be done, which means dividing the project into modules and their respective sub-modules.
After the breakdown, each module has to prioritized. This is done using intuition combined with code complexity. Each module’s intuition priority is combined with its revision risk, which will provide the final priority for each module, recursively doing this until no further depth could be reached. I.e. until no child module exists for the current module.
The findings gave concrete steps of how to prioritize test cases in a software project with a limited or no requirements specification, which are the following:
1. Break down the project into its modules
2. Set the likelihood of failure and failure severity level for each module, and calculate the intuition priority
3. Generate the number of revisions and cyclomatic complexity, and calculate the revision risk
4. Combine the intuition priority and revision risk into combined priority
5. Repeat the steps for top prioritized module’s child modules, recursively, until no further depth can be reached
6.5 Further research
To further research the subject, it is recommended that the method is tested on other similar software projects to further strengthen and generalize the concluded result. The study could also be compared to other methods that prioritize test cases based on a requirements specification, which could further prove or completely discredit the results of this study.
22
7 References
[1] M. Olan, "Unit testing: Test early, test often," Journal of Computing Sciences in Colleges, vol. 35, no. 5, p. 10, 2003.
[2] D. L. Asfaw, "Benefits of Automated Testing Over Manual Testing," International Journal
of Innovative Research in Information Security (IJIRIS), vol. 2, no. 1, pp. 5-13, 2015.
[3] R. S. Sangwan, P. Vercellone-Smith and P. A. Laplante, "Structural Epochs in the Complexity of Software over Time," IEEE Software, vol. 25, no. 4, pp. 66-73, 2008.
[4] M. Polo, S. Tendero and M. Piattini, "Integrating techniques and tools for testing automation," Software: Testing, Verification and Reliability, vol. 17, no. 1, pp. 3-39, 2006.
[5] N. Tracey, J. Clark, K. Mander and J. McDermid, "Automated test-data generation,"
SOFTWARE - PRACTICE AND EXPERIENCE, vol. 30, no. 1, pp. 61-79, 2000.
[6] E. Daka and G. Fraser, "A Survey on Unit Testing Practices and Problems," in 2014 IEEE
25th International Symposium on Software Reliability Engineering, Naples, Italy, 2014.
[7] P. S. M. d. Santos and G. H. Travassos, "Action Research Use in Software Engineering: an Initial Survey," in Proceedings of the Third International Symposium on Empirical
Software Engineering and Measurement, Lake Buena Vista, Florida, USA, 2009.
[8] C. Rigg and D. Coghlan, "Action learning and action research – revisitingsimilarities, differences, complementarities andwhether it matters," Action Learning: Research and
Practice, vol. 13, no. 3, pp. 201-203, 2016.
[9] Microsoft, "Code metrics values," 11 02 2018. [Online]. Available:
https://docs.microsoft.com/en-us/visualstudio/code-quality/code-metrics-values?view=vs-2019. [Accessed 21 07 2020].
[10] A. Aurum and C. Wohlin, "Requirements Engineering: Setting the Context," in
Engineering and Managing Software Requirements, 2005.
[11] C. Denger and T. Olsson , "Quality Assurance in Requirements Engineering," in
Engineering and Managing Software Requirements, 2005.
[12] M.-F. Wendland, M. K. and I. K. Schieferdecker, "A systematic approach to risk-based testing using risk-annotated requirements models," in The Seventh International
23 [13] V. Antinyan, "Proactive Software Complexity," University of Gothenburg, Gothenburg,
2017.
[14] G. Jay, H. E. Joanne, D. Hale, R. K. Smith and N. A. Kraft, "Cyclomatic Complexity and Lines of Code: Empirical Evidence of a Stable Linear Relationship," Journal of Software
Engineering and Applications, vol. 2, no. 3, pp. 137-143, 2009.
[15] Microsoft, "Maintainability Index Range and Meaning," 20 11 2007. [Online]. Available: https://docs.microsoft.com/en-us/archive/blogs/codeanalysis/maintainability-index-range-and-meaning. [Accessed 05 05 2020].
[16] X. Bai, R. S. Kennet and W. Yu, "Risk Assessment and adaptive group testing of semantic web services," in International Journal of Software Engineering and Knowledge
Engineering, World Scientific Publishing Company, 2012.
[17] S. Banitaan, K. Daimi, Y. Wang and M. Akour, "Test Case Selection using Software Complexity and Volume Metrics," in 24th International Conference on Software
Engineering and Data Engineering, 2015.