M¨
alardalen University
School of Innovation Design and Engineering
V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Computer Science with
Specialization in Embedded Systems 30.0 credits
AUTOMATIC PLANNING OF
COLLABORATING AUTONOMOUS
UNMANNED AERIAL VEHICLES
Joakim Kareliusson
jkn11013@student.mdh.se
Examiner: Dag Nystr¨
om
M¨alardalen University, V¨aster˚as, Sweden
Supervisor: Baran C¨
ur¨
ukl¨
u
M¨alardalen University, V¨aster˚as, Sweden
Company supervisor: Zoran Sjanic, Lars Rundqwist
SAAB AB, Link¨oping, Sweden
Abstract
Collaboration between autonomous robots allows for complex mission to be executed more efficiently. A collaborative mission typically consists of a number of robots and tasks where the robots have different roles and need cooperatively assign the tasks to the team resulting in a faster overall mission execution time. Furthermore, certain tasks may require more than one robot for successful execution which further extend the application areas of the systems.
In this work, a team of unmanned aircraft is considered. Aircraft operate in dynamic environments where the conditions for the team can quickly change. Under such circumstances, the team must be able to independently update the current plan in real-time on embedded computers on-board the aircraft during mission execution in a fast and predictable manner. The planning system has to generate good quality solutions and fulfill certain application specific requirements set by the company. The work starts by presenting a limited structured literature review within the multi-agent task planning domain with specific focus on important criteria for the aircraft domain, namely real-time performance, connectivity requirements and solution quality. With the review as a basis, two market based approaches are modified and extended upon the handle the application specific requirements. Simulations show that the resulting systems produce good quality and conflict free plans regardless of inconsistencies in situational awareness among the aircraft. The two approaches are numerically ana-lyzed with respect to the above-mentioned criteria, and show promising results for real-time planning and replanning in dynamic environments.
Contents
1 Introduction 5 1.1 Problem definition . . . 5 1.2 Ethical considerations . . . 6 1.3 Definitions . . . 6 1.4 State-of-the-art . . . 6 1.5 Thesis outline . . . 72 Multi-agent task planning: a limited structured literature review 8 2.1 Introduction . . . 8
2.1.1 An overview of the structured literature review . . . 8
2.2 Review method . . . 10
2.2.1 Specifying the research questions . . . 10
2.2.2 Developing a review protocol . . . 10
2.2.3 Identification of studies . . . 11
2.2.4 Selection of primary studies . . . 11
2.2.5 Study quality assessment . . . 12
2.2.6 Data extraction . . . 13
2.2.7 Data synthesis . . . 13
2.3 Results . . . 14
2.3.1 Studies included in the review . . . 14
2.3.2 Quality assessment . . . 17
2.4 Analysis . . . 18
2.4.1 RQ1: What are the existing solutions to the multi-agent task planning problem with focus on the specified criteria? . . . 18
2.4.2 How do the solutions compare to each other with respect to the different criteria? 18 2.4.3 What implications do these findings have when creating a task planning system for the UAV domain? . . . 20
2.5 Conclusions . . . 20
3 Methodology 21 3.1 Planning requirements . . . 21
3.2 Consensus based bundle algorithm . . . 21
3.2.1 Local information structures . . . 22
3.2.2 Task selection phase . . . 22
3.2.3 Consensus phase . . . 24
3.2.4 Convergence . . . 25
3.3 Coalition formation algorithm . . . 26
3.4 Score function . . . 29
3.4.1 Score in the CBBA . . . 29
3.5 Obstacle avoidance . . . 30
3.5.1 Obstacle avoidance in the CBBA . . . 30
3.5.2 Obstacle avoidance in the CFA . . . 31
3.6.1 Step 1 . . . 31
3.6.2 Step 2 . . . 32
3.6.3 Step 3 . . . 33
3.6.4 Calculating paths for threats . . . 33
3.6.5 Differences between CBBA and CFA . . . 34
3.7 Re-plan triggers . . . 34
4 Results and discussion 36 4.1 Scenario description . . . 36
4.2 Demonstration of example scenario . . . 36
4.2.1 CBBA . . . 37
4.2.2 Coalition formation algorithm . . . 38
4.3 Numerical simulations . . . 40 4.3.1 Execution times . . . 40 4.3.2 Communication requirements . . . 44 4.3.3 Solution quality . . . 46 5 Conclusions 49 6 Future work 50 Bibliography 51
List of Figures
3.1 High level overview of the CBBA. . . 22
3.2 Difference between greedy (a) and sequentially greedy (b). . . 23
3.3 The task selection process for one agent. . . 24
3.4 Action rules for agent i (receiver) after receiving a message from agent k (sender), regarding task j [9]. . . 25
3.5 Task selection process for the auctioneer and the responding agents. The procedure of the responding agents is also executed internally on the auctioning agent. . . 27
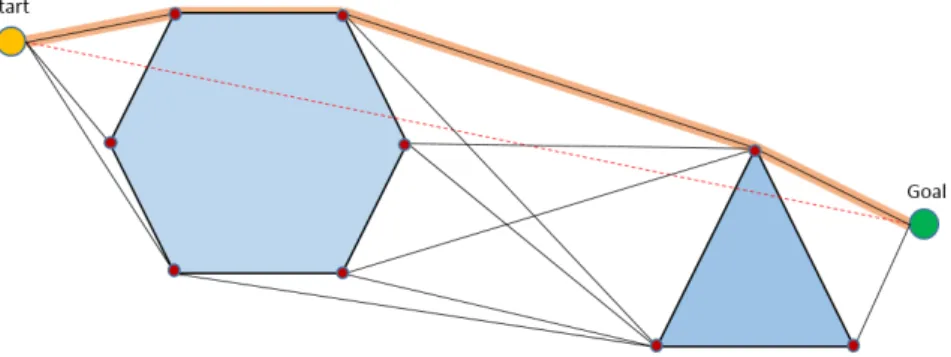
3.6 Visibility between a start and goal position. The red dotted line indicate that a straight line cannot be drawn without intersecting an obstacle. The black lines represent possible routes around the obstacles, and the thicker orange line represents a final feasible route. 30 3.7 (a) A scenario where a task lies inside a threatened area, d is the distance from the center of the threat normalized by its radius. (b) A Gaussian curve with x = 0.8 and the corresponding y value marked in red. . . 32
3.8 A fuzzy decision maker to determine whether a risk is worth taking. . . 32
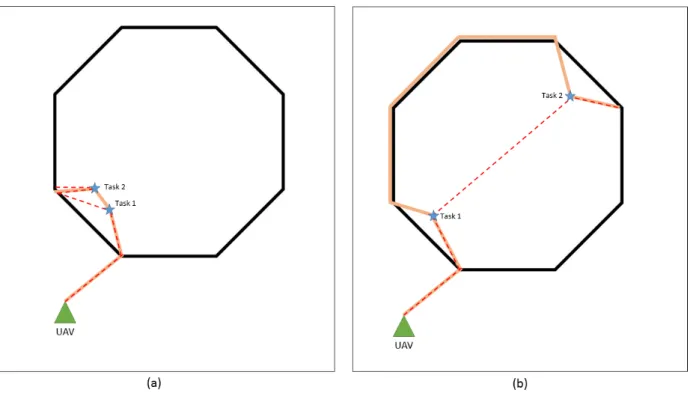
3.9 Different scenarios for multiple tasks inside threats. In (a) the best option would be to execute the two tasks before leaving the threat (orange line). In (b) the best option would be to leave the threat between the two tasks (orange line). . . 34
4.1 Initial knowledge of tasks and threats for the team. . . 37
4.2 The CBBA solution for different events. . . 38
4.3 The CFA solution for different events. . . 39
4.4 Average planning time (s) for a varying number of UAV:s and tasks with Sb = Nt. . . 41
4.5 Average planning time (s) for a varying number of UAV:s and tasks with Sb = 3. . . . 42
4.6 Average planning time (s) for a varying number of UAV:s and tasks. . . 43
4.7 Average planning times for the different algorithms with 10 UAV:s and a varying number of tasks. . . 44
4.8 Average number of sent messages for a varying number of UAV:s and tasks with different planning horizons. . . 44
4.9 Total amount of sent messages for a varying number off UAV:s and tasks. . . 45
4.10 Communication instances for the different algorithms with 10 UAV:s and a varying number of tasks. . . 46
4.11 Differences in solution qualities with different planning horizons. . . 46
4.12 Average total mission time for 5 UAV:s over a varying number of tasks. . . 47
List of Tables
2.1 Studies selected for the review through the study selection process . . . 14 2.2 Quality assessment of the included studies . . . 17 4.1 Average, minimum and maximum execution times (s) for a varying number of UAV:s
and tasks with Sb = Nt. . . 40
4.2 Average, minimum and maximum execution times (s) for a varying number of UAV:s and tasks with Sb = 3. . . 41
4.3 Average, minimum and maximum execution times (s) for a varying number of UAV:s and tasks. . . 42
Chapter 1
Introduction
As of today most unmanned aircraft operate at a relatively low level of autonomy. They are typically either remotely piloted, or follow a predefined flight path that can be manually changed during flight and require repeated operator interactions. Furthermore they typically operate alone and any collab-oration is performed at an operator level [31].
Collaboration between unmanned aircraft allows for more complex missions to be executed more effi-ciently and provides benefits in both military applications such as strike and reconnaissance missions and in civilian domains such as search and rescue missions. A collaborative mission typically consists of a number of different tasks to be executed which may need coordination in space and time. In such a scenario, a feasible plan including coordination in the task execution and motion planning needs to be calculated for a group of unmanned aircraft where each aircraft has its individual tasks and trajectory. The environment in which an aircraft operates is highly dynamic and uncertain. Internal or external events such as unforeseen threats, newly identified targets or equipment failure may occur rendering the current plan unfeasible. The plan must then be recalculated taking the new conditions into account online and in real-time. This causes a challenge as the computational burden rapidly increases with the number of aircraft and targets [4]. Furthermore, as the communication link between the aircraft has limited bandwidth, and may entirely lose contact under certain circumstances, it is desirable to exchange limited information between the aircraft while still calculating non-conflicting plans [2]. To accommodate future requirements from the industry, Saab’s goal is to increase its knowledge in the field of multiple collaborating unmanned aircraft such that less human interaction is needed to perform a given mission. This work investigates and compares planning algorithms for a team of unmanned aircraft on the behalf of Saab.
1.1
Problem definition
In this thesis, a distributed planning system is considered where the algorithms will eventually run on an embedded computer on-board each individual aircraft. The goal is to investigate, design and com-pare different planning algorithms capable of dynamic planning and re-planning of task assignments and motion planning for a team of unmanned aircraft to carry out a given mission.
The scenario considered herein is a surveillance mission, where some objects of interest are discovered at different locations. The team have to autonomously assign each team member to visit a number of locations such that all objects of interest are visited in an efficient manner. The team should also avoid obstacles in the area, and adapt to dynamic world events such as newly discovered tasks, lost or malfunctioning aircraft and newly detected or removed obstacles. All of this need occur online, while the mission is being executed. As a result, the problem lies in creating fast and predictable algorithms suitable for real-time that are robust to potential connectivity issues and generate good solutions. Hence the research is focused around the real-time performance, connectivity requirements,
communication burden and solution quality of the algorithms.
1.2
Ethical considerations
This thesis considers application areas in the military domain, and as a consequence there are some ethical considerations involved. The use of unmanned aerial vehicles (UAV:s) for strike and attack missions have raised much controversy around the world. The scenario considered herein is however a surveillance mission and the UAV:s are assumed to be unarmed, hence the debate regarding armed UAV:s will be left alone.
Some concerns regarding UAV:s for the purpose of surveillance have also arisen. One issue is the impact surveillance can have on personal privacy. The authors of [18] mention that efficient rules re-garding the handling, storage and ownership of the collected information are needed. Personal privacy issues may be of greater concern for surveillance in the civilian domain, the authors of [15] argue that further legislations are needed in order to ensure civil liberties and privacy.
Even though the UAV:s themselves are unarmed, there may be defenses in the areas they are surveilling. Losing a UAV to enemy fire will in most cases only lead to material damages, there is however an unavoidable potential risk for civilians in close vicinity of the crash site.
Though some drawbacks exists, many areas can benefit from aerial surveillance. The authors of [18] for example, argue that the use of UAV:s for surveillance can have significant advantages for United Nations (UN) peacekeeping missions, the access to surveillance data can improve the situational aware-ness of UN troops, aid in the protection of civilians and allow them to act upon human rights abuses as well as violations of international humanitarian law.
It should also be noted that the majority of the thesis handle multi-agent cooperation in general and can be applied to any robot system. Some parts may only be applicable for military purposes, but the thesis as a whole is not specialized for the military domain.
1.3
Definitions
Definition 1 {Agent}. An agent is an autonomous entity, the exact definition may differ in different fields of study. Herein it is defined as a physical robot of some sort.
Definition 2 {Task}. A task is a job that the agent has to perform. How the job is performed is not of concern in this thesis, hence a task can be considered a position which the agent has to visit.
1.4
State-of-the-art
The problem falls under the multi-agent planning domain which has attracted researchers for many years and a large variety of planning methods have been developed [29]. The overall objective of the planning procedure is usually to maximize some global reward for the mission, or to minimize some global cost, depending on how the objective function is formulated. Generating optimal plans for a team of agents is often computationally intractable for anything but a very small number of agents and tasks and research is often focused on relieving the computational burden by creating approximation methods that generate sub-optimal solutions.
On the highest level, previous work in the area can be divided into two coarse subsections, cen-tralized approaches and decencen-tralized, or distributed, approaches. Cencen-tralized planning is performed on one main computer for all of the agents. Therefor, it has the advantage of always calculating non-conflicting plans. It does however put large stresses on the communication links between the agents as it has to gather the situational awareness (SA) from all of the agents and distribute the calculated
plans to the entire system. Conducting all calculations on one computer also results in a single point of failure in the system affecting the robustness. In distributed planners, the agents themselves perform all the calculations and communicate with each other to resolve any conflicts and agree on a final plan for the team. This essentially divides a complex problem into smaller sub-problems and removes the single point of failure in the system.
Mixed integer linear programming (MILP) is a way of calculating the optimal solution for a task assignment problem. The optimization often require long computation times. One approximation method for relieving the computational burden is introduced in [1] where a receding horizon is incorpo-rated to only perform the optimization over a small number of tasks, resulting in shorter computation times while maintaining near optimal solutions. This is a centralized approach which is converted to a distributed approach in [2] by adopting implicit coordination. The idea is that the agents perform consensus on the SA before the planning procedure and then a centralized planner runs internally on each agent. If the SA is consistent, all agents arrive at the same solution. Implicit coordination is also used to distribute other types of centralized planning algorithms in [34], [31].
Market based approaches imitates an economic model where the agents place bids on the various tasks and the highest bidder “wins” the task. Various frameworks for this have been developed, some where one of the agents acts as an auctioneer [26], [19], [27], [25], [32]. Any agent can assume the role of auctioneer making the approach more robust to failures. Since one agent determines the winner of each task, these approaches guarantee a conflict free assignment regardless of inconsistencies in SA. Other approaches completely remove the need of an auctioneer by incorporating consensus protocols on each agent that specify how conflicts should be resolved [9], [11], [37], thus making it completely distributed. Common for all of these approaches is that they are conceptually simple frameworks and offer low time complexities.
A Markov decision process (MDP) is framework for making sequential decision problems that have been applied to multi-agent planning [6], [30]. An agent takes an action in the current state based on a probability that it will lead to the highest reward in the next state. This type of framework is particularly useful for modeling uncertain environments, where the exact variables such as task locations are unknown.
Game theory is another research field that have been applied to multi-agent planning [3], [7]. All agents are are self-interested players that make decisions to maximize its own reward based on the knowledge of other agents and the environment. The overall goal is to arrive at at state where the agents do not gain anything by changing their own strategy.
Other approaches include genetic algorithms [14], [33], [13], [8] and particle swarm optimization [10]. These approaches aim at relieving the complexity of solving the overall optimization problem and are shown to produce near optimal solutions. They are however more concerned with the optimization problem itself and do often not address how these solutions can be adapted in a real world scenario where SA inconsistencies and inter-agent communication become important.
1.5
Thesis outline
The remainder of the thesis is organized as follows: Chapter 2 presents a limited structured literature review in the multi-agent task planning domain, which is the research methodology used in this thesis. Based on the literature review, two approaches that fulfill certain requirements are presented together with extensions and modifications to fit the application area in chapter 3. Chapter 4 presents the results of the work. In chapter 5 some conclusions are provided, and finally in chapter 6 some future directions of the work are presented.
Chapter 2
Multi-agent task planning: a limited
structured literature review
This chapter presents a limited structured literature review within the multi-agent task planning domain. First, section 2.1 gives a general introduction to the structured literature review as a research method. Next, section 2.2 describes the methodology used in the review. Section 2.3 presents the results of the research. In section 2.4 the results are analyzed and the research questions are answered. Finally, section 2.5 provides some conclusions.
2.1
Introduction
A structured, or systematic, literature review (SLR) is a research method with origins in the medicine domain. It is a formal way of synthesizing all the available studies relevant to a set of research ques-tions in a fair and unbiased manner. The objective is to map out existing soluques-tions to a problem by using a framework with a set of well defined steps that are carried out in accordance with a predefined review protocol. The review protocol should define exactly how each step is performed, making the work thorough and reproducible, thus gaining scientific value [21].
An SLR should identify and evaluate all relevant research which is a time consuming process. Due to the time constraints of a master’s thesis, the aim in this work is not to conduct a full SLR, but rather to apply the thorough framework of an SLR to identify and evaluate the most relevant research based on certain criteria. The procedure is herein referred to as a limited SLR. The approach is centered around the guidelines given in [21], which is where most of the generic criteria has been collected. The SLR presented in [24] has also been used as an inspiration.
2.1.1 An overview of the structured literature review
This section will give a short summary of the steps involved in a general structured literature review according to [20]. The review consists of three main phases: 1) planning, 2) conducting and 3) report-ing, which are divided into several steps. An SLR should be carried out by more than one researcher to reduce researcher bias.
Planning the review
1. Identification of the need for a review - The need may be to summarize the available research in a thorough manner, or as a base for further research activities.
2. Commissioning a review - In some cases an organization may need information on a specific topic and commissions researchers to carry out the work. In such cases, a commissioning doc-ument must be produced specifying the required work. If this is not the case, the step can be omitted.
3. Specifying the research questions - In this step, the questions that are meant to be answered by the review are specified.
4. Developing a review protocol - The review protocol should define exactly how each step of the review is performed.
5. Evaluating the review protocol - The review protocol should be evaluated by a group of experts.
Conducting the review
1. Identification of research - A search strategy must be defined that specifies how the research has been identified.
2. Selection of primary studies - The searches will likely return a large number of articles. Some basic initial inclusion criteria should be specified to reduce the number of articles such as removal of duplicates and removal of articles published before a certain date.
3. Study quality assessment - The purpose of this step is to further reduce the number of studies based on more rigorous inclusion and quality criteria. This is a three step process:
(a) Abstract inclusion criteria screening (b) Full text inclusion criteria screening
(c) Full text quality screening
In the first step, studies are filtered by reading only abstracts and potentially conclusions based on some primary inclusion criteria. The next step is to read the full texts and filter the studies further based on some secondary inclusion criteria. The remaining work is classified according to quality criteria. The quality criteria is defined as yes and no questions where each study receives a score based on the questions. All studies scoring above some defined threshold will be included in the succeeding phases. All this should be well defined in the protocol.
4. Data extraction - In this stage, the data required to answer the research questions is collected from the studies.
5. Data synthesis - This last step of the conducting phase involves synthesizing the data in order to answer the research questions.
Reporting the review
1. Specifying a dissemination strategy - In this phase, the dissemination strategy should be determined. This typically include journals, conferences, PhD dissertations and to a lesser extent master’s theses.
2. Formatting the main report - This stage involves reporting the review and its findings. 3. Evaluating the report - In this last stage, the report should be evaluated by experts in the
field.
The evaluation of the review protocol and the report can be considered optional and is subject to quality assurance. The steps should be conducted in chronological order, but some iteration may be required.
2.2
Review method
As a structured literature is primarily aimed at higher level research, the optional steps mentioned in section 2.1.1 are not considered applicable to a master’s thesis and are excluded in the limited SLR provided herein, as well the dissemination strategy which is this chapter of the thesis. The following steps were included in the work and will be described in detail in the upcoming sections.
Step 1: Specifying the research questions Step 2: Developing a review protocol Step 3: Identification of studies Step 4: Selection of relevant studies Step 5: Study quality assessment Step 6: Data extraction
Step 7: Data synthesis
Step 8: Formatting the report
2.2.1 Specifying the research questions
The goal of the literature review is to apply the systematic framework of an SLR to map out and thoroughly analyze the most prominent existing solutions to the multi-agent task planning problem with respect to the following criteria:
• Real-time performance - UAV:s operate in a dynamic environment. Changes may occur and it is important that the system can adapt to these changes in a fast and predictable manner. This is considered the most important criteria.
• Connectivity and communication requirements - Maintaining a perfect communication link may be difficult under certain circumstances and it is desirable that the task planning system can handle different network topologies. Furthermore, in the military domain it is also desirable to keep the information exchange between the agents to a minimum as excessive communication can increase the risk of discovery.
• Solution quality - To avoid excessive energy consumption, it is desirable that the system generate good and efficient solutions. There will likely be a trade-off between computational load and solution quality as a better more optimal solution generally takes longer to calculate. Based on the above criteria the following research questions (RQ) were formulated:
RQ1 What are the existing solutions to the multi-agent task planning problem in dynamic environments with focus on the specified criteria?
RQ2 How do the solutions compare to each other with respect to the different criteria?
RQ3 What implications do these findings have when creating a task planning system for the UAV domain?
2.2.2 Developing a review protocol
The review protocol defines how each step of the limited SLR is conducted. An initial review protocol was defined prior to the start of the research, the protocol was iterated and further refined throughout the process. The review protocol is presented as part of the different steps described in this chapter.
2.2.3 Identification of studies
The purpose of this step is to identify relevant studies with respect to the research questions. The preferred way is to specify which digital libraries have been searched and what search strings have been used. By doing so the searches can be reproduced and validated by other researchers.
This was the initial approach adopted for the work. When trying different search strings and browsing through the references of different studies it became clear that a large variety of titles and key-words are used by researchers and constructing search strings to capture all of these was proven to be very difficult. The searches were either too vague resulting in thousands of hits, many being irrelevant, or too specific returning only a few results.
Instead a snowball search method [23] was adopted. The approach starts with a key study, from this study, one can find either earlier publications by going through the reference list, or more recent publications by looking at studies that have cited the document. The process is repeated for each relevant study that is found. The approach clearly challenges the reproducibility of the research, but considering this is a limited SLR, not aimed at identifying all relevant research, it was deemed an acceptable compromise.
The snowballing started from a recently published survey on the subject [29]. Only studies pub-lished after 2005 were considered to avoid incorporating outdated solutions and to apply a primary filter to the possible candidates. When a relevant title was found, the abstract of the study was read and if it was deemed relevant for the RQ:s, it was selected for the next step. By doing so the abstract inclusion criteria screening was incorporated in this stage. It should be noted that many abstracts were quite vague and when it was unclear if the study was relevant, it was included anyway.
As mentioned earlier, there is a large amount of publications in the area and when just over 100 studies had been selected the procedure was terminated as a larger quantity could not be handled.
2.2.4 Selection of primary studies
The goal of this step was to filter down the research into a set of high quality studies that are thematically relevant to answer the research questions. As mentioned in section 2.1.1, it is done in a three step procedure, where more criteria are applied to each step:
1. Abstract inclusion criteria screening 2. Full text inclusion criteria screening 3. Full text quality screening
Since the limited SLR was conducted by one researcher, step 2 and 3 were carried out simultaneously. Abstract inclusion criteria screening
In this limited SLR the goal was to filter away a significant portion of the literature at this stage to generate a manageable set of studies given the time frame for the next stage. To achieve this, some specific inclusion criteria (IC) for the problem at hand were applied together with some more general criteria:
IC1: The study’s main focus is the multi-agent task planning problem. IC2: The study is a primary study.
IC3: The study considers a distributed approach.
IC5: The study has some focus on real-time performance or computational complexity.
As a result of quite rigorous filtering in this stage, and since the abstracts had already been read, the full texts were browsed through quickly and some key parts were read until a decision could be made. Therefor, the name ”abstract inclusion criteria screening” is somewhat misleading for this particular research, and the step could perhaps be referred to as a ”rough initial filtering”. Some studies had to be filtered due to lack of access to the full text, though it was a small portion.
Based on the above criteria, total of 36 studies were passed on to the the full text inclusion stage. Full text inclusion and quality criteria screening
In this stage the full texts of the remaining studies were assessed more thoroughly based on further inclusion criteria and quality criteria (QC):
IC1: The study presents an algorithm capable of dynamic planning and re-planning in uncertain environments.
IC2: The study considers real-time performance in these environments.
IC3: The study considers at least one of the criterion upon which the research questions are based other than real-time performance.
QC1: There is a clear statement of the aim of the research.
QC2: The research is put into context with other research and studies.
One observation made during this stage was that there is a large variety of performance metrics used to evaluate the algorithms, making it somewhat difficult to determine how they perform based on the criteria used in this work. Many studies were filtered away because they did not provide results or an analysis regarding the criteria upon which this research is based. It also became clear while reading the full texts that improvement on one criterion often comes at the cost of another. Initially IC2 was defined as: the study considers all criteria upon which the research question are based. Due to nearly no studies passing that IC, it was divided into IC2 and IC3 as defined above to include real-time which is the most important criterion and at least one of the others.
A total of 10 studies passed all the inclusion steps and were included in the limited SLR.
2.2.5 Study quality assessment
In this stage the quality of the final studies was assessed. The purpose for this is to assure that the conclusions drawn in the review are based on high quality research. The quality criteria were created in form of yes and no questions where yes gives 1 point, no 0 points and partly 0.5 points. The following quality questions were used (QC1 and QC2 from the previous step are also included):
QC1: Is there a clear statement of the aim of the research.
QC2: Is the research is put into context with other research and studies. QC3: Is the test data set reproducible?
QC4: Is the algorithm reproducible?
QC5: Is it stated which algorithms the proposed algorithm has been compared to? QC6: Are the performance metrics used in the study explained and justified? QC7: Are the test results thoroughly analyzed?
Criteria motivation
QC1 and QC2 are related to good research practice in general, by stating the aim and relating to other research, the contributions of the study can be motivated. QC3 and QC4 cover the reproducibility of the experiments. If the data sets can not be reproduced, the algorithm can not be verified by other researchers and may lose credibility. In order to evaluate an algorithm, one needs to know what it has been compared to and understand the performance metrics used, which is covered in QC6 and QC7. QC8 aims to reveal researcher bias of publishing only good results, one should also present potential drawbacks, compromises or limitations in a proposed method.
2.2.6 Data extraction
The purpose of this step is to extract the data required to answer the research questions. The following data was extracted from the studies:
• Aims and objectives of the study • Type of algorithm used
• Overall theory of the system • Testing procedure
• Performance metrics used
• Reported real-time performance or characteristics
• Communication and connectivity requirements between the agents • Solution quality of the proposed algorithm
• Scalability of the proposed algorithm
2.2.7 Data synthesis
The extracted data was synthesized according to the solution type of how the multi-agent planning problem was solved, which basically provides an answer to research question one. The second and third research questions were then answered by analyzing and comparing the extracted data from the different studies.
2.3
Results
In this section the results of the limited SLR are presented. Each subsection will start with a summary of the identified approach, followed by a quick summary of the studies belonging to that solution category. The summaries of the approaches have some overlap with section 1.4, but they are repeated here for completion.
2.3.1 Studies included in the review
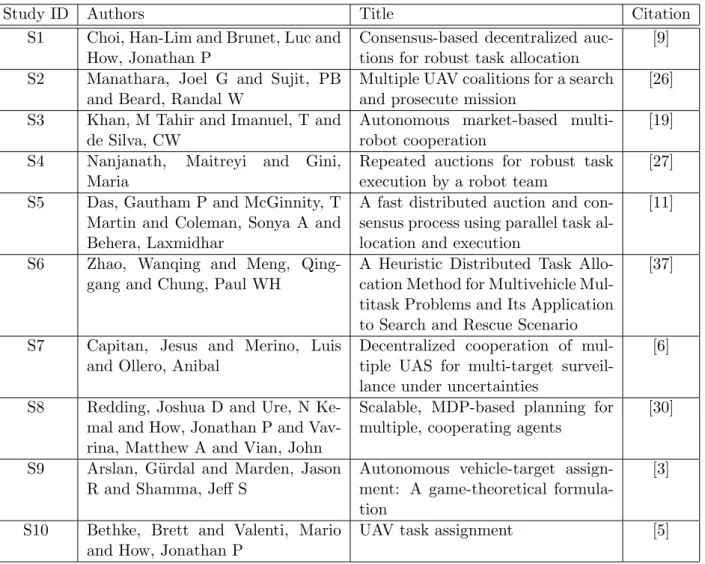
The included studies together with a study identifier used for easier reference within this chapter and the corresponding citation in the bibliography can be seen in table 2.1.
Study ID Authors Title Citation
S1 Choi, Han-Lim and Brunet, Luc and How, Jonathan P
Consensus-based decentralized auc-tions for robust task allocation
[9] S2 Manathara, Joel G and Sujit, PB
and Beard, Randal W
Multiple UAV coalitions for a search and prosecute mission
[26] S3 Khan, M Tahir and Imanuel, T and
de Silva, CW
Autonomous market-based multi-robot cooperation
[19]
S4 Nanjanath, Maitreyi and Gini,
Maria
Repeated auctions for robust task execution by a robot team
[27] S5 Das, Gautham P and McGinnity, T
Martin and Coleman, Sonya A and Behera, Laxmidhar
A fast distributed auction and con-sensus process using parallel task al-location and execution
[11]
S6 Zhao, Wanqing and Meng,
Qing-gang and Chung, Paul WH
A Heuristic Distributed Task Allo-cation Method for Multivehicle Mul-titask Problems and Its Application to Search and Rescue Scenario
[37]
S7 Capitan, Jesus and Merino, Luis and Ollero, Anibal
Decentralized cooperation of mul-tiple UAS for multi-target surveil-lance under uncertainties
[6]
S8 Redding, Joshua D and Ure, N Ke-mal and How, Jonathan P and Vav-rina, Matthew A and Vian, John
Scalable, MDP-based planning for multiple, cooperating agents
[30]
S9 Arslan, G¨urdal and Marden, Jason R and Shamma, Jeff S
Autonomous vehicle-target assign-ment: A game-theoretical formula-tion
[3]
S10 Bethke, Brett and Valenti, Mario and How, Jonathan P
UAV task assignment [5]
Table 2.1: Studies selected for the review through the study selection process
Market based approaches
These approaches aim to mimic the economical market where the agents place bids on the tasks that improve their own objective function the most. The agent who has the highest bid for a task is se-lected as a winner. Common traits for these approaches are that they are conceptually simple and they can be solved in polynomial time with relatively low time complexities. Several frameworks for this approach have been developed.
The authors of [26] (S2) and [19] (S3) present similar frameworks for the task planning. The general idea is that one agent acts as an auctioneer for a specific task that the agent has found, a role which any agent can assume. A task has certain requirements and if the agent does not possess the capabili-ties to execute the task independently, a message for help is sent containing the necessary information
about the task. When another agent receives the message it compares its own capabilities to those required by the task, and if it can contribute, it responds with a bid for the task based on the distance it would need to travel. The auctioning agent then selects the required agents with the best bids to form a coalition for the task. The process is repeated every time a new task is discovered by any of the agents. In S2 a scenario involving UAV:s is simulated and in S3 box pushing robots are simulated. Both present successful executions of the scenarios.
In [27] (S4) another auction based approach is presented where the goal is to generate relatively optimal plans in terms of total distance traveled at a low computational cost. The approach is based on running repeated auctions for all tasks, where the plan for an agent keeps changing over time. Given an initial task set, an agent starts executing its closest task. Every time a task is completed, an agent acts as auctioneer and runs an auction on all its remaining tasks. If another agent responds with a higher bid for a task, it will be passed over. The procedure is executed by each agent every time a task is completed resulting in a plan that is continuously updated and improved, and the final plan is not known until the end of the mission. The algorithm is tested both in simulations and on an experimental testbed with real ground moving robots and results show that the proposed algorithm has a final assignment that is close to optimal.
Other approaches completely remove the need for an auctioneer by incorporating consensus proto-cols on each agent, thus making them completely distributed.
One such approach called the consensus based bundle algorithm (CBBA) is presented in [9] (S1). The CBBA is a general purpose distributed auction based algorithm where multiple tasks can be allocated to each agent. It consist of iterations between two phases: a bundle construction phase and a task consensus phase. During the bundle construction phase, each agent calculates bids and continuously adds tasks to its bundle until no tasks are left or the predefined maximum assignment size has been reached based on its own local situation awareness. The process is followed by the consensus phase where the agents share their local information with their neighboring agents and process the newly received information. A protocol specifies what action an agent should take given the new information and how agent assignment vectors are updated. The algorithm keeps iterating between these two phases until it converges. The CBBA ensures a conflict free task assignment with different situational awareness between the agents. Theoretical proof is provided that guarantee 50% of optimal performance, although from simulations, it is empirically shown to perform within 93% of the optimal solution [4].
Another fully distributed consensus based task allocation algorithm is presented in [11] (S5), which is basically a mixture between S1 and S4. The goal is to develop a fast task allocation algorithm by reducing the computational complexity of current approaches. Similar to the CBBA it iterates between two phases, a task selection phase and a consensus phase in which the agents resolve conflicts through a consensus protocol. Communication between the agents occur between each phase. Rather than creating a bundle of tasks by sequentially adding tasks before the mission starts, the idea is to continuously add tasks in parallel with the mission execution, similar to S4. Only one task at the time is allocated to an agent, while traveling to the allocated task the agents place bids on their next task based on their current position through the currently allocated task. These bids are continuously updated as the agent moves and the next task is not allocated until the current task is completed. By applying this protocol, routes are continuously updated and simulations show advantages to other similar approaches. Furthermore, due to its dynamic nature, adding new tasks into an ongoing mission can be done without the need of a re-plan. The low computational complexity of adding only one task at the time makes it fast and scalable to large systems.
In [37] (S6) an approach is suggested which has some similarities with the auction based consen-sus methods. Though not strictly a market based approach, it is included in this category due to these similarities. Rather than having an agent selfishly choosing tasks to optimize its own cost or
score as an auction based approach, the algorithm aims at optimizing an overall mathematically for-mulated objective. To achieve this, a new concept called significance is introduced. The significance measure the contribution of a task to the local cost of a vehicle. If certain criteria are satisfied, the overall cost of the objective function can be decreased when switching tasks between agents. The algorithm iterates between three phases, a task inclusion phase where the significance values are cal-culated individually on each vehicle. A consensus phase where the significance values are exchanged between the vehicles and consensus is reached. Lastly, a task removal phase where an agent removes tasks if a lower global cost was achieved by releasing the task to another agent during the consensus phase. Experimental simulations show that the algorithm quickly converge at near optimal solutions. Markov decision process
A Markov decision process (MDP) provides a mathematical framework for sequential decision prob-lems. An agent takes an action in the current state based on the probability that the action will lead to the highest reward in the following states. Solving an MDP exactly will quickly become intractable for anything but very small problems as the number of possible actions and states rapidly increases, and research has been focused on approximation methods. The framework is particularly useful for modeling uncertainties in the environment.
In [6] (S7) a surveillance mission for multiple UAV:s and multiple targets is solved using a partially observable Markov decision process (POMDP). In order to reduce the computational complexity in-volved in solving POMDPs the authors propose a role based auctioning method where each agent solves its POMPD locally and communicate to achieve consensus on the plan. This makes the sys-tem scalable and the computational complexity is dependent on the size of the local communication neighborhood of each UAV. The method is verified in both simulations and on a real test-bed of two quadcopters and two targets.
In [30] (S8) the authors address the scalability problem of MDP:s. The aim is to design an ap-proximation method that allows for larger multi-agent systems to be solvable online and in real-time without sacrificing too much optimality. The solution is to introduce the group aggregate decentralized multi-agent Markov decision process (GA-Dec-MMDP). In this approach an agent can approximate its teammates as a group with a single reduced model. The general idea is that as long as the mission goals are satisfied, an individual agent does not need to know specifically who does it or how. Using this model, the growth of the state space can be made linear with the number of agents. Simulations are run for a surveillance mission and the results show significant advantages in scalability compared to a Dec-MMDP and a centralized MMDP while generating solutions within 80% of the optimal solution. Game theory
Game theory is a large research field and can be applied to multi-agent planning. In principle, all agents are individual decision makers that perform actions to maximize their own local utility based on the knowledge of other agents and the environment. The goal is to arrive at a state where the agents do not gain anything by changing their own strategy. Similar to MDP:s, research is often focused on designing approximation algorithms to reduce the computational burden.
In [3] (S9) the problem is stated as a multi-player game where the vehicles are self-interested players with their individual utility functions. The authors review different techniques for designing vehicle utility functions with respect to computational burden, information exchange and ability to lead to a high global utility. Two new negotiation mechanisms are introduced to address the shortcomings of the existing methods, generalized regret monitoring with fading memory and inertia, and selective spatial adaptive play. Large scale numerical simulations consisting of 200 vehicles and 200 targets show that these techniques can quickly converge to near optimal target assignments if vehicle utilities and negotiation mechanisms are chosen properly.
Mixed integer linear programming
Formulating the task allocation as a mixed integer linear programming (MILP) problem is one way of obtaining the optimal solution given some objective function. The optimization problem cannot be solved in polynomial time and quickly becomes intractable for larger problems leading to development of different approximation methods.
The authors of [5] (S10) extend upon the receding horizon task assignment RHTA by incorporat-ing a health feedback to model failincorporat-ing sensors and fuel limitations. The RHTA works by optimizincorporat-ing the task assignment for each UAV over a small number of tasks at each iteration rather than all tasks at once which quickly becomes computationally intractable. The algorithm works by first calculating all possible routes to visit the specified number of tasks using graph search techniques for each UAV. A MILP problem is then solved to assign each UAV to a path. Once each UAV has its optimal path for specified number of tasks, the procedure is repeated but this time starting at the last task from the previous round until all tasks have been served or some other constraint is met. The number of tasks to perform the optimization over can be modified as a trade-off between optimality and computational speed. The algorithm was verified in simulations and implemented on a small scale real test-bed of three quadcopters assigned to track two ground vehicles.
2.3.2 Quality assessment
The results of the quality assessment of the included studies can be seen in table 2.2. All the studies do well in motivating the research (Q1, Q2), creating reproducible data sets and algorithms (Q3, Q4) and stating what the algorithms are compared to (Q5). Larger variations occur when presenting the performance metrics (Q6), though all studies explain the metrics well, it is not always clear why it is an interesting metric. There is a large variety of performance metrics used in the literature and researchers do not always agree on which aspects of the algorithms are the most important. Unfortunately this leads to difficulties when trying to evaluate the different approaches. There are also some differences in how well the results are analyzed (Q7) and the studies came out worst at presenting limitations, possible drawbacks and compromises (Q8). In general all studies maintain a comparable quality. S3 scored the lowest with 5 points and and S4 the highest with 8 points.
ID QC1 QC2 QC3 QC4 QC5 QC6 QC7 QC8 tot S1 1 1 1 1 1 1 1 0 7 S2 1 1 1 1 1 1 1 0 7 S3 1 1 0.5 1 0 0.5 1 0 5 S4 1 1 1 1 1 1 1 1 8 S5 1 1 1 1 1 0.5 0.5 1 7 S6 1 1 1 1 1 0.5 0.5 0 6 S7 1 1 1 1 1 0.5 0.5 0 6 S8 1 1 1 1 1 0.5 0.5 0 6 S9 1 1 1 1 1 0.5 0.5 1 7 S10 1 1 1 1 1 1 0.5 0 6.5 tot 10 10 9.5 10 9 7 7 3 avg=6.55
2.4
Analysis
In this section the extracted data is analyzed and the research questions are answered.
2.4.1 RQ1: What are the existing solutions to the multi-agent task planning problem with focus on the specified criteria?
Not all the encountered solutions focus on all of the defined criteria, improvement of one often comes at the cost of another, and some trade-offs have to be made. The following solution types were identified:
• Market based approaches (S1, S2, S3, S4, S5, S6) • Markov decision process (S7, S8)
• Game theory (S9)
• Mixed integer linear programming (S10)
2.4.2 How do the solutions compare to each other with respect to the different criteria?
Real-time performance
Real-time is not necessarily equivalent to fast, for an algorithm to run in real-time, it must always execute within a certain time frame in a predictable manner. For the type of system considered herein, faster is better and there is no lower bound on how fast the algorithm executes as it reacts to a change in the environment. There is however an upper bound, though not exactly set, it is considered to be in the order of a few seconds. After this time, continuing to follow a plan that is no longer feasible could potentially result in a catastrophic event such as crashing into an obstacle. The consequences of a deadline overshoot are however somewhat event specific and the system would likely fall under the soft real-time category as a small overshoot does not necessarily result in a system failure, and the average case performance is more important.
Due to the nature of the problem, no systems can offer a constant execution time regardless of the problem size. A larger team of agents servicing a larger amount of tasks simply requires more calculations. The number of UAV:s sent off on a mission is known beforehand, the number of tasks they are about to service may not be. Hence an increase in computation time with the number of agents, and not the number of tasks would still make the system predictable.
All the market based approaches offer a polynomial time complexity thus putting an upper bound on the execution time. S2 and S3 consider scenarios where no tasks are known before hand, and only one task at the time is auction as it is encountered, hence the complexity is only dependent on the number of agents. This does however come at the cost of the solution quality, if more than one task is known before hand the solution quality will depend on the order in which they are auctioned. This problem is addressed in S4 and S5 where the tasks are repeatedly auctioned resulting in the same complexity, but a better final solution at the cost of more inter agent communication. In S1 and S6 the task bundle of each agent is sequentially built resulting in a complexity dependent on both the number of agents and tasks. This is however partially addressed by limiting the number of tasks an agent can add to its bundle, and perform a re-plan once the current tasks are executed. Computa-tion time still increases with the number of tasks an agent can choose from, but it can be significantly reduced by stopping once a predefined number of tasks are added compared to adding all possible tasks. The complexity of the MDP approximation method in S8 is linear in the number of agents which should make it predictable. It is considered by the authors to be solvable on-line in real-time, though the exact requirements involved in being on-line solvable are not stated. In S7 the complexity depends on the local communication neighborhood of each agent rather than the number of agents, a parameter
which is also likely to be known.
In the game theory approach presented in S9, a large scenario of 200 vehicles and 200 targets is simu-lated and very low computation times are presented given the size of the problem(<3s). Though these results look very promising for real-time purposes, no time complexity is presented making it unclear what parameters affect the execution time and somewhat difficult to compare to the other approaches. The MILP solution upon which S10 is based also show computation times within the range of seconds for a scenario of up to 8 agents and 40 tasks. Though this is a fairly large scenario, a MILP problem cannot be solved in polynomial time. Unless the size of the mission is known before hand, it could result in unpredictable behavior.
Communication and connectivity requirements
No specific communication protocol is considered in this work and the communication requirements are analyzed on a high level. The focus is on the connectivity requirements for the algorithms to con-verge and message instances. Clearly the amount of data transfer in each message is also of concern but one of the reasons for adopting distributed solutions is to the reduce the amount of data transfer compared to a centralized approach and no solutions exchange an excessive amount of data.
The market based approaches are generally quite robust to connectivity issues. In the solutions involving an auctioneer S2, S3 and S4, a temporary drop in connectivity for a responding agent would simply lead to that agent not participating in the auction, assuming other agents are still connected the task can likely be solved anyway. If the auctioneer itself looses connectivity the consequences could be worse since the task cannot be auctioned at all. In the consensus based approaches S1, S5 and S6, the requirement is that all the agents are connected in some way, a direct link is not required but there has to exist a link via some other agent. If this constraint is not met the algorithms are likely to result in conflicting assignments as the agents would be treated as multiple teams, independently bidding on the same tasks. A downside with these algorithms is that they converge when no changes have been made in the allocations for a certain amount of iterations, thus essentially passing messages for no reason. S4 and S5 rely on repeated auctions to improve the solution quality which clearly leads to more communication instances, but on the other hand, less information is required at each instance. The MPD based approach in S7 does not require constant connectivity, should connection be lost the agents can continue to make independent decisions. Whenever they are in communication range, they share information to enforce the cooperation. In the game theory approach (S9), the agents only communicate with other agents sharing the same target to resolve conflicts, this reduces the overall information exchange. The consequences of loosing communication between these agents are however not addressed. S8 and S10 do not discuss communication requirements at all making them difficult to evaluate from this perspective.
Solution quality
The quality of the solution is generally compared the optimal solution obtained through a mathemat-ical optimization given an objective function. The objective could for example be to carry out the mission in the shortest possible time.
The market based approaches in S2 and S3 consider a scenario where tasks are found as the mis-sion progresses. This myopic approach does not consider any impact of future tasks, hence no solution quality can be guaranteed and it will only depend on the order in which the tasks are found and auctioned. In S5 the solution quality is compared to the solution obtained by a similar algorithm. Significant improvements are presented in the comparison but it remains unclear how it compares to the optimal solution. The remaining studies all present near optimal solutions.
2.4.3 What implications do these findings have when creating a task planning system for the UAV domain?
The approaches that account for most of the defined criteria are the market based approaches. They can all be solved in polynomial time and execute relatively fast due to the simplicity of the framework, two attractive properties for real-time execution on embedded computers with moderate performance. Though the other methods also present good results on this criterion, they fail to provide more detailed discussions on computational requirements and time complexities. The load on the network and the connectivity requirements also tend to be discussed more thoroughly in the market based approaches. The approaches running parallel task execution and task allocation (S4, S5) offer a low time com-plexity and good solution qualities. The repeated communications are however not desirable in a military domain as it increases the risk of detection. The single task allocation approaches (S2, S3) have low time complexities, but due to their myopic nature they offer no guarantees on the solution quality. Based on this review, the most suitable algorithm to extend upon given all of the criteria is deemed to be the CBBA (S1) as it is robust to different network topologies, offers good solution qualities and relatively low time complexity. Furthermore the planning horizon can be varied as a trade off between solution quality and computation time. S2 and S3 both incorporate a cooperation mechanism to allow for multiple agents to service the same task when required. This is an attractive feature that can be useful in many scenarios. Together with the good real-time properties, it is an interesting algorithm for comparison, these advantages could potentially outweigh the better solution qualities obtained with the CBBA.
2.5
Conclusions
In this chapter a limited structured literature was carried out in order to evaluate different solutions to the multi-agent task planning problem with respect to certain important criteria for the UAV domain. The goal was not to identify all different solutions but rather to apply the framework of an SLR to properly evaluate some of the most suitable solutions. The identified methods fulfilling most of the criteria were approaches applying auction techniques.
Even with the large selection of research, finding studies that present convincing results on the spec-ified criteria was not an easy task. Furthermore, many studies ignore certain real-world constraints and make simplifying assumptions such as consistent SA and access to global parameters that are only available in simulations. Another issue encountered throughout this research was the lack of common performance metrics in the literature which made made evaluation and comparisons difficult. Database searches were also found difficult as there is no standardized set of key-words. Furthermore multi-agent task planning in general is a large area to conduct an SLR within. More appropriate may be to perform an SLR within a specific solution category, such as market based approaches or game theory.
Chapter 3
Methodology
This chapter outlines the methods and approaches used in this work. First, section 3.1 describes some of the real world scenarios the algorithms must be able to handle. Section 3.2 and 3.3 describe the core functionality of the task planning procedure for the two approaches that were chosen based on the literature review. Section 3.4 - 3.6 provide more details on how the baseline algorithms have been extended to handle the requirements. Finally section 3.7 defines how the algorithms respond to certain dynamic world events that require an online re-plan.
3.1
Planning requirements
The planning algorithm has to fulfill certain requirements to handle real world scenarios:
• The algorithm must be able to avoid obstacles in the path. In this thesis these are either no fly zones, such as airspace around airports, or threats such as surface to air missiles. Threats can be either known before hand, or ”pop-up” during mission execution. For more general purpose scenarios an obstacle can be anything that an agent is not able or allowed to travel through. • The algorithm must be able to handle loss of a vehicle. Should a vehicle be lost due to technical
problems, or any other reason, the remaining vehicles must know which tasks the lost vehicle was assigned to and perform a re-plan.
• The algorithm must be able to perform some risk assessment. A task may be located inside a threatened area, in such a case the agent must assess the risk of performing the task, and evaluate whether or not the risk is worth taking.
3.2
Consensus based bundle algorithm
The consensus based bundle algorithm (CBBA), originally presented in [9], is a fully distributed market based task planning algorithm. It iterates between two main phases until convergence: (1) task selection phase, where agents sequentially place bids and add tasks to their bundle based on their local SA. (2) Consensus phase, where the agents communicate with its neighbors and resolve any conflicting assignments. After the consensus phase a convergence criteria is checked, if the algorithm converged the task selection is finished, otherwise all agents remove any tasks they may have lost during the consensus and the procedure is repeated. A high level overview of the CBBA can be seen in figure 3.1. A prerequisite for the algorithm is that all agents are aware of the locations of the tasks.
Figure 3.1: High level overview of the CBBA.
3.2.1 Local information structures
For the baseline algorithm, each agent carry a set of information structures containing the local knowledge of the agent:
• Bundle: b = [b1, b2, ..., bSb], where each element contains the index of the tasks that the agent
is currently winning. The tasks are added to the bundle in the order they are chosen. Sb is
the maximum size of the bundle and cannot exceed the number of tasks. This variable sets the planning horizon of the algorithm and can be varied to modify the execution time, a shorter planning horizon will give a faster execution time at the cost of a less optimal path.
• Path: p = [p1, p2, ..., pSb], the path contains the same elements as the bundle, but rather than
being ordered chronologically, it is ordered according to when the agent plans to execute the task.
• Winning bids: y = [y1, y2, ..., yNt], where Ntis the number of tasks. Each element contains the
agents knowledge of the current winning bid on the task index corresponding to that element. • Winning agents: z = [z1, z2, ..., zNt], where each element contains the index of the agent who
has the highest bid, i.e. the winning bid on the task.
• Time stamps: s = [s1, s2, ..., sNa], where Na is the number of agents. Each element contains
the iteration count of when an agent received an information update from each of the other agents in the network.
The bundle and the path are only used locally on each agent. The winnings bids, winning agents and time stamps are used locally but these also contain the information required for the consensus phase and are communicated and updated at each iteration. Initially all elements are set to 0.
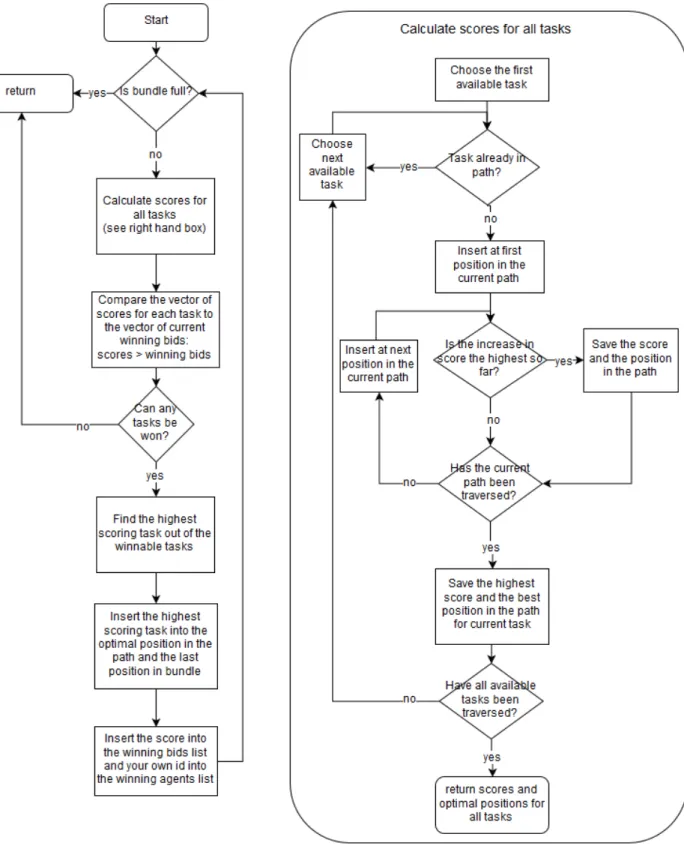
3.2.2 Task selection phase
During the task selection phase, each agent adds tasks to its bundle until the bundle is full or until no more tasks can be won. This is done in a sequentially greedy fashion, meaning that it always chooses the next best task, but rather than putting it last in the path as a greedy algorithm, it in-serts the task into every position given the current path, and calculates the increase in total score of the path. The position that generated the largest score increase is then chosen as the optimal position. Figure 3.2 illustrates the difference between a greedy task selection (a) and a sequentially greedy selection (b) in a scenario where the agent has a start and goal position, and three tasks to perform. Consider a simple scoring scheme as a function of distance and task value, where the score of per-forming the task decreases with traveled distance. The greedy algorithm does not consider any future impact of selecting a task and will simply select the highest scoring task first and the lowest scoring task last, resulting in a path where it travels away from the goal position after the first task. The sequentially greedy algorithm will select the tasks in the same order, but rather than adding them at the end of the path, it calculates the increase in total score by testing every position in the current path. This means that task 1 will be selected first and added to the empty path. Next, it will select
task 2 and realize that the increase in score is higher when adding it at the first position in the path. Lastly it will select task 3, and again calculate the highest increase in score when added at the first position in the path. The sequentially greedy approach requires more computation time as it needs to test inserting a task in every position in the current path, but it produces more optimal solutions than the greedy approach.
Figure 3.2: Difference between greedy (a) and sequentially greedy (b).
An overview of the task selection process for one agent can be seen in figure 3.3. The process is exe-cuted simultaneously on-board every agent in the network. Since the winning bids vector is initialized to 0, the agents can win every task they bid on at the first iteration. These potentially conflicting assignments are resolved in the consensus phase.
In the first step the agent calculates the score for each task by inserting it into every position in the current path (empty for the first iteration). The score for a task is the increase in score for the entire bundle by adding the task to the bundle. The highest score and the position in the path that yielded that score for every task is saved in a vector.
In the second step, the vector of scores is compared to the winning bids vector, where
canW in = (
1 if scorei > winningBidsi
0 otherwise
Out of all tasks that can be won, the highest scoring task is added to the bundle and inserted into the optimal position in the path. The winning agents and winning bids vectors are updated, with the agent’s id and the score for the task respectively.
The procedure is repeated until the bundle is full or until the agent cannot win any tasks (canW in = 0 for all tasks).
Figure 3.3: The task selection process for one agent.
3.2.3 Consensus phase
During the consensus phase, the agents communicate with each other over some communication net-work. Three vectors are exchanged: the winning agents list (z), the winning bids list (y) and the list of time stamps (s). In a fully connected network all agents communicate directly to each other, this is however not required. As long as an agent can receive information about an agent via some other agent, the algorithm will produce conflict free assignments.
There are three actions a receiving agent i can take regarding task j upon receiving a message from another agent k.
1. update: yij = ykj, zij = zkj (Update internal information to match senders information.)
2. reset: yij = 0, zij = 0
3. leave: yij = yij, zij = zij (No information is changed).
The information received from agent k is passed through a decision table, seen in figure 3.4 [9], that specifies what action the receiving agent i should take.
Figure 3.4: Action rules for agent i (receiver) after receiving a message from agent k (sender), regarding task j [9].
The first column indicates who the sender k believes to be the winner of the task, the second column indicates who the receiver i believes to be the winner of the task and the third column indicates what action the receiver should take. The logic favors higher and more recent bids. An agent sends its own information to all other agents it is connected to, and receives information from the same agents. Next, the agents take one message at the time and iterate through all tasks in parallel on their internal computers.
3.2.4 Convergence
After the consensus phase, all agents have an updated winning agents and winning bids vector, the agents can now compare the the winning agents of the tasks to the tasks in its current bundle, if an agent was outbid on a task, that task and all subsequent tasks must be removed from the bundle and path. Since the score of a task is calculated as an increase in score given a current path, not removing the tasks added after the lost task in the bundle would lead to false scores on those tasks which could lead to a degradation in performance [28]. Once the consensus phase has executed twice the size of the network (the number of agents) times without any change in bid information, the algorithm has converged and is terminated. Otherwise it starts over with the bundle building phase.
3.3
Coalition formation algorithm
The second algorithm is a semi-distributed market based auction algorithm based on the approach presented in [26], but with some modifications, and is herein referred to as the coalition formation algorithm (CFA). One agent acts as an auctioneer for one or a set of tasks, a role which any agent can assume. The auctioneer collects bids on a task from all other agents within communication range who place their bids based on their local SA, it also calculates its own bid on the task. The auctioneer then selects the highest bid as the winner of the task. The task selection is done in a greedy fashion, thus sacrificing solution quality in favor of execution speed.
The algorithm incorporates a coordination mechanism for tasks that require more than one agent for successful execution, a scenario that can be applied to many real world situations. Each task has a vector of required resources:
Rtaski = [Rtype1, Rtype2, .., RtypeNr]
where Rtypen is a number representing how many of that type of resources are required. Consider
for example Rtaski = [2, 0, 1], which would show that task i requires 2 type-1, 0 type-2, and 1 type-3
resources. Each agent then carry a similar vector of available resources, or capabilities Ra. In this
work, the available resources of an agent do not deplete with use and are represented with a binary vector where 1 indicates that the agent has the resource, and 0 that it does not.
An overview of the task planning process for the auctioneer and the responding agents can be seen in figure 3.5. The auctioneer is assumed to have knowledge about one or more tasks, these can either be known beforehand or discovered as the mission progresses. Due to the greedy nature of the algorithm, the order in which the tasks are auctioned has a direct impact on the solution quality. Auctioning the tasks in a random order would basically create a completely randomized solution. Therefor, the auctioneer has to auction the tasks in some systematic order. The best results were achieved when the auctioneer sorts the tasks according to the distance from its own position, and then auctions the tasks in order of ascending distance. After sorting the tasks, the auctioneer broadcasts the task information to all agents within communication range. All agents who can contribute to the task (has at least one of the required resources), calculate its score for the task and respond with the score as a bid, its capabilities and its estimated time of arrival at the task. The task information is also saved to update the world knowledge of the agents. Meanwhile, the auctioning agent calculates its own bid for the task, assuming it has at least one of the available resources. The auctioning agent then sorts all the responses, including its own according the the highest bid first. Next, the auctioneer forms the minimum coalition required to execute the task, this is a two step process outlined in algorithm 1.
Figure 3.5: Task selection process for the auctioneer and the responding agents. The procedure of the responding agents is also executed internally on the auctioning agent.



![Figure 3.4: Action rules for agent i (receiver) after receiving a message from agent k (sender), regarding task j [9].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4778881.127706/28.892.92.802.245.738/figure-action-rules-receiver-receiving-message-sender-regarding.webp)