TIO N S TE R EO -V IS IO N O F H IG H F R A M E-R A TE A N D L O W L A TE N C Y T H R O U G H F P G A -A C C EL ER A TIO N 20 19 ISBN 978-91-7485-453-4 ISSN 1651-4238
Address: P.O. Box 883, SE-721 23 Västerås. Sweden Address: P.O. Box 325, SE-631 05 Eskilstuna. Sweden E-mail: info@mdh.se Web: www.mdh.se
Mälardalen University Press Dissertations No. 304
EMBEDDED HIGH-RESOLUTION
STEREO-VISION OF HIGH FRAME-RATE AND LOW
LATENCY THROUGH FPGA-ACCELERATION
Carl Ahlberg
2020
School of Innovation, Design and Engineering
Mälardalen University Press Dissertations No. 304
EMBEDDED HIGH-RESOLUTION
STEREO-VISION OF HIGH FRAME-RATE AND LOW
LATENCY THROUGH FPGA-ACCELERATION
Carl Ahlberg
2020
School of Innovation, Design and Engineering
Copyright © Carl Ahlberg, 2020 ISBN 978-91-7485-453-4
ISSN 1651-4238
Printed by E-Print AB, Stockholm, Sweden
Copyright © Carl Ahlberg, 2020 ISBN 978-91-7485-453-4
ISSN 1651-4238
Mälardalen University Press Dissertations No. 304
EMBEDDED HIGH-RESOLUTION STEREO-VISION OF HIGH FRAME-RATE AND LOW LATENCY THROUGH FPGA-ACCELERATION
Carl Ahlberg
Akademisk avhandling
som för avläggande av teknologie doktorsexamen i datavetenskap vid Akademin för innovation, design och teknik kommer att offentligen försvaras
tisdagen den 28 januari 2020, 09.15 i Kappa, Mälardalens högskola, Västerås. Fakultetsopponent: Professor Ignacio Bravo Munoz, Alcalá de Henares Spain
Akademin för innovation, design och teknik
Mälardalen University Press Dissertations No. 304
EMBEDDED HIGH-RESOLUTION STEREO-VISION OF HIGH FRAME-RATE AND LOW LATENCY THROUGH FPGA-ACCELERATION
Carl Ahlberg
Akademisk avhandling
som för avläggande av teknologie doktorsexamen i datavetenskap vid Akademin för innovation, design och teknik kommer att offentligen försvaras
tisdagen den 28 januari 2020, 09.15 i Kappa, Mälardalens högskola, Västerås. Fakultetsopponent: Professor Ignacio Bravo Munoz, Alcalá de Henares Spain
Akademin för innovation, design och teknik
referred to as computer vision. Computer vision, and specifically stereo-vision algorithms, are complex and computationally expensive, already considering a single stereo pair, with results that are, in terms of accuracy, qualitatively difficult to compare. Adding to the challenge is a continuous stream of images, of a high frame rate, and the race of ever increasing image resolutions. In the context of autonomous agents, considerations regarding real-time requirements, embedded/resource limited processing platforms, power consumption, and physical size, further add up to an unarguably challenging problem. This thesis aims to achieve embedded high-resolution stereo-vision of high frame-rate and low latency, by approaching the problem from two different angles, hardware and algorithmic development, in a symbiotic relationship. The first contributions of the thesis are the GIMME and GIMME2 embedded vision platforms, which offer hardware accelerated processing through FGPAs, specifically targeting stereo vision, contrary to available COTS systems at the time. The second contribution, toward stereo vision algorithms, is twofold. Firstly, the problem of scalability and the associated disparity range is addressed by proposing a segment-based stereo algorithm. In segment space, matching is independent of image scale, and similarly, disparity range is measured in terms of segments, indicating relatively few hypotheses to cover the entire range of the scene. Secondly, more in line with the conventional stereo correspondence for FPGAs, the Census Transform (CT) has been identified as a recurring cost metric. This thesis proposes an optimisation of the CT through a Genetic Algorithm (GA) - the Genetic Algorithm Census Transform (GACT). The GACT shows promising results for benchmark datasets, compared to established CT methods, while being resource efficient.
ISBN 978-91-7485-453-4 ISSN 1651-4238
referred to as computer vision. Computer vision, and specifically stereo-vision algorithms, are complex and computationally expensive, already considering a single stereo pair, with results that are, in terms of accuracy, qualitatively difficult to compare. Adding to the challenge is a continuous stream of images, of a high frame rate, and the race of ever increasing image resolutions. In the context of autonomous agents, considerations regarding real-time requirements, embedded/resource limited processing platforms, power consumption, and physical size, further add up to an unarguably challenging problem. This thesis aims to achieve embedded high-resolution stereo-vision of high frame-rate and low latency, by approaching the problem from two different angles, hardware and algorithmic development, in a symbiotic relationship. The first contributions of the thesis are the GIMME and GIMME2 embedded vision platforms, which offer hardware accelerated processing through FGPAs, specifically targeting stereo vision, contrary to available COTS systems at the time. The second contribution, toward stereo vision algorithms, is twofold. Firstly, the problem of scalability and the associated disparity range is addressed by proposing a segment-based stereo algorithm. In segment space, matching is independent of image scale, and similarly, disparity range is measured in terms of segments, indicating relatively few hypotheses to cover the entire range of the scene. Secondly, more in line with the conventional stereo correspondence for FPGAs, the Census Transform (CT) has been identified as a recurring cost metric. This thesis proposes an optimisation of the CT through a Genetic Algorithm (GA) - the Genetic Algorithm Census Transform (GACT). The GACT shows promising results for benchmark datasets, compared to established CT methods, while being resource efficient.
ISBN 978-91-7485-453-4 ISSN 1651-4238
Abstract
Autonomous agents rely on information from the surrounding environment to act upon. In the array of sensors available, the image sensor is perhaps the most versatile, allowing for detection of colour, size, shape, and depth. For the latter, in a dynamic environment, assuming no a priori knowledge, stereo vision is a commonly adopted technique. How to interpret images, and extract relevant information, is referred to as computer vision. Computer vision, and specifically stereo-vision algorithms, are complex and computationally expensive, already considering a single stereo pair, with results that are, in terms of accuracy, qualitatively difficult to compare. Adding to the challenge is a continuous stream of images, of a high frame rate, and the race of ever increasing image resolutions. In the context of autonomous agents, considerations regarding real-time requirements, embedded/resource limited processing platforms, power consumption, and physical size, further add up to an unarguably challenging problem.
This thesis aims to achieve embedded high-resolution stereo-vision of high frame-rate and low latency, by approaching the problem from two different angles, hardware and algorithmic development, in a symbiotic relationship. The first contributions of the thesis are the GIMME and GIMME2 embedded vision platforms, which offer hardware accelerated processing through FGPAs, specifically targeting stereo vision, contrary to available COTS systems at the time. The second contribution, toward stereo vision algorithms, is twofold. Firstly, the problem of scalability and the associated disparity range is addressed by proposing a segment-based stereo algorithm. In segment space, matching is independent of image scale, and similarly, disparity range is measured in terms of segments, indicating relatively few hypotheses to cover the entire range of the scene. Secondly, more in line with the conventional stereo correspondence for FPGAs, the Census Transform (CT) has been identified as a recurring cost metric. This thesis proposes an optimisation of the CT through a Genetic
i
Abstract
Autonomous agents rely on information from the surrounding environment to act upon. In the array of sensors available, the image sensor is perhaps the most versatile, allowing for detection of colour, size, shape, and depth. For the latter, in a dynamic environment, assuming no a priori knowledge, stereo vision is a commonly adopted technique. How to interpret images, and extract relevant information, is referred to as computer vision. Computer vision, and specifically stereo-vision algorithms, are complex and computationally expensive, already considering a single stereo pair, with results that are, in terms of accuracy, qualitatively difficult to compare. Adding to the challenge is a continuous stream of images, of a high frame rate, and the race of ever increasing image resolutions. In the context of autonomous agents, considerations regarding real-time requirements, embedded/resource limited processing platforms, power consumption, and physical size, further add up to an unarguably challenging problem.
This thesis aims to achieve embedded high-resolution stereo-vision of high frame-rate and low latency, by approaching the problem from two different angles, hardware and algorithmic development, in a symbiotic relationship. The first contributions of the thesis are the GIMME and GIMME2 embedded vision platforms, which offer hardware accelerated processing through FGPAs, specifically targeting stereo vision, contrary to available COTS systems at the time. The second contribution, toward stereo vision algorithms, is twofold. Firstly, the problem of scalability and the associated disparity range is addressed by proposing a segment-based stereo algorithm. In segment space, matching is independent of image scale, and similarly, disparity range is measured in terms of segments, indicating relatively few hypotheses to cover the entire range of the scene. Secondly, more in line with the conventional stereo correspondence for FPGAs, the Census Transform (CT) has been identified as a recurring cost metric. This thesis proposes an optimisation of the CT through a Genetic
i
Algorithm (GA) – the Genetic Algorithm Census Transform (GACT). The GACT shows promising results for benchmark datasets, compared to established CT methods, while being resource efficient.
Algorithm (GA) – the Genetic Algorithm Census Transform (GACT). The GACT shows promising results for benchmark datasets, compared to established CT methods, while being resource efficient.
Sammandrag
Autonoma agenter ¨ar beroende av information fr˚an den omgivande milj¨on f¨or att agera. I en m¨angd av tillg¨angliga sensorer ¨ar troligtvis bildsensorn den mest m˚angsidiga, d˚a den m¨ojligg¨or s¨arskillnad av f¨arg, storlek, form och djup. F¨or det sistn¨amnda ¨ar, i en dynamisk milj¨o utan krav p˚a f¨orkunskaper, stereovision en vanligt till¨ampad teknik. Tolkning av bildinneh˚all och extrahe-ring av relevant information g˚ar under ben¨amningen datorseende. Datorseende, och specifikt stereoalgoritmer, ¨ar redan f¨or ett enskilt bildpar komplexa och ber¨akningsm¨assigt kostsamma, och ger resultat som, i termer av noggrannhet, ¨ar kvalitativt sv˚ara att j¨amf¨ora. Problematiken ut¨okas vidare av kontinuerlig str¨om av bilder, med allt h¨ogre bildfrekvens och uppl¨osning. F¨or autonoma agenter kr¨avs dessutom ¨overv¨aganden vad g¨aller realtidskrav, inbyggda sy-stem/resursbegr¨ansade ber¨akningsplattformar, str¨omf¨orbrukning och fysisk stor-lek, vilket summerar till ett otvetydigt utmanande problem.
Den h¨ar avhandlingen syftar till att ˚astadkomma h¨oguppl¨ost stereovision med h¨og uppdateringsfrekvens och l˚ag latens p˚a inbyggda system. Genom att n¨arma sig problemet fr˚an tv˚a olika vinklar, h˚ardvaru- och algoritmm¨assigt, kan ett symbiotiskt f¨orh˚allande d¨aremellan s¨akerst¨allas. Avhandlingens f¨orsta bidrag ¨ar GIMME och GIMME2 inbyggda visionsplattformar, som erbjuder FPGA-baserad h˚ardvaruaccelerering, med s¨arskilt fokus p˚a stereoseende, i kontrast till f¨or tidpunkten kommersiellt tillg¨angliga system. Det andra bidraget, h¨arr¨orande stereoalgoritmer, ¨ar tudelat. F¨orst hanteras skalbarhetproblemet, sammankopplat med disparitetsomf˚anget, genom att f¨oresl˚a en segmentbaserad stereoalgoritm. I segmentrymden ¨ar matchningen oberoende av bilduppl¨osningen, samt att disparitetsomf˚anget definieras i termer av segment, vilket antyder att relativt f˚a hypoteser beh¨ovs f¨or att omfatta hela scenen. I det andra bidraget p˚a al-goritmniv˚a, mer i linje med konventionella stereoalgoritmer f¨or FPGAer, har Censustransformen (CT) identifierats som ett ˚aterkommande kostnadsm˚att f¨or likhet. H¨ar f¨oresl˚as en optimering av CT genom att till¨ampa genetisk algoritm
iii
Sammandrag
Autonoma agenter ¨ar beroende av information fr˚an den omgivande milj¨on f¨or att agera. I en m¨angd av tillg¨angliga sensorer ¨ar troligtvis bildsensorn den mest m˚angsidiga, d˚a den m¨ojligg¨or s¨arskillnad av f¨arg, storlek, form och djup. F¨or det sistn¨amnda ¨ar, i en dynamisk milj¨o utan krav p˚a f¨orkunskaper, stereovision en vanligt till¨ampad teknik. Tolkning av bildinneh˚all och extrahe-ring av relevant information g˚ar under ben¨amningen datorseende. Datorseende, och specifikt stereoalgoritmer, ¨ar redan f¨or ett enskilt bildpar komplexa och ber¨akningsm¨assigt kostsamma, och ger resultat som, i termer av noggrannhet, ¨ar kvalitativt sv˚ara att j¨amf¨ora. Problematiken ut¨okas vidare av kontinuerlig str¨om av bilder, med allt h¨ogre bildfrekvens och uppl¨osning. F¨or autonoma agenter kr¨avs dessutom ¨overv¨aganden vad g¨aller realtidskrav, inbyggda sy-stem/resursbegr¨ansade ber¨akningsplattformar, str¨omf¨orbrukning och fysisk stor-lek, vilket summerar till ett otvetydigt utmanande problem.
Den h¨ar avhandlingen syftar till att ˚astadkomma h¨oguppl¨ost stereovision med h¨og uppdateringsfrekvens och l˚ag latens p˚a inbyggda system. Genom att n¨arma sig problemet fr˚an tv˚a olika vinklar, h˚ardvaru- och algoritmm¨assigt, kan ett symbiotiskt f¨orh˚allande d¨aremellan s¨akerst¨allas. Avhandlingens f¨orsta bidrag ¨ar GIMME och GIMME2 inbyggda visionsplattformar, som erbjuder FPGA-baserad h˚ardvaruaccelerering, med s¨arskilt fokus p˚a stereoseende, i kontrast till f¨or tidpunkten kommersiellt tillg¨angliga system. Det andra bidraget, h¨arr¨orande stereoalgoritmer, ¨ar tudelat. F¨orst hanteras skalbarhetproblemet, sammankopplat med disparitetsomf˚anget, genom att f¨oresl˚a en segmentbaserad stereoalgoritm. I segmentrymden ¨ar matchningen oberoende av bilduppl¨osningen, samt att disparitetsomf˚anget definieras i termer av segment, vilket antyder att relativt f˚a hypoteser beh¨ovs f¨or att omfatta hela scenen. I det andra bidraget p˚a al-goritmniv˚a, mer i linje med konventionella stereoalgoritmer f¨or FPGAer, har Censustransformen (CT) identifierats som ett ˚aterkommande kostnadsm˚att f¨or likhet. H¨ar f¨oresl˚as en optimering av CT genom att till¨ampa genetisk algoritm
iii
(GA) – Genetisk Algoritm Census Transform (GACT). GACT visar lovande re-sultat f¨or referensdataset j¨amf¨ort med etablerade CT-metoder, men ¨ar samtidigt resurseffektiv.
(GA) – Genetisk Algoritm Census Transform (GACT). GACT visar lovande re-sultat f¨or referensdataset j¨amf¨ort med etablerade CT-metoder, men ¨ar samtidigt resurseffektiv.
It is what it is
It is what it is
Acknowledgements
Ingen n¨amnd, ingen gl¨omdis Swedish for no one mentioned, no one forgotten, which constituted, until the final day of submission, this entire section. However, in fear of forgetting someone, there are some people I feel the need to explicitly express my gratitude towards. But first some background.
Some twenty years ago I was doing my master studies in Uppsala. The education program was called Information Technologies, a quite new program, and one of the driving spirits behind it was Lars. To crown the education was the big robotics project, which spanned one semester of full time studies and involved several educations. Lars being the responsible for the project course, and never lacking ambition or enthusiasm, set the goal to develop a full-scale humanoid robot, later baptised Murphy. I remember several late evenings in the basement of the former regiment with my hand covered in hydraulic oil. During this project is when I first met Fredrik, who was studying electrical engineering, and worked on the electronics of Murphy. Towards the end of the project Lars presented the opportunity to, as a master thesis, develop a virtual keyboard, using gesture recognition instead of physical keys. My classmate Stefan and I accepted. That was the start of SenseBoard. Fredrik was one of the first to join SenseBoard, and him, Stefan and I became the three musketeers. Though my SenseBoard adventure only lasted about two years, in hindsight it feels considerably more. Fast forward eight years, and I find myself working at Hectronic, a company developing custom computers, mainly for industrial applications. However, one project is to develop a FPGA-based system for image processing for M¨alardalen University. As it turns out Lars has relocated from Uppsala to V¨aster˚as and has started the robotics program, and is initiating a research group within robotics, with the focus on robotic vision. One of the people in the group is Fredrik. He said that there was an open position in the group and encouraged me to apply. And here we find ourselves ten years later... First of all Fredrik, my brother in arms throughout this extensive process.
vii
Acknowledgements
Ingen n¨amnd, ingen gl¨omdis Swedish for no one mentioned, no one forgotten, which constituted, until the final day of submission, this entire section. However, in fear of forgetting someone, there are some people I feel the need to explicitly express my gratitude towards. But first some background.
Some twenty years ago I was doing my master studies in Uppsala. The education program was called Information Technologies, a quite new program, and one of the driving spirits behind it was Lars. To crown the education was the big robotics project, which spanned one semester of full time studies and involved several educations. Lars being the responsible for the project course, and never lacking ambition or enthusiasm, set the goal to develop a full-scale humanoid robot, later baptised Murphy. I remember several late evenings in the basement of the former regiment with my hand covered in hydraulic oil. During this project is when I first met Fredrik, who was studying electrical engineering, and worked on the electronics of Murphy. Towards the end of the project Lars presented the opportunity to, as a master thesis, develop a virtual keyboard, using gesture recognition instead of physical keys. My classmate Stefan and I accepted. That was the start of SenseBoard. Fredrik was one of the first to join SenseBoard, and him, Stefan and I became the three musketeers. Though my SenseBoard adventure only lasted about two years, in hindsight it feels considerably more. Fast forward eight years, and I find myself working at Hectronic, a company developing custom computers, mainly for industrial applications. However, one project is to develop a FPGA-based system for image processing for M¨alardalen University. As it turns out Lars has relocated from Uppsala to V¨aster˚as and has started the robotics program, and is initiating a research group within robotics, with the focus on robotic vision. One of the people in the group is Fredrik. He said that there was an open position in the group and encouraged me to apply. And here we find ourselves ten years later... First of all Fredrik, my brother in arms throughout this extensive process.
vii
Without you I would have neither started nor finished my PhD studies. I am not sure whether to thank you for the first, but I most definitely do, for the later.
Lars, a big thank you, not only for creating the robotics group and being my thesis supervisor, but for everything before. I wish I could have half your enthusiasm and drive.
Micke, I know that it cannot have been easy for you to inherit me as your student. You are one of the most patient people I know and always take time for me. You never shy away from digging in, no matter the task, and have a special ability to solve problems by letting me explain. The previous two gentlemen may have made me start, but you made me finish.
I would also like to thank my co-authors Giacomo (also assistant supervisor), J¨orgen, Miguel and Mohammad.
Thank you to Maria, Martin and Dag Stranneby for reviewing my proposals. The robotics group, thank you for being my colleagues and friends, Jonas, Gita, Lennie, Batu, Branko, Baran, Lana, Afshin, Henrik.
To my colleagues at IFT, IDT and students, whether trying to make an underwater robot working, eating a rabbit, running down a volcano, sharing a tea at the Grand Bazaar, or something as exciting as an Uppsala commute. Thank you all for the good times.
A final thank you goes to my former Hectronic colleagues Kjell, Mats and Lennart for their work on GIMME, and Magnus at af inventions, for the design of GIMME2.
Carl Ahlberg V¨aster˚as, December, 2019
Without you I would have neither started nor finished my PhD studies. I am not sure whether to thank you for the first, but I most definitely do, for the later.
Lars, a big thank you, not only for creating the robotics group and being my thesis supervisor, but for everything before. I wish I could have half your enthusiasm and drive.
Micke, I know that it cannot have been easy for you to inherit me as your student. You are one of the most patient people I know and always take time for me. You never shy away from digging in, no matter the task, and have a special ability to solve problems by letting me explain. The previous two gentlemen may have made me start, but you made me finish.
I would also like to thank my co-authors Giacomo (also assistant supervisor), J¨orgen, Miguel and Mohammad.
Thank you to Maria, Martin and Dag Stranneby for reviewing my proposals. The robotics group, thank you for being my colleagues and friends, Jonas, Gita, Lennie, Batu, Branko, Baran, Lana, Afshin, Henrik.
To my colleagues at IFT, IDT and students, whether trying to make an underwater robot working, eating a rabbit, running down a volcano, sharing a tea at the Grand Bazaar, or something as exciting as an Uppsala commute. Thank you all for the good times.
A final thank you goes to my former Hectronic colleagues Kjell, Mats and Lennart for their work on GIMME, and Magnus at af inventions, for the design of GIMME2.
Carl Ahlberg V¨aster˚as, December, 2019
List of Publications
Publications included in the thesis
1Paper A
GIMME - A General Image Multiview Manipulation Engine, Carl Ahlberg, J¨orgen Lidholm, Fredrik Ekstrand, Giacomo Spampinato, Mikael Ekstr¨om and Lars Asplund, International Conference on ReConFigurable Computing and FPGAs (ReConFig 2011), Cancun, Mexico, 30 Nov.-2 Dec., 2011, pp. 129-134.
Paper B
Towards an Embedded Real-Time High Resolution Vision System, Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om and Giacomo Spamp-inato, 10th International Symposium on Visual Computing (ISVC 2014), Las Vegas, Nevada, USA, 7-9 December, 2014.
Paper C
GIMME2 - an embedded system for stereo vision and image process-ing with FPGA-acceleration, Carl Ahlberg, Fredrik Ekstrand, Mikael Ekstr¨om and Lars Asplund, International Conference on ReConFigurable Computing and FPGAs (ReConFig 2015), Mayan Riviera, Mexico, 7-9 December, 2015, pp. 1-8.
Paper D
Unbounded Sparse Census Transform using Genetic Algorithm, Carl Ahlberg, Miguel Leon, Fredrik Ekstrand and Mikael Ekstr¨om, 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waiko-loa Village, Hawaii, USA, 7-11 January, 2019, pp. 1616-1625.
1The included publications are reformatted to comply with the thesis printing format.
ix
List of Publications
Publications included in the thesis
1Paper A
GIMME - A General Image Multiview Manipulation Engine, Carl Ahlberg, J¨orgen Lidholm, Fredrik Ekstrand, Giacomo Spampinato, Mikael Ekstr¨om and Lars Asplund, International Conference on ReConFigurable Computing and FPGAs (ReConFig 2011), Cancun, Mexico, 30 Nov.-2 Dec., 2011, pp. 129-134.
Paper B
Towards an Embedded Real-Time High Resolution Vision System, Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om and Giacomo Spamp-inato, 10th International Symposium on Visual Computing (ISVC 2014), Las Vegas, Nevada, USA, 7-9 December, 2014.
Paper C
GIMME2 - an embedded system for stereo vision and image process-ing with FPGA-acceleration, Carl Ahlberg, Fredrik Ekstrand, Mikael Ekstr¨om and Lars Asplund, International Conference on ReConFigurable Computing and FPGAs (ReConFig 2015), Mayan Riviera, Mexico, 7-9 December, 2015, pp. 1-8.
Paper D
Unbounded Sparse Census Transform using Genetic Algorithm, Carl Ahlberg, Miguel Leon, Fredrik Ekstrand and Mikael Ekstr¨om, 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waiko-loa Village, Hawaii, USA, 7-11 January, 2019, pp. 1616-1625.
1The included publications are reformatted to comply with the thesis printing format.
ix
Paper E
The Genetic Algorithm Census Transform, Carl Ahlberg, Miguel Leon, Fredrik Ekstrand and Mikael Ekstr¨om, Journal of Real-Time Image Pro-cessing (JRTIP), 2020 (submitted).
Additional peer-reviewed publications not included
in the thesis
• Navigation in a box. Stereovision for industry automation Giacomo Spampinato, J¨orgen Lidholm, Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Advances in Theory and Applications of Stereo Vision, INTECH, ISBN: 978-953-7619-X-X, October, 2010.
• An Embedded Stereo Vision Module for 6D Pose Estimation and Mapping Giacomo Spampinato, J¨orgen Lidholm, Carl Ahlberg, Fredrik Ekstrand, Mikael Ekstr¨om, Lars Asplund, Proceedings of the IEEE inter-national conference on Intelligent Robots and Systems IROS2011, San Francisco, September, 2011.
• Resource Limited Hardware-based Stereo Matching for High-Speed Vision System Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Giacomo Spampinato, Proceedings of the 5th International Conference on Automation, Robotics and Applications (ICARA 2011), Wellington, December, 2011.
• Utilization and Performance Considerations in Resource Optimized Stereo Matching for Real-Time Reconfigurable Hardware Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Giacomo Spamp-inato, International Conference on Computer Vision Theory and Applica-tions (VISAPP 2012), Rome, Italy, February, 2012.
• An Embedded Stereo Vision Module For Industrial Vehicles Automa-tion Giacomo Spampinato, J¨orgen Lidholm, Carl Ahlberg, Fredrik Ek-strand, Mikael Ekstr¨om, Lars Asplund, Conference on Industrial Technol-ogy (ICIT 2013), Cape Town, South Africa, February, 2013.
• High-speed segmentation-driven high-resolution matching Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Giacomo Spampinato, Pro-ceedings of the 7th International Conference on Machine Vision, ICMV 2014, 19-21 November 2014.
Paper E
The Genetic Algorithm Census Transform, Carl Ahlberg, Miguel Leon, Fredrik Ekstrand and Mikael Ekstr¨om, Journal of Real-Time Image Pro-cessing (JRTIP), 2020 (submitted).
Additional peer-reviewed publications not included
in the thesis
• Navigation in a box. Stereovision for industry automation Giacomo Spampinato, J¨orgen Lidholm, Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Advances in Theory and Applications of Stereo Vision, INTECH, ISBN: 978-953-7619-X-X, October, 2010.
• An Embedded Stereo Vision Module for 6D Pose Estimation and Mapping Giacomo Spampinato, J¨orgen Lidholm, Carl Ahlberg, Fredrik Ekstrand, Mikael Ekstr¨om, Lars Asplund, Proceedings of the IEEE inter-national conference on Intelligent Robots and Systems IROS2011, San Francisco, September, 2011.
• Resource Limited Hardware-based Stereo Matching for High-Speed Vision System Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Giacomo Spampinato, Proceedings of the 5th International Conference on Automation, Robotics and Applications (ICARA 2011), Wellington, December, 2011.
• Utilization and Performance Considerations in Resource Optimized Stereo Matching for Real-Time Reconfigurable Hardware Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Lars Asplund, Giacomo Spamp-inato, International Conference on Computer Vision Theory and Applica-tions (VISAPP 2012), Rome, Italy, February, 2012.
• An Embedded Stereo Vision Module For Industrial Vehicles Automa-tion Giacomo Spampinato, J¨orgen Lidholm, Carl Ahlberg, Fredrik Ek-strand, Mikael Ekstr¨om, Lars Asplund, Conference on Industrial Technol-ogy (ICIT 2013), Cape Town, South Africa, February, 2013.
• High-speed segmentation-driven high-resolution matching Fredrik Ekstrand, Carl Ahlberg, Mikael Ekstr¨om, Giacomo Spampinato, Pro-ceedings of the 7th International Conference on Machine Vision, ICMV 2014, 19-21 November 2014.
xi
• Embedded Acceleration of Image Classification Applications for Stereo Vision Systems Mohammad Loni, Carl Ahlberg, Masoud Danesh-talab, Mikael Ekstr¨om, Mikael Sj¨odin, Design, Automation & Test in Europe Conference & Exhibition DATE’18, 2018.
xi
• Embedded Acceleration of Image Classification Applications for Stereo Vision Systems Mohammad Loni, Carl Ahlberg, Masoud Danesh-talab, Mikael Ekstr¨om, Mikael Sj¨odin, Design, Automation & Test in Europe Conference & Exhibition DATE’18, 2018.
Errata
Paper A, 7.1, p. 86 Jin et al not Sin et al.
Paper C, 9.6.3, p. 140 V = M AX(R, G, B) not V = M AX(R + G + B) Paper D, 10.5.2, p. 164 Figure 10.9 not Figure 10.10
xiii
Errata
Paper A, 7.1, p. 86 Jin et al not Sin et al.
Paper C, 9.6.3, p. 140 V = M AX(R, G, B) not V = M AX(R + G + B) Paper D, 10.5.2, p. 164 Figure 10.9 not Figure 10.10
xiii
List of Acronyms
ACT Adaptive Census Transform AD Absolute Difference ADSW Adaptive Support Weights
ASIC Application Specific Integrated Circuit COT S Commercial off-the-shelf
CSCT Centre Symmetric CT CT Census Transform
CN N Convolutional Neural Network DP Dynamic Programming DSI Disparity Space Image DSP Digital Signal Processor F P GA Field-Programmable Gate Array f ps frames per second
GA Genetic Algorithm
GACT Genetic Algorithm Census Transform GIF Guided Image Filter
GIM M E General Image Multi-view Manipulation Engine
GP U Graphics Processing Unit HDL Hardware Description Language HLS High-Level Synthesis
LRC Left-Right Consistency M CT Mini Census Transform M DE Mega Disparity Estimation M DH M¨alardalen University N CC Normalised Cross-Correlation RGBD RGB and Depth
xv
List of Acronyms
ACT Adaptive Census Transform AD Absolute Difference ADSW Adaptive Support Weights
ASIC Application Specific Integrated Circuit COT S Commercial off-the-shelf
CSCT Centre Symmetric CT CT Census Transform
CN N Convolutional Neural Network DP Dynamic Programming DSI Disparity Space Image DSP Digital Signal Processor F P GA Field-Programmable Gate Array f ps frames per second
GA Genetic Algorithm
GACT Genetic Algorithm Census Transform GIF Guided Image Filter
GIM M E General Image Multi-view Manipulation Engine
GP U Graphics Processing Unit HDL Hardware Description Language HLS High-Level Synthesis
LRC Left-Right Consistency M CT Mini Census Transform M DE Mega Disparity Estimation M DH M¨alardalen University N CC Normalised Cross-Correlation RGBD RGB and Depth
xv
SAD Sum of Absolute Differences SGM Semi-Global Matching SoC System-on-Chip SP Super Pixel
SSD Sum of Squared Differences
V HDL VHSIC (Very High Speed Integrated Circuit) Hardware Description Language W M F Weighted Median Filter
W T A Winner Takes All ZSAD Zero mean SAD
SAD Sum of Absolute Differences SGM Semi-Global Matching SoC System-on-Chip SP Super Pixel
SSD Sum of Squared Differences
V HDL VHSIC (Very High Speed Integrated Circuit) Hardware Description Language W M F Weighted Median Filter
W T A Winner Takes All ZSAD Zero mean SAD
Contents
I
Thesis
1
1 Introduction 3 1.1 Motivation . . . 5 1.2 Contributions . . . 5 1.3 Thesis Overview . . . 6 2 Background 7 2.1 Demosaicing . . . 7 2.2 Camera Model, Calibration and Undistortion . . . 8 2.3 Epipolar Geometry, Stereo Calibration and Rectification . . 13 2.4 Stereo Matching by Example . . . 17 2.5 FPGA Acceleration . . . 21 2.6 Stereo Matching for FPGAs . . . 23 2.6.1 Cost Computation . . . 24 2.6.2 Cost Aggregation . . . 25 2.6.3 Disparity Computation . . . 29 2.6.4 Disparity Refinement . . . 29 2.7 Stereo Datasets and Evaluation . . . 303 Research Goals and Method 33
3.1 Research Goals . . . 33 3.1.1 Goal A . . . 33 3.1.2 Goal B . . . 33 3.1.3 Goal C . . . 34 3.1.4 Goal D . . . 34 3.2 Research Method . . . 34 xvii
Contents
I
Thesis
1
1 Introduction 3 1.1 Motivation . . . 5 1.2 Contributions . . . 5 1.3 Thesis Overview . . . 6 2 Background 7 2.1 Demosaicing . . . 7 2.2 Camera Model, Calibration and Undistortion . . . 8 2.3 Epipolar Geometry, Stereo Calibration and Rectification . . 13 2.4 Stereo Matching by Example . . . 17 2.5 FPGA Acceleration . . . 21 2.6 Stereo Matching for FPGAs . . . 23 2.6.1 Cost Computation . . . 24 2.6.2 Cost Aggregation . . . 25 2.6.3 Disparity Computation . . . 29 2.6.4 Disparity Refinement . . . 29 2.7 Stereo Datasets and Evaluation . . . 303 Research Goals and Method 33
3.1 Research Goals . . . 33 3.1.1 Goal A . . . 33 3.1.2 Goal B . . . 33 3.1.3 Goal C . . . 34 3.1.4 Goal D . . . 34 3.2 Research Method . . . 34 xvii
21
4 Related Work 37 4.1 Cost Computation . . . 38 4.2 Cost Aggregation . . . 39 4.2.1 Adaptive Support Weights and Guided Image Filter . . 40 4.2.2 Semi-Global Matching . . . 41 4.3 Disparity Selection . . . 45 4.4 Disparity Refinement . . . 46 4.5 Miscellaneous . . . 46 4.6 Accuracy and Performance . . . 48 4.7 Conclusion . . . 49 5 Results 55 5.1 Included Papers . . . 55 5.1.1 Paper A . . . 55 5.1.2 Paper B . . . 56 5.1.3 Paper C . . . 58 5.1.4 Paper D . . . 59 5.1.5 Paper E . . . 60 5.2 Papers with respect to research goals . . . 61
6 Conclusions and Future Work 63
6.1 Conclusions . . . 63 6.2 Future work . . . 64
Bibliography 67
II
Included Papers
81
7 Paper A:
GIMME - A General Image Multiview Manipulation Engine 83 7.1 Introduction . . . 85 7.2 GIMME Hardware Design . . . 87 7.2.1 FPGA and Memory . . . 87 7.2.2 Image Sensors . . . 89 7.2.3 Ethernet . . . 89 7.2.4 FTDI and Flash Memory . . . 90 7.2.5 Qseven and H6049 . . . 90 7.2.6 Power and Physical Dimensions . . . 91 7.3 Experiments and Results . . . 91
4 Related Work 37
4.1 Cost Computation . . . 38 4.2 Cost Aggregation . . . 39 4.2.1 Adaptive Support Weights and Guided Image Filter . . 40 4.2.2 Semi-Global Matching . . . 41 4.3 Disparity Selection . . . 45 4.4 Disparity Refinement . . . 46 4.5 Miscellaneous . . . 46 4.6 Accuracy and Performance . . . 48 4.7 Conclusion . . . 49 5 Results 55 5.1 Included Papers . . . 55 5.1.1 Paper A . . . 55 5.1.2 Paper B . . . 56 5.1.3 Paper C . . . 58 5.1.4 Paper D . . . 59 5.1.5 Paper E . . . 60 5.2 Papers with respect to research goals . . . 61
6 Conclusions and Future Work 63
6.1 Conclusions . . . 63 6.2 Future work . . . 64
Bibliography 67
II
Included Papers
81
7 Paper A:
GIMME - A General Image Multiview Manipulation Engine 83 7.1 Introduction . . . 85 7.2 GIMME Hardware Design . . . 87 7.2.1 FPGA and Memory . . . 87 7.2.2 Image Sensors . . . 89 7.2.3 Ethernet . . . 89 7.2.4 FTDI and Flash Memory . . . 90 7.2.5 Qseven and H6049 . . . 90 7.2.6 Power and Physical Dimensions . . . 91 7.3 Experiments and Results . . . 91
Contents xix
7.3.1 Streaming of Image Data . . . 91 7.3.2 Result Image Data . . . 93 7.3.3 Streaming of Harris Features . . . 93 7.3.4 Result Harris Features . . . 97 7.3.5 Two-camera Harris Extension . . . 97 7.4 Discussion and Conclusions . . . 98 7.4.1 Use cases . . . 98 7.4.2 GIMME compared to the Specification Requirements . 99 Bibliography . . . 101 8 Paper B:
Towards an Embedded Real-Time High Resolution Vision System 105 8.1 Introduction . . . 107 8.2 Related Work . . . 108 8.3 Approach . . . 110 8.3.1 Segmentation . . . 111 8.3.2 Segment Correspondence . . . 112 8.4 Experimental Results . . . 115 8.5 Conclusions . . . 117 8.6 Future Work . . . 118 Bibliography . . . 119 9 Paper C:
GIMME2 - an embedded system for stereo vision and processing of megapixel images with FPGA-acceleration 123 9.1 Introduction . . . 125 9.2 Hardware . . . 128 9.3 Programmable Logic . . . 130 9.4 Block Design . . . 134 9.5 Processing System . . . 135 9.6 Example designs . . . 137 9.6.1 Stereo Matching . . . 138 9.6.2 Harris Corner and Edge Detector . . . 139 9.6.3 RGB2HSV . . . 140 9.6.4 Col Disc . . . 140 9.7 Results . . . 141 9.8 Conclusion and future work . . . 144 Bibliography . . . 147
Contents xix
7.3.1 Streaming of Image Data . . . 91 7.3.2 Result Image Data . . . 93 7.3.3 Streaming of Harris Features . . . 93 7.3.4 Result Harris Features . . . 97 7.3.5 Two-camera Harris Extension . . . 97 7.4 Discussion and Conclusions . . . 98 7.4.1 Use cases . . . 98 7.4.2 GIMME compared to the Specification Requirements . 99 Bibliography . . . 101 8 Paper B:
Towards an Embedded Real-Time High Resolution Vision System 105 8.1 Introduction . . . 107 8.2 Related Work . . . 108 8.3 Approach . . . 110 8.3.1 Segmentation . . . 111 8.3.2 Segment Correspondence . . . 112 8.4 Experimental Results . . . 115 8.5 Conclusions . . . 117 8.6 Future Work . . . 118 Bibliography . . . 119 9 Paper C:
GIMME2 - an embedded system for stereo vision and processing of megapixel images with FPGA-acceleration 123 9.1 Introduction . . . 125 9.2 Hardware . . . 128 9.3 Programmable Logic . . . 130 9.4 Block Design . . . 134 9.5 Processing System . . . 135 9.6 Example designs . . . 137 9.6.1 Stereo Matching . . . 138 9.6.2 Harris Corner and Edge Detector . . . 139 9.6.3 RGB2HSV . . . 140 9.6.4 Col Disc . . . 140 9.7 Results . . . 141 9.8 Conclusion and future work . . . 144 Bibliography . . . 147
10 Paper D:
Unbounded Sparse Census Transform using Genetic Algorithm 151 10.1 Introduction . . . 153 10.2 Related Works . . . 155 10.3 Genetic Algorithm . . . 159 10.4 Experimental Setup . . . 160 10.5 Experimental Results . . . 162 10.5.1 Search space analysis . . . 162 10.5.2 Training results of GA . . . 164 10.5.3 Overall result and comparison . . . 167 10.6 Conclusion . . . 170 Bibliography . . . 173 11 Paper E:
The Genetic Algorithm Census Transform 177 11.1 Introduction . . . 179 11.2 Related Work . . . 181 11.3 Genetic Algorithm . . . 187 11.4 Experimental Setup . . . 189 11.4.1 Parameters, Data . . . 191 11.4.2 Implementation/Processing platform . . . 193 11.5 Experimental Result . . . 200 11.5.1 Training . . . 201 11.5.2 Evaluation – Square GACT . . . 202 11.5.3 Distribution – Square GACT . . . 204 11.5.4 Evaluation – Lateral GACT . . . 205 11.5.5 Distribution – Lateral GACT . . . 205 11.5.6 Implementation . . . 209 11.5.7 Evaluation with respect to Related Work . . . 211 11.5.8 Outlook . . . 214 11.6 Conclusion . . . 214 Bibliography . . . 217
10 Paper D:
Unbounded Sparse Census Transform using Genetic Algorithm 151 10.1 Introduction . . . 153 10.2 Related Works . . . 155 10.3 Genetic Algorithm . . . 159 10.4 Experimental Setup . . . 160 10.5 Experimental Results . . . 162 10.5.1 Search space analysis . . . 162 10.5.2 Training results of GA . . . 164 10.5.3 Overall result and comparison . . . 167 10.6 Conclusion . . . 170 Bibliography . . . 173 11 Paper E:
The Genetic Algorithm Census Transform 177 11.1 Introduction . . . 179 11.2 Related Work . . . 181 11.3 Genetic Algorithm . . . 187 11.4 Experimental Setup . . . 189 11.4.1 Parameters, Data . . . 191 11.4.2 Implementation/Processing platform . . . 193 11.5 Experimental Result . . . 200 11.5.1 Training . . . 201 11.5.2 Evaluation – Square GACT . . . 202 11.5.3 Distribution – Square GACT . . . 204 11.5.4 Evaluation – Lateral GACT . . . 205 11.5.5 Distribution – Lateral GACT . . . 205 11.5.6 Implementation . . . 209 11.5.7 Evaluation with respect to Related Work . . . 211 11.5.8 Outlook . . . 214 11.6 Conclusion . . . 214 Bibliography . . . 217
I
Thesis
1I
Thesis
125
Chapter 1
Introduction
Autonomous robots will possibly have as great influence on society over the next 50 years as computers have had during the last 50. However, a major part of the potential success of robots is the intelligence, the ability to adapt, to evaluate a situation, to understand, to solve problems, and all this without detailed instructions, but rather through natural language and gestures, as per human communication. With this as a premise, it not only possible but probable, that autonomous robots will play a major part in future everyday life.
An autonomous system relies on information to react to and/or interact with the surrounding environment. This information is provided by a sensory system and is referred to one stimulus or several stimuli. The more complex the environment, the more complex the task, the higher the demand on the sensory system, both in terms of resolution, spatial and time-wise, and the amount of processing (intelligence) required to extract relevant information, from sensory input, to determine and plan the appropriate response or action, or sequence thereof. Us humans exist in a dynamic and complex environment and to create an awareness of, and assimilate to, that environment the human cognition is based on several (five) senses, namely; sight, hearing, taste, smell and touch. Each sense adhere to a modality and sensory information is combined, or fused, to enhance perception. The same reasoning can be applied to intelligent systems, or systems that are perceived to be intelligent, where the type, modality and number of sensors, depend on the application.
Sight, or vision, i.e. the process to acquire and extract information from the visible light, is the dominant, and possibly the most diverse, of human senses. It has been estimated that up to 80% of learning, cognition and activities are
3
Chapter 1
Introduction
Autonomous robots will possibly have as great influence on society over the next 50 years as computers have had during the last 50. However, a major part of the potential success of robots is the intelligence, the ability to adapt, to evaluate a situation, to understand, to solve problems, and all this without detailed instructions, but rather through natural language and gestures, as per human communication. With this as a premise, it not only possible but probable, that autonomous robots will play a major part in future everyday life.
An autonomous system relies on information to react to and/or interact with the surrounding environment. This information is provided by a sensory system and is referred to one stimulus or several stimuli. The more complex the environment, the more complex the task, the higher the demand on the sensory system, both in terms of resolution, spatial and time-wise, and the amount of processing (intelligence) required to extract relevant information, from sensory input, to determine and plan the appropriate response or action, or sequence thereof. Us humans exist in a dynamic and complex environment and to create an awareness of, and assimilate to, that environment the human cognition is based on several (five) senses, namely; sight, hearing, taste, smell and touch. Each sense adhere to a modality and sensory information is combined, or fused, to enhance perception. The same reasoning can be applied to intelligent systems, or systems that are perceived to be intelligent, where the type, modality and number of sensors, depend on the application.
Sight, or vision, i.e. the process to acquire and extract information from the visible light, is the dominant, and possibly the most diverse, of human senses. It has been estimated that up to 80% of learning, cognition and activities are
3
mediated through vision [1]. Vision enables distinction of colour (a combination of hue, saturation, brightness), shape, and distance. Depth perception is achieved by a combination of visual cues, such as structures, perspectives and a priori information, i.e. assumptions, regarding object size, and, of course, stereopsis. This is the fusion of simultaneous information from the two eyes.
With the diversity of human vision in mind, to create a sensor system for autonomous robots, as versatile as possible, it would be advantageous to base it on vision. As vision implies, the system needs to be capable, not only of acquiring images, but also of processing thereof, to extract relevant information. Or, even better, to base it on stereopsis, referred to stereo vision in the context of computer vision, in order to facilitate depth perception. Granted, given a priori knowledge of an object, such as physical size, the distance to the object can be determined from its image size, given the physical parameters of the camera system. Further, stereo vision can be accomplished using a single camera by capturing a scene from different vantage points, also referred to as temporal stereo. There are however problems to this approach: 1) Temporal difference – moving objects will have changed position, during the relocation of the camera, and will hence be estimated to an incorrect depth. Similarly, the problem is reversed in the case of ego-motion, where, from an image perspective, the entire world is moving. 2) Spatial difference – precise information about the two camera positions is required to produce an accurate depth estimate, unless averaging over multitude of images. On that point also stereo-camera systems, where the camera positions are fixed with respect to each other, require calibration. This is also the case when using single cameras for measurement. To conclude, to accomplish visual depth perception, in an unknown and dynamic environment, at least two simultaneous images, of known geometric relation, must be acquired, and processed, also referred to (static) stereo vision.
If the autonomous agents are to collaborate or interact with humans, response time, or latency, should be at least en par with human reaction, to be perceived as real-time. Of course, the lower the latency of the sensor the longer the time to reason and act. However, this is considering a single event. The environment is a constant flow of events, and hence the sample rate, or update frequency, must be part of the equation. A parallel is, when a sequence of static images appears as motion, if shifted fast enough. In the motion picture industry 24 frames per second (fps) was long been a standard, but now higher frequencies are adopted. In practice latency and frame rate go hand in hand, i.e. high frame-rates dictates on-the-fly processing, to avoid data buffering.
Further, as autonomous robots are predicted to be of ever smaller size and lower cost, sensor solutions need to be compact, cost effective and power
mediated through vision [1]. Vision enables distinction of colour (a combination of hue, saturation, brightness), shape, and distance. Depth perception is achieved by a combination of visual cues, such as structures, perspectives and a priori information, i.e. assumptions, regarding object size, and, of course, stereopsis. This is the fusion of simultaneous information from the two eyes.
With the diversity of human vision in mind, to create a sensor system for autonomous robots, as versatile as possible, it would be advantageous to base it on vision. As vision implies, the system needs to be capable, not only of acquiring images, but also of processing thereof, to extract relevant information. Or, even better, to base it on stereopsis, referred to stereo vision in the context of computer vision, in order to facilitate depth perception. Granted, given a priori knowledge of an object, such as physical size, the distance to the object can be determined from its image size, given the physical parameters of the camera system. Further, stereo vision can be accomplished using a single camera by capturing a scene from different vantage points, also referred to as temporal stereo. There are however problems to this approach: 1) Temporal difference – moving objects will have changed position, during the relocation of the camera, and will hence be estimated to an incorrect depth. Similarly, the problem is reversed in the case of ego-motion, where, from an image perspective, the entire world is moving. 2) Spatial difference – precise information about the two camera positions is required to produce an accurate depth estimate, unless averaging over multitude of images. On that point also stereo-camera systems, where the camera positions are fixed with respect to each other, require calibration. This is also the case when using single cameras for measurement. To conclude, to accomplish visual depth perception, in an unknown and dynamic environment, at least two simultaneous images, of known geometric relation, must be acquired, and processed, also referred to (static) stereo vision.
If the autonomous agents are to collaborate or interact with humans, response time, or latency, should be at least en par with human reaction, to be perceived as real-time. Of course, the lower the latency of the sensor the longer the time to reason and act. However, this is considering a single event. The environment is a constant flow of events, and hence the sample rate, or update frequency, must be part of the equation. A parallel is, when a sequence of static images appears as motion, if shifted fast enough. In the motion picture industry 24 frames per second (fps) was long been a standard, but now higher frequencies are adopted. In practice latency and frame rate go hand in hand, i.e. high frame-rates dictates on-the-fly processing, to avoid data buffering.
Further, as autonomous robots are predicted to be of ever smaller size and lower cost, sensor solutions need to be compact, cost effective and power
1.1 Motivation 5
efficient, as power resources are limited. But still, for fine motor ability and object interaction, an accurate representation of the scene is necessary.
1.1
Motivation
The introduction above can be condensed into the following motivation for the thesis: To equip mobile robots with the sense of vision, with the focus on stereo-vision, given the following prerequisites:
• Unknown and dynamic environment • Real-time operation
• Power efficient • Limited size
• High performance-to-cost ratio
This motivation is reflected by the thesis title; Embedded high-resolution stereo-vision of high frame-rate and low latency through FPGA-acceleration. Breaking down the title, there is the term embedded, implying a limited size and power consumption. High resolution has not been discussed yet, but image resolution has undoubtedly increased over the years, with the positive corollary of higher granularity of the scene, and potentially more accurate vision. The drawback being the processing cost, not considering physical characteristics of image sensors, and that many computer-vision algorithms do not scale well, including stereo vision, involving two images. Stereo vision, as mentioned, to enable depth perception in the unknown and dynamic environment. High frame-rate and low latency relates to real-time operation. Through FPGA-acceleration implies that this is the means to achieve all of the above. This is partly true, as the Field-Programmable Gate Array (FPGA) is only as good as an algorithm and the implementation thereof. However, the inherent parallelism of many vision algorithms can be exploited by FPGA processing, allowing for power efficient hardware acceleration.
1.2
Contributions
To accomplish real-time stereo-vision, a holistic approach is adapted, spanning from hardware system to algorithm, via implementation thereof, to suit the processing platform.
1.1 Motivation 5
efficient, as power resources are limited. But still, for fine motor ability and object interaction, an accurate representation of the scene is necessary.
1.1
Motivation
The introduction above can be condensed into the following motivation for the thesis: To equip mobile robots with the sense of vision, with the focus on stereo-vision, given the following prerequisites:
• Unknown and dynamic environment • Real-time operation
• Power efficient • Limited size
• High performance-to-cost ratio
This motivation is reflected by the thesis title; Embedded high-resolution stereo-vision of high frame-rate and low latency through FPGA-acceleration. Breaking down the title, there is the term embedded, implying a limited size and power consumption. High resolution has not been discussed yet, but image resolution has undoubtedly increased over the years, with the positive corollary of higher granularity of the scene, and potentially more accurate vision. The drawback being the processing cost, not considering physical characteristics of image sensors, and that many computer-vision algorithms do not scale well, including stereo vision, involving two images. Stereo vision, as mentioned, to enable depth perception in the unknown and dynamic environment. High frame-rate and low latency relates to real-time operation. Through FPGA-acceleration implies that this is the means to achieve all of the above. This is partly true, as the Field-Programmable Gate Array (FPGA) is only as good as an algorithm and the implementation thereof. However, the inherent parallelism of many vision algorithms can be exploited by FPGA processing, allowing for power efficient hardware acceleration.
1.2
Contributions
To accomplish real-time stereo-vision, a holistic approach is adapted, spanning from hardware system to algorithm, via implementation thereof, to suit the processing platform.
The first contribution comes in the form of the GIMME and GIMME2 vision systems. These were developed as there were no available Commercial-Of-The-Shelf (COTS) FPGA-based stereo-vision systems. Using FPGA development boards inferred restrictions regarding camera integration, such as limiting inter-face bandwidth, and robot integration. The GIMME boards were to be made publicly available, so that other research groups could benefit from the work, sharing a common platform, instead of going through a similar development process.
The second contribution is a segment-based stereo algorithm that copes well with high-resolution images and large disparity ranges. By shifting from pixel space to segment space, the matching part is decoupled from image resolution. The implementation is effective through incremental line-wise segmentation.
The third, and most recent, contribution returns to more conventional stereo matching, by evolving a commonly adopted cost metric for similarity – the Census Transform (CT). By adopting a Genetic Algorithm (GA) optimal com-parison schemas for CT are derived, for neighbourhoods of different size, and schemas of different sparseness. This method is referred to as the Genetic Algorithm Census Transform (GACT) and shows promising results, compared to established CT-methods, for benchmark datasets.
1.3
Thesis Overview
This thesis is divided into two main parts, the kappa followed by the publications. In the kappa, the included papers are put into context with respect to each other, the related work, and the research goals. First the background is provided, introducing theoretical concepts and terminology related to the topic of stereo vision. This is followed by a chapter on the research goals and method. A chapter on related work goes deeper into published works specifically for FPGA-based stereo vision. Next the results of the thesis are discussed, that is the research contributions of the publications, the contribution by the author to the publications, and how these contributions relate to the research goals. The kappa is then concluded with a summary and an outlook to future works. The second part of the thesis is a collection of five peer-reviewed (final paper in submission at the time for printing) research articles.
The first contribution comes in the form of the GIMME and GIMME2 vision systems. These were developed as there were no available Commercial-Of-The-Shelf (COTS) FPGA-based stereo-vision systems. Using FPGA development boards inferred restrictions regarding camera integration, such as limiting inter-face bandwidth, and robot integration. The GIMME boards were to be made publicly available, so that other research groups could benefit from the work, sharing a common platform, instead of going through a similar development process.
The second contribution is a segment-based stereo algorithm that copes well with high-resolution images and large disparity ranges. By shifting from pixel space to segment space, the matching part is decoupled from image resolution. The implementation is effective through incremental line-wise segmentation.
The third, and most recent, contribution returns to more conventional stereo matching, by evolving a commonly adopted cost metric for similarity – the Census Transform (CT). By adopting a Genetic Algorithm (GA) optimal com-parison schemas for CT are derived, for neighbourhoods of different size, and schemas of different sparseness. This method is referred to as the Genetic Algorithm Census Transform (GACT) and shows promising results, compared to established CT-methods, for benchmark datasets.
1.3
Thesis Overview
This thesis is divided into two main parts, the kappa followed by the publications. In the kappa, the included papers are put into context with respect to each other, the related work, and the research goals. First the background is provided, introducing theoretical concepts and terminology related to the topic of stereo vision. This is followed by a chapter on the research goals and method. A chapter on related work goes deeper into published works specifically for FPGA-based stereo vision. Next the results of the thesis are discussed, that is the research contributions of the publications, the contribution by the author to the publications, and how these contributions relate to the research goals. The kappa is then concluded with a summary and an outlook to future works. The second part of the thesis is a collection of five peer-reviewed (final paper in submission at the time for printing) research articles.
Chapter 2
Background
In this section concepts, notations of, and prerequisites for stereo matching are presented for the reader to get an understanding of the problem, and later the related works.
2.1
Demosaicing
A digital image sensor comprises of an array of small photosensors (photo diodes, CMOS), each contributing to a pixel element in the output image. The photo diodes are not limited to a specific bandwidth, but rather excited by light of all colour, indirectly translating to a intensity based, monochrome, image. By introducing a Colour Filter Array (CFA) between the light source and the sensor, only light of a specific colour will excite pixels, according to a defined pattern, resulting in a mosaic, i.e. a colour image where the pixels have one specific colour. To estimate full colour image, commonly according to the RGB colour model, is referred to as demosaicing (demosaicking) or debayering, for the specific case of the common Bayer filter mosaic [2].
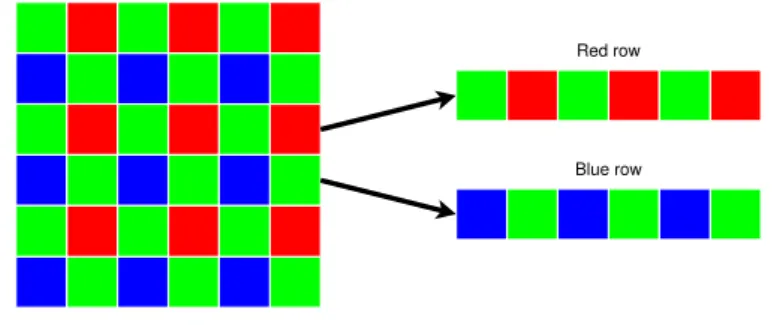
The Bayer pattern, inspired by the physiology of the human eye, has two green pixels for every red and blue pixel arranged in two types of rows, red and blue, as shown in Figure 2.1. The naive approach to demosaicing is simple combination of four neighbouring single colour Bayer pixels into one RGB pixel, as shown in Figure 2.2a. This will result in an image a quarter of the original size. To retain the full size of the image bilinear interpolation can be adopted, where adjacent pixels are sampled to determine the full colour of the
7
Chapter 2
Background
In this section concepts, notations of, and prerequisites for stereo matching are presented for the reader to get an understanding of the problem, and later the related works.
2.1
Demosaicing
A digital image sensor comprises of an array of small photosensors (photo diodes, CMOS), each contributing to a pixel element in the output image. The photo diodes are not limited to a specific bandwidth, but rather excited by light of all colour, indirectly translating to a intensity based, monochrome, image. By introducing a Colour Filter Array (CFA) between the light source and the sensor, only light of a specific colour will excite pixels, according to a defined pattern, resulting in a mosaic, i.e. a colour image where the pixels have one specific colour. To estimate full colour image, commonly according to the RGB colour model, is referred to as demosaicing (demosaicking) or debayering, for the specific case of the common Bayer filter mosaic [2].
The Bayer pattern, inspired by the physiology of the human eye, has two green pixels for every red and blue pixel arranged in two types of rows, red and blue, as shown in Figure 2.1. The naive approach to demosaicing is simple combination of four neighbouring single colour Bayer pixels into one RGB pixel, as shown in Figure 2.2a. This will result in an image a quarter of the original size. To retain the full size of the image bilinear interpolation can be adopted, where adjacent pixels are sampled to determine the full colour of the
7
Red row
Blue row
Figure 2.1: Bayer filter mosaic
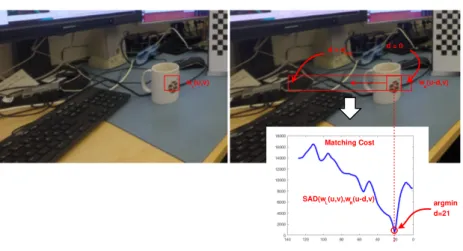
current pixel. Due to the Bayer pattern there are 4 different cases to consider; green pixel on red row, red pixel on red row, blue pixel on blue row, and finally green pixel on green row. Considering a green pixel on a red row, green is, of course, the value of the current pixel, red and blue are given by averaging the two adjacent pixels horizontally and vertically, respectively, as shown in Figure 2.2b. For the case of a blue or a red pixel, there are four pixels to interpolate for the other colours. The resulting image will be of full size but suffer zippering artefacts and colour distortions (bleeding) along edges. From the research in demosaicing, the Malvar-He-Cutler method [3], addresses these problems by improved interpolation through colour cross-bleeding, while remaining implementation efficient, based on linear 5 × 5 filters, with coefficients suitable for hardware (bit shift). Figure 2.2c shows how the red and blue values are calculated for green pixel - red row. Both patterns and weights vary depending on position.
As an alternative, as many stereo vision algorithms rely solely on intensity information, is to opt for monochrome sensors, and thereby eliminate demo-saicing, and at the same time get more detailed images. A major advantage of monochrome sensors is that there is no need for a CFA, and hence all incoming light excites the sensor, not only light of a specific colour. The result is a more light-sensitive sensor, which is beneficial for low light and high-speed scenarios.
2.2
Camera Model, Calibration and Undistortion
From an image processing perspective demosaicing is the first step in a vision pipeline, excluding sensor signal interfacing/pixel decoding. However, from a camera perspective there is some modelling going on before the light rays
Red row
Blue row
Figure 2.1: Bayer filter mosaic
current pixel. Due to the Bayer pattern there are 4 different cases to consider; green pixel on red row, red pixel on red row, blue pixel on blue row, and finally green pixel on green row. Considering a green pixel on a red row, green is, of course, the value of the current pixel, red and blue are given by averaging the two adjacent pixels horizontally and vertically, respectively, as shown in Figure 2.2b. For the case of a blue or a red pixel, there are four pixels to interpolate for the other colours. The resulting image will be of full size but suffer zippering artefacts and colour distortions (bleeding) along edges. From the research in demosaicing, the Malvar-He-Cutler method [3], addresses these problems by improved interpolation through colour cross-bleeding, while remaining implementation efficient, based on linear 5 × 5 filters, with coefficients suitable for hardware (bit shift). Figure 2.2c shows how the red and blue values are calculated for green pixel - red row. Both patterns and weights vary depending on position.
As an alternative, as many stereo vision algorithms rely solely on intensity information, is to opt for monochrome sensors, and thereby eliminate demo-saicing, and at the same time get more detailed images. A major advantage of monochrome sensors is that there is no need for a CFA, and hence all incoming light excites the sensor, not only light of a specific colour. The result is a more light-sensitive sensor, which is beneficial for low light and high-speed scenarios.
2.2
Camera Model, Calibration and Undistortion
From an image processing perspective demosaicing is the first step in a vision pipeline, excluding sensor signal interfacing/pixel decoding. However, from a camera perspective there is some modelling going on before the light rays
2.2 Camera Model, Calibration and Undistortion 9 1/2 1/2 1 1 (a) Combination 1/2 1/2 1/2 1 1/2 (b) Interpolation 5 -1 -1 -1 -1 -1 -1 4 4 1/2 1/2 5 -1 -1 -1 -1 -1 -1 4 4 1/2 1/2 (c) Malvar-He-Cutler
Figure 2.2: Bayer demosaicing, green pixel - red row.
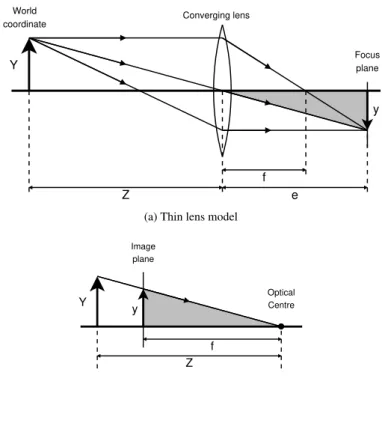
excites the photo receptor. Between the world and the sensor there is a lens, which refracts the light rays, to converge at a certain point, the focal point. The distance between this point and the lens is referred to as the focal length. The light rays re-intersect at the focus plane. Objects that are located further or closer to the lens, will not have intersecting rays, and hence be unsharp, or unfocused. This is referred to the thin lens camera model and is shown in Figure 2.3a. Using similar triangles, the relationship between the distance between the object and the lens, Z, the lens and the focus plane, e, and the focal length, f , can derived, as seen in Equation 2.1, also known as the thin lens equation or simple lens law.
1 Z + 1 e = 1 f (2.1)
A simplification is assuming a pinhole instead of a lens, inferring that a point on the image plane can only be hit by a single light ray. This is the same as having an infinitely small aperture, and consequently infinitely large depth of field, and focus independent on distance. Assume, that Z >> f , 1/Z → 0,
2.2 Camera Model, Calibration and Undistortion 9
1/2 1/2 1 1 (a) Combination 1/2 1/2 1/2 1 1/2 (b) Interpolation 5 -1 -1 -1 -1 -1 -1 4 4 1/2 1/2 5 -1 -1 -1 -1 -1 -1 4 4 1/2 1/2 (c) Malvar-He-Cutler
Figure 2.2: Bayer demosaicing, green pixel - red row.
excites the photo receptor. Between the world and the sensor there is a lens, which refracts the light rays, to converge at a certain point, the focal point. The distance between this point and the lens is referred to as the focal length. The light rays re-intersect at the focus plane. Objects that are located further or closer to the lens, will not have intersecting rays, and hence be unsharp, or unfocused. This is referred to the thin lens camera model and is shown in Figure 2.3a. Using similar triangles, the relationship between the distance between the object and the lens, Z, the lens and the focus plane, e, and the focal length, f , can derived, as seen in Equation 2.1, also known as the thin lens equation or simple lens law.
1 Z + 1 e = 1 f (2.1)
A simplification is assuming a pinhole instead of a lens, inferring that a point on the image plane can only be hit by a single light ray. This is the same as having an infinitely small aperture, and consequently infinitely large depth of field, and focus independent on distance. Assume, that Z >> f , 1/Z → 0,
Converging lens Z World coordinate e f Y y Focus plane
(a) Thin lens model
Z Image plane f Y y Optical Centre (b) Pinhole camera
Figure 2.3: The thin lens and pinhole camera model
and thus, f ≈ e. This is known pinhole approximation and the pinhole camera model. To further simplify, the image plane can be moved in front of the optical centre to preserve image orientation, avoiding image flip, as shown in Figure 2.3b.
It is obvious that focal length has an impact on how the scene is captured. Larger focal lengths provide a large magnification factor, and vice versa. From Figure 2.3b, once again using similar triangles, the following relationship can be derived: y = f ZY (2.2) Converging lens Z World coordinate e f Y y Focus plane
(a) Thin lens model
Z Image plane f Y y Optical Centre (b) Pinhole camera
Figure 2.3: The thin lens and pinhole camera model
and thus, f ≈ e. This is known pinhole approximation and the pinhole camera model. To further simplify, the image plane can be moved in front of the optical centre to preserve image orientation, avoiding image flip, as shown in Figure 2.3b.
It is obvious that focal length has an impact on how the scene is captured. Larger focal lengths provide a large magnification factor, and vice versa. From Figure 2.3b, once again using similar triangles, the following relationship can be derived:
y = f