V¨
aster˚
as, Sweden
Thesis for the Degree of Master of Science in Engineering - Dependable Systems
30.0 credits
IMPROVING SITUATIONAL AWARENESS
IN AVIATION: ROBUST VISION-BASED
DETECTION OF HAZARDOUS OBJECTS
Alexandra Levin
alewin1995@gmail.com
Najda Vidimlic
najda.vidimlic@gmail.com
Examiner: H˚
akan Forsberg
M¨
alardalen University, V¨
aster˚
as, Sweden
Supervisor: Mohammad Loni
M¨
alardalen University, V¨
aster˚
as, Sweden
Company Supervisor: Per-Olof Jacobson,
SAAB AB, J¨
arf¨
alla, Sweden
Acknowledgement
We wish to express our gratitude towards SAAB for giving us the opportunity to collaborate during our master thesis. Especially, we would like to extend our sincerest gratitude toward Per-Olof Jacobson, our company super-visor, who provided us with valuable guidance and resources throughout the work. Furthermore, we wish to thank Jan H¨o¨og and Per-Olof Jacobson for giving us the opportunity to work at SAAB all these years and for believing in us. A sincere appreciation to Mohammad Loni, our academic supervisor, for his commitment in aiding us, enthusiasm for the research area and continuous guidance throughout the process. We would also wish to extend our gratitude towards Emil Bj¨orklund and Johan Hjorth, our friends and classmates at M¨alardalen University, for providing us with fused images, a quality metric method, report corrections, and emotional support throughout the process. Your support has been invaluable. Not to forget, our dear friends from graduating class of 2020 in Dependable Systems, thank you for all these memorable years. To our families, our dearest thank you for your patience and support. Additional thanks to Professor Mikael Ekstr¨om, Doctor Martin Ekstr¨om, Head of Division Fredrik Ekstrand, and Henrik Falk at M¨alardalen University for providing useful information and a facility to conduct our master thesis.
Abstract
Enhanced vision and object detection could be useful in the aviation domain in situations of bad weather or cluttered environments. In particular, enhanced vision and object detection could improve situational awareness and aid the pilot in environment interpretation and detection of hazardous objects. The fundamental concept of object detection is to interpret what objects are present in an image with the aid of a prediction model or other feature extraction techniques. Constructing a comprehensive data set that can describe the operational environment and be robust for weather and lighting conditions is vital if the object detector is to be utilised in the avionics domain. Evaluating the accuracy and robustness of the constructed data set is crucial. Since erroneous detection, referring to the object detection algorithm failing to detect a potentially hazardous object or falsely detecting an object, is a major safety is-sue. Bayesian uncertainty estimations are evaluated to examine if they can be utilised to detect miss-classifications, enabling the use of a Bayesian Neural Network with the object detector to identify an erroneous detection. The object detector Faster RCNN with ResNet-50-FPN was utilised using the development framework Detectron2; the accuracy of the object detection algorithm was evaluated based on obtained MS-COCO metrics. The setup achieved a 50.327 % AP@[IoU=.5:.95] score. With an 18.1 % decrease when exposed to weather and lighting conditions. By inducing artificial artefacts and augmentations of luminance, motion, and weather to the images of the training set, the AP@[IoU=.5:.95] score increased by 15.6 %. The inducement improved the robustness necessary to maintain the accuracy when exposed to variations of environmental conditions, which resulted in just a 2.6 % decrease from the initial accuracy. To fully conclude that the augmentations provide the necessary robustness for variations in environmental conditions, the model needs to be subjected to actual image representations of the operational envi-ronment with different weather and lighting phenomena. Bayesian uncertainty estimations show great promise in providing additional information to interpret objects in the operational environment correctly. Further research is needed to conclude if uncertainty estimations can provide necessary information to detect erroneous predictions.
Acronyms
ADS-B Automatic Dependent Surveillance - broadcast. 3 ALS Approach Landing System. 40
AP Average Precision. 10, 12–14, 22, 33, 38, 39, 43, 45, 49, 57–59, 61, 62 AUC Area under curve. 13
BDL Bayesian Deep Learning. 16, 20
BNN Bayesian Neural Network. 20, 38, 59, 62
CAT Category. 3
CNN Convolutional Neural Network. 8, 16, 17
DCN Deformable Convolutional Network. 43, 44
DenseNet Dense Convolutional Network. 7, 16, 17, 19, 43, 44 DH Decision Height. 3
DL Deep Learning. 4, 8, 9, 14, 16, 20, 22, 56, 61 DPM Deformable Part-based Model. 8
DPN Dual Path Network. 43, 44
DSSD Deconvolutional Single Shot Detector. 43, 44
EASA European Union Aviation Safety Agency. 3
EUROCAE European Organisation for Civil Aviation Equipment. 13
FAIR Facebook AI Research. 26 FN False negative. 10, 46, 47, 49, 50 FOD Foreign Object Debris. 25, 26, 39, 60 FP False positive. 10, 12
FPN Feature Pyramid Network. 7, 8, 26, 27, 37, 38, 40, 43–49, 51–54, 57, 58, 60–62
GAN Generative Adversarial Network. 18, 19 GDPR General Data Protection Regulation. 41 GPS Global Positioning System. 1
ICAO International Civil Aviation Organization. 3, 4, 14, 25
IoU Intersection over Union. 10–13, 45, 49, 57–59, 61, 62 IR Infra-red. 53, 54, 59
JSON JavaScript Object Notation. 34, 37, 38
ML Machine Learning. 9, 13, 14
MS-COCO Microsoft Common Objects in Context. 9, 13, 14, 22, 26, 31, 34, 35, 37, 39, 43, 44, 62
NDA Non-disclosure agreement. 25, 41 NIN Network in Network. 17
NIQE Natural Image Quality Evaluator. 32, 49, 58, 61
NN Neural Network. 4–9, 14, 16, 17, 19–21, 24, 38, 39, 57, 59, 61
OpenCV Open Computer Vision. 32, 38
Pascal VOC Pattern analysis, statistical modelling and computational learning Visual Object Classes. 9, 13, 14, 31, 33–35, 43
PCA Principal Component Analysis. 16–18
RCNN Region with Convolutional Neural Networks. 7, 8, 26, 27, 37, 40, 43–49, 51–54, 57, 58, 60–62 RDRT-s Runway Detection Robust Test set. 28, 31–34, 38, 40, 49, 51–53, 59, 61
RDRTr-s Runway Detection Robust Training set. 28, 31–35, 49–54, 58, 59, 61 RDT-s Runway Detection Test set. 28, 31–33, 38, 42, 45–48, 54, 55, 58, 59, 61, 62 RDTr-s Runway Detection Training set. 28, 31–33, 35, 37, 38, 45–49, 51–54, 58, 59, 61 ReLU Rectified Linear Unit. 6, 16, 17, 57, 58, 62
ResNet Residual Neural Network. 7, 16, 17, 19, 26, 27, 38, 40, 43–49, 51–54, 57, 58, 60–62 ResNeXt Residual Neural Network Next Dimension. 19, 26, 27, 37, 38, 43–46, 57, 61, 62
SNIP Scale Normalization for Image Pyramids. 43, 44 SOD Salient object detection. 8, 9
SPPNet Spatial Pyramid Pooling Network. 8 SSD Single Shot Multibox Detector. 7, 8, 43, 44
STDN Scale Transferable Object Detection Network. 43, 44 SURF Speed-Up Robust Feature. 4
SVM Support Vector Machine. 8
TAWS Terrain Awareness and Warning System. 3 TCAS Traffic Collision Avoidance System. 3 TDM Top-Down Modulation. 43, 44
TN True negative. 10 TP True positive. 10, 12
UAV Unmanned Aerial Vehicle. 1
VGG Visual Geometry Group. 7, 16, 43, 44
XML Extensible Markup Language. 33–35
Table of Contents
1. Introduction 1
2. Background 3
2.1 Runway Visual Range Regulations . . . 3
2.1.1 Contaminated Runway Regulations . . . 4
2.2 Comparing Object Detection Methods . . . 4
2.3 Theory behind Neural Networks . . . 4
2.3.1 Transfer Function . . . 5
2.3.2 Training the Neural Network . . . 6
2.3.3 Performance Generalisation . . . 6
2.4 Object Detection . . . 7
2.4.1 History of Object Detection . . . 8
2.4.2 Object Detection Categories . . . 8
2.5 Benchmark Data Sets . . . 9
2.5.1 Pattern analysis, statistical modelling and computational learning Visual Object Classes (Pascal VOC) . . . 9
2.5.2 Microsoft Common Objects in Context (MS-COCO) . . . 9
2.5.3 ImageNet . . . 10
2.6 Accuracy measurement . . . 10
2.7 Introducing Machine Learning in Avionics Systems . . . 13
2.7.1 Machine Learning Safety Issues . . . 14
2.8 Summary Background . . . 14
2.9 Collaboration . . . 14
3. Related Work 16 3.1 Improve Generalisation of Deep Neural Network Backbones . . . 16
3.2 Data Augmentation Techniques . . . 17
3.3 Estimating Uncertainty . . . 20
3.4 Summary Related Work . . . 21
4. Problem Formulation 22 4.1 Definitions . . . 22
4.2 Research questions . . . 22
5. Method 24 5.1 Systematic Literature Review . . . 25
7. Results 42
7.1 Systematic Literature Review . . . 42
7.2 First Test Session . . . 45
7.3 Second and Third Test Session . . . 49
7.4 Uncertainty Estimation . . . 54
8. Discussion 56 9. Conclusions 61 9.1 Future Work . . . 62
References 71
Appendix A Image credentials 72
1.
Introduction
The interest of computer vision for enhancement or replacement of traditional human environment interpretation has grown in the last years. The main goal of computer vision is to obtain meaningful information from an image or video sequence [1]. A practical challenge in computer vision includes detection, classification, and positioning objects within images, known as object detection [2].
Object detection has already been deployed in commercial products, some of which are used by most of society daily, such as smartphones. One popular feature deployed in smartphones is face detection, which requires detection to be performed before the recognition phase [3]. The technology has gained attention in several domains and used in applications such as obstacle avoidance and path planning for robots [4, 5] to video surveillance in cities [6, 7].
Today, Unmanned Aerial Vehicles (UAVs) uses vision-based solutions for navigation and environment interpre-tation, and their applications are versatile. Proposed environment interpretation applications are object detection for monitoring of disaster areas [8] and using object detection to scan the ocean’s surfaces [9]. Since the applications for UAVs are vast, navigation solutions need to follow the same principle. UAVs can be deployed in unexplored and sometimes hostile environments, where traditional navigation techniques might not be supported, such as Global Positioning System (GPS). Object detection methods such as automatic landing on a moving target [10] and autonomous navigation with the aid of obstacle detection [11] are some of the implementations.
Object detection is a broad field, and the most suitable method for a vision task depends on the applications’ operational environment. Appropriate hardware and computing capabilities could enhance the performance of the detection application. However, in specific industries, the overall feasibility of object detection is questioned and is related to restrictions imposed by regulatory organs. The concerns are related to the object detection system’s capability of providing safe and reliable predictions about the environment.
Discussions and questions about this topic have already started in the automotive industry, where autonomous platforms have been deployed in self-driving cars, and visual object detection is used to locate pedestrians, obstacles, and traffic signs [12]. The ability of the vision-systems in charge of control in self-driving cars was further questioned when multiple accidents occurred with the Tesla car operating in autonomous mode. One event in particular, which is questionable and relates to object detection, is the crash between a Tesla car and a truck, where the obstacle detection system could not distinguish between a white truck and the sky [13].
One of the most stringent industries regarding system safety is the aviation industry. The development of an avionic system is strictly regulated and needs to comply with domain standards in order to be deployed. Nevertheless, enhanced vision and object detection could be useful in the aviation domain in situations of bad weather or cluttered environments. In particular, enhanced vision and object detection could aid the pilot in environment interpretation and detection of hazardous objects. The environment in which aircraft operates has numerous objects to consider, and one challenging question is how to assess if a particular object could cause hazardous consequences for the aircraft in operation, particularly during the landing phase. In 2009 in Dublin, Ireland, a Boeing 757-200 surpassed a lawnmower still present near the runway during landing. The lawnmower, travelling in the same direction as the aircraft was 18.5 m from the aircraft centerline, unknowing of the incoming
and resource-demanding. Thus, techniques and methods developed to address the lack of comprehensive data will be of great interest in this research. The object detection needs to be robust to changing environmental condi-tions, including weather and lighting variations. Techniques to incorporate robust detection will also be considered.
The thesis is structured in the following manner: following the introduction in Section 1, a background describing essential concepts for this work are provided in Section 2, followed by related work in Section 3. The research aim and direction of the thesis is defined in problem formulation, Section 4. Further, the method and conducted experiments are described in Section 5, followed by identified ethical and societal consideration in Section 6. Ob-tained results from the systematic review and experiment is presented in Section 7. The work is concluded with a discussion of the obtained results in Section 8, a conclusion for each defined research question and future work in Section 9.
2.
Background
The airborne safety depends on multiple factors, one major factor is the pilot’s ability to interpret the surrounding environment the aircraft currently finds itself within. The ability to correctly interpret the surrounding environment is an important part of the pilots Situational Awareness (SA). The environment is built up by two information sources; visual interpretation and information provided by navigation-, safety-, and decision support systems. Knowledge of terrain height and positions of airborne and ground-based objects in close proximity of the aircraft can reduce the risk of collision [16, 17]. Example of such aiding systems in service are Automatic Dependent Surveillance - broadcast (ADS-B), Traffic Collision Avoidance System (TCAS) [18], and Terrain Awareness and Warning System (TAWS). These systems are incessantly enhanced to provide as much aid as possible to the pilot, to increase the airborne safety. The impact of collision reduction systems may be further amplified by applying the usage of algorithms to detect, track, and interpret objects in the aircraft’s proximity. Object detection algorithms would reduce the workload resting upon pilots, and from a long-term perspective, further increase the airborne safety.
2.1
Runway Visual Range Regulations
Earlier detection of objects increases the time available for decision making, and the number of available trajectory options might be multiplied. By enhancing the ability to track positions of dynamic and static objects, actions necessary to avoid future collisions are more predictable and facilitates the choice of a collision-free trajectory. The plausibility of a correct decision correlates with the ability to interpret various objects in the environment.
The pilot may be even more dependent upon such aiding systems during critical phases of flight due to different circumstances (weather and location). European Union Aviation Safety Agency (EASA) defines ’Critical phases of flight’ in Annex I Definitions [19] to include take-off run, take-off flight path, final approach, missed approach, landing, and landing roll. Furthermore, accident statistics from International Civil Aviation Organization (ICAO), covering all commercial aircraft in operation above 5.7 tonnes over the world, shows inflation of runway safety-related accidents during the past three years [20]. Concerning the runway safety, Boeing’s statistical summary indicates that the final approach phase is the most affected when it comes to aircraft incidents [21]. Hence, the prime focus of this thesis will lie upon object detection during the final approach and landing phases to identify a possible aiding system for landing safety. The runway has to be clear of hazardous objects in order to allow for a safe landing. Visual enhancement is necessary to detect these possible hazardous objects, or circumstances, in time. There exist available methods to detect objects on runways from ground level. On manned airports, this is done through inspection and camera aided surveillance of the runway. However, this does not generate a complete overall picture of the current situation, and therefore the methods are unable to guarantee the runway to be hazardous free. On the contrary, unmanned airports have limited access to the human inspection of the runway. During the landing phase, there are regulations that the pilot and aircraft have to follow. The restrictions regulate under which circumstances an aircraft can perform a landing, as well as decision height for when a landing
To decrease the decision height, the pilot could benefit from support-systems that may aid in the interpretation of the current environment. Object detection could be a part of such a system that helps detect potentially hazardous objects during the landing phase when the pilot is unable to interpret the surroundings due to bad weather or poor visibility.
2.1.1 Contaminated Runway Regulations The runway surface is divided into three categories [19]
• Contaminated runway
> 25 % of runway surface is covered by water, slush, or loose snow, equivalent to > 3 mm water, snow, ice, or wet ice.
• Wet runway
< 25 % of runway surface is covered by water, slush, loose snow, snow, ice, or wet ice. The definition also includes the occurrence of a moist reflective surface.
• Dry runway
A runway with no contamination’s or wet surface.
The breaking and steering abilities of the aircraft will be affected by the current condition of the runway. Thus, the pilot is informed of the runway condition by the airport to maintain safety according to regulations from ICAO [23]. Awareness of the current runway condition is regulated by ICAO, detecting water, ice, snow, and other weather phenomenons present on the runway.
2.2
Comparing Object Detection Methods
In the field of computer vision there exists both conventional methods, such as Scale Invariant Feature Transform (SIFT) and Speed-Up Robust Feature (SURF), and Deep Learning (DL) based solutions, which includes training a Neural Network (NN), to solve vision tasks. N.O’Mahony et al. [24] compare traditional and DL based methods to solve vision tasks. These tasks could be image classification, object detection, or image recognition. Before the emerge of DL based methods, traditional methods were used to perform object detection. According to N.O’Mahony et al. the main advantage of algorithms such as SIFT and SURF is that they are independent of the input space used. The algorithms are general and unbound to any class, compared to the DL model, which learn features to detect based on the input space and are highly dependent on the quality of the data set. These properties of traditional methods make them useful for image stitching and image reconstruction. An advantage of DL based approaches for object detection is that the model is trained on a specific input space, whereas algorithms such as SIFT and SURF are handcrafted for specific features. The complexity increases with the number of classes that need to be detected with traditional methods, which could be unmanageable when many classes are added. All classes that are added requires manual tuning of features, which could be an extensive and complicated task since each description for each feature could vary greatly between classes. DL based object detection train NNs on data sets which contain several classes. The training process of the NN aims to learn the pattern of the input space and extract features. In [25], A. Lee tests both traditional methods and a DL based approach for object detection in a mobile robot. The traditional methods tested, and SURF, were effective to implement with respect to the amount of training data that needs to be collected to get at a descriptive model. However, DL based object detection exceeded in detection accuracy and number of classes that could be detected, compared to the traditional methods.
2.3
Theory behind Neural Networks
NNs are built up by one or more layers of artificial neurons, and these will be referred to as neurons. A neuron consists of an input, weight, activation function, and possibly a bias. Figure 1 illustrates neuron functionality.
The different layers of a NN may have an unequal amount of neurons. Each layer is classified either as a hidden layer or an output layer, where the second refers to the layer producing the final output, see Figure 2a. The input multiplied with the weight is added with the bias (if there is one), which produces the net input to the activation function. Together the activation function and output function represent the transfer function, which defines the net output. Thus the characteristics of the NN are defined by the chosen transfer function(s) [26].
F
W NI B Input OutputNeuron
Transfer functionFigure 1: Example of a neuron structure, where w represents the weight, b the bias, NI the net input, and F the activation function.
2.3.1 Transfer Function
As mentioned in Section 2.3, the activation function and the output function composes the transfer function. The available activation functions for the neurons may be arranged in three categories, according to W. Duch and N. Jankowski [27], activation by inner product, distance, or a combination of both. Activation by inner product, also known as weighted activation, is the most commonly used activation technique and is the base for sigmoidal transfer functions. The base for Gaussian transfer functions is activation by distance—the euclidean distance between the input vectors and a reference. Similarly, the output functions are categorised as soft or hard, step functions and multistep functions are classified as hard due to their binary output, while other functions able to produce intermediate values are classified as soft functions. Furthermore, the NN layers are not required to utilise the same activation and output functions, a distinction between the hidden layers and the input and output layers are usually made [27, 28].
With that said, the activation functions have a significant influence on the characteristics of the NN, amplifying the weight of making the right choice to achieve the desired performance. Research of this topic is still ongoing, but there are some frequently used activation functions which concepts are discussed below [29].
The tanh function suffers from vanishing gradients due to the same reason as sigmoid. The key distinction between the two is the sensitivity to input data; tanh has an even sharper derivative than sigmoid [30].
Rectified Linear Unit (ReLU) [31] is a popular activation function, in similarity to sigmoid and tanh it is also a non-linear approach. ReLUs output corresponds to Equation (3), producing n as output if n is positive and zero as output if n is negative. However, the output is not constrained by the function, allowing the output to range from zero to infinity.
F (n) = max(0, n) (3)
The characteristic of ReLU to not activate neurons when the input is negative comes with both benefits as well as drawbacks. Less activated neurons are advantageous when creating deep networks due to increased efficiency. On the other hand, it causes another problem named dying ReLU. The phenomenon is a result of a zero gradient, which occurs when the neuron is repeatedly fed a negative input causing the neuron to stop responding to input. Different variations of ReLU have been created to avoid a zero gradient, e.g., leaky ReLU, by adding a small factor to the function in the case of a negative input [30].
2.3.2 Training the Neural Network
A data set representative for the prospective environment and its objects of interest are required to train the NN to be able to function as an object detector. The data set is initially divided into sets of training and test. The training set may be further divided into two sets, training and validation. The division of the data set for the three sets are optional, M. T. Hagan et al. [26] suggested 70 percent for training, 15 percent for validation, and the remaining 15 percent for test as an initial guideline. In a basic sense, NN models update initial weights based on the error made from the data set used for training. The weights are altered for every epoch made, and one epoch represents one iteration of the whole training data set. For the majority of the time, the data set is too large to be able to be processed by the NN at once. Therefore one epoch is divided into batches or mini-batches. The number of iterations is equal to the number of batches required to be completed to complete one epoch [32]. The epochs are repeatedly performed until the model is deemed sufficient, or the learning is stopped [33, 34]. The validation set can be used as a mean to analyse the NN during training, indicating when to stop the learning process to avoid overfitting [26, 35]. S.-i. Amari et al. [35] commend the usage of a validation set to identify a suitable learning stop if the size of the training data is less than 30 times the amount of weight parameters. Further, the size of the validation set is advised to be the size of the training set divided by the square root of the number of weight parameters multiplied by two. After the training session is completed, the NN generalisation capabilities are assessed based on the test set results. The NN performance, given a comprehensive test set, predicts the outcome to expect when applied in future applications [26].
2.3.3 Performance Generalisation
The performance of a NN is affected by errors present, such as interpolation and extrapolation errors [26]. Inter-polation errors, also known as overfitting, occurs when the model generated fits the training data set with high complexity. Thus, causing prediction accuracy to be high with the training data set, and arbitrary when exposed to a new data set [36, 37, 26].
Extrapolation error, also known as underfitting, occurs due to a lack of variations in the training data set, resulting in low prediction accuracy and consecutively resulting in an unreliable object detection algorithm [37, 26]. The performance of the NN is the model’s ability to generalise, generalisation, and is assessed by measuring how the model performs on data that is not part of the training set. For the model to be robust and useful, increasing generalisation performance is crucial. Methods can be applied directly to the architecture of the model, and the concepts are described below.
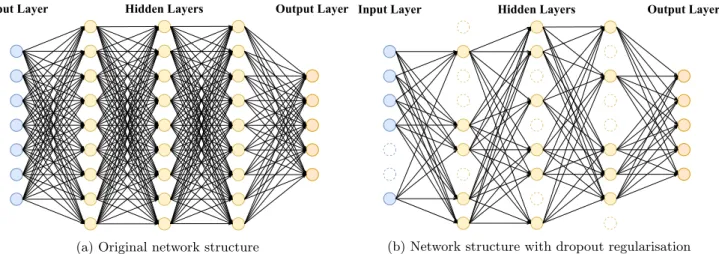
Dropout regularisation refers to a technique used while training the NN, neurons are removed at random during training to take samples from various narrowed down network architectures. The neurons may be removed from any layer, but the output layer, Figure 2 illustrates the difference between a network utilising dropout
regularisation and a network that does not. The amount of neurons to drop is decided by the retain probability p. Guidelines for choosing p depend on the layer, input layers and convolutional layers are recommended a higher probability, while others may receive a standard probability of 0.5 [38, 39]. Furthermore, a validation set can help determine p. The method limits the risk of over-training the NN on the given data set by the alternating structure of the NN [38].
Input Layer Hidden Layers Output Layer
(a) Original network structure
Input Layer Hidden Layers Output Layer
(b) Network structure with dropout regularisation Figure 2: Two images illustrating network layout. a) Example of an original layout of the NN structure. b) Example of a possible layout during one mini-batch of the NN structure caused by dropout regularisation.
Batch normalisation addresses the problem of internal co-variance shift, referring to the learning inefficiency caused by an alternating input due to the domino effect caused by prior layers input alteration. In other words, normalisation is applied for each mini-batch to normalise the input to decrease the required training time. As a result, the NN will produce a non-deterministic output. Therefore, the effect or need of applying the previously mentioned technique, dropout regularisation, may decrease when applying batch normalisation [40].
Transfer learning aims at shortening the time to find the optimal weights for a task, reusing weights of a NN with a similar function as initial weights of the NN to be created. The method may decrease the number of epochs required [41].
Pre-training refers to training a NN on a data set before re-training and fine-tuning the NN based on another data set, the purpose of the method is to decrease the training error. For smaller data sets, the technique helps with generalisation performance, while more extensive data sets reap greater benefits in terms of generalisation [42].
2.4.1 History of Object Detection
The fundamental concept of object detection is interpreting what objects are present in an image with the aid of a prediction model or other feature extraction techniques. Zhengxia Zou et al. [45] presents a comprehensive and in-depth review of the evolution of object detection for the past 20 years. Object detection techniques have changed during the last years with the rise of DL techniques. Before DL emerged and became the standardised approach for object detection, other techniques were used. These techniques were mainly crude and involved performing advanced computation to detect objects within the image. One of the first algorithms to gain attention was the Viola-Jones Detector [47]. This object detection algorithm performed face detection in images. The method involved iterating of all positions in the image, called the sliding window. Today’s detectors are influenced by these early solutions, and one which contributions still play a major part is the Deformable Part-based Model (DPM) proposed by P. Felzenszwalb, D. McAllester, and D.Ramanan [48]. Contributions such as bounding box regression and mixture models, among others, are still used in today’s object detection methods. After insight about Convolutional Neural Networks (CNNs) ability to learn the representation of features, progression in object detection has been successful and at a high rate. The progress has ever since been in the domain of DL, and the progress may be grouped into two distinct categories, as mentioned in Section 2.4, one-stage detectors and two-stage detectors [45].
The evolution of two-stage detectors started with Region with Convolutional Neural Networks (RCNN), pro-posed by R. Girshick et al. [49]. The method used for detection in RCNN involves extraction of object candidate boxes and is performed with selective search. Each extracted candidate is sent to a CNN [50]. The CNN model used in RCNN has been trained on ImageNet. The final step in the detection process uses linear Support Vector Machine (SVM) [51] classifiers.
The SVM takes each region and predicts if an object can be found within the region. One major problem with RCNN was the slow detection speed, the result of computing multiple intersections. To overcome the slow detection speed, solutions such as Spatial Pyramid Pooling Network (SPPNet) [52], Fast RCNN [53], Faster RCNN [54], and FPN [55] were proposed to speed up the detection process and accuracy.
Parallel with the evolution and contribution of two-stage detectors to the object detection domain, one-stage detectors gained attention. The main idea behind the two-stage detector was to detect and verify, in contrast to the one-stage detector, which utilises one NN for the entire image. You Only Look Once (YOLO), was the stepping stone into one-stage detectors and was proposed by R.Joseph et al. [56]. The YOLO detector proved to be very fast in comparison with other detection methods at the time. Bounding boxes and probabilities are predicted for each section of the image simultaneously to decrease the computation time required. However, one major drawback of the YOLO detector is the poor localisation accuracy of small objects compared to the two-stage detectors. To cope with the localisation accuracy problem in one-stage detectors SSD was proposed by W.Liu et al. [57]. Despite that, two-stage detectors remained superior with better accuracy results. In 2017, T.-Y.Lin et al. proposed a solution by introducing Focal loss [58]. The solution was realised in RetinaNet, and the contribution made one-stage detectors accuracy of the same standard as two-stage detectors. In general, two-stage detectors are known to archive higher accuracy than one-stage detectors, while one-stage detectors have a faster detection speed [45].
2.4.2 Object Detection Categories
There are several categories of object detection and each specialised and aimed for a specific detection application and available resources. The branches are versatile, ranging from text detection and highlight detection to 3D point cloud detection and 2-3D pose detection. In this section, a few related categories will be presented.
Weakly supervised object detection is a detection model that only provides a limited number of fully-annotated images during training, but detects a greater number of objects. The training is performed with limited bounding box annotations of the object classes [59].
Salient object detection (SOD) focuses on extracting objects that are ultimately prominent in an image. The method consists of two separate parts, where the first part is detecting one or more salient objects, and the second is a segmentation of the found object(s). Before the emergence of DL, detecting salient regions in an image
was performed by computing colour contrasts and edges. The DL methodology for SOD, given a model trained for a specific data set, is to minimise the error between ground truths and the salience maps. The ground truths can be obtained by annotations [60, 61].
Edge detection is used to extract boundaries and prominent edges in an image or video sequence by detecting how the brightness in the image is changing. The irregularities and distinct changes in the image’s brightness are marked as object edges, and hence detecting the object [59].
Multi-domain object detection aims to use object detection to detect various objects from different envi-ronments, essentially a universal detector. There are many challenges in this area, and the researcher is proposing several solutions from diverse data sets to cope with generalisation problems to methods for reducing annotation time by utilising pre-trained models [59].
Object detection in videos has its challenges to address but is highly applicable in several real-world ap-plications, such as surveillance and autonomous vehicles. The challenges in detection from video sequences are related to image quality and are the result of the scenery and the motion of objects. Phenomenons such as motion blur or video defocus can occur, which can cause unreliable predictions [59].
2.5
Benchmark Data Sets
While the mentioned training and layer-tuning techniques for NNs are beneficial for the general performance, the overall performance relies heavily on the available training data. The training data is the fundamental building block for a NN feature extraction capabilities. The model will learn the features to detect based on the training data. Thus the model is only as good as the data it has seen. Therefore, the quantity and quality of the data are essential to achieve good performance from the model. Generally, the amount of data depends on the complexity of the prediction task. However, a more extensive data set will contain more information for the model to learn from and thus more accurate and correct predictions. A comprehensive data set contains not only a large amount of data but also varying data describing the different classes. It is a comprehensive task to collect, process, and deploy the data since each image needs to be annotated by hand. Several open-source benchmark data sets are publicly available for object detection tasks, which speeds up the object detector development [62].
2.5.1 Pattern analysis, statistical modelling and computational learning Visual Object Classes (Pascal VOC)
Pascal VOC is the name of both the recognition and detection challenge as well as the data set. The data set is publicly available and contains images and annotations for 20 classes. The first version of the data set was released in 2005 and contained four classes with approximately 1500 images. The set increased each year until the latest version, released in 2012. Pascal VOC 2012 contains approximately 11500 images and 27000 annotated instances, where 12 of the data set is split into training and validation. The images in Pascal VOC are collected from the image and video hosting website Flickr1. The developers of Pascal VOC reported using these types of images to
split configurations for different detection competitions. In the 2017 data set, the split is divided into development (test-dev) and challenge (test-challenge) with approximately 20000 images in each split [65, 66].
2.5.3 ImageNet
The ImageNet data set contains a large collection of images, approximately 14 million with 21000 object classes, and is a research project maintained by researchers around the world. This large collection of images contains approximately 1 million annotated images of the different classes. The data set is not publicly available as a compound data set; the distributed image URL achieves access. Further, ImageNet organises competitions on a subset of the ImageNet data set in both image classification and object detection. The competition is called ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Before each competition, the training data set is released, which contains annotated instances for 1000 classes of objects. Further, the test data set is released without annotations, and each contestant annotates the test data set before submitting for evaluation [67, 68, 69].
2.6
Accuracy measurement
The demonstration of accuracy calculations in this section follows the principle described in [70, 71]. Object detectors are evaluated based on how accurate the predictions are. To retrieve this evaluation, the Average Precision (AP) is calculated. Calculating AP is dependent on three different parameters, precision, recall, and Intersection over Union (IoU). The classification predictions are computed to calculate precision and recall. The classification is divided into positive and negative classes. From this, predictions are divided based on correct and incorrect predictions.
The definitions are as follows:
• True positive (TP) - Correct prediction of positive class • True negative (TN) - Correct prediction of negative class • False positive (FP) - Incorrect prediction of positive class • False negative (FN) - Incorrect prediction of negative class
Based on the classifications predictions, precision and recall are calculated following Equation (4) and (5).
P recision = T P
T P + F P (4)
Recall = T P
T P + F N (5)
IoU measures how well the predictions are in comparison to the ground truth. The ground truth refers to the annotated bounding box, and the predictions to the output from the object detector’s predicted bounding box. An illustration is shown in Figure 3, where the black bounding box is the ground truth, and the purple is the predicted bounding box.
Figure 3: The image shows an example of annotated ground truth bounding box (purple) and predicted bounding box (black).
From the ground truth and predicted bounding box, the area of overlap and union is extracted, shown in Figure 4.
From the parameters precision, recall, and IoU, the AP can be calculated by pre-defining a IoU threshold for correct predictions and plot the results in a precision-recall curve.
An example of how this is performed will be shown by computing the AP for a simple made-up data set containing rabbits. Table 2 show calculations for precision and recall. In this example, the predictions will be deemed correct if IoU ≥ 0.7.
Prediction IoU≥ 0.7 Precision Recall
1 Yes 0.90 0.3
2 Yes 0.90 0.35
3 No 0.45 0.35
4 Yes 0.5 0.7
Table 2: Calculations for precision, recall and IoU threshold for example made-up rabbit data set.
By presenting precision and recall from Table 2 in a graph, AP can be obtained. The precision result will vary depending on the occurrence of FP or TP and thereby increase and decrease as predictions are made. To maintain a robust AP that is not effected by small variations, the curve is smoothed. The original curve, which corresponds to the values in Table 2 and the smoothed curve can be seen in Figure 5.
Figure 5: Precision-recall graph for entries in Table 2. The xy-axis have been re-scaled for better overview.
where p is precision and r is recall.
AP = Z 1
0
p(r)dr (7)
Interpolated AP was used in Pascal VOC until 2008. The prediction where deemed to be a correct positive if IoU ≥ 0.5, and for multiple object detection of the same class classified as negatives. The method calculates an average over 11 points, from 0.0 to 1.0, for the recall to obtain the AP score. The definition for 11-point interpolate AP is shown in Equation (8), where r is the recall value.
X r∈(0.1,0.2,..1.0)
APr (8)
Area under curve (AUC) is used by Pascal VOC to compute AP since 2008. The interpolate method failed to capture if the precision dropped. In this method, each recall value is considered, and the accuracy is calculated for each drop in the precision. This method is also applied for AP calculations for ImageNet.
MS-COCO AP uses 101-point interpolate AP calculation. The AP score is calculated using multiple IoU thresholds, staring from 0.5 to 0.95 and stepping 0.05 between each threshold. The average over the thresholds corresponds to the AP score. MS-COCO reports several metrics, which can be viewed in the Table 3.
AP@[0.5:0.95] Mean AP over multiple IoU thresholds, step size 0.05
APIoU =0.5 AP for IoU=0.5 (Pascal VOC metric)
APIoU =0.75 AP for IoU=0.75
APsmall AP small objects (pixel resolution <32x32 )
APmedium AP medium objects (32x32 <pixel resolution <96x96)
APlarge AP large objects (pixel resolution >96x96)
Table 3: Overview of MS-COCO AP metrics.
2.7
Introducing Machine Learning in Avionics Systems
To allow the usage of ML in safety-critical software for the aviation domain, evidence to support the claim of sufficient safety measures has to be presented. The aviation industry is one of the most stringent industries of system safety. Certification requirements are placed upon systems intended for usage within avionic applications to achieve system safety. Various standards have been presented over the years to provide guidelines to achieve compliance with certification requirements, such as DO-254 [72] for avionic hardware and DO-178B [73] for avionic software by the Radio Technical Commission for Aeronautics (RTCA) and the European Organisation for Civil Aviation Equipment (EUROCAE). ARP4761 [74], Guidelines and Methods for Conducting the Safety Assessment
2.7.1 Machine Learning Safety Issues
Providing evidence for the safety case proposes quite a challenge for ML, S.Burton et al. [78] identified measurable performance criterion, transparency, environment adaption, and data set comprehension to be the key parameters to impact the safety case.
The first parameter refers to the challenge of producing test cases able to evaluate critical tasks. For instance, when validating the application’s ability to push for a collision-free trajectory when exposed to the scenario of harmful objects present on the runway. The produced test cases need to provide enough support to achieve the evidence necessary to claim acceptable safety.
While DL algorithms affect safety by obstructing the transparency, in other words, predictability has to be achieved despite the fact that the course of action is concealed.
Learning over time during execution is another common phenomenon for ML; this entails requirements upon speed and interpretation accuracy when operating in motion. For products to be used within aviation, this could be adopted prior to finalising the product. Therefore, the ability to adapt to the current environment within the airspace is crucial to maintain an acceptable safety level while finalising the product. Furthermore, S.Burton et al. emphasise the importance of details, acknowledging the characteristics in the data set is of utmost importance due to the effect a change of context may inflict on the algorithm’s performance in real-life situations. For example, if all images in a data set were taken with a specific tilting-angle of the camera lens, the end application would have to have a corresponding tilting-angle of the camera attached.
Another significant aspect is how comprehensive the collected data is—in particular, covering innumerable scenarios without overstepping acceptable means to collect them. E.g., get access to the data representations of dangerous landing situations with hazardous objects present on the airport runway. Each of these parameters is to be considered when evaluating the safety level. As a result, a need to know the outcome for every input is required to achieve system safety for ML, according to S. Burton et al. and J. M. Faria.
2.8
Summary Background
In the background section, methods to perform object detection are discussed, as well as regulations of contaminated runways. Runway contaminations, such as water or ice, are regulated by ICAO. Both traditional methods and DL based approaches are evaluated, where recent years progress and rapid advances in DL based approaches have achieved great success of object detection tasks. Further, the fundamentals of DL based approaches are discussed, such as NNs as feature extractors, training processes of NNs and common issues, as well as the evolution of object detection architectures over the past years. The importance of a comprehensive data set to achieve the desired performance of the object detector is discussed, as well as benchmark data set, MS-COCO and Pascal VOC, and the metric AP to measure performance between models. Further, the discussion concludes with the importance of considering the safety issue with the introduction of deep learning in a safety-critical application. Among several failure conditions that are emphasised, a consistent and comprehensive data set of the operational environment is of great importance to achieve a good description of the environment.
2.9
Collaboration
This master thesis is executed in collaboration with SAAB Avionics Systems, combining the knowledge gained from the Dependable Systems program with the interest of one major manufacturer of aircraft components for both military and commercial purposes. SAAB produces new inventions and techniques to aid with the protection of people and society. The company in large strives to offer solutions for air, land, naval, civil security, and commercial aeronautics. They are located in various countries across the world, as well as cities in Sweden, with their headquarter located in Stockholm, Sweden.
The motivation of this thesis is to provide a knowledge base for SAAB’s work with Cleansky 2 [79]. Cleansky 2 is a collaboration between the European Commission, universities, and companies to reduce greenhouse gas and noise pollution through the development of new technologies for civil aircraft. SAAB is involved in two Cleansky 2
programs, contributing to the Large Passenger Aircraft Programme and Systems Programme for Avionics Extended Cockpit. This work is primarily conducted to provide a knowledge base for the Large Passenger Aircraft Programme, which aims to develop new technologies for enhanced vision and awareness to reduce the pilot workload. From the company’s perspective, object detection could be one of the stepping stones necessary to combine a solution that would provide enough support to reduce the pilots’ workload.
3.
Related Work
A large part of the recently published work presents solutions to vision-tasks involving DL techniques. As mentioned in Section 2.3.3, DL techniques require a large amount of comprehensive data to increase generalisation performance and to avoid overfitting and underfitting problems. In the following related work sections, NN architectures designed to cope with these issues are discussed, as well as different augmentation techniques to build a comprehensive data set. Further, recent advances in uncertainty estimations for predictions using Bayesian Deep Learning (BDL) are investigated.
3.1
Improve Generalisation of Deep Neural Network Backbones
There exist several architectures that incorporate solutions to counteract poor generalisation into their model, such as AlexNet, GoogLeNet, VGG-16, ResNet, Inception-V3 and DenseNet [36, 43].
One of the first models to get attention was AlexNet, proposed by A. Krizhevsky et al. [80] in 2012. The attention was mainly the result of AlexNet winning the ILSVRC in 2012. Their NN architecture consisted of five conventional layers and three fully-connected layers and used ImageNet, which consists of 15 million labelled images with 22000 categories. Their architecture requires the dimensions of the image to be constant, while ImageNet had various dimensions. Therefore, each input image was given a fixed resolution of 256 x 256 and the training was performed with raw Red Green Blue (RGB) values. The authors also showed that the use of ReLU activation in their architecture yielded shorter training and prevented vanishing gradient problems, which, in short terms, caused weights and biases not to be updated. Their contribution extends beyond the result of ILSVRC and the use of ReLU activation and is related to their architectural approach to address overfitting. The two first fully-connected layers used dropout, see Section 2.3.3, which was used to reduce the dependency between neurons and, as a result, learn features more robust. The authors reported that removing dropout made the network overfit. A part from architectural modification to increase generalisation, they used data augmentation techniques to increase their data set in order to address overfitting. They used two distinct methods, horizontal reflections and altering intensities of the RGB channels through Principal Component Analysis (PCA) Colour Augmentation. The main idea of PCA is to change the RGB values which are most distinct in the image. To each RGB pixel, Ixy = [IxyR, IxyG, IxyB], the following is added,
[p1, p2, p3][α1λ1, α2λ2, α3λ3]T (9) where pi are eigenvalues and λi are eigenvectors, belonging to the RGB pixel values co-variance matrix and αi is the random variable [81]. The authors reported that the PCA augmentation highlighted an important property of objects, showing that their specific characteristics are independent of changes in intensity and colour. The authors concluded that their architecture and used techniques show great promise in achieving promising results on challenging data sets [82]. From this point, NNs kept on getting deeper in the hope of achieving better performance results. However, adding layers without a clear goal proved to be unnecessarily computational heavy. Additionally, overfitting showed to be an issue for very deep NNs, passing information through many layers, the complexity is increased and allows for a polynomial of a higher degree to fit the trends of the data. In the same manner, information can be obstructed if the model is too simple, causing the trend of the data to be of a higher degree than the polynomial possible to create. Further issues were large variations in the location and size of objects in images. In some images, information was scattered while in others, the information occupied smaller portions. Depending on how the information was distributed, a suitable size of the kernel in convolution operations changed. Szegedy et al. [83] proposed a solution targeting the mentioned issues with their CNN called Inception-V1, namely GoogleNet. Szegedy et al. proposed kernels with various sizes in a layer, essentially expanding the architecture width instead of the depth. However, the architecture was still considered to be deep and subject to vanishing gradient problem, which caused weights and biases in the initial layers not to be updated. Since the initial layers are important for the extraction of crucial patterns of the input data, the total accuracy of the network declines. The Inception-V1 computed the total loss by introducing two auxiliary classifiers, in which they utilised softmax at the output of their inception module to computed the auxiliary loss, which was weighted with the total loss.
Additionally, they introduced a dropout layer to address the problem of overfitting. Short after Inception-V1 was introduced, both V2 and V3 were presented by Szegedy et al. [84]. They made further improvements on the convolutions and the size of kernels to cope with representational bottleneck, which could cause information of the feature to be lost. Further, they argued that the auxiliary classifiers mainly contributed to improvements at the end of the training. Due to this, batch normalisation was added, which would act as a regularisation method. Additionally, they used label smoothing to prevent overfitting. Label smoothing is added to the loss function and will lower the confidence of each predicted label, which will result in lower loss each time there is a false prediction. The authors concluded that the added batch normalisation and label smoothing made it possible to train relatively small data sets while achieving high performance results compared with other denser networks [85].
In conjunction with the release of Inception-V2 and -V3, another network addressing the depth of NNs was presented by K.He et al. [86], Residual Neural Network, known under the name ResNet. To achieve better performance with deeper networks, they introduced shortcut connections between each convolutional 3x3 layer pair. The shortcuts required the dimensions of the feature maps to be of equal dimension, hence two solutions were proposed. The first solution padded the mapping with zero entries, while the second solution utilised a convolutional 1x1 layer to get coherent dimensions. The solution reused the PCA colour augmentation and scale augmentation used by AlexNet for processing images provided by ImageNet. The authors state that normalisation was applied after every convolutional layer before activation, as recommended by S. Ioffe and C. Szegedy, who introduced batch normalisation. Due to the recommendations from the said paper, dropout regularisation was not applied. Their experiments proved successful for deep NNs, achieving the lowest test error with 110 layers. However, when attempting an aggressive approach of 1202 layers, their solution indicated negative test error results compared to the 110 layer version, which they believed to be due to overfitting. Regularisation methods were discussed as possible future countermeasures, as well as the impact of a small data set in contrast to the depth. Such methods include dropout and maxdrop, which removes features from the feature map with a probability p.
As mentioned earlier, generalisation performance is a main criterion for evaluating NNs. Techniques are designed to achieve more robust and valuable models. The flow of information is another parameter that has been a research topic aimed at improving the performance of networks. Aiming to decrease the iterations required for training and fluctuation of prediction accuracy, as well as increased available information in the network [87]. Huang et al. [88] presents a new detection engine, named DenseNet, with a unique connectivity pattern and CNN as backbone. They were inspired by the common denominator, connectivity patterns, of ResNets, Highway Networks [89], Stochastic depth [90], and FractalNets [91]. Their design consists of three convolutional layers, three ’dense blocks’, three pooling layers, and one linear layer. In the experiment architecture, every dense block represents a 3-layer dense block, where every layer in the block consists of an input layer, batch normalisation layer, ReLU layer, and convolutional layer. The purpose is to apply filters on all layers, generating feature maps as output for each layer. Additionally to the input received from the previous layer, feature maps from all previous layers are delivered as an additional input to all the succeeding layers. Thus, their coinage of the term dense. Furthermore, during their experiment, they also applied dropout regularisation after each convolutional layer (not part of a dense block) but the first, if the data set under evaluation had not been exposed to data augmentation. Their solution
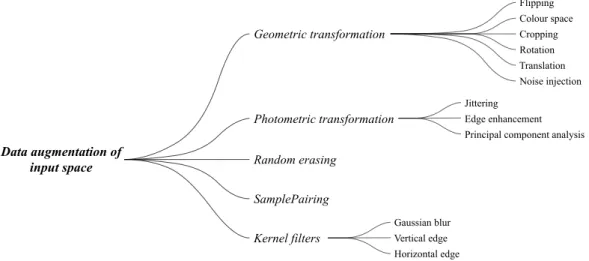
transformation, photometric transformation, kernel filters, random erasing, and sample-pairing. Despite the first three methods emerging a couple of years back, these techniques are frequently used to extend the data set to enrich the quantity and variety. A visualisation of the sectioning of available data augmentation techniques for the input space can be seen in Figure 6.
Geometric transformation refers to transformations that alter an image’s geometry, such as axis flipping, editing of RGB, cropping, or rotation of the image. Apart from those common techniques used for image editing, this term also includes translation and noise injection. The first technique refers to shifting an object’s position in an image to the left, right, bottom, or top. The shifting of object positions in images prevents the algorithm from repeatedly being subjected to images with nearby object pixel positions. The added space needed to shift the image in a direction can be either constant values or noise. The second method refers to simply adding random values to the pixels of the image, such as Gaussian noise [36]. While photometric transformation is a term for techniques that affects the pixel values, e.g., jittering, edge enhancement, and the PCA colour augmentation introduced in conjunction with AlexNet in 2012. Jittering entails pre-defined or random modification of the pixel values, whereas edge enhancement adjusts merely the pixels surrounding objects to highlight the outlines of interesting objects [95]. In contrast to geometric and photometric transformations, kernel filters adjust the sharpness of an image. The filters can either increase clarity or blurring. To increase the sharpness, vertical or horizontal edge filters can be applied, while Gaussian blur filters can be used to reduce the sharpness. The filters are applied by traversing through the image with a nxn matrix [36].
In 2017 a new augmentation technique was presented by Z. Zhong et al. [96] named Random erasing. This method randomly extracts a rectangular area in an image and replaces the old pixel values within that area with new randomly generated values. The method is developed to increase the robustness by training the network on a training set that contains images with loss of information.
Further advancement in the research of data augmentation was made when H. Inoue [97] published SamplePair-ing in 2018. The data augmentation technique takes two images, A and B, with two labels to create a new image. Each pixel of the new image is constructed by taking the average pixel intensity of the corresponding two old pixel values. The new image is given the label of image A. Inoue observed different gains in reduction of training and validation error depending on if image B is collected from the training set or not, as well as if it is chosen with or without limiting conditions. Best results were achieved by collecting image B from the training set but without any conditions. Flipping Colour space Cropping Rotation Translation Noise injection Jittering Edge enhancement Principal component analysis Gaussian blur Vertical edge Horizontal edge Geometric transformation Photometric transformation Random erasing SamplePairing Kernel filters Data augmentation of input space
Figure 6: Visualisation of classification of data augmentation techniques for the input space.
Adversarial Network, today known as GANs for short. These networks opened the door to the creation of new images from scratch, in other words extending the data set for a NN using two combined networks. This can facilitate the development of a comprehensive data set by enabling the creation of situations difficult or resource-demanding to capture. GANs consists of a generator and a discriminator, the two NNs. Where the generator has the task to identify the transfer function representing the object to be illustrated, and the discriminator has the task to identify if the input consists of generated data or real data. Essentially, pasting objects into an image and thereby creating a synthesised image of the environment. By setting them against each other, one may push the other to the better and vice versa [99].
Another sidetrack is style augmented images, first introduced in 2015 by L.A. Gatys et al. [100], also known as style transfer. They developed this method to create artistic images using NNs. The idea is to take an input image and a style image. Perform alterations such that the merged image inherits properties from the style image while retaining the original features from the input image. The layers are separated to identify the shapes and colour of the style image and characteristic features of the input image. Furthermore, R. Geirhos et al. [101] applied style transfer to evaluate if shape or texture impacts object recognition. Their results shed light upon the importance of texture rather than shape for the object detectors. They proposed images to be stripped of their original texture by utilising this knowledge to train the networks on shapes rather than texture. Geirhos observed increased generalisation when the networks were exposed to distortion, including situations and distortions not trained upon.
Distortions include natural distortions, distortions plausible to exist in reality, such as snow, rain, fog, and light exposure. Recent methods enrich the data set by applying distortions, commonly known as corruption, in addition to adjustments of images as well as the creation of new ones [102]. Hendrycks and Dietterich [102], applies 15 different corruption methods to enrich ImageNet and create ImageNet-C. An essential aspect of the distortion was the intensity of the various corruptions, representing varying size and amount, small or big snowflakes, heavy or light rain, to mention a few. For ImageNet-C, five intensity levels were available for each of the 15 corruption methods, resulting in 75 scenarios considered in the test. C. Michaelis et al. [103] adopted the corruption approach of Hendrycks and Dietterich, creating the three corruption data sets Pascal-C, Coco-C, and Cityscape-C. Similarly, they utilised the three data sets to evaluate robustness towards corruption, concluding a significant decrease in performance when tested upon. They conducted a second test to evaluate if style transfer data augmentation could increase the overall robustness to various corruption categories. When extending the training set with style augmented images, their results indicate a significant increase of performance when tested on corrupted images without compromising the performance of images not exposed to distortion.
The corruption robustness of DenseNet and Residual Neural Network Next Dimension (ResNeXt) [104], among other networks, is evaluated by Hendrycks and Dietterich [102], by applying 15 different corruption methods to enrich imageNet and create ImageNet-C. They trained various NN models on training data from ImageNet, while utilising ImageNet-C for the test data. This gave an indication of each network’s robustness capabilities, their results insinuate that DenseNet and ResNeXt shows greater promise than ResNet.
3.3
Estimating Uncertainty
Despite the forthcoming of DL methods, there are no guarantees for predictions to be correct. False predictions with high accuracy or objects not detected are still uncertainties that impose a safety issue. Additionally, large data sets are needed to fill in the gaps between the known and unknown. Building an object detection algorithm with high awareness of the operational environment does not only include constructing a robust data description of the environment. It could be beneficial to extract what parts of the image the model is uncertain about before displaying the potentially hazardous object to the pilot. The information about uncertainties and predictions from the algorithm could be incorporated into a fault-tolerant design to perform comparisons or voting in a safety-critical application.
To address the issues with uncertainties and lack of comprehensive data sets, BDL shows great promise. BDL is a combination of state-of-the-art DL techniques to extract and interpret objects and Bayesian Probability theory to address uncertainties [105, 106].
The general idea is to estimate, through probability theory, the prediction uncertainty for the input of the NN. The parameters of the NN, weights and biases, determine what output corresponds to a certain input. In Bayesian Neural Networks (BNN), the values of the parameters are not statically assigned. Instead, the parameters each have a distribution, and each time a prediction is computed the weights and biases are sampled from the assigned distribution. This operation is performed multiple times from which an output distribution is constructed. From the output probability distribution, estimations of uncertainty and confidence can be extracted. The complicated part is to estimate the probability distribution for the NN parameters. In most cases, the initial distribution is assumed to be Gaussian. In that case, the mean-value, µ, corresponds to the sampled value for the NN weights, and the variance, σ2, will correspond to the prediction uncertainties. Estimating the probability distribution for the weights and biases is computed with Bayes’ theorem, see Equation (10).
P (A | B) = P (B | A) P (A)
P (B) (10)
The theorem estimates posteriors, P (A | B), which is the updated parameters of the NN. In Equation (10), A corresponds to the initial estimation of weight and bias distribution, and B is the input images and matching labels.
The uncertainties are obtained by computing the variance of the posterior distribution, which is composed of both aleatoric and epistemic uncertainties, see Equation (11).
V ar(P (A | B)) = aleatoricuncertainty+ epistemicuncertainty (11) The aleatoric uncertainty holds the statistical uncertainties in the input data. If the input data is noisy, the aleatoric uncertainty will be high. The epistemic uncertainty provides insight into systematic uncertainties in the predictive model. From epistemic uncertainty, an indication about how well the NN model is predicting the input-space. If epistemic uncertainty is high, the NN model could be further developed to better understand the input data [107, 108].
M.E. Khan et al. [109] highlights the importance of addressing uncertainties in DL to obtain robust and reliable detection. In their work, they present an algorithm with natural-gradient and is performed by interfering with the network weight. They suggest that the weight-perturbation method requires less memory and computation while obtaining uncertainty estimations with comparable quality as other methods.
Y. Gal and Z. Ghahramani [106] presents a BNN, claiming the BNN to possess characteristics to suit smaller data sets, as well as to reduce the probability of an overfitting phenomena.
X. Zhang et al. [110] use a Bayesian framework to perform object detection on moving objects that blend into the background. The algorithm uses both Discriminative modelling and Camouflage modelling to identify areas that are both camouflaged and non-camouflaged. The result showed that Bayesian framework object detection capabilities are preferable to other comparable detection algorithms.
3.4
Summary Related Work
The results from related work show that the majority of deep learning backbones used in research incorporate methods to improve generalisation, and each has been successful. As the network architectures became deeper in aim to improve performance, new methods emerge to counteract generalisation problems by altering the kernel sizes and applying batch normalisation. However, choosing a NN architecture that can generalise well is only part of the solution. Constructing a comprehensive data set that can describe the operational environment and be robust for weather and lighting conditions is vital if the object detector is to be utilised in the avionics domain. The related work shows that building a comprehensive data set can be done by applying various augmentation techniques. Augmentations can be used to extend the data set but also to enrich, by adding objects to images to create synthesised representation of the environment. Additionally, Bayesian uncertainty estimation would serve as a great compliment in assuring the reliability of the output predictions from the network, by providing uncertainty outputs.
4.
Problem Formulation
To introduce vision-based object detection as a part of a decision-support system to enhance SA, evaluating accuracy and robustness is crucial.
The background and related work study indicated DL methods developed in the last years as successful in object detection tasks. Several industries are interested in applying object detection within their domain and affirm the potential success of introducing it. However, DL based object detection has limitations, and one of particular interest is the need for a comprehensive data set. The object detection algorithm in this work would need to detect specific objects during the final approach to an airport, where availability of a comprehensive data set of the operational environment is limited and needs to be constructed. Further, the detection capabilities must be maintained regardless of environmental conditions, such as fog, snow, and rain. A representation of the different environmental conditions needs to be incorporated into the data set to achieve accurate and robust detection. In this work, research will be focused on constructing a robust representation of the operational environment. The object detection algorithm suitable for the detection task will be selected based upon the highest obtained accuracy for state-of-the-art object detection algorithms. Potential hazardous objects need to be detected from a distance, giving the pilot enough time to plan and complete an appropriate manoeuvre to avoid a collision. Therefore, the selected object detection algorithm needs to show potential in detecting small objects, since objects detected from a distance can appear small in the image frame. Further, by only considering the improvement of robustness, no guarantees are provided for correct detection of potentially hazardous objects to be correct.
Erroneous detection, referring to the object detection algorithm failing to detect a potentially hazardous object or falsely detecting an object, is still a major safety issue. The possibility of providing uncertainty estimations for regions of the image which could be used to improve detection will be investigated. Introducing new software components into avionics systems requires a rigorous development process to embed safety measures such as fault-tolerant techniques and redundancy to comply with domain standards. However, this work is conducted as a concept phase to test whether the constructed data set with the chosen object detection algorithm can provide robust and accurate detection in the operational environment.
4.1
Definitions
The object detector’s ability to perform detection with the lack of a comprehensive data set will be assessed by measuring and quantifying accuracy. From the obtained results, an analysis of the object detection algorithm’s robustness can be performed. In this section, a definition for each is defined.
• Accuracy
The overall accuracy of the object detection algorithm is defined as the AP score, AP @[IoU=.5:.95], obtained from MS-COCO metrics, see table 3.
• Robustness
Robustness refers to the object detection algorithm’s ability to provide accurate detection with change of light settings and weather.
4.2
Research questions
Based on the information and conclusions from Problem Formulation, Section 4., research questions were formu-lated with the aim to address the problems.
RQ1: Which object detection algorithm can provide high prediction accuracy, including high prediction accu-racy for small objects, with benchmark data sets?