Teknik och samhälle Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Datainsamling och rekommendationssystem för
musiktjänster
Data Collection and Recommendation Systems for Music Services
Anton Nilsson
Examen: kandidatexamen 180 hp Huvudområde: Datavetenskap(övriga)
Program: Datavetenskap och applikationsut-veckling
Datum för slutseminarium:
Handledare: Carl Magnus Olsson Examinator: Carl Johan Orre
Sammanfattning
Musiktjänster, som Spotify och Apple Music, samlar in data om sina användare. Antalet användare är stort och tjänsterna är tillgängliga för både dator och telefon. Datainsam-lingen ligger till grund för att generera en mer personlig upplevelse för användaren genom rekommendationer av musik och anpassat material för att användaren ska ha möjlighet att hitta rätt i de stora mediabiblioteken. Tjänsterna måste därför ständigt leta sätt att förstå vad användaren vill ha genom att se på användares beteenden. Hur tjänsterna sedan väljer att analysera den insamlade datan är lika viktigt som själva insamlingen.
I detta arbete diskuteras sambandet och problematiken mellan rekommendationssystem och datainsamling. Problemformuleringen är tydlig: vilken data, vilken analys av datan och vilket arbetssätt är relevant vid datainsamling till och för rekommendationssystem i musiktjänster. Den sammanlagda analysen av dessa tre frågor vill hjälpa till att lösa problem kring vilken data musiktjänster bör samla in, hur de ska analysera den och hur de kan arbeta med den för att på bästa sätt tillhandahålla personligt material till sina användare.
Genom en jämförelse mellan tre stora strömningstjänster av musik samt en musiktjänst för en användares lokala musikfiler, är det möjligt att analysera vilken data som samlas in av olika tjänster. Vidare ges en bild kring hur den insamlade datan används och analyseras av tjänsterna för att skapa musikrekommendationer till användaren. Slutligen diskuteras förhållningssätt och arbetssätt med datan i dess olika stadier från det att den skapas hos användaren till det att den raderas ur tjänstetillverkarens databas.
Abstract
Music services like Spotify and Apple Music collect data about their users. The amount of users is great and the services are available for computers as well as phones. Data collection is one of the cornerstones in creating a more personal experience to the user by providing recommendations of music and customized content, to make it easier for the user to find interesting material in the large media libraries. These services therefore constantly need to look for ways to understand what the user wants, by looking at the user’s behaviour in the service. The way to analyze this data is just as important as the collection itself.
This study discusses the connection and the problems of recommendation systems and data collection. The problem at hand is clear: what data to collect, how to analyze that data and which way of working with the data is relevant while collecting data to and for recommendation systems in music services. The combined analysis of the three issues aims to help solving the problems regarding which data that is important to collect for their music service, how to analyze that data and how to work to give the users as good personal material as possible.
By comparing three big streaming services and a music service for local files, an analysis about what data is collected by different services is possible. An analysis regarding how the collected data is used and handled by the services to create music recommendations is presented. At the end there’s a discussion on how to approach and work with the data in the different stages the data goes through, from the moment it is created by the user to the point where it is erased from the service database.
Innehåll
1 Inledning 1
2 Nulägesbeskrivning och tidigare studier 2
2.1 Musikindustrins nya tjänster . . . 2
2.2 Rekommendationsmotorer . . . 3
2.3 Analys av användare . . . 4
2.4 Ett datadrivet arbetssätt . . . 5
3 Metod 6 3.1 Metodinledning . . . 6
3.2 Metodbakgrund . . . 7
3.3 Forskningsinriktning . . . 7
3.4 Datainsamling och analys . . . 9
3.5 Systematisk litteraturstudie . . . 10
3.6 Begränsningar . . . 12
4 Resultat 13 4.1 Fas 1: En jämförelse av tre existerande musiktjänster . . . 13
4.1.1 Tjänstebeskrivning och tjänsters olika rekommendationer . . . 13
4.1.2 Profilering av användare . . . 16
4.1.3 Statistik och typer av insamlad data . . . 17
4.2 Fas 2: En musiktjänst för lokala filer . . . 21
4.2.1 Datainsamling i dagsläget . . . 22
4.2.2 Datainsamling för användarprofilering . . . 23
4.2.3 Problematik kring rekommendationer . . . 24
4.3 Fas 3: Ett datadrivet anpassat arbetssätt . . . 24
4.3.1 Skapande . . . 24 4.3.2 Analyserande . . . 26 4.3.3 Användande . . . 27 4.3.4 Försvinnande . . . 27 5 Diskussion 28 5.1 Vilken data? . . . 28 5.2 Vilken analys? . . . 29 5.3 Vilken arbetssätt? . . . 30 6 Slutsatser 31 Referenser 32
1
Inledning
Att den globala musikindustrin växer är idag ingen överraskning. Exempelvis dubblade strömningstjänsten Spotify sin omsättning 2015 till 18,2 miljarder kronor(Dagens Indu-stri, 2016). Genom olika strömningstjänster för musik är det möjligt för användare att tillgodose sig bland bibliotek med miljontals låtar. Mycket uppmärksamhet har kommit genom ökat fokus på lagliga strömningstjänster, men inom dessa såväl som i andra musik-tjänster är personliga upplevelser och rekommendationer på ny musik vanliga drivkrafter för att bibehålla sina användare. Rekommendationssystem är idag ett ämne som stadigt växt inom alla områden där stora mängder data från användarbeteende samt nytt innehåll kontinuerligt läggs till. Givet dess centrala roll inom den växande flora av musiktjänster finns alltjämt ett behov att utforska och praktiskt tillämpa rekommendationssystem inom detta område, då inga de facto best practices ännu etablerats.
Idag arbetar många av de stora strömningstjänsterna av musik med rekommendatio-ner av olika typer. Övergripande ger ett rekommendationssystem användare förslag utifrån användarens lyssnande och agerande i tjänsten(Boratto och Carta, 2010). Även om rekom-mendationerna ofta ges till enskilda användare, identifieras ofta relevanta användare genom gruppering. Att skapa subgrupper av användare med snarlika beteenden samt genom att fokusera på avvikelser och trender inom dessa subgrupper är det möjligt att identifiera förslag för enskilda som andra från samma subgrupp uppskattar. Musiktipset i sig ger inte bara mervärde för användaren, utan agerar även som en påminnelse till användaren att desto mer den använder tjänsten, desto fler (och ofta bättre) tips på ny musik kan denne få.
Centralt i rekommendationer är dock den data som dessa baseras på. I just en musik-tjänst är det vanligt att användaren får förslag på olika låtar, album och spellistor utefter olika insamlingspunkter som musiktjänsten satt upp. Det kan vara vad användare lyssnat på, vilket land de bor i eller vad för låtar som användare lagt till i sina egna spellistor. Men vad gör företagen bakom tjänsterna av denna data?
Begreppet big data har under de senaste åren blivit ett av de mest omdiskuterade inom IT-sektorn. I sin kärna innebär begreppet att extremt stora volymer data, ofta insamlade över längre tider och med stor variation i termer av datatyper, analyseras på ett så effektivt sätt som möjligt för att agera som beslutsstöd för såväl mänskliga användare som för andra system (Fan och Biffet, 2013). Själva arbetsprocessen för att behandla och raffinera dessa datamängder beskrivs ofta som big data mining, men underförstått är naturligtvis att den data som insamlas och behandlas är relevant för det område där big data mining tillämpas. Det övergripande syftet med denna studie är att förstå vilka olika värdeskapande roller rekommendationssystem kan spela för moderna musiktjänster. De tre specifika frågor av relevans för detta arbete är sålunda:
1. Vilken data är viktig att samla in för att bygga rekommendationssystem till musik-tjänster?
2. Vilka sätt att analysera denna data är särskilt relevanta?
3. Vilket arbetssätt behövs för att stödja såväl vidareutveckling av rekommendations-system som analys av insamlad data?
Mitt övergripande intresse i denna studie är att förstå datainsamlings och rekommenda-tionssystems roll i musiktjänster. För att göra detta inleds arbetet med en jämförelse av tre stora strömningstjänster: Spotify, Apple Music, Deezer. Därefter studerades Sony Mobile som fallstudieobjekt i fas två motiverat av en önskan om att, utöver motsvarande data från deras icke strömmande tjänst Music, även få tillgång till intervjuer med nyckelpersoner för att testa de sammantagna resultaten från fas ett och den tillhörande analys som gjorts. Sony Mobiles musikapplikation kunde också tillhandahålla data likt de jämförda ström-ningstjänsterna dock här i ett mer lämpligt format för att laborera med min personliga data. Slutligen studeras relevanta arbetssätt utifrån skapande med tillhandahållen data och intervjuer med personal från Sony Mobile.
Praktiskt är studien indelad i tre delar: (1) jämförelse av datainsamling från ovan nämnda musiktjänster, (2) analys av metoder och slutligen (3) en analys av arbetssätt som behövs för att stödja 1 och 2.
Metodmässigt är detta arbete en fallstudie av rekommendationssystems roll i moderna musiktjänster, där såväl existerande tjänster som vetenskapliga studier är relevanta för respektive forskningsfråga. En fallstudie syftar, likt denna, till att gå på djupet kring ett fenomen i sin naturliga kontext istället för att kvantitativt sammanställa data(Runesson och Höst, 2009). Bidragsmässigt syftar arbetet till att såväl förmedla en nyanserad bild av state-of-practice som state-of-research, som att identifiera särskilt lovande riktningar i termer av relevanta datatyper, analyser, samt arbetssätt med rekommendationssystem för moderna musiktjänster. Arbetet innehåller sålunda såväl praktiska som teoretiska bidrag. Strukturen i övriga dokumentet är enligt följande: Sektion två introducerar tidigare studier i ämnet och presenterar därmed musikindustrins nya tjänster, rekommendations-motorer, analys av användare samt ett datadrivet arbetssätt. Sektion tre går därefter vidare genom att utveckla hur tidigare arbete - praktiskt såväl som akademiskt - identifierats och använts för att informera denna studie. Efter denna metodsektion, följer en resultatdel, där studier kring datainsamling och rekommendationsmotorer beskrivs. Efter resultatet följer en diskussion där mina resultat diskuteras och för att sedan avslutas med slutsatser med tillhörande sammanfattning av arbetet.
2
Nulägesbeskrivning och tidigare studier
Tidigare har en hel del gjorts i respektive ämne, dock är sambandet mellan rekommen-dationssystem och datainsamling för strömningstjänster ett område med outforskad mark. Detta har tvingat arbetet att titta närmare på studier ur huvudämnena för att skapa en god bild av de olika områdena. De finns även en del skriven litteratur kring datadrivet arbetssätt och personifieringsprocesser.
2.1 Musikindustrins nya tjänster
Man kan idag i media läsa hur musiktjänster köper upp mindre företag med unika lös-ningar för musik. Spotify har senaste senaste året investerat i ett tiotal musikrelaterade företag(Spotify, 2017). Under samma tid har Apple och deras strömningstjänst Apple Music investerat i 3 företag för datahantering och maskininlärning(MacRumors 2016; TechCrunch 2016; AppleInsider 2015). Det stora intresset kommer ur den stora utveckling dels inom datainsamling, dels kring rekommendationssystem.
Som användare av en strömningstjänst för musik kan det vara svårt att veta var man ska börja titta efter ny musik. De stora strömningstjänsterna har lagt allt större vikt vid rekommendationer till användarna. Det kan vara genom färdiga spellistor utformade efter dina lyssningar och förslag på låtar vid skapandet av nya spellistor. Vad grundas då dessa på då? Genom att vid varje lyssningshändelse i applikationen spara en rad variabler om händelsen kan tjänsten skapa sig en bild av användaren. En variabel skulle kunna vara låtens namn, hur länge en användare lyssnat och hur denna hittat till låten. På detta sätt kan strömningstjänsterna för musik erbjuda något som inte en analog musiklyssning kan ge.
Samtidigt växer en trend bland användare fram som lägger stor vikt kring hur mycket data som olika tjänster samlar om dem. Det stora uppvaknandet av användare har också lett till den EU-lag som slår i kraft under maj 2008(DataInspektionen, 2017). Reformen innehåller tillägg kring förflyttning av data samt vissa förändringar kring ansvarstagande och konsekvenser vid missbruk. Till stor del är dock lagen lik den existerande person-uppgiftslagen. På detta sätt behöver inte bara strömningstjänsterna av musik se över sin datainsamling. Alla företag bör se över de personuppgifter som samlas in.
2.2 Rekommendationsmotorer
Rekommendationssystem har varit aktuellt under många år. Grupprekommendationer be-skrivs som ett sätt att gruppera människor och baserat på detta ge rekommendationer anpassade till gemensamma aspekter för de identifierade grupperna. Med andra ord delas användare med samma mål eller intressen in i grupper för att de har liknande användar-mönster och därmed troligen kan erbjudas samma rekommendation. På detta sätt kan enskilda användare ges material som upplevs som individuellt anpassat material, men som i verkligheten databehandlats i små eller stora grupper(Boratto och Carta, 2010;Schafer, J. Ben, et al. 2007; Linden, Smith och Jeremy York 2003; Sarwar, Badrul, et al. 2001). Två exempel relevanta för arbetet är tjänsterna Apple Music och Deezer där nya användare ges möjlighet att välja olika genres och artister som de tycker är intressanta. På detta sätt ges användare en möjlighet att få direkta förslag om musik ur dessa genres och från de olika artisterna de visat intresse för.
Vid samtal kring rekommendationer utifrån andra användare i tjänsten diskuteras ofta så kallad collaborative filtering. Traditionell collaborative filtering innebär att hela katalo-gen, alltså i en strömningstjänst hela biblioteket av media, fylls inuti en vektor. För varje användning av mediet ökar värdet för den parameter som mediet tillhör med 1(Schafer, J. Ben, et al. 2007; Linden, Greg, Brent Smith, and Jeremy York 2003; Sarwar, Badrul, et al. 2001). Därefter jämförs användare med liknande vektorer och användare ges förslag kring de parametrar där den ena användaren saknar parametrar där den andra har. Collabora-tive filtering blir dock generellt datormässigt dyr då vektorerna blir enorma och antalet nollor överväldigande. För att göra sig av med tomma vektorer används Explicit Matrix Factorization. Då görs också antaganden utefter vad användaren skulle kunna tänkas upp-skatta utefter hur andra användare uppupp-skattat liknande media(Johnson , 2014. Ett annat sätt att tillhandahålla rekommendationer är genom att göra innehållsbaserade rekommen-dationer(Van den Oord, Dieleman och Schrauwen, 2013). Rekommendationerna baseras på kategorisering och att användare som gillar en kategori också gillar annat innehåll i samma kategori. Modellen kan dock vara svår att göra personlig utan behöver någon form
av profilering av användare för att fungera på bästa sätt(Van den Oord, Dieleman och Schrauwen, 2013).
Spotify visade under Machine Learning Conference 2014 sitt arbete med ett antal oli-ka latent-factor models(Johnson , 2014). Bland annat visas hur användning av PLSA, Probabilistic Latent Semantic Indexing av Hoffman(1999) kan användas för modellering. Resultaten av en sådan modell visar värden utifrån likhet till andra låtar. Latent Factor-modeller är både snabbare och bättre skalbara än andra algoritmer för rekommendationer. Idag kombinerar ofta strömningstjänster flera rekommendationsmotorer. Spotify av-slöjade användning av fem olika rekommendationsmotorer för att på olika sätt jämföra resultaten. Apple Music och Deezer fokuserar den största delen av sina rekommendatio-ner från aktiva val från användaren. Det kan vara genom att låta användaren fylla i vilka genres användaren gillar eller om den markerar låten som bra eller dålig. På detta sätt är det möjligt att bygga genrejämförelser mellan användare på ett lättare och snabbare sätt. Dock är interaktion från användare ofta en svår del att basera grupprekommendationer på, då användares vanor att interagera med denna sortens funktioner kan skifta drastiskt.
2.3 Analys av användare
Grundläggande för att kunna skapa givande rekommendationer, som upplevs personligt givande, är att implementera någon form av datainsamling av användarbeteende kopplad till sin tjänst och det specifika innehåll som erbjuds dessa. I strömningstjänster skulle detta kunna vara vilka låtar användaren lyssnat på eller hur länge denna lyssnat, vilket också kan gagna tjänsteutvecklaren i termer av vilket innehåll som uppskattas, samt hur, när och var detta konsumeras.
Ett begrepp direkt kopplat till den pågående trenden om att samla in sådan data är vad som kallas big data och det tillhörande analysbegreppet big data analytics. Big data är inte ett bestämt format eller utformning av datainsamlingen, utan beskriver data med stor volym, velocitet och variation (Fan och Biffet, 2013). Volym beskriver mängden data, som bara fortsätter att växa. Velociteten beskriver datans höga inflöden samtidigt som att vi försöker extrahera data i realtid. Variation beskriver den stora variation som finns i datan, med allt från text och siffror till sensordata och video.
All data som samlas in om användarna sparas hos företaget. Ibland sparas bara datan hos företaget en begränsad tid, då färsk data uppges återspegla den bästa bilden av an-vändares beteende. Dock kan den användas för att, som tex. Spotify, hela tiden utforma en profil av datan. Spotify väljer att kalla denna för sin “taste profile”, där användarens musiksmak sparas regelbundet som en profil med genres och artister. Detta är ett bra ex-empel på big data mining, datan förfinas för att kunna analysera dess innehåll(Han, Pei och Kamber, 2011).
När datainsamling för ett antal år sedan växte som aldrig tidigare skådat, sågs behovet av ett verktyg för att hantera och ha möjlighet att processa mängderna av data. Google, ett av företagen som behövde uppdatera sina system för att kunna fortsätta arbeta, utvecklade då MapReduce(Dean och Ghemawa, 2008). MapReduce innebar en algoritm som delade upp processandet av den stora datan till mindre bitar för att det sättet sprida kraften över flera mindre datorer. När algoritmen sedan körts skickades det fulla resultatet tillbaka till användaren som en enhet. MapReduce används senare som utgångspunkt för det open source projekt som fick namnet Hadoop. Hadoop låter helt enkelt andra applikationer köra
MapReduce-algoritmen.
Cluster analysis är den process som sker när ett antal objekt grupperas på det sätt att de är mer lika varandra än andra objekt är som tillhör andra clusters(Han, Pei och Kamber, 2011). Ofta används Hadoop för denna sortens operationer. För att använda Hadoop finns sedan en uppsjö av bra verktyg. Ett populärt verktyg är Spark, som många av de stora företagen idag använder. Spark förenklar många av de existerande verktygen och processerar data genom att låta användaren, genom sk. notebooks skapa celler som kan köras parallellt (Zaharia, Matei, et al., 2010).
Att sedan modellera datan är svårt, eftersom det före arbetet gjorts kan vara svårt att ha en god uppfattning över vad som är relevant. För att analysera datan krävs en precis uppfattning av datans innehåll samt hur analysen av datan slutligen ska användas(Han, Pei och Kamber, 2011). Även om tidigare studier kan visa en viss modell som givande i ett fall är detta något som beror av vad just den data som modellerats visar. Modellerna i sig är därmed inte en garant för att få relevanta svar, men tidigare forskning utgör ändå en bra indikation på vilka modeller som kan vara av relevans. Han, Pei och Kamber(2011) presenterar ett antal olika clustering metoder.
Han, Pei och Kamber(2011) delar in de olika clustering metoderna i partitioning met-hods, hierarchical metmet-hods, density-based methods och grid-based methods. Att använda partitioning metoder är det vanligaste sättet att analysera cluster. Här delas resultaten in i mindre grupper eller cluster som specificerats utefter olika parameter som skaparen sätter. En vanlig partitioning metod är k-means. En hierarchical metod grupperar datan hierarkiskt i en trädarkitektur. Datan specificeras utefter deras relation till annan data. En density-based metod är utformad för att hitta cluster som inte ser naturligt sfäriska ut. Ibland har tex. partitioning metoder svårt att modellera cluster som inte ser ut som alla andra. Det finns också grid-based metoder. Dessa metoder delar in allt i ett stort rutnät fullt av celler, för att därigenom hantera datan. Genom dessa celler kan sedan operationer göras på datan.
2.4 Ett datadrivet arbetssätt
I sektionerna ovan har tidigare studier diskuterat såväl rekommendationssystem som da-tainsamling. För att strategiskt arbeta med detta och kontinuerligt vidareutveckla tjänster krävs även en förståelse för hur ett datadrivet arbetssätt lämpligen bedrivs.
Mjukvaruindustrin måste ständigt samla in data för att bygga en produkt som passar användaren(Olsson och Bosch, 2014). Detta kan vara genom predeployment data, alltså genom data från användare innan det att tjänsten lanserar något nytt, eller postdeployment data, alltså datainsamling från användaren efter det att något släppts. Postdeployment datan är idag ett vanligt sätt att se användares interaktioner med tjänsten och mycket data kring användarna samlas av olika tjänster. Denna data kan sedan användas för att ta datadrivna beslut, alltså beslut baserade på den data tjänsten samlar in(Olsson och Bosch, 2014).
När datainsamlingen ska bli till rekommendationer bör initialt en personfieringsprocess skapas. Processen, eller loopen, ska innehålla tre delar - en förståelsedel, en leveransdel och en mätdel. I förståelsedelen samlas data och en profil byggs för att förstå användaren. I leveransdelen hittas de mest relevanta resultaten för användaren och dessa levereras. I mätdelen mäter vi hur användaren uppfattar det vi levererat. Detta läggs till i
använda-rens profil och används för nästa cykel(Adomavicius och Tuzhilin, 2014). Hur den direkta implementationen ser ut här kan variera, men skulle generellt kunna delas in det i 6 steg:
1. Samla så mycket användbar data som möjligt om användaren.
2. Skapa en så omfattande bild om användaren som möjligt baserad på den insamlade datan. Spara denna som en profil.
3. När profilerna skapats, måste användarprofilen vara utformade på ett sådant vis att rekommendationssystem, statistiksystem och regelbaserade system kan utnyttja profil.
4. Leverans på visuellt sätt till användaren.
5. Utvärdera hur genomslaget av rekommendationerna blev. Mycket aktivitet eller an-vändning av rekommendationerna kan vara tecken på lyckad personalisering, mindre användning kan vara tvärtom.
6. Slutligen bör den den befintliga användarprofilen uppdateras. Den sista delen bör hela tiden skapa en mer fullständig bild av användaren.
I den här listan tillhör 1 och 2 förståelsedelen, 3 och 4 tillhör leveransdelen tillika 5 och 6 tillhör mätdelen. Det viktigaste i personifieringsprocessen är att den informationen som samlas in i förståelsedelen representerar användaren på ett relevant sätt i förhållande till det man vill personifiera för. Olika strömningstjänster för musik arbetar på olika sätt med detta. Spotify använder sig av en taste profile för att behålla information om sina använda-re. Där analyseras användares lyssningar för att skapa bygga profil av olika användaanvända-re. Hos Deezer och Apple Music byggs en profil utifrån användares lyssningar men också utifrån ett antal val användaren har gjort kring sina favoritgenres och favoritartister. Alla företag som undersökts använder någon form av personifieringsprocess, dock på lite olika sätt.
Under utvecklingen av en sån här process är det viktigt att reflektera över sitt ar-betssätt för hela utvecklingsprocessen. Olsson och Bosch(2014) skriver att företag överlag måste förbättra sitt datadrivna fokus både för att förbättra produkten och se var framtida investeringar bör läggas. Dock visar det sig att företag ofta inte utnyttjar den data som samlas in, utan förbises till förmån för egna åsikter och intuition inne från teamet(Sauvola, Tanja, et al., 2015). Detta leder till att personer i Research Development och det utveck-lande teamet lägger energi på att utveckla saker som slutanvändare inte har efterfrågat eller heller skulle använda vid en eventuell release.
3
Metod
3.1 Metodinledning
Vid arbetets början lokaliserades tre stora strömningstjänster(Spotify, Apple Music och Deezer) samt en musiktjänst för lokalt material(Sony Mobiles musikapplikation) för en jämförelse. Tjänsterna användes och datan från de olika samlades in, med hjälp den svens-ka personuppgiftslagen. Därefter jämfördes datan från de olisvens-ka tjänsterna. Att sedan ha denna data och en uppfattning kring hur dessa användarprofiler skulle kunna skapas, gavs möjlighet att börja bygga liknande användarprofiler utifrån den data kring mig själv som
tillhandahållits från Sony Mobiles musikapplikation. Sony Mobiles musikapplikation till-handahöll min personliga data i csv-format vilket gjorde det möjligt att analysera och modellera datan med hjälp av Apache Spark.
3.2 Metodbakgrund
Detta arbete är skapat som en fallstudie av problematiken mellan datainsamling och re-kommendationssystem. Metoden är passande då den är framtagen för att studera moderna fenomen i sin naturliga kontext(Runesson och Höst, 2009). En fallstudie, menar förfat-tarna, är sammanfattat en forskningsstrategi för att ge kunskap tillräcklig att skapa en teori om hur något fungerar genom att undersöka problemet djupgående. Fallstudien har en lång historia av användning och har argumenterats som introducerad 1829 av Frederic Le Play (Healy, 1947), då i ett arbete om statistiskt arbete om familjers budgetar. Under 1900-talet växte sig sedan forskningsstrategin starkare i sociologi, psykologi och antropo-logi. Idag används fallstudie som forskningsstrategi inom alla områden, fortfarande dock främst inom samhällsvetenskapen. De senaste seklerna har också ett stort antal fallstudier om datavetenskapen och mjukvaruutveckling gjorts.
Klein och Myers (1999) är bland av de allra mest citerade inom tolkande fallstudier. De argumenterar och styrker hur forskare systematiskt kan arbeta för att försöka förstå ett fenomen genom att förstå hur detta fenomen uppstår och agerar i den kontext det observeras i, vilket vanligen även inkluderar hur mänskliga aktörer i denna kontext agerar och beskriver sin förståelse och påverkan av detta fenomen. Även om fallstudier är särskilt vanliga inom exempelvis samhällsvetenskap, har såväl dess relevans för forskning av in-formationssystem (Klein och Meyers, 1999) och mjukvaruutveckling (Runesson och Höst, 2009) gjort att metoden idag är accepterad även inom mer tekniknära studier.
Sony Mobile och deras musikapplikation studeras som fallstudieobjekt i fas två och delvis i fas tre. Semistrukturerade intervjuer skedde med personal vid Sony Mobile utöver att datan, precis som i den inledande jämförelsen tillhandahölls.
Fallstudier genererar ofta inte lika entydiga resultat som kontrollerade experiment gör, men ger i gengäld en djupare förståelse kring fenomenet(Runesson och Höst, 2009) och den kontext det är relevant i. Detta åstadkommer fallstudier genom tydlighet i jämförelser samt transparens i analyser baserat på den insamlade datan. Då en fallstudie ofta utgår från författarens synvinkel - medvetet eller omedvetet - kan en nackdel också bli att tolk-ningar färgas. Goda fallstudier är därför baserade på välkänd litteratur och vetenskapliga artiklar som dessa tolkningar görs utifrån i så stor omfattning som möjligt. Detta berikar såväl tidigare forskning i termer av nyanserade behov av vidareutveckling av existerande teori, samt agerar som kvalitetsgarant för att tolkningar görs i relation till tidigare studier som publicerats och accepterats som vetenskapligt väl motiverade och relevanta i den ve-tenskapliga diskursen. En praktisk aspekt av fallstudier är att de ofta kräver mer tid än andra forskningsformer på grund av bland annat den rikedom i insamlad data, vilket får följder på analysen av denna.
3.3 Forskningsinriktning
Syftet med arbetet är att knyta samman existerande trender inom rekommendationssystem för musiktjänster, den data dessa baseras på, samt ett datadrivet arbetssätt.
Många arbeten av snarlik karaktär som denna studie har gjorts antingen i enkätform eller som fallstudier. De som gjorts i enkätform har till största del varit undersökningar av hur användare upplevt olika sorters rekommendationer (Johnson och Svensson, 2014; Gus-tavsson och Schaffer, 2015; Karlsson, 2017) eller strömningstjänster (Nilsson och Freskgård, 2013; Lidbrink och Älgevik, 2012; Gustafsson och Nilsson, 2016). Publicerade fallstudier (Swanson, 2013) har haft ett liknande upplägg som den studie som rapporteras i denna text, dvs har skett i samarbete med ett företag vilket föranlett en undersökning av problem-ställningar med viss variation på de exakta forskningsfrågorna, baserat på dels behovet av ny forskning, dels behovet som den specifika fallstudien har.
I detta arbete har forskningsansatsen delats in i tre delar: 1. En jämförelsestudie av tre stora strömningstjänster av musik.
Arbetets första del bygger på en jämförelse av tre stora strömningstjänster av mu-sik(Spotify, Apple Music och Deezer) för att analysera vilken data de samlar in som sina användare. Detta sker i form av en beskrivning av tjänsten, en beskrivning av da-tainsamlingen samt för- och nackdelar med det rekommendationssystem/algoritmer som används. Syftet med detta steg är att ge en god bild kring olika musiktjänster och deras datainsamling, men också är att se hur datainsamlingen för strömnings-tjänster ser ut, för att förslagsvis se hur en icke strömmande musiktjänst skulle kunna utnyttja deras sätt att samla data om användare och lyssnande.
2. En analys av en musiktjänst för lokala filer och dess datainsamling.
Arbetets andra del tillhandahåller en analys av Sony Mobiles musikapplikations da-tainsamling, en analys av vilket sätt den används i dagsläget, samt hur den skulle kunna användas i framtiden. I analysen dras paralleller mot den datainsamling som sker hos strömningstjänsterna från den första delen. Syftet med detta steg är att sätta den inledande jämförelsen i en kontext gentemot en musiktjänst utan rekom-mendationer eller strömningsmöjlighet. På detta sätt är det möjligt att praktiskt lokalisera vad och var insamling av data är relevant.
3. En analys kring hur arbete kan ske för att stödja såväl vidareutveckling av rekom-mendationssystem som analys av insamlad data
Arbetets tredje och sista del tillhandahåller en analys kring arbetssätt för att arbeta med denna sortens datainsamling för rekommendationer. Analysen kommer innehål-la reflektioner kring den befintliga datainsamlingen och det befintliga arbetssättet. Analysen syftar till att bidra med inblick i ett datadrivet arbetssätt för rekommen-dationssystem. Detta steg i sig fyller för denna studie syftet att lyfta fram vikten av att anpassa sitt arbetssätt till de två tidigare delarna samt hur detta skulle kunna göras.
Ansatsen är utformad på detta sätt för att initialt ge en bild av sambandet mellan datainsamling och rekommendationsmotorer inom musikrelaterade tjänster. Arbetet syftar i sig inte i till att bryta ny mark inom något av dessa två, utan fyller främst rollen att skapa en rimlig övergripande bild av problemområdets nuläge, dvs en så kallad state-of-the-art review, för att kunna diskutera detta i relation till lämpliga datadrivna arbetssätt.
3.4 Datainsamling och analys
I tidigare studier har datainsamling skett på olika sätt. I fall av enkätstudier har datain-samling skett genom enkät och intervjusvar. I fallstudierna har författarna följt en eller flera olika fenomen för att analysera problemfall eller ett visst beteende.
Datainsamlingen för den första delen sker genom insamling av data från olika musik-tjänster. Detta genom att författaren har extraherat sin personlig information från de olika musiktjänsterna i kraft av den svenska personuppgiftslagen. Personuppgiftslagen tvingar företagen att tillhandahålla all information en användare har sparad på deras tjänst.
Kring dataanalysen har i tidigare arbeten oftast en kvalitativ dataanalys skett. I tidi-gare studier har fenomenen som undersökts fått förklaring utifrån författarnas teorier. I alla tidigare studier har också dessa teorier baserats på någon form av relevant litteratur, genom olika intervjuer eller observationer eller genom experiment inom området. Också detta arbete har en kvalitativ analys men med en mer deduktiv inriktning. Arbetet an-vänder de tre mindre forskningsfrågorna för att därigenom gruppera datan för att se på likheter och skillnader.
Här följer en tabell med all insamlad data i detta arbete. Kolumnen datatyp beskriver vilken sorts data det är. Insamlingssätt beskriver hur datan har samlats in dvs. hur ar-betet för att få in relevant data utifrån ansatsens problemställning har gått till. Slutligen beskriver kolumnen analys på vilket sätt datan analyserats för användning i arbetet.
Tabell 1: Insamlad data och analysmmetod.
Datatyp Insamlingssätt Analys
Relaterad litteratur
Systematisk litteratursökning, re-laterad litteratur utifrån välkända artiklar, rekommendationer på god litteratur och artiklar från profes-sorer vid Malmö Högskola och ex-perter vid Sony Mobile
kvalitativ analys av datan, utifrån texternas innehåll.
Mejlkonversationer
Konversationer med data och per-sonuppgiftsansvariga på Spotify, Apple Music och Deezer.
kvalitativ analys av svaren från an-svariga. alla svaren är möjligtvis inte sanningsenliga - tas upp i dis-kussionsdelen.
Personlig data(Sony Mobile) Uthämtat från Sony Mobile genom krav av Personuppgiftslagen.
kvalitativ undersökning av datan Sony Mobile samlat om författa-ren. datan tillhandahölls i lämpligt format för modellering.
Personlig data(Deezer) Uthämtat från Deezer genom krav av Personuppgiftslagen.
kvalitativ undersökning av datan Deezer samlat om författaren. Personlig data(Spotify) Uthämtat från Spotify genom krav
av Personuppgiftslagen.
kvalitativ undersökning av datan Spotify samlat om författaren. Personlig data(Apple Music) Uthämtat från Apple genom krav
av Personuppgiftslagen.
kvalitativ undersökning av datan Apple samlat om författaren. Intervju Samtal med personal vid Sony
Mo-biles musikapplikation.
kvalitativ intervju. används för att beskriva applikationen i dagsläget.
Sammanfattningsvis har arbetet till stor del en kvalitativ datainsamling och analys. Arbetet har inte ett lika strukturerat resultat, utan är mer ett arbete för att ge mening, erfarenhet och nya synsätt på området.
3.5 Systematisk litteraturstudie
Under uppstartsperioden för arbetet formulerades en forskningsfråga kring datainsamling och rekommendationssystem, som direkt delades in i tre frågor som speglar problemställ-ningen i arbetet:
1. Vilken data är viktig att samla in för att bygga rekommendationssystem till musik-tjänster?
2. Vilka sätt att analysera denna data är särskilt relevanta?
3. Vilket arbetssätt behövs för att stödja såväl vidareutveckling av rekommendations-system som analys av insamlad data?
Vid arbetets start tillhandahölls ett antal artiklar från handledare på Malmö Högskola. Arbetets handledare vid Malmö Högskola gav artiklar kring grupprekommendationer samt kring datadrivet arbetssätt och continous innovation av Helena Holmström Olsson som senare användes. Från experter vid Sony Mobile tillhandahölls i samband med intervju ett antal artikelreferenser som behandlade big data, MapReduce och clustering som också använts som referenser för arbetet.
För att söka efter material användes sökverktygen Google Scholar, ACM, Springer, IEEE och Malmö Biblioteks sökverktyg. Detta då dessa fem är en kombination av data-vetenskapligt erkända sökverktyg(ACM, IEEE och Springer) och sökverktyg som söker i hundratals databaser samtidigt. Under processen fördes en loggbok som tillhandahållits av Malmö Bibliotek. Vid sökningen har jag i enlighet med den process Sørensen (1994) be-skriver först läst titel, därefter abstract och conclusions, för att avgöra om relevansen i att läsa de kompletta texterna. Med hjälp av denna process har jag kunnat garantera att inget material av relevans fallit bort under förutsättningen att sökningorden varit specificerade på ett relevant sätt.
Därefter tog jag i samarbete med handledare ut ett antal keywords baserade på forsk-ningsfrågans ämnesområden. I denna process noterades tidigt att ett antal olika keywords från olika ämnen var relevanta vid en vidare sökning. Vid vidare litteratursökning användes de keywords som lokaliserats och skapats utifrån forskningsfrågorna. Dessa keywords var från de tre kategorier som utgör forskningsfrågorna och kan sorteras:
• Datainsamling och dataanalys(“big data”, “big data mining”, “big data analytics”) • Rekommendationssystem(“recommendation systems”, “recommendations”,
“rekommen-dationer”, “collaborative filtering”)
• Datadrivet arbetssätt (“data driven software engineering”, “data driven desicionma-king”)
Tabell 2: Sökord och antal träffar vid respektive sökverktyg.
ACM Springer Google Scholar IEEE Malmö Bibliotek “big data“ 7160 24235 170000 19820 80260 “big data analytics“ 8000 3000 27900 2300 5000 “big data mining“ 33 417 3870 145 501 “big data mining“ + "cluster analysis" 0 32 213 10 5
“deezer“ 1 90 3900 4 2
“spotify“ 17 891 18800 24 135
“apple music“ 0 82 2460 0 0
“recommendation systems“ 3591 6181 37600 887 2715 “recommendation systems“ + “spotify“ 7 48 512 0 3 “recommendation systems“ + “deezer“ 0 4 64 0 0 “recommendations systems“ + “apple music“ 0 2 41 0 0 “rekommendationer“ + “spotify“ 0 0 360 0 0 “rekommendationer“ + “deezer“ 0 0 8 0 0 “data driven desicions making“ 28 570 16100 45 1205 “collaborative filtering“ 1400 2100 87400 2300 5500 “collaborative filtering“ + “recommender systems“ + “item-based“ 0 0 2 0 0
Baserat på keywordsen var det först och främst viktigt att se över att det tillhandahåll-na materialet var relevant för arbetet. Boratto och Cartas State-of-the-art in group recom-mendation and new approaches for automatic identification of groups (2010), tillhandahölls som material från handledare vid Malmö Högskola. På samma sätt tillhandahölls Olsson och Boschs From opinions to data-driven software RD: a multi-case study on how to close the’open loop’problem(2014) samt Sauvola, Tanja, et al. Towards customer-centric soft-ware development: a multiple-case study (2015). Alla tre källorna kontrollerades och gicks igenom på samma sätt som alla källor som använts gjort, genom granskning av keywords samt kontroll av relevans i abstract och conclusion. Alla tre var av relevans för arbetet och innehållet i artiklarna används som stöd för denna uppsats. Dessa kunde räknas in under kategorin för rekommendationssystem respektive datadrivet arbetssätt.
Från experter vid Sony Mobile tillhandahölls ett antal välrenommerade artiklar som beskriver big data, MapReduce och clustering. Här tillhandahölls MapReduce: simplified data processing on large clusters(Dean och Ghemawat, 2008), Cluster Analysis: Basic Con-cepts and Methods, In Data mining: conCon-cepts and techniques(Han, Pei och Kamber, 2011) och Spark: Cluster Computing with Working Sets(Zaharia, Matei, et al., 2010). Även dessa genomgick samma granskning som all annan litteratur och ansågs hålla den kvalite och relevans som krävs av ett arbete likt detta. Dessa är aktuella inom området med datain-samling och dataanalys. Detta ledde alltså till att jag redan vid starten av detta arbete hade viss litteratur inom detta arbetes huvudsakliga ämnesområden.
Därefter startade den litteratursökning som beskrivs i Tabell 2. Ett antal sökningar kring “big data” gav ett allt för stort antal träffar för att ha möjlighet titta igenom alla. Vid sökning på “big data mining” gav ACM 33 resultat, som var rimligt att gå igenom. Här hittades då Mining big data: current status, and forecast to the future(Fan och Bifet, 2013), som ansågs relevant för arbetet. Detta då den behandlar nuläget och framtiden för big data. Inga resultat i form av använda artiklar gavs för sökningarna av “big data analytics”. Dock återfanns de artiklarna som tillhandahållits från Sony Mobile(Dean och Ghemawat, 2008; Han, Pei och Kamber, 2011;Zaharia, Matei, et al., 2010) vilket gjorde att deras relevans styrktes.
Vidare gjordes sökningar kring “recommendations systems”, både separat och med olika tjänsters namn. På detta sätt hittades en del referenslitteratur vad gäller exempel på tidi-gare artiklars metod(Swanson, A case study on Spotify: exploring perceptions of the music streaming service, 2013). Vid sökningar på svenska “rekommendationer” med olika tjänsters
namn hittades ett antal olika resultat vilka var möjliga att gå igenom(med 360 stycken på Google Scholar med “spotify”, 46 stycken med “deezer” och 41 stycken med “apple music”). Trots att största delen av litteraturen representeras av uppsatser liknande denna, finner jag deras värde användbart i den mån att deras blotta existens är ett bevis på liknande arbeten. I samband med sökningarna på “recommendation systems” lokaliserades även “col-laborative filtering” som ett passande nyckelord. Ensamt gav “col“col-laborative filtering” även detta lite för många träffar(87000 på Google Scholar). Däremot genom en mer specificerad sökning kan bra resultat ges. Genom sökningen “collaborative filtering” + “recommender systems” + “item-based” gavs två resultat på Google Scholar i form av Collaborative fil-tering recommender systems(Schafer et al., 2007) och Collaborative filfil-tering recommender systems(Ekstrand, Riedl och Konstan, 2011). Efter genomläsning av båda ansågs Schafers artikel vara mer relevant för arbetet än Ekstrand, Riedl och Konstans. Detta då den reflek-terar dels över rekommendationer men också kring vilken datainsamling som är relevant för att göra rekommendationer av den sorten som är relevant för detta arbete.
Utifrån Collaborative filtering recommender systems lokaliserades Personalization te-chnologies: a process-oriented perspective(Adomavicius och Tuzhilin, 2005) och Amazon. com recommendations: Item-to-item collaborative filtering(Linden, Smith och York, 2003). Detta då Collaborative filtering recommender systems själv refererade till dessa artiklar.
Då dessa artiklar kring collaborative filtering alla refererar till Item-based collaborative filtering recommendation algorithms(Sarwar, Badrul, et al. 2001) läste jag även igenom denna artikel, vilken kunde tillföra nytt innehåll. Guidelines for conducting and reporting case study research in software engineering (Runesson och Höst, 2009) hittades som refe-renslitteratur till Olsson och Bosch, 2014 men också till Sauvola, Tanja, et al. 2015. På samma sätt lokaliserades A set of principles for conducting and evaluating interpretive fi-eld studies in information systems (Klein och Meyers, 1999) som refererades i de båda artiklarna i deras beskrivning av metoden. Artiklarna beskriver den typ av fallstudie som detta arbete vill efterlikna och är relevant för metodelen av arbetet, som senare också genomsyrar arbetet i sin helhet.
I uppsatsen kan noteras att ett antal nyhetsartiklar förekommer. Dessa ger ingen di-rekt fakta som ligger till grund för det uppsatsen, utan agerar istället som underliggande hjälp för läsare att förstå hur marknaden ser ut idag samt tjänsternas och musikindustrins historia. På samma sätt används ett antal föredrag från de olika tjänsterna. Dessa används för att dra slutsatser kring hur olika teknologier används av olika tjänster. Sökningarna kring “recommendations systems” gav bäst resultat, särskilt i kombination med någon av de tjänster jag var intresserad av. Vid rekommendationssökningar som gjorts på svenska hittades det svenska material som alltså används i metoddelen. Sökningarna startade ofta i någon av de datavetenskapliga verktygen. Hittades det inget som var av intresse gick jag därefter vidare med Malmö Biblioteks sökverktyg och Google Scholar. Trots sitt något sto-ra omfång är Google Scholar, det sökverktyg som fungesto-rat bäst för detta arbetet. Google Scholar gav en bred bild som både kunde underlätta i starten av sökningarna på ett ämne, eller i slutet för att summera och uppfatta om man sett alla texter kring sökordet.
3.6 Begränsningar
Inriktningen för arbetet ligger på hur datainsamling ser ut och hur den används för re-kommendationer. Som tidigare nämnts kan detta arbete inte bryta ny mark varken kring
rekommendationssystem eller datainsamling genom mjukvarutjänster utan fokuserar istäl-let på sambandet mellan de två. Detta då det finns en mängd bra artiklar och litteratur skrivet i båda ämnena. Då detta arbete även är tidsbegränsat ges inte heller möjlighet att göra några större utläggningar kring de olika delmomentens(1,2 och 3) problemom-råden. Inte heller formler och information kring hur rekommendationssystemen fungerar utöver grundläggande information. Detta då det enda som är relevant för detta arbete om rekommendationssystemen är deras funktion och resultat. För att strategiskt hantera det som saknas läggs istället kraften på en god state-of-the-art-analys för att ge en god bild av sambandet mellan de båda än att gå djupgående om någon av de två. Den data som presenteras är alltså tillräcklig och relevant nog för att förstå resterande av arbetet. Fokuset för det datadrivna arbetssättet kommer att lägga större vikt vid den insamla-de postinsamla-deployment datan än preinsamla-deployment datan. Detta då insamla-denna sortens data är mer relevant för det specifika fallet.
4
Resultat
4.1 Fas 1: En jämförelse av tre existerande musiktjänster
I denna resultatets första del följer en beskrivning av tre olika musiktjänster. Först beskriver jag tjänsterna och deras olika sätt att praktiskt göra rekommendationer i sina respektive tjänster. Därefter följer ett avsnitt med tabeller kring de olika tjänsternas datainsamling och rekommendationer. Slutligen kommer en kort analys baserad på relevant litteratur.
4.1.1 Tjänstebeskrivning och tjänsters olika rekommendationer
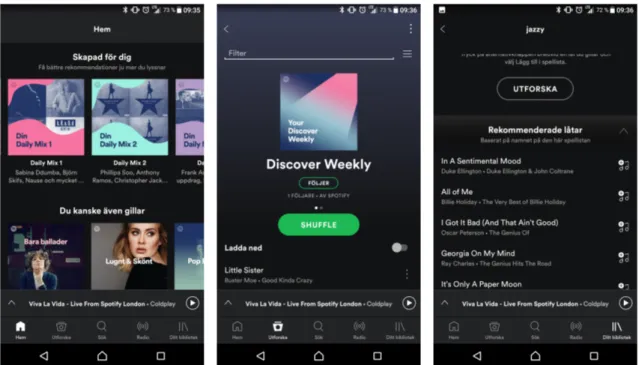
Spotify är en svensk musikströmningstjänst, som blivit en stor export med många an-vändare från hela världen. Det är en sk. freemium-tjänst med en gratisversion och en premiumversion för betalande användare. Spotifys rekommendationstjänst Discover Week-ly fokuserar på att rekommendera låtar du inte Week-lyssnat på i tjänsten förut som tjänsten tror att du uppskattar. Den innehåller även några rekommendationer som ligger väldigt nära tex. en låt av användarens mest lyssnade artist som den ännu inte lyssnat på. En an-nan tjänst som erbjuds är Daily Mix. Daily Mix baseras på en genre eller likan-nande musik som användaren lyssnat på, men innehåller också låtar som jag faktiskt lyssnat, uppblan-dat med ett antal låtar jag inte lyssnat på i samma genre. När användaren skapar en ny spellista på Spotify ges denna ett antal olika typer av rekommendationer. Först baseras rekommendationerna utifrån namnet eller bilden på spellistan. När en låt är tillagd ges re-kommendationer utifrån de låtar som är tillagda i spellistan. Denna rekommendation kan också baseras utifrån bild. Det är också möjligt att få en rekommendation på en annan spellista genom att högerklicka på en existerande spellista och få rekommendation genom en liknande spellista.
Figur 1: Spotifys utseende
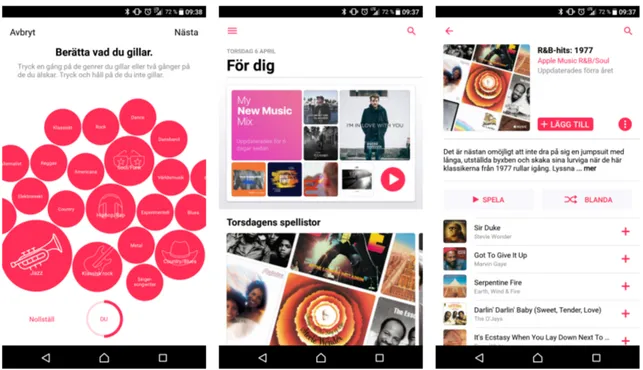
Apple Music är en amerikansk strömningstjänst för musik från företaget Apple. Ap-ple Music är bara för betalande kunder och har alltså ingen gratisversion. I ApAp-ple Music finns möjlighet till rekommendationer under fliken För dig. Dessa baseras på de genres och artister användaren sagt att denna uppskattar vid skapandet av en användare i tjänsten. En personlig profil baseras på dessa genres och artister. I den personliga profilen markeras också om den låt som markerats som en bra eller dålig låt under lyssning. Den personliga profilen ligger sedan till grund för innehållet på För dig. I dagsläget finns ingen rekommen-dationshjälp vid skapandet av en ny spellista. För att få nya rekommendationer under För dig i framtiden krävs därför viss aktivitet från användaren.
Figur 2: Apple Musics utseende
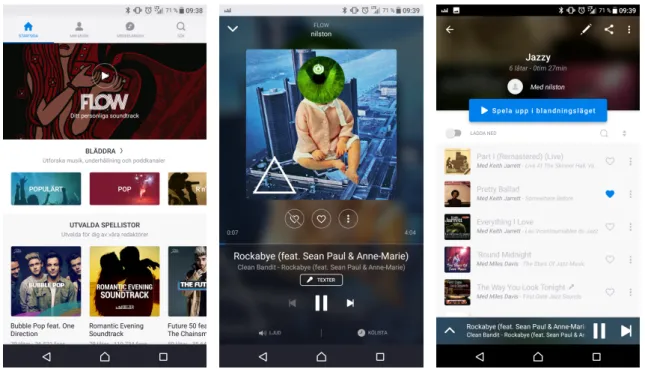
Deezer är en fransk strömningstjänst för musik. Deezer är även denna en freemium-tjänst. Deezer använder ett antal olika sätt att rekommendera musik till sina användare. Att sätta igång läget Flow är att sätta igång ett antal låtar baserade på det du lyssnat på. Ofta finns även ett antal av låtarna som rekommendationerna baseras på också med i Flow. Deezer har en tjänst för att hjälpa till att hitta låtar till en spellista som heter Föreslå låtar. Rekommendationerna baseras då på din personliga musikprofil utifrån dina valda genres och lyssningshistorik.
Figur 3: Deezers utseende
4.1.2 Profilering av användare
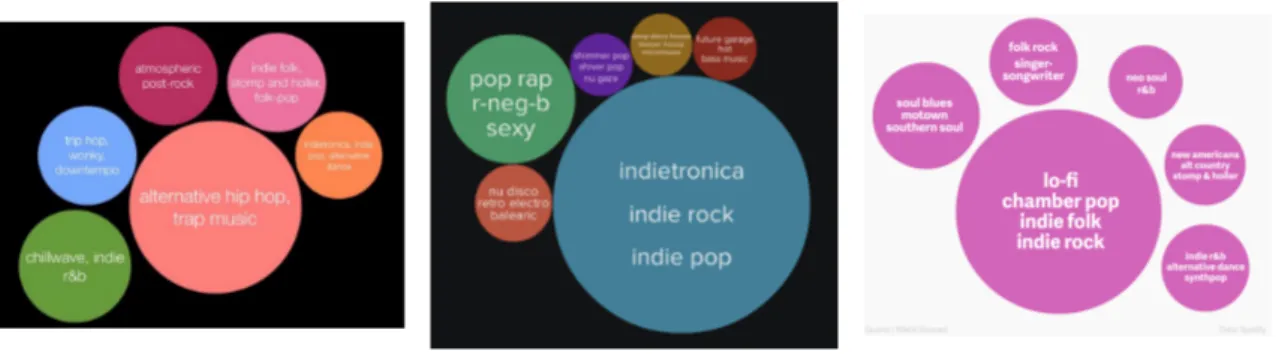
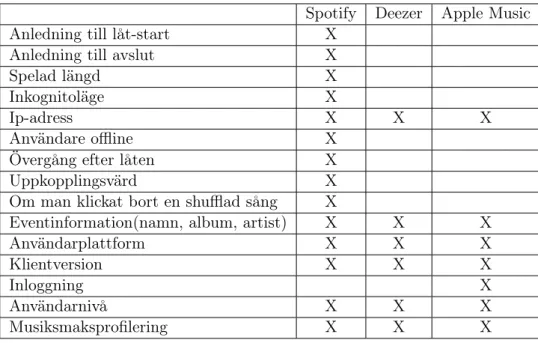
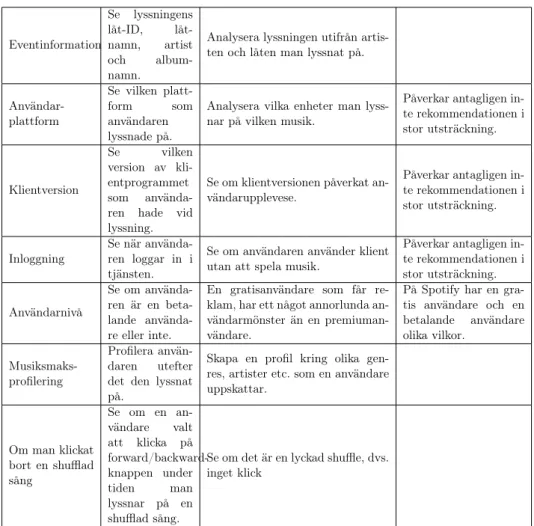
Alla tjänster säger att de på något sätt profilerar användaren. Dock är det svårt att få tag i en profil, då företagen bakom musiktjänsterna helst inte delar med sig om de analyser de gör om användarna. Att profilera användaren gör det möjligt att ge rekommendationer som inte bara baseras på relaterade artister på det användaren tidigare lyssnat på. Istället kan nya genregrupperingar genreras för varje användare. En användares syn på en genre är oftast individuell, vilket gör att genres som är förutbestämda efter valda mönster inte alltid är användbara. Nedan ser ni ett antal musiksmaksprofiler som ett antal olika journalister fått ta ut kring sina användare på Spotify(Dredge, 2015; Heath, 2015;Pasick 2015). Spotify visar också upp både sina användarprofiler och sina rekommendationssystem på Sonar + D under 2016(Ogle och Kalia, 2016).
Figur 4: Spotifys taste-profiles
Profilerna bygger alltså på att användarens lyssnande byggs kring flera närliggande genres. På det sättet låses inte användaren mot en speciell genre utan ges en unik identi-tet utifrån des personliga smak. Profilering är en grundsten i rekommendationer och kan byggas på med mer djupgående information i takt med en ökande datainsamlingen. En musiksmaksprofil är alltså beroende av datainsamlingen. Mer insamlad data betyder dock inte per automatik en mer väl utformad profil. Då stora mängder brus, kommer in till systemet varje dag, kan datapunkter bli missvisande. Brus i detta fall, skulle kunna vara missvisande låttitlar, artistnamn eller genretyp.
När profilen är konstruerad kan jämförelser med andra användare som ser ut som an-vändaren i fråga vara en möjlighet. Det finns också möjlighet att se mönster i anan-vändarens akustiskt musikaliska smak. Med musikaliska verktyg kan egenskaper som harmonik och tempo analyseras för att se vad användaren uppskattar utan faktorer som genrer och ar-tister.
4.1.3 Statistik och typer av insamlad data
Tabell 3 visar statistik från Google Play, som är en av de största marknadsplatserna för mobilapplikationer. Tabellen visar antalet nedladdningar i Google Play, lanseringsdatumet för tjänsten och antal användare i slutet av 2016. Dessa tre är med då de ger en bild kring de olika applikationernas storlek, omfattning och användarantal.
Tabell 3: Information om musiktjänsterna.
Nedladdningar Startdatum Antal användare(slutet av 2016)
Spotify 100-500 miljoner 7 oktober 2008 ∼ 100 miljoner(50miljoner betalande)
Deezer 100-500 miljoner augusti 2007 ∼ 17 miljoner(6 miljoner betalande)
Apple Music 10 - 50 miljoner 30 juni 2015 ∼ 20 miljoner
Tabell 4 visar antalet behörigheter applikationerna söker för användning. Behörighe-terna har ingen direkt relation mot vad tjänsBehörighe-terna slutligen samlar in. BehörigheBehörighe-terna ger dock rätt att koppla ihop applikationen mot andra funktioner i exempelvis en telefon. De olika kategorierna som Google Play använder sig av innehåller ett antal behörigheter i den kategorin. Siffrorna i tabellen representerar hur många behörigheter man söker under varje behörighetskategori.
Tabell 4: Behörigheter musiktjänsterna söker vid användning.
Spotify Deezer Apple Music
Identitet 2 1 0 Kontakter 1 1 1 Telefon 1 1 1 Fonton/media/filer 2 2 2 Lagringsutrymme 2 2 2 Wi-Fi anslutningar 1 1 1
Enhets-Id och samtalsinfo 1 1 1
Enhets- och apphistorik 0 2 0
Övriga 12 13 7
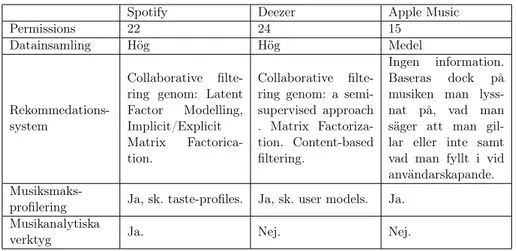
Tabell 5 visar dels vilken data olika tjänster samlar in och definitioner. Datainsamlingen och anledningarna baseras på den information som tillhandahållits av Spotify, Deezer och Apple Music. De olika raderna är sammanställningar av olika datapunkter. Datapunkterna förklaras i tabell 6 och 7.
Tabell 5: Jämförelse mellan musiktjänsternas datainsamling.
Spotify Deezer Apple Music
Anledning till låt-start X
Anledning till avslut X
Spelad längd X
Inkognitoläge X
Ip-adress X X X
Användare offline X
Övergång efter låten X
Uppkopplingsvärd X
Om man klickat bort en shufflad sång X
Eventinformation(namn, album, artist) X X X
Användarplattform X X X
Klientversion X X X
Inloggning X
Användarnivå X X X
Tabell 6: Förklaring till fälten i Tabell 5.
Betydelse Anledning ur
rekommendations-perspektiv. Kommentar Anledning till låt-start Se hur användaren började lyssna på låten. Se om användaren hamnade där med vilje, eller bara hamnade på låten av misstag. Skulle kunna se anledningar till att användaren lyssnat färdigt på den.
Anledning till av-slut
Se hur användaren slutade lyssna på låten.
Se om användaren klickat bort lå-ten för att den inte gillat den, eller att låten spelat färdigt.
Spelad längd
Se hur lång tid av låten som använ-daren lyssnat på
Se om användaren gillade låten, genom att lyssna på hela.
Inkognitoläge Se om användaren är i inkognitoläge.
Se om man ska spara låten för att läggas till i Musiksmaken för an-vändaren. Påverkar antagli-gen inte rekommen-dationen i stor ut-sträckning. Ip-adress Se användarens IP-adress.
Lokalisera var användaren befinner sig. Användare offline Se om använda-ren är online/eller spelar offlinespa-rat material.
Låtar som användaren spara offline skulle kunna vara låtar som använ-daren värderar bättre än snittet.
Transition efter låten
Se om övergången till nästa låt var obruten eller inte.
Se på användarens intresse bero-ende på hur den uppskattar över-gångarna. Påverkar antagli-gen inte rekommen-dationen i stor ut-sträckning. Uppkopplingsvärd Se vilken server som hanterade streamingen med användarens client Analysera om uppkopplingen på något sätt påverkat användarens upplevelse. Påverkar antagli-gen inte rekommen-dationen i stor ut-sträckning.
Tabell 7: Forts. förklaring till fälten i Tabell 5. Eventinformation Se lyssningens låt-ID, låt-namn, artist och album-namn.
Analysera lyssningen utifrån artis-ten och låartis-ten man lyssnat på.
Användar-plattform Se vilken platt-form som användaren lyssnade på.
Analysera vilka enheter man lyss-nar på vilken musik.
Påverkar antagligen in-te rekommendationen i stor utsträckning. Klientversion Se vilken version av kli-entprogrammet som använda-ren hade vid lyssning.
Se om klientversionen påverkat an-vändarupplevese.
Påverkar antagligen in-te rekommendationen i stor utsträckning. Inloggning Se när använda-ren loggar in i tjänsten.
Se om användaren använder klient utan att spela musik.
Påverkar antagligen in-te rekommendationen i stor utsträckning. Användarnivå Se om använda-ren är en beta-lande använda-re eller inte.
En gratisanvändare som får re-klam, har ett något annorlunda an-vändarmönster än en premiuman-vändare.
På Spotify har en gra-tis användare och en betalande användare olika vilkor. Musiksmaks-profilering Profilera använ-daren utefter det den lyssnat på.
Skapa en profil kring olika gen-res, artister etc. som en användare uppskattar. Om man klickat bort en shufflad sång Se om en an-vändare valt att klicka på forward/backward-knappen under tiden man lyssnar på en shufflad sång.
Se om det är en lyckad shuffle, dvs. inget klick
Den sista tabellen i detta avsnitt innehåller en sammanfattning av de olika ström-ningstjänsterna. I tabellen beskrivs en sammanställning av de tidigare tabellerna samt information kring rekommendationssystem.
Tabell 8: Sammanställningen jämförelse av musiktjänster.
Spotify Deezer Apple Music
Permissions 22 24 15
Datainsamling Hög Hög Medel
Rekommedations-system
Collaborative filte-ring genom: Latent Factor Modelling, Implicit/Explicit Matrix Factorica-tion.
Collaborative filte-ring genom: a semi-supervised approach . Matrix Factoriza-tion. Content-based filtering. Ingen information. Baseras dock på musiken man lyss-nat på, vad man säger att man gil-lar eller inte samt vad man fyllt i vid användarskapande.
Musiksmaks-profilering Ja, sk. taste-profiles. Ja, sk. user models. Ja. Musikanalytiska
verktyg Ja. Nej. Nej.
Att ha möjlighet att skapa en så omfattande bild om användaren som möjligt är viktigt. Dock är det viktigt att inte samla in för mycket information om det inte finns möjlighet att hantera den. Den större medvetenheten från användare gör också att användare ur ett förtroendeperspektiv kan lämna tjänsten för andra alternativ som samlar in mindre data. Det är också viktigt att se över hur länge datan är relevant att spara. Spotify menar att data som är äldre än 90 dagar är inte relevant att bygga rekommendationer utifrån. Dock läggs denna data som variabler i användarens musiksmaksprofilering. Rekommendationer är komplicerat i många stadier av en användares interagerande med en musiktjänst.
I ett tidigt stadie av användande, är det lätt att möta ett “kallstartsproblem”. Att inte ha någon data att utgå ifrån, gör det svårt för tjänsten att ge rekommendationer överhu-vudtaget. Tjänsterna Deezer och Apple Music tacklar detta genom att låta användaren fylla i information om sin musiksmak redan när användaren använder tjänsten första gång-en. Tjänsten Spotify låter istället användaren själv söka upp musik eller skapa en spellista för att komma igång. Alla tjänsterna erbjuder en startsida med ett antal förslag, baserade på populär musik och landet som användaren kommer ifrån.
I ett något senare stadie kan det vara svårt för användaren att få intressanta rekom-mendationer. Om inte musiksmaksprofilen ständigt uppdateras, kan en längre period av en speciell sorts musik förstöra framtida rekommendationer, då en “tidigare” smak kan få en för stor del av alla framtida smaker. Spotify menar att de endast sparar de senaste 90 dagarna av data om en användare. Spotify menar att musiksmak är en “färskvara” som skiftar regelbundet, även om förändringarna inte alltid är så stora. Informationen sparas dock i användarens taste profile i som en slags historik.
4.2 Fas 2: En musiktjänst för lokala filer
I denna fas beskrivs Sony Mobiles musikapplikation samt hur datainsamlingen kan se ut och analyseras i jämförelse med det som presenterats i Fas 1.
4.2.1 Datainsamling i dagsläget
Sony Mobiles musikapplikation ‘Musik’( eng. ‘Music’) är den musikapplikation som kommer förinstallerad på en Sonytelefon när du köper den. Tjänsten går endast att ladda ner på Google Play för Sony Mobile-användare, men har drygt 40 miljoner användare varje månad(Ngo, 2017). Applikationen är en applikation för att låta användare spela upp sina lokala ljudfiler. Det är också möjligt att sortera låtarna i biblioteket och spara låtarna till olika spellistor.
Figur 5: Sony Mobile: Music taste-profiles
Sony Mobiles musikapplikation har inga rekommendationer eller rekommendationssy-stem. Datan som samlas in är till för statistiska insiktskort som skickas till användare vid något tillfälle i månaden(Ngo, 2017). Sony Mobiles musikapplikations datainsamling ser ut på det här sättet i jämförelse med de tjänsterna som presenterats i Fas 1:
Tabell 9: Jämförelse med Sony Mobile: Music.
Spotify Deezer Apple Music Sony Mobile: Music
Anledning till låt-start X
Anledning till avslut X
Spelad längd X X
Inkognitoläge X
Ip-adress X X X
Användare offline X
Övergång efter låten X
Uppkopplingsvärd X
Om man klickat bort en shufflad sång X
Eventinformation(namn, album, artist) X X X X
Användarplattform X X X X
Klientversion X X X X
Inloggning X
Användarnivå X X X
Musiksmaksprofilering X X X
I jämförelse med strömningstjänsterna av musik samlar Sony Mobiles musikapplikation inte in så mycket data från sina användare. Många av fälten blir tomma då till exempel ingen uppkoppling krävs för att spela musik. I intervju berättar Mikael Ngo att av de sam-manlagda användarna av musikapplikationen uppskattas ungefär en tiondel godkänna att låta data om deras användning skickas(2017). För att skicka data i Sony Mobiles musikap-plikation måste användaren acceptera detta efter ett antal användningar av tjänsten. Då Sony Mobiles musikapplikation är en musiktjänst för lokala filer är datainsamlingen något annorlunda mot de undersökta strömningstjänsterna av musik. Strömningstjänsterna har ofta stora färdiga kataloger i systemet med välstrukturerad metadata kring låtars olika egenskaper. Egenskaper som artist, album och genre, blir avsevärt mycket svårare att få från en tjänst som skickar datan kring användarens egna lokala filer med deras egen me-tadata. Vidare berättar Mikael Ngo att ett problem med Sony Mobiles musikapplikations datainsamling är den dåliga metadata de får in vid insamling(2017). Då det inte finns några kataloger att utgå ifrån likt på en strömningstjänst för musik, är det svårt att lokalisera vilka filer som har samma innehåll.
4.2.2 Datainsamling för användarprofilering
För att avgöra vilken data som bör samlas in för att kunna bygga ett system för mu-siksmaksprofiler presenterar detta arbete en teori. I dagsläget baserar musiktjänster enligt den insamlade datan framförallt sina profiler på tre stora block. De baserar dels sina profiler på användarens historik från det den lyssnat på i tjänsten. Dels på vad andra användare som har en liknande historik som jag har lyssnat på. Det finns också ofta någon form av analyser kring olika genres som dessa har gemensamt. Det kan också vara analyser kring hur låtar användaren lyssnat på eller andra användare med samma preferenser som användaren, har för tempo, harmonier osv.
För att sedan skapa rekommendationer är det möjligt att använda den musiksmaksprofil för att jämföra mot andra användare, artister och låtar.
För att anpassa datainsamling för rekommendationer med hjälp av musiksmaksprofiler är det viktigt att fokusera på att skapa en rimlig modell, för att successivt lägga till data, än att börja med att samla in stora mängder data. Profilering av användaren kan ske i stor eller liten utsträckning . I ett inledande scenario hade profileringen inte behövt vara mer än en profil kring vilka genres användaren verkar uppskatta på samt artister, låtar och album som användaren lyssnat mycket på.
4.2.3 Problematik kring rekommendationer
För att tackla det kallstartsproblem som tidigare nämnts är det möjligt att be användaren fylla i vilken musik den gillar på något sätt och samla in denna data. På så vis ges använ-daren en chans att få rekommendationer redan från starten innan använanvän-darens egentliga lyssnande har startat. Dock har kallstartsproblemet inte lika stor effekt i en tjänst med lokala filer, då användaren lägger till filerna själv för att starta interaktionen med tjänsten. Det bör nämnas att Spotify samlar in väldigt många datapunkter gällande interaktioner med tjänsten. Detta sker genom att Spotify samlar in olika parametrar kring hur använ-daren hittat musiken de lyssnar på.
Sammanfattningsvis kan rekommendationer göras och anpassas utefter datainsamling-en. Det går alltid att göra någon form av rekommendationer utifrån den insamlade da-tan. Dock bör man, vid mindre välutvecklade rekommendationstjänster vara transparent mot användaren vad rekommendationerna bygger på. På detta sätt kan användaren förstå sambandet mellan datainsamling och rekommendation och behöver därför inte känna sig förnärmad av att rekommendationerna skulle spegla deras personliga smak utan är bara summan av deras handlingar.
4.3 Fas 3: Ett datadrivet anpassat arbetssätt
I denna sista fas beskrivs hur ett datadrivet arbetssätt skulle kunna ske i en arbetsprocess där datainsamlingen ligger till grund för den den slutgiltiga produkten. Fas 3 är uppdelad i fyra delar som beskriver en datadriven utvecklingsprocess från det att datan skapas till det att datan försvinner ur systemet. För att belysa denna process har en användarprofilering av den data som Sony Mobile tillhandahållit gjorts som ett exempel. I slutet av varje avsnitt ges en beskrivning kring de olika delarna i denna process.
4.3.1 Skapande
I en datadriven process är det viktigt att se var flödet startar. Det datadrivna arbetssättet bör alltid vara direkt anslutet till användaren. Användaren är inte alltid medveten om det, men lämnar alltid ett tydligt spår av data tillbaka till tjänsteägaren. Det kan vara genom den systematiska datainsamlingsintegrationen i mjukvaran, genom kommentarerna på ett betaforum eller möjligtvis genom frånvaron av någon som helst respons från användaren om tillverkarens tjänst. Data samlas, oftast i en tidig fas i ett projekt, också in genom att möta användaren för intervjuer, formulär och undersökningar på olika sätt(Olsson och Bosch, 2014). Detta är dock något som bör fortsätta att ske trots att datan kan samlas in statistiskt i en mjukvarutjänst. Användarens användande av en tjänst reflekterar inte
alltid den aktion som användaren önskar att göra, utan möjligtvis tvingas att göra. Därför blir ett betaforum eller en återkommande fokusgrupp ett tillskott för en tjänst som är svår att ersätta med en systematisk datainsamling.
Med detta sagt är inte den systematiska datainsamlingen något dåligt, utan tvärtom, något i många fall nödvändigt. Skapandet av den här typen av data sker när användaren på något sätt accepterar att låta tjänsten samla den data om användarens integration med tjänsten som tjänsten begär. I många tjänster är det dock inte alla som accepterar datain-samlingen. I Sony Mobiles musikapplikation godkänner, som tidigare nämnts, en mindre del av användarna att låta data om deras användande samlas(Ngo, 2017). Vilken del av användarna som representeras av datan bör prioriteras i alla led av datans användning. Datainsamlingens precision bör vara väl förankrad i hela utvecklingsteamet, från dataa-nalytiker till produktägare för att alla ska kunna utnyttja de möjligheter och svagheter den ger. Urvalet av vilken data som bör samlas in specificeras för att varje datapunkt i en systematisk datainsamling av den typ som en mjukvarutjänst gör möjlig, ska vara så anpassad för ändamålet som möjligt. Det är viktigt att undvika redundans och missvisande information för att underlätta användandet.
Idag ges nya möjligheter för datainsamling genom verktyg som Google Analytics. Goog-le Analytics skapar data utifrån användares interaktion med tjänster. Det kan ske genom att redovisa hur mycket specifika vyer eller sidor öppnas, eller hur mycket trafik applika-tionen har tagit emot under en tidsperiod. Att utnyttja olika verktyg kan alltså skapa mer data som illustreras och presenteras på det sätt som användaren själv vill ha.
Vid skapande av datan är det också önskvärt att skilja på kvantitativ och kvalitativ data och ta beslut kring hur tolkning och beslut sker utifrån olika data. Dock är det bra praktik att använda både kvantitativ och kvalitativ data under utvecklingsprocessen vid datadrivet arbete. I ett scenario kring rekommendationer är kvantitativ data den insam-lade systematiska datan grundläggande. Dock beskriver Spotify att de rekommendationer som lanserats oftast gått genom testanvändare på Spotify först, för att undersöka om re-kommendationerna överhuvudtaget är rimliga för lansering till användare eller betaforum. I ett fall kring rekommendationstjänsten Discover Weekly beskrivs att den respons som mottogs från testanvändare gjorde det möjligt att lansera tjänsten till användare.
Datan som samlas in av Sony Mobiles musikapplikation kring användaren, sker alltså genom insamling av användares data som användaren har accepterat genom den datain-samlingsförfrågan som applikationen ger(Ngo, 2017). Det som skiljer Sonys data från någon av de jämförda strömningstjänsterna i fas 1 är att metadatan från Sony inte är lika väl-strukturerad som den strömningtjänsterna använder sig av. Detta då det är användaren själv som står som ansvarig för metadatan och inte ett fördefinierat mediabibliotek.
Om en låt heter följande: Artist: Ed Sheeran Låtnamn: Shape of you Genre: Pop, R’n’B
Kan denna representeras av filer med namn som: Artist: ed-sheeran
Låtnamn: track1 – shape of you -Genre: rock/pop/singersongwriter
En lösning är att bygga filter som tar bort icke-alfanumeriska tecken och vanliga namn på okända filer(”unknown”, ”track”).