Technology and Society
Computer Science and Media Technology Bachelor thesis 15 credits, first cycle
Manual micro-optimizations in C++
An investigation of four micro-optimizations and their usefulness
Manuella mikrooptimeringar i C++
En undersökning av fyra mikrooptimeringar och deras nytta
Viktor Ekström
Degree: Bachelor 180hp Main field: Computer Science Programme: Application Developer Final seminar: 4/6 2019Supervisor: Olle Lindeberg Examiner: Farid Naisan
Abstract
Optimization is essential for utilizing the full potential of the computer. There are several different approaches to optimization, including so-called micro-optimizations. Micro-optimizations are local adjustments that do not change an algorithm.
This study investigates four micro-optimizations: loop interchange, loop unrolling, cache loop end value, and iterator incrementation, to see when they provide performance benefit in C++. This is investigated through an experiment, where the running time of test cases with and without micro-optimization is measured and then compared between cases. Measurements are made on two compilers.
Results show several circumstances where micro-optimizations provide benefit. However, value can vary greatly depending on the compiler even when using the same code. A micro-optimization providing benefit with one compiler may be detrimental to performance with another compiler. This shows that understanding the compiler, and measuring performance, remains important.
Sammanfattning
Optimering är oumbärligt för att utnyttja datorns fulla potential. Det finns flera olika infallsvinklar till optimering, däribland så kallade mikrooptimeringar. Mikrooptimeringar är lokala ändringar som inte ändrar på någon algoritm.
Denna studie undersöker fyra mikrooptimeringar: loop interchange, loop unrolling, cache loop end value, och iterator-inkrementering, för att se när de bidrar med prestandaförbättring i C++. Detta undersöks genom experiment, där körtiden för testfall med och utan mikrooptimeringar mäts och sedan jämförs. Mätningar görs på två kompilatorer.
Resultatet visar flera situationer där mikrooptimeringar bidrar med prestandaförbättringar. Värdet kan däremot variera beroende på kompilator även när samma kod används. En mikrooptimering som bidrar med prestandaförbättring med en kompilatorn kan ge prestandaförsämring med en annan kompilator. Detta visar att kompilatorkännedom, och att mäta, är fortsatt viktigt.
Table of Contents
1 Introduction 7
1.1 Background 7
1.1.1 Interchange 9
1.1.2 Unrolling 9
1.1.3 Cache loop end value 10
1.1.4 Iterator incrementation 10 1.2 Research question 11 2 Method 12 2.1 Method description 12 2.2. Method discussion 13 3 Results 14 3.1 Interchange 15 3.2 Unrolling 16
3.3 Cache loop end value 17
3.4 Iterator incrementation 19 4 Analysis 20 4.1 Interchange 20 4.1.1 int[][] 21 4.1.2 int** 21 4.1.3 vector<vector<int>> 21 4.1.4 int[col * row] 22 4.2 Unrolling 23 4.2.1 int[] 23 4.2.2 vector<int> 23 4.2.3 vector<float> 24 4.2.4 vector<float> * 0.5 24
4.3 Cache loop end value 24
4.3.1 Short string, subscript 24
4.3.2 Long string, subscript 25
4.3.3 Long string, iterator 25
4.3.4 vector<int>, subscript 25
4.3.5 vector<int>, iterator 26
4.4 Iterator incrementation 26
4.4.2 Vector<float> DLL 26
5 Discussion 27
5.1 Interchange 27
5.2 Unrolling 27
5.3 Cache loop end value 28
5.4 Iterator incrementation 29
6 Conclusion 30
References 31
1 Introduction
Modern computers are fast, and tend to become faster each year. Modern computers are however not fast enough for programmers to completely disregard how efficient their programs are. Spending some effort to maximise efficiency can provide numerous benefits. The program may run faster or be smaller, making time and space for other processes, or save time for the user. The possibility of using less powerful, but cheaper, hardware is a monetary gain, and with lower electricity consumption, it is also good for the environment. The key to efficiency is optimization . There are many approaches to optimization, including (at least in a C++ context, which this study is interested in): using a better compiler, a better algorithm, a better library or a better data structure [1]. These optimization approaches imply large changes, but they can also provide large benefits. Of course, the optimization approach of least effort is to simply let the compiler handle it, which is possibly also the most important optimization of them all.
Another approach is micro-optimizations , defined in this study as local adjustments that does not alter any algorithm. These are small changes, that tend to be easy to perform, that provide some benefit. This study investigates when micro-optimizations are beneficial to perform on compiler optimized code.
1.1 Background
For all the potential benefits involved, optimization is a fairly opinionated field. Donald Knuth implored in 1974 that optimization has its time and place, and that premature optimization is the root of all evil, creating needlessly complicated code [2]. Knuth is widely quoted even today [3], and commonly so to dismiss curiosity regarding optimization. Michael A. Jackson presented two rules in 1975: Do not optimize, and do not optimize yet, because in the process of making it small or fast, or both, it is liable to also make it bad in various ways [4]. These opinions are from an era when assembly code reigned (meaning everything was more complicated from the start, with or without optimization) and the validity of applying these quotes to the sphere of modern high-level programming languages can be questioned.
Kernighan and Plauger appealed in 1974 to not “sacrifice clarity for small gains in ‘efficiency’”, and to let your compiler do the simple optimizations [5]. Wulf et al. argued that efficiency is important, but also saw compiler optimization as a way of having both convenient programming and efficient programs [6]. The importance of compiler optimization has been known and studied for a long time by now. McKeeman claims that the barrier to good compiler optimization is cost in time and space [7]. Stewart and White show that optimization improves performance in applications, stemming from improvements like path length reduction, efficient instruction selection, pipeline scheduling, and memory penalty minimization [8]. A hardware aware compiler, with the proper support for the features of the hardware, is important for performance [8].
Scientific investigations of the benefits of manual micro-optimizations seem uncommon based on the literature search performed for this study. Unpublished opinions are still to be found on the web, where writers may also do some investigation. Scientific studies of micro-optimizations tend to focus on one in particular and some specific aspect of their application, most common as a compiler optimization.
Dependence analysis , the analysis of which statements are dependent on which statements, is an important part of understanding and performing loop transformations, such as interchange [9]. Song and Kavi show that detecting and removing anti-dependencies, making loops appear cleaner, can expose further opportunities for analysis and optimization [10]. Sarkar show that performance improvements can be gained by treating the loop unrolling factor selection for perfectly nested loops as an optimization problem [11]. Carr et al. show that unroll-and-jam, or outer-loop unrolling, can improve pipeline scheduling, a desired outcome for regular unrolling as well [12]. Huang and Leng have created a generalized method for unrolling not just for loops but all loop constructs, with modest speed increase but easy to perform [13].
Vectorization, operations on several array elements at once, is possible only under certain circumstances, but will increase performance thanks to the use of SIMD (Single Instruction Multiple Data ) instructions [14]. It can be achieved by letting the compiler handle it, which is the easiest, but Pohl et al. show that the best performance comes from manual implementation, for example through the use of intrinsics [15].
There are many studies comparing performance between different compilers. Jayaseelan et al. show that the performance of integer programs is highly sensitive to the choice of compiler [16]. Gurumani and Milenkovic compare Intel C++ and Microsoft Visual C++ compilers in a benchmark test and find that Intel C++ perform better in every case [17]. A similar study by Prakash and Peng, with the same compilers but with a later version of the benchmark, show that Intel C++ mostly outperforms Microsoft Visual C++ [18]. Calder et al. compare the performance between GNU and DEC C++ compilers, but without much discovered difference [19]. Calder et al. do however show that object-oriented C++ programs force the compiler to do more optimization compared to that of a C program [19]. Some of this is due to a larger number of indirect function calls [19], which is the subject of several studies, aiming to improve performance, for example by Mccandless and Gregg, and Joao et al. [20], [21]. Karna and Zou show that GCC is in general the most efficient C compiler on Fedora OS [22], which is a very specific thing to investigate, but likely of great interest to C programmers using Fedora. While compiler comparisons are always interesting, any single study risks becoming irrelevant with each compiler update. This is a good argument to always keep doing them.
Spång and Hakuni Persson investigate four types of C++ micro-optimizations: loop interchange, loop unrolling , caching of the loop end value , and proper iterator incrementation, on two compilers, GNU G++ and Clang, to see what benefits can be gained from their use [23]. Their findings show both benefits and drawbacks. Interchange and caching the loop end value are found to be beneficial, and unrolling and iterator incrementation are found to be either detrimental or causing no change. While time measurements are performed, assembly code analysis is not, leaving the results somewhat unexplained.
Since this study also investigate the same four micro-optimizations, an introduction to them follows in the next four sections.
1.1.1 Interchange
Loop interchange will change the order of two perfectly nested loops, with no additional statements added or removed [24]. The basic idea is to get the loop that carries the most dependencies to the innermost position [25]. While it may seem simple, loop interchange is a powerful transformation that can provide increased performance via vectorization, improved parallel performance, reduced stride, increased data access locality, register reuse, and more [24], [26].
for(j = 0; j < len; j++) for(i = 0; i < len; i++)
sum += arr[i][j]; Fig 1. Original code
for(i = 0; i < len; i++) for(j = 0; j < len; j++)
sum += arr[i][j]; Fig 2. Interchanged code
The innermost loop of nested loops determines which array dimension is accessed sequentially (whichever dimension the loop is iterating over), which is a reason why loop interchange can be powerful [25]. Array data is fetched in a certain order, row- or column-major order, and likely cached. If the loop accesses these elements in the correct order, then these element will more likely be found in the cache, and new data need not be fetched from main memory. Efficiency is thus gained by adhering to row/column-major order, which for C++ specifically is row-major.
Register allocation and reuse is another important optimization factor. Interchange can achieve this by having the innermost loop be the one carrying the most dependencies [25]. As the variable is often needed it will likely stay in a register. The best choice for this problem is not necessarily the best choice for accessing cached data, which is why interchange can require a careful study of the loop dependencies [25], [24].
1.1.2 Unrolling
An unrolled loop will have the statements of its body repeated in the code, such as they would have been repeated by the loop itself. The unroll factor with which statements are repeated and with which loop iterations are divided is the same. As this factor grows so does the size of the code, which is one of the drawbacks of unrolling [27]. Unevenly divided iterations and loops with variable control parameters require additional code for the extra loops and to check for end states, again increasing code size [11], [27]. Aggressive unrolling can increase register pressure, where the number of live values exceed the number of registers [28], [11]. This leads to register spilling, where slow memory will be used instead of fast registers.
Luckily the benefits are also plentiful. The number of executed instructions are reduced, since fewer comparisons and increments/decrements will be performed [27]. Where
statements are not dependent on each other, instruction-level parallelism can be gained from unrolling as well [27]. Loop unrolling can be done on both a single loop or perfectly nested loops, and in that case, as is implied, on the innermost loop.
for(i = 0; i < len; i += 4) { sum += arr[i]; sum += arr[i + 1]; sum += arr[i + 2]; sum += arr[i + 3]; }
Fig 3. Loop unrolled by factor 4.
1.1.3 Cache loop end value
In loops where some value in the loop condition is returned by a function, storing that value in its own variable before the loop body could possibly provide improved performance by reducing the number of function calls from one for each iteration to one in total [1].
for(i = 0; i < arr.size(); i++) sum += arr[i];
Fig 4. Not cached loop end value
int len = arr.size(); for(i = 0; i < len; i++)
sum+= arr[i]; Fig 5. Cached loop end value
If the function would indeed be called every iteration, the performance benefit would depend on whatever work that function is doing. One would not be faulted to assume that modern compilers are capable of recognising repeated function calls with identical return values, and optimize these automatically. Not calling strlen() to get length of a C-style string every iteration of a loop is one example where caching of the loop end value will provide increased performance [1].
1.1.4 Iterator incrementation
The difference between post- and pre-incrementation of an iterator is (or should be) that the post-incrementation return a copy of the iterator as it was before the pointer was incremented [29]. The possibility of any performance increase here is to save the work of copying and returning an unused iterator. Most C++ programmers likely know the difference and will neither confuse nor misuse these, but it is also possible they assume it does not matter, as they trust the compiler.
1.2 Research question
This study aims to examine the effects of manual micro-optimizations in C++ to see if any performance benefit can be gained from their use. The purpose of this is: to see if manual micro-optimizations are worth performing; to validate any benefit of a micro-optimization; to learn the behaviour of the compiler, to see how it reacts to certain micro-optimizations; and to learn when a micro-optimization hinders efficient compiler optimization.
Performance benefit in this study refers to reduced running speed of the code, and not any other aspects such as reduced memory imprint or code size, which could be a more important factor in some circumstances.
This study, focusing on four micro-optimizations, pose the following questions: - When can performance benefit be gained from manual loop interchange? - When can performance benefit be gained from manual unrolling of loops? - When can performance benefit be gained from caching of the loop end value? - When is proper iterator incrementation relevant to performance?
- When can performance penalties occur from any of the four manual micro-optimizations?
The four types of micro-optimizations have been chosen because they are investigated in a previously performed study by Spång and Hakuni Persson [23]. That study failed to fully look into the effects of the manual micro-optimizations by neglecting assembly code analysis, meaning that there likely are conclusions still left to be discovered in regards to these four types. Including additional micro-optimization types would be possible, but the investigatory depth given to each would be more limited. This could provide less interesting results while also increasing the workload of the study.
The following predictions are made for the questions posed:
- Manual interchange is expected to be beneficial when used with nested loops implemented in column-major order. Interchange is expected to provide significant performance increase when the compiler does not perform it.
- Manual unrolling is expected to provide faster executed loops when used with all loops, increasingly so for each unrolling factor. It is expected that the compiler will not perform proper unrolling due to code size penalties.
- Caching the loop end value is not expected to provide noticeable performance increase when used with size() or end() . It is expected that calls to size() or end() , if they are made each iteration, are fast enough already for it to not be noticeable. - Post-incrementation of an iterator where the return value is unused is expected to
be optimized by the compiler, meaning that a change to pre-increment has no effect. If the iterator is from a dynamically linked library, post-incrementation is not expected to be optimized by the compiler, and manual altering to pre-incrementation will provide small performance benefit.
2 Method
The method for this study is an experiment [30], in which the running time of a number of test cases is measured. The results of these measurements are presented in the Results section. The assembly code for each test case is also collected, and is analysed in the Analysis section to explain the measurements.
While the initial intention of this study was to repeat the experiment performed in [23], since the test cases or code used where not preserved, an exact repetition is not possible.
2.1 Method description
The quantitative data, the running time measurements that is to be compared, and the assembly code to be analysed, will be collected through 42 different tests cases. The content of all test cases are described in the Results section, but all involve loops. Test cases are in part inspired from what was available in the previously performed study’s text [23], such as mostly doing integer addition in the working loop; using unrolling factor one, four and sixteen; and testing interchange on pseudo two-dimensional arrays. Some test cases are based on the results of measurements when further measurements seemed relevant. The limit to the number of test cases is set by imagination and time constraint.
Two compilers are used for measurements: GNU G++ 8.2.0 and Microsoft Visual C++ 19.11.25547, hereafter referred to as MSVC . G++ test cases are compiled with optimization flag O3 , and warning flag Wall . MSVC test cases are compiled with optimization flag O2 , and warning flag EHsc. No code is compiled without compiler optimization.
The running time is measured for each test case. This is done with the CPU’s Time Stamp Counter, which counts clock cycles [31]. On Linux the counter is available in the x86intrin.h header and on Windows in intrin.h . Time measurement code is from [32]. A test case is run 110 times, with the first ten runs ignored, since the first runs might have much higher cycle count before the data and code are fully loaded into the cache. The average cycle count is calculated from the remaining hundred tests, and taken as the result. If any of the hundred results exhibit abnormally high clock counts (due to unknown interference), the test is redone so that one or a few high values does not skew the average. Time is measured from the start of the working loop to the end; no setup or I/O included.
For G++ the assembly code is generated from the G++ object files using objdump , available on Unix. For MSVC the FAsuc flag is used when compiling, which will generate an assembly file. Intel x86 syntax is produced by both methods. The GDB (GNU Project Debugger) disassembler and Microsoft Visual Studio ’s built-in disassembler, capable of stepping assembly code, are used when some extra investigation is needed in the Analysis section.
MSVC is used on an Intel Core i7-4790S , with Windows 10 . G++ is used on an Intel Core i3-6100U, with Ubuntu 18.04 . Both CPUs are 64 bit with instruction set extensions SSE4.1 ,
SSE4.2, and AVX2 [33]. These are the instruction sets containing the SIMD instructions, enabling vectorization. The i3 has a 32kb level 1, a 256kb level 2, and a 3mb level 3 cache. The i7 has a 128kb level 1, a 1024kb level 2, and a 8mb level 3 cache.
2.2. Method discussion
Given that the method involves observations of running time data, which is numerical, and that the difference between two test cases tends to be only a single adjustment, experiment is an appropriate method for this study [30]. With the same code and the same compiler version and processor, the experiment should be repeatable.
Measuring running time with high precision is a difficult task on a modern computer due to the many different processes inevitably running at the same time [1]. The measured program is not guaranteed uninterrupted CPU time, and the cycle count will fluctuate on every one of the hundred measurements for any one test case. However, after a hundred tests the clock cycles reveal some range they fall in. Clock cycles is an appropriate unit for measurement in this study as it corresponds somewhat with the instructions performed, which can be useful for the assembly code analysis.
The fact that the two compilers are being used on two different computers is an unfortunate consequence of circumstances. However, with the processors being of similar make and having the same instruction set, they pair well enough. Results from the two different computers and compilers are not directly compared against each other, but differences might be reflected upon in the Analysis and Discussion sections.
Drawing conclusions from the running time as to what the compiler has done is difficult. By analysing the generated assembly code it is possible to see what transformations and adjustments were made by the compiler, even if it will not always reveal why.
With memory speeds trailing behind CPU speeds, the CPU cache has become an important factor for performance in modern computers [34]. Measuring cache misses could provide additional data to better explain results, but focus was placed on time measurements only, in an interest of limiting the workload of the study.
The two compilers used for this study, GNU G++ and Microsoft Visual C++, have been chosen due to their widespread use. Using more than one compiler provides interesting perspective on different optimization approaches, but more than two would make for an encumbering workload, especially when analysing assembly code.
3 Results
This section describes the test cases and presents the results of the running time measurements. These results are further explained through assembly code analysis in the Analysis section.
A test case without a manually applied optimization is a base case, and a test case with the applied optimizations is compared against the base case. The base case is represented by 1.00 together with the base case’s measured clock cycle count in parenthesis. The case with the applied optimization will either have a larger number, meaning a speed increase by as many times compared to the base case, or a smaller number meaning a speed decrease by as many times. For example 2.00 would mean it is two times faster than the base case, and 0.50 would mean that a test case is two times slower than the base case. The clock cycle count is not presented for the cases with the applied optimization for a cleaner presentation. Divide the base case cycle count with the result for a test case with the applied optimization to get its cycle count.
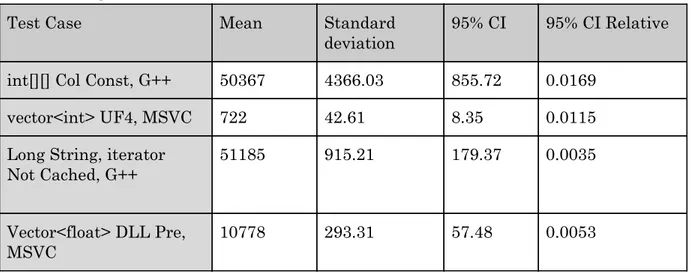
An approximation of the margin of error of the measurements performed is presented in Table 1, based on four test cases, showing the mean for the hundred runs for one test case, the Standard Deviation , the 95% Confidence Interval or CI , and the 95% Confidence Interval Relative.
Table 1. Margin of error
Test Case Mean Standard
deviation 95% CI 95% CI Relative int[][] Col Const, G++ 50367 4366.03 855.72 0.0169
vector<int> UF4, MSVC 722 42.61 8.35 0.0115 Long String, iterator
Not Cached, G++ 51185 915.21 179.37 0.0035 Vector<float> DLL Pre, MSVC 10778 293.31 57.48 0.0053
3.1 Interchange
All interchange measurements involve two-dimensional data structures with int as the data type. Four different data structures are used: built-in array (int[][] ) for compile time array sizes, pointer to pointer array (int**) for running time array sizes,
std::vector<std::vector<int>>, and pseudo two-dimensional array, which is a one dimensional array with the size of cols * rows, accessed with row * cols + element.
112 rows and 1024 columns, column elements are random numbers in the range of 1 and 150, read from a file. The number of columns and rows were chosen to be evenly divisible. For each data structure one test case use row-major order and one use column-major order. For std::vector and int[col * rows] , one variation has the loop size present at compile time and one where it is given at run-time. Row and column sizes are passed as arguments when given at run-time, except for std::vector where push_back() is used. The inner loop add the sum of all elements.
In Table 2.1 and 2.2 Col refers to a column-major implementation, where the inner loop is iterating over the first dimension, and Row to a row-major implementation, where the inner loop is iterating over the second dimension, meaning interchange has been applied. In Table 2.2 Const means the sizes of the loops/arrays/vector are available at compile time and
Input means it is provided at run-time. Table 2.1 Interchange measurements results
int[][] Col Row
G++ 1.00 (50368) 0.96
MSVC 1.00 (43112) 0.94
int** Col Row
G++ 1.00 (250361) 4.07
MSVC 1.00 (310693) 6.75
Both compilers are seemingly capable of performing interchange on int[][] , when the sizes are known at compile time. The row-major cases are very close to the base cases (they appear to even be slightly slower), and a performed interchange should show a larger performance gain.
This larger performance gain can be seen with the int** results. The sizes were given at run-time and neither compiler seems capable of performing interchange, suggested by how the row-major cases are four and and nearly seven times faster than the base case.
Table 2.2 Interchange measurement results cont.
vector<vector<int>> Col Const Row Const Col Input Row Input
G++ 1.00 (264317) 4.88 1.00 (265088) 4.04
MSVC 1.00 (300758) 4.83 1.00 (233666) 1.47
int[col * row] Col Const Row Const Col Input Row Input
G++ 1.00 (63504) 1.00 1.00 (609135) 9.55
MSVC 1.00 (643328) 16.44 1.00 (501708) 11.20
Neither compiler appears to be performing interchange for std::vector no matter the circumstance, as both Row Const and Row Input show a speed increase by four times compared to the base cases. MSVC has, at least compared with the other speed increases, a humble speed increase with just 1.47 for Col/Row Input . Worth looking into in the Analysis.
Only G++ performs interchange on int[col * row] , and only with compile-time sizes. When interchange is performed manually, and a difference is noticeably, the speed increase is significant, 16.44 times faster as the biggest increase.
3.2 Unrolling
Unrolling is measured on built-in int array, std::vector<int> , and std::vector<float> . The main loop summarize the elements, with one variation using std::vector<float> that also multiply each element with 0.5 before adding it to the sum. Each of these were measured with unrolling factor 1, 4 and 16. Numbers for the structures are read from a file, 1024 random numbers in the range of 1 to 150, or 1.0 to 150.0 for float . 1024 is again chosen to be evenly divisible. Loop length is known at compile time for all cases.
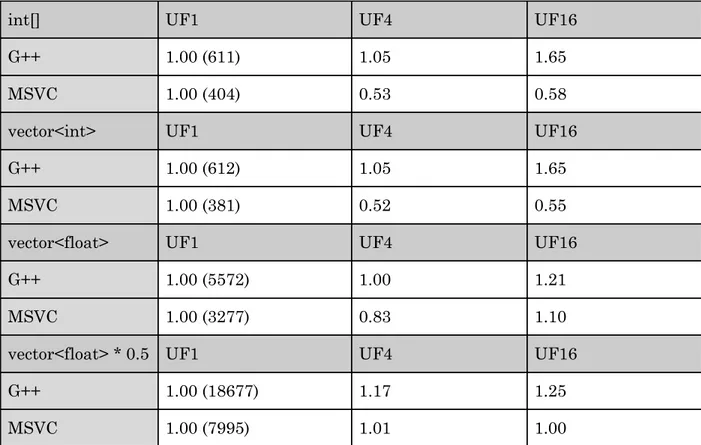
In Table 3 the base case is always column UF1 , where no manual unrolling has been done, so both UF4 , where the loop is unrolled by four, and UF16 , where the loop is unrolled by sixteen, are compared against UF1.
Table 3. Unrolling measurements results
int[] UF1 UF4 UF16
G++ 1.00 (611) 1.05 1.65
MSVC 1.00 (404) 0.53 0.58
vector<int> UF1 UF4 UF16
G++ 1.00 (612) 1.05 1.65
MSVC 1.00 (381) 0.52 0.55
vector<float> UF1 UF4 UF16
G++ 1.00 (5572) 1.00 1.21
MSVC 1.00 (3277) 0.83 1.10
vector<float> * 0.5 UF1 UF4 UF16
G++ 1.00 (18677) 1.17 1.25
MSVC 1.00 (7995) 1.01 1.00
For int[] , std::vector<int> and std::vector<float> G++ show no or a very small difference between UF1 and UF4 , but some speed increase going up to UF16 . This could mean that G++ already performs an unrolling of factor 4 in the base case.
MSVC, perhaps surprisingly, performs worse on the first three data structures when unrolled, except std::vector<float> UF16 with a small speed increase. It is possible that the manual unrolling is hindering the compiler from applying vectorization, but the assembly code analysis will have to answer this.
std::vector<float> with multiplication show small increases with each larger unrolling factor with G++ but no difference with MSVC. Seeing small increases like the ones for G++ fits with the expected benefits of unrolling, shaving off iterations and executing fewer instructions. This effect is not apparent with MSVC.
3.3 Cache loop end value
Caching of the loop end value is tested on std::string and std::vector<int> . Measurements are made with one test case where the loop end variable is Cached , meaning the size or ending address is stored in a variable before the loop and with this variable being used in the loop condition, and one test case where it is Not cached , meaning size() or end() is called in the loop condition.
Test cases involving std::string has the loop check if the current character is a space character and in that case replacing it with an asterisk. It is tested on short and long strings with subscript, and on long strings using iterator. The short string, “Hello world”, was written in code and the long string was read from a file; the first 7000 or so characters from the Bible. Test cases with std::vector<int> perform the same work as in the unrolling test cases, summation of 1024 int.
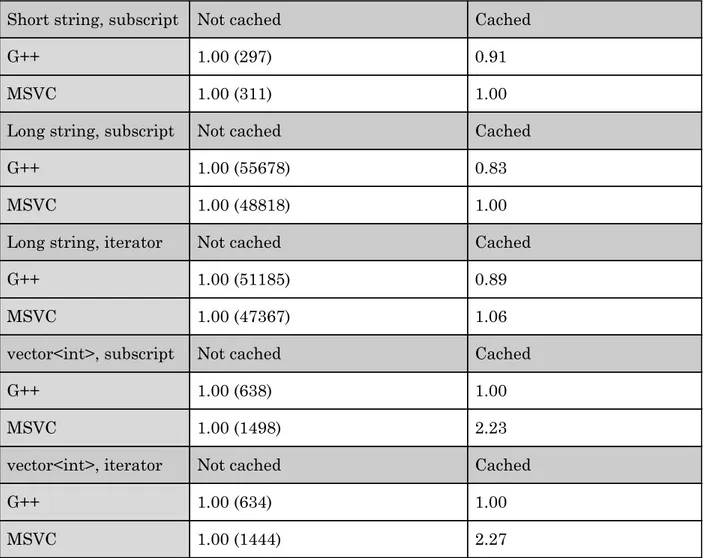
In Table 4 Not cached means i < size() or it != it.end() is present in the loop condition. This is used as the base case. Cached means that the function call is replaced with a variable initialised before the for loop and the condition will have either i < len or it != end instead.
Subscript or iterator refers to how an element is accessed.
Table 4. Cache loop end value measurements results
Short string, subscript Not cached Cached
G++ 1.00 (297) 0.91
MSVC 1.00 (311) 1.00
Long string, subscript Not cached Cached
G++ 1.00 (55678) 0.83
MSVC 1.00 (48818) 1.00
Long string, iterator Not cached Cached
G++ 1.00 (51185) 0.89
MSVC 1.00 (47367) 1.06
vector<int>, subscript Not cached Cached
G++ 1.00 (638) 1.00
MSVC 1.00 (1498) 2.23
vector<int>, iterator Not cached Cached
G++ 1.00 (634) 1.00
MSVC 1.00 (1444) 2.27
The assumption was that caching would make no difference, or at most a very small increase in speed. MSVC supports this on test cases involving std::string , where the results mostly show 1.00 vs. cirka 1.00, but not for std::vector , where Cached has a 2.23 and 2.27 times speed increase. This is too great of an increase to only be because of any saved calls to
size(), which is a simple and short function. The assembly code analysis will provide an answer.
Most surprising is the performance on std::string from G++, which performs worse on every case when Cached . Again, the answer to this must be left to the Analysis section. For
std::vector<int> there is no difference in performance between Not cached and Cached.
3.4 Iterator incrementation
Iterator incrementation is measured on three data structures: std::vector<int> ; Vector<int> and Vector<float> , which is a custom vector and iterator written to resemble std::vector ; and a Vector<float> packaged as a dynamically linked library.
Measurements for each data structure has a test case with pre-incrementation and a test case with post-incrementation. The loop is adding together 1024 int or float , in the range of 1 to 150, or 1.0 to 150.0, which are read from a file. The dynamically linked library (shared object, .so , on Ubuntu and DLL , .dll , on Windows), contains the FloatVector class (and its iterator) which is a non-templated, specialized version of Vector<float> . The reason for doing measurements with a dynamically linked library is that the definitions contained in it are not linked until run-time, meaning that the compiler does not get a chance to optimize the code.
In Table 5 Vector is the custom vector. Post means post-incrementation is used and Pre means pre-incrementation is used. DLL means the Vector is packaged as a dynamically linked library.
Table 5. Iterator incrementation measurements results
std::vector<int> Post Pre
G++ 1.00 (645) 0.99
MSVC 1.00 (1315) 0.99
Vector<int> Post Pre
G++ 1.00 (700) 1.05
MSVC 1.00 (1317) 0.99
Vector<float> Post Pre
G++ 1.00 (5575) 1.00
MSVC 1.00 (7782) 0.99
Vector<float> DLL Post Pre
G++ 1.00 (28479) 1.33
The results for all test cases except the ones for Vector<float> DLL show no real difference between Post and Pre . 1.00 to 1.05 for Vector<int> is the largest difference, of the non-DLL cases, but this is more likely due to other variances. The DLL Pre test case increase performance with 1.33 times for G++ and 1.17 times for MSVC, which is a noticeable difference. Note how Vector<float> DLL Post has twice or several times the measured clock cycles compared to Vector<float> Post . This means that there are many other optimizations as well that is not performed by either compiler due to the use of the DLL. In the other cases it seems clear that both compilers will optimize away the unnecessary copying performed by post-incrementation, when given a chance to optimize all of the code.
4 Analysis
In this section the various results from the previous section are explained through looking at the assembly code for the test cases produced by the two compilers. Each micro-optimization has their own section, with the data structures representing the different test cases as subsections. The code from both compilers are described within a subsection. Some basic x86 assembly understanding may be required to fully enjoy this section. Two important, and oft mentioned, concepts for the analysis, the cache and vectorization, are for the uninitiated briefly described below.
The cache refers to the CPU cache which is a block of small but fast static RAM, located closer to the CPU than the main RAM [28]. It is divided into three levels of increasingly larger size, where the first level is the fastest and smallest. The cache is filled with lines of contiguous data, since contiguous data is often used in sequence [28]. The cache will be checked first on memory reads or writes, and if the cache contains the data, it is a hit, and if it does not have the data it is a miss [28]. A miss means that the data must be loaded from somewhere else, farther away, which takes more time. The difference between finding data in the cache and fetching it from main memory can be over one hundred cycles [32]. Suffice it to say, cache hits are desirable.
Vectorization, treating several elements of a vector as one, is the most important factor for the performance increases for many of these test cases. Adding four elements to a sum requires four ADD instructions in a non-vectorized solution, but can be done with one
PADDD, Add Packed Integers, in a vectorized solution. PADDD in particular appears frequently throughout the assembly code, and wherever absent, is sorely missed.
4.1 Interchange
The results in Table 2.1 and 2.2 suggest that the compilers are mostly not capable of performing interchange for the various test cases. In three separate cases with manual interchange the measured time is 1.00 or close to.
Due to the different memory layouts and nested loops, interchange is a particular challenge to analyse and describe in a concise manner. The most important aspects to look for is if a
test case has been interchanged, and if vectorization has occurred in that case. These two factors will explain the majority of all performance increases.
4.1.1 int[][]
The assembly code for Col and Row test cases are identical, for both compilers, meaning the loops in Col have been interchanged. A non-interchanged Col would have the inner loop iterate over the rows, adding one int from each row every iteration. Instead, with the inner loop iterating over the columns, several int from each row become available sequentially, and vectorization can be performed. This means PADDD is used instead of ADD. G++ use one PADDD per iteration, while MSVC use two.
MSVC’s outer loop is only a single instruction, loading a register with the inner loop length. G++’s outer loop is 14 instructions, mostly used to unpack values from XMM register, something that MSVC does not do until after the outer loop ends. This is not to say that the G++ outer loop is inefficient, it is not performed as often as an inner loop after all, it is more to say that MSVC’s is elegant.
4.1.2 int**
The memory layout of the data in int** is more complicated than that of int[][] . int[][] is guaranteed to have all the int stored contiguously in memory, array after array. int** is only guaranteed to have the int within each array stored contiguously. The array at arr[1] does not necessarily follow the array stored at arr[0] in memory. Now the compiler also does not know the loop lengths, as these are passed run-time. These two factors may contribute to why Col is not interchanged for either compiler.
G++ has the inner loop of Col adding elements in the style of ADD sum-register, [row-register + column-register] . Each inner loop increments the row register, while the outer loop increments the column register. MSVC use two ADD per inner iteration, adding to two registers, and naturally incrementing the row register twice.
Row use one PADDD per inner iteration for G++ and two PADDD for MSVC , with the row register now being incremented in the outer loop. It is clear why the results show that this performs four and six times better than Col . Vectorization reduces the number of instructions and the cache can be used properly.
4.1.3 vector<vector<int>>
Interchange is not performed by either compiler when using std::vector , not even with loop lengths known at compile-time. Again, a std::vector in a std::vector is a more complex memory layout, with int values sequential in each vector, but with vectors possibly scattered. It is likely that the reasons why int** is not interchanged, is the same for why this case is not interchanged. A two-dimensional std::vector has a similar memory layout as
int**, as a std::vector<int> is basically a wrapped int*.
For Col Const , G++ use one ADD per inner loop, adding one int from each vector (or row) and incrementing the register pointing to each std::vector , with the outer loop incrementing
the column access register. MSVC does similar work, except using two ADD each inner loop. Row Const , being interchanged, can access the column elements in a more efficient manner, so G++ use one PADDD each inner iteration, and MSVC use two PADDD.
For Col Input , G++ is basically the same as Col Const . MSVC however now use only one ADD, instead of two as it has before. With Row Input G++ switch to one PADDD per inner iteration, as expected. However, MSVC still use only a single ADD for Row Input , despite the manual interchanging of the nested loops. With the inner loop length not being fixed (meaning j < vec[i].size() is used), MSVC appears too cautious to use PADDD despite having sequential access to the column elements.
MSVC’s Row Input being 1.47 times faster than Col Input still show that much can be gained from respecting the memory layout, and taking advantage of the cache, even if no vectorization occurs.
4.1.4 int[col * row]
Now the memory layout is more simple again, with all the int placed contiguously, regardless if the size was given at compile-time or run-time. Again, an array of this type is accessed in the style of arr[row * cols + element].
G++ generates the same code for Col Const and Row Const , explaining the 1.00 measurement of Row ; one PADDD in the inner loop. It is nearly identical to the code from the int[][] test cases as well (which were also identical to each other), except int[][] having one instruction more per inner iteration, a MOVDQU , Move Unaligned Packed Integer . Despite having one instruction more, int[][] is on average ten thousand cycles faster than
int[col * row]. This is curious, but beyond the expertise of the writer to be explained.
MSVC’s Col Const is not interchanged, despite loop lengths available as constant values at compile-time, and a contiguous memory layout. The most interesting instructions of the inner loop can be seen in Fig. 5 with register names changed for a clearer presentation.
add
sumReg1
, DWORD PTR [
rowReg
-
4096
]
lea
rowReg
, DWORD PTR [
rowReg
+
8192
]
add
sumReg2
, DWORD PTR [
rowReg
-
8192
]
Fig. 5. Part of inner loop of MSVC Col ConstTwo ADD per inner iteration, offset from the register holding the current row with the number of columns (1024, 4 byte each). The outer loop increments the register holding the row. A stride this big seems likely to cause plenty of cache misses on each inner loop. Each of the instructions in Fig. 5 appears dependent on rowReg as well, possibly hindering out-of-order execution, meaning each cache miss is all the more expensive. MSVC’s Row Const access the data sequentially, and is vectorized with two PADDD. This is clearly more efficient, as the 16.44 times performance increase show.
G++’s Col Input , not interchanged, has one ADD per inner iteration, incrementing the register holding the address by the number of columns. The outer loop adds four bytes to the same register. Potential cache miss problems are again likely. Row Input , being interchanged, looks much like what has been seen before. One PADDD each iteration, elements accessed sequentially.
MSVC’s Col Input , not interchanged, has a similar inner loop as Col Const ; two ADD, but now using more registers, possibly alleviating some of the dependence issue that could exist in Col Const . The outer loop has become quite large and complex, compared to that of Col Const. This is true for Row Input as well. Some of the extra code in Row Input is in case of unevenly divisible loops (meaning it will not be visited for these measurement), but much of the rest’s purpose is unclear. Regardless, it is unlikely to have much negative impact being in the outer loop. Row Input employ two PADDD each inner iteration, as is expected by now, again dramatically increasing performance.
4.2 Unrolling
The results in Table 3 show for G++ mostly no difference between UF1 and UF4 , but some increase with UF16 . Results for MSVC show performance decrease on both UF4 and UF16 compared to the base cases.
4.2.1 int[]
The code for UF1 and UF4 generated by G++ is identical, with one PADDD per iteration, effectively unrolling the loop by factor four. UF16 has an unrolling factor of sixteen by using four PADDD each iteration. MSVC’s UF1 has two PADDD per iteration, while UF4 and
UF16 have four and sixteen ADD, respectively.
Manual unrolling gets in the way of vectorization for MSVC, while G++ can handle these test cases fine. An explanation for why this happens can unfortunately not be provided here. G++ UF16 has some performance gain on UF1/4 , due to fewer iterations as it is unrolled by factor 16 while UF1/4 is unrolled by factor 4.
4.2.2 vector<int>
The pattern from int[] for G++ and the vector<int> is identical: UF1 and UF4 use one PADDD, UF16 use four. MSVC also exhibits the same pattern it did for int[] , with no vectorization for the manually unrolled cases, but with UF1 using two PADDD.
G++ use an instruction to move the packed integers to a register and then PADDD from that register to another register. This means one extra register is used for each PADDD, with eight XMM-registers being used for UF16 , since there are four PADDD. While not yet an issue here, running out of registers is one of the possible drawbacks of excessive unrolling [28].
4.2.3 vector<float>
UF1 in G++ is unrolled using four ADDSS , Add Scalar Single-precision Float . Despite loading the floating point values packed from memory, they are first unpacked and consequently added with the four ADDSS, instead of using one ADDPS, Add Packed Single-precision Float . While not otherwise identical in code, UF4 also use four ADDSS, and
UF16 use sixteen. One could suspect that G++ would not perform this type of traditional unrolling, as unrolling is not explicitly part of optimization level 3 and with additional loop unrolling flags available for use [35], but the compiler is clearly of another opinion.
MSVC unroll UF1 with eight ADDSS, UF4 use four, explaining the dip in performance, and
UF16 use sixteen. Again, some performance is gained from fewer iterations with unrolling factor 16. Both compilers choose to load the sum from memory at the start of each iteration, and store it at the end, instead of storing it in a register, despite many registers being available.
Sidenote: In this and some other cases, MSVC will use SUB to count down the loop counter. When using SUB on a register, and it reaches zero, the Zero flag in the Status Register is set, which can be used immediately with a conditional jump instruction without using a compare instruction. G++ never use SUB for this purpose in any of these test cases in this study.
4.2.4 vector<float> * 0.5
G++ performs no unrolling in UF1 . The work in the loop is likely considered too heavy for the savings from fewer iterations to matter. Some would say that this is true for any floating point operations [32], but according to the the findings for vector<float> the compilers disagree. Any difference in performance between unrolling factors is due to fewer iterations. MSVC however unrolls UF1 with eight ADDSS, and otherwise with what was requested. Despite a differing number of iterations, a difference in running time cannot be seen. No explanation can be offered for this, unfortunately.
4.3 Cache loop end value
The results in Table 4 show no difference between Cached and Not cached for std::string for MSVC or std::vector for G++. Cached cases with std::string perform worse on G++, and
Cached cases with std::vector perform better on MSVC.
4.3.1 Short string, subscript
G++ has the string size on the stack pointer, and any potential call to size() is inlined as a load from that stack location. In Not cached the size is moved to a register before the loop and is refreshed only on iterations where the character is found to be a space. Cached never touch this register in the loop. MSVC’s Not cached also loads the string size when a space is found, and this single MOV instruction is the only difference between it and Cached.
The results suggest G++ is slower Cached , but why is difficult to tell from the generated assembly code. Cached has all the loop code placed closer together compared to Not cached , so the jumps are shorter when a space character is found, while Not cached jumps further down the code. The address to the current character is in Not cached calculated with one
LEA, Load Effective Address , but in Cached with a MOV and an ADD. It is possible that this could contribute to any differences.
Sidenote: The Cached version for G++ completely unrolls the loop when the string size is fifteen characters or less, but only when the Timer class used for measurement in the test cases is removed from the code. The timer is an important part of the code, so much further investigation has not been done, but it is frightening to wonder what else could change with it removed. MSVC does not unroll the loop even when the string is one character long.
4.3.2 Long string, subscript
The loop code in this test case is for both compilers basically identical to their code from 4.3.1. With the longer string, meaning longer work and more cycles, it is now clear from the measurements that G++ Cached performs worse. Suspects responsible are the same as for 4.3.1.
Sidenote: This is one of several cases where MSVC use INC to increment a loop counter. INC (and DEC, Decrement ) only partially change the Status Register flags, which on some Intel architecture can cause a cycle penalty [36], [37]. For Sandy Bridge architecture, Intel recommend use of fewer INC instructions, opting for ADD instead, even with the partial write replaced by a micro-operation [37]. Since a later architecture (Haswell ) is targeted here it is possible that this is no longer the recommendation, or that MSVC simply does not see it as a problem. G++ never use INC or DEC in any of these cases.
4.3.3 Long string, iterator
G++ Not cached has an inlined end() in each iteration, as a single LEA instruction. Cached never touch the register holding the end address. MSVC’s Not cached use five instructions to find the end address. All of this is removed in Cached , reducing instructions in the loop from fourteen to seven, with the register holding the end value untouched.
MSVC shave off some cycles with Cached , but G++ still performs worse when Cached . As the address calculation from 4.3.1 and 4.3.2 is no longer present, the jumps, which again are structured as in previous cases, could be the culprits. No solid explanation can be given, but branch prediction misses is one possibility.
4.3.4 vector<int>, subscript
G++’s loop code for Not cached and Cached are identical. Five instructions, featuring one PADDD. The register holding the size is never touched in either case. MSVC also never care to look up the size in the loop for either case. For MSVC they are however different, with
Not cached using one ADD and Cached using two PADDD.
The performance gain in MSVC’s Cached is clearly explained with the vectorization, but it is not as clear as to why it needs to have the loop length set before the loop to enable it, especially when G++ does not.
4.3.5 vector<int>, iterator
G++ generates identical loop code, as it did for 4.3.4, for both cases. MSVC, while not completely identical to previous variation due to the use of an iterator, repeats the pattern of using one ADD for Not cached and two PADDD for Cached.
4.4 Iterator incrementation
The results in Table 5 show a performance increase for Pre only on the DLL test cases. It is assumed that Post is properly optimized by the compiler for the other test cases.
4.4.1 std::vector<int>, Vector<int>, Vector<float>
As expected, both compilers know how to optimize Post , there is no difference between it and Pre for any of the different data structures used. The code is identical between the test cases, for each compiler.
4.4.2 Vector<float> DLL
Definitions from a dynamically linked library are not visible to the compiler, and can for this reason not be optimized. This is evident from these test cases. Note: ++() is pre-incrementation, ++(int) is post-incrementation.
A non-dynamically linked library version of the Vector will in G++ look similar to using
std::vector<float>, seen in section 4.2.3, with four ADDSS, most importantly. The DLL version only has one ADDSS per iteration. Three function calls are made each iteration, *() ,
++()/++(int), and end() . The compiler does not get a chance to inline these simple functions, meaning for these test cases there are 3072 function calls, involving many PUSH and POP in addition to whatever else the function is doing, compared to a better optimized version of the program which would have zero calls. The function ++(int) is particularly expensive since it will also return a new iterator, meaning it has a function call in itself to the copy constructor. This makes it a nested function, and these should be avoided in the innermost loop [32].
The point of Pre , using pre-incrementation, is mainly to remove this unnecessary copy. As the results show, this change does have an effect on the performance. The Post loop has three instructions that differ from the Pre loop code, one extra XOR and MOV, and one MOV using different registers. These are likely only for setting up the function call, and it is the work inside the function that makes up the difference in performance. ++() consist of one MOV and one ADD. ++(int) is eleven instructions, plus another function call, as mentioned. It is an inefficient program whichever incrementation is used, thanks to the DLL, but more inefficient when using post-incrementation.
The differences in the loop code for MSVC are of a similar small nature as they are for G++. There are three instructions more in Post : two PUSH, one LEA. The DLL’s code for ++() consist of one ADD and one MOV. ++(int) is not very involved with five instructions and no function call, unlike G++’s version. This explains why the performance gain switching to
Pre is not as generous for MSVC as it is for G++.
5 Discussion
This section will summarise and give some perspective on the results of the measurements and the analysis of this study.
5.1 Interchange
Interchange is a valuable and easy to perform micro-optimization that should be considered whenever possible. Interchange is highly beneficial when performed on nested loops that are in column-major order, when two dimensional pointer based data structures are iterated, and when loop lengths are not known at compile time. As long as row-major order is respected, interchange does not have any performance penalties. Both G++ and MSVC benefit from interchange.
Of the tested cases, both compilers perform interchange when the most simple multidimensional data structure, int[][] , is used. G++ is also capable of interchanging loops iterating a so-called pseudo two-dimensional array, int[col * row] , with compile-time loop lengths, while MSVC is not. When two-dimensional pointer based data structures are involved, as with int** or with std::vector<std::vector>> , compile-time loop lengths no longer matter; the compiler does not interchange the loops.
Statements on the behaviour of the cache on the test cases made in the analysis section of this study are not based on cache performance measurements, and the cache’s assumed importance show that measuring cache hits and misses can be an important part of this type of study.
As the analysis show, test cases that iterate loops in row-major order are in all cases but one (MSVC’s vector<vector<int>> Input ) vectorized by the compiler. Vectorization is one of the claimed benefits of interchange [26]. This study shows that vectorization provides much performance benefit, and, where applicable, a programmer is wise to make sure the compiler is capable of performing it, or use intrinsics to do it manually.
5.2 Unrolling
The results and analysis of the unrolling measurements show that awareness of the compiler’s behaviour is important when applying manual unrolling. Unrolling beyond factor 4 can be beneficial with G++ to reduce iterations for a small increase in performance. Unrolling should be avoided with MSVC as it hinders vectorization.
Manual unrolling of factor 4 when using G++ is meaningless for the tested cases. The base case will already have either one PADDD, effectively unrolled by four, or four ADDSS when working with float . Unrolling factor 16 provides some performance benefit due to yet fewer iterations. The one base test case that is not unrolled by G++ is std::vector<float> with multiplication, and for it the unrolling provides some performance benefit with each additional factor.
MSVC does not react favourably to unrolling, and performance is lessened in nearly every case. The base cases already have generous unrolling, with two PADDD per iteration, and any manual application hinders continued vectorization. Cases with unrolling factor 4 will use four ADD instead of one PADDD. This is unlikely to be obsequious behaviour from MSVC, but speculation on the cause is beyond the expertise of the author. MSVC, unlike G++, unrolls the heavy work of the std::vector<float> with multiplication base case.
Unrolling is the one micro-optimization of the four investigated in this study that is the most cumbersome to write, especially so for unrolling factor 16 or more. The programmer’s own judgment must be used to assess whether the additional code is worth the minor performance benefit.
This study does not provide any measurements for the unrolling behaviour when loop lengths are not known at compile time. However, section 4.3.4 does show possible behaviour for a base case. The unrolling behaviour of the compilers with compile-time loop lengths, or fixed (const or not const ) loop lengths in the loop declaration is worthy of further study. Its omission from this study is a fault.
As this study focused on int or float array summation as the work in the loop, work that can be vectorized, potential for increased performance for other types of loop work are ignored. It is possible that MSVC can gain performance from unrolling in cases where vectorization is not relevant. Any further study should attempt to cover these circumstances.
5.3 Cache loop end value
Caching of the loop end value is shown to provide no benefit for MSVC while iterating a
std::string, but much performance benefit when iterating a std::vector . For G++ it is shown to be of no benefit when iterating a std::vector , and detrimental to performance when iterating a std::string . This means that, while simple to perform, the possible benefit from caching of the loop end value depends much on compiler and circumstances.
One of the more confounding findings of this study is how G++ reacts unfavourably to caching of the loop end value with std::string , with performance penalties for all test cases. In section 4.3.3, given that the loop contains an if-clause, branch prediction misses is given as a possible explanation, even if this fails to explain why the non-cached test case does not exhibit the same performance penalty. This is an interesting observation, but since the form and content of if-clauses can vary widely, it is not possible to claim that caching cannot provide benefit in other circumstances involving std::string or if-clauses with G++. Further study is recommended, and any such investigation is wise to include more detailed measurements, such as number of branches and branch prediction misses.