School of Innovation Design and Engineering
V¨aster˚
as, Sweden
Thesis for the Degree of Master of Science in Software Engineering
30.0 credits
MODEL-DRIVEN ENGINEERING FOR
MOBILE ROBOT SYSTEMS: A
SYSTEMATIC MAPPING STUDY
Giulio Cattivera
gca14001@student.mdh.se
Giuseppina Lucia Casalaro
gco14001@student.mdh.se
Examiner: Jan Carlson
M¨alardalen University, V¨aster˚
as, Sweden
Supervisor: Federico Ciccozzi
M¨alardalen University, V¨aster˚
as, Sweden
Co-Supervisors: Ivano Malavolta, Patrizio Pelliccione
Gran Sasso Science Institute, L’Aquila, Italy
Chalmers University in Gothenburg, Sweden
Acknowledgments
Giulio
This thesis concludes (hopefully) my academic career as a master student. I would like to thank the people who gave me an invaluable support in these two years, without which I would not have been successful in this thing. Thanks to my family, especially to my parents Ludovico and Daniela, and to my grandfather Mimmo. Without their help I would probably have ended up drying rocks on the sea for all my life! Thanks to my historical “mighty friends of steel”, especially Ser -Mighty-Fabio, Marco -Demon Plax-, Luca -Ultimate Warrior-, Marco -Choko Culo Capuz-, Danilo -Danlo-, Paolo -Barone-, for all the “brutal” evenings and all the talks about our future. Thanks to Melissa, despite all I know you have always been sincerely happy for me and my achievements. Thank you so much to my band DragonhammeR, that despite the geographical distance has always been sup-portive, allowing me to release an album and playing around Europe! Special thanks to the person who in the past two years has been close to me as a colleague, friend, sister, and sometimes also mother: Pina! A mighty epic thanks to the brave warrior Antonio! To have spent time together for the whole year studying, improving ourselves and eating loooooots of animals. I learned a lot from you! An epic thanks to “your majesticness” “the beast” Gijs Bos! For the epic moments spent studying and lifting cows in the gym! Thanks to all the colleagues in Italy and Sweden with whom I shared projects, studies, work and “talks” with God, especially Valerio! Finally thanks to my supervisor Ivano and Federico, two guys who really enjoy their work!
Pensa e immagina, rifletti e ragiona, ama la tua strada e chi ci incontrerai. Goditi il successo.
Giuseppina
The hard work that led to the creation of this thesis deserves some special thanks. Thanks to everyone who believed in me, who supported me in this thing. Thanks to Ivano and Federico, our supervisors, friends and advisers. Without them it would not have been possible to realize such a great work. Thanks to my parents, my mom Margherita and my daddy Antonio, who have always believed in me, who taught me that if you believe in your dreams then it is easy to reach them. Thanks to my dearest friends Maddalena and Salvatore for sticking around even when everything seemed to be insurmountable. Thanks to Giulio who has always had the right words for any situ-ation, and thanks to his affinity and his tireless courage. Thanks to Antonio who was like a father to us, and who has always helped us in every moment. Thanks to Valerio, Gabriele, Bahodir and all the other friends I met in Sweden, thanks for have shared with me this wonderful experience. Thanks to my roommates Eleonora and Amelia, and the entire group at University of L’Aquila, with whom I spent unforgettable moments. Finally, thanks to those who decided not to be part of my life, because it gave me the opportunity to transform anger into courage and determination. Imparate ad amare voi stessi, ci che vi porter ad essere grandi uomini.
Abstract
The development of autonomous Mobile Robot Systems is attracting nowadays more and more interest from both researchers and practitioners, mainly because they may open for a wide range of improvements for quality of life. Mobile robots are systems capable of accomplishing missions by moving in an unknown environment without human supervision. Throughout mechanisms of detection, communication and adaptation, they can adapt their behavior according to changes of the environment. Individual robots can even join teams of autonomous mobile robots that, through individual tasks, accomplish common missions. These are called Mobile Multi-Robot Systems and are meant to perform missions that a single robot would not be able to carry out by itself.
When it comes to the development of Mobile Robot Systems, currently there is no standard method-ology. This is mainly due to the complexity of the domain and the variety of di↵erent platforms that are available on the market. A promising methodology that recently has gained attention in software industry for its ability of mitigating complexity and boosting platform-independence, is Model-Driven Engineering.
This thesis proposes a systematic mapping study on the state-of-the-art of Model-Driven Engi-neering for Mobile Robot Systems. Through our contribution, researchers can get a picture of the actual trends and open challenges for further research, while practitioners can realize the suitability of Model-Driven Engineering by checking to what extent it has been applied to real-world projects.
Table of Contents
1 Introduction 6
1.1 Models . . . 6
1.2 Mobile Robot Systems and Model-Driven Engineering . . . 7
1.3 Model-Driven Engineering . . . 8
1.4 Problem: need for a systematic mapping study . . . 9
2 Method 11 2.1 Process . . . 11
2.2 Team . . . 13
2.3 Research Questions . . . 13
2.4 Search and selection strategy . . . 14
2.5 Selection Criteria . . . 17
2.5.1 Inclusion criteria . . . 17
2.5.2 Exclusion criteria . . . 17
2.6 Classification framework definition . . . 18
2.6.1 Publication and research trends . . . 18
2.6.2 MDE methods and techniques and MRSs characteristics . . . 19
2.7 Data extraction . . . 20
2.8 Data analysis . . . 21
2.9 Threats to Validity . . . 22
3 Performing the systematic mapping study 23 3.1 Automatic search . . . 23
3.2 Applying inclusion and exclusion criteria . . . 24
3.3 Forward snowballing . . . 24
3.4 Classification scheme definition and keywording . . . 25
3.5 Data extraction . . . 26
3.6 Data analysis . . . 27
4 Mapping results and discussion 28 4.1 Vertical Analysis . . . 28 4.1.1 Results analysis of RQ1.1 . . . 28 4.1.2 Results analysis of RQ1.2 . . . 28 4.1.3 Results analysis of RQ1.3 . . . 29 4.1.4 Results analysis of RQ1.4 . . . 30 4.1.5 Results analysis of RQ2 . . . 30 4.1.6 Results analysis of RQ3.1 . . . 32 4.1.7 Results analysis of RQ3.2 . . . 32 4.1.8 Results analysis of RQ4 . . . 33 4.1.9 Results analysis of RQ5 . . . 34 4.2 Horizontal analysis . . . 34 4.3 Related research . . . 39 5 Conclusion 41 5.1 Future Work . . . 41 References 43 A Primary studies 44 B Clusters of keywords 49
D List of publications 52
List of Figures
1 Overview of the MDSE methodology. [6] . . . 9
2 The Systematic Mapping Process. . . 12
3 Search and Selection Strategy. . . 15
4 Keywording process. . . 20
5 Most targeted venues. . . 28
6 Research type over the years. . . 29
7 Contribution type over the years. . . 30
8 Publication rate by years. . . 30
9 Robot type. . . 31
10 Robot type over the years. . . 31
11 MDE methods and techniques over the years. . . 32
12 Robot aspect(s) over the years. . . 33
13 Types of validation percentages. . . 33
14 Types of validation over the years. . . 34
15 Types of tool(s) percentages. . . 34
16 Types of tool(s) over the years. . . 35
17 Mapping results. . . 36
18 Mapping results. . . 37
19 Mapping results regarding RQ3.1. . . 38
20 Mapping results between RQ3.1 and RQ2. . . 39
21 Mapping results between combination of RQ3.1 and RQ3.2. . . 40
List of Tables
1 Digital Libraries used for the automatic research . . . 152 The PICOC structure of the search string . . . 16
3 Research Type [7] . . . 19
4 Contribution Type . . . 20
5 Digital libraries pros and cons. . . 23
6 Number of studies from the searches. . . 24
7 Number of studies from the searches after the data extraction phase. . . 27
8 Research type percentages. . . 29
9 Contribution type percentages. . . 30
10 MDE methods and techniques percentages. . . 32
AGV Autonomous Guided Vehicle CASE Computer-aided Software Engineer DSMLs Domain-Specific Modeling Languages GPMLs, GMLs, GPLs General-Purpose Modeling Languages MDE Model-Driven Engineering
multi-MRSs Mobile Multi-Robot Systems MRSs Mobile Robot Systems
NASA National Aeronautics and Space Administration PICOC Population Intervention Comparison Outcome Context
1
Introduction
Since the 2000s the presence of software has significantly increased so that nowadays companies that produce software are among the largest and most prolific in business. One of the main reasons is that software covers a primary role within most of the current technologies and services. It is therefore true that for those companies that produce software, a costly development process or the presence of inadequacies in the architecture and design can cause serious economic issues [1]. Among the major causes for bad software and high costs of production, there is the complexity of the software itself. The intricacy of paradigms and criteria upon which the structure of the software is based, can bring serious issues both during the development and the maintenance phases of a system lifecycle.
During time, engineers have dealt with software complexity by seeking means of abstraction. Giving the developer the ability to abstract from the underlying environment can help him/her in focusing on the design intents rather than on surrounding platform and technology details.
Historically it is possible to find numerous examples: the first programming languages such as Assembly shielded developers from the details of the machine code, the Operating Systems provided abstraction from the hardware so that developers did not have to program directly on it.
Strides have been increasingly made until in 1980’s Computer-aided Software Engineer (CASE) was introduced. Its aim was essentially to express programs with graphical elements such as state machine diagrams, structure diagrams, flow diagrams and so on in order to reason on the goals without any distractions from implementative platform details. One of the purposes of CASE was also to generate code directly from the graphical representations. But it was not that much used in practice because the mapping between objects and code was poor and the supported operating systems were single node, missing of several quality of service properties (e.g., security, fault tolerance etc) [2].
More recently, high-level programming languages such as Java, C++ or C# have been introduced and they have strongly raised the level of abstraction from platforms. However nowadays the number of new platforms and their complexity are increasing much more faster than the capacity of these languages to mask the complexity. For example a way to simplify the platform complexity with Java and C# is represented by middleware platforms like J2EE and .NET, but on the other hand their structure is so full of hidden dependencies that subtle e↵ects always appear.
However, when it comes to large-scale complex systems composed of hundreds or thousands of software components, the structure is never so immediate to the point of being able to visualise and immediately implementing it with whatever high-level programming language.
The software of a system has its inner construction paradigms - criteria, that establish the structure of the system. It is not possible to recognise the suitable construction paradigms of large systems at the level of programming languages. This is due to their level of abstraction that is too much low and it makes no possible to figure out the entire system.
1.1
Models
An abstraction mechanism suitable for simplifying the complexity of large software systems is rep-resented by the use of models. Through them it is possible to represent systems in an e↵ective and concise way so that developers have a reference to the design criteria that must be respected to match the desired system. However, the role of models in traditional software engineering method-ologies presents at least two noteworthy disadvantages. Firstly, they relegate the role of models to mere documentation, thus the relation between models and code is not formal but it is left to the intention of the developer. In fact, developers generally start from scratch, and have to comply the adherence with models by constantly doing manual consistency checks between code and models. This is because it must be avoided the risk of going out of the system design criteria and generating problems that may propagate within the whole system [1].
The second disadvantage concerns the maintainability of models and code. Since system archi-tectures and design are not static, they may be changed during several stages of the life-cycle. Thus, the documentation of models must be scrupulously updated and for large systems this can
represent a tricky task [1]. Moreover, after a change in the model, the code must be kept consistent with the new modifications and in traditional software engineering this task is done by hand. This way of proceeding may itself require long production times and if the risks discussed above are not properly considered, there could be even more delay in the release of the final product and a consequently increase of production costs.
1.2
Mobile Robot Systems and Model-Driven Engineering
Since the 70s, the presence of robots in industry has become more and more massive. The most typical robots are robotic arms called manipulators (or assembly robots), they are fixed on a surface and they are able to accomplish tasks with high speed and accuracy. For instance, in the electronics industry, it is the presence of these robots that makes possible products such as computers and smartphones.
However, the biggest limitation for these type of robots is the lack of freedom in terms of movement. In fact, they are attached on a fixed plan and thus they have a limited range of action. On the other hand, there exists another category of robot systems defined as Mobile Robot Systems (MRSs). As the name suggests, they are able to move freely in the space, that is, going around the space in a non-supervised manner to accomplish their tasks [3]. Due to this ability, the field of application for these robots is wide, a mobile robot can be used not only in the industrial production but also in the services. For example, the robot Autonomous Guided Vehicle (AGV) independently carries parts between di↵erent production stations. Moreover, the ”Helpmate service robot” carries medicines between hospitals. Then there are also robots that explore planets themselves, and others that are used to clean large buildings or subways.
However, when a multiple number of mobile robots are put together to accomplish a group task, a new category of robots is identified: mobile multi-robots. Thus, a system of such robots is called Mobile Multi-Robot Systems (multi-MRSs). In multi-MRSs robots cooperate in team, each robot has its specific task in order to achieve the overall mission assigned to the entire team. Using multiple robots together opens for several new opportunities. In fact, there are missions that requires group characteristics and cannot be accomplished by a single robot, moreover a team can perform missions much more quickly than a single robot [4].
In the last years, multi-MRSs have become more and more anthropomorphic and their use as well as the related research, is continuously increasing. Nowadays multi-MRSs are so mainstream that it is reasonably expected that future will be pervaded by them [4]. Underwater, terrain, and flying robots will simplify the everyday life of people and will add plenty of new opportunities of applications.
Software development for multi-MRSs and, in general for MRSs, is still very complex and there is not yet a standard neither in terms of methodology nor in terms of platforms. Although there have been made several attempts and proposals, an agreement has not yet been reached. The most relevant limitation that was found in these attempts is that they were strongly dependent on the underlying platform, programming languages and interfaces of the various components of the robot [5]. In fact, in a MRS there are sensors, actuators, artificial intelligence modules, network devices and each of them is implemented as a single component that needs an appropriate framework, programming language and interfaces [5]. The traditional software engineering methodologies that have been used so far were too much influenced by this componentization. Being so strongly influenced by the componentization is not desirable in MRSs, because it is in their inner nature to be highly multidisciplinary and this cannot be changed, thus we want software engineering methodologies that can efficiently manage this aspect and overcome the related issues. We want a methodology that permits abstracting from the nature and structure of the robot components and that can efficiently overcome issues of heterogeneity. Heterogeneity issues are always present in high componentized and multidisciplinary systems like the MRSs and these strongly a↵ect the production of code. This happens because MRSs are always developed with methodologies that provide for the componentization of modules, where each of them is developed using its appropriate technology, framework, patterns and programming language. This led to problems of interoperability among modules but also among di↵erent MRSs [5].
The need for software engineering methodologies that can efficiently support development and maintenance of MRSs is high. Currently Model-Driven Engineering (MDE) seems a very e↵ective methodology for the development of MRSs: it would simplify the complexity of robots by auto-matically generating code from models defined with domain concepts and not based on platform and technology.
1.3
Model-Driven Engineering
MDE can be defined as a methodology for applying the advantages of modelling to software en-gineering activities [6]. “Everything is a model” is the paramount principle of MDE according to which MDE aims at manage, guide and found the process of developing a software system on the concept of model. In other words, the aim of MDE is to create formal models to represent systems and from which it is possible to generate the majority of code of the final implementation [1]. Thus, all MDE methods and techniques consider the logical role of models at the same level of the code.
In addition to models, the second fundamental concept in MDE is the model transformation. A transformation is an operation that can be performed on one or more models in a certain domain. In other words, all the desired manipulations on models must be formally defined through trans-formations. Thus, both the definitions of models and transformations should be done throughout some notation, i.e. throughout modelling languages. The latter may be either general-purpose languages or domain-specific languages. However, regardless of the type of language, the ethic of MDE is to formalise and to define models according only to the domain of the system, and not according to the programming language that will be used for the final implementation [6]. Moreover, the definition of a modelling language itself is considered as a model in MDE. In fact, this procedure is called metamodelling, with which it is actually modelled a modelling language. Theoretically, this process can be recursive: in fact one can model a metamodel, which means to define a meta-metamodel. All MDE approaches share this ethic in all the fields of application [1]. One of the biggest misunderstandings when talking about MDE is to associate the task of modelling to the simple activity of drawing graphical objects, that can possibly be in compliance with some syntactic rules. Instead, in MDE modelling has a much wider meaning. With models it’s possible to carry out actions like syntactical validation, model checking, model simulation, model trans-formations, model execution either through code generation or model interpretation, and model debugging. All these possibilities are meant to simplify the development and maintainability of the system, since both the creation and manipulations of models can be automatically reported on the real system. Thus, it goes without saying that this is something that can not be made from mere graphical drawn objects [6]. Figure1 summarises the fundamental ingredients of MDE and their connections.
The main flow of events that represents the typical MDE scenario is the one that goes from the application model down to the implementation. As shown in Figure 1, this flow contains trans-formations and code generation. The latter is the one that reflects one of the main advantages of MDE: reuse the models to generate code on di↵erent platforms. The realization level is the soft-ware that actually runs on a certain platform, if the platform changes, new code can be generated starting from the same application models that can be subject to model transformations in order to match the new platform. This is possible thanks to the definition of models and transformations performed with modelling languages, that in turn are defined by metamodelling languages [6]. It goes without saying that the concept of modelling language is one of the main ingredients of the MDE and it is worth spending some more explanation.
A modelling language is an abstract language that allows to specify models for a certain do-main of systems. There are two types of modelling language: Dodo-main-Specific Modeling Lan-guages (DSMLs) and General-Purpose Modeling LanLan-guages (GPMLs, GMLs, GPLs).
Domain-Specific modelling Languages: they are languages defined for modelling only things of a specific domain in order to enhance the task of people involved in the creation of things of that context.
Figure 1: Overview of the MDSE methodology. [6]
any domain. The typical examples are the UML language or Petri-nets.
In a practical sense, metamodels basically constitute the definition of modelling languages, since they provide a way of describing the whole class of models that can be represented by that language. As mentioned, this process can be recursive, but in practice it is seen that the metamodels typically can be defined by themselves and therefore does not make much sense to go beyond this level of abstraction.
Regarding transformations of models, they are also defined through specific languages that are called transformation languages and that provide everything needed to create transformation rules. Transformations are performed between a source and a target model (or text), which can conform to di↵erent metamodels [6].
1.4
Problem: need for a systematic mapping study
A software development methodology for MRSs has not been standardized yet. This together with the myriad of di↵erent robot hardware platforms currently available make the development of these robots still very complex.
There is a need for a methodology that permits to efficiently abstract from the complexity of robots and that can efficiently overcome issues of heterogeneity often present in high componentised and multidisciplinary systems like MRSs. The ultimate goal would be to agree on a unified development process and move on from the current situation characterised by a variety of di↵erent domain-specific solutions that hinder exchangeability, adaptability, and reuse.
Towards this goal, we believe that MDE could be of help.
To the best of our knowledge, currently no secondary research has been carried out on MDE for MRSs. This means that a view of the current research e↵orts and open challenges is missing. This view would be useful to researchers for identifying interesting research directions and to practitioners for discovering advantages and drawbacks of applying MDE to real-world projects of MRSs. Without secondary research, it is still unclear what was proposed, what has been completed successfully and what instead has failed.
Contribution
In this thesis we will carry out a systematic mapping study of the current state-of-the-art of MDE for MRSs. The contribution is meant to support researchers and practitioners in exploring,
under-standing, and finding directions to contribute to the application of this promising methodology for the development of MRSs, which are progressively becoming part of our everyday life.
This thesis is organized in the following sections: in Section2we describe in details the protocol we have defined to carry out the systematic mapping, then in Section3we illustrate how we followed the protocol in practice. We conclude with Section4 and Section 5 where we show results and conclusions, respectively.
2
Method
Since MDE applied to robotics is a quite recent area, identifying the various publication venues and trends is an indispensable step to fully understand the research possibilities in this area. In this scenario, a systematic mapping study should be used as a first step toward a review of the state-of-the-art. The area is given a structure through the mapping and thereafter a specific direction in the area is investigated with a systematic review [7].
A systematic mapping study requires the definition of a rigorous and validated process, which defines the steps to follow during the research. The process is divided into three basic steps, which will be discussed in the next subsection. At the end of the study, the researchers can take advantage of the statistical results and the final discussions, to get an overview on the topic. In this way, investing on a specific aspect of MDE for MRSs instead of another will be possible, and finding information on the state-of-the-art will be easier.
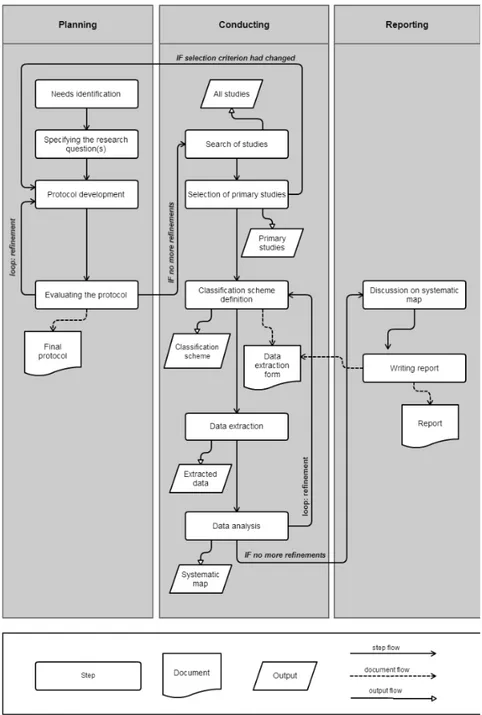
2.1
Process
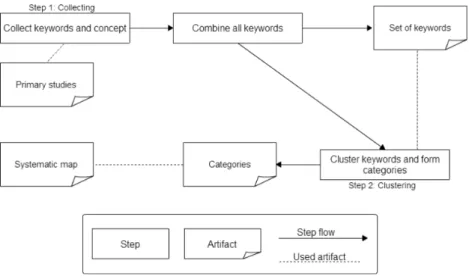
We define the process of systematic mapping study following the guidelines defined in [8]. Figure
2shows the overview of the whole process. Three well-established phases of a systematic mapping study in software engineering are defined as follows in accordance with [7]:
• Planning the study by defining a formal protocol
• Conducting the study by collecting, analyzing, and classifying relevant research on the topic • Reporting and discussing the findings
The planning phase begins with the identification of the motivation and the need of a systematic mapping study. Subsequently, the research questions are defined following the PICOC guidelines [8]. During the planning phase, the protocol can be improved through an iterative loop or re-finements that might occur after the evaluation step. When no more reasonable rere-finements are necessary, then a document containing the current version of the protocol is produced.
The conducting phase represents the mapping study, and it includes the following steps: • Search for studies: in this step all studies are collected;
• Selection of primary studies: all initial studies are reduced by applying the inclusion and exclusion criteria. At the end of this step the set of primary studies is defined;
• Classification scheme definition: A classification scheme is defined and, from it, a data extraction form is produced. It is based on the classification scheme, and it is a spreadsheet in which columns represent the attributes defined by facets, and each row represents a study; • Data extraction: In this step the data extraction form is filled in;
• Data analysis: in this last step the primary studies are analyzed in order to answer the research questions. If the analysis of the extracted data confirms the appropriateness of the classification scheme, then the creation of the systematic map is considered to be com-pleted, otherwise an iterative process of refinements is carried out in order to improve the classification scheme.
The last reporting phase involves the systematic discussion on the map and the writing of the report of the entire study.
To sum up, we will first define the core of the entire mapping study that is the protocol. Basically the protocol of a mapping study formalises the process of the study. With the protocol, we define the rules by which the study is carried out, the way in which research literature is selected, how information from literature is extracted, how results are presented and the procedures to validate and verify the study strategy and the obtained results.
2.2
Team
The team is composed of 5 people organized as follows:
Principal Researchers: Giulio Cattivera, Giuseppina Lucia Casalaro
Master students in Software Engineering with knowledge in MDE and MRSs. They perform most of the tasks of the systematic mapping study.
Secondary Researchers: Ivano Malavolta, Federico Ciccozzi
Post-doctoral researchers active in the field of robotics and MDE, with knowledge also in system-atic literature reviews and systemsystem-atic mapping studies. They constantly support and review the work carried out by the principal researchers. They also resolve conflicts to avoid endless discus-sions among principal researchers [9].
Advisor: Patrizio Pelliccione
Senior researcher with many-years expertise in Software Engineering. He supports researchers dur-ing the data analysis and finddur-ings analysis.
Both the principal researchers together with Federico Ciccozzi (secondary researcher) are at M¨alardalen University in V¨aster˚as, Sweden. The advisor Patrizio Pelliccione is at Chalmers University in Gothenburg, Sweden while Ivano Malavolta (secondary researcher) is located at the University of L’Aquila, Italy.
2.3
Research Questions
Considering that the purpose of this systematic map is to show the current state-of-the-art of MDE for MRSs, then we have identified the following overall research question:
What is the state-of-the-art of MDE for MRSs?
Then, in order to address this research question we have first applied the Population Intervention Comparison Outcome Context (PICOC) criterion in accordance with [8], and secondly we have also defined a set of sub-research questions that address di↵erent aspects of the state-of-the-art of MDE for MRSs.
Our PICOC criterion definition is the following: • POPULATION: Mobile Robot Systems
• INTERVENTION: Model-Driven Engineering approaches for Mobile Robot Systems • COMPARISON: not applicable
• OUTCOMES: a classification of the primary studies that reflects the current state-of-the-art of MDE for MRSs.
• CONTEXT: academic peer-reviewed publications with a software engineering perspective. Then, the sub-research questions are:
RQ1: What are the publication trends of the studies about MDE for MRSs?
Objective: existing research on MDE for MRSs. This research question is divided into specific sub-questions that will be addressed.
⇤ RQ1.1: Which are the most target venues that address the topic of MDE for MRSs? ⇤ RQ1.2: What types of research have been applied and to what extent?
⇤ RQ1.4: What is the publication rate by year?
Outcomes: The outcome of this research question will illustrate the current state of publication on the topic by classifying the collected primary studies according to publication year, venue, author, contribution type and research type.
RQ2: Which kind of MRSs are supported by existing MDE methods and techniques? Objective: to identify and classify the type of MRSs that have been engineered by MDE methods and techniques.
Outcomes: This research question will illustrate characteristics of MRSs supported by MDE methodology, like: types of robots (e.g. aquatic, flying, terrestrial, etc.), number of involved robots (e.g. tens, thousands, etc.).
RQ3: How do existing MDE methods and techniques support MRSs?
Objective: To classify the current MDE methods and techniques for MRSs by showing the adopted MDE-based strategies and the aspect(s) of the robot that is engineered. This research question is investigated through the following subquestions.
RQ3.1: In which way MDE methods and techniques support MRSs?
Outcomes: This research question will illustrate the way MDE methods and techniques support MRSs. The scenario will be illustrated by surveying on the following categories [2]:
1. Domain-specific modeling languages
2. Automation: engines, transformations and generators
RQ3.2: Which aspect(s) of MRSs is engineered by MDE methods and techniques?
Outcomes: This research question will illustrate aspect(s) of MRSs that are engineered by MDE methods and techniques (e.g. behavior, movement, image recognition, path finding, architecture, etc.).
RQ4: Which type of validation has been done for the MDE method and techniques that support MRSs?
Objective: To classify the type of validation or evaluation of MDE methods and tech-niques for MRSs according to [10]
Outcomes: A map that will illustrate in which way MDE methods or techniques for MRSs have been validated or evaluated. For example: real-world software projects, empirical examples, case study, experiment, formal analysis.
Note that this research question focuses on the type of validation that a primary study is providing to support the validity of its proposed method or technique. While RQ1.2 focuses on the type of research that a primary study is showing.
RQ5: Which tools have been proposed for realizing MDE methods and techniques for MRSs? Objective: To identify the tools achieving MDE methods and techniques for MRSs. Outcomes: This research question will illustrate the MDE based tool(s) that are used to realize MRSs, showing the type (eclipse-based or not eclipse-based).
2.4
Search and selection strategy
In a secondary research, the search and selection strategy of primary papers is a critical phase that ensures a comprehensive coverage of the topic under consideration. For this reason it must be strictly defined and documented. An e↵ective search and selection strategy should include many relevant papers but at the same time it should also exclude many of the irrelevant ones. There are two measures that are generally used for describing the accuracy of a search strategy: recall and
precision. Recall is defined as the proportion between retrieved relevant material and all available relevant material, while precision is defined as the proportion of relevant material between the retrieved material. However it is unlikely to define a search strategy that can bring 100% of both precision and recall, thus, we should come out with a good trade-o↵ resulting in a manageable volume of irrelevant material included and not too much relevant material missed [11].
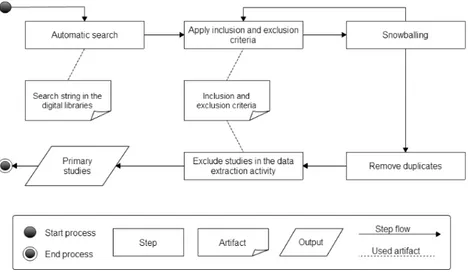
Our search and selection strategy is divided in 4 steps. First, we carry out an automatic search on the most relevant scientific digital libraries, then we apply some criteria on the gathered pa-pers that allow us to include only papa-pers that are pertinent to the topic. Then we continue with augmenting this set through the manual technique of snowballing and eventually we eliminate all duplicates. Figure3 shows the composition of our search and selection strategy.
Figure 3: Search and Selection Strategy.
Step 1: Automatic search
In order to identify as many pertinent papers as possible, we chose to perform automatic searches on multiple digital libraries since it is the most popular method used in systematic studies [8]. These automatic searches have been carried out on the 24th of March 2015.
Electronic Libraries
We chose the digital libraries for scientific literature that have been recognized as high valuable sources of papers in software engineering [12] [13] [14]: ACM Digital Library, IEEE Xplore Digital Library, ScienceDirect, Scopus, Web of Science. According with [8] we have included two indexers (Scopus and Web of Science) together with databases (the remaining). Moreover these digital libraries support functionalities that have been proven to be very e↵ective for performing automatic searches: (i) advanced command search that permits to perform complex query strings and (ii) exporting of the search results to well-defined formats like CSV, in order to perform data manipulation on the results.
Digital Library URL
ACM Digital Library http://dl.acm.org/
IEEE Xplore Digital Library http://ieeexplore.ieee.org/
ScienceDirect http://www.sciencedirect.com/
Scopus http://www.scopus.com/
Web of Science http://www.webofknowledge.com/
Search string
The search string is created based on PICOC [8], as shown in Table 2
POPULATION: Mobile robot systems (mobile OR driv* OR cruis* OR rover OR ground OR *water* OR aer* OR fly* OR sail*) AND (robot* OR vehicle* OR un-manned OR self OR autonomous
INTERVENTION: Model driven engineering approaches for mobile robot systems
(MDE OR MDD OR MDA OR MDSD OR meta-model OR metamodel OR dsl OR domain-specific OR dsml OR model-driven OR model driven)
COMPARISON Not applicable
OUTCOMES Classification scheme
CONTEXT Academic peer-reviewed publications in the context of MDE applied to MRSs
Table 2: The PICOC structure of the search string
Syntax of the search string:
(mobile OR driv* OR cruis* OR rover OR ground OR *water* OR aer* OR fly* OR sail*)
AND
(unmanned OR self OR autonomous OR robot* OR vehicle*) AND
(MDE OR MDD OR MDA OR MDSD OR meta-model OR metamodel OR dsl OR domain-specific OR dsml OR model-driven OR model driven)
The search strings used in practice can be slightly di↵erent, depending on the syntax of each digital library.
Step 2: Eliminating the exact duplicates and combining equal studies First of all, we insert all the studies in a spreadsheet.
– We consider two or more papers to be exactly duplicated if the followings match: title, authors, publication year and the venue of publication. In case of di↵erent versions of the same paper, the most recent one will be chosen.
– In case a study is published in di↵erent type of papers (e.g. both in a conference and in a journal paper) we consider only one instance of the study, according to the completeness of the publication. Mostly the journal version will be kept since it is generally the most complete, but according to [15] when it comes to the data extraction phase also the others will be considered.
Step 3: Selection of primary studies
In this step we apply the inclusion and exclusion criteria. These criteria permits us to consider only those papers that are pertinent to the research questions and to discard all the others. These criteria will be applied considering TITLE, ABSTRACT and KEYWORDS, but if these are not enough for answering then the introduction and conclusion will be also considered. Inclusion and exclusion criteria will be discussed in details in Section5.
Step 4: Forward snowballing
The starting set of papers will be augmented with the procedure of forward snowballing, in accordance to [16]. This procedure consists of identifying those papers citing the papers being examined (primary studies), they will be found using the cited by feature of Google Scholar. The iterations loop ends when no new papers are found by using forward snowballing.
Step 5: Combining the primary studies
Once the gathering of papers is completed we proceed in grouping them together and elimi-nating duplicates by doing the following activities:
1. eliminating the exact duplicates that can be possibly generated from the forward snow-balling activity
2. collapsing identical studies
2.5
Selection Criteria
The use of these criteria aims to identify the primary studies that completely match the purposes of our systematic map. The criteria are applied to the papers collected during the automatic search and snowballing phase. In order to reduce the likelihood of bias, these criteria are determined during the protocol definition and could be refined during the search process [8]. These criteria are composed of inclusion and exclusion criteria and are based on the research questions. They are applied to Title, Abstract, Keywords, Introduction and Conclusion sections of a study. Considering a paper, it is part of the primary studies if it meets all the inclusion criteria and none of the exclusion criteria. On the other hand, a paper is not part of the primary studies if it meets at least one of the exclusion criteria.
2.5.1 Inclusion criteria
I1) Studies proposing MDE methods or techniques for MRSs. We consider the definition of methodology given by [17] where it is considered as a set of methods and techniques, possibly supported by a tool.
I2) Studies focussing on MDE for MRSs analyzed from a software engineering perspective. For example we do not consider studies that cite MDE as a background and that actually focus on robotics engineering, mechanical or industrial, hardware etc.
l3) Studies including a kind of evaluation or validation of the proposed MDE method or technique. For example: real-world software projects, empirical examples, case study, exper-iment, formal analysis.
I4) Peer-reviewed studies: journal papers, workshop papers, conference papers. I5) Studies written in English language.
I6) Studies available in full-text.
2.5.2 Exclusion criteria
E1) Secondary literature studies.
E2) Tutorial papers, short papers, poster papers, editorials, books, keynotes, tutorial sum-maries, tool demonstrations and panel discussions, books, introductory papers for books and workshops, technical reports and other non peer-reviewed publication.
E3) Studies not in software engineering field (e.g. robotics engineering, mechanical or indus-trial, hardware etc.).
E4) Studies published before 2000. Since MDE is generally recognized to be born after the OMG standard for model-driven architecture proposed in 2000 [18].
2.6
Classification framework definition
The classication scheme will be composed of these facets, each of them addressing a research question. Each facet can be constituted of two or more sub-facets, and each facet or sub-facet is constituted of one or more data items. Each data item assumes a value that can be a number or a boolean. These are the facets that pertain to our study:
1. Publication and research trends (RQ1) 2. Characteristics of MRSs (RQ2)
3. Characteristics of MDE methods and techniques (RQ3) 4. Evaluation and validation of methods and techniques (RQ4) 5. Type of tools (RQ5)
2.6.1 Publication and research trends
The type of data that we will extract from the papers in order to show publication and research trends of MDE for MRSs are represented by the following sub-facets of RQ1:
• Year of publication: to obtain the publication tendency per year.
• Publication venue: to obtain their distribution and the distribution over time – conference papers
– journal papers – workshop papers
• Research group: to obtain (i) the number of authors that have been worked on the topic, and (ii) for each author, how many of the collected primary studies he/she has contributed for. • Type of research: we refer to the classification given in [10], since it is used mainly for
systematic mapping studies rather than for literature reviews. A paper can be classified in one or many of the following categories (data items):
– validation research – evaluation research – solution proposal – philosophical papers – opinion papers – experience papers
• Contribution type: this facet results from [7] and we will use it because it is widely used in the literature of systematic studies [19]. A paper can be classified in one or many of the following categories (data items):
– model – method – metric – tool – open items
Category Description
Validation Research Investigated techniques are novel and have not yet been imple-mented in practice. Techniques used are for example experi-ments, i.e., work done in lab.
Evaluation Research Techniques are implemented in practice and an evaluation of the technique is conducted. That means, it is shown how the technique is implemented in practice (solution implementa-tion) and what are the consequences of the implementation in terms of benefits and drawbacks (implementation evaluation). This also includes identification of problems in industrial set-tings.
Solution Proposal A solution for a problem is proposed, and can be either novel or a significant extension of an existing one. The potential benefits and the applicability of the solution is shown by a small example or a good line of argumentation.
Philosophical Papers These papers sketch a new way of looking at existing things by structuring the eld in form of a taxonomy or conceptual framework.
Opinion Papers These papers express the personal opinion of somebody whether a certain technique is good or bad, or how things should been done. They do not rely on related work and re-search methodologies.
Experience Papers Experience papers explain on what and how something has been done in practice. It mirrors the personal experience of the author.
Table 3: Research Type [7]
2.6.2 MDE methods and techniques and MRSs characteristics
The facets of RQ2, RQ3, RQ4 and RQ5 are created by using the method of “keywording” [7]. Keywording is a way to create a classification scheme when facets cannot be known a priori.
Steps of keywording:
• Collecting: For each research paper we read abstract, introduction and conclusion. While reading, we collect keywords and concepts that pertain to MDE methods and techniques and characteristics of MRSs that are achievable by them. We keep in mind possible synonyms and homonyms that possibly might deceive us during this phase. Regarding RQ3 in particular, the keywording will be done by inspecting the following areas, in accordance with [2]:
– Domain-specific modeling languages (DSLs): this area focuses on languages created specifically for a certain domain, context, or company to promote the development of robot in that domain. In other words, this area focuses on what is going to be modeled and with which concepts the modeling is carried out.
– Automation: this area focuses on engines, transformations (like to-model, model-to-text, etc.) and generators of executable code. In other words the focus is on the purposes of models.
At the end of this step, the set of keywords from di↵erent papers are combined together [7]. • Clustering: Once the collection of keywords from all papers is complete, all generated key-words are grouped into equivalence classes called clusters. In this way each cluster finally provides a data item. Then, since we are in the context of RQ2, RQ3, RQ4 and RQ5, each of the founded data item describes a method or a technique or some characteristics of MRSs.
Category Description
Model It refers to papers that conceptually discuss information, rep-resentations, and abstractions used in MDE for MRSs. Method It refers to papers that present general concepts and working
procedures to address specic concerns about MDE for MRSs. Metric It refers to papers that focus on proposing or applying metrics
to evaluate certain properties of MDE for MRSs.
Tool It refers to papers that focus on providing tool support for MDE for MRSs, either in the form of a prototype or a tool that can be integrated with existing frameworks.
Open items It refers to papers that presents identified issues and challenges that must be addressed by further research.
Table 4: Contribution Type
The approach we followed for keywording is summarized in Figure4:
Figure 4: Keywording process.
2.7
Data extraction
The data extraction form is a well-defined form that includes data extracted from each primary study and it is formalized by the classification scheme [7]. Formally, it is a spreadsheet in which the columns represent the attributes defined by the facets, and each row represents a study. In order to ensure a reasonable level of agreement between the researchers during the data extraction, the following two activities will be performed together with the use of the Cohen Kappa coefficient: Activity 1: The data extraction form will be independently filled by each of the principal researchers during the extraction of data from the set of primary studies. The Cohen Kappa coefficient [8] will be calculated for each attribute of a study, then for each study the associated final value of the Cohen Kappa coefficient is the result of the average of the coefficients previously calculated for its attributes [8].
Activity 2: An empty copy of the data extraction form will be filled by the secondary researchers by extracting data from sample studies. Sample studies are chosen randomly. Then the Cohen Kappa statistic will be applied in the same way as for Activity 1.
These two activities will be performed independently by the principal and the secondary researchers to ensure bias avoidance during the data extraction process. In case of conflict between the two
principal researchers, the dispute will be solved by discussing together. After a decision has been made, then the secondary researchers will investigate the dispute and will establish if the reached solution is reasonable.
At the end of the data extraction activity, the Cohen Kappa statistic for each study must be greater or equal to 0.80 [8], otherwise each disagreement must be discussed and resolved by principal and secondary researchers.
2.8
Data analysis
This phase involves analyzing, counting, clustering, summarizing and classifying data extracted from the primary studies in order to produce the actual systematic map about MDE methods and techniques for MRSs. Data analysis is meant to provide answers for the research questions defined in Section2.4.
We will perform both qualitative and quantitative analysis depending on the research questions. All research questions will be addressed with quantitative analysis, and RQ2, RQ3, RQ4 and RQ5 will be addressed also with qualitative analysis.
Regarding the quantitative analysis method, it consists of two phases:
• counting: counting the number of primary studies for each category of the classification framework (see Section2.7).
• mapping: arranging and displaying data from the extraction forms in a consistent and read-able way with respect to the research questions (bubble plots, tread-ables, bar charts, cake charts, etc.).
Regarding the qualitative analysis, we will perform vertical and horizontal analysis in a way ac-cording to [20]:
• Vertical analysis:
For each research question we consider the related attributes in the extraction form, then for each of them, we analyze the data that come from each paper. The aim is to extract the main trends about the topics associated to the research questions.
For closed-end parameters in order to extract trends we consider the occurrence of each possible answer.
For open-end questions we identify categories whose definition comes out both from a keywording performed on the answers and from the relevant concepts of MDE. Then the observations and reasonings of the analysis are carried out from them.
The coding method will be also performed in support of the open-end questions analysis. It aims at encoding qualitative data coming out from the questions in order to apply quantitative and statistical data analyses techniques. Both the categorization and the coding phases will be supervised by the secondary researchers in order to mitigate possible biases between principal researchers. The outputs of this step are: (i) the categorization of responses; (ii) a description of the trends from the statistical analyses. • Horizontal analysis:
We investigate the data resulting from the answers in order to discover possible relations across related questions. Basically we cross-tabulate and group the answers, and make com-parisons between two or more nominal attributes of the extraction form. The aims of our horizontal analysis are two:
Checking consistency of the given answers by cross-analyzing di↵erent questions. Verifying hypotheses that we had previously done during the pursuance of the mapping study. Mainly we will use cross-tabulation for the verification of our hypotheses.
2.9
Threats to Validity
Threats to validity for this mapping study are classified according to common guidelines [15]. Construct validity:
Construct validity represents how the mapping study really reflects the intent of the researchers and what really is asked by the research questions.
First of all we we want to stress the fact that we have followed the guidelines for systematic maps/reviews in software engineering by [7] and [8].
Both MDE and MRSs are well established concepts thus they represent good candidates to be used in a search string. Moreover to enhance the results we have used the snowballing sampling method, that has been proven to be very e↵ective, especially in specific technical areas [11]. We ensure also the depth of our research by investigating for primary studies in the most accessed and complete scientific forum for scientific publications [11][12][13][14].
Internal validity:
Internal validity includes all those threats that can lead to a causal relationship between the treatment and the results, which does not reflect reality. Regarding the data analysis activity, we will use descriptive statistics, therefore we can be reasonably confident that the threats are minimal [21]. The use of a rigorously dened protocol and the use of rigorous data extraction form mitigate this kind of threat to validity.
External validity:
According to [15], threats to external validity are those that limit the generalizability of the work produced, i.e. the systematic map and the final results.
In our research the set of primary studies may not represent the entire set of existing studies on the topic (MDE for MRSs). This threat is mitigated by the choice of our search strategy:
• First of all, our search strategy consists in both an automatic search, and then the forward snowballing. This second step allows us to include in the set of primary studies all those papers that were not captured by the search string in digital libraries. Furthermore, the forward snowballing ensures that the most recent relevant publications are included in our study.
• Secondly, our protocol provides inclusion and exclusion criteria which are used to refine the set of primary studies, including only studies that meet the topic. Moreover, we choose only studies in English because it is the language used for high-quality scientific papers. Other studies written in other languages concerning our topic may exist, but we consider this threat minimal. We choose to exclude the gray literature for the same quality motivation.
Conclusion validity:
Threats to conclusion validity are conditions that may invalidate the conclusions of the work [15]. The conclusions resulting from the relationship between the extracted and synthesized data and the map produced and findings.
In our study, there may be pollution in the data extraction activity and in the classification scheme. We will mitigate this by the following:
• a rigorously defined protocol, that is reusable by other researchers for reproducing our study, and a rigorous data extraction form;
• the data extraction form will be filled independently by principal researchers and it will be validated by secondary researchers;
• a disciplined definition of the classification scheme;
• this protocol and the final report of this study will be preliminary evaluated by external independent researchers.
3
Performing the systematic mapping study
As described in the method, the process of systematic mapping study is divided into three steps: planning, conducting and reporting. In the planning phase, the protocol described in section2has been defined. In this section we describe the step of conducting.
3.1
Automatic search
The first step to search studies was defining a search string that allowed us to perform an auto-matic search on the selected digital libraries (ACM Digital Library, IEEE Xplore Digital Library, ScienceDirect, Scopus, Web of Science). The search string produced many results, since it was fairly general. We chose a pretty open search string to avoid relevant studies to get lost in the automatic search. The syntax for the search string defined in the method is generic, so, for each library, we had to adapt it to fit the library.
We identified some benefits and drawbacks during the automatic search, shown in Table5.
Digital Library
Drawback Benefit
ACM Digital Library
The research supports a maximum of 10 terms in the search string
The research supports a maximum five wildcards in the search string
Splitting of the search string into 28 substrings for each scope ->28 sub-strings for the Abstract, 28 for the Key-words and 28 for the Title
No guidelines and limitations on the syntax of the query
No possibility to download .csv results, then a third party tool is needed
Possibility to apply filters on the search
IEEE Xplore Digital Library
The research supports a maximum of 15 terms in the search string
Download .csv file, containing all the re-sults of the search string
Possibility to apply filters on the search ScienceDirect Search in the entire document =“dirty”
results
Download .csv file, containing all the re-sults of the search string
Possibility to apply filters on the search Scopus - No limitations on the terms of the
search string
Download .csv file, containing all the re-sults of the search string
Possibility to apply filters on the search Web of
Science
Splitting of the search string into three substrings
No limitations on the terms of the search string
Possibility to apply filters on the search
Table 5: Digital libraries pros and cons.
The next step was the elimination of duplicates and clustering of studies with the same title, author, and year but with di↵erent venues. The studies obtained with the automatic search were 1274.
3.2
Applying inclusion and exclusion criteria
The selection phase was based on exclusion and inclusion criteria, defined in section 2.6. Each study was evaluated by reading Title, Abstract and Keywords. If the reading of them did not allow a proper selection, we also read Introduction and Conclusion.
Some problems have been reported in this phase. The most important was the lack of clarity of the aforementioned sections of the papers.
We have noticed that a large number of peer-reviewed papers did not have an accurate description of the approaches, and they presented vague and unclear introductions pretty often. In addition they did not use a homogeneous terminology when it comes to software engineering from author to author. In other cases the keywords were even missing altogether. Consequently, the phase of selection was long since we had to search keywords within the full-texts. In some cases it was necessary to read the entire paper.
During the selection phase, all the papers that matched the criteria were included in the set of primary studies. So, at the end of the selection phase, the number of primary studies was 63.
3.3
Forward snowballing
After the definition of the set of primary studies, the forward snowballing phase was performed. For each study, we looked for the papers citing it using the ”cited by” function of Google Scholar. At each iteration of snowballing, exact duplicates were eliminated.
At the end of the first iteration of forward snowballing, we obtained 344 studies. For each study, the selection was performed in the same way as in the first selection phase. After the selection of the papers found with the first iteration of forward snowballing, we selected 27 studies to be included in the set of primary studies.
At this point, we performed a second snowballing iteration on the studies identified in the first iteration. The second iteration produced 53 results, and after applying inclusion and exclusion criteria, 6 of them were selected and included in the set of primary studies.
Iteratively we applied the snowballing on these six papers, and obtained 11 results from the third iteration. They were subjected to the selection process, and none of them was selected.
The process of snowballing ended at the third iteration. To summarise, during the three snow-balling iterations we identified 408 papers and included 33 in the set of primary studies.
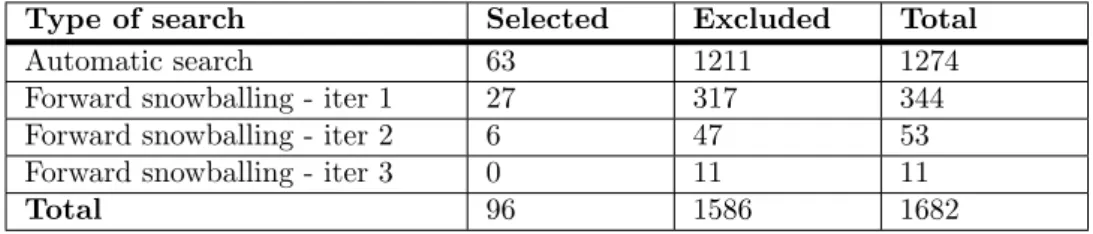
After automatic search and snowballing the set of primary studies consisted of 96 studies (see Table6).
Type of search Selected Excluded Total Automatic search 63 1211 1274 Forward snowballing - iter 1 27 317 344 Forward snowballing - iter 2 6 47 53 Forward snowballing - iter 3 0 11 11
Total 96 1586 1682
Table 6: Number of studies from the searches.
The phase of selection, both after the automatic search, that after each iteration of snowballing, was performed separately by the two principal researchers. At the end, conflicts were resolved through discussion between them. Only 8 conflicts were not resolved and needed the intervention of the secondary researchers. The computed Cohen Kappa coefficient was above the threshold of 0,80, that according to [8] assures a high level of agreement.
3.4
Classification scheme definition and keywording
The step of conducting proceeds with the definition of the classification scheme. In order to define it the facets were chosen. In practice, the facets are the columns of data extraction spreadsheet. The facets of RQ1 were defined in section 2.6.1in accordance with [7]. While the facets for the remaining research questions were derived from the process of keywording, defined in section2.6.2. The keywording process is composed of two stages. The first stage is the collecting, in which all of the keywords of the primary studies have been collected with respect to each research question. The second stage is the clustering, where the keywords have been grouped into equivalence class-es/clusters. Each cluster contains keywords with synonyms or keywords that refer to the same topic or that are logically related. At the end of this process, each cluster represents a data item. For example, the model transformations, like model-to-model, model-to-text, and so on, have been grouped in the ”transformation” data item relative to the RQ3.1.
Our data items for RQ2, RQ3, RQ4 and RQ5 are the following: • RQ2 represents robot type:
– Terrestrial – Aerial – Aquatic – Spatial
– Generic autonomous mobile
• RQ3.1 represents MDE methods and techniques: – DSML
– UML
– Transformation – Code generator – Models@run-time
• RQ3.2 represents engineered robot aspects – Behavior
– Navigation
– System validation and certification – Architecture
– Optimization
• RQ4 represents validation type that has been done for MDE methods and techniques – Experiment
– Case study – Example
– Real-world software project – Simulation
• RQ5 represents the type of tool(s) used for MDE methods and techniques – Eclipse-based
The reasons that led us to this clustering are explained below for each research question: RQ2
The proposed data items (terrestrial, aerial, etc.) cover all the types of robots encountered while reading the primary studies. The data item ”generic autonomous mobile” has been added because some studies proposed MDE approaches which were suitable for all types of mobile autonomous robot.
RQ3.1
The data items of this research question have been chosen according to the categories defined in [2]: domain-specific languages and automation. UML was added because it is quite used in the creation of domain-specific profiles.
RQ3.2
The keywording for this research question showed a variety of robot aspects that are modelled and engineered by MDE. For example, the data item ”behaviour” contains keywords like com-munication, mission adaptation, collaborative robotics behaviour, task coordination, variability, cooperation, movement.
RQ4
This keywording was simple because the data items (example, experiment, case study, and so on) are explicitly mentioned in each paper.
RQ5
The keywording showed the use of several di↵erent tools, and the only reasonably possible grouping was to show whether the tool(s) was eclipse-based or not. When the type of tool was not specified or when proprietary tools were mentioned, the data item ”not eclipse-based” has been marked during classification. On the other hand, the data item ”eclipse-based” was chosen only when the study mentioned it explicitly.
All clusters are shown in AppendixBtogether with the keywords that led to their definition.
3.5
Data extraction
After the keywording process and after the definition of the spreadsheet for data extraction, clas-sification of primary studies was performed separately by the two researchers. During this phase, the full-texts were analysed to answer the research questions. The result was reasonably accurate data, which allowed us to get a comprehensive view of the state-of-the-art of MDE applied to MRSs. From this, we derived detailed statistical analysis that led to notable conclusions on the topic (see Section4).
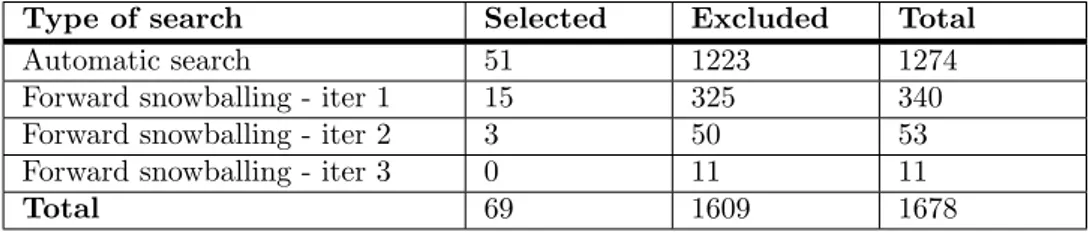
At the end of the classification stage, all conflicts among principal researchers were solved, and it was produced a single spreadsheet containing all classification data. During the merging of the spreadsheet between the two principal researchers, some papers were eliminated from the set of primary studies. This decision was taken by mutual agreement between the two researchers be-cause the studies did not fully meet inclusion criteria.
The excluded studies were 27, and they were not excluded in the selection phase because their reading was limited to only some sections of the paper, according to the defined protocol an the guidelines [7] [8] about mapping studies. Thus, the phase of classification allowed us to further evaluate the selected studies, and to leave in the set of primary studies only those that were rele-vant to the research, 69 papers.
Table7shows the number of included and excluded papers, considering the studies excluded during classification. The documents produced during the implementation of the mapping study showed traceability between the papers of the automatic search and the related studies obtained through snowballing, then the elimination of studies was easy.
At the end of the data extraction phase, a set of 10 random studies was sent to the secondary researchers, who classified them independently. This operation was carried out to check the
cor-Type of search Selected Excluded Total Automatic search 51 1223 1274 Forward snowballing - iter 1 15 325 340 Forward snowballing - iter 2 3 50 53 Forward snowballing - iter 3 0 11 11
Total 69 1609 1678
Table 7: Number of studies from the searches after the data extraction phase.
rectness and the validity of the classification performed by the principal researchers.
The final Cohen Kappa coefficient was computed on the basis of agreement and disagreement among researchers, and it resulted to be above the threshold of 0,80.
3.6
Data analysis
The conducting step ends with the data analysis. This phase allowed the analysis of the acquired data and the discussion of the results. Two types of analysis were performed: quantitative and qualitative. The quantitative analysis show the objective description of the percentage of the collected data, while the qualitative analysis shows the relevant research trends. We show the most used MDE techniques for the development of MRSs. The most engineered aspects of a robot and other significant information discovered during the analysis will be useful for steering further research. In addition, these results are helpful for practitioners that can figure out to what extent MDE has been applied to real-world software projects.
4
Mapping results and discussion
In this section we present the results obtained from the data analysis phase. We have carried out a quantitative and qualitative analysis of the results. The whole analysis is supported by charts, tables and related descriptions. Percentages are computed out of the total number of primary studies for all the results. For the interested reader, the list of primary studies can be found in AppendixA.
4.1
Vertical Analysis
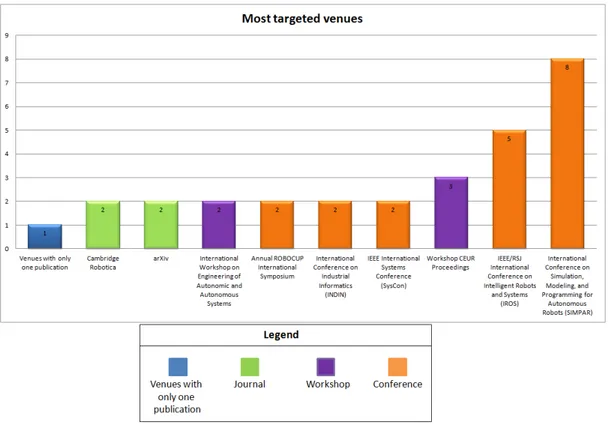
4.1.1 Results analysis of RQ1.1
Figure 5 shows the number of studies per publication venue. We have grouped the venues with only one publication for a better readability of the chart. The complete list of publication venues can be found in AppendixD.
Figure 5: Most targeted venues.
The chart in5shows that the most targeted venues are conferences. In fact, among the venues who had more than one publication , 5 out of 9 (˜55%) are conferences. In particular the most targeted one is the International Conference for Autonomous Robots (SIMPAR). On the other hand, both workshops and journals are represented by 2 venues each out 9 (˜22%).
The number of authors that have contributed is 202. For a complete details on the contribution for each author, the reader can refer to the AppendixE.
4.1.2 Results analysis of RQ1.2
Table8shows the total number of studies per research type, while Figure6shows the distribution over the years.
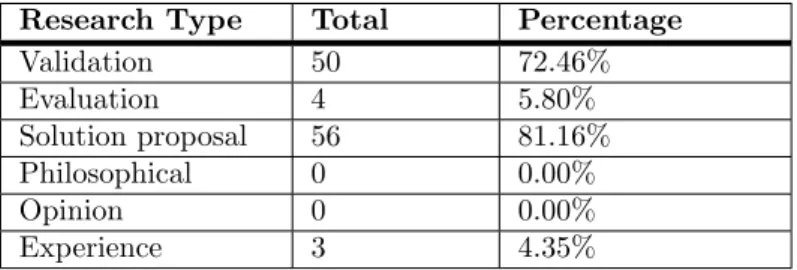
Research Type Total Percentage Validation 50 72.46% Evaluation 4 5.80% Solution proposal 56 81.16% Philosophical 0 0.00% Opinion 0 0.00% Experience 3 4.35%
Table 8: Research type percentages.
It is clear from Table8, that the most common research types are solution proposal and validation with a percentage of ˜60% and ˜80%, respectively. While evaluation and experience papers have percentage of ˜6% and ˜4% respectively. This result may imply that collaborations between research and industry had been scarce since usually evaluations and experience research involve support from practitioners. But the same results may also suggest that because of the novelty of MDE there is not a huge presence of experience and evaluation papers yet.
Figure 6: Research type over the years.
Figure 6 presents the distribution of research types over the years, that has been provided to support better the previous results. We do not consider the 2015 to analyse trends, since our study was carried out in the beginning of that year and we obtained only one study from the search.
A considerable trend that is worth to mention is that solution proposals have been constantly growing in the considered period. Moreover it can be seen that validation slightly fluctuated over the years but that, in general, it had increased until 2014.
4.1.3 Results analysis of RQ1.3
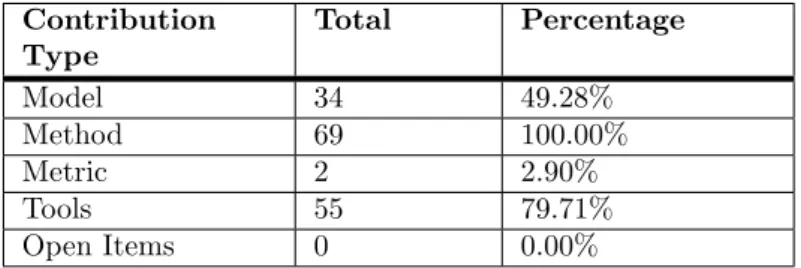
Table 9 shows the total number of studies per contribution type, while Figure 7 illustrates the distribution over the years.
It is not surprisingly that each primary study proposed at least a method. Indeed, every study presented a working procedure to address some concerns of MDE for MRS. It is also important to notice that no primary study contributes with an open item.
Another relevant result is that half of the studies proposed a model to conceptually discuss ab-stractions; more specifically, these studies proposed DSMLs.
As it can be seen in Figure 7, the number of studies proposing methods, tool and model have increased for the whole considered period. Despite some minor fluctuations, this testifies that interest and research e↵orts on the topic is constantly growing.
Contribution Type Total Percentage Model 34 49.28% Method 69 100.00% Metric 2 2.90% Tools 55 79.71% Open Items 0 0.00%
Table 9: Contribution type percentages.
Figure 7: Contribution type over the years.
4.1.4 Results analysis of RQ1.4
Figure8illustrates the overall distribution over the years.
Figure 8: Publication rate by years.
Basically it is clear to see how the interest on the topic had constantly grown for the entire period, since the publication rate had always increased despite a minor reduction in 2012.
4.1.5 Results analysis of RQ2
Figure9ashows the total number of studies for each type of robot, while Figure9billustrates the percentage of studies proposing MRSs or multi-MRSs.
![Figure 1: Overview of the MDSE methodology. [6]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4684638.122695/13.892.185.699.137.416/figure-overview-of-the-mdse-methodology.webp)
![Table 3: Research Type [7]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4684638.122695/23.892.147.739.119.590/table-research-type.webp)