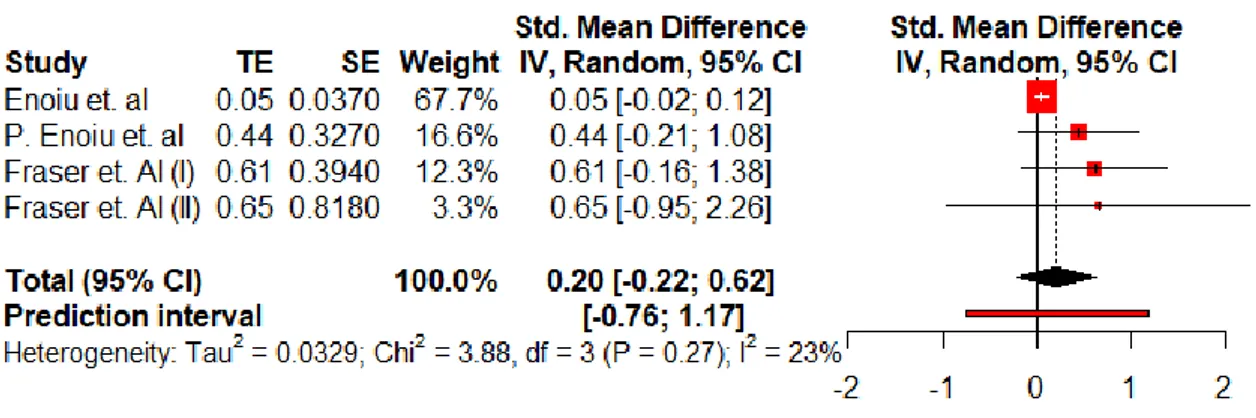M
ÄLARDALENU
NIVERSITYS
CHOOL OFI
NNOVATION,
D
ESIGN ANDE
NGINEERINGV
ÄSTERÅS,
S
WEDENMaster Thesis on Master of Science programme (60 hp) in Computer Science
with Specialization in Software Engineering 15.0 hp
DVA 423
A SYSTEMATIC LITERATURE REVIEW AND
META-ANALYSIS COMPARING AUTOMATED TEST
GENERATION AND MANUAL TESTING
Ted Kurmaku
Musa Kumrija
tku18001@student.mdh.se mka18003@student.mdh.se
Examiner:
Daniel Sundmark
Mälardalen University, Västerås, Sweden
Supervisor:
Eduard Paul Enoiu
Mälardalen University, Västerås, Sweden
Abstract
Software testing is among the most critical parts of the software development process. The creation of tests plays a substantial role in the evaluation of software quality yet being one of the most expensive tasks in software development. This process typically involves intensive manual efforts and it is one of the most labor-intensive steps during software testing. To reduce manual efforts, automated test generation has been proposed as a method of creating tests more efficiently. In recent decades, several approaches and tools have been proposed in the scientific literature to automate the test generation. Yet, how these automated approaches and tools compare to or complement manually written is still an open research question that has been tackled by some software researchers in different experiments. In the light of the potential benefits of automated test generation in practice, its long history, and the apparent lack of summative evidence supporting its use, the present study aimed to systematically review the current body of peer-reviewed publications on the comparison between automated test generation and manual test design. We conducted a systematic literature review and meta-analysis for collecting data from studies comparing manually written tests with automatically generated ones in terms of test efficiency and effectiveness metrics as they are reported. We used a set of primary studies to collect the necessary evidence for analyzing the gathered experimental data. The overall results of the literature review suggest that automated test generation outperforms manual testing in terms of testing time, test coverage, and the number of tests generated and executed. Nevertheless, manually written tests achieve a higher mutation score and they prove to be highly effective in terms of fault detection. Moreover, manual tests are more readable compared to the automatically generated tests and can detect more special test scenarios that the ones created by human subjects. Our results suggest that just a few studies report specific statistics (e.g., effect sizes) that can be used in a proper meta-analysis. The results of this subset of studies suggest rather different results than the ones obtained from our literature review, with manual tests being better in terms of mutation score, branch coverage, and the number of tests executed. The results of this meta-analysis are inconclusive due to the lack of sufficient statistical data and power that can be used for a meta-analysis in this comparison. More primary studies are needed to bring more evidence on the advantages and disadvantages of using automated test generation over manual testing.
Table of Contents
1.
Introduction ... 4
2.
Background ... 6
3.
Method ... 7
3.1. Research question ... 7 3.2. Search process ... 8 3.3. Study selection ... 93.4. Inclusion and exclusion criteria ...10
3.5. Quality assessment ...10
3.6. Data collection...12
3.7. Meta-analysis ...12
3.8. Study Selection Process ...13
4.
Systematic Literature Review Results ... 16
4.1. Description of the primary studies ...17
4.2. Characteristic and quality of each paper ...32
5.
Meta-Analysis Results ... 35
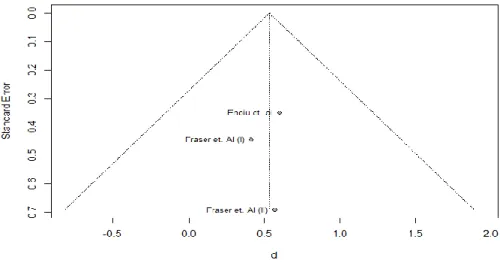
5.1. A meta-analysis on decision coverage ...37
5.1.1. Heterogeneity ... 39
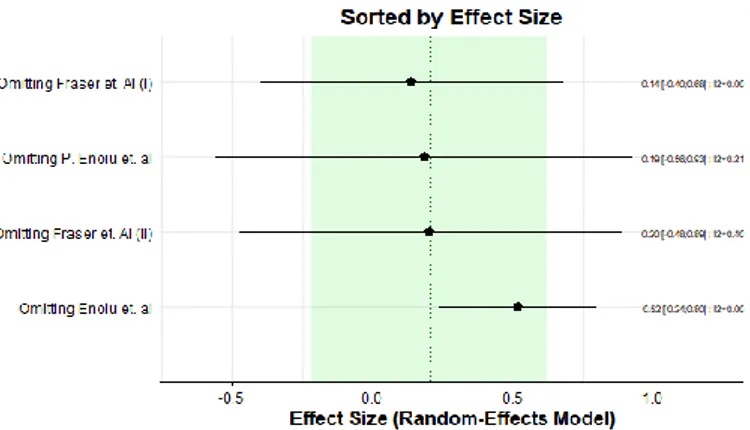
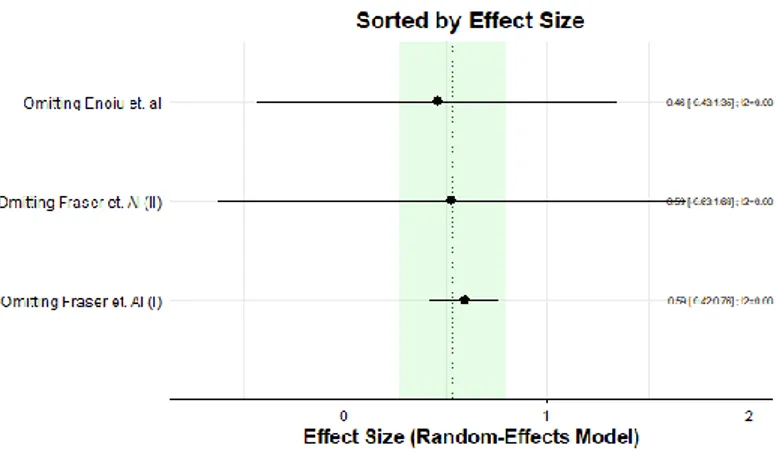
5.1.2. Subgroup Analysis ... 40
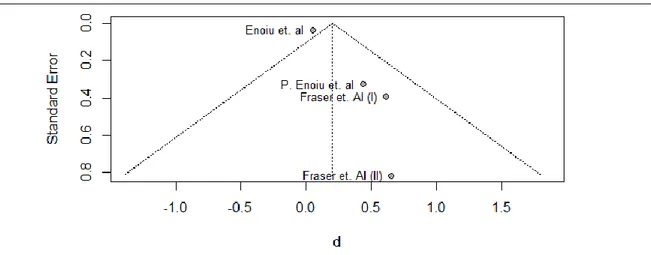
5.1.3. Publication bias ... 41
5.2. A meta-analysis on mutation score ...42
5.2.1. Heterogeneity ... 43
5.2.2. Subgroup Analysis ... 44
5.2.3. Publication bias ... 44
5.3. A meta-analysis on number of tests ...45
5.3.1. Heterogeneity ... 45
5.3.2. Subgroup Analysis ... 46
5.3.3. Publication bias ... 47
6.
Discussion ... 48
6.1. Limitations ...48
7.
Conclusions and Future Work ... 50
8.
Acknowledgements ... 53
1. Introduction
To identify and remove the faults, software engineers use many test design testing techniques. Software testing is a process designed to ensure that software does only what it was designed for and, does not act unintentionally. Software should be certain and persistent, introducing no unexpected scenarios to users [5]. Software testing is an essential part of the software development process. Although testing is helpful and widespread, creating, executing, and maintaining the tests is one of the costliest phases of software development [6]. Software testing is required to assure a certain level of quality, detect faults, and determine its correctness. Software companies continuously search for ways to optimize and increase the effectiveness and efficiency of their testing processes. Manual testing refers to the activity of writing and executing the test s without the aid of any automation tools. These tests are traditionally written by software developers. A great human effort is required to create high-quality tests, which in large projects that need more testing, can be obstructive [7]. Since the writing and specification of manual tests is hard and time-consuming, over the past years, several approaches for automating the test case generation have been proposed [8]. The first step toward automation which has already been adopted by software companies is the automatic test execution, which typically means that these tests still have to be written manually but they are compiled as executable test programs and are used to test the system automatically. A more advanced form is the automatic generation of executable tests with the aid of test automation tools, based on the source code or models. The quality of the automatically generated tests varies, and how these tests compare to the manually written ones remains unclear [3]. Developers often create high-quality tests when given sufficient time and resources, yet, the focus of the tests depends on the software developer, the objective of the project, and the specifications evolved from the company or community [9]. Different developers and testers write different tests; some aim to increase the coverage, principally in terms of covering certain statements or branches while others focus on improving code that is prone to certain failures or checking the compliance to different standards [10]. However, writing the tests manually becomes more expensive as the complexity and the expected quality of the software increases [11].
Even so, mature tools for automated test generation are still few and consequently, the evidence regarding the comparison of automated test generation and manual testing is scarce. There is a need for a meta-analysis structuring this evidence and providing an overarching comparison.
In this thesis, we present a meta-analytical approach on comparing two (and rather broad) classes of software test design techniques, specifically automated and manual test design, based on the findings of several primary studies. Meta-analysis refers to the process of finding, selecting, analyzing, and combining information relevant to a particular research question or goal [19]. The thesis reports the result of the application of meta-analysis on a set of selected papers with their focus on comparing automated and manual testing techniques. We conduct three separate meta-analyses with respect to mutation scores, decision coverage, and the number of tests produced by each testing technique. Mutation scores measure the fault-detecting effectiveness of the test suites based on capturing the seeded faults of the system under test [26]. Decision coverage aims to ensure that each one of the possible branches from each decision point has been executed at least once and all the reachable code has been executed [46]. We refer to mutation scores and decision coverage scores as proxies for effectiveness and fault detection and the number of tests created as a proxy for evaluating the testing cost. In addition, in this study we used another statistical method, vote counting, and a qualitative synthesis method, narrative synthesis, as additional methods to obtain further metrics results, such as code and method coverage, number of naturally-occurring faults detected, the necessary time to generate and run the tests suites, and readability. Our results suggest that automated tests are more effective in terms of decision coverage and number of tests generated, and their efficiency is higher regarding the time to generate and execute tests, as well as the time needed to detect the faults, while manual tests prove to be better at the mutation score and fault detection. Even though the mutation scores are higher for manual testing, there is no statistically significant difference between these techniques. The results for the achieved mutation score become statistically significant when the test suite sizes are controlled for size. Manual testing exhibits significantly better results regarding fault detection, being better in detecting logical and timer
type of faults. These tests prove to be more effective in capturing special cases, since they are written with the application’s logic in mind. Decision coverage is higher for the automated test generation and it can be obtained in much less time compared to the manual testing; however, the statistical difference does not appear to be significant. The low mutation scores and the high coverage indicate that there is little correlation between these two metrics for these test suites. Furthermore, manual tests archive a lower decision coverage as the lines of code of the system under test increase, while automated test cases are not affected by this factor. Decision coverage is positively correlated with fault detection, but higher coverage does not automatically indicate a higher fault detection rate. Automated tests are able to detect a higher number of defects in a shorter period compared to the tests written manually by developers. The number of tests generated automatically is higher than in the case of manual test design. There is a large correlation between the lines of code and the number of tests; their number will increase as the size of the programs increases. The opposite is true for the branch coverage as it drops while the number of generated tests increases. Automated test generation tools reduce considerably the amount of time and effort required for the creation of the test suite. The reductions in development time are mostly due to automated test generation. The tools also cover many basic test scenarios, allowing the developers to have more time for thinking of more special and system-specific test scenarios. Manually written tests seem to be more readable than their automatic counterparts. However, developers often neglect the readability of tests. Test cases created by automated test generation are less understandable, do not exercise meaningful scenarios, and include meaningless data. The difficulty in interpretation makes debugging more of a challenge. The complexity depends on the diversity of the tools and techniques while the correctness of the generated test oracles remains a challenge.
2. Background
Testing is one of the most important activities in the software development process, although writing good tests is one of the most challenging and expensive activities. In the past few years, an increasing amount of effort has been dedicated to identifying and develop tools and approaches for automatically generating test suites [12]. Test automation refers to the process of automatically generating and executing test cases, compared to the manual testing, in which the former processes are done by humans. Researchers have proposed different approaches to support developers to produce quality tests, such as random testing, model-based testing, etc. In random testing, to exercise the system under test, independent and random inputs are automatically generated, and the outputs are compared to the program specification to determine whether the test passed or failed. Model-based testing introduces the creation of models for the system under test to automatically generate and execute the tests. The automated approaches typically aim to maximize testing effectiveness mainly in terms of code coverage, mutation score, or faults detected. Code coverage as a structure-based standard, expects the execution of certain structures and variables of the program [13]. Mutation scores measure the fault-detecting effectiveness of the test suites based on capturing the seeded faults of the system under test [14]. It is worth noting that current evaluations on testing techniques suggest that each one of them has its imperfections.
Meta-analyses are present in the software engineering literature, even though only a few studies have been performed [15]. To the best of our knowledge, the study presented in this thesis is the first meta-analysis endeavor in the comparison between automated test generation and manual testing. Kakarla et al. [16] in their paper conduct two separate meta-analyses to measure and compare mutation and data flow testing techniques. The results presented in this paper show that mutation is more effective than data-flow testing, however, the former appears to be less efficient than data-flow testing. Hays et al. [17] developed an algorithm to aid the automation of statistical analysis. The process automatically analyses the experimental results. They applied their approach in a meta-analysis to evaluate the work presented at the International Conference on Software Testing, Verification, and Validation in 2013 and found that six papers had distorted the significance of their results. Moreover, the statistical results differed from the empirical methods the authors had used. Gomez et al. [18] conducted a replication of a controlled experiment and synthesized the previous experiments to understand the efficiency of code reading, black-box, and white-box testing techniques. The participants applied a random testing technique to the programs under test and a meta-analytical approach was used to synthesize the results. The results showed that there were no significant differences in the efficiency of the techniques, however, the effect on efficiency was statistically significant. As a conclusion, the engineers should have a clear picture of the program they will test, prior to the testing activity.
3. Method
This thesis has been conducted based on the guidelines for a systematic literature review and meta-analyses proposed by Kitchenham in a technical report [19].
A literature review identifies, analyzes, and synthesizes available appropriate evidence to a research question or topic [19]. A systematic literature review is a form of literature review, which uses a well-defined research question and methodology to identify, select, analyze and interpret the available evidence from primary studies related to the question, avoiding bias and make the study replicable to a certain degree [15]. The systematic literature review process starts with the selection of the studies that meet several specific criteria and seem relevant for the process. The selected studies, as mentioned before, must be primary studies, which refer to empirical studies, investigating a specific research question. After the studies are identified, the process continues by selecting the studies, based on the criteria which are previously defined. The criterion helps researchers define which studies should be included or excluded from the subset of the primary studies. The selection procedures should describe how the selection criteria will be applied to the subset and how the contradictions between researchers will be resolved. The quality assessment of each study is a very important step that needs to be done in the process. The researchers should make a checklist to help them make decisions for the studies. After the studies are selected from the aforementioned steps, the researchers need to extract the data, defining how they will obtain the required information from each primary study. The final step of conducting a review is data synthesis, defining whether a meta-analysis will be conducted, and what techniques will be used.
Meta-analysis refers to the process of finding, selecting, analyzing, and combining information relevant to a particular research question or goal. The meta-analysis begins with formulating a problem, search the literature, selecting the studies, extraction of values such as differences and means, and the statistical analysis and calculations [19]. The combination of p-values from independent tests over the same hypotheses regarding cost and fault detection is performed. Since combining p-values may not be always helpful when the effects of the difference between manual and automated test generation in the combined studies are not consistent, the effect sizes of different studies can be combined in order to have a clearer overview of the overall effect size of these differences. Two approaches can be used when pooling the effect sizes for meta-analysis: The Fixed Effect Model or the Random Effect Model [20]. The fixed-effects-model presume that all studies and their effect sizes derive from a homogeneous population. In the random-effect-model, the study effect has a larger variance than the data drawn from the same population. In fact, in the random-effects-model, that data is drawn from a huge heterogeneous population.
3.1. Research question
The research question states the motivation behind every primary empirical study considered and specifies in broad terms what the report is going to examine. This thesis addresses the following research question:
RQ: How does automated test generation compare with manual testing in terms of cost and fault
detection?
This question is important since the evidence regarding the comparison of automated test generation and manual testing is scarce. There is a need for a systematic literature review and a meta-analysis structuring this evidence and providing an overarching comparison.
3.2. Search process
The focus of the search process is to identify relevant primary studies. One of the most popular methods when conducting the search process is the automated searching for the literature using digital libraries and indexing systems [15]. Another method is searching in the journals and conference publications, as well as the cited papers in famous papers related to our topic. The search strategy aims to archive completeness of the process on acceptable terms. Manual search is usually time-consuming, although it helps to have an unbiased set of primary studies. In practice, the search methods are usually combined in order to archive the best coverage possible. In addition to the two methods mentioned above, although not so common, there is another method, where researchers can directly contact the known paper’s author to be directly involved in the topic addressed in their study. It is sometimes quite challenging to find primary studies to use in the secondary study. In our study, we have used both automated and manual methods for finding primary studies. Another crucial step in performing the search process, after deciding which search method we should use, is determining the sources where the search will be conducted. The best way is to have a mix of two sources, including digital libraries and indexing systems.
We need to define a search string to run the search in the desired online resources. A search string is a combination of numbers, words, and symbols used to search in a search engine. In the literature review, we can define the search string relying on the research question. However, we used another approach to construct our search string, which has proved to be quite successful. PICO (Population, Intervention, Comparison, and Outcomes) is a useful tool to identify keywords from the research question, in order to create the search string as follows:
• Population: The identified population in software engineering varies from a specific role in the aforementioned field to a category of software engineers including novices and expert engineers to different application areas and industry groups [19]. The population in our context is the literature regarding automated and manual testing approaches.
• Intervention: In the context of software engineering, intervention specifies a software methodology, procedure, tool, or technology. The identified intervention of this study is the automated and manual testing methodology.
• Comparison: In this study, we compare automated test generation with the manual testing approaches in terms of cost and efficiency, as well as different techniques within each testing approach.
• Outcomes: We relate our outcomes to the above-mentioned terms, which are cost and efficiency, how to improve each approach, and what interventions need to be made in order to increase this efficiency.
The identified keywords are automated, manual, generate, test, software, and compare. The keywords are organized into sets, including their identified synonyms. Therefore, we used the following three sets:
• Set 1: Limiting the search within the scope of software engineering.
• Set 2: Directly related search terms to the intervention such as “automated” and “manual”. • Set 3: Other terms related to the process such as “generate”, “test”, “software” and “compare”. The keywords identified from the research question are similar to the keywords identified from the PICO criteria. Therefore, the next step is to organize the keywords into a precise set and perform our search. Although we had to modify our set several times to get the best coverage and the results from the search, we concluded that the following search string was the one giving the best results for finding a predefined set of manually searched papers on this topic (in terms of coverage and completeness):
test AND generation AND (manual OR handcrafted OR handmade OR manually) AND software AND (evaluation OR experiment OR case study OR comparative OR comparison)
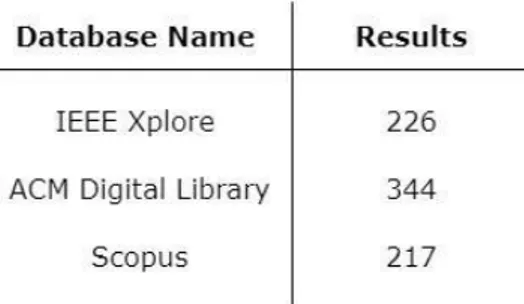
We selected IEEE Xplore and ACM Digital Library as the digital libraries, and Scopus for the indexing system. The search process was performed in March 2020. The search results per each database are reflected in Table 1.
TABLE 1: Number of studies per database.
After performing the search, we exported the results and saved them as BibTex files. We used two software to manage our results, JabRef and Zotero. A manual search was primarily conducted looking at the references of several papers and guidelines regarding the comparison of automated and manual testing. This is usually a high-demanding process, and in our case, our results identified two relevant papers.
3.3. Study selection
Study selection is usually performed in several steps. The process starts with removing the studies that are obviously irrelevant from the set of the identified candidate papers. After the first screening, the papers need to be looked at more in detail. The process continues with reading the titles and abstract, going deeper into introduction, as well as full-text reading. For the set of papers, we took the following steps: First, the duplicates were removed with the help of the software. Second, the titles were read in order to determine whether the articles were focusing on testing, automated or manual testing and test generation in the scope of software engineering Third, we read the abstracts to check whether the studies had an empirical background and were not secondary studies, whether they contained the search words and made a comparison of manual and automated tools or technique on software or systems. It is important to notice that we found several papers that were not easy to understand whether they were relevant to our study by reading the abstract. Those papers were not excluded immediately. When in doubt, we went further from reading the introduction to full-text reading. For the first steps of the selection, the work was divided between two of us, but for the not-so-clear papers, the introduction and the full-text was read together, followed by the discussion whether the paper was related to our study or not. Since the selection process is conducted by the two of us, there is the opportunity to verify the results of the selection process of each of us separately. We performed a kappa analysis to check our level of agreement. To complete this procedure, we used a free tool on the internet. We archived a kappa value k=0.608, which indicates a substantial strength of agreement.
We found several papers that reported more than one study. As suggested by Kitchenham [15], these papers can be considered as separate studies for the sake of the analysis. This fact was used in the process of meta-analysis, as it is reported in the later sections of this study. Another thing worth mentioning is that we also came across several papers, which were replications of a previous study, or reporting an experiment conducted in a certain period, and later this experiment was replicated and both experiments were reported in a later study. On such papers, we decided to keep only the latest papers, since these papers can be considered as replication of each other.
3.4. Inclusion and exclusion criteria
The following inclusion criteria were applied to each paper during the selection process: • Studies that compare manual testing and automated testing.
• Studies that compare model-based testing and manual testing. • Studies that compare random testing and manual testing
• Studies present the research method and result of a systematic mapping study. • Studies are in the field of software engineering.
• Studies were published after 2010.
• Studies which have an empirical background. The exclusion criteria apply as follows:
• Studies presenting summaries of conferences/editorials or guidelines/templates for conducting mapping studies.
• Studies presenting non-peer reviewed material. • Studies not accessible in full text.
• Books and gray literature.
• Studies that are duplicates of other studies. • Secondary studies
3.5. Quality assessment
Quality assessment is described as “The degree to which a study employs measures to minimize bias and error in its design, conduct, and analysis" [21]. Quality assessment is about deciding which amount the set of the primary studies is valid and unbiased. For systematic literature reviews and meta-analysis, reviewing the quality of primary studies can improve its value in different ways. There are numerous examples of scares results when low-quality studies have been used, therefore this step is of significant importance. Assessing the quality of the studies is quite a challenging task, with no specific or standard definition of quality.
In our case, after screening the results and evaluating the set papers for our study, there was still space to determine whether the papers were reliable. The following quality assessment questions are the base of the main criteria:
• QA1: Was the literature review based on well-formulated and described the research questions? • QA2: Was the inclusion and exclusion criteria well-defined?
• QA3: Was the approach used in the research strategy systematic?
• QA4: Was the literature carefully examined by both of us, considering the inclusion and exclusion criteria, in order to minimize the bias?
• QA5: Was the quality of each paper autonomously assessed by both of us in order to determine its internal validity?
Question 1. Question formulation
The research question of this study is clear and well-specified. It makes it quite easy to understand what kind of primary studies we need in order to answer this question. The research question makes it quite clear which techniques are we comparing, and to which terms these techniques are being compared. We based our search on finding papers that compare automated and manual testing, so we can surely say this assessment is complete.
Question 2. Suitability criteria
The reader needs to have a clear justification of why studies were included or excluded. First, for the inclusion criteria, we only need papers which make a comparison of automated, or model-based testing or random testing, since the core of these techniques is automated testing and manual testing. As a second criteria, we wanted our papers to be in the field of software engineering. We need papers that are primary studies and have an empirical background since these types of papers are relevant to perform a literature review and meta-analysis. We limited our set of primary studies to papers published after because we believed that the testing tools are growing, changing, and improving rapidly, so the scope of ten years seemed to be relevant enough for our study. We do not need duplicates for obvious reasons, and secondary studies since we cannot use those studies in the systematic literature review and meta-analysis. Books do not seem to be relevant for this study, so we decided to exclude those as well. Another category of studies to be excluded were the studies which were not accessible in full text, but this was not our case, since we could access the databases using the institutional login. As a result, the answer to the second question would be yes, the inclusion and exclusion criteria is well defined.
Question 3. Literature search
The research strategy used a detailed, systematic approach to collect all possible evidence related to the topic of interest. An extensive review has the following characteristics:
• Computerized searches were performed using various scientific databases, such as IEEE Xplore, ACM, Scopus, etc.
• Manual searches in articles and textbooks in addition to the electronic searches.
The approach used in the research process was highly systematic, following well-specified guidelines of conducting such research. First, the research question was defined, followed by the definition of the search string. Second, the set of papers was carefully examined, removing the irrelevant papers, reading the duplicates, titles, abstracts, and full texts when it was needed. The process was conducted by both of us, in order to minimize as much as possible, the risk of bias and having a valuable set of papers for the next steps of our study. The research process is clearly described; therefore, the research can be duplicated and furnish similar results.
Question 4. Pair studies review to conclude which should be included and excluded
We examined the articles starting from the titles, to abstract and so on, to conclude which of the previously found papers should be included and which to be excluded in our study. We worked together in reviewing the papers and deciding for each of the papers whether it would be included in the final set. Another factor to strengthen this fact, mentioned in a previous section, is the kappa analysis, which resulted in a value of 0.608, which indicates a substantial strength of agreement. This said, we believe the bias is minimized as much as possible, resulting in a valid set of papers.
Question 5. Internal validity analysis
We read the studies one by one, in order to examine whether the actual set of studies was relevant for our study, as well as to define each study’s internal validity. The internal quality of each study is important, but as we mentioned above, in our case, it is crucial. Experience has shown that different quality studies produce different sets of results therefore the validity of the conducted study may be compromised by the internal validity of each paper in the set. Thus, the internal validity analysis is accomplished.
3.6. Data collection
We extracted the following data from each study: • The source of the paper (journal or conference)
• The method used to conduct the study (experiment, case study, survey)
• The type of comparison (manual and automated, manual and model-based testing)
• The program or system under test • The language of each system under test
• The size of each program (LOC, classes, methods)
Many studies suggested this process has two actors, the extractor, and the reviewer, but we preferred to do both roles, for each process. We first extracted all the needed information for the paper and checked the accuracy of the results. When there was a disagreement, one’s reasoning and interpretation were discussed, until both authors agreed.
3.7. Meta-analysis
Meta-analyses use statistical methods to analyze and pool the results from several primary studies, usually experiments, that have measured the outcome of two different treatments or interventions. Meta-analyses provide a higher statistical meaning for their outcomes than individual primary studies [15]. Meta-analysis exists in a small number in software engineering since most of the engineers use fewer proper forms.
When the data extraction process begins, we need to define what are the treatments on the primary studies. Methods, algorithms, processes, tools, and techniques are considered to be the treatments in the field of software engineering. Meta-analyses require to define a control group which is referred to as the current standard on software engineering. Results, often referred to as outcomes, are related to the effectiveness of each treatment, in terms of time, cost, fault, or overall effort.
A meta-analysis combines statistical values extracted from the set of primary studies that report a statistical analysis of the same or similar hypothesis. We needed to identify the study type, which can be an experiment, case study, survey, quasi-experiment, benchmarking, or data mining. Second, the participants of the study needed to be identified. In the field of software engineering, for most of the studies, the participants are students, testers, developers, engineers, practitioners, or academics. It illustrates the population in which the results can be applied. Third, the materials used to conduct the experiments, surveys, or case studies are identified. The materials refer to the tools, programs, specifications, or test cases. It defines the systems to which the study applies. Fourth, the settings under the study are taking place is defined. It may be an academic environment, a training course, or an industrial environment. This indicates the scale of realism of the settings. Fifth, the task’s complexity and time are defined, illustrating the authenticity of each task.
A complete meta-analysis process involves the following steps:
1. All meta-analysis is based on calculations of the effect-sizes for a specific outcome and its variance. In case there are different types of outcomes from the primary study, we need not analyze each metric independently.
2. The results of the previous step, such as the effect size, the variance, and the number of observations need to be reflected in a table.
3. There is a need to check whether the data collected from an individual study does not depend on the previously published studies of the same author. If that is the case, a multi-level meta-analysis should be conducted.
4. The data should be imported to appropriate statistical software such as R Studio to do the necessary calculations and analysis.
5. There is a need to decide which of the two effect-size models should be used to perform the analysis. The first method is the fixed-effect-size model. This method should be used in a case where there are a small number of effect sizes to be pooled and they come from a relatively similar replication. The second method is the random-effect-size model, which is widely used in cases where the heterogeneity among primary studies is significant [22].
6. In cases where heterogeneity is not significant, the data synthesis process is considered to be complete and the overall mean and variance provides the results of the best estimate between the treatment outcomes.
7. In cases where heterogeneity is significant, there is a need to investigate which of the factors impacted the outcomes, and in this case, the mixed-effect-size methods are used.
8. Sensitivity analysis demonstrates how the primary studies affected the outcomes. The primary studies of low quality or high-influence studies have a significant effect on the outcomes. There is a major problem with the empirical studies in software engineering; there is no clear understanding of what a representative sample should look like [16]. Usually, the results of primary studies are incomparable, and providing relevant knowledge through these methods is quite challenging. Several authors and researchers are yet not convinced whether meta-analysis can be successfully applied to the present software engineering experiments and whether the results can be relevant. Some researchers go further posing the following question [23]: Is software engineering ready for meta-analysis? The facts suggest that even though combining the study's outcome is improbable to solve all problems, it improves the efficiency of the results. Most of the studies encounter inconsistency among the statistics reported; they are incomparable, thus conducting a mathematical synthesis such as meta-analysis is certainly complicated [16].
3.8.
Study Selection Process
Study selection is a multi-stage screening method that excludes non-relevant papers from the candidate primary research papers collection. This selection is documented in the review protocol [15]. Study selection is mostly done in several steps. Once the set of papers is identified, the irrelevant papers can be removed based on the title or the abstract. After the first process is complete, the papers need to be looked into in more detail. In case when reviewers have excluded a paper based on reading only some of the sections, it may be necessary that the full text of the papers is read before the final decision can be made. On the other hand, some papers may be included in the later steps on the review process i.e. when a paper is excluded from one reviewer, but after screening it once more from the reviewing group, it is decided to be included on the final set of papers. A common scenario occurring in the selection process is that when researchers find a large number of candidate papers which can be simply resolved by refining the search string, reducing the scope of the review, improving the research questions, increasing the number of the reviewers or by using the aid of mining tools.
A critical matter of the systematics review is the link between papers and individual studies. In software engineering, the papers frequently overlap, and this can be due to several reasons:
• The same study may be reported by several papers. The most common scenario is when a conference paper is followed by a more complete journal-published version.
• A large study may have its results published in several papers. • A single paper may report results from several separate studies.
A systematic review must not count these studies, especially in the case when a meta-analysis will be performed.
The study identification refers to the search for papers and their screening [29]. It is four activities process that starts with the definition of the search strategies that will take place, performing the search,
evaluating the search, and applying inclusion and exclusion criteria on the set of papers. The most frequent way of doing this is the automatic search within the databases, followed by the manual search. The search terms are usually extracted from the research question but there are additional ways of doing this. The search terms can derive also from the keywords of known papers, from the search terms of PICO (Population, intervention, comparison, and outcome), from consulting experts of the field. Although we mentioned several strategies of doing it, the most usual is PICO and the extraction of keywords from the known papers, which are the strategies we followed in our study as well. There are three identified strategies researchers use to include and exclude the papers retrieved from the search. The first strategy is to define the rules on the base of which the decision will be made after the evaluation of a paper from different researchers. The second strategy is to add other reviewers to see if there is a level of disagreement among the initial researchers, or if the papers are not clear enough for the initial researchers to decide. The third strategy is to have a test set for the reviewers where they can test their level of agreement. In our study, we have used the first strategy, we defined the rules on how to decide after we examine each study. As the first rule, we set the quality assessment of the studies and for the meta-analysis whether the papers reported any statistical values or not.
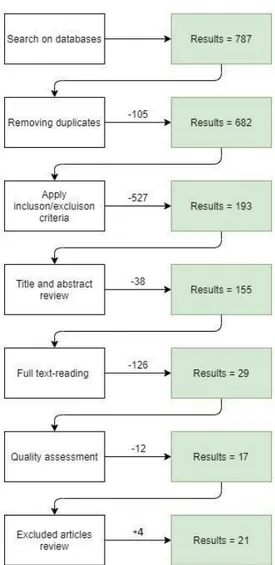
The process of study selection in our study began after the search process was complete and we had the set of papers identified. The first step of the process was to remove the duplicates from the set of papers. To accomplish this task, we imported the set of papers in a program called “Zotero”, which is specialized for dealing with BibTex files. The set of papers consisted of a total number of 787 papers. The program we were using had an option where it allows users to identify the duplicates and decide whether the elimination process is automatic or manual. We preferred to complete the process manually to eliminate any mistakes that may occur with the automatic process. We ended up having a total of 682 papers. In the next step, we applied the inclusion and exclusion criteria. First, we used the “Advanced Search'' feature of the program to identify and remove from the papers the books and those which were published after the year 2010. The process resulted in a total of 470 papers. Second, the tags and keywords of the papers were examined where we searched if the tags or keywords contained any of the keywords identified in the search string. The first search was done using the keywords software, programs, and systems. The number of the results dropped from 470 to 236 papers. We ran the search once again, but this time using the keywords test or testing. The inclusion and exclusion criteria were applied to this set as well. This time we collected 193 results. Third, the title and the abstract were examined in order to remove further irrelevant papers. The abstract was read to understand if the papers were comparing manual testing with the test generated automatically with the aid of tools. We collected 155 papers from this step. In the next step, we read the papers in full text and we accumulated a total of 29 papers. Quality assessment was the last step in which we applied several criteria mentioned in Section 3.4. The set of papers was reduced to 18 papers. The search process had not come to an end yet. The first steps of the process were done separately by each of us; however, we had a second set of papers which we found necessary to examine in pairs. These were the papers that were not so clear, and we named this process the excluded papers review. These papers were not excluded right away, instead they were kept apart for further examination. The full text of these papers was read in pairs, followed by a discussion of whether the papers were relevant to our study or not. This process concluded with 6 more papers to add to the set, therefore, the final set consisted of a total of 21 papers.
Figure 16 shows a flow diagram representation of the process and the number of papers resulted in each step. Besides the automated search using the search string in the databases, we performed a manual search process as well. This process, which is described in the previous section, consisted of searching the references of other papers to find relevant papers to our topic which may have not been found by the automated process. We found several papers that we aggregated to the results from the initial set of papers derived from the automated search. When the duplicates were removed, we noticed that most of the papers we found from the manual search were also found by the automated search, resulting in only two additional papers that automated search was unable to find.
4. Systematic Literature Review Results
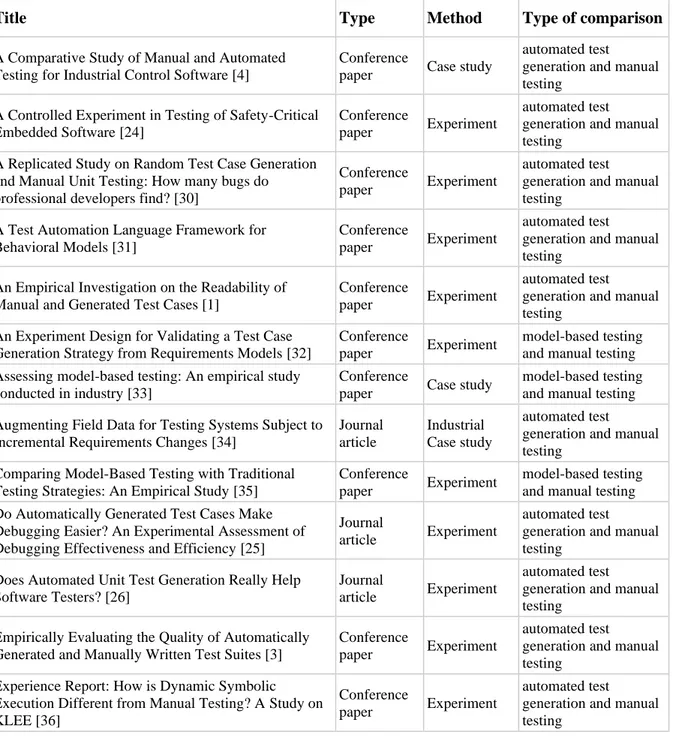
We reported the data of our set of papers in Table 2. The data reported for each paper are: • The title of the paper
• The type of paper i.e. journal article or conference paper.
• The empirical method used for each paper i.e. experiment, case study, survey
• The type of comparison between testing techniques i.e. automated test generation and manual testing or model-based testing with manual testing.
TABLE 2: The final set of studies included during the study selection process.
Title Type Method Type of comparison
A Comparative Study of Manual and Automated Testing for Industrial Control Software [4]
Conference
paper Case study
automated test generation and manual testing
A Controlled Experiment in Testing of Safety-Critical Embedded Software [24]
Conference
paper Experiment
automated test generation and manual testing
A Replicated Study on Random Test Case Generation and Manual Unit Testing: How many bugs do professional developers find? [30]
Conference
paper Experiment
automated test generation and manual testing
A Test Automation Language Framework for Behavioral Models [31]
Conference
paper Experiment
automated test generation and manual testing
An Empirical Investigation on the Readability of Manual and Generated Test Cases [1]
Conference
paper Experiment
automated test generation and manual testing
An Experiment Design for Validating a Test Case Generation Strategy from Requirements Models [32]
Conference
paper Experiment
model-based testing and manual testing Assessing model-based testing: An empirical study
conducted in industry [33]
Conference
paper Case study
model-based testing and manual testing Augmenting Field Data for Testing Systems Subject to
Incremental Requirements Changes [34]
Journal article
Industrial Case study
automated test generation and manual testing
Comparing Model-Based Testing with Traditional Testing Strategies: An Empirical Study [35]
Conference
paper Experiment
model-based testing and manual testing Do Automatically Generated Test Cases Make
Debugging Easier? An Experimental Assessment of Debugging Effectiveness and Efficiency [25]
Journal
article Experiment
automated test generation and manual testing
Does Automated Unit Test Generation Really Help Software Testers? [26]
Journal
article Experiment
automated test generation and manual testing
Empirically Evaluating the Quality of Automatically Generated and Manually Written Test Suites [3]
Conference
paper Experiment
automated test generation and manual testing
Experience Report: How is Dynamic Symbolic Execution Different from Manual Testing? A Study on KLEE [36]
Conference
paper Experiment
automated test generation and manual testing
FormTester: Effective Integration of Model-Based and Manually Specified Test Cases [37]
Conference
paper Experiment
model-based testing and manual testing How do Developers Test Android Applications? [38] Conference
paper Survey
automated test generation and manual testing
Introducing Test Case Derivation Techniques into Traditional Software Development Obstacles and Potentialities [39]
Conference
paper Case study
model-based testing and manual testing On the Effectiveness of Manual and Automatic Unit
Test Generation: Ten Years Later [2]
Conference
paper Case study
automated test generation and manual testing
One Evaluation of Model-Based Testing and its Automation [40]
Conference
paper Case study
model-based testing and manual testing Random Test Case Generation and Manual Unit
Testing: Substitute or Complement in Retrofitting Tests for Legacy Code? [41]
Conference
paper Experiment
automated test generation and manual testing
Skyfire: Model-Based Testing with Cucumber [42] Conference paper
Industrial Case study
model-based testing and manual testing Test scenario generation for web application based on
past test artifacts [43]
Journal
article Case study
automated test generation and manual testing
(a)The number of studies (b)The number of studies (c)The number of studies based on type based on method based on comparison
Fig. 17. A graphical representation for the number of studies based on their type, journal article or conference paper; the empirical method used in each study and based on the comparison made.
We reported the number of studies for each data type in Figure 17 where (a) represents the second column of the table and shows the type of papers and the number of papers for each category. There are seventeen conference papers and four journal articles. The second chart (Figure 17 (b)) represents the third column of the table which shows what the empirical method has been used in each paper in order to obtain the results. There are twelve experiments, eight case studies, two of them are industrial case studies, and one survey. The third chart (Figure 17(c)) represents the type of comparison column of the table. The papers report data of automated test generation in comparison with manual testing, or they compare the model-based testing and manual testing. The results show there are fourteen papers regarding automated test generation and manual testing and seven papers that compare model-based testing and manual testing.
4.1. Description of the primary studies
In this section, we give a brief description of each paper along with the benefits and the challenges of each testing technique identified by authors.
Enoiu et al. [4]: In this paper, the authors investigate how the automated test cases compared to the
manual tests in terms of cost and effectiveness. The main area of their investigation is the control software used in the industry. In these types of software, strict requirements are usually met using manual testing. The authors conducted a case study to compare the automatically generated test cases with test cases written manually. They test 61 real-world industrial programs written in IEC 61131-3. The automatically generated test cases reach a similar code coverage with the manually written tests, but they generate the test cases almost 90% faster. Regarding fault detection, the automatic test cases do not achieve better results; instead, manual testing is more effective in detecting logical, timer, and negation type of faults [4]. The authors suggest studying further the way that manual testing is done in industrial environments and how automated testing can be improved for more reliable systems.
• Fault detection. Manually written test cases archived a higher mutation score than automatically generated ones with an average improvement of 3%. On the other hand, statistically, there is no significant difference. The main difference comes from the differences in the size of test suites, where the use of automated test generation results in 40% fewer test cases, compared to the manual. When the test suite size is equal, manually written tests are superior to automatically generated tests, and the difference is statistically significant. In case when coverage-adequate test suites with equal size are used, their fault detection is still not showing better results compared to manually written ones. The manually written test suites detect an average of 12% more logical types of faults than automated tests. Regarding negation and timer types of faults, the manually written test cases archive better results with an average of 13% more faults. • Coverage. Manually written test cases archive 100% decision coverage for most on the
programs under test. Random test suites obtain lower decision coverage with an average of 61% compared to the manual test suites, with coverage ranging from 63% to 100%, with an average of 96%. The overall results show the difference in code coverage is not statistically significant between two techniques, even when test cases are created to cover all decisions.
• Cost. The cost of manually written tests measured in terms of time the engineers need to write the tests. The average time for the writing of manual tests from each of the three engineers is 165 minutes on average. For the automated test generation, the total cost involves both machine and human effort. The total cost of the automated tool was an average of 19 minutes. The cost in terms of time is more effective for the automatically generated tests with an average of 146 minutes shorter. The overall results suggest that using the automated test generation tool has a lower cost in terms of creation, execution, and reporting.
• Benefits. The results of this study suggest that manually written test cases have a higher mutation score than automatically generated ones with an average improvement of 3%. Regarding the coverage, manually written test cases archive 100% decision coverage for most on the programs under test. Another benefit of a manual test is that the test suites are more effective at detecting particular types of faults than automated test suites. On the other hand, automated tests reduce the cost of test suites generation in terms of time, by a great amount. Automatically generated tests obtain similar decision coverage but in much less time.
• Challenges. The automated tests are slightly worse in terms of fault detection compared to manual testing. The test suites generated with the aid of automated tools do not show better mutation scores than manual tests. Regarding the manual test, the cost of generating the test suites by engineers is very high in terms of time, compared to the automated test generation.
P. Enoiu et al. [24]: In this paper, the authors investigate specification and implementation-based testing
on two programs of safety-critical software systems, written in IEC 61131-3 language. Their goal is to measure the efficiency and effectiveness of fault detection by conducting a controlled experiment using a test written by twenty-three master students of software engineering. The participants worked
individually to write test cases manually and generate the test cases with the aid of automated tools of each of the two programs. The authors collected and analyzed the tests in terms of mutation score, decision coverage, number of tests, and testing duration. The overall outcomes suggested that specification-based testing includes more effective tests in terms of the number of faults detected. These tests, compared to implementation-based tests, were more effective in detecting types of faults such as comparison and value replacement. The implementation-based automated test generates a lower number of tests and the tests are created in a shorter time compared to the ones created based on specification.
• Fault detection. The fault detection for both the programs under test was superior for tests manually written based on specification than tests written based on implementation and test generated with the aid of automated tools. This is since generated tests based on the implementation are weak in detecting certain types of faults. Tests are written using specification-based techniques detect a higher number of faults than tests generated from automated tools, with values respectively at 7,9% more comparison type of faults, 19.1% more value replacement type of faults, 38% more logical types of faults and 51% more value replacement faults. In this case, the introduction of four measures aimed at detecting the remaining faults has increased the reliability of the fault-finding. As a secondary result, this particular example demonstrates that one does not rely exclusively on a decision coverage criterion to obtain better tests.
• Decision coverage. Automated tests archive 100% decision coverage, although the results for both programs do not show any significant statistical difference. On the other hand, specification-based manually written tests archive a high coverage as well, but this test archives the best results in implementation coverage for both programs. Decision coverage is better for implementation-based testing compared with random testing.
• Number of tests. Automated tests and implementation-base manual tests result in a smaller number of tests for both programs compared to specification-based manually written tests. A human tester, given enough time, seems to be producing many more tests using SMT than IMT or IAT. Specification-based manual testing archives a bigger number of tests for a similar level of coverage.
• Mutation score. Random tests are less effective than SMT and IAT in terms of mutation score. The mutation scores are between 15% and 31% larger compared to random tests of the same size.
• Testing duration. Automated tests have a lower duration than manually derived tests. The subjects of automated testing have a shorter completion time over specification-based manual testing and implementation-based manual testing which ranges from 85,5% to 15,5%.
• Benefits. Specification-based testing, which is a manual testing technique, includes more effective tests in terms of the number of faults detected. These tests, compared to implementation-based tests, were more effective in detecting types of faults such as comparison and value replacement. The number of faults detected is higher than tests generated from automated tools, with values respectively at 7,9% more comparison type of faults, 19.1% more value replacement type of faults, 38% more logical types of faults, and 51% more value replacement faults. Specification-based manually written tests archive a high coverage as well, but this test archives the best results in implementation coverage for both programs. A human tester, given enough time, seems to be producing many more tests using SMT than IMT or IAT. On the other hand, automated tests archive 100% decision coverage, although the results for both programs do not show any significant statistical difference. Automated tests have a lower duration than manually derived tests. The subjects of automated testing have a shorter
completion time over specification-based manual testing and implementation-based manual testing which ranges from 85,5% to 15,5%.
• Challenges. Automated tests and implementation-base manual tests result in a smaller number of tests for both programs compared to specification-based manually written tests. Regarding the number of tests, an implementation-based automated test generates a lower number of tests compared to the automated test generation technique.
Ramler et al. [30]: In this paper, the authors describe the comparison of the tool-supported test case and
manually written unit tests. This paper is a replication of an empirical study that describes an experiment involving professional engineers with several years of experience in the software industry compared to the students from the initial study, and an extended time limit. The paper investigates the differences between students from the initial study and professionals from this study, as well as the extended time limit impact. The experiment also confirms the result of the initial study regarding two testing techniques, where automated test generation can have the same efficiency as manual test cases and it can be used alongside the manual technique.
• Number of defects. In the original study, the experiment was of 60 minutes, the number defects detected from the test cases generated automatically using Randoop was higher than the number of defects found by the tests that were manually written from the students, 9 by Randoop and average of 3 defects from the students. The second experiment had a time limit of 120 minutes; the difference was reduced because the professionals found 8.35 defects on average for the program under test. The results suggest that the automated tool is on the same level as the professionals, and it can be used as a complement of the manual testing approach.
• Differences in detected defects. In the original study, the tests generated from the automated tool detected four more defects that students were unable to find, increasing the improvement by 16.7%. In the second study, professionals found a higher number of defects altogether, yet Randoop was able to find an additional of 3 defects, which translates to improvement by 9.4%. The defects found by Randoop are special cases that human subjects may not be able to detect. • Benefits. Automated test cases are able to detect a higher number of defects in a shorter time compared to the test cases written manually from the developers. Another benefit of the test cases automatically generated is the ability to find defects that manual tests were unable to find. On the other hand, manual tests perform better or similar if the time limit does not exist and these tests may find different defects.
• Challenges. Manual testing is highly dependent on the expertise and knowledge of the developer writing the tests. Manual test suites usually take a longer time to be written and they may not be able to detect some special types of defects.
Li et al. [31]: In this paper, the authors present a language framework that creates mappings for concrete
tests automatically based on abstract tests. They address three issues: the creation of mappings and test value generation, the transformation of graphs, and the usage of coverage criteria to generate test paths and solving constraints and generating real tests. The second part of the papers is an empirical comparison where testers use the framework with manual mapping on a total of 17 programs. Another goal of this paper is to avoid redundancy, which is a major problem among testers, because they may write redundant code since some elements appear multiple times in the tests.
• Errors detected. The authors examined the manual and automated tests. The results showed that a number of 48 errors were found in the manually written test and zero errors in the automatically generated tests. There are two types of errors found, the first type is unmatched
code for the transition, meaning that an abstract element may have a wrong implementation or there is no corresponding concrete test code. The second error is the presence of a redundant code for the same transitions. When tests have several abstract elements, it was easier for the engineers to make an error, especially with large programs. On the other hand, the framework could avoid both errors.
• Time. The automated testing technique was able to save more on the process of mapping abstract tests to concrete tests. The automated process took an average of 11.7% to 60.8% of the time of the manual process and an unweighted average of 29.6%.
• Benefits. The automated tests showed an impressive number of zero errors in the tests mainly because testers make more mistakes on large programs with a big number of abstract elements. The experiments identified two types of errors and the automated tool was able to avoid them both. Automated testing also saves time with an average of 29.6% of the time spent by manual testing.
• Challenges. Manual tests are error-prone especially when the program under test is of a large scale. In addition to that, manual testing requires more time than automated testing.
Grano et al. [1]: In this paper, the authors compare the readability of manually written test cases and
the classes they test, and further, examining the readability of automatically generated test cases. An exploratory study is conducted to obtain the results. The results suggest that the readability is often neglected by developers and that the automatic test cases are much less readable in general than those written manually. The experiment’s results suggest that the manual tests have a higher readability compared to the automatically generated test cases. Three projects are taken under examination, and the results show that, for two out of three projects, the readability of manual test cases is highly significant, and these tests are usually shorter, and the number of control structures is lower.
Schulze et al. [33]: In this paper, the authors compare manually written test cases with
mode-based-testing on two different versions of a web-based data collection and review system. They conducted the experiment in the following way: both developers tested each version of each software, having identical testing goals and resources, but the technique used was different. The first developer used manual testing and the second used model-based-testing with the aid of automated test generation tools. The authors compare the effectiveness in terms of defects found and efficiency in terms of effort spent to complete each process.
• Effectiveness. For the first version of the program, manual tests detected 21 issues compared to 29 issues detected by the MBT tests. MBT tests found 8 more issues, a slightly higher number. The manual test found 13 distinct issues compared to MBT which found 21 issues. For the second version of the program, manual tests detected 17 issues compared to 29 issues detected by the MBT tests. The overlap this time is greater, but for other aspects such as “usability”, the techniques detected a similar number of issues: 5 and 6. The issues detected on the second version of the program under test were distinct; 19 of the 36 issues were reported only by MBT tests and 7 only from the manual tests. The two approaches reported a similar number of issues for the overall comparison, with manual testing reporting 29 issues and MBT reporting 36, but they reported different issues: 17 only from manual tests and 24 only from MBT. Regarding the severity of issues found, manual tests resulted in a severity score of 46 while MBT’s score was 73. MBT has a higher score which was about 60% higher than the manual’s score. The observations showed that only a few of the defects were detected by both techniques. Even though the testing goal was the same, the testers focused their effort on different aspects. • Effort in terms of time spent. The following tasks were identified to measure the effort of each
Test Case Development. For the first task, both testers spent a similar number of hours,16, to analyze the requirements, ask questions, and explore the system. Modeling and test infrastructure implementation were carried out only by the tester who used MBT tests. These two tasks took an additional 111 hours to complete. The test case development task was carried out only by the tester using the manual test because the test cases for MBT are automatically generated. This task took 16 hours. The total effort of MBT was 127.5 hours compared to 32 hours of the manual tester. For testing the first version of the program, the testing activity was 4 hours for the MBT tester and 26 hours for the manual tester. For the second version of the program, the total effort was 7 hours for manual testing and 8 hours for MBT. The overall effort of all tasks was 139.5 hours for MBT and 65 hours for manual testing, which translates to around 47% improvement for manual testing.
• Benefits. MBT is very suitable for testing these types of programs because it requires many test cases to cover all necessary scenarios. It is more systematic and is able to detect more issues. MBT archives a severity score that is about 60% higher compared to manual testing. On the other hand, the manual techniques required less preparation time and have an overall effort half of the effort of MBT.
• Challenges. Manual testing requires a bigger effort for the same type of testing. Also, a manual tester might make mistakes in entering the test data making the test case invalid and the manual test coverage is to some extent uneven. MBT technique may not be able to detect a specific issue if it is not specified such as to check for the existing data when invalid new data is entered. Another drawback is that MBT requires more preparation time.
Di Nardo et al. [34]: In this paper, the authors propose an automated model-based approach to generate
test inputs for testing new data requirements by modifying the old data. The empirical study shows that the approach produces better results when it results in many structured and complex data. The test input data from this approach has a significantly larger size compared to the data generated using constraint solving only. Another improvement is the archived code coverage, which is greater than the test cases implemented by experienced software engineers.
• Number of test cases. The number of test cases generated from the proposed approach is 103.1 on average, compared to 32 test cases from the manual technique.
• Coverage. Manual testing covers 8 branches and 68 instructions of the new data requirements, translated in percentage, 72.7%, and 71.6% respectively. On the other hand, automated testing covers 9 branches and 74 instructions, respectively 81.8% and 77.9%. The results suggest that automated testing has a slightly better performance in terms of coverage. Even why the difference is small, it is critical in a real-life project, since uncovered branches can trigger critical faults.
• Number of covered bytecodes. Tests that use the proposed approach cover more bytecode instructions overall. The tests generated with this approach execute an average of 386.1 more bytecode instructions compared to manual testing.
• Time. Test cases generated using the proposed approach take 21 more minutes to execute compared to manual testing, which in practice are insignificant. The complete test suite generated automatically can be run in 31 minutes which can make it possible to execute the test suite daily.
• Benefits. The proposed automated approach performs better in terms of instruction and branch coverage respective to the new requirements. When considering all requirements, the overall coverage archived is better. The number of test cases is significantly higher, and the bytecode