PAPER WITHIN Informatics & Product Development AUTHOR: Bilal Ahmad, Saqib Ahmed
TUTOR: He Tan
JÖNKÖPING July 2020
Transforming Requirements
to Ontologies
Presenting a set of rules for software requirements to
requirement ontology transformation
the topic “Transforming Requirements to Ontologies”. This thesis work is a part of the two-year’s Master of Science programme.
The authors take full responsibility for opinions, conclusions and findings presented.
Examiner: Anders Adlemo Supervisor: He Tan
Scope: 30 credits (second cycle) Date: 9th July 2020
Summary
Capturing client’s needs and expectations for a product or service is an important problem in software development. Software requirements are normally captured in natural language and mostly they are unstructured which makes it difficult to automate the process of going from software requirements to the executable code. A big hurdle in this process is the lack of consistency and standardization in software requirements representation. Thus, the aim of the thesis is to present a method for transforming natural language requirement text into ontology. It is easy to store and retrieve information from ontology as it is a semantic model, and it is also easy to infer new knowledge from it.
As it is clear from the aim of this work, the main component of our research was software requirements, so there was a need to investigate and decide the types of requirements to define the scope of this research. We selected INCOSE guidelines as a benchmark to scrutinize the properties which we desired in the Natural Language Requirements. These natural language requirements were used in the form of user stories as the input of the transformation process. We selected a combination of two methods for our research i.e. Literature Review and Design Science Research. The reason for selecting these methods was to obtain a good grip on existing work going on in this field and then to combine the knowledge to propose new rules for the requirements to ontology transformation. We studied different domains during literature review such as Requirements Engineering, Ontologies, Natural Language Processing, and Information Extraction. The gathered knowledge was then used to propose the rules and the flow of their implementation. This proposed system was named as “Reqtology”. Reqtology defines the process, from taking the requirements in form of user stories, to extracting the useful information based on the rules and then classifying that information so that it can be used to form ontologies. The workflow consists of a 6-step process which starts from input text in form of user stories and at the end provides us entities which can be used for ontologies formation.
Keywords
Software Development Life Cycle (SDLC), Requirements Engineering, Requirements Elicitation, Natural Language Requirements, Natural Language Processing, Ontology, Information Extraction,
Contents
1
Introduction ... 1
1.1 BACKGROUND ... 1
1.2 PURPOSE AND RESEARCH QUESTIONS ... 3
1.3 DELIMITATIONS ... 4
1.4 OUTLINE ... 5
2
Theoretical background ... 6
2.1 SOFTWARE DEVELOPMENT PROCESS ... 6
2.2 REQUIREMENT ENGINEERING ... 6
2.3 REQUIREMENTS IN NATURAL LANGUAGE ... 7
2.3.1 Natural Language Processing ... 7
2.3.2 Requirement Patterns ... 8
2.4 INFORMATION EXTRACTION... 8
2.4.1 Information Extraction and Software Requirement Engineering ... 10
2.4.2 Information Extraction Architecture... 10
2.4.3 Information Extraction Tasks and Sub-Tasks ... 11
2.5 PRE-REQUISITE FOR REQUIREMENTS ... 12
2.5.1 IEEE Guidelines ... 13
2.5.2 INCOSE Rules ... 14
2.6 ONTOLOGY ... 16
2.6.1 Types of Ontologies ... 16
2.6.2 Ontologies in Software Engineering ... 18
2.6.3 Ontologies in Requirement Engineering ... 19
2.6.4 Ontology Development Language ... 20
2.7 IMPORTANCE OF FORMALIZING SOFTWARE REQUIREMENTS ... 20
3
Methods and implementation ... 21
3.1 RESEARCH METHODS &TECHNIQUES... 22
3.1.1 Literature Review... 22
3.1.2 Design Science Research ... 23
4
Findings and analysis ... 25
4.1 FINDINGS ... 25
4.1.1 Choice of Requirement Type ... 25
4.1.2 Choice of Transformation Method ... 26
4.2 ANALYSIS ... 29
4.2.1 Input source for Reqtology ... 30
4.2.2 Categories of Information in User Stories ... 31
4.2.3 Processing of Requirements in Textual Form ... 33
4.2.4 Name Entity Extraction ... 36
4.2.5 Relationship Extraction ... 38
5
Discussion and conclusions ... 41
5.1 DISCUSSION OF METHOD ... 41
5.1.1 Selected Research Methods ... 41
5.1.2 Validity of the Research ... 41
5.1.3 Reliability of the Research ... 42
5.2 DISCUSSION OF FINDINGS ... 43
5.2.1 Purpose of Research ... 43
5.2.2 Challenges in Reqtology ... 43
5.4 FUTURE WORK... 54
6
References ... 55
7
List of Abbreviations ... 58
8
Appendices ... 59
8.1 INCOSERULES TO CHARACTERISTICS MAPPING ... 59
8.2 LIST OF KEYWORDS ... 62
8.3 REQTOLOGY PROTOTYPE ... 63
8.3.1 ReqTology.java ... 63
8.3.2 RuleBase.java ... 66
8.4 SIRTSPRODUCT BACKLOG ... 73
8.5 TEST CASES FOR REQTOLOGY PROTOTYPE ... 76
8.5.1 Test ID # 1 ... 76 8.5.2 Test ID # 2 ... 77 8.5.3 Test ID # 3 ... 78 8.5.4 Test ID # 4 ... 79 8.5.5 Test ID # 5 ... 79 8.5.6 Test ID # 6 ... 80
List of Figures
FIGURE 1:EXAMPLE OF INFORMATION EXTRACTED FROM NEWS ARTICLE (PISKORSKI,2012) ... 9
FIGURE 2:ARCHITECTURE OF INFORMATION EXTRACTION SYSTEM (BIRD,2015) ... 10
FIGURE 3:TYPE OF ONTOLOGIES (SALEM,2012) ... 16
FIGURE 4:REQUIREMENT ENGINEERING ACTIVITIES (WILLIAMSON,2002)... 19
FIGURE 5:RESEARCH DESIGN ... 21
FIGURE 6:TWO NODES SET IN CIRCUS(MARY ELAINE CALIFF,2003) ... 26
FIGURE 7:EXAMPLE OF INSTANCE CONCEPT NODE IN CIRCUS(MARY ELAINE CALIFF,2003) ... 27
FIGURE 8:EXAMPLE FOR EXTRACTION PATTERN OF RAPIER(CALIFF,2003) ... 28
FIGURE 9:EXAMPLE OF INFORMATION EXTRACTED THROUGH RAPIER(MARY ELAINE CALIFF,2003) ... 28
FIGURE 10:EXAMPLE OF A SOFTWARE REQUIREMENT ... 30
FIGURE 11:EXAMPLE OF A USER SOFTWARE REQUIREMENT (EXAMPLE USER STORIES,2004) ... 30
FIGURE 12:CATEGORIES OF INFORMATION IN USER STORIES ... 32
FIGURE 13:EXAMPLE OF DOT DELIMITER IN THE MIDDLE OF SENTENCE. ... 33
FIGURE 14:RULE FOR SEGMENTING SENTENCES USING DOT AND CAPITAL LETTER DELIMITER. ... 34
FIGURE 15:EXAMPLE OF USER SOFTWARE REQUIREMENT (EXAMPLE USER STORIES,2004) ... 34
FIGURE 16:EXAMPLE FOR PART OF SPEECH TAGGING (SARAWAGI,2008) ... 35
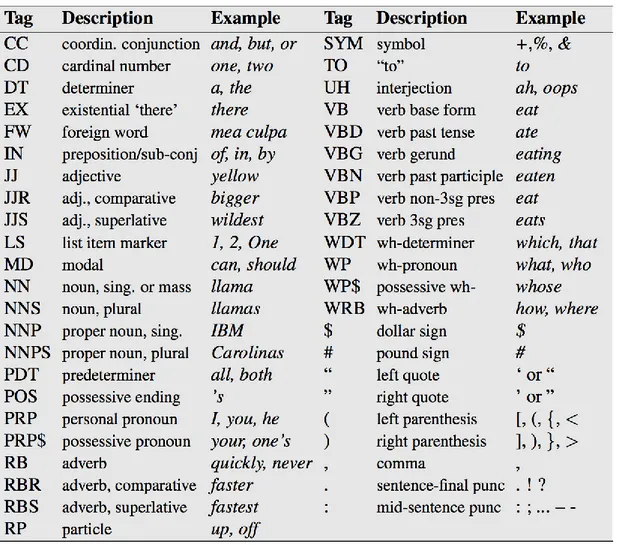
FIGURE 17:PENN TREEBANK PART OF SPEECH TAGS (JURAFSKY,2016) ... 36
FIGURE 18:WORKFLOW OF REQTOLOGY ... 44
FIGURE 19:ENTITIES (ACTORS) ... 49
FIGURE 20:ENTITIES (DESIRED FUNCTIONALITY) ... 50
FIGURE 21:ENTITIES (OUTPUT OF DESIRED FUNCTIONALITY) ... 50
List of Tables
TABLE 1:INCOSEREQUIREMENT CHARACTERISTICS ... 15TABLE 2:RELATIONSHIP TYPES ... 39
TABLE 3:TOKENIZATION OUTPUT ... 45
TABLE 4:POSTAGGING INPUT ... 46
1 Introduction
The aim of this chapter is to provide background description of our thesis which we are conducting for our Master Program. The focus here is to provide an overview of our research problem, its purpose, background, and delimitations. We will also describe the course of action to solve that problem. The last section of this chapter provides an outline of the remaining chapters and structure of thesis report.
1.1 Background
Digitalization and automation have become an integral part of almost every domain nowadays and that have made software a core component in all major business models and processes. We can see software systems spread from governmental organizations to public and private sector institutions. There is no doubt that inclusion of software systems in different organizations has helped immensely in capitalizing and optimizing the resources, but it has also increased the diversity of software and as a trickle-down effect, complexity level of software development processes has also been increased.
Owing to the needs of diverse software implementations and vast range of target customers, multiple SDLC’s (Software Development Life Cycle) have been proposed. To name a few, we have Waterfall Method, Spiral Method, Rational Unified Process, and a wide range of Agile Methodologies such as Extreme Programming (XP) and Scrum. Following the intuition for separation of concerns (Majumdar, 2009), software development process has been divided into several distinct segments which covers the tasks from requirement gathering to the actual development and then testing & deployment. All SDLC’s have different approaches to order and prioritize these segments and it has been an evolutionary process where focus has been shifted more towards customer satisfaction and their involvement in the development process as mentioned in (Mahalakshmi, 2013). Traditionally, requirement gathering was considered as a pre-development process (e.g. in waterfall method) but now due to constant interaction with clients, requirement engineering have become way more complex and dynamic. Now it is necessary to incorporate the changes in requirements throughout the development phase.
Requirement Engineering has been an essential part of the process but all SDLC’s do not take care of it due to their different priorities and nature of development. Although work has been done in this field and there are certain guidelines available for requirement elicitation and modelling (Nuseibeh, 2000) but still some grey areas are present when it comes to transforming those requirements into actual product. The reason for this uncertainty is lack of consistency and standardization in requirement representation and that is the basis of our research problem.
Requirements are normally represented in form of natural language statements but sometimes they can also be in form of mathematical functional specification (Software Requirements, 2004). Due to lack of standardization, no formal ways are present to transform those requirements into code and that is solely dependent on Business Analyst and Developer’s understanding, which may vary from the client’s viewpoint. Also, some requirements may be unrealistic or impractical and it may not be possible to comply with them in the final product. This can cause a conflict among different stakeholders and effect the integrity of the developed product. One solution could be to have a yardstick that can calibrate the relevancy and efficiency of requirements i.e. by taking and converting requirements in such form where they can be tested & evaluated.
Keeping in view the above-mentioned background, it is evident that understanding of requirements is crucial in agile SDLC’s since they evolve over time and their complexity also increase likewise. We can imagine the case where a software development team may need to add or remove some functionality from their legacy code and how much time they will have to spend on understanding the existing dependencies and how much it increases the chance of breaking down some old functionality i.e. affecting the software product stability. On the other hand, requirements are gathered & recorded in natural language, and we know that there are many techniques available for extracting relevant information (discussed later in the report) from the text. However, there is nothing specifically available for catering software requirements in natural language and visualizing them into a more concrete way. This leads us to a knowledge gap, which is the inability to automize software development due to inconsistency and lack of standardization in natural language software requirements.
In short, we want to bridge the gap so that all the stakeholders can be on a same page in terms of understanding and implementing the requirements. This can be done by representing requirements in such a structured form where they become easy to analyze for stakeholders and even readable for machines. There can be multiple approaches to tackle this problem by bringing in different domains such as ontologies where entities and their relationships are defined. By using ontologies, we can transform requirements represented in natural language into a more structured format. A normal workflow would be to take the requirements and converting them into a form where they can be represented as models. Here our focus would be on defining the rules for converting requirement into such form where they can be modeled and the role of ontologies will come in the end, for the representation of those model. However, this process is not simple due to different methods of requirement elicitation which results in representation of requirements in different forms (as text can be written in many ways and can have multiple meanings). For smooth transformation, requirements should exhibit certain properties such as mentioned in (Society, 1998). A detailed exploration of mentioned areas would be done in coming chapters.
1.2 Purpose and research questions
The aim of this research is to develop such rules which can be used to transform requirements and automate software development to some extent by using the transformed requirements. The goal of this thesis would be to,
• Define high level rules and patterns for the requirements to ontologies transformation, where requirements are parsed according to defined rules and resultant information is used to define entities and relationships i.e. transforming requirements to ontologies.
The work to achieve this goal can be divided into two parts,
• Input: Software requirements will be used as baseline and they will be analyzed by using some approach (aim of research),
• Output: Some rules and patterns would be identified and that can lead towards the formation of high-level ontology representing software requirements. This can make requirements more testable and could enable model driven software development in the future.
We have selected INCOSE compliant software requirements (Fuentes, 2016) in order to narrow down the diversity and to ensure that our requirements exhibits certain properties such as degree of necessity, stability and traceability. It also ensures that requirements are following a template where purpose and scope are defined. Although the scope of our research will be limited to the above-mentioned area, the outcome can be beneficial for future research. The rules can lead to the development of some program that can process natural language requirements and then generate the snippets which can be used as input for ontology development. It could prove to be a benchmark and could eventually support model driven software development.
In order to reach the aim of the work presented in this report, a research question has been formulated:
RQ: What is a possible way of transforming INCOSE compliant software
requirements (Fuentes, 2016) into a high level requirements ontology?
1.3 Delimitations
The topic of our research is of diverse nature involving different domains such as requirements engineering, natural language processing and ontologies. Therefore, we have imposed some limits to make research more practical and achieve some tangible results. Firstly, the software requirements format which we are considering to use will follow the INCOSE compliant software requirement specification (INCOSE, 2012). The reason for this choice is to provide a clear set of inputs in a standardized form with a focus only on functional requirements. The following step would be defining rules and patterns for transforming the requirements into ontologies. This will be explained by high level models and we will not go in low level details. Testing of the proposed model could be done on some real-life software requirements but due to time limitations, this was not done. Only an ocular revision was performed.
1.4 Outline
Our focus in this chapter was to provide an overview about the problem background and enlighten the reader about subject of thesis. The basis of our research is the gap which we have identified in existing knowledge and want to further investigate it. After that, a research question was formed, and the constraints of our research were mentioned in the delimitation section. At this point we want to provide a brief description of the report structure so that reader can visualize the workflow and what to expect in coming chapters.
• Chapter 2: In this chapter, we have provided the Theoretical
Background of the subject area. It is important to familiarize the reader
with the base concepts and domain knowledge of different areas involved in the research. Extensive literature review has been conducted to identify relevant existing knowledge that lays the foundation for implementation and evaluation of thesis work.
• Chapter 3: This chapter named as Methods and Implementation is explaining the research design of our thesis. It covers the data collection method and evaluation criteria of collected data. Along with describing the nature of research, motivation for selection of method is also provided. • Chapter 4: In this chapter, Findings and Analysis of the research
problem have been carried out. Investigation has been done according to the method selected in Chapter 3 and analysis is carried out for bridging the gap between natural language requirements and actual software development.
• Chapter 5: In this chapter, Discussion and Conclusion of our research is discussed. Results are based on analyzing the findings and by listing down the merits and demerits. The validity and reliability of the research work is also discussed where conclusion is providing the outcome along with motivation and recommendations for future research.
2 Theoretical background
The purpose of this section is to explain the relevant terms and knowledge of different areas which are used in this research. This chapter describes the theoretical background of different domains in the research area so that the reader can build an understanding about them. Domain of software engineering, requirement engineering, natural language processing and ontologies will be explained in this chapter. Theoretical background sections will establish the basis to understand the research problem and in later sections will also help to address our research problem.
2.1 Software Development Process
Software development life cycle (SDLC) consist of different process or activities that are carried out during the development of a software product. Typical stages of a software development life cycle include planning, defining, designing, building, testing and deployment. Since the start of the software development, software development life cycles are also evolving to meet the ever-changing needs of the consumers. There are different kinds of SDLC that are being used to guide the process of software development and some of these are waterfall, iterative, spiral, V-model, and agile SDLC (Mahalakshmi, 2013). The use of these SDLCs rely upon the needs and different constraints of the software project. In the past when software products were not so complicated or time was not a big constraint, almost every other software product was built using waterfall, iterative, spiral or V-model but in recent years due to high demand to complete the software projects in less time the use of these SDLC has seen a decline (Mahalakshmi, 2013). Another reason of this trend is that a lot of changes occurs in requirement, scope and technology during the lifespan of a project (Highsmith, 2009). In traditional software development life cycles, it is difficult to move back to a previous stage which has already been completed. For example, in waterfall model a change in software requirements at testing stage would cause the project to delay further. Due to these mentioned reasons software industry is leaning towards agile software development methods such as SCRUM (Mahalakshmi, 2013).
2.2 Requirement Engineering
A typical software development life cycle has many distinct segments. A software development life cycle manages these segments in different phases throughout the software development process. One of the main parts of this software development life cycle is software requirements capturing. Traditional SDLCs and agile development method both have their own requirement gathering and management techniques and they are represented in different forms (Rodríguez, 2009). Capturing software requirements is very important, not only for making a functional software but also for ensuring efficient and cost-effective development procedures. If software requirements are not understood properly in the start,
then it will lead towards unsatisfied customers and there would be a need to incorporate many changes at later stages (Nuseibeh, 2000). Despite being an essential part all SDLC’s, Requirement Engineering is often not prioritized or catered due to different nature of development.
2.3 Requirements in Natural Language
We are focusing on high level requirements due to their meaningfulness because the stakeholders involved in requirement gathering can be non-technical persons such as Product Owner or Business Analysts which take requirements from customers through different techniques. Most of the times these requirements are in natural language which can be ambiguous or carry different meanings. Therefore, we need to consider some ways which can extract the useful information available from user requirements. This useful information is basically the sections or tokens in requirement statements which refer to some actor or any functionality related to them (Osborne, 1996). That information then can be used for modelling in the later stages.
2.3.1 Natural Language Processing
In computer science, natural language processing is the technique of parsing textual information to convert it in a form that is understandable for the computers. The ultimate goal of natural language processing (NLP) is “to accomplish human like language processing” (Liddy, 2001). Natural language processing has four standard approaches which are symbolic, statistical, connectionist, and hybrid (Liddy, 2001). Applications of this field in area of computer science are the use of natural language processing in artificial intelligence, informational retrieval systems, information extraction systems, machine translation and software requirement specification (Liddy, 2001) (Osborne, 1996). In recent years, considerable work has been done to integrate natural language processing in the process of software requirement specification. The use of natural language processing in requirement specification are using NLP for verifying requirements and generating ontologies from requirement specification (Arellano, 2015). An example of how natural language processing techniques can be used to integrate ontologies with software requirement specification is a web-based software called TextReq validation. This tool stores the ontological model of the requirements in a relational database, alongside the system (which is to be developed) and its requirements. It determines which features of the system has been covered and which ones are missing by doing the analysis on the system requirements and then matching them against the properties of the model (Arellano, 2015).
2.3.2 Requirement Patterns
Requirement Patterns are used to express requirements in standard structural form (Requirements Patterns and Ontologies, 2017). These patterns are also known as boilerplates or disciplined natural language (Requirements Patterns and Ontologies, 2017). Requirement patterns can improve expressiveness of requirements written in natural language moreover requirement patterns can help the reviewers to judge if the given requirements are up to the standards (Requirements Patterns and Ontologies, 2017). Requirement patterns are generated by using syntactic keywords and domain specific placeholders. An example of a requirement pattern could be (extracted from (Requirements Patterns and Ontologies, 2017)):
{While} <system state> <actor> {shall} <action> <object of action> <further refinement of action>
In this example {while} {shall} are syntactic keywords whereas the rest of the attributes are domain specific keywords (Requirements Patterns and Ontologies, 2017). A requirement pattern for a remote-controlled drone by using the above-mentioned requirement pattern format would be:
{While} <on> <auto navigation> {shall} <Navigate> <Drone to end point> <by avoid the obstacles>
To use the requirement patterns, organizations need to develop their own pattern language to suit the needs of a project and to do so, the organization must identify several patterns which are best suited for the application (Requirements Patterns and Ontologies, 2017). Requirement patterns and natural language processing both can transform the text i.e. requirements written in natural language into a form which is understandable for the machines. This is related to our work as we are also exploring how requirements written in natural language can be transformed into a formalized way.
2.4 Information Extraction
In recent years as the society is becoming more data oriented, the amount of data being generated is getting larger and larger with every passing day. Consequently, new techniques are created to handle this huge amount of data. This huge amount of data also poses a big question, that of how to extract the right and relevant information from this diverse unstructured data? Different techniques and methods have been generated to answer this question. Which include Information extraction, information retrieval, data mining and many more and these all techniques serves different purposes (Piskorski, 2012). For example, information
mostly in the form of text, data mining is used to find relevant information from unstructured information and that information is usually hidden in nature whereas information extraction is the process of automatic extraction of information from unstructured sources. Information extraction comes under the umbrella of NLP which is also known as Natural Language Processing.
Two decades ago, and in the early days of information extraction, researchers were mostly focusing on extracting the named entities and the relationships of those entities with each other for example extracting the names of people and organizations from unstructured data (Sarawagi, 2008). These early information extraction techniques were mainly based on hard coded rule. With the passage of time these techniques have evolved to meet the ever-growing need of information extraction as amount of data being generated has increased significantly in the last two decades. As extracting information with manually coding rules was a tedious task, algorithms were generated for automatic rule learning from examples (Sarawagi, 2008).
2.4.1 Information Extraction and Software Requirement Engineering
Information extraction helps in extracting useful information from unstructured text (Sarawagi, 2008). This makes information extraction a useful tool that can be applied to different areas in the field of computer science to minimize the time of different processes and techniques. One of such processes is the process of software requirement engineering. Software requirement engineering is an essential part of and software development life cycle. Success or failure of many software project depends upon capturing software requirements properly and correctly. If software requirements are not understood properly at the start it can lead to a disaster. A lot of time is required to understand and capture the software requirements and in modern day software development industry, time is a major factor for achieving success. Minimizing the time required to develop a software will have beneficial impacts. This section of our research focus on possible use of information extraction techniques in simplifying the software requirement engineering process.
2.4.2 Information Extraction Architecture
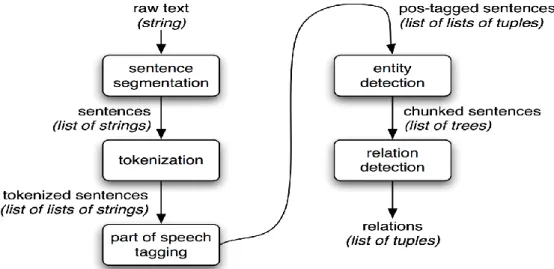
Figure 2 shows the architecture of a typical information extraction system. Unstructured Raw text is used as an input for the system and then this raw text gets split into sentences in the sentence segmentation step using a sentences segmenter. In next step, these sentences are sub-divided into words with the help of a tokenizer. Next, in part of speech tagging step, each tokenized sentence is tagged with parts of speech. After part of speech tagging, comes the entity detection step. In this step system receives the tokenized words which are tagged with parts of speech. These parts of speech tagging help in searching for potentially interesting entities in each sentence. The last step in the IE system is relation detection. In this step system searches for relations between the entities (Bird, 2015).
2.4.3 Information Extraction Tasks and Sub-Tasks
In this section, we will investigate details about the information extraction tasks & subtasks and how the structured view of the information gets generated from the unstructured text. There are four main tasks in information extraction with several subtasks to achieve the human like processing of data. These name entity extraction tasks include the following subtasks:
• Name Entity recognition
Name entity recognition task performs the task of recognizing entity’s names, which could be people, organizations, and places in the early days of information extraction. Now other terms like names of papers, journals, proteins, diseases etc. also fall under the category of entities. This entity recognition task is done with the help of existing domain knowledge. To recognize entities there is a typical task in name entity recognition that is called named entity detection. This task tries to detect entities without any existing knowledge about it. For example, in the sentence “Saqib likes to eat fish”, the named entity detection would detect that the word “Saqib” refers to a person but without having any previous or domain knowledge about it.
• Co-reference resolution
Co-reference is the task of detection of co-reference and anaphoric links between the entities and it is mostly performed on the already found entities from the text. For example, in the sentence “Saqib likes to eat fish but he does not like to cook fish” finding that “he” also refers to Saqib or “JU” and “Jonkoping University” are same entities will make the extracted information more accurate or meaningful.
• Relationship Extraction
In relationship extraction sub task, relationships between entities are extracted. These entities are already extracted from the text. Following are some examples of relationships between entities (Piskorski, 2012):
o EmployeeOf(Saqib Ahmed, IBM):
This relationship is extracted from text “Saqib Ahmed works for IBM” and describe the relationship between a person and a company.
o LocatedIn(Spotify, Stockholm):
This relationship is extracted from text “Spotify is located in Stockholm” and describes the relationship between an organization and location.
o SubsidiaryOf (DGS, TRG):
This relationship is extracted from text “TRG is a parent company of DGS” and describe the relationship between two companies.
• Event Extraction
Event extraction task deals with the extraction of events, information related to that event and relationships between the extracted entities from unstructured text. In other words, it extracts from the text that “who did what to whom, when, where, through what methods (instruments), and why” (Piskorski, 2012).
There are also a number of other information extraction tasks that are being used. Although most of the information extraction systems uses the above-mentioned information extraction tasks but the use of information extraction tasks depends upon the requirement of the system.
Recently the area of information extraction has expanded exponentially and now it is not limited to the task of extracting information from text. Recent development in the non-textual document has increased which includes extracting information from multimedia.
2.5 Pre-Requisite for Requirements
Owing to the fact that requirements in natural language can be quite complex and open ended, there was a need to select some guidelines which can used as a benchmark to consider the quality of requirements. It is very necessary not only to define the scope of our research but also to have clear inputs for the system we will propose to transform software requirements into high level requirement ontologies. Represented below is the study of two widely used guidelines for writing natural language Software Requirements.
2.5.1 IEEE Guidelines
IEEE provides some guidelines for specifying the software requirements, in order to ensure the correctness and completeness of specifications document. The objective of this guide is to provide a template where customers can accurately describe their envisioned product, suppliers can understand exactly what customer desires and to standardize the format of Software Requirement Specifications (SRS). According to (Society, 1998), a well-defined SRS can be beneficial in following ways,
• Establish a basis for agreement between customers and suppliers, • Reduce development effort,
• Provide a basis for estimating costs and schedule, • Provide a baseline for validation and verification, • Facilitate transfer,
• Serve as a basis for enhancement.
The process of producing a good SRS includes all phases such as planning, development, prototyping and embedding the design in requirement specifications. An IEEE compliant software requirement specification should be Correct, Unambiguous, Complete, Consistent, Ranked for importance/stability, verifiable, modifiable and traceable (Society, 1998). It is a fact that requirements written in natural languages are prone to ambiguity and the above-mentioned characteristics must be adhered to overcome the shortcomings of using natural language for requirement specifications. A great deal of focus has been put for the joint preparation of requirement specifications because customers usually do not understand the technical obligations of software design whereas developers do not get proper hold of the customer view and problem area.
Therefore, writing requirements should be a joint effort to produce well-articulated and comprehensible requirements. If the requirements are well defined, then it is easy to evolve the requirement specifications to cater future needs or upscaling whereas embedding design in requirements also become easy because modularity and flow of control can easily be designed. From a management perspective, it is also easy to integrate aspects such as cost, delivery schedules, reporting and acceptance procedures (Society, 1998). These all characteristics provide a very relevant template to produce good software requirement specifications.
2.5.2 INCOSE Rules
INCOSE Requirements Writing Guide was prepared by the International Council on Systems Engineering to standardize the way in which software requirements can be represented in the context of Systems Engineering. The main focus of this guide is not to provide any methods to elicit or gather software requirements, but it focuses on the clarity and precision of the text in which requirements are represented, so that they can be used easily for further analysis and development. The good thing about INCOSE rules is the flexibility it provides by letting the writers of requirements decide that which template or format they want to use, based on their customer needs or organizational compliance. Despite of having other methods to represent requirements such as Diagrams or Tables, textual requirements still have the upper hand due to following advantages (INCOSE, 2012):
• There is no limitation on the concepts that can be expressed.
• Sentences and grammatical structure provide a means of tracing meaningful elements.
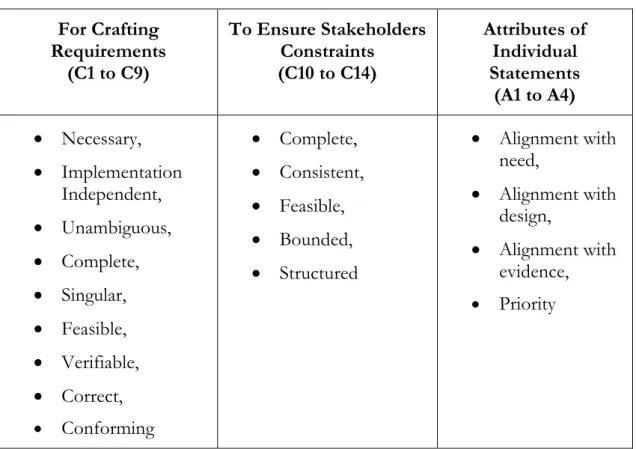
According to (INCOSE, 2012) the approach for capturing good requirements is by taking care of two elements i.e. characteristics and practical rules. Characteristics define the importance of having rules and covers the problem domain, whereas rules describe that how should we write the requirements. There are several things which affect the sanctity of software requirements, such as level of abstraction because we have a wide range from high level requirements (based on customer needs) to low level requirements (important from design perspective). After that, we have to consider the types of requirements which can be categorized in functional or non-functional domains. Requirements may also differ based on specific disciplines like development, production, and maintenance. Therefore, authors of (INCOSE, 2012) have put emphasis on understanding the need of characteristics and rules. Following table sums up the characteristics provided in this guide,
Table 1: INCOSE Requirement Characteristics For Crafting Requirements (C1 to C9) To Ensure Stakeholders Constraints (C10 to C14) Attributes of Individual Statements (A1 to A4) • Necessary, • Implementation Independent, • Unambiguous, • Complete, • Singular, • Feasible, • Verifiable, • Correct, • Conforming • Complete, • Consistent, • Feasible, • Bounded, • Structured • Alignment with need, • Alignment with design, • Alignment with evidence, • Priority
As we can see in the above-mentioned characteristics, the criteria are provided as a benchmark for testing the correctness and relevance of software requirements. Now comes the second part i.e. how you can ensure that these characteristics are maintained. For this purpose, 49 rules are mentioned in (INCOSE, 2012) which covers the precision, concision, non-ambiguity, singularity, completeness, realism, conditions, uniqueness, abstraction, quantifiers, tolerance, quantification, traceability, uniformity of language and modularity of requirements (see appendix 8.1).
The instructions of INCOSE Requirements Guide ensure that during the whole process of taking customer input to the development of a software product, requirements must be well understood so that Software Developers can draw candid interpretations and market needs are captured with precision.
2.6 Ontology
There are different definitions of ontologies and the most standard one is: “The branch of metaphysics that deal with the nature of being.” (Collins, 2017) Another definition of ontologies which is more suitable in the field of computer science is:
“An ontology is a hierarchically structured set of terms for describing a domain that can be used as a skeletal foundation for a knowledge base.” (Swartout, 1997) Ontologies are domain-specific dictionaries, which describes the meaning of entities and their relationship with each other. Ontologies provides common understanding and structure of information among different people and systems (Noy, 2001). Ontologies can be used to specify or describe the objects, their types and properties, relationship of these objects with each other and the concepts within a specific domain (Chandrasekaran, 1999). Ontologies are being used in different kind of areas in informatics for example the use of ontologies is increasing in the fields of Artificial Intelligence, agent systems, Information systems, Database or web technology (Wolfgang, 2005).
2.6.1 Types of Ontologies
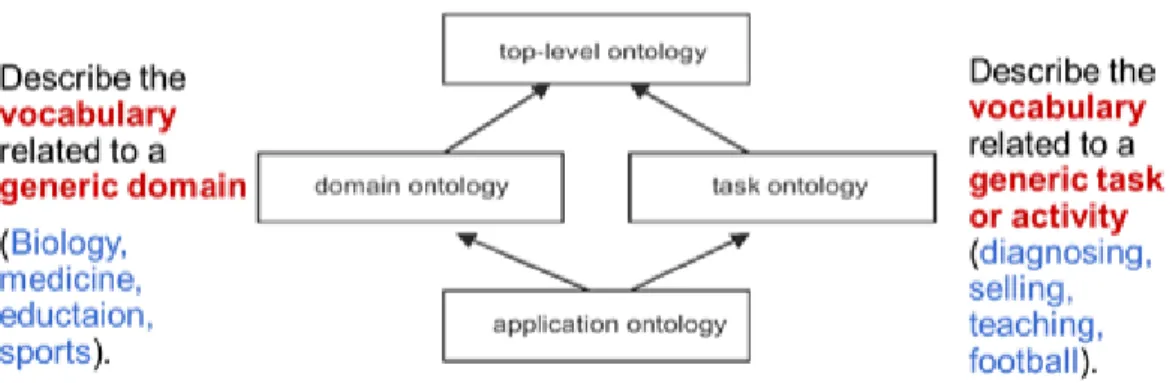
There are different kind of ontologies, but three basic type of ontologies are Top-level ontology, Domain ontology and Application ontology.
2.6.1.1 Top-Level Ontology
Top-level ontologies stipulate semantics for very general terms which are same across all the domains and disciplines. The terms in the top-level ontology are called top level terms (Bittner, 2007). Top level ontologies aid the semantic integration of domain ontologies. As top level or upper level ontologies contains general terms that are same across all the domains and disciplines, they facilitate in the development of new domain ontologies by providing ontological foundation (Hoehndorf, 2010).
2.6.1.2 Domain Ontology
Domain ontologies provides semantics for terms which are used to describe a specific domain (Bittner, 2007). Domain ontologies describe the classes, concepts, and relationships among these concepts in a specific domain. These types of ontologies are extended form of top-level ontologies i.e. they use top level ontologies as their function.
2.6.1.3 Application Ontology
Application ontologies are developed for a specific use or for an application. Their scope lies within the boundaries of a specific application. Application ontologies are developed for modeling cross-domain experiments in biology, for data annotation or virtualization (Malone, 2010). Application ontologies are built by importing the required parts from the reference ontologies and they use the top-level ontologies as their foundation (Hoehndorf, 2010). Reference ontologies are basically representation of basic science in such a manner where it could be used in multiple ways (Brinkley, 2006). Although application ontologies have a number of benefits, but they also have some drawbacks. As Application ontologies are built by importing relevant parts from the reference ontologies it is important keep a track of the imported terms as ontologies tends to change quickly and these terms might not be the updated one.
2.6.1.4 Choice of Ontology
The focus of our work is to develop rules and patterns that can transform the requirements which are specified in natural language to a formalized form that can later be transformed into ontologies. Ontologies represent information in a way that is machine readable and transforming formalized requirements into ontologies will not only support the requirement engineering process, but it can also be used to check whether the final software product is meeting the requirements or not. To achieve this, a domain ontology can be built as it would be more suitable for this purpose, since these formalized requirements are for a specific domain, which in this case is software requirements. Furthermore, these formalized requirements will be in the form of classes, instances, and relations, which can be used to make domain ontology.
The reason for not choosing application ontology is that application ontology is more suitable for a specific software project or product. Moreover, application ontologies are built by importing required parts from reference ontologies. One more thing that eliminate application ontology to be used in this research is that they use top level ontology as their foundation (Hoehndorf, 2010).On the other hand top level ontology uses general terms which are common across different domains, so this fact also makes top level ontology unsuitable to be used as our choice of ontology.
2.6.2 Ontologies in Software Engineering
A classic software development life-cycle has different phases throughout the development process. These phases are analysis and design, implementation, deployment, and maintenance (Happel, 2006). These four main phases have further sub-phases. A software project is developed by performing the activities in these phases.
In the last three decades, the software development has changed rapidly due to the ever-changing needs of the industry. Because of this trend, new methodologies and techniques are being integrating into the software development life cycle to develop frameworks that can support the software development to meet industry’s demands. In recent years, significant research has been done to support different phases of software development lifecycle by integrating ontologies in the software engineering processes (Happel, 2006). Ontologies are being used in different kind of areas in informatics. For example the use of ontologies is increasing in the fields of Artificial Intelligence, agent systems, Information systems, Database or web technology (Wolfgang, 2005).In recent years use of ontologies in software engineering has increased exponentially (Wolfgang, 2005). Ontologies can offer several benefits to different phases of software engineering lifecycle phases. Some of these (adopted from (Happel, 2006)) are:
• Ontologies can support the requirement engineering process in terms of knowledge representation.
• Component reuse during the design phase can benefit from ontologies. Ontologies can be used to describe the functionality of different components thus making it easier for the software engineer to look for components that can be reused.
• Ontologies can support the maintenance of a software project by providing representation for problem domain of software and source code.
• Ontologies can be used to support the testing phase. As knowledge in an ontology is machine readable, ontologies could help in generating basic test cases which could lead towards software test automation (Tarasov, 2019).
2.6.3 Ontologies in Requirement Engineering
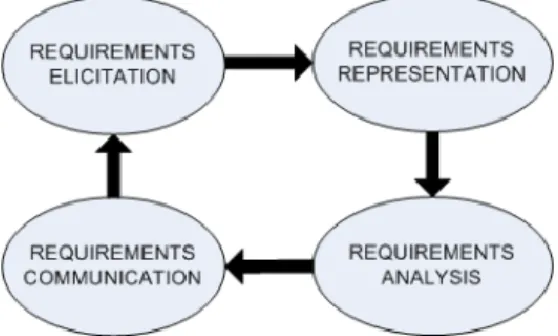
Requirement engineering is a vital part of the software engineering life cycle. Requirement engineering is the process of measuring that whether a software product is meeting its purpose for which it was built or not. In a typical requirement engineering process, stakeholders of the intended software product and their needs are identified and documented (Castañeda, 2010). These requirements are usually in the form of use cases and are expressed in natural language.
Figure 4: Requirement Engineering Activities (Williamson, 2002)
As shown in Figure 4, requirement engineering consists of multiple steps ranging from requirement elicitation to communication. Therefore, if software requirements are not understood properly in the start of the software development life cycle, then it will lead towards unsatisfied customers and there would be a need to incorporate many changes at later stages. This can be avoided by incorporating other methodologies and techniques. As explained in the section 2.6.2 that ontologies are being used in different areas of software engineering and how they can help in build better software products in less time. So, to make the process of software requirement engineering more efficient ontologies can be incorporated into software requirement engineering.
Ontologies can support the process of requirement engineering by describing the requirement specification documents and by representing requirement knowledge formally (Happel, 2006). As most of the requirements are in the form of use cases and written in natural language (Castañeda, 2010), there is a need to formalize and standardize these requirements so that they can be mapped on to ontologies. This approach will reduce the development time and number of defects in the final software product.
2.6.4 Ontology Development Language
Since the start of ontology development different ontology development languages has been introduced. These ontology development languages are used in multiple contexts (Slimani, 2015). Despite of several types of ontology development languages which are used in different ontology development methods, most common ones are RDF (Resource Description Framework), RDFS (RDF Schema) and OWL (Web Ontology Language) (RDFS vs. Owl, 2017). All three of these languages were built by W3C (Group R. W., 2014) and are the most widely used ontology development languages. After comparing these languages, we have concluded that the most suitable language for the ontology which can be used to map the formalized requirements is OWL. Although OWL was built over RDFS, it is more expressive than both RDF and RDFS because vocabulary in OWL is vast as compared to RDF and RDFS (RDFS vs. Owl, 2017). Using OWL for ontology development will be a better option if in the future there is a need to express relationship between different ontologies of requirements, it can be done easily because OWL does provide a framework to serve this purpose (RDFS vs. Owl, 2017).
2.7 Importance of formalizing Software Requirements
Software requirement engineering has a great significance in a software project which is evident from a study conducted by the Standish group in 1995 (Ewusi-Mensah, 2003). This study reveals that most of the software projects tends to fail in spite of the fact that how good was the development process. Study showed that only 9% of the projects developed by big companies and 16% of the projects developed by small companies were finished within the time and budget constraints. According to the study, there were eight primary reasons accounted for the project's failure, which are Lack of User Input, Incomplete Requirements & Specifications, Lack of Executive Support, Technology Incompetence, Lack of Resources, Unrealistic Expectations and Unclear Objectives (Group T. S., 2014). Out of these eight reasons five were related to requirement engineering and their elicitation (Palomares, 2014). This trend of software project failure due to sloppy requirement engineering practices still continues today. Significant research has been done in recent years to develop methods in order to improve the RE process. One promising method which can improve the RE process is the use of natural language processing techniques in software requirement engineering. This points towards a gap in transforming the software requirement specifications to formal requirements. There is a need to develop rules which can support the process of transforming software requirement specifications into formalized requirements.
3 Methods and implementation
While conducting and undergoing a research thesis, it is of vital importance to design and structure the research method properly. A well-designed research method does not only provide a framework for conducting research but also allow researcher to achieve valid and reliable results. According to (Williamson, 2002, p. 6) research is defined as,
“Research is an organized, systematic, data-based, critical, scientific inquiry or investigation into a specific problem, undertaken with an objective of finding answers or solution to it”
A basic research design consists of methods and techniques for data collection and evaluation to build some system or knowledge base. It defines the traceable procedure for obtaining the intended outcomes from that research. The research we are planning to conduct has two phases.
• Collection of information (existing domain knowledge),
• Using that information to fill the gap identified by proposing some rules. In-depth account of methods and techniques is provided in next section, but an overall research design is depicted below,
3.1 Research Methods & Techniques
The book (Williamson, 2002) provides us with a wide range of research methods and techniques. To name a few, we have methods such as survey research, case study, experimental design, design science research, ethnography, Delphi method, action research and historical research. These methods provide a wide spectrum to carry out different kinds of research. Selection of method is purely based upon the type of data involved and classification of intended outcomes.
3.1.1 Literature Review
As mentioned earlier, we wanted to make use of existing domain knowledge. Therefore, the first method we have selected for information collection is literature review. As mentioned in (Williamson, 2002, s. 62),
“According to Marshall and Rossman (1995, p. 28) ‘a thoughtful and insightful discussion of the literature builds a logical framework for the research that sets it within a tradition of inquiry and a context of related studies.’”
Literature Review is of prime importance to obtain relevant knowledge for theory building and that is the reason to select this method for our research. Our research consists of multiple domains i.e. ontologies, requirements engineering and natural language processing therefore we need to extract the knowledge and combine it to achieve desired results. It was important to build a strong knowledge base to remove all the ambiguities which enable us to further enhance the knowledge and use it for transforming requirements to ontologies. We have built the logical framework by reading material (such as research papers, reports, and journal articles) from all relevant domains and then used that framework for the development of rules and patterns.
Certain criteria about information collection has been used to maintain the consistency in research. We have identified different domains involved in our research and searching was done based on those keywords (see appendix 8.2). Specifically, we have used Google Scholar for the extraction of material and special emphasis has been done on the number of citations and date of publishing while selecting the research papers. Other sources were also accessed through Google Search Engine on World Wide Web to get hold of general articles and cross check the information obtained. The information was then classified and then further used for analysis. In general, it was an iterative work which helped us in refining, narrowing down and improvising the research problem.
3.1.2 Design Science Research
After building the knowledge base and understanding, we moved towards the second phase of our research which involves in making rules to transform requirements to ontologies. At this stage, our research moved from basic to applied phase and that is where our second research method Design Science Research comes into play (Bisandu, 2016). Our intention was not just to present a theory but also to identify and define rules/patterns which comes under introducing a new functionality in an information system. Due to this reason Design Science Research best fitted in our research. This approach enabled us to build the concept, architecture and eventually develop some artifact. Design Science Research is defined in (Dresch, 2015) page 67 as,
“Design Science Research is a method that establishes and operationalizes research when the desired goal is an artifact or a recommendation. In addition, research based on design science can be performed in an academic environment and in an organizational context.”
The process starts with stating a meaningful research question which is then investigated based on the understanding the processes/procedures. This is where we have combined the knowledge gained through literature review with the design science research methodology. A system architecture was then defined which shows the workflow of our solution (it will be presented in “Findings and Analysis” section). This research design is iterative i.e. it allowed us to go back at different stages to ensure that we are on right track and achieving tangible results. Following is an illustration of how our research complied with design science research method,
• Constructing a Conceptual Framework:
Here we defined the problem area and a solution for that i.e. formalizing requirements by transforming them to ontologies.
• Developing System Architecture:
In this stage, rules were defined for transforming the requirements to ontologies.
• Analyze the Design:
Rules were analyzed iteratively to eliminate the shortcomings and making the process more refined. This was done to make sure that the rules which we proposed were logical and can fulfil the desired task.
• Build the System:
Here the process of taking requirements and parsing them according to defined rules was formalized.
• Evaluate the System:
Our proposed system was tested through a real problem to see its potential and effectivity.
As the scope of our research was limited so due to time constraints, we have not developed the program to take requirements and process them according to defined rules automatically. However, this can be a next step and motivation for future research that can lead towards the full automation of process.
4 Findings and analysis
In this chapter, we will present the findings from the literature review and then later do analysis on them in order to define a framework which can address our research problem. As it was clear from our research question, our research was based on transforming requirement to ontologies. It involved different domains such as requirement engineering, techniques to extract useful information from requirements and then finally transforming them to ontologies.
4.1 Findings
Findings of the literature review in all sub-domains are presented below.
4.1.1 Choice of Requirement Type
As requirements exists in multiple forms, it was necessary from the start to restrict the type of requirements to be used, so that the scope of research could be defined. We were considering high level software requirements and as customers are involved in that phase therefore the requirements to be considered were natural language requirements. Owing to the open-ended and complex nature of natural language requirements, it was necessary to use some template which ensure the sanctity and correctness of requirements. Some properties were considered to measure the relevance of requirements such as unambiguity, verifiability, and stability. Based on these properties, we studied two standards for software requirements in detail which are IEEE Guidelines and INCOSE Rules (a detailed discussion on both is done in Chapter 3 of this report). Both of these standards ensure the above-mentioned qualities in software requirements but based on our research work, we found INCOSE Rules more in alignment to our problem domain.
The requirement characteristics mentioned by INCOSE (defined in Table 1) comprehensively covers the properties which ensure well-structured and understandable Software Requirements. These characteristics are implemented by the rules (see Appendix 8.1) and these INCOSE rules make sure that a candid interpretation of requirements can be made throughout the Software Development Lifecycle.
4.1.2 Choice of Transformation Method
The focus of this research is to create rules or patterns that can extract information from software requirement documents. After doing the literature review, we have decided to apply the information extraction techniques to accomplish this task. The reason for selecting information extraction is that it allows us to make segments of useful information from Natural Language Software Requirements. Information extraction helps in extraction of information using rules from natural language text, which is the core of this research. We will first list down some of the existing techniques in information extraction to build a basic understanding that how information extraction works. Some of the information extraction techniques used now a days are presented below.
4.1.2.1 CIRCUS
CIRCUS uses domain specific dictionary of concept nodes (Califf, 2003). These concept nodes are used to extract information from the text. These concept nodes are structures and contains a set of specific slots.
Figure 6: Two nodes set in CIRCUS (Mary Elaine Califf, 2003)
Each concept node extract information from the sentence using each of its node to get the relevant information. In Figure 6, there are two definition slots $MURDER-ACTIVE$ and $MURDER-PASSIVE$. These two slots predict that victim is murdered by whom (Califf, 2003).
CIRCUS was developed in the early days of information extraction and it does not support the learning. It needs domain knowledge to be implemented thus it required domain specific dictionaries. For example, MUC-4 system uses two type of dictionaries (Califf, 2003) and these dictionaries are:
• POS Dictionary:
Part of speech dictionary contains lexical definitions which also includes domain specific words.
• Dictionary of concept nodes definitions:
Dictionary of concept node definition contains concept nodes definition for the domain of terrorism.
Figure 7: Example of instance concept node in CIRCUS (Mary Elaine Califf, 2003)
Figure 7 shows the extraction information using concept node and shows that victims were three peasants and perpetrator were guerrillas.
4.1.2.2 RAPIER
The RAPIER system uses one slot extraction patterns as compared to CIRCUS. The extraction patterns in RAPIER uses less syntactic information as compare to other information extraction techniques.
The extraction rules in RAPIER have three parts (Califf, 2003) • Pre Filler Pattern
• Filler Pattern • Post Filler Pattern
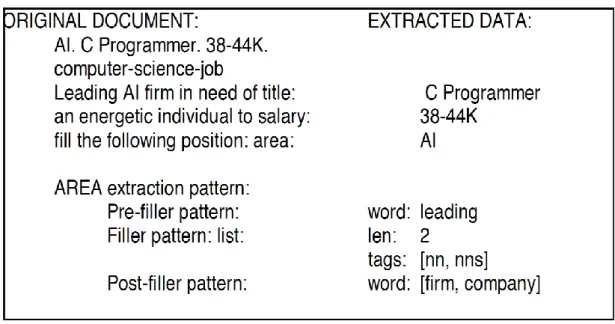
Figure 8: Example for extraction pattern of RAPIER (Califf, 2003)
As shown in Figure 8, there are three slots in the extraction pattern of RAPIER. Among these three mentioned patterns pre-filler pattern and post filler pattern are the left and right delimiters and the third pattern which is filler pattern was used to describe the information which is to be extracted.
Figure 9: Example of information extracted through RAPIER (Mary Elaine Califf, 2003)
4.2 Analysis
The aim of this research is to develop rules and patterns that can extract information from software requirement documents in a form that can be mapped onto ontologies. The literature review enabled us to gain the necessary knowledge to accomplish this task. We found that the process of information extraction allows us to tokenize and make segments of different entities within a single sentence. This technique is more suitable to our needs as our inputs, which is user stories, are only one-line sentences. Other technique such as data mining is suitable for large amount of data and they also serve different kind of purpose and are not suitable for extracting entities. We have reviewed some existing information extraction techniques to develop a basic understanding that how these information extraction techniques work. These were made to perform on specific domain and cannot be used for information extraction from software requirement documents.
As explained in the previous section, there are several tasks and sub-tasks that comes under the umbrella of information extractions. After careful consideration we have also decided to use a mix of these techniques to get more accurate results. The reason for using mix of CIRCUS and RAPIER is,
- CIRCUS uses domain specific dictionaries for information extraction and rely more on POS tagging.
- RAPIER relies on three (pre, post and filler) patterns to extract the required entity from the text.
In short, we can say that main purpose of CIRCUS and RAPIER is to extract the entities from text. Whereas our proposed system not only extract the entities from text but also helps to extract the relationships among those entities. We have named the system we are proposing as Reqtology. It basically refers to the transformation of Requirements to Ontology. Reqtology does not rely on domain specific dictionaries and rely less on POS tagging as compare to CIRCUS. On the other hand, it can also extract the required entity using two conditions whereas RAPIER requires three conditions to be fulfilled.
Relationship extraction is also an important aspect of Reqtology because it paves the way for automation by extracting relationship among three types of entities (actor, action, and desired output) in a user story. The workflow of Reqtology is discussed below.
4.2.1 Input source for Reqtology
Information extraction systems perform the task of extracting information from text. They use input source according to the need for which they are build. There are a number of input sources available for information extraction systems such as structure databases, labeled unstructured text and raw unstructured. Our focus is to develop rules and patterns to extract required information from software requirement documents. Software requirement documents are usually in raw text form so the input source for the proposed information extraction technique will be in raw text form. However, the requirements must be INCOSE compliant and would be in form of user stories.
Figure 10: Example of a software requirement
Figure 11: Example of a user software requirement (Example User Stories, 2004)
Above figures are the examples of software requirement specifications in raw textual form.
4.2.2 Categories of Information in User Stories
In order to extract the information from the user stories we need to categorize the information contained in the user stories text. The reason for this categorization is to devise a way to only focus on relevant information and discard the irrelevant text. After reviewing some sample user stories (Example User Stories, 2004) we identified three main categories which are defined below:
4.2.2.1 Actor
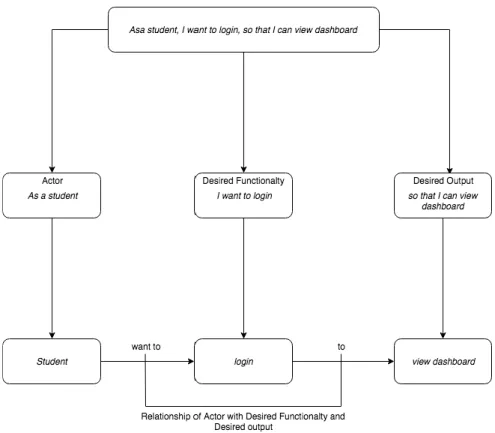
Actors are the entities which perform certain function in order to achieve some task or get some kind of functionality done, for example in the user story,
“As a student, I want to login, so that I can view dashboard”
student is an actor who wants login functionality.
4.2.2.2 Desired Functionality
Desired functionality or Action is the category for entities that are required functionalities by the actors, for example in the user story,
“As a student, I want to login, so that I can view dashboard”
login is the required functionality that is required by the actor which in this case is
student.
4.2.2.3 Output of Desired Functionality
This category contains entities that are described as the desired output in the user stories, for example in the user story,
“As a student, I want to login, so that I can view dashboard” view dashboard is the desired outcome.
Figure 12: Categories of information in user stories
The reason for categorizing this information is to make the relationship extraction more accurate. In a normal relationship extraction task, relationship is extracted based on trigger words between the extracted entities for example in Saqib lives in Jonkoping text the relationship between Saqib and Jonkoping can be extracted using keyword lives in. Using these keywords is an effective way to extract relationships but it is a tedious task because all the rules must be manually hand coded. To reduce this, we have divided the information into three categories as described in the picture.
As it is clearly visible from the above picture, if we divide the user story into three categories the relationship can be extracted easily without using any keywords. For example, in the above example shown in the Figure 12, the user story is divided into three categories of actor, desired functionality and output of desired
functionality. The relationship between these categories is that “Actor want to
required functionality To output of required functionality”.
In some case the categories of required functionality and output of required functionally can be further divided into subcategories. For example, in User story
As a user, I want to login to application, so that I can view dashboard
Required functionality “I want to login to application” can be divided into
following categories: