V¨
aster˚
as, Sweden
DVA423
Thesis for the Degree of Master of Science (60 credits) in Computer
Science with Specialization in Software Engineering, 15.0 credits
INPUT PARTITIONING IMPACT ON
COMBINATORIAL TEST COVERAGE
Rea Ballkoci
rbi19003@student.mdh.se
Examiner: Sasikumar Punnekkat
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisors: Jan Carlson, Eduard Paul Enoiu
M¨
alardalen University, V¨
aster˚
as, Sweden
Company supervisor: Ola Sellin,
Bombardier, V¨
aster˚
as, Sweden
ACKNOWLEDGEMENTS
To Jan Carlson and Eduard Paul Enoiu, my supervisors at M¨alardalen University, for the continuous enthusiasm, patience and willingness to help whenever I needed them.
To Bombardier, for making me feel comfortable, resourceful and for always being there to support me.
To My Hoang Nguyen, for being a friend!
Abstract
Software testing is a crucial activity when it comes to the software lifecycle as it can say with a certain confidence that the software will behave according to its specified behavior. However, due to the large input space, it is almost impossible to check all the combinations that might possibly lead to failures. Input partitioning and combinatorial testing are two techniques that can partially solve the test creation and selection problem, by minimizing the number of test cases to be executed. These techniques work closely together, with input partitioning providing a selection of values that are more likely to expose software faults, and combinatorial testing generating all the possible combinations between two to six parameters.
The aim of this Thesis is to study how exactly input partitioning impacts combinatorial test coverage, in terms of the measured t-way coverage percentage and the number of missing test cases to achieve full t-way coverage. For this purpose, six manually written test suites were provided by Bombardier Transportation. We performed an experiment, where the combinatorial coverage is measured for four systematic strategies of input partitioning, using a tool called Combinatorial Coverage Measurement (CCM) tool. The strategies are based on the interface documentations, where we can partition using information about data types or predefined partitions, and specification documentations, where we can partition while using Boundary Value Analysis (BVA) or not.
The results show that input partitioning affects the combinatorial test coverage through two factors, the number of partitions or intervals and the number of representative values per interval. A high number of values will lead to a higher number of combinations that increases exponentially. The strategy based on specifications without considering BVA always scored the highest coverage per test suite ranging between 22% and 67% , in comparison to the strategy with predefined partitions that almost always had the lowest score ranging from 4% to 41%. The strategy based on the data types was consistent in always having the second highest score when it came to combinatorial coverage ranging from 8% to 56%, while the strategy that considers BVA would vary, strongly depending on the number of non-boolean parameters and their respective number of boundary values, ranging from 3% to 41%. In our study, there were also some other factors that affected the combinatorial coverage such as the number of manually created test cases, data types of the parameters and their values present in the test suites.
In conclusion, an input partitioning strategy must be chosen carefully to exercise parts of the system that can potentially result in the discovery of an unintended behavior. At the same time, a test engineer should also consider the number of chosen values. Different strategies can gener-ate different combinations, and thus influencing the obtained combinatorial coverage. Tools that automate the generation of the combinations are adviced to achieve 100% combinatorial coverage.
Table of Contents
1. Introduction 1
1.1. Problem Formulation . . . 1
1.2. Overview . . . 2
2. Background 3 2.1. Test Creation and Selection Problem . . . 3
2.2. Testing Activities during Software Development . . . 3
2.2.1 V-model . . . 3
2.2.2 Functional Testing . . . 4
2.2.3 Non-functional Testing . . . 4
2.3. Input Partitioning . . . 5
2.4. Procedures for Input Partitioning . . . 5
2.4.1 Category-Partitioning . . . 5
2.4.2 Redefined Partitioning . . . 6
2.4.3 Partition Analysis . . . 6
2.5. Input Parameter Modelling . . . 6
2.5.1 Interface-based Modelling . . . 6
2.5.2 Functionality-based Modelling . . . 7
2.5.3 Boundary Value Analysis . . . 7
2.6. Combinatorial Testing . . . 7
2.6.1 T-way Combinations . . . 7
2.6.2 Combinatorial Coverage . . . 8
2.6.3 Cost and Practical Considerations . . . 9
2.7. Input Partitioning and Combinatorial Testing Relationship . . . 9
3. Related Work 10 3.1. Effectiveness of Input Partitioning and Combinatorial Testing . . . 10
3.2. Test Set Reduction . . . 11
3.3. Approaches to Input Partitioning . . . 11
3.4. Functional Dependencies . . . 12
3.5. Combinatorial Coverage of Manual Test Cases . . . 12
3.6. Comparison between Random Testing and Combinatorial Testing . . . 13
3.7. Automating Combinatorial Testing and Test Generation . . . 14
4. Method 15 4.1. Research Methodology . . . 15
4.2. General Approach to Input Strategies . . . 15
4.3. Research Process . . . 18
5. Ethical and Societal Considerations 20 6. Experiment Conduct 21 6.1. The Setup Phase . . . 21
6.1.1 Test Suites . . . 21
6.1.2 Input Data . . . 22
6.1.3 Input Domain Models . . . 23
6.2. The Experimental Phase . . . 25
6.3. The Data Analysis Phase . . . 26
7. Results 28
7.1. Base Case . . . 28
7.2. Individual Test Suite Analysis . . . 28
7.2.1 Test Suite 1 . . . 29 7.2.2 Test Suite 2 . . . 30 7.2.3 Test Suite 3 . . . 31 7.2.4 Test Suite 4 . . . 32 7.2.5 Test Suite 5 . . . 33 7.2.6 Test Suite 6 . . . 34
7.3. Overall Comparison between Strategies . . . 34
8. Discussion 37 8.1. Future Work . . . 37
9. Conclusions 38
1.
Introduction
Nowadays software programs are blended in our daily lives to help us through a large number of activities, across different domains. A lot of software are safety-critical, their behavior being crucial to the safety of human lives and the surrounding environment. Thus, they need to be reliable. The process of testing shows whether the software can be justifiably trusted because it tests its behavior and tries to finds possible faults [1]. Testing can assure with a certain level of confidence that the software will perform reliably well. However, there is no given systematic way on how to test or when to stop testing, while also considering the cost-efficiency.
The process of testing itself includes the creation of some test cases that can be later grouped into test suites. The results of each test are compared against the expected behavior of the system. The best way to test the software would be to put it in all the possible scenarios. That can be done by combining all the parameters with each other and looking at their interactions. For large systems, that becomes near to impossible because there are thousands of parameters and even more combinations of them. Nevertheless, empirical research has shown that not all the combinations cause failures and it is the combination of two to six parameters that can be more prone to errors [2]. Combinatorial testing is a proposed technique to come up with test cases that are covering the interactions between parameters and it has proven to be effective in detecting bugs.
Input partitioning is the first step of combinatorial testing as it selects the actual values whose combination will be tested. It would certainly be better if we could test with every single value, but the input space is so large that it would take even years. Therefore, it is easier to identify the values which are more likely to put the software in a faulty state, based on past experiences and domain knowledge. This technique is about essentially dividing the input space into equivalence classes, where all the values belonging to one class would result in a similar behavior of the software [3]. However, there are no systematic ways on how to choose these partitions and every test engineer can come up with different ones.
1.1.
Problem Formulation
Different partitions can result in different chosen values. The process of deciding the equivalence classes is very subjective and it depends on the test engineer’s own experience, but in any way it has a great impact on the resulting combinatorial coverage. Even if the test cases do not change, the combinatorial coverage changes with respect to the input partitioning strategy. Therefore, it would be interesting to explore this relationship and study which are the characteristics of the strategies that directly affect the coverage. This study suggested four well-defined strategies that show how to systematically partition the input space, and applied them to test cases from Bombardier Transportation company in Sweden to measure the combinatorial test coverage.
The main focus of this study is how exactly does each strategy affect the combinatorial coverage, which changes accordingly, while keeping the test cases unchanged. It will emphasize that is really difficult to say whether the test cases are good or bad just based on the percentage of combinatorial coverage, because that it is strongly associated with the input partitioning strategy that is used. Especially when it comes to systems with a large number of integer parameters, whose range is really varying and whose number of values that can be picked is higher.
A low combinatorial coverage does not necessarily mean that the test cases are not good enough. However, a higher coverage would be more desirable, considering the nature of safety-critical software that Bombardier works with. In this Thesis, it is shown how different strategies of input partitioning can affect the combinatorial coverage and the resulting number of missing test cases. Also, we hope that this Thesis is able to provide experimental evidence on their relationship.
The objective of this research is to give answer to the following research questions:
• RQ1: How does input space partitioning affect the combinatorial coverage achieved by test cases manually created by experienced engineers in industry?
• RQ2: How does input space partitioning affect the number of missing test cases needed to achieve a 100% t-wise combinatorial coverage?
We obtain the answers to these questions by considering six test suites from Bombardier. Each test suite has a different number of parameters and different parameter data types. The combinatorial coverage is calculated automatically by the Combinatorial Coverage Measurement (CCM) tool which is developed by the National Institute for Standards and Technology (NIST).
Although there are studies measuring the combinatorial coverage of manual test cases [4,5,6] or coming up with different input partition strategies [7, 8], to the best of our knowledge none of them study specifically the relationship between input partitioning and combinatorial coverage. It is widely accepted that input partitioning, being the first step of combinatorial testing, has an impact on it, but this Thesis aims to quantitatively define the relationship between them.
1.2.
Overview
Chapter 2 gives a background overview on the basic concepts of testing techniques while narrowing down to the two concepts of combinatorial testing and input partitioning. Chapter 3 gives the state-of-art related to our topic,emphasizing what previous research is done in this field and how our research is positioned amongst them. Chapter 4 explains the general method which is followed to come up with the results. Chapter 5 talks about the ethical and societal considerations with respect to our experiment. In chapter 6, the process of generating the results is described step by step in a way could be repeatable by other researchers given that they want to redo the experiment. The results are finally represented in chapter 7 using tables and also analyzed. Chapter 8 follows a discussion about the results and the way that they can benefit software test engineers and eventually conclusions are drawn in chapter 9.
2.
Background
This section aims to provide all the necessary knowledge that the reader needs to be aware of in order to understand the basic concepts, the research questions and how we worked our way through the results.
2.1.
Test Creation and Selection Problem
Software testing is an activity that checks whether the actual behavior of the program reflects the expected behavior specified in the requirements [1]. It also helps in detecting errors, faults or missing requirements and can be done either manually or automatically. There are two types of testing techniques, black-box testing, where you only look at the specifications, and white-box testing, where you look at the source code. Usually test engineers have limited resources to work with, those mainly being time or budget, and that is why they must choose carefully what and how will be tested.
The problem with software though, is that programs are intangible. In traditional engineering, the resulting artefacts display a continuous behavior. Let us take a bridge construction for example, the engineers can say that the bridge can hold up to two thousand kilograms and they guarantee with 100% confidence that if it holds for this weight, it holds for all weights lower than this as well. In software engineering, the software has a discrete behavior which means that if it works fine for a certain value it does not necessarily mean that it will work the same for all the values below or above. In this case the test engineers cannot say that a software works properly for a certain value unless tested individually.
It can be proven that even for small programs the number of values that a variable can take is pretty large. In a simple software with two integer variables, the number of values that we need to test is 65536 x 65536 = 4294967296 input combinations. And if the number of variables increases to six the time it would take is much more that the universe’s estimated age. It becomes clear that testing with all the values it is impossible. Hence, only some values can be chosen from the input domain, which consists of all the possible values that a program can take. Ideally, the test selection process should select a subset T of the input domain such as that the execution T will reveal all the errors. There are several approaches to this as discussed below.
2.2.
Testing Activities during Software Development
Testing is about exercising the software and trying to find errors rather than passing it as fault-free [1]. A wide-spread approach when it comes to safety critical systems is using the V-model, which will be briefly explained below. It is a step by step process that shows the software lifecycle. The focus of this Thesis will be on the right side of the model, which includes testing activities. There are various techniques that can be used to perform testing, but these can be divided into two main categories. We will introduce these categories as it is of utmost importance in order to narrow them down to the actual testing strategies that will be used in this study.
2.2.1 V-model
In software engineering the V-model represents a software development process that was initially derived from the traditional waterfall model, but instead of being linear, the process is bent upwards after the implementation phase to resemble a ’V’ [9] shape. It is also known as Verification and Validation model as it puts extra emphasis in the testing activities. It is based on the association of a testing phase with a correspondent development phase. As can bee seen in Figure 1, the left side shows the development process, from the conception phase until the detailed design phase of the software. The implementation phase joins the left side with the right side. The right side represents different levels of testing.
1. Unit Testing - These tests are written during the detailed design phase, usually by the developer. They test a simple module, which can be from a single method, to a class or interface. This process in mostly automated, for example in Java with Junit.
2. Integration Testing - These test are written during the architectural design phase. The reason is to test whether the modules operate correctly together, thus having the same interfaces to communicate, since they may be individually developed by different developers.
3. System Testing - These test are written during the requirements’ definition phase. They practically check if all the requirements are fulfilled and if the software exhibits the intended behaviour.
These tests are hierarchical which means that in order to go to the next phase you must have already finished testing in the current phase.
Figure 1: V-model [9]
2.2.2 Functional Testing
Functional testing is a type of software testing whereby the system is tested against the functional requirements or specifications [10]. Its purpose is to test each function of the software application by providing some input and verifying the actual output against the expected output. In this case, the test engineer has no information about the internal logic of the system. It is normally performed during the level of System Testing [9]. It can, on its own, be divided into positive functional testing where valid inputs are given, and negative functional testing where an invalid combination of input is given resulting in an unexpected software behavior [10].
Some advantages include that it shows if there are any faulty or omitted functionalities. It is especially helpful for a software with many lines of code, because code access is not necessary. It is less exhaustive and time consuming. It helps in finding out ambiguities in specifications, if any [10]. Test cases can be written as soon as the specifications are completed. Usually test engineers can perform the tests without having any previous experience with the implementation, programming language or operating system information [11].
Disadvantages include that the techniques belonging to this category can miss critical and logical errors. Also, performed on its own, it cannot guarantee the readiness of the software to be used. In addition, if the specifications are ambiguous or unclear, like it happens most of the time, test cases are not efficiently designed. In case a bug is found, a test engineer does not know how to correct it due to the fact that he has no knowledge about the implementation so he has to refer it to the developer.
2.2.3 Non-functional Testing
Non-functional testing checks the performance, reliability, scalability and other non-functional as-pects of the software system [10]. The test engineer has access to the source code and internal implementation. It is usually performed after functional testing and it is mostly automated by using several tools. Techniques belonging to this category are not concerned with the software requirements but only performance parameters, like speed. In other words, non-functional test-ing describes how good the product works. Some examples include stress testtest-ing, load testtest-ing, performance testing.
Non-functional testing has a great influence on customer and user satisfaction regarding the product. One of its advantages includes covering the test criterion which cannot be covered by functional testing such as statement or branch coverage. It ensures that the application runs efficiently and it is reliable. However, it does not help in identifying missing requirements.
2.3.
Input Partitioning
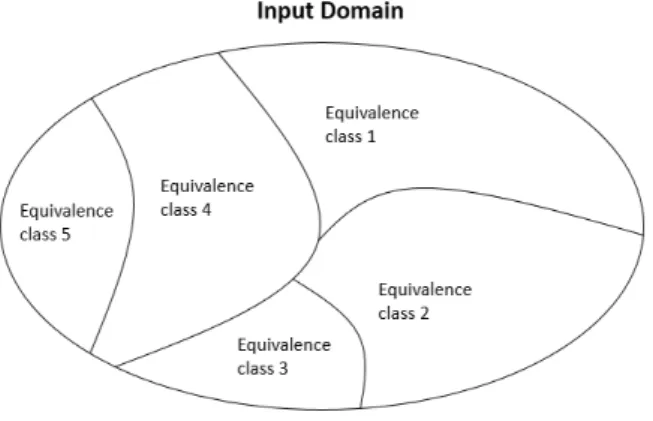
Input partitioning is part of the functional test design techniques, but rather than covering all functionalities, it is aimed at the most vulnerable parts of implementation. A standard approach to generating specification-based functional tests is first partitioning the input domain into equiv-alence classes and then selecting a representative value from each class [12]. The input domain includes all possible values that a program can take, and is divided into two or more disjoint sub-sets (not overlapping with each other), that are the equivalence classes. In literature, this process is known as subdomain revealing [13] or homogeneous subsets [14]. Any point in the space can be identified to lie in exactly one of these classes.
The idea behind input partitioning relies on the assumption that within an equivalence class, all the values are more likely to expose the same problems from a testing point of view. Hence, ideally, any element in a class will expose a problem as well as any other element inside the same class would. So, either the software produces a correct behavior for every value inside a partition or it produces an incorrect behavior. The goal of such partitioning is such that when the test engineer selects test cases, the resulting test suite will be able to exercise the entire domain [15].
Figure 2: Example of input partitioning for a specific input domain showing five equivalence classes
2.4.
Procedures for Input Partitioning
In literature, there are proposed some general steps to apply input partitioning. In this subsection we will go through some of them.
2.4.1 Category-Partitioning
Ostrand et al. [16] propose a method that begins with tracing the functional requirements to the functional units that can be tested independently. In this case, a functional unit can be a top-level user command or a function in the system. This process is similar to the high-level decomposition done by software designers. The next step, is identifying the parameters and environment condi-tions that affect the behavior of the system. Parameters are inputs to a functional unit provided by the user or another program. Environment conditions are characteristics of the state of the system at a given time.
The actual test case should include input values and expected outcomes. To select these values, the next step is finding categories that characterize each parameter and environment condition. This is done by reading the specifications to ensure that each parameter will have the same char-acteristics inside a category. Ostrand then explains that distinct choices that include all kind of
values (valid, invalid, erroneous or boundary values), should be made. This can be done based on the test engineer’s past experience or general knowledge about what kind of errors are more likely to occur. After this step, the values are written into test specifications. Constrains can be introduced since some interactions between values can be infeasible or can cause an undesirable effect.
2.4.2 Redefined Partitioning
Adrion et al. [17] state that there is no direct or systematically stated procedure for performing input partitioning. It would all depend on the requirements of the system under test, the experience and the understanding of the test engineer. Nevertheless, he recommends that input partitioning should be done throughout all the software life cycle. At the requirements’ definition phase, the specifications of the system would provide a coarse partitioning. Moving from one phase to other in the traditional V-model, the partitions would be refined more. In the design phase, the separate modules and their functionalities would give a clearer view that would again be further redefined in the implementation phase. This is called a top-down approach and allows for test cases to be derived at any development phase.
Once the partition is done, the input data should be identified. It should lie both on a partition and at the boundaries of each partition, which seems to be more likely to catch errors. Boundary values can be included in the special category together with zero-input values or input values that drive the output to zero. For more complicated data structures, the equivalent null data structures should also be tested. That would include for example, an empty stack or null pointer. For numerical values on the other side, values that are numerically very close and numerically quite different should be chosen.
2.4.3 Partition Analysis
Richardson et al. [18] provide a method called Partition Analysis to increase the software reliability. Their method would assist the testing process by considering information from both the system specifications and implementation. The idea is to partition the input domain into procedure subdomains, so that the elements inside each subdomain are treated uniformly by the specification and processed the same way by the implementation. The specification and implementation impose two different partitions, representing two ways in which the input space can be divided. In this method, an equivalence class that will take in consideration both of of the partitions and will be constructed by specifically overlapping them. The subdomains formed are called procedure subdomains.
Using the information related to each subdomain, test data can be selected through a process called Partition Analyzing Testing. One or more values can be chosen from each procedure sub-domain. In order to increase the probability of finding the bugs, the values should be selected appropriately to exercise the implementation with both typical data and unlikely data, specifically chosen to uncover bugs. This data includes, among other things, data that will cause the output to be zero and data of small and large magnitude. For polynomial computations, the number of values should reflect the highest order of the polynomial. Moreover, boundary points expose a great number of errors.
2.5.
Input Parameter Modelling
In this subsection we discuss on how to choose the most appropriate values based on different criterion.
2.5.1 Interface-based Modelling
The idea is to identify individual parameters and study them in isolation. Depending on their data types different representatives would be selected. For an integer, the highest and the lowest valid value within the range, and zero (if included) should be selected. For a string there should also be an option containing legal strings and another option containing illegal strings. For example, if
we had the name of a person, we would try with numbers as well. For arrays, depending on the expected size, options with larger size or empty arrays should be tested.
2.5.2 Functionality-based Modelling
The idea is to identify classes of inputs that would result the system to behave in the intended and unintended way. Mainly, the focus is on the specifications document and identifying the important values defined in the requirements. Another focus in this input modelling would be pre-conditions and post-conditions, by testing with values that are in alignment or not with the conditions. For example, if the function requires a parameter to be TRUE as a pre-condition, then we shall test it with TRUE and FALSE as well. Also, relationships between parameters can be studied such as the effect that they have on each other or if two parameters point at the same object.
2.5.3 Boundary Value Analysis
The Boundary Value Analysis (BVA) is a well-tested technique, that tests with values just outside or on the boundaries of partitions where the software should theoretically change drastically. Even with all the testing, maintaining the intended behavior near the boundaries is hard [19]. This technique is a follow-up to input partitioning and encourages the test engineer to pick values from the boundaries between partitions. The pitfall of it is that is very dependent on the identification of partitions or subdomains. BVA assumes that these subdomains exist, but it does not explain in any way how to derive them from the specifications, specially considering that the requirements documents are often ambiguous, unclear and even contradictory. Studies show that the system is more likely to fail with boundary input values [12], so a special attention should be given to these values.
2.6.
Combinatorial Testing
Software testing is always facing a seemingly big problem regarding to the large number of possible input combinations that make it practically impossible to show whether a program works correctly for all the inputs. Combinatorial testing offers a partial solution by reducing the size of a test suite. It is based on empirical research that shows that only certain values of one or two inputs trigger the failure regardless of the values of the other inputs [20,21,22,23]. This is known as the interaction rule. Hence, even if the input combinations are tested for a small number of values, the outcome will still be a very efficient testing at a low cost.
2.6.1 T-way Combinations
The more a software is used, the more likely is for failures to be discovered. These failures are known as interaction failures, because they occur when two or more values interact with each other causing the program to deviate from its intended behavior. Thus, they do not depend only on one parameter which leads to the need of testing the combinations between parameters.
Not every parameter contributes to every failure and usually failures are caused by one single parameter value or the interaction between a small number of parameters. For example, a software fails whenever x < 100 and y < 50 are true. This is called a 2-way combination or pairwise testing, where all the possible pairs of parameter values are included in the test cases at least once. It is very effective when it comes to locating errors, as research shows that most failures include one or two parameters [20]. However, there are cases where the unusual combination or three, four or more can result in a failure. We would need to test for 3-way and 4-way combinations. That means that every possible combination of values for three or four variables that someone can think of, should be included in the test cases.
In real software, the number of parameters whose combination can cause a failure can go up to six, according to research [2]. In Figure 3, we can see that a high percentage of faults can be found just with 2-way testing and this percentage increases to nearly 100% with 6-way combinations, tested on several software. There are progressively fewer failures induced by the interaction between three or more parameters. In that context, covering all 3-way interactions is similar to exhaustive testing from a fault detection point of view. It will not test all inputs, but
those inputs that are not tested will not make any difference in revealing errors. The interaction rule provides high assurance, if we are able to ensure the 100% coverage of all 3-way, possibly up to 6-way combinations.
Figure 3: Fault detection of t-way combinations [2]
2.6.2 Combinatorial Coverage
Combinatorial testing is a reasonable approach considering the fact that it is nearly impossible to test all the combinations. However, many companies might probably have already well-established testing procedures, that are developed over time and that they are unwilling to include combinato-rial testing because it is seen as extra effort. The test engineers are used to a certain way of testing and they would like to reuse their test cases to save money and time. These tests are not usually derived based on combinatorial testing. Nevertheless, combinatorial methods can still be useful if this kind of environment. By introducing the term of combinatorial coverage, we can measure the percentage of t-way combinations for which all possible variable-value configurations are covered. For a set of t variables, a variable-value configuration is a set of t valid values, one for each of the variables [2]. For example, given 3 binary variables, a, b and c, one of the possible variable-value configurations would be a=1, b=1, c=1. Another one would be a=0, b=1, c=1. This are 3-way combinations. For 2-way combinations we would choose a=1, b=0 or b=0, c=0 and so on.
Combinatorial coverage can check the quality of test cases, proving this way to be an important aspect of software assurance. If the test suite, for example, covers almost all 3-way combinations, then it might be sufficient for the amount of assurance that is needed. It also helps with under-standing the degree of risk that remains after testing. If the coverage is high then we can presume that the risk is small, but if the coverage is low then the risk can be substantial. There are also other ways to test the software such as statement coverage, path coverage or branch coverage, but in order to execute them you need access to the source code. On the other hand, combinatorial coverage is a black-box technique, so the input is specified based on the specifications and no further knowledge of the inner workings of the software.
To understand better the concept of combinatorial coverage, we provide the following example from [24].
In the table there are represented four binary values a,b,c,d and each row represents a test case. Of the six possible 2-way variable combinations, ab, ac, ad, bc, bd, cd, only bd and cd have all four binary values covered, so the simple 2-way coverage for the four tests in Table 1 is 1/3 = 33.3%.
Table 1: Test cases with four binary values [24]
2.6.3 Cost and Practical Considerations
Generally, using combinatorial testing is a cost-effective choice, especially for safety-critical systems. But, as with any engineering field, trade-off must be made, considering for example the risk of failing to find more bugs while increasing the number of test cases, which can be a very time-consuming activity on its own. Depending on the resources, the size of test cases may vary. Unfortunately, there does not exist any formula which can directly give the number of test cases necessary for fully testing a software. However, there are studies that show when the cost of testing will exceed its benefits. [25,26].
The recommended method though, is to start using pairwise combinations, continue to increase strength t until no errors are detected by the t-way tests, and optionally try t+1 to ensure that no other errors are found [2]. The number of test cases would increase logarithmically with the number of parameters, so for example if a system with 30 parameters requires seven hundred test, a system with 50 parameters would only require a few dozen more.
2.7.
Input Partitioning and Combinatorial Testing Relationship
As mentioned before, one of the main advantages of combinatorial testing is the interaction rule which says that failures, most of the time, include only the interaction of a few parameters. Thus, combinatorial testing makes the testing process more efficient, but if input partitioning is included, it will be more effective. Usually, test engineers just select representative values based on the requirements document, so they can exercise every feature of the software that is being developed. That means that a few important combinations can be missed, and even though the software passes through all tests, it is still not guaranteed that it will behave correctly all the time.
To illustrate the problem, the requirement specified in Figure 4 shall be studied [2]. Choosing representative values is easy most of the time. They are mostly boolean parameters so the values in that case would be either TRUE or FALSE. Also, the days of the week are specified and we have seven values. When it comes to time, which in this case is represented in minutes, it can be seen that there are 1441 values that is can take. Now that can be a problem, from a combinatorial testing point of view. Since the number of test cases is proportional to vtwhere v is the number
of variables and t is the strength of the combinations, the result for a 4-way combination would be 14414, therefore around 4,3 x 1012 tests. This is where input partitioning can come in handy.
By dividing the input values into partitions and selecting one representative, the number of views will be considerably lower, and consequently the number of combinations will also be lower. Thus, input partitioning is usually the first step of combinatorial testing. Both of this these methods in combination will produce a smaller set of test cases that will be necessary for testing purposes.
3.
Related Work
Combinatorial testing and input partitioning are an active area of research. This section will outline some of the most recent papers and articles published in the literature. It will also identify where does our research stand compared to other publication and what are we adding to the general body of knowledge.
3.1.
Effectiveness of Input Partitioning and Combinatorial Testing
The first point to consider when talking about the effectiveness of input partitioning is how the subdomains (partitions) are chosen. Even though it is a key technique in functional testing, there are little systematic approaches that explain the steps on how to do it [16]. Dividing into equivalence classes can be quite difficult in many cases. Unless these classes are identified correctly, such as putting values who are likely to cause the same type of behavior in one partition, it can prove to be a waste of time [14]. And if the partitions are poorly chosen, then the coverage will not be as good as it shows [27]. In one study [28], the authors raise the problem that the equivalence classes are not always obvious and that rather than promoting input partitioning as a technique, the skill and knowledge to do it well, should be promoted instead: ”...the instruction ’do domain testing’ is almost useless, unless the tester is well versed in the technology to be tested and proficient in the analysis required for domain partitioning”. Moreover, in practice testers do not do real input partitioning, especially at the start: ”Rather then selecting points each subdomain, they first select several test cases, ignoring the subdomain divisions, run the test cases, and see which of the subdomain remains ’untouched’ or insufficiently tested” [15].
The input space modelling is an important task, as well as one of the main challenges, thus should be managed carefully especially when it comes to combinatorial testing [29]. The values that are picked will serve as an input to the test cases. Among techniques such as random testing, each-choice and base-choice testing, the combinatorial testing, more specifically pairwise testing as the most economical alternative to testing all the combinations, is the most prominent [30]. It generates all the possible combinations for each possible pair of inputs. It has a lot of benefits such as increased Combinatorial Coverage up to full coverage, increased fault detection ratio and reduced overall costs for a software. However, Kuhn et al. [23] suggests that for software with a large number of parameters, faults are also likely to be found by 3-way or higher n-way combinations. This kind of testing is rare because algorithms are very slow.
In one study [29], Borazjany et al. used real-life applications to study the effectiveness of combinatorial testing. The results showed that combinatorial testing is very effective in terms of achieving high code coverage and fault detection. In his book, Copeland says: ”The success of this technique on many projects, both documented and undocumented, is a great motivation for its use” [31]. In another study [32], Lei et al. suggest that pairwise testing is effective for various types of systems.
On the other hand, in their study [28], Bach and Schroeder say that even though combinatorial testing can be very helpful, it can create false confidence if not applied wisely. They say that critical thinking requires us to change some misconception about pairwise testing such as:
1. Pairwise testing cannot find all the bugs.
2. Pairwise testing is more efficient compared to testing all the combinations but not necessary when compared to testing the combinations that matter.
3. Some bugs are less likely to happen because the user inputs are not randomly distributed. Therefore, the study [28] concludes that all the testing techniques are heuristic, which means they are shortcuts to success but do not guarantee it. There is not just one testing strategy that can be used to guarantee with confidence that the system will work. To be more successful the test engineer should develop his skills and judgement. That can be a long-term learning process but it is the responsibility of each of them to do so.
3.2.
Test Set Reduction
Reducing the number of test cases is of a great importance because it means that less resources will be used (budget, time, human resources). Test engineers should always aim for a cost efficient number of test cases that can exploit most faults in the software. There have been proposed several techniques in literature to do that.
In their work [33], Fang and Li introduce an agile strategy called Equivalence Classification Partitioning (ECP) that divides the test suites into subdomains. The subset of the subdomains selected would have to provide a complete coverage for a test criterion that could be a full statement coverage, path coverage, combinatorial coverage etc. During the software life cycle there is a lot of testing activities. The developers would periodically test the software after for example, adding a new feature or making a small change. To save cost there is the need to better choose the test suites that would result in finding the largest number of bugs. This method, which is implemented as a tool, will improve the efficiency of re-testing. It is mostly automatic, with little manual pre-processing and uses the Classification Tree Method (CMT). The equivalence partitions are derived from the requirements document and the CMT expresses the complete combinations. The tool prioritizes a test suite T, which among all the test suites has proved to have a higher contribution to the test selection criterion.
Another study [34], suggests a test reduction technique by using combinatorial coverage. The greedy algorithm that they implement, considers the combinatorial coverage of events and also the order in which they occur. They use a 2-way combinatorial coverage criterion because it is easier to maintain it close to 100% fault detection effectiveness. They also introduce two new concepts: ”...the consecutive sequence-based criterion counts all event sequences in different orders, but they must occur adjacent to each other. The sequence-based criterion counts pairs in all orders without the requirement that events must be adjacent”. The results are promising as they lower the number of test cases in the experiments and also manage to find 100%, 95% and 96% of the bugs respectively in the three use cases that were studied.
Blue et al. [7] also propose another method called the Interaction-based Test Suite Minimization (ITSM). It is very easy to model and does not have the feature of adding constraints. However, it can be applicable when creating new test cases is expensive or when there are complex restrictions that are difficult to model.Compared to a naive implementation, the algorithm that they present is improved in three ways: avoiding unnecessary calculations, test prioritizing and maintaining a mapping from each test to the target it covers. It is also backed up by two case studies. The results show that 70% of the initial test set is reduced.
In our research we have used the default tool CCM for measuring the combinatorial coverage and generating the test cases. This tool can automatically generate the minimum number of missing test cases, so in that sense we are also doing some test set reduction.
3.3.
Approaches to Input Partitioning
One study [8], proposes new strategies to perform the input partitioning. Even though equivalence partitioning is traditionally a specification-based technique, it is often difficult to cover all the possible combinations that might result in bugs just from the specification information. The strategies that they suggest are white-box and grey-box, based on the information gained through the source code to partially help with equivalence partitioning. The experimental results showed that these strategies performed better than the traditional equivalence testing technique. It could be noticed that white-box technique discovered 39,8% of the planted bugs compared to the black-box technique that only had 37,3%. Grey-black-box method eventually was the most efficient in detecting the number of bugs around 64,9%, but the most ineffective in terms of time.
The aim of our study is to measure the combinatorial coverage from the point of view of different strategies. In that context this is a valuable input for our research. White-box and grey-box technique can be definitely one of the potential ways to partition the input space, however not one of the suggested strategy in this research due to the complexity of the source code of the system under test.
3.4.
Functional Dependencies
One study [35], makes suggestions and imposes rules on how to accommodate functional depen-dencies.Those are constraints between variables and what values they can take, which makes it a little bit more complex to generate all the possible combinations from combinatorial testing. This problem has been recognized since earlier [36]. In this case, equivalence partitioning is used to group the values that have a common characteristic into classes. That way it is easier to know if the combination between two classes is feasible or not, according to the specifications. The study shows the impact of these constraints in the total combinatorial coverage. The constraints would normally lower the combinatorial coverage and increase the number of test cases, because there would be some fixed dependencies that needed to to be respected.
Another study [37], again points out the ongoing challenge of generating test cases while con-sidering constrains. There are two main challenges. The first one is providing valid test cases. Combinations that are impossible to occur should not be generated. There is a difference between combinations that are impossible or conceptually wrong, and combinations that lead to an unin-tended behavior of software, also seen as a wrong behavior. The latter should be tested thoroughly. The second challenge is more subtle and it is related to the input partitioning. Not all the valid test cases are equivalent if the input space is not adequately partitioned. The paper suggests a way to incorporate embedded functions in combinatorial measurement tool that would allow engi-neers to add constraints in natural language. They used PHP as a prevalent language in software engineering.
Constraints are an important part of input modelling. They can come in the form of depen-dencies or more generally in the form of valid ranges for intervals. The test cases that we are working with do not have any invalid combination explicitly mentioned in the test specifications. Therefore no constraints were included in the input models. However, special attention was paid to parameters’ range constraints.
3.5.
Combinatorial Coverage of Manual Test Cases
When it comes to testing activities, a key issue is how much testing is enough. According to Kuhn [38], usually testers stop when they reach some coverage criterion such as code coverage. But for black-box testing that is much more difficult to tell. Combinatorial coverage is one of the proposed way to measure the quality of test cases [39].
In one study [4], Miraldi et al. reported the combinatorial coverage of manually created test cases by test engineers. He also measured the number of missing test cases to achieve a 100% coverage for t-way combinations, with t varying from two to six. The results showed that that manual test cases achieve on average 78% 2-way combinatorial coverage, 57% 3-way coverage, 40% 4-way coverage, 20% 5-way combinatorial coverage and 13% for 6-way combinatorial coverage. However, this study did not consider the effect of input partitioning as it only took into account the values that were present in the manual test cases whereas in reality a variable would take a wider range of values. While the engineers who wrote these test cases probably did some input partitioning in order to choose the representative values present in test cases, its impact to the combinatorial coverage was not the main focus of the paper. Another study [5], also measured the combinatorial coverage of different test suites taken from spacecraft companies. The results from the paper are represented below in Table 1,2,3.
Table 2: Results from spacecraft software 1
Maximoff et al. [6] in their study, use partial t-way coverage to analyze Integration and Test (I&T) data from three separate NASA spacecraft. They call it space coverage where the state-space of n variables is represented by a n-dimension vectors. Each vector represents a parameter
Table 3: Results from spacecraft software 2
Table 4: Results from spacecraft software 3
with all the values it can take. Two notions of partial combinatorial testing are developed because they cover one limitation for the traditional way of doing it. If the test cases are not written with combinatorial coverage in mind they will most probably score a low coverage, leading test case with varying efficacy to have the same combinatorial coverage. From a quantitative point of view, that is not good when it comes to comparing test suites between each other. It is also briefly mentioned that the test cases do not even achieve a 100% pairwise coverage: ”...the identification of those pairs could suggest deficiencies in the initial test set ”.
Kuhn et al. [38] also studies some manual test sets focusing on the number of faults that can be discovered by the t-way combinatorial testing of different strength.. The results showed that 66% of the failures were triggered by only a single parameter value, 97% by 2-way combinations, and 99% by 3-way combinations. Another study [40], also uses manual test cases to show that most of the failures are found by low strength t-ways combinations. This is especially true for systems with high number of boolean parameters.
In our Thesis we will also find the combinatorial coverage achieved by the manually written test cases and then compare it with the coverage achieved by our proposed strategies.
3.6.
Comparison between Random Testing and Combinatorial Testing
When it comes to partition testing there are two extreme cases, exhaustive testing and random testing [15]. While exhaustive testing requires every value of the parameters to be explicitly tested like it was a partition on its own, random testing consists of only one partition.
Duran et al. [41] first compared partition testing with random testing. They calculated the probability of finding at least one set of inputs who would lead the software to an erroneous behavior. They did a lot of experiments and checked the number of bugs that were found. Their conclusion was very interesting because of the fact that random testing performed relatively well. If in some case partition testing is too expensive compared to random testing for the same number of test cases, the latter is more cost effective in terms of cost per fault discovered. Even though partition testing was better than random testing at finding bugs, the difference in effectiveness is small.
Hamlet et al. [14] replicated the same study because they thought that the results were coun-terintuitive. It was surprising to see that the best systematic technique was little improvement of the worst. They came to the same conclusions, those being that the input partitioning is not a good technique to inspire confidence, unless partitions with high failure probability are identified. If they are not identified correctly, which happens quite a lot, then partition testing in no better than random testing.
In one study [42], Schroeder et al. designed a controlled experiment to compare the fault detection ability between t-way testing and random testing. The results also showed that there is no significant difference in the fault detection effectiveness for the applications that were studied. However, they do not expect for these results to apply to every possible scenario.
In another study, Vilkomir et al. [43] looked at the relationship between random testing and combinatorial testing. In other words the values were picked at random to create test cases, whose combinatorial coverage was later measured. The results concluded that random testing achieved a high level of 2-way combinatorial coverage. They usually provided a 90-97% coverage, but still a lot of tests were needed to achieve 100% coverage.
The results are overall very interesting. It would be very interesting if the same study is replicated again using different Input Partition strategies and see if the coverage provided by those strategies and random testing is still the same. But, that is not the scope of this thesis even though it would be something to consider for future work.
3.7.
Automating Combinatorial Testing and Test Generation
Combinatorial Testing has been automated by a lot of tools such as Combinatorial Coverage Measurement tool (CCM) [44], which is the tool that we have used in our research work as well. It was developed by the National Institute of Standards and Technology (NIST), and it has been proven to be an essential tool in assuring that critical points are included in the test cases. It is widely spread and its functionality well tested. Considering that the number of parameters that contribute in an unintended behavior of the software is relatively small [22], the tool implements a way to measure up to six-way combinatorial coverage using covering arrays. It also has additional features to provide the number of missing test cases and which are these test cases.
In literature there are several algorithms to automate Combinatorial Testing and calculate the coverage:
1. Algebraic - this algorithm uses the Covering Arrays (CA) and it is based in mathematical calculations. It can generate arrays with minimal size, which is the minimum number of test cases needed to achieve a 100% combinatorial coverage. It needs three parameters; t - is the strength of the CA which shows how fully we cover the possible rows in the array, v - the number of possible values that a variable can take, k the number of all the columns in an array.
2. Greedy - where CAs are build incrementally using heuristic search. The heuristic search is a technique to solve problems faster than the classic method, in a reasonable amount of time. For example most problems are exponential but the heuristic search allows us to reduce it to polynomial. Therefore, this approach is very wide spread even though it sets an upper limit for the size of the array which cannot be surpassed.
3. Other algorithms such as genetic algorithms that are being used for optimal solutions. Based on these algorithms more than 50 tools have already been published [45]. Most tools however lack practical features to be used in a real industrial setting.
There is also an attempt to automate the input partitioning process. Nguyen et al. [46] propose a method to automatically generate partitions based on machine learning. The idea behind that is simply starting from a random input generation and then grouping together the inputs for which the software behaves similarly. That would create equivalence classes and the results show that these classes are rather close to what can be manually done by engineers. This automated inference can later be used in combinatorial tests to come up with all configurations.
Nonetheless, there is no further work in trying to automate the process of generating t-way combinations from equivalence classes which could as well be one of the future goal for this Thesis.
4.
Method
In this section we will talk about the research methodology and the reason why it was specifically selected. We will suggest some input partitioning strategies that will be used on the test suites to measure the combinatorial test coverage. Eventually, we will explain in detail the research process that was followed.
4.1.
Research Methodology
For this research project we decided to go with a semi-controlled experiment. Semi-controlled experiments are used when the researcher can some control over the situation and can partially manipulate the behavior of the variables directly, precisely and systematically [47]. In our situation, we have total control over the input partitioning strategies that we chose and partial control over the test cases. Even though the project is done in collaboration with a company, Bombardier Transportation, we were offered a wide variety of test cases and we selected the the ones which better allowed a diversity, and which were not similar to each other. By this approach we can generalize the results more. Semi-controlled experiments can be done offline in the laboratories, but also online in the field, like this project.
Experiments can investigate in which situations a claim is true. This means it can be used to confirm theories or conventional wisdom, to explore relationships and validate measures [47]. In our case our claim is that Input Partition has an impact on Combinatorial Test Coverage. That is more or less a conventional wisdom, but we aim to precisely explore the relationships between the two concepts, quantitatively. The independent variable is the input partitioning strategy and the dependent variable is the combinatorial coverage. Another variable that we would like to keep constant is the experience of the test engineers who wrote the test cases. Ideally, all the test cases are written by equally experienced engineers and that will not affect the results.
The fundamental of an experiment is randomness [47]. However, our sample of test cases is a convenience sample which means that it was not selected on random and that due to time constraints. Although, the sample was chosen to represent as well as it can the variety of test cases and parameters.
This approach compared to a systematic mapping study because there is not very much infor-mation regarding the topic. Also, it was chosen over a survey because every company uses different methods of input partitioning, which it is most of the time done implicitly by the developers and that defeats the purpose of this study to be conducted using only systematic approaches. A case study would seem like a good choice because the study is being conducted at a company, however case studies are mostly used when you are observing a phenomenon and trying to come up with a theory [47]. At the company, they are only testing using one strategy of input partitioning, but the aim of this research is larger, looking at different strategies. Therefore we decided that a semi-controlled experiment would be a better choice.
4.2.
General Approach to Input Strategies
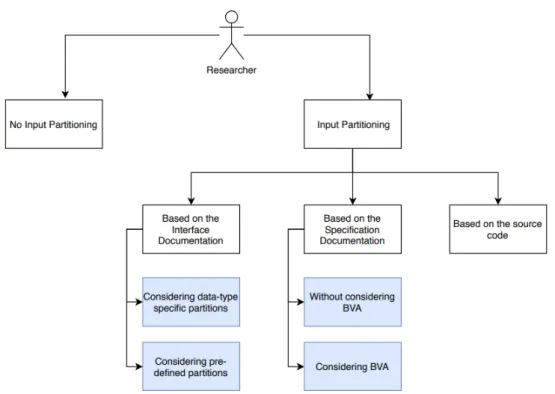
Input partitioning can be a very subjective task and different engineers can reach different con-clusions. In Figure 5, we suggest some systematic strategies that can be chosen to perform input partitioning. We found particularly interesting to see how the combinatorial coverage changes when we have little to no knowledge about the system under test compared to when we have the specifications. In the first case, we could come up with two strategies, either we use the informa-tion that we know about data types and create the partiinforma-tions based on that, or we define several partitions with so specific rule. In the second case, we thought we could either use Boundary Value Analysis or not. Two other strategies include no input partitioning, which is not in itself a strategy, and partitioning from the source code, as a form of white-box testing.
No Input partitioning
This strategy considers every possible value that a parameter can take. It is known as exhaustive testing and the results would show with a great confidence if the system behaves as expected under every situation. However, it is computationally expensive and very much time consuming.
Figure 5: Input partitioning strategies
Parameters can take a lot of values, from two values if we are talking about booleans to 1014 for a long long int parameters. If we were to combine all of these values, with all the values of other parameters to perform a combinatorial testing, the resulting coverage would be too low. It is almost impossible to measure all the combinations, hence the test cases for such a strategy will always be bad, in the sense that they will achieve very low coverage, possibly below 1%. This is the reason why this method is never used in practice, and once more the importance of input partitioning is highlighted.
Input partitioning based on the Interface Documentation
With large software, interfaces are essential. Different modules may be developed by different engineers and they must have a common way to communicate with each other, so the integration process becomes easier and the software works well as a whole. In order to do that, there must be some information about the data types that are required between different modules. Interface documents provide the necessary information such as inputs and outputs of the module. Let us take for example a smart air conditioner which turns ON if the temperature is below 22◦C and turns OFF when the temperature is larger than or equal to 27◦C. It gets the information from a temperature sensor which sends a signal every five minutes. The interface document in this case would specify the type of parameter that is being exchanged between the sensor and the air conditioner which is a int data type. In other words, the sensor has no inputs, but it has an int output, while the air conditioner has an input which has to be int as well, and no output.
• Based on datatypes
Since we already have information about the data types, we can easily check their range and partition accordingly. For each parameter it would be interesting to check its minimum and maximum value. Also, look for the so-called special values, such as 0. We would expect this method to reach a higher coverage because these are very important values that should be included in the test cases. The typical partitions would be the following:
– UNIT16: [0,0] ]0,65535[ [65535,65535]
– INT8: [-127,-127] ]-127,0[ [0,0] ]0,128[ [128,128]
– INT16: [-32768,-32768] ]-32768,0[ [0,0] ]0, 32767[ [32767,32767] – Boolean: 1, 0
• Based on predefined partitions
Since we already know the data types and their ranges, we can try to further divide their input space into smaller partitions, not just by considering the minimum or maximum value. These partitions are predefined while having no information at all about the specifications of the system, therefore it is expected a lower coverage since the engineers mostly focus on the values relevant to the specifications. The predefined partitions were chosen to be the following: – UINT8: [0,0] ]0,10[ [10,100[ [100,255] – UNIT16: [0,0] ]0,10[ [10,100[ [100,1000[ [1000,10000[ [10000,65535] – INT8: [-127,-100[ [-100,-10[ [-10,0[ [0,0] ]0,10[ [10,100[ [100,128[ – INT16: [-32768,-1000[ [-1000,-100[ [-100,-10[ [-10,0[ [0,0] ]0,10[ [10,100[ [100,1000[ [1000, 32767] – Boolean: 1, 0
Input partitioning based on the Specification Documentation
The specification document includes requirements which are derived from the client for a specific software product. It specifies how the system should behave under every circumstance. The requirements should be complete, non-ambiguous and not conflicting with each other, so that the testing process can become more efficient. Also, test cases should be easily traceable to the requirements.
• Not considering BVA
From the specification document we can get insights about important values. Continuing with the example of the air conditioner, we would definitely consider as important the values 22 and 27, as these are mentioned particularly over all the other values that an int can take. Once we have identified those, we also have identified our partitions. In this case those would be [min value,22] ]22,27[ [27, max value] and we would choose as a representative value something below 22, something between 22 and 27 and something greater than 27. This however, is not considered to be very effective because as mentioned before studies show that boundary values are more prone to expose errors. Nevertheless, these values are very important and should be tested to see how the software works generally.
• Considering BVA
It is always advised that Boundary Value Analysis (BVA) should always accompany input partitioning techniques. That means that values just a little bit lower or greater than the boundary plus the boundary itself should be tested. Boundary values are the important values that we identified earlier from the specifications. Those are located in the joint points between two partitions. Following the example above, the values suggested by BVA would also be 21, 23 and as well 26, 28 in addition to 22 and 27.
Input partitioning based on the Source Code
Eventually, a strategy that is a type of white-box testing can be used. In this strategy all the information will be derived from the source code. That is because whenever there is a boundary value that would be equivalent to an if statement in the code, so we could identify the partitions. In this strategy the test engineer does not have access to the specifications but he can partition according to the values that are mentioned in the code.
In our experiment we have decided to go with the strategies represented with a blue color in Figure 5, as we have concluded that the the source can get complex very quickly and it would be hard to identify every important values and no input partitioning is very exhaustive and time consuming. The idea is to see how each strategy impacts the combinatorial coverage and then relatively comparing the number of missing test cases between them.
4.3.
Research Process
The process will follow several steps. Firstly, the input domain of the program will be identified. That would require several weeks to get used to the system under test, terminology and abbre-viations. After that, the requirements will be properly studied, which will help in identifying the input variables, their data type and any pre or post conditions related to them. To continue, the input domain will be divided into partitions with the expectation that every value in a partition would be likely to make the system behave in a similar way. Input partitioning can be a subjective approach, however the strategies were created in such a systematic way so the process can be repeatable and generalized. Representative values will be chosen from each partition and through the Combinatorial Coverage Measurement (CCM) tool, developed by National Institute of Stan-dards and Technology (NIST), the combinatorial coverage will be measured. The automation of this whole process, though not one the aim of our research, is included fur future work references. The same process will be repeated for each strategy. If any problems arise during the process the researcher will ask for help from the university supervisors and from the company supervisor to find the best solution.
Figure 6: Research process used to study the impact of several input partitioning strategies on combinatorial coverage
For each of the input partitioning strategies the number of missing test cases will also be generated. This number will help in relatively comparing the strategies between each other. A low number of missing test cases would show that the test engineer is really close at achieving 100% combinatorial coverage for the specific test suite. Also, the number of missing test cases will be compared between strategies within one test suite, not between test suites. That is to avoid that the characteristics of the test cases to affect the results, since they are taken from different projects, written by different test engineers and include different data types. If one strategy has a high coverage, let’s say 70% for one test suite, and a low coverage for another 5%, that does not necessarily mean that one test suite is better than the other. However, we would expect that the strategies are proportionally equivalent from one test suite to the other.
To sum up, the input data for our experiment will the the input variables in the test speci-fications. This can be boolean, int, unsigned int or analog. They can take different values based on their type, which are independent from other data types. That is why the input data that we take is the independent variable. The output data from the experiment, or the data that we will collect, is the combinatorial coverage percentage for different strategies and the number of missing test cases accordingly. These are the dependent variables. They will help us in understanding
which strategy is closest to reaching full coverage and why, what are the missing test cases and if it would be feasible to include them in the test specifications.
5.
Ethical and Societal Considerations
In this research project there are a lot of stakeholders which are included among which, the university and the company that is helping with the test cases. There are some ethical principles in research that this study has taken into consideration:
• Consent - it has the consent of the company to look and explore through the data. The researcher, before exposing any information to the public, has gotten the consent from the supervisor that represents the company’s side regarding to sensitive information.
• Confidentiality - the researcher signed a Non Disclosure Agreement (NDA) with the company which stands for protecting the privacy, confidentiality and integrity of the data and of the participants. That is done through limiting access to data.
• Scientific value - it considers the greater good for the society of test engineers while hoping to help them produce better test cases. This topic has not been researched before and we believe it would be a good addition to the body of knowledge.
• Researcher skills - the researcher followed scientific methods and the results are reproducible. Also she has the necessary skills to conduct the research and also she received help from several senior supervisors.
• Harm to Company-Society relations - the researcher was careful is not exposing quality shortcomings when it came to the company’s testing techniques.
• Psychological harm - it also considers the welfare of participants. The researcher understands that colleagues at the company have their own duties and did not interfere during their busiest hours.
Finally, similarly to the Hippocratic Oath, the researcher pledges to always practise integrity, privacy of information and respect, while using her skills to serve to the development of software testing activities.
6.
Experiment Conduct
This section will describe all the steps that we have followed in order to come up with the results. The goal is to give a clear and logical structure of the work. It also includes additional background information that the reader needs to understand our interpretation of results. The experiment is described in such way that its steps can be repeatable and its results can be similar for anyone who follows the same process.
6.1.
The Setup Phase
Before continuing with the actual experiment, the researcher needs to get familiar with the domain and gain some general knowledge. Then, she can choose between different test suites, so they best represent a diversity of variables and situations. From the test suites, the input values need to be identified as they will serve as the input data for the experiment. These values are chosen as representative by the test engineers. After that, the input models will be created based on the different strategies as depicted in Figure 5. The chosen strategies are input partitioning based on the interface and specification documentation.
6.1.1 Test Suites
The test suites that we have selected represent a convenience sample. They were chosen to be most dissimilar from each other in terms of data type variety and number of test cases.
Test Suite 1
The test suite number one is about one component of the train that decides whether emergency brakes should be applied or not based on the train speed. It is composed of four variables, where three of them are boolean which describe signals from the brake sensors and the fourth one is an unsigned int UINT16 which is the train speed. It has 16 bytes and therefore it can vary from 0 to 65535. The train speed should be positive and according to the requirements is should not overpass 86 km/h.
Test Suite 2
The test suite number two is about the battery charger. This test suite includes four inputs: one unsigned int UINT8 to represent the battery voltage that ranges between 0 and 255, one unsigned int UINT16 that represents the DC load current, one int INT8 that represents the battery temperature and ranges between -127 to 128, and finally one int INT16 that represents the battery current and ranges between -32768 to 32767. According to the specifications, the following are the valid intervals for these variables.
• UINT8: 0 to 150 • UINT16: 0 to 1500 • INT8: -127 to 128 • INT16: -2000 to 2000 Test Suite 3
The test suite number three is about measuring the temperature. The test suite has only two inputs which are the transformer oil temperatures from two sources. Its data type is represented as ANALOG16 that ranges between -32768 to 32767. This data type shows that the system is receiving a signal which is continuous. Since the software itself has a discontinuous behavior it has to sample the signal periodically and round it up to the closest integer. So it essentially works as if it would be an INT16. The valid range from the specifications is the same as its data type range between -32768 and 32767.
![Figure 1: V-model [9]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4551258.115920/9.892.259.637.318.540/figure-v-model.webp)
![Figure 3: Fault detection of t-way combinations [2]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4551258.115920/13.892.258.633.213.509/figure-fault-detection-of-t-way-combinations.webp)
![Figure 4: Specification of input parameters to an access control module [2]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4551258.115920/14.892.338.558.975.1054/figure-specification-input-parameters-access-control-module.webp)