Teknik och samhälle
Datavetenskap och medieteknik
Examensarbete
15 högskolepoäng, grundnivå
Exploring the quality attribute and performance
implications of using GraphQL in a data-fetching API.
En studie om GraphQLs inverkan på kvalitetsattribut och prestanda i ett data-fetching API.
Daniel Wikander
Examen: kandidatexamen 180 hp Huvudområde: datavetenskap Program: systemutvecklare Datum för slutseminarium: 2020-06-04Handledare: Johan Holmberg Examinator: Mia Persson
Abstract
The dynamic query language GraphQL is gaining popularity within the field as more and more software architects choose it as their architectural model of choice when designing an API. The dynamic nature of the GraphQL queries provide a different way of thinking about data fetching, focusing more on the experience for the API consumer. The lan-guage provides many exciting features for the field, but not much is known about the implications of implementing them. This thesis analyzes the architecture of GraphQL and explores its attributes in order to understand the tradeoffs and performance impli-cations of implementing a GraphQL architecture in a data-fetching API, as opposed to a conventional REST architecture.
The results from the architectural analysis suggests that the GraphQL architecture values the usability and supportability attributes higher than its REST counterpart. A performance experiment was performed, testing the internal performance of GraphQL versus REST in a use-case where its dynamic functionality is not utilized (returning the same static response as its REST equivalent). The results indicate that the performance of GraphQL implementations are lower than that of its REST equivalents in use-cases where the dynamic functionality is not utilized.
Acknowledgments
I’d like to thank Johan Holmberg and Helena Holmström for their invaluable feedback when writing this thesis. I’d also like to thank Columbus Global for their support and inspiration.
Contents
1 Introduction 1
1.1 Background . . . 1
1.2 Motivation and related work . . . 1
1.3 Research questions . . . 2 1.4 Scope . . . 2 2 Method 2 2.1 Literature review . . . 2 2.2 ATAM . . . 3 2.3 Representative example . . . 3
2.4 GraphQL static query performance experiment . . . 3
2.4.1 GraphQL-JIT . . . 6
2.4.2 Environment . . . 6
2.5 Threats to validity . . . 7
3 REST 8 3.1 The REST principles . . . 9
3.2 Measuring RESTfulness - Richardson’s Maturity Model . . . 9
3.3 Use cases for a REST API . . . 10
3.4 Architecture of a REST API . . . 11
3.5 HTTP Status codes . . . 11
4 GraphQL 12 4.1 Origin of GraphQL . . . 12
4.2 GraphQL in a nutshell . . . 13
4.3 Describing data - The Schema Definition Language . . . 14
4.3.1 Types & Fields . . . 14
4.3.2 Arguments . . . 15 4.3.3 Interfaces . . . 16 4.3.4 Root types . . . 16 4.3.5 Operations . . . 16 4.3.6 Directives . . . 17 4.3.7 Mutations . . . 18 4.4 Introspection . . . 19
4.5 Asking for data - Querying a GraphQL API . . . 19
4.6 Additional GraphQL features . . . 20
5 Quality attributes 20 5.1 FURPS . . . 20
6 Architecture Tradeoff Analysis Method (ATAM) 21
6.1 Defining the quality attributes . . . 22
6.2 Defining scenarios . . . 22
6.2.1 Use case scenarios . . . 22
6.2.2 Growth scenarios . . . 22
7 Representative Example 22 7.1 Quality attribute characterizations & concerns . . . 23
7.1.1 Performance . . . 23
7.1.2 Usability . . . 23
7.1.3 Supportability . . . 23
7.2 Scenarios . . . 24
7.2.1 Use case scenarios . . . 24
7.2.2 Growth scenarios . . . 25
8 ATAM on the representative example 25 8.1 Scenario U1 - Display available resources to API consumers . . . 25
8.1.1 REST . . . 25
8.1.2 GraphQL . . . 26
8.2 Scenario U2 - Query a single resource in the API. . . 26
8.2.1 REST . . . 26
8.2.2 GraphQL . . . 27
8.3 Scenario U3 - Query multiple resources in the API simultaneously . . . 28
8.3.1 REST . . . 28
8.3.2 GraphQL . . . 31
8.4 Scenario U4 - Modify a single resource in the API . . . 33
8.4.1 REST . . . 33
8.4.2 GraphQL . . . 34
8.5 Scenario U5 - Modify multiple resources in the API . . . 35
8.5.1 REST . . . 35
8.5.2 GraphQL . . . 36
8.6 Scenario U6 - Handle an invalid request . . . 37
8.6.1 REST . . . 37
8.6.2 GraphQL . . . 38
8.7 Scenario G1 - Add a new resource type to the API . . . 39
8.7.1 REST . . . 39
8.7.2 GraphQL . . . 39
8.8 Scenario G2 - Updating a resource type in the API . . . 40
8.8.1 REST . . . 40
9 Results 41
9.1 GraphQL ATAM profile for the representative example . . . 41
9.1.1 Risks . . . 41
9.1.2 Sensitivity points . . . 41
9.1.3 Tradeoffs . . . 41
9.2 GraphQL static query performance experiment . . . 41
9.2.1 GraphQL-JIT . . . 43
10 Analysis & discussion 44
11 Conclusions & future research 45
List of Figures
1 The schema used by the GraphQL implementations in the experiment. . . 5
2 The query used by the GraphQL implementations in the experiment. . . . 5
3 The hardware, software and virtualization settings used in the experiment. 7 4 Example of a REST API architecture. . . 11
5 Example of a GraphQL-APIs architecture. . . 14
6 Example of a product type definition in a GraphQL schema. . . 15
7 Example of an Enum type definition in a GraphQL schema. . . 15
8 Example of an interface type in a GraphQL schema. . . 16
9 Example of an object type which implements the ProductInterface inter-face from Figure 8. . . 16
10 Example of a root Query type with a single operation in a GraphQL schema. 17 11 Example of a GraphQL query using a directive to decide whether to re-trieve the names of similar products in the response or not. . . 18
12 Definition of a mutation operation in a GraphQL schema. . . 18
13 Example of a response from the operation defined in Figure 12. . . 18
14 Example of an introspection query for retrieving the names of all types in a GraphQL schema. . . 19
15 Response object from the introspection query in Figure 16. The schema has two types: product and user . . . 19
16 Example of a query for retrieving the name and description of a product with the id: ’101’ in a GraphQL API. . . 20
17 Response object from the query in Figure 16. . . 20
18 A GET request and its subsequent response from the REST API endpoint: /product/<id>. . . 27
19 GraphQL query on a single resource. Note that the query only requests the name and description fields of the product resource, whilst the REST equivalent has no choice but to fetch all fields regardless of the API-consumers needs. . . 28
20 Workflow of a REST API when querying multiple resources simultane-ously. Three separate calls are made to three separate endpoints. . . 30
21 Internal flow of a GraphQL API when querying three separate resources (types) simultaneously: product, similar and interested. . . 32
22 A PUT (update) request and its subsequent response from the REST API endpoint: /product/<id>. The request successfully modifies the name and description fields of a product resource where the id = 001. . . 34
23 A GraphQL mutation query modifying the name and description fields of a product where the id=101, and then retrieving the modified fields within the same query. . . 35
24 Workflow of a REST API when modifying multiple resources simultane-ously. Two separate calls are made to two separate endpoints. . . 36
25 A GraphQL mutation request modifying multiple resources, and returning the modified fields within the same request. . . 37 26 An invalid request and its subsequent response from the REST API
end-point /product/<id>. The API consumer sends a request to modify a prod-uct where the id = 001. There is a typo on the name field and the HTTP status code ’400 - Bad request’ is returned. . . 38 27 An invalid request on the /graphql endpoint and its subsequent response.
There is a typo in the query attempting to fetch the field kname instead of name. The response details the error and its location in the query. . . . 39 28 Table showing the number of requests per second that different API
im-plementations can handle when API consumers repeatedly query for a static 120 field object. The table also shows the latency between an API consumer sending a request and receiving the object, as well as the data throughput rate of the API implementation. . . 42 29 Bar graph showing the average number of processed requests per second
on different API implementations when API consumers repeatedly query for a single 120 field object. . . 42 30 Table showing the number of requests per second that different API
imple-mentations (including GraphQL-JIT impleimple-mentations) can handle when API consumers repeatedly query for a single 120 field object. The ta-ble also shows the latency between an API consumer sending a request and receiving the object, as well as the data throughput rate of the API implementation. . . 43 31 Bar graph showing the average number of processed requests per second
on different API implementations (including GraphQL-JIT, both as stan-dalone and middleware for frameworks) when querying a single 120 field object. . . 44
1
Introduction
1.1 Background
REST has long been the most common architecture for web-APIs and applications since its introduction in Fieldings dissertation in 2000 [15]. Since the introduction of REST, frameworks and technologies for the web have evolved at a rapid rate. The area of API query systems has remained remarkably static however, and REST has remained the architectural style of choice for API developers. In recent years a competing architecture has arisen in the API query system domain. GraphQL, a dynamic query language that puts the users experience in the spotlight by allowing the consumer to define the structure of the data response themselves has been rising in popularity. The language has sparked a debate on the topic of how we access and manipulate data. It provides interesting features and many seem optimistic about its future as an architectural style for data fetching APIs. However, not much is known about the implications of implementing GraphQL.
This thesis analyzes the architecture of GraphQL and compares it to a conventional REST architecture in order to understand the quality attribute tradeoffs that are made when implementing a data-fetching API using GraphQL over REST. It also assesses the performance implications of doing so in use-cases where GraphQLs dynamic functionality cannot be utilized.
1.2 Motivation and related work
The study by Brito et al. [7] analyzing the potential for reduced response sizes when migrating from a REST to a GraphQL architecture highlighted the need for an archi-tectural analysis and internal performance assessment of GraphQL. The study migrated seven API clients from calling a REST API to calling the GraphQL equivalent of the same API. The study then compared the median size of the responses before and after the migration. The study concluded that the median number of fields in the responses were decreased by 94%, and the median number of bytes per response was decreased by 99%. Even though the study was limited to testing seven clients calling only two APIs — and those two APIs returned a particularly large number of unused fields per resource — the study showed the potential benefits of implementing GraphQL in its best-case scenario compared to REST: a use-case where its dynamic query system can greatly reduce the size or quantity of its responses. However, not all APIs can strip away 94% of the fields in its responses. So what are the implications of implementing GraphQL in a use-case where the dynamic query functionality can not be utilized? What would such an imple-mentation mean for the internal performance of the API? The study inspired this thesis to further analyse the implications of choosing GraphQL over REST for data-fetching APIs, and to test the internal performance of a GraphQL architecture when its dynamic query functionality can not be utilized.
By providing an architectural analysis and quality attribute assessment of the ar-chitecture — as well as assessing the internal performance of it when stressed in its
worst-case scenario — this thesis aims to provide a baseline of data for future research on GraphQL to build upon.
This thesis relies heavily on the work of the Software Engineering Institute at Carnegie Mellon University [40]. Their work on quality attributes [4][5] and software quality evaluation [29][30][31][23] has provided guidelines and methods that were invaluable for the analysis.
1.3 Research questions
RQ 1: What quality attribute tradeoffs are made when choosing GraphQL over REST for a data-fetching API?
RQ 2: What are the performance implications of choosing GraphQL over REST for a data-fetching API that does not utilize the dynamic query functionality?
1.4 Scope
This study will analyze the quality attribute tradeoffs within a data-fetching GraphQL API as compared to a data-fetching REST API. The study will look at the internal structure and functionality of the architecture, excluding the network and data-source layer. In other words, the study will analyze the internal workings of the architecture isolated from its variable context. Scenarios from an API consumer’s perspective will be looked at, but network and data sources are considered out of scope for this study.
The performance experiment in Section 9.2 is limited to a single use-case: a static query requesting a single resource. The experiment tests the performance of various implementations in this use-case only. The experiment intends to assess the limitations and performance implications of GraphQL when stressing it in its worst-case scenario.
2
Method
2.1 Literature review
In order to survey the areas of web APIs, GraphQL, REST, and system architecture eval-uation, an initial literature review was carried out. The literature review was conducted using the methodology proposed by Kitchenham [3] as a guideline. The major goals of the review was to understand what previous research has been done on GraphQL and its architecture, to identify gaps in that research and finally to identify methodologies in the field of software architecture evaluation that could prove valuable when analyzing GraphQL. A large pool of research was found regarding architecture evaluation, APIs and the REST architecture. As expected, less information was found regarding GraphQL and dynamic queries, since it is still a relatively new subject.
Searches were made in the major research databases of Computer Science, such as IEEE Xplore, ACM Digital Library, ScienceDirect and SpringerLink. Keywords such as GraphQL, dynamic queries, API, quality attributes, software architecture evaluation, REST, representational state transfer, and various variations and combinations of these
keywords were used in the search. Citations and references of the relevant results were looked through to identify additional keywords and papers of interest.
2.2 ATAM
The literature study found that the Architectural Tradeoff Analysis Method [29] (ATAM) proposed by Kazman would provide a solid foundation for analyzing the GraphQL ar-chitecture and make a valuable comparison with the primary competing arar-chitecture — REST. ATAM was chosen since it is the only analysis method that was found to con-sider several quality attributes in one evaluation, and was also the only one that handles tradeoffs between different architectures in a systematic way [9][33].
2.3 Representative example
A representative example API served as an input for the ATAM. It aimed to represent a data-fetching API in order for us to better comprehend how such an API would be affected by the architectural patterns in a GraphQL implementation. The study had ini-tially planned to conduct interviews with professionals working with data-fetching APIs in e-commerce contexts in order to elicit the driving quality attributes and scenarios for the representative example. Due to unfortunate circumstances surrounding the Covid-19 pandemic, the interviews were cancelled. Instead, guidelines by Google [24] and Mi-crosoft [35][36] as well as a study on API design by Murphy et al. [37] that interviewed 24 professionals working in the field was used as a basis for the representative example. The choice to use a representative example for the analysis was based on a recommen-dation in Barbaccis paper Principles for Evaluating the Quality Attributes of a Software Architecture [5]. Barbacci argues that it is near impossible to fully elicit the attribute needs and requirements of a system before the completion of its development, but by using representative examples one can attempt to generalize a systems attribute needs in advance.
Whilst it is not possible to generalize the full width of the API design landscape since each implementation will have its own specific needs, we attempted to generalize the attribute requirements of a data-fetching API by looking at what they have in common. By studying the answers provided by the professionals in the study by Murphy et al. [5] and the guidelines provided by Google [24] and Microsoft [35][36] we concluded that usability, supportability and performance are frequently sought after attributes and they were therefore chosen as the driving quality attributes for the representative example. 2.4 GraphQL static query performance experiment
An experiment was performed in order to help answer RQ 2: What are the perfor-mance implications of choosing GraphQL over REST for a data-fetching API that does not utilize the dynamic query functionality? The experiment measured and compared the average number of requests per second that various API implementations could process. The experiment queried all implementations using the same static query for an object
that was stored locally as a javascript object within the Node.js process. Essentially, the experiment aimed to implement scenario U2 (see Section 8.2) — albeit with a different schema — and measure the performance difference between REST and GraphQL imple-mentations. In other words, the experiment is testing the performance difference when repeatedly querying the same static resource within various API implementations. The experiment does not test any of GraphQLs dynamic features or the potential gains of querying multiple resources in one request.
The scenario of querying for a single static resource was identified by the ATAM analysis to be the use-case with the highest potential performance loss compared to REST (see Section 8.2). By testing GraphQL in its worst-case scenario we are both analyzing the limits of GraphQL and its potential use-cases, as well as providing a basis for future research to perform more experiments that could include the variable contexts of an API, and further analyze the implications of the dynamic query system.
The open source HTTP benchmarking tool AutoCannon [2] was used to stress the implementations and measure the results. The experiment measured the average number of requests that various GraphQL and REST implementations could process per second. All implementations were tested in sequence under identical circumstances. AutoCannon was configured to continuously send requests during 10 minutes for each implementation. Requests were sent from 10 simultaneous connections using 1 pipeline, all running locally on the same virtualmachine. Node.JS was chosen as the language to perform the experi-ment in. It was chosen because it is the language that the developers of GraphQL wrote their reference implementation in.
First, reference implementations of both REST and GraphQL were built. The REST implementation used the http package to receive requests and return the response object. The GraphQL implementation used the http package to receive the requests, the refer-ence implementations graphql package to validate the query, call the relevant resolvers and construct the response, and finally the http package to return the response. In order to provide data on the possible performance implications of using various implementa-tions of REST and GraphQL, popular Node.JS frameworks that had both a REST and a GraphQL implementation available were included in the experiment. Since there is no overall usage statistics available on the number of active systems using each frame-work, the number of ’stars’ on GitHub was used as a measurement for each frameworks popularity. The three most popular frameworks that had both GraphQL and REST implementations available were identified to be:
Express Express is a popular Node.JS framework for web applications and APIs [10]. Fastify Fastify is a Node.JS framework that focuses on performance [12].
Koa Koa is a newer, lightweight framework made by the Express developers, it is intended to be faster and less bloated than Express [32].
A minimal implementation of both REST and GraphQL was built for each framework. The Express GraphQL implementation used the express-graphql [11] package. The Fastify
GraphQL implementation used the fastify-gql [13] package. The Koa GraphQL imple-mentation used the graphql-api-koa [26] package. A GraphQL schema was built, and data was generated for each field. The schema can be seen in Figure 1.
type Category { id: ID! name: String! md5: String! products: [Product!]! } type Product { id: ID! name: String! description: String! } type Query { categories: [Category!]! }
Figure 1: The schema used by the GraphQL implementations in the experi-ment. { categories { id name md5 products { id name description } } }
Figure 2: The query used by the GraphQL implementations in the experiment.
Data was generated by the open-source placeholder data generator faker. The same seed was used on all iterations of the experiment in order to ensure that identical data was generated. Twenty Category resources were generated, each containing three Product
resources. All resources combined contained a total of 120 fields.
All data except for the Category types md5 field was generated ahead of time. The
Category types md5 field was instead generated individually for each request. All im-plementations performed the same md5 hash function on the same string in order to generate the hash. The md5 field was introduced in order to make sure that the imple-mentations did not cache the result object directly simply because it was a static local object. This optimization could potentially have prevented the GraphQL implementa-tions from reaching the resolver layer, which would not represent the general use-case of a data-fetching API where some computation or external fetching is necessary for each resource. The md5 field ensured that each implementation did the same amount of com-putation per request, excluding each implementations internal processes — which is what the experiment aimed to measure the performance of. The GraphQL implementations computed the hash string in the Category resources resolver function, and the REST im-plementations computed the hash string directly in their respective response functions. The GraphQL implementations were queried using the query presented in Figure 2. The query requested the categories resource, all it’s fields, and all the fields of its products. In other words, the query requested all the data in the API — 120 fields. The REST implementations are built to return the same 120 field object by returning it directly in
their respective response functions. 2.4.1 GraphQL-JIT
A separate section was included showing the results of GraphQL-JIT implementations. GraphQL-JIT is a GraphQL implementation that uses a just-in-time compiler that com-piles the resolver function flow from validated queries into functions that can be cached. Incoming queries are compared to the implementations cache. If the incoming query already exists in the cache, the pre-compiled function is run directly from the cache, bypassing the schema validator and resolver layer. If it is not in the cache, the imple-mentation runs as normal, and then compiles the resulting flow of resolver calls into its own function that is then cached. This means faster processing of previously validated queries since the schema validator does not need to repeat the schema validation and resolver routing process for queries that have been previously validated.
GraphQL-JIT implementations were not included in the results listed in Section 9.2 since — at the time of writing this thesis — it lacks the directive functionality (see section 4.3.6), and thus does not fully comply with the 2018 GraphQL specification. However, since the performance difference between an implementation using a just-in-time compiler with cached queries and an implementation without compiled queries could be drastic — and certainly valuable information for anyone looking into the specific use-case of single static queries presented in this experiment — a decision was made to include implemen-tations with just-in-time compilation as a separate section (Section 9.2.1). Experiments were performed using GraphQL-JIT both as middleware for the frameworks used in Sec-tion 9.2, as well as a standalone implementaSec-tion. The GraphQL-JIT implementaSec-tions used the graphql-jit [27] package to provide the just-in-time compilation feature.
2.4.2 Environment
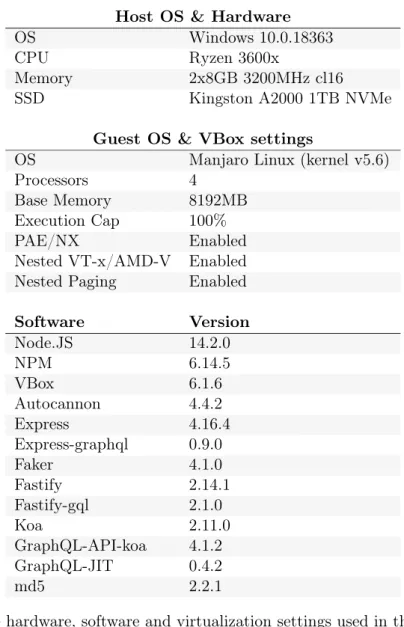
The experiment was run in a Linux virtualmachine using the virtualization software VBox to ensure minimal interference with other system processes. The virtualmachine ran a minimal version of the Linux distribution Manjaro, using kernel version 5.6. All software used in the experiment used the latest up to date version as of the time of writing this thesis. Further information about hardware, virtualization settings and software versions can be seen in Figure 3. The code used in the experiment can be found at:
Host OS & Hardware
OS Windows 10.0.18363
CPU Ryzen 3600x
Memory 2x8GB 3200MHz cl16 SSD Kingston A2000 1TB NVMe
Guest OS & VBox settings
OS Manjaro Linux (kernel v5.6)
Processors 4
Base Memory 8192MB Execution Cap 100%
PAE/NX Enabled
Nested VT-x/AMD-V Enabled Nested Paging Enabled
Software Version Node.JS 14.2.0 NPM 6.14.5 VBox 6.1.6 Autocannon 4.4.2 Express 4.16.4 Express-graphql 0.9.0 Faker 4.1.0 Fastify 2.14.1 Fastify-gql 2.1.0 Koa 2.11.0 GraphQL-API-koa 4.1.2 GraphQL-JIT 0.4.2 md5 2.2.1
Figure 3: The hardware, software and virtualization settings used in the experiment.
2.5 Threats to validity
GraphQL has an official specification defining its inherent features. REST is an archi-tectural style without an official specification. Therefore what is considered a part of a REST architecture can at times be ambiguous, as much of it is up to the individual implementation. This analysis has chosen to represent a data-fetching REST API using guideline articles from Google [24] and Microsoft [35][36]. Whilst using the guidelines to portray a data-fetching API means it is accurate to the definitions and best practices provided by Microsoft and Google, individual implementations of a REST API could provide functionality that is excluded from the analysis in this study. The set of scenar-ios used by the representative example were also chosen by studying the most common operations detailed in the guidelines, and other implementations of data-fetching APIs
might prioritize a different set of scenarios.
REST has been around for a long time, and there is a vast ecosystem of libraries providing functionality to developers that are building an API. Many of these libraries provide similar functionality to what GraphQL offers. Since it is not possible to accu-rately analyze all possible implementations of a REST API, the guideline articles act as a basis for this thesis definition of a REST API.
The experiment used Github stars to measure the popularity of Node.js frameworks with REST and GraphQl implementations. This method is not sufficient to state with certainty that one framework or implementation is more popular or performant than oth-ers, it simply means that more users have marked their interest on the GitHub repository. Thus, this selection of frameworks does not necessarily represent the most performant frameworks available. It is possible that other frameworks with differing performance to the ones represented in this experiment could provide a different set of data.
3
REST
REST, or REpresentational State Transfer is an architectural model first introduced in Fielding’s dissertation in 2000 [15]. It has since become one of the key architectural principles of the world wide web. The core idea surrounding REST is the retrieval and manipulation of resources using the HTTP protocol [14]. Resources are organized using endpoints (URIs), with each resource having a separate endpoint. The resource is accessed by making a request with an HTTP verb to the endpoint. Ideally the response of the resource should then contain the next possible actions that the user can make on that resource. This type of state-transfer is referred to as HATEOAS (Hypertext As The Engine Of Application State). A good way to conceptualize HATEOAS is through website navigation. We navigate websites using hyperlinks to reach the next state (in the case of the web, the next state is another hypertext document). The document we reach should always contain links to the next possible states that the user can reach from there. That is the core idea of REST, using HTTP to transfer between — or manipulate — resources.
The REST model is used for more than just hyperlink navigation however. REST is commonly implemented as an architectural model for API endpoints. In a REST API, endpoints are modelled after resources. Each resource should have it’s own endpoint that is accessed through HTTP verbs. API consumers call the resources endpoint using the appropriate HTTP verb to fetch or manipulate the resource. The HTTP verbs correspond to the four methods described in the CRUD model [34] (see Table 1).
CRUD HTTP Action
Create POST Create a resource Remove GET Retrieve a resource Update PUT Update a resource Delete DELETE Delete a resource
Table 1: CRUD operations and their corresponding HTTP verbs.
3.1 The REST principles
An API can be considered more or less ’RESTful’ depending on how well it adheres to the REST principles, as defined by Fielding [15][39]. The REST principles define six architectural constraints that define the RESTfulness of a system:
Uniform interface A resource in the system should have only one logical URI (end-point), and that URI should provide a way to fetch related or additional data.
Client-server A separation between client (API consumer) and server (API) should be maintained. The client should only know the required resource URIs, and should not need to know anything else about the server.
Stateless All client-server interactions should be stateless. The server should not store any information about previous requests. All requests should be treated as new. No history or session information should be saved.
Cacheable Caching should be applied to resources where applicable.
Layered All components of the system (client, server, intermediary soft-ware) should follow the layered pattern. That is, each component of the system should only know of its closest layer. (API consumer should not know about the database for example)
Code on demand (optional) Sending textual representations of executable code is accepted.
3.2 Measuring RESTfulness - Richardson’s Maturity Model
A good way of measuring how well an API adheres to the REST principles (how RESTful it is) is by looking at Richardson’s Maturity Model [35][38][22]. Richardson’s model measures the RESTfulness of an API by looking at the following three factors: URIs, HTTP verbs and HATEOAS (Hypertext As The Engine Of Application State). The model has four levels for describing the RESTfulness (maturity) of an API:
Level 0: Single URI and single HTTP verb
The API uses a single URI and a single HTTP verb. This is how many web-APIs are implemented, but it is not considered RESTful.
Level 1: Multiple URI and single HTTP verb
The API uses multiple URIs but only a single HTTP verb for each URI. Level 2: Multiple URIs and multiple HTTP verbs
The API uses multiple URIs and provides multiple HTTP verbs for each URI. This is commonly referred to as pragmatic REST, and it is the level of REST-fulness most commonly strived for when building an API. It does not adhere to HATEOAS, which means that the APIs consumers will rely heavily on documentation in order to know what resources, endpoints and methods are available to them.
Level 3: HATEOAS, multiple URIs and multiple HTTP verbs
The API uses multiple URIs and multiple HTTP verbs for each URI. In addi-tion to this, the API adheres to HATEOAS - which means that the responses include the URIs to all possible state-transitions from the current one. This means that the APIs consumers should not need previous knowledge about the service in order to move from one state in the application to another. The endpoints should lead the user through each possible state transition using information provided in the responses. This level is rarely achieved — or even strived for — when building an API [35].
3.3 Use cases for a REST API
The word API is commonly associated with public or commercial service APIs, where users contact an API to make use of a service. This could mean filtering their data in some way, or simply requesting a set of data from the API. These type of APIs are commonly made available using a subscription model where users pay to access the API as a service.
The REST API architecture is not only used for public or commercial service APIs. They are commonly used when developing the backend structure of websites and ap-plications. This type of REST API is usually not made available for users outside the organization that built the website or application. Instead, here the API acts solely as the backend for a single application by serving data to its frontend. This is a common architecture used when building modern web applications. By structuring the backend as a REST API, a separation between the frontend and backend of the application is cre-ated. This separation facilitates future modifications to the frontend since it constructs its views based on combinations of resources gathered by calls to the relevant REST API endpoints — instead of for example a backend with endpoints constructed specifically for each view of the frontend, which would intuitively makes sense, but could require rewrites of the backend whenever new features need to be implemented or the frontend is modified [6].
3.4 Architecture of a REST API
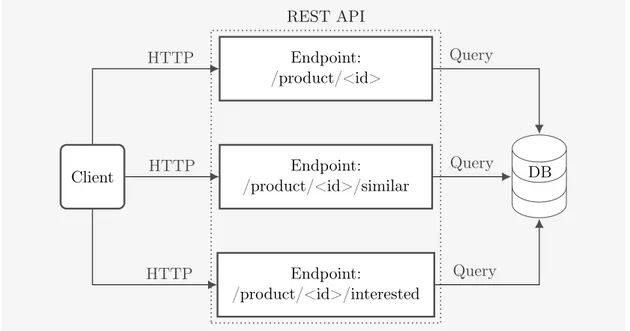
Figure 4 shows an example architecture for a section of a REST API that caters data to an e-commerce website. Since REST APIs have separate endpoints for each resource, a REST API with a large number of resources can quickly amount to a very large amount of endpoints. In the example in Figure 4, we show only three endpoints, all related to the product resource. Consider a full API for an e-commerce website with endpoints for plenty of other resources such as users, posts, promotions etc. The number of endpoints can become quite large. This means that there are a lot of things for the API consumers to keep track of. Developers of the API will need to write extensive documentation for the endpoints in order for the API consumers to efficiently make use of the API [24] [36].
Client Endpoint: /product/<id>/similar Endpoint: /product/<id> Endpoint: /product/<id>/interested DB HTTP HTTP HTTP Query Query Query REST API
Figure 4: Example of a REST API architecture.
3.5 HTTP Status codes
HTTP status codes are a three digit code detailing the status of a request [14]. The first digit indicates the status category, and the second and third digits provide further detail. 1xx: Informational Request received, continuing process
2xx: Success The action was successfully received, understood, and accepted 3xx: Redirection Further action must be taken in order to complete the request 4xx: Client Error The request contains bad syntax or cannot be fulfilled
Examples of common HTTP status codes are ’200 - OK’ or ’404 - Resource not found’. A REST API always returns an HTTP status code in its response.
4
GraphQL
GraphQL is an open specification for a dynamic query language [16]. GraphQL intends to simplify the process of developing stateless applications by using declarative resource requests. Declarative resource requests means that the API consumer declares what data they want to retrieve or mutate in their request. This allows API consumers to build the structure of the response themselves, and choose what resources and which fields within those resources they want to retrieve. That means that API consumers can request several resources with one request. It also means that the API consumers can select exactly what fields they wish to retrieve within each resource. This flexibility allows GraphQL APIs to reduce the amount of requests necessary to fetch data, and simultaneously strip away any excess data that the API consumer does not want in their response.
4.1 Origin of GraphQL
In 2012 a group of engineers at Facebook discerned some limitations with the REST API that fetched data for their mobile application. The application was making a lot of requests to the REST API backend, and fetching excessive amounts of data that was not being used. The number of requests and the amount of unnecessary data that was being fetched was pinpointed to be the largest bottleneck for the performance of the application. Most mobile internet connections were slow and unreliable at the time, which further exacerbated the problem. The mobile applications userbase was also rising rapidly as smartphones were gaining popularity and users were migrating from desktop to smartphone applications. Failing to adjust to this shift could have seriously impacted the companies future. The data that Facebook was handling was also becoming increasingly complex, and the need for a more efficient way to define complex data requirements was becoming apparent [8]. In an effort to improve the performance and flexibility of the application, the team started experimenting with ways to improve the underlying architecture. Modifying the existing REST API to create custom endpoints that provided only the data that was needed for each view of the mobile application would solve the performance issue in the short term. However, this solution would not be flexible. It would break the RESTfulness of the API, and would further convolute the process of querying for complex data by adding yet another set of endpoints. Future changes to the frontend could require large modifications or possibly even complete rewrites of the API. The solution was deemed unsustainable, and the team started working on something new [8]. The team started experimenting with declarative data fetching, allowing the API consumer to declare the structure of the response themselves. The team soon realized the potential of this approach and started putting more resources into its development. The end result was GraphQL, a declarative query language specification. The solution aptly
provided the company with a way to reduce the complexity of their API by providing a single endpoint that handles all the requests. They could now make complex data queries for the application without building new sets of endpoints each time a modification was made to the app. The number of requests and unnecessary data was reduced since the application could now define exactly what data it wanted in each request. This increased the applications performance since it no longer had to retrieve and process unused data. GraphQL was used and developed internally at Facebook until 2015, when the com-pany decided to publicly open-source it. It has since had several major releases featuring improvements suggested by the open-source community. In addition to the major re-leases, there is a continually updated working draft available on their website. This analysis will be looking at the June 2018 release, as that is the latest major release avail-able when this thesis was written. In November of 2018, the project was transferred to the newly established GraphQL Foundation [18], hosted by the non-profit consortium The Linux Foundation [21].
4.2 GraphQL in a nutshell
The data in a GraphQL API is organized in terms of types and fields, instead of a set of endpoints like in REST. All queries and mutations on a GraphQL API are instead done on a single endpoint. This endpoint is the single entryway for the full width of the APIs functionality. It is considered good practice (see Best Practices in the official documentation [19]) to name this endpoint /graphql.
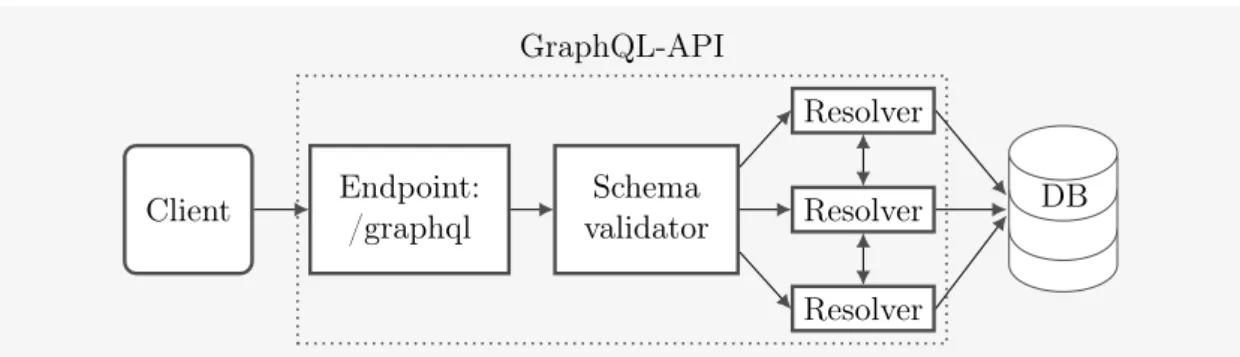
GraphQL does not use the HTTP protocol in the same manner as REST, where separate HTTP verbs correspond to different CRUD operations (see Section 3) that retrieve or manipulate data. Instead, a GraphQL API consumer sends an HTTP POST request with a JSON object named after the type of operation it wishes to perform. Note that GraphQL does support using GET for querying as well, but it is not considered good practice [19]. The GraphQL implementation receives the object, parses it and matches it against its schema (see more information on schemas in Section 4.3). If the object matches the schema — that is to say: If the fields in the object are defined in the schema, and the data types of those fields match the ones defined in the schema — it handles the request. Handling the request means calling the appropriate resolver functions for each field in the request object. The resolver functions are responsible for fetching the requested fields from the data source that is connected to that particular field. GraphQL is indifferent to what type of data source each field/resolver is connected to. The implementation can handle this in whatever way they choose. Resolvers can for example fetch data directly from a single database, from multiple databases, from another API, produce the data by itself, or use any combination of the above. The resulting fields from all the called resolvers are combined and an object with data that mirrors the structure of the query is returned.
Endpoint: /graphql Schema validator Resolver Resolver Resolver DB GraphQL-API Client
Figure 5: Example of a GraphQL-APIs architecture.
4.3 Describing data - The Schema Definition Language
In February 2018, the GraphQL Schema Definition Language (SDL) formally became part of the GraphQL specification [17]. The Schema Definition Language (SDL) is a language used for defining the APIs capabilities. The language is used to create a schema for the API that is shared with the API consumer. The schema can be seen as a contract between the API and the API consumer, defining what data exists and what functionality is available for the consumer to use on it. The schema also acts as a verification model. If the API receives a request that does not conform to the types defined in the schema, the API will invalidate the request and an error will be returned. By using Introspection, API consumers can always retrieve the latest version of the schema from the API (see more on Introspection in Section 4.4). The retrieved schema provides an up to date list of all the types that are available to the API consumers. The schema can even be used as input for linting software, streamlining the development process for consumers of the API even further by providing autocomplete and error highlighting features in their editor. 4.3.1 Types & Fields
SDL uses a type system for expressing the structure of data. It allows the developers to describe the types of data that is available and the relationships between those types. Types consist of fields. Fields in turn consist of a name and a type. The type of a field is either another type defined in the schema or a scalar type. GraphQL comes with a set of default scalar types out of the box, and developers can add their own if they need to. If developers choose to add their own scalar type they must also define how the type should be serialized, deserialized and validated. These are the default scalar types that come with GraphQL (excerpt from GraphQLs official documentation [20]):
Int: A signed 32-bit integer.
Float: A signed double-precision floating-point value. String: A UTF-8 character sequence.
Boolean: true or false.
ID: The ID scalar type represents a unique identifier, often used to refetch an object or as the key for a cache. The ID type is serialized in the same way as a String; however, defining it as an ID signifies that it is not intended to be human-readable.
SDL also supports Enumerables. An enumerable is a scalar type that is limited to a specific set of values, an example of what an enumerable looks like in SDL can be seen in Figure 7. type Product { id: ID! name: String! description: String color: [String]
size(market: Market = EUROPE): String }
Figure 6: Example of a product type definition in a GraphQL schema. enum Market { EUROPE AMERICA ASIA }
Figure 7: Example of an Enum type definition in a GraphQL schema.
Fields in a type can also be defined as Lists. A field defined as a list means that the field will return an array of that type. Lists are defined by wrapping the type in square brackets. For an example of a List, see the color field in Figure 6. SDL is strongly typed, meaning that all query and mutation requests must conform to the types defined in the schema if they are to be processed by the GraphQL API. It is however possible to let the fields of a type be null, if they are not defined as non-nullable. So it is for example not allowed to put a sequence of characters in a field defined as an Int. It is however allowed to leave a field empty, as long as it has not been defined as non-nullable in the schema. Non nullable fields are defined with a ’ !’ character at the end of the type definition in the field (see the name and id fields in Figure 6).
4.3.2 Arguments
Fields in a GraphQL type can take zero or more arguments. The arguments of a field must be named, and can be placed in any order, separated with a comma. Like fields, arguments are strongly typed and can be defined as non-nullable. Fields can also take default arguments. Default arguments are automatically given to the field if the argument was not passed in the query. An example of a field with a default argument can be seen in Figure 6, where the size field has the argument market, which is of the enum type
4.3.3 Interfaces
Interfaces are an abstract type, they define a set of fields that types which implement the interface must include. An example can be seen in Figure 9, where the ProductInterface
interface from Figure 8 is implemented by the Jacket type. By implementing the
ProductInterface interface, the Jacket must include the id and name fields. Interfaces are useful for repurposing queries for multiple types.
interface ProductInterface { id: ID!
name: String! }
Figure 8: Example of an interface type in a GraphQL schema.
type Jacket implements ProductInterface { id: ID!
name: String! description: String color: [String]
size(market: Market = EUROPE): String }
Figure 9: Example of an object type which im-plements the ProductInterface interface from Figure 8.
4.3.4 Root types
There are three root types in SDL, each representing a type of functionality that API consumers can access via requests. The root types are:
Query: The Query type is used for defining the fetching of data.
Mutation: The Mutation type is used for defining the modification of data using one of the CRUD [34] (Creating, Removing, Updating or Deleting) operations.
Subscription: The Subscription type is used for defining subscriptions to events in the system. An example of an event that consumers could subscribe to could be a data mutation on a specific type. Subscribers would be notified whenever a mutation operation is done on a chosen type. All GraphQL schemas must define a root query type. The mutation and subscription types are optional. Within each root type in the schema, operations using the respective functionality can be defined.
4.3.5 Operations
Operations are a subtype within one of the root types. That means an operation can be one of the tree types described above: Query, Mutation or Subscription. Operations can be named in order to simplify querying for the API consumers. A simple way to explain this is by drawing a parallel between operation names and function names in
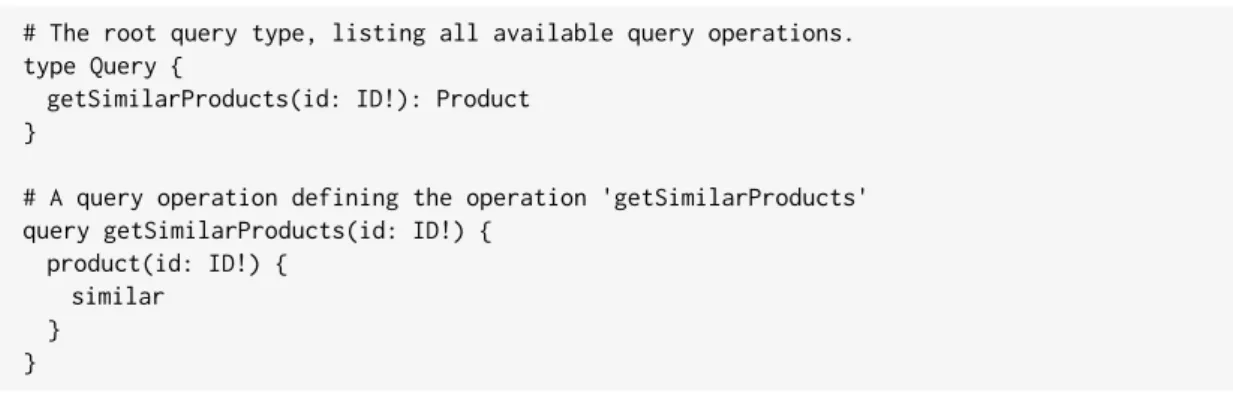
programming languages. We could make an anonymous function that provides a specific functionality. The anonymous function fills its purpose, but if it is to be used more than once in the program, it needs to be written again. When this happens we give the function a name and simply call the function name instead of repeating ourselves. Operations work in a similar way, a client can write and send a request and the GraphQL implementation will handle it. But if the developers of the GraphQL API know that this operation is commonly requested, they can place it in the schema and give it a name. This way API consumers can simply call the operation name and they do not need to write the operation themselves. Defining operations for common requests also helps with caching, by keeping the structure of common queries identical it is easier to save and predict future usefulness of fetched fields. Defining names for operations can also be helpful for developers when debugging, as browsing through a log list of named request operations is easier than a list of unnamed objects. In order for API consumers to access a named operation, it needs to be defined under the appropriate root type in the schema. An example of a Query operation can be seen in Figure 10, where a Query operation called getSimilarProducts has been defined.
# The root query type, listing all available query operations. type Query {
getSimilarProducts(id: ID!): Product }
# A query operation defining the operation 'getSimilarProducts' query getSimilarProducts(id: ID!) {
product(id: ID!) { similar
} }
Figure 10: Example of a root Query type with a single operation in a GraphQL schema. Note that the syntax for the Query type is the same as the Product type in Figure 6. The Query, Mutation and Subscription types are special root types, and its fields are handled separately by the GraphQL implementation, but syntactically they are like any other type in the schema.
4.3.6 Directives
Directives allow API consumers to manipulate the structure of a response based on an argument. There are two directives included in the GraphQL specification:
@include(if: Boolean): Include this field in the result if the argument is true.
@skip(if: Boolean): Skip this field in the result if the argument is true.
Additional directives can be implemented in the GraphQL implementation if more com-plex functionality is required, but these are the only two directives that are required in order to conform to the official 2018 specification. An example of what the @include
directive looks like when defined in an operation can be seen in Figure 11.
query Product($id: ID!, $includeSimilar: Boolean!) { Product(id: $id) {
name
similar @include(if: $includeSimilar) { name
} } }
Figure 11: Example of a GraphQL query using a directive to decide whether to retrieve the names of similar products in the response or not.
4.3.7 Mutations
Mutations are operations that modify data. Just like with queries, it is up to the imple-mentation to decide how the operation will be handled. Technically a query field resolver could also modify data, but by convention only Mutations should modify data. Mutation operations are defined in a syntactically identical way to Queries in SDL. There is not much difference in how the GraphQL implementation handles them either. Each field in the Mutation operation has its own resolver that handles the data manipulation, just like each field in a Query operation has its own resolver that handles the data fetching. Mu-tation operations can also be defined to return an object in its response. The structure of this object is also defined in the operation, just like a Query. This feature is normally used to return the newly created or manipulated data from the API without having to make a separate request.
The main difference between how GraphQL handles mutations and queries are the execution of their resolvers. The resolvers for each field in a query operation are run in parallel in order to reduce the fetching time. The resolvers for the fields in a mutation operation are run in series in order to ensure that the operation does not end up in a race condition.
mutation createProduct($name: String!, $id: ID!) { createProduct(name: $name, id: $id) {
name id } }
Figure 12: Definition of a mutation operation in a GraphQL schema.
{
"data": {
"createProduct": { "name": "Gray Sweater", "id": "101"
} } }
Figure 13: Example of a re-sponse from the operation de-fined in Figure 12.
4.4 Introspection
GraphQLs introspection feature allows API consumers to request information about the resources defined in the schema. API consumers can send a request to the /graphql
endpoint asking for information about any type and field in the schema. The request can for example ask for a list of all available types, their respective fields and what scalar type each field is made of. The extent of the information and which resource to fetch information about is constructed by the API consumer in the same way they construct any other query. An example of a GraphQL introspection query and its response can be seen in Figures 14 & 15.
{ __schema { types { name } } }
Figure 14: Example of an introspec-tion query for retrieving the names of all types in a GraphQL schema.
{ "data": { "__schema": { "types": [ { "name": "product" }, { "name": "user" } ] } } }
Figure 15: Response object from the intro-spection query in Figure 16. The schema has two types: product and user
4.5 Asking for data - Querying a GraphQL API
Queries resemble JSON objects, but without the values. This is not a coincidence, GraphQL means to simplify the building of queries for API consumers as much as pos-sible. The structure of the response will mirror the structure of the query. A query for simply retrieving a products name and description can be seen in Figure 16.
{ product(id: "101") { name description } }
Figure 16: Example of a query for re-trieving the name and description of a product with the id: ’101’ in a GraphQL API.
{
"data": { "product": {
"name": "Gray Sweater",
"description": "A gray sweater." }
} }
Figure 17: Response object from the query in Figure 16.
4.6 Additional GraphQL features
There are many additional features in the GraphQL specification, such as Subscriptions, Aliases, Fragments, Union types, Input types etc. which we will not describe in depth in this thesis. For more information on these features see the official documentation [16].
5
Quality attributes
A quality attribute describes a nonfunctional characteristic of a system. The IEEE Standard 1061-1998 defines software quality in the following way: ”Software quality is the degree to which software possesses a desired combination of attributes (e.g., reliability, interoperability)” [1]. There is no universal definition for all quality attributes. Various definitions can be found in different standards, many of whom describe the same or similar characteristics, but using different denominations [9] [6]. The main difference between models are the number of attribute definitions and their specificity. This analysis has chosen to use the FURPS quality model, proposed by Grady [25]. FURPS was chosen because its attribute definitions were found to be clear, concise and adequately descriptive for the analysis. There are other models with a higher number of attribute definitions with more specificity available, but they were found to provide no additional benefit to the analysis over the FURPS model.
5.1 FURPS
FURPS is a model for quality attribute definitions. It contains a set of five quality attributes, under which more specific concerns can be defined. FURPS is an acronym for:
Quality attribute Common concerns
Functionality Capability, Reusability, Security
Usability Human Factors, Aesthetics, Documentation, Responsiveness Reliability Availability, Failure Extent & Time-Length, Accuracy Performance Speed, Efficiency, Throughput, Capacity, Scalability Supportability Maintainability, Testability, Flexibility, Localizability
Table 2: The FURPS quality attributes and their common concerns.
5.1.1 Concerns
Concerns are the requirements used to assess a quality attribute of an architecture [4]. Example of concerns for the Performance quality attribute (excerpt from Barbacci [4]): Latency: How long does it take to respond to a specific event?
Throughput: How many events can be responded to over a given interval of time? Capacity: How much demand can be placed on the system while continuing to
meet latency and throughput requirements?
6
Architecture Tradeoff Analysis Method (ATAM)
The Architecture Tradeoff Analysis Method (ATAM) is a method for analyzing an ar-chitecture’s ”suitability” to a certain system. The ATAM was developed by the Software Engineering Institute at Carnegie Mellon University. The ATAM aims to measure how well an architecture would satisfy the quality attribute goals of a system. Quote from ATAM: Method for Architecture Evaluation [23]: The purpose of the ATAM is to assess the consequences of architectural decisions in light of quality attribute requirements.
The final evaluation of the architectural design aims to uncover:
Risks: Architectural decisions that could cause problems in one or more attributes.
Sensitivity points: Properties of one or more components/relationships that are vital for achieving an attribute goal. In other words, sensitive parts of the system which can have drastic effects on the quality of the overall system if changed.
Tradeoffs: Architectural decisions that affect more than one attribute. We start by defining the driving quality attributes of the system. After the driving quality attributes have been defined, we define scenarios testing the attributes. We then evaluate the architectures response to the scenarios in order to uncover its tradeoffs, risks and sensitivity points. Descriptions of these procedures follow in the sections ahead.
6.1 Defining the quality attributes
In order to evaluate an architectural designs fitness for a certain system, characterizations of its most important quality attributes are necessary. Excerpt on what to consider when defining the important quality attributes for an architecture, from ATAM: Method for Architecture Evaluation [23]: What are the stimuli to which the architecture must respond? What is the measurable or observable manifestation of the quality attribute by which its achievement is judged? What are the key architectural decisions that impact achieving the attribute requirement?
6.2 Defining scenarios
A scenario describes a stakeholders interaction with the system. Quote from Software Architecture In Practice [6]: ”A quality attribute scenario is a description of a testable quality attribute requirement.” Each scenario should describe a stimulus and a response. The scenarios act as interactions that test the viability of the architecture by analyzing its response to the stimuli.
6.2.1 Use case scenarios
Use case scenarios describe a users interaction with the existing system. Example of a use case scenario: API consumer requests a resource during peak period and recieves it within 1 second.
In the above example, the scenarios stakeholder is the API consumer, its stimulus is the request of a resource during peak period, and its response is returning the resource within 1 second.
6.2.2 Growth scenarios
Growth scenarios describe anticipated changes to the system. These scenarios mainly affect the supportability attribute, but can also affect other additional attributes. Ex-ample of a growth scenario: Add a new resource to the API in less than 20 hours of development time.
In the above example, the scenarios stakeholder is the project manager, its stimulus is the addition of a new resource to the API, and its response is succeeding to add the new resource within 20 hours of development time.
7
Representative Example
The representative example API will serve as an input for the ATAM. It aims to represent a data-fetching web API in order for us to better comprehend how such an API would be affected by the architectural patterns in a GraphQL implementation. The example
represents a data-fetching API connected to a database. A data fetching API was chosen for the representative example in order to highlight the declarative fetching feature of GraphQL. Since declarative fetching is the main feature that sets it apart from other architectures in the area, it was predicted that analyzing an API that utilizes this feature would provide the most valuable analysis.
7.1 Quality attribute characterizations & concerns
This section contains characterizations on the quality attribute concerns for the repre-sentative example API.
7.1.1 Performance
The performance attribute can be split into the following concerns:
Latency: How long does it take for the architecture to process a request and return a response? (excluding network latency)
Throughput: How much data can the architecture process and return within a given timeframe?
Capacity: How many requests can the API handle within a given timeframe? 7.1.2 Usability
The usability attribute can be split into the following concerns:
Documentation: How consistent is the documentation? How easy is it for an API consumer to find and process the information he or she needs? Customizability: How much can the API adapt to an API consumer’s needs? (How
much can the API consumer modify the responses to their liking?) 7.1.3 Supportability
The supportability attribute can be split into the following concerns:
Modifiability: How difficult is it for the API developers to modify the API? (How easy is it to add or update resources?)
Maintainability: How difficult is it for API developers to maintain the API? (How easy is it to maintain the code and provide support for the API?)
7.2 Scenarios
This section lists the scenarios defined to test the quality attributes of the system. These scenarios are built to prompt analysis on the most affected parts of the architecture. The scenarios are based on the common operations detailed in the Google and Microsoft API design guidelines [24][35][36]. The scenarios are categorized by scenario type (see Section 6.2). Scenarios are named after the scenario type, with the first letter of the type as a prefix. Eg. Scenario U(se case)1.
7.2.1 Use case scenarios
Scenario U1: Display available resources to API consumers
Stimulus: API consumer requests to see what resources are available to them.
Response: The API returns a list of the resources that the API con-sumer can access in < 200ms.
Scenario U2: Query a single resource in the API.
Stimulus: API consumer queries a single resource in the API. Response: The API parses the request and returns a response object < 200ms.
Scenario U3: Query multiple resources in the API simultaneously.
Stimulus: API consumer queries multiple resources in the API at the same time.
Response: The API parses the request and returns a response object (or objects) in < 200ms.
Scenario U4: Modify a single resource in the API.
Stimulus: API consumer sends a request to modify a single resource in the API.
Response: The API parses the request, modifies the resource and returns a response confirming the modification in < 200ms.
Scenario U5: Modify multiple resources in the API.
Stimulus: API consumer sends a request to modify multiple resources in the API.
Response: The API parses the request, modifies the resources and returns a response confirming the modifications in < 200ms.
Scenario U6: Handle an invalid request.
Stimulus: API consumer sends an invalid request to the API. Response: The API parses the request and returns an error code detailing what is invalid in the request in < 200ms.
7.2.2 Growth scenarios
Scenario G1: Add a new resource type to the API.
Stimulus: The API developers add a new resource type to the API for consumers to fetch and manipulate.
Response: A new resource type should be developed and added to the API in < 40 working hours.
Scenario G2: Update a resource type in the API.
Stimulus: The API developers update a resource type in the API. Response: A resource type in the API should be updated in < 40 working hours.
8
ATAM on the representative example
This section goes through the scenarios from Section 7.2 and analyzes the representative examples response to the scenarios stimulus in order to uncover the risks, sensitivities and tradeoffs that are present in a GraphQL implementation of the data-fetching API. The REST section under each scenario describes how a conventional REST implementation would respond to the scenarios stimulus in order for a comparison to be made between the two architectures.
Note about the term ’resource’ in the following scenario comparisons: A resource in REST is represented by an endpoint. The equivalent of a resource in a GraphQL implementation is a type. They are discussed interchangeably in these comparisons as they represent the same data structure in both implementations.
8.1 Scenario U1 - Display available resources to API consumers Stimulus: API consumer requests to see what resources are available to them. Response: API consumer is presented with a list of the resources that they can access. 8.1.1 REST
A REST implementation that is considered highly RESTful (Level 3 on Richardson’s maturity scale, see Section 3.2) would include the possible actions that the user could take on a resource (or relevant resources) within its regular query responses. This is beyond what is considered pragmatic REST and is not included in most REST API
implementations, but it is a part of the REST philosophy [15]. In a pragmatic REST API, all resources are documented separately from the API responses, usually in a hypertext document [24][35]. There is no direct equivalent to GraphQL’s introspection feature available in a REST architecture, in the sense that the API consumer themselves can build a request asking for specific information. REST API schema systems such as OpenAPI [28] exist to fill a similar function, but these systems are not inherent to RESTs architectural design.
8.1.2 GraphQL
In a GraphQL implementation, the API consumer can use introspection (see Section 4.4) to request a list of all available types, fields and operations from the API. Information can be fetched about the full schema of resources (types, fields and operations), or it can be fetched about a single resource, or any number of combinations of resources. The API consumer builds a query themselves where they can choose which resource to retrieve information about, and what specific information about that resource they wish to retrieve (what types exist in the resource, what kind of scalar type a field is defined as etc.). The introspection feature automatically builds the responses using the GraphQL schema, and is therefore always up to date with the current version of the API with no extra effort from the API developers. See more about introspection in Section 4.4. Note that introspection does not inherently include a text description explaining what the resource represents. Introspection only provides information about the technical details such as it’s scalar types etc. It is of course possible for an implementation to implement a constant string field within each type describing what it represents, which could make the full width of the APIs resources and possible actions documented within a single response.
8.2 Scenario U2 - Query a single resource in the API. Stimulus: API consumer queries a single resource in the API.
Response: The API consumer receives a response object with the data they requested. To demonstrate the architectural differences between REST and GraphQL in regards to querying a resource, we will show what a request for the product resource would look like in both implementations.
8.2.1 REST
Querying a resource in REST means sending an HTTP GET request to that resources endpoint. The endpoint parses the request, validates potential authorization fields or other parameters and — if all is well — returns the requested resource. Query validation is not an inherent part of the REST architecture, and is handled on an implementation basis. The endpoint replies with a fixed response based on the implementation of that
specific endpoint. An example of the REST workflow for querying a single resource can be seen in Figure 18. Client Endpoint: /product/<id> REST API DB # Query:
HTTP GET /product/001 # Response:{ "product": {
"id": "001",
"name": "Gray Sweater"
"description": "A gray sweater.", "color": "gray",
"size": "XL" }
}
Figure 18: A GET request and its subsequent response from the REST API endpoint: /product/<id>.
8.2.2 GraphQL
Querying a resource in a GraphQL API means constructing a query that includes the resource (type) and the requested fields within it. The query is sent to the /graphql
endpoint with an HTTP POST request. The endpoint parses and validates the request against its schema. If the request is valid (if the requested type and its fields exist in the schema, and potential arguments are of the correct scalar type), resolvers for each field in the request are called asynchronously. The resolvers fetch or produce the requested fields and place them in a response object, which mirrors the structure of the query. Once all the resolvers have placed their fields in the response object, it is returned to the requesting client. The addition of the schema validator and resolver layers could mean a significant amount of additional processing required per request compared to REST. This is especially true for use-cases where queries do not utilize the dynamic query system to limit the number of fields to fetch. In such a use-case, none of GraphQLs features are utilized but the performance overhead from the dynamic query system is still applied, making this the worst-case performance scenario versus its REST counterpart. An example of the GraphQL workflow for retrieving a single resource can be seen in Figure 19.
Schema validator Endpoint:
/graphql product description
name DB GraphQL-API Resolvers Client # Query: HTTP POST /graphql { product(id: "101") { name description } } # Response: { "data": { "product": {
"name": "Gray Sweater",
"description": "A gray sweater." }
} }
Figure 19: GraphQL query on a single resource. Note that the query only requests the name and description fields of the product resource, whilst the REST equivalent has no choice but to fetch all fields regardless of the API-consumers needs.
8.3 Scenario U3 - Query multiple resources in the API simultaneously Stimulus: API consumer queries multiple resources in the API at the same time. Response: The API consumer receives a response object (or objects) with the data
they requested.
To demonstrate the architectural differences between REST and GraphQL in regards to querying multiple resources we will display the workflow of an API consumer that wishes to send a list of recommended products to users who have expressed an interest in a specific product. The API consumer wishes to retrieve the name and description fields of the product resource, a list of users interested in the product, and the name, id and
description fields of three similar products. 8.3.1 REST
Queries are made on separate endpoints, one for each requested resource. The end-points handle each request separately, and they are all returned as separate objects from their respective endpoints. All endpoints return fixed responses, meaning the API consumer cannot choose which fields to retrieve. Figure 20 shows what endpoint calls would be necessary in a typical REST API to perform the function described above. The endpoint /product/<id> is called to retrieve information about a product. The end-point /product/similar/<id> returns a list of products similar to <id>. The endpoint