V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Engineering
-Intelligent Embedded Systems 15.0 credits
TIGHTER INTER-CORE DELAYS IN
MULTI-CORE EMBEDDED SYSTEMS
UNDER PARTITIONED SCHEDULING
Lamija Hasanagi´c
lhc19001@student.mdh.seTin Vidovi´c
tvc19001@student.mdh.seExaminer: Mohammad Ashjaei
M¨alardalen University, V¨aster˚as, Sweden
Supervisors: Saad Mubeen
M¨alardalen University, V¨aster˚as, Sweden
Matthias Becker
KTH Royal Institute of Technology, Stockholm, Sweden
Company supervisor: Kurt Lennart-Lundb¨
ack,
Arcticus Systems AB, J¨arf¨alla, Sweden May 20, 2020
Table of Contents
1. Introduction 1 1.1. Problem Formulation . . . 2 1.2. Initial Assumptions . . . 3 1.3. Thesis Outline . . . 4 2. Background 6 2.1. Embedded Systems . . . 62.2. Real-Time Embedded Systems . . . 7
2.3. Real-Time Tasks . . . 7
2.4. Multi-Core Architectures . . . 8
2.5. Global and Partitioned Scheduling . . . 9
2.6. Schedulability Analysis . . . 10
2.7. End-to-End Data-Propagation Delays . . . 10
2.8. Inter-Core Data-Propagation Delays . . . 12
2.9. Resource Optimization . . . 13
2.9.1 Constraint Programming . . . 13
2.9.2 IBM ILOG CP Optimizer . . . 14
2.10. Rubus-ICE Tool Suite . . . 14
3. Related Work 16 3.1. Timing Verification . . . 16
3.2. Temporal Isolation . . . 17
3.3. Optimization of Offline Scheduling . . . 18
3.4. Industrial Standards and Benchmarks . . . 18
4. Research Method 20 4.1. System Development Research Method . . . 20
4.2. Platform-Based Development . . . 21
4.3. Discussion . . . 21
4.4. Application of the Research Method . . . 23
5. System Model and Prototype Development 24 5.1. System Model Assumptions . . . 24
5.2. Application Model . . . 25
5.2.1 Task Model . . . 25
5.2.2 Task Set Model . . . 25
5.2.3 Task Instance Model . . . 26
5.2.4 Task Chain Model . . . 26
5.3. Platform Model . . . 27
5.4. Prototype Of The Optimization Engine . . . 28
5.5. Prototype Of The Industrial Tool . . . 28
6. Approach 30 6.1. Constraint Programming Problem Formulation . . . 30
6.1.1 Decision Variables . . . 30
6.1.2 Constraints . . . 33
6.1.3 Objective Function . . . 34
6.2. Solving the Constraint Programming Problem . . . 35
7. Evaluation and Results 36 7.1. Experimental Setup . . . 36
7.1.1 Generation of Empty Task Chain Structures . . . 37
7.1.2 Generation of Independent Tasks . . . 39
7.1.3 Generation of the Properties of the Created Tasks . . . 39
7.2. Experiments . . . 41
7.2.1 Complexity of the Optimization Problem . . . 42
7.2.2 Solving Time . . . 44
7.2.3 Tightened vs. Optimized vs. Infeasible Schedules . . . 47
7.3. Industrial Case Study . . . 49
7.3.1 Industrial Case Study Setup . . . 49
7.3.2 Response Time . . . 52
7.3.3 Start Time Jitter . . . 52
7.3.4 Inter-Core Data-Propagation Delays . . . 53
7.3.5 Age Delays . . . 54
7.4. Discussion . . . 54
7.4.1 Experiment . . . 54
7.4.2 Industrial Case Study . . . 56
8. Limitations 57 8.1. Threats to Validity . . . 58 8.1.1 Internal Validity . . . 58 8.1.2 External Validity . . . 59 9. Conclusions 60 9.1. Research Questions . . . 60 10.Future Work 62 10.1. Dynamic Task-to-Core Allocation and Task Migrations . . . 62
10.2. Preemptive Scheduling . . . 62
10.3. Different Task Models . . . 62
10.4. Different Platform Models . . . 63
10.5. Jitter, Age Delays and Reaction Delays . . . 63
11.Acknowledgments 64
List of Figures
1 Block diagram of the MPC5777C micro-controller [1]. . . 5
2 The multi-core architecture considered in this thesis. . . 9
3 End-to-end data-propagation delays [2]. . . 11
4 a) Sampling done often enough b) Sampling not done often enough. . . 12
5 Inter-core data propagation delay. . . 13
6 System Development Research Method [3]. . . 20
7 Platform-Based Development Flow [4]. . . 22
8 Task τi and two of its instances. . . 25
9 A circular task chain. . . 27
10 A semi-circular task chain. . . 27
11 Block diagram of The Optimization Engine. . . 28
12 Block diagram of the industrial tool. . . 29
13 Potentially communicating producer-consumer pairs. . . 32
14 Potentially and actually communicating producer-consumer pairs. . . 33
15 Synthetic Test Case Generator flow chart. . . 37
16 Average number of tasks with respect to the number of task chains. . . 43
17 Average number of task instances with respect to the number of task chains. . . . 43
18 Average number of constraints with respect to the number of task chains. . . 43
19 Average number of constraints with respect to the number of potentially communi-cating producer-consumer pairs. . . 44
20 Average solving time with respect to the number of task chains. . . 46
21 Average solving time with respect to the utilizations of two cores. . . 46
22 Average solving time with respect to the number of potentially communicating producer-consumer pairs. . . 47
23 Tightened vs. Optimized vs. Infeasible number of schedules when number of task chains changes. . . 48
24 Tightened vs. Optimized vs. Infeasible number of schedules when utilizations of the cores change. . . 48
25 Tightened vs. Optimized vs. Infeasible number of schedules when the number of potentially communicating producer-consumer pairs changes. . . 49
26 Task chains in the case study embedded system application. . . 51
27 Rubus-ICE model of core 0 with its accompanying software components. . . 51
28 Rubus-ICE model of core 1 with its accompanying software components. . . 52
List of Tables
1 Platform model specifications. . . 28
2 Interval decision variables and their parameters. . . 31
3 Probability distribution of the number of involved activation patterns per task chain. 38 4 Probability distribution of the number of tasks per activation pattern. . . 38
5 Probability distribution of the periods of tasks. . . 38
6 The relationship of communicating producer-consumer pairs based on the periods of their activation patterns. . . 39
7 Probability distribution of read/write label sizes. . . 41
8 Number of potentially communicating consumer-producer pairs used in the experi-ments. . . 43
9 Utilization pairs used in the experiments. . . 45
10 Tasks in the case study embedded application. . . 50
11 Maximum response times of each task for both of the schedules. . . 53
12 Maximum inter-core data-propagation delays. . . 54
Glossary
Term Description
Constraint programming An optimization technique used for solving optimization prob-lems which are constrained by a set of constraints
End-to-end data-propagation delay The time needed for data to propagate from the start of a task chain to the end of a task chain
Hyperperiod The period of time after which the schedule of an embedded system application starts repeating, defined as the least com-mon multiple of all of the periods of the tasks in the application Inter-core data-propagation delay The delay between the end and start of execution of two com-municating task instances in a chain executing on different cores
Scheduling The process of arranging all of the instances of the tasks of an embedded system application in a way that ensures all timing and any additional constraints are met
Task A unit of execution consisting of a set of instructions with the aim of achieving a particular result
Task chain An ordered set of tasks that define propagation of data Task instance A particular execution of a task
Task set A collection of all the tasks defined in an embedded system application
Acronyms
Term Meaning
AUTOSAR AUTomotive Open System ARchitecture
CP Constraint Programming
GCD Greatest Common Divisor
HP Hyperperiod
ICE Integrated Component Model Development Environment IMA Integrated Modular Avionics
I/O Input/Output
IP Intellectual Property LCM Least Common Multiple
RCM Rubus Component Model
RTA Response-Time Analysis RTOS Real-Time Operating System
SWC Software Component
Abstract
There exists an increasing demand for computing power and performance in real-time embedded systems, as new, more complex customer requirements and function-alities are appearing every day. In order to support these requirements and func-tionalities without breaking the power consumption wall, many embedded systems are switching from traditional single-core hardware architectures to multi-core architec-tures. Multi-core architectures allow for parallel execution of tasks on the multiple cores. This introduces many benefits from the perspective of achievable performance, but in turn introduces major issues when it comes to the timing predictability of the real-time embedded system applications deployed on them. The problem arises from unpredictable and potentially unbounded inter-core interferences, which occur as a result of contention for the shared resources, such as the shared system bus or shared system memory. This thesis studies the possible application of constraint programming as a resource optimization technique for the purpose of creating offline schedules for tasks in real-time embedded system applications executing on a dual-core architecture. The main focus is placed on tightening inter-dual-core data-propagation interferences, which can result in lower over-all data-propagation delays. A proto-type of an optimization engine, employing constraint programming techniques on ap-plications comprised of tasks structured according to the Phased Execution Model is developed. The prototype is evaluated through several experiments on a large number of industry inspired intellectual-property free benchmarks. Alongside the experiments a case study is conducted on an example engine-control application and the resulting schedule is compared to a schedule generated by the Rubus-ICE industrial tool suite. The obtained results show that the proposed method is applicable to a potentially wide range of abstract systems with different requirements. The limitations of the method are also discussed and potential future work is debated based on these results.
1.
Introduction
Most micro-controllers nowadays are used in embedded systems rather than in PCs, with the estimated number of produced embedded systems reaching the figure of 10,000 million as early as 2013 [5]. Embedded systems are microprocessor-based systems contained in a larger system (a TV, a microwave, a phone, a car) and built for controlling some of its functions. The spread of embedded systems nowadays is massive, and it is hard to imagine a world without them [6]. The growth of em-bedded systems has resulted in the increasing number of complex, computationally demanding functionalities that are expected from them. In order to satisfy these computational demands, without breaking the energy consumption limit, embedded systems have started using multi-core architectures more and more as opposed to the traditional single-core architectures used almost exclusively in their early days [7].
Many embedded systems are used in real-time applications. Real-time embedded systems, as a special class of embedded systems, have specific timing constraints that must be fulfilled. Timing analysis techniques are used in order to ascertain if these constraints are met. These timing analysis techniques, also known as schedulability analysis, are well developed in the case of single-core real-time systems [8] [2] [9].
In comparison to single-core architectures, multi-core architectures contain shared resources such as the shared system bus and shared caches. These shared resources can become points of contention between tasks, running concurrently on different cores, which introduces interferences not present in the case of single-core architec-tures. These interferences affect the timing analysis of real-time multi-core embed-ded systems and therefore need to be taken into consideration during timing analysis. Estimates of worst-case execution times (WCET) for the tasks can be obtained by placing an upper bound on inter-core interference delays, but this can result in a severe overestimation of the actual WCET, resulting in a lower level of performance [10] [11] [12]. This problem leads to the idea of introducing timing predictable and analyzable access to the shared resources in multi-core embedded systems. ”For a given system model and a set of assumptions, the system is considered to be timing predictable if it is possible to show, prove or demonstrate that all specified timing requirements will be satisfied when the system is executed, during timing analysis” [13]. Research in this field is still young and active and therefore open to additional contributions.
In state-of-the-art research, different approaches to achieving timing predictabil-ity are considered. Approaches focusing on minimizing the inter-core data-propagation delays, which are delays between two communicating tasks mapped to different cores, are especially relevant for this thesis. An example of one such approach is the ap-proach adopted in [14], where task-to-core mapping is given beforehand. A global offline schedule of tasks is considered as opposed to a partitioned one [15]. An of-fline schedule for the shared system bus access is also provided. These schedules are optimized from the perspective of inter-core data-propagation delays in the system. This thesis considers a partitioned scheduling approach instead of the global scheduling approach used in [14]. Therefore, each core has its own offline schedule. The goal of this thesis is to propose new techniques to optimize these schedules in order to tighten the inter-core data-propagation delays. The proposed techniques are implemented through two prototype systems; a tool taking input from the
Rubus-ICE industrial tool suite1 [16] and an optimization engine, that attempts to produce
optimized schedules for the input application from the perspective of inter-core propagation delays. Unoptimized schedules (from the perspective of inter-core data-propagation delays) for each of the cores are provided by the tool suite. This is due to the fact that Rubus-ICE, assumes the use of its certified single-core Real-Time Operating System (RTOS) that runs on each of the cores. It should be noted that the development of the Rubus multi-core hypervisor that would instantiate the certified single-core RTOS in each core is a work in progress. Currently, Rubus creates the schedule of each core independently, while the arbitration of shared resources is assumed to be managed by the hypervisor layer. The single-core schedules created by Rubus-ICE are used as the input to the proposed optimization engine, and from them the necessary data about the application is extracted. The schedules of the cores are then optimized by the optimization engine, from the perspective of inter-core data-propagation delays and the provided schedules are subsequently returned to the Rubus-ICE tool suite. The performance of the optimization tool prototype is evaluated under a set of Intellectual Property (IP) free industrial benchmarks and the properties of the provided schedule are examined through an industrial case study. Our approach successfully minimizes all inter-core data-propagation delays in the case study and as a consequence produces a schedule with lower data-propagation delays than in the schedule generated by the Rubus-ICE tool suite.
1.1. Problem Formulation
As previously mentioned, multi-core architectures introduce additional interference to the execution of tasks, due to resource contention between multiple cores. This makes guaranteeing the timing predictability of real-time multi-core embedded sys-tems a major issue [17]. The interference affects the data-propagation delays, in task chains which can be distributed over multiple cores. Here data-propagation delays refer to the delays in the propagation of data through a task chain [18]. One way to address this problem is to adopt partitioned scheduling of tasks, and then opti-mize the schedules for each of the cores with respect to inter-core data-propagation delays. An appropriate constraint programming model can then be constructed for the purpose of finding the optimal schedule.
The reduction of inter-core data-propagation delays may lead to the reduction of data-propagation delays in general. However, the schedule produced in this manner is not necessarily optimal from the perspective of data-propagation delays. This is due to the fact that a task chain can be comprised of tasks executing on the same core, in which case the reduction of inter-core data-propagation delays obvi-ously does not help in reducing data-propagation delays in general. The same can be said for some important metrics of the individual tasks, like start time jitter and/or response times, which are discussed further in Subsection 2.3. Therefore it is interesting to analyze the produced schedule from the perspectives of these metrics when compared to a schedule generated by an industrial tool suite such as Rubus-ICE. It is important to note here that Rubus-ICE uses response-time analysis with offsets [19] heuristics in order to generate the offline schedules for each of the cores. With this in mind this thesis aims to address the following research questions:
RQ1: How can constraint programming techniques be used for optimizing sched-ules of real-time embedded system applications executing on multi-core architectures under partitioned scheduling?
RQ1.1: How can inter-core data-propagation delays be tightened in such sched-ules using constraint programming techniques?
RQ1.2: How can response times of individual tasks be shortened in schedules with tightened inter-core data-propagation delays using constraint programming tech-niques?
RQ2: How does such a schedule compare to a schedule generated by the Rubus-ICE industrial tool suite in terms of data-propagation delays, response times and start time jitter?
The thesis approaches these questions in a systematic way and backed by an appropriate research method, described in Section 4. Furthermore, the outcome of this thesis is a tool able to generate optimized schedules in the sense of inter-core data-propagation delays based on application specifications provided by the user.
1.2. Initial Assumptions
Some initial assumptions must be made in order to reduce the complexity and the scope of the research done through this thesis. These assumptions limit the thesis to a size appropriate for the resources allocated towards it as a master thesis of 15 ECTS credits:
• The thesis considers only hard real-time embedded systems. Hard real-time systems have strict deadlines, which must all be met in order for the system to be considered schedulable. Using this assumption and making the satisfying of all hard deadlines a necessity, focuses the work and provides a foundation for further work, involving different types of systems.
• Task-to-core mapping is assumed to be given apriori in accordance to par-titioned scheduling described in Subsection 2.5. Considering the problem of task-to-core mapping would increase the scope of the thesis. This problem is well-researched and known to be NP-complete and as such is not considered in this thesis. In accordance to partitioned scheduling it is assumed that once allocated to a core, the tasks can not be allocated to a different core during run-time, i.e. there is no task migration.
• It is also assumed that non-preemptive scheduling is used. In non-preemptive scheduling, as opposed to preemptive scheduling, once a task starts to execute on a core it can not be interrupted by any other task. Therefore, once a task instance starts to execute it is assumed that it will execute without interruptions from start to finish.
• Only periodic tasks are considered in this thesis. This helps in reducing the scope of the research, while also providing a suitable background for further work. The tasks are also assumed to abide by the Phased Execution Model, meaning that the tasks are separated into two memory phases, namely the read and write phases, and an execution phase. This model helps limit the
interference of concurrently executing tasks with regards to memory accesses. Furthermore, it is assumed that tasks communicate via register communica-tion. This means that a producer task writes all necessary data to registers (represented as global variables). The registers are assumed to be over-writable and the data in the registers is assumed to be non-consumable. This means that the data stays in the register after it is read by a consumer. Furthermore, when new data arrives at a register, it over-writes the existing data in that reg-ister. When reading the consumer task assumes that the data in the register is temporally valid and that the correct data will therefore be read.
• This thesis also focuses on a specific automotive multi-core architecture namely the MPC5777C micro-controller architecture, [1] as it is one of the prominent commercial-of-the-shelf (COTS) micro-controller architectures in the automo-tive domain. This architecture consists of two computational cores with sep-arate, private, 16-KB instruction and data caches respectively. There are no additional caches. The communication between the cores and the peripherals, including the RAM controllers is facilitated by a crossbar switch architecture. Figure 1 illustrates the architecture under observation. This is of course, just one type of multi-core architectures, which limits the applicability of the re-sults to the same types of architectures and invites further work in order to generalize the findings.
• It is also assumed that the task codes for each of the tasks executing on a core are prefetched into the local cache of the appropriate core. Therefore tasks do not have to access the shared memory in order to load their execution code but only in order to read/write to/from their memory labels. This is a simplification of the real world but helps in limiting the scope of the thesis
• Finally, since both cores are located on the same physical chip and share the same clock on the considered architecture, the assumption of total synchroniza-tion between them can be made.
1.3. Thesis Outline
The remainder of this thesis is structured as follows. In Section 2. relevant back-ground is explained. Section 3. presents the overview of current research relevant to the topic of this thesis. In Section 4. the used research method is introduced and the reasoning behind the choice is given. Section 5. describes the application and platform models as well as the two prototypes developed in accordance with the research method, while the implementation specifics are given in Section 6. Next, in Section 7. the evaluation of the implemented prototype is conducted through a set of controlled experiments as well as through an industrial case study comparing the properties of the generated schedule with those of a schedule produced by an industrial tool suite. Afterwards, the obtained results are also discussed in detail. In Section 8. and Section 9. the limitations of the work done in the thesis are discussed, and based on them, and the presented results, certain conclusion, drawn from them, are presented. Finally, Section 10. contains proposals for future work.
2.
Background
This thesis considers several topics in the area of real-time embedded systems. Each of the following subsections provides a thorough insight into the main characteristics of the concepts and techniques that will be used and referenced throughout this thesis.
2.1. Embedded Systems
Even though the term ”microprocessor” is usually related to general-purpose com-puters such as laptops and desktop comcom-puters, its application stretches beyond that, and people use microprocessors in every day life without even knowing it. The pro-cess of embedding propro-cessors into consumer devices and equipment, started even before the introduction of personal computers and it became a wide-spread trend that increases rapidly on a daily basis [20] [21].
Microprocessor-based systems that are built for a specific purpose, as opposed to general purpose computers, and embedded into other larger devices with the aim of controlling them, are called embedded systems. Embedded systems can be observed as a three-stage pipeline system that reacts upon the environment. The first stage of the pipeline collects input data and information, the second stage of the pipeline processes the input, while the third stage of the pipeline gives the output data. In order to perform such functionalities, embedded systems are built as a combination of electronic hardware, software and mechanical parts [20].
Embedded systems hardware is application-specific hardware and generally consists of: a processor, memory and peripherals. Embedded processors can vary between single-core and multi-core processors and are chosen by cost, performance, power consumption criteria etc. Embedded systems memory is often in the form of EEP-ROM, RAM or ROM and is used for the storage of the software that will run on the system and the storage of the data. Memory in embedded systems is software de-pendent as well and it dictates the way that software will be developed later on. The main purpose of peripherals (binary outputs, serial outputs, converters, displays) in embedded systems is to provide the connection between the embedded system and the environment [20].
The software in embedded systems, also known as embedded software, defines the behaviour of the system and the ways through which that behaviour is achieved. Embedded software as well as hardware depends on the application of the system and is usually executed by the RTOS. In addition to the operating system, em-bedded software consists of application, configuration, initialization, error handling, debugging support software and so on [20].
Nowadays, e.g. cars and trucks contain hundreds of embedded systems of differ-ent functions, such as air bag, cruise control, navigation, anti-lock brake systems etc [22]. Embedded microprocessors can be found in consumer electronics (mobile phones, MP3 players, digital cameras), household equipment (microwaves, wash-ing machines), medical equipment, automotive industry, military applications and
avionics.
2.2. Real-Time Embedded Systems
A special case of embedded systems, that are in the main focus of this thesis, are real-time embedded systems. Real-time embedded systems are embedded systems in which not only the correctness of the system’s output is important, but also the time at which the output is provided. Real-time embedded systems react upon the stimuli from the environment and produce the output within clearly specified time intervals. The point in time by which the output from the real-time embedded systems must be given is called the deadline [20] [8].
There are several types of deadlines: hard, soft and firm. Based on the features of the system’s output in the case when a corresponding deadline is missed, a real-time embedded system can be either a hard real-time, a soft real-time or a firm real-time embedded system. If the deadline is not met, in a hard real-time embedded system, the system’s output can lead to catastrophic consequences. If a system’s output is of some usefulness, even though the deadline is missed occasionally, the system is considered to be a soft real-time embedded system. Finally, a firm real-time embedded system is one in which a deadline miss leads to the output of no value at all [20] [8].
Despite the fact that real-time embedded systems are time-constrained, the design of these systems does not have to be explicitly correlated with speed. Rather, real-time embedded systems should be designed as timing predictable systems, which means that the guarantee that all specified timing requirements in those systems will be met, should exist. Software and hardware architecture as well as the interaction between them play the key role in providing such a guarantee. It is the job of the designer of real-time embedded systems to guarantee the reliability of these systems under any circumstances [20].
2.3. Real-Time Tasks
Tasks, sometimes also referred to as threads or processes are described as units of work that are executed by operating systems and have control of the resources [20]. Various types of tasks exist, but those that are analyzed in the scope of this thesis are real-time tasks. Real-time tasks are tasks executed by real-time operating systems within certain timing constraints. Therefore, it can be easily concluded that one of the main parameters of a real-time task is its execution time and its deadline.
Real-time tasks can be sporadic, aperiodic or periodic. Sporadic and aperiodic real-time tasks are usually described as event-triggered tasks, as the activation times of those tasks, are not known in advance. The only difference between sporadic and aperiodic tasks is that the next instance of an aperiodic real-time task may or may not be activated at any point after its predecessor, while the next instance of the sporadic real-time task can be activated only when a certain amount of time called the minimum inter-arrival time has passed, or it can not be activated at all. Periodic real-time tasks are, on the other hand, time-triggered real-time tasks, which are periodically activated. Periodic real-time tasks are considered throughout this thesis. In addition to their deadline and their execution time, periodic real-time tasks also have their period as a parameter. Each seperate activation of a task is called a task instance or a job. Here, the terminology concerning real-time tasks used
throughout this thesis is explained. The important parameters that characterize a task τi are formally presented:
• Ti - period time of the task: The time between activation of two consecutive
task instances.
• Di - relative deadline of the task: The latest time at which the task has to
finish after its release.
• Ci - worst case execution of the task (WCET): The time necessary for the
processor to execute the task without any interruptions.
• Ji - start time jitter of the task: The difference between the earliest and the
latest point in time a task starts to execute (relatively to the nominal start time).
The important parameters that characterize the j − th instance τi,j of a task τi are
described below:
• ri,j - absolute release time of the instance: The time when the task instance
becomes ready to execute (is released).
• si,j - start time of the instance: The time when the task instance starts to
execute.
• ei,j - end time of the instance: The time when the task instance has completed
its execution.
• rti,j - response time of the instance: The time interval between the absolute
release time and the end time of the task instance.
• di,j - absolute deadline of the instance: The latest point in time the instance
has to finish its computation and produce an output.
2.4. Multi-Core Architectures
The central part of an embedded system is its processor, an electronic circuit, which can execute some basic instructions. Traditionally these processors consisted of a single core (processing unit) on a chip. Apart from techniques such as pipelining, branch prediction etc., these single-core architectures achieved performance gains through the ever increasing number of transistors on a chip, which according to Moore’s Law approximately double each two years, and with them the increased processor frequency as well [23].
However, the increasing number of transistors on a chip meant more heat and eventually a frequency wall was hit. This wall limits the frequency of a processing unit, as the cooling techniques necessary to facilitate further frequency gains become too expensive [24].
As processor frequency had reached a plateau, computer architects needed a new approach in order to increase processor performance. Adding multiple cores to a chip was the solution to this problem. Having several processing cores meant significant boosts in performance without the need to increase clock rates further.
This approach is also appealing in embedded systems as it allows more complex functionalities to be performed without additionally increasing the cost or power dissipation of the system [7].
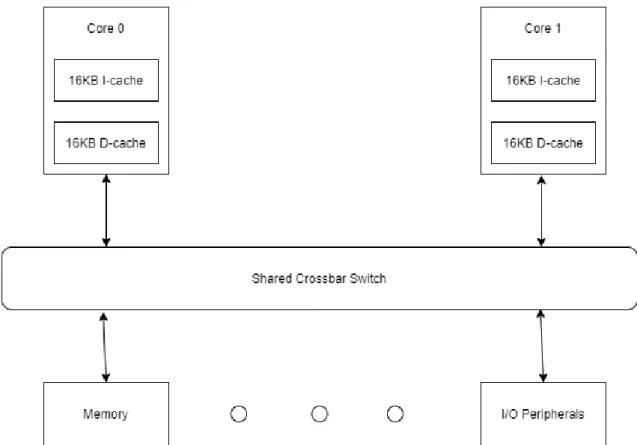
There are many types of multi-core architectures, depending on the number of cores, levels and number of private and shared caches, the interconnect used to access the shared resources and so on. This thesis considers an architecture with two computational cores, each with a single level of private, separate 16KB instruc-tion and data caches and a crossbar switch architecture, used to access the shared resources, as shown in Figure 2.
Figure 2: The multi-core architecture considered in this thesis.
Multi-core architectures also introduce several problems not present in single-core architectures such as inter-core dependencies and timing unpredictable data propa-gation delays. This is a major issue in any real-time embedded system application [7], and will be the main focus of this thesis.
2.5. Global and Partitioned Scheduling
Real-time scheduling refers to the process of creating a schedule for a given task set, consisting of hard real-time tasks, in a way that all of the tasks in the task set meet their deadlines and any other constraints they may have [8].
We distinguish between online (during run-time) and offline (before run-time) scheduling. Offline scheduling is employed in critical systems in the automotive and aviation industry, as it provides a proof-by-construction that all hard real-time tasks will meet their constraints. For this reason offline scheduling of tasks on the individual cores will be considered throughout this thesis.
One way to classify scheduling on multi-core architectures is global and partitioned. It should be noted that other types of scheduling also exist such as semi-partitioned scheduling [25]; however they are out of the scope of this thesis and are not consid-ered here. One way of solving this problem is to use global scheduling. In global scheduling there exists a shared global ready queue containing all task instances that are ready to execute. The global scheduler then assigns the ready task instances to the cores during run-time [15].
Another approach to solving this is to use partitioned scheduling. In partitioned scheduling each of the cores has their own ready task queue and their own scheduler and the tasks are assigned to one of the cores before run-time. Task instances can only execute on the core they were assigned to, i.e. there is no task migration [15].
The advantages of partitioned scheduling are a higher degree of timing pre-dictability, low run-time overheads (as task migration is not allowed) and the ability to keep legacy scheduling on individual cores, and as such is considered in the scope of this thesis.
2.6. Schedulability Analysis
The term schedulability analysis refers to the process of determining if a task set can be scheduled in a way in which all of the tasks in the task set meet their deadlines and any other constraints they may have. When it comes to determining whether or not a given task set is schedulable two complimentary steps are taken:
• Worst-Case Execution Time Analysis: A task normally exhibits variation in actual execution times, due to the input data or different state of its execution environment. Worst-Case Execution Analysis or WCET Analysis for short has the goal of determining the longest possible time needed for a task to finish its execution when the task is executed in isolation from other tasks [26].
• Response-Time Analysis: Response-Time Analysis or RTA for short has the aim of determining the Worst-Case Response Time of a task, while considering its execution context as opposed to considering the task in isolation. RTA is an exact schedulability test, which takes into account the preemptions, caused by higher priority tasks, and blocking, caused by lower priority tasks, locking shared resources [27].
In traditional single-core embedded system architectures, these two methods pro-vided satisfactory schedulability analysis. However, in multi-core architectures, where contention for shared resources from tasks executing on different cores in parallel is present, their applicability in isolation is diminished. This is a conse-quence of a major problem pointed out in [17], which is the fact that tasks can no longer be considered in isolation for the sake of WCET analysis, due to shared resource contention.
2.7. End-to-End Data-Propagation Delays
Task chains are sequences of tasks executing one after another and are a typical way of designing embedded system applications. Such chains consist of multiple task instances in which each task instance uses the data processed by its predecessor in
the task chain. Task chains consisting of tasks with different periods are referred to as multi-rate task chains and introduce additional complexity into embedded system applications [28]. The delays for the propagation of data from one end of the task chain to the other are of particular importance in safety critical real-time embedded system applications.
Real-time systems impose strict constraints on the end-to-end data-propagation delays of these task chains in order to determine if the data in the system is valid and usable, or if it is outdated and should not be considered. Thus, if a real-time task set can not meet its imposed end-to-end data-propagation delay constraints, it is considered to be unschedulable. The techniques for the analysis of end-to-end data-propagation delays are illustrated well in [16] [18].
Four types of end-to-end data-propagation delays are considered in [2] and de-noted in Figure 3 with a, b, c and d. The delays dede-noted with a and d are called the reaction and age delays respectively and are of particular interest for the auto-motive industry. For example, the reaction delays are considered in applications in the body electronics domain in vehicles (e.g. button-to-action delay), while the age delays are considered in control systems applications (e.g. maximum age of data still considered useful). Delay constraints corresponding to age and reaction delays are also part of the AUTOSAR de facto standard [29] as well as several automo-tive domain specific architecture description and modeling languages [30]. These additional timing constraints obviously increase the time necessary to find a feasible schedule. A feasible schedule in the context of real-time embedded systems is one in which all tasks meet their deadlines and any other constraints (e.g. the age and reaction constraints) imposed on the system are also satisfied [8].
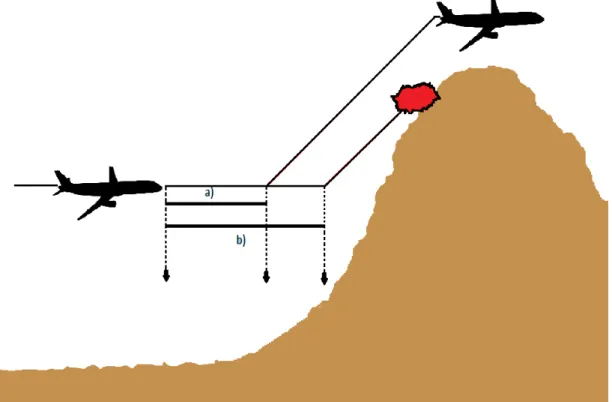
An example often used to illustrate the importance of the end-to-end data-propagation delays is that of an aeroplane, traveling at high speed and sampling its environment in order to detect obstacles. If one task in a task chain samples data and another processes it, it is crucial that the read data is temporally valid in order to provide desired functionality. In Figure 4 the potentially catastrophic consequences of sampling being done often enough, and sampling being done too rarely, and therefore the sampled data being temporally valid or not, are shown.
Figure 4: a) Sampling done often enough b) Sampling not done often enough.
2.8. Inter-Core Data-Propagation Delays
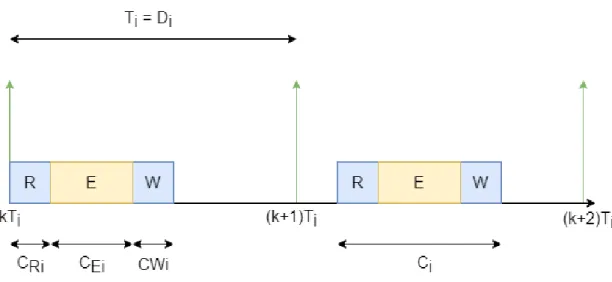
This thesis mainly focuses on minimizing inter-core data-propagation delays. Inter-core data-propagation delays refer to the delay between the execution of two commu-nicating tasks in a task chain, allocated to different cores. More formally, inter-core data propagation delay is the amount of time between the end of execution and start of execution of two communicating tasks in a task chain, executing on differ-ent cores. Figure 5 illustrates this concept nicely for two communicating tasks in a chain executing on core 0 and core 1 respectively.
Figure 5: Inter-core data propagation delay.
2.9. Resource Optimization
Resource optimization techniques in the broadest sense are a set of methods for finding the ”best” values for a set of problem variables using certain criteria. In its simplest form it consists of minimizing (maximizing) a real function by system-atically selecting values for the problem variables from a set of allowed values and then computing the value of the function, until the minimal (maximal) value is found. Resource optimization represents a large part of applied mathematics and is used in solving problems from vastly different domains, including computer sci-ence, economics, engineering etc. In order to apply these optimization techniques the problems under observation must be presented in the form of an optimization problem [31].
There are various types of optimization techniques that are used nowadays such as local optimization techniques, global optimization techniques, linear program-ming, constraint programming and so on.
2.9.1 Constraint Programming
Constraint programming refers to the problem of finding a specific value for a set of problem variables. The possible values these variables can take are constrained by a set of constraints. It can be used to effectively model many types of reasoning and therefore applied to many different problem domains.
The common form of single-object, non-linear, constrained optimization problem is given as follows [31]:
Minimize f (x) Subject to: gj(x) ≤ 0, j = 1, m (1) hk(x) = 0, k = 1, p (2) xiL ≤ xi ≤ xiU, i = 1, n (3)
The f (x) in the above formulation represents the objective function (the function which is being optimized), gj(x) represent the inequality constraints, while hk(x)
represent equality constraints. The x represents the design variable and xiL and xiU
represent the lower and upper bounds of the design variable respectively. Together they describe the set of constraints imposed upon the system under optimization.
2.9.2 IBM ILOG CP Optimizer
The IBM ILOG CP Optimizer2 is a software library which provides a constraint
programming engine for modeling and solving both satisfiability and optimization problems. It is especially appropriate for use in the scope of this thesis, as its features allow for easy modeling and solving of scheduling problems such as the one considered in this thesis.
The software library provides several quality of life features for applications
con-cerning scheduling over time. Most scheduling applications are concerned with
scheduling activities that have a start and end time. The CP Optimizer makes modeling such variables easy through the use of interval variables. Alongside these interval variables there also exist specialized constraints for use with them. Using these, it is possible to limit the possible positions of an interval variable, specify the precedence relations between two interval variables, or relate the position of an interval variable to a set of other interval variables [32].
The specialized constraints that will be referred to in this thesis are endBefor-eStart ,noOverlap and IloIfThen constraints. The endBeforendBefor-eStart(a, b, t) constraint is a precedence constraint that specifies that activity a must end at least t time units before activity b starts, the noOverlap(array) constraint ensures that no two vari-ables in the array of interval decision varivari-ables array overlap, while the IloIfThen(a, b) logical constraints intoduces the constraint b if condition a is true [32].
2.10. Rubus-ICE Tool Suite
In the scope of this thesis a prototype tool intended to be plugged in with the Rubus-ICE tool suite is developed. The Rubus-Rubus-ICE tool suite was developed by Arcticus
Systems AB3 in close collaboration with M¨alardalen University and several other
academic and industrial partners. It has been used in industry since 1996 by many
different companies such as Haldex, Volkswagen, VCE, BAE Systems H¨agglunds,
Elektroengine, BorgWarner, Hoerbiger and Knorr-Bremse as the development soft-ware for vehicular embedded systems [33]. Rubus-ICE is a part of the Rubus tool chain alongside with the certified Rubus Real-Time Operating System and Rubus Component Model (RCM) used for the modeling of applications. The Rubus tool chain consists of modeling, analysis, simulation tools and code generators. An ap-plication modeled in Rubus-ICE can be executed on different hardware as well as software platforms (RTOS). The main characteristics of Rubus-ICE tool suite are resource efficiency and existence of timing predictable and analyzable control func-tions. It provides support for RTA and end-to-end delay analysis [16]. RTA of tasks with offsets which is proposed in [19] and [34], and later on improved in [35] is used. When it comes to the end-to-end delay analysis, the analysis proposed in [2], is implemented.
3.
Related Work
This thesis focuses on the optimization of task schedules on dual-core systems with a crossbar architecture and a shared RAM memory. Research in this area, or parts of this area, is becoming increasingly more active since 2006 as shown in [36], where an exhaustive survey of the research is provided. The report differentiates research into timing verification of multi-core systems into four main categories, namely:
• Full Integration: Research in this area attempts to fully integrate all infor-mation about the behaviour of the different tasks running on the multi-core architecture into the timing analysis for every task.
• Temporal Isolation: Research in this area attempts to achieve temporal isolation of the tasks under observation through the use of different software and hardware techniques.
• Integrating Interference Effects into Schedulability Analysis: This type of research aims to integrate the effects of the use of shared hardware resources and potential interferences of concurrently executing tasks into the schedulability analysis.
• Mapping and Scheduling: This category of research focuses on providing optimal task-to-core mapping in regard to the timing behaviour and the im-posed memory requirements.
As previously mentioned, the research proposed by this thesis, focuses on pro-viding schedulability guarantees using temporal isolation techniques such as the Phased Execution Model. The feasible offline schedules obtained in this way, are then optimized in order to provide tighter inter-core delays.
3.1. Timing Verification
As previously mentioned, real-time systems must meet both their functional require-ments as well as their timing constraints. These timing constraints are normally expressed in the form of deadlines and can be imposed on a single task or task chains.
Traditionally, in single-core architectures, the process of timing verification was comprised of the two steps described in Subsection 2.6. However, as pointed out in [17] the applicability of this type of timing verification to multi-core architec-tures, where additional interferences due to contention for shared resources exist, is diminished. When a task is executed in full isolation on a multi-core platform the behaviour of the system is affected by that task alone. This changes when multiple tasks are run concurrently on the different cores because the contention for the shared hardware resources can lead to timing unpredictable and potentially unbounded delays [37][38][39]. This problem can be addressed by calculating the WCET of tasks that are context independent. In other words one can consider the maximum possible delay for each shared resource request of a task. However, this approach can lead to severely pessimistic results, and suffers from scalability prob-lems, as the search space explodes with a larger number of tasks and cores that are observed.
A number of approaches to dealing with this problem can be distinguished. These approaches are summarized in [36]. The category of interest to the research carried out in the scope of this thesis is temporal isolation and as such the related work in this field is presented in the following subsection.
3.2. Temporal Isolation
Temporal isolation aims at providing an upper bound on the delays experienced by a single task, independent of the tasks executing concurrently on the other cores [40]. This is done by shaping the access to the shared resources through various software and hardware techniques. The research on techniques relevant to this thesis is summarized below:
• Phased Execution Model: The research papers that can be encompassed into this subcategory refactor the tasks to abide by the Phased Execution Model. In such a model a task is split into memory access phases (typically a read and a write phase) and a computational phase. If the tasks are structured in such a way the scheduler can completely avoid contention for the memory accesses by simply not overlapping the memory phases of the concurrently run-ning tasks [41] [42] [43].
Kim et al. [44] proposed a method for constructing offline schedules in avionics applications for multi-core architectures. In order to avoid conflicts due to I/O transactions each task is divided into three sequential phases:
1. Device Input, where all necessary data is read from the main memory. 2. Processing of the Data, where adequate operations are performed on the
retrieved data.
3. Device Output, where the generated data is copied to the memory and/or the output devices.
The paper then presents a heuristic to help calculate a static schedule that meets all the deadline and precedence constraints.
Research in this subcategory usually limits concurrently executing memory phases to one at a time. In doing so, temporal isolation is achieved and anal-ysis is simplified. However, this also results in sub-optimal use of the systems resources.
• Hardware Isolation: The research papers in this subcategory aim to bound interference delays independently of the behaviour of concurrently executing tasks. This can be achieved by using a Time-Division Multiple Access (TDMA), Round-Robin or Fixed-Priority arbiter on the shared system crossbar for ex-ample.
Kelter et al. in [45] derived formulae for calculating the bounds on worst-case scenario bus access delays for different arbitration policies: Round-Robin, TDMA, priority division and priority-based arbitration. Kelter et al. [46] also conduct an investigation on two techniques for reducing the WCETs in partitioned multi-core systems.
Further interesting research in the context of this thesis was done by Desari et al. in [47]. They provide a framework for the analysis of memory con-tention. Mathematical models for Fixed-Priority, Time-Division Multiplexing and a work-conserving arbiter are provided.
The obvious drawback to this approach is the necessity for specific hardware designs to exist in the first place. Arbitration policies such as TDMA and Fixed-Priority are non work-conserving policies and as such result in lower resource utilization.
3.3. Optimization of Offline Scheduling
An optimized schedule is obviously preferred to an unoptimized one. This is es-pecially the case in multi-core architectures where the previously mentioned issues lead, in most cases, to pessimistic solutions.
Research contribution in this area is mainly focused on single-core architectures as stated in [48][49], where constraint programming techniques as optimization tech-niques are proposed. The frameworks presented in those research papers can be used as a basis for work to be done in the context of this thesis.
Thompkins in his thesis [50] proposes a mixed-integer linear programming ap-proach for solving complex scheduling problems in distributed multi-agent systems. In this thesis, after the formulation of the problem, the problem itself is divided into a precedence-constrained set of problems. The optimal allocation of these sub-problems to individual agents is then devised, which guarantee their completion in optimal time. Constraints that arise regarding the resulting schedule are execution time of the tasks, job release times, precedence relations and communication delays among the agents. This approach is very interesting from the perspective of this thesis as well.
Pufftsch et al.[51] investigate in their paper the ways of enforcing timing pre-dictability in safety-critical many and multi-core embedded systems. They propose the rule-based execution model of tasks and their own method for offline mapping of the applications. In order to provide the offline schedule, constraint programming techniques are used.
Becker et al. in [43] and [52] propose an execution model for clustered many-cores platforms with memory constraints. The proposed execution model allocates a subset of tasks to the cores’ local memory in order to utilize memory in a better way and reduce the expensive accesses to off-chip memory. The constraint programming optimization technique is used in these papers for the selection of statically allocated tasks and generation of the entire system schedule.
In their thesis [14], Groˇsi´c and Hasanovi´c propose an approach for optimizing inter-core data propagation delays which serves as a great starting point for this particular thesis. In order to create optimized schedules they use constraint pro-gramming technique as an optimization technique and assume the Phased Execution Model for the tasks.
3.4. Industrial Standards and Benchmarks
In this thesis special importance is given to industrial level applications, especially in the automotive and avionics domains. AUTomotive Open System ARchitecture
(AUTOSAR)4is a set of de facto standards that is a result of a worldwide partnership
of vehicle manufacturers and service providers. The main goals of AUTOSAR are to ensure vehicle requirements such as availability, safety and maintainability, to increase scalability and flexibility, to enable the re-use of software where possible, and to accelerate the development process while minimizing costs. In the avionics industry a similar purpose is served by the Integrated Modular Avionics (IMA) architecture. The good practices proposed in these two architectures influence the chosen application model in this thesis, described in Section 5.
In AUTOSAR and IMA applications, software is structured into components, e.g. Software Components used in AUTOSAR. Components in turn contain runnables that are subject to scheduling. The tasks and task instances used in the application model throughout this thesis can be equated to software components and runnables, respectively.
Another important characteristic of AUTOSAR (in the case of implicit com-munication) and IMA is the fact that access to shared memory is confined to the beginning and end of a software component, similar to the Phased Execution Model studied in the scope of this work. In [41] it is shown that this execution model pro-duces the best results among several different execution models, further solidifying the decision to adopt it.
In order to provide a meaningful evaluation of the results, it is desirable to perform the evaluation on a set of realistic industrial-level applications. However, due to IP concerns, such realistic benchmarks are difficult to obtain. In [53] a method is proposed that provides a way of generating IP-free, yet realistic, free benchmarks. The benchmarks used in this thesis are created using the proposed method.
Finally, the model industrial engine-control application described in [54] serves as a base model to the application used in the case study conducted as a part of this thesis.
4.
Research Method
4.1. System Development Research Method
The System Development Research Method as presented by Nunamaker and Chen in [3] is an appropriate research method for this thesis as it facilitates research where the development of a system is a key component of the research. As described by Nunameker and Chan it consists of four main phases:
• Theory Building • System Development • Experimentation • Observation
Figure 6 shows the connections between the different phases of the System De-velopment Research Method.
Figure 6: System Development Research Method [3].
Theory building is comprised of brainstorming for new ideas, concepts and/or methods, followed by a construction of a conceptual framework. Because this process is a general one it often has limited practical value.
In the Experimentation phase, laboratory and field experimentation is employed in order to bridge the gap between theory building and observation. The experi-mental designs are in turn guided by theory and facilitated by system development.
In an iterative process the results from the experimentation phase can be used to further refine theory.
The Observation phase includes surveys, case and field studies with the aim to understand what is involved in the scope of the research. It helps formulate hypothesis which are tested through experimentation and system development.
Finally, the Systems Development phase consists of concept design, constructing the architecture of the system, prototyping, product development and technology transfer. The work done in this thesis includes prototyping the implementation of methods discussed in Section 1.1., in order to provide proof-of-concept and to demonstrate feasibility of the proposed solutions [3].
4.2. Platform-Based Development
A similar methodology to the Systems Development Research Method is the
Platform-Based Development approach to embedded system development described in [4].
Platform-Based Development aims to provide an embedded system development model which addresses the key issues present in their development including design-ing highly reusable systems, considerdesign-ing the different constraints on cost, weight, size and performance. It is aimed at all abstraction levels from conception to im-plementation with an emphasis on guaranteed correctness of the system.
As can be seen in Figure 7, Platform-Based Development provides a means of separating the development process from the architecture implementation process and provides a meet-in-the middle approach combined with iterative refinement in order to implement and revise the abstracted model and its implementation.
4.3. Discussion
The reasoning for choosing the System Development Research Method over Platform-Based Development is given below.
Both methods are suited to the proposed research from the developmental view-point. The work that is conducted values the actual development of the proposed methods as a proof-of-concept and both methodologies support this type of research. They both also suit research in the applied category, meaning research conducted for practical reasons rather than to confirm the authors’ hypotheses.
One key difference between the two approaches lies in the initiation phase. Platform-Based Development assumes an abstracted model of the desired system, while the System Development Research Methodology derives the model through an iterative research and implementation process. This is more suited to the research carried out in this thesis, as it fits into the explorative category of research aiming to investigate and develop new methods and not to verify an initial hypothesis.
Another key difference, is the domain in which these methods can be applied. Platform-Based Development focuses on the design and implementation process more so than on the research perspective, while the System Development Research Method values the explorative side of the research more. Since this thesis aims to conduct scientifically relevant research, the System Development Research Method-ology suits it better.
4.4. Application of the Research Method
The research procedure followed in this thesis is based on the previously described System Development Research Method, a multi-methodological approach to com-puter science research, which places system development in the core of the research process. Based on the previously described phases comprising the System Develop-ment Research method the planned research procedure consists of the following set of steps:
1. Analysis of system under observation. 2. Modeling of system under observation.
3. Selection of the most appropriate optimization algorithms based on the state-of-the-art.
4. Implementation of the proposed methods for schedule implementation. 5. Analysis of the results and subsequent report writing.
It should be noted, that this is an iterative process, meaning that outputs from one step of the research procedure may lead to refinement of the outputs of a different step. The process is described in a more detailed manner below.
The embedded system application executing on the multi-core architecture un-der observation is first analyzed and modeled as an optimization problem. This means that the task sets, along with their constraints and execution contexts, are represented by appropriate variables in order to form a solvable optimization prob-lem. After the modeling phase, the proposed methods for schedule optimization is implemented. An appropriate optimization algorithm based on related research is employed. After a satisfactory proof-of-concept prototype system is implemented, it is tested and evaluated in an experimental setup using a set of IP-free benchmarks and in an industrial setup through an example industrial engine-control application case study.
5.
System Model and Prototype Development
The first part of this section is concerned with the system model. The systems under observation consist of an embedded software application that is executing on a specific hardware platform. As such, both the application model and platform model are described in detail and all assumptions made are discussed in depth.
The second part of the section describes the prototypes developed as a central part of the research method selected to conduct the research presented in the thesis. Both the prototype of the optimization engine and the prototype of the tool connecting the optimization engine to the Rubus-ICE industrial tool suite are described.
5.1. System Model Assumptions
The assumptions made in Section 1.2. can now be equated to the assumptions made for the system model. The platform model assumes the use of the MPC5777C micro-controller architecture and as such directly defines the described platform model.
When it comes to the application model, the first assumption that has to be taken into consideration is the use of partitioned scheduling. It is assumed that partitioned scheduling is used and that each core has a number of tasks allocated to it during the design of the application model. This means that each task τi is
allocated to a core pi and there are no task migrations during run-time. In the
application model this also implies that the main task set, consisting of all of the tasks in the embedded system application, is split into multiple smaller task sets each holding tasks allocated to one of the cores.
All tasks are also assumed to be periodic tasks. This means that each task has a relative deadline equal to its period Di = Ti. This also means that each instance’s
absolute deadline is equal to the absolute release time of the following task instance or di,j = ri,j+1.
Another important assumption is that the tasks are structured according to the Phased Execution Model. This means that each task is structured into two memory phases, namely the read and write phases, during which it reads/writes the nec-essary data to/from the shared memory and an execution phase in between them during which the necessary operations are done without the need to access the shared memory. It is also assumed that the codes of each of the tasks are prefetched and stored in the local cache of the appropriate core. This ensures that the only ac-cesses to the shared memory made by the tasks are the ones in the read and execute phases. In the scope of the application model this means that each task τi has its
worst-case read, execute and write phase execution times (CRi, CEi and CW i)
associ-ated with it. A task instance τi,j also has associated parameters s(r)i,j, s(e)i,j, s(w)i,j,
and e(r)i,j, e(e)i,j, e(w)i,j, representing the absolute start and end times of each phase
respectively.
Further, it is assumed that tasks communicate via register communication. The register is represented as a global variable, updated by the producer task and read by the consumer task, without any signaling between them. This implies that the consumer task assumes temporal validity of the value read from the register during its read phase.
This limits the scope of the research to non-cyclic task chains only.
Finally it is also assumed that non-preemptive scheduling is used. Therefore, once a task starts to execute it has to finish its execution before any other task can be allowed to execute.
5.2. Application Model
An application is defined by one main task set split into two task sets, one for each core, and a set of task chains. Each task in a task set implies a number of task instances, which are subject to scheduling. The following sub sections describe the models of all the individual components of an application.
5.2.1 Task Model
A task is represented by the tuple τi = (CRi, CEi, CW i, T i), where CRi, CEi and CW i
are the WCETs of the read, execute and write phases in the Phased Execution Model and Ti is the period of the task. In accordance to the system model assumptions,
the relative deadline of the task is not declared explicitly but is considered to be equal to the period of the task. This means that the absolute deadline of a task instance is considered to be the absolute release time of the following task instance. Figure 8 shows all the characteristics of a task visually.
Figure 8: Task τi and two of its instances.
5.2.2 Task Set Model
All tasks, executing on core i are grouped into a task set Γi. Each task set has an
associated hyperperiod (HP). The HP is the period of time after which the schedule begins repeating. Therefore, only task instances in the first HP are considered and subjected to scheduling and it is assumed that the execution of the application is repeated after the first HP. The HP of a task set Γi is obtained by calculating the
least common multiple (LCM) of all the periods of the tasks it contains.
5.2.3 Task Instance Model
Seeing as the system model assumptions specify the observation of periodic tasks, each task τi in the task set Γi implies n task instances of the corresponding task,
where
n = HP (Γi) Ti
.
The j-th task instance of a task τi is represented by the tuple τi,j = (τi, r),
where τi is the task that the task instance belongs to and ri,j the absolute release
time of the task instance. These parameters implicate the existence of the following parameters: s(r)i,j, s(e)i,j and s(w)i,j which represent the absolute start times, of the
read, execute and write phases of the instance respectively, and e(r)i,j, e(e)i,j and
e(w)i,j which represent the absolute end times, of the read, execute and write phases
of the task instance respectively, and di,j which represents the absolute deadline of
the task instance. From here, for the j-th instance of a task τi in accordance to the
system model assumptions it must hold:
ri,j = jTi (5)
di,j = ri,j + Ti (6)
s(r)i,j+ CRi = e(r)i,j = s(e)i,j (7)
s(e)i,j+ CEi = e(e)i,j = s(w)i,j (8)
s(w)i,j + CW i = e(w)i,j (9)
ri,j ≤ s(r)i,j ≤ di,j− (CRi+ CEi+ CW i) (10)
ri,j + (CRi+ CEi+ CW i) ≤ e(w)i,j ≤ di,j (11)
(CRi+ CEi+ CW i) ≤ Ti (12)
From here it is clear that by determining the values for the start and end times of the phases of all the task instances within one HP a schedule is created.
5.2.4 Task Chain Model
A task chain ξi consists of an ordered set of tasks through which data is propagated
from the first task to the final task in the task chain. A task chain can be comprised of tasks with different periods which leads to over-sampling or under-sampling intro-ducing further complexity to the application model. According to the system model assumptions one task can only occur in a task chain once, e.g. the following ordered set of tasks is not considered a valid task chain as the task τ2 occurs two times in a
single task chain creating a cyclic task chain: (τ2, τ4, τ2, τ1, τ8). However, tasks are
from one core to another without any restrictions allowing for both circular and semi-circular task chains. Intuitively, a circular task chain is one whose execution moves from one core to another and later moves back to first core again. Figures 9 and 10 illustrate the idea of circular and semi-circular task chains on an example two-core platform, respectively.
Figure 9: A circular task chain.
Figure 10: A semi-circular task chain.
5.3. Platform Model
It is assumed that the embedded system application is executed on a dual-core platform. Each core is assumed to have one private cache and no shared caches. It is assumed that task execution can be simultaneous for tasks running on different cores. It is also assumed that the access to shared memory is given to only one core at a time in chunks of 32 bits (4 bytes) via a shared system bus regulated by a Round-Robin arbitration policy. This assumption is useful when converting the tasks from Rubus-ICE, in which only the total WCET is given, as it allows for placing upper bounds on the WCET of memory phases in the Phased Execution Model assumed by the optimization engine prototype. The cores are assumed to operate synchronously with the system clock, which therefore assures mutual synchronization between the two cores.
The platform model is a simplified version of the MPC5777C micro-controller architecture [1]. The platform is chosen as it as an example of a standard platform for automotive and industrial engine management. The important assumed parameters chosen for the platform model are presented in Table 1. The parameters are based on the dual-core MPC5777C micro-controller architecture [1]. The clock frequency is assumed to be 300MHz, which is one of the standard modes of operation of the
MPC5777C. The size of the system bus is assumed to be 32 bits (1 word). The final parameter assumed is the amount of bytes that can be read in one clock cycle. According to the datasheet [1] the first access to the shared memory takes 3 cycles while subsequent ones take 2 cycles each. From here we assume that 10 clock cycles are needed in order to read/write one byte of data.
Parameter Value Number of Cores 2 Clock frequency (fclk) 300 MHz
Shared bus size 1 word Bytes R/W per clock cycle (vbps) 10·clockcycle1·B
Table 1: Platform model specifications.
5.4. Prototype Of The Optimization Engine
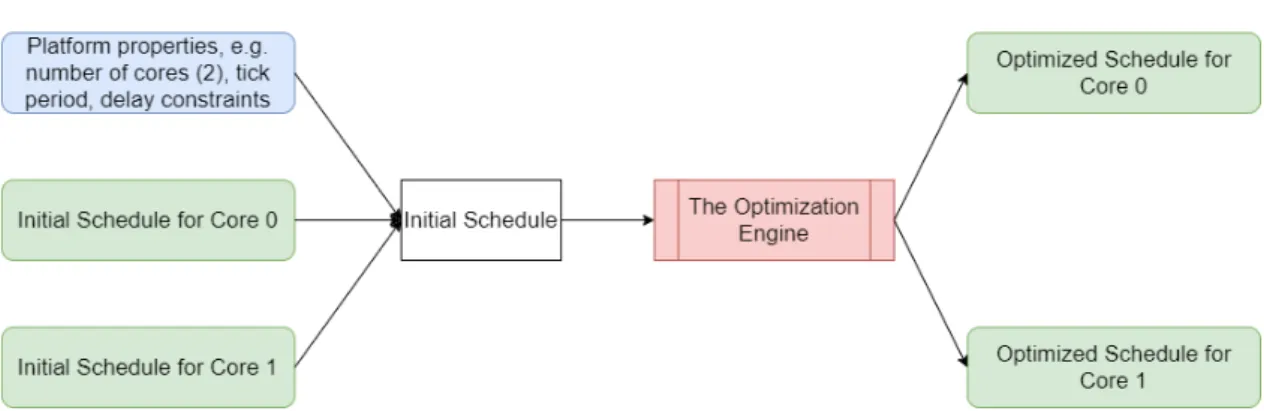
In accordance with the System Development Research Method described in Section 4., as an integral part of the conducted research a prototype of an optimization engine, responsible for the scheduling of the input embedded system application, is presented here. The developed prototype, from here on called the Optimization Engine, is written in the C++ programming language. The Optimization Engine is designed in a manner that allows for easy modeling of applications in accordance to the previously described application model. The Optimization Engine receives, as the required input, a vector of task sets (one for each core), containing all the tasks partitioned to a specific core and a vector of task chains. There are also two optional input parameters, one specifying the maximum allowed sum of inter-core data-propagation delays, and one flag specifying if the schedule should be optimized from the perspective of the response times, after being optimized from the perspec-tive of inter-core data-propagation delays. Based on this input the Optimization Engine creates a constraint programming model of the application specific problem using the IBM ILOG CP Optimizer software library and produces, as an output, a schedule optimized from the perspective of inter-core data-propagation delays. The block diagram of the Optimization Engine is shown in Figure 11.
Figure 11: Block diagram of The Optimization Engine.
5.5. Prototype Of The Industrial Tool
The prototype of the developed Industrial Tool is described next. The Industrial Tool has, as its main part, the previously described Optimization Engine. Apart
from The Optimization Engine, there is a module that allows for the extraction of an initial schedule generated by the Rubus-ICE industrial tool-suite for a single core from the trace files Arcticus Systems AB provide as the input. After the initial schedules have been extracted for both cores, they are transformed into proper forms and fed to the Optimization Engine. After the schedules have been optimized, a third module transforms them back into the format required by the Rubus-ICE tool-suite. The block diagram of the prototype of the Industrial Tool is shown in Figure 12.
![Figure 1: Block diagram of the MPC5777C micro-controller [1].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4908026.135041/12.892.158.743.312.914/figure-block-diagram-mpc-c-micro-controller.webp)
![Figure 3: End-to-end data-propagation delays [2].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4908026.135041/18.892.168.764.643.1080/figure-end-to-end-data-propagation-delays.webp)


![Figure 7: Platform-Based Development Flow [4].](https://thumb-eu.123doks.com/thumbv2/5dokorg/4908026.135041/29.892.144.772.165.1077/figure-platform-based-development-flow.webp)