Kandidatuppsats
Statistiska institutionen
Bachelor thesis, Department of StatisticsNr 2020:x
Restauranger och serveringars
anpassning under coronapandemin
Restaurant adaptation during the COVID-19 pandemic
Michael Nilsson och Kursat Tuncer
Självständigt arbete 15 högskolepoäng inom Statistik III, HT2020 Handledare: Per Gösta Andersson
Sammanfattning
Vi har genomfört en enkätundersökning om restaurangers och serveringars ekonomiska utsatthet och anpassning under coronapandemin. 139 restauranger och serveringar från Stockholms kommun valdes slumpmässigt ut för att delta i studien. Varje servering fick tillgång till ett formulär, som bland annat inkluderade frågor relaterade till beställnings- och överlämningsmetoder samt försäljning. Svaren från respondenterna användes sedan för att göra punkt- och intervallskattningar om olika parametrar i populationen. Vi tar även fram en logistisk regressionsmodell för att skatta sannolikheter för att serveringar genomför olika anpassningsmetoder. Utifrån urvalet kan vi se att många serveringar har valt att införa någon sorts ny strategi som svar på pandemin. För de flesta har dock försäljningen minskat. Det verkar också som att serveringar som har fått färre kunder tenderar att ha en högre sannolikhet att anpassa sig. På grund av att bara runt 15,38 procent av de kontaktade serveringarna valde att svara, finns det stor osäkerhet i våra skattningar.
Abstract
We have conducted a survey about the adaptation and economic vulnerability of restaurants and food services during the COVID-19 pandemic. 139 restaurants from Stockholm
Municipality were randomly chosen to participate. Each restaurant was provided with a form that included questions related to different methods for ordering and serving food, and sales. The answers from the respondents were later used to form point and interval estimates for different population parameters. We have also used a logistic regression model to estimate the probability that food services utilize a new adaptation strategy. The results from the sample indicate that many food services have chosen some kind of new strategy in response to the pandemic. For most, sales have decreased. It also seems to be the case that food services that have had a decrease in customers tend to have higher probability for adaptation. Since only 15.38 percent of the food services that were included in the sample chose to participate, there exists large uncertainty in our estimates.
Förord
Vi vill ge ett stort tack till vår handledare Per-Gösta Andersson och vår kursexaminator Dan Hedlin, som båda två har gett oss vägledning och svarat på frågor under arbetet med
uppsatsen. Vi vill också tacka alla restauranger och serveringar som deltog i vår studie. Utan er hade detta arbete inte varit möjligt.
Innehållsförteckning
1. Inledning 1 1.1 Vår studie 1 1.2 Tidigare studier 1 2. Insamling av data 2 2.1 Urvalsram 2 2.2 Urvalsstorlek 32.3 Kontakt med respondenterna 4
2.4 Informationsbrev 5
2.5 Svaren från respondenterna 5
2.6 Bortfall 15
2.7 Mekanismer för icke-respons 16
3. Inferens och modeller 17
3.1 Konfidensintervall 17
3.1.1 Konfidensintervall baserade på normalfördelningen 17 3.1.2 Konfidensintervall baserade på bootstrap-metoder 19
3.2 Logistisk regression 20
4. Resultat 22
4.1 Konfidensintervall 22
4.2 Logistisk regression 24
5. Diskussion och slutord 27
Referenser 29
Appendix 1 – Urvalsprocessen 31
Appendix 2 – Frågeformuläret 32
1. Inledning
Restauranger har länge drivit sina verksamheter utefter olika metoder för att locka fler kunder. Det kan vara allt från det historiskt vanligaste att invänta kunden och sedan servera eller att servera kunden genom en pandemianpassad metod. Sverige har aktivt drivit att bli världsbäst på att använda digitaliseringens möjligheter. Restauranger följer den utvecklingen där digitala innovationer framställer nya metoder som hjälper restaurangerna att bättre kunna kommunicera och servera sina kunder (Regeringskansliet 2020).
Den 11 mars 2020 meddelade världshälsomyndigheten (WHO) att covid-19 blivit en
pandemi. Kunskapsläget kring pandemin låg på bottennivå och det medförde turbulens under våren vilket skakade världens ekonomi. I Sverige har Folkhälsomyndigheten haft en central roll i att öka befolkningens medvetenhet om smittspridningen. I början uppmanades
restauranger att följa Folkhälsomyndighetens föreskrifter och allmänna råd, och från och med den 1 juli 2020 började även lagen om tillfälliga smittskyddsåtgärder att gälla. Enligt lagen behöver den som driver ett serveringsställe utföra en mängd smittskyddsåtgärder för att förhindra spridningen av viruset (Folkhälsomyndigheten 2020).
Riksbanken befarade en lågkonjunktur till följd av coronapandemin. Det visar en rapport från skatteverket, där statistiken visar att restauranger men även hotell har beviljats mest
omställningsstöd (Skatteverket 2020a). Ytterligare en rapport från skatteverket rapporterar att omsättningen har minskat för restauranger, minskningen är knappast förvånande med tanke på de restriktioner som getts och åtgärder som tagits för att minska den sociala interaktionen mellan människor (Skatteverket 2020b). Därför kan det falla naturligt för restauranger i Stockholm att ta till sig nya grepp för att locka till sig kunder när själva grunden för restaurangnäringen – att människor träffas på lokal – är försvagad (Heick 2020).
1.1 Vår studie
Syftet med studien är att undersöka restauranger och serveringars ekonomiska utsatthet efter den skärpta säkerheten i restaurangmiljöer. Vi vill också se i vilken utsträckning restauranger och serveringar anpassar sig. Studien är en enkätundersökning, där vi utifrån ett urval
kontaktar restauranger och serveringar i Stockholms kommun för att få svar på frågor som är kopplade till ekonomiska förhållanden och anpassning under pandemin. Med de ekonomiska frågorna vill vi mäta förändring av försäljning, samt huruvida pandemin har förhindrat restauranger och serveringar ifrån att uppnå olika mål. Genom frågorna som är relaterade till anpassning vill vi se ifall restaurangerna har tillämpat någon ny beställningsmetod eller något nytt sätt att lämna över mat till kunden, som svar på pandemin. Utifrån svaren på enkäten vill vi kunna göra inferens om parametrar för hela populationen av restauranger och serveringar i Stockholms kommun. Vi hoppas att studiens resultat kan ge en klarare bild av restauranger och serveringars situation under coronapandemin.
1.2 Tidigare studier
Vid Uppsala universitet arbetar man bland annat med att undersöka vilka ekonomiska utmaningar pandemin tillfört samhället. Detta är ett globalt ämne som medför stora välfärdskostnader av karantänsregler. I en rapport kring karantänsregler vill forskare från Uppsala universitet mäta direkta och indirekta välfärdskostnader av att införa karantänsregler som begränsar människors möjlighet att lämna sina hem (Scheinert 2020).
En del av forskningen är att komma med strategier som kan förebygga restaurangers- och serveringars ekonomiska utsatthet under pandemin (Alsne 2020). Redan innan pandemin gick samhället mot en digitalisering, det är endast nu under pandemin som efterfrågan på digitala tjänster ökat drastiskt. Digitaliseringens påverkan på arbetsmarknaden visar tydligt på rutinarbetens automatisering. Yrken som exempelvis en servitris kan ersättas av digitala medel (Frey & Osborne 2013:2). Studier har visat att företag som använder sig av digitala tjänster tenderar att ha bättre relation till sina kunder jämfört med de som inte använder digitala tjänster. Kunders förmåga att beställa mat blir därmed ett viktigt ämne, det finns i nuläget inga tidigare studier kring hur restaurang- och serveringars användning av metoder fungerat under pandemin. Därför vill vi undersöka hur pandemianpassade metoder men även metoder som inte är anpassade för en pandemi fungerar inom restaurang- och
serveringsverksamheter. Studier har även visat att kunder är generellt intresserade av att använda digitala beställningsmetoder (Mallat 2007:414).
2. Insamling av data
Det övergripande syftet med alla urvalsundersökningar är att kunna uppskatta egenskaper hos den population som studeras. Ett urval som nära avspeglar målpopulationen ger mer
tillförlitliga resultat; vi vill därför gärna ha ett så representativt urval som möjligt. Graden av representativitet kan bero på en mängd olika orsaker: egenskaper hos urvalsramen, hur urvalet görs, storleken på urvalet, hur värden på variabler mäts, bortfall, med mera (Lohr 2019:16–36). Alla dessa faktorer är viktiga att tänka på när en urvalsundersökning ska genomföras. I denna del beskriver vi hanteringen av insamlingen av data: från valet av urvalsram och urvalsmetod, till introduktionsbrevet och respondenternas svar på formuläret. Vi tar även med ett avsnitt kring bortfall, där vi diskuterar hur icke-responsen påverkar vår undersökning. Här följer en diskussion kring den bias som uppstår vid icke-respons. Slutligen tar vi upp mekanismer som förklarar olika anledningar till att en icke-respons uppstår.
2.1 Urvalsram
För att öka sannolikheten att ett urval är representativt för populationen behöver
urvalsenheterna komma från en bra urvalsram. I den bästa av världar innehåller urvalsramen exakt samma enheter som också ingår i målpopulationen. Det är i många fall orealistiskt att hitta en urvalsram som matchar målpopulationen exakt; oftast finns det övertäckning och undertäckning närvarande, informationen i urvalsramen kan vara utdaterad, enheter kan vara duplicerade, och somliga enheter i urvalsramen kan vara kluster som inkluderar fler än en enhet från målpopulationen (Lohr 2019: 19–21).
Uppgiften att hitta en lämplig urvalsram för restauranger och serveringar i Stockholms kommun visade sig vara inte helt oproblematisk. Vi upplevde att det var svårt att hitta en urvalsram som dels var representativ för vår målpopulation, och som vi också kunde använda praktiskt för att dra ett urval. I början övervägde vi att använda information från hemsidor vars primära syfte var att visa recensioner och omdömen om restauranger från kunder. Det fanns huvudsakligen två problem med dessa hemsidor. Det första problemet var att vi inte visste exakt hur restaurang och servering definierades på hemsidorna, samt hur kompletta listorna var. Vi uppskattade att det fanns en påtaglig risk för att listorna karaktäriserades av substantiell undertäckning. Det andra problemet var hur vi skulle kunna genomföra ett
slumpmässigt urval: listorna fanns inte tillgängliga att ladda ner som dataset, och att manuellt registrera alla restauranger och serveringar hade tagit för lång tid.
I slutändan valde vi att kontakta Stockholms stad för att se ifall de hade en urvalsram som vi kunde använda. Från livsmedelskontrollen på miljöförvaltningen fick vi tillgång till en lista över alla registrerade livsmedelsanläggningar i Stockholms stad. Listan fanns som en xls-fil och innehöll 8091 enheter; med kompletterande information om adress och fastighet. Som urvalsram var listan långt ifrån perfekt: i och med att listan täckte alla
livsmedelsanläggningar, fanns det många enheter som inte tillhörde vår målpopulation – utöver restauranger och kaféer innehöll listan också bland annat förskolor, livsmedelsbutiker, och vårdhem. En till bristfällighet med listan var att det inte fanns sekundär information som hade kunnat användas för stratifiering. Till sist beslutade vi oss för att använda listan över livsmedelsanläggningar som vår urvalsram, trots befintliga nackdelar. I vårt fall var övertäckningen i sig inte något större problem: i urvalsprocessen kunde enheter som inte tillhörde målpopulationen snabbt och enkelt selekteras bort och ersättas (detta beskrivs mer på djupet i Appendix 1). Jämfört med de alternativa listor som lyftes fram innan ansåg vi att det var sannolikt att listan från miljöförvaltningen hade relativt liten undertäckning. Rent praktiskt var det också enklare att dra ett slumpmässigt urval: eftersom listan redan fanns tillgänglig som en xls-fil kunde vi enkelt dra urval från listan via R.
2.2 Urvalsstorlek
Nästa steg var att dra ett slumpmässigt urval från urvalsramen. Först behövde vi bestämma vilken urvalsstorlek som skulle användas. Desto större urval som dras, desto mer information kommer det att finnas om populationen. Samtidigt kan ett större urval innebära att det behövs mer arbete och tid för att genomföra undersökningen. Ett vanligt tillvägagångssätt vid valet av urvalsstorlek är att på förhand specificera en felmarginal 𝜀, och en signifikansnivå 𝛼 så att
𝑃$%𝜃' − 𝜃% ≤ 𝜀* = 1 − 𝛼 (2.1) där 𝜃 är en given parameter, och 𝜃' är den estimator som har valts för att skatta 𝜃. Om 𝑆!"# betecknar variansen av 𝜃', har vi att
𝑆!"# = 3 𝜀 𝑧$ #⁄ 5 # (2.2) Om 𝑆!"# = 𝑓(𝑛), där 𝑓(∙) är bijektiv, ges 𝑛 av 𝑛 = 9𝑓&':3 𝜀 𝑧$ #⁄ 5 # ;< (2.3)
I och med att vi med frågorna mäter svar på flera variabler kan vi inte utgå ifrån att en urvalsstorlek är optimal för alla estimatorer. Eftersom formuläret innehåller många frågor som används för att mäta proportioner, valde vi ändå att utgå ifrån urvalsproportionen 𝑝̂ =
'
(∑ 𝑦) (
)*' , 𝑦)~Bernoulli(𝑝) som estimator när vi valde urvalsstorleken. I och med att 𝑝 är
okänd, utgick vi från att 𝑝 = arg max
+∈[.,'] 𝑆+1
# = 0,5 i uttrycket för 𝑛, för att vi skulle kunna vara
eftersom populationsstorleken är okänd. Detta leder till att vi får ett lite större värde på 𝑛 än vad som egentligen behövs. Med 𝜀 = 0,7, 𝛼 = 0,1, får vi att 𝑛 = 139.
När urvalsstorleken var bestämd återstod det bara att dra urvalet från urvalsramen. I vårt fall hade vi möjlighet att se hur många enheter som tillhörde målpopulationen, genom att i efterhand se vilken typ av verksamhet som var kopplad till respektive anläggning. Genom att selektera bort enheter som inte tillhörde målpopulationen för att sedan ersätta med nya
observationer, kunde vi dra ett slumpmässigt urval från undersökningspopulationen. På grund av att smittspridningen av coronaviruset var väldigt hög under den period då vi ämnade att kontakta restaurangerna valde vi till en början att avgränsa vår undersökningspopulation till de restauranger och serveringar som gick att kontakta på distans. En sådan avgränsning kan ge upphov till selektionsbias, vilket är viktigt att ha i åtanke.
2.3 Kontakt med respondenterna
Vi befinner oss idag i en situation som inte är lik det vi är vana vid. Att ta ställning till hur undersökningen skall genomföras under pandemin, där social kontakt undanbedes.
Utförandet av urvalsundersökningen utgick efter några centrala punkter; genomförbarhet, kostnader och tidsplan (Dahmström 2011:75–77). Vi gjorde ett avvägande av distansbaserade strategier när det kom till genomförbarheten, kostnaden och tidsplanen. Vi bedömde
telefonsamtal, kontakt via e-post och sociala medier som genomförbara distansbaserade metoder. När det kommer till val av metod övervägde vi mellan e-postenkät, där
respondenten direkt kan besvara via mejl, och webbenkät där vi ber respondenten besöka en webbsajt för att fylla i enkäten. Vi valde att använda en webbenkät, då e-postenkäten
transformerade original enkäten till något som vi bedömde inte var lättförståeligt för respondenten att besvara. Webbenkäten behöll originalformen (Bryman 2011:599).
Eftersom vi till en början begränsade oss i kontakt via e-post eller sociala medier medförde det ett stort antal bortfall i vår undersökning. Vi skickade då ut webbenkäten vid tre olika tillfällen, varav ett tillfälle där mottagaren får enkäten för första gången och två påminnelser. När dagen passerat sista svarsdag hade vi fortfarande ett högt bortfall. För att hantera
bortfallet försökte vi använda oss utav tvåfasurval. Det innebär att vi drog ett obundet
slumpmässigt urval om 5 observationer från vårt ursprungliga urval. Dessa fem observationer motsvarar icke-respondenter, tanken var att dessa fem skulle representera icke-responsen. Eftersom det nu passerat sista svarsdagen på enkäten, har vi inte mycket tid kvar att ägna åt insamling av data. Vi har det i åtanke att fem observationer troligtvis är för lite för att ge representativa slutsatser, men vi ville ändå försöka utföra detta för att se om tvåfasurvalen skulle minska vårt icke-respons bias. Vi försökte i första hand få kontakt med dessa fem via telefon, då det inte fungerade bestämde vi oss för att avbryta tvåfasurval. Vi valde att istället kontakta övriga respondenter som ännu inte svarat i ett försök att minska bortfallet.
Även om vi befinner oss i en pandemi blev valet att nu fysiskt besöka ett urval av restaurang- och serveringar som ännu inte svarat. Fysiska besöken visade sig vara mycket effektiva, vi besökte mycket få verksamheter på grund av smittspridningsrisken, men fick vi hög svarsfrekvens. Ett större urval av fysiska besök hade sannolikt givit oss färre bortfall i undersökningen. Att skapa en fungerande och tillitsfull relation handlar därför om en relativt svår balansakt som vi tyckte var lättare att skapa vid fysisk kontakt jämfört med e-post eller telefon. Att presentera informationsbrevet kort och koncist muntligt för en andel respondenter ansåg vi vara den metod som vi tyckte var mest effektiv när det handlar om att skapa en tillitsfull relation till respondenten. Genom fysisk besök var det möjligt för oss att med hjälp
av leenden och ögonkontakt kunna presentera oss och vår undersökning på ett tillitsfullt sätt. (Bryman 2011:213)
När det kommer till svaren är vi medvetna om att restauranger kan ha en e-post eller dator/telefon som många använder. Vi vill således undvika att få duplicerade svar, därför använde vi svarskoder för att säkerställa att varje restaurang endast givit ett svar. Svarskoden formade vi med hjälp av R, genom att ta 139 slumpmässigt valda bestående av fyra tal från intervallet 1–9999. Varje observation har fått olika svarskoder, vilket illustreras med ett fiktivt exempel; xxxx-1234 (Bryman 2011:603)
2.4 Informationsbrev
Informationsbrevet kan ses som ett medel för att skapa en tillitsfull relation till respondenterna och därmed en åtgärd för att minska bortfallet. Tanken var att genom informationsbrevet ville vi ge respondenten friheten att svara på enkäten på det sätt som passar denne bäst, vare sig om respondenten föredrar elektroniskt eller annat finns det möjlighet för det. Eftersom vi i första hand kontaktar respondenterna via e-post eller sociala medier, anser vi att det är nödvändigt att ge respondenterna en trovärdig anledning att delta i enkäten. Vi beskriver vilka vi är och vilken roll vi har, vilket syfte undersökning har, varför den är viktig, vilken typ av information som samlas in, varför och hur respondenten har valts med mera. Det innebär således att vi förhållandevis snabbt behöver skapa en relation som gör att respondenten är villig att delta i vår undersökning. Informationsbrevet är koncist, detta för att undvika att respondenten svarar på ett visst sätt som lutar sig åt hur vi som är ansvariga för studien vill att de ska svara eller på ett visst sätt bara för att denne ska få en positiv bild från oss ansvariga (Bryman 2011:212). För att ytterligare göra respondenten mer bekväm med sina svar informerar vi respondenten i informationsbrevet att svaren skyddas för obehöriga (Dahmström 2011:169–170).
2.5 Svaren från respondenterna
Efter det sista svarsdatumet: den 10:e december, hade vi fått in sammanlagt 24 svar från de 139 restauranger och serveringar som vi hade skickat enkäten till. Eftersom två svarskoder inte var giltiga, var vi tvungna att plocka bort två svar från urvalet (detta av gav oss en svarsandel på runt 15,83 procent). I diagrammen nedanför visas fördelningen av svaren från de respondenter som svarade i urvalet. Varje diagram har en figurtext som beskriver vad som mäts, och inkluderar en siffra som ger information om vilken enkätfråga som diagrammet tillhör. Diagrammen är även uppdelade efter olika delar, där Del 1 handlar om serveringars- och restaurangverksamheters bakgrund, Del 2 handlar om anpassning under pandemin och Del 3 handlar om försäljning under pandemin. Hela formuläret finns tillgänglig i Appendix 2. Att förstå frågan innebär allt från att förstå de enskilda orden, därför har vi tagit med tydliga avgränsningar och definitioner för att det klart ska framgå vad som ingår i frågan och att undvika tolkningsproblem. Vi har valt att ha mer generella frågor i början där vi exempelvis frågar efter vilken typ av verksamhet som drivs. Det följer att vi valt att utforma enkätens frågeföljd utifrån den så kallade “tratt-tekniken”, vilket innebär att ha känsliga frågor längre ner i enkäten, exempelvis ”försäljning”.
Del 1
I Figur 2.1 ser vi fördelningen av restaurangers- och serveringar. Begreppet Restauranger- och serveringar definieras utifrån de kategorier som finns i Figur 2.1, därför har vi placerat vissa respondenter som svarat något utöver alternativen som vi angivit, i någon utav de kategorier som vi ansåg att de passade in. Diagrammet visar en majoritet av lunch- och kvällsrestauranger (72,73 %). I denna fråga har vi också försökt vara tydliga kring hur respondenten skall besvara frågan. För varje svarsalternativ finns en ruta som respondenten markerar och eftersom vi endast ville ha en markering per respondent på den här frågan skrev vi ”markera ett alternativ”. Anledningen till varför vi ville undvika att respondenten markerar flera svarsalternativ (även om det ibland inte går) är för att det ofta innebär problem när det gäller analysen (Bryman 2011:255).
Figur 2.1 Stapeldiagram över andelen av olika restaurangverksamheter (1)
Figur 2.3 Stapeldiagram över andelen av olika överlämningsmetoder (3)
Beställningsmetoder och överlämningsmetoder är begrepp som kan vara missvisande. Därför ansåg vi att det inte räckte med att vi bara gav exempel på beställnings- och
överlämningsmetoder, se Figur 2.2 och 2.3. Vi ansåg vikten av att ha en definition av
begreppen, därav lade vi en definition vid sidan av frågan. Vi ser att den mest förekommande beställningsmetoden är beställning i lokal (85,71 %) och när det kommer till överlämning av mat/dryck är bordsservering vanligast (86,36 %).
När vi konstruerade frågan var det viktigt för oss att alltid tänka ”har respondenterna den kunskap som behövs för att kunna besvara?”. Språket som en helhet har vi försökt anpassa för målgruppen, där målgruppen direkt skall kunna se vad som är de viktiga orden i frågan och vad som är väsentligt. Vi använder därför ord som är vanligt förekommande inom verksamheten, exempelvis avhämtning, hemkörning, app, hemsida med mera (Dahmström 2011:149–150).
Del 2
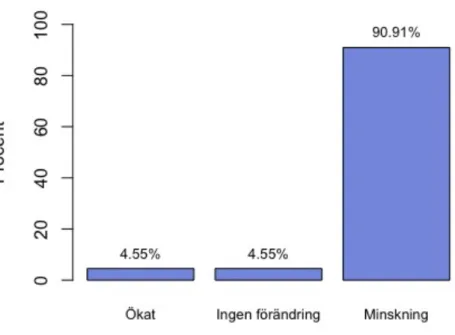
I Figur 2.4 redovisas förändringen av kundbesök under pandemin och det blir därmed intressant att se om det finns skillnader mellan antalet kundbesök hos restaurang- och serveringsverksamheter. Här har vi valt att ha en stängd fråga med alternativ som respondenten får välja mellan, se Figur 2.4. När vi frågar efter förändring av antalet kundbesök vill vi undvika att respondenten tolkar det siffermässigt, alltså att respondenten inte behöver veta det faktiska antalet utan bara en uppskattning i form av ökat, ingen förändring eller minskning. Det innebär att svaren är ömsesidigt uteslutande. Diagrammet visar en minskning på 90,91 % av antalet kundbesök under pandemin.
I detta fall kan en stängd fråga användas för att eliminera risken att respondenten inte vet hur hen skall svara (Lohr 2010:13). Slutna frågor kan även klargöra för respondenten, då
respondenten kan vara osäker på vad frågan egentligen betyder eller vad den syftar till och en beskrivning av olika svarsalternativ kan hjälpa till (Bryman 2011:245).
Figur 2.5 redovisar förändring av antalet hemkörningar under pandemin, det här är då en följdfråga på enkäten, där respondenter som angivit att de tidigare haft hemkörning (se Figur 2.3) endast skall svara på den här frågan. Diagrammet visar att 40 % angett att hemkörningar minskat under pandemin. Den här frågan (Fråga 5) har vi lagt till på detta vis för att undvika dubbla frågor, i och med att dubbla frågor bryter mot regeln att frågorna ska vara entydiga (Bryman 2011:253)
Figur 2.4 Stapeldiagram över förändring av antalet kundbesök under pandemin (4)
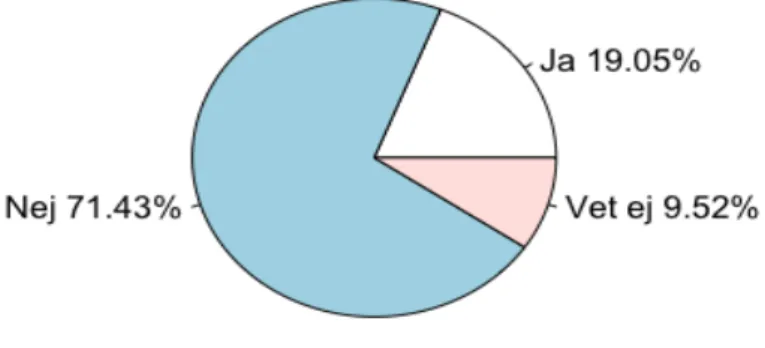
Figur 2.6 Cirkeldiagram över huruvida nya beställningsmetoder har införts (6)
Figur 2.7 Stapeldiagram över hur nöjda restauranger är med nya beställningsmetoder (8)
Figur 2.6 handlar om att vi vill ta reda på om restaurang- och serveringsverksamheter infört nya beställningsmetoder. Därför har vi endast Ja/Nej/Vet Ej som svarsalternativ. Men detta ger oss inte tillräckligt med information, därför har vi en relaterad fråga som följer hur nöjda restauranger- och serveringar är med nya beställningsmetoder. Figur 2.7 illustreras med en likertskala och representerar endast restaurang- och serveringar som svarat Ja på fråga 6 (se Figur 2.6). I enkäten informeras respondenten att 1=mycket missnöjd och 5=mycket nöjd. Vi ser att en majoritet svarat 3=varken eller (45,45%) över hur nöjda de är med sina nya
beställningsmetoder. Exempel på en ny beställningsmetod som restaurang- och serveringsverksamheter infört: swishbetalning.
Inkonsistenta svar ger oss möjlighet att kunna hitta restauranger- och serveringar som svarar på ett ogenomtänkt sätt. Det innebär att om någon restaurang- eller servering markerar ”Nej” på infört ny beställningsmetod och sedan markerar ”mycket nöjd” på hur pass nöjd man är med nya beställningsmetoden är det sannolikt att respondenten i fråga påverkats av en skev svarstendens och att svaren sannolikt inte ger någon hållbar bedömning av nya
beställningsmetoder (Bryman 2011:235).
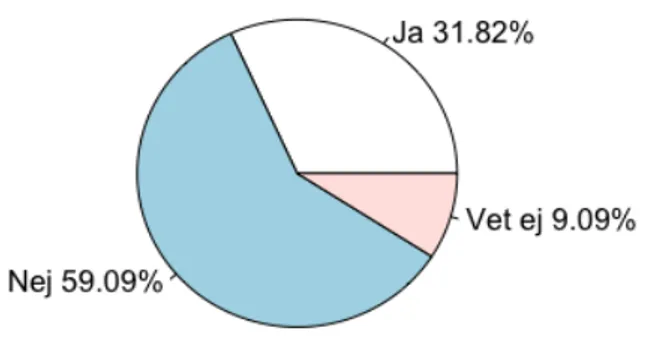
Figur 2.8 Cirkeldiagram över huruvida nya överlämningsmetoder har införts (9)
Figur 2.10 Cirkeldiagram över ifall det har införts nya övriga strategier (12)
I Figur 2.8 frågar vi efter om restauranger- och serveringar använt nya överlämningsmetoder som svar på pandemin. Återigen, här drar vi liknande resonemang som Figur 2.6 och 2.7 med en likertskala där 1=mycket missnöjd och 5= mycket nöjd. Det visar sig att 83,33 % svarat 3=varken eller över hur pass nöjda de är med de nya överlämningsmetoderna. Exempel på nya överlämningsmetoder som restaurang- och serveringsverksamheter infört: Överlämning av mat/dryck utomhus vid entrén.
Här vill vi alltså undersöka om restauranger- eller serveringar infört nya metoder att ”lämna över” mat och dryck. I detta fall uttrycks ”servering” av mat istället som ”överlämning”, därför att inom restaurang- och serveringsverksamheten innefattas ofta ”servering av mat” som traditionell servering i lokal. Även om restaurang- och serveringsverksamheten vet vad serveringsmetoder innebär kan de ha olika uppfattningar av betydelsen, i och med att det är ett vanligt förekommande ord i sitt yrkesspråk, därför har vi istället valt att använda och definiera vår tolkning av serveringsmetod, vilket i vår term motsvarar överlämningsmetod (Bryman 2011:254).
I Figur 2.10 visas fördelningen av svaren på frågan om restauranger- och serveringar använt någon annan strategi utöver beställnings- och överlämningsmetoder. Exempel på nya övriga strategier som uppstått som svar på pandemin; Dra ner på personal, rabatt för avhämtning, sprida ut borden, informationsskyltar, ändra öppettider vid behov, nytt kösystem med mera. Del 3
Figur 2.11 redovisar hur restaurang- och serveringsverksamheters försäljning förändrats under pandemin. Förändringen av försäljningen hänger samman med huruvida restriktioner hindrat restauranger- och serveringar från att nå ett mål (se Figur 2.12). Vi ser att 86,36 % har svarat att försäljningen minskat under pandemin och 86,36% har svarat att restriktionerna hindrat sig från att nå ett mål.
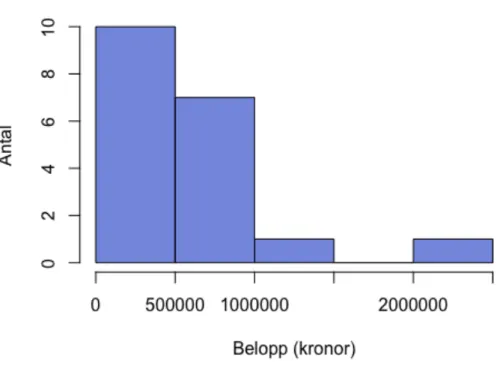
I Figur 2.13 och 2.14 redovisas en uppskattad försäljning under juli 2019 och 2020. Här har vi valt att undersöka både 2019 och 2020 för att kunna jämföra huruvida restaurang- och serveringars försäljning förändrats med hänsyn till pandemin. I formuläret har vi informerat respondenten om varför vi har med just juli månad, ”Den 1 juli 2020 trädde en ny lag om smittskyddsåtgärder på serveringsställen i kraft[…]”. Av histogrammen framgår att
försäljningen under juli 2019 och 2020 är något snedfördelad med tyngdpunkt förskjuten åt vänster, mot lägre försäljning.
Figur 2.11 Stapeldiagram över hur försäljning har förändrats under pandemin (14)
Figur 2.12 Cirkeldiagram över huruvida restriktioner har hindrat restauranger- och serveringar från att nå mål (15)
Figur 2.13 Försäljningsfördelningen för juli 2020 för restaurang- och serveringsverksamheter, histogram (16)
Figur 2.14 Försäljningsfördelningen för juli 2019 för restaurang- och serveringsverksamheter, histogram (17)
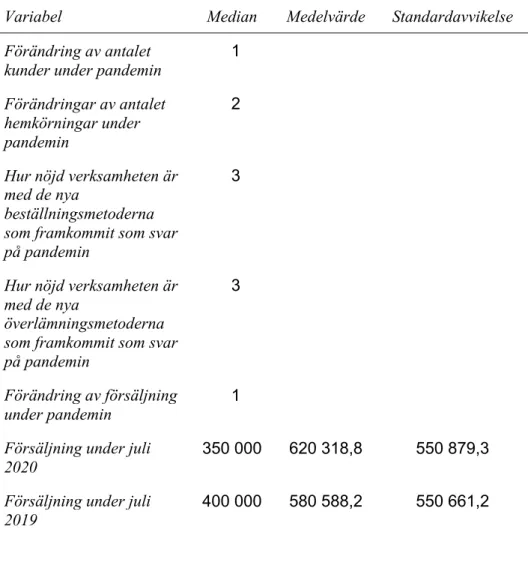
Nedan redovisas central- och spridningsmått för respektive histogram (se Tabell 2.1). Om vi ser på både juli 2020 och 2019 är det troligt att dessa har påverkats en extremvärde, vi har två olika observationer som angivit 250 0000 miljoner kr försäljning under juli 2020 respektive 2019, vilket skiljer sig starkt från övriga observationer. Här har vi möjligheten att
komplettera med ett robust centralmått, nämligen medianen som anger värdet för den
mittersta observationen. I vårt fall avviker medianen för både juli 2020 och 2019 (350 000kr & 400 000kr) neråt från medelvärdet (620 318,8 respektive 580 588,2kr) på grund av
snedheten i fördelningen (Djurfeldt, Larsson, Stjärnhagen 2018:59-60).
Standardavvikelsen är ett mått att jämföra variationen för variablerna. Utifrån Tabell 2.1 ser vi att standardavvikelsen för juli 2020 är (550 879,3 kr).Under juli 2019 har vi en
standardavvikelse på (550 661,2 kr). Det visar således att vi har en någonlunda stor variation för båda två, vilket innebär graden av hur mycket de skiljer sig från medelvärdet.
(Dahmström 2011:52)
Tabell 2.1 Central- och spridningsmått för ordinal- respektive kvotskalevariabler
Variabel Median Medelvärde Standardavvikelse Förändring av antalet
kunder under pandemin
1 Förändringar av antalet hemkörningar under pandemin 2 Hur nöjd verksamheten är med de nya beställningsmetoderna som framkommit som svar på pandemin
3
Hur nöjd verksamheten är med de nya
överlämningsmetoderna som framkommit som svar på pandemin
3
Förändring av försäljning under pandemin
1
Försäljning under juli 2020
350 000 620 318,8 550 879,3
Försäljning under juli 2019
2.6 Bortfall
Bortfall beror på att vi inte får svar från alla personer i urvalet. Det finns alltid (ofta) ett antal personer som är med i urvalet som man inte får svar från. Somliga får man inte tag i och andra vägrar svara. Vi kan inte heller veta hur de skulle ha svarat. Bortfallet resulterar därför i skattningar där en skevhet (bias) uppstår (SCB). Finns det i sådana fall skillnader mellan de som svarat på enkäten och de som inte svarat? Det är inte helt klart för oss om det finns, det huvudsakliga problemet som orsakas av icke-respons är bias. Tidigare nämnde vi olika sätt att försöka minska bortfallet (se kontakt med respondenterna) och anledningen att vi inte ökade urvalsstorleken är för att undvika att biasen ökar. Det kräver mer tid om vi ökar
urvalsstorleken och det innebär att mer resurser måste användas som istället kan användas för få kontakt med de som vi redan har kontaktat (Lohr 2010:330–331).
Om urvalsmedelvärdet för icke-respons skiljer sig från respons har vi en bias som är approximativ:
𝐵𝑖𝑎𝑠(𝑦Z ) ≈2 (\
( (𝑦]2− 𝑦]3) (2.4)
Där 𝐵𝑖𝑎𝑠(𝑦Z ) är icke-responsbias av det ojusterade responsmedelvärdet. Termen 𝑦2 Z är 2
responsmedelvärdet av målgruppen i urvalet och 𝑦]3 motsvarar icke-responsmedelvärdet. Där termen 𝑛 innebär hela urvalet och 𝑛3 representerar storleken för icke-respons. Man utgår från antagandet att mätfelen är obefintliga när approximativa biasen beräknas.
När vi drar ett urval kan vi aldrig förutse vad svarsfrekvensen kommer att bli, ett nytt urval kan mycket möjligt ge oss en högre svarsfrekvens men också lägre. Alla observationer i urvalet har en icke observerbar responsbenägenhet (en sannolikhet, en likelihood) av att vara en respondent respektive icke-respondent, vilket kan noteras 𝛷).
Det följer att den approximativa biasen för det genomsnittliga responsvärdet kan skrivas: 𝐵𝑖𝑎𝑠(𝑦Z ) ≈2 4`a
56 (2.5)
Där 𝜎75 motsvarar populations kovariansen mellan undersökningsvariabeln y och
responsbenägenheten 𝛷, 𝛷Z är genomsnittliga responsbenägenheten i målpopulationen. Det uttrycker att likelihooden att få respons är en slumpmässig variabel och icke-respons biasen är en funktion av hur korrelerad undersökningsvariabeln är till responsbenägenheten. I vårt fall har vi fått en mycket låg svarsfrekvens och det innebär troligtvis en hög icke-responsbias. Det medför att vi endast kan uppskatta en icke-responsbias utefter antagandet att icke-responsbenägenheten sannolikt är korrelerad på olika sätt med olika
undersökningsvariabler. Det innebär att hälsa, språk, kunskap med mera är exempel på faktorer som kan påverka icke-respons biasen (Groves 2006:648–650).
Leverage-salience teorin kan användas för att förklara hypoteser kring när variation i icke-responsbenägenheten resulterar i icke-respons bias (Groves, Singer och Corning 2000). Enligt teorin varierar respondenters benägenhet att delta i en undersökning från person till person. Vi vet i förväg inte vilka kännetecken som stimulerar personer att svara på enkäten, därför tar vi upp kännetecken i början av enkäten (Sailence) som exempelvis; enkäten tar 2–4 minuter att besvara. Kännetecken i detta sammanhang innebär att ta upp saker som vi tror stimulerar personer inom målpopulationen att svara på enkäten. Enligt teorin innebär det att
att ha en hög icke-respons bias. Vi kan därför säga att det finns faktorer som har ett stort inflytande (leverage) när det kommer till att respondenten deltar i vår undersökning. Även om dessa faktorer i vårt falltill viss del är okända, kan vi använda teorin för att dra slutsatsen att vi har en hög icke-respons bias (Groves, Peytcheva 2008:169)
2.7 Mekanismer för icke-respons
När vi diskuterar bortfallet behöver vi fastställa de antaganden som finns. Vi kan endast anta och kan i princip omöjligen peka ut orsaker till bortfallet (Allison 2012:73).
MCAR (Saknas helt slumpmässigt)
Här utgår man från att det endast är en variabel 𝑍 som saknas och en annan variabel 𝑋, som helt observeras. Låt 𝑅8 vara en dummy variabel där 𝑅8=1 motsvarar respons och 𝑅8=0
icke-respons. Antagandet kring ”MCAR” skrivs utifrån följande:
𝑃(𝑅8 = 1|𝑋, 𝑍) = 𝑃(𝑅8 = 1) (2.6) Det innebär att sannolikheten inte beror på 𝑋, 𝑍 eller urvalsdesignen. Detta kan även
uttryckas med att sannolikheten att en observation 𝑍) ger saknad data beror inte på sig självt eller andra variabler 𝑋). Om vi låter 𝑍) = 1 stå för restauranger och 𝑍) = 0 kaféer, följer det att vare sig den ena eller andra verksamheten skall båda vara lika benägna att svara på enkäten oavsett vilken grad av kunder, hemkörningar, beställningar med mera (𝑋)), då kan vi anta att vår data är ”MCAR” (Lohr 2010:338).
MAR (Saknas slumpmässigt)
När vi talar om att data saknas slumpmässigt, menar vi att variabel 𝑍 har data som saknas och sannolikheten att data saknas från variabel 𝑍 beror på 𝑋). Notera att ”MCAR” är ett
specialområde av ”MAR”, om data är ”MCAR” kan man även säga att den är ”MAR” (Allison 2012:74). Ett uttryck för ”MAR”:
𝑃(𝑅8 = 1|𝑋, 𝑍) = 𝑃(𝑅8 = 1|𝑋) (2.7) Om vi återigen låter 𝑍) = 1 stå för restauranger och 𝑍) = 0 för kaféer, följer det att vi kan uttala oss att svarsbenägenhet på enkäten beror exempelvis på vilken grad av kunder, hemkörningar, beställningar med mera (𝑋)). Det vill säga, kaféer som haft en ökad
hemkörning, alternativt restauranger som haft en ökad beställning via telefon kan påverka svarsbenägenheten. Vi talar då om att data saknas slumpmässigt (MAR).
NMAR (Saknas inte slumpmässigt)
Om sannolikheten att inte få ett svar beror på värdet av en saknad respons variabel och när detta inte kan förklaras av värden i den observerade data, då talar vi om att icke-responsen inte är slumpmässig (Lohr 2010:339). Ett annat uttryck kan vara när data strider mot ”MAR”, då kan vi uttala oss om att vi arbetar med data som är ”NMAR” (Allison 2012:74). Det är dock svårt för oss att fastställa om data inte saknas slumpmässigt, då det finns många olika möjliga faktorer som kan spela roll. Ett fall kan vara att restaurang- och serveringar som varit nära konkurs kan i lägre utsträckning vara mindre benägna att svara på enkäten jämfört med de som inte varit nära konkurs. Då kan vi uttala oss om NMAR.
3. Inferens och modeller
I denna del presenterar vi de metoder som vi använder vid inferens om restauranger och serveringar i Stockholms kommun. Den första delen beskriver de konfidensintervall som vi har använt vid skattningar av parametrar i populationen, medan den andra delen beskriver hur logistisk regression kan användas för att skatta sannolikheten att restauranger inför en ny anpassningsmetod.
3.1 Konfidensintervall
När svaren ifrån respondenterna redovisades, presenterades proportioner och medelvärden utifrån urvalet. Det är dock inte tillräckligt att utgå ifrån informationen i urvalet när vi vill säga någonting om parametrar i populationen. För att ge en bild av vart ett givet
parametervärde kan hamna, är det vanligt att använda konfidensintervall. I denna del presenterar vi två metoder för konfidensintervall som vi kommer att tillämpa. I den första metoden antas det att estimatorns samplingfördelning är tillräckligt lik normalfördelningen, vilket är ett rimligt antagande om urvalsstorleken är tillräckligt stor. Den andra metoden är att använda ett bootstrap-intervall: här görs det inget antagande om typen av samplingfördelning, utan samplingfördelningen skattas istället genom att göra ett stort antal delurval (med
återläggning) från den empiriska fördelningen.
3.1.1 Konfidensintervall baserade på normalfördelningen
Om en estimator 𝜃' är normalfördelad med parametrar 𝜃, 𝑆!"#, ges ett 100(1 − 𝛼)%
konfidensintervall för 𝜃 av
𝜃' ± 𝑧$ #⁄ 𝑆!" (3.1)
Ifall 𝑛 är tillräckligt stort, har vi att samplingfördelningen för urvalsmedelvärdet 𝑦] är tillräckligt nära normalfördelningen, och ett konfidensintervall kan ges av
𝑦] ± 𝑧$ #⁄ i1 −
𝑛 𝑁
𝑆7
√𝑛 (3.2) där 𝑁 är populationsstorleken, 𝑛 är urvalsstorleken, och 𝑆7 är standardavvikelsen för 𝑦. Vi kan på ett liknande sätt ge ett konfidensintervall för proportionen 𝑝
𝑝̂ ± 𝑧$ #⁄ l
𝑁 − 𝑛 𝑁 − 1
𝑝(1 − 𝑝)
𝑛 (3.3) där 𝑝̂ är urvalsproportionen. Om variansen för estimatorerna är okända kan konfidensintervall ges med hjälp av t-fördelningen:
𝑦] ± 𝑡$ #,(&'⁄ i1 −
𝑛 𝑁
𝑠7
𝑝̂ ± 𝑡$ #,(&'⁄ ln1 −
𝑛 𝑁o
𝑝̂(1 − 𝑝̂)
𝑛 − 1 (3.5) Lägg märke till att vi behöver veta värdet på populationsstorleken för att kunna använda samtliga intervall ovan. Detta värde är dock okänt för oss. I och med att vår urvalsram har förhållandevis mycket övertäckning så kan det vara svårt att ungefärligt gissa storleken på vår målpopulation. Ett alternativ är att skatta populationsstorleken utifrån urvalsramen. Lohr (2019:172) beskriver metoder vid skattning av parametrar för olika domäner i en population. Om vi ser urvalsramen som en egen population med storlek 𝐾, kan målpopulationen betraktas vara en domän av urvalsramen med storlek 𝑁. Ifall vi drar ett urval med storlek 𝑛 kan vi låta 𝑛𝒰 vara antalet enheter i urvalet som tillhör målpopulation. Det gäller då att
𝑛𝒰~Hypergeometric(𝐾, 𝑁, 𝑛) (3.6) Vi kan då använda 𝑝̂𝒰 =((𝒰 för att skatta proportionen av element från målpopulationen som
finns med i urvalsramen, 𝑝𝒰. Det kan sedan uppfattas naturligt att använda 𝑁r = 𝐾𝑝̂𝒰 för att skatta 𝑁. 𝑁r är väntevärdesriktig, och Var$𝑁r* = 𝐾#n:&(
:&'o
+𝒰('&+𝒰)
( . Vi kan även forma
konfidensintervall för 𝑁r. Notera att
𝑁r − 𝑁 i𝑉𝑎𝑟$𝑁r* = ⎣ ⎢ ⎢ ⎡ 𝑝̂ 𝒰− 𝑝𝒰 in𝐾 − 𝑛𝐾 − 1o𝑝𝒰(1 − 𝑝𝒰) 𝑛 ⎦⎥ ⎥ ⎤ (3.7)
Utifrån den centrala gränsvärdesatsen för urval utan återläggning som lyftes fram av Hájek (1960) kan vi säga att +1𝒰&+𝒰
=>{|}{|~?•𝒰(~|•𝒰)}
går mot en standard-normalfördelning när 𝑛 växer. Med detta i åtanke, om 𝑛 är tillräckligt stort, ges ett (1 − 𝛼)% konfidensintervall av
€𝑁r − 𝑧$ #⁄ l𝐾#•𝐾 − 𝑛𝐾 − 1‚𝑝𝒰(1 − 𝑝𝒰 ) 𝑛 , 𝑁r + 𝑧$ #⁄ 𝐾l𝐾#• 𝐾 − 𝑛 𝐾 − 1‚ 𝑝𝒰(1 − 𝑝𝒰) 𝑛 „ (3.8) I och med att 𝑝𝒰 är okänd kan vi istället skatta variansen för 𝑁r med 𝑉𝑎𝑟† $𝑁r* =
𝐾#n1 −( :o
+1𝒰('&+1𝒰)
(&' . Det korrekta konfidensintervallet blir då
€𝑁r − 𝑡$ #⁄ ,(&'l𝐾#n1 −𝐾𝑛o𝑝̂𝒰(1 − 𝑝̂𝑛 − 1𝒰), 𝑁r + 𝑡$ #,(&'⁄ l𝐾#n1 −𝐾𝑛o𝑝̂𝒰(1 − 𝑝̂𝑛 − 1𝒰) „ (3.9)
I det allra första delurvalet som vi drog från urvalsramen, hade vi 58 stycken restauranger och serveringar. Utifrån detta delurval är vår punktskattning av urvalsstorleken
𝑁r = 8091 ∙ 58
Vår skattning av variansen är
𝑉𝑎𝑟† $𝑁r* = 113 366,02 (3.11)
Slutligen, får vi 2710,45– 4041,75 som konfidensintervall, med 𝛼 = 0,05. Om vi sätter in 𝑁r istället för 𝑁 i formlerna för konfidensintervallen för proportioner och medelvärden, får vi approximativa konfidensintervall för den parameter som ska skattas. Anledningen till att konfidensintervallen inte är exakta är för att – om vi exempelvis tittar på urvalsmedelvärdet – mängden 𝑦] − 𝐸[𝑌] i1 −@(" B`
√(
Œ har en okänd sannolikhetsfördelning (och är troligen inte t-fördelad). Om vi behandlar 𝑁r som vår bästa gissning på 𝑁, kan vi utgå ifrån att det riktiga konfidensintervallet förmodligen har en liknande bredd.
3.1.2 Konfidensintervall baserade på bootstrap-metoder
De tidigare konfidensintervallen är användbara givet att urvalsstorleken är tillräckligt stor. För vissa variabler kan det dock vara svårt att veta när urvalet är stort nog. Om vi misstänker att urvalsstorleken inte är tillräcklig för normal-approximering är det bättre att försöka använda andra metoder där det inte görs några antaganden om fördelningar. Davison och Hinkley (1997) presenterar en rad olika bootstrap-metoder som kan användas för att generera konfidensintervall. Om vi begränsar oss till icke-parametriska metoder är den grundläggande idéen är att den empiriska fördelningen av en undersökningsvariabel 𝑌 i urvalet, konvergerar mot fördelningen av 𝑌 i populationen, när urvalsstorleken växer. Ifall vi antar att 𝑌', 𝑌#, … , 𝑌( är oberoende och identiskt fördelade utifrån en okänd kumulativ fördelningsfunktion 𝐹, är det rimligt att anta att den empiriska fördelningsfunktionen 𝐹' kan användas för att skatta 𝐹 (givetvis varierar dessa skattningar från urval till urval, och precisionen beror på urvalsstorleken). Om 𝐹' är nära 𝐹 kan 𝐹' användas som utgångspunkt för att uppskatta
samplingfördelningen för en given estimator 𝑇. Genom att använda statistiska program (som t.ex. R) kan vi utgå ifrån 𝐹' och dra flera urval 𝑌'∗, 𝑌
#∗, … , 𝑌(∗ med återläggning. Eftersom 𝑇 är
väntevärdet i den empiriska fördelningen, skattas 𝑇 med 𝑇2∗ i urval 𝑟: där 𝑟 = 1,2, … 𝑅 (𝑇 2∗ är
samma estimator som 𝑇, men den tillämpas på urval 𝑟). Tanken är att 𝑇2∗ har en fördelning
som efterliknar samplingfördelningen för 𝑇 när 𝑅 växer. Ett annat sätt att uttrycka detta på är att om 𝐺(𝑢) = 𝑃(𝑇 − 𝜃 ≤ 𝑢), utgår vi ifrån att 𝐺(𝑢) kan skattas med 𝐺'(𝑢) = 𝑃(𝑇∗− 𝑇 ≤
𝑢), samt att
𝐺'E(𝑢) = |{𝑇2∗: 𝑇2∗− 𝑇 ≤ 𝑢}|
𝑅 (3.12) konvergerar mot 𝐺'(𝑢) när 𝑅 blir större. Observera att
1 − 𝛼 = 𝐺'$𝑡(EF')('&$) #∗ ⁄ − 𝑡* − 𝐺'$𝑡 (EF')$ #∗ ⁄ − 𝑡* ≈ 𝐺$𝑡(EF')('&$) #∗ ⁄ − 𝑡* − 𝐺$𝑡 (EF')$ #∗ ⁄ − 𝑡* = 𝑃$𝑡(EF')$ #∗ ⁄ − 𝑡 ≤ 𝑡 − 𝜃 ≤ 𝑡(EF')('&$) #∗ ⁄ − 𝑡* = 𝑃$𝑡 − 𝑡(EF')$ #∗ ⁄ ≥ 𝜃 − 𝑡 ≥ 𝑡 − 𝑡 (EF')('&$) #∗ ⁄ * (3.13) = 𝑃$2𝑡 − 𝑡(EF')$ #∗ ⁄ ≥ 𝜃 ≥ 2𝑡 − 𝑡(EF')('&$) #∗ ⁄ *
Ett approximativt 100(1 − 𝛼)% konfidensintervall ges därför av •2𝑡 − 𝑡(EF')('&$) #∗ ⁄ , 2𝑡 − 𝑡
(EF')$ #∗ ⁄ –. (3.14)
3.2 Logistisk regression
En annan av vår undersöknings primära syften är att ge mer information om serveringars anpassning under pandemin. Det är rimligt att anta att sannolikheten för att ett
serveringsställe tillämpar en ny strategi inte är oberoende av andra faktorer som mäts i
enkäten. Vi är därför intresserade av en modell som inkorporerar andra variabler för att skatta sannolikheten att en servering anpassar sig på ett särskilt sett. Eftersom alla våra variabler som är kopplade till införanden av nya strategier är binära variabler, är det bra ifall vi
specificerar en generell modell som gäller för alla binära variabler. Låt en stokastisk variabel 𝑌 ha en bernoullifördelning, med 𝑝 = 𝑃(𝑌 = 1|𝐱); där 𝐱 = (𝑥', 𝑥#, … , 𝑥G). Vi har då att
𝐸(𝑌|𝐱) = ™ 𝑦𝑃(𝑌 = 𝑦|𝐱)
7∈{.,'}
= 𝑝. (3.15)
I ordinarie regressionsmodeller antas det att 𝐸(𝑌|𝐱) kan skrivas som 𝛽.+ 𝐱𝛃, där 𝛽. är
interceptet och 𝛃 = (𝛽', 𝛽#, … , 𝛽G)J är en vektor med de förklarande variablernas
koefficienter. Det kan då antas vara rimligt att använda samma linjära modell för 𝑝.
Dessvärre uppkommer det väsentliga problem med denna specifikation: ett av de mest tydliga problemen är att en linjär modell kan anta värden utanför intervallet [0,1]. Istället kan vi överväga en mer generell klass av modeller med formen
𝑝 = 𝐺(𝛽.+ 𝐱𝛃), (3.16) där alla 𝐺 ∈ [0,1]. Det finns då en länkfunktion 𝐺&'(𝑝) = 𝛽
.+ 𝐱𝛃 som är linjär. En vanlig
länkfunktion som används för binära variabler är logit-funktionen: som ges av 𝐺&'(𝑝) = ln 𝑝
1 − 𝑝. (3.17) Här är '&++ oddsen för att 𝑌 = 1, givet 𝐱. En fördel med att använda logit-funktionen är att parametrarna 𝛽., 𝛃 är enklare att tolka jämfört med andra länkfunktioner: som t.ex. probit-funktionen. Ifall vi löser för 𝑝 utifrån logit-funktionen, får vi att
𝑝 = 𝐺(𝛽.+ 𝐱𝛃) = 1
1 + 𝑒&(KžF𝐱𝛃) (3.18)
𝐺(𝛽.+ 𝐱𝛃) kan skattas genom att, utifrån maximum likelihood-metoden, skatta 𝛽., 𝛃 (mer
För att enklare illustrera hur logistisk regression kan användas, kan vi begränsa oss till enbart två frågor i enkäten. Vi kanske vill veta huruvida förändringen av kundbesök under pandemin (Fråga 4) förändrar sannolikheten för att restauranger inför nya överlämningsmetoder (Fråga 9). För att använda informationen från frågorna i logistisk regression behöver vi skapa dummyvariabler. Låt 𝑛𝑦𝑜𝑣𝑒𝑟 = 1 om ett serveringsställe har infört en ny
överlämningsmetod; ifall respondenten svarar nej har vi att 𝑛𝑦𝑜𝑣𝑒𝑟 = 0 (om respondenten svarar ”Vet ej” registreras ingen observation för variabeln). Fråga 4 mäts på ordinalskala och kan vara svår att tolka i en regressionsmodell. En lösning är att behandla svaren som att de mäts med nominalskala (Wooldridge 2018:230–232). Vi kan då skapa två dummyvariabler 𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 och 𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 som antar värdet 1 när respondenten svarar ”Ingen förändring” respektive ”Ökat”. Om antalet kundbesök har minskat antar bägge variablerna värdet 0. Låt 𝑝 = 𝑃(𝑛𝑦𝑜𝑣𝑒𝑟 = 1) beteckna sannolikheten för att en restaurang har infört en ny överlämningsmetod. Om vi använder logistisk regression utgår vi ifrån att
ln[odds(𝑛𝑦𝑜𝑣𝑒𝑟 = 1)] = 𝛽. + 𝛽'𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 + 𝛽#𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 (3.19) där 𝛽. är modellens intercept, 𝛽', 𝛽# är koefficienterna framför de förklarande variablerna,
och odds(𝑛𝑦𝑜𝑣𝑒𝑟 = 1) ='&++ .
Vi kan välja att lägga till fler förklarande variabler i vår modell. Vi skulle exempelvis kunna se ifall typen av serveringsställe har en inverkan på 𝑝. Ett sätt skulle kunna vara jämföra restauranger och kaféer. Precis som vi gjorde tidigare kan vi lägga till dummyvariabler; låt 𝑟𝑒𝑠𝑡 = 1 om en servering endast kan räknas som en restaurang (annars har vi att 𝑟𝑒𝑠𝑡 = 0). Det kan vara på det viset att en observation kan räknas som både restaurang och kafé; det kan i sådana fall vara lämpligt att lägga till en dummyvariabel: låt 𝑟𝑒𝑠𝑡𝑘𝑎𝑓𝑒 = 1 om en servering kan räknas som både en restaurang och ett kafé (annars är 𝑟𝑒𝑠𝑡𝑘𝑎𝑓𝑒 = 0). Vårt nya uttryck för logit-funktionen blir
ln[odds(𝑛𝑦𝑜𝑣𝑒𝑟 = 1)] = 𝛽.+ 𝛽'𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 + 𝛽#𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 + 𝛽N𝑟𝑒𝑠𝑡 + 𝛽O𝑟𝑒𝑠𝑡𝑐𝑎𝑓𝑒 (3.20) Det finns givetvis väldigt många variationer som vi kan få genom att lägga till variabler. Hur kan vi veta ifall de variabler vi inkluderar gör att modellen passar? Vi kan börja med att titta på likelihoodfunktionen 𝐿 = 𝐿(𝛉r, 𝐲), som vi kan definiera som sannolikheten för att få exakt de observationer 𝐲 som tillhör vår datamängd, givet att våra parameterskattningar 𝛉r, är korrekta. Vi kan sedan transformera likelihoodfunktionen till −2 ln 𝐿: som har en chitvåfördelning med 𝑛 − 𝑞 frihetsgrader, där 𝑛 är antalet observationer och 𝑞 är antalet modellparametrar (Sharma 1996:323). Transformationen av likelihoodfunktionen kan sedan användas som teststatistika vid hypotesprövningar. Om vi exempelvis låter 𝛼 = 0,05 så är vår slutsats att det inte finns bevis nog för att modellen inte passar datasetet om −2 ln 𝐿 < 𝜒.,.P# . För att hitta de variabler som borde inkluderas i modellen går det att använda olika
4. Resultat
Nedan presenteras resultatet av de tidigare nämnda metoderna. Resultaten är baserade på data som vi har samlat in, där variabler som mest omfattar 22 av 139 observationer. Vi börjar med att presentera konfidensintervall baserade på t-fördelningen och bootstrap. Sedan följer en presentation av resultatet för logistisk regression, där vi redovisar en sammanfattning av hur givna förklarande variabler påverkas av ett antal oberoende variabler, även mått på hur signifikanta dessa är tas med. Slutligen presenterar vi resultatet kring sannolikheten att införa en ny metod, givet en förklarande variabel.
4.1 Konfidensintervall
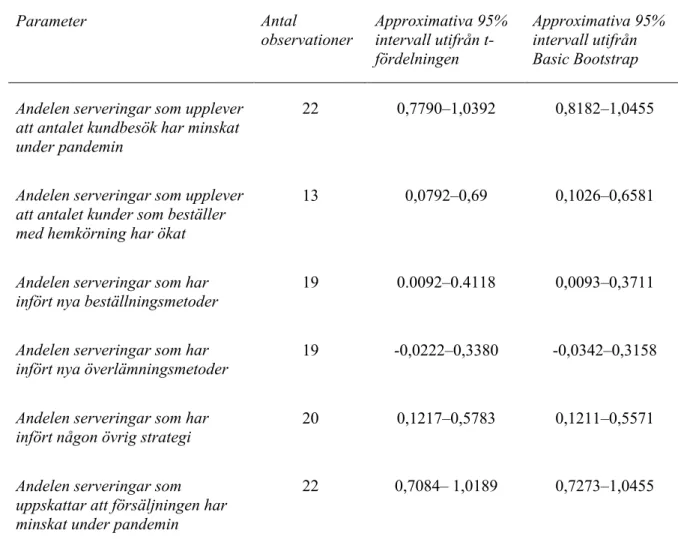
I Tabell 4.1 presenteras det parametriska- respektive icke- parametriska konfidensintervallet. t-fördelningen antar normalfördelning och Basic Bootstrap-metoden antar en okänd
fördelning. Här kan vi jämföra och se vilken metod som skulle vara ”bättre” att använda för given parameter. Då vi inte har tillräckligt med data för att med säkerhet säga att ett givet tal ligger inom intervallet, utgår vi från ett approximativt 95 % intervall. Graferna nedan
illustrerar vilken metod som skulle passa ”bättre” att utgå ifrån.
Tabell 4.1 Parametriska respektive icke-parametriska konfidensintervall
Parameter Antal observationer Approximativa 95% intervall utifrån t-fördelningen Approximativa 95% intervall utifrån Basic Bootstrap Andelen serveringar som upplever
att antalet kundbesök har minskat under pandemin
22 0,7790–1,0392 0,8182–1,0455
Andelen serveringar som upplever att antalet kunder som beställer med hemkörning har ökat
13 0,0792–0,69 0,1026–0,6581
Andelen serveringar som har infört nya beställningsmetoder
19 0.0092–0.4118 0,0093–0,3711
Andelen serveringar som har infört nya överlämningsmetoder
19 -0,0222–0,3380 -0,0342–0,3158
Andelen serveringar som har infört någon övrig strategi
20 0,1217–0,5783 0,1211–0,5571
Andelen serveringar som uppskattar att försäljningen har minskat under pandemin
Andelen serveringar där restriktionerna har hindrat serveringar från att uppnå mål
20 0,8457–1,0543 0,9000–1,0579
Medelvärde för procentuell förändring av försäljning under juli 2019–2020
17 -32,0572–154,2055 -32,73–136,02
I Figur 4.1-4.4 presenteras resultatet av de uträcknade proportionerna. Vi har tagit med parametrarna ”Andelen serveringar där restriktionerna har hindrat serveringar från att uppnå mål” och ” Andelen serveringar som har infört någon övrig strategi”. Dessa två variabler ser vi utifrån figurerna att de skiljer sig åt. När percentilerna ligger nära linjen visar det att fördelningen går mot en normalfördelning. I histogrammen ser vi att figur 4.1 har en tydlig skevhet och större variation och figur 4.3 visar en mer tendens av att gå mot
normalfördelning. Om bootstrapfördelningen avviker från normalfördelningen finns det skäl att tro att den centrala gränsvärdesatsen inte håller: vi borde därför välja bootstrapintervallet istället.
Figur 4.1-4.2 Illustrerar basic bootstrapfördelningen och ett Q-Q-diagram för parametern ”Andelen serveringar där restriktionerna har hindrat serveringar från att uppnå mål”
Figur 4.3-4.4 Illustrerar basic bootstrapfördelningen och ett Q-Q-diagram för parametern ”Andelen serveringar som har infört någon övrig strategi”
4.2 Logistisk regression
I metodbeskrivningen redogjorde vi för hur sannolikheten att en given anpassningsmetod tillämpas kan skattas med hjälp av logistisk regression. Vi definierade en dummyvariabel (𝑛𝑦𝑜𝑣𝑒𝑟): som var lika med värdet 1 när en respondent angav att en ny överlämningsmetod hade införts, och lika med värdet 0 annars. På ett liknande sätt kan vi definiera två
dummyvariabler 𝑛𝑦𝑏𝑒𝑠𝑡 och 𝑛𝑦𝑠𝑡𝑟𝑎𝑡 för nya beställningsmetoder respektive nya övriga strategier. I början var utgångspunkten den modell som specificerades i modellbeskrivningen: om 𝑝 representerar sannolikheten att en given anpassningsmetod tillämpas, ges den
specificerade modellen av ln • 𝑝
1 − 𝑝‚ = 𝛽.+ 𝛽'𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 + 𝛽#𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 + 𝛽N𝑟𝑒𝑠𝑡 + 𝛽O𝑟𝑒𝑠𝑡𝑐𝑎𝑓𝑒 (4.1) För en del variabler var det för lite variation i datamaterialet för att vi skulle kunna skatta variabelns koefficient: i dessa fall var vi tvungna att ta bort variabeln från modellen och utgå ifrån en reducerad modell. För en del respondenter fanns det inte observationer på samtliga variabler som inkluderades i modellen: dessa respondenter ingår inte i den datamängd som den logistiska regressionen tillämpas på. I Tabell 4.2, 4.3, och 4.4 visas sammanfattningar av logistisk regression för 𝑛𝑦𝑏𝑒𝑠𝑡, 𝑛𝑦𝑜𝑣𝑒𝑟, och 𝑛𝑦𝑠𝑡𝑟𝑎𝑡.
Tabell 4.2 Sammanfattning av logistisk regression för 𝑛𝑦𝑏𝑒𝑠𝑡
Koefficient Skattning Standardfel z-värde p-värde
Intercept -18,5661 3765,8471 -0,0049 0,9961
𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 0 7531,6943 0 1
𝑟𝑒𝑠𝑡 17,6498 3765,8472 0,0047 0,9963
Null deviance 19,5568 med 18 frihetsgrader
Residual deviance 16,7515 med 15 frihetsgrader
AIC 24,7515
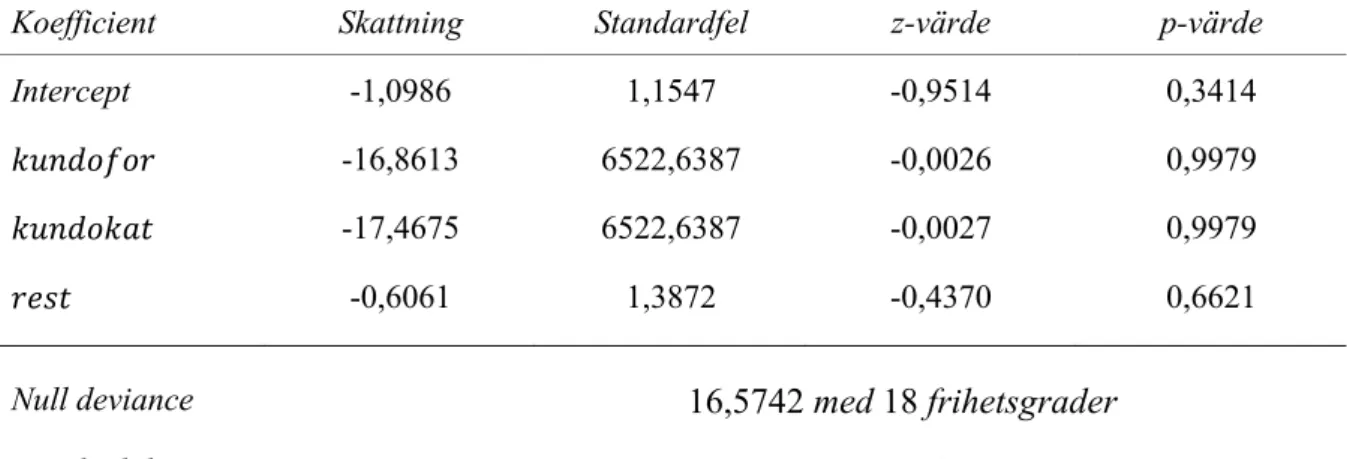
Tabell 4.3 Sammanfattning av logistisk regression för 𝑛𝑦𝑜𝑣𝑒𝑟
Koefficient Skattning Standardfel z-värde p-värde
Intercept -1,0986 1,1547 -0,9514 0,3414
𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 -16,8613 6522,6387 -0,0026 0,9979
𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 -17,4675 6522,6387 -0,0027 0,9979
𝑟𝑒𝑠𝑡 -0,6061 1,3872 -0,4370 0,6621
Null deviance 16,5742 med 18 frihetsgrader
Residual deviance 15,6611 med 15 frihetsgrader
AIC 23,6611
Tabell 4.4 Sammanfattning av logistisk regression för 𝑛𝑦𝑠𝑡𝑟𝑎𝑡
Koefficient Skattning Standardfel z-värde p-värde
Intercept -1,0986 1,1547 -0,9514 0,3414
𝑘𝑢𝑛𝑑𝑜𝑘𝑎𝑡 -15,4675 2399,5450 -0,0064 0,9949
𝑟𝑒𝑠𝑡 0,6932 1,2693 0,5461 0,5850
Null deviance 25,8979 med 19 frihetsgrader
Residual deviance 24,6890 med 17 frihetsgrader
AIC 30,689
För alla parameterskattningar är p-värdena väldigt höga. Vi misstänker att en ledande orsak till de höga p-värdena är den relativt låga urvalsstorleken. Ifall fler serveringar hade
kring parameterskattningarna. Tidigare i modellbeskrivningen presenterades en teststatistika (−2 ln 𝐿) för hypotesprövning vid logistisk regression. Om −2 ln 𝐿 < 𝜒$# fanns det inte bevis
nog för att förkasta nollhypotesen om att modellen passar vårt data. För samtliga av de tre modellerna kan vi inte förkasta nollhypotesen då 𝛼 = 0,05. Det är dock mer intressant att jämföra modellerna med relaterade modeller som enbart har ett intercept. Skillnaden mellan ”Null deviance” och ”Residual deviance” har en chitvåfördelning med 𝑞 − 1 frihetsgrader; och kan användas som en teststatistika. Vid detta test kan nollhypotesen beskrivas som hypotesen att modellen som inkluderar förklarande variabler inte passar datamaterialet bättre än intercept-modellen. Ifall vi får ett värde som överskrider 𝜒$#, kan nollhypotesen förkastas.
Vi kunde inte förkasta nollhypotesen för någon av våra modeller: det finns därför inte bevis nog för att bortse ifrån att de inkluderade förklarande variablerna inte har någon effekt på införande av anpassningsmetoder. I Tabell 4.5, 4.6, och 4.7, visas de skattade sannolikheterna som ges av modellerna. I och med att variationen i vårt data var relativt liten, misstänker vi att en del sannolikheter är alldeles för låga. I modellen för 𝑛𝑦𝑠𝑡𝑟𝑎𝑡 fick vi ta bort 𝑘𝑢𝑛𝑑𝑜𝑓𝑜𝑟 eftersom det inte fanns någon variation alls för den variabeln.
Tabell 4.5 Sannolikheter för serveringar att införa nya beställningsmetoder, givet förklarande variabler
Antalet kundbesök har minskat
Antalet kundbesök har
inte förändrats Antalet kundbesök har ökat
Restaurang 0,2857 8,6469 ∙ 10-® 0,2857
Kafé 8,6469 ∙ 10-® 1,8692 ∙ 10-¯° 8,6469 ∙ 10-®
Tabell 4.6 Sannolikheter för serveringar att införa nya överlämningsmetoder, givet förklarande variabler
Antalet kundbesök har
minskat Antalet kundbesök har inte förändrats Antalet kundbesök har ökat
Restaurang 0,1538 8,6469 ∙ 10-® 4,7164 ∙ 10-®
Kafé 0,25 1,5853 ∙ 10-± 8,6469 ∙ 10-®
Tabell 4.7 Sannolikheter för serveringar att införa nya övriga strategier, givet förklarande variabler
Antalet kundbesök har
inte ökat Antalet kundbesök har ökat
Restaurang 0,4 1,2778 ∙ 10-²
5. Diskussion och slutord
Vår möjlighet att dra slutsatser utifrån våra intervall- och sannolikhetsskattningar är mycket begränsade. För flera av de utvalda parametrarna blev intervallen väldigt stora, vilket indikerar att det finns större osäkerhet kring var de faktiska parametervärdena befinner sig. Det fanns heller inte tillräckligt med bevis för att utgå ifrån att några av våra logistiska regressionsmodeller passade datamaterialet bättre än modeller med enbart ett intercept. Båda problem har i grunden samma orsak: standardfelen är väldigt höga som en följd av att det finns relativt lite observationer. I och med att vi har färre observationer så är det inte heller lämpligt att använda konfidensintervall utifrån t-fördelningen för de variabler där det krävs många observationer för att estimatorns samplingfördelning ska gå mot normalfördelningen. Även när det gäller bootstrap-intervallen leder detta till problem, i och med att den empiriska fördelningen tenderar att approximera fördelningen i populationen sämre desto färre
observationer som finns tillgängliga.
Antalet observationer blev mindre än vad vi hade räknat med för att majoriteten av de
serveringar och restauranger som kontaktades inte svarade. Vi vidtog åtgärder för att reducera bortfallet (t.ex. utskick av påminnelser under svarsperioden, fysiska besök hos en andel av icke-respondenterna m.m.), men i slutändan hade vi behövt fler svar för få mer precisa skattningar. En till källa till det låga antalet observationer är partiellt bortfall. En del respondenter som valde att delta i studien svarade inte på alla frågor, vilket gav oss olika mängder observationer för olika variabler. Denna typ av bortfall försökte vi minimera primärt genom innehållet i enkäten: frågorna formulerades så tydligt som möjligt (ibland med
förtydliganden och definitioner i parenteser), och de frågorna som var mer känsliga valde vi att placera mot slutet av enkäten.
Det partiella bortfallet visar att icke-responsbenägenheten sannolikt är korrelerad med vissa frågor på enkäten: detta märks tydligast på frågan kring försäljning under juli 2019, här är svarsfrekvensen något lägre i jämförelse med övriga frågor. Vi vet återigen i förväg inte vad som stimulerar respondenter att svara på frågorna. Det kan mycket möjligt vara brist när vi tar upp kännetecken. Ett kännetecken kunde ha varit att erbjuda respondenten att svara på ett annat språk. Vid kontakt med respondenterna visade språk sig vara en tydlig faktor när det kom till svarsbenägenheten. Även om vi konstruerade språket på ett lättförståeligt sätt vore det mer optimalt att ha både en svensk- och engelskspråkig enkät. I och med att språk visade sig vara en faktor med starkt inflytande när det kommer till svarsbenägenheten, har vi starka skäl att utgå från att vi har en hög icke-respons bias. Flera restauranger- och serveringar kunde inte svara på enkäten, då de nämnt sig vara extra utsatta av pandemin. Det innebär att vi troligtvis har en del restauranger- och serveringar vars svarsbenägenhet är NMAR (saknas inte slumpmässigt), där de som varit mer utsatta under pandemin är mindre benägna att svara på enkäten jämfört med de som inte varit lika utsatta. Vi har ingen möjlighet att veta om icke-responsen är slumpmässig eller inte, troligtvis varierar det från verksamhet till verksamhet. Mallat (2007) tog i tidigare studier upp om kunder är generellt intresserade av att använda digitala beställningsmetoder. I vårt fall visade sig resultaten av svaren att vissa restaurang- och serveringar uppvisar intresse till just nya beställningsmetoder, där flera varit nöjda över sina nya metoder. Det kan handla om att en del verksamheter tycker pandemianpassade beställningsmetoder ger bättre kundflöde och dessa verksamheter kan möjligen känna mer intresse att delta i vår undersökning. Vår poäng är att vi ser en tendens av att vissa
verksamheters svarsbenägenhet troligtvis beror på MAR (saknas slumpmässigt), det betyder att det finns en variabel 𝑋) som påverkar verksamheternas svarsbenägenhet på olika sätt.
Därför blir en viktig del av den här diskussionen att just diskutera icke-respons eftersom det har en signifikant effekt på undersökningen som inte kan ignoreras.
Om vi utgår ifrån svaren i enkäten verkar det som att ungefär hälften av serveringarna som svarade ändå har infört någon sorts ny strategi som svar på pandemin. Av dessa är det bara ett serveringsställe som anger att försäljningen inte har minskat – även fast majoriteten av
restaurangerna har haft en minskad försäljning under pandemin kan de nya
anpassningsmetoderna ändå ha reducerat själva minskningen. Sannolikheterna som skattades med hjälp av logistisk regression är väldigt osäkra, men om vi utgår ifrån punktskattnigarna så verkar det som att minskade kundbesök leder till högre sannolikhet för anpassning. Generellt verkar det som att restauranger är mer benägna att införa nya beställningsmetoder och övriga strategier, medan det är mer sannolikt för kaféer att införa nya
överlämningsmetoder. I och med att våra resultat väldigt osäkra skulle det behöva göras en liknande studie på större skala, där fler serveringsställen kontaktas. Mer studier behöver också göras om anpassningsmetodernas effekt på försäljningen och mer information om fungerande strategier behöver spridas runt bland befintliga serveringsställen.
Referenser
Alnse (2020). Ny kommission ska visa vägen bortom corona.
https://www.uu.se/nyheter-press/nyheter/artikel/?id=15064&typ=artikel [2020-12-24] Allison, Paul D (2012). Missing Data. Elektroniskt format
Bryman, Alan (2011). Samhällsvetenskapliga metoder. 2., [rev.] uppl. Malmö: Liber Dahmström, Karin (2011). Från datainsamling till rapport: att göra en statistisk
undersökning. 5. uppl. Lund: Studentlitteratur
Davison och Hinkley (1997). Bootstrap methods and their applications. Cambridge University Press. Elektroniskt format
Djurfeldt, Göran, Larsson, Rolf & Stjärnhagen, Ola (2018). Statistisk verktygslåda 1:
samhällsvetenskaplig orsaksanalys med kvantitativa metoder. Tredje upplagan Lund:
Studentlitteratur
Folkhälsomyndigheten (2020). Nya föreskrifter och allmänna råd till serveringsställen.
https://www.folkhalsomyndigheten.se/nyheter-och-press/nyhetsarkiv/2020/juli/nya-foreskrifter-och-allmanna-rad-till-serveringsstallen/ [2020-12-24]
Frey, Carl & Osborne Michael (2013). The future of employment: How susceptible are jobs to computerisation? Elektroniskt format
Groves, Robert M (2006). Nonresponse rates and nonresponse bias in household surveys. Elektroniskt format.
Groves, Robert, Eleanor Singer, and Amy Coming. 2000. "Leverage-Saliency Theory of Survey Participation: Description and an Illustration." Puhlic Opinion Quarterly 64:299-308. Groves, Robert M & Peytcheva, Emilia (2008). The impact of nonresponse rates on
nonresponse bias. Elektroniskt format
Hájek, J. (1960). Limiting distributions in simple random sampling from a finite
population. Publications of the Mathematical Institute of the Hungarian Academy of Sciences, 5, 361– 371
Heick (2020). Restauranger tänker nytt för att försöka överleva.
https://www.svt.se/nyheter/lokalt/stockholm/restauranger-tanker-nytt-for-att-forsoka-overleva
[2020-12-24]
Lohr, Sharon L. (2010). Sampling: design and analysis. 2. ed. Boston, MA: Cengage Brooks/Cole