Prestandajämförelse mellan Xception, InceptionV3
och MobileNetV2 för bildklassificering på
nätpaneler
HUVUDOMRÅDE: Datateknik FÖRFATTARE: Fleury Birindwa HANDLEDARE: Peter Larsson-Green
Detta examensarbete är utfört vid Tekniska Högskolan i Jönköping inom [se huvudområde på föregående sida]. Författarna svarar själva för framförda åsikter, slutsatser och resultat.
Examinator: Maria Riveiro Handledare: Peter Larsson-Green
Abstract
In recent years, deep learning models have been used in almost all areas, from
industry to academia, specifically for image classification. However, these models are huge in size, with millions of parameters, making it difficult to distribute to smaller devices with limited resources such as mobile phones. This study addresses
lightweight pre-trained models of convolutional neural networks which is state of art in deep learning and their size is suitable as a base model for mobile application development.
The purpose of this study is to evaluate the performance of Xception, InceptionV3 and MobilNetV2 in order to facilitate selection decisions of a lightweight
convolutional networks as base for the development of mobile applications in image classification. In order to achieve their purpose, these models have been implemented using the Transfer Learning method and are designed to distinguish images on mesh panels from the company Troax. The study takes up the method that allows transfer of knowledge from an existing model to a new model, explain how the training process and the test process went, as well as analysis of results.
Results showed that Xception had 86% accuracy and had 10 minutes processing time on 2000 training images and 1000 test images. Exception’s performance was the best among all these models. The difference between Xception and InceptionV3 was 10% accuracy and 2 minutes process time. Between Xception and MobilNetV2 there was a difference of 23% in accuracy and 3 minutes in process time. Experiments showed that these models performed less well with smaller training images below 800 images. Over 800 images, each model began to perform prediction over 70% accuracy.
Keywords - image classification, Machines Learning, deep learning, convolutional neural network, CNN, Xception, InceptionV3, MobilNetV2, artificial intelligence, AI, decision
Sammanfattning
Under de senaste året har modeller för djupinlärning använts inom nästa alla områden, från industri till akademi, särskilt för bildklassifikation. Dessa modeller är dock enorma i storlek, med miljontals parametrar, vilket gör det svårt att distribuera till mindre enheter med begränsade resurser såsom mobiltelefoner. Denna studie tar upp små modeller av faltningsnätverk som är toppmoderna inom djupinlärning och vars storlek är lämplig för mobilapplikation.
Syftet med denna studie är att utvärdera prestanda på faltningsnätverken Xception, InceptionV3 och MobilNetV2 för att underlätta vid valbeslut av faltningsnätverk som bas vid utveckling av mobila applikation inom
bildklassificering. För att uppnå syftet har dessa faltningsnätverk implementeras med hjälp av överföringsinlärning metod samt utformas för att skilja på bilder av
nätpaneler från företaget Troax. Studien tar upp metoden som möjliggör att överföra kunskap från befintliga förtränade modeller till nya modeller. Studien förklarar även hur träningsprocessen och testprocessen gick till samt analys kring resultatet.
Resultat visade att Xception hade 86 % noggrannhet med en processtid på 10 minuter på 2000 träningsbilder och 1000st testbilder. Xceptions prestation var bäst bland alla dessa modeller. Skillnaden mellan Xception och Inception var på 10 % noggrannhet och 2 minuter processtid. Mellan Xception och MobilNetV2 var skillnaden på 23 % noggrannhet och 3 minuter processtid. Experimentet visade att dessa modeller presterade mindre bra vid mindre träningsbilder under 800st. Över 800st bilder började respektive modell att utföra prediktering över 70 % noggrannhet.
Nyckelord - bildklassificering, maskininlärning, djupinlärning, faltningsnätverk, Xception, InceptionV3, MobilNetV2, artificiell intelligens, AI, omdömen
Innehållsförteckning
Abstract ... i
Sammanfattning ... ii
Innehållsförteckning ... iii
1
Introduktion ... 5
1.1.1 BAKGRUND ... 5 1.1.2 PROBLEMBESKRIVNING ... 71.1.3 SYFTE OCH FRÅGESTÄLLNINGAR ... 8
1.1.4 OMFÅNG OCH AVGRÄNSNINGAR ... 8 1.1.5 DISPOSITION ... 8
2
Teoretiskt ramverk ... 9
2.1.1 BILDKLASSIFICERING ... 9 2.1.2 ARTIFICIELLT NEURONNÄT ... 9 2.1.3 FALTNINGSNÄTVERK ... 11 2.1.4 ÖVERFÖRNINGSINLÄRNING METOD ... 12 2.1.5 DATAFÖRSTORING ... 13 2.1.6 MOBILETNETV2 ... 13 2.1.7 INCEPTIONV3 ... 14 2.1.8 XCEPTION ... 14 2.1.9 MÄTMETODER ... 14 2.1.10 NOGGRANNHET ... 14 2.1.11 PROCESSTID ... 14 2.1.12 INLÄRNINGSMETODER ... 14 2.1.13 FÖRLUSTFUNKTION... 15 2.1.14 TENSORFLOW ... 15 2.1.15 TIDIGARE FORSKNING ... 153
Metod och genomförande ... 15
3.1.2 ARBETSPROCESSEN ... 16
3.1.3 ANSATS ... 16
3.1.4 EXPERIMENT ... 16
3.1.5 BILDER TILL EXPERIMENT ... 16
3.1.6 DESIGN ... 18
3.1.7 UTRUSTNING OCH UTVECKLINGSMILJÖ ... 18
3.1.8 IMPLEMENTATION ... 18 3.1.9 TROVÄRDIGHET ... 20
4
Empiri ... 21
4.1.1 INCEPTIONV3 ... 21 4.1.2 MOBILNETV2 ... 25 4.1.3 XCEPTION ... 295
Analys ... 34
5.1.1 FRÅGESTÄLLNING 1 ... 34 5.1.2 FRÅGESTÄLLNING 2 ... 356
Diskussion och slutsatser ... 37
6.1.1 RESULTAT ... 37
6.1.2 JÄMFÖRELSE MED ANDRAS RESULTAT ... 37
6.1.3 IMPLIKATIONER ... 38
6.1.4 BEGRÄNSNINGAR ... 38
6.1.5 SLUTSATSER ... 38
6.1.6 VIDARE FORSKNING ... 38
7
Referenser ... Fel! Bokmärket är inte definierat.
Bilagor ... 42
1
Introduktion
Kapitlet ger en bakgrund till djupinlärning som är tekniken bakom datorseende och bildklassificering på digitala bilder. Kapitlet introducerar även befintliga förtränade faltningsnätverk som kan användas till utveckling av mobila applikationer. Vidare presenteras studiens problembeskrivning, syfte och dess frågeställningar. Därtill beskrivs studiens omfång och avgränsningar. Kapitlet avslutas med rapportens disposition.
1.1.1 Bakgrund
Maskininlärning är ett område inom datavetenskap som handlar om metoder där datorer löser uppgifter på egen hand, utan inblandning av en programmerare. Det vill säga att datorer får en uppgift samt data att lära sig utifrån för att sedan kunna lösa den specifika uppgiften. Ett exempel på maskininlärning är självkörande bilar, där bilar är kapabla att navigera utan mänsklig styrning. Inom maskininlärning finns det tekniker som kallas för djupinlärning.Djupinlärning är en del av maskininlärning som är inspirerad av sättet den mänskliga hjärnan fungerar. Våra hjärnor uppfattar något genom att tänka på det och sedan drar en slutsats. På samma sätt arbetar
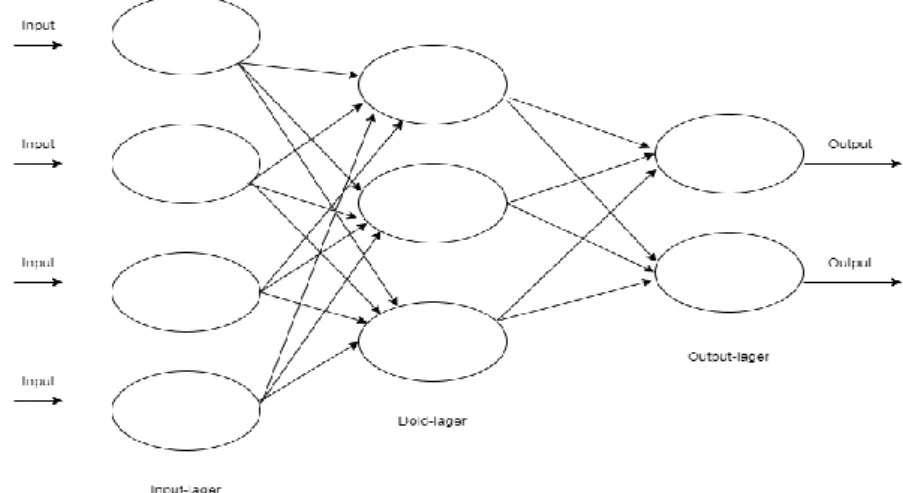
djupinlärnings modeller för att kunna hitta mönster i bilder. Det vill säga att hitta mönster genom beräkningar samt jämföra med bilder de tränades på. Djupinlärning bygger på artificiella neuronnät som är en sammankopplad grupp av ett stort antal noder som imiterar neuronnät, där varje nod har förbindelser med andra noder [1]. Detta kan liknas med de biologiska nätverk av neuroner som finns i våra hjärnor. Där varje neuron har uppgifter att ta emot, att analysera samt att föra vidare nervimpulser till de andra neuronen. Se figur 1.
Figur 1. Bilden Illustrerar ett artificiellt neuronnät.
Djupinlärning kan tillämpas inom flera olika datavetenskapliga områden där bland annat datorseende. Datorseende handlar om att automatisk bearbeta information som hämtas från digitala bilder. Datorseende innefattar bland annat bildklassificering som syftar på en process som kan kategorisera bilder enligt dess visuella innehåll [2]. Djupinlärningsmodeller inom dataseende är baserade på faltningsnätverk. Faltningsnätverk är ett artificiellt neuronnät som används mest inom bland annat bildklassificering och bildigenkänning som är en metod som handlar om att detektera ett objekt i bilder. Anledning till att faltningsnätverk är det populäraste sättet att implementera datorseende på, är på grund av dess prestanda i form av snabbhet och noggrannhet [3].
Att bygga en anpassad faltningsnätverk från grunden är en lång process som kräver lång träningstid, samt tillgång till stor datamängd och kraftfulla datorer. Ett billigt alternativt till detta är att använda sig av överföringsinlärningsmetod som innebär att ett befintligt förtränat djupfaltningsnätverk överför sina kunskaper till ett nytt
faltningsnätverk [4] [5]. Överföringsinlärning redogörs i kapitel 2.1.4.
Det finns en världsledande tävling inom datorseende som går ut på att låta forskare och stora IT företag från hela världen att jämföra deras faltningsnätverk för
bildklassificering på ImageNets databas med över 14 miljoner bilder [6].
Inlärningsmodellerna som har vunnit denna tävling brukar klassas som världens mest moderna modeller inom datorseende. Dessa världsledande modeller kan därefter användas som bas vid utveckling av djupinlärningsapplikationer.
I tabellen nedan visas de ledande modeller där noggrannhet är indelade i top-1 och top-5. Top-1 är noggrannhet där modells prediktering med högsta sannolikhet måste vara exakt det förväntade svaret. Top-5 är noggrannhet där modell har predikterat ett antal rätt av 5. Till exempel modeller får uppgift att utföra prediktering av en bild på en katt där modellerna ger resultat i form av sannolikhet:
- Hund 0.3 - Björn 0.4 - Katt 0.1 - Lejon 0.09 - Fågel 0.02
Dessa svar kommer att räknas som falsk enligt top-1 eftersom modellen första svar är inte rätt. Alla svar måste vara rätt för att det ska räknas i top-1. Men samma svar kommer räknas som rätt enligt top-5 eftersom en av 5 svar är rätt. Det vill säga att katt 0.1 matchar bilden. De befintliga faltningsnätverk visas i tabell 1.1.
Modell Storlek Top-1 Noggrannhet Top-5 Noggrannhet
Xception 88 Mb 0.790 0.945 VGG16 528 Mb 0.713 0.901 VGG19 549 MB 0.713 0.900 ResNet50 98 Mb 0.749 0.921 ResNet101 171 MB 0.772 0.928 ResNet152 232 MB 0.766 0.931 ResNet50V2 98 Mb 0.760 0.930 ResNet101V2 171 Mb 0.772 0.938 ResNet152V2 232 Mb 0.780 0.942 InceptionV3 92 MB 0.779 0.937 InceptionResnetV2 215 MB 0.803 0.953 MobilNet 16 MB 0.704 0.895 MobilNetV2 14 MB 0.713 0.901
NasNetLarge 343Mb 0.825 0.960
Tabell 1.1 Visar befintliga djupa inlärningsmodeller som kan användas som basmodell [13].
Xception, InceptionV3 och Mobilnät är några av de ledade faltningsnätverk som inte kräver för mycket minnesplats. Dessa befintliga faltningsnätverk har respektive storlekar av 88mb, 92 mb och 14 mb vilken gör dem lämpliga till att användas i mobila enheter för bildklassificering [7] [8].
Prestanda är ett mått på hur väl en modell utför sin uppgift, därmed i detta arbete är prestanda en kombination av de två variablerna processtid och noggrannhet. Tidigare studier har visat att det krävs mindre resurser för att bygga upp en modell baserat på förtränade modellen samt träna upp modellen att bli bra för en annan uppgift [6]. 1.1.2 Problembeskrivning
Begränsade resurser i mobila enheter i form av processor och minne ställer till ett problem vid utveckling av mobila applikationer där man väljer att utveckla en applikation som använder ett befintligt förtränade djupfaltningsnätverk [9]. Därför kommer denna studie att undersöka prestandajämförelse mellan Xception,
InceptionV3 och MobilNet. Dessa högpresterande djupfaltningsnätverk är valda på grund av dess resultat på noggrannhet från världsledande tävling inom
bildklassificering samt på grund av dess mindre storlek som lämpar sig som
basmodell för utveckling av applikation för bildklassificering. Att dessa modeller är i mindre storlekar betyder även att deras struktur består av mindre parametrar. Desto större parametrar desto mer kapacitet och snabbhet får modellen att lära sig att hitta mönster i bilder [10]. För att modellen ska kunna distribueras i mindre enheter såsom mobila enheter krävs det att modellen ska vara av mindre storlek, eftersom modellen skulle laddas i RAM-minnet samt ta upp resurser från processor. Detta leder till en utmaning i form av samspel mellan modellstorlek, processtid och noggrannhet [9].
För att kunna undersöka prestandajämförelse kommer respektive modell att utformas för att skilja på bilder av nätpaneler från företaget Troax. Utmaningen med dessa bilder är att olika modeller för nätpanelerna kan ses som identiska. Skillnad mellan dem kan vara små detaljer som till exempel millimeter skillnad i djup storlek. Noggrannhet är därför en primär faktor för att skilja mellan olika nätpanelers modeller. Det finns olika faktorer som kan påverka resultatet på noggrannhet av en modell såsom kvalitet på bilder och mängden av bilder. Därför kommer respektive modell att även tränas och utvärderas med samma kvalitet på bild och samma olika antal bilder från 100st, 200st, 400st och 800st. Detta är för att undersöka närmare hur respektive modellens noggrannhet ändras beroende på antalet av träningsbilder. Tiden det ta för modellerna att utföra utmatningen är viktig på grund av att
modellerna bör kunna behandla en stor mängd av bilder inom en rimlig tidsram. Då modellerna ska kunna distribueras i en mobil enhet är det viktigt att modellen inte förbrukar för mycket resurser i form av ström i enhetens batteri [9].
1.1.3 Syfte och frågeställningar
Syftet med denna studie är att utvärdera prestanda på Xception, InceptionV3 och MobilNetV2 för att underlätta vid valbeslut av faltningsnätverk modeller som
grundmodell vid utveckling av mobila applikation inom bildklassifikation.Därmed är studiens frågeställningar:
1) Hur skiljer sig Xception, InceptionV3 och MobilNetV2 när det kommer noggrannhet? 2) Hur lång tid ta det för respektive modell att tränas och att utföra en prediktering?
Anledningen till att studiens frågeställningar är fokuserad på noggrannhet och
processtid är för att kunna undersöka hur bra samspel det är mellan respektive modell med tanke på deras mindre storlek. En studie gjort av institutionen för datavetenskap, Marist college i USA har undersökt noggrannhet hos Xception modellen på djurbilder [11]. En annan studie gjort av Journal of infrastrukturer systems har undersökt
noggrannhet hos InceptionV3 modellen genom att klassificera damm mängderna på grusvägar [12]. Deras resultat går inte att generalisera på bilder av nätpaneler som ingår i denna studie, eftersom deras modeller inte är tränade på bilder som liknar nätpaneller från troax.
1.1.4 Omfång och avgränsningar
Denna studie omfattar inte att göra experiment i mobila enheter utan att allt kommer att utföras på en stationär dator. En stor anledning är att träning av en
djupinlärningsmodell kräver mycket datorkraft och kan ta flera träningstimmar beroende av modellen. Därför sker träning aldrig på mobilen.
1.1.5 Disposition
Kapitel 2 – Teoretiskt Ramverk: Tidigare relevant forskning och Teori redogörs Kapitel 3 – Metod och genomförande: Beskriver metod, arbetsprocess och genomförande
Kapitel 4 – Empiri: Beskrivning av data som samlats från experiment
Kapitel 5 – Analys: Beskriver resultaten, analys och frågeställningarna besvaras Kapitel 6 – Diskussion och Slutsatser: En sammanfattning av studien och
2
Teoretiskt ramverk
I följande kapitel beskrivs den teori som ger en teoretisk grund för att besvara studiens frågeställningar.
2.1.1 Bildklassificering
Bildklassificering är en del av datorseende som handlar om att kategorisera eller sortera bilder enligt dess visuella innehåll [2]. Inom djupinlärning utförs
bildklassificering av modeller som är byggd och tränade till att identifiera objekt som finns i bilder. Till exempel en bild på ett djur där man vill ta reda på vad det är för djur. I detta exempel är modellen tränad på att identifiera flera typer av djur. Modellen kommer att analysera bilden samt jämföra med data den tränades på. Resultat kommer ges i form av sannolikheterna på vad den imatade bilden representerar.
2.1.2 Artificiellt neuronnät
Artificiellt neuronnät är en klassificeringsmodell som imiterar sättet den mänskliga hjärnan behandlar information. Hjärnan består av celler som samlar och bearbetar elektriska signaler. En sådan cell kallas neuron eller nervcell. Neuron bearbetar information i hjärnan på så sätt att det kopplas till förmågan att bilda flera neuronnätverk.[1] Artificiellt neuronnät funkar på samma sätt. Arkitektur i ett
artificiellt neuronnät består av ett input-lager, ett output-lager och en dold-lager som i sin tur innehåller noder som är kopplade till varandra genom länkar. Länkarnas funktion är att föra vidare signalen som även kallas för vikt till nästa nod. Först beräknas summan av varje nod av dess input som kommer från andra noder sedan läggs in i en aktiveringsfunktion. Aktiveringsfunktion är den funktion som bestämmer om noden ska aktiveras. Det vill säga att noden aktiveras om den har fått rätt input. en aktiverat nod skickar en 1:a som output och en icke aktiverad nod skickar en 0:a. Se figur 2 som visar struktur på ett enkelt artificiellt neuronnät.
En enskild nod är oftast för enkel för att kunna ge pålitliga resultat på ett problem. Därför brukar noder grupperas när man bygger upp en modell. Till exempel utgående länk från en nod kopplas till ingående länk till en annan nod och utgående länkar ur dessa kopplas igen till andra ingående länkar. På detta sätt bildas output- lager. På motsvarade sätt bildas input-lager och dold-lager.
Input-lager
Är lager som tar hand inkommande anslutningar från andra neuroner. Dold-lager
Är den lager som består av beräkningsenheten. Här summeras alla inkommande signaler som kommer via länkar. Summering av dessa signaler tillsammans med aktiveringsfunktion bestämmer om noden ska aktiveras eller inte.
Figur 3. Dold-lager operation
Figur 3 visar en neuron som få in fyra inkommande signaler (S1,S2,S3,S4) via länkar från andra noder(X1,X2,X3,X4). Beräkningsenheten summerar in alla signaler med hjälp av Linjärkombination formeln. Sedan körs aktiveringsfunktion (f) med
summering av dessa signaler för att bestämma om noden ska aktiveras eller inte.
Output-lager
Är den lager som beräknar utgående anslutningar. Här samlas all information för att kunna dra slutsats på vad inmatade bilder motsvarar.
2.1.3 Faltningsnätverk
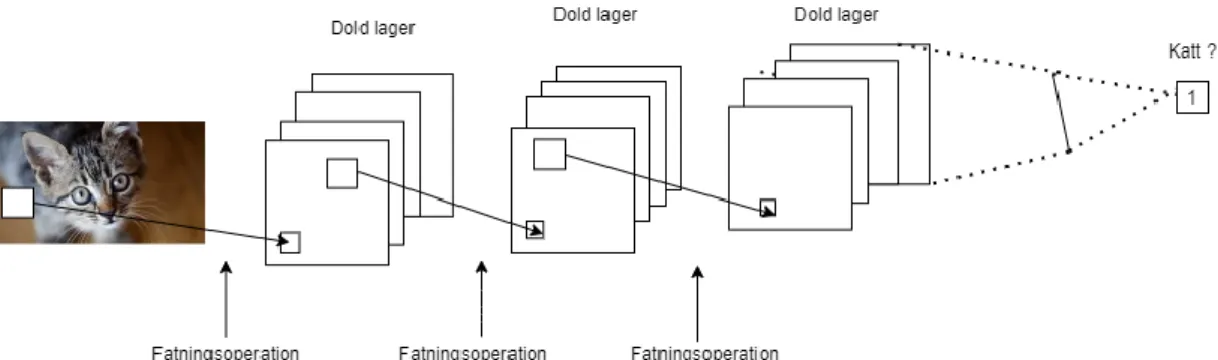
Faltningsnätverk (eng. Convolutional neural networks) förkortas vanligtvis som CNN eller ConvNets. Det är ett annat slag av artificiellt neuronnät som är ledande inom datorseende där inmatade data är i form av flera matriser såsom färgbilder. Färgbilder består av tre st. tvådimensionella-vektorer som omfattar tre färg kanaler (röd, grön, blå) i pixeln. Arkitektur av ett vanlig faltningsnätverk består utav av ett input-lager, ett output-lager och flera dolda lager som i sin tur inkluderar faltningslager, poollager och helt anslutna lager. Faltningslager har till uppgift att känna igen lokala mönster, och samlings lagers uppgift är att slå ihop likadana motiv. Se figur 4.
Figur 4. vanlig faltningsnätverk process.
Figur 4 illustrerar hur en vanlig faltningsnätverk modell utför sina processer. Där den inmatande bilden delas upp i ett antal bildpunkter, sedan samarbetar olika lager med att förutsäga vad bilden motsvarar. T.ex. första lager hittar ett öga och skickar vidare information till de andra lager, de andra lager hittar näsan och så vidare tills sista lagret samlar all information för att dra slutsats om vad bilden motsvarar.
Faltningslager
Här utförs faltning matematisk operation där operation kärnan är ett filter som används för att utlösa funktionerna från bilderna. Filtret är en matris som rör sig över inmatning bilden, utför skalärprodukt med regioner av bilden och får utdata som matris för skalärprodukten. Filtret rör sig på bilden med stegvärde. Om stegvärdet är 1, flyttas filtret med 1 kolumner med pixlar i ingångsmatrisen [13]. Se figur 5.
Figur 5. Faltning operation där inmatade bilden visualiseras som matrix som ska
Poollager
Poollager används för att minska storleken på bilder i ett faltningsnätverk och för att komprimera informationen till en mindre skala [13]. Se figur 6.
Det finns flera alternativ för att poola, de tre vanligaste är: max pooling behåller bara det största värdet för varje ruta
genomsnittlig poolning kommer att bygga genomsnittet från varje ruta sum-pooling kommer att bygga summan av varje ruta
Figur 6. Illustration av max pooling Stoppning och stegstorlek
Två viktiga parametrar av faltningsnätverk är stoppning och stegstorlek. Deras syfte är att valfritt lägga till "falska" pixelvärden till bilderna. Detta görs för att skanna alla pixlar samma antal gånger med filtret och för att hålla bildens storlek densamma genom olika dold lager.
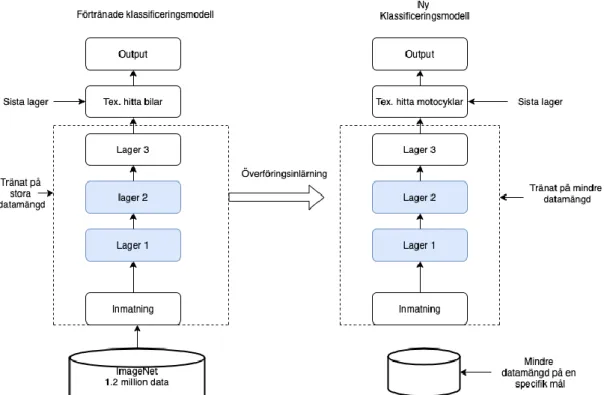
2.1.4 Överförningsinlärning metod
Överföringsinlärning är en metod som gör det möjligt att kunna överföra kunskap från en förtränad modell till den nya modellen. Förtränade modeller i denna studie är modeller som är tränade på en stor datamängd, exempelvis ImageNet, som är en databas med över 1.2 miljoner bilder med 1000 kategorier av olika bilder. Överförningsinlärning metoden minskar träningstid hos den nya modellen och förbättrar dess kunskap [5]. Metoden görs genom att ersätta det näst sista lagret i den förtränade modellen med det nya lagret som skall utföra nya uppgifter. Sedan tränas den nya modellen på den datamängd som uppgiften är till. Se Figur 7.
Figur 7. Bilden illustrerar exempel på hur överföringsinlärning kan ske mellan en gammal
modell och en ny modell.
2.1.5 Dataförstoring
De senaste framstegen i modeller för djupinlärning har till stor del hänförts till mängden och mångfalden av data som samlats in under de senaste åren.
Dataförstoring är en strategi som gör det möjligt för att öka mångfalden av bilder som finns tillgängliga för träningsmodeller, utan att faktiskt samla in nya data.
Dataförstärkningstekniker som original, beskärning och horisontell vändning används ofta för att träna stora neurala nätverk [14] .
Figur 8. Visar en bild på en katt i originalform och med tillämpade grundläggande
dataförstoring
2.1.6 MobiletNetV2
MobileNetV2 är en faltningsnätverk-modell för bildklassificering. Modellen var utformad för att effektivt maximera noggrannheten samtidigt som man tar hänsyn till de begränsade kapacitet hos mobila enheter. Modellen har mindre storlek för att kunna passa in i mobila enheter. Modellen består av en struktur som använder sig av
en djupgående faltning operation som använder 8 till 9 gånger mindre beräkningar jämfört med standard faltning operation[15]. MobilNetV2 har storlek på 14MB och 4 253 864 antal parametrar.
2.1.7 InceptionV3
Grundaren till InceptionV3 var intresserade av beräkningseffektivitet för träning av större nätverk, med andra ord hur faltningsnätverk kan skalas utan att öka
beräkningskostnaden. Forskningens lösning på problemet är att implementera 1x1 faltning [4]. Meningen med 1x1 faltning är att reducera dimensionen genom att tvinga data till att passa in i en mindre dimension. InceptionV3 har storlek på 92 MB och har 23 851 784 antal parametrar [4].
2.1.8 Xception
Xception är modell som utvecklad av Google. Modellen har en nätverksarkitektur som involverar djupavskiljbara faltning. Google beskriver djupavskiljbara faltning operation som ett mellansteg mellan den vanliga faltning operation och djupgående faltning operation [16]. Målet med detta är att öka effektivitet av användning av modellens parametrar. Xception har storlek på 88MB och 22 910 480 antal parametrar [16].
2.1.9 Mätmetoder 2.1.10 Noggrannhet
Noggrannhet är en metrisk för utvärdering av modeller, i denna studie kommer noggrannheten baseras på den bråkdel som modellen hade rätt. Formel för noggrannhet [17].
𝐴𝑛𝑡𝑎𝑙 𝐾𝑜𝑟𝑟𝑒𝑘𝑡𝑎 𝑠𝑣𝑎𝑟
𝑇𝑜𝑡𝑎𝑙 𝑎𝑛𝑡𝑎𝑙 𝑠𝑣𝑎𝑟 = Noggrannhet
2.1.11 Processtid
Processtid i denna studie syftar på genomsnittstid det tar för en modell att klassificera de inmatande bilder och genomsnittstid det tar för en modell att tränas upp.
2.1.12 Inlärningsmetoder
Inom djupinlärning är de två vanligaste sätten att träna en modell övervakad inlärning och oövervakad inlärning [18] :
gör det enklare att utvärdera att modellen har lärt sig rätt. Övervakad inlärning är den träningsmetod som används i denna studie.
– Oövervakad inlärning innebär att modellen tränas genom en okänd träningsdata där modellen har uppgift att hitta något mönster i data och lära sig av det. Här finns det inget rätt eller fel eftersom det inte finns något facit att utvärdera modellen.
2.1.13 Förlustfunktion
Förlustfunktion är en funktion som hjälper till att hitta de bästa möjliga parametrarna (inmatade datamängd) för en modell under träningsfasen. På så sätt lär sig modellen att prestera lika bra på ny datamängd som inte använts under träningsfasen [19]. 2.1.14 TensorFlow
TensorFlow är ett öppet programvarubiblotek som används för att bygga maskininlärningsmodeller [20]. Det gör det möjligt för utvecklare att skapa storskaliga neurala nätverk med många lager. TensorFlow används främst för: Klassificering, perception, förståelse, upptäckt, förutsägelse och skapande. 2.1.15 Tidigare forskning
Många studier har tidigare gjorts på bildklassificering som [21] där de jämför prestanda på två förtränade modeller AlexNet och CaffeNet med tre modeller som inte var förtränade. Överföringsinlärning teknik användes på de förtränade modellerna för att kunna användas till att lösa problemet. Testresultaten visar att förtränade modeller ger bättre resultat än de modeller som byggdes från grund [21]. I en studie gjord av Journal of infrastrukturer systems [12] där InceptionV3 implementerades för att klassificera damm mängderna på grusvägar i fyra
huvudnivåer (Ingen, Låg, Medium och Hög). I denna artikel samlades en datamängd med 4 000 bilder av grusvägar. För träning användes 80 % av datauppsättningen och 20 % användes för testning, resultatet visades att den förtränade modellen uppnådde noggrannhet på 72 %.
3
Metod och genomförande
3.1.1 Koppling mellan frågeställningar och metod
Till denna studie har ett och samma experiment genomfört för att besvara båda studiens frågeställningar. En litteratursökning genomfördes genom att leta efter studier som tidigare har gjorts samt hitta relevant information för att sätta upp miljön där experiment ska utföras. Litteratursökning i detta sammanhang innebär användning av relevanta artiklar som hjälpmedel för att kunna skaffa den teoretiska kunskapen till att sätta upp experimentdelen. Relevant information eller relevanta artiklar i detta sammanhang kan vara till exempel bruksanvisning om djupinlärningsmodell i ramverket TensorFlow.
Figur 9. Visar koppling mellan frågeställning och experiment
3.1.2 Arbetsprocessen
Studiens arbetsprocess bestod av sex huvudsakliga steg. Där första steg handlade om att samla in relevanta kunskaper genom litteratursökning. Andra steg handlade om att bestämma experimentet. Sedan inleddes genomförandet av experimenten. Fjärde steg handlade om att samla in data från experimentet. Femte steg handlade om att
analysera resultat från experiment för att säkerställa att resultat är trovärdigt. Sista steg sammanställdes slutresultatet.
Figur 10. Visar arbetsprocessen 3.1.3 Ansats
En kvantitativ ansats genomfördes för att experiment ska generera data som är mätbara. Mätbara data avser data som är oftast numerisk och kan tolkas i form av statistik [22].
3.1.4 Experiment
Experiment är en vetenskaplig metod som används för att undersöka specifika faktorer och dess relationer. Syftet är att ta fram pålitlig information som ska hjälpa till att klargöra osäkerheten som kan finnas bakom en teori, hypotes eller metod [23]. Studiens experiment bestod av två delar. Första del handlade om att träna upp
respektive modell med träningsbilder samt mäta upp träningstider och
predikteringstid. Andra del handlade om att mäta upp noggrannhet med hjälp av testbilder.
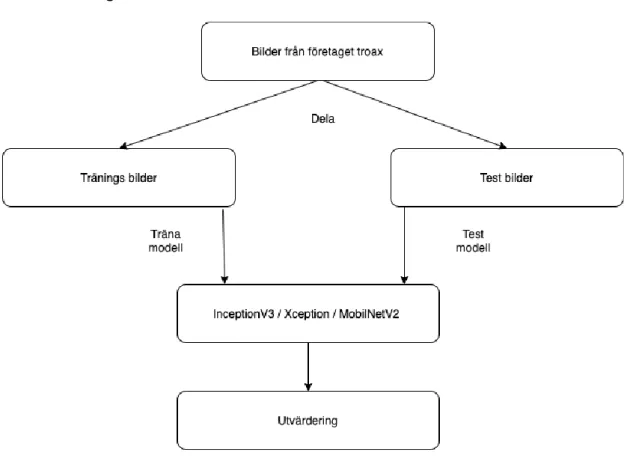
3.1.5 Bilder till experiment
Bilder som användes för att utföra denna studie är bilder på nätpaneler från företaget Troax. Bilderna är tagna från deras produktion och finns i olika form av tjocklek. Alla bilder konverterades till samma dimension och delades in i två kategorier; 2000 träningsbilder och 1000 testbilder. Träningsbilder användes vid träningsprocessen och de bestod av 3 klasser av nätpanellers modeller. Varje klass hade rätt namn på
bilder med märkning av namn följd siffror såsom bild1, bild2 och så vidare. Se figur 42 och 43 i bilagor för exempel bilder.
3.1.6 Design
Figur 11. Visar experimentdesign Samma uppdelning gjordes för alla tre modeller.
3.1.7 Utrustning och utvecklingsmiljö
Alla experiment gjordes på en stationär dator. Experiment utfördes i Pycharm. Pycharm är en integrerad utvecklingsmiljö som används för utveckling i programmeringsspråk Pyton och ramverk såsom TensorFlow.
3.1.8 Implementation
Först importerades alla bibliotek som ska användas i implementationen, se figur 12. Os bibliotek användes för att kunna komma åt filsystemet. Biblioteket tillåter även att packa upp ZIP-filer.
1. immport os
2. immport tensorflow as tf
3. from tensorflow.keras.applications.inception_v3 immport Inception_v3
4. from tensorflow.keras.applications.mobilnetv_v2 immport Mobilnetv_v2, prepro cess_input, decode_predictions
5. from tensorflow.keras immport layers
6. from tensorflow.keras immport Model
Efter importering av bibliotek, hämtades bilder från Troax som innehöll 2000 träningsdata samt 1000 testdata. Därefter användes tekniken dataförstoring som förklarades i kapitel 2.1.5 och visas i figur 13. Detta är ett viktigt steg innan modellerna tränas och testas för att förbättra resultatet.
Data generator läser bilderna och sedan konvertera dem till tf.float32. Tf. Float32 är en enda precision som lagars i 32 bitars form (1 bitars tecken, 8 bitars exponent och 23 bitar mantissa) [24]. Data generator är en generator som används till att förstora data. Den generar ny data efter de värden som man har valt. En generator skapades för träning data och en annan för valideringsdata. I träningsbilder används inte tekniken dataförstoring för att modellen inte ska validera på samma data som modellen har tränats på. Endast rescale som förklaras nedan användes för testbilder.
Efter flera iterationer av testning och med hjälp av [14] blev de värden som visas i figur 13 som användes för dataförstoring.
Några tillgängliga alternativ för dataförstorting:
Rescale är ett värde som multipliceras med data innan någon annan
behandling. Bilder består av RGB-koefficienter (0–255) med sådana värden så är det för höga för modellen att bearbeta, så värden riktas istället mellan 0 och 1 genom att skala med 1/255.
rotation_range är värde i grader (0–180), ett intervall vilket slumpmässigt roterar bilden
width_shift och height_shift (värdet är en bråkdel av den totala bredd eller höjd) som slumpmässigt kompilera bilder vertikalt eller horisontellt shear_range är för att beskära bilder
zoom_range är för att zooma in i bilderna
horizontal_flip är för vända bilderna horisontellt
1. train_dataGen = ImageDataGenerator(rescale =1. / 255., 2. rotation_range=40, 3. width_shift_range=0.2, 4. height_shift_range =0.2, 5. shear_range=0.2, 6. zoom_range=0.2. 7. horizontal_flip=true)
Figur 13. Visar alternativ för dataförstoring
Efter importering av bibliotek och förberedelse av data var det nu dags att implementera modellerna.
1. pre_trained_model= InceptionV3(input_shape=(150,150,3),
2. include:top= False
3. )
4. For layer in pre_trained_model.layers:
5. layer.trainable = False
Figur 14. Visar implementation av InceptionV3
De förtränade modellerna laddades ner, modifierades och tränades på 2000 bilder. I figur 14 kan man se att layer.trainble är i in loop och även satt till false. Detta gör att utgångs lager tränas till att anpassa sig till problemet.
Därefter implementerades callbacks funktionen som används under träningsfasen. Den ena callbacken används för att skriva ut träffsäkerheten och den andra för att stoppa träning om träffsäkerheten inte förbättras under de senaste 5 stegen. Se figur 44 för den fullständiga koden.
3.1.9 Trovärdighet
Testningsbilderna är olika från träningsbilderna när det kommer till vinkel och
avstånd från där bilderna togs. För att ytterligare hålla trovärdigheten hög som möjligt utfördes alla tester och träningsprocesser i samma dator och visualiserades alla steg via grafer med hjälp av matplotlib python skript [25].
4
Empiri
Data som presenteras i graferna under 15–17 visar noggrannheten samt tiden att utföra valideringen för respektive modell. Data som presenteras i graferna figur: 21, 22, 29, 30, 37 och 38 visar noggrannheten där respektive modell tränades med mindre bilder 100st, 200st, 400st och 800 st.
4.1.1 InceptionV3
Nedan presenteras Empiri på InceptionV3 tränad på 2000 bilder och validering på 1000 testbilder.
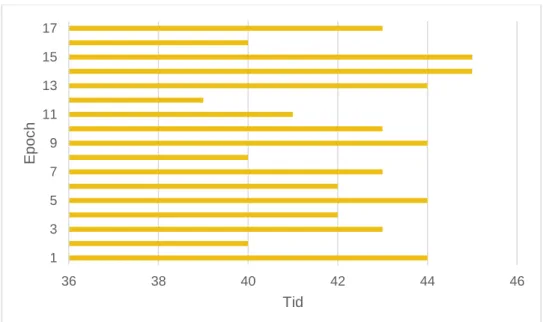
Validering på 10 steg gav 36,5 %. Ökningen i valideringen för InceptionV3 i 10 steg är ca 1.02% per steg.
Figur 15. Visar träffsäkerheten för InceptionV3 under 10 steg
Figur 16. Visar tiden för InceptionV3 att utföra varje steg
Validering på 15 steg gav 62 %. Ökningen i valideringen för InceptionV3 i 15 steg är ca 1,7 % per steg.
Figur 17. Visar träffsäkerheten för InceptionV3 under 15 steg
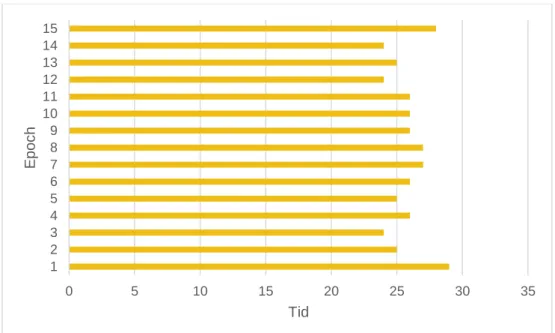
Den totala tiden för InceptionV3 att utföra 15 är ca 11 minuter.
36 38 40 42 44 46 1 2 3 4 5 6 7 8 9 10 Tid S teg
Figur 18. Visar tiden för InceptionV3 att utföra varje steg
Validering på 20 steg gav 76,5 %. Ökningen i valideringen för InceptionV3 i 20 steg är ca 0,95 % per steg.
Figur 19. Visar Träffsäkerheten för InceptionV3 under 20 steg
0 5 10 15 20 25 30 35 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Tid E po c h
Den totala tiden för InceptionV3 att utföra 20 steg är ca 12 minuter.
Figur 20. Visar tiden för InceptionV3 att utföra varje steg
Nedan presenteras Empiri på InceptionV3 när modellen tränades på respektive 100, 200, 400 och 800 träningsbilder. Figur 21 visar noggrannhet på 100 och 200
träningsbilder. Figur 22 visar noggrannhet på 400 och 800 träningsbilder.
Figur 21. Visar träffsäkerheten för InceptionV3 tränad med respektive 100 och 200 bilder
36 38 40 42 44 46 1 3 5 7 9 11 13 15 17 Tid E po c h
Figur 22. Visar träffsäkerheten för InceptionV3 tränad med respektive 400 och 800 bilder
4.1.2 MobilNetV2
Nedan presenteras Empiri på MobilNetV2 tränad på 2000 bilder och validering på 1000 testbilder.
Validering på 10 steg gav 41,5 %. Ökningen i valideringen för MobileNetV2 i 10 steg är ca 0,45 % per steg.
Figur 23. Visar Träffsäkerheten för MobileNetV2 under 10 steg Den totala tiden för MobileNetV2 att utföra 10 steg är ca 6 minuter.
Figur 24. Visar tiden för MobileNetV2 att utföra varje steg
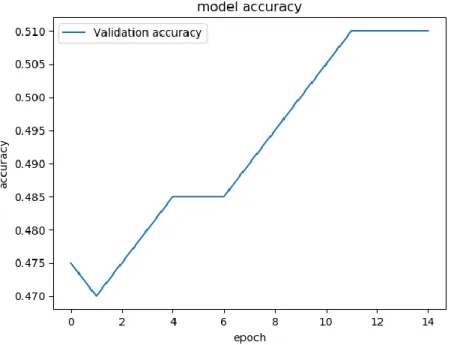
Validering på 15 steg gav 51 %. Ökningen i valideringen för MobileNetV2 i 15 steg är ca 0.26% per steg.
Figur 25. Visar Träffsäkerheten för MobileNetV2 under 20 steg Den totala tiden för MobilNetV2 att utföra 15 steg är ca 9 minuter.
30 32 34 36 38 40 42 1 2 3 4 5 6 7 8 9 10 Tid E po c h
Figur 26. Visar tiden för MobileNetV2 att utföra varje steg
Validering på 20 steg gav 63 %. Ökningen i valideringen för MobileNetV2 i 20 steg är ca 0,5 % per steg.
Figur 27. Visar Träffsäkerheten för MobileNetV2 under 20 steg
Den totala tiden för MobileNetV2 att utföra 20 steg är ca 12,5 minuter.
30 32 34 36 38 40 42 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Tid E po c h
Figur 28. Visar tiden för MobileNetV2 att utföra varje steg
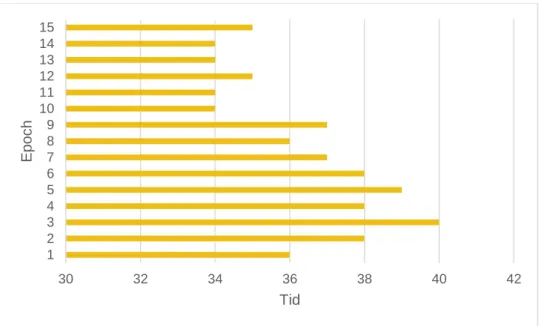
Nedan presenteras Empiri på MobilNet när modellen tränades på respektive 100, 200, 400 och 800 träningsbilder. Figur 29 visar noggrannhet på 100 och 200 träningsbilder. Figur 30 visar noggrannhet på 400 och 800 träningsbilder.
Figur 29. visar träffsäkerheten för MobilNetV2 tränad med respektive 100 och 200 bilder
0 10 20 30 40 50 1 3 5 7 9 11 13 15 17 19 Tid E po c h
4.1.3 Xception
Nedan presenteras Empiri på Xception tränad på 2000 bilder och validering på 1000 testbilder.
Validering på 10 steg gav 69 %. Ökningen i valideringen för Xception i 10 steg är ca 2,4 % per steg.
Figur 31. Visar Träffsäkerheten för Xception under 10 steg
Figur 32. Visar tiden för Xception att utföra varje steg
Validering på 15 steg gav 75,4%. Ökningen i valideringen för Xception i 15 steg är ca 0,26 % per steg.
Figur 33. Visar Träffsäkerheten för Xception under 15 steg Den totala tiden för Xception att utföra 20 steg är ca 7 minuter.
22 23 24 25 26 27 28 29 1 2 3 4 5 6 7 8 9 10 Tid E po c h
Figur 34. Visar tiden för Xception att utföra varje steg
Validering på 20 steg gav 86 %. Ökningen i valideringen för Xception i 20 steg är ca 0,92 % per steg.
Figur 35. Visar Träffsäkerheten för Xception under 20 steg
Den totala tiden för Xception att utföra 20 steg är ca 10 minuter.
0 5 10 15 20 25 30 35 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Tid E po c h
Figur 36. Visar tiden för Xception att utföra varje steg
Nedan presenteras Empiri på Xception när modellen tränades på respektive 100, 200, 400 och 800 träningsbilder. Figur 37 visar noggrannhet på 100 och 200 träningsbilder. Figur 38 visar noggrannhet på 400 och 800 träningsbilder.
Figur 37. Visar träffsäkerheten för Xception tränad med respektive 100 och 200 bilder
0 5 10 15 20 25 30 35 1 3 5 7 9 11 13 15 17 19 Tid E po c h
5
Analys
5.1.1 Frågeställning 1
För att besvara studiens första frågeställning “Hur skiljer sig InceptionV3,
MobilnetV2 och Xception när det kommer till noggrannhet?” har en genomgående analys utförts.
Figur 39. Visar noggrannheten för InceptionV3, MobileNetV2 och Xception
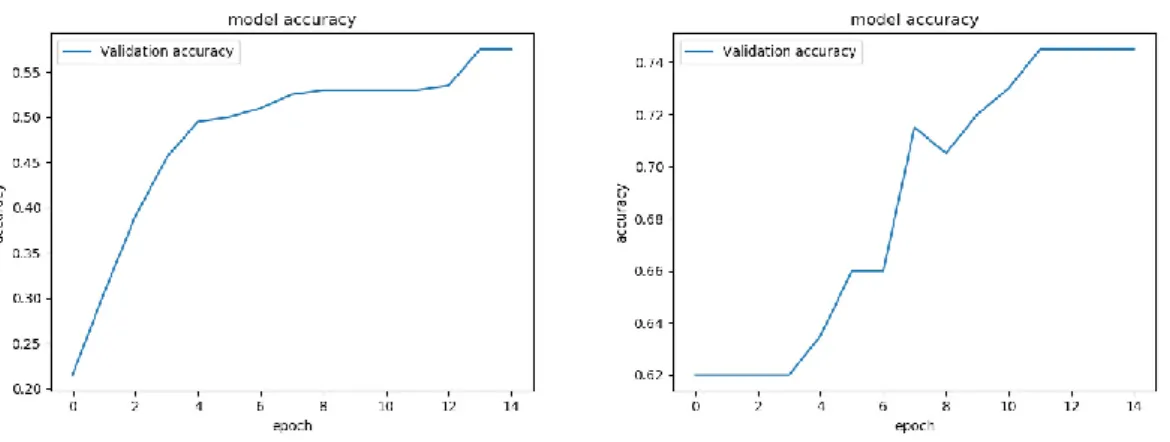
Figur 39 visar att Xception hade presterat högst med 86 % noggrannhet på validering av testdata. Följt av InceptionV3 med 76 % noggrannhet och Mobilnet med 63 % noggrannhet. Mobilnät presterade bättre under de 10 första stegen, där Mobilnet hade högre noggrannhet än InceptionV3. Xception hade 69 % noggrannhet på de 10 första stegen. Vilket är ca 30 % bättre än MobilNetV2 och InceptionV3.
Figur 39 visar även att Xception nådde 74,4 % noggrannhet redan efter 15 steg, vilket är förbättring med 6,4 % på 5 steg. MobilNetV2 hade då 51 % noggrannhet vilket är också förbättring med 10 %. InceptionV3 hade 61 % med förbättring på 26 %. En träffsäkerhet mellan 60–80% är anses vara låg träffsäkerhet. Det betyder att det var 650 korrekta klassicerande och 350 felaktiga bland de 1000 testdata. Med låg
datamängd är InceptionV3 och MobileNetV2 oanvändbar men däremot Xception med 86 % noggrannhet visade sig prestera bäst.
0,00% 10,00% 20,00% 30,00% 40,00% 50,00% 60,00% 70,00% 80,00% 90,00% 100,00% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
5.1.2 Frågeställning 2
För att besvara studiens andra frågeställning ” hur lång tid ta det för respektive modell att tränas och att utföra validering?” har en genomgående analys utförts kring
medelvärdet och den totala tiden på respektive modell.
Figur 40. Visar total tid
Figur 41. Visar medeltid
I ovanstående grafer syns det ett tydligt mönster där InceptionV3 modellen tar längst tid att utföra validering i alla steg. Den totala tiden för InceptionV3 att utföra 10 steg är ca 7 minuter, 15 steg för 11 minuter och 20 steg för 12 minuter.
10 15 20 Inception 416 649 722 MobileNET 376 545 751,8 Xception 282,7 413,8 604 0 100 200 300 400 500 600 700 800 T id (s )
Total Tid
10 15 20 Inception 41,6 43,26 42,4 MobileNet 37,6 36,3 35,8 Xception 25,7 25,8 28,8 0 5 10 15 20 25 30 35 40 45 50 T id (s )Medel Tid
Xception modellen visade imponerade resultat på tiden att utföra testet. På 10 steg är den totala tiden för Xception att utföra valideringen ca 5 minuter. Det är 2 minuter snabbare än InceptionV3 och 1 minut snabbare än MobileNetV2. På 15 steg är den totala tiden för Xception att utföra valideringen ca 7 minuter och 20 steg för 10 minuter. Det motsvarar 2 minuter snabbare än InceptionV3 och 1 minut snabbare än MobileNetV2.
Medeltiden för MobileNetV2 att utföra 10, 15 och 20 steg visade sig att minskas med 1 sekund när stegen ökades. Däremot ökade Xceptions medeltid när stegen ökades. I figur 41 syns det en ökning på 3 sekunder mellan steg 15 och steg 20. Medeltiden för InceptionV3 var högst i alla steg med medeltiden i steg 15 på 43,26 sekunder.
6
Diskussion och slutsatser
6.1.1 Resultat
Resultat från experimentet visade att Xception hade mest noggrannhet bland dessa tre modeller. Även när Xception har samma antal parametrar som InceptionV3 beror inte bättre prestanda på ökad kapacitet snarare en effektivare användning av
modellparametrar [16]. En annan anledning till bättre prestanda är faltning
operationen som används i Xception. Enligt teori använder Xception djupavskiljbara faltning och InceptionV3 använder en standard 1x1 faltning [16]. MobilNetV2 med sin storlek på 14 Mb hade ett tillfredsställande resultat på
noggrannhet och tid. Enligt teori har Xception en storlek på 88 Mb och InceptionV3 har storlek på 92 MB. Ändå kunde MobilNetV2 prestera på en medeltid som är lite snabbare än InceptionV3. Detta kan bero på att MobilNetV2 använder
djupvisseparerbar faltning operation som gör snabbare beräkning jämför med InceptionV3 som använder en standard faltning operation [15].
6.1.2 Jämförelse med andras resultat
I denna studie hade Xception 86 % noggrannhet och InceptionV3 hade 76 %
noggrannhet vilket är högre i jämförelse med [12] där de implementerade InceptionV3 för att klassificera damm. Deras modell uppnådde 72 % noggrannhet som är betydligt lägre än i denna studies experiment. I studien [12] användes 4000 bilder där 80 % av bilder var träningsbilder och 20 % var testbilder. I denna studie användes 3000 bilder där 67 % av bilderna är träningsbilder och 33 % är testbilder.
I en annan studie [11] om djur klassificering. Användes modellen Xception för att klassificera olika hundraser. Modellen tränades på bilder från en databas som innehåller 10,222 bilder av hundar och 120 bilder av olika hundraser. Modellen i deras studie uppnådde upp till 99,559 % noggrannhet på testbilder. Deras modell testades även på andra testbilder som inte var från samma databas då svarade
modellen med 82 % noggrannhet. Deras resultat på 99,559% noggrannhet är högre än denna studie resultat på 86 % noggrannhet. Däremot 86 % noggrannhet från denna studie högre än 82 % noggrannhet som [11] fick med testbilder som inte ingick i samma databas.
Det finns många orsaker som kan har orsakat till att modellen på denna studie inte kunde nå resultat i närheter av resultat på 99,559 % noggrannhet [11]. Några av orsaker är antalet av träningsbilder. Deras modell tränades med 10,222 bilder jämför med 3000 bilder i denna studie. Andra orsaker som även kan leda till bättre eller sämre resultat är även kvalité på bilderna och även hur mycket bilderna skiljer sig. Om träningen utfördes med ungefär likadana bilder. Till exempel bilder med samma belysning och en viss vinkel, kan modellen vänja sig att kunna identifiera bilder som endast har den belysningen och den vinkeln.
En annan orsak är att Xception som användes i denna studie är modellen som tränades på imageNets databasen som inte innehåller mycket bilder som liknar bilderna på
nätpanel som användes i denna studie. Det betyder att modellen i denna studie inte hade mer än 3000 bilder på nätpaneler att lära sig av.
6.1.3 Implikationer
Denna studie bidrar till en ökad Kännedom kring prestanda på befintliga
faltningsnätverk och kan även användas som mall till att besluta om vilken modell som ska användas som bas till mobila applikationen. Detta åstadkoms med hjälp av studiens experiment som tränar och testar respektive modell med likadan data och under samma omständigheter.
6.1.4 Begränsningar
Detta examensarbete utfördes under en begränsad tid, vilken ledde till att inte mer än 2000 träningsbilder och 1000 testbilder kunde samlas till experimentet. Om mer bilder hade funnit skulle fler tester utföras med olika steg för att kunna få ett brett resultat. Mer data skulle göra det mer möjligt att analysera samt komma till en mer utvecklad slutsats.
6.1.5 Slutsatser
Syfte med denna studie var att utvärdera prestanda på Xception, InceptionV3 och MobilNetV2 för att underlätta vid valbeslut av förtränade faltningsnätverk. Resultatet från experimentet visade att modellerna hade olika prestanda vid olika steg på
validering. Skillnaden kan bero på faktorer såsom olika faltning operation i respektive modeller och mängden på träningsbilder. Vid jämförelse av detta resultat med andra studier visade sig att modellen Xception fick mest noggrannhet än andra studier där samma modell användes till att skilja bilder av damm. Detta kan tyda på att samma modell kan ge olika resultat som beror bland annat på bildkvalitet och hur väl modellen hittar mönster på bilder de har tränat till.
Resultat från experiment visade också att dessa modeller presterade mindre bra vid mindre tränings bilder. Där respektive modell tränades i respektive 100, 200, 400 och 800st bilder. Inga av dessa modeller kunde utföra prediktering under 100
träningsbilder. Från 800 tränings bilder började modeller att utföra prediktering över 70 %. Detta kan tyda på att dessa modell kan ge högre noggrannhet när de tränas med bilder som är över 800st.
6.1.6 Vidare forskning
För vidare forskning hade varit intressant att förlänga detta experiment genom att utföra tester i mobila enheter och sedan mäta noggrannhet och processtid på respektive modell baserad på bilder som tas direkt från samma mobila enheter. Det skulle vara intressant att jämföra resultat i förhållande till resultat från den här studien. Det finns några maskininlärnings ramverk som gör det möjligt att kunna överföra
7
Referenser
[1] L. Yann, B. Yoshua och H. Geoffrey, ”Deep Learning,” 2015. [Online] Tillgänglig:
https://www.researchgate.net/publication/277411157_Deep_Learning
[Hämtad: 21 December, 2020]
[2] L. Sehla och A. Afef, ”Machine Learning framework for image classification,” Advances in
Science, Technology and Engineering Systems Journal , vol. 3, pp. 01-10, 2018.
[3] L. Tobías, A. Ducournau, F. Rousseau, G. Mercier och R. Fablet, ”Convolutional Neural Networks for object recognition on mobile devices: A case study,” 23rd International
Conference on Pattern Recognition (ICPR), nr 10.1109, pp. 3530-3535, 2016.
[4] C. Szegedy, V. Vanhoucke, S. Ioffe och J. Shlens, ”Rethinking the Inception Architecture for Computer Vision,” arXiv preprint arXiv:1512.00567, 2015.
[5] L. Torrey och J. Shavlik, ”Transfer Learning,” 2009. [Online] Tillgänglig:
https://ftp.cs.wisc.edu/machine-learning/shavlik-group/torrey.handbook09.pdf
[Hämtad: 21 December, 2020]
[6] ImageNet, ”Large Scale Visual Recognition Challenge,” [Online]. Tillgänglig:
http://www.image-net.org/challenges/LSVRC/. [Hämtad: 21 Maj, 2020]
[7] Google Cloud, ”Advanced Guide to InceptionV3 on Cloud TPU,” 2019. [Online]. Tillgänglig: https://cloud.google.com/tpu/docs/inception-v3-advanced
[Hämtad: 21 December, 2020]
[8] N. D. Lane, S. Bhattacharya, P. Georgiev, C. Forlivesi, L. Jiao, L. Qendro och F. Kawsar, ”DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices,” 2016 15th ACM/IEEE International Conference on Information Processing in
Sensor Networks (IPSN), pp. 1-12, 2016.
[9] A. Riese, ”Classifying hand-drawn documents in mobile settings,using transfer learning and model compression,” 2017. [Online]. Tillgänglig:
https://www.diva-portal.org/smash/get/diva2:1137260/FULLTEXT01.pdf
[Hämtad: 27 December, 2020]
[10] T. M. T. ,. C. Y. ,. S. W. ,. P. S. ,. M. S. N. ,. M. H. ,. B. C. V. E. ,. A. A. S. A. a. V. K. A. Md Zahangir Alom, ”A State-of-the-Art Survey on Deep Learning Theory and
Architectures,” Department of Electrical and Computer Engineering, University of Dayton, OH 45469, USA, USA, 2019.
[11] K. M. o. P. Rivas, ”Dog Breed Identification with a Neural Network over Learned
Representations from the Xception CNN architecture,” Department of Computer Science, Marist College, Poughkeepsie, NY, United States.
[12] O. Albatyneh, L. Forslöf och K. Ksaibati, ”Image Retraining Using TensorFlow
Implementation of the Pre-trained Inception-V3 Model for Evaluating Gravel Road Dust,”
Journal of Infrastructure Systems, vol. 26, 2020.
[13] D. Suryani , S. Kom och M. Eng, ”Convolutional Neural Network,” 2015. [Online]. Tillgänglig:
https://socs.binus.ac.id/2017/02/27/convolutional-neural-
network/?fbclid=IwAR0pTMH1mYdAal4hn1N-rVER7tsSmcllgMmib99UL-yeKUdj1qrujuNIUtg [Hämtad: 27 December, 2020]
[14] C. Shorten och T. Khoshgoftaar, ”A survey on Image Data Augmentation for Deep Learning. J Big Data,” 2019. [Online]. Tillgänglig:
https://www.researchgate.net/publication/334279066_A_survey_on_Image_Data_Augment
ation_for_Deep_Learning [Hämtad: 27 December, 2020]
[15] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Weijun, T. Weyand, M. Andreetto och H. Adam, ”MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” arXiv preprint arXiv:1704.04861, 2017.
[16] F. Cholet, ”Xception: Deep Learning with Depthwise Separble Convolutions,” i IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[17] L. Törnvist, P. Vartia och Y. Vartia, ”How Should Relative Changes Be Measured?,” The
American Statistician, vol. 39, nr 10.1080, pp. 43-46, 1985.
[18] G. Rätsch, ”A brief introduction into machine learning,” 2004. [Online]. Tillgänglig:
https://events.ccc.de/congress/2004/fahrplan/files/105-machine-learning-paper.pdf
[Hämtad: 27 December, 2020]
[19] M. Claesen och B. De Moor, ”Hyperparameter Search in Machine Learning,” i The XI
Metaheuristics International Conference, Agadir, 2015.
[20] TensorFlow ”TensorFlow,” [Online]. Tillgänglig: https://www.tensorflow.org/
[Hämtad 20 April 2020]
[21] G. Yiğit och M. Ozyildirim, ”Comparison of convolutional neural network models for food image classification,” Journal of Information and Telecommunication, pp. 1-11, 2018.
[22] N. Walliman, Research Methods: The Basics, 2004. [Online]. Tillgänglig:
https://www.taylorfrancis.com/books/research-methods-basics-nicholas-walliman/10.4324/9780203836071 [Hämtad 20 April 2020]
[23] R. Patel och B. Davidson, ” Forskningsmetodiken grunder: Att planera, genomföra och rapportera en undersökning, ” Lund: Studentlitteratur, 2016.
[25] Matplot, ”matplotlib,” [Online]. Tillgänglig: https://matplotlib.org [Använd 1 Maj 2020] [26] O. Alsing, ”Mobile Object Detection using TensorFlow Lite and Transfer Learning,” Diva,
Bilagor
Steg Noggrannhet 1 27% 2 28% 3 29% 4 31% 5 32% 6 33% 7 32% 8 33% 9 34% 10 36%
Tabell 0.1. Visar InceptionV3 noggrannhet i 10 steg.
Steg Noggrannhet 1 36% 2 40% 3 45% 4 49% 5 53% 6 56% 7 58% 8 59% 9 61% 10 62% 11 62% 12 62% 13 62% 14 62% 15 62%
Steg Noggrannhet 1 67% 2 68% 3 68% 4 69% 5 69% 6 70% 7 72% 8 73% 9 74% 10 74% 11 74% 12 74% 13 75% 14 75% 15 76% 16 76% 17 76% 18 76% 19 76% 20 76%
Tabell 0.2. Visar noggrannhet för InceptionV3 i 20 steg.
Steg Noggrannhet 1 29% 2 29% 3 30% 4 32% 5 33% 6 35% 7 37% 8 38% 9 40% 10 41%
Steg Noggrannhet 1 47% 2 47% 3 47% 4 48% 5 48% 6 48% 7 49% 8 49% 9 50% 10 50% 11 51% 12 51% 13 51% 14 51% 15 51%
Tabell 0.4. Visar noggrannhet för MobileNetV2 i 15 steg.
Steg Noggrannhet 1 53% 2 54% 3 54% 4 56% 5 58% 6 58% 7 58% 8 58% 9 59% 10 60% 11 61% 12 62% 13 62% 14 62% 15 63% 16 62% 17 63% 18 63% 19 63% 20 63%
Steg Noggrannhet 1 45% 2 49% 3 53% 4 60% 5 63% 6 64% 7 66% 8 66% 9 68% 10 69%
Tabell 0.6. Visar noggrannhet för Xception i 10 steg.
Steg Noggrannhet 1 65% 2 70% 3 71% 4 72% 5 72% 6 73% 7 73% 8 73% 9 73% 10 73% 11 73% 12 74% 13 74% 14 74% 15 75%
Steg Noggrannhet 1 68% 2 72% 3 73% 4 74% 5 74% 6 74% 7 74% 8 75% 9 75% 10 75% 11 76% 12 76% 13 76% 14 79% 15 80% 16 81% 17 83% 18 84% 19 84% 20 86%