V¨
aster˚
as, Sweden
DVA423
Thesis for the Degree of Master of Science (60 credits) in Computer
Science with Specialization in Software Engineering — 15.0 credits
TOWARD AN EVALUATION OF THE
COGNITIVE PROCESSES USED BY
SOFTWARE TESTERS
Gerald Tukseferi
gti19001@student.mdh.se
Examiner: Daniel Sundmark
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisor: Eduard Paul Enoiu
M¨
alardalen University, V¨
aster˚
as, Sweden
Abstract
Software testing is a complex activity based on reasoning, decision making, abstraction and collabo-ration performed by allocating multiple cognitive resources. While studies of behavior and cognitive aspects are emerging and rising in software engineering research, the study of cognition in software testing has yet to find its place in the research literature. Thus, this study explores the cognitive processes used by humans engaged in the software testing process by evaluating an existing: the Test Design Cognitive Model (TDCM). To achieve our objective, we conducted an experiment with five participants. The subjects were asked to test a specific Java program and verbalizing their thoughts. The results were analyzed using the verbal protocol analysis guidelines. The results suggest that all the participants followed similar patterns as those hypothesised by the TDCM model. However, certain patterns specific to each participant were also evident. Two participants exhibited a failure pattern, in which both followed the same sequence of actions after evaluating the test case and verifying that it fails. The experiment protocol and the preliminary results provide a framework from which to investigate tester knowledge and expertise and it is the first step in understanding, evaluating and refining the cognitive processes of software testing.
Acknowledgment
This thesis would not have been possible without the guidance of my thesis supervisor, Eduard Paul Enoiu. His quick replies, constructive feedback, and his continuous encouragement have helped me throughout my thesis. Thank you very much Edi.
I am and will always be thankful to my family, who have supported me financially and emotionally during my entire time in Sweden.
Special thanks go to the experiment’s participants. This entire thesis would not have been pos-sible without you. Thank you so much!
Table of Contents
1. Introduction 1 2. Background 2 2.1 TDCM Model . . . 2 3. Experiment 4 3.1 Research Methodology . . . 43.2 Goals of the experiment . . . 4
3.3 Experiment Units . . . 5
3.4 Experiment Material . . . 5
3.4.1 Informed Consent . . . 5
3.4.2 Survey for the selection of the participants . . . 6
3.4.3 Program for the preliminary experiment . . . 7
3.4.4 Program for the experiment . . . 8
3.4.5 Software specification document for the preliminary experiment program . . 9
3.4.6 Software specification document for the experiment program . . . 9
3.5 Tasks of the participants . . . 10
3.6 Procedure . . . 11
3.7 Analysis Procedure . . . 11
4. Analysis of the results 14 4.1 Results of the Survey . . . 14
4.2 Individual Participant Analysis . . . 14
4.3 Overall Analysis of the Observed Steps . . . 20
4.4 Observed Patterns of the Participants . . . 21
4.5 Discussion . . . 22
5. Related Work 24 5.1 Cognitive Models in Software Engineering . . . 24
5.2 Exploratory Software Testing . . . 26
6. Validity Threats 28
7. Conclusion 29
References 31
Appendix A Survey 32
Appendix B Software Specification Document 33
List of Figures
Figure 1 Test Design Cognitive Model [1] . . . 3
Figure 2 Problem-Solving and Declarative Knowledge Model [2] . . . 24
Figure 3 Debuggers’ cognitive processes [3] . . . 25
List of Tables
Table 1 Software Testing Encoding Scheme . . . 12Table 2 Activities of Participant 1 . . . 14
Table 3 Activities of Participant 2 . . . 16
Table 4 Activities of Participant 3 . . . 17
Table 5 Activities of Participant 4 . . . 18
Table 6 Activities of Participant 5 . . . 19
1.
Introduction
Throughout the history of software testing and software engineering [4], it has been repeatedly found that the human testers involved are a factor in the success or failure of any project regardless of the technology used. The development of the software applications that is produced nowadays, is basically a human made process, where even though there are cases of automatic generations of executable code, the majority is a human activity. Revealing bugs efficiently is one of the biggest issues of the software engineering field. Itkonen et al. [5] has stated that most of the new defects are found by manual testing, as test automation is mostly seen as a method of discarding the enact-ment of simple and constant tasks of testers, so they could have more free time for creative manual testing. Thus the tester’s skills and expertise are crucial in test execution as they have a strong effect on the the outcome of the tests. However, finding approaches to lessen the number of bugs in software, like targeting certain stages of the development process(e.g., testing) or improving the entire process is a major issue in software engineering field. There have been thousands of studies addressing this problem, but not many have investigated the origin of this problem, mainly the human mistake during the development process. Duraes et al. [6] has stated that several studies that investigated the characterizations of software faults carried out by independent teams using closed-source code and open-source code, shared related occurrences of fault types, mainly made by the human factor. Thus the source of bugs is ultimately related to the way the programmers think. With the increasing maturity of the field, the amount of research centered on the human aspect has increased. The global information technology market is expected to reach 5.2 trillion dollars by the end of 2020 [7] and being that software testing is quite an important part of this value, the relevance of the contribution that it is made on the software area to improve it’s reliability is immense. However, to improve software testing we don’t only need more automation and test creation tools, we also need a deeper understanding of how great testers think when conducting their work.
The amount of research focusing on the human and psychological aspects has been limited com-pared to research with technology or process focus [8]. Some researchers have studied the process and goals used by testers. Itkonen et al. [5] observed testing sessions of 11 software professionals performing system-level functional testing. They identified 9 practices for test session strategy and 13 practices for test execution techniques. Offutt and Ammann [9] have identified two ways of creating tests in practice: based test design and human-based test design. The criteria-based design consists of designing tests in order to satisfy some engineering requirements such as coverage criteria. On the other hand, the human-based test design is used for creating tests mostly based on the tester’s knowledge about the software under test and the specific domain the software is used. Nevertheless, these views of test creation are rather simplistic and are not explaining the cognitive aspects of creating test cases.
Recently, a model for explaining these aspects has been developed [1] as TDCM or Test De-sign Cognitive Model. The new model has grounded in problem-solving theory, which presumes a goal-oriented approach. However, we still do not have a clear study with real data, on how can the cognitive processes intervene with software testing. In response to the need for a greater understanding of the software testing processes, this work explores the cognitive processes used by humans engaged in the software testing process by evaluating TDCM using a verbal protocol analysis of data gathered during a test creation session. In the end, the sequence in which the different tasks in this process are performed is evaluated.
The outline for the rest of the study will be, Section 2. will continue on the background of software testing and cognitive processes, Section 3. will discuss briefly the research methodology and the protocol that is going to be used for the experiment. Section 4. will analyze the results of the experiment, Section 5. will discuss some of the previous works and Sections 6. and 7. will be respectively the validity threats and the conclusions of this study.
2.
Background
A software application can be defined as a specific program and all of the associated information and materials that this particular program has, which are necessary to support its execution. On the other hand, software engineering refers to the disciplined application of engineering, scientific, mathematical propositions and the means to the production of a quality software application [10]. Part of the software engineering is various processes, which are activities for managing the creation of software, such as analysis of the requirement, coding or testing. Bentley et al. [11] explain that software testing is the process of verifying and validating that a software application or program meets the business and technical requirements that guided its design and development and works as expected and also identify important errors or flaws. This testing process can also be described as the method of selecting and executing test cases one by one. Binder et al.[12] defines a test case as the pretest state of the software under test, which is a sequence of test inputs, and a declaration of the expected test outcome. Such test cases can be executed in specific unit testing frameworks, such as Junit framework, which is an open-source framework used for writing and executing test cases in an integrated development environment like Eclipse.
In order to get into the minds of these testers, and understand the basic of why they create certain test cases, cognition processes are an important asset for us. According to the American Heritage Dictionary of the English Language [13], the definition of the cognition can be defined as: 1. The mental process of understanding, including aspects such as awareness, observation,
rea-soning, and judgment.
2. That which comes to be known, as through perception, reasoning, or intuition; knowledge. When programmers of different experiences read and understand part of the code, he or she is exe-cuting a cognitive process of reasonable complexity. The same can be said about software testing, where testers use certain kinds of cognitive processes, such as perception and high reasoning, when testing a program. By understanding these processes it would help to clarify in what basis do the programmers test their code and derive good practices, based on the observations and analysis, that are naturally used by software engineers.
2.1
TDCM Model
In response to the need for a cognitive process model used by testers who are engaged in software testing, Enoiu [1] explores a problem-solving approach to map the steps and sequence by which testers perform test activities. The resulting model is shown in Figure 1 and is based on the ob-servation that test design and execution is viewed as a problem-solving approach.
This software testing cycle is composed of various stages where the human operative must accom-plish the following tasks:
Figure 1: Test Design Cognitive Model [1]
1. Identify Test Goal – The testers should pinpoint and identify the test goal as a problem that needs to be solved, which could be a present problem (given to the testers directly) or a discovered and created test goals (where it should be identified).
2. Define Test Goal – The testers should define and understand the test goal mentally and what the test cases are supposed to do.
3. Analyze Knowledge – The human operative must organize its testing knowledge regarding the test goal and approach the problem situation correctly.
4. Form Strategy – After analyzing their knowledge, the testers develop a solution strategy to create crucial test cases.
5. Organize Information and Allocate Resources – The testers should organize their information and allocate their mental and physical resources to create and execute the test cases. 6. Monitor Progress – They should monitor their progress on accomplishing the test goal by
checking the result of test creation and execution (e.g., checking the test oracle).
7. Evaluate – Lastly, the testers must evaluate their test cases by checking if the test goal is met. If not, they can make corrections by evaluating the previous stages. Once the test goal is completed, it may give rise to a new one, which is then repeated.
3.
Experiment
The following section will discuss the research methodology that is going to be used and the protocol that will be followed to conduct the experiment.
3.1
Research Methodology
The experiment is a test, which is launched under controlled conditions to measure the validity of a hypothesis or to assess the effectiveness of different techniques. In order to solve the hypothesis and to have the variables that are going to be used in control, a controlled experiment will be used. Basili et al. [14] has stated that experimentation is performed to help us better assess, predict, understand, control, and enhance the software development process and product. According to Robson et al. [15], an experiment or a controlled experiment is characterized by measuring the effects of manipulating one variable on another variable and is used when we want to have control over the situation. Other research methodologies, such as case study, survey, or systematic mapping studies, are not useful in this study, as there have not been many studies regarding the cognitive processes in software testing and none on using the verbal protocol analysis to study the cogni-tive processes during the testing process. Also, we want to keep all the possible variables on the control when conducting the experiment, so external factors will not affect the outcome of the study. The analysis of the data gathered from the experiment will be conducted via the verbal proto-col analysis method. Verbal protoproto-col analysis or VPA is a qualitative think-aloud method, where any verbalization generated by a subject while problem-solving will directly represent the contents of the subject’s working memory [16]. Ericsson and Simon [16] show some guidelines on how to use verbal protocol analysis (VPA). Protocol analysis will be used to investigate the test design behavior of several testers, and based on those data, an encoding scheme will be generated to help analyze those behaviors. The data that will be gathered from these subjects will provide the basis for the results discussed in this thesis. Subjects will be asked to test an already developed Java program. All subjects will have background domain and testing knowledge necessary to test the program. The next section will define step by step what is the entire procedure that the partici-pants will undertake during the experiment.
Singer [17] has once stated that writing a protocol is like writing the recipe of the experiment. In order to develop the protocol, the guidelines of Jedlitschka et al. [18] are used. Based on these guidelines, the protocol of the experiment that will be conducted will have the elements which are described in the following sections.
3.2
Goals of the experiment
In response to the need to better understand the software testing process, this experiment explores the cognitive processes used by testers engaged in software testing. In this experiment we use a problem solving approach to map the steps and sequence by which testers perform test activities. Empirically evaluating Enoiu’s TDCM theoretical model [1] requires studying the process used by testers. This is accomplished through an experiment during which subjects are asked to test a program while thinking aloud. The resulting verbal protocols are then coded to provide data, content analysis is used to validate the hypothesized process steps. This overall goal can be divided in three sub-goals:
• Empirically Investigating the TDCM Model. Determining whether the steps in the TDCM cycle are exhibited by participants when performing during the experiment.
• Identification of TDCM patterns. Identifying of patterns and relationships between the process steps distinguished in the content analysis.
• Identification of certain comprehension strategies used in the experiment. Identifying and verifying whether specific comprehension strategies, such as the usage of prior knowledge or questioning, have been used in the experiment.
We acknowledge here that we are employing content analysis of verbal protocols that are used to test the TDCM theory. For this purpose, the encoding scheme is defined formally before the experiment and this context greatly constraints the range of possible interpretations of the content. Since the data is gathered to test a model, there is a risk of over-fitting the steps actually taken by participants to TDCM. To counter this, the data interpretation and encoding scheme is as simple as possible.
3.3
Experiment Units
The individuals that will complete the survey and enter the experiment, will be the ones that have passed the course CDT414 - Software Verification and Validation in M¨alardalens H¨ogskola. The reason behind this choice is that the students have learned to apply different software testing techniques, for example, Functional and Structural Testing [19], and as such, they can successfully test a program. The populations from which the sample is drawn are the Master and Ph.D. level students, as the participants must have certain characteristics like experience and educational level. The reason that these types of inclusion criteria are put in the sample is that the subjects must have had some experience with the Junit framework before the experiment. As such, being that the students of the first cycle have not participated in the course CDT414 based on the information from [19], it is concluded that they may not have the necessary experience for the experiment. There may be cases where a bachelor student is working or has worked prior to software testing in a company or project, but since we do not have evidence of their capabilities, certain restrictions must be embedded for the validity of the experiment.
The representative data set was collected via an online survey as described in Sector 3.4.2, where the subjects were randomly selected in a particular group of interest. As mentioned prior in this subsection, the reason behind this is that the chosen students have the right knowledge for this experiment, and also the students have more free time than the professionals working in the in-dustry, and they are more accessible and more comfortable to organize.
The participation in the experiment was very quickly motivated, mostly influenced by the cu-riosity of the subjects. The thinking aloud protocol is a type of method that is not heard by many people, and thus they are quite eager to learn it first hand. Also, most of the population of the experiment, have not participated prior to any study, hence making the subjects excited and eager to participate.
It should also be mentioned that all the experiment’s units will follow the same procedure, thus avoiding an unbiased allocation of the subjects.
The confidentiality of the subject’s data is assured via an Informed Consent, where it is stated the confidentiality of the participants and their duties in the experiment.
3.4
Experiment Material
The experiment materials for the conduction of the experiment are, the Informed Consent, the survey for the selection of the participants, the programs of the preliminary and actual experiment, as well as each of the software specification documents for each of the program.
3.4.1 Informed Consent
The Informed Consent form is a type of document which gives the participants the basic idea of what the experiment is about and what their participation will involve. The form will contain the following information:
1. Purpose: The purpose of this research is to understand the software testing process by exploring the cognitive processes used by testers engaged in software testing. In this study, we will use the information that the participants provide to map the steps and sequence by
which testers perform test activities and evaluate whether these steps correspond to existing models.
2. Participant Recruitment and Selection: To be recruited for this study, the participants should be comfortable talking about their daily routine in creating test cases, technology usage, and thoughts about all aspects influencing their test creation process. More details of it are mentioned in the questions.
3. What will the participants be asked to do: We will need from them to provide detailed information about their thought process during testing. For more information regarding it, they can contact the researcher responsible.
4. What type of information will be collected: Their anonymity will be strictly main-tained. The data that will be collected will be labeled with an anonymous participant ID. Participants will remain anonymous, but researchers will refer to participants (if at all) by an ID in all subsequent analysis artifacts. Any identifying pieces of information will be erased. 5. What are the risks or benefits of participation: The risks of participation are intended
to be none or minimal. However, because they will provide detailed information about their work, there are concerns about privacy. To mitigate this risk, the subjects can choose what information they are comfortable revealing. At the end of the study, the subjects will get a copy of the study, which may help in their future testing carrier.
6. What happens to the information the participants provide: No one except the researchers will be allowed to see any of the information they provide. All electronic data and data collected as part of the study will be kept on an external hard drive and stored in a locked cabinet. It is expected to issue papers and presentations describing this research. Public presentations of the results will essentially present the results in an aggregate form. In cases where the individual participant data is disclosed, such as comments or quotes, we will ensure that the selected data does not suggest participant identities.
7. Acceptance of this form: The subjects by signing this form, which is given by the re-searcher responsible:
1) understand satisfaction with the information provided to them about their participation in this research project,
2) and agree to participate as a research subject.
This type of form will also serve as instruction material for the participants, as they need to read the document and sign it before the beginning of the experiment.
3.4.2 Survey for the selection of the participants
The questionnaire for this survey will be composed of scaled questions, where the participants will rate their responses on a numerical scale from 1–10, where the meaning of the numbers are described in the actual survey, as can be seen in A. Before the beginning of the questions, participants must read the Informed Consent that is stated in there. Afterward, they will write their email address so they will be notified regarding the time and location of the experiment and their name and surname for identification purposes. After the subjects read the Informed Consent carefully, they will proceed with answering the following questions of the survey:
1. From 1 to 10, how much experience do you have with Java programming? 2. From 1 to 10, how much experience do you have with Junit Testing?
As the experiment that will be conducted, will have its main focus on the Junit Testing in a Java program, as it is necessary to know whether the participants will have sufficient knowledge. In cases where the participants may not have at all expertise on Junit, it may influence the outcome of the experiment negatively. After the participant has answered, the following questions will be asked:
4. From 1 to 10, how capable are you to explain to other people what you are programming? According to the American Psychology Association [20], multitasking can take place when some-one tries to perform two tasks simultaneously, in essence, the individual switches from some-one task to another or perform two or more tasks in rapid succession. As the participants will focus on pro-gramming, being asked to think aloud changes the task into multitasking. On the third question, we focus on asking the subject how well he on multitasking is and if he can manage to do this in the experiment. Even though he may manage to multitask, the focus of the experiment is mainly on the explanation that he will give for the tasks. Because of that, the fourth question helps us to create a general idea of whether the subject is able to explain. The subject will answer the question based on their histories, such as in school or work area, on explaining their program to others. The fifth question will be as follows:
5. From 1 to 10, how capable are you speaking in front of the cameras?
Scopophobia is an anxiety disorder that brings an intense fear of being looked at or the fear of being in camera. As stated in Sector 3.6, in the room will also be a camera to record the experiment, and as such, it is needed to know whether the subject is comfortable with being registered. After the participant answers, the last question will be asked:
6. From 1 to 10, how comfortable are you with me being in the same room?
In the thinking aloud method, different guidelines such as [18] have stated that the researcher re-sponsible for this protocol method should be in the same room in cases when the participants stop talking for more than a certain amount of time, such as seven or ten seconds. Thus, it is neces-sary to know whether the subject has problems with another person being in the same room as him. At the end of the survey questionnaire, it has been stated the contact information of the responsi-ble researcher, in cases when the participants want extra information regarding the experiment or they want to withdraw from the experiment.
3.4.3 Program for the preliminary experiment
The program that was firstly chosen for the experiment was developed in [21] and is a UNO Card Game code. The code is written in java and is an easy implementation of the classic card game of matching colors and numbers. The program is composed of the following four classes: Card, CardPile, Player and Uno. Like any other UNO game, the deck consists of 108 cards, of which there are 76 Number cards, 32 Action cards. However, since this program does not have animated objects like cards, the deck is as follows:
i. Number cards
There are numbers from 0 to 9 for each of the colors (yellow, blue, red, green), and these are multiplied by two as there two same cards in a deck (exception is 0, as there are only four 0 in a deck). Thus, in total, we have 76 Number Cards. In the program, the card is written like the following ”0 yellow” or ”5 green”, where the number (0,5) represents the card number, and the color (yellow, green) is the color of the card.
ii. Action or Wild cards
In total, there are 32 Action Cards, which have the following effects in the game: • Skip – The next player in line misses a turn.
• Reverse – Order of play switches direction, e.g., if the players follow the clockwise direction while playing after this card has been put into play, the direction for the rest of the game will be counterclockwise.
• Draw two – Next player in sequence draws two cards.
• Draw four – Next player in sequence draws four cards and declares a new color. • Wild – Player declares a new color.
In the program the Action or Wild Cards have respective numbers attached to them, i.e. Skip = 10, Reverse = 11, Draw2(Draw two) = 12, Wild = 13, Draw4(Draw four) = 14. The deck in the program for this type of card is written as follows, ”10 red” or ”14 black”, where the number represents the type of Wild card, and the color is the shade of the card. The color black represents the two Wild cards, Draw four and Wild, as they do not have matching colors as the other cards.
The classes in this implementation play different roles, such as card shuffling or methods for delivering a new card. The classes and methods are described as follows:
A. Class Card
In this class, the main focus is the initialization of the Wild Cards and the methods of assigning value to numbers and color to them, e.g., getValue(), which returns an integer value or getColor() which return a string of color. Also, the method toString() assigns colours to the wild cards. The total number of code lines in this class is 40.
B. Class CardPile
This class consist of several methods, where the main ones are CardPile() which generates a deck of cards, nextCard() updates the next Card in the deck and shuffle() for shuffling the deck of cards. Other methods serve for generating certain variables, such as discard(Card discard) for adding the Card argument to the top of the discard pile or getTopCard() which generates the top card of the discard pile. Lastly, the function wildSetColor(String color) changes the color of the top card when a Wild type card is played. The total number of code lines in this class is 81.
C. Class Player
As the name suggests, the focus of this class is regarding the interactions between players (takeCard(Card c)), putting into play a specific card (playCard(int c)) or returning the number of cards in the players hand getNumCardsInHand(). The total number of code lines in this class is 34.
D. Class Uno
This is the main class and consists of several statements, mainly for the interaction computer - human, the messages on the screen, or when the player plays a card that matches either the color or the value of the prior card.
3.4.4 Program for the experiment
The program that is chosen for the conduction of this experiment was taken from a university assignment that we had on the course CDT414 (Software Verification and Validation) and is a Bowling Game Calculator. The code is written in java, which has nearly 129 lines of code, and it calculates the score of the rounds of a normal bowling game. The program has only one public class called BowlingGame, which is composed of several methods and class, which are described below:
1. public BowlingGame(String game) – This method initializes the rounds that are going to be used for the game, via an ArrayList<Frame >() and also concerns with how the these rounds should be formatted, e.g. game.split(“//[]”) which splits each of the rounds via a square brackets or String regex that shows how many numbers the rounds should have and what their limit.
It also has a for statement, which is for(int i = 1; i<parts.length; i++). This statement tries to regulate the length of each round.
Lastly, it has an if statement, which is if(a + b >10). This statement is regarding the case, when a regular frame a and b cannot be larger than ten, as only ten pins exists.
2. public int getScore() – This method is the main one for the calculation of the rounds. Part if this method are certain statements, such as if (rounds.get(i).IsStrike()) for calculating the strike in bowling, else if(rounds.get(i).IsSpare()) for calculating the spare, if(i<rounds.size() -1) which makes sure the rounds exist. In the end it returns the sum that is calculated.
3. public class Frame – This class concerns with the frame of the rounds, where each frame should have chanceOne and chanceTwo or two shots per round.
3.4.5 Software specification document for the preliminary experiment program This software specification document provides an overview of the UNO Card Game program, that is also described on Section 3.4.3, developed by [21], and intended to be used for the Verbal Protocol Experiment that will be conducted for this thesis. The document will cover specific aspects of the program, such as a short overview of the program, the rules of the game, and some of the system’s technical specifications (e.g., methods and classes). The expected audience of this document will be the researchers, participants in the experiment, and third parties interested in the protocol or outcome of the experiment.
• System Overview
UNO Card Game is a type of card game that is played with a specially printed deck. The game is for 2-10 players, where each player starts with seven cards dealt face down. The rest of the cards are placed in a Draw Pile face down, and next to the pile, space is designated for a Discard Pile. The deck consists of 108 cards, where 76 of them are Number Cards, and the rest are Wild or Action Cards. The system that is developed by [21] shares similarity with the card game, with the exception that the system does not generate cards with colors in it, but instead, each card is assigned a value, e.g.,” 0 green” where 0 represent the number of the card and green is the color of the card. In cases of Action Cards, each of these types of cards is assigned a number, e.g., Skip Card = 10, Reverse Card = 11.
• Rules of the game
The following rules of the UNO Card Game have been stated according to the official rules described in [22].
Every player checks his or her cards and tries to match the card in the Discard Pile ei-ther by the number, color, or the symbol/Action, e.g., if the Discard Pile has a green card that is a three, a person has to place either a green card or a card with a three on it. The player can also play an Action card, such as a wild card (to change the current color in play ) or draw four cards (the next player clockwise gets four cards, and the current color in play is altered).
If the player has no matches or they choose not to play any of their cards even though they might have a match, they must draw a card from the Draw pile. After they take a new card they can either put it in play or the person can keep the card and the game continues with the next player in line.
A player can only put down one card at a time and cannot stack two or more cards to-gether on the same turn, e.g., cannot put down a Draw Two on top of a different Draw Two or Wild Draw Four during the same turn.
The game continues until a player has one card left, where he must shout UNO, or otherwise, the person gets a penalty where he/she must draw two new cards from the Draw Pile. An-nouncing ”Uno” needs to be reiterated every time the player has been left with only one card. Once a player has no cards remaining, the game round is over, points are scored, and the individual with the highest score wins.
3.4.6 Software specification document for the experiment program
This software specification document provides an overview of the Bowling Game program, which is intended to be used for the Verbal Protocol Experiment that will be conducted for this thesis. The document will cover specific aspects of the program, such as a short overview of the program,
the rules of the game, and some of the system’s technical specifications (e.g., methods and classes). The expected audience of this document will be the researchers, participants in the experiment, and third parties interested in the protocol or outcome of the experiment.
• System Overview
Bowling Game is a type of sport where players try to hit ten pins located at the top of a wooden path using a bowling ball. The pins at the end of the lane are arranged in a triangular shape, usually by an automated machine. The game aims to knock down more pins than the opponent. The program is a Bowling Game Score Calculator, which computes the game’s score based on how many pins are knocked down. The following section will explain the rules of the scoring in Bowling.
• Rules of the game
The following rules of the Bowling Game Scoring have been stated according to the Professional Bowling Association [23].
1. Open Frame – The bowler simply gets credit for the number of pins knocked down. E.g., If the frames are: [1,5][3,6][7,2][3,6][4,4][5,3][3,3][4,5][8,1][2,6] then the score would be 81. 2. Spare – The players earns ten points plus the points for the next ball thrown of the next
frame. E.g., If the frames are: [1,5][3,6][7,2][3,6][4,4][5,3][3,3][4,5][8,2][2,6] then the score would be 84
3. Strike – The score would be 10 plus the total number of pins knocked down in the next frame. E.g., If the frames are: [10,0][3,6][7,2][3,6][4,4][5,3][3,3][4,5][8,1][2,6] then the score would be 94.
4. Multiple spares – E.g., If the frames are: [8,2][5,5][7,2][3,6][4,4][5,3][3,3][4,5][8,1][2,6] then the score would be 98.
5. Multiple strikes – E.g., If the frames are: [10,0][10,0][4,3][9,0][4,2][3,2][2,1][1,1][1,1][1,1] then the score would be 77.
6. Strike followed by a spare – The strike is calculated as a normal strike. E.g., If the frames are: [10,0][5,5][4,3][9,0][4,2][3,2][2,1][1,1][1,1][1,1] the score would be 70.
7. Spare as a last throw – The player is given a bonus throw. E.g, If the frames are: [3,2][5,5][4,3][9,0][4,2][3,2][2,1][1,1][1,1][5,5][8] the score would be 71.
8. Strike as a last throw – The player is given two bonus throw. E.g., If the frames are: [3,2][5,5][4,3][9,0][4,2][3,2][2,1][1,1][1,1][10,0][8,1] the score would be 72.
9. Perfect Score – would be a 300 game, which represents 12 strikes in a row or a total of 120 pins knocked down. E.g., If the frames are: [10,0][10,0][10,0][10,0] [10,0][10,0][10,0][10,0][10,0] [10,0][10,10] then the score would be 300.
10. In cases when the last frame of the game is spare and bonus throw is a strike, there are no additional throws.
3.5
Tasks of the participants
1. Participants will read the specification document containing the necessary information of the program ( Section 3.4.6).
2. Participants will test the program (Section 3.4.4) and search for any hidden error in it. They will need to create Junit test cases and systematically test the program to increase their confidence that the software works and to find bugs.
– We are specifically interested in their thinking process and experiences in creating new test cases. It is essential for us to understand what the participants are thinking about as they work on the test creation task, starting with identification and understanding the test goal or purpose until they execute the created test case.
3. Participants will complete both tasks 1 and 2 while using the VPA.
• While executing task 1, the subjects will articulate all their thoughts and opinions that they might have while reading the document.
• While executing task 2, the subjects will express everything that they are doing, e.g., why they are creating specific test cases or when they will stop testing a particular class. • It is required from the participants to talk about everything that they are thinking from the moment they start the task until the subjects have completed the task, where they must continuously talk and clearly state the order of their thinking and events.
3.6
Procedure
The participants will enter the room one by one in different schedules, where the only individuals in the area of the experiment will be the subject and the researcher responsible. The room will be a quiet one, where the participant will have its table with a comfortable chair and a glass of water in its hands (the experiment may take some time and will be tiresome for the voice and throat of the subject). The subject will be provided with a computer where he or she will create the test cases and a specification document containing the program’s information. The windows will be closed to avoid noise interference, and the curtains or shutters of the window will be closed so the light will not interfere with the camera’s visual. The camera will be installed near the subject where the camera’s frame will capture the participant’s front side and partly the researcher. As the room will be quiet, the camera will also capture the audio of the experiment. Nevertheless, an audio-capturing device will also be in the room in case of any noise interference that may come from outside the room. The researcher will also have a notebook with himself, to note any specific details from the experiment, e.g., cases where the participant may be perplexed from certain situations. According to Daniel Pink [24], in his book, it is stated that a person has its peak performance during the daytime, and as such, the experiment will be conducted during this time. Also, the subjects are advised to bring with themselves any object that may make them comfortable, e.g., some may want to bring their laptop.
The moment the participant enters the room, he or she will be greeted by the researcher and be directed to his chair. The moment when the subject is shown with the specification document, the camera, and the audio capturing device will be turned on by the researcher and will be on that state until the subject has expressed the ending of his or her testing process. At that moment, the researcher will close the supporting tools and express gratitude to the subject for participating in the experiment. Before the subject has left the room, the researcher will confirm whether the video and audio data have been captured correctly and after the verification has been done successfully, he or she will accompany the subject to the door.
3.7
Analysis Procedure
The analysis of the data will be based on the verbal protocol encoding approach used by [16]. The behavior of the participants will be captured on the video and audio format, followed by a transcription of their recordings. These data will then be break into segments, which could be phrases, sentences, clauses, or passage. After this, the segments will then be encoded.
The encoded data will then be analyzed via two different steps, the content and pattern analy-sis. Content analysis provides an independent assessment of whether the process steps articulated in the TDCM model wholly and accurately represent the problem-solving activities exhibited by the participants. The pattern analysis examines the existence of patterns and relationships via a within-subject analysis and between-subject analysis based on the information gathered by the content analysis. The within-subject identifies for each subject process steps series that may occur
more often than others, while the between-subject analysis identifies the process step series that often occur between the participants.
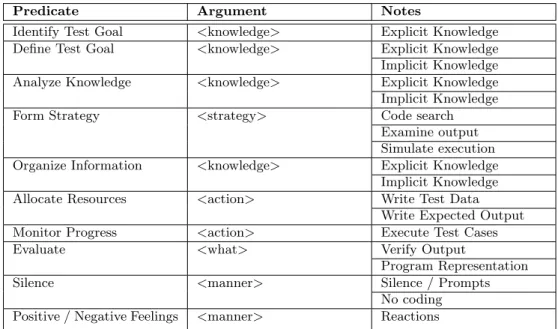
Both of the upper mentioned types of analyses will be executed based on an encoding scheme shown in Table 1. Each of the segments will refer to a specific predicate, and after all the segments have been encoded, the analysis will start. Table 1 will state each of the predicates that will be used for the experiment, where most of them are part of the TDCM Model (Figure 1), and the other predicate are necessary for a correct analysis of the experiment.
Predicate Argument Notes
Identify Test Goal <knowledge> Explicit Knowledge Define Test Goal <knowledge> Explicit Knowledge Implicit Knowledge Analyze Knowledge <knowledge> Explicit Knowledge Implicit Knowledge Form Strategy <strategy> Code search
Examine output Simulate execution Organize Information <knowledge> Explicit Knowledge
Implicit Knowledge Allocate Resources <action> Write Test Data
Write Expected Output Monitor Progress <action> Execute Test Cases Evaluate <what> Verify Output
Program Representation Silence <manner> Silence / Prompts
No coding Positive / Negative Feelings <manner> Reactions
Table 1: Software Testing Encoding Scheme
Itkonen et al. [25] have stated that there are different types of knowledge that a tester may have when building a test case. Such knowledge can be categorized into two types, which are explicit knowledge and implicit knowledge. Explicit knowledge concerns with the systems knowledge or the documentation, so the information that is regarding the software or documentation, while implicit knowledge is another type of knowledge which focuses on the domain knowledge and the experience that a tester has, e.g., practical or conceptual knowledge of the subject matter and tools. Being that such types of knowledge are being used, various predicates in the Encoding Scheme have a <knowledge>argument. Identify Test Goal uses the explicit knowledge of the testers in regards to the documentation or the code. Define Test Goal uses both the explicit and implicit knowledge of the testers as while defining the test goal, the tester needs to understands the code entirely based on prior experience as well. Analyze knowledge, as the name suggests, needs both types of knowledge to analyze the necessary information to form a strategy for the creation of the test case. Another predicate that uses both types of knowledge is the Organizing Information as the tester needs to have all the possible information if he or she is going to reason on them.
Form Strategy has another argument <strategy>, which refers to code searching, in order to find a new type of information or to support the current findings. Another way to create a strategy is also through examining the output, so if the test case completes the test goal, and also through a simulation of the test case to see if the strategy needs to be fixed.
The <action>argument that is mentioned on two different predicates in the scheme refers to two different actions. The predicate Allocate Resources concerns with the action that needs it to write the input on the test case and also its expected outcome, while the predicate Monitor Progress refers to the execution of the test case via the oracle.
Evaluate has an argument of <what>, which deals with verifying the output of the test case and check if the test goal has been met.
The other two predicates are Silence and Positive / Negative Feelings which both have the ar-gument <manner>. For the Silence, it refers to the times when there is no codding, and no words are being spoken, while Positive / Negative Feelings refers to the positive or negative reactions that a tester may express during the entire procedure of the creation of the test case.
4.
Analysis of the results
In the first subsection of this section, it is analyzed the results of the survey that was conducted, and in the second part of this section is investigated each of the data that were gathered from each of the participants. The third subsection is an overall analysis of the data gathered, and the last subsection will discuss specific patterns exhibited by the participants. In total, five participants took part in the experiment.
4.1
Results of the Survey
In total there were seven individuals that completed on the survey.
For the first question, most respondents chose either option five or six to represent their expe-rience in Java programming, and only one chose option four. In the second question regarding their experience in Junit, nearly all of them chose option five as an answer, and only one partic-ipant option four. From the answers to both the questions, we can say that the particpartic-ipant had the valid knowledge to proceed with the experiment, as the program would be a basic one, and the testing procedure will use a basic Junit syntax.
Regarding the third and the fourth question, which asked explicitly the subject ability to explain to other people what they are programming and whether they could speak aloud and program at the same time, nearly all of the respondents in both of the questions chose option seven or eight as the answer, and only one chose option six as the answer of the third question. Based on their reply, we can assume that the participants would have been comfortable to experiment and would not have any problem to explain what they are doing.
The last two questions concerned the subject’s comfortability before a camera and in the same room as the researcher. For the fifth question, the respondent chose answers from seven to ten, thus we can assume that they would not have camera fear during the experiment. Furthermore, for the last question, all of them chose either option nine or ten, which shows that they would be comfortable with another individual in the same room as them.
4.2
Individual Participant Analysis
The first participant expressed the results outlined in Table 2. The experiment lasted in total 21.2 minutes.
Predicate Mean Percentage of Total Activities
Identify Test Goal 14.6 %
Define Test Goal 8.1 %
Analyze Knowledge 4.9 % Form Strategy 26.7 % Organizing Information 15 % Allocate Resources 3.8 % Monitor Progress 2.5 % Evaluate 9.5 % Silence 12 % N/A 2.9 %
Table 2: Activities of Participant 1
Table 2 illustrates the mean percentage of the time the first participant dedicated to each of the predicates or stages of the TDCM Model (Figure 1). As seen from this table, most of its time, the first participant dedicated it to forming strategies for creating test cases and organizing information regarding the test cases. The third most used predicate is the identification of the test goals, followed by Silence and Evaluation. The other predicates, such as Define Test Goal, Monitor
Progress, Analyze Knowledge and Allocate Resources, were less used during the experiment. The predicate N/A refers to the words or sentences that could not be identified as any of the predicates in the TDCM Model, such as the times when the researcher is speaking or when the participant is expressing the reason why he or she stopped testing, e.g.:
– [21.15] So I believe, 11 test cases are enough. - Participant 1
– [21.19] Okay, thank you very much for your participation. - Researcher
The first participant followed a similar pattern as the stages in Figure 1, where firstly he or she identified the test goal or the problem that needs to be solved, then continued with defining this problem, analyzed the knowledge that the subject had on the test case and started to create a strategy on how to solve this problem. After the strategy was created, the participant continued by organizing information through inferencing or case-based reasoning. After the required infor-mation has been gathered the participant continues with allocating the resources, monitoring the progress of test cases while executing the oracle and then evaluates this test case.
It is interesting to see that nearly 48% of the time, the participant was trying to identify and define the problem and also creating a strategy for solving this problem. The pattern on creating test cases that this participant used, states that for this subject is necessary to gather all the information that he or she has on the problem and then starts to create test cases. This pattern is also evidential on the transcription, where most of its time, the subject was trying to understand the test case before starting to create it. Such examples can be shown below:
– [02.20] If a player knocks down 1 pin on their first ball and 5 on their second, the open frame would be worth 1+5, or 6 points. Example of an open game, ok. - Participant 1
– [03.10] So what I can do is to, the game had 10 frames, so what I can do is write 10 frames where all frames are open frames, meaning that less than 10 pins are not down in each frame. And calculate the score. - Participant 1
– [03.23] And I am going to create a Junit Test. - Participant 1
Another predicate that must be analyzed is also Silence. It is interesting to see that most of the time that this subject stayed in silence was when he or she was reading the software specification document or the code and stopped reading midway or when the participant was inputting the data in the test case but was not expressing it. Even though we cannot analyze the silence via the Verbal Protocol Analysis as the subject did not say any word, we can assume that during this time he or she was either forming strategy and organizing the information that was evident or was allocating the resources, by inputting the data in the test case. Such an example is shown below: – [09.53] So the result, I expect to have in this case, I am going to calculate it using a scientific
calculator of the laptop. - Participant 1 – [10.04] /*silence*/
– [10.19] I made the calculation correctly, I expect to have the score 49. - Participant 1
The second participant expressed the results outlined in Table 3. The experiment lasted in total 24.1 minutes.
Table 3 illustrates the mean percentage of the time the second participant dedicated to each of the predicates or stages of the TDCM Model (Figure 1). The second subject also dedicated a lot of its time to form a strategy, but in contrast to the first participant, it can be seen that this subject spend 12.2 % of his or her time to analyzing knowledge as the second most used predicate of the TDCM Model. Based on the data on Table 3, 38.7 % of the entire time the second subject analyzed the knowledge that he or she had on the test case, formed the strategy to solve the problem and organized the information it was gathered during the prior stages. The other predicates, such as Identify Test Goal, Define Test Goal, Allocate Resources, etc., were used
Predicate Mean Percentage of Total Activities
Identify Test Goal 6.4 %
Define Test Goal 4.3 %
Analyze Knowledge 12.2 % Form Strategy 14.6 % Organizing Information 12 % Allocate Resources 3.9 % Monitor Progress 2.7 % Evaluate 7.9 % Silence 26.5 %
Positive and Negative Feelings 1.1 %
N/A 8.1 %
Table 3: Activities of Participant 2
less during this experiment. Positive and Negative Feelings refers to expressions that the subjects might have expressed during the experiment. In this participant, these feelings were conveyed during 1.1% of the time via laughing or happy words, such as:
– [04.38] Yess (happy). - Participant 2
The predicate N/A refers to the times when the researcher might have spoken or when the subject was having a small conversation with the researcher:
– [15.20] Please talk out loud. - Researcher
– [20.06] I am totally trusting that the engineer did a good job when calculating this numbers.-Participant 2
It is interesting to see that this participant followed nearly the same pattern throughout the entire experiment. At the beginning of the experiment was trying most of his or her time to identify what the problem was by reading mostly the software specification document, and after it was understood what the program was supposed to do, he or she started to form strategies regarding the test cases. After that, it was used the same pattern for the rest of the experiment, where the subject analyzed the information he or she had, and created a strategy based on their knowledge and started reasoning on this strategy, e.g., what is the test case expected outcome.
– [10.38] so lets try with the first string. - Participant 2
– [10.45] let me see the specification now because it is already calculated. - Participant 2 – [11.13] I also have them on the pdf, so I can just copy paste. - Participant 2
– [12.42] So i wrote the first test, lets see if it runs. - Participant 2 – [12.45] Okay, it passed. - Participant 2
The predicate Silence must also be carefully analyzed in this participant. As we said prior, we cannot try to analyze the silence via the Verbal Protocol Analysis as the subject did not say any word during this time. However, if we compare the transcription with the video data that was gathered, most of the time that the participant stayed in silence was when he or she was allocating resources, e.g., putting the data in the test case, or when monitoring progress, e.g., pressing the oracle on executing the test case and see if it passed. However, certain words were classified as Silence, such as:
– [16.48] Hmmm. - Participant 2 – [17.20] Ummm. - Participant 2
In this case, we can assume that the subject could be organizing information that he or she has gathered or even forming strategies.
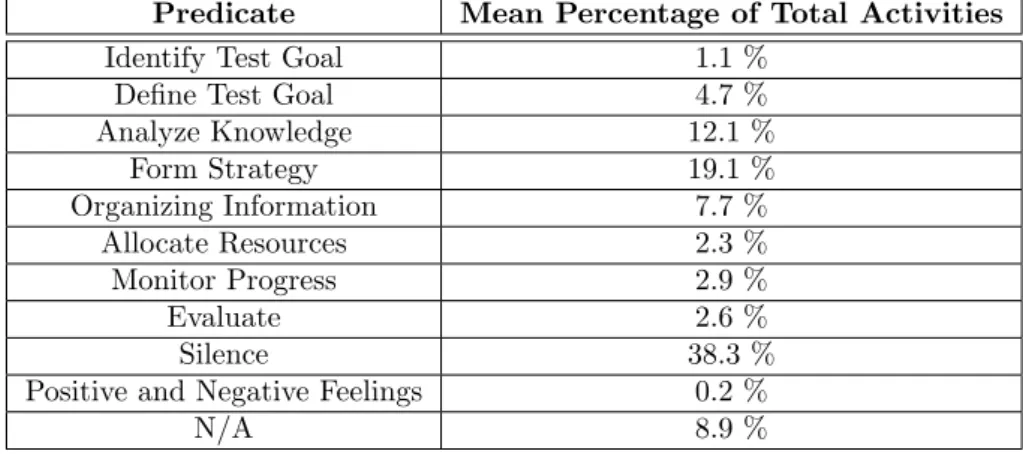
The third participant expressed the results outlined in Table 4. The experiment lasted 21 minutes.
Predicate Mean Percentage of Total Activities
Identify Test Goal 1.1 %
Define Test Goal 4.7 %
Analyze Knowledge 12.1 % Form Strategy 19.1 % Organizing Information 7.7 % Allocate Resources 2.3 % Monitor Progress 2.9 % Evaluate 2.6 % Silence 38.3 %
Positive and Negative Feelings 0.2 %
N/A 8.9 %
Table 4: Activities of Participant 3
Table 4 illustrates the data that were gathered from the third subject. From this table, it can be seen that most of their productive time, circa 39 % the participant used for forming a strategy, analyzing knowledge and organizing information. The rest of the predicates of the TDCM Model were used in a low percentage of their total activity, where all of them combined are 13.6 %. One variable that may affect the validity of this experiment is the high percentage of the Silence predicate, namely 38.3 %. It must be stated that one of the reasons that the participant has been in silence is because he or she could not remember the creation of the test case correctly. As such, at the beginning of the experiment, the subject demonstrated a high percentage of silence. Nevertheless, even during the experiment, the subject exhibited lots of cases of silence. However, if we compare the transcription document for this participant with the data gathered from the video, we can determine that in some of those cases, the subject was typing in silence, thus allocating resources or fixing the error in the test case. The high percentage of N/A, 8.9 %, corresponds with the Silence predicate, as in many times, the researcher was trying to remind the participant to talk out loud. Also, occasionally the subject expressed some positive statements, which took 0.1 % of their time.
Nonetheless, we can still analyze the pattern that this particular subject followed in the cre-ation of the test cases. As we can notice from the table, Form Strategy was a predicate that was quite used in the experiment, where the subject was trying to find ways to test the specification document and some parts of the code. After they had created a way to test the problem, the subject started allocating the resources by inputting the data in the case and then executing the oracle and evaluating the test case.
– [06.23] So, we should, I think to know how the string should be probably written, we should see the regex expression. - Participant 3
– [06.33] So, yeah it is in brackets and then coma and it’s a string. - Participant 3 – [06.37] I am copying the frames from the pdf of the document. - Participant 3 – [07.20] Okay, run the Junit test. - Participant 3
– [07.23] And we see that the test, passed. - Participant 3
The pattern that the third subject used is similar to the first subject, where both of them spend most of their productive times in creating strategies and reasoning behind those strategies and finally executing them.
The fourth participant expressed the results outlined in Table 5. The experiment lasted 15.2 min-utes.
Predicate Mean Percentage of Total Activities
Identify Test Goal 13.3 %
Define Test Goal 7 %
Analyze Knowledge 12.2 % Form Strategy 8.1 % Organizing Information 6.4 % Allocate Resources 6.4 % Monitor Progress 3.9 % Evaluate 8 % Silence 30.3 %
Positive and Negative Feelings 0.3 %
N/A 4.6 %
Table 5: Activities of Participant 4
Table 5 illustrates the data that were gathered from the fourth subject. From this table, we can derive the activities that the participant has exhibited during the experiment. Most of his or her productive time, circa 40.6 %, the fourth subject has been trying to identify and define the test goal, analyze the information he or she had on those goals, and, finally, form a strategy to execute those test. During the rest of the time they spent on the completion of the test case creation, the subject had been organizing information gathered prior, inputting the necessary data into the test case, and finally executing the test case via the oracle and evaluating its validity. For quite some time, circa 30.3 % the participant had been silent and not exhibiting any emotions or words, while during 0.3 % of the time, it shows his or her positive and negative feelings through certain statements. Here, the N/A predicate refers to the times the researcher may have been speaking, or the participant was stating the reason he or she stopped testing, such as:
– [00.04] Hello and thank you for participating in this experiment. - Researcher – [04.19] Please, talk out loud. - Researcher
– [14.59] Well, if I have tested all the specifications that the client want from us I will stop testing it. - Participant 4
During his or her time, the subject has been exhibiting a similar pattern during the entire experi-ment, where we have firstly the identification of the problem, then the analyzes of the information that he or she has, such as:
– [02.08] Okay, so we have a class called Bowling Game, which has another class called Bowling Game, which I can see that it has a parameter of string, called game. - Participant 4 Later, the subject has been creating strategies on how they should test the problems that they have identified:
– [03.44] I am going to create a new object called bowlinggame, so I can get the data from the class. - Participant 4
After they have allocated the data on the test case they continue with executing the test case and evaluating it:
– [04.35] Okay, now I am running the test. - Participant 4 – [04.37] It passed. - Participant 4
The subject followed a similar pattern on the entire experiment, where small deviations may have been found, such as the participant continued with creating the test case without forming a strategy. Nevertheless, being that during those times, the subject had been in silence between analyzing the
knowledge and monitoring the progress, we can assume that he or she had been doing these tasks mentally without expressing them.
The fifth participant expressed the results outlined in Table 6. The experiment lasted 15.6 minutes. Predicate Mean Percentage of Total Activities
Identify Test Goal 0.1 %
Define Test Goal 2.9 %
Analyze Knowledge 24.4 % Form Strategy 11.6 % Organizing Information 10.6 % Allocate Resources 8.9 % Monitor Progress 2.3 % Evaluate 3.4 % Silence 31.4 %
Positive and Negative Feelings 0.3 %
N/A 3.5 %
Table 6: Activities of Participant 5
Table 6 illustrates the data that were gathered from the fifth subject. From this table, it can be seen that most of their productive time, circa 24.4 %, the subject was analyzing the knowledge that he or she had on the test case, by analyzing the code or the specification document. After all the necessary information had been obtained, it was continued with the creation of a strategy on how to develop test cases based on the attained knowledge.
– [14.22] So, the last rule states, in case when the last frame of the game is spare and bonus throw is a strike, there are no additional throws. - Participant 5
– [14.30] Well let me have the test ready first then I can edit it. - Participant 5
As we can observe from the above example, the subject firstly tried to identify the knowledge that he had based on the specification document and then tried to form a strategy to test the obtained information. The same pattern has been identified throughout the experiment.
During the rest of the time, the participant was trying to organize the information based on inferencing or case-based reasoning and allocating the data on the test case. After all the data have been inputted, he or she then proceeded to monitor and evaluate the execution of the case.
– [06.46] Copy the data from the document for the spare. - Participant 5 – [07.01] And paste it here. - Participant 5
– [07.08] The excepted outcome is supposed to be 84. - Participant 5 – [07.11] Great, so now we can run it. - Participant 5
– [07.17] And passed. - Participant 5
Based on the above example, the participant firstly inputted the data from the specification doc-ument to the test case and then proceeded to explain how the outcome should be. From this fact, we can say that the subject did not follow a regular pattern as the TDCM Model, where firstly we organize the information and allocate the resources, but rather an irregular one, where he first allocated the data and then started to reason about them.
The N/A predicate in this subject refers to the times when the researcher might have spoken or when the participant was explaining why he stopped testing:
– [15.48] Well if the specification from the client is okay, then the application will be good and the client happy. - Participant 5
The Silence predicate must also be analyzed as it took 31.4 % of the entire experiment. Similar to the other participant, this one too, was being in silence during certain times that could be categorized as Organizing Information or Allocate Resources:
– [10.55] So I will copy the former test and change the name. - Participant 5 – [11.07] /*Silence*/
– [11.22] The test passed. - Participant 5
From this example we can see that from the subject had been in silence during the time where he was inputting the data into the test case and running the program.
4.3
Overall Analysis of the Observed Steps
Predicate Percentage of Participant Demonstrating Step
Average Mean Percent-age of Total Activities
Identify Test Goal 5/5 7.1 %
Define Test Goal 5/5 5.4%
Analyze Knowledge 5/5 13.1 % Form Strategy 5/5 16.1 % Organizing Information 5/5 10.3 % Allocate Resources 5/5 5.1 % Monitor Progress 5/5 2.6 % Evaluate 5/5 6.3 % Silence 5/5 27.6 %
Positive and Negative Feelings 4/5 1 %
N/A 5/5 5.3 %
Table 7: Analysis of Observed Process Steps
Table 7 portrays the analysis of the observed process steps for all the participants. From this table, we can see that nearly all the participants have executed all the steps of the TDCM Model, which is depicted in Figure 1. Nearly 12.4 % of the time, the subject was identifying and defining the test goal by firstly pinpointing the problem the needs to be solved and understanding this problem mentally and what is the test case supposed to do. Then, for circa 39.5 % of their time, the subjects attempted to evaluate the knowledge that they had regarding the test goal and then started to plan approaches on how to resolve the test goal. Later on, they continued organizing their information via inferencing or case-based reasoning. Inference can be stated as the process of drawing a conclusion based on the facts that a person has, together with previous knowledge and experience that he or she has, while case-based reasoning is similar to inferencing when a person solves new problems with the help of the solutions of similar past problems. After the necessary information had been gathered, the subject started to allocate their mental and physical resources to create and execute the test cases.
During the rest of their productive time or the time they spend on creating the test case, for nearly 9% they continued with monitoring the progress of the test case by executing the oracle and evaluating the result.
The other predicates not in the TDCM Model are the Silence, Positive / Negative Feelings, and N/A, where all of them combined makeup one-third of the experiment. Out of all the five par-ticipants, only four of them showed any reactions when creating a test case, and the one that did not show any was pretty neutral during the experiment. It is interesting to see that the same
participant that was quite neutral had the lowest percentage of being silent and quite a high per-centage on the step of Form Strategy, 26.7 %, which was the highest among the other participants. The Silence predicate, being that no words had been spoken, we cannot analyze it via the Verbal Protocol Analysis, based on the guidelines of [16]. Nevertheless, as examined on each of the partic-ipants, we may assume that the silence could be related mostly to the Allocation of Resources or Organizing Information due to a red thread circumstance that was observed on the transcription records. The N/A predicates refer to the sentences that could not be enlisted on either of the previous predicates, such as when the researcher was asking the participants to speak out loud or when the participants were exhaling why they stopped testing.
4.4
Observed Patterns of the Participants
Most of the time, the first participant followed the stages of the TDCM Model on the same pattern as in Figure 1; however, some special patterns could be seen through the experiment. The subject during the test case creation went from Analyzing Knowledge to Define Test Goal and back to Analyze Knowledge and in other cases he went from the Define Test Goal stage to Form Strategy stage. On the latter, it was accompanied by the Silence predicate, and as such, we may assume that the participant was analyzing the information he had during this time. A special pattern that was observed was during the time there was a failure, where the subject went from Evaluate predicate, to Analyze Knowledge, continued with Organize Information and lastly it ended with Evaluate.
The second participant followed the stages of the TDCM Model on the same pattern as in Figure 1, but some other patterns were observed during the experiment. The subject, while defining the test goal of the test case, continued directly to the Form Strategy predicate, followed by the Analyze Knowledge and lastly again with Form Strategy. This could be the subject while defining the test goal, thought what could be a strategy to resolve the problem, and being that he did not have the necessary information, he reanalyzed the information he had. Another interesting pattern was that the participant showed any positive reactions before he or she evaluated the test case, and the results, precisely the subject, showed any reactions between the Monitor Progress predicate and Evaluate predicate. Lastly, we could also analyze the pattern that the participant showed during the times there was a failure, where he or she went from the Evaluate predicate, to Or-ganize Information, continued with Form Strategy and ending it again with the Evaluate predicate. The third participant again followed the stages of the TDCM Model on the same pattern as in Figure 1, but other patterns were also noticed. In certain parts of the experiment, the subject would go from the Form Strategy to Allocate Resources and back to Form Strategy, continued with the Analyze Knowledge and again ending it with Allocate Resources. Typically, this pattern was only observed when the participant was inputting the data of the test case and then went back to analyze the outcome of the test case. The failure pattern or the pattern when there is a failure in the program is also evident in this participant, where he or she after it evaluated that the test failed, continued with the Analyze Knowledge and again with Evaluate. However, between the two latter predicates, there was also present the Silence predicate, from which we can argue that it was used for inputting the data or reasoning on why the test failed.
The fourth participant followed the same patterns as the TDCM Model (Figure 1). However, two specific patterns were also noticed. The subject after the Identify Test Goal continued with the Analyze Knowledge, so it skipped one stage of the TDCM, Define Test Goal. The second pattern was when the participant, after the identification of the problem, continued directly to the Allocate Resources and then back to Organize Information. The latter pattern was evident in the cases when the subject started the test case by copying the former test case he had developed for convenience purposes. The failure pattern is also evident in this participant, where after the subject evaluated the test case that it failed, continued to reason why it happened through the Organize Information predicate, and lastly, it ended again with Evaluate predicate.
![Figure 1: Test Design Cognitive Model [1]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4903625.134803/8.892.265.649.131.520/figure-test-design-cognitive-model.webp)





![Figure 2: Problem-Solving and Declarative Knowledge Model [2]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4903625.134803/29.892.304.588.622.1089/figure-problem-solving-and-declarative-knowledge-model.webp)
![Figure 3: Debuggers’ cognitive processes [3]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4903625.134803/30.892.306.587.432.905/figure-debuggers-cognitive-processes.webp)
