EXAMENSARBETE I
MJUKVARU TEKNIK
30 HP, AVANCERAD NIVÅ
Akademin för innovation, design och teknik
Component Repository
Browser
MASTER THESIS IN
SOFTWARE ENGINEERING
30 HP, ADVANCED LEVEL
School of Innovation, Design and Engineering
Component Repository
Browser
ABSTRACT
The main goal of this thesis is to investigate efficient searching mechanisms for searching and retrieving software components across different remote repositories and implement a supporting prototype called “Component Repository Browser” using the plug-in based Eclipse technology for PROGRESS-IDE. The prototype enables users to search the ProCom components and to import the desired components from a remote repository server over different protocols such as HTTP, HTTPS, and/or SVN. Several component searching mechanisms and suggestions were studied and examined such as keyword, facet-based search, folksonomy classification, and signature matching, from which we selected keyword search along with facet-based searching technique to help component searchers to efficiently find the desired components from a remote repository.
Date: 10 January 2010
Carried out at: Mälardalen hogskola, Västerås Sweden Advisor at MDH: Severine Sentilles
PREFACE
We dedicate this thesis to our parents.
Västerås, January 2010 Rafique and Sajjad
CONTENTS
Chapter 1 INTRODUCTION 1
1.1 Component-based Software Engineering ... 1
1.1.1 Why Reusability? ... 1
1.2 Component Model ... 2
1.2.1 PROCOM Component Model ... 2
1.3 PROGRESS-IDE ... 4
1.4 Problem Definition ... 5
1.5 Structure of the Thesis ... 5
Chapter 2 SEARCH AND RETRIEVAL TECHNIQUES 6 1.6 Related Research ... 6
2.1.1 Keyword and Full-Text Keyword Search ... 6
2.1.2 Faceted Searching ... 8
2.1.3 Folksonomy Classification ... 10
2.1.4 Signature Matching ... 12
2.2 Summary of Searching Techniques ... 13
2.3 Proposed Techniques ... 14
Chapter 3 INDEXING AND SEARCHING 16 3.1 Indexing ... 16
3.1.1 Boolean Retrieval Model ... 16
3.1.2 Inverted Index... 18
3.2 Apache Lucene API... 20
3.2.1 Lucene Indexing Process ... 21
3.2.2 Lucene Searching Process ... 22
Chapter 4 SYSTEM REQUIREMENTS 24 4.1 Use-Case Diagram ... 24
4.1.1 Search Components ... 25
4.1.2 Change Preferences ... 25
4.1.3 Import Components ... 25
Chapter 5 SYSTEM ARCHITECTURE 26 5.1 System Overview ... 26
5.2 Detailed Architecture ...27
5.2.1 Repository Access Service ... 28
5.2.2 Analyze Document ... 28
5.2.3 Index Document ... 28
5.2.4 Query Manager ... 28
5.2.4 Component Searcher ... 28
5.2.4 Component Ranker... 28
Chapter 6 IMPLEMENTATION AND APPLICATION TUTORIAL 30 6.1 Implementation Details ... 30
Figure 18: Component Repository Browser Plugins ... 30 6.1.2 Core Classes ... 32 6.1.2.1 Facets ... 32 6.1.2.2 Indexer ... 33 6.1.2.3 Query ... 34 6.1.2.4 Searcher ... 35 6.1.2.5 TaskThread ... 36 6.2 Application Tutorial ...37
6.2.1 Search Components Dialog ...37
6.2.2 Setting up Environment ... 38
6.2.2.1 Setting up Facets ... 39
6.2.2.2 Setting up Logging ... 41
Chapter 7 EVALUATION AND RESULTS 42 7.1 Recall and Precision ... 42
7.2 Evaluation ... 42
7.2.1 Sample Queries ... 42
7.2.2 Results ... 43
Chapter 8 CONCLUSION AND FUTURE WORK 46
Chapter 9 ACKNOWLEDGEMENTS 47
Chapter 1
INTRODUCTION
This thesis investigates efficient searching techniques for searching components across different repositories and implements a supporting prototype using the plug-in based Eclipse technology to search and retrieve desired components for IDE. The PROGRESS-IDE is an integrated development environment developed by Mälardalen Real-Time Research Centre (MRTC)1 within the research project PROGRESS2 for creating ProCom
components for automation and vehicular systems.
In this introductory section, first we discuss some fundamental concepts of component-based development (CBD) and its importance in the field of software engineering then we present basic concepts of ProCom Component Model, and finally we define problem of this thesis.
1.1 Component-based Software Engineering
The component-based software engineering (CBSE) or component-based development (CBD) emphasizes the development of applications based on components so that the applications are easy to maintain, and extend. The main constituent of component-based development (CBD) is component.
The term component has been defined in many different ways. We use the general definition of Brown [6], who defines that “a component is an independent and self-sufficient part of a system having complete functionalities”. The main idea of using component-based development is reusability. CBSE is different compared to other development strategies in a sense that when a component is developed it is intended that it can be integrated with other systems [9]. According to Emmerich [25], the key characteristics of component approach is that it promotes high degree of abstraction in software design, implementation, and deployment, and facilitates flexible configration of software, and promotes software reuse.
1.1.1 Why Reusability?
Today, many works are found that discuss the advantages of component-based development (CBD). For example, [5][6][7][8] have discussed that using components does not only increase maintainability, replaceabilty, flexibility and performance, but it also reduces development costs. Most importantly it increases reusability [5], which is a process of utilizing and applying already developed components. For example, much of the functionalities of weather applications are same such as daily forecast, weekly forecast,
1
Mälardalen Real-Time Research Centre (http://www.mrtc.mdh.se)
2
A strategic research center funded by Swedish Foundation of Strategic Research (http://www.mrtc.mdh.se/progress)
forecast of a city/region/country/global, and detailed/brief weather view. Therefore, it is a good idea that common functionalities are provided by the same set of components. However, to effectively take the advantage of component reusability, it is important that the desired components are found from a component repository [6], where they reside in. In section 2, we discuss the problem of component search and retrieval in details, and propose three types of efficient searching techniques to find components from a repository.
1.2 Component Model
The component model defines how a component can be structured. The famous examples of component model include CORBA component model, JavaBeans and Entriprise JavaBeans, Microsoft’s .NET model, and Component Object Model (COM). PROGRESS developed ProCom Component Model for automation and vehicular systems. In the subsequent sections, we provide a brief view and features provided by ProCom Component Model.
1.2.1 PROCOM Component Model
The ProCom Component Model envisions to support the a) entire development process, b) various needs which exist at different system levels, c) analysis, and d) deployment of components [4]. The model is designed in a layered manner [2]. It consists of two layers, the upper layer is called ProSys and lower layer is called ProSave [2][3]. The ProSys layer is used to model active and concurrent subsystems that communicate by means of message passing. While ProSave layer defines the component-based design language for modeling components with complex control structures and functionality found usually in embedded control-intensive systems. The system modeling elements of ProSave layer are different entities like composite, services, ports, connections, and connectors. Furthermore, these components are passive unlike the components in ProSys layer and they need some triggers or event activate them.
ProCom has two specialized elements: clocks and message ports that build a communication bridge between upper layer and lower layer, so that design components of both layers can communicate with one another. Table 1 presents summary of different system modeling elements used to model ProCom components [2] [3].
Elements Description Input message port represents messages it receives. Output message port represents massages it sends.
Message channel is used to connect input and output message ports.
Trigger port reads the current value at the input data port and processes the value.
Data port is used to hold some value.
Input/Output port group has at least a trigger port and a data port.
Data fork connector has one input data port and no less than two output data ports. It splits a data connection to several outgoing ones.
Data or connector has no less than two input data ports and one output data port. It combines a number of data connections to one.
Data muxer has not less than two input data ports and one output data port, which is used at system level. It groups many data inputs into one output. Data demuxer is the inverse of Data muxer. It has one input data port and no less than two output data port.
Control fork connector has one input trigger port and no less than two output trigger ports. It splits control flow to a number of parallel paths. Control join has one no less than two input trigger ports and one output trigger port. It combines the control flow of a number of parallel paths.
Selection has one input trigger port, and several output trigger ports and no less than one input data port. It could be used to select a path of the control flow depending on a state.
Clock has one output trigger port. It is used to produce periodic triggers.
Table 1: System modeling elements used to model PROCOM components [3]
In Figure 1, (a) illustrates graphical representation of a simple ProSave component with one input group and one output group, (b) illustrates a subsystem with three input message ports and two output message ports, and (c) illustrates connecting message ports to a message channel. Data fork Data muxer Data demuxer Control fork Control join Data or Selection Clock
Figure 1: (a) ProSave component, (b) SubSystem, and (c) Message Ports and Message Channel [2] [3]
Table 2 summarizes three different types of representations of a simple ProSave component developed in PROGRESS-IDE (the current version does not support creating graphical models). The first column shows System Model of a simple ProSave component with one input port group and one output port group, the XML notation of the model is given in the second column, and the third column shows the graphical representation of the component.
System Model XML Notation Graphical Model
<?xml version="1.0" encoding="UTF-8"?> <ProComMetamodel.ProSave:Component xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:ProComMetamodel.ProSave="http:///ProCo mMetamodel/ProSave.ecore" name="ABR"> <service name="S1"> <inputPortGroup> <trigger name="IT1"/> <data name="IDP1" initialValue="String"/> </inputPortGroup> <outputPortGroup> <trigger name="OT1"/>
<data name="ODT1" type="String"/> </outputPortGroup>
</service>
</ProComMetamodel.ProSave:Component>
Table 2: Three types of representation of a ProSave component
1.3 PROGRESS-IDE
The PROGRESS-IDE is an integrated development environment based on open-source IDE framework Eclipse3 for creating ProCom components. The interface of the PROGRESS-IDE can be customized by the use of different views, and panes. The PROGRESS-IDE provides various views such as Component Repositories, Project Explorer and Properties etc. It also has a list of wizards, for example the New ProCom Project wizard helps to create new ProCom project and the Export Component wizard assists to export the desired components to a specific repository. The IDE also contains editors to create ProCom components.
3 http://www.eclipse.org/ SubSystem (a) (b) (c) ABR
1.4 Problem Definition
PROGRESS-IDE enables creation of ProSys and ProSave components, which can be exported to different repositories. However, the creation of components alone is not enough if they cannot be reused. For reusing components, it is necessary to find them. The current version of PROGRESS-IDE does not support searching of ProCom components from remote repositories. In this thesis, we present several component searching mechanisms, elaborate their pros and cons and finally, describe the proposed solution and its implementation in form of a prototype called Component Repository Browser.
This process included having an acquaintance with ProCom Component Architecture and its terminologies, familiarization with PROGRESS-IDE environment and studying other material available on the ProCom model. Most importantly we had an extensive study in how to design and develop java based RCP applications and solve other related issues as a part of this master thesis.
1.5 Structure of the Thesis
The remaining of this thesis is organized as follows: Chapter 2 details different searching techniques. Chapter 3 explains indexing and its process, and Apache Lucene API. Chapter 4 presents the application requirements with UML and textual representations. Chapter 5 explains the architecture of the application, and Chapter 6 presents the implementation details and application tutorial. Chapter 7 gives the evaluation results and in the last section, the conclusion and suggestions of directions for the future work are presented.
Chapter 2
SEARCH AND RETRIEVAL TECHNIQUES
One of the major challenges in the field of component-based software engineering is searching components from a repository [10]. In this section, we present some of the existing search techniques, and also explain what techniques are suitable in the context of this master thesis.
1.6 Related Research
The existing searching techniques can be divided into four different types: a) keyword or string search, b) faceted classification, c) folksonomy classification, and d) signature matching. Today, many search engines use keyword searching (see 2.1.1). In the keyword search, a user gives a query based on a set of strings. The search engines match those strings with the strings in documents where the search is performed, and the results are retrieved accordingly. This mechanism is detailed in section 2.1.1. Faceted classification (see 2.1.2) categorizes components based on facets (taxonomies) such as type of component, functional area, and domain of a component, etc. This technique is helpful for items that can be divided into groups. Folksonomy classification (see 2.1.3) is a collaborative way of tagging, which may help to find components based on those tags. Signature matching (see 2.1.4) is useful for searching source code based on method types and number of arguments in a method.
The subsequent sections define each of these searching techniques in detail, and a summary of all these techniques with their pros and cons is presented in Table 4.
2.1.1 Keyword and Full-Text Keyword Search
Keyword search is the most commonly used technique for searching purposes. In this type of searching technique, a user inputs keywords (set of strings) to search and as a result a ranked list of documents is returned. Today, we can see a number of search engines using keyword search technique to search documents on Internet. For instance, search engines like Google4, Yahoo5, MSN6 search, and AltaVista7 are some well-known web search engines that
support keyword-based searching as a basic searching technique to search documents and websites etc.
Generally, two processes are involved in keyword search: indexing and searching (see section 3). The indexing process looks into all the available documents in different repositories or databases and creates a list of search items, which could be used for search
4 http://www.google.com 5 http://www.yahoo.com 6 http://www.msn.com 7 http://www.altavista.com
purpose. In the searching process, when a query is given then only the index created in the indexing process is referred rather than all the repositories or databases that contain documents to search the desired documents. Keyword search gives freedom to users to freely submit any query to search engines; however this freedom may rise following two problems as identified in [10] [11] [13]:
• Recognize keywords that best explain the need of users • Possible ways in which a user may search
1. Recognize keywords that best explain the need of users
For search engines it is difficult to recognize the specific keywords from a given query that best explain the need of the users, who want to search something. Let’s say we want to know and search documents that explain the following question.
“What role do facets play in searching?”
There are two major concepts in the above question: facets, and searching. However, other keywords are not much important and useful, because those keywords are used only to join the key concepts. The useful keywords could be facets, and searching. The most of the current search engines are not able to extract the key concepts from a given query. They merely try to search documents that contain most of the words in the query.
Let’s take another example, if a keyword “xml” is used to find the string from the xml document as shown in Figure 2, this makes little sense because it is a common word used in all XML documents. The useful keywords for this XML document could be “ABS”, “ProSys” “Speed”, “LF Wheel Speed”, and “InputMessagePort” etc.
Figure 2: XML Document
2. Possible ways in which a user may search
It is also difficult for search engines to know all possible ways in which a user may search for a document [12]. Many times, it happens that the search does not bring any result or if there is any, then the results are not relevant because there was no keyword match between the keyword that has been searched and what is in documents or index. For example, if we try to search “flare cut pants” from some online shopping websites then, unless the search engine knows that every “jeans” is a “flare cut pants”, it cannot bring all results against our search.
<?xml version="1.0" encoding="UTF-8"?> <ProComMetamodel.ProSys:Subsystem xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema- instance" xmlns:ProComMetamodel.ProSys="http:///ProComMetamode l/ProSys.ecore" name="ABS"> <ports xsi:type="ProComMetamodel.ProSys:InputMessagePort" name="LF Wheel Speed" type="Speed"/>
Furthermore, another challenge in keyword search is usage of synonyms [13]. For example, if a user searches for the keyword “baggage”, “luggage”, or “suitcase” not all desired results might be obtained. The same is true for the keywords such as “organization” and “organisation”. We submitted these queries to Google search engine and found different results for the words that have same meaning but different spellings. The results are shown in
Table 3.
Keyword Total links retrieved Time (in seconds) Baggage 12,200,00 0.08 Luggage 39,000,000 0.06 Suitcase 7,510,000 0.29 Organization 241000000 0.24 Organisation 133,000,000 0.25
TABLE 3: Documents retrieved by Google against each keyword (The results are based on query submitted to Google on 27th Oct 2009 01.30)
Searching on keywords also depends on how the document has been indexed. Using indexing increases speed and performance in searching relevant documents for a given query [19]. Some search engines index all the documents in their repositories or databases without excluding common and regular words such as “a”, “an”, “on”, “of”, “the”, etc. This is the case for Atla Vista [13]. This type of indexer is called full-text indexer and the search engines using full-text indexers provide full-text keyword search capability. However, there are some indexers that do not index those common words. In some cases, some search engines also discriminate upper-case from lower-case.
Despite the two problems mentioned above, the keyword search is most commonly and widely used searching technique because it gives freedom to users to freely input keywords and is also easy to implement.
2.1.2 Faceted Searching
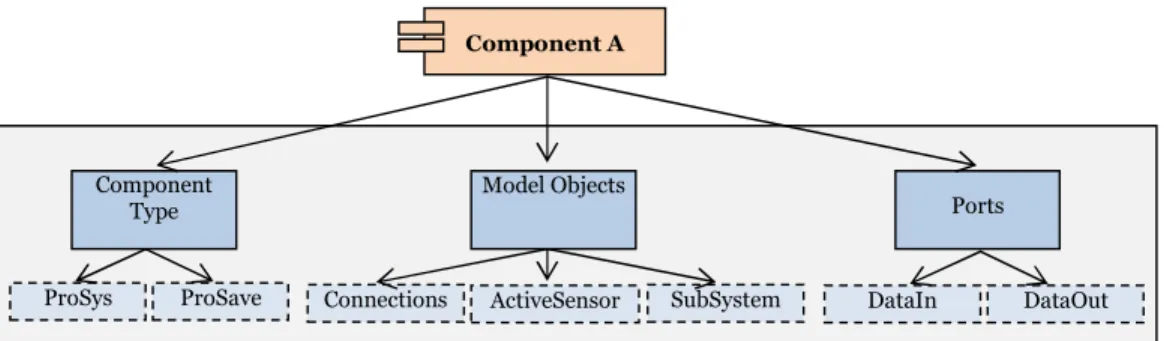
Faceted searching, also known as faceted navigation or faceted browsing, was proposed by Prieto-Diaz and Freeman in 1987 [8]. Unlike keyword search, it is a technique that allows users to search by filtering available information. Each facet has some values, which depict the important characteristics of an object [8]. For example, Figure 3 denotes the component facets and the logical classification of their values. The blue boxes with solid lines represent facets, and the light blue boxes with dotted lines represent the corresponding facet values, whereas the box in orange color corresponds to the UML notation of a component.
Figure 3: Facet and their values
For example, in Figure 3, Component A has three facets: a) Component Type with facet values ProSys, and ProSave, b) Model Objects with facet values Connections, Active Sensor, Subsystem, and c) Ports with facet values DataIn and DataOut.
Sometimes faceted search is also referred to explorative search and guided search, because users are given choice to select features available for search. This “guided” freedom helps the users to accomplish his/ her search goals quickly and efficiently [15]. A good example of a facet-based search is FacetBrowser [15], which supports creation of multiple search facets. In the FacetBrowser, each user is given a user profile, which holds facet “storyboards”. A storyboard is a container for facets. User selects the facets from the storyboards and search accordingly. A screenshot of FacetBrowser is given in Figure 4. Another good example is VisualFlamenco8 [16]. It is a web-based image browsing tool which
helps to search images based on facets.
Facets are generally derived by analyzing the text using entity extraction techniques, which is a technique used to locate text and classify text accordingly [14]. Facet-based searching is a good technique in the sense that it provides the user with an opportunity to freely pick key available features for the search [16].
8
It is based on the original Flamenco prototype (http://flamenco.berkeley.edu/) Component
Type
ProSys ProSave
Model Objects
Connections ActiveSensor SubSystem
Ports
DataIn DataOut Component A
Figure 4: A screenshot of FacetBrowser [10]
2.1.3 Folksonomy Classification
Folksonomy is a combination of two words: “folk” and “taxonomy”. It is also known as collaborative or social tagging system, because it allows creating and organizing tags collectively by one or several users. In the best of our knowledge, www.flickr.com is the best example of folksonomy classification. It is an online photo management and sharing application. Once a photo is added in a photo album, users may add various tags to the picture. Figure 5 presents a screenshot from the flickr website (slightly modified for the purpose of report format), in which a user can add different tags to the picture. Each tag is separated with a space e.g. ProSave ProSys, or several words are associated together in one tag through the use of double quotes e.g. “ProCom Component” “Composite SubSystem”.
Figure 5: Screenshot from www.flickr.com
Another good example of the folksonomy classification is www.delicious.com. It is a social bookmarking website, which allows users to tag, save, send messages and share web pages. Normally, users save their favorite websites in their internet browsers. Delicious helps them to store their favorite links on its website. The links could be tagged so that users may also search for their own tags or any other tags to search the bookmarks of different websites. One of the most powerful elements in tagging is multi-term tagging. It provides a better way to keep the related tagged terms together. Taking as example, Figure 6 illustrates a tag comprising of two related terms “ProCom” and “Component” combined in one tag.
Figure 6: Multi-term tagging
However, different interfaces use different ways to handle multi-term tags. For example, flickr uses double quotes to join multi-terms to form one tag as shown in Figure 5. However, Yahoo! Bookmarks9 provides textboxes for single or multi-terms. In Yahoo! Bookmark as
shown in Figure 7, after entering a tag, using the tab button will bring another textbox to store a new tag.
Figure 7: Yahoo Bookmarks - Add a bookmark
Yet another of folksonomy classification is Knowledge Plaza10. It is a knowledge
management and social search platform for companies. It helps organizing, sharing, and mobilizing documents, web sites, emails, contacts, ideas, or even discussion in a company. Users can use its search feature to find relevant information. The Plaza allows tagging the information and allows searching on tags, facets, and full text search.
Taciana at al. [20] present the use of the folksonomy in Maracatu, a java source code search engine. For tagging, they are of opinion that there should be three elements in folksonomy: i) the tag, ii) a clear understanding of object being tagged, and iii) identification of the user tagging the element. According to our study, the Maracatu is a good and only example of folksonomy usage in source code. Figure 8 is a screenshot of the
9
http://bookmarks.yahoo.com/
10
Maracatu’s source code tagging mechanism, wherein association of tags of a source code (test.java) is shown.
Figure 8: MARACATU Source Code Classification [11]
In (1), the developer enters tags to the specific file in this case test.java or may select a set of tags from the tag suggestions (2), top tags (3), and top author tags (4) lists. A blank space is used to separate one tag from other, as in flickr.com. An important feature of Maracatu is if the tag entered in (1) already exists in any of the tag lists (2) (3) or (4) then the particular tag is enabled automatically in the list.
2.1.4 Signature Matching
If developers are interested in finding components, they may search or browse components by the component names if they know them already. However, it is difficult to remember the names of components; since components could be program units (e.g. Java or C++ classes, C functions etc) then it is difficult to search for specific class or method that performs a specific task. Yet, there is another searching technique used specifically for finding components that are based on source code. To search components by the matching signatures of methods is called signature matching [17].
Signature matching is a method for “organizing, gathering, navigating through, and retrieving from software libraries” [17]. The type of a function or method is called its signature. Signature matching helps to search a specific function by using the function’s input or return-arguments. Figure9 contains two simple Java classes: Shape and ComponentDesc, which together define four functions: shape(), getShape(), getComponentProvider(), and addComponentType(). If we want to search for a particular function, so instead of searching by its name, we can perform a query based on the function’s input and return arguments. For
example, getComponentProvider() function in the ComponentDesc class take two strings as parameters and returns an object of type string. In the same way, addComponentType() function takes two types of parameters List<String>, and string, respectively, and returns a list of string type.
Signature matching is helpful to search components that are source code based, but this type of searching is not good for metadata search. It is also helpful for developers to organize components into orderly and disciplined groups [17].
Figure 9: Shape and ComponentDesc Java Classes
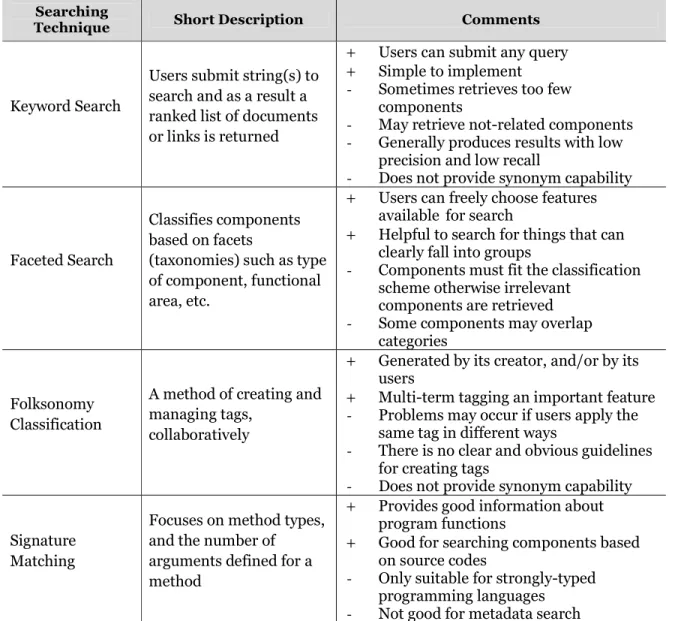
2.2 Summary of Searching Techniques
The table below presents advantages and disadvantages of the search techniques discussed in the above sections. The plus (+) sign represents advantage of the corresponding searching technique, whereas the minus (-) sign represents disadvantage.
public class Shape {
private int widht, height; public Shape(int h, int w) { this.widht = w;
this.height = h; }
public Shape getShape(int height, int width) { return new Shape(height, width);
} }
public class ComponentDesc {
public String getComponentProvider(String repositoryID, String compName) { String compProvider = "UnKnown";
if(repositoryID.length() > 0 && compName.length() > 0) { compProvider = "MDH";
}
return compProvider; }
public List<String> addComponentType(List<String> supportedTypes, String compType) {
supportedTypes.add(compType); return supportedTypes;
Searching
Technique Short Description Comments
Keyword Search
Users submit string(s) to search and as a result a ranked list of documents or links is returned
+ Users can submit any query + Simple to implement - Sometimes retrieves too few
components
- May retrieve not-related components - Generally produces results with low
precision and low recall
- Does not provide synonym capability
Faceted Search
Classifies components based on facets
(taxonomies) such as type of component, functional area, etc.
+ Users can freely choose features available for search
+ Helpful to search for things that can clearly fall into groups
- Components must fit the classification scheme otherwise irrelevant
components are retrieved - Some components may overlap
categories
Folksonomy Classification
A method of creating and managing tags,
collaboratively
+ Generated by its creator, and/or by its users
+ Multi-term tagging an important feature - Problems may occur if users apply the
same tag in different ways
- There is no clear and obvious guidelines for creating tags
- Does not provide synonym capability
Signature Matching
Focuses on method types, and the number of arguments defined for a method
+ Provides good information about program functions
+ Good for searching components based on source codes
- Only suitable for strongly-typed programming languages
- Not good for metadata search Table 4: Summary of Component Retrieval Techniques
2.3 Proposed Techniques
As a basis to investigate possible solutions to the problem of component search and retrieval, we discussed in the previous section some search practices. Several work [20] [21] [22] [23] [24] suggest to use more than one searching technique to search and identify components from different repositories. Ostertag et al. [22] have suggested two techniques for component search. Those are: a) free-text keyword, and b) faceted-search. Taciana et al. [20] have discussed the importance and usage of three techniques for component retrieval in their Eclipse plug-in based application, “Maracatu”. The search techniques used by them are: a) keyword search, b) facet-based search, and c) folksonomy classification. Mili et al. [24] have suggested using into three different types: a) keyword and string match, b) faceted classification, and c) signature matching.
In context of this master thesis, we propose to use the component search techniques used by Taciana et al. [20] in their prototype application Maracatu, which is basically a java
source code search engine. It searches and retrieves java classes from file systems. However, to the best of our knowledge, there exists no search engine which uses keyword, faceted-classification, and folksonomy classification for metadata search from a remote repository. Moreover, we allow users to perform CRUD (create, read, update, and delete) operations on facets.
The combination of keyword and faceted classification will help to search and retrieve components. However, the searching mechanism can be improved by introducing another searching technique like folksonomy. In PROGRESS-IDE folksonomy can be used to tag the components at design time by the component designer/ developer or later on by the component users.
Suggested Search Techniques for PROGRESS-IDE
1. Keyword search 2. Faceted-based search 3. Folksonomy classification
Table 5: Suggested search techniques for PROGRESS-IDE
Previous work [20] shows that it is better to use keyword and facet-based searching techniques together rather than alone. Recall (to get all the relevant components) and precision (all the retrieved components are exact as per query submitted by a user) are the two measures used to check the efficiency and effectiveness of a searching mechanism. A good search mechanism should have good recall and high presision. In Figure 34, we have mentioned the results of average recall and precision for some search terms (Table 11 and
Table 12) used to search ProCom components from a repository.
Introducing folksonomy will increase the precision and response-time of component retrieval [20] [21]. The tags could be stored in a file and there could be only one file for a repository to track changes in the tags. So whenever a user wants to search for components from the repository, he can see the tags that reflect the information about the components and their services, interfaces etc. Using this tagging system can be very helpful to search and find the components as it can guide to find right component [20].
Indexing plays an important role in component search and retrieval. The subsequent chapter explains the process of indexing in detail. It also discusses the Apache Lucene API, which we proposed to use for the purpose of indexing and searching.
Chapter 3
INDEXING AND SEARCHING
We had been exploring several open source tools for indexing within the context of this master thesis. In this section, we discuss the idea of two common indexing techniques: a) Boolean retrieval model, and b) inverted index. This section also discusses the tool used for the indexing purpose.
3.1 Indexing
Indexing is a way to collect and parse text for fast information retrieval. The main purpose of storing an index is to find relevant documents quickly and efficiently. Without an index, a search engine will scan each and every document, which is not only time consuming but requires much computing power. Search engine architectures vary in the way indexing is performed and in methods of index storage to meet the various design factors. In subsequent sections, we present types of indices and explain how they store text in an index.
3.1.1 Boolean Retrieval Model
The Boolean retrieval model is a model for component retrieval. In it, queries are modeled using Boolean operators such as AND, OR, and NOT. The model views each document as a set of words [10]. To illustrate the concept of this model, let’s assume there are three ProCom components: ABS, CBR, and SDR in a repository. The description of these components is shown in Figure 10, Figure 11, and Figure 12, respectively. We want to search for ProSys components that contain the keyword InputMessagePort, but exclude components that contain OutputMessagePort. The query is:
ProSys AND InputMessagePort NOT OutputMessagePort
One way of finding the above keywords is to simply linearly examine the description of these three components and search for the keywords contained in the query. But scanning through every component is a complex and time consuming task. Indexing is a way to avoid linearly scanning the text for each query [10]. Let us continue with above query, and use it to introduce the basics of the Boolean retrieval model.
Figure 10: ABS Component Description (DocID = 1)
Figure 11: CBR Component Description (DocID = 2)
Figure 12: SDR Component Description (DocID = 3)
The first step is to convert the document into a “binary term-document incidence matrix”. The binary term-document incidence matrix shows the relationship between ABS, CBR, and SDR components. Terms are the indexed elements, which are the keywords. The matrix can be examined considering either rows or columns; we can have a vector for each element. This shows the components, in which the terms occur. We have recorded the binary term-document incidence matrix of each component (ABS, CBR, and SDR) in Table 6.
<?xml version="1.0" encoding="UTF-8"?> <ProComMetamodel.ProSys:Subsystem xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ProComMetamodel.ProSys="http:///ProComMetamodel/ProSys.ecore <ports xsi:type="ProComMetamodel.ProSys:InputMessagePort"/> <ports xsi:type="ProComMetamodel.ProSys:OutputMessagePort"/> </ProComMetamodel.ProSys:Subsystem> <?xml version="1.0" encoding="UTF-8"?> <ProComMetamodel.ProSys:CompositeSubsystem xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:ProComMetamodel.ProSys="http:///ProComMetamodel/ProSys.ecor <internalSubsystems> <implSubsystem href="component:/ECS/Dil/ABS/557#/"/> </internalSubsystems>
<channels name="Vol" type="float"/>
</ProComMetamodel.ProSys:CompositeSubsystem> <?xml version="1.0" encoding="UTF-8"?> <ProComMetamodel.ProSys:Subsystem xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ProComMetamodel.ProSys="http:///ProComMetamodel/ProSys.eco <ports xsi:type="ProComMetamodel.ProSys:InputMessagePort"/> </ProComMetamodel.ProSys:Subsystem>
Terms ABS Component CBR Component SDR Component ProSys 1 1 1 InputMessagePort 1 0 1 OutputMessagePort 1 0 0 CompositeSubSystem 0 1 0 Channel 0 1 0
Table 6: Binary term-document incidence matrix
To answer the query (ProSys AND InputMessagePort NOT OutputMessagePort), we take the vectors for ProSys, InputMessagePort, complement the last, and then do a bitwise AND. This means that the query is now equivalent to:
111 AND 101 AND 011 = 001
The answer for this query is thus SDR component, because it is a ProSys component and contains InputMessagePort but not OutputMessagePort.
3.1.2 Inverted Index
The above idea of term-document matrix looks well compared to a linear searching of each document. However, taking into consideration a 500K x 1M matrix contains half-a-trillion 0s and 1s, which is too big to fit in a standard personal computer. It is a better idea to store only the things that occur, which is the central idea of the inverted index. [10]
Inverted index, which is also known as positional index, is a data structure that stores a mapping from content. It maintains the locations of the terms or words in a document files. The basic idea of the inverted index is illustrated in Table 7. In it, a dictionary of terms is stored of the component description documents presented in Figure 10, Figure 11, and Figure 12.
There are three major steps involved to build an inverted index of documents: 1) collect the documents to be indexed, 2) tokenize the text, and 3) index the documents. These steps are illustrated in Figure 13. The process of collecting documents includes getting the desired documents to be indexed. In the text tokenization, characters are split into pieces, called tokens.
Figure 13: Steps involved in Inverted Index
Table 7 shows the terms and documents in which they occur. The sequence of terms of each document is associated with their Document ID (left side). The middle column is alphabetically sorted. The dictionary in the table stores the terms, and has a pointer to the postings list for each term in the dictionary. It also stores some other information such as frequency of each term. The postings list keeps the list of documents in which the term occurs. Sweden France Pakistan … Tokenize Text Collect documents
Sweden France Pakistan So we are done
Index Documents
So we are done…
Table 7: Inverted Index of Doc1, Doc2, and Doc3
(For simplicity, we have used only the main elements in the ABS, CBR, and SDR component descriptions as shown in Figure 9, 10, and 11)
3.2 Apache Lucene API
Apache Lucene [19] is an open source API for indexing and searching from the documents. Lucene API provides an integration and implementation approach to provide basic search engine capabilities. It is capable of lexically processing the documents which are in plain-text format and provides supporting libraries to help parsing other documents formats such as XML, pdf, Microsoft Office format, etc. The API can be used to add search capability to any application consisting of data that can be converted to textual format. It indexes the input text in the form of inverted positional index and records many other information such as term position, frequency etc. in a document. Moreover, it also allows users to add some extra information in the index document such as filename, filedata, filecount etc.
Lucene API provides several approaches for query handling including TermQuery, Boolean Query, Phrase Query, Range Query, and Wildcard Query (see Table 8). It also provides tools like stop-word remover for filtering out the tokens from the given text. It also
gives methods to sort and rank the result based on term frequency-inverse document frequency (tf-idf) [10] [19], which is used to measure the importance of a word.
Query Explanation
Term Query A basic query to search for smallest index part “term”. Matches documents containing a term
Boolean Query Based on one ore more Boolean operators such as AND, OR, and NOT. In Lucene API, keywords used without any operator are considered as OR operation e.g ProSave ProSys Phrase Query Keywords used in double quotes create Phrase query such as “This is a text”. It matches documents containing sequence of
terms.
Range Query Handles number ranges within specified limits. This could help to find components based on version ranging from and to a specified limit.
Wildcard Query Allows to use wildcards in a query such as “?”, and “*”. Table 8: Types of queries used in Lucene API
Lucene API has various analyzers, which help to tokenize text. For example, Whitespace Analyzer breaks up tokens at whitespace, Stop Analyzer removes stop words, Simple Analyzer puts text in lowercase, and Standard Analyzer removes stop words, puts text in lower case, and recognizes Chinese and Japanese characters.
3.2.1 Lucene Indexing Process
In Lucene index, every index has one or more segments and every segment holds one or more documents. Documents contain one or more fields and every field has one or more terms, which contain one or more words. Lucene API uses inverted index for its index structure. It uses segment-based approach to build inverted index. Figure 14 gives an idea how index files are managed in Lucene API. In the figure, each ellipse is a segment, which contains documents, and each document has one or more fields, which further consists of one or more terms.
At a low level, Apache Lucene API uses five main classes for the purpose of indexing. Those are: a) IndexWriter, b) Directory, c) Analyzer, d) Document, and e) Field. Figure 11 shows how these classes participate in the indexing process.
Figure 14: Classes used for indexing in Apache Lucene [2]
The central class of Apache Lucene indexing process is the IndexWriter. This class creates a new or opens an existing index, and then adds, deletes or updates the documents in the index. The Directory class represents the location of the index. The IndexWriter class cannot index the given text unless the text has been broken into tokens first using the Analyzer class. So, the Analyzer extracts tokens out of the text. The Document class represents the collection of fields with their associated value.
Table 9 shows an example of Lucene index files generated of twelve simple text files.
Files Remarks
This is a segment file, which contains current generation of the index.
This is also a segment file, which stores information about segments e.g. segment size, segment count, deletion files etc. This name of this file ended with a number, which represents number of segments the index contains.
This is a compound file, which is a container of all files. It contains filename, filedata, filecount etc.
Table 9: Apache Lucene Index Files
3.2.2 Lucene Searching Process
At a low level Apache Lucene use four classes for searching. Those are: a) IndexSearcher, b) Term, c) Query, and d) TopDocs. The IndexSearcher class is main class used for searching. It opens the index in a read-only mode. There are number of methods to search in the index. The simplest search (as shown below) takes a Query object (query submitted by a user) and an int TopN (number of documents) count as parameter and returns a TopDocs (highly relevant documents) object.
A Term is the basic unit of searching; it consists of a pair of string elements: the name of the field and the word (text value) of that field. Following is the simplest example of the Term used for searching.
The above code tries to find top 10 documents that contain the word “ProSave” in a field named contents, sorting the documents by descending relevance.
Query is the common abstract class and comes with a number of concrete Query classes, such as TermQuery, BooleanQuery, PrefixQuery, PharseQuery, RangeQuery, SpanQuery, and FilteredQuery.
Yet, another important class used for searching is TermQuery, which is the most basic type of query supported by Apache Lucene. It is used for matching documents that contains fields with specific values. And finally, TopDoc class is a simple container of pointers to the top N ranked search results – documents that match a qiven query.
IndexSearcher searcher = new IndexSearcher("/index");
Query query = new TermQuery(new Term("contents", "ProSys")); TopDocs hits = searcher.search(query, 10);
searcher.close();
Query query = new TermQuery(new Term("contents", "ProSave")); TopDocs hits = searcher.search(query, 10);
Chapter 4
SYSTEM REQUIREMENTS
The PROGRESS-IDE is built on top of Eclipse RCP to develop ProCom components. It provides a basic support for component management in a repository: import, export and a basic viewing of the repository content, but there exists no support for efficient search of components. The goal of this thesis is to build an advanced component browser to search ProCom components in different remote repositories. Furthermore, the project should provide different searching mechanism to find components.
In this section, we discuss the system requirements for the Component Repository Browser. We also describe the use-case test done to verify that it fulfills the envisioned requirements. This use case test is attached in annexure.
4.1 Use-Case Diagram
The diagram below gives the graphical representation of the use cases for the Component Repository Browser and describes the functionality of the component browser. Use cases are presented by ovals and the actor is presented by a stick figure.
Figure 15: Use-case Diagram
In the above use case diagram of the Component Repository Browser, the PROGRESS-IDE User is able search components. The results are shown in the Search View. The user should also be able to change the preferences of facets and the application logs. Furthermore, the user should also be able to import the searched components.
4.1.1 Search Components
The PROGRESS-IDE User should be able to search for components against a keyword-based and/or facet-keyword-based query. However, it is required for the searcher that all the components in the selected repository have been indexed, wherein the user wants to search. Once, the desired component(s) are searched, the component(s) are shown in the search view. The tabular description of the use-case can be found at Annexure-I.
4.1.2 Change Preferences
The PROGRESS-IDE User should be able to change the preferences (facets, logs) settings. The user must be provided control to add, delete, and edit the facets, so that he or she is able to search the components accordingly. The tabular description of the use-case can be found at Annexure-II.
4.1.3 Import Components
Once the desired component(s) have been searched, the PROGRESS-IDE User should be able to import the component(s) into the working space. The tabular description of the use-case can be found at Annexure-III.
Chapter 5
SYSTEM ARCHITECTURE
In this section, we discuss system design and architecture details of the Component Repository Browser. It outlines the major details about application architecture and individual sub-systems and modules used in the application.
5.1 System Overview
The architecture of the Component Repository Browser consists of several key modules all working together. However, major concern has been given to the modules responsible for indexing, ranking of components and searching ProCom components from an index.
The Component Repository Browser consists of four major modules: i) repository access service, ii) index service, iii) component searcher, iv) component ranker, and v) result viewer. As illustrated in the Figure 16, PROGRESS-IDE is running on a client machine and uses its repository access service (see 5.2.1) to communicate with the repository server over different protocols i.e. HTTP, HTTPS, and/or SVN. Once, a ProCom component is successfully exported to a repository, the local index service (see 5.2.2) is executed, which then creates the index of the exported component using Apache Lucene API and merges its index into the main index folder, which contains the index of all the exported components. The repository access service is again called to update the index of the exported component in the actual repository, where components reside. The component searcher (see 5.2.3) module is used to find the desired components from the local index folder. The component ranker (see 5.2.4) module is responsible for ranking the components. Finally, the result viewer is responsible for displaying the top ranked components in the search view.
The whole architecture is designed to make different system modules loosely coupled from each other. This will help to easily extend or make changes in the system, without affecting the system. A user-friendly graphical user interface is also provided to allow the component developers to search the ProCom components and re-use the component easily and in efficient way. The core of the application is indexing and searching modules.
5.2 Detailed Architecture
The figure below shows, the detailed architecture of our application. Once, a component is ready to be exported, the repository access service is called. The Repository Access Service uses Apache Lucene API for the purpose of indexing and searching the ProCom components. The following sections describe the key modules of the Component Repository Browser.
5.2.1 Repository Access Service
When the repository access service is called by the application it communicates to work with a repository via different protocols i.e. HTTP://, HTTPS://, SVN://, SVN://+XXX://, SSH or FILE:///. Two cases emerge: a) the repository has not been indexed before, or b) the repository has been indexed before. In the first case, this means that no index folder exists either in the repository server or in the local system, so the index service creates the local index of the successfully exported component. In the second case, where there already exists an index folder, then the newly created index is merged with the local index folder. The whole process is illustrated in the Figure 17. For the purpose of indexing, we have used Apache Lucene API 2.4.1, which provides full text indexing and searching capability.
5.2.2 Analyze Document
For indexing it is necessary that the text is analyzed. Analyze document is the process of breaking text into a series of individual elements, called “tokens”. Each token represent a word in a language. Apache Lucene API provides various document analyzers that allow breaking text into tokens. After this process, the content is ready for indexing.
5.2.3 Index Document
To search components from the repository or the local system, it is important that all the components are indexed before the search. This is done through Apache Lucene API. The Lucene API provides everything necessary to index the document. Lucene maintains an inverted index for retrieval of the synonyms. It uses the WordNet (An open source API for adding language processing capabilities in applications) prolog package to build its index, which can be queried with a particular word, and returns an array of all the synonyms for that particular word.
5.2.4 Query Manager
The query manager is mainly responsible for handling the query. It offers two kinds of queries which the user may use to search ProCom components i.e. facet-based classifier, and keyword searcher. Both of these classifiers will provide modules to handle faceted and keyword search in effective way. The query parser shall build a concrete query from the selected facets and keywords expressions.
5.2.4 Component Searcher
Once the components in a repository have been indexed, the components are ready to be searched. We used the Apache Lucene API for searching capability. When querying the Lucene index, a TopDocs instance is returned, which holds the top ranked components. It is not necessary to retrieve the actual component information for all components, so we retrieve only the components that will be presented to the user or shown in the search view.
5.2.4 Component Ranker
Once the query is submitted to an index, the retrieved results are ranked based on how relevant results are with the query submitted by a user. Ranking is very important for the
users, as it is extremely hard to go through all the components to get the desired component. The component ranker tries to filter out the most accurate and relevant components, to be given as the first set of results. The ranking of components is mainly done with built-in mechanism provided by Lucene API. In it, the components are checked for their term frequency-inverse document frequency (tf-idf). The tf-idf scoring sorts the document based on number of times a particular query term is occurring within a document. [19]
We have maintained a data structure for ranking that keep the records of component name and its score (ranking value) that is of float type. We are also using a comparator that compares the searched component ranking value and displays them in the search view. That means that when a component is found by the search service, the information like component name and its ranking value is being stored in its data structure that is later being used by comparator of the search view to display them in the view.
Chapter 6
IMPLEMENTATION AND APPLICATION TUTORIAL
In this section, we discuss the implementation details of Component Repository Browser. This section also gives application tutorial to use the ProCom Component Browser User Interface (UI) to search components, and using its preferences settings. Finally, we discuss how to change the system settings, which we have been implemented in the application.6.1 Implementation Details
The Component Repository Browser is implemented in Java, using the plugin-based technology offered by Eclipse. In this section, we discuss the plugin details used in Component Repository Browser.
6.1.1 Component Repository Browser Plug-ins
Eclipse provides mechanism to build applications based on plugins. This approach helps to reuse functionality in an application. We have implemented following three main plugins for Component Repository Browser.
Figure 18: Component Repository Browser Plugins
The se.mdh.progresside.tools.browser plugin contains various packages and classes related with facets, indexing, query, searching, and svn etc. The se.mdh.progresside.tools.browser.logging plugin contains packages and classes related with application logging, and the se.mdh.progresside.tools.browser.ui plugin has various packages classes related with user interfaces. Table 10 presents list of all the packages and classes in a corresponding plugin.
Plugins Packages Classes
se.mdh.progresside.tools.browser se.mdh.progresside.tools.browser Context.java se.mdh.progresside.tools.browser.facets Facet.java se.mdh.progresside.tools.browser.facets.util FacetUtils.java se.mdh.progresside.tools.browser.indexer Indexer.java IndexMerger.java IndexUtils.java LuceneIndexer.java se.mdh.progresside.tools.browser.query FBQuery.java KBQuery.java Query.java se.mdh.progresside.tools.browser.query.decorators KFQuery.java QueryDecorator.java se.mdh.progresside.tools.browser.query.factory QueryFactory.java QueryFactoryImp.java QueryTypeEnum.java se.mdh.progresside.tools.browser.repositoryadapter ITargetRepository.java RepositoryAdapter.java se.mdh.progresside.tools.browser.searcher ISearcher.java SearchedComponent.java Searcher.java se.mdh.progresside.tools.browser.settings AbstractBrowserSettings.java BrowserSettings.java IBrowserSettings.java se.mdh.progresside.tools.browser.svn RemoteRepository.java se.mdh.progresside.tools.browser.task TaskThread.java se.mdh.progresside.tools.browser.logging se.mdh.progresside.tools.browser.logging Log.java
ULoggerFactory.java se.mdh.progresside.tools.browser.ui se.mdh.progresside.tools.browser.ui BroswerUIPlugin.java
se.mdh.progresside.tools.browser.ui.dialogs CustomizeFacetDialog.java RepositoryDialog.java SearchDialog.java se.mdh.progresside.tools.browser.ui.handlers SearchHandler.java se.mdh.progresside.tools.browser.ui.logging LogAppender.java Logging.java se.mdh.progresside.tools.browser.ui.preferences BrowserPreferenceConstants.java FacetPreferencePage.java FacetsPreferences.java LogPreferencePage.java se.mdh.progresside.tools.browser.ui.util MessageDialog.java ResourceUtils.java StackTraceErrorDialog.java WidgetUtils.java se.mdh.progresside.tools.browser.ui.views SearchView.java SearchViewContentProvider.java SearchViewLabelProvider.java se.mdh.progresside.tools.browser.ui.widgets CustomizeFacetComposite.java FacetComposite.java FacetControls.java KeywordComposite.java RepositoryComposite.java ScopeComposite.java SelectionList.java
6.1.2 Core Classes
As presented in Table 10, we have written various classes to implement the Component Repository Browser. In this section, we discuss the core classes and their methods used in the browser.
6.1.2.1 Facets
To create facets, we have used two classes: Facets, and FacetUtils. The Facet class contains public methods to set and get facet name and facet values. The FacetUtils class contains public static methods to add, delete facets and facet values.
Figure 19: Classes used for Facets
The methods used in the Facet class are defined below:
• setFacetName(String): This public method sets the name of a given facet. The facet name is, basically shown to the users as a category, which further contains facet values e.g. Component Type is a valid facet name.
• getFacetName( ): This public method returns the name of a facet.
• addFacetValue(String): This public method adds a new value to the values list of a specific facet e.g. ProSave is a valid facet value.
• setFacetValuesList(List): This public method sets the values of a specific facet e.g. ProSave, ProSys are valid values of a facet.
• getFacetValuesList( ): This public method returns the values of a specific facet. The methods used in the FacetUtils class are defined below:
• addFacet(Facet): This public method adds a new facet to facet list.
• deleteFacet(Facet): This public method deletes a specific facet from the facet list. • deleteFacetValue(Facet, String): This public method deletes a specific facet
value from a facet.
• addFacetValue( ): This public method adds a new facet value to a facet. • getDefaultFacets( ): This public method gets default facets from the browser. • buildString(List<?>): This public method gets the string notation of elements
from a specific list separated by comma
• createFacet(String, String): This public method creates a new facet depending on the values retrieved from properties
• buildList(String): This private method splits the comma separated values of facets and builds a list of those values.
6.1.2.2 Indexer
For indexing, we have an interface called indexer. Client should implement this interface for implementing the index service to index any file or repository for further component searching process.
Figure 20: Classes used for indexing
The indexer interface has two public methods, which are defined as below:
• doIndex( ): It indexes the repository working folder and current user workspace. This service is used when a new repository is added by a user.
• prepareIndexer(File, String): Sets the required resources for performing index. Repository information is required to update the index in a repository against the new exported component.
The indexer interface is implemented by LuceneIndexer class, which uses Apache Lucene mechanism to index a repository. Main methods used in the class are defined below:
• getAnalyzer( ): This public method gets the analyzer to be used for tokenizing the terms
• getMergeFactor( ): This public method gets the merge factor
• performMerging( ): This private method merges two or more indexes
• acceptFile(File): This private method checks whether the file is acceptable for indexing
• acceptFolder(File): This private method checks whether the folder is acceptable for further traversing for indexing its files
• indexFile(File): This private method is responsible for indexing a specified file • index(string): This private method traverses each folder in the data directory and
passes file(s) to the indexFile method for indexing
• createDirectory(File, String): This private method creates a directory on a specific path
• flushTempDirs( ): This private method recursively deletes temporary directories that are created during the indexing process
The index merging is performed by LuceneIndexer class with the help of IndexMerger class, which merges two or more indexes and stores it in the main repository index folder. The IndexMerger has following two core static public methods:
• mergeIndex(String source, String destination): It merges a given index to a single destination index. The first argument is the destination to which source index is to be merged. The second argument is the index source, which is to be merged to the destination index.
• getMergeFactor(String, List<String>): It merges all given indexes together to a single index.
6.1.2.3 Query
As mentioned in the above sections, we are using two kinds of queries: a) keyword-based query, and b) facet-based query. Both of these queries are inherited from an abstract class called Query. As shown in the diagram from Figure 21, QueryDecorator class extends Query class. The QueryDecorator class is used to wrap the different types of queries. In our case, it wraps KBQuery and FBQuery.
Figure 21: Classes used for Query (Decorator Pattern) - 1
The abstract Query class represents the query that could be a simple keyword or facet-based query against which user will search components from a repository. It provides following methods, which are implemented by KBQuery and FBQuery classes.
• getValidatedQuery( ): Returns the validated query. • setQuery( ): Sets a query.
• buildQuery( ): It builds a query.
• validateQuery( ): It validates the given query.
To create concrete query objects, we have taken the help of Factory design pattern. The QueryFactory interface is used to provide implementing methods for creating concrete query objects of concrete query classes depending on QueryTypeEnum.
Figure 22: Classes used for Query (Factory Pattern) - 2
The QueryFactoryImp class provides the implementation of the QueryFactory interface to instantiate objects of sub classes of Query class.
6.1.2.4 Searcher
Three main classes have been created for searching purpose. The ISearcher interface contains some methods for searching module. This interface is implemented by the Searcher class. The SearchedComponent class contains information about component for the purpose of ranking.
Figure 23: Classes used for Searching
The ISearcher interface has following public methods:
• search(List<String>, String): This will search for components on the given index paths
• getFoundComponentsMap( ): This will get a map of components that are found against the user query
ISearcher interface is implemented by the Searcher class. The description of methods defined in the Searcher class follows:
• getComponentName(Document): This private method returns the component name of a component
• getRepoId(Document): This private method returns the repository id
• doSearch(String, String): This private method searches for components based on query from an index
• setFoundComponentsMap(String, String, float): This method makes the entries in a map that contains information about the repository and components that are found against the user’s search query
• isExist(List<SearchedComponent>, String, float): This checks if component with this name is already exists in the list
The SearchedComponent class represents a data structure for a component that is found during the searching process. Searched component consists of name and score. Score represents the level of similarity.
6.1.2.5 TaskThread
This is a worker class that runs all the jobs i.e. Runnable by putting them in a job queue and further processing them by taking them out from the queue.


![Figure 4: A screenshot of FacetBrowser [10]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4692727.123135/17.918.291.629.394.845/figure-a-screenshot-of-facetbrowser.webp)

![Figure 8: MARACATU Source Code Classification [11]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4692727.123135/19.918.244.699.169.569/figure-maracatu-source-code-classification.webp)