Faculty of Technology and Society Computer Engineering
Bachelor Thesis 15 ECTS
Hand gestures as a trigger for system initialisation
Handgester som metod för initialisering av system
Jake O’Donnell
Jason Tan
Abstract
Biometric solutions for access control is a thriving concept, Precise Biometrics is a company that focuses on just that. YOUNiQ is a product that focuses on facial identification for access control, with it comes an issue in where every person’s face is being identified. This means identifying people that do not want to use the facial identification module. This thesis focuses on implementing an intent-aware system, a system which uses a trigger to begin a process. This thesis was done in collaboration with engineers at Precise Biometrics. Instead of identifying faces without permission the intent-aware system uses a trigger based on different hand gestures to begin the process. This thesis does not focus on face identification but instead the trigger before a specific process begins. The development phase consisted of an iterative process in creating the prototype system. In order to evaluate the system, test cases were done to verify accuracy of each hand gesture. Thereafter, a scenario was created to simulate an activation of the prototype system. The evaluation was used to determine the convenience and guidance when implementing intent-aware systems. Furthermore, the system can be seen as a form of trigger to allow for extracting biometric data in for example face identification.
Sammanfattning
Biometriska lösningar för åtkomstkontroll är ett blomstrande koncept. Precise Biometrics är ett företag som fokuserar på just biometriska lösningar relaterade till åtkomstkontroll. YOUNiQ är en produkt som fokuserar på ansiktsigenkänning. Denna produkt använder ansiktsigenkännig för att ge åtkomst till registrerade användare i systemet. Ett problem som uppstår vid att använda ansiktsigenkänning är att alla som befinner sig tillräckligt nära kameran blir skannade, även de som inte är registrerade. Denna avhandlingen har som mål att implementera ett avsiktsmedvetet system som använder en utlösare för att starta ett system. Istället för att använda ansiktsigenkänning på alla individer använder systemet gester som en utlösare för att starta systemet. Denna avhandlingen fokuserar inte på ansiktsigenkännning utan istället på utlösaren för att starta en process. Utvecklingsfasen sker i form utav en iterativ process för att skapa en prototyp. För att utvärdera systemet utfördes testfall för varje gest som är inkluderat i systemet. Efter testfallen var färdigställda sattes dem i ett verkligt scenario för att simulera en komplett interaktion med systemet. Utvärderingen användes sedan för att bestämma och vägleda för implementationen av ett avsiktsmedvetet system. Denna implementation kan ses som en signal till underliggande funktioner för att extrahera biometrisk data för till exempel ansiktsigenkänning.
Acknowledgements
We would like to express our appreciation to Precise Biometrics allowing us the opportunity to perform this thesis on their behalf. Additionally, we are deeply grateful for the support and help with our thesis from Theodor Breimer, Adam Ly and Johan Windmark at Precise Biometrics. We would also like to thank Radu-Casian Mihailescu for his advice, ideas and feedback throughout the thesis work. Finally, we would like to thank every volunteer participating in our research and helping out with the test results.
Contents
1 Introduction 1
1.1 Background . . . 1
1.2 Problem and purpose . . . 2
1.3 Research Questions . . . 3
1.4 Limitations . . . 3
2 Theory and technical background 4 2.1 Spoofing . . . 4
2.2 Human-Computer Interaction . . . 4
2.3 Object tracking and image processing . . . 4
2.4 Confusion matrix . . . 5
2.5 Hand gesture recognition . . . 6
2.6 Single-shot detector (SSD) . . . 6 2.6.1 SSD Training . . . 8 2.6.1.1 Negative mining . . . 8 2.6.1.2 Data augmentation . . . 8 2.7 TensorFlow . . . 9 2.8 MediaPipe . . . 10 2.9 OpenCV . . . 11 2.10 XND-6080R . . . 12 3 Related work 13 3.1 Audio-visual intent-to-speak detection for human-computer interaction . . . 13
3.1.1 Comments . . . 13
3.2 Consent Biometrics . . . 13
3.2.1 Comments . . . 14
3.3 Robust hand gesture recognition with Kinect sensor . . . 14
3.3.1 Comments . . . 14
3.4 Position-Free Hand Gesture Recognition Using Single Shot MultiBox Detector Based Neural Network . . . 15
3.4.1 Comments . . . 15
4 Method 16 4.1 Literature Study . . . 16
4.3.3 Analyse and design the system . . . 18
4.3.4 Build the prototype system . . . 18
4.3.5 Observe and evaluate the system . . . 19
5 Results 20 5.1 Stakeholders involvement . . . 20
5.1.1 System requirements . . . 21
5.2 Construct a conceptual framework . . . 23
5.2.1 Problem tree . . . 23
5.2.2 Video feed . . . 23
5.2.3 Software . . . 24
5.2.4 Literature study . . . 24
5.2.5 Intent . . . 25
5.3 Develop a system architecture . . . 26
5.3.1 System functions . . . 26
5.3.2 Camera . . . 26
5.3.3 Software . . . 27
5.3.4 Intent . . . 27
5.4 Analyse and design the system . . . 27
5.4.1 Camera choice and computer-vision . . . 27
5.4.2 TensorFlow . . . 27
5.4.3 Sequence diagram . . . 28
5.5 Build the prototype . . . 28
5.5.1 Pose estimation . . . 29
5.5.2 Blazepalm recognition . . . 29
5.5.3 Algorithms . . . 30
5.5.3.1 Pose estimation algorithm . . . 30
5.5.3.2 Intent-trigger algorithm . . . 31
5.5.3.3 Hand recognition algorithm . . . 32
5.5.4 Activity Diagram . . . 33
5.6 Observe and evaluate the system . . . 34
5.6.1 Test case requirements . . . 34
5.6.2 Verifying computer-vision . . . 34
5.6.3 Verifying intent-trigger . . . 35
5.6.4 Validating the system . . . 36
6 Discussion and Analysis 38 6.1 Related work . . . 38 6.2 Method discussion . . . 39 6.3 Analysis of results . . . 39 7 Conclusion 40 7.1 Research questions . . . 40 7.2 Contribution . . . 41 7.3 Future Work . . . 41
1
Introduction
Image processing is being implemented more and more into our daily life and is often used as a form of access control or identification. Image recognition, in the form of facial recognition, can be used to allow access into buildings or smartphones. Facial recognition searches for features of a person’s face to identify a previously linked name to the face being processed.[1], [2]. Several different actions can be taken dependent on what authority the person whose face was processed holds, a clear example of this is not letting unfamiliar faces unlock your phone when using face recognition. Furthermore, it is important to only process images of a person who has given their permission, this is where a major problem is introduced. Is it possible to solve the issue where an individual’s face is being processed without their permission?
1.1 Background
Biometrics is a term used to describe a person’s anatomical characteristics as well as their behaviour. Biometric recognition was invented due to it being more reliable than traditional identification methods such as passports/ID cards or passwords. As the traditional methods are prone to forging, being forgotten and getting lost, biometrics are unique and can not get lost or forgotten and are in most of the cases much more difficult to forge [1]. Humans have been using biometrics as a form of identification before computer systems were created, however, during this period such biometrics were not stored in databases but rather in the form of card files [3]. During the development of this technology, information regarding a person’s physical characteristics such as face, gait or even voice has been used to identify a person. Perhaps the most common form of biometric identification is fingerprint which was originally used within crime-solving along with helping single out certain people from a group of individuals [3]. For an anatomical feature to be considered a biometric there are some requirements needed to be fulfilled:
• Distinctiveness: The characteristic has to be distinctive in a sense that it has to be different from any other.
• Universality: Every person should have this characteristic. • Permanence: The characteristic shall not be prone to change.
For a system that uses biometrics as a form of identification there are issues which are needed to be considered. A system has to be implemented to an extent where people accept that their body characteristics are used as an identifier in their daily life. Secondly, the system must not be unstable to fraudulent methods. Last but not least, a biometric system has to have high accuracy and speed when identifying a person. A biometric system uses acquired data from individuals where features from previously stored data are compared with the real-time images retrieved from e.g. a camera [3].
Concerns regarding one’s safety and privacy is a problem in image recognition where people are being recorded and identified without their consent. It is important to only scan for a person’s biometric data if they are willing to have their biometrics compared with biometric data in the database. This can be done by showing an intent or Yang’s terminology consent signature [4]. An intent is a cue for the system to start a process in a touchless and natural manner. A cue can be audio or visual-based, typical audio intent could be to activate the voice assistant in smartphones such as ”hey Siri” or ”ok Google”. While a visual intent could be a form of hand gesture, facial expression or body movement, such as a wave or blinking with an eye [5].
1.2 Problem and purpose
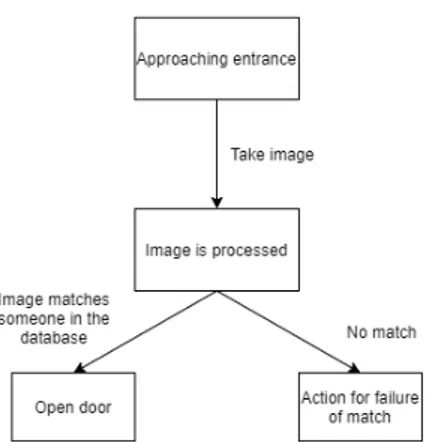
Precise Biometrics is a technology company that focuses on biometrics as a form of identification. The company offers biometric solutions to ensure digital identity to other companies in the finance, betting, healthcare and transport industry [6]. Precise Biometrics develops different types of biometric solutions for identification and access control. Since 2019 Precise Biometrics has developed an access system named YOUNiQ [7]. This is a facial recognition system that is capable of face identification in real time [8], the system is built in a way that it starts running whenever someone approaches a door. How this system is designed in high abstraction is shown in figure 1. However a problem that arises by performing face identification without the person’s knowledge is the question of personal integrity. The purpose of this thesis is to create an intent-aware system that restricts the face recognition process such as YOUNiQ to individuals that has given their approval to the system. The system should not accidentally be triggered by people in the background or someone just wanting to access whatever is behind the camera without using the face recognition module.
Figure 1: Simple description of YOUNiQ access
1.3 Research Questions
Instead of using access cards or keys to open a door or gate, it would be possible to create a camera that uses facial recognition in order to unlock a door based on an intent. Together with Precise biometric we decided that the intent would be hand gestures. In this context an intent refers to a request for a system like YOUNiQ to begin an identification process. Research questions addressed:
• RQ1: How can hand gestures be used as an intent in human-computer interactions (HCI)?
• RQ2: RQ2: How can hand gestures be identified in an accurate and robust manner to start a process?
• RQ3: How can the intent-trigger be tied to the correct person performing a predefined gesture?
1.4 Limitations
The system is limited to a single camera. A problem that arises when only processing an image in two dimensions is the increased vulnerability to spoofing(2.1). Furthermore, the research has not taken in consideration of what camera that is being used. This research uses an XND-6080R as well as an ordinary desktop camera from a laptop. The outcome of the results may vary depending on the camera unit, as well as computer specifications. An intent gesture is limited to a set of hand gestures which can be seen in appendix B(7.3). The aware system is separate from any processes that comes after an intent-trigger has been identified.
2
Theory and technical background
This section covers background and information that is required to understand sections later on such as results and analysis as well as technical specifications of hardware and third-party libraries which are used.
2.1 Spoofing
Spoofing is the situation when someone is trying to recreate an identification artificially, for example recreating a face, this could be done with a face printed on a piece of paper or simply falsifying the email address to send spam or harming emails [9]. Many daily devices such as laptops and smart phones are vulnerable to spoofing. Well-renowned brands such as Lenovo, Toshiba and Apple has proven vulnerable to spoofing in the past. By using fake facial images of a user, researchers at Security and Vulnerability Research Team of the University of Hanoi managed to gain access to user’s computer [10]. Furthermore, when Apple introduced fingerprint identification it was reported that a German hacker managed to gain access to the phone with the help of a faux finger. In order to obstruct spoofing one countermeasure is to detect signs of life, for instance, combining facial and voice recognition [10]. Another anti-spoofing technique proposed by Chen et al. is using regional-based convolutional neural network meant to reduce or challenge spoofing by extracting regions from the image where each region is classified by the network. Each region is classified through a region of interest which is selected by a well-trained network [9].
2.2 Human-Computer Interaction
Human-computer interaction (HCI) is the study regarding how humans and computers interact in an effective way. As computing is taking a greater part of the daily life the importance of usable and consumer friendly systems are increasing. Previously, computer interaction required elaborate training and experience to manage. As access to computers increased, attention to usability was driven by competitiveness between companies. This meant to reduce frustration and user training to handle computers. A typical example of HCI is the graphical user interface (GUI), creating interfaces that are easy to orientate and manage. HCI allows for researches to move forward in developing new interactive technology and study how well users can learn to handle the new interactions [11].
2.3 Object tracking and image processing
A video consists of a sequence of frames, where each frame is a picture of the scene. A video is being captured by a number of frames per second (FPS). In computer vision video cameras are used to detect specific objects in motion, this video analysis is applicable in several areas such as motion-based recognition and human-computer interaction. Objects can be defined as ”anything that is of interest for further analysis” thereby, an object could be either a moving car, a person walking [12] or hands.
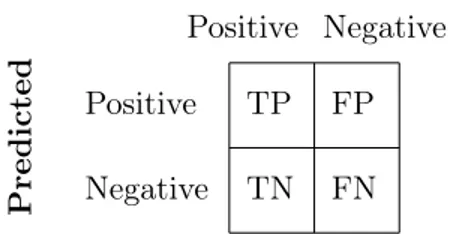
2.4 Confusion matrix
A confusion matrix consists of labels representing true respectively false positive as well as true respectively false negatives, what correlates as a specific label can be found in 4.3.5. There are some metrics which are important to define and understand when studying a confusion matrix. TN FN TP FP Positive Negative Positive Negative Predicted True
Figure 2: Confusion matrix example
When studying a confusion matrix accuracy, recall, precision and F1-score can be calculated [13].
The accuracy is an overall estimation[13] of how well the system can detect intent-triggers, the accuracy can be calculated by:
Accuracy = T P + T N
(T P + T N + F P + F N ) (1) Recall is a measurement of the ratio between the true positives and all the observations[13], [14] e.g. recall can be used to measure how many of the gestures where accurately anticipated as positive which were also labeled as positive. Recall can be calculated by:
Recall = T P
(T P + F N ) (2)
Similar to recall, precision is a ratio of true positives however, precision only measures the ratio of true positives between all positive predictions[13], [14] e.g. precision is used to measure how many of the gestures predicted where actually the gesture performed. Precision can be calculated by:
P recision = T P
(T P + F P ) (3)
Accuracy can result is skewed values should the ratio between the gestures be imbalanced, in this case F1-score can provide more accurate results. F1-score produces a subcontrary
2.5 Hand gesture recognition
Hand gesture recognition is described as a research problem in the area of HCI, it involves recognising gestures in a continuous video as a means to communicate with a computer to achieve certain tasks [15] instead of using graphical interfaces. Some pertinent gestures involve controlling a computer cursor based on predetermined hand gesture which correlates to certain commands e.g. showing one finger represents one mouse click, and two fingers represents a double click [16]. Hand recognition has also been applied to sign language where each word or letter can be translated into audio or text [17].
2.6 Single-shot detector (SSD)
Single-shot detector is a framework used for detection and training methodology for image recognition, which is also used by MediaPipe, 2.8. The framework requires an input image and ground truth boxes i.e. boxes created through direct observation in order to train the network. Small set of default boxes with varying aspect ratios evaluate the image at different locations within the image. For each box a confidence score is determined as well as a location for the object which can be seen in the image below [18].
The SSD is a feed-forward convolutional network, where unlike usual neural networks form a continuous cycle it only feeds in one direction [19]. The feed-forward produces multiple bounding boxes for the object within the boxes, finally a non-maximum suppression stage is done to detect the object, the outcome is a final detection with only one boundary box [18], which can be seen in figure 4b below. The box with the most overlaps is the one with highest confidence score and thus the box is kept.
(a) Illustration of a feed-forward network[20]
(b) Non-maximum suppression[21]
The SSD model consists of multiple layers in order to detect features, the first network layers are meant for image classification and is called the base network. An assisting layer structure is implemented to help detect key features, at the end of the base network convolutional layers are added which declines in image resolution to allow object detection at multiple scales. The convolutional feature layers are added for predicting object detection which are different for each layer [18]. The last 3x3 and 1x1 filters forward a transformation of one feature map to the next with the help of max-pooling. The final predictions are made at the end of the network which produces either a class score, localisation offset as well as object detection [18], [22]. The final stage in the model is a non-maximum suppression of the object in the image.
Figure 5: SSD Layers [18]
2.6.1 SSD Training
Training SSD involves negative mining and data augmentation strategies as well as determining default boxes, which during network training default boxes are matched with ground truth detection. The matching is done by a selection of default boxes with varying aspect ratios, scale and location. Matching is done based on the jaccard overlap determined by,
IoU = Area of Overlap
Area of U nion (5)
an intersection over union (IoU) closer to 1 determines a better object detection [18]. 2.6.1.1 Negative mining
The majority of default boxes are usually negative if the number of possible default boxes detected are large. This results in a disproportion between positive and negative training examples. For faster optimisation images are sorted and chosen based on highest confidence score. Preferably, the ratio between negative and positive should be three to one [18]. 2.6.1.2 Data augmentation
A robust model is created by randomly selecting a training image with different shapes and sizes. Each trained image is selected based on either: an original input image, a minimum jaccard score of 0.1, 0.3, 0.5, 0.7 or 0.9 or a random sample of a given patch in the image. A patch size ranges from 0.1 to 1 with an aspect ratio between 0.5 and 2 of the original image [18].
2.7 TensorFlow
TensorFlow is a library created by Google for describing, training and applying different machine learning models, it allows developers to utilise ”novel optimizations and training algortims” [23], [24]. TensorFlow’s machine learning algorithms are characterised as directed or computational graphs. Such graph consists of nodes and edges(tensors), where each node describes an operation and tensors represents data which flows between the operations.
Figure 6: Directed graph, the figure represents a simple directed graph. The graph consists of two nodes which are input variables x and y and the operation’s result z.
The computational graphs shows a simple + (addition) operation, TensorFlow provides a range of varying operations from mathematical operations to neural network units. Upon creating an operation in TensorFlow such as the operation above a tensor object is returned, in this case z, this tensor could be used for other operations as an input. An operation takes m ≥ 0 tensors as inputs and produces n ≥ 0 outputs, hence, an operation can for example, have no inputs and one or more outputs. [23], [24].
Table 1: TensorFlow operations.
Category
Operation examples
Matrix Operations
matrix_inverse, matrix_determinant
Element-wise operation
add, argmax, argmin, log
Neural network units
conv2d, softmax
TensorFlow has proven to provide solutions for object recognition through images and can be used to train large sets of data to recognise certain objects. Furthermore, TensorFlow includes a library in which the user can save or restore as necessary. This allows users to maintain checkpoints with the highest evaluation score, it is also reusable in the sense that it can be used for fine-tuning a model or unsupervised learning [24].
2.8 MediaPipe
MediaPipe is a Google owned open-source framework used to apply machine learning pipeline. The framework is multimodal, meaning that it can be applied to different media such as audio and video [25]. MediaPipe lets the developer build and analyse systems via graphs and further develop the systems as applications. MediaPipe shares an interface built on time-series data which allows for easy cross-platform developing. All the fundamental steps from retrieving sensor data as input to achieving specific results from the application are done in the pipeline configuration. Each pipeline created can run without difference in behaviour on varying platforms, allowing for easy scalability on mobile and desktop. MediaPipe is built on three fundamental parts: performance evaluation, framework for retrieving sensor data and a collection of components called calculators [25] which are reusable. Creating a prototype pipeline can be done incrementally, a pipeline is a graph of components - calculators, each calculator is connected by streams where packets of data flow through. Developers can remove, replace or define custom calculators anywhere in the graph creating their own application. The calculators and streams combined creates a data-flow diagram, the graph below is created with MediaPipe where each node is a calculator and the nodes are connected by streams [25].
Figure 7: MediaPipe hand recognition graph [26]
To detect and recognise a hand/palm in real-time, MediaPipe uses a single-shot detector model (2.6). The hand recognition module is trained by first training a palm detector model due to it being easier to train palms since fingers consists of joints. Furthermore, the non-maximum suppression works significantly better on small objects such as palms or
fists [27]. Creating a hand landmark model involves locating 21 joint or knuckle coordinates within the hand region. The 21 coordinates represents a location on each knuckle see figure 8.
Figure 8: Hand coordinates
2.9 OpenCV
OpenCV provides tools to retrieve and capture computer-vision, the library contains a mix of image-processing functions and algorithms for biometric detection [28]. OpenCV has the ability to find comparable images from a database, follow eye movement and image manipulation among others [12].
2.10 XND-6080R
The XND-6080R camera is an IP camera by Hanwha, it has a combination of IR technology and RGB camera [29]. The camera offers its own low light technology with three main elements. First, in order to improve low light performance the sensor has a large aperture opening i.e. letting more light reach the sensor. Second, the camera uses high sensitivity sensor which lets the camera react well to low light environments. With large sensor and large pixels the pixels cover a larger surface area which increases sensitivity, due to the fact that more light affects each pixel. Last but not least, the camera contains software to reduce noise which especially occurs in low light environments. It uses low pass filtering to reduce noise based on the previous frame [30].
Figure 9: XND-6080R [31] Technical specifications and key features:
Table 2: Camera specs.
XND-6080R
Camera
2 megapixel (1920x1080) resolution
Frames
up to 60 frames per second
Field of view (FOV) Horizontal: °119.5(Wide) 27.9°(Tele),
Vertical: 62.8°(Wide) 15.7°(Tele)
IR Viewable Range
30m
The camera also has features such as audio and motion detection, lens distortion correction. Infrared cut removal (ICR) which helps with reduce excess light in order to generate high quality images. The camera offers a range of resolutions with the highest being 1920x1080 and the lowest 320x240.
3
Related work
This chapter covers work that is relevant to the thesis. The papers conferred covers potential algorithms, architectures or similar implementations of intent-aware systems.
3.1 Audio-visual intent-to-speak detection for human-computer interaction
de Cuetos et al. presents a solution for a system to begin listening for an audio cue based on facial recognition. A face is detected based on its features such as nose, mouth and eyes as well as a face score. The face score is measurement of the probability that the object in the cameras frame is considered a face [5]. The authors single out the mouth region to detect a visual indication of audio - in this case speech. Once a face and a visual indication that the user is speaking has been detected, the system begins to listen.
Furthermore, after testing the audio speech activity detection rates in the system, results showed a 92.99% accuracy in detecting silence and 87.80% accuracy in detecting speech. Results regarding Visual speech classification results are of lower accuracy at a reported 70.19% to 77.37% for detection of silence and 54.72% to 77.37% for detection of Speech [5]. The varying results within visual based detection are caused by dynamic variables in the functions used to calculate the probability.
3.1.1 Comments
de Cuetos et al. are using an intent mainly based on visual cues for a microphone to begin recording as well as the system to begin listening. This brings forth a solution of handling intent based on audio as well as visual cues for the system to begin processing.
The results of accuracy regarding different types of intents should be taken into consideration when creating intents for a system.
3.2 Consent Biometrics
The paper proposes a terminology called consent signature, consent signature is similar to an intent-trigger in the sense that is a biometric based signature to show or allow the user’s characteristics or behavioural features to be extracted [4]. Yang et al. describes the consent signature system as distinguishing the true intentions of the user. Furthermore, two schemes are introduced; combinational consent biometrics and incorporating consent biometric. The combinational scheme uses two inputs. A consent signature and biometric feature is received and recognised separately, thereafter combined to give a final identification. The second scheme acquires the intent simultaneously as the user’s biometric data. Each user has a predetermined behavioural password. The camera records a pattern of biometric
3.2.1 Comments
Yang et al. introduces ideas which are useful for implementing an intent-aware system. The results presented in the paper includes a proposal to use consent biometrics to further secure the system. In comparison with traditional biometric systems an implementation of consent biometrics can provide further information for recognition and therefore improve recognition accuracy along with protection of personal and security. A similar combinational scheme presented in the paper was implemented, extracting intent separate from the biometric process which comes after.
What separates intent and consent signature is that a consent signature is used to show consent that the system is allowed to extract biometric data. Meanwhile, an intent regards a broader spectrum of beginning a process which may include biometric identification.
3.3 Robust hand gesture recognition with Kinect sensor
Hand gesture recognition is an emphasised research issue within Human-Computer interaction due to its broad spectrum of applications from recognising sign language to virtual reality and computer games. The main issues regarding video based computer-vision is often lighting and background clutter [32]. Ren et al. proposes two challenging problems within the field; hand detection and gesture recognition. In order to solve these issues the authors presents a solution that involves hand segmentation and shape representation to solve the hand detection problem. The system uses depth map and color image to detect hand shapes. The solution to gesture recognition is using a distance measurement called Finger-Earth Mover’s Distance, which is specifically designed for matching hand shapes. The FEMD measures dissimilarities between hand shapes by considering each finger as a cluster and penalises any unmatched fingers. By doing this the system can detect which fingers are hidden, once compared to the template a gesture can be identified. Finally the video feed received as input is matched with a template [32].
Ren et al. applies the hand gesture recognition in a rock-paper-scissor game against the computer as well as arithmetic computation. Where each gesture represents either a number or an arithmetic computation.
The results presented in the paper are quite promising with 90% accuracy on the specific dataset tested [32].
3.3.1 Comments
The results presented are quite promising with 90% accuracy, however, only tested on their own dataset. Furthermore, the paper is relevant since it utilises gesture recognition through a camera in order to control or interact with a computer to achieve certain tasks.
3.4 Position-Free Hand Gesture Recognition Using Single Shot MultiBox Detector Based Neural Network
Tang et al. proposes a hand gesture recognition system that can detect and determine a hand gesture in any position of the screen [33]. The Single-Shot MultiBox Detector (SSD) is meant to find the hand’s position and Convolutional Neural Network (CNN) to classify a hand gesture. Real-time video feed is captured with a web camera, the image is transferred to a trained SSD network to produce a bounding box on the hand that has the best score of representing a hand. A frame along the bounding box is cropped to produce a segmentation and passed into CNN [33], thereafter a gesture is predicted. The figure below shows an overview of how the process of gesture recognition is done.
Figure 10: Process overview [33]
The purpose of the paper is to process and recognise gestures of American sign language which is done by teaching the network to recognise images of gestures from a dataset from Massey University [33]. With the use of their algorithm and neural networks the system has a 95.05% accuracy. Furthermore, the authors believe a better results is achievable as there exists mislabeling in the database as well as the hand segmentation done is not accurate enough which may also affect the accuracy.
3.4.1 Comments
The work shows promising results as 95% accuracy is relatively satisfactory, especially using a standard web camera. Using SSD or CNN can be helpful in increasing accuracy in image processing. Moreover, as MediaPipe uses SSD for hand recognition similar results could be achieved. It is however, not mentioned how the camera and computer specifications may affect the results.
4
Method
This section covers the method used for the creation development of an intent aware system. It is a combination of literature study and Nunamaker as well as working together with Precise Biometrics to develop a usable system. The literature study was utilised to determine the different structures of how an intent-aware system can be implemented as well suitable architectural structure for creating an efficient system. Nunamaker was chosen due to its iterative and systematical approach in creating a system from concept to prototype system.
4.1 Literature Study
The purpose of the literature study is mainly to understand how an intent aware system can be created, its functions and its limitations. This is mostly done through previous related work, where methods and techniques used in the paper are studied closer.
The literature studied was primarily focused on digital libraries such as IEEEXplore Digital Library. This is due to a large database and coverage of scientific and technical content. IEEE is also a renowned organisation within the technical field. During the search process studies conducted before year 2000 was filtered away since there has not been much research in the field of intent aware systems before this time period. It was also interesting to learn about older studies as this would give an insight of how the term and definition has been interpreted. The risk of studying obsolete methods are quite low since the use of intent aware systems are still uncommon.
Below is a conclusive table of the literature studies regarding similar intent-aware implementations along with keywords.
Table 3: Similar intent-aware implementations.
Source Author Keywords
Audio-visual intent-to-speak [...] de Cuetos et al. camera recognition intent Consent Biometrics Yang et al. biometric consent
Table 4: Hand recognition implementations.
Source Author Keywords
Robust Hand Gesture Recognition with Kinect Sensor Ren, Zhou et al. hand recognition (google.scholar.com) Position-Free Hand Gesture Recognition Using J. Tang, hand gesture recognition Single Shot MultiBox Detector Based Neural Network X. Yao et al. single shot detector
4.2 Stakeholders involvement
In order to select and achieve an optimal system solution it is required to gain knowledge and differences between different implementations as well as discussing these implementations. To be able to accomplish this we worked conjointly with experts in the field at Precise Biometrics throughout the time of the thesis. Together a reasonable system implementation were built by working through agile software development. Through continual improvement and adaptive planning a desired system was achieved. Short meetings were held weekly to bring forth ideas and plans as well as limitations or solutions.
Main issues of discussion revolved around: • Recommended libraries
• System requirements
The results regarding recommended libraries, system requirements and implementations of intent-aware systems can be found in 5.1.
4.3 Nunamaker and Chen’s system development
Nunamaker is an iterative and systematic concept which consists of five stages. Each step or stage is set up in a successive way from research question to prototype and evaluation. The five steps leads to an iterative process which is displayed below [34].
4.3.1 Constructing a conceptual framework
In the first stage research questions was proposed and possible solutions were investigated. In order to bring forth reasonable research questions relevant to the research domain requirements, functionality and possible implementations of the system had to be studied closer. By evaluating potential problems a problem tree was created to get an overview of problems the system could encounter. This was done to increase resilience in case of possible problems. The knowledge gained from the literature study could help to find sufficient solutions to the problems stated in the problem tree regarding intent-aware systems.
The results from constructing a conceptual framework are presented in 5.2.1. 4.3.2 Develop a system architecture
In this process the problems have been broken down in the problem tree including its sub-problems. The different sub-problems and their relations are identified within the intent aware system. When developing a system architecture the requirements and technical specifications in step one were taken into account. An architectural view includes the components used and their interrelations.
The results from developing a system are presented in 5.3. 4.3.3 Analyse and design the system
With the help of the system architecture developed in the previous stage a conceptual model was created, this is typically a Unified Modeling Language (UML) design over the systems functionality. It was important to understand the area when designing a system. Hence, obtaining relevant information regarding the systems technical requirements and functionality early on was crucial to hinder any unsuitable solutions. The UML designs created are sequence diagram of the system, from receiving the video feed to intent detection and trigger.
The results from analysing the system are presented in 5.4 4.3.4 Build the prototype system
In order to demonstrate the systems functionalities and feasibility a prototype of the system was built. This allows for efficient testing and verifying any ideas or theories regarding the system. The previous stages were meant to acquire information to implement a feasible system. From the implementation any observations regarding the system’s advantages and disadvantages could be made. Any new insights made from the observations was used to re-design the system. The iterative process allowed for easy reconstruction of the system if required.
in 5.3 and 5.4. With the help of the diagrams created in previous steps a systematical approach in developing the system was achieved.
4.3.5 Observe and evaluate the system
Observation and evaluation is the core of the final stage of Nunamaker’s five steps. This step was meant to observe impacts on individuals and groups who used the created system. Moreover, the test results observed was evaluated based on previous framework and defined requirements. The experiences gained helped to further develop the system.
In order to evaluate and verify the system, scenarios with test cases were constructed based on the systems functionality. Test cases were defined in 5.6 including each test case’s requirements. Each test case was executed on the system to ensure full functionality. Verifying intent-triggers consisted of testing each gesture individually, each frame of the gesture was saved in a designated folder on the computer. The images in the correct folder were manually checked. Each gesture had a folder dedicated to specific gesture, if an image of the gesture five was placed in the folder dedicated to the gesture five it is considered to be placed in the correct folder. If an image in the correct folder did not represent a correct gesture it was regarded as a false positive (FP), the correct gestures in the correct folder were regarded as true positives (TP). The images in the incorrect folders were also manually checked. The images of a correct gesture but in an incorrect folder were regarded as false negatives (FN), images of any gesture other than the tested gesture that was found in folders other than the correct folder were regarded as true negatives (TN).
5
Results
This chapter assesses the results and findings of the stakeholders involvement followed by the literature study and Nunamaker et.al method presented in chapter 4.
5.1 Stakeholders involvement
At the heart of the solution a camera was mounted on the wall next to a door capturing the scene as shown in the image below. At Precise Biometrics the camera was meant to capture the scene while their YOUNiQ system identifies employees who wishes to enter and leave the office space.
Figure 12: Camera field of view
In the most simple form of implementation an intent-aware system contains a button which triggers software to perform an action depending on what function is linked to the button-push. However, recently more complex system have been achieved with touchless functions such as voice assistants which execute commands depending on a predetermined line of voice commands. Precise Biometrics are looking to implement an intent-aware system based on image recognition i.e. showing a hand gesture in order to begin YOUNiQ or any other process.
The current system runs facial recognition on everyone including people who has not registered for their YOUNiQ service. With an implemented intent-aware system YOUNiQ is only required to run when a person wishes to use their identification module.
Figure 13: Current system implementations and the new intent-aware system. In the first half of the image above, a general overview of the current system can be seen. It uses the company’s own product, YOUNiQ to identify an employee. In the lower half(2) the new intent-aware system can be seen. It functions by having an intent aware-system which is meant to detect when someone wants to use the YOUNiQ function or not. With the help of showing intent gestures the YOUNiQ system does not run on people who does not want to be identified.
MediaPipe and TensorFlow are Google owned open-source libraries and image recognition software solutions recommended by supervisors at Precise Biometrics. MediaPipe handles the hand recognition and blazepalm recognition which is built on TensorFlow. For pose estimation the pose estimation library [35] used was altered to suit the system, however mostly built on TensorFlow’s library. The pose estimation was altered in a way where only necessary tracking points on the body were returned to the main program.
5.1.1 System requirements
System requirements were composed based on the event where a person wants to unlock the office door by using intent-trigger. An example scenario consisted of a person wanting to enter or leave the office building. As the person approached the door an intent-trigger shall be shown as a means of wanting to use the system. The facial recognition software should not run until an intent has been shown.
R1 The system should be able to detect the triggers below. All gestures can be found in Appendix B, 7.3.
R1.1 Gesture: One, closed fist with index finger spread.
R1.2 Gesture: Two, closed fist with index and middle finger spread.
R1.3 Gesture: Three, index, middle and ring finger spread or thumb, index and middle finger spread.
R2 The system should detect a person’s nose, shoulder, elbow and wrist that is shown within the frame.
R3 If multiple people are within the frame, the system shall recognise which person is showing an intent-trigger.
5.2 Construct a conceptual framework
In this step information surrounding intent-aware systems were assembled in order to set up problem trees to predict eventual problems.
5.2.1 Problem tree
Problems which were evaluated are displayed in the problem tree below, the tree is an overview of the main problems with three branches. In this section each branch is further divided into smaller branches.
Figure 14: Problem tree
5.2.2 Video feed
In order to extract a user’s intent the system had to receive a set of frames, this is done through the video feed. The video feed from the camera are inputs to the recognition software, which is dealt with concurrently from a queue.
Figure 15: Video feed sub-tree
In order to receive frames as an input a camera was mounted on the outside of the office. The camera was facing away from the door, once a person walked towards the door the
5.2.3 Software
The software sub-tree consists of the image recognition software, it uses the video feed as an input. With the help of third party libraries such as OpenCV, MediaPipe objects within the camera’s frame can be detected.
Figure 16: Software sub-tree
By using pose estimation and hand detection simultaneously a person can be singled out should there be more than one person in the frame. The hand can be tied to the person showing the intent-trigger based on joint movement.
5.2.4 Literature study
A literature study was made to determine and identify an intent in order to begin a process. The study [5], in which an intent-aware system was implemented mentioned a camera with the focus of keeping track on the mouth region when a face was detected, once the mouth opened a microphone would start recording. In lieu of a system that triggers on the mouth being opened, the intent-aware system that was implemented in this thesis used hand recognition where the joints were tracked to calculate the gesture given by an individual interacting with the system.
A similar scheme such as the combinational scheme mentioned in 3.2 was implemented, where an intent-trigger was extracted separately before the main-process meant to begin starts.
5.2.5 Intent
The intent sub-tree is broken down into three layers.
Figure 17: Intent sub-tree
An intent can be identified by observing the joint coordinates in the hand. There are 21 coordinates each representing a joint/knuckle in the hand. An intent can be triggered based on which joints in the hand are folded into the palm of the hand. An intent-trigger is extracted before the process which comes thereafter begins.
5.3 Develop a system architecture
In this step system functionalities are presented including the interconnected parts as well as the relation between the subsystems. The system consists of three parts: a camera, image recognition software and intent-awareness.
5.3.1 System functions
In order to create a system architecture the system’s functions are broken down into a tree.
Figure 18: System functionalities
The system functionality consists of a camera to capture real-time video, software that recognises body, hand and fingers. As well as detecting intent-triggers through predetermined intent templates. Within the intent-aware system a camera is required to capture the
Figure 19: System Architecture
scene. This was done with the camera supplied by Precise Biometrics. Technical camera specifications can be found in 2.10. Moreover, the captured scene had to differentiate recognisable objects, background, static objects or moving objects from hands and body. Once a hand has been identified the system will search for an intent, if an intent is present it is matched with the predetermined intent templates.
5.3.2 Camera
The camera that was used was a XND-6080R, which was mainly responsible for capturing the scene in order for the software to run its pose estimation and hand recognition software. The software is not restricted to the XND-6080R and can run on a desktop camera.
5.3.3 Software
The software is the core of the system. Its main purpose is to identify a user’s hand and pose estimation. In case there are more than one person in a frame the pose estimation can be tied to the person’s hand, thereby connecting a hand to a person.
5.3.4 Intent
Once a hand has been detected and connected to a person, the orientation of the hand is checked. If the hand of a person is tilted to either side with an angle of more than 90 degrees an intent will automatically be discarded. However, if the fingers are pointed in an angle less than 90 degrees the gesture is extracted and tested to achieve a possible match with an intent template.
The result of an intent is what would trigger the underlying system software to run or not, for instance an identification module.
5.4 Analyse and design the system
This section contains the preparations made before developing the system, this includes design choices and sequence diagrams.
5.4.1 Camera choice and computer-vision
The main choice of camera is a XND-6080R from Hanwha Techwin, the secondary choice of camera is a MacBook Pro 2014 web camera. The secondary camera was used during the development phase where new features were implemented. The system functions equally as well on both sets of cameras. However, system performance may vary depending on computer specifications. As for computer-vision, OpenCV was used to recognise objects within the scene (12).
5.4.2 TensorFlow
TensorFlow was used to retrieve pose estimation, the library received was written by a supervisor at Precise Biometrics which in its core is TensorFlow’s model that is altered to only return necessary points on the body. The pose estimation program uses PoseNet to find joints on the human body. PoseNet is a pre-trained model that estimates a person’s body joints through computer-vision and is included in the TensorFlow pose estimation library [36]. 7 joints in the body receive numbered coordinates ranging from 0 to 6. The seven upper body coordinates translates to nose, left respectively right shoulder, elbow and wrist.
5.4.3 Sequence diagram
Figure 20: System sequence diagram
As shown in figure 20 the video feed is received as input to OpenCV, from there pose estimation, hand and palm detection is done simultaneously. An intent-trigger is validated depending on finger position within or around a dynamic boundary box, a closer look on the intent algorithm can be found in 5.5.3. Once an intent is verified the process can begin or end depending on the outcome.
Furthermore, also shown in figure 20, as long as the system is running it receives a video feed, the recognition system contains OpenCV as computer-vision in which TensorFlow’s pose estimation comes in play as well as hand and palm detection in order to notice if a person wants to use the intent system. If there are significant signs of a person wanting to use the intent system, an intent validation will start to listen. Signs of wanting to use the intent system is composed by tracking the person’s hand location. If the hand is above the level of the elbow and upright (fingers pointing upwards) the intent-awareness will begin. This is done since the arm is in an unnatural position, thus minimising accidental intent-triggers.
5.5 Build the prototype
This part involves the procedure of building a prototype, what parts are included and what they have in common. It includes programming language, how hand recognition was setup, how the intent-aware system was constructed. As well as activity diagram over the system to illustrate in which order activities run as well as showing how the intent
algorithm determines a gesture as an intent.
Python was recommended as programming language by Precise Biometrics and the system is thus built in Python. Python allows for ease when prototyping a system as well as vast libraries. Both MediaPipe and Tensorflow uses a pre-trained model for recognising body joints for pose estimation as well as hand and finger detection.
5.5.1 Pose estimation
Pose estimation involves tracking joints in the body. The pose estimation is used to keep track of humans in the frame as well as connecting hands to arms belonging to the person. Connecting the hands to the person is important in case there are multiple people in the frame and to associate the intent-gesture with the correct person. An intent will not be validated if the hand is not connected to the tracked points of the upper body belonging to the person performing a gesture.
Pose estimation runs on every frame and attempts to detect if any bodies are present. In the event that there are no existing bodies in the frame an intent can not be validated. The system only detects upper body joints as aforementioned.
The algorithm for how pose estimation is utilised can be found in 5.5.3.1.
Figure 21: Example output from pose estimation
5.5.2 Blazepalm recognition
”Blazepalm” is Google’s own terminology for finger and palm detection. Blazepalm recognition uses MediaPipe in order to detect hands as well as determining hand gestures. Hand recognition runs every frame if there are any hands visible, however only validating gestures every other frame due to the fact that a gesture must be present for two frames before it is accepted as a valid gesture. As previously mentioned, the hand must have significant clear signs of wanting to perform a gesture. Mainly as a reason for not running the intent system if the user wants to use an alternative to begin a process. In order to begin the
The algorithm for hand recognition and intent gesture can be found in 5.5.3.3. 5.5.3 Algorithms
5.5.3.1 Pose estimation algorithm handles the detection of bodies within the frame, each body assigns eleven key points for every upper body joint ranging from nose to wrist. If a score of a joint is higher than a given threshold the joint is accepted as a valid point of a body. If a full connection is made from the nose to the wrist and the length between the wrist and palm is reasonable a full body is considered detected.
Algorithm 1:Pose estimation Result: Validate intent and body Get coordinates from TensorFlow model; for Each body tracking point do
if Score > Threshold then Draw point on frame; for Each tracking pair do
Draw connection, get length; Get orientation of hands; if Right hand is tracked then
if Full right body is connected from nose to hand then
if Gesture == argument.gesture(Decided gesture when started program) then
Intent accepted, process can begin; end
end end
if Left hand is tracked then
if Full left body is connected from nose to hand then
if Gesture == argument.gesture(Decided gesture when started program) then
Intent accepted, process can begin; end end end end end end
5.5.3.2 Intent-trigger algorithm uses a predetermined set of gestures which is identified based on a dynamic boundary box surrounding the palm. Gestures are identified based on finger coordinates inside a smaller boundary box covering the palm see figure 22. Intent-trigger uses MediaPipe’s blazepalm to keep track of fingers, while hand recognition is done to crop the frame surrounding the hand with a larger boundary box.
Algorithm 2:Intent-trigger Result: Get gesture
Get coordinates for fingertips; for Each pre-defined gesture do
if Fingers within palm match defined gesture then return gesture;
end end
5.5.3.3 Hand recognition algorithm is used to track all the hands in an image. The boundary box from the hand recognition algorithm is used to crop the image and create separate images that only contains one hand each. All the images are used as inputs to blazepalm that returns coordinates of all the joint of the respective hand making multiple hand recognition possible.
Algorithm 3:Hand recognition Result: Get hand model for Each hand detected do
if score > threshold then Draw boundary boxes; for Each hand do
Crop new image of hand; Draw joint model;
Set orientation and coordinates; end
end
return [Cropped image, coordinates, hand orientation and gesture] end
5.5.4 Activity Diagram
Figure 23: Activity diagram of the system
The system has a scheme that is similar to the combinational scheme which Yang et al. proposed, where an intent-trigger was capture separately from the process.
When the system is started a video capture begins by putting frames in a queue. An image is pulled from the queue and the hands in that frame are detected. Once a hand is detected a new cropped images is created. By doing this it is possible to individually analyse all the hands in an image. When the hands are detected the position of the fingers are analysed to match a pre-defined gesture while simultaneously, the system is also tracking the body that the hand belongs to. In order for the intent-trigger to be valid the system must find a hand that is showing a pre-defined intent and the hand needs to be connected through the body. The body is tracked through the nose, left and right wrist, elbow and shoulder which sums up seven key points. By checking this criteria the system can validate the intent and begin a process such as identifying a face which is connected to the hand performing the gesture.
5.6 Observe and evaluate the system
This chapter consists of the test cases that were performed in order to verify the subsystems performance. A set of requirements were set up by validating the performance. Test cases were performed on different individuals in order to assure accurate and robust intent detection. A consent form was handed and signed by every participant before participating in the test. This is mandatory when monitoring people’s behaviour and processing data according to GDPR [37]. A copy of the consent form handed to each volunteer can be found in appendix D, 7.3. No data was saved except for the pass/fail in the table.
5.6.1 Test case requirements
Test cases were constructed with the requirements described in section 5.1.1 in mind. The test cases consisted of performing each gesture once. Every person volunteering was shown images of each intent as in 7.3 and was asked to imitate each gesture. For the sake of testing once an intent-trigger was completed the system would print which hand was held up as well as which gesture was performed. This was done mainly as a proof of concept that a process could begin after an intent-trigger or result of a given intent.
5.6.2 Verifying computer-vision
Verifying computer-vision consisted of a person standing within the camera’s frame. Human detection consisted of testing how pose estimation would be applied to a human. Each time a person was within a frame the pose estimation would be applied through computer-vision. However, the time for pose estimation to be applied could vary. The results from the test can be found in figure 24 in the appendix.
5.6.3 Verifying intent-trigger
The test used a boundary box surrounding the hand and smaller bounding box inside the hand surrounding the palm as seen in figure 22. The program captures every frame, in order for a gesture to go through it has to be crosschecked with the previous frame and contain the same gesture in both. Furthermore, the test consisted of doing 30 iterations of each gesture, each folder would be studied closer to determine accuracy for each gesture. The test consisted of 210 total hand gestures, the program failed to detect 2 out of 210 hands resulting in an accuracy of hand detection at 99%. This is considerably high in comparison to the 95.7% presented by the authors [27].
Table 5: Intent-trigger test
Intent Trigger TP TN FP FN Accuracy Precision Recall F1 Score
One 21 9 5 0 85.7 % 80.8 % 100 % 89.4 % Two 24 6 9 0 76.9 % 72.7 % 100 % 84.2 % Three 25 5 4 0 88.2 % 86.2 % 100 % 92.6 % Four 28 2 2 1 90.9 % 93.3 % 96.6 % 94.9 % Five 29 1 0 1 96.8 % 100 % 96.7 % 98.3 % Fist 25 5 0 0 100 % 100 % 100 % 100 %
Rock and roll 30 0 0 0 100 % 100 % 100 % 100 %
Table 6: Macro-average
Accuracy Precision Recall F1 Score 91.2 % 90.4 % 99.0 % 94.5 %
The test proved overall acceptable results. Below is a confusion matrix of the gestures tested. It is also apparent that accuracy decreases when more fingers are folded into the palm.
26 33 31 32 31 25 30 2 210 0 0 0 0 0 0 30 3 0 2 0 0 25 0 0 0 0 0 29 0 0 0 0 0 28 1 0 0 0 2 25 2 1 0 0 2 24 2 2 0 0 0 21 7 2 0 0 0 0 0 0 1 1 0 0 0 30 30 30 30 30 30 30 One Two Three Four Five Fist RnR Total
One Two Three Four Five Fist RnR Other Total
A
ctual
Predicted
The ”other” column contains the images of which the system failed to detect a gesture and recognise other objects as a hand e.g a pillow might have been predicted to be a hand showing the gesture ”Five”.
5.6.4 Validating the system
Validating the system consisted of composing a scenario as accurate as possible where volunteers would perform gestures. A camera was held static at a distance of about one to two metres from the participant. The person performed an intent and if the intent was accepted the system would print out which hand performed the gesture as well as which gesture triggered the print as a form of confirmation that the intent-trigger passed the score threshold and was identified properly.
No data extracted from the test case to validate intent triggers were saved except for the result which can be found in table 7 below. Each participant was informed about the possible gestures, other than that limited information was given in order to achieve as natural results as possible.
Additionally, stress tests separate from the test mentioned above were done in order to examine the effect of light dependency on the system. Different light conditions e.g. natural daylight, dark lighting (curtains closed and lights turned off) and lastly indoor lighting turned on. As well as compatibility of multiple(2) people in the frame. The test consisted of four office-like scenario:
• a person standing in the background
• walking next to each other
• walking behind the person giving an intent
5.6.5 Results and limitations from validation of the system
The validation process from three participants performing the intent-trigger is summed up in the table below. Further details, expected results and result test outcome can be found in 7.3.
Table 7: Intent-trigger test case.
Intent Trigger Participant 1 Participant 2 Participant 3
One
Pass
Pass*
Pass
Two
Pass
Pass
Pass
Three
Pass
Pass
Pass
Four
Pass
Pass
Pass
Five
Pass
Pass
Pass
Fist
Pass
Pass
Pass
Rock and roll
Pass
Pass
Pass
*Initially the system failed to recognise participant 2 ”One” gesture. Light sources where adjusted which lead to the trigger being recognised. Light sensitivity was a known issue to affect the computer-vision prior to the test.
A stress test was done to examine the results of when the system would fail. In natural light as well as indoor lighting turned on, the system’s functionality was up to par where each test passed. However, in low light the system showed poor performance where the results where not measurable and no intents were recognised. Additionally, a test in an office-like scenario with two people in the frame was done. In the first scenario, where a person was standing in the background the system functioned relatively well when the person kept a distance of more than 2 metres away from the person giving the intent. In the second scenario, the system had similar results to the previous and did not trigger on any unintentional intent-triggers when holding the phone. In the third and fourth scenario the system failed entirely. Walking side-by-side or too close to the person giving an intent meant that the system had trouble identifying what body that was connected to the person give an intent.
6
Discussion and Analysis
In this section related work and research method are discussed. Additionally, an analysis of the results is made.
This thesis is quite unique in the sense that not many related work have done the same implementations or used image recognition as a form of process initialisation. Despite this the related work in the thesis offered a guideline for creating useful schemes and avoiding drawbacks.
6.1 Related work
Intent-ware implementations are relatively new, previous work with intent-aware systems are thereby quite sparse. However, the closest related work regarding system implementations in this thesis is Consent biometrics by Chen et al. who proposes two concepts of extracting intent-triggers [4]. The paper’s results consists of using the ”incorporating” concept, on the other hand, this thesis uses the ”combinational” concept presented in the paper [4]. Furthermore, the implementation used iris recognition instead of hand recognition as in this thesis. The iris’ orientation translates to a gestures based on specific predetermined templates, similarly, the solution herein uses predetermined templates but for hand gesture rather that iris orientation.
The paper Position-Free Hand Gesture Recognition Using Single Shot MultiBox Detector Based Neural Network [33] was helpful for the thesis in understanding how hand gestures could be recognised as well increasing general knowledge regarding single-shot detector. This paper [33] proposed a method using SSD as well as CNN, where SSD was used to detect the location of the hand and CNN to perform a prediction of the gesture. This thesis similarly uses SSD for finding a hand within the frame, however, instead of using CNN to determine what gesture was given this thesis uses a predetermined template of gestures which are matched with the gesture in frame. Furthermore, the authors presented a solution using hand segmentation, which did not work as well during this thesis, this was due to further distance from the camera as well as lighting problems. The distance from the camera meant that the program had difficulties figuring out what was background and what was foreground and thus, the hand could sometimes be interpreted as background which resulted in it being discarded or with decreased accuracy. Additionally, in different lights the hand could blend in together with the surroundings making it difficult to separate a hand from the background.
Robust hand gesture recognition with Kinect sensor [32] provided insight on how hand detection and gesture recognition can be done. The paper [32] presented potential issues for gesture recognition in which there may be difficulties in precise segments in small objects such as fingers. This thesis bypass the problem by instead of considering the entire finger as a cluster, the program utilises finger coordinates. Thereby, only focusing on which coordinate is folded into the palm of the hand. The paper [32] also presented an applicable framework for hand detection and hand gesture recognition. Which was useful in creating the system in this thesis.
The paper Audio-visual intent-to-speak detection for human-computer interaction [5] provided insight in how a system based on a visual cue can predict intentions of speech. Differently to the paper, rather than focusing on speech, hand gestures are used as a trigger to begin a process. Similarly, by determining a face based on score threshold [5] this thesis uses a score threshold for hands to decide weather the frame contains a hand.
6.2 Method discussion
The methodology behind Nunamaker and Chen’s process for system development meant that a clear path of how to progress and potential problems during the research phase was set up. Combining the methodology of Nunamaker with agile development with supervisors at Precise Biometric allowed for discussion surrounding the ideas of implementations and framework gathered in the first stage. Furthermore, Nunamaker allows for an iterative development which was mostly applied when constructing the prototype. The first iteration consisted of hand detection and gesture recognition while the second iteration comprised of adding pose estimation.
Another viable method could be Design Science by Peffers et al. [38] similarly to Nunamaker it is also an iterative process for system development. The significant difference between the two methods lies in the final activity of Design Science. The last activity is meant to present the importance of the work to the audience or practicing professionals. Since this thesis was done together with engineers in the field, Design Science could be a viable substitute for Nunamaker. While Design Science is a feasible method, Nunamaker allowed for a methodology which was less restrained resulting in room for exploration and customising stages in the method while still retaining its path to progression.
6.3 Analysis of results
The purpose of the thesis was to study the possibilities of an intent-aware system as well as to try to create the forenamed system. Intent-aware systems are as aforementioned, a rather new concept and has a lot of room to expand and improve. There are many approaches for identifying and comparing biometric data, each with their own pros and cons. The system proposed in this thesis are based on hand gesture recognition and test cases consisted of analysing gesture recognition accuracy, precision, recall and F1-score as well as volunteers testing the entire system. Furthermore, stress tests were done to examine when the system failed. Results can be found in section 5.6.
The difference between the hand recognition implementations presented in table 7 has both pros and cons. For example, using hand segmentation allows for better accuracy but decreases the range of which the system can recognise an intent-trigger. For the system
![Figure 3: Predictions are done for a set of different boxes aspect ratios [18].](https://thumb-eu.123doks.com/thumbv2/5dokorg/3951578.75155/14.892.198.693.582.789/figure-predictions-set-different-boxes-aspect-ratios.webp)
![Figure 5: SSD Layers [18]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3951578.75155/16.892.140.766.186.369/figure-ssd-layers.webp)

![Figure 7: MediaPipe hand recognition graph [26]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3951578.75155/18.892.341.551.550.966/figure-mediapipe-hand-recognition-graph.webp)

![Figure 9: XND-6080R [31] Technical specifications and key features:](https://thumb-eu.123doks.com/thumbv2/5dokorg/3951578.75155/20.892.341.554.414.608/figure-xnd-r-technical-specifications-key-features.webp)
![Figure 10: Process overview [33]](https://thumb-eu.123doks.com/thumbv2/5dokorg/3951578.75155/23.892.150.739.409.568/figure-process-overview.webp)

