IN
DEGREE PROJECT MECHANICAL ENGINEERING, SECOND CYCLE, 30 CREDITS
, STOCKHOLM SWEDEN 2016
Flexible Updates of
Embedded Systems
Using Containers
SANDRA AIDANPÄÄ
ELIN MK NORDMARK
KTH Industrial Engineering and Management
Master of Science Thesis MMK2016:92 MDA 565
Flexible Updates of Embedded Systems Using Containers
Sandra Aidanp ¨a ¨a Elin MK Nordmark
Approved Examiner Supervisor
2016-06-13 De-Jiu Chen Viacheslav Izosimov
Commissioner Contact person
Tritech AB Mats Malmberg
Abstract
In this thesis the operating-system-level virtualization solution Docker is investigated in the context of updating an embedded system on application level. An updating sequence is designed, modelled and implemented, on which experiments are conducted to measure uptime and current. Within the popular notion of the Internet of Things, more and more things are being connected to the Internet and thereby the possibility of dynamic updates over the Internet is created. Being able to update remotely can be very beneficial, as systems may be costly or unpractical to reach physically for software updates. Operating-system-level virtualization, software contain-ers, are a lightweight virtualization solution that can be used for dynamic updating purposes. Virtualization properties, like resource isolation and letting software share hardware capabili-ties are used in determining the architecture. The container architecture used is a microservice architecture, where systems are composed from many smaller, loosely coupled services.
The application area for the results of this thesis are start-ups in the Internet of Things field, delimited to low complexity systems such as consumer products.
The update regime is created with the properties of microservice architectures in mind, creating a self-propelling, self-testing, scalable and seamless dynamic updating process that can be used for systems of different complexity. The update regime is modeled to give proof of concept and to help design the implementation. The implemented update regime was made on an ARM based single board computer with a Linux-kernel based operating system running Docker. Experiments were then conducted in order to give a clear indication of the behavior of a dynamically updated embedded system.
The experiments showed that the update regime can be seamless, meaning that the uptime properties are not affected by this kind of updating. The experiments also showed that no significant changes in current can be noted for container limitations during this kind of update.
KTH Industrial Engineering and Management
Master of Science Thesis MMK2016:92 MDA 565 Flexibel uppdatering av inbyggda system
med hj ¨alp av containrar
Sandra Aidanp ¨a ¨a Elin MK Nordmark
Approved Examiner Supervisor
2016-06-13 De-Jiu Chen Viacheslav Izosimov
Commissioner Contact person
Tritech AB Mats Malmberg
Sammafattning
I denna uppsats unders¨oks virtualiseringsl¨osningen Docker i samband med uppdatering p˚a applikationsniv˚a i ett inbyggt system. En uppdateringsekvens ¨ar utformad, modellerad och genomf¨ord, samt experiment genomf¨orda f¨or att m¨ata upptid och str¨om.
Samh¨allet blir mer och mer uppkopplat, fler och fler saker ¨ar anslutna till Internet och d¨armed skapas m¨ojligheter f¨or dynamiska uppdateringar via Internet. Att kunna genomf¨ora fj¨ arr-uppdateringar kan vara v¨aldigt f¨ordelaktigt eftersom det kan vara dyrt eller opraktiskt att fysiskt n˚a system f¨or programuppdateringar. Operativsystemniv˚a-virtualisering, mjukvarucontainrar, ¨
ar en l¨attviktig virtualiseringsl¨osning som kan anv¨andas f¨or dynamiska uppdaterings¨andam˚al. Virtualiseringsegenskaper, s˚asom resursisolering och att programvara delar h˚ardvarufunktioner, anv¨ands f¨or att best¨amma arkitekturen. Containerarkitekturen som anv¨ands ¨ar en mikrotj¨ anst-arkitektur, d¨ar systemen ¨ar uppbyggda av m˚anga mindre, l¨ost kopplade tj¨anster.
Anv¨andningsomr˚adet f¨or resultaten av denna avhandling ¨ar nystartade f¨oretag som befinner sig i marknadsomr˚adet f¨or det uppkopplade samh¨allet, begr¨ansat till system med l˚ag komplexitet s˚asom konsumentprodukter.
Uppdateringssekvensen skapas med egenskaperna hos mikrotj¨anstarkitekturer i ˚atanke; en sj¨ alv-g˚aende, sj¨alvtestande, skalbar och s¨oml¨os dynamisk uppdateringsprocess, som kan anv¨andas f¨or system av olika komplexitet. Uppdateringssekvensen modelleras f¨or att ge bevis p˚a kon-ceptet och f¨or att underl¨atta utformningaen av genomf¨orandet. Den genomf¨orda uppdater-ingssekvensen gjordes p˚a ARM-baserad enkortsdator med ett Linux-k¨arnbaserat operativsystem som k¨or Docker. Experiment utf¨ordes sedan f¨or att ge en tydlig indikation p˚a beteendet vid dynamisk uppdatering av ett inbyggt system.
Experimenten visade att uppdateringssekvensen kan vara s¨oml¨os, vilket inneb¨ar att upptid-egenskaperna inte p˚averkas av denna typ av uppdatering. Experimenten visade ocks˚a att inga v¨asentliga f¨or¨andringar i str¨om kan noteras f¨or begr¨ansningar av containern under denna typ av uppdatering.
Hofstadter’s Law:
It always takes longer than you expect,
even when you take into account Hofstadter’s Law.
Contents
1 Introduction 1 1.1 Background . . . 1 1.2 Objectives . . . 1 1.3 Scope . . . 3 1.4 Method . . . 3 1.5 Sustainability . . . 4 1.5.1 Environmental Sustainability . . . 41.5.2 Social Sustainability and Ethics . . . 5
1.5.3 Economical Sustainability . . . 5
1.6 Reading Instructions . . . 5
2 Prestudy 7 2.1 Definitions . . . 7
2.2 Target Market and Parameters of Interest . . . 7
2.2.1 Taxonomy of System Parameters . . . 7
2.2.2 Target Market . . . 8
2.3 Taxonomy of Virtualization . . . 11
2.4 Linux Containers . . . 13
2.4.1 Docker . . . 14
2.4.2 Related Work . . . 17
2.4.3 Docker Compatible Hardware . . . 18
2.5 Remote Update . . . 21
2.5.1 Dynamic Software Updating . . . 22
2.5.2 Microservices Principle . . . 23
3 Implementation 27 3.1 Update Regimes with Containers . . . 27
3.2 Design Guidelines . . . 29
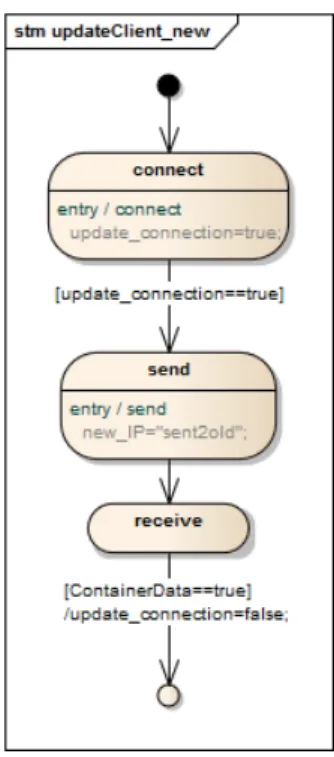
3.3 Overview of the Chosen Updating Regime . . . 30
3.4 Detailed Model . . . 31 3.5 Implementation Setup . . . 34 3.5.1 Platform Specifics . . . 34 3.5.2 Docker . . . 35 3.5.3 Development Environment . . . 35 3.6 Container Implementation . . . 36
3.6.1 Hardware Specific Container . . . 36
3.6.2 Application Containers . . . 37
3.6.3 Container Communication . . . 38
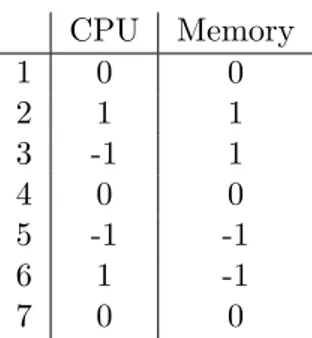
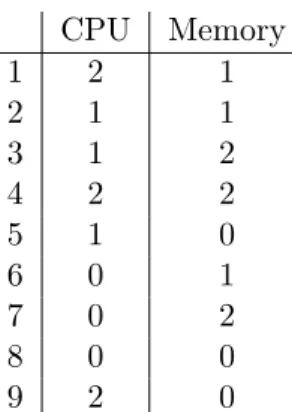
4 Experiment Design 41 4.1 Experiment Method . . . 41
4.1.1 EX 1: Normal Distribution Check . . . 42
4.1.2 EX 2: 2-factor, Full Factorial 2-level Experiment with Center Points . . . 42
4.1.3 EX 3: 2-factor, Full Factorial 3-level Experiment . . . 43
4.2 Analysis . . . 43
4.3 Measurements . . . 43
4.3.2 Changes in Current . . . 44
5 Result 45 5.1 Uptime . . . 45
5.1.1 EX 1: Normal Distribution Check . . . 45
5.1.2 EX 2: 2-factor, Full Factorial 2-level Experiment with Center Points . . . 47
5.1.3 Comparison to Behavior Without Container . . . 48
5.2 Current Measurements . . . 50
5.2.1 EX 1: Normal Distribution Check . . . 50
5.2.2 EX 2: 2-factor, Full Factorial 2-level Experiment with Center Points . . . 50
6 Conclusion 55 7 Discussion 57 7.1 Result . . . 57
7.2 Update Regime and Model . . . 57
7.3 Implementation . . . 59 7.4 Method . . . 59 7.5 Security . . . 59 8 Future Work 61 9 Bibliographies 63 A Work Division I
B Hardware List III
C Model V
D Code XV
D.1 Docker Files . . . XV D.2 GPIO Container . . . XVI D.3 Application Containers . . . XXIV
Abbreviations
ADC Analog to Digital Converter API Application Programming Interface App Application
appc App (application) Container (project) ARM Advanced RISC Machine
BCET Best-Case Execution Time BSD Berkeley Software Distribution CISC Complex Instruction Set Computing
CPS Cyber-Physical System CPU Central Processing Unit CSV Comma Separated Value DSP Digital Signal Processors DSU Dynamic Software Updating
ES Embedded System
FPGA Field-Programmable Gate Array GNU GNU’s Not Unix
GPIO General Purpose Input/Output GPL General Public Licence GPU Graphics Processing Unit
HDMI High-Definition Multimedia Interface HPC High Performance Computing HTTPS HyperText Transfer Protocol Secure
IBM International Business Machines Corporation I/O Input/Output
I2C Inter-Integrated Circuit ID Identifier
IoT Internet of Things IP Internet Protocol IT Information Technology KVM Kernel-based Virtual Machine
LED Light-Emitting Diode lmctfy let me contain that for you
LXC LinuX Containers
MIPS Microprocessor without Interlocked Pipeline Stages NPB NAS Parallel Benchmarks
OCI Open Container Initiative OS Operating System PC Personal Computer
PID Proportional–Integral–Derivative PLC Programmable Logic Controller PMMU Paged Memory Management Unit
PWM Pulse Width Modulation PXZ Parallel XZ
RAM Random Access Memory
RISC Reduced Instruction Set Computing RMS Root Mean Square
ROM Read-Only Memory RQ Research Question SBC Single-Board Computer
SD Secure Digital
SMPP Short Message Peer-to-Peer SoC System-on-a-Chip
STREAM Sustainable Memory Bandwidth in Current High Performance Computers TCP Transmission Control Protocol
UDP User Datagram Protocol UHS Ultra High Speed
UI User Interface
UML Unifed Modeling Language USB Universal Serial Bus
VM Virtual Machine
VMM Virtual Machine Monitors VPS Virtual Private Server WCET Worst-Case Execution Time
1
Introduction
1.1 Background
This thesis investigates how containers for Linux-like operating systems (built on the Linux kernel), specifically Docker, can be used for updating the software of mechatronical and em-bedded products. Containers, also called operating-system-level virtualization, is a technique for resource isolation that lets software share the hardware capabilities of a computer using virtualization. Containers, however, differ from virtual machines in the way that they do not simulate the hardware, instead everything is done directly on the kernel. The thesis topic was initialized by Tritech Technology AB, which is a consulting firm that specializes in intelligent systems for the connected society. In the field of Cyber-Physical Systems, the trend that can be seen is the notion of the Internet of Things [1, 2], where the Cyber-Physical Systems are not only controlling themselves, but also connected and communicating to other systems. However, there is no clear definition of Internet of Things [3, 4]. Embedded systems within the notion of the Internet of Things can be seen as the result of the increasing computing capabilities of em-bedded systems and the development of the Internet where broadband connectivity is becoming cheaper and more common [2].
There are several benefits of having embedded systems connected. These systems may be impos-sible or unpractical to reach physically for software updates, as they are permanently enclosed or situated in remote places. Accordingly, if a software update fails and the embedded system is stuck in an error state, so that it only can be put back in to service by physical access, it may amount to serious problems and costs. Benefits can be found in enabling software development to continue after launching an embedded product, and allowing it to adopt to changing use or environment. Tritech Technology AB wants to see how containers can be used in a remote update.
Cyber-Physical systems often have additional requirements than purely computational systems (e.g. servers). Though they can be expressed similarly, purely computational systems can be migrated, while the computational unit of a Cyber-Physical system might be the only thing connected to the hardware. The effects of utilizing a container for software updates therefore need to be examined at a whole system level. So, there is a need to evaluate the capabilities of these containers. This is to be the start, or first building block, for the company to further investigate or develop systems on this technology.
Updating an embedded system may be a critical activity that introduces some challenges. The hardware resources such as memory and CPU are limited, and therefore puts constraints on the software that can be run on the device for e.g. updating. It is also common for an embedded system to have performance requirements that introduces deadlines or timing constraints for processes. In these cases, the tasks of the system must not be impeded by a process such as an software update. Being able to perform a reliable update on an embedded system may be of paramount importance in terms of functionality, performance, safety and security.
1.2 Objectives
The main objective for this thesis is to investigate containers capabilities of performing a seamless software update in an embedded system by utilizing a microservice-approach. This will be done
by implementing a software update regime, and then by examining how the performance of a hardware platform as an embedded system will be affected by utilizing this regime. The performance is in the context of an embedded system, where the embedded system is expected to remain connected and perform certain tasks. Focus lies on the embedded system context, investigating effects on its external performance instead of its internal. One case of typical embedded systems was chosen; cyber-physical system prototypes for start-ups in the Internet of Things field. More specifically targeting low complexity systems such as consumer products, typically in home automation or ”smart homes”. Representative examples of the products in mind are power- or water consumption monitoring systems or irrigation systems. The container solution used is Docker, an operating-system level virtualization tool that can be run on a Linux kernel.
Experiments will be performed by limiting the resources and investigating how and if this affects the update performance. An updating approach inspired by microservices is going to be designed, modeled and implemented. The effects of utilizing containers when updating will be investigated with regards to some quantitative properties of the system: power consumption and uptime. The research questions that needs to be answered are:
RQ 1: What kind of hardware capabilities is needed to utilize Docker containers? RQ 1.1: What CPU capabilities are needed to run Docker containers?
RQ 1.2: What memory capabilities are needed to run Docker containers?
RQ 2: While updating soft-deadline functionality software in an embedded system utilizing containers as microservices, what is the effect on uptime performance for that function-ality?
RQ 3: How are changes in power consumption of the embedded system related to the update? The major contribution this thesis means to make is to propose an updating regime suitable for using with containers as well as to collect metrics and give results regarding the research questions in order for future researchers to be able to benchmark other solutions against them. It also means to give engineers results for them to determine if Docker is the solution that suits their requirements, when comparing their requirements on the parameters investigated in this report to the results given in this report. This work also aims to illuminate a fraction of the possibilities of using containers in embedded systems, especially Docker, and to contribute to evaluating the suitability of utilizing this technique in this way. It wishes to demonstrate relationships in this kind of update regime as well.
1.3 Scope
The chosen application domain induces some limitations on the characteristics of the systems on which the update could be implemented. Cyber-physical system prototypes for start-ups in the Internet of Things field implies low-cost, non-specialized hardware. Furthermore, the implementation will foremost focus on uptime, rather than real-time requirements. There will, however, be an ongoing discussion and a readiness to implement for real-time systems as this is often a part of cyber-physical systems. Any other properties that are not related to the market of interest will not be investigated.
The updating regime, as implemented in this work, will be representative as a method. It is however not intended to be implemented and used as it is. No effort will be put on ensuring the security of the system, nor to implement any major handling in case of errors due to bugs. The implementation should be viewed as a proof of concept rather than a regime to be set into production.
The model of the updating regime is made to give an overall understanding of the logic of the regime, as well as further give a proof of concept. It is not designed to generate code from, neither will it perfectly represent the code written for the containers, due to limitations in the modeling. This thesis does not make any claims to produce reliant absolute data, but is instead investigating relationships, changes and differences.
Only the Linux domain will be looked into and no other operative systems, as Linux is ubiquitous in embedded systems and the only OS linking containers and embedded systems together. The thesis will not give a clear indication of whether container virtualization should be used for embedded systems or not, this due to the fact that it is dependent on the implementation and the requirements on the system. It does, however, show that it could be used for this purpose. By uptime, in this thesis, availability and the ability to perform a task without interruption or corruption is meant. Uptime is investigated from the designed update regime’s point of view. The investigation assumes non-harmful programs (applications) and a stable Docker Engine and Linux kernel. The experiments designed in this thesis will be made within the limitations of what is measurable. They are conducted within the objectives of the thesis (1.2 Objectives) and with an embedded systems and cyber-physical systems point-of-view.
1.4 Method
The chosen approach will be a quantitative method. A container is a software implementation, its characteristics intended to be investigated in this thesis can be quantified. For the external validity, a quantitative method is to be preferred. A qualitative method could also be used, however, the point of interest would then be tilted towards usage, or appropriate usage, of a container [5, 6]. Knowledgeable professionals would be interviewed to get an insight into the current perception of containers. A more inductive reasoning could be used, with a literature study in the end. A mixed method could also be used; conclusions would be drawn from the literature studies, earlier evaluations and finally a case study. These approaches with a qualitative method used demands, however, that there is a reasonable amount of knowledgeable professionals and/or literature on the subject already. Knowledgeable professionals seem to be quite hard to find, unfortunately, due to the novelty of the technology in this broader area of cyber-physical systems.
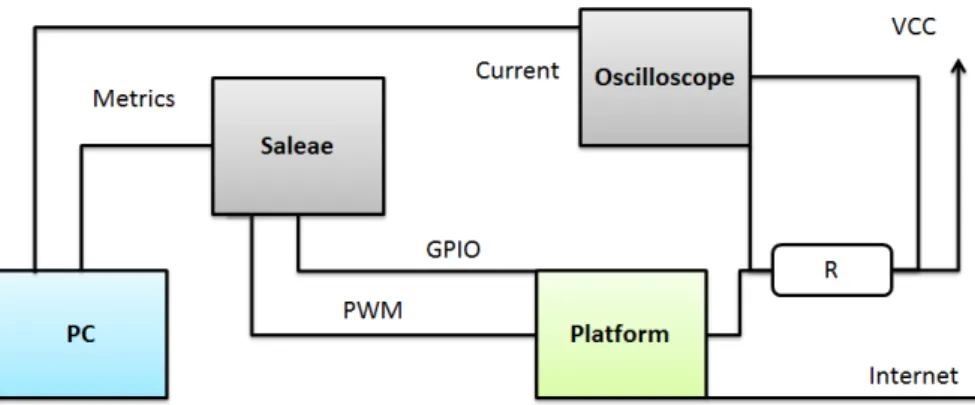
In the method used, the research questions will be investigated by conducting experiments. Firstly a prestudy will be conducted to get a clear picture of the operating-system-level virtual-ization (containers) as a whole, what it is and how it works. A taxonomy of virtualvirtual-ization will be presented and related research concerning performance of containers as well. Docker, as a container solution, will then be described in detail. The same will be made within the topic of updates, and remote updates. Furthermore, information on which embedded system hardware that can run a container will be investigated, one of these hardware options will then be utilized for experimenting. However, the external validity of the hardware used for the experiments has to be motivated in order to generalize on the findings [6], thus it has a qualitative aspect. A typical mechatronical system will be implemented on the hardware chosen, motivation for its typicality will also be included in order to generalize on the findings. The measured effect on the system by a container, in terms of the research questions (1.2 Objectives), will be investigated by designing experiments and setting up a test environment (both software and hardware). The experiments will be designed by using the methods described in the e-Handbook of Statistical Methods [7], measuring how the embedded system handles a software update when utilizing a container. Finally, Docker containers will be implemented on the platform in accordance with the experiment design. For analysis, statistics will be used to quantify the data gathered from the experiments. The work division can be seen in Appendix A.
The method has two elements that are qualitative; the hardware choice and the mechatronical system design. This is the result of the scope of the thesis, it is neither practical nor possible within the timespan of this thesis to test all possible hardware options. The hardware options chosen will therefore need to be representative in some way. Besides being a hardware that is used for embedded systems, and capable of running a container environment, it will represent hardware used by startup companies or for prototyping. It will be the type of hardware that has a set design and therefore a low initial cost. Embedded hardware can be designed by the companies to fit their specific needs, but this demands that the companies knows exactly what they require for the system. When building prototypes, however, the requirements might be changed within the prototyping process, and so it might be beneficial to postpone the choice of hardware design. Companies in the IoT-startup market (see 1.2 Objectives) might want to skip the hardware design all in all, for cost reasons or for the fact that the development boards already fulfill the requirements and re-design would only be an additional cost. In order to let the choices represent this market, the CPU architecture will be the major factor of design. The findings will therefore be useful for the specific hardware and can be generalized on within the typical type of CPU architecture. The experiment environment will also have to be designed to be representative of a typical embedded- or mechatronical system in the IoT-startup market. So, also here, the external validity will also be rigorously motivated and substantiated by literature.
1.5 Sustainability
1.5.1 Environmental Sustainability
The updating regime presented in this thesis is to be seen as a solution within the notion the Internet of Things. IoT can be used in order to benefit the environment; like Green-IT and energy efficiency in logistics [2]. Besides the positive aspects that IoT might bring with it, there are more direct positive sustainability aspects of updating with software containers. Being able to update cyber-physical systems in a reliable way might lead to less hardware changes, this might save a lot of material and energy losses connected to renewing hardware. It may also
lessen the impact of needing to reach embedded systems in remote areas in order to update them. During this thesis work, power overhead of the updates by the containers will be looked into, in order for further environmental evaluation being conducted.
1.5.2 Social Sustainability and Ethics
The Internet of Things (IoT) field may have many different applications that are beneficial for the connected society; it might produce jobs and have a positive impact on the safety end security of systems. It might also be used for the opposite. As a system becomes more and more complicated, the harder it is to test to assure that all safety requirements are always met. The same applies to security. A connected system has the risk of security breaches by unwanted parties. Systems might keep a lot of information about its users, and might also have other sensitive information this is needed to be protected. Another question that should be considered before using or implementing a connected device is whether the provider of the device own or have access to the information the user gives to it. The question of surveillance is still very much on the agenda [8] and before the Internet of Things is readily implemented, the question of integrity should be sorted out.
1.5.3 Economical Sustainability
The Internet of Things (IoT) may also have a positive economic impact due to the creation of more products and the possibility of streamlining services. At the same time, the more machines are able to perform work originally done by a human, the less work there will be for humans. In this case, the fact that the update can be done remotely means that no-one need to be hired to visit all systems and connect to them. The question of what will impact the economy most, the work created by technology or the work overtaken by technology, is something not really considered in a capitalist market.
1.6 Reading Instructions
This thesis report continuously refers, for clarification purposes, to different parts of the report with both chapter enumeration and title. For further details regarding the implementation the report refers to the extensive appendices, referenced at relevant points in the text. The abbreviations-page at the beginning of the report provides the full names of a great number of terms. References are referred to by numbers and presented in the bibliography, in the order they are introduced in the text.
The research questions that follow the entire report are denoted with bold style. Bold is also used occasionally to identify different alternatives or parts. Italics are used to emphasize but also to denote programs, file systems, kernel features etc. Commands, functions and system calls are accentuated as command.
2
Prestudy
In this section the prestudy is presented on which the basis this thesis relies on. The literature that will be used is presented.
2.1 Definitions
Throughout this thesis, different concepts and words are going to be used. In this section definitions of these concepts and words are presented. Within the realm of virtualization, the concept ”host” refers to the physical node or computer. The concept ”guest” refers, on the other hand, to the application or OS or other service that is run within a virtualization, on an abstraction layer. By the word ”container”, throughout this thesis, the operating-system-level virtualization technique, a software container, is meant (see 2.3 Taxonomy of Virtualization), and by Docker is meant the tools gathered under the name Docker to build and deploy containers and software within them (see 2.4.1 Docker). By embedded system (ES), a system that has a specific task and is controlling or monitoring something physical or electrical is usually meant. However, for embedded systems, the definition will become a bit blurry as the update of such a system can change their function and might therefore in some way be able to be regarded as multi-purpose. For this thesis, when talking about embedded systems, the systems regarded will traditionally have specific tasks. As the application area also can be described as cyber-physical system products, and as this area is closely related to both embedded systems and the Internet of Things, the cyber-physical systems domain will be investigated together with that of embedded systems.
2.2 Target Market and Parameters of Interest
2.2.1 Taxonomy of System Parameters
Embedded systems is a wide and loose term, but can shortly be described as ”information processing systems that are embedded into a larger product” as stated by Marwedel [9]. A cyber-physical system is, as described by Lee and Seshia, ”an integration of computation with physical processes whose behavior is defined by both cyber and physical parts of the system” [10]. Lee and Seshia further states that cyber-physical systems (CPS) are composed of physical subsystems, computation and communication, and having both static and dynamic properties. The physical parts of the system can vary significantly as CPS are found in the application range from entertainment and consumer products, via energy and infrastructure to aerospace and automotive industries. The contact to the physical environment is possible through sensors and actuators, which acts as the intermediators between the discrete world of numerical values and the analog world of physical effects [9].
In order to design and analyze these kinds of systems, certain aspects and properties must be regarded as decisive for the system performance. Marwedel lists several characteristics, such as embedded systems having a connection to the physical environment through sensors and actuators, and being dependable in terms of reliability, maintainability, availability, safety and security. He also states efficiency as a characteristic, expressed in the following key metrics for evaluation:
• Energy - as many systems are mobile and batteries are a common energy source
• Code-size - as hard disc storage often is not available, SoCs are common and therefore all code must be stored in the system with its limited resources
• Run-time efficiency - to use the least possible amount of hardware resources and energy consumption, supply voltage and clock frequency should be kept at a minimum, and only components that improve the WCET through e.g. memory management should be kept, etc.
• Weight - if it is a portable system, weight is of great importance
• Cost - especially the consumer market is characterized by hard competition where low costs puts constraints on hardware components and software development
This list can further be extended with these design considerations for networked embedded systems, listed by Gupta et al [11]:
• Deployment - where safety, durability and sturdiness are important parameters
• Environment interaction - to react to an ever-changing environment and adapt to changes, correct and precise control system parameters concerning e.g. a feedback loop becomes crucial
• Life expectancy - low power consumption and fault tolerance
• Communication protocol - in a distributed network of nodes, dynamic routing, loss toler-ance and reconfiguration abilities in terms of communication may be needed
• Reconfigurability - making it possible to adjust functionality and parameters after deploy-ment
• Security - for which computationally light-weight security protocols are important
• Operating system - the hardware constraints may require an optimized OS which in turn sets terms for the software running on the system
Other characteristics are real-time constraints. Many embedded systems perform in real-time, where tasks not only have to be delivered correctly, but a crucial aspect in the performance is that they are delivered on time. The real-time behavior can affect both the quality and the safety of the system service. Here it is possible to distinguish between soft and hard deadlines, as well as average performance and corner cases. Thiele and Wandeler states that most often the timing behavior of the system can be described by the time interval between two specific events [11]. These can be denoted as arrival and finishing events, e.g. a sensor input, an arriving packet, the instantiation and the finishing of a task. This applies to both external communication as well as the internal task-handling of the processor. Keywords in this area are execution time and end-to-end timing. System parameters affecting these may include, and are not limited to: response time, end-to-end delay, throughput, WCET, BCET, upper and lower bounds, jitter and deadlines.
2.2.2 Target Market
The Internet of Things environment possess a high degree of both hardware and software hetero-genity, concerning both functionality and network protocols. Because of this, recent suggestions
point towards moving away from these specificities to facilitate interoperability and to support application development. Platforms that aim to achieve this should ”(i) efficiently support the heterogeneity and dynamics of IoT environments; (ii) provide abstractions over physical devices and services to applications and users; (iii) provide device management and discovery mecha-nisms; (iv) allow connecting these elements through the network; (v) manage large volumes of data; and (vi) address security and scalability issues” as stated by Cavalcante et al. [12]. How-ever, they also state that no complete consensus exist on which functional and non-functional properties that should be possessed by an IoT platform. According to Kanuparthi, Karri and Addepalli [13], a typical Internet of Things (IoT) system architecture contains:
• Sensing and data collection, (sensors)
• Local embedded processing, at the node and the gateway
• Activating devices based on commands sent from the nodes, (actuators) • Wired and/or wireless communication (low-power wireless protocols) • Automation (software)
• Remote processing (federated compute-network-storage infrastructure)
They describe the architecture as consisting of several tiers, from low processing capability sensors through processing nodes which also have limited storage, processing and power to gateway Internet interfaces with good processing power and memory.
Konieczek et al. point out that as most IoT devices observe and manipulate their environment through sensors and actuators (i.e. acts as a cyber-physical system), and as the physical world is continuous, the execution time of the applications must conform to certain boundaries [14]. These are referred to as real-time requirements, as described earlier. Three levels of real-time applications can be discerned, depending on the properties of the deadlines. Hard real-time applications cannot miss any deadline, or system failure and dire consequences will occur. Firm real-time applications can be described as the information delivered after a deadline having no value, while soft real-time applications’ delivered information rather decrease in value with time passed since the violated deadline, this is shown in Figure 1. For this kind of applications occasional violations of the deadlines may be acceptable behavior, and having only task and operating system call priorities may even be sufficient as soft deadline scheduling frequently is based on extensions to standard operating systems [9].
In the field of Internet of Things, and in particular that of the smart home, sensors and actua-tors could for example be: motion, light, pressure, temperature, sound, distance and humidity sensors, and electric motors, LEDs, cameras, speakers and valves. When connected to e.g. a motor, position and velocity may be parameters that are added to the set of system parameters worth analyzing. When it comes to computation, CPU properties and memory management are vital in deciding the performance of the system. For the processor clock speed and workload are significant, and for memory it is size, type and usage that are highly interesting. A typical IoT smart home system might for example be a monitoring system, such as a power or water consumption monitoring system. This kind of systems consists of monitoring sensors, collecting information to a processing unit which then communicates information to the outside world or possibly also performing a task with an actuator. Communication can typically be performed through a display, some LEDs or through more complex data being sent to a mobile phone or computer through the Internet. A typical actuating task may be rotating a servo, starting
Figure 1: This figure shows the difference between hard- and soft-deadline real-time systems, where an example function is shown for the loss of value for the information in a soft real-time system.
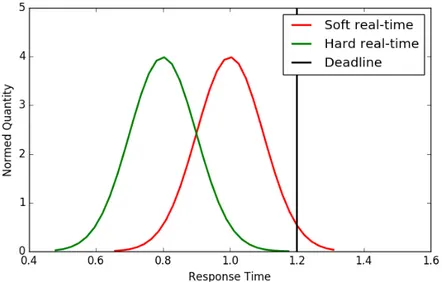
Figure 2: Distribution example of the response time for hard and soft real-time where the deadline represents the real-time when the system is viewed as non- or very slow-responsive.
a timer or flicking a switch. Other smart home implementations might include switching on and off lights or controlling curtains, where the system might be triggered by sensors or by an internal system clock. It may also be controlled by another device, such as a mobile phone or a computer.
There are no limitations to the types of systems that may be included in smart homes. A monitoring system relies on some amount of uptime to be able to produce accurate information; the system might be a polling system with hard or soft deadlines. In this thesis, soft deadlines are foremost of interest (see 1.3 Scope). Different periods between the polling or actuating may exist. For a monitoring system, updates every minute or every 10 minutes may be of interest. For curtains and light, some responsiveness is to be preferred if the system is controlled by a user. This responsiveness should be in the order of seconds but can still be a soft-deadline system, with a distribution of the response time depending on communication and computation. For these types of systems, having a system performing as fast as possible is often good enough for the user, as long as the peaks of the response time is not outside a reasonable interval. This interval depends on the system and requirements set on it, an example of the distribution can be seen in Figure 2.
2.3 Taxonomy of Virtualization
”Virtualization is a term that refers to the abstraction of computer resources” [15]. What this means, in short, is that some part of the computer is put on a level of abstraction for some other part of the computer in order to simulate the environment to run applications on. The computer can virtualize that it has multiple or other hardware or software components running. Virtualization can be used for a number of reasons, Sahoo, Mohapatra and Lath [15] lists the main reasons as:
• Resource sharing - Sharing hardware capabilities of the host as memory, disk and network. • Isolation - Virtual machines can be isolated from each other, they are unaware of each
other and are inherently limited to effect each other.
There are several types, or levels, of virtualization. Sahoo, Mohapatra and Lath [15] lists them as: A. Full Virtualization B. Hardware-Layer Virtualization C. Para Virtualization D. OS-Layer Virtualization E. Application Virtualization F. Resource Virtualization G. Storage Virtualization
Full virtualization is when the level of virtualization is so high that any application or op-erating system installed within the virtual environment, need no modification or needs not to be made aware that it is running within a virtual environment. This creates a very isolated environment but can lessen the performance by 30% [15]. This type of virtualization can be
binary translation; it emulates one processor architecture over another processor architecture, it is a complete emulation of an instruction set. Also in this category, some virtual machines are placed, which are created by virtual machine monitors VMMs. VMMs were defined by Popek and Goldberg in 1974 as having three characteristics: ”First, the VMM provides an environ-ment for programs which is essentially identical with the original machine; second, programs run in this environment show at worst only minor decreases in speed; and last, the VMM is in complete control of system resources” [16]. Popek and Goldberg also claims that the demand on efficiency removes emulators from the VM category. A VMM is also often called a hypervisor in the literature, no clear distinction can be found between the two and is therefore deemed equivalent.
Hardware-layer virtualization, or hardware assisted virtualization, is when a VMM (Virtual Machine Monitor) runs directly on hardware and the guests run their own OS. It has low overhead and is sometimes called native or bare metal-hypervisors. Example solutions in this category are Kernel-based Virtual Machine (KVM), Xen, Hyper-V, and VMware products [17]. Para virtualization is when the interface to the hardware is modified to control what the guest can do. Here the guest OS must be modified in order to use this interface and guest machines know that they are running in a virtualized environment. It is simple and lightweight which allows Para virtualization to achieve performance closer to non-virtualized hardware. Example solutions in this category are Denali, Xen, and Hyper-V [17].
OS-layer virtualization, also called containers, is what is going to be the virtualization technique this thesis has its emphasis on. It has its virtualization layer on top of a kernel or an OS. Here it is not the hardware, but the host OS that is the one being virtualized. This way of virtualizing is less performance draining than the full virtualization. Resources like memory, CPU and disk space can be reassigned both at creation and at runtime. It does however not have the same level of isolation as the full virtualization. This is the type of virtualization that is the focus of this thesis.
In Application virtualization, the user runs an application without installing it. Instead a small virtual environment with only the resources needed for the application to execute is run. This virtualization is often used for isolation to see if an application is safe to install (safe meaning it fulfills requirements on safety and security). Isolation for this purpose can also be called sandboxing.
Resource virtualization can be adding an abstraction level in order to make applications see isolated parts of a distributed system (memory, computing capabilities) as one whole. Or, the reverse, in order to create partitioning and isolation. Storage virtualization is within this category where scattered memory is seen as one whole memory ”pool” [15].
Rodr´ıguez-Haro et al. [17] couples Operating System-level virtualization with Para-virtualization because the two techniques are based on execution of modified guest OS’s. They also couple binary translation virtualization with hardware assisted virtualization because they both are based on execution of unmodified guest OS’s.
Other benefits that Sahoo, Mohapatra and Lath [15] list include migration properties; if the application is in a virtualization layer, it is easier to migrate onto other hardware, perhaps with more hardware capability, and can therefore give a more reliable execution and benefits like availability, flexibility, scalability, and load balancing over a distributed system. Other benefits listed are the ability to fully utilize hardware and the cost-efficiency connected to the economics
of scale and labour overhead among others. Security is also mentioned, due to separation and isolation, if one service is compromised, the other services are unaffected.
The classification made in this section is not the only classification of virtualization that can be made. For hypervisors, they have been divided into 2 classes in some cases [18]:
• Type-1 - bare metal hypervisors • Type-2 - hosted hypervisors
Where Type-1 refers to the types run directly on the hardware and Type-2 refers to the type that is hosted by an operating system.
2.4 Linux Containers
In this thesis, we concentrate on operating-system-level virtualization for Linux kernel based operating systems, specifically Docker (see 2.4.1 Docker). There are, however, solutions for other operating systems, such as Spoon Containers and VMware ThinApp for Windows [19, 20]. Unix is an operating system developed by Ken Thompson and Dennis Ritchie (and others) in the 1970’s, developed for multitasking and multi-user applications [21]. Since this, there has been many derivations of the Unix operating system, now Unix has been adopted to mean the Single UNIX Specification describing the qualities that Unix aimed at. Operating systems derived from UNIX are called Unix-like operating systems. The containers for Unix-like operating systems are all in some way based on chroot [22] which is a functionality or process for most Unix-like operating systems, where the root directory is virtualized for a process (and its children). This virtualized environment is sometimes called a ”jail”. It is important, however, to note that in contrast to what it implies, there are ways for processes to break out of this virtualized root directory. The chroot mechanism was introduced in the late 1970’s for the Unix operating system [23]. There has been tools developed for the same purpose since then like systemd-nspawn for Linux [24].
The Linux kernel was created by Linus Torvalds and aims at the Single Unix Specification and was developed to be a clone of Unix [25]. In contrast to other operating systems that has a container implementation (Solaris, Windows, FreeBSD) [26], it is open source, widely used, and used in embedded systems [27]. The Linux kernel has a built in container solution called LXC (LinuX Containers) [28], that is built upon the cgroup (control group-) feature of the kernel that offers isolation and limitation of a group of processes (container) regarding CPU, memory etc. It also utilizes namespaces for further isolation for the processes as well as chroots and other kernel features. Linux-VServer is similar to LXC, it uses chroot and some other standard tools for virtualization [29]. It is not, however, embedded in the Linux Kernel distributions. Linux-VServer creates what is called Virtual Private Servers (VPS), containers, which is designed for server applications and to fulfill server demands on isolation and resource management. The last logged change in their releases is from 2008, so there seem to be no major development of this container solution.
Another solution is Virtuozzo Containers, which is a solution package of containers specifically for servers and cloud solutions [30]. It is a proprietary software that creates containers for either Linux or Windows. The basis for creating the Virtuozzo containers, however, is OpenVZ [31] which is a free software under GNU GPL license. It should be noted that as of March 2015, Virtuozzo containers support Docker containers to be run within, noting the Docker capabilities
of simplifying the container management and deployment, but, adding security with Virtuozzo containers as they have more security implementation [30].
Let me contain that for you, shortened lmctfy [32], is the open source version of Googles container stack [33]. Googles container is a container solution also building upon cgroups in the Linux kernel but is designed for Google and Googles needs of scalability and concurrency, due to the vast amount of processes within their servers [34]. Lmctfy has however been abandoned for Dockers libcontainer [32] (now called runC).
The operating system developers behind Core OS, an OS also based on the Linux kernel, started appc [35]. Appc, short for App (application) Container, was a project in which to define a standard for application containers. Core OS also developed their own container mechanism in December of 2014. They named the runtime rkt (pronounced ”rock-it”) [36], based on the appc standard.
The container mechanism that will be used in this thesis is Docker [37]. Originally, Docker used LXC to create containers, but moved over to their own container mechanism, libcontainer, in the 0.9 release 2014 [38]. In 2015 Docker announced that libcontainer would be the foundation for the Open Container Initiative (OCI) [39, 40], joining with appc [41] for development. The objective is to make an industry standard for containers and a number of actors have joined in: Apcera, AWS, Cisco, EMC, Fujitsu Limited , Google, Goldman Sachs, HP, Huawei, IBM, Intel, Joyent, Pivotal, the Linux Foundation, Mesosphere, Microsoft, Rancher Labs, Red Hat, and VMware among them. Core OS had created appc and rkt as an alternative to Docker, still utilizing namespaces and cgroups, but, developing further for containers where they thought Docker lacked [42]. They, at the time, saw Docker becoming more of a platform rather than a Container development, the OCI means to again strive for a standard. The container mechanism developed through the Open Container Initiative is runC [43], libcontainer as a project has been stopped.
One of the motivations for using Docker, an thereby runC, as the container platform is the fact that other initiatives have been abandoned for the Docker platform and its mechanisms, like lmctfy. The mechanism, runC, is also a product of the Open Container Initiative, which means that the container will follow a standard supported by both the Linux Foundation and Microsoft, indicating that this standard will be the global standard for all operating-system-level virtualizations in the future. Docker as a platform also has tools simplifying deployment and other features presented in the next section.
2.4.1 Docker
Docker is an open-source container technology, wrapped up in a ”developer workflow” [44] that aids developers in building containers with applications and sharing those in their team. It was developed in order to provide a technology where code can be easily shared and portable through the entire development process to production, and that would run in production the same way it ran in development. Docker containers are described on the Docker web page [37] to ”wrap up a piece of software in a complete filesystem that contains everything it needs to run: code, runtime, system tools, system libraries”. This way it is enabled to run the same way regardless of environment, and applications can be composed avoiding environment inconsistency. The Docker architecture is of client-server type and has a daemon running on the host that builds, runs and distributes containers. The user interacts with the daemon through the client (docker
binary), the primary user interface, which accepts commands from the user and communicates with the daemon via sockets or a RESTful API. The client and daemon can run on the same system, or with the daemon running on a remote host.
Dockers containers are created from images, which are read-only templates that can contain applications and even operating systems, settings for the environment, among other things. Images can be built, updated or downloaded. With Docker Hub comes a public registry from which images can be downloaded. The Docker containers hold everything that is needed to run an application. Roughly, the Docker core functionality is: building images to hold applications, creating containers from the images to run applications, and sharing images through a registry. Docker images are made up of layers, combined together by UnionFS. This file system makes it possible to layer branches (files and directories of separate file systems) transparently to form a single file system. The images are updated by adding a new layer, so that there is no need to replace and rebuild the whole image. All images are built from base images, upon which layers are added using instructions, including running commands, adding files or directories or creating environment variables. The instructions used to create new layers on an image are stored in a Dockerfile, so that Docker can read this file, execute the instructions and return a new image when requested.
Every container is created from an image, which contains information about what the container consists of, what processes to run when launching the container, environment settings and other configuration data. Docker is adding a read-write layer to the image when running a container, in which the users application can be run. The container holds an OS, user-added files and meta data. To run a container, the Docker client communicates the image to run the container from and a command to run inside the container when launching to the daemon through the docker binary or the API. For example, when creating a container from an Ubuntu base image and starting a Bash shell inside it, the following takes place:
1. Docker pulls an image from the registry, layer by layer, if not already present at host. 2. Creates a container from the image.
3. Allocates file system, adds a read-write layer to the image. 4. Creates a network interface to let the container talk to the host. 5. Attaches an available IP address.
6. Runs an application.
7. Connects and logs standard inputs, outputs and errors.
The container technology depends mostly on two kinds of kernel features, called namespaces and control groups. When running a container, Docker creates a set of namespaces for that container in order to create the isolated workspace. This means that each aspect of the container runs isolated in its own namespace. The control groups control the sharing of hardware resources to and between containers, if necessary putting constraints on resource access to make sure the containers can run successfully in isolation. Docker uses union file systems as the building blocks to create containers in a layered and light-weight way. The combination of namespaces, control groups and union file systems make up a wrapper Docker calls a container format.
The Docker daemon can be bound to three different kinds of sockets: a (non-networked) Unix domain socket, a TCP socket, or a Systemd FD socket. By default, the daemon takes requests
from the Unix socket, which requires root permission. When accessing the daemon remotely, i.e. the daemon and Docker host is on another system than the client, the TCP socket has to be enabled for root access on the host. This however creates un-encrypted and un-authenticated direct access to the daemon, so that a HTTPS encrypted socket or a secure web proxy must be used to secure the communication. Matters of network security are however outside the scope of this study, and no effort will be put into securing the socket as this is of no concern for the experiments conducted.
A Docker image is created by writing instructions in a Dockerfile, each instruction creating and adding a layer to the local image cache. When creating an image, an already existing base image is often used as foundation. After this, instructions such as run commands can be written to extend or modify the image. For every instruction, a container will be run from the existing image, within the running container the instruction is executed, and finally the container is stopped, committed (creating a new image with a new ID) and removed. For a following instruction, a new container is started from the last saved image committed by the previous container, and the process is repeated. In this way, all images are made up of layers, but every layer is an image in itself, or rather a collection of images. Therefore a container can be created from any layer with an ID, and layers can also be re-used for building different images. When adding things to an existing image a new image is created, but instead of rebuilding the entire new image it instead keeps a reference to a single instance of the starting image saved in the cache. By this, image layers do not need to exist more than once in the local file system, and do not need to be pulled more than once [45]. This also leads to a much faster image build when a Dockerfile is re-used. Image trees may exist in the cache, forming an image relations history with parents and children. The Dockerfile is processed by scanning all children of the parent image to see if one matching the current instruction already exists in cache. If it does, Docker jumps to the next instruction, if it does not, a new image is created. Because of this, if an instruction in the Dockerfile is changed all of the following instructions in the file are invalidated in the cache, and the children of the altered instruction/layer/image are invalidated. From this it is possible to conclude that in order to re-use as much as possible from an already-in-cache image and have a fast image build, changes in layers should be kept to the latest instructions. When creating a container from an image, all the images layers are being merged, creating a significantly smaller file.
There are two approaches to update an image, according to Docker’s documentation [37]: 1. Update a container created from an image and commit the results to a new image.
— Run container on the image that should be updated. In the container, make desired changes. Exit the container. Use docker commit to copy the container and commit it to a new image that is created and written to a new user. Run a new container on the new image.
2. Use a Dockerfile to specify instructions to create a new image.
— Use docker build to build images: create a Dockerfile. State a source for the base image. If wanted, add RUN instructions to the Dockerfile to execute commands in the image for e.g. updating or installing packages, thus adding own new layers to the base image. Use the docker build command and assign the image a user, specify location etc. Run a container from the new image.
When building a similar image (same base image, but new added build instructions in the Dockerfile) Docker will reuse the layers already built for this image and only create the new
build instruction layer from scratch. Reusing layers like this makes image building fast. The image’s history will be saved containing all its building steps so that rollback is possible.[37]
2.4.2 Related Work
Raho, Spyridakis, Paolino and Raho [46] compares the Docker solution with a hardware sup-ported hypervisor (KVM and Xen) on an ARMv7 development board (Arndale). KVM and Xen are full virtualization techniques, hypervisors, that have hardware support in the ARMv7 pro-cessor. They lift the fact that hypervisors provide high isolation given by hardware extensions. They use Hackbench to measure time it takes to send data between schedulable entities, IOzone to measure file I/O performance for read/write operations and Netperf to measure networking activity (unidirectional throughput and end-to-end latency). They also use Byte-Unixbench that measures a number of aspects; CPU performance (instructions per unit time in integer calcula-tions), speed of floatpoint operations, excel calls per unit time, pipe throughput and pipe-based context switching, memory bandwidth performance (when creating processes), shell script (start and reap per unit time) and system call overhead. The results from Hackbench showed a small or negligible overhead for all techniques, IOzone showed lower overhead for Docker when it came to the write operation, all other operations gave better scores for Xen and KVM due to their caching mechanisms. Netperf showed results close to non-virtualization operation with packets of 64 bytes or more, Xen outperformed when it came to smaller packets. Byte-Unixbench gave similar results for all experiments. So, in conclusion, the performance overhead for all three virtualization techniques was very small.
Felter, Ferreira, Rajamony and Rubio [47] also compares Docker with KVM. They use micro-benchmarks to measure CPU, memory, network, and storage overhead. Their setup consists of an IBM System x3650 M4 server with two 2.4-3.0 GHz Intel Sandy Bridge-EP Xeon E5-2665 (64-bit) processors. They measure two real server applications as well: Redis and MySQL. The results conclude that containers are equal or better in almost all aspects. The overhead for both techniques is almost none considering CPU and memory usage; they do, however, impact I/O and OS interaction. They claim this to be because of extra cycles for each I/O operation, meaning that small I/Os suffer much more than large ones. They specifically measure throughput for PXZ data compression where Docker performs close to an non-virtualized environment. KVM, however, is 22% slower. They also measure performance when solving dense system of linear equations with Linpack, since this is have very little to do with the OS, Docker performs close to the non-virtualized environment. KVM, however, needs to be tuned in order for it to give performance in par with a non-virtualized environment. They also measure using the STREAM benchmark program, which measures sustainable memory bandwidth. For STREAM, the non-virtualized and the non-virtualized environments perform very close to each other. The same result can be seen when testing random memory access with RandomAccess. They also measure Network bandwidth utilizing nuttcp, here there is a difference in time between transmitting and receiving where KVM performs close to native when transmitting, but Docker demands some more CPU cycles. When receiving however, KVM is slower whereas Docker demands more or less the same amount of CPU cycles. The network latency is also measured, here they have used netperf. The results show that Docker takes almost twice the time as the native system, and KVM slightly less than Docker. Block I/O is measured using fio where non-virtualized and the virtualized environments perform similarly when measuring sequential- read and write. When measuring random- read and write there is however an overhead for KVM.
Xavier et al [48] makes their research tilted towards HPC (High Performance Computing) with an experiment setup of four identical Dell PowerEdge R610 with two 2.27GHz Intel Xeon E5520 processors and one NetXtreme II BCM5709 Gigabit Ethernet adapter. Because they are looking into HPC, they use the NAS Parallel Benchmarks (NPB), they also use the Isolation Benchmark Suite as well as Linpack, STREAM, IOzone, and NetPIPE (network performance). The con-tainer technologies tested are Linux VServer, OpenVZ and LXC, against Xen. The conclusion is that all container-based systems have a near-native performance of CPU, memory, disk and network. The resource management implementation show poor isolation and security, however. Joy [49] makes a performance comparison between Linux containers and virtual machines looking specifically at performance and scalability. The experiments are conducted on an AWS ec2 cloud and two physical servers. The comparison made was between ec2 virtual machines and Docker on physical servers. The application performance comparison is done with Joomla and Jmeter, and the scalability comparison is made with upscaling the virtual machine until it reaches maximum CPU load and utilizing Kubernetes clustering tool for Docker. Joy concludes that containers outperform virtual machines in terms of performance and scalability.
This thesis will investigate operating-system-level virtualization from an embedded system point of view, and look more into metrics measurable form outside rather than benchmark testing like [46, 47]. This gives this thesis the possibility for engineers, together with the related work presented in this section, to better determine the suitability of using Docker to update with when implementing a similar solution later described in this thesis.
2.4.3 Docker Compatible Hardware
There is a number of operating systems the Docker containers can run on: [37] (”Install Docker Engine”) Linux-kernel based, Windows and OS X. Linux-based operating systems are widely used for embedded systems and will therefore be used in this thesis. It is also free and open-source, making it easier to use. For using a Linux kernel based operating system, the Docker Engine has to have a Linux Kernel (3.10 or later) with an adequate cgroupfs hierarchy and some other utilities and programs installed (Git, iptables, procps, XZ Utils). So, the size of the system can be anywhere in between a large mainframe and a small embedded system. Containers can also be slimmed [50] for more efficient memory usage. The same logic can be applied to other types of containers, since the container creating mechanisms utilizes built in programs in the kernel, such as cgroups and namespaces. The requirements for the operating system to run containers can be very small and mostly dependent on what is to run within the container. The hardware requirements for running a Linux-kernel based operating system differs between the operating systems, the kernel itself can also be slimmed down [51] so there is no clear requirements for the memory capabilities.
So, answering the first research question, RQ 1 (see 1.2 Objectives), nothing can generally be said about the hardware capabilities needed to run a container. Continuing with RQ 1.1 and 1.2, the CPU and memory capabilities needed are in their entirety dependent on what kind of applications that is to be run within the containers, as well as the settings you make when building the Linux kernel and installing container mechanism (if it is not included in the kernel). It has already been shown in section 2.4.2 Related Work, that Docker and other container mechanisms have been known to show very little overhead. Docker had a challenge in 2015, where the premises was to build as many Docker containers as possible on a Raspberry Pi
[52], this showed that a) Docker do not really know how small their solution can be made and b) the question of hardware capabilities is relative to what is to be accomplished within. Some operating systems have instructions on the Docker website, and one can therefore conclude that Docker must be able to run without major fault on them [37]. The listed Linux kernel based operating systems are Arch Linux, CentOS, CRUX Linux, Debian, Fedora, FrugalWare, Gentoo, Oracle Linux, Red Hat Enterprise Linux, openSUSE, SUSE Linux Enterprise and Ubuntu. Of these, the ones that are specifically designed for embedded systems are Arch Linux, Debian and Gentoo.
The processor architectures the Linux kernel can run on can be found in the release notes of the latest release (4) [25]. The release notes lists a number of processor architectures it can run on, also implying it can be run on more general-purpose 32- or 64-bit processor architectures if they have a paged memory management unit (PMMU) and a proper setup of the GNU C compiler (gcc).
The architectures for the operating systems listed on the Docker website [37] can be seen in Table 1. Of the architectures listed, some are used (and designed) for high performance embed-ded systems like workstations, gateways and/or servers, like: MIPS, z/Architecture and IBM Power architectures. This compilation will concentrate on hardware that suit the implemen-tation presented in 1.3 Scope and further described in 2.2 Target Market and Parameters of Interest; ARM- and x86 architectures. Where the ARM architectures, 32 bit and 64 bit have RISC instruction set design. The x86 architectures usually refers to the 32-bit versions (IA-32) but some has 64 bit enabled (called x86-64). The x86 architecture has more towards a CISC instruction set design.
Arch Linux ARM architectures, IA-32, x86-64 CentOS x86-64
CRUX Linux x86-64
Debian ARM architectures, i686, IA-32, IA-64, IBM Power architectures, x86-64, MIPS architectures, z/Architecture Fedora ARM architectures, IBM Power architectures,
x86-64, MIPS architectures, z/Architecture FrugalWare i686, x86-64
Gentoo ARM architectures, DEC Alpha, IA-32, IA-64, IBM Power architectures, x86-64, PA-RISC, SPARC 64, Motorola 68000 Oracle Linux IA-32, x86-64
Red Hat Enterprise Linux IA-32, IBM Power architectures, x86-64, S/390, z/Architecture openSUSE (SUSE) IA-32, x86-64
Ubuntu ARM architectures, IA-32, IBM Power architectures, x86-64 Table 1: The listed architectures on the Docker website [37] and the processor architectures
Hardware for embedded systems can be designed into the smallest detail by the engineer. In this thesis, the market which this study is investigating is prototype-making with low start-up costs and short time to market. Ergo, the hardware must be single-board computers (SBC) [53] or single-board microcontrollers or similar that are viable options for the IoT-startup market that is the regarded implementation area (see 2.2 Target Market and Parameters of Interest). Linux can be run on FPGAs [51] programmed to look like CPU:s, but since this is largely a
work-around to use Linux, in this compilation only hardware based on CPU:s will be regarded. There is a great number of vendors for SBCs (and similar) with ARM or x86 architectures that can run one of the listed operating systems. However, it often needs to have a patched or a specifically built Linux kernel. One of the most popular architectures for embedded systems of the implementation type this thesis looks at, is ARM. Ubuntu has a 64-bit ARMv8 system server installation of their operating system [54], the embedded systems of this architecture often use a 32 bits, however. Gentoo has a number of 32-bit installations and Debian has both 32- and 64-bit installations of ARM. There is also the option of customizing a kernel and a Linux-based operating system. Linux Yocto is a project that has a Build System for creating custom Linux-based systems. The benefit of Yocto is that the kernel can be built and streamlined for the application. But, the downside is that it needs to be rebuilt when adding new software resources to the operating system and therefore is not suitable to develop directly on, since it can be hard to know in development everything needed in advance.
There are many boards that are designed specifically for embedded systems, often with real time support, that has ARM architectures of their CPUs and that are able to run Linux. They are, however, often very expensive and delivered with a pre-ordered real-time operating system and features that need to be customized. These factors makes them not suitable for start-ups within our scope (1.3 Scope), as the initial cost increases. Hardware options considered are SBCs that has:
• an ARM, IE-32 or x86-64 processor • wifi or ethernet connection
• general purpose I/O (GPIO)
Where the the possibility of Internet connection is required for the Internet in the Internet of Things, and GPIOs are often required for the system to be connected to an actuator or sensor in the Internet of Things. The embedded systems that fulfills these requirements include the ARM based boards Raspberry Pi, Orange Pi, Banana Pi, Beagle Boards, ODROID, Wandboard and Cubieboard among many others. For x86 IA-32 there is Intel Galileo, Intel Edison kit, Versa Logic Newt (VL-EPIC-17) and Minnow Board, among others. And for the x86-64, VersaLogic Iguana, VIA EPIA P910 could fulfill all requirements. A longer list can be found in Appendix B, this list does not make any claim to be entirely correct (due to the fact that the information found was on the Internet and not always the most reliable sources) nor complete. Many SBCs of the x86 architecture does not have GPIO, they are designed more for being workstations or servers. Some include a Graphics Processing Unit (GPU), this unit is designed for large calculations related to graphics. FPGAs can not only be used alone in an embedded system, but also used for performance enhancement together with a CPU. It is connected to the CPU, that runs the operating system, and can be used for computing acceleration, often offering parallel execution. For this thesis however, FPGA and GPU will not be used as it would demand platform specific configuration and is not standard for all SBCs nor always needed for the solutions within the scope. Many boards also incorporate a micro-controller for the peripherals. Processors or co-processing units may also be digital signal processors, DSPs, these processors are designed for filtering or compressing digital signal inputs. DSPs will not be considered within this scope either since it is neither standard for SBC for the purposes stated nor overtaking general-purpose CPUs or micro-controllers but instead seem to be co-processing, just as a GPU or FPGA.