V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Computer Science with
Specialization in Embedded Systems 30.0 credits
ROBUST COMMUNICATION IN
HETEROGENEOUS AND
DISTRIBUTED SYSTEMS
Lennart Eriksson
len12007@student.mdh.se
Examiner: Masoud Daneshtalab
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisor: Mohammad Ashjaei and Nandinbaatar Tsog
M¨
alardalen University, V¨
aster˚
as, Sweden
Company supervisor: Fredrik Bjurefors,
Saab, J¨
arf¨
alla, Sweden
Abstract
This thesis work has aimed to implement a robust communication system for military aircrafts produced by Saab. A big part of the thesis focuses on a comparison study of different possible designs and their impact on the system. From the comparison study a decentralized, Peer to Peer, Publish/Subscribe system was selected for implementation. All publications are sent directly from a publisher to the subscribers without any intermediate forwarding node. This has shown good results in comparison to the previous centralized solution where all data had to pass through a single server node. The new system has one master node that is responsible for registrations of both publishers and subscribers and distribute any necessary information to affected clients. This thesis has shown that the Single Point of Failure that was one of the main issues on the previous design has been removed and the performance of the system has increased as well. The Round Trip Time of a set of messages has shown to be improved up to 70.78%.
Contents
1 Introduction 7 1.1 Motivation . . . 7 1.2 Requirements . . . 7 1.3 Problem Formulation . . . 8 1.4 Thesis Overview . . . 8 1.5 Outline . . . 8 2 Method 9 3 Background 10 3.1 Distributed and heterogeneous systems . . . 103.2 Real-time and best-effort systems . . . 10
3.3 Electronic warfare . . . 10
3.4 Fiber optic Ethernet . . . 10
3.5 Internet Protocols . . . 11
3.6 Publish/Subscribe . . . 11
4 State-of-the-art analysis 12 4.1 Centralized vs. Decentralized Communication . . . 12
4.2 Publish/Subscribe . . . 14
4.3 Monitoring of Distributed Systems . . . 15
5 Technical Description 16 5.1 Hardware setup . . . 16
5.2 UDP or TCP . . . 16
5.3 Type of Publish/Subscribe . . . 16
5.3.1 Topic or Content Based . . . 16
5.3.2 Centralized or decentralized . . . 16
5.3.3 Comparative study of decentralized designs . . . 17
5.4 Multicasting . . . 27
5.5 Final System Design . . . 27
5.5.1 General overview . . . 27 5.5.2 Master Node . . . 27 5.5.3 Publishing/Subscribing Nodes . . . 28 6 System Model 29 7 Result 30 7.1 Experimental result . . . 30 7.1.1 Performance . . . 30 7.1.2 Availability . . . 32 7.1.3 Reliability . . . 33
7.2 RQ1 What are the solutions to provide a reliable communication in the mentioned system? . . . 34
7.3 RQ2 What is the most suitable solution to provide reliability, availability and per-formance in the system? . . . 34
7.4 RQ3 How the selected solution can be implemented in an efficient way? . . . 35
8 Conclusion 36 8.1 Discussion . . . 36
8.2 Future work . . . 36
References 37
List of Figures
1 The research method . . . 9
2 An example of a C/S architecture . . . 12
3 An example of a P2P architecture . . . 13
4 An example of a hybrid architecture . . . 13
5 An example of a multicast tree . . . 14
6 Client publishing time . . . 31
7 Server and master node forwarding time . . . 31
8 Comparison of the time to distribute one message. . . 32
9 Rount Trip Time (RTT) tests . . . 33
10 Number of messages handled by the server per one publication of topic t1. . . 34
11 Number of lost messages out of 10,000 . . . 34
A1 Decentralized system using Distributed Hash Table (DHT) or similar. . . 40
A2 Decentralized system using DHT or similar. . . 42
A3 Decentralized system with one of the publishers of one topic is responsible for dis-tributing the data to subscribers. . . 44
A4 Semi centrailized system where a master node is responsible for all the registrations and deregistrations of both subscribers and publishers. After the registration the communication will be direct and not going through the master. . . 46
A5 Decentralized system where the connection of publishers and subscribers are handled by the switches in the system. . . 48
A6 Semi centralized system where a publisher sends data to the closest switch, the switch then distributes the data to those nodes that are subscribers of that data. . 50
List of Tables
1 Explaining Pugh matrix value for testability . . . 18
2 Explaining Pugh matrix value for integrability . . . 19
3 Explaining Pugh matrix value for maintainability . . . 20
4 Explaining Pugh matrix value for availability . . . 20
5 Explaining Pugh matrix value for reliability . . . 21
6 Explaining Pugh matrix value for performance . . . 22
7 Explaining Pugh matrix value for monitorability . . . 22
8 Explaining Pugh matrix value for scalability . . . 23
9 Explaining Pugh matrix value for complexity . . . 24
10 Explaining Pugh matrix value for network load . . . 24
11 Explaining Pugh matrix value for timeliness . . . 25
12 A Pugh matrix with the same weight on all parameters . . . 25
13 A Pugh matrix with higher weights on testability, integrability, availability and complexity . . . 26
14 A Pugh matrix with higher weights on availability, reliability, performance, scala-bility, network load and timeliness . . . 26
A1 Explanation of abbreviations . . . 39
B1 Client sending time to other clients in new version. . . 52
B2 Test results for client sending to the server in old version. . . 53
B3 Test results for server sending to clients in old version. . . 54
B4 Test results for RTT time in new solution. . . 55
Acronyms
CAN Control Area Network C/S Client/Server
DHT Distributed Hash Table EMI Electromagnetic Interference EW Electronic Warfare
HTS Herman Transaction Service IP Internet Protocol
IPC Inter-process Communication ORTE Open Real-Time Ethernet P2P Peer to Peer
PC Personal Computer P/S Publish/Subscribe QoS Quality of Service
RACED Rate-Adaptive Complex Event Detection ROS Robot Operating System
RQ Research Question
RTPS Real-Time Publish/Subscribe RTT Rount Trip Time
SMR State Machine Replica SOTA State-of-the-art SPF Single Point of Failure S-RIO Serial RapidIO
TCP Transmission Control Protocol
TOPS Transaction Oriented Publish/Subscribe TTP Time Triggered Protocol
1
Introduction
In the area of surveillance, Saab group offers efficient solutions for decision making and surveillance systems to detect and protect from different types of threats. Saab builds Airborne, land based and marine radar systems for signal intelligence- and self protection systems. With the newest generation of electronic warfare systems for the aircrafts Gripen and Globaleye under development, an upgraded version of the communication system is of interest. The system itself is a highly distributed system of heterogeneous nature with more than 10 but less than 20 nodes. These nodes, or subsystems, are placed on different locations of the aircrafts to either collect or act upon information to or from other systems. Therefore the communication system is necessary in order for the subsystem to communicate with each other in a real-time manner in order to act upon incoming threats as fast as possible and thus possibly avoid accidents. So far the communication speed has been increased by the use of fiber optical Ethernet. Fiber optical Ethernet has a few advantages where high throughput and less interference from electronic warfare systems [1] are amongst the most demanded.
1.1
Motivation
When it comes to distributed systems of any kind, the communication is key to everything. In a distributed system, several subsystems are connected to each other in order to share information and help on making decisions for what to do. In order to create a robust communication the entire system needs to have a common understanding on how messages are structured and what kind of information that are sent out on the bus. This thesis work aims to improve an existing Inter-process Communication (IPC) that are implemented on military aircrafts in order to provide a more robust and reliable system.
1.2
Requirements
When looking at IPC in distributed systems there are several aspects to consider, e.g. availability of data, transfer speed, error handling and so on. Now looking at a distributed system in the military domain and especially in military aircrafts, on which this thesis has its focus, the reliability of the communication becomes crucial. The aircrafts from Saab contain several computational devices, also called nodes, that holds sensors, actuators and other computational devices that need to communicate with each other in a best-effort way, but predictability should always be considered. It is important that the communication is fast and reliable, meaning that the overhead should be kept to a minimal but still make sure that important messages do not get discarded, since the system might need to act on incoming threats, or the pilot might need important information from the system to make the best possible decision at any given time.
A few requirements that are set up by Saab are:
1. The software should be able to send messages to other software in the system 2. The software should be able to choose what type of messages that should be received 3. The software should not have to know the recipient of a specific message
4. The software should not have to know where recipients are located (the address of a nodes) 5. All communications should be monitored
6. If one node in the system stops working the communication between the rest of the system should not be affected
7. The software needs to be portable and be able to move between hardware 8. The communication should not use low level acknowledgment
9. The communication should not use flow control mechanisms 10. The communication should be asynchronous
11. The software should provide communication integrity, i.e., interface versions are the same as the rest of software
12. The communication should be fault tolerant, Erroneous messages should be discarded 13. It should be possible for software to choose on message level which messages should be
received
14. Delay of data should be handled by the above layer of software
15. Retransmission of messages should be handled by above layer of software
1.3
Problem Formulation
In the list of requirements mentioned in the previous section, software is referring to the above layer, hence, not the implementation done in this thesis but rather the parts of the system that are calling the implemented version. The communication on the other hand is where the focus of this thesis will be and these are the direct requirements that needs investigation.
By looking at these requirements it is possible to form a set of Research Question (RQ)s that this thesis should aim to answer, these RQs are listed below:
RQ1 What are the solutions to provide a reliable communication in the mentioned system? RQ2 What is the most suitable solution to provide reliability, availability and performance in the
system?
RQ3 How the selected solution can be implemented in an efficient way?
1.4
Thesis Overview
The main issue with the system that Saab uses today is that it has a Single Point of Failure (SPF), making it less robust then desired. They are using a centralized Publish/Subscribe implementation, which has the disadvantage that one node is responsible for all the distribution of data going through the system. If the node would crash, or loose connection with the rest of the system, no data will be transferred and the entire system could therefore be considered as dead. Also, the server node becomes a bottleneck since all communication has to pass through it, meaning that the throughput of data is highly dependent on that node. The system that is to be investigated is at the moment a best-effort system but with predictability in mind when it comes to design choices of communication and similar. This makes it important that the communication is both fast and also reliable to some extent, which is what this thesis aims to provide by doing a State-of-the-art (SOTA) analysis in order to find a suitable implementation. The implementation will then be evaluated in order to verify the new system and compare against the existing. In communication there are many parameters that can be evaluated like testability, integrability, availability of data, reliability, etc. and since the scope of this thesis cannot evaluate all these things the main focus will be on availability, reliability and performance.
1.5
Outline
The rest of this document is outlined as follows. Section2 will explain the research method that will be used in this thesis and Section3 will explain some of the technical information used in the thesis work. In Section4 a presentation of the current state-of-the-art in the thesis area are presented and Section 5 will go through the decision process over the thesis period as well as present a comparison study over a set of designs. Subsequently, Section6 will explain the design of the system model used for evaluation and in Section7the result of the evaluation of the system is presented. In Section8 we conclude the work and discuss the result as well as future work.
2
Method
This section will explain the research method to be used for the thesis. Also, the requirements and RQs presented in Section1.2and1.3 will be addressed with a proposed way of solving them.
For this thesis there will be two methods used to come up with a suggested implementation. First a literature study followed by a comparative review. The main research method will be the literature study, to determine the SOTA in the field. Related work needs to be checked in order to determine suitable solutions of the problems. A literature study is probably the most suitable and effective method to use for this purpose.
From the literature study, a set of suggested designs can be presented. Each of these imple-mentations will then be explained in short where the main characteristics are listed and possible benefits and drawbacks are explained. The characteristics of the different designs will then be compared against each other in a Pugh matrix1 in order to find the most suitable solution. The
benefit of Pugh matrices is that each criteria that the systems are evaluated against can be weighted differently depending on importance. This gives the effect that different weighting could lead to different results and by comparing the results it is possible to find what implementation would be more beneficial over others.
From the comparison it is possible to get a design that should be implemented and evaluated. Along with the implementation it is important to come up with a set of tests and desired outcomes that the system can be evaluated by. There should be tests that can be applicable on both the system under development as well as on the existing one, so that the possible improvements can be verified. There will most probably be tests that are not applicable on the existing system but they should still be implemented so that further evaluation can be done on the new system.
During the evaluation it should be shown how the availability of data, the reliability and the performance of the system correspond to what is expected from the SOTA analysis and the comparative study. Possible ways to evaluate the availability are to see how often the data that are sent out to the system is actually received by all the nodes that request it. Reliability on the other hand should show how the system handles possible loss- and corruption of data, and how the communication might be affected by this. The performance of the communication should always be sufficient for the system so that tasks in the different nodes are not halted or missing out on important data in order to meet necessary deadlines.
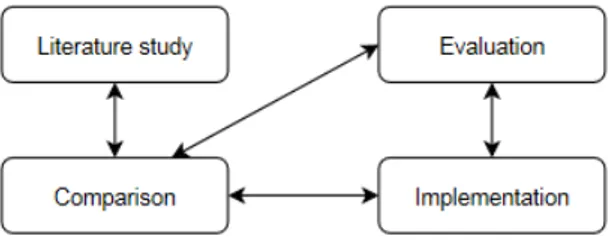
A suggested graph of the research method used for this thesis is shown in Figure1.
Figure 1: The research method
Looking at the requirements in Section1.2it can be seen that the first is rather obsolete since if a software cannot send messages to other parts of the system, then there are no communication. Looking at requirements 2–4 it can be seen that the communication should be somewhat anonymous and it is the receiver that should decide on what type of data it wants to listen for. This is something that Publish/Subscribe (P/S) provides and therefore a big part of the SOTA will be dedicated in this area. Along with the P/S, requirements 10 and 13 will be solved on its own since the receiver decides what content it is interested in and the communication will be asynchronous. In the P/S paradigm it is possible to solve requirements 5, 6 and 12 by implementing different solutions in to the protocol. The rest, requirements 7–9, 11–12 and 14–15, will be matter of design for the system and therefore will not require any research in the SOTA.
3
Background
In this section the fundamentals of communication within distributed and heterogeneous systems will be discussed. A small section about electronic warfare will be presented and the benefits of fiber optic Ethernet is explained.
3.1
Distributed and heterogeneous systems
Tannenbaum and Van Steen defines distributed systems as a collection of independent computers that appears to its users as a single coherent system [2]. This means that there are several com-puters, also called subsystems or nodes, that need to collaborate with each other and distribute their knowledge. By doing this it is possible to make up a better prediction of the reality and perhaps predicts possible outcomes in the near future. One characteristic that is very common in distributed systems is that the different subsystems consist of different types of computer or processing units. They can hold different type of operating systems, if any at all, and the type of processing unit can be of different manufacturers and thus not be fully compatible on every level. This is what describes a heterogeneous system and they need a common link in between so that they can transfer their information regardless of what type of processing unit it is and interpret it correctly. This is where the IPC comes in and creates a bridge between all systems. The communication can act as a middleware that uses the same protocol on all processing units and thus making them compatible with each other.
3.2
Real-time and best-effort systems
Real-time systems in comparison to general purpose systems, which are satisfied with getting the correct result but not necessarily care about the time, requires predictability in the timeliness of actions. It is simply not enough for the results to be correct, it is also important that the system is not halted and making itself or other parts suffer and missing deadlines.
Real-time systems can be either hard, firm or soft real-time. Hard real-time systems are often safety critical systems where the miss of a deadline can make the system suffer from a total failure where fatality or big cost damages might be the outcome. Soft real-time systems on the other hand will not cause any fatal outcomes on the miss of a deadline but the Quality of Service (QoS) is affected.
A best-effort system is referring to the communication service used where the network do not provide any guarantees that data is delivered or the QoS. Services will make their best effort to deliver messages but the delivery might be delayed because of the traffic load etc.
3.3
Electronic warfare
Electronic Warfare (EW) is any military action that uses the electromagnetic spectrum to include direct energy in order to control the electromagnetic spectrum or attack an enemy. The purpose of EW is to deny advantages of the electromagnetic spectrum to enemies and can be applied from both air, sea, land or space. The point of EW is to make noise in the form of radar frequencies, radio communication and other things. This can be used to escape possible attacks from enemy aircrafts or similar.
3.4
Fiber optic Ethernet
When it comes to communication mediums in distributed systems standards like RS232 and RS485 or even I2C are not very good options since they lack high speed [3]. Instead there are other mediums that suit better like Control Area Network (CAN), FlexRay and Time Triggered Protocol (TTP) [4]. Recently fiber optic Ethernet has become more common since it makes the system higher anti-interference [3]. It also benefits from the built in addressing of nodes that comes with the use of TCP/IP. Also Serial RapidIO (S-RIO) has received a lot of attention since it is a high performance, low pin count, packet switching system [5]. Next Generation Space Interconnect Standard (NGSIS) recently choose S-RIO as their base protocol for digital data transport in there future projects because of its high performance of 6.25 Gbps per lane used [6]. As mentioned in
the report the use of 8 – 16 lanes would give capacities of 40 – 80 Gbps. As mentioned in papers [7,8] fiber optic Ethernet currently transmits data with 40 Gbps moreover the technology is ready for 100Gb/s already. Although, S-RIO benefits from having a low overhead and acknowledgment scheme on a hardware layer as well as the error handling, thus making potential errors being detected earlier [9]. However, fiber optics has the benefit of not being susceptible of Electromagnetic Interference (EMI), which for example can be the case of coaxial cables [1]. It is also harder to tap the communication since it does not have any electronic radiation.
3.5
Internet Protocols
When using Ethernet as a communication medium it is common to use the Internet Protocol (IP). The IP has the possibility to address other nodes in the system by a so called IP-address, there are two major protocols that are built on top of the IP, namely Transmission Control Protocol (TCP) and User Datagram Protocol (UDP). Both are widely used in many areas of computer communication and is a standard for regular Personal Computer (PC)s. Nowadays it is starting to be more and more common in the embedded area as well since it is easy to address other nodes in the system with less wires. Although it is not possible to provide real-time communication with these protocols, TCP provides a guaranteed communication and UDP provides a best-effort one. TCP is reliable and deterministic in the packet ordering but if only one packet is delivered out of order the protocol demands to retransmit the data again. It also uses acknowledgment to verify that the information is received on the other end of the line. UDP on the other hand has no such mechanisms and can therefore keep the header information for each message much smaller and provide higher throughput of data. This comes with the price that no information are guaranteed to arrive at the receiving end without corruption or losses.
3.6
Publish/Subscribe
In the area of communication within distributed systems there has been several ways to send data over the entire system. Today more and more are moving toward the P/S architecture where nodes are connected with each other in an indirect manner. The system often consists of a broker node that acts as either a store and forward node or a rerouting node. In general the subscribers register the interest in a specific topic or a pattern of events and later on receives any event matching the prescription, regardless of whom the publisher node is [10]. Since subscribers do not have to listen to specific publishers it is an interesting technique that could be beneficial in this type of application. P/S is also known as event-based systems and has the strength in being fully decoupled in both time, space and flow in between publishers and subscribers. There are several subsets of the P/S communication where push/pull-based, topic/content-based amongst other which are described in more details in [10,11].
4
State-of-the-art analysis
In this section the SOTA will be carried out and related systems and the current status of the different parts of the communication will be discussed and compared. By looking at similar systems it is possible to find inspiration on how to possibly improve the implementation that this thesis aims to implement and thus come up with new approaches that yet have not been evaluated.
4.1
Centralized vs. Decentralized Communication
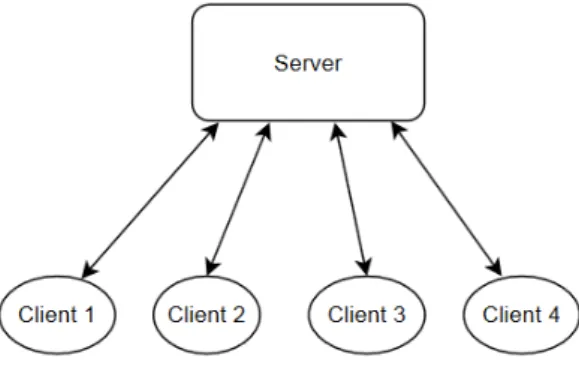
Client/Server (C/S) communication paradigm is the most common centralized communication and has been around for a very long time. It builds around the fact that a server holds all the information that a client can expect to get. This is the back bone of protocols such as HTTP, SSH, Telnet and many more [12]. Although it is widely used and have the benefit of being simple in the way that the user knows where to look for the expected data, it also comes with a lot of drawbacks. Since the communication is centralized around the server it is clear that it becomes a bottleneck when more clients are added. The computational load increases for the server with an increased number of connected clients which makes the system less scalable and making the performance suffer. The server is also target of SPF since if the server dies all the clients suffer form not getting data and can thus also be considered as dead [13]. Although it is possible to employ faster and better hardware or even implement redundant hardware to increase the performance it does not solve the problem entirely. Figure2shows a common C/S setup.
Figure 2: An example of a C/S architecture
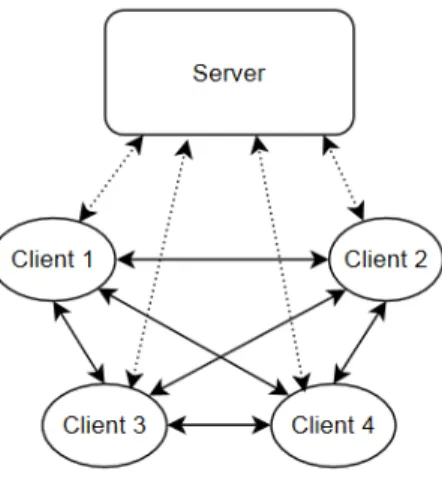
Looking at fully Decentralized system the communication do not go through a specific node, the processing and forwarding of data is done in a more distributed way. This is achieved by having direct coupling between 2 nodes that shares data. Pure Peer to Peer (P2P) communication is one example of this where the system is decentralized, self-organizing and scalable [14], where nodes communicate directly with each other, easing the network and computational load for an individual node in the system. The overall performance of the system can in that case also increases since the data can go directly to the node that requires it and not having to be forwarded in any way. By using decentralized solutions the SPF is removed since if one node in the system fails to communicate or by some means stops working the rest of the system can still continue as usual without any major interrupts. Although the drawback of a pure P2P network is that the complexity increases and since there is no server in the system, the security and configuration becomes an issue [13]. The data on the network is also not coherent and there are no part of the system that checks if specific nodes are present or if they have suffered from any failure. An example of a pure P2P network is shown in Figure3.
There are also the possibility to create hybrid solutions where a master node is responsible of providing peers with information about where other peers of interest might exist. The master node, unlike the server node in the current version used by Saab, do not distribute any data but instead holds the necessary information about the system and acts like a dictionary for the peers instead. One example of this solution is Robot Operating System (ROS) [15] where P/S is implemented in such a way that one node in the system, called master node, is responsible for holding the information about all topics that are present in the system. Whenever a node wants
Figure 3: An example of a P2P architecture
to subscribe for a new topic it tells the master node about its interest and the master node then tells the publishers of that topic that a new subscriber has arrived. The publisher then adds the new subscriber to the topic and once a new publication is available the information is sent directly to the node and not through the master. This could be of interest for this thesis since it provides the possibility of subscribe or unsubscribe from topics by only calling one node and not having to search the entire network. This type of solution would also remove the SPF although it has the disadvantage of using a master node. If the master node for some reason stops working it will not be possible to create new connections between publishers and subscribers. But on the other hand those connections that are already established are not affected by this. In Figure4the example of such a hybrid solution is shown.
Figure 4: An example of a hybrid architecture
Another way of semi-centralization is shown by Castro et al. where they have implemented a system called SCRIBE [16]. They use rendezvous nodes that builds up a tree of subscribers dependent on the topic id. SCRIBE is built upon PASTRY [17] which is a P2P system that uses a key value pair for every IP address in the system and by sending to any id the node with the numerically closest key will receive the message. This is utilized by SCRIBE in a way that SCRIBE builds a multicast tree from a rendezvous node that is associated with a topic. Each PASTRY node can have a 128 bit id and every topic is a numeric value in the same range (could be decided by the user). Each topic id is then compared with the PASTRY node ids and the PASTRY node numerically closest to a topic id will act as a rendezvous node for that topic. From this rendezvous node a tree can be built so that the forwarding of data can be balanced amongst several nodes instead of a single one. The downside of this type of solution is that if the rendezvous node fails in some way the entire topic will get lost, although this is handled by PASTRY by sending keep-alive messages in order to verify that no node in the system disappears without informing the rest of the system. An example of a the treelike structure is shown in Figure5.
Figure 5: An example of a multicast tree
4.2
Publish/Subscribe
There has been a lot of advancements in the P/S area over the last decade and the main differences are about centralization vs decentralization and topic vs content-based solutions.
K¨undig et al. [18] present a P/S system for large scale networks that does not use any broker nodes. Instead of using brokers they try to build paths by sending out messages to the system. If two messages intersects it has two options, either the two messages are the same and in that case the messages are merged and the search of a path continues. If the two messages instead were a match between a publisher and a subscriber of the specified topic the path is complete and confirmation messages are sent back to both parties. This is an interesting technique that could give better response to the system but also creates a higher order of complexity that makes the system harder to evaluate. Another down-side of this type of solution is that it creates a sort of flooding in the system in order to find possible connections and thus using more bandwidth than necessary.
Dolejs et al. [19] test a real time communication model based on 100 MB/s Ethernet using UDP/IP and P/S architecture. They look at processing time over transmission time of packets and found that the main bottleneck for the Open Real-Time Ethernet (ORTE) and Real-Time Publish/Subscribe (RTPS) under evaluation was the processing of packets. They give the hint that a better implementation and faster hardware could solve these problems and the throughput can potentially be sufficient for real-time applications such as the one implemented in this thesis. Cugola and Margara [20] and Shatsky et al. [21] presents solutions for multiple event based P/S systems which can have a higher complexity of the types of events that a subscriber listens for. Cugola and Margara call their implementation Rate-Adaptive Complex Event Detection (RACED) and it has its own event definition language that the programmer uses to link several events together. Shatsky et al. call their system Transaction Oriented Publish/Subscribe (TOPS) and is based on Herman Transaction Service (HTS). This system is meant to be broader in the way that it can be used and supports customization in a large variety of features. Their evaluation of these systems shows good result and the use of more complex events could be useful in many areas including this thesis.
Triantafillou and Aekaterinidis [22] and also Pandey et al. [23] uses DHT as an overlay in order to get a decentralized system. Both paper builds upon CHORD which is a widely used DHT implementation and they claim that their respective systems are highly scalable and self-organizing. Trianfillou and Aekaterinidis use a two layer CHORD ring where nodes can be divided by the possible performance on the network. Those nodes that have greater processing possibilities belongs to the main ring, whereas the nodes that cannot spend as much time distributing data belongs to smaller sub-rings where they handle smaller amounts of data. This is an interesting solution that gives possibility to actually scale a system without increasing the workload on nodes that otherwise might not be able to handle it. However, for such a small scale system as the one this thesis is focused on it might be more complexed than necessary. The number of nodes in the
system are quite static and especially during flight time no new nodes will be attached, therefore the benefits would most probably be neglectable.
Baldoni et al. [24] present a publish subscribe solution with focus on availability of the data. They have a centralized P/S system which is content-based and their main focus is on the possibility to have different ranges of availability in the different messages. They classify the availability in three classes, 0-availability, ∆-availability and ∞-availability. The 0-availability means that the message is only available at the time of the publication, all subscribers that are not registered for the information or for some other reason are not able to receive at the moment will not get that information. ∆-availability on the other hand are publications that will stay alive and available for a set period before it either goes obsolete or for some other reason is removed from the system. ∞-availability means that the information will stay available till the infinity, or until the system is turned off. This is interesting since many systems could benefit from not loosing information as soon as it has left the publisher.
4.3
Monitoring of Distributed Systems
When looking at related work for monitoring of data in P/S systems, most articles are focused on centralized solutions where all data go through one broker node and thus making the monitoring simple but still efficient. Examples of such work is presented by Witting et al. from IBM [25] where they monitor data going through a few web pages. Their solution has a central broker who receives all publications and then distributes the data to those subscribers who show interest in said topic.
ROS, being a semi-centralized system, have the possibility to choose 2 different ways of monitor-ing data, one called loggmonitor-ing and one called record and replay as can be seen in the ROS handbook [26]. The logging consists of 5 types of messages that are sent for logging independent parts of the system. This is mostly for debugging and error logging where an individual node in the system might fail. The record and replay on the other hand records the communication by selecting what topics that are of interest. As mentioned in their handbook it is possible to listen to all topics but for larger systems with a lot of data going through, the computation will be heavy. Although this seems like a good solution there are no motivation to why this technique was chosen and it is also never mentioned if it has any possibility to record everything but later on sort the data or select to playback only certain topics from the system. This is something that could be of interest for this thesis and even if it is supposed to be more decentralized than ROS some inspiration can be taken about having a recording node or set of nodes.
5
Technical Description
During the work with this thesis, decisions regarding the technical parts and the design of the implementation have been made. This section is divided into smaller sections which covers the different parts of the communication and include different choices made along the way. In the final part of this section the final design is explained.
5.1
Hardware setup
The nodes on the aircraft are the same as used on todays platform and the tests will be conducted on an evaluation platform that is simulating the setup of the aircraft. These nodes are provided by Saab and the code base that these systems are running will be available to our disposal in order to get a better test setup, saving both time and possible errors. The connection between the nodes are fiber optic Ethernet and this is not undergoing changes in the nearest future and thus will be the target of evaluation. Since Ethernet is used, the IP protocols will be used.
5.2
UDP or TCP
When looking at transport protocols there are two major solutions, namely TCP and UDP. They have different characteristics and both are used in a wide area of applications. TCP, being reliable and deterministic in the packet ordering, also provides error-checking as a built in solution with acknowledgment on a lower level. This is suitable for applications where reliability is more impor-tant than the latency that is introduced with it. UDP on the other hand provides a more efficient communication where the smaller overheads and no mechanisms for retransmission are key to the increased data throughput. There are also no mechanism that provides any guaranty of packet ordering or if a packet is lost or corrupted. Although as can be seen by requirement 8 in Section
1.2, the system should not use any low level acknowledgment and along with the fact that some reliability can be built upon the UDP protocol it is decided that this is what to be used on the system.
5.3
Type of Publish/Subscribe
There are several decisions to be taken in this section regarding how the P/S system should be designed. Therefore this section is divided into even smaller sections that covers the different aspects that affects the design.
5.3.1 Topic or Content Based
The topic based systems provide lower complexity when it comes to matching publications with subscribers and this creates the possibility of less computational power as well. Content based systems are good when it comes to systems where 100 or more nodes are interested in the infor-mation. For those cases the content based solutions can make sure that the information actually is of interest. Since this system is rather small for being a P/S system and the nodes should not be put under more stress then necessary a topic based system is to prefer. Also, todays system is built with topics, making the implementation more consistent with the current solution.
5.3.2 Centralized or decentralized
A centralized system, as the one used by Saab today, have the benefits of being simple to implement and having low computational power on the publishing nodes. All nodes in the system only has to know about the server node that all communication goes through. With that said, it is not an elegant solution when it comes to failure in the system. One example is the case that if the server node goes down all communication will go down with it, also known as SPF, Single Point of Failure. A decentralized solution on the other hand does not have a SPF, but depending on the way it is implemented some parts of the communication can still suffer from a single node failing. Having a fully decentralized system where all nodes send their publications directly to the subscribers in a P2P manner will always stay alive even if a single node fails. And even if a multiple broker system
is used it is possible to only loose some part of the system if one node goes down. The rest of the system that is not directly related to the failing node will not suffer at all. This is a good reason to go for a decentralized system where the higher throughput and more reliable communication can be created.
5.3.3 Comparative study of decentralized designs
Five different types of systems have been designed in order to find the most suitable implementation for the communication. All these designs will be compared in a Pugh matrix further down where the different criteria are weighted differently. A short explanation of the suggested designs are given here but more details are shown in AppendixA.
Design 1 A fully decentralized P2P system where every node has a DHT in which the informa-tion about every recipient that the node communicates with is held. This system is quite scalable but has the disadvantage of connecting new nodes to the system since it is necessary to inform all nodes about its arrival. This is similar to the systems described in [22, 23].
Design 2 A multi master system where each topic is assigned to a responsible node. Every publication of a topic will go through the node responsible over that topic and the responsible node will distribute the data to the subscribers of the topic. This is how systems like SCRIBE [16] works and it is quite scalable although if a node gets to much subscribers it will suffer and possibly get to heavy workload.
Design 3 A system similar to ROS [15,26] where one node in the system acts as a master node with all the information about the publishers and subscribers. The communication between publishers and subscribers, however, goes directly to the intended nodes without any interference from the master or any other node for that matter. This system is highly scalable and since all registrations of publishers and subscribers go through a common node it is less complex implementation. Although the downside of having one master node is if it goes down, which would lead to new registrations of publishers or subscribers cannot take place. However, those connections that are already established will not be affected.
Design 4 Similar to Design 3 where the switches in the system can be used as master nodes and leading to a more distributed registration system. When a new publisher or subscriber registers for the system it tells the closest switch about its new interest and that switch will in turn tell the affected nodes. However, if one of the switches would go down only the nodes connected to that switch would be affected if they try to register a new interest. The rest of the system would still continue as usual. The complexity will increase since the switches need implementation as well as the information shared amongst them must be kept redundant and up to date.
Design 5 This system is a combination of todays system and Design 4 where the switches are the ones distributing all data. The publishing nodes will only publish to their closest switch which in turn will distribute the data to the subscribers of that topic. This creates slightly less complexity and data going from publishers. However, the complexity and computational load for the switches will increase more.
These designs will be evaluated in a Pugh matrix which is a qualitative technique to rank multi-dimentional options of an option set. A regular decision matrix differs a bit in the way that parameters are evaluated since for Pugh matrices each parameter can get a weight of which the parameter is multiplied. Regular decision matrices only consider the first score and add the parameters sum together. In the Pugh matrices shown here it is used as a way of ranking different designs against each other on a set of parameters and their importance on the system. The score of each design is calculated as shown in Equation 1. d stands for the design, p is parameter, n is the number of parameters, dp is the parameters value for design d, wp stands for the weight of parameter p and Scored is the final score that a design gets.
Scored= n X
p=0
dp∗ wp (1)
The parameters that each design will be evaluated by in the Pugh matrix are Testability, Integrability, Maintainability, Availability, Reliability, Performance, Monitorability, Scalability, Complexity, Network load and Predictability. Below, each parameter will be explained in short and compared, and the values used in the Pugh matrices will be explained. The Pugh matrices will then be shown with different weights for different parameters in order to compare what solution would be beneficial in what scenario. Todays system is the reference system that each parameter is compared against. A score of 0 means that it is the same as todays system while negative points are worse than today and positive is an improvement over todays system. The ranges are between -2 and 2 in order to keep the complexity of deciding a score simpler and more efficient.
Testability
For the purpose of evaluating the system there are a necessity to write tests that can 1) verify that the implementation behaves as expected, 2) find possible bugs in the system that could potentially cause problems, and 3) validate the performance of the system. For this reason it is good to see what impact each design comes with. The evaluation of testability is presented in Table1.
Design Score Explanation
Design 1 -2 This design will be more difficult to test than todays system since there are no common source or node in the system, every test, therefore, needs to be performed on each individual node.
Design 2 -2 This design compared to design 1 has a lot bigger complexity where the decision making of responsibility amongst the nodes needs to be considered. Thus the tests needs to be more extensive. Although when the structure of the nodes are decided the tests around the communication should be easier than Design 1 since it becomes more of a centralized system.
Design 3 0 This design is probably the easiest amongst the systems to test and could possibly be simpler but at least similar to todays system since the design has the central broker that will keep track of the nodes and have partial responsibility over the connections.
Design 4 -1 For this design the testing would be similar to design 3 with the difference that this is more distributed. It is also necessary to have tests that can verify the redundancy between switches so that all nodes are up to date. Design 5 -1 Just as for design 4, this design suffers from the fact that the brokers are
distributed amongst the switches. Although the switches becomes some what a more centralized point in the system and thus making it a easier than Design 1 and 2.
Table 1: Explaining Pugh matrix value for testability Integrability
In order to integrate the system into the current there are a few things that can be compared. How much of the current system will be affected by this, and is there any changes that are required by the above layers of implementation. The evaluation of integrability is presented in Table2.
Design Score Explanation
Design 1 -2 This design will require structural changes in how registrations of topics are designed and how the nodes should be informed about where to send their information. All nodes needs to know about at least one other node in the system to which it can ask for information about publisher or subscribers of a topic. The node that is asked, in turn, need to know about the system or forward the requests to another node etc. which would require some additional mechanisms that is not available in the current system.
Design 2 -2 Similar to Design 1 this also needs additional mechanism for registration of publishers and subscribers as well as a mechanism to decide which node is fit for being responsible over certain topics, meaning that the node should for instance have enough processing power to distribute a topic to the set of subscribers etc. Thus this design could be seen as worse than Design 1 although -2 is the lowest rank possible.
Design 3 0 This design, being the most similar to todays system, benefits from the fact that there already exists a node that gets all the information about publishers and subscribers for topics. This makes it possible to use the cur-rent design and redo the parts where todays server forwards messages and making the clients do that instead. When clients registers as a subscriber or publisher for a topic the new master node just forwards the necessary information to those nodes affected by the change instead.
Design 4 -1 This design is similar to design 3 however the fact that there are several masters that needs to be kept redundant will affect the system slightly more. There is a need of an additional mechanism to keep the redundancy amongst the masters for example.
Design 5 -1 Same as for design 4 but with the fact that the clients could be kept more similar to todays system where the server would forward the messages.
Table 2: Explaining Pugh matrix value for integrability Maintainability
As mentioned in [27] maintainability is the ease of which a software can be modified. This represent the majority of the cost for the life-cycle of software development and is therefore an important aspect in the any design of a system. Maintainability includes, but is not exclusive to, the time it takes for a person to get up to speed with the system in order to solve problems or improve the system. There are several ways that this can be done but most solutions are based on estimations in some way, as for this thesis. The comparison of the maintainability in the system is presented in Table3.
Design Score Explanation
Design 1 -1 Being a fully distributed system makes the maintainability degraded with respect to todays system since more things needs to be handled by each node. This means that the future maintenance of the system will be more difficult because of the complexity of the system.
Design 2 -2 This design is also highly complex and thus will probably be harder to maintain. The need of an external decision making mechanism for which node being responsible for what topics will also need maintenance and every time something is altered on the node the parameters on which the decision is based on needs to be verified.
Design 3 2 This design has the advantage that the system has a central node for the mapping of publishers and subscribers. This implementation will be fairly simple to understand and thus much easier to maintain than todays system. Although the rest of the nodes in the system will be slightly more complex than todays but still not by much.
Design 4 2 Same as for Design 3, although the need for redundancy amongst the switches increases the complexity slightly but it will still be a fairly simple maintenance for this system since the redundancy should not need updates as often as the rest of the system.
Design 5 1 This design has similar drawbacks as for design 4 although since the mes-sages are distributed by the switches the complexity on those would increase and thus be harder to maintain. For the rest of the nodes in the system however the complexity would pretty much be the same and thus it will not be more complex than todays system over all.
Table 3: Explaining Pugh matrix value for maintainability Availability
Availability, being one of the main focuses for this thesis, is an important aspect and it can be measured in 2 ways as described by Baldoni [24]. First, how likely is it that the subscibers of a topic actually gets the content that it requests. Second, for how long period of time can a publication stay alive in the system. The second being more a question about how to implement the system and can be solved more or less on any of these designs, thus the first definition will be the main focus here. The evaluation of the availability is presented in Table4.
Design Score Explanation
Design 1 2 The likelihood of a subscriber receiving the information that it has re-quested is rather high for this type of system since it is based on P2P communication and most of the data does not go through any intermediate nodes. This gives less possible places where data can be corrupted or lost. Design 2 0 This solution has potential for good availability although since almost all data has to pass through a separate node before being distributed to the rest of the system it is more or less the same as today. The only advantage is that each topic potentially could be on a separate node. However, the node responsible for a topic could potentially get to heavy computational load because of the distribution.
Design 3 1 Same as for Design 1 although since there are only one node responsible for holding information about the publishers and subscribers it is more likely that the registration of new subscriptions or similar are lost, if the node is failing for example.
Design 4 2 This design is most likely to get the best score for availability since data does not go through any intermediate node. As mentioned in [28] having redundancy in a P2P system creates better availability, meaning that if one node, or switch in this case, goes down the system will not fail entirely but rather just be downgraded to some extent.
Design 5 1 The availability of this design would be better than todays system since the distribution of data is itself distributed amongst several switches and could therefore potentially handle more information. The SPF is also removed because of this. However, since the data has to go up on the switches before they can be forwarded there are more potential places where things can go wrong than for Design 3 and 4.
Table 4: Explaining Pugh matrix value for availability Reliability
Reliability can be seen as the probability that messages arrive at the destination with correct information even if some links or nodes in the system fails [10], this is also one of the main focuses
of this thesis. Usually the communication protocol is what provides reliability in this type of system but it can also be seen that intermediate nodes that forwards information will increase the potential of corrupting data or similar. Here, reliability also focuses a bit on how well the systems can keep all lists of subscribers up to date for all publications. The reliability of the different designs are compared in Table5.
Design Score Explanation
Design 1 1 Same as for the availability this design benefits from being highly decen-tralized and most communication going directly from a publisher to a sub-scriber. However, the fact that it is more difficult to keep the DHT up to date for all nodes in this type of system make it suffer in reliability. Design 2 0 This design has similar issues as Design 1 since it needs to have updated lists
of recipients on not only the responsible publishers but also all publishers of a topic needs to be up to date with whom the master of the topic is. This Also suffers from the fact that if one node goes down, the topics that the node is responsible over might be lost for a period of time before it is detected and new nodes can be assigned. However it is not worse than todays system since not all communication relies on one node.
Design 3 2 The reliability for this design is fairly good since there are no intermediate nodes forwarding the publications. The risk of corrupted or lost data is less as well as the chance of missing a registration of new subscribers. This gives a good grade for this type of solution.
Design 4 2 Same as for Design 3. Although, since the information about publishers and subscribers are distributed amongst several switches it could possibly be a bit better because of the redundancy. However, it is also necessary to keep all switches up to date and the reliability could suffer from not getting updated fast enough.
Design 5 1 This design, being similar to Design 4, suffers slightly more since the data has to go up a few layers before it can be forwarded to its final destinations. This make it slightly less reliable than Design 3 and 4, however, it is still better than the current design since it is more distributed and don’t have the SPF.
Table 5: Explaining Pugh matrix value for reliability Performance
Performance can be measured in many ways but here it is mostly focusing on the time it takes to send out a message to all subscribers of a topic. This means both the sending time for a publisher as well as latencies provided by forwarding of potential intermediate nodes. The comparison of the performance is shown in Table6.
Design Score Explanation
Design 1 1 This design potentially requires several instances of a message to be sent from a publisher in order for all subscribers to receive the message. Also, a message can possibly have intermediate nodes where it needs to be for-warded and thus experience some additional latencies. However, the overall throughput should be better than todays system.
Design 2 0 This design will experience similar latencies as todays system since all mes-sages has to pass through the node that is responsible for the topic. Al-though this benefits slightly from the forwarding of data being distributed amongst the nodes in the system. However, the node responsible for a topic could potentially get to heavy workload and thus make the perfor-mance suffer.
Design 3 2 This design will have better performance than todays system since there are no latencies from forwarding any information. However publishers will have slightly higher workload than in todays system since the publishers needs to send a message for every subscriber of a topic. Although this should not be close to the time it takes for the server in todays system to first receive the message and then forward it to all subscribers.
Design 4 2 Same as for Design 3 with the only difference that a few more messages needs to be sent out to the system in order to keep all redundant switches updated.
Design 5 1 This is a combination of todays system and Design 4 and it has the bene-fit over todays system of being distributed in the forwarding of messages. However, as for todays system it suffers from the fact that all messages need to pass through a forwarding node which creates latency in the system.
Table 6: Explaining Pugh matrix value for performance Monitorability
Monitorability is the ability to monitor the data going through the system by either listen in on every message or in the case of P/S subscribe for every topic as an example. The possibility to monitor the system is compared in Table7.
Design Score Explanation
Design 1 1 For this design it would be necessary to add an extra node to the system that could act as a subscriber of every topic. The upside from todays system is that the node responsible for todays forwarding of information could be used as the monitoring node. Currently the server node is not capable of both forwarding and monitoring the system which makes this design slightly better.
Design 2 1 Just as for Design 1, this design would require a separate node for moni-toring of data. It could be possible for the system to keep monimoni-toring each topic on responsible nodes but it would increase both the computational load as well as the memory usage.
Design 3 2 This design will have the possibility to use the master node as a monitoring node as well. This node will be idle for most of the time anyway and only during the startup of the system it would be much processing for it. Also, the master node will already receive any information about registrations for topics etc. which makes it even easier to monitor the system.
Design 4 1 For this design it could be possible to use the switches as monitoring nodes, although this creates a downside of synchronizing the data since there will always be drifts in time. Thus this will just as Design 1 and 2 benefit from having a central unit that subscribes for all topics.
Design 5 1 Same as for Design 4.
Table 7: Explaining Pugh matrix value for monitorability Scalability
Scaling a system means that the number of nodes or the number of topics will increase or decrease over time. This is common in many P/S systems but looking at the system that are used in this thesis it can be seen that once an aircraft has booted up the network size is fixed and will not scale. However, over the time of development the system can grow which should be accounted for. The scalability of the different designs are compared in Table8.
Design Score Explanation
Design 1 1 This design is quite scalable [22, 23], although it suffers when it comes to keeping the system coherent and having the same view over the entire system. This would also lead to an increased workload for each individual node in the system.
Design 2 0 This design suffers greatly when it comes to scalability since it relies on a master per topic, meaning that the workload increases for specific nodes when more publishers and subscribers are added to the system. This could potentially lead to a system where a topic master gets to heavy workload and cannot carry out the other tasks that it is supposed to. However this is the same problem as todays system is suffering from and thus this design will get the same grading as it.
Design 3 2 This has a very good scalability since the connection between publishers and subscribers are direct and the workload will not increase by much for the publishing nodes whenever a new subscriber is added to a topic. Another positive thing for scalability is the separate node that keeps track of publishers and subscribers, meaning that whenever a node registers for a new topic it only has to send the request to one place.
Design 4 2 Same as for Design 3.
Design 5 1 Since this is a combination of todays system and Design 4 it will be more scalable than the current system but less scalable than Design 4. The benefit over todays system is that the splitting of messages are distributed amongst all the switches in the system.
Table 8: Explaining Pugh matrix value for scalability Complexity
Complexity refers to the level of difficulty that an implementation brings to the system. Also the ability to reuse parts of the code for more than one purpose in the system can be considered. The evaluation of the complexity is presented in Table9.
Design Score Explanation
Design 1 -1 Comparing Design 1 with todays system it can be seen that it is slightly more complex because of the DHT implementation. This makes it possi-ble to remove the server node from the system. However, the complexity of the remaining system will increase substantially because of the DHT implementation and therefore the overall complexity will be greater. Design 2 -2 This design is the most complex because it not only needs a solution for
publishing and subscribing but also a decision mechanism for what node should be assigned as master for what topics. The decision mechanism needs to consider several parameters such as workload on the node and what spare capacity it has, estimation of the worst case of workload for each topic etc. Each time the code for a node or frequency of a topic is changed these parameters needs to be updated as well in order to make sure that the workload do not exceed what the specific node can handle. This system also needs extra solutions for publishing since if a regular node that is not a master should only send to the master of the specific topic but the master node needs a solution to forward the information to all subscribers of the topic.
Design 3 2 This solution, being similar in the setup as todays system, will be much less complex on the previous server node. This node would mostly act as a dictionary for the rest of the system and although the rest of the nodes implementation would be slightly more complex they will all have the same implementation. And also the complexity on the new master node makes the system much easier to both maintain and evaluate.
Design 4 1 This design is slightly more complex than Design 3 since it needs to be implemented on the switches as well as having some sort of redundancy mechanism keeping the switches up to date at all time.
Design 5 0 This design will have similar complexity with todays system since the switches will basically do what the server node does today. However, since the switches needs to have some sort of redundancy it might even be slightly more complex than todays system but not by much.
Table 9: Explaining Pugh matrix value for complexity Network load
Network load is the amount of data going out on the actual network. Things like processing and forwarding are not accounted for in this parameter. Since this thesis do not have time for implementing multicasting this will not be considered here either. The network load is compared in Table10.
Design Score Explanation
Design 1 0 In the worst case of a DHT solution it could be at least one intermediate node between the publisher and subscriber of a topic and thus the network load would be similar with todays system.
Design 2 0 For this design all topics has to pass through the master of that topic before reaching the subscribers and thus it will have the same network load as todays system.
Design 3 1 Since this system would have a P2P connection between publishers and subscribers the network load will be eased slightly from todays system. Design 4 1 Same as for Design 3 but with some additional data traffic to handle the
redundancy on the switches.
Design 5 0 This is the same as todays system since all data has to pass through a switch before being sent out to the subscribers. Additionally, just as for Design 4, some extra traffic is required for handling the redundancy.
Table 10: Explaining Pugh matrix value for network load Timeliness
Timeliness, deriving a bit from predictability of the system, is the way that the data can be predicted in time of delivery. As an example passing through several nodes before reaching the destination means more places where latencies can be unpredictable, thus it is harder to predict the timeliness. In Table11the timeliness of the different designs are compared.
Design Score Explanation
Design 1 1 In terms of timeliness the DHT implementations are fairly predictable since it will try to take the direct path from publisher to subscriber but in the worst case it might pass through at least one node. This is still a bit better than todays system where all publications for all topics has to pass through a single node.
Design 2 0 Since this has the same issue of forwarding data as todays system it will have similar predictability as well.
Design 3 2 This system is more predictable since the connection between publishers and subscribers are more direct and thus there are less places of unpre-dictable latencies.
Design 4 2 Same as for Design 3. Design 5 0 Same as for Design 2.
Table 11: Explaining Pugh matrix value for timeliness The Pugh Matrices
All designs are compared against the current system which is shown in the first column of concepts with a total score of 0.
In Table12, a Pugh matrix where all parameters are weighted the same in the system is shown. We can observe that design 3 is the superior solution with a total score of 16. On the other end of the chart it can be seen that design 2 scores the lowest with -11. This is mainly because of the complexity and the number of hops a message has to do in the system. Design 4 on the other hand is pretty close to design 3 with a score of 13 and thus being close to take the lead. The main reason for design 4 to be slightly lower than 3 is the fact that it is slightly more complex and harder to test and monitor.
Concepts Todays
Design choices Weight system Design 1 Design 2 Design 3 Design 4 Design 5
Availability 1 0 2 0 1 2 1 Reliability 1 0 1 0 2 2 1 Performance 1 0 1 0 2 2 1 Testability 1 0 -2 -2 0 -1 -1 Integrability 1 0 -2 -2 0 -1 -1 Maintainability 1 0 -1 -2 2 2 1 Monitorability 1 0 -2 -1 2 1 1 Scalability 1 0 1 0 2 2 1 Complexity 1 0 -1 -2 2 1 1 Network load 1 0 0 -2 1 1 0 Timeliness 1 0 1 0 2 2 0 Score 0 -2 -11 16 13 5
Table 12: A Pugh matrix with the same weight on all parameters
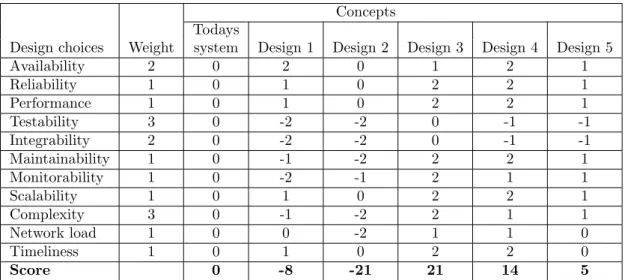
In Table 13 the same matrix is shown but with more weight on the integrability, testability, availability and complexity in the system. In this case design 3 scores even higher than any other design. This is mostly because of the fact that it will not be downgraded anything from the testability factor as well as benefiting from high availability and quite low complexity. Design 2 still gets the lowest score and goes far below the current system in the scoring. This is mostly because of the fact that it has low scores for both testability and integrability as well as for complexity. Also design 1 gets a negative score because of the complexity and the testability of the design. Design 4 and 5 stays rather still on where they were from the beginning since the testability degrades them but the complexity and availability adds to the score slightly.
Table 14 shows another result of the Pugh matrix where more weight is put on availability, reliability, performance, scalability, network load and timeliness. First three of these are the main parameters that this thesis has its focus on and the following three are some what related to them. Here it can be seen that design 3 still comes out at the top but the space between it and design 4 is very small. Design 4 benefits from the fact that it has a higher score on the availability. The other parameters that are of higher weight are the same for the two designs. Design 2 on the other
Concepts Todays
Design choices Weight system Design 1 Design 2 Design 3 Design 4 Design 5
Availability 2 0 2 0 1 2 1 Reliability 1 0 1 0 2 2 1 Performance 1 0 1 0 2 2 1 Testability 3 0 -2 -2 0 -1 -1 Integrability 2 0 -2 -2 0 -1 -1 Maintainability 1 0 -1 -2 2 2 1 Monitorability 1 0 -2 -1 2 1 1 Scalability 1 0 1 0 2 2 1 Complexity 3 0 -1 -2 2 1 1 Network load 1 0 0 -2 1 1 0 Timeliness 1 0 1 0 2 2 0 Score 0 -8 -21 21 14 5
Table 13: A Pugh matrix with higher weights on testability, integrability, availability and com-plexity
hand stays below the current system in the total score and the network load is one of the main reasons here. Design 1 and 5 scores better than the current system but still substantially less than design 3 and 4.
Concepts Todays
Design choices Weight system Design 1 Design 2 Design 3 Design 4 Design 5
Availability 2 0 2 0 1 2 1 Reliability 3 0 1 0 2 2 1 Performance 3 0 1 0 2 2 1 Testability 1 0 -2 -2 0 -1 -1 Integrability 1 0 -2 -2 0 -1 -1 Maintainability 1 0 -1 -2 2 2 1 Monitorability 1 0 -2 -1 2 1 1 Scalability 3 0 1 0 2 2 1 Complexity 1 0 -1 -2 2 1 1 Network load 2 0 0 -2 1 1 0 Timeliness 2 0 1 0 2 2 0 Score 0 7 -13 32 30 12
Table 14: A Pugh matrix with higher weights on availability, reliability, performance, scalability, network load and timeliness
Conclusion
As a result of the Pugh-matrices above it can be seen that design 3 and 4 are amongst the more desirable. Since they are rather similar in the design, with the difference of having one master node or several masters distributed on top of the switches in the system, it is therefore decided to start with design 3 and if time allows for it maybe test design 4 as well. Going from design 3 to design 4 would require very small changes on the client side while the master side would need some sort of redundancy mechanism to keep the information up to date on all masters. Also it needs some mechanism for the clients to know which switch it is supposed to be connected to and should communicate with. For monitoring purposes it would most probably still be one node responsible of collecting data since spreading it out on several nodes would lead to different nodes drifting differently in time which would make it hard to synchronize the data correctly.