Teknik och samhälle
Datavetenskap
Examensarbete
15 högskolepoäng, grundnivå
Vala – Ett optimeringsverktyg för resursfördelning
inom grundskolan i Lunds kommun
Vala – An optimization tool for resource allocation in Lund
municipality’s elementary schools
Andreas Indal
Jimmy Lindström
Examen: Kandidatexamen 180 hp Huvudområde: Datavetenskap Program: Systemutvecklare Datum för slutseminarium: 2017-05-30Handledare: Ivan Kruzela Examinator: Bengt J. Nilsson
Förord
Vi vill inleda med att tacka vår handledare, Ivan Kruzela, för allt stöd vi fått under våren. Ditt engagemang har varit otroligt inspirerande! Vi vill dessutom tacka Britt Steiner och Patrik Persson på Lunds kommun som hjälpt till att ta fram material och data som underlättat genomförandet av studien.
Avslutningsvis vill vi också passa på att tacka våra familjer och vänner för allt stöttande och peppande.
Bilden på framsidan, Völvan från Völuspá, illustrerades av Carl Larsson 1893. Bil-den är hämtad från Projekt Runeberg (http://runeberg.org/eddan/ed0048.jpg) som arbetar på frivillig grund med att skapa fria elektroniska utgåvor av klassisk nordisk litteratur och göra dem öppet tillgängliga över Internet.
Sammanfattning
Idag sker resursfördelning inom grundskolan i Lunds kommun av kommunfullmäk-tige i en skolpeng. Skolpengen består av en grundresurs, som är lika för alla skolor, samt en tilläggsresurs som baseras på olika socioekonomiska aspekter och är indi-viduell för varje enskild skola. För att räkna fram tilläggsresursen använder Lunds kommun en resursfördelningsmodell. Kommunpolitikerna menar att de inte kan fast-ställa ifall modellen gör någon verklig skillnad utifrån de resultat som redovisas.
Vi tillämpar åtta inlärningsalgoritmer på data från Lunds kommun och Skolver-ket för att ta reda på om resursfördelningen kan optimeras med hjälp av maskinin-lärning. Vi använder feature selection och standardisering för att förbehandla datan, och k-delad korsvalidering för att utvärdera prediktionerna.
I våra experiment uppnår vi en lägsta felmarginal på 4,6 procentenheter. Al-goritmen Ordinary Least Squares visar sig ha bäst prestanda initialt. När övriga algoritmers parametrar optimeras och datan förbehandlas uppnår sex av åtta algo-ritmer samma resultat på 4,6 procentenheter.
Abstract
Today, resource allocation for elementary schools in Lund municipality is done by the town council. The money each school receives is divided into a base resource, which is the same for every school, and an additional resource, that is based on socio-economic aspects and is unique for each school. Lund municipality is using a resource allocation model to calculate the additional resource. The politicians claims that it’s hard to determine if the model is making any real difference from the results that have been presented.
We apply eight different learning algorithms on data from Lund municipality and Skolverket to find out if the resource allocation can be optimized with machine learning. We use feature selection and standardization to preprocess the data, and k-fold cross validation to evaluate the predictions.
In our experiments, we reach a margin of error percentage of 4.6. The Ordinary Least Squares algorithm has the best performance initially. When the parameters of the other algorithms are optimized and when the data is preprocessed, six out of eight algorithms reach the same result of 4.6.
Innehåll
1 Inledning 1
1.1 Bakgrund och tidigare forskning . . . 1
1.1.1 Resursfördelning inom grundskolan i Lunds kommun . . . 1
1.1.2 Maskininlärning . . . 3 1.1.3 Maskininlärningsprocessen . . . 3 1.2 Syfte . . . 4 1.3 Frågeställning . . . 6 1.4 Avgränsningar . . . 6 2 Metod 7 2.1 Metodbeskrivning . . . 7 2.1.1 Litteraturstudie . . . 7 2.1.2 Experiment . . . 10 2.2 Metoddiskussion . . . 15 3 Experiment 16 3.1 Beskrivning av dataset . . . 16 3.1.1 Information om attribut . . . 16 3.2 Utförande . . . 17 3.2.1 Initiala experiment . . . 17 4 Resultat 22 4.1 Experiment utan feature selection . . . 22
4.2 Experiment med feature selection . . . 24
4.3 Valas prediktioner på modifierad data . . . 26
5 Diskussion och analys 28 5.1 Algoritmernas prestanda . . . 28
5.2 Vikten av datasetets attribut . . . 29
5.3 Jämförelser med relaterad forskning . . . 30
6 Slutsatser och vidare forskning 31 6.1 Användning av Vala . . . 31
6.2 Vidare forskning . . . 32
1
Inledning
1.1
Bakgrund och tidigare forskning
1.1.1 Resursfördelning inom grundskolan i Lunds kommun
Resursfördelning inom grundskolan i Lunds kommun sker sedan 2008 av kommun-fullmäktige i en skolpeng [15]. Skolpengen är uppdelad i grundresurs, som är lika för alla skolor, och en tilläggsresurs, som baseras på olika socioekonomiska aspek-ter för varje enskild skola. De socioekonomiska aspekaspek-ter som används för beräkning av tilläggsresursen är könsuppdelning, antal nyanlända, högsta utbildningsnivå för vårdnadshavare, vårdnadshavares ekonomiska bistånd, och elevens familjeförhållan-den.
Figur 1: Resursfördelningsmodell (redigerad) [34]
Under 2017 budgeterades drygt 2.4 miljarder kronor för barn- och skolnämnden i Lunds kommun [14]. Men kommunpolitikerna i Lund [17] uppger i en rapport att de inte med säkerhet kan säga om resursfördelningen gör någon verklig skillnad utifrån den resultatredovisning som finns att tillgå. De menar i rapporten att andelen elever som når de uppsatta målen är väldigt lika över åren, men att det trots det jämna
genomsnittet i kommunen är stora skillnader mellan de genomsnittliga värdena i respektive skola.
En stor anledning till att det är svårt att utläsa några resultat av den resurs-fördelning som görs, menar kommunpolitikerna i Lund, beror på den svårhanterliga mängden data som idag används i beräkningsmodellen. Hur pengarna som distri-bueras ut till respektive skola sedan används är heller inget som kommunpolitikerna ansvarar över, utan den fördelningen görs av rektorerna på varje individuell skola. Hur resurserna används finns dokumenterat, men används idag inte i beräkningen av resursfördelningen mellan skolorna i kommunen.
Figur 2: Träffsäker, objektiv och legitim resursfördelningsmodell [34]
Sveriges Kommuner och Landsting [34] menar att en resursfördelningsmodell behö-ver vara träffsäker, objektiv och legitim (se Figur 2) för att fungera bra, och beskribehö-ver egenskaperna enligt följande:
Med träffsäkerhet avses att modellen så väl som möjligt ska fånga in skillnaderna i elevgruppernas behov, så att ersättningen hamnar på den skola eller de skolor där den kan göra mest nytta. [...] Med objektiv avses att fördelningen bygger på data som inte kräver några subjektiva bedömningar eller avvägningar samt att skolorna inte kan påverka dessa data. [...] Att en resursfördelningsmodell är legitim handlar om att den uppfattas som väl underbyggd, är begriplig och accepteras av de berörda. Det ska vara möjligt att förstå varför en skola får en viss tilldelning jämfört med andra skolor.
Vi tror att det finns möjligheter att med hjälp av maskininlärning optimera resur-fördelningen, och på så vis göra modellen såväl mer träffsäker och objektiv som legitim. Genom att i steget Process som definierats i Figur 1 inkludera information från en tränad modell som underlag för kommunpolitikernas diskussion tror vi att resursfördelningen kan förbättras.
1.1.2 Maskininlärning
Maskininlärning (eng. machine learning) är en teknik som under det senaste årtion-det fått mycket uppmärksamhet inom fler fält än bara datavetenskapen [5][18][20]. Maskininlärning har använts bland annat för att modellera mänsiklig aktivitet som hälper oss att förstå vår miljöpåverkan, och för att genomföra genetiska analyser av det mänskliga genomet som hjälper oss att diagnostisera sjukdomar [20].
Ahamed et. al. [1] utförde en studie i syfte att med hjälp av maskininlärning pre-diktera elevers akademiska resultat utifrån vissa socioekonomiska och psykologiska faktorer. Deras studie behandlade dock inte skolans ekonomiska förutsättningar, vilket är en central aspekt i vår studie.
I sin bok hävdar Marsland [18] att maskininlärning handlar om att få en dator att anpassa sig och modifiera sitt beteende så att den kan utföra ett givet arbete på ett mer träffsäkert sätt, där träffsäkerheten mäts i hur korrekt resultatet är i slutändan.
Enligt Marsland [18] är en av anledningarna till att maskininlärning blivit så populärt att mängden data vi samlar in växer (han nämner som exempel att The Large Hadron Collider, världens största partikelacceleratoranläggning [4], vid CERN producerar 25 petabytes av data varje år), samtidigt som våra mänskliga hjärnors kapacitet är begränsad. Genom att använda maskininlärning och låta en dator pro-cessera de enorma mängder data vi besitter kan vi slippa de problem som medförs av människans begräsningar, menar han.
Marsland [18] belyser vikten av valet av attribut i datan som används av datorn vid maskininlärning. Det kan ibland vara nödvändigt att modifiera den existerande datan så att den passar syftet; exempelvis kan attributet tid vara av intresse för en given datamängd. Författaren menar att om tiden är representerad i närmaste millisekund i vår datamängd, medan det vi är intresserade av är ungefär vilken tid på dygnet det rör sig om, kan resultaten bli missvisande. Det kan då vara nödvändigt att förbehandla datan så att inlärningsalgoritmen kan ta fram en relevant modell [18][37]. Exempelvis kan det för det specifika fallet vara klokare att representera tiden i form av morgon, eftermiddag, kväll eller natt när modellen tränas [18].
1.1.3 Maskininlärningsprocessen
Marsland [18] beskriver processen för att lösa ett problem med hjälp av maskinin-lärning i sex olika steg. Det första steget är datainsamling och förberedelse. Viktigt att tänka på i det här steget, menar författaren, är att datan är ren och inte
innehåller allt för mycket felaktigheter. Marsland menar också att om problemom-rådet är nytt och outforskat bör datainsamlingen slås ihop med nästa steg, feature selection, med syfte att endast samla in den data som faktiskt behövs. Feature selection handlar om att identifiera och välja ut de attribut (eng. features) hos datan som är mest användbara för att lösa problemet, och även att se till att välja egenskaper som enkelt kan samlas in.
Nästa steg i processen, beskriver Marsland [18], är val av algoritm, vilket kräver en förståelse för hur de olika algoritmerna fungerar och kan användas. För många av de maskininlärningsalgoritmerna som finns krävs det att vissa parametrar sätts ma-nuellt. Detta görs i nästa steg, parameter- och modellval, och Marsland förklarar att steget kräver experimentering för att hitta optimala värden att använda. Först efter att ovanstående steg är utförda byggs med hjälp av den valda algoritmen och datan en modell som används för att förutse värden för ny data. Detta steg kallar Marsland för träning. Det sjätte och sista steget, förklarar Marsland, är utvär-dering, som innebär att den tränade modellen testas och modellens träffsäkerhet utvärderas.
1.2
Syfte
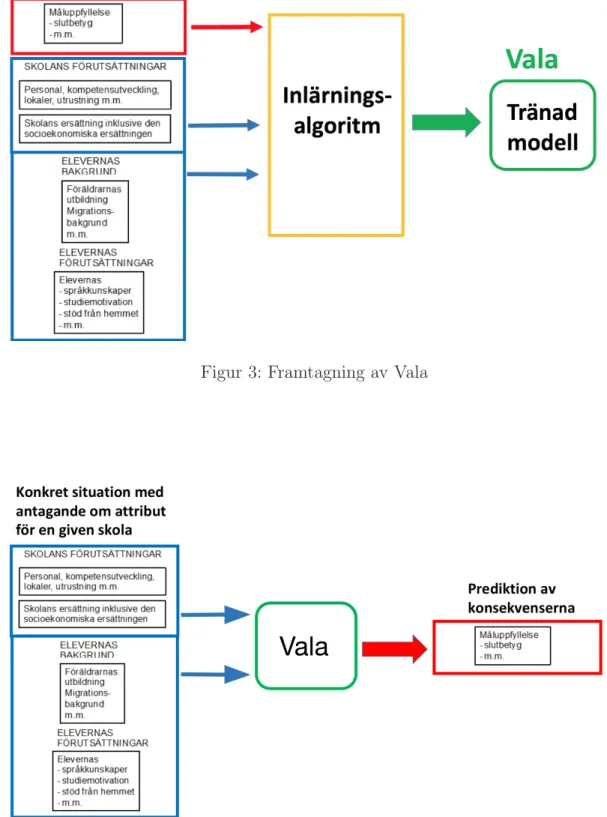
Syftet med denna studie är att undersöka hur maskininlärning kan användas för att optimera de beräkningar som idag görs vid resursfördelning för grundskolorna i Lunds kommun. Genom att undersöka möjligheterna är målet att baserat på resul-taten ta fram ett verktyg (se Figur 3), som vi valt att döpa till Vala efter spåkvin-norna i den fornnordiska mytologin [36], som kan hjälpa till vid resursfördelningen till grundskolorna (se Figur 4).
I den bästa av världar hade målet med studien varit att uppnå resultat som direkt kan användas av kommunen vid resursfördelningen. Två primära skäl till att vi väljer att göra avgränsningar i studien är:
1. Ingen tidigare forskning har gjorts inom området resursfördelning med hjälp av maskininlärning.
2. Det finns mer data som vi inte har tillgång till, men som vi tror hade kunnat bidra till bättre prediktioner och säkrare resultat. Exempelvis har kommunerna tillgång till data för varje enskild elev, och dessutom information kring hur de fördelade pengarna faktiskt används utav skolorna.
Med dessa punkter i åtanke blir vår primära utgångspunkt att undersöka möjlig-heterna som maskininlärning erbjuder för problemområdet. Vi granskar olika inlär-ningsalgoritmers resultat på den data vi har att tillgå, och bereder en grund för framtida forskning inom området.
Figur 3: Framtagning av Vala
1.3
Frågeställning
– Hur kan maskininlärning användas för att optimera kommunernas resursför-delning till grundskolor?
1.4
Avgränsningar
Det finns stora mängder data från grundskolan i Lunds kommun under de senaste åren. Vi har valt att avgränsa studien till att endast behandla data för elever i nionde klass. Skälet till detta är att vi anser att attributet för antalet elever som uppnått kunskapsmålen är viktigt för att kunna mäta resultatet på ett relevant sätt, och denna parameter finns endast tillgänglig för niondeklassare. Den data vi har att tillgå är från 2011 och framåt. En mer detaljerad beskrivning av datamängden redovisas i avsnitt 3.1.
2
Metod
I detta avsnitt beskrivs de metoder som används vid genomförandet av studien. Vidare diskuteras för- och nackdelar med de valda metoderna, samt andra metoder som hade kunnat användas i forskningen men som av olika skäl valts bort.
2.1
Metodbeskrivning
För att besvara de forskningsfrågor vi ställer oss måste vi genomföra praktiska un-dersökningar där vi tillämpar ett antal maskininlärningsalgoritmer på den data som Lunds kommun idag använder vid resursfördelningen.
De praktiska undersökningar vi genomför behöver förankras i den forskningslitte-ratur som finns att tillgå idag. Detta för att säkerställa att undersökningarna utförs på ett optimalt sätt. Med tanke på den stora mängd inlärningsalgoritmer som ex-isterar behöver ett urval göras, då det inte finns möjlighet att testa samtliga av dem.
De metoder vi valt att använda för att utföra studien är dels en litteraturstudie, som är tänkt att ge oss en gedigen grund i ämnet och en inblick i tillvägagångssätt och resultat från tidigare forskning, följt av en serie experiment, där vi applicerar och vidareutvecklar informationen från litteraturstudien praktiskt på den data vi har att tillgå. Då vår specifika angreppspunkt, maskininlärning som verktyg för resursfördelning till grundskolor, är ett outforksat område, kommer experimenten delvis utföras på ett explorativt vis.
2.1.1 Litteraturstudie
Med syfte att få en förståelse av ämnet vi forskar kring, och för att utlägga en grund för de experiment vi utför, genomför vi en litteraturstudie. Målet är primärt att hitta tidigare akademisk forskning som berör maskininlärningsalgoritmer, dataför-behandling och feature selection som applicerats på data lik den vi har att tillgå.
Vi söker information främst i fyra tidskriftsdatabaser: ACM Digital Library (ACM), IEEE Xplore Digital Library (IEEE), SpringerLink (SPRINGER) och Google Scholar (GOOGLE). De tre förstnämnda databaserna, ACM, IEEE och SPRINGER, är inom datavetenskapen allmänt erkända databaser, och används i första hand. Vid tillfällen då vi inte hittar tillräckligt med information från nämnda databaser an-vänder vi oss av GOOGLE, som är en aggregerande sökmotor som söker i flera andra databaser samtidigt. Ett problem med GOOGLE är att sökningar oftast ger en väldigt stor mängd resultat, vilket kan göra det svårt att orientera sig i informationssök-ningen. Detta är också anledningen till att vi väljer att huvudsakligen använda oss av de andra tre databaserna.
För att göra informationssökningen så effektiv som möjligt har vi identifierat ett antal nyckelord att använda oss av:
• Maskininlärning
Nyckelord: ”machine learning”, ”supervised learning”, ”feature selection”, ”regres-sion”, ”pre-processing”
• Resursfördelning
Nyckelord: ”resource allocation”, ”socioeconomic”, ”economic distribution”
Nyckelorden används var och ett, men även i kombinationer tillsammans med andra nyckelord, för att genomföra sökningar i ovan nämnda databaser. Under sökningens gång prövar vi även att byta ut nyckelorden mot synonymer för att bredda sökning-arna. Se Tabell 1 nedan för en komplett redogörelse de sökord som använts och antal träffar som sökningarna i respektive databas har resulerat i.
Vid sökningar som genererar 80 resultat eller färre går vi igenom repsektive resultats titel och nyckelord för att utvärdera om artikeln är relevant för studien. För var och en av de artiklar som vi finner titeln eller nyckelorden relevanta fortsätter vi sedan med det som Keshav [9] beskriver som The Three-Pass Approach. Efter varje pass tar vi ett beslut baserat på vår uppfattade relevans om att antingen gå vidare med nästa pass, eller att lämna artikeln och gå vidare till nästa.
Om en artikel efter de tre passen bedöms vara relevant för studien sparar vi den för att använda i litteraturstudien. Oavsett om artikeln sparas eller inte går vi igenom artikelns referenslista för att hitta andra potentiella källor. Vi tittar på de källor som artikeln refererar till, och dessutom artiklar som refererar till den givna artikeln, och undersöker därefter dessa i syfte att hitta ytterligare relevant information.
Nedan listas i Tabell 1 de sökningar som gjorts i de olika databaserna. Notera att sökningarna i databaserna ACM, IEEE, och SPRINGER gjorts med exakt samma sökord, medan sökningarna i GOOGLE är betydligt färre. Detta av anledningarna nämnde ovan; vi använder endast GOOGLE då vi anser att vi ej hittat tillräckligt med resultat i övriga databaser. Utöver sökningarna listas även i Tabell 2 den akademiska litteratur som litteratursökningen har resulterat i.
Tabell 1: Antal sökträffar
Sökord ACM IEEE SPRINGER GOOGLE ”machine learning” 19 982 35 776 50 046 – ”machine learning” AND ”feature selection” 1 117 1 655 7 006 – ”machine learning” AND ”feature selection” AND
”resour-ce allocation”
1 1 36 1 960 ”machine learning” AND ”feature selection” AND
”socioe-conomic” 0 1 14 –
”machine learning” AND ”feature selection” AND ”survey” 10 20 1 721 – ”machine learning” AND regression 2 507 2 081 10 261 – ”machine learning” AND regression AND evaluation 652 217 6 205 – ”machine learning” AND regression AND ”feature
selec-tion”
325 104 2 230 – ”machine learning” AND regression AND ”feature
extrac-tion”
70 254 1 425 – ”machine learning” AND regression AND preprocess 25 6 1 772 – ”machine learning” AND ”multivariate regression” 11 12 135 6 430 ”machine learning” AND ”economic distribution” 4 0 3 52 ”machine learning” AND ”distributing resources” 14 0 421 – ”machine learning” AND ”distributing money” 0 0 1 3 ”machine learning” AND ”money distribution” 1 0 2 11 ”machine learning” AND ”socio-economic” 6 30 873 – ”machine learning” AND preprocess* 202 763 18 519 – ”machine learning” AND socioeconomic 3 7 653 – ”machine learning” AND correlation AND ”feature
selec-tion”
111 165 2 645 – ”supervised learning” 2815 6 773 15 904 – ”supervised learning” AND ”feature selection” AND
”re-source allocation”
0 317 50 666 ”supervised learning” AND ”resource allocation” 2 15 317 – ”supervised learning” AND ”economic distribution” 0 0 0 8 ”supervised learning” AND ”distributing resources” 1 0 48 33 ”supervised learning” AND ”distributing money” 0 0 0 0 ”supervised learning” AND ”money distribution” 0 0 0 1 ”supervised learning” AND ”socio-economic” 2 6 149 2 000 ”supervised learning” AND ”socio-economic” AND
”featu-re selection”
0 20 376 17 – ”socio-economic ” AND ”feature selection” 0 4 165 2 130 ”feature selection” AND ”resource allocation” 3 11 245 3 210 regression 4 584 24 522 25 186 – regression AND evaluation 1 261 2 344 14 161 –
För att komplettera sökningarna i de angivna databaserna letar vi även upp relevanta examensarbeten som gjorts på kandidat- och masternivå. Vi söker i databaserna MUEP1
och Uppsatser.se2
. Syftet bakom dessa sökningar är inte att använda det
1
http://muep.mah.se/
2
material vi hittar direkt, utan istället att granska arbetenas referenslistor för att hitta vetenskapliga artiklar att komplettera vår egen studie med.
I Tabell 2 listas de artiklar och böcker som litteratursökningen resulterat i. Ma-terialet har studerats och används vidare som stöd i de empiriska undersökningar vi utför i studien, och dessutom i studiens analys- och diskussionsdelar för att nyansera de resultat vi uppnått.
Tabell 2: Resulterande material
Titel Referensnummer
Prediction of HSC examination performance using socioeconomic, psycho-logical and academic factors
[1] A study of machine learning regression methods for major elemental
ana-lysis of rocks using laser-induced breakdown spectroscopy
[3] A few useful things to know about machine learning [5] Ridge Regression: Biased Estimation for Nonorthogonal Problems [6] An introduction to statistical learning [7] Approximating Number of Hidden layer neurons in Multiple Hidden Layer
BPNN Architecture
[8] A survey of feature selection and feature extraction techniques in machine
learning
[10] Feature Extraction for Regression Problems and an Example Application
for Pose Estimation of a Face
[11] Feature Selection Methods and Algorithms [12] Quantifying the Impact of Learning Algorithm Parameter Tuning [13] Behaviour Analysis of Multilayer Perceptrons with Multiple Hidden
Neu-rons and Hidden Layers
[19] Lowering the barrier to applying machine learning [20] Scikit-learn: Machine Learning in Python [21] Cross-Validatory Choice and Assessment of Statistical Predictions [33] Regression Shrinkage and Selection via the Lasso [35] Data Mining: Practical Machine Learning Tools and Techniques [37] Detection of Alzheimer’s disease by displacement field and machine
lear-ning
[38]
2.1.2 Experiment Data
Vi utför experimenten enligt de steg som Marsland [18] beskriver i sin maskinin-lärningsprocess. I det första steget samlar vi in den data vi behöver. Vårt dataset består av data som Lunds kommun har tillhandahållit gällande skolorna i Lund. I dessa data kan vi utläsa, för varje enskild skola och år, följande parametrar: antal elever, antal elever med utländsk bakgrund och hur stor skolpeng per elev skolan blivit tilldelad. Vår data innehåller även information om hur stort ekonomiskt tillägg skolan fått. Tillägget grundas på andelen elever med utländsk bakgrund samt ut-bildningsnivån på elevernas föräldrar [15].
Figur 5: Framtagning av dataset
För att få fler faktorer att väga in i experimenten aggregerar vi parametrar med ytterligare data som vi hämtar från Skolverkets databas SALSA3
(se Figur 5), vars data är uppdelad för varje skola. Från datan i SALSA väljer vi ut attributen könsupp-delning, den genomsnittliga utbildningsnivån hos elevernas föräldrar, antalet lärare per elev samt andel elever som uppnår kunskapsmålen då vi anser att de komplet-terar attributen i datan från Lunds kommun väl. För en mer utförlig beskrivning av datasetet, inklusive exempeldata, se avsnitt 3.1.
Nästa steg i processen är enligt Marsland [18] att undersöka de attribut vi samlat in för att avgöra om de är de mest relevanta. Detta steg handlar i många fall om att minska dimensionaliteten av datan (eng. dimensionality reduction) [10][11][12]. Ladha och Deepa [12] förklarar att det finns två metoder för att utföra detta steget, feature selection eller feature extraction. Feature selection söker efter den delmängd av våra attribut som genererar bästa möjliga approximation av resultat, vilket in-nebär att den eliminerar de attribut som inte är relevanta eller korrelerar bra med resultatet. Feature extraction i sin tur gör en transformation av alla attribut till en lägre dimension utan att vi förlorar någon data. Enligt Khalid et. al. [10] är en nackdel med feature extraction att vi förlorar möjligheten att mäta hur mycket ett givet attribut faktiskt bidrar till resultatet på grund av transformationen av
attri-3
buten. Då vi vill ha möjligheten att undersöka relevansen hos våra attribut väljer vi att använda oss av feature selection. Vidare kategoriserar författarna av [10] och [12] attributen i ett dataset som antingen relevanta, icke-relevanta eller redundan-ta. Relevanta attribut, menar de, har en påverkan på resultatet och deras roll kan inte ersättas av övriga; icke-relevanta attribut har ingen påverkan på resultatet, och deras värde är randomiserat för varje exempel; redundanta attribut är de attribut som kan ta rollen av andra attribut.
Algoritmer
Det tredje steget i maskininlärningsprocessen enligt Marsland [18] är algoritmval. För de experiment vi utför används program implementerade i programmeringssprå-ket Python. Vi använder oss av biblioteprogrammeringssprå-ket scikit-learn4
som är ett väletablerat och erkänt bibliotek för maskininlärning. scikit-learn tillhandahåller en rad olika verktyg för maskininlärning, såväl algoritmer för att träna modeller som verktyg för att testa modellerna och mäta resultat och träffsäkerhet [21].
Marsland [18] beskriver fyra olika typer av maskininlärning: supervised learning, unsupervised learning, reinforcement learning och evolutionary learning, där han menar att den förstnämnda är den allra vanligaste formen. Supervised learning för-utsätter att varje instans av data, i ett givet dataset, har ett resultat, ofta kallat klass eller label. För att kunna generalisera och prediktera resultat för annan data av samma typ tränas en modell med alla dessa instanser och deras givna, korrekta resultat och en given maskininlärningsalgoritm.
Om det är en specifik klass som skall predikteras så kallas uppgiften för klassifi-sering [18]. Vid approximering av ett kontinuerligt värde, snarare än prediktering av klass, kallas uppgiften regression [2]. Då vår data har labels använder vi supervised learning. Vidare stämmer vår data överens med ett typiskt regressionsproblem, då vi skall approximera ett värde på antalet elever som uppnår kunskapsmålen. Därför använder vi oss i följande experiment av regressionsmetoder för att approximera våra resultat.
Det finns både linjära och icke-linjära metoder för att utföra regression. Boucher et. al. [3] uppmärksammar i sin studie att icke-linjära regressionsmetoder visat sig prediktera resultat sämre än linjära metoder. Detta påstående styrks även av Ja-mes et. al [7], som menar att de flesta metoder för att approximera funktionen f för ett kontinuerligt värde Y historiskt sett har varit linjära. För att få ett stör-re djup i vår studie väljer vi dock att använda oss av både linjära och icke-linjära inlärningsalgoritmer. Nedan listas de algoritmer som vi valt att utvärdera på våra dataset:
– Ordinary Least Squares (OLS)
OLS är en linjär regressionsalgoritm som skapar en modell genom att skatta parametrarna. Målet är att minimera den residuala kvadratsumman mellan
4
de observerade resultaten i datasetet och de predikterade resultaten från den linjära approximationen [7]. Skattningar på parametrarna sparas som koeffici-enter för senare prediktioner.
– Ridge Regression (RR)
RR är en OLS-regressionsmodell, fast med tillägget av en straffterm α som krymper koefficienteranas storlek [6]. Detta görs för att modellen skall bli mer robust när datasetet innehåller parametrar med hög korrelation.
– Least absolute shrinkage and selection operator (Lasso)
Även Lasso är en OLS-modell och likt RR finns en straffterm α som krymper koefficienterna mot noll. Men Lasso sätter även en del koefficienter till exakt noll [3][35]. Detta innebär att de attributen inte påverkar resultatet positivt och kan uteslutas ur modellen. Detta kan generera mer sparsamma och lätttolkade modeller.
– Elastic Net (EN)
EN är en hybrid av Lasso- och RR-regression [3]. Även denna algoritm har en straffterm α som krymper koefficienternas värde mot noll. EN har även en pa-rameter l1-ratiomed värde mellan 0 och 1. Den senare parametern kontrollerar
strafftermen och är en så kallad mixing parameter. När l1-ratio = 0 löser EN problemet som RR, och när l1-ratio = 1 som Lasso. Värden däremellan så löses
problemet med en kombination av både RR och Lasso [24]. – Multi-Layered Perceptron Regressor (MLPR)
MLPR är av typen neurala nätverk. Karsoliya [8] beskriver att neurala nätverk oftast består av tre typer av lager med noder. Vidare menar författaren att alla attribut blir noder i det första lagret, input-lagret, och resultatet noder i det sista lagret, output-lagret. Författaren förklarar även att där finns ett varierande antal gömda lager mellan de tidigare nämnda lagren, som i sin tur innehåller ett varierande antal noder. Alla noder i det lägre lagren av noder är kopplade med bågar till alla noder i nästkommande lager. Dessa bågarna har vikter associerade till sig [18]. Det är dessa vikter som MLPR skattar för att minimera kvadraten av felen vid träningen av en modell. Det finns ett antal parametrar som kan optimeras vid användning av MLPR. scikit-learns im-plementering av MLPR kan tränas med en av dessa tre algoritmer: Stochastic gradient descent, Adam eller lbfgs. De två första algoritmerna använder sto-kastisk optimering av parametrarna, medans den sista algoritmen, lbfgs, ap-proximerar funktionens Hessian matris. I scikit learns dokumentation [30] rekommenderas lbfgs-algoritmen för beräkning av vikterna (solver). Detta för att den ofta presterar bättre och är snabbare i sin exekvering vid mindre dataset vilket vi anser vara fallet för oss. Utöver den parametern finns det även en aktiveringsfunktion (activation) på noderna som avgör vilken output noderna har beroende på sin input. Vi kan även ställa storlek och antal på de gömda skikten av noder, hidden layer sizes. MLPR nyttjar även en straffterm
α liknande den som beskrevs för RR. Enligt Panchal et. al [19] är en fördel med MLPR enkelheten vid användning och att den kan approximera alla typer av input/output. De påpekar dock att MLPR är långsam, och kräver mycket träningsdata, vid träningen av modellen.
– Decision Tree (DT)
Målet med DT är att bygga en modell, i form av ett binärt träd, utifrån enkla beslutregler som läses ut från parametrarna i datasetet. Det används inga speciella parametrar vid inlärningen av modellen. Det man kan optimera vid användningen av DT är djupet på trädet som skapas, max depth, och antalet instanser av data det krävs för att skapa ett så kallat löv, min samples leaf [23]. Det finns möjlighet att välja mellan olika algoritmer för att skapa trädet men det är inget som påverkar precisionen i algoritmen utan exekveringstiden, och det beror på hur datan ser ut. En fördel med DT är att den skapar en enkel och relativt lätttolkad modell där det är enkelt att utläsa vad som sker och varför [18].
– Bayesian Ridge Regression (BRR)
BRR är en variant på RR, men skattar koefficienter utefter en probabilistisk modell baserad på en normalfördelning. Fördelen men detta är att modellen anpassar sig efter datan som finns till hands. [27]
– k-Nearest Neighbors Regression (KNN)
I KNN representeras alla träningsinstanserna som punkter i ett flerdimensionellt rum. Vid klassifisering används en avståndsberäkning för att beräkna de k närmsta instanserna, grannarna, i rymden med antagandet att ifall flera av attributen är samma tillhör de troligtvis samma klass. Storleken på k ((n neighbors)) är ett av användaren valt värde. Vid regression fungerar det på liknande vis med skillnaden att resultatet blir medelvärdet av de k närmsta instanserna [3]. Som standard i scikit-learn beräknas alla de k närmsta grannarna som likvärdiga. Det finns möjlighet att ändra parametern weights för att vikta grannarna så de som ligger närmre får större inflytande över resultatet [29].
I ovan beskrivna algoritmer finns det ett antal så kallade hyperparametrar. Dessa används för att finjustera prestandan i algoritmen utefter den data som används. Detta för oss till nästa steg i Marslands [18] beskrivning, parameterval. Han menar att det, som vi tidigare nämnt, inte finns något gyllene värde som passar alla dataset, utan det krävs experiment för att hitta optimala värden för den data vi använder. scikit-learnerbjuder möjligheter att experimentera med dessa parametrar genom korsvalidering för flera algoritmer. Detta innebär att algoritmen tränar en modell på vår data i olika iterationer med olika värden på parametrarna. Algoritmen genomför prediktionerna och väljer de parametervärden som genererat lägst felmarginal. Den-na teknik finns inte tillgänglig för alla algoritmer. För de algoritmer där stöd sakDen-nas gör vi manuella experiment med parametrar baserat på den kunskap vi införskaffat
oss i litteraturstudien. Detta har bidragit till att vissa algoritmer inte optimerats i samma utsträckning som andra.
Träning och utvärdering
De två sista stegen Marsland [18] beskriver är träning och utvärdering av model-len. Vi använder oss av k-delad korsvalidering för träning och utvärdering. För att utvärdera de olika modellernas prestanda använder vi det absoluta medelvärdet av felen, mean absolute error (MAE). Detta innebär att vi beräknar det absoluta medel-värdet av skillnaderna mellan de predikterade värdena och de verkliga resultaten. Anledningen att vi väljer MAE är dels för att det anges i samma enhet som resultat attributet, i vårt fall Andel elever (%) som uppnått kunskapsmålen. Det-ta underlätDet-tar tolkningen av resulDet-tatet. En annan anledning till att vi valt MAE är att SALSA redovisar den residuala skillnaden mellan deras modellberäknade resultat samt det faktiska resultatet. I deras tabeller kan vi läsa ut faktiskt värde (F ), modell-beräknat värde (B) och residual (R), vilket är skillnaden F − B = R, för varje skola [22]. I SALSA rapporteras det inte som absolut värde vilket vi gör men detta beror på hur funktionen i scikit-learn är implementerad, då den rapporterar medelvärdet av felen i absolut värde för varje delmängd k i den k-delade korsvalideringen.
2.2
Metoddiskussion
Många av maskininlärningsalgoritmerna är väldigt komplexa och har många hyper-parametrar som kan justeras för att optimera deras prestanda. Då vi implementerar åtta olika algoritmer har det varit svårt att finjustera alla dessa med deras olika parametrar. scikit-learn har varit till stor hjälp då en del av deras algoritmer kan optimeras med hjälp av korsvalidering. De algoritmerna som saknar den möj-ligheten optimerar vi genom att göra enklare tester och justera de parametrar vi anser lämpliga baserat på kunskap införskaffad under litteraturstudien. Ett alterna-tivt angreppsätt hade varit att implementera färre algoritmer och fokusera på att optimera deras prestanda mer vilket eventuellt kunnat generera bättre resultat.
Ytterligare en faktor som påverkar resultatet är den totala mängden data som finns tillgänglig. För att ta fram det dataset som används i studien slår vi samman den data som Lunds kommun tillhandahållit med data från Skolverkets databas SALSA. Men den totala mängden data är fortfarande relativt liten. För att få ett stabilare resultat med lägre felmarginal kan mer historisk data bidra. Ett alternativ som diskuterades var att träna en modell med data från alla Sveriges skolor för att sedan se hur den modellen presterar vid prediktioner på Lunds skolor. Problemet som uppstod då var att vi saknade en del vitala parametrar då det inte fanns tillgång till dessa direkt från SALSA. Ett exempel på data som inte finns tillgänglig via SALSA är hur stor skolpeng varje enskild skola tilldelats.
3
Experiment
3.1
Beskrivning av dataset
Nedan beskrivs det dataset som använts vid träning av våra modeller. I beskriv-ningen finns information om hur många instanser datasetet innehåller, hur många attribut som finns, och källan till datan. För en fullständig redogörelse för all data som datasetet innehåller, se Bilaga 1.
Attributtyp: Reella tal Antal instanser: 102 Område: Grundskola Antal attribut: 7 Associerad
upp-gift:
Regression Saknade vär-den:
Nej
Ett dataset över alla grundskolor i Lunds kommun med utgångsbetyg för årskurs 9 mellan åren 2011 och 2016. Datasetet är en sammanslagning av data hämtad från Skolverkets databas SALSA och data levererad av Lunds kommun. Predikterat attribut: Andel elever som uppnår kunskapsmålen.
3.1.1 Information om attribut A Huvudman (kommunal/privat)
Attributet beskriver huruvida skolans huvudman är kommunal eller privat. Värdet anges binärt, och är 0 för kommunal och 1 för privat.
B Elever per lärare
Genomsnittet för antal elever per lärare sett över samtliga klasser för årskurs 9 i skolan. Värdet anges med en decimal.
C Föräldrarnas genomsnittliga utbildningsnivå
Attributet beskriver föräldrarnas utbildningsnivå och poängsätts enligt föl-jande: 1p) genomgången folkskola/grundskola, 2p) genomgången gymnasial utbildning, 3p) eftergymnasial utbildning. Värdet som anges är genomsnittet för skolans samtliga elever i årskurs 9. [22]
D Andel (%) pojkar
Attributet beskriver hur stor andel av skolans elever i årskurs 9 som är pojkar, angiven i procent.
E Andel (%) elever med utländsk bakgrund
Elever med utländsk bakgrund avser elever vars båda föräldrar, eller eleven själv, är födda i utlandet [16].
F Skolpeng i tkr per elev
Attributet beskriver hur mycket pengar skolan fått. Värdet anges i tusen kro-nor per elev med två decimaler.
G Andel (%) elever som uppnår kunskapsmålen
Attributet beskriver hur stor andel av skolans elever i årskurs 9 som fått god-känt slutbetyg i samtliga ämnen.
I Tabell 3 följer exempel med data enligt beskrivningarna ovan. Tabellen innehål-ler data från skolorna Freinetskolan (2016), Lerbäckskolan (2015) och Svaneskolan (2013). Tabell 3: Exempeldata A B C D E F G 1 9.0 2.5 31 21 72.3 75 0 14.0 2.8 45 14.69 69.4 91 0 13.2 2.7 43 14.62 65.5 77
3.2
Utförande
Tillvägagångssättet för utförandet av de experiment som beskrivs nedan är i grunden likadant. Utförandet går ut på att vi tränar en modell med respektive algoritm, och gör prediktioner och utvärderar resultaten med korsvalidering (eng. cross-validation) [33]. Vi använder oss av metoden k-delad korsvalidering (eng. k-fold cross-validation) (se Figur 6), vilket innebär att vi partionerar upp vår data i k lika stora delar. Vi kör igenom respektive algoritm i k iterationer; för varje iteration använder vi en av uppdelningarna som testdata medan resterande k − 1 delar används för att träna modellen [38]. Modellen utvärderas baserat på modellens MAE, som beräknas utav medelvärdet av differensen mellan algoritmens prediktioner och datans verkliga värden. För samtliga experiment nedan är k = 10.
3.2.1 Initiala experiment
E01 Vi inleder det första experimentet genom att köra igenom samtliga algoritmer på vårt dataset. Vi justerar inga parametrar på algoritmerna, med undantag för MLPR vars solver-parameter vi sätter till värdet lbfgs. Anledningen till detta beskrivs i avsnitt 2.1.2.
E02 Vi väljer att köra experimentet med s.k. standardisering (eng. feature standar-disation), vilket skalar samtliga attribut så att medelvärdet för varje attribut blir 0 och de får en enhetlig varians. Detta gör att koefficienterna, och i vissa fall de vikter som adderas till värdena, hålls på en rimlig nivå [18]. Marsland [18] menar dessutom att för vissa algoritmer är det direkt nödvändigt att an-vända standardisering. Vi använder verktyget StandardScaler från sci-kit learn för att utföra standardiseringen [31].
E03 I samtliga av de algoritmer vi använder finns möjligheten att ställa ett antal olika parametrar som påverkar inlärningen, med undantag för OLS. Marsland
Figur 6: k-delad korsvalidering [38]
[18] menar att det inte finns något ”rätt” sätt att ställa parametervärdena på, utan det varierar från algoritm till algoritm och dataset till dataset. Vida-re Vida-redogör han för att det kan krävas att man prövar sig fram för att hitta lämpliga värden. Lavesson och Davidsson [13] finner i sin studie att parame-teroptimering ofta är viktigare och har större inverkan på prestandan än valet av algoritm.
Nedan beskrivs samtliga parametrar som vi ställt i respektive algoritm för E03. Notera att vi inte använder standardisering av datan under detta experiment.
Lasso Vi väljer att använda oss av cross-validation för att hitta optimala pa-rameterinställningar. Detta innebär att algoritmen testar olika värden för strafftermen α, och väljer den som presterar bäst [25]. Efter cross-validation sätter vi alpha=0.036.
DT De parametrar som rekommenderas att sättas är max depth och minimum samples leaf [23]. Efter tester och utvärdering sätter vi max_depth=5 och min_samples_leaf=5.
RR Den enda parametern vi justerar i RR är strafftermen α. Parametern måste vara ett positivt flyttal, och är initialt satt till värdet 1.0 [28]. För detta experiment väljer vi efter tester att sätta alpha=0.5.
EN För denna algoritm väljer vi att använda oss av cross-validation för att sätta mixingparametern, l1-ratio, och strafftermen α.
Cross-validation-algoritmen kräver för att räkna ut l1-ratio en mängd med tänkbara värden
mellan 0 och 1 som input, och väljer utifrån de värdena det värdet som ger bäst resultat. sci-kit learns dokumentation [24] rekommenderar att mängden består av en majoritet av värden som snarare ligger närmre 1 än 0. Vi väljer i detta experiment att sätta mängden till [0.1, 0.5, 0.7, 0.9, 0.95, 0.99, 1]. Efter att ha kört cross-validation rekommenderar algoritmen att sätta l1_ratio=1.0 och alpha=0.047.
BRR De parametrar som finns att sätta är α1, α2, λ1, och λ2 [27]. Samtliga
parametrar har 1.0E-6 som standardvärde. Vi prövar initialt att låta λ-värdena vara intakta, och att höja båda α-värdena till 1.0E-5.
KNN Algoritmen har två parametrar som vi sätter: n neighbors, som har stan-dardvärdet 5, och weights, som har stanstan-dardvärdet ”uniform”. n neigh-bors måste vara ett positivt heltal och avgör hur många grannar som algoritmen ska ta med i beräkningen [29]. weights-parametern har två möjliga värden: ”uniform”, vilket innebär att alla grannar blir viktade på samma sätt, eller ”distance”, vilket ger närmre grannar högre vikter [29]. Vi väljer att sätta n_neighbors=7 och låter weights=”uniform”.
MLPR Vi fortsätter att använda oss av värdet lfgbs för solver-parametern. Vid användning av nämnda solver-parameter finns det ytterligare tre para-metrar att justera för algoritmen: hidden layer sizes, activation och alpha. För att hitta ett alpha-värde rekommenderas i sci-kit learns dokumen-tation [30] att använda cross-validation på mängden [1.0E-1, 1.0E-2, 1.0E-3, 1.0E-4, 1.0E-5, 1.0E-6]. Vi följer rekommendationen och använder cross-validation, men utökar det till att även hjälpa oss hit-ta optimala värden för parametrarna hidden layer sizes och activation. Efter att ha kört cross-validation får vi ut att värdena alpha=1.0E-6, activation=”identity” och hidden_layer_sizes=(100,) är optimala för algoritmen.
OLS För OLS finns inga parametrar att sätta manuellt.
E04 För detta experiment väljer vi att slå ihop de åtgärder som utfördes för experi-menten E02 och E03, vilket innebär att vi applicerar inlärningen på datasetet med både standardisering, och dessutom ställer parametrar för inlärningsalgo-ritmerna i enlighet med E03.
E05-E25 Samtliga av experimenten E05–E25 baseras på den förbehandling som pre-senterades i experiment E04, som inkluderar standardisering från E02 och parameterinställningar från E03. För experimenten E05–E10 tar vi bort ett attribut från respektive instans i datasetet. För experimenten E11–E25 tar vi bort två attribut från respektive instans i datasetet. I Tabell 4 redogör vi för vilka attribut som exkluderats vid respektive experiment.
E26-E27 För att utvärdera hur Valas prediktioner förändras när ett av attributen för en given skola modifieras väljer vi att utföra ytterligare två experiment på fyra slumpmässigt utvalda skolor under året 2016. I följande experiment använder vi oss av standardiseringen från E02, men väljer att endast använda oss av al-goritmen OLS då den i de tidigare experimenten presterat bra. För experiment E26 och E27 antingen ökar eller minskar vi samtliga attribut i syfte att studera hur Vala gör prediktioner baserat på små förändringar i enstaka attribut åt gången. Vi jämför sedan de prediktioner som gjorts när attribut modifierats med den ursprungliga prediktionen (som gjorts på verklig data). De skolor vi slumpmässigt valt ut är Fågelskolan, Killebäckskolan, Svaleboskolan och Vikingaskolan. Nedan följer beskrivningar för hur attributen modifieras för respektive experiment. I tabell 5 beskrivs modifieringarna som görs för attri-buten i respektive experiment.
Tabell 4: Exkluderade attribut i experiment
Experiment Exkluderade attribut E05 Huvudman (kommunal/privat) E06 Elever per lärare
E07 Föräldrarnas genomsnittliga utbildningsnivå E08 Andel (%) pojkar
E09 Andel (%) elever med utländsk bakgrund E10 Skolpeng i tkr per elev
E11 Huvudman (kommunal/privat) + Elever per lärare
E12 Huvudman (kommunal/privat) + Föräldrarnas genomsnittliga utbild-ningsnivå
E13 Huvudman (kommunal/privat) + Andel (%) pojkar
E14 Huvudman (kommunal/privat) + Andel (%) elever med utländsk bak-grund
E15 Huvudman (kommunal/privat) + Skolpeng i tkr per elev
E16 Elever per lärare + Föräldrarnas genomsnittliga utbildningsnivå E17 Elever per lärare + Andel (%) pojkar
E18 Elever per lärare + Andel (%) elever med utländsk bakgrund E19 Elever per lärare + Skolpeng i tkr per elev
E20 Föräldrarnas genomsnittliga utbildningsnivå + Andel (%) pojkar E21 Föräldrarnas genomsnittliga utbildningsnivå + Andel (%) elever med
utländsk bakgrund
E22 Föräldrarnas genomsnittliga utbildningsnivå + Skolpeng i tkr per elev E23 Andel (%) pojkar + Andel (%) elever med utländsk bakgrund
E24 Andel (%) pojkar + Skolpeng i tkr per elev
E25 Andel (%) elever med utländsk bakgrund + Skolpeng i tkr per elev
E26
Attribut Förändring
Elever per lärare +4,5
Föräldrarnas genomsnittliga utbildningsnivå +0,3
Andel pojkar +15
Andel elever med utländsk bakgrund +9
Skolpeng +9
E27
Attribut Förändring
Elever per lärare -4,5
Föräldrarnas genomsnittliga utbildningsnivå -0,3
Andel pojkar -15
Andel elever med utländsk bakgrund -9
4
Resultat
4.1
Experiment utan feature selection
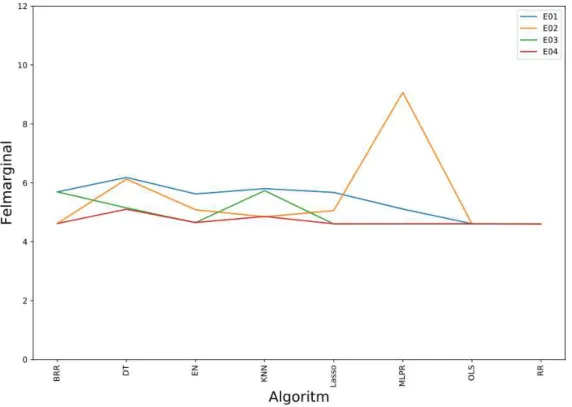
Resultaten från de utförda experimenten tyder på att algoritmernas prestanda i många fall är ganska jämn. Utvärderingarna har gjorts med k-delad korsvalidering på algoritmernas predikterade resultat. Felmarginalen är MAE, beräknat på skillnaden mellan de predikterade värdena och de verkliga värdena, i samma enhet som vårt resultattribut, det vill säga Andel elever (%) som uppnått kunskapsmålen. Om vi tittar på Figur 7 som med den blå linjen visar resultaten för experiment E01 kan vi se att felmarginalen ligger mellan 4,6 och 6,5. OLS och RR har bäst prestanda, och DT har sämst prestanda.
För experiment E02, som införde standardisering av datasetet, ser vi marginella skillnader från det första experimentet. OLS och RR har fortfarande bäst prestanda med en felmarginal som ligger kvar på 4,6. De algoritmer som standardiseringen gjort tydligast skillnad för är BRR vars felmarginal gick från 5,7 till 4, 6, och KNN som gick från 5,8 till 4,8. Dessutom ökade prestandan för algoritmerna EN, Lasso och DT av standardiseringen. Värt att notera är att prestandan hos MLPR sjönk och uppnådde en felmarginal på 9, 1. Resultaten från E02 visas med den gula linjen i Figur 7.
I experiment E03 ställde vi parameterinställningar i algoritmerna och från Figur 7 kan vi se att ett större antal algoritmer nått samma prestanda som OLS och RR hade i E01. Det är bara BRR, som ligger kvar på samma prestanda som i E01, KNN, vars felmarginal minskade med 0,1, och DT som inte nåt samma felmarginal – 4,6 – som övriga algoritmer. Felmarginalen för DT minskade dock från 6,2 i E01 till 5,1 i E02. Under experiment E04 kombinerade vi metoderna som applicerades under E02 och E03. Vi kan se att prestandan hos samtliga algoritmer har ökat, jämfört med E01. Fem algoritmer ligger på felmarginalen 4,6 (vilket även var den lägsta felmarginalen som uppnåddes i experiment E01): BRR, Lasso, MLPR, OLS och RR.
4.2
Experiment med feature selection
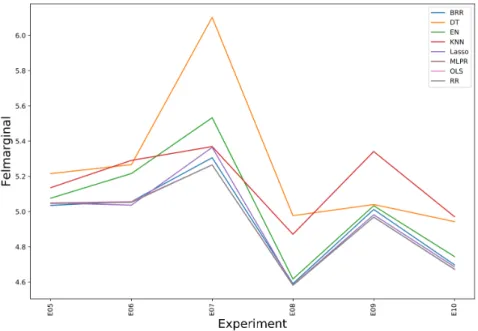
För experimenten E05-E10 användes samma parameterinställningar i algoritmerna som för E03 och algoritmerna applicerades på standardiserad data enligt E02. För respektive experiment togs ett av datasetets attribut bort. Resultaten för experimen-ten E05-E10 visas i Figur 8. Notera att vardera kurva representerar en algoritm, och x-axeln markerar varje nytt experiment, till skillnad från figurerna 4-6. Av experi-menten E05-E10 visade sig E08 ge bäst resultat, där attributet ”Antal (%) pojkar” togs bort ur datan. Felmarginalen för sex av algoritmerna (BRR, EN, Lasso, MLPR, OLSoch RR) hamnade i E08 på 4,6. Näst bäst var E10, där attributet ”Skolpeng per elev” exkluderades. Rangordningen av algoritmerna i E10 var samma som vid E08, med undantaget att DT presterade bättre än KNN vid E08.
Figur 8: Experiment E05–E10
Experimenten E11-E25 utfördes på samma sätt som E05-E10, med enda skillnaden att två attribut exkluderades ur datasetet istället för ett. Resultaten för experimen-ten E11-E25 presenteras i Figur 9. Av experimenexperimen-ten E11-E25 fick E24 bäst resultat, där felmarginalerna för samtliga algoritmer hamnade på 4,9 eller lägre. Felmargina-len för fyra algoritmer (Lasso, MLPR, OLS och RR) hamnade på 4,6, tre algoritmer hamnade på 4,7 (BRR, EN och KNN) och en algoritm (DT) hamnade på 4,9.
4.3
Valas prediktioner på modifierad data
För experimenten E26 och E27 lät vi Vala göra prediktioner på data där vi modifie-rade attributen för fyra slumpmässigt utvalda skolor. I Figur 10 och 11 presenteras resultaten för experimenten. Varje enskilt experiment presenteras i en egen graf och inkluderar fem körningar, en för varje modifierat attribut. På x-axeln visas körning-arna för varje enskilt modifierat attribut. Resultatet längst till vänster på x-axeln är i samtliga grafer skolans verkliga värde; näst längst till vänster är den predik-tion som Vala gjort utan att något av attributen modifierats. Värdena används som referensvärden för att se hur de modifierade attributen påverkat prediktionerna.
När attributen höjdes i experiment E26 gjorde attributen Elever per lärare, Föräldrarnas genomsnittliga utbildning och Skolpeng per elev att prediktio-nerna höjdes. Höjda värden för attributen Andel pojkar och Andel elever med utländsk bakgrund sänkte det predikterade resultatet. Raka motsatsen skedde i experiment E27, där attributen sänktes. När attributen Elever per lärare, Föräld-rarnas genomsnittliga utbildning och Skolpeng per elev sänktes hade det en negativ påverkan på prediktionen, medan när attributen Andel pojkar och Andel elever med utländsk bakgrund sänktes höjdes prediktionerna.
5
Diskussion och analys
5.1
Algoritmernas prestanda
Efter att ha genomfört experimenten kan vi konstatera att den lägsta felmarginalen uppnåddes redan under experiment E01, där både OLS och RR hamnade på en fel-marginal i genomsnitt på 4,6. Den standardisering och de parameterinställningar vi applicerade ökade prestandan på flera algoritmer. Detta resulterade i att sex av de åtta algoritmerna vi utvärderat slutligen uppnådde den lägsta uppmätta felmargi-nalen.
Standardisering av vår data utfördes under experiment E02, vilket påverkade de flesta algoritmernas prediktioner positivt alternativt inte alls. BRR sänkte sin felmarginal på prediktioner med 23%, KNN med 20% och både EN och Lasso med 11%. En algoritm presterade dock sämre vid standardisering av vår data och det är MLPR vars prediktioner blev 44% sämre i genomsnitt mot att inte förbehandla vår data. Vi finner detta särskilt intressant då scikit-learn [30] rekommenderar standarisering av datan vid användning av MLPR.
Vid experiment E03 utfördes optimering av algoritmerna med hjälp av ett antal olika justerbara parametrar. Vid jämförelse mot det första experimentet, E01, pre-sterade samtliga algoritmer bättre eller likvärdigt. De algoritmer där optimeringen gjorde störst skillnad på resultatet var DT, EN och Lasso. Felmarginalerna för respek-tive algoritm sänktes med 20%, 21% och 23% efter optimeringen av dess parametrar. Även MLPR presterar bättre efter optimering, och sänker sin felmarginal med 11%.
Som vi tidigare konstaterat hade vi redan vid första experimentet ett bra resultat på OLS, och en del av de optimeringar som gjorts på algoritmerna tyder på att det är den optimala lösningen för vårt dataset. Vid optimeringen av Lasso justerade vi strafftermen som är skillnaden mellan Lasso och OLS. scikit-learn satte den vid korsvalideringen till ett värde väldigt nära 0 vilket innebär att algoritmen löser problemet likt OLS [26]. När det gäller EN, som är en hybrid mellan Lasso och RR så har vi två parametrar som justeras, en straffterm samt en mixing parameter. Vid korsvalideringen justerades värdena till att motsvara parametrarna som sattes för Lasso, vilket i sin tur leder till att de presterar likvärdigt. Den slutsatsen vi drar efter E03 är som tidigare nämnt att OLS verkar vara en optimal lösning till vårt problem.
När vi sedan i experiment E04 både standardiserar vår data samt använder de optimerade algoritmerna så presterade alla våra algoritmer relativt jämnt med en felmarginal på mellan 4.6 och 5.1. Däremot uppnådde ingen av algoritmerna ett bättre resultat än vad som redan uppnåtts i antingen E02 och E03. Med andra ord kan vi konstatera att ingen av algoritmerna blir bättre av både standardisering av data och optimering av parametrar.
Figur 12: Korrelation mellan attribut
5.2
Vikten av datasetets attribut
Om vi ser till experimenten E05-E25 kan vi konstatera att feature selection inte gjorde någon märkbar skillnad på resultatet jämfört med när ingen feature selection användes. I de flesta fall försämrades snarare prediktionerna vilket innebär att de exkluderade attributen är relevanta för experimenten. De två attributen som visar på minsta vikt är Andel pojkar och Skolpeng per elev vilket vi kan utläsa i experiment E08 och E10, där respektive attribut exkluderats, samt E24 där båda attributen exkluderats. I experiment E08 och E24 uppnåddes en lägsta felmarginal på 4,6, vilket är den lägsta nivån som uppnåtts sett över samtliga experiment. I experiment E10 var den lägsta uppmätta felmarginalen 4,7. Detta innebär att dessa attribut hade kunnat exkluderats. Då skolpengen är en av de faktorer som Lunds kommun faktiskt kan påverka i modellen, och attributens närvaro bevisligen inte påverkar resultatet togs beslutet att behålla dem för experimenten E26 och E27.
För experimenten E26 och E27 justerade vi varje enskilt attribut för att undersö-ka hur vart och ett av dem påverundersö-kade prediktionerna. Dessa experiment speglar hur Vala är tänkt att användas av kommunpolitikerna (se Figur 1 och Figur 4). Något vi tyckte var intressant var att när attributet Skolpeng per elev ökades så ökade även det predikterade resultatet. Detta kan tänkas självklart, men om vi isolerar attributen Skolpeng per elev och Andel elever som uppnår kunskapsmålen och studerar korrelationen mellan dem (se Figur 12) så kan vi se att lägre skolpeng generellt kan förknippas med högre resultat. Detta skulle förmodligen kunna vara på grund av att skolor med sämre resultat fått mer pengar än de med bättre resultat,
men ännu inte kommit upp i samma nivå. Trots att korrelationen är logisk tycker vi att det är intressant att Vala predikterar ett högre resultat bland eleverna när mer pengar tillförs skolan.
5.3
Jämförelser med relaterad forskning
En studie utförd av Ahamed et. al. [1] hade som mål att prediktera elevers akademis-ka resultat utifrån socioekonomisakademis-ka, psykologisakademis-ka och aakademis-kademisakademis-ka faktorer. Studiens författare samlade in data via ett frågeformulär. Deras dataset består av 423 instan-ser och 33 attribut, vilket är betydligt mycket mer än det dataset vi använt i denna studie. Vi finner det intressant att författarna i sin studie använder flera attribut som återfinns även i vårt dataset, till exempel kön och föräldrarnas utbildningsnivå. Författarna uppger att de uppnått bäst resultat i sin studie med artificiella neurala nät (eng. artificial neural networks). De uppnår 89.48% precision, efter att datan förbehandlats med feature selection och standardisering.
6
Slutsatser och vidare forskning
Syftet med denna studie var att undersöka hur maskininlärning kan användas för att optimera resursfördelningen inom grundskolan i Lunds kommun. För att utvärdera studien satte vi samman ett dataset med data från Lunds kommun och Skolverket. Vi utförde experiment där vi jämförde prestandan hos åtta inlärningsalgoritmer och undersökte hur förbehandling av vår data påverkade resultaten.
6.1
Användning av Vala
Vi kan efter experimenten konstatera att det bästa resultatet uppnåddes redan i det första experimentet. Algoritmen OLS hamnade på en felmarginal på 4,6 utan någon förbehandling av datan. Resultaten av experimenten visar även att de valda attributen korrelerar med resultatet och att vi inte vinner något på att exkludera något av dem.
I Skolverkets databas SALSA [22] anges för varje skola ett modellberäknat värde som räknas ut genom regressionsanalys, skolans verkliga resultat samt en residual. Residualen är skillnaden mellan skolans modellberäknade värde och dess verkliga resultat och kan jämföras med felmarginalen i vår studie. Genom att beräkna ge-nomsnittet av residualerna i SALSA får vi ett medelvärde på 5,5. Vi kan därmed konstatera att vår modell har en genomsnittlig felmarginal som är 0,9 procentenhe-ter lägre än den som används av Skolverket. Vår uppfattning är således att det finns potential i att använda maskininlärning för att optimera resursfördelningen inom grundskolan i Lunds kommun, och med det anser vi att frågeställningen besvarats.
Sveriges Kommuner och Landsting [34] menar att en resursfördelningsmodell behö-ver vara träffsäker, objektiv och legitim för att fungera bra. Vi anser att vår modellen uppnår träffsäkerhet genom att använda en rad olika socioekonomiska attribut i be-räkningarna. Träffsäkerheten hade i framtiden kunnat stärkas av fler attribut och mer data.
Attributen i datasetet som använts är ren kvantitativ data, och således kan mo-dellen betraktas som objektiv. Inga av attributen som används kräver några sub-jektiva bedömningar, och skolorna kan heller inte manipulera dem för att indirekt påverka resultatet.
Det sista kriteriet som Sveriges Kommuner och Landsting tar upp är att mo-dellen behöver vara legitim. Vi anser att vi uppnått detta genom att utvärdera en rad olika metoder för att ta fram resultaten, och resultaten är dessutom relativt pricksäkra (jämfört med exempelvis Skolverkets modellberäknade värden). Men le-gitimiteten kan i framtida forskning givetvis stärkas genom att använda mer data och fler attribut som i sin tur hade lett till en mer gedigen grund.
Då vi anser att vi uppfyller de, av Sveriges Kommuner och Landsting, uppsatta kriterierna för en resursfördelningsmodell skulle vår modell kunna bidra med yt-terligare information till kommunpolitikerna vid fördelningen av resurser. Modellen
skulle även kunna användas för att experimentera med de olika attributen för att få större inblick i vad som händer med resultatet för en skola när ett attribut ökas alternativt sänks. Likaså kan modellen utvärderas framöver för att kontrollera hur väl den presterar på ny data.
6.2
Vidare forskning
Denna studie bereder en grund för framtida forskning och vi anser att en särskilt intressant punkt hade varit att utföra studien med ett större dataset. Ett större da-taset hade kunnat innebära såväl mer historisk data som fler attribut. Ytterligare ett alternativ hade varit att använda data på individnivå istället för genomsnittsvärden för varje enskild skola. Vid användning av data på individnivå hade man kunnat utvärdera varje elev som en instans och kunna anpassa tilläggsbidraget ytterligare för skolorna.
En annan möjlighet för utveckling skulle kunna vara att utvärdera ytterliga-re algoritmer och metoder för förbehandling eller utforska kombinationer av flera inlärningsalgoritmer.
I den modell som används av Lunds kommun idag mäter de föräldrarnas utbild-ningsnivå på ett lite annorlunda sätt än det värdet vi har haft med i vårt dataset. I vår modell är högsta värdet för attributet eftergymnasial utbildning, medan attri-butet som används av kommunens modell, som vi tyvärr inte fått tillgång till, även tar hänsyn till eventuell forksarutbildning hos föräldrarna. Vi kan från resultaten på experiment E26 utläsa att en ökning av föräldrarnas utbildningsnivå ger högre prediktioner, så vi anser att det förmodligen hade varit intressant att i framtida stu-dier använda kommunens attribut i beräkningarna. Kommunens modell använder även ett attribut som speglar ifall elevens föräldrar har ekonomiskt bidrag i någon form. Detta är ytterligare data som inte varit tillgänglig för denna studien men som troligtvis är givande att inkludera i framtida studier.
Något vi tror hade varit intressant är att ta med information om hur pengarna används av varje skola i framtida undersökningar. Detta bör vara en faktor som kan ha stor betydelse för resultatet i slutändan. Ett attribut i datasetet som använts i den här studien, antal elever per lärare, har med fördelningen av pengar att göra, men vi anser att det hade varit intressant att ha med mer detaljerad information med fler typer av utgifter dokumenterade. Ett alternativ är att med hjälp av ma-skininlärning utvärdera alla skolornas olika fördelningmodeller för sina resurser och se vilken fördelning som ger bäst resultat i form av ökning av skolans resultat.
Referenser
[1] A. T. M. S. Ahamed, N. T. Mahmood, och R. M. Rahman, ”Prediction of HSC examination performance using socioeconomic, psychological and academic factors”, 2016 9th Interna-tional Conference on Electrical and Computer Engineering (ICECE), pp. 263–266, 2016. [2] C. M. Bishop, Pattern Recognition and Machine Learning. New York, NY: Springer, 2006. [3] T. F. Boucher, M. V. Ozanne, M. L. Carmosino, M. D. Dyar, S. Mahadevan, E. A. Breves, K. H. Lepore, och S. M. Clegg, ”A study of machine learning regression methods for major elemental analysis of rocks using laser-induced breakdown spectroscopy”, Spectrochimica Acta Part B: Atomic Spectroscopy, vol. 107, pp. 1–10, 2015.
[4] CERN. ”The Large Hadron Collider”. home.cern. [Online]. Tillgänglig: http://home.cern/topics/large-hadron-collider [Hämtad 2017-02-27].
[5] P. Domingos, ”A few useful things to know about machine learning”, Communications of the ACM, vol. 55, no. 10, pp. 78–87, 2012.
[6] A. E. Hoerl och R. W. Kennard, ”Ridge Regression: Biased Estimation for Nonorthogonal Problems”, Technometrics, vol. 12, no. 1, pp. 55-67, 1970.
[7] G. James, D. Witten, T. Hastie, och R. Tibshirani, An introduction to statistical learning. New York, NY: Springer, 2013.
[8] S. Karsoliya, ”Approximating Number of Hidden layer neurons in Multiple Hidden Layer BPNN Architecture”, International Journal of Engineering Trends and Technology, vol. 3, no. 6, pp. 714-717, 2012.
[9] S. Keshav, ”How to Read a Paper”, ACM SIGCOMM Computer Communication Review, vol. 37, no. 3, pp. 83-84, 2007.
[10] S. Khalid, T. Khalil, och S. Nasreen, ”A survey of feature selection and feature extraction techniques in machine learning”, 2014 Science and Information Conference, pp. 372–378, 2014.
[11] N. Kwak, S.-I. Choi, och C.-H. Choi, ”Feature Extraction for Regression Problems and an Example Application for Pose Estimation of a Face”, Lecture Notes in Computer Science Image Analysis and Recognition, pp. 435–444, 2008.
[12] L. Ladha och T. Deepa, “Feature Selection Methods and Algorithms”, International Journal on Computer Science and Engineering, vol. 3, no. 5, pp 1787-1797, 2011.
[13] N. Lavesson och P. Davidsson, ”Quantifying the Impact of Learning Algorithm Parameter Tuning”, 3rd Joint SAIS/SLSS Workshop, pp 395-400, Västerås, 2005.
[14] Lunds kommun. ”Ekonomi- och Verksamhetsplan 2017-2019”. 2016.
[15] Lunds kommun. ”Resursfördelningsmodell till förskola, grundskola och fritidshem i Lunds kommun”. 2016.
[16] Lunds kommun. ”Socioekonomisk resursfördelning till skolor i Lunds kommun”. 2015. [17] Lunds kommun. ”Översyn av direkt skolpeng”. 2016.
[18] S. Marsland, Machine Learning: An Algorithmic Approach. (2. ed). Boca Raton, FL: CRC Press, 2015.
[19] G. Panchal, A. Ganatra, Y. P. Kosta, och D. Panchal, ”Behaviour Analysis of Multilayer Perceptrons with Multiple Hidden Neurons and Hidden Layers”, International Journal of Computer Theory and Engineering, pp. 332–337, 2011.
[20] K. Patel, ”Lowering the barrier to applying machine learning”, CHI ’10 Extended Abstracts on Human Factors in Computing Systems. pp. 2907-2910, 2010.
[21] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and É. Duchesnay, ”Scikit-learn: Machine Learning in Python”, The Journal of Machine Learning Research, vol. 12, pp. 2825-2830, 2011.
[22] SALSA. ”SALSA tabell”. siris.skolverket.se. [Online]. Tillgänglig: http://siris.skolverket.se/siris/f?p=SIRIS:165:0::NO::: [Hämtad 2017-04-13].
[23] scikit-learn. ”1.10. Decision Trees”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/tree.html [Hämtad 2017-04-04].
[24] scikit-learn. ”3.2.4.1.1. sklearn.linear_model.ElasticNetCV”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html [Hämtad 2017-04-04].
[25] scikit-learn. ”3.2.4.1.3. sklearn.linear_model.LassoCV”. scikit-learn.org. [Online]. Tillgäng-lig: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LassoCV.html [Hämtad 2017-04-04].
[26] scikit-learn. ”sklearn.linear_model.Lasso”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
[Hämtad 2017-04-17].
[27] scikit-learn. ”sklearn.linear_model.BayesianRidge”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.BayesianRidge.html [Hämtad 2017-04-04].
[28] scikit-learn. ”sklearn.linear_model.Ridge”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html [Hämtad 2017-04-04].
[29] scikit-learn. ”sklearn.neighbors.KNeighborsRegressor”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html [Hämtad 2017-04-04].
[30] scikit-learn. ”1.17. Neural network models (supervised)”. scikit-learn.org. [Online]. Till-gänglig: http://scikit-learn.org/stable/modules/neural_networks_supervised.html [Häm-tad 2017-04-03].
[31] scikit-learn. ”sklearn.preprocessing.StandardScaler”. scikit-learn.org. [Online]. Tillgänglig: http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html [Hämtad 2017-08-10].
[33] M. Stone, ”Cross-Validatory Choice and Assessment of Statistical Predictions”, Journal of the Royal Statistical Society. Series B (Methodological), vol. 36, no. 2, pp. 111-147, 1974. [34] Sveriges Kommuner och Landsting. ”Socioekonomisk resursfördelning till skolor”. 2014. [35] R. Tibshirani, ”Regression Shrinkage and Selection via the Lasso”, Journal of the Royal
Statistical Society. Series B (Methodological), vol. 58, no. 1, pp. 267-288, 1996.
[36] Wikipedia. ”Völva – Wikipedia”. sv.wikipedia.org. [Online]. Tillgänglig: https://sv.wikipedia.org/wiki/Völva [Hämtad 2017-04-10].
[37] I. H. Witten, Data Mining: Practical Machine Learning Tools and Techniques. (2. ed). Amsterdam: Morgan Kaufmann, 2005.
[38] Y. Zhang och S. Wang, ”Detection of Alzheimer’s disease by displacement field and machine learning", PeerJ 3:e1251, 2015.
Bilaga 1
I denna bilaga finns det dataset som använts vid experimenten i vår studie. Nedan beskrivs kolumnerna, och därefter följer datan. Datasetet innehåller 102 instanser.
Kolumnbeskrivningar
A Huvudman (0=kommunal, 1=privat) B Elever per lärare
C Föräldrarnas genomsnittliga utbildningsnivå D Andel (%) pojkar
E Andel (%) med utländsk bakgrund F Skolpeng tkr per elev
G Antal elever (%) elever som uppnått kunskapsmålen
A B C D E F G 1 9.0 2.5 31 21 72.3 75 0 10.9 2.3 65 38 80.4 74 0 12.1 2.6 57 35 76.9 87 0 11.5 2.4 39 7 74.3 89 0 11.4 2.4 54 38 80.0 95 1 19.1 2.6 31 30 75.2 100 0 14.9 2.6 66 16 72.6 92 0 12.2 2.5 57 9 72.5 87 1 16.4 2.7 47 11 70.0 99 0 11.3 2.8 45 15 71.2 90 1 8.8 2.8 50 6 67.8 95 0 10.8 2.6 53 10 72.1 90 1 10.3 2.9 48 32 74.2 100 0 10.8 2.4 58 9 73.3 87 0 12.6 2.7 46 19 72.8 91 0 12.7 2.8 51 12 68.6 89 0 10.6 2.2 31 49 84.8 77 0 10.6 2.8 54 25 72.8 86 1 8.4 2.6 29 19 70.8 81 0 14.4 2.2 53 35 77.6 75 0 14.0 2.7 42 34 75.2 88 0 11.5 2.2 61 5 71.4 88 0 11.3 2.5 55 33 76.6 80 0 14.5 2.6 61 20 72.1 92 0 12.7 2.5 45 9 70.8 90
1 16.4 2.6 40 11 68.8 98 0 14.0 2.8 45 15 69.4 91 1 9.6 2.8 40 5 66.6 95 1 10.2 2.7 50 15 70.1 100 1 11.7 2.6 47 23 71.7 88 0 11.8 2.5 58 7 69.7 90 1 9.3 2.7 46 32 73.7 96 0 9.9 2.4 50 7 71.1 89 0 12.5 2.6 51 18 70.6 84 0 13.7 2.9 42 15 68.6 94 0 12.1 2.6 65 21 70.7 91 1 9.1 2.8 47 31 69.5 100 1 8.1 2.5 56 24 69.2 88 0 11.6 2.6 64 36 74.0 76 0 12.9 2.6 57 35 72.0 80 0 13.0 2.3 43 5 68.8 68 0 13.3 2.4 54 34 73.5 86 0 14.9 2.6 61 20 69.2 88 0 13.2 2.5 49 9 68.3 91 1 16.9 2.6 51 14 66.6 96 0 13.2 2.7 60 16 67.0 91 1 9.2 2.8 38 4 63.6 95 1 11.5 2.7 48 25 69.2 86 0 13.9 2.6 50 9 67.0 89 0 12.5 2.4 43 8 68.7 96 0 13.7 2.7 48 19 68.1 88 0 13.5 2.8 59 17 66.8 88 0 10.5 2.4 41 49 79.2 72 0 11.2 2.7 38 23 68.7 85 1 10.4 2.8 56 33 68.3 89 0 11.8 2.4 62 36 71.6 79 0 12.4 2.7 46 35 70.0 87 0 12.2 2.5 54 34 71.3 93 1 10.3 2.3 17 13 68.4 83 0 14.1 2.6 62 18 66.2 85 0 13.4 2.5 53 9 66.3 89 1 16.8 2.6 47 16 66.7 99 0 12.8 2.7 51 17 65.6 92 1 9.2 2.8 50 4 62.3 95 0 11.2 2.6 48 10 66.1 87 0 12.8 2.4 45 7 66.7 85 0 13.2 2.7 43 15 65.5 77 0 13.5 2.9 49 17 64.8 85
![Figur 1: Resursfördelningsmodell (redigerad) [34]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4128939.87956/11.892.153.735.529.920/figur-resursfördelningsmodell-redigerad.webp)
![Figur 2: Träffsäker, objektiv och legitim resursfördelningsmodell [34]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4128939.87956/12.892.215.690.429.782/figur-träffsäker-objektiv-och-legitim-resursfördelningsmodell.webp)


![Figur 6: k-delad korsvalidering [38]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4128939.87956/28.892.145.643.206.627/figur-k-delad-korsvalidering.webp)