EXAMENSARBETE I DATAVETENSKAP
En jämförande studie av
JDBC och Hibernate
med avseende på användbarhet
A Comparative Study of JDBC and HibernateFocusing on Usability
Andreas Nilsson och Henrik Persson 2010-05-21
Handledare: Examinator:
ii
Resumé
Två grundläggande paradigm inom datavetenskap är objektorienterad programmering och relationsdatabasteknik. En kombinering av applikationer gjorda i ett objektorienterat programmeringsspråk med den beständighet och funktionalitet som ges av relationsdatabaser är en möjlig vidareutveckling av ens kunskaper inom dessa områden. Kombinationen av dessa båda förutnämnda paradigm innebär åtminstone ett problem som uppkommer då en relationsdatabas lagrar data i tabeller och en objektorienterad applikation lagrar data i objekt. Detta problem kallas objekt/relations paradigmens missanpassning. På grund av detta problem så måste kopplingen mellan paradigmen skötas av ett ramverk av något slag. I vår rapport så undersöker vi två av de ramverk som behandlar kopplingen mellan paradigmen. Specifikt i våran studie kommer vi att fokusera på kvalitetsattributet användbarhet. De ramverk som vi undersöker heter Java Database Connectivity (JDBC) och Hibernate. Båda dessa verktyg är skapade för det objektorienterade programmeringsspråket Java.
Abstract
Two of the fundamental paradigms within computer science are object oriented programming and relational databases. A combination of an object oriented application with the persistence and functionality provided by relational databases is a further development of one’s knowledge within these areas. The combination of the two aforementioned paradigms will yield at least one problem, which occurs because in a database data is stored in tables whereas an object oriented application stores data in objects. This problem is called the object/relational paradigm mismatch. Because of this problem the connection between the paradigms must be handled by some kind of framework. In our report we investigate two of the frameworks which handle the connection between the paradigms. Specifically in our study we will focus on the quality attribute usability of the two frameworks and conduct a comparison between these two. The frameworks we investigate are called Java Database Connectivity (JDBC) and Hibernate. Both of these tools are created for the object oriented programming language Java.
iii
Innehåll
Resumé ...ii Abstract ...ii 1. Introduktion ... 1 1.1 Bakgrund ... 1 1.2 Syfte ... 1 1.3 Frågeställnig ... 2 1.4 Metod ... 2 2. Teknisk bakgrund ... 3 2.1 Objektorientering... 32.1.1 Klasser och Objekt ... 3
2.1.2 Objektidentitet ... 3 2.1.3 Attribut ... 3 2.1.4 Metoder ... 3 2.1.5 Inkapsling ... 4 2.1.6 Arv ... 5 2.2 Relationsdatabaser ... 6
2.2.1 Entity Relational (ER) modellering ... 6
2.2.2 Relationsmodellen ... 7
2.2.3 Normalformer och normalisering ... 7
2.2.4 Structured Query Language (SQL) ... 7
2.3 Object Relational Mapping (ORM) ... 8
2.3.1 Objekt/relations paradigmens missanpassning och mappning ... 8
2.3.2 Varför behövs ORM? ... 8
2.3.3 När skall ORM användas... 9
2.3.4 När skall ORM inte användas? ... 9
2.4 Java Database Connectivity (JDBC) ... 9
2.4.1 JDBC arkitektur ... 10
2.5 Hibernate ... 11
2.5.1 Hibernates arkitektur ... 11
2.5.2 Hibernate i union ... 12
2.5.3 Hibernate Query Language (HQL) ... 13
2.6 Java Enterprise Edition (Java EE) och NetBeans ... 13
iv 4. Konceptuellt ramverk ... 16 5. Studie ... 17 5.1 ISO-grundande frågeformulär ... 17 5.2 Uppsättning av utvecklingsmiljöer ... 18 6. Diskussion ... 19
6.1 Terminologi och systeminformation ... 19
6.2 Inlärning ... 21
6.3 Systemets förmåga ... 22
6.4 Övergripande reaktion på mjukvaran ... 24
7. Slutsats ... 26 8. Framtida studier ... 27 9. Litteraturförteckning ... 28 Appendix A ... 30 Appendix B ... 62 Appendix C ... 68
1
1. Introduktion
I denna uppsats vill vi undersöka hur Hibernate och Java Database Connectivity (JDBC) skiljer sig med avseende på deras användbarhet för utvecklaren. Det är intressant då Object Relational Mapping (ORM) verktyg är relativt okänt i den akademiska världen men används däremot mer frekvent i industrin[22]. Detta har uppkommit vid en initial undersökning vi gjorde av arbetsmarknaden i hela Sverige med sökordet ”hibernate”. Då fann vi att en sökning gjord på Arbetsförmedlingens hemsida gav 26 träffar på företag som vill ha Hibernatekunniga medarbetare och med eventuella Javakunskaper[24].
1.1 Bakgrund
Från studier inom datavetenskap på Malmö högskola har vi fått en bakgrund inom objektorienterad programmering och relationsdatabaser. Eftersom vi initialt har arbetat med ett objektorienterat tänkande kommer det sig naturligt att även göra detta vid databaser. Under en relationsdatabaskurs uppkom det att det finns, utöver relationsdatabaser, andra databasmodeller som har inslag av objektorienterat tänkande.
När vi skulle välja inriktning på examensarbetet låg ett intresse om att fördjupa våra kunskaper inom databaser. Ett bra sätt att summera vår utbildning är att fördjupa oss inom två olika paradigm som vi arbetat med. Valet föll på objektorienterade relationsdatabaser då detta är ett bra sätt att erhålla fördjupande kunskaper inom datavetenskap. En vidareutveckling av dessa har funnits intressant och en studie av ORM har växt fram.
Vidare har vi fått kunskaper inom hur programmeringsspråket Java kommer till användning vid utvecklande av databasapplikationer.
I denna studie kommer vi att fokusera på skillnader i användbarheten hos de två ramverken Hibernate och JDBC. Vårt val här motiveras av det faktum att vid mjukvaruprojekt så jobbar utvecklare ofta med en inkrementell metod. Detta medför att en snabb prototyp skall tas fram och för att göra detta måste utvecklare veta vilket redskap som gör det enklast att snabbt ta fram nya prototyper[28].
1.2 Syfte
Inom ORM området finns det ett ledande verktyg kallat Hibernate [11]. Problematiken med ORM och i synnerhet Hibernate är att det inte är så känt inom den akademiska världen[22].
Vårt syfte med uppsatsen är att beskriva ramverken JDBC och Hibernate samt jämföra dessa med avseende på användbarhet. Vidare kan detta arbete även användas som en introduktion av dessa ramverk inom akademin.
2
1.3 Frågeställnig
Vår studie kommer att fokusera på följande forskningsfrågor:
Vilket ramverk Hibernate eller JDBC är bäst med avseende på användbarhet för utvecklaren?
Gör något av ramverken applikationer oberoende underliggande databashanterare?
1.4 Metod
En omfattande studie bör göras med hjälp av böcker och artiklar för att skapa förståelse om ORM. Den metodik vi använder kommer utifrån konceptuellt ramverk som beskrivs i kapitel 4.
För att få kunskap i Hibernates vitala funktioner gör vi en instruktionshandling för uppsättning av en utvecklingsmiljö för ramverket (se Appendix A).
Vidare görs en implementering av Hibernate och JDBC i Virtuell PC vilket låter oss få en djupare förståelse om de olika ramverken, se deras användningsområde och gör det möjligt att göra en jämförelsestudie dessa två emellan (se kapitel 5).
Efter uppsättning av de två olika miljöerna så har vi tagit fram ett ISO-grundande frågeformulär som beskrivs i avsnitt 5.1 där det är tänkt att utsätta testgruppen för de båda ramverken.
3
2. Teknisk bakgrund
I detta kapitel tar vi upp de begrepp som är relevanta för att införskaffa sig en förståelse för rapporten.
2.1 Objektorientering
Ett vanligt sätt att programmera idag är att använda sig av objektorientering. Dess fördelar är återanvändning av kod, lätt att underhålla, hög produktivitet och ökad kvalitet. Objektorientering är inte så mycket programmering utan ett sätt att tänka på då det modellerar en avgränsad del av verkligheten[29]. Detta används vanligtvis i dagens programmering men även i databasmodellering[23][27].
2.1.1 Klasser och Objekt
I objektorientering är en klass något som beskriver en sak i verkligheten och sätter regler och krav på hur den ska hanteras i sitt sammanhang. En klass är en ritning på hur ett objekt skall se ut. Objektet i sin tur fylls med värden och beteenden som blir specifika för det objektet. Ett objekt i programmering är en instans av en klass som består av en typ och möjligen en eller flera funktioner[10].
2.1.2 Objektidentitet
Flera objekt kan avbilda en och samma klass, men ett objekt i sig blir unikt tack vare att varje objekt har ett eget unikt id. Alltså ger det en möjlighet att alltid skilja på två objekt med exakt samma värden med hjälp av den specifika identitet varje objekt innehar[10]. Objektets identitet påminner mycket om en primär nyckel i en relationsdatabas som gör tabellerna unika.
2.1.3 Attribut
Objekt definieras av sina attribut, även kända som instansvariabler, och utgör en uppbyggnad av värden som gör klassen till en avbild av verkligheten. Varje attribut består av ett namn, en typ och ett värde (om inget värde har getts så tilldelas automatiskt värdet NULL i java). Ett exempel kan vara bokklassen i figur 2.1. En bok kan definieras av namn, författare och pris. Finns det flera exemplar som är identiska med exakt samma värden så skiljs objekten åt med hjälp av sina unika id. Ett attribut består av ett namn, en typ och ett värde i java som används i exemplet[27].
2.1.4 Metoder
Objektets egenskaper bestäms av något som kallas för metoder. Metoder, också kallade funktioner, ger programmerare möjlighet att modifiera eller hämta objektets attribut[27]. I exempelklassen som ses i figur 2.1 finns möjligheter att hämta eller ändra namn, författare och pris.
4
Figur 2.1 Klassexempel i Java [27]
2.1.5 Inkapsling
Attribut och metoder klassas alltid i en synlighetsgrad kallade private, ingen deklaration, protected eller public. När attribut/metoder deklareras som private innebär det att endast klassen dessa är deklarerade i får tillgång till attributen/metoderna. I de flesta fall och som är en god praxis är att deklarera sina attribut som private. Detta gör att attributen kapslas in och ej kan nås utanför klassen. Vidare syns övriga synlighetsgrader i figur 2.2 nedan. Public som används i deklarationen av metoderna i figur 2.1 innebär den högsta graden av synlighet. Set- och get-metoder bör alltid deklareras public då dessa ger den enda möjligheten att hämta och ändra attributvärden i och med att dessa bör deklareras private[27].
5
Synlighetsgrad Klass Paket Subklass Global synlighet
private x
ingen deklaration x x
protected x x x
public x x x x
Figur 2.2 Olika synlighetsgrader i Java[27]
2.1.6 Arv
Genom att använda en fördefinierad klass (superklass) ges möjlighet att skapa en ny klass (subklass) som ärver den fördefinierade klassens attribut och egenskaper. Återanvändningen av kod som är en av objektorienterad programmerings stora styrkor kommer från arv. En subklass ärver alla de attribut och metoder som superklassen har, men har också möjlighet att skapa nya samt skriva över redan existerande attribut och metoder. Ett exempel på arv är att du har superklassen Form, som har underklasserna Cirkel, Rektangel och Kub (se figur 2.3). Klassen Form som är superklassen har ett generellt attribut som är färg som gäller för alla subklasser. I sin tur har subklasserna egna specifika attribut som gäller endast för de klasserna. I exemplet visas att Cirkel har attributet radie gemfört med Rektangel som har attributen bredd och höjd. Dessa attribut kan användas för att räkna ut den gällande arean för den specifika formen och returnera korrekt värde[27].
6
2.2 Relationsdatabaser
Ett vanligt och bra sätt att lagra data i stora mängder är att använda sig av databaser. Detta gör att en databashanterare behövs för att hantera den aktuella data som skall lagras. Databashanterare bör ej förknippas med databas utan heter explicit databashanterare då en databas är endast den rådata som lagras. Det finns flera olika databashanterare idag, både de som har öppen källkod och de som är kommersiella. Några av de mest kända databashanterarna med öppen källkod är MySQL och PostgreSQL och motsvarighet på kända verktyg på den kommersiella sidan är Oracle, DB2 och Microsoft SQL Server[23][10].
2.2.1 Entity Relational (ER) modellering
Entity Relational (ER) modellering likt objektmodellering är en avbild av verkligheten. Detta för att på ett enkelt sätt kunna konstruera och bena ut de viktiga komponenterna i en databas. Att det är en avbild av verkligheten gör att en grupp människor kan diskutera fram en lösning genom att alla är överrens om en konvention. I ER- modellen beskrivs en databas med hjälp av entiteter, attribut och relationer[26][5].
I ER modellering är entiteter, likt objekt i objektmodellering, saker som finns i verkligheten. Ett exempel på ett ER-diagram ses i figur 2.4 i vilken endast två entiteter visas samt en relation mellan dessa. Vidare syns också information om till exempel olika attribut så som namn, ISBN och pris i entiteten Bok medan entiteten Författare har attributen förnamn, efternamn och personnummer. Även relationen kan ha ett namn som då ger ytterligare information till personer som är inblandade i utvecklingen av databasen. I det enkla exemplet i figur 2.4 namnges relationen ”Skriven av” som ger en beskrivning på förhållandet entiteterna emellan. Även en multiplicitet visas vid förhållandet i relationen och kan beskrivas på följande sätt:
En bok kan skrivas av många olika författare. På andra hållet i förhållandet kan en författare skriva många böcker. Figur 2.4 ER-diagram [23] Bok +ISBN +Titel +Pris Författare +Personnummer +Förnamn +Efternamn Skriven av * *
7 2.2.2 Relationsmodellen
Relationsmodellen är en datamodell populär blanda databaser och introducerades redan 1970. Modellen skapades av en man vid namn av Edgar Frank Codd som publicerat en bok som heter ”The Relational Model for Database Management: Version 2”[4] som är grunden till modellen.
Relationsmodellen lagrar data i tabeller och använder dessa för att beskriva verkligheten[23]. I en relationsmodell används nycklar, tuplar, attribut och domäner. Dessa parametrar har en viktig betydelse i skapandet av en modell. I relationsmodellens terminologi kallas en tabell för en relation, en överskrift till en kolumn för attribut och en rad i tabellen kallas för en tupel[9]. En viktig del i relationsmodellen är att lägga en hel del komplexitet i uppbyggnaden av sin databas för att i sin tur underlätta vidare programmering. En struktur kan göras med hjälp av olika nycklar så som att en primärnyckel blir specifik för en tabell och att referensintegritet hindrar användarna att ta bort data som är beroende av varandra och därmed förstöra delar av databasen[10][4].
2.2.3 Normalformer och normalisering
Ett steg i utvecklandet av en databasimplementering är att göra en normalisering av ER-modellen. Detta görs med hjälp av ett par olika steg och regler som är till för att få ett bra slutresultat[9]. Antal steg i normaliseringen kan variera men slutmålet brukar vara det samma, att få en bra struktur på ens databas[10]. I exemplet (figur 2.5) nedan är en normalisering gjord på föregående figur(2.4) där en ny entitet har skapas för att hantera ”många till många” förhållande och få två ”ett till många” förhållande som gör det möjligt att implementera ER-modellen som en databas. I den nyskapade tabellen används de unika attributen i respektive tabell som blir en referens till vardera entitet.
Figur 2.5 Normaliserat ER-diagramm [23]
2.2.4 Structured Query Language (SQL)
För att skapa en databas använder sig utvecklare av ett programmeringsspråk som kallas Structured Query Language (SQL). Det används för att skapa tabeller, mata in, förändra eller förstöra data i en databas och primärt för att söka. SQL delas upp i olika subkategorier som tar hand om olika delar av möjligheterna i SQL. De kategorier som finns under SQL är Data Definition Language (DDL), Data Manipulation Language (DML), Data Control Language (DCL) och slutligen Data Query Language
Bok +ISBN +Titel +Pris Författare +Personnummer +Förnamn +Efternamn Skriven av +bokISBN +författarePnr * 1 * 1
8
(DQL). DDL används för att skapa, förkasta och förändra databasens och tabellernas struktur och innehåller kommandona CREATE, DROP och ALTER. För att förstöra, uppdatera eller lägga in data i tabeller används kommandona DELETE, UPDATE och INSERT som tillhör DML. Hantering av rättigheter för databasen hanteras i nästa grupp som är DCL som innehåller kommandona GRANT och REVOKE. Sista gruppen som är kvar är DQL som används för att framskaffa data ur databasen och detta görs igenom SQL-kommandot SELECT[23][10].
2.3 Object Relational Mapping (ORM)
Objektrelationsmappningsverktyg gör det möjligt att integrera objektorienterade programmeringsspråk med relationsdatabaser. Detta ger både styrkan av paradigmet objektorientering, som används till exempel i programmeringsspråket Java, och relationsdatabasens beständighet och funktionalitet. Med hjälp av ORM- ramverk kan databasobjekt bearbetas i ett programmeringsspråk[1].
2.3.1 Objekt/relations paradigmens missanpassning och mappning
En viktig sak som ORM bistår med är objekt/relations paradigmens missanpassning. I detalj betyder detta uttryck att när ett försök görs vid att koppla samman en relationsdatabas med ett objektorienterat programmeringsspråk så finns där ett motstånd som ej gör detta möjligt. Motståndet ifråga uppkommer av att en relationsdatabas handskas med data tabulärt medan programmeringsspråket Java använder objekt. Problematiken löses genom att använda olika metoder för mappning Dessa metoder kallas ”relationship mapping” och ”inheritance mapping”. Relationship mapping är den mappning som tar hand om hur en relation (aggregation, komposition och association) skall transformeras medans inheritance mapping är mappningen av den arvshierarki som finns[31][19]. När en ORM implementering görs så löser ORM- verktyget denna opassande koppling och utvecklaren får möjlighet att använda sig av paradigmet objektorientering tillsammans med relationsdatabaser[1]. 2.3.2 Varför behövs ORM?
Då en applikation kan vara komplicerad att utveckla kan det vara bra att göra en mappning från en relationsdatabas till objekt då detta ger en möjlighet att lösa komplicerade problem som lättare görs i ett objektorienterat språk. Som nämnts i kapitlet om objektorientering så fås tillgång till bland annat metoder, arv, och inkapsling samt så ges en möjlighet att återanvända kod som tidigare skrivits för andra applikationer[1][27].
ORM- verktyg gör att utvecklaren kan koncentrera sig på att utveckla applikationen istället för att hantera databasen. Detta gör att en utvecklare kan specialisera sig på ett mindre område och skapa bättre applikationer.
9
Christian Bauer och Gavin King beskriver ORM på detta sätt:
”In a nutshell, object/relational mapping is the automated (and transparent) persistence of objects in a Java application to the tables in a relational database, using metadata that describes the mapping between the objects and the database.” [1, sid 25]
2.3.3 När skall ORM användas
Ett bra scenario för att få användning av ORM är att en relationsdatabas redan är skapad med data av olika slag och en vidareutveckling behövs göras för att behandla denna data. Föredragande väljer utvecklaren ett objektorienterat programmeringsspråk att arbeta med för att utveckla den framtida applikationen och gör det då passande att använda ORM.
Ett annat exempel kan vara när en underliggande databashanterare skall bytas, till exempel från MySQL till PostgreSQL. Här är det bra att ha ett ORM ramverk som hanterar mappning av relationsdatabasen och gör att applikationen kan hållas oförändrad[1].
2.3.4 När skall ORM inte användas?
I kortare projekt som har en snäv tidsbegränsning så bör ORM- verktyg inte användas om inte utvecklarna redan besitter kunskap och vetskap om ramverket i fråga. Detta på grund av att inlärningstiden kan vara lång och tidskrävande.
Erik Öjebo diskuterar ORM på följande vis:
”Något som ofta nämns som en nackdel för ORM-ramverk är försämrad prestanda jämfört med handskriven SQL. Som tidigare nämndes är detta dock något som det råder delade meningar om. ORM-ramverk inför ett ytterligare lager av abstraktion, för att förenkla utvecklingsarbetet . Som med alla abstraktionslager innebär det en viss prestandaförlust. Många ramverk erbjuder dock andra fördelar ur prestandasynvinkel så som cachning och optimering av SQL-frågor efter databashanteringssystem. 29 30 Dessa kan potentiellt kan leda till en bättre prestanda än handskriven
SQL, trots den prestandakostnad som abstraktionslagret medför. I de fall ett mer komplext ramverk används kan det även finnas många möjligheter till optimering som behöver behärskas innan ramverkets prestanda kan utnyttjas fullt ut. Otillräcklig kunskap om ramverket kan således leda till att ramverket upplevs ha sämre prestanda än vad det potentiellt kan ha.”[35, sid 15]
2.4 Java Database Connectivity (JDBC)
Industrins standard för databasoberoende kopplingar mellan programmeringsspråket Java och en mängd olika databashanterare är JDBC Application Programming Interface (API)[17]. Innan ORM- ramverk kunde nyttjas kunde en applikation bara kommunicera med en specifik SQL- dialekt. Om den nuvarande databashanteraren skulle behöva bytas så måste utvecklare lära sig en ny dialekt samt att
10
applikationen måste skrivas om så att den ges möjlighet att kommunicera med den nya databashanteraren[25].
JDBCs API är en ”call-level API” för SQLbaserad databasåtkomst. Denna låter Javaapplikationer kommunicera med olika databashanterare[17]. Detta ger fördelar för att utvecklaren då han inte behöver ändra i sin applikation förutom i de delar som har hand om databaskommunikationen och programmeraren behöver lära sig är den nya SQL-dialekten.
JDBC ger möjlighet att utföra tre uppgifter. Den första uppgiften är att skapa en koppling med en databas eller att framskaffa tabulär data. Andra uppgiften är att skicka SQL-kommandon. Slutligen så skall JDBC bearbeta resultaten av SQL-kommandon[18].
2.4.1 JDBC arkitektur
De klasser som implementerar JDBC-gränssnitt för en speciell databashanterare kallas en JDBC Driver. För att låta utvecklaren fokusera på själva applikationen så skalas detaljerna bort från de olika databashanterarna. På grund av detta behöver utvecklaren inte ändra i applikationen förutom i de delar som har hand om databaskommunikationen vid byte av databashanterare. JDBC arkitektur visas i bilden nedan. Där finns Javaapplikationer som det översta lagret och databashanterare i det understa där JDBC ligger mellan dessa för att sköta kopplingen[18][25].
11 MySQL Oracle Postgre
JDBC
Javaapplikation 1 Javaapplikation 2 Figur 2.6 JDBC- arkitektur [18]2.5 Hibernate
Hibernate är ett gratis ORM-ramverk med öppen källkod och ramverket är ett av de ledande i sitt område gällande användning av Java och databashanering[11][12]. Hibernate låter utvecklaren se sina databastabeller som rena Javaobjekt. Detta görs genom att ORM- verktyget mappar databastabellerna till objekt med hjälp av konfigurationsfiler som i sin tur generas av Hibernate[1]. Utvecklaren som är van att jobba med Javaobjekt behöver ej bry sig om översättningen från tabeller till objekt och vise versa då Hibernate står för denna del i utvecklandet av projektet[6][8].
2.5.1 Hibernates arkitektur
Hibernate använder sig av JDBC och tillsammans utgör de ännu ett lager av en abstraktion till en applikation. I Hibernate konfigureras kopplingen till databasen som i sin tur består av JDBC och detta görs med hjälp av konfigurationsfiler. Så som bilden visar nedan verkar Hibernate närmst Javaapplikationerna och så som dens främsta ändamål skapar den Javaobjekt som utvecklaren har till förfogande[13].
12 MySQL Oracle Postgre
JDBC
Javaapplikation 1 Javaapplikation 2Hibernate
Figur 2.7 Hibernatearkitektur[13] 2.5.2 Hibernate i unionFör utvecklaren så täcker Hibernate allt utom själva Javaapplikationen. I mer detalj tar Hibernate hand om databasuppkopplingen via JDBC genom att använda de olika konfigurationsfilerna som autogenereras. För att kunna hantera SQL frågorna och databashanterarna använder sig Hibernate av ett inneboende frågespråk detta kallat Hibernate Query Language (HQL) som definieras vidare i nästa avsnitt. Ett exempel på hur utvecklaren ser Hibernate kan ses i bilden som följer nedan[1][12].
13 MySQL Oracle Postgre
JDBC
Javaapplikation 1 Javaapplikation 2Hibernate
Figur 2.8 Hibernate i utvecklarens ögon [13]
2.5.3 Hibernate Query Language (HQL)
I Hibernate finns det inkluderat ett kraftfullt frågespråk som kallas Hibernate Query Language eller kort HQL. Frågespråket som används i Hibernate är likt SQL som beskrevs i kapitlet om Structured Query language (se avsnitt 2.2.4). HQL skiljer sig däremot i några viktiga aspekter, bland annat är det ett objektorienterat frågespråk och använder sig därför av styrkorna som ingår i objektorientering[14].
2.6 Java Enterprise Edition (Java EE) och NetBeans
Java EE är ett objektorienterat programmeringsspråk och utvinner de fördelar som är förklarade i tidigare avsnitt om objektorientering. Till skillnad från den enklare versionen Java Standard Edition
14
(Java SE) så är Java EE en utökning av olika bibliotek i form av klasser förskrivna för att förenkla för utvecklare vid främst skapandet av webbapplikationer[16].
NetBeans är ett gratis opensource Integrated Development Environment (IDE) som kan köras på olika plattformar, Windows, Linux, Mac OS X och Solaris[32]. Den senaste versionen av detta IDE är, den tolfte april 2010, version 6.8 och denna innehåller verktyg för att skapa professionella applikationer med hjälp av till exempel programmeringsspråket Java. Bland dessa verktyg så finns bland annat möjlighen att ladda ner önskvärda plugins. Med plugin menas att ett tillägg kan göras för att utöka en specifik funktion eller ge möjligheter för att förenkla utvecklarens arbetsbörda. Ett exempel på användning av plugin är när en exempeldatabas behövs för att snabbt komma igång med utveckling av applikationer[32].
15
3. Användbarhet
I vår rapport vill vi undersöka hur Hibernate och JDBC skiljer sig med avseende på användbarhet för utvecklaren. För att göra detta måste först användbarhet definieras. En bra metod för att angripa detta problem är att undersöka befintliga standarder. Vi har valt att definiera användbarhet genom att använda oss av en pålitlig och reell källa. Denna källa är en ISO standard vilket är en erkänd standard inom dataveteskapen[30]. Standarden vi har valt att använda oss av är ISO 9241-11 [15]. Denna standard beskriver användbarhet på detta sätt:
”Extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use.”[15, sid 2]
Alla dessa tre egenskaper ändamålsenlighet, effektivitet och tillfredställelse utgör tillsammans användbarhet. Dessa tre egenskaper definieras vidare i ISO standarden, vilken börjar med ändamålsenlighet och definieras enligt följande citat:
”Accuracy and completeness with which users achieve specified goals.” [15, sid 2] Vidare så definieras effektivitet enligt följande:
”Resources expended in relation to the accuracy and completeness with which users achieve goals.” [15, sid 2]
Slutligen definierar standarden tillfredsställelse på följande vis:
16
4. Konceptuellt ramverk
Ett konceptuellt ramverk (conceptual framework) kan vara baserat på olika teorier och aspekter som forskaren argumenterar skall vara relevant och viktigt för att besvara en forskningsfråga. Ramverket är i sig uppbyggt av en samling aktuella och breda källor. Validiteten av det valda ramverket är beroende av sammanhanget i sin helhet och att läsaren ”känner igen sig” i den beskrivna situationen. Vid analys av data är metoden att använda ett konceptuellt ramverk motiverat av att metoden är lämplig att använda i en initial och utforskande studie[2]. Vårt konceptuella ramverk baseras på den tekniska bakgrunden och den litteratur som förekommer i rapporten[2].
17
5. Studie
Detta examensarbete påbörjades i augusti 2009 och har pågått fram till dagens datum som är den 21/5-2010. Under denna studie har vi jobbat med att få fram förståelse för ramverket Hibernate vilket vi inte hade någon kännedom om i början av projektet. En utökning av vår förståelse för hur JDBC används och är uppbyggt har även erhållits under denna tid. Detta medför att det är svårt att finna lämpliga kandidater till att utföra denna studie vi har arbetat fram och därför att vi har valt att utföra undersökningen ifrån den utgångspunkten vi hade för ett år sedan vilket motiveras av konceptuellt ramverk. Som testgrupp har vi valt en grupp om två personer som har datavetenskaplig utbildning och vi har även här tillämpat metodiken konceptuellt ramverk för analys av insamlad data. Vi anser att en testgrupp bör ha kunskaper i objektorienterad programmering (framförallt inom Java), relationsdatabaser, ER-modellering, normalisering, Hibernate, SQL och HQL. På grund av dessa omständigheter så blir undersökningen av kvalitativ natur.
5.1 ISO-grundande frågeformulär
Metodiken konceptuellt ramverk används för att utföra en objektiv studie kring användbarhet och ISO 9241-11[15] föreslår här ett frågeformulär med attitydskala. Frågoformulär kring detta har tagits fram med hjälp av ett arbete vid namn, Development of an Instrument Measuring User Satisfaction of the Human-Computer Interface [3], som delvis gjorts kring användbarheten vid mjukvaruutveckling. Detta arbete[3] har användts för att skapa ISO standarden 9241-11[15] och är även en grund för frågeformuläret för denna studie. Metodiken konceptuellt ramverk används för att ta fram frågorna för studien vilka kommer från en filtrering av den ursprungliga källan och är passande i denna studie då de behandlar viktiga aspekter på hur det är för en utvecklare att arbeta med verktygen Hibernate kontra JDBC. Filtreringen i sig har tagits fram genom att göra ett initialt test av frågeformuläret till respektive ramverk. I detta test reducerade vi frågor som inte var relevanta för att se användbarhet i de ramverk studien grundar sig på. Frågeformuläret används för att lyfta fram vilket verktyg, Hibernate kontra JDBC, som är mest användbart.
Frågorna i formuläret Usability Questionnaire (Appendix B) är indelade i olika sektioner. Den första sektionen i formuläret är en fördjupning på hur bra terminologin och systeminformation upplevs. Detta är en viktig del av hur användbarheten upplevs av verktyget i fråga då en bra terminologi kan hjälpa utvecklaren genom att hålla en konsekvent namngivning. Systeminformationen i sin tur ger information till användaren när något har gått fel och är mestadels till för att beskriva problemet och peka på var problemet befinner sig. Nästa sektion på frågeformuläret som står på tur att besvaras är inlärning. Detta är viktigt för att bland annat se hur snabbt utvecklaren lär sig funktioner och kommandon i verktyget. Hur utförlig dokumentationen är kommer även in under denna sektion. Den tredje sektionen i formuläret behandlar systemets förmåga, alltså hur snabbt och pålitligt respektive verktyg känns samt vilka behov som tas i beaktning när de används. För att få en helhetsuppfattning så
18
ställs utvecklaren inför en sista sektion där denna får besvara en övergripande reaktion på mjukvaran. Detta frågeformulär är en del av ett besvarande av forskningsfrågorna ställda i denna rapport.
5.2 Uppsättning av utvecklingsmiljöer
För att kunna använda oss av frågeformuläret som beskrivs ovan i avsnitt 5.1 och besvara de frågor som ingår i formuläret har vi valt att sätta upp två utvecklingsmiljöer. En miljö för JDBC och en för Hibernate. Dessa utvecklingsmiljöer innehåller i sig två stycken emulerade datorer. De emulerade datorena har skapats med hjälp av ett program vid namn Windows Virtual PC [34]. Detta emulatorprogram har valts på grund av att det är gratis, använder sig av Windows vilket är ett operativsystem vi känner till väl och har introducerats för oss under vår utbildning på Malmö högskola.
I dessa emulerade datorer så har vi installerat MySQL som databashanterare. Detta val kommer sig av att MySQL är en applikation till vilken det finns fördefinierade databaser. Vi använder en av dessa fördefinierade databaser i vår implementering av utvecklingsmiljöer.
Vidare så har vi valt ett IDE att arbeta i. Detta IDE är NetBeans 6.8 och anledningen till att valet faller på NetBeans är att det är gratis och att där finns tillägg som tillhandahålls av detta IDE. Den största anledningen förutom de som beskrivs ovan är att i version 6.8 av NetBeans så finns en möjlighet att initialt välja till ramverket Hibernate för de projekt som skapas.
Slutligen installeras en miljö med respektive ramverk för att utföra studien. För en beskrivning av hur vi gått till väga vid uppsättning av utvecklingsmiljöer se Appendix C.
19
6. Diskussion
Utvecklarna är två studenter på Malmö högskola som går en datavetenskaplig utbildning och anses vara en lämplig testgrupp för vår studie.
Vi har valt att sammanställa tabeller innehållande resultaten av våra besvarade frågeformulär, detta för att skapa en översikt av insamlad data över ramverken Hibernate och JDBC . Vi har valt att sammanställa insamlad data enligt följande:
1. Kolumn ett innehåller frågorna som testgruppen har besvarat och en attitydskala från ett till sex.
2. Kolumn två innehåller poängen given av Andreas per fråga och samt en sammanställning underst över totalsumman.
3. Kolumn tre innehåller poängen given av Henrik per fråga och samt en sammanställning underst över totalsumman.
I dessa tabeller redogörs i detalj vad varje utvecklare har svarat vid varje fråga. Vi har valt att utveckla vissa resultat som utkom vid besvarandet av frågeformuläret (Appendix B).
6.1 Terminologi och systeminformation
Den första sektionen utvecklaren ställs för att besvara är terminologi och systeminformation. Med terminologi och systeminformation så har vi valt att avse följande aspekter:
Användandet av termer genom systemet
Terminologi är relaterad till det du gör
Felmeddelanden
Användandet av ovan nämnda aspekter för att studera terminologi och systeminformation motiveras av tidigare nämnda publikation Development of an Instrument Measuring User Satisfaction of the Human-Computer Interface[3].
Vi har valt att fokusera på följande aspekter i vår diskussion eftersom dessa besvarar våra forskningsfrågor:
Terminologi är relaterad till det du gör
Felmeddelanden
Vad gällande frågan om hur terminologin är relaterad till vad utvecklaren gör så tar vi ut ett exempel gällande inskrivning av data till databasen. I JDBC skapas ett SQL kommando som används för att sätta in data i en mySQLdatabashanterare som ser ut enligt exempel:
20
I detta exempel så fylls frågetecknen som finns i SQL kommandot på med värden och skickas sedan till databashanteraren som i sin tur bearbetar dessa. En viktig skillnad mellan de två ramverken är att i Hibernate så arbetar utvecklaren direkt med objekt som skapats av de klasser Hibernate automatiskt genererar och gör därmed anrop till dessa då en insättning av data skall ske. Detta är en anledning för att Hibernate får högre poäng än JDBC vid denna fråga.
I fråga om felmeddelande så är de båda ramverken relativt lika eftersom båda är Javabaserade verktyg. En av de skillnader som finns är när det uppkommer ett fel angående frågespråken de olika ramverken använder sig av. I JDBC så hänvisas oftast utvecklaren till manualen för den SQL dialekt som används medans Hibernate som använder HQL har mer utförliga felmeddelanden eftersom det alltid gäller samma frågespråk. Skillnaden mellan de två ramverken är inte stor men där finns en betydelsefull fördel för Hibernate där utvecklaren får snabbare tillgång till hjälp.
Inom terminologi och systeminformation visar undersökningen på att Hibernate har fått en högre poäng än JDBC under denna sektion.
Sektion: Terminologi och
systeminformation (JDBC) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Användandet av termer genom systemet 4 2
Terminologi är relaterad till det du gör 4 3
Felmeddelanden 1 3
Summering 9 8
Figur 6.1 Sektion över Terminologi och systeminformation för JDBC
Sektion: Terminologi och
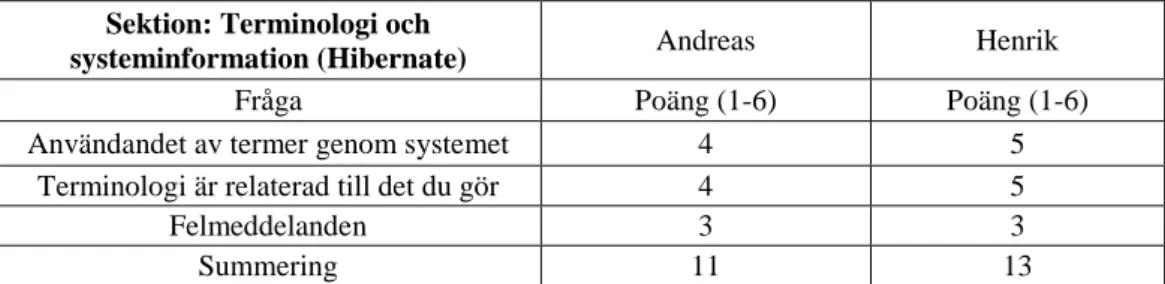
systeminformation (Hibernate) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Användandet av termer genom systemet 4 5
Terminologi är relaterad till det du gör 4 5
Felmeddelanden 3 3
Summering 11 13
21
6.2 Inlärning
Med inlärning så har vi valt att avse följande aspekter:
Lära sig använda verktyget
Lära sig utforska nya funktioner genom att prova sig fram
Lätt att komma ihåg kommandon
Uppgifter kan lösas genom att gå rakt på problemet
Dokumentation
Användandet av ovan nämnda aspekter för att studera inlärningströskeln motiveras av tidigare studier om inlärning (se Development of an Instrument Measuring User Satisfaction of the Human-Computer Interface[3])
Vi har valt att fokusera på följande aspekter i vår diskussion eftersom dessa besvarar våra forskningsfrågor:
Lära sig att använda verktyget
Dokumentation
Under sektionen inlärning så ställs bland annat frågan om verktyget var lätt eller svårt att lära sig för respektive ramverk. Undersökningen indikerar att båda verktygen i sig har en hög inlärningströskel. Genom att analysera vår insamlade data så framgår det att Hibernate är svårare att lära sig, med andra ord så har Hibernate en högre inlärningströskel än JDBC.
För att styrka ovan nämnda diskussion om inlärningskurvans höjd och längd så citerar vi nedan erfarna utvecklares erfarenheter om Hibernates inlärningströskel:
”A matter of a month to cover the basics and start utilizing effectively."Fully" understanding took 5
months (NonUniqueObjectException, states of an object).”[33]
En annan aspekt som uppmärksammas under inlärning är dokumentationen. Denna är en viktig del av hur användbart ramverket i sig är då det är först och främst dokumentationen utvecklaren vänder sig till när problem uppkommer. JDBC får en stark dokumentation eftersom det är en delmängd av programmeringsspråket Java. Mätningarna visar att båda ramverken har god dokumentation och att Hibernate har en snar fördel i resultatet. Som tidigare nämndes är dokumentation viktig vid användandet av ramverken och denna aspekt visar att även Hibernate har en mycket god dokumentation. Detta gör att Hibernate kan användas fullt ut och alla dess funktioner kan implementeras vid behov.
Överlag inom sektionen inlärning visar undersökningen på att det är lika mellan de två ramverken. Endast mindre avvikelser skiljer på detaljnivå mellan dessa två.
22
Sektion: Inlärning (JDBC) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Lära sig använda verktyget 2 2
Lära sig utforska nya funktioner genom att
prova sig fram 1 3
Lätt att komma ihåg kommandon 3 3
Uppgifter kan lösas genom att gå rakt på
problemet 3 5
Dokumentation 4 4
Summering 13 17
Figur 6.3 Sektion över Inlärning för JDBC
Sektion: Inlärning (Hibernate) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Lära sig använda verktyget 2 1
Lära sig utforska nya funktioner genom att
prova sig fram 1 3
Lätt att komma ihåg kommandon 3 2
Uppgifter kan lösas genom att gå rakt på
problemet 4 4
Dokumentation 5 5
Summering 15 15
Figur 6.4 Sektion över Inlärning för Hibernate
6.3 Systemets förmåga
Denna del kan antas innehålla mätvärden av de olika aspekter som sektionen innehåller. Dock har vi fokuserat på att undersöka själva upplevelsen för hur de olika ramverken uppfattas och känns i förhållande av hastighet och pålitlighet. Detta val motiveras av att det redan finns olika mätningar på dessa aspekter. Ett exempel på mätningar gjorda inom ORM- ramverk är Erik Öjebos publikation
Objekt-relationsmappning i datacentrerad applikation[35].
Med systemets förmåga avser vi följande egenskaper: Hastighet
Pålitlighet
Erfarna och icke erfarna utvecklares behov tas i beaktning
Inom denna sektion har vi valt att ta upp följande aspekter för diskussion eftersom dessa besvarar våra forskningsfrågor:
Hastighet
23
Under aspekten hastighet enligt det redovisade resultatet på studien så syns att JDBC känns snabbare än Hibernate. En orsak för detta är att Hibernate tillför ett extra lager av abstraktion till en applikation eftersom JDBC är en delmängd av Hibernate (se avsnitt 2.5). Detta abstraktionslager påvisas bland annat genom att JDBC använder SQL till att direkt kommunicera med databashanteraren medans i Hibernate så används HQL. Frågespråket måste därför översättas till SQL för att databashanteraren skall kunna uppfatta kommandon och utföra instruktioner. Detta är då en motivation för att JDBC får ett högre genomsnitt för denna aspekt.
En annan aspekt under sektionen systemets förmåga är hur erfarna och icke erfarna utvecklares behov tas i beaktning. Hibernate har här fått en högre medelpoäng än JDBC. En motivering till detta är att i Hibernate finns det större möjlighet att arbeta objektorienterat med hjälp av ett objektorienterat frågespråk. Hibernate är gjort för att förenkla för utvecklarna och detta görs med hjälp av abstraktionen av databashanteringen. Abstraktionen påvisas här på att Hibernate tar bort behovet av att utvecklare manuellt bearbetar data med SQL tillsammans med JDBC.
Överlag inom sektionen systemets förmåga visar undersökningen på att det är lika mellan de två ramverken. Endast mindre avvikelser skiljer på detaljnivå mellan dessa två.
Sektion: Systemets förmåga (JDBC) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Hastighet 4 5
Pålitlighet 4 5
Erfarna och icke erfarna utvecklares behov
tas i beaktning 1 2
Summering 9 12
Figur 6.5 Sektion över Systemets förmåga för JDBC
Sektion: Systemets förmåga (Hibernate) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Hastighet 3 4
Pålitlighet 5 4
Erfarna och icke erfarna utvecklares behov
tas i beaktning 1 4
Summering 9 12
24
6.4 Övergripande reaktion på mjukvaran
Den sista sektionen vi tar upp är övergripande reaktion på mjukvaran. Här har vi ännu en gång använt oss av Development of an Instrument Measuring User Satisfaction of the Human-Computer Interface[3] för att motivera valet av vilka aspekter vi använder oss av för att studera övergripande reaktion på mjukvaran. Dessa aspekter följer i listan nedan:
Hemsk – Underbar
Svår – Lätt
Frustrerande – Njutbar
Otillräckligt kfartfull – Tillräckligt kraftfull
Tråkig – Stimulerande
Stelt – Flexibelt
Vi har under denna sektion valt att ta upp följande aspekter till diskussion eftersom dessa besvarar våra forskningsfrågor:
Svår – Lätt
Otillräckligt kraftfull – Tillräckligt kraftfull
Stelt – Flexibelt
Här ges utvecklaren möjlighet att svara på olika påståenden angående hur ramverket känns att arbeta med. Vi börjar med att ta upp hur svårt respektive lätt det är att hämta ut data ur databasen samt skriva till den. Som det syns i tabellerna nedan är både JDBC och Hibernate resultatmässigt nära besläktade i fråga om detta. Vid en uthämtning av data i JDBC fås ett ResultSet (se Appendix C) som måste efterbehandlas och processeras för att det skall gå att använda den data som fås och själv skapa objekt. Här framkommer en av de viktiga fördelarna med att använda Hibernate då klasser som senare blir objekt blir genererade av ramverket. Detta sparar utvecklare arbetet med att själva skapa koden för att göra tabulär data till objekt.
Vidare under övergripande reaktion på mjukvaran så görs en utveckling av hur kraftfulla respektive ramverk är. I Hibernate så används det kraftfulla frågespråket HQL som tidigare är definierat i avsnittet om ORM. JDBC använder sig fullt ut av den SQL dialekt som databashanteraren i fråga använder medans Hibernate översätter från HQL till den använda dialekten. Hibernate kan dock också använda sig av ren SQL istället för att översätta från HQL om detta skulle krävas och därför så har Hibernate fått högre antal poäng än sin motsvarighet JDBC.
En annan aspekt i vårt frågeformulär vi har fokuserat på är om programvaran är flexibel respektive stel. Här grundar vi det skiljande resultatet på att i Hibernate så finns där ett gemensamt frågespråk vid namn HQL och detta är generellt över användandet av olika databashanterare. Detta innebär att
25
Hibernate är flexibelt när olika databashanterare eller SQL dialekter behövs användas. Däremot i JDBC används varje specifik databashanterares olika dialekter, därför saknas möjligheten att använda en gemensam SQL dialekt som i Hibernate och detta gör att JDBC är mindre flexibelt än motsvarande verktyg.
Inom övergripande reaktion på mjukvaran visar undersökningen på att Hibernate har fått en högre poäng än JDBC under denna sektion.
Sektion: Övergripande reaktion på
mjukvaran (JDBC) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Hemsk – Underbar 2 3
Svår – Lätt 1 2
Frustrerande – Njutbar 2 2
Otillräckligt kraftfull – Tillräckligt kraftfull 3 3
Tråkig – Stimulerande 3 2
Stelt – Flexibelt 4 4
Summering 15 16
Figur 6.7 Sektion över Övergripande reaktion för JDBC
Sektion: Övergripande reaktion på
mjukvaran (Hibernate) Andreas Henrik
Fråga Poäng (1-6) Poäng (1-6)
Hemsk – Underbar 4 4
Svår – Lätt 2 2
Frustrerande – Njutbar 2 3
Otillräckligt kraftfull – Tillräckligt kraftfull 5 5
Tråkig – Stimulerande 3 5
Stelt – Flexibelt 5 5
Summering 21 24
26
7. Slutsats
Efter utförd undersökning och analys kan vi dra följande slutsatser:
1. Inom terminologi och systeminformation är Hibernate mer användbart än JDBC 2. Inom inlärning är de två ramverken lika i fråga om användbarhet
3. Inom systemets förmåga är de två ramverken igen lika i fråga om användbarhet 4. Inom övergripande reaktioner på mjukvaran är Hibernate mer användbart än JDBC
Dessa fyra slutsatser implicerar alltså att Hibernate har högre användbarhetsvärde än JDBC vilket besvarar vår främsta forskningsfråga.
Notera den andra forskningsfrågan, nämligen:
”Gör något av ramverken applikationer oberoende underliggande databashanterare?”
besvarades redan i sektion 2.5 och svaret var att Hibernate men inte JDBC gör applikationer oberoende underliggande databashanterare.
27
8. Framtida studier
En möjlighet till en framtida studie skulle kunna vara att utföra studien igen fast på en större testgrupp. Dessa bör inneha samma förutsättningar som de kandidater som utför studien i denna rapport, det vill säga att kandidaterna bör ha kunskaper inom objektorienterad programmering (framförallt inom Java), relationsdatabaser, ER-modellering, normalisering, Hibernate, SQL och HQL.
En annan möjlighet är att dela upp olika testgrupper beroende på vilken bakgrund de har. Till exempel låta en av testgrupperna utgöra individer av redan erfarna utvecklare för vardera ramverk samt en testgrupp som inte har någon tidigare erfarenhet av varken Hibernate eller JDBC. Detta skulle kunna ytterligare förstärka vår initiala studie och vara ett stöd i processen att avgöra vilket ramverk som är bäst anpassat för de olika förutsättningar testgrupperna har.
28
9. Litteraturförteckning
[1]Bauer, C., & King, G. (2007). Java Persistence with Hibernate. Greenwich: Manning Publications Co.
[2]Bergsten, C. (2007). Investigating Quality of Undergraduate Mathmatics Lectures. Mathematics
Education Research Journal Vol. 19 No. 3, (pp. 48-72). Linköping.
[3]Chin, J. P., Diehl, V. A., & Norman, K. L. (1988). Development of an Instrument Measuring User
Satisfaction of the Human-Computer Inerface. College Park: University of Maryland.
[4]Codd, E. F. (1990). The Relational Model for Database Management: Version 2. Boston: Addison-Wesley Longman Publishing Co., Inc.
[5]Connolly, T., & Begg, C. (2005). Database Systems, A Practical Approach to Design,
Implementation, and Management. Harlow: Pearson Education Limited.
[6]Doernhoefer, M. (2007, Juli). Surfing the Net for Software Engineering Notes. McLean, Illinois, USA: ACM.
[7]Download details: Virual PC 2007. (2007, Februari 19). Retrieved Mars 9, 2010, from Microsoft Download Center: http://www.microsoft.com/downloads/details.aspx?FamilyId=04D26402-3199-48A3-AFA2-2DC0B40A73B6&displaylang=en
[8]Elliott, J. (2004). Hibernate: A Developer's Notebook. O'Reilly Media.
[9]Elmasri, R., & Navathe, S. B. (1994). Fundamentals of Database Systems Second Edition. Redwood City: The Benjamin/Cummings Publishing Company, Inc.
[10]Garcia-Molina, H., Ullman, J. D., & Widom, J. (2002). Database Systems: The Complete Book. Stanford: Prentice Hall.
[11]Hart, A. M. (2005, April). Hibernate in the classroom. Mankato, Minnesota, USA. [12]Hibernate - JBoss Community. (n.d.). Retrieved April 6, 2010, from Hibernate: http://www.hibernate.org/
[13]Hibernate Community Documentation. (2004). Retrieved April 27, 2010, from Chapter 2. Architecture: http://docs.jboss.org/hibernate/core/3.3/reference/en/html/architecture.html
[14]Hibernate Community Docummentation. (2004). Retrieved April 27, 2010, from Chapter 14. HQL: The Hibenate Query Language:
http://docs.jboss.org/hibernate/core/3.3/reference/en/html/queryhql.html
[15](1998). INTERNATIONAL STANDARD ISO 9241-11. Geneve: International Organization for Standardization.
[16]Java EE at a Glance. (2010). Retrieved April 13, 2010, from ORACLE Sun Developer Network (SDN): http://java.sun.com/javaee/index.jsp
[17]Java SE Technologies - Database. (2010, Mars 15). Retrieved from http://java.sun.com/javase/technologies/database/
29 [18]JDBC Overview. (2010, Mars 15). Retrieved from http://java.sun.com/products/jdbc/overview.html
[19]Mapping Object to Relational Databases: O/R Mapping In Detail. (n.d.). Retrieved April 6, 2010, from Agile Data: http://www.agiledata.org/essays/mappingObjects.html
[20]MySQL ::. (2007). Retrieved April 5, 2010, from MySQL: http://dev.mysql.com/doc/sakila/en/sakila.html
[21]MySQL :: The World's most popular open source database. (n.d.). Retrieved April 5, 2010, from MySQL: http://www.mysql.com/
[22]O'Neil, E. (2008). Object/Relational Mapping 2008: Hibernate and the Entity Data Model (EDM). Boston, Massachusetts, USA.
[23]Padron-McCarthy, T., & Risch, T. (2005). Databasteknik. Lund: Studentlitteratur. [24]Platsbanken. (n.d.). Retrieved April 6, 2010, from Arbetsförmedlingen:
http://platsbanken.arbetsformedlingen.se/Standard/SokFritext/SokFritext.aspx?q=s(t(hibernate))sp(67) sr(1)c(2431F52D)&ps=
[25]Reese, G. (2000). Database Programming with JDBC and Java, Second Edition. Sebastopol: O'Reilly Media, Inc.
[26]Rob, P., & Coronel. (1997). Database Systems Design, Implementation and Management, Third
Edition. Cambrige: Thomson Publishing.
[27]Skansholm, J. (2005). Java direkt med Swing. Lund: Studentlitteratur.
[28]Sommerville, I. (2007). Software Engineering 8. Edinburgh Gate: Prentice Hall. [29]Stevens, P., & Pooley, R. (2006). Using UML Software Engineering with Objects and
Components second Edition. Edingburgh Gate: Addison Wesley.
[30]Umar, A., & Tatari, K. K. (2008). Appropriate Web Usability Evaluation Method during Product
Development. Ronneby: Blekinge Institute of Technology.
[31]Van Zyl, P., Kourie, D. G., & Boake, A. (2006). Coparing the Performance of Object Databasese and ORM Tools. Saicsit .
[32]Welcome to NetBeans. (n.d.). Retrieved April 1, 2010, from NetBeans: http://www.netbeans.org/ [33]Who uses Hibernate. (2010, Mars 15). Retrieved Maj 10, 2010, from JBoss Community:
http://community.jboss.org/wiki/WhousesHibernate
[34]Windows Virtual PC: Home Page. (n.d.). Retrieved April 7, 2010, from Microsoft: http://www.microsoft.com/windows/virtual-pc/
[35]Öjebo, E. (2009). OBJEKT-RELATIONSMAPPNING I DATACENTRERAD APPLIKATION. Örebro: Örebro universitet.
30
Appendix A
Hibernatetutorial
med hjälp av Maven
och NetBeans
Andreas Nilsson (tdt07009) Henrik Persson (tda07014)31 1. Java Development Kit
Ladda ner och installera Java SE Development Kit - JDK 6 update 17 eller senare version från http://java.sun.com/javase/downloads/index.jsp suns hemsida. Välj plattform (för tutorialen windows) och tryck på download. Ladda ner filen och starta installationen. Följ instruktionerna, välj nästa tills installationen påbörjas och finish när den är klar.
2. Installation av NetBeans
Installera netbeans 6.7.1 (används i denna tutorial). Finns på http://netbeans.org/downloads/index.html Välj alternativet som innehåller stöd för alla program språk och servrar, tryck download och starta installationen. Ändra inga inställningar och acceptera licensavtalet. Välj en sökväg där netbeans skall installeras. Det krävs inte någon registrering eller att ge användardata. Se till att uppdatera netbeans efter installationen. Om det ej är uppdaterat kommer det upp en ruta med information om uppdateringar som bör installeras. Netbeans kan behöva startas om ett par gånger innan alla uppdateringar har slutförts.
3. Installation av databashanterare MySQL
I tutorialen används MySQL som databashanterare. Ladda ner en Windows MSI Installer (x86) från http://dev.mysql.com/downloads/mysql/5.1.html#win32 . klicka på ”Pick a mirror” länken efter MSI Installer (x86). Installationen som används i denna tutorial är mysql-5.1.40-win32.msi. Det behövs ingen inloggning utan välj länken som tar en direkt till nerladdningen. Eftersom vi är i Sverige väljer vi Sweden [Sunet]. Välj vilket sätt installationen skall laddas ner på, antingen http eller ftp. Starta installationen. På Setup type välj Typical och fortsätt sedan installationen. När den är klar ges möjligheten att konfigurera MySQL servern. Avmarkera registreringen och se till att konfigurering är markerad. Välj next efter välkomstmeddelandet. Välj standardkonfigurationen.
32
Under windows options välj att installera som Windows Service. Behåll värdena som redan är ifyllda, vilka är Service Name och rutan för att starta MySQL servern automatiskt.
Markera rutan ”Modify Security Settings” på säkerhetsinställningarna. Fyll i textrutorna med valfritt lösenord, i tutorialen används ”admin”, och tryck next.
33
Välj execute så utförs alla gjorda konfigureringar. När det är klart tryck på finish och MySQL servern är klar att användas.
34
För att testa att servern fungerar, öppna kommandotolken, och skriv in kommandot
"C:\Program\MySQL\MySQL Server 5.1\bin\mysqlshow" -u root -p mysql
Kontrollera att MySQL är insatllerat på den angivna sökvägen. När uppmaning om att skriva in lösenrod uppkommer så skriv det lösenord som valdes när MySQL servern konfigurerades, i tutorialen ”admin”.
35 4. Databas med hjälp av Netbeans
4.1 Skapa en förbindelse med MySQL
Starta Netbeans 6.7.1. Välj Services fliken i katalogträdshanteraren, öppna Databases och högerklicka på MySQL. Om det inte redan finns en MySQL server bland databaserna, högerklicka på Databases och välj Register MySQL server. Om där finns en MySQL server i listan högerklicka på den och välj properties. Ändra inte i server Host Name eller Server Port number. Skriv in root i Administrator user name och skriv lösenordet som valdes under installationen av MySQL servern. Bocka för Save Password och tryck OK.
36 4.2 Sakila-Plugin
Välj tools från menyn och därefter Plugins. Om Plugins inte öppnas på Available Plugins fliken, välj den. Skriv in ”sakila” i sökrutan högt upp till höger vilket är namnet på en fördefinierad databas. Markera databasen och installera. Se till att Sakila Sample Database står med bland de plugin som skall installeras. Tryck på next, acceptera licensen, tryck på install och sedan finish. Stäng ner Plugins rutan.
4.3 Sakila-förbindelse
Välj Services fliken i katalogträdshanteraren, öppna Databases. Högerklicka på MySQL Server och tryck start (Detta kan redan var gjort och databasen är startad). Högerklicka på MySQL server och välj create database. Välj sakila i dropdown menyn, tryck OK.
37
Databasen skapas, detta kan ta en liten stund. Högerklicka på sakila schemat och välj connect om det inte är inaktiverat. Om allt gått rätt till skall du nu kunna se databasen och dess innehåll genom att öppna sakila fliken.
38 5. Maven
5.1 Nerladdning av Maven
Ladda ner senaste versionen av Maven från http://maven.apache.org/download.html (apache-maven-2.2.1-bin.zip för denna tutorial). Välj zip filen, ladda ner och spara den på skrivbordet. Extrahera den och lägg den direkt i C:\ sökvägen som används i tutorialen är ”C:/apache-maven-2.2.1”.
5.2 Windows installation av Maven
För att installera Maven måste nya miljövariabler läggas till. Högerklicka på ”den här datorn” och välj egenskaper. Gå till fliken Avancerat och välj miljövariabler. I den översta rutan (användarvariabler) skapa tre nya variabler. En för en sökväg till maven som namnges till: M2_HOME och som variabelvärde skriv in sökvägen till maven som extraherades i 5.1 Nerladdning av Maven, för tutorialen är det C:\apache-maven-2.2.1.
40
Skapa en ny variabel som döps till M2 med variabelvärdet: %M2_HOME%\bin.
Slutligen skapa en variabel som skall heta JAVA_HOME med variabelvärdet sökvägen till ditt JDK, för tutorialen är värdet C:\Program\Java\jdk1.6.0_17.
41
Tre nya miljövariabler har skapats och sökvägarna skall läggas in i Path som hittas i den undre rutan (Systemvariabler). Markera Path och tryck redigera. I slutet av Path, lägg till ;%M2%;%JAVA_HOME%\bin till Path.
För att kontrollera att maven installerats, öppna kommandotolken och gå till C:\apache-maven-2.2.1\bin och skriv där in kommandot: mvn --version.
43 5.3 Netbeans installation av Maven
För att installera maven i netbeans, starta netbeans, öppna tools och välj options. Gå in på Miscellaneous och fliken Maven. I External Maven Home ange sökvägen till maven installationen C:/apache-maven-2.2.1. Tryck OK.
44
För att se om rätt sökväg lagts in i local repository, gå till window, other och välj maven repository browser. Där går det sedan att öppna t.ex. HTTPClient och se en .jar fil.
6. Maven projekt
6.1 Skapa projektet
Skapa ett maven projekt. För att skapa ett projekt, välj file new project och välj Maven Project i listan. Som Archetype välj Maven Quickstart Archetype och tryck next.
45
46
Tryck Ok får att komma vidare. Om detta är det första maven projektet som skapas på datorn kommer maven att ladda ner plugins och artefakter till local repository.
6.2 Format och kodning
Högerklicka på projektet i listan och välj properties. Välj sources kategorin och ändra Souce/Binary Format till 1.5 och Encoding till UTF-8. tryck OK.
7. Hibernate
7.1 Skapa konfigureringsfilen
47
48
Behåll filnamnet hibernate.cfg. Välj src/main/resources som Folder. Välj Sakila som Database connection och tryck finish.
Detta kan ta lite tid att skapa. Utöver att hibernate.cfg skapas ändras också pom filen. När filen skapats syns hibernate.cfg.xml, vilket är en konfigurationsfil gällande hibernateramverket.
7.2 Möjliggör debugging av SQL frågor.
Se till att hibernate.cfg.xml är öppen på design fliken, öppna optional properties och därefter configuration propertiess. Klicka på add och välj property name som hibernate.show_sql och sätt property value till true. Nu skall sql frågor vara möjliga att debugga. Glöm ej att spara ändringarna.
49 7.3 Erhålla ett sessions objekt.
För att kunna använda hibernate måste en hjälpklass skapas som har hand om uppstart och använder hibernates SessionFactory för att erhålla ett sessions objekt.
Högerklicka på source packages, välj new och sedan other. Välj Hibernate i kategorier och välj HibernateUtil som filtyp och klicka på next.
50
51 7.4 Reverse Engineering filen.
Högerklicka på source packages, välj new och sedan other. Välj Hibernate i kategorier och välj Hibernate Reverse Engineering Wizard som filtyp och klicka på next. Skriv in hibernate.reveng som filnamn och src/main/resources som paketnamn. Välj sedan next.
Välj alla tillgängliga entiteter och tryck finish. Nu skapas en ny mapp vid namn sakila.util som innehåller klassen hibernate.reveng.
7.5 Hibernate Mapping filer.
Högerklicka på source packages, välj new och sedan other. Välj Hibernate i kategorier och välj Hibernate Mapping Files and POJOs from Database som filtyp och tryck nästa.
52
Om hibernate.cfg.xml inte är valt som Configuration File, välj det i dropdown listan. Om hibernate.reveng.xml inte är valt som Configuration File, välj det i dropdown listan. Se till så att Domanin Code och Hibernate XML Mappings är ikryssade, och skriv sakila.entity som paketnamn och tryck på finish.
53
Nu skapas Java objekt för alla entiteter i src/main/java/sakila/entity och xml filer i src/main/resources/sakila/entity.
8. Skapa ett enkelt Applikations GUI.
Högerklicka på source packages, välj new och sedan other. Välj Swing GUI Forms och JFrame Form som filtyp, klicka nästa.
54
Skriv in DVDStoreAdmin som klassnamn och sakila.ui som paketnamn tryck sedan finish.
55
Markera hela GUIt genom att vänsterklicka på det, gå till Code och ändra Form Size Policy till Generate Resize Code.
Dra nu in tre labels som skall döpas till respektive Skådespelare, Förnamn och Efternamn. Dra in två Text Fields, en till förnamn och en till efternamn, ta bort defaulttexten från dem och döp dem till firstNameTextField respektive lastNameTextField. Dra in en Knapp och ändra texten till sök och döp knappen till queryButton. Dra in en Table och döp den till resultTable.
57 9. Skapa en fråga i HQL query editorn.
Öppna Projekt fliken, gå till Other Sources, src/main/resources, default package. Högerklicka på hibernate.cfg.xml och välj run HQL Query.
58
För att testa att allt fungerar än så länge. Skriv in t.ex. from Actor i HQL fönstret och exekvera frågan genom att trycka på exekveringsknappen.
10. Lägg till fråga till formuläret.
Öppna DVDStoreAdmin.java och klicka på source fliken. Lägg till följande kod till klassen:
private static String QUERY_BASED_ON_FIRST_NAME="from Actor a where a.firstName like '"; private static String QUERY_BASED_ON_LAST_NAME="from Actor a where a.lastName like '";
private void runQueryBasedOnFirstName() {
executeHQLQuery(QUERY_BASED_ON_FIRST_NAME + firstNameTextField.getText() + "%'"); }
private void runQueryBasedOnLastName() {
59 }
private void executeHQLQuery(String hql) { try {
Session session = HibernateUtil.getSessionFactory().openSession(); session.beginTransaction();
Query q = session.createQuery(hql); List resultList = q.list();
displayResult(resultList);
session.getTransaction().commit(); } catch (HibernateException he) { he.printStackTrace();
} }
Byt till Designfönstret, dubbelklicka på sökknappen för att skapa ett event och lägg till följande i queryButtonActionPerformed metoden. if(!firstNameTextField.getText().trim().equals("")) { runQueryBasedOnFirstName(); } else if(!lastNameTextField.getText().trim().equals("")) { runQueryBasedOnLastName(); }
Skapa sedan följande metoder för att visa upp data i tabellen.
private void displayResult(List resultList) {
Vector<String> tableHeaders = new Vector<String>(); Vector tableData = new Vector();
![Figur 2.1 Klassexempel i Java [27]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4013879.81262/8.892.241.652.100.695/figur-klassexempel-i-java.webp)
![Figur 2.3 Arvexempel[27]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4013879.81262/9.892.208.702.683.1026/figur-arvexempel.webp)
![Figur 2.5 Normaliserat ER-diagramm [23]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4013879.81262/11.892.155.748.747.848/figur-normaliserat-er-diagramm.webp)
![Figur 2.8 Hibernate i utvecklarens ögon [13]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4013879.81262/17.892.206.691.101.828/figur-hibernate-i-utvecklarens-ögon.webp)



![Figur 1.1 Sakila ER-diagram[20]](https://thumb-eu.123doks.com/thumbv2/5dokorg/4013879.81262/74.892.123.769.121.579/figur-sakila-er-diagram.webp)
